1. Introduction
Traditionally, pathologists have used the microscope to analyze the micro-anatomy of cells and tissues. In recent years, the advancement in Digital Pathology (DP) imaging has provided an alternative way to enable the pathologists to do the same analysis over the computer screen [
1]. The new DP imaging modality is able to digitize the Whole Slide Imaging (WSI), where the glass slides are converted into digital slides that can be viewed, managed, shared and analyzed on a computer monitor [
2].
In Colorectal Cancer (CRC), tumor architecture changes during tumor progression [
3] and is related to patient prognosis [
4]. Therefore, quantifying the tissue composition in CRC is a relevant task in histopathology. Tumor heterogeneity occurs both between tumors (inter-tumor heterogeneity) and within tumors (intra-tumor heterogeneity). In fact, Tumor Micro-Environment (TME) plays a crucial role in the development of Intra-Tumor Heterogeneity (ITH) by the various signals that cells receive from their micro-environment [
5].
Colorectal Cancer (CRC) is considered as the fourth most occurring cancer and it is the third leading cancer type to cause death [
6]. Indeed, early stage CRC diagnosis is decisive for therapy of patients and saving their lives [
7]. The evaluation of tumor heterogeneity is very important for cancer grading and prognostication [
8]. In more detail, intre-tumor heterogeneity can aid the understanding of TME’s effect on patient prognosis, as well as identify novel aggressive phenotypes that can be further investigated as potential targets for new treatment [
9].
In recent years, automatic tissue phenotyping, in Whole Slide Images (WSIs), has become a fast-growing research area in computer vision and machine learning communities. In fact, state-of-the-art approaches have investigated the classification of two tissue types [
10,
11] or multi-class tissue types analysis [
8,
12,
13]. The two tissue types are tumor and stroma tissue categories. Actually, the classification of just two tissue categories is not suitable for more heterogeneous parts of the tumor [
12]. To overcome this limitation, the authors of [
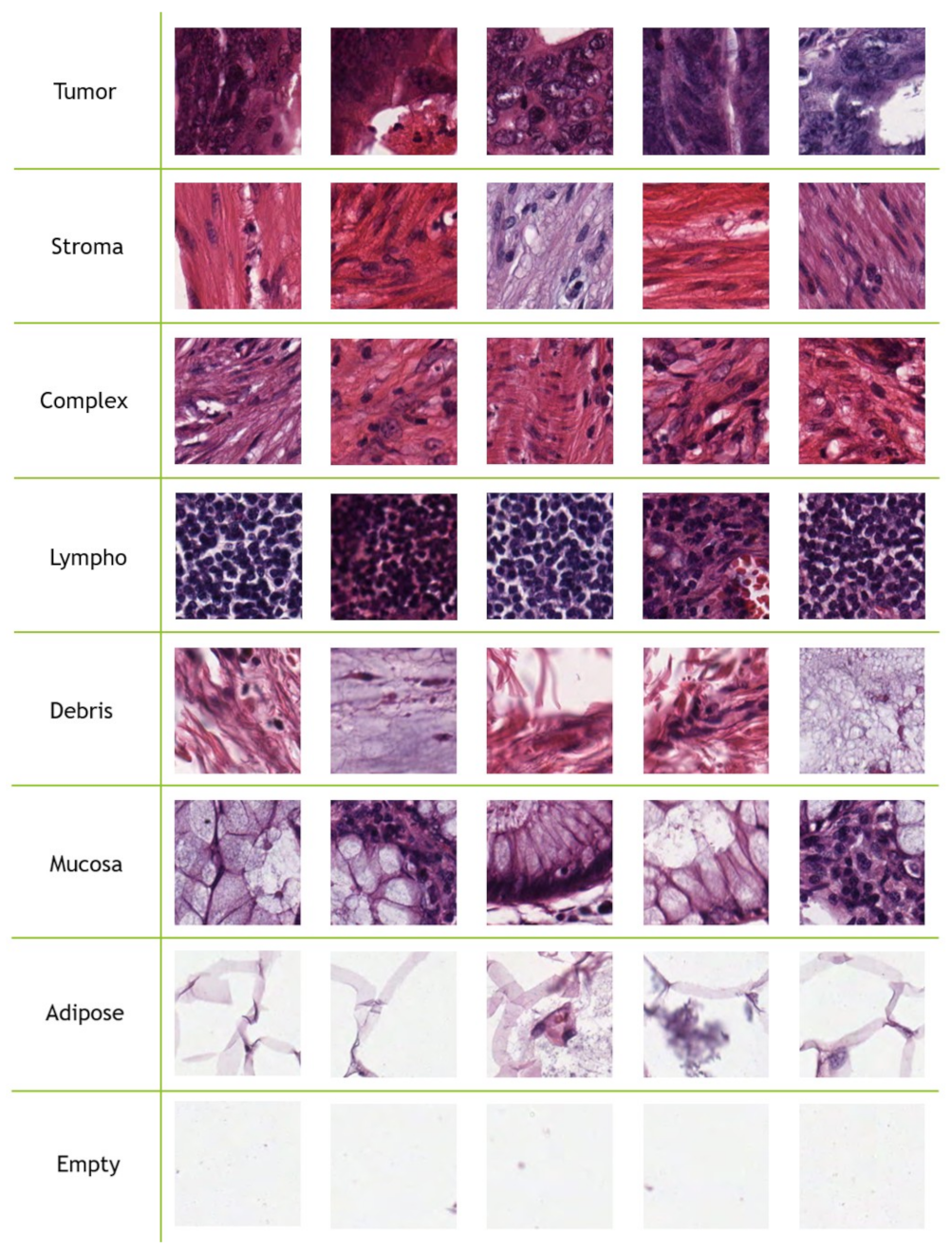
12] proposed the first multi-class tissue type database, where they considered eight tissue types.
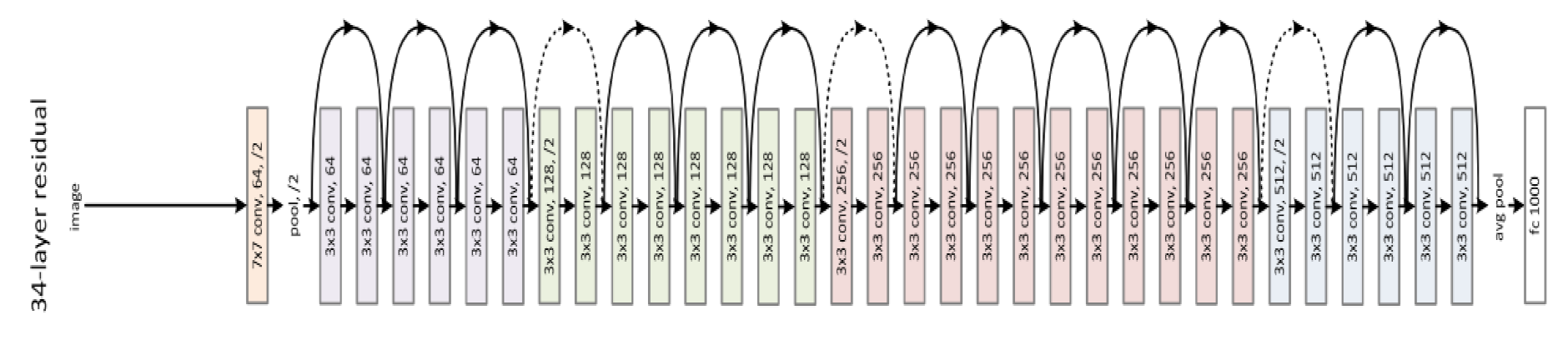
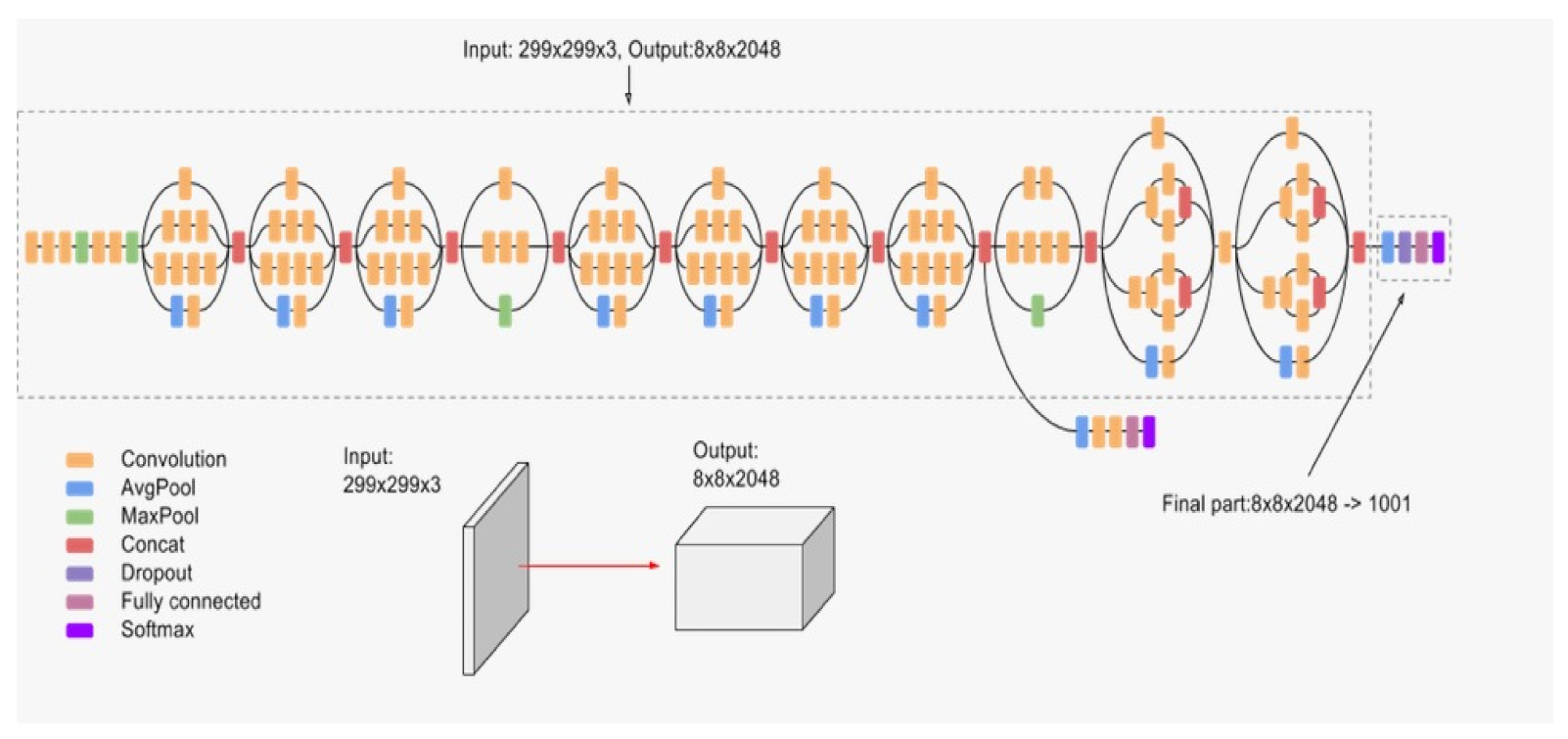
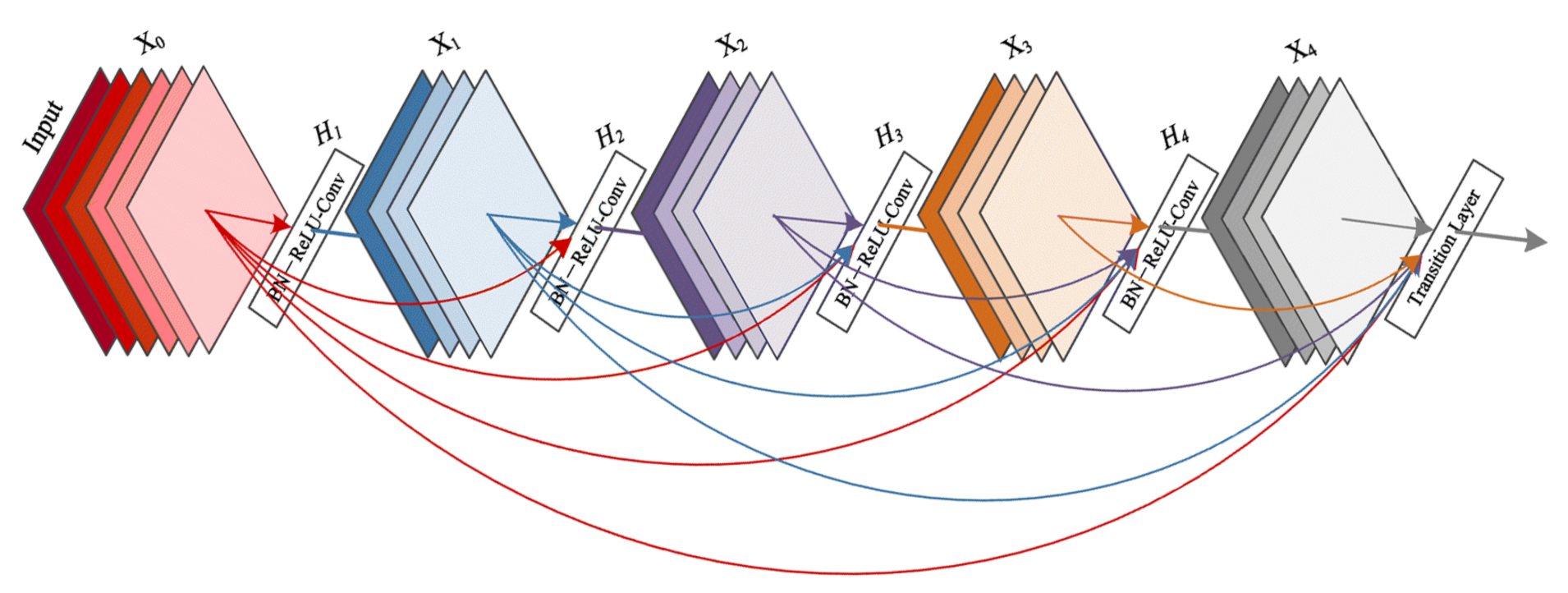
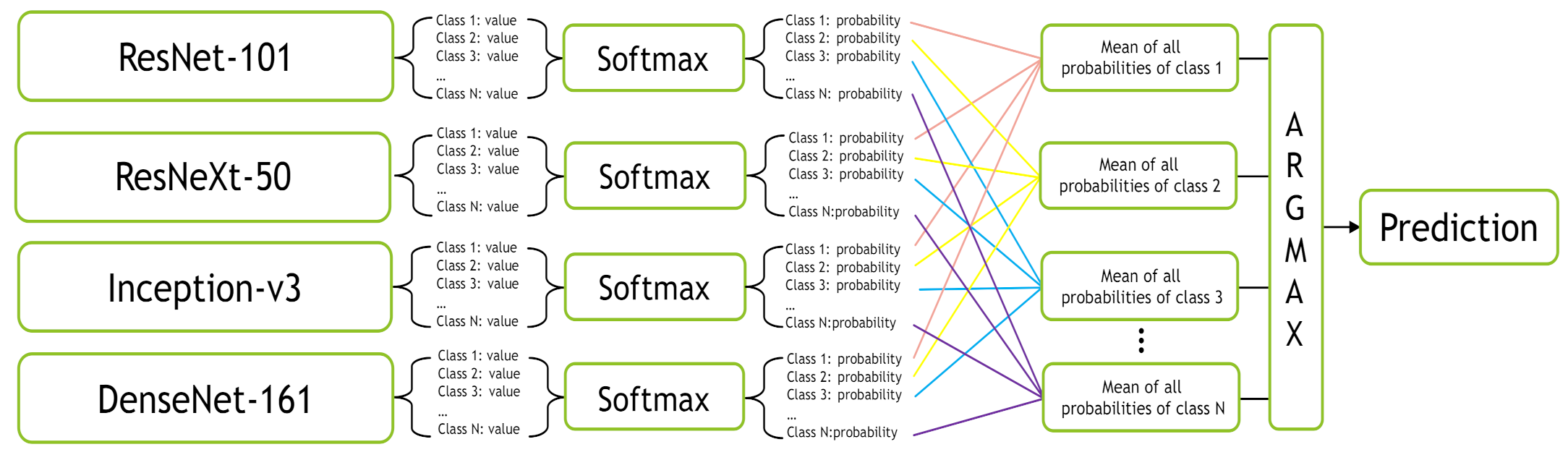
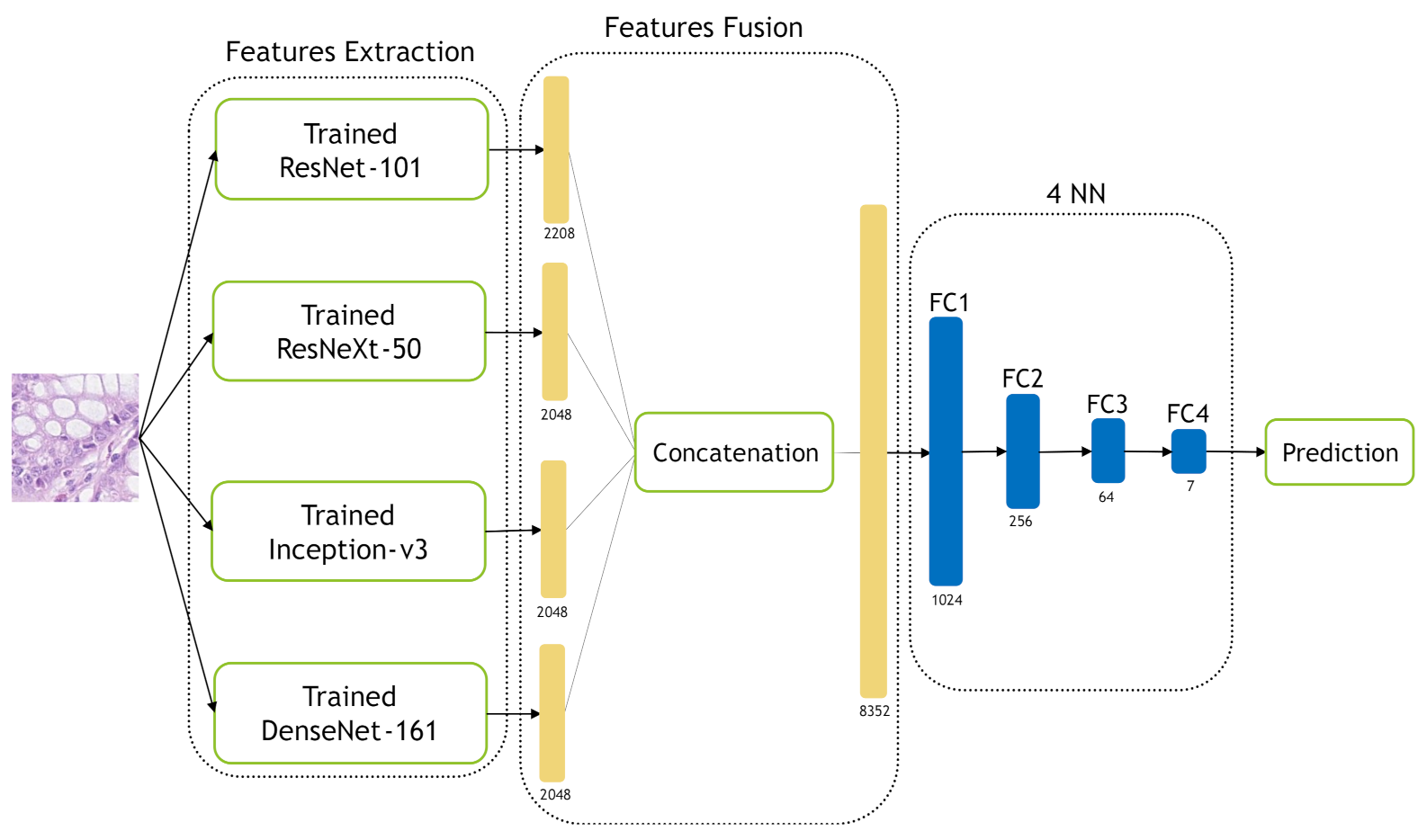
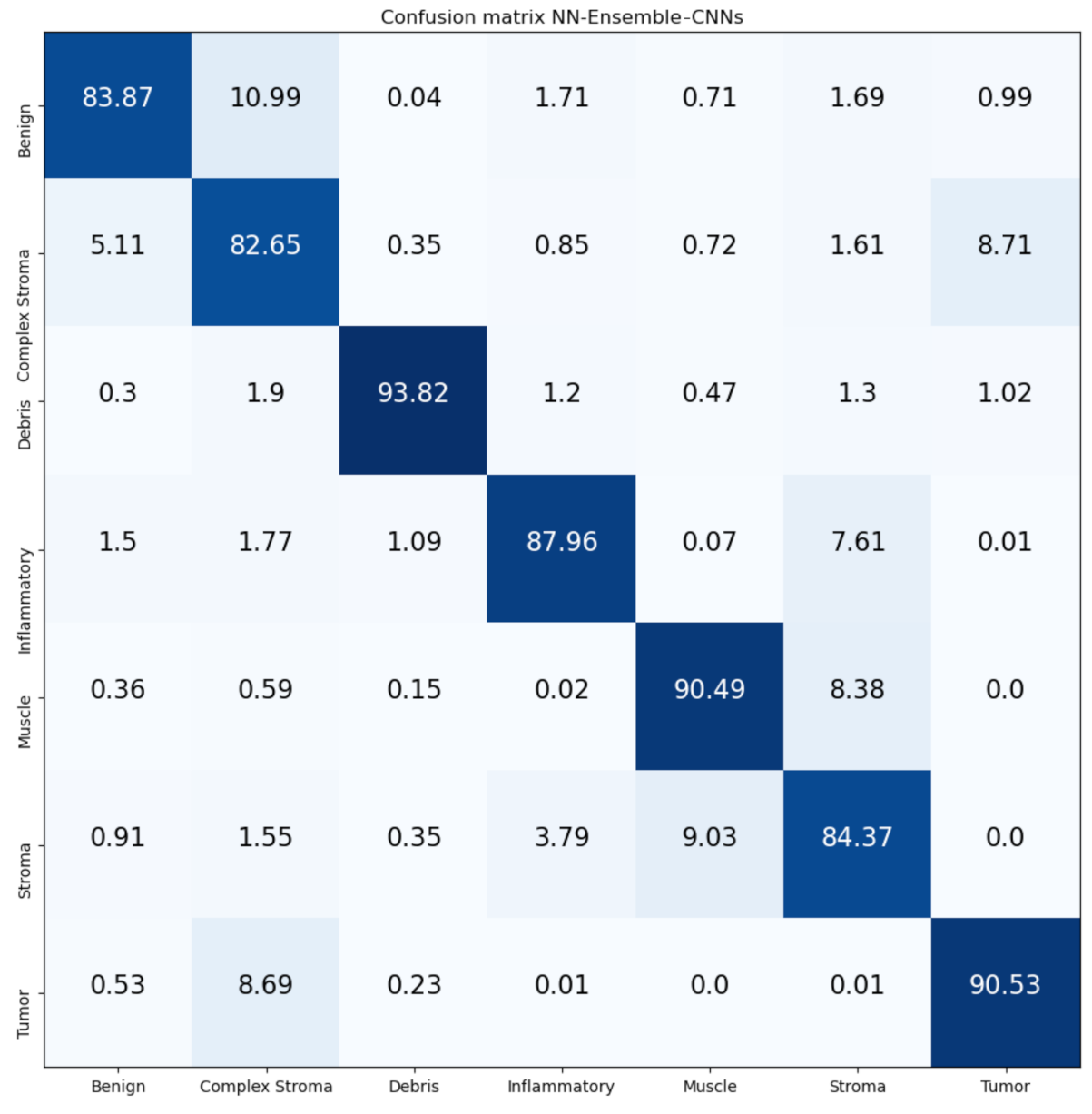
In this work, we deal with the classification of multi-class tissue types. In order to classify different CRC tissue types, we proposed two ensemble approaches which are: Mean-Ensemble-CNNs and NN-Ensemble-CNNs. Our proposed approaches are based on combining four trained CNN architectures, which are ResNet-101, ResNeXt-50, Inception-v3 and DenseNet-161. Our Mean-Ensemble-CNN approach uses the predicted probabilities of different trained CNN models. On the other hand, the NN-Ensemble-CNN approach used combined deep features that were extracted from different trained CNN models, then classified them using NN architecture. Since automatic multi-class CRC tissue classification is a relatively new task, we evaluated two hand-crafted descriptors which are: LPQ and BSIF. In addition, two classifiers were used which are SVM and NN. As summary, the main contributions of this paper are:
We proposed two ensemble CNN-based approaches: Mean-Ensemble-CNNs and NN-Ensemble-CNNs. Both of our approaches combine four trained CNN architectures which are ResNet-101, ResNeXt-50, Inception-v3 and DenseNet-161. The first approach (Mean-Ensemble-CNNs) uses the predicted probabilities of the four trained CNN models to classify the CRC tissue types. The second approach (NN-Ensemble-CNNs) combines the deep features that were extracted using the trained CNN models, then it uses NN architecture to recognize the CRC phenotype.
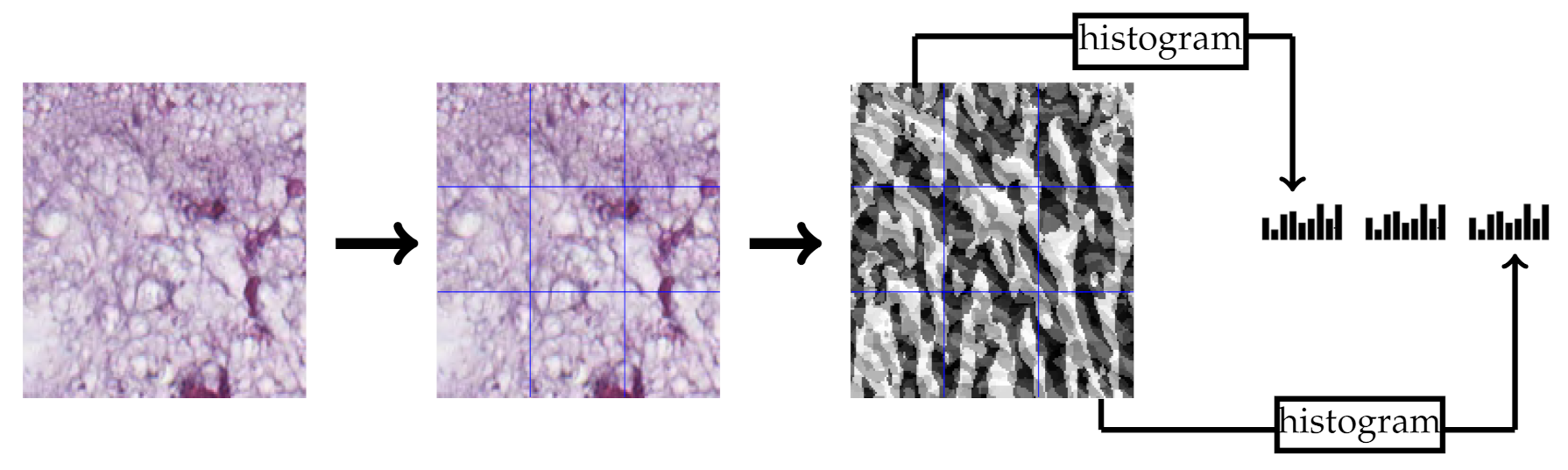
We conducted extensive experiments to study the effectiveness of our proposed approaches. To this end, we evaluated two texture descriptors (BSIF and LPQ) and their combination using two classifiers (SVM and NN) in two CRC tissue types databases.
Implicitly, our work contains comparison between CNN architectures and hand-crafted feature-based methods for the classification of CRC tissue types using two publicly databases.
This paper is organized as follows: In
Section 2, we describe the state-of-the-art methods.
Section 3 includes description of the used databases, methods and evaluation metrics. In addition,
Section 3 contains an illustration of our proposed approach and experimental setup.
Section 4 represents the experimental results. In
Section 5, we compare our results with the state-of-the-art methods. Finally, we conclude our work in
Section 6.
2. Related Works
In recent years, CRC tissue phenotyping has been subject to increasing interest in both computer vision and machine learning fields due to the availability of CRC-tissue-type databases such as [
8,
12,
14,
15]. Supervised methods are widely used to classify the tissue types in histological images [
12]. The supervized state-of-the-art methods for phenotyping the CRC tissues can be categorized as texture [
10,
11,
12,
16], or learned methods [
8,
15,
17,
18]. In addition, there are some works that combined deep and shallow features such as [
19]. The texture methods are hand-crafted algorithms that were designed based on mathematical model to extract specific structures within the image regions [
20]. However, deep learning methods have the ability to learn more relevant and complex features directly from the images across their layers. In particular, when there is no prior knowledge about the relationship between input data and the outcomes to be predicted. Since the pathology imaging tasks are very complex and little is known about which quantitative image features predict the outcomes, deep learning methods are suitable for these tasks [
21,
22]. In this section, we will describe the state-of-the-art works that have addressed multi-class CRC tissue types and used supervized methods.
In [
12], J. N. Kather et al. were the first who addressed CRC multi-class tissue types, where they created their database from 5000 histological images of human colorectal cancer including eight CRC tissue types. J. N. Kather et al. tested several state-of-the-art texture descriptors and classifiers. Their proposed approach is based on the combination GLCM and LBP local descriptors beside with global lower-order texture measures which achieved promising performance. In [
19], Nanni et al. proposed the General Purpose (GenP) approach which is based on ensemble of multiple hand-crafted, dense sampling and learned features. In their combined approach, they trained each feature using SVM then combined all of them using the sum rule. Cascianelli et al. [
23] compared deep and shallow features to recognize the CRC tissue types. In their work, they studied the impact of using dimensionality reduction strategies in both accuracy and computational cost. Their results showed that the best trade-off between accuracy and dimensionality using CNN-based features is possible.
In [
15], J. N. Kather et al. used 86 H&E slides of CRC tissues from the NCT biobank and the UMM pathology to create a training image set of 100,000 images that were labeled into eight tissue types. They tested five pretrained CNN models: VGG19 [
24], AlexNet [
25], SqueezeNet version 1.1 [
26], GoogLeNet [
27], and ResNet-50 [
28]. They concluded that VGG19 was the best model among the five CNN models. Javed et al. [
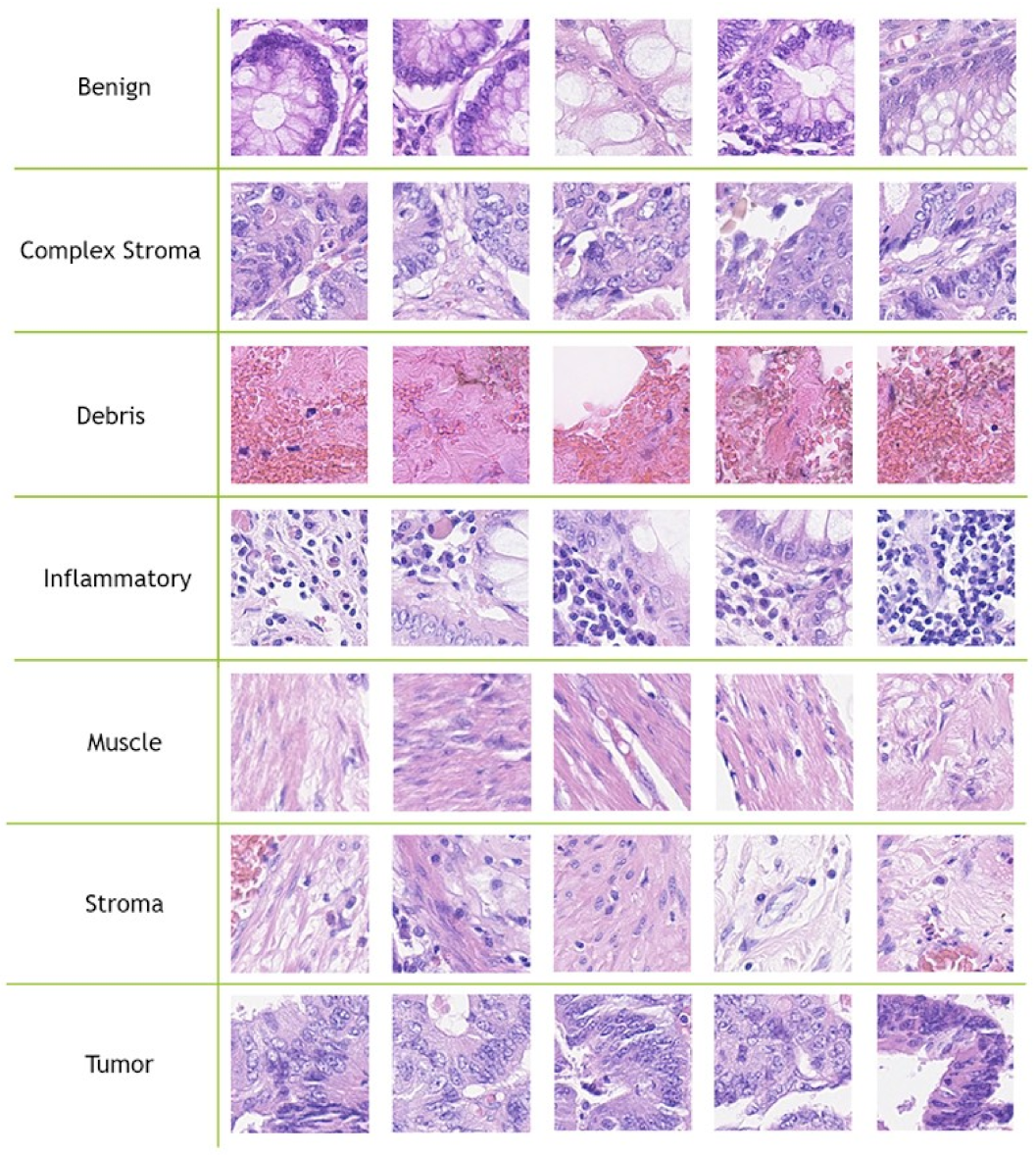
8] proposed a new CRC-TP database which consists of 280K patches extracted from 20 WSIs of CRC; these patches are classified into seven distinct tissue phenotypes. To classify these tissue types, they used 27 state-of-the-art methods including texture, CNN and Graph CNN-based (GCN) methods. From their experimental results, the GCN outperformed the texture and CNN methods. Despite hand-crafted feature-based and deep learning methods having been used for multi-class CRC tissue type classification, the performance of these methods still needs more improvement. To this end, we proposed two ensemble-CNN approaches that achieved considerable improvement on two popular databases.
5. Discussion
In this section, we will compare our results with state-of-the-art methods.
Table 7 contains the comparison between our proposed approaches and the state-of-the-art methods. In [
12], J. Kather et al. tested different texture descriptors with an SVM classifier. In [
41], Ł. Rączkowski et al. proposed the Bayesian Convolutional Neural Network approach. In [
19], L. Nanni et al. proposed an ensemble (FUS_ND+DeepOutput) approach based on combining deep and texture features. The comparison in
Table 7 shows that our proposed ensemble approaches outperform the state-of-the-art methods.
Table 8 contains the comparison between our proposed approaches and the state-of-the-art methods on the CRT-TP database. In [
8], S. Javed et al. used supervized and semi-supervized learning methods. In this comparison, we consider the results of the supervized approaches which are similar to our approaches. In
Table 8, we compare our approaches with texture and deep learning methods that were tested on [
8]. The comparison shows that our approaches (Mean-Ensemble-CNNs and NN-Ensemble-CNNs) outperform the state-of-the-art methods. The comparison with the hand-crafted feature-based methods, deep learning architectures and the state-of-the-art methods proves the efficiency of our proposed ensemble approaches (Mean-Ensemble-CNNs and NN-Ensemble-CNNs).
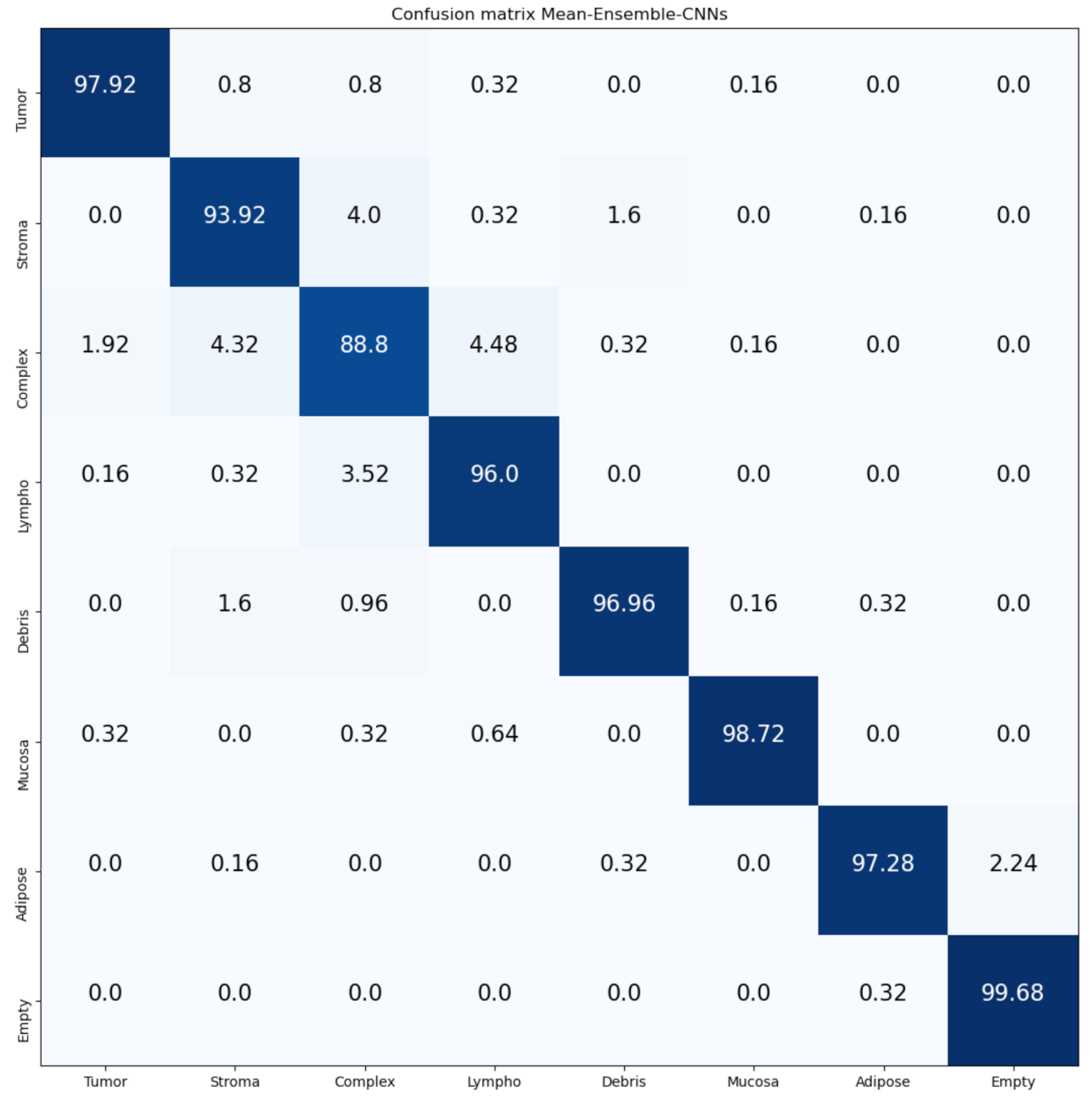
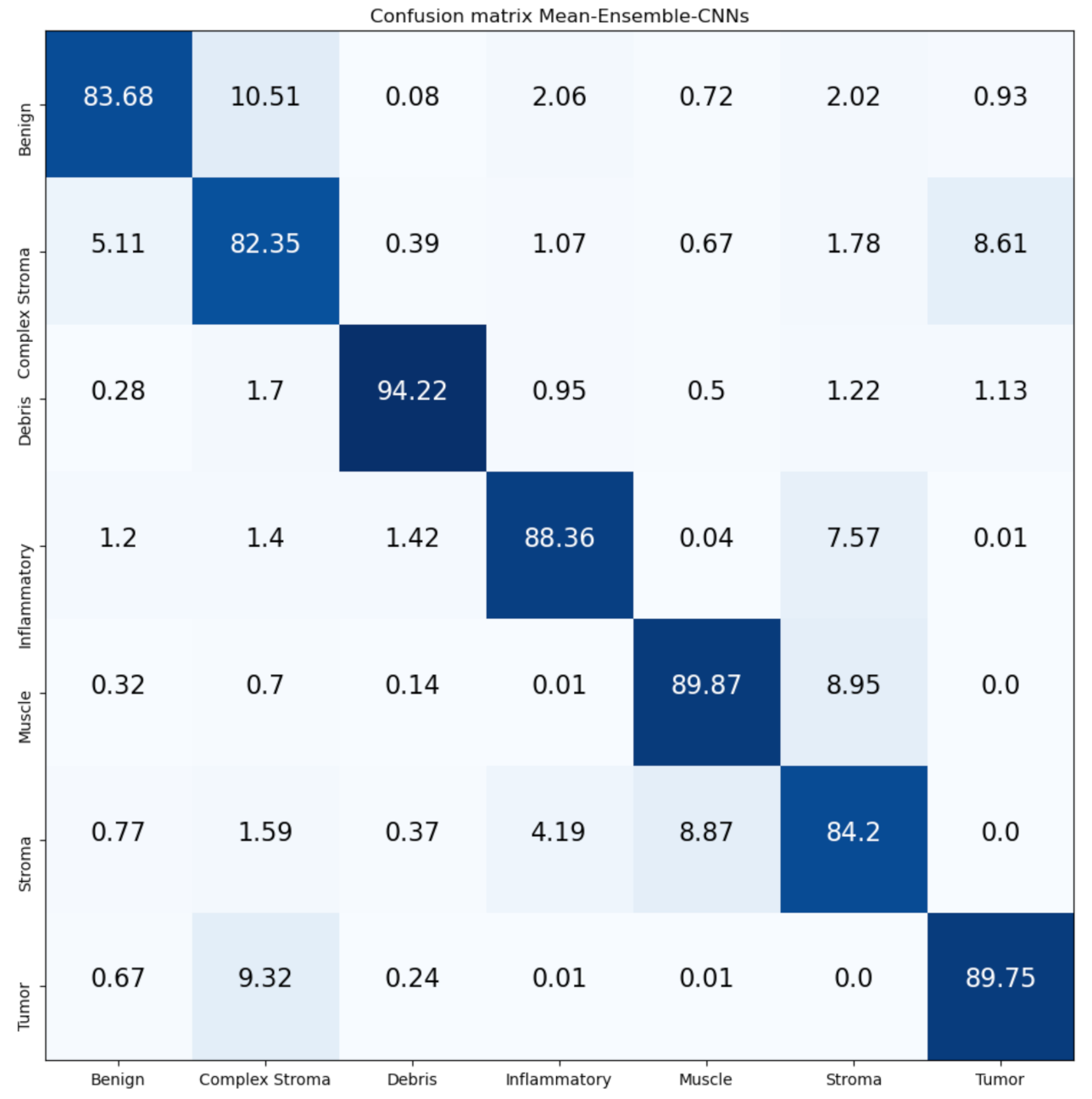
From the results on the Kather-CRC-2016 database, we notice that our proposed approaches (Mean-Ensemble-CNNs and NN-Ensemble-CNNs approach) achieved similar results (
Table 7). Meanwhile, in the CRC-TP database, we notice that the NN-Ensemble-CNNs performance is better than Mean-Ensemble-CNNs (
Table 8). On the other hand, we noticed that the performance of different methods on Kather-CRC-2016 is better than the performance on the CRC-TP database. This is probably because the CRC-TP database contains more challenging classes than Kather-CRC-2016. In addition, CRC-TP is not a balanced database that can influence the overall performance. Another possible reason can be the splitting and labeling of the tissue types, which were performed by different expert pathologists for each database. Despite our approach outperforming the state-of-the-art methods in both databases, the results in the CRC-TP database need more improvements for real-world applications. One possible solution is to use more data augmentation techniques to increase the training data.
6. Conclusions
In this paper, we proposed two Ensemble deep learning approaches to recognize the CRC tissue types. Our proposed approaches are denoted by Mean-Ensemble-CNNs and NN-Ensemble-CNNs, which are based on combining four trained CNN architectures. The trained CNN architectures are ResNet-101, ResNeXt-50, Inception-v3 and DenseNet-161. In our Mean-Ensemble-CNN approach, we combined the CNN architectures by averaging their predicted probabilities. In our NN-Ensemble-CNN approach, we combined the deep features from the last fully connected layer of each trained CNN architecture, then feed them into four layers NN. In addition to evaluating the four CNN architectures and our proposed approaches, we evaluated two texture descriptors and two classifiers. In more detail, we evaluated LPQ features, BSIF features and their combination by using two classifiers which are: SVM and NN.
The experimental results showed that deep learning methods (single architecture) surpass the hand-crafted feature-based methods. On the other hand, our proposed approaches outperform both the hand-crafted feature-based methods and the CNN architectures. In addition, our ensemble approaches outperform the state-of-the-art methods in both databases. As for future work, we are planning to use more data augmentation techniques to augment the training data. Moreover, including other powerful CNN architectures to our ensemble approaches will help to improve the performance.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}