
Design and Comparison of Image Hashing Methods: A Case Study on Cork Stopper Unique Identification





Abstract
1. Introduction
- They can undergo several tampering attempts such as interception of communication, data corruption, forgery, and cloning.
- Systems as simple as serial numbers or bar codes are quite simple to forge or reproduce.
- Small components produced in large quantities, such as screws, would be made more expensive by the insertion, in each of them, of an RFID or NFC tag or other identification object. For even smaller components, it may be impossible to incorporate any type of identifier.
- The combination of label materials with those of the component could lead to obstacles at recycling.
- allows for the reduction in noise and non-relevant data at an early stage of the process;
- tests and compares a set of hashing methods and image-processing techniques for the treatment of cork stopper images;
- proposes the optimized design for the cork stopper authentication process.
2. Background of Concepts
2.1. Bicubic Interpolation on Rescaling
2.2. Gaussian Filter
2.3. Cropping
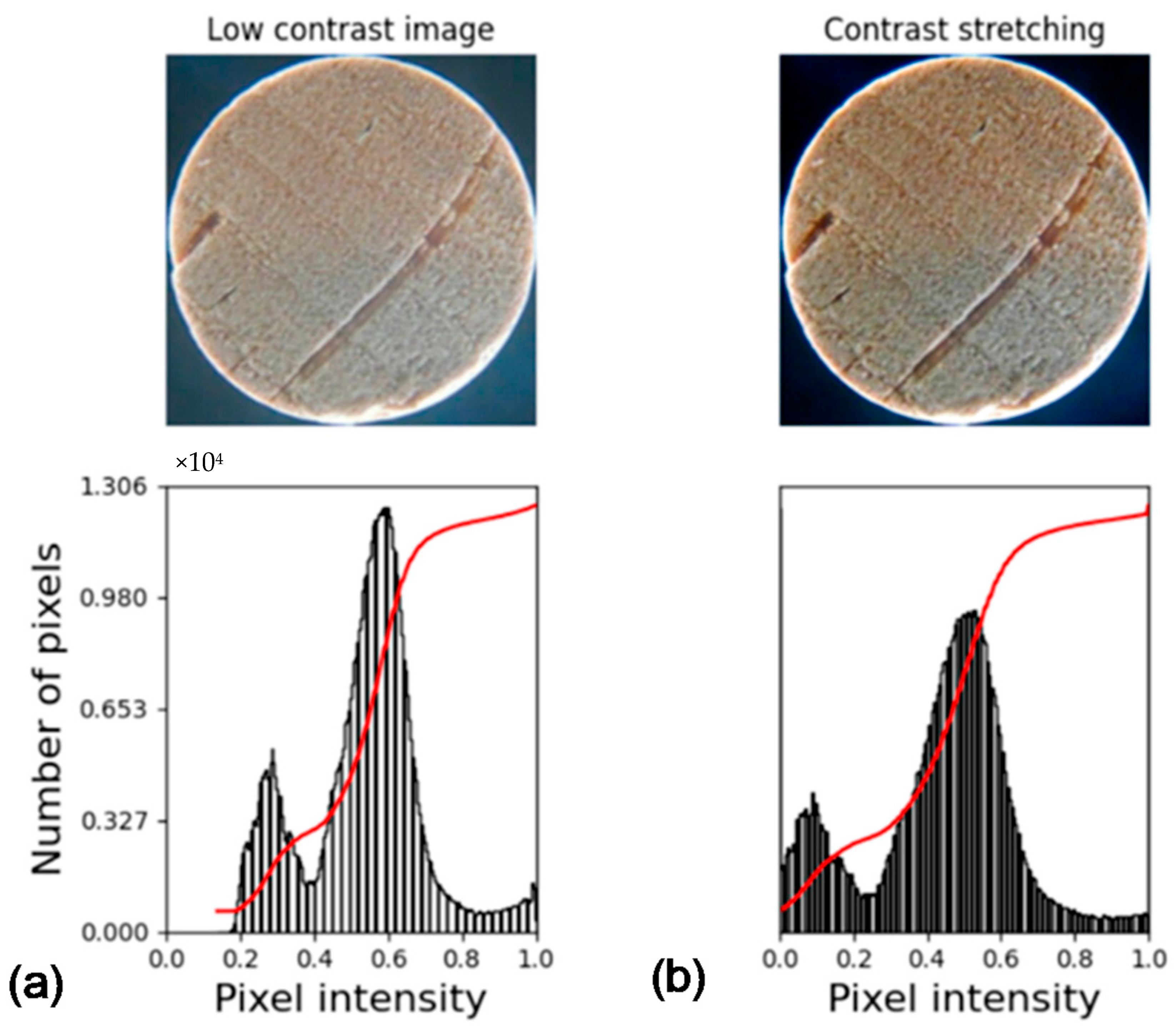
2.4. Contrast Stretching
2.5. Discrete Cosine Transform (DCT)
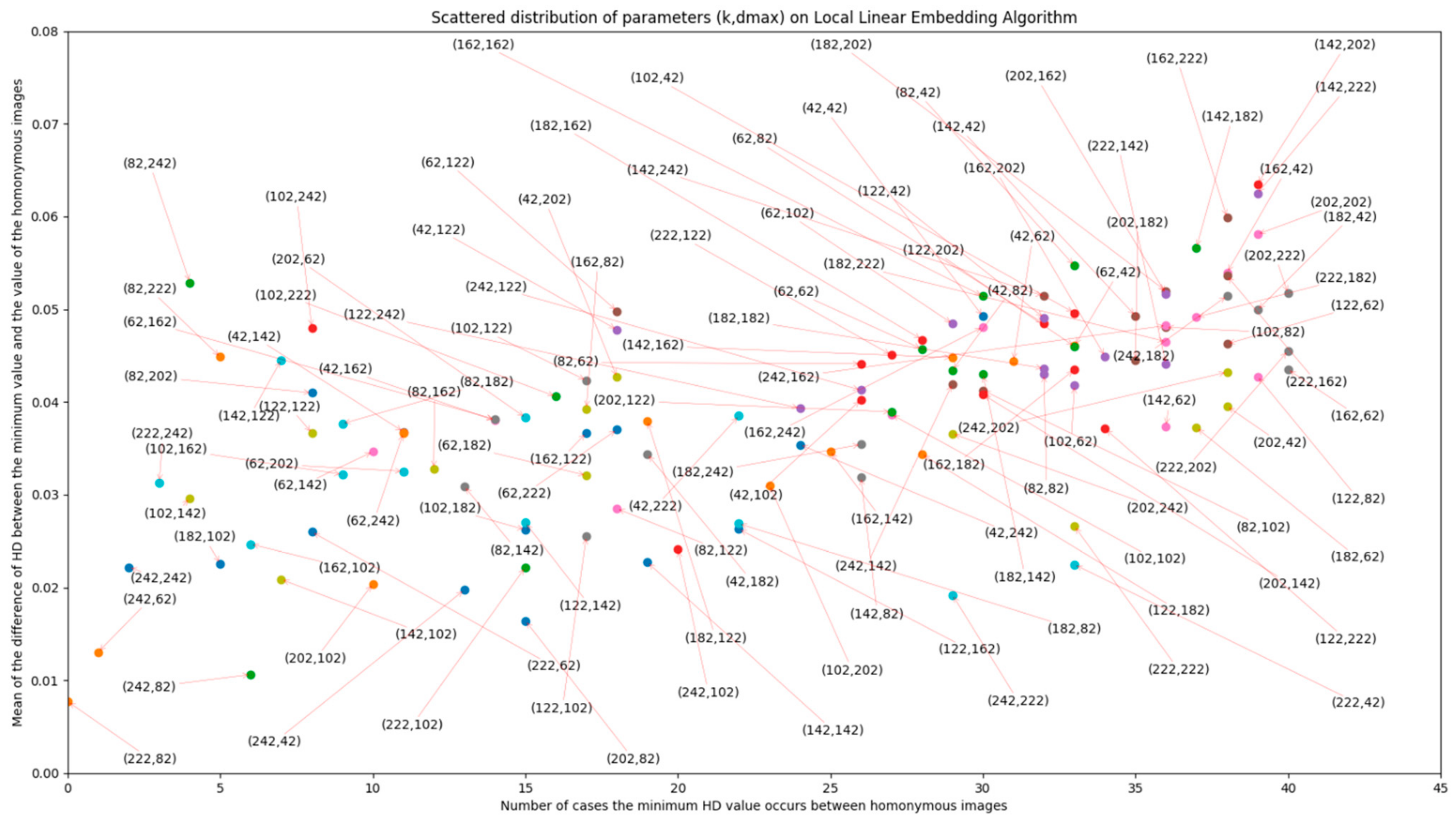
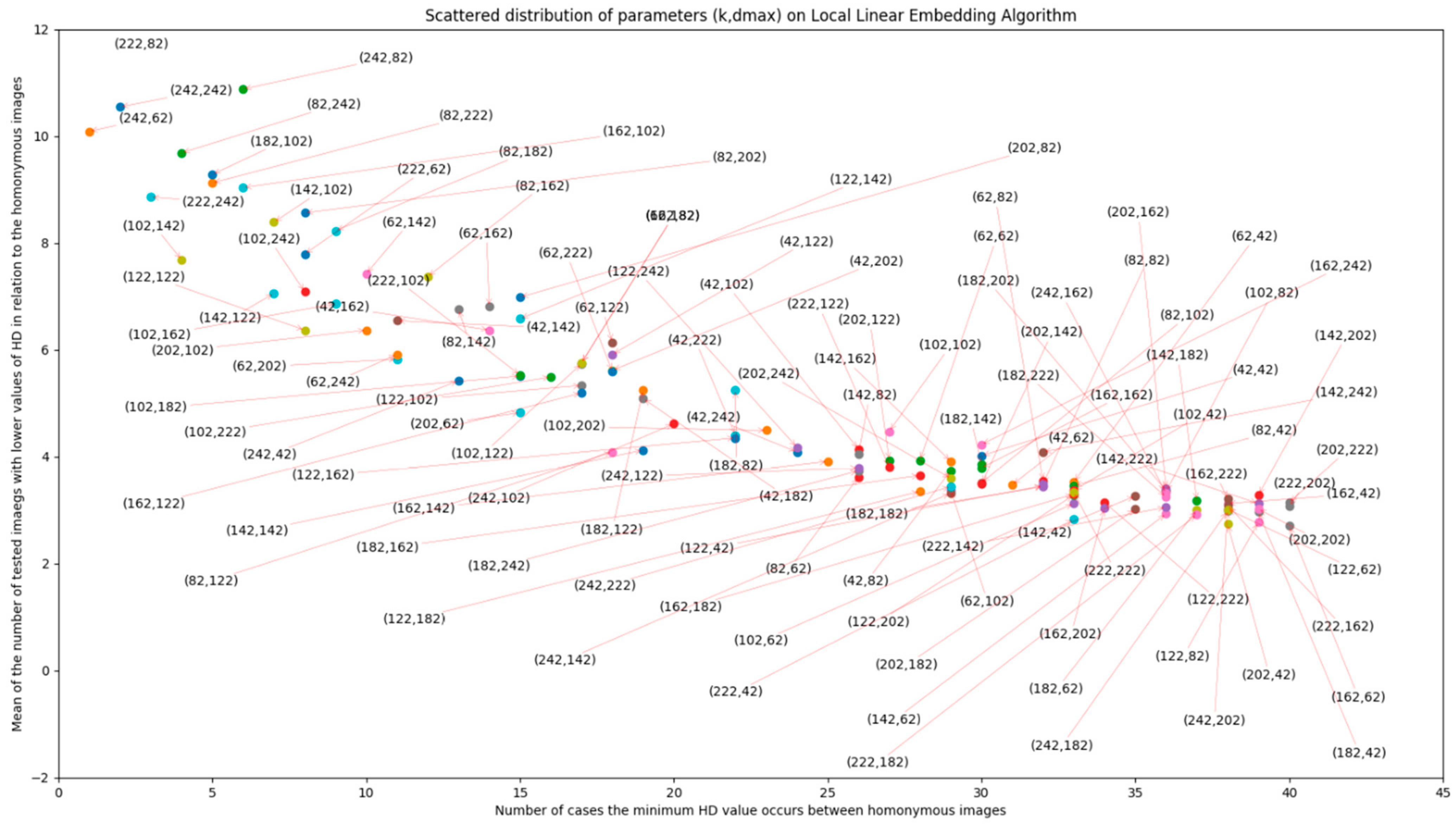
2.6. Local Linear Embedding (LLE)
2.7. Discrete Wavelet Transform (DWT)
2.8. Difference Hash (DH)
2.9. Average Hash (AH)
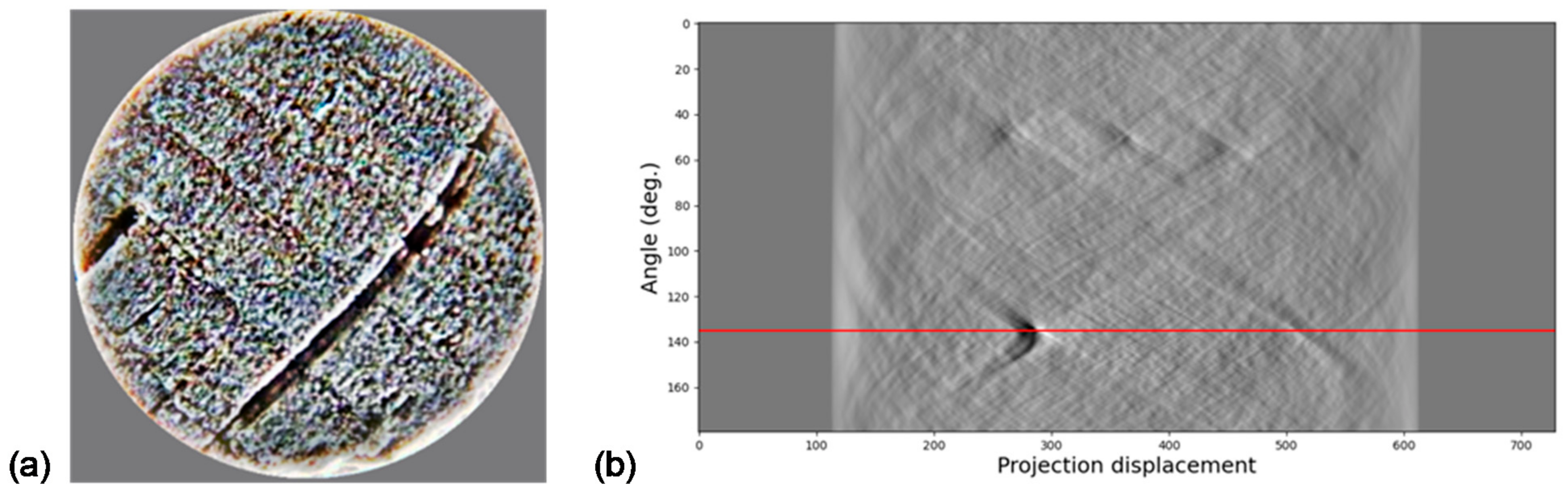
2.10. Radon Transform (RT)
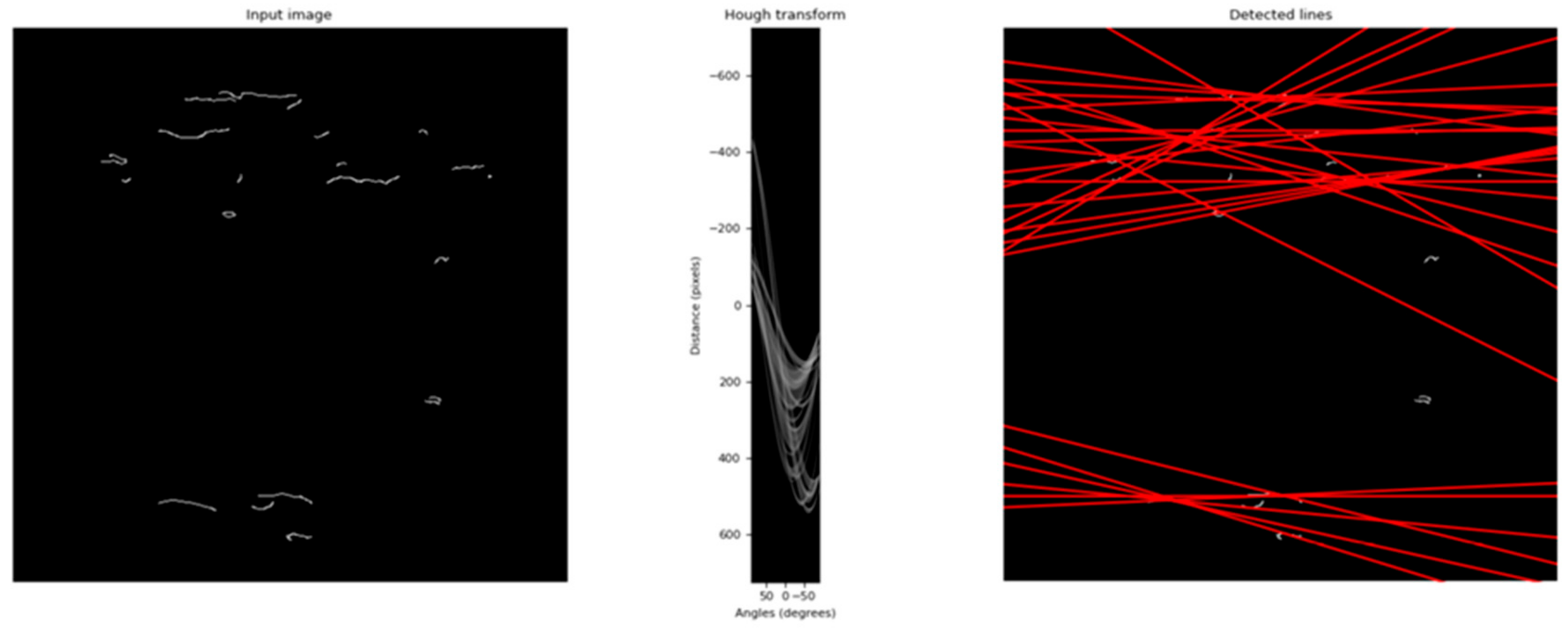
2.11. Hough Transform (HT)
2.12. Hamming Distance
3. State of the Art
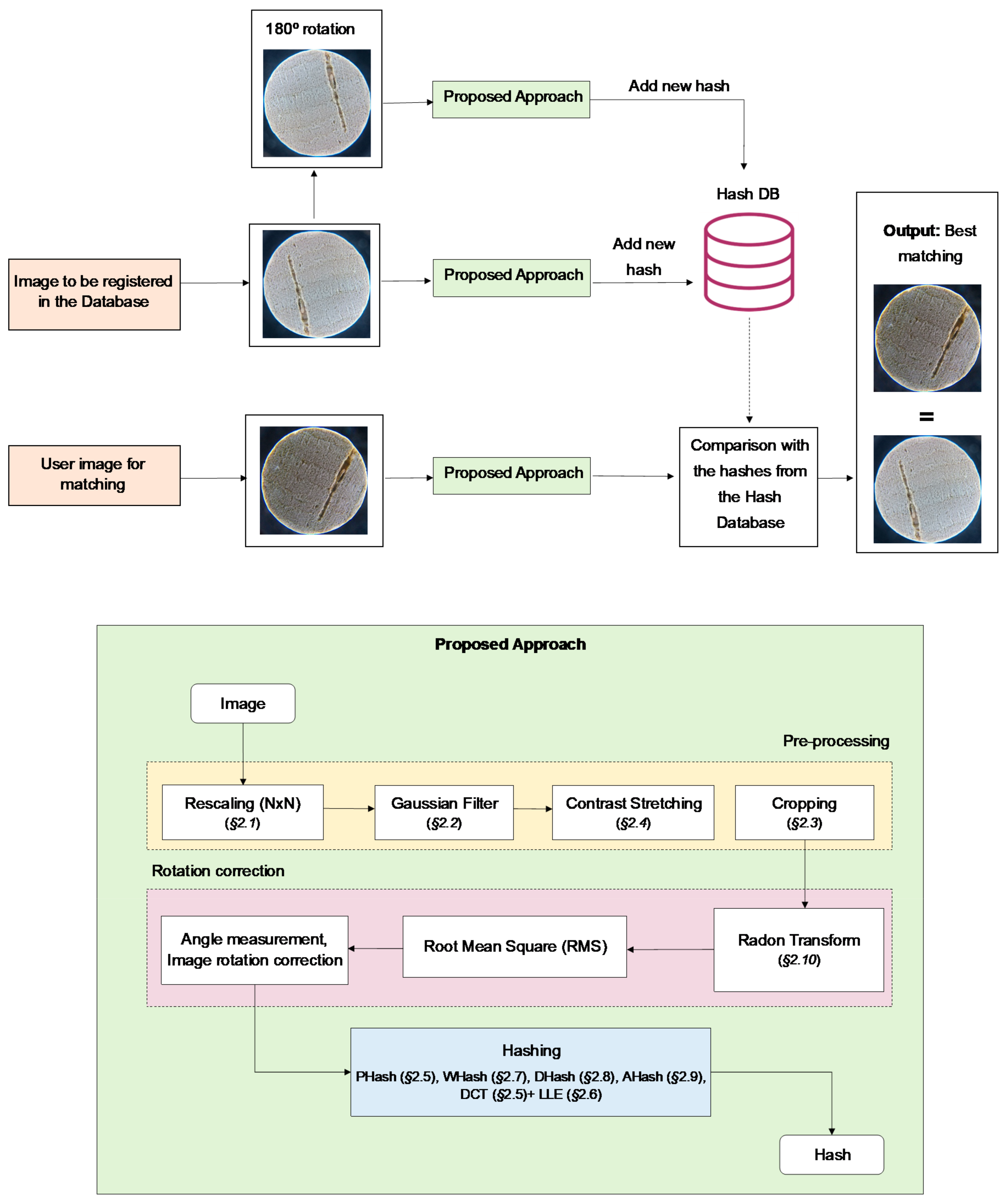
4. Methodology
5. Results and Discussion
- S1: Hash codes from all images in the database
- S2: Hash codes from images successfully rotated by RT (0° or 180°)
- S3: Hash codes from images successfully rotated by RT to the correct side (0°)
5.1. Testing Methods without Pre-Processing
General Results and Comparison for the Different Methods
5.2. Rotation Correction
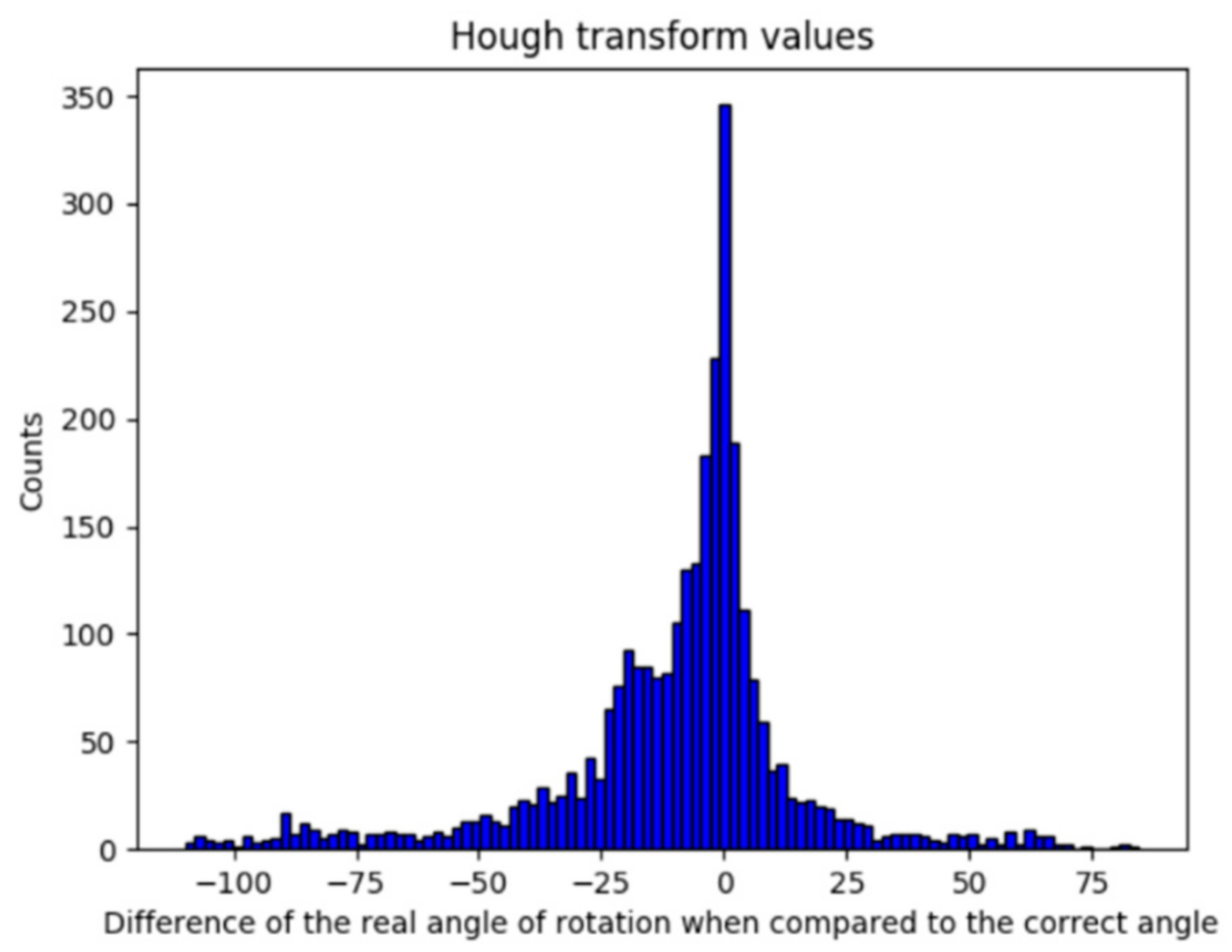
5.2.1. Rotation Correction Using Hough Transform Operation
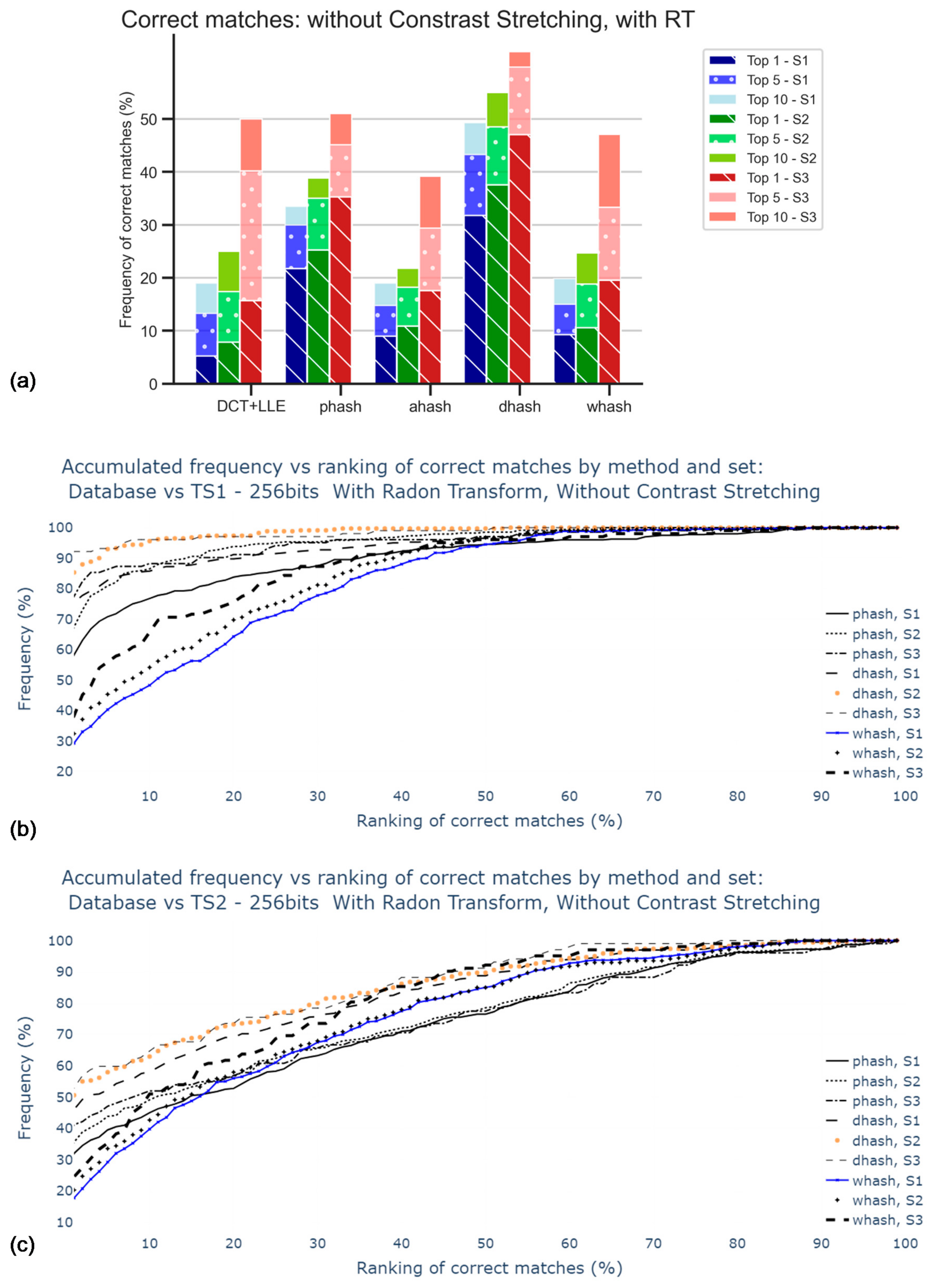
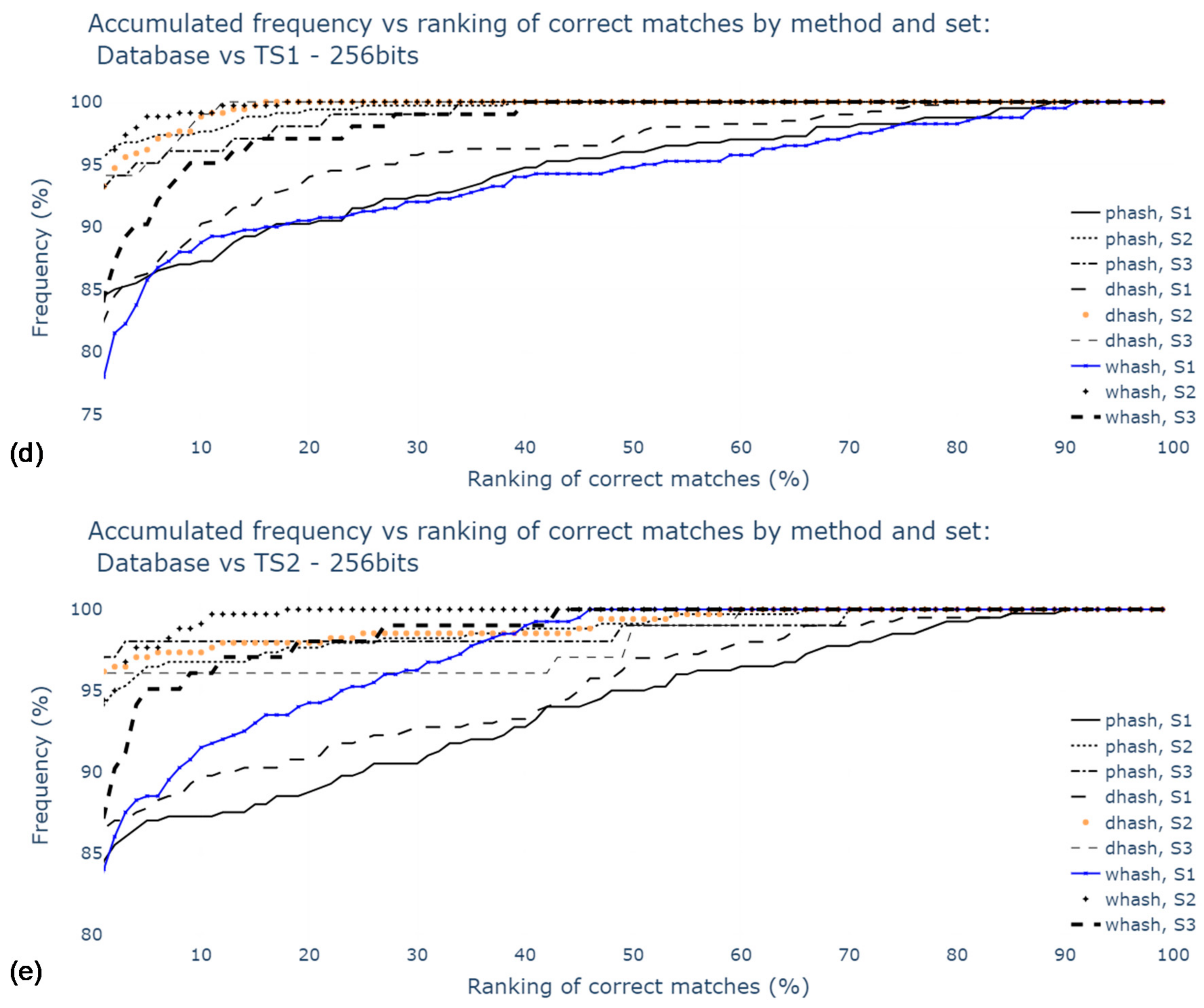
5.2.2. Rotation Correction Using Radon Transform
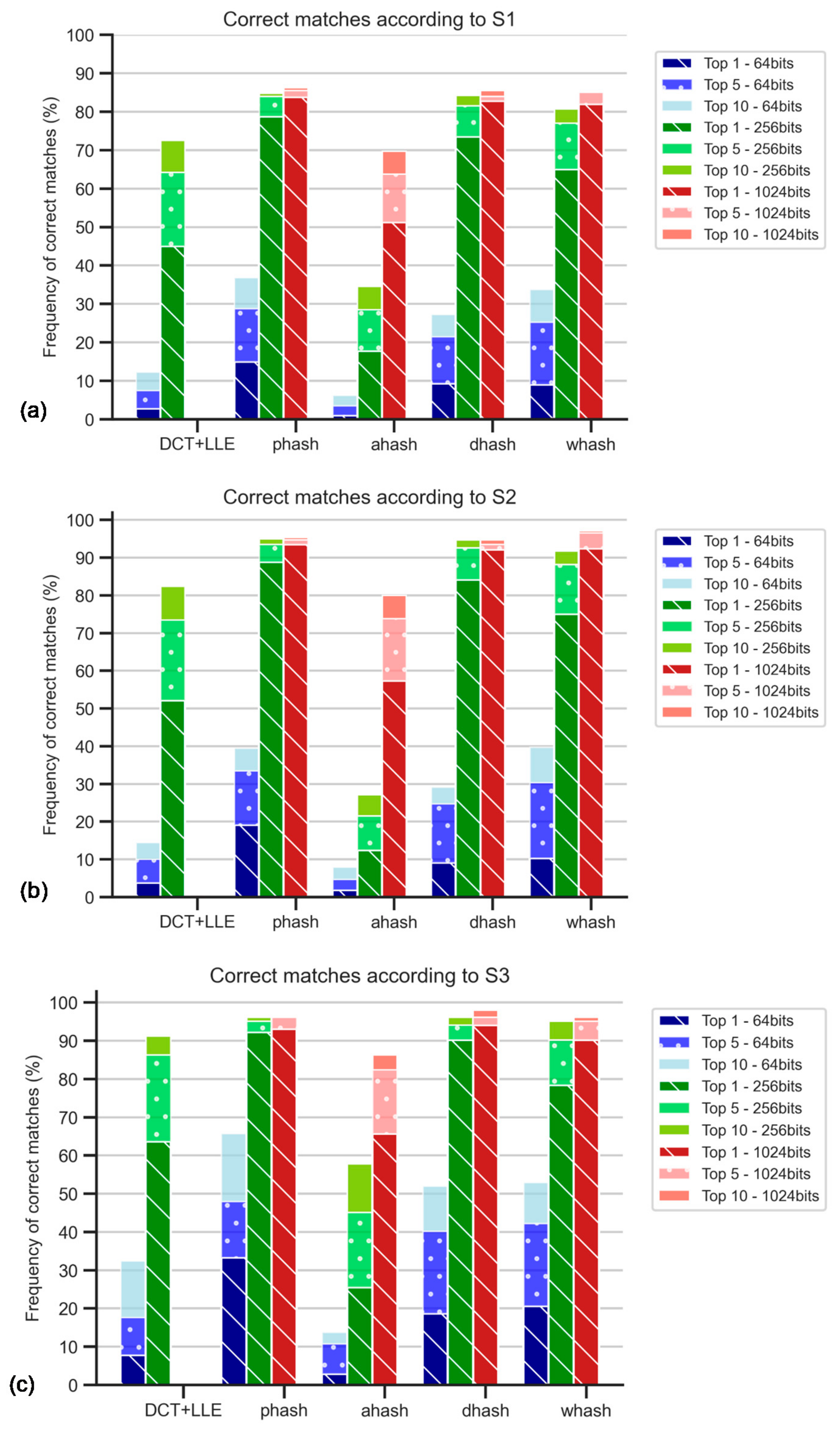
5.3. Contrast Stretching and Hash sizes
5.4. Time Performance
- Step 1: Image acquisition
- Step 2: Pre-processing (Gauss filter, contrast stretching, cubic interpolation)
- Step 3: Radon transform and angle calculation
- Step 4: Image-to-hash conversion
- Step 5: Hamming distance and final correspondence
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


Appendix B. Tables of Accuracy Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 6.8% | 6.5% | 1.3% | 5.0% | 0.8% |
| Top 5 | 12.3% | 10.8% | 3.3% | 14.8% | 4.3% | |
| Top 10 | 16.0% | 12.3% | 5.0% | 21.0% | 9.3% | |
| S2 | Top 1 | 8.5% | 7.1% | 1.2% | 6.2% | 1.2% |
| Top 5 | 13.8% | 11.5% | 4.1% | 17.4% | 5.9% | |
| Top 10 | 20.3% | 14.7% | 5.0% | 23.5% | 10.0% | |
| S3 | Top 1 | 11.8% | 7.8% | 2.9% | 3.9% | 5.9% |
| Top 5 | 23.5% | 13.7% | 7.8% | 19.6% | 18.6% | |
| Top 10 | 30.4% | 20.6% | 12.7% | 25.5% | 31.4% | |
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 3.8% | 1.5% | 0.0% | 4.8% | 3.8% |
| Top 5 | 7.3% | 4.0% | 2.5% | 11.3% | 9.0% | |
| Top 10 | 11.0% | 5.5% | 4.3% | 17.0% | 10.8% | |
| S2 | Top 1 | 4.1% | 1.5% | 0.0% | 5.0% | 4.1% |
| Top 5 | 8.5% | 3.8% | 2.9% | 10.9% | 8.8% | |
| Top 10 | 12.6% | 7.4% | 5.0% | 15.3% | 11.5% | |
| S3 | Top 1 | 5.9% | 2.9% | 2.9% | 12.7% | 11.8% |
| Top 5 | 22.5% | 13.7% | 9.8% | 24.5% | 22.5% | |
| Top 10 | 35.3% | 22.5% | 20.6% | 37.3% | 35.3% | |
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 5.3% | 21.8% | 9.0% | 31.8% | 9.3% |
| Top 5 | 13.3% | 30.0% | 14.8% | 43.3% | 15.0% | |
| Top 10 | 19.0% | 33.5% | 19.0% | 49.3% | 19.8% | |
| S2 | Top 1 | 7.9% | 25.3% | 10.9% | 37.6% | 10.6% |
| Top 5 | 17.4% | 35.0% | 18.2% | 48.5% | 18.8% | |
| Top 10 | 25.0% | 38.8% | 21.8% | 55.0% | 24.7% | |
| S3 | Top 1 | 15.7% | 35.3% | 17.6% | 47.1% | 19.6% |
| Top 5 | 40.2% | 45.1% | 33.3% | 59.8% | 33.3% | |
| Top 10 | 50.0% | 51.0% | 42.2% | 62.7% | 47.1% | |
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 15.8% | 45.3% | 12.8% | 62.8% | 15.3% |
| Top 5 | 30.3% | 54.8% | 16.8% | 74.3% | 25.5% | |
| Top 10 | 37.8% | 61.8% | 20.3% | 77.3% | 31.5% | |
| S2 | Top 1 | 20.6% | 53.8% | 15.6% | 72.4% | 17.9% |
| Top 5 | 37.9% | 66.2% | 20.9% | 84.7% | 30.9% | |
| Top 10 | 48.2% | 72.9% | 24.7% | 87.9% | 37.1% | |
| S3 | Top 1 | 33.3% | 72.5% | 18.6% | 88.2% | 32.4% |
| Top 5 | 52.9% | 85.3% | 29.4% | 93.1% | 53.9% | |
| Top 10 | 67.6% | 87.3% | 39.2% | 96.1% | 61.8% | |
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 3.3% | 16.5% | 1.3% | 9.3% | 15.5% |
| Top 5 | 11.5% | 28.8% | 3.5% | 21.5% | 27.5% | |
| Top 10 | 17.8% | 37.5% | 6.3% | 29.0% | 37.3% | |
| S2 | Top 1 | 3.8% | 20.0% | 1.8% | 10.9% | 17.9% |
| Top 5 | 14.1% | 35.0% | 4.7% | 25.3% | 32.1% | |
| Top 10 | 20.3% | 45.0% | 7.9% | 34.4% | 43.5% | |
| S3 | Top 1 | 7.8% | 33.3% | 2.9% | 18.6% | 20.6% |
| Top 5 | 17.6% | 48.0% | 10.8% | 40.2% | 42.2% | |
| Top 10 | 35.3% | 65.7% | 13.7% | 52.0% | 52.9% | |
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 2.8% | 15.0% | 1.0% | 9.5% | 9.0% |
| Top 5 | 7.5% | 28.8% | 4.0% | 22.0% | 25.3% | |
| Top 10 | 12.3% | 36.8% | 7.5% | 27.3% | 33.8% | |
| S2 | Top 1 | 4.1% | 19.1% | 1.8% | 9.1% | 10.3% |
| Top 5 | 10.0% | 33.5% | 5.3% | 24.7% | 30.3% | |
| Top 10 | 14.4% | 39.4% | 10.6% | 29.1% | 39.7% | |
| S3 | Top 1 | 7.8% | 36.3% | 4.9% | 24.5% | 23.5% |
| Top 5 | 27.5% | 58.8% | 13.7% | 45.1% | 48.0% | |
| Top 10 | 32.4% | 73.5% | 24.5% | 66.7% | 58.8% | |
| DCT+LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 48.5% | 78.8% | 17.8% | 73.5% | 65.0% |
| Top 5 | 67.0% | 84.0% | 28.5% | 81.5% | 77.0% | |
| Top 10 | 73.0% | 84.8% | 34.5% | 84.3% | 80.8% | |
| S2 | Top 1 | 57.6% | 90.3% | 12.4% | 84.1% | 75.0% |
| Top 5 | 76.2% | 95.3% | 21.5% | 92.6% | 88.2% | |
| Top 10 | 82.4% | 96.5% | 27.1% | 94.7% | 91.8% | |
| S3 | Top 1 | 70.6% | 92.2% | 25.5% | 90.2% | 78.4% |
| Top 5 | 87.3% | 95.1% | 45.1% | 93.1% | 90.2% | |
| Top 10 | 91.2% | 96.1% | 57.8% | 98.0% | 95.1% | |
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 45.0% | 78.8% | 22.5% | 76.5% | 68.3% |
| Top 5 | 64.3% | 84.0% | 32.5% | 86.5% | 79.3% | |
| Top 10 | 72.5% | 85.0% | 37.3% | 86.8% | 82.3% | |
| S2 | Top 1 | 52.1% | 88.8% | 16.8% | 87.1% | 77.6% |
| Top 5 | 73.5% | 93.5% | 22.4% | 96.2% | 88.5% | |
| Top 10 | 82.9% | 95.0% | 27.9% | 96.5% | 92.4% | |
| S3 | Top 1 | 63.7% | 96.1% | 34.3% | 93.1% | 84.3% |
| Top 5 | 86.3% | 98.0% | 50.0% | 96.1% | 94.1% | |
| Top 10 | 94.1% | 98.0% | 60.8% | 96.1% | 96.1% | |
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 0.5% | 85.3% | 51.8% | 85.0% | 82.0% |
| Top 5 | 0.5% | 85.8% | 63.8% | 86.3% | 85.0% | |
| Top 10 | 7.0% | 86.5% | 69.8% | 87.0% | 85.3% | |
| S2 | Top 1 | 0.6% | 97.1% | 59.4% | 96.5% | 93.2% |
| Top 5 | 0.6% | 97.4% | 73.8% | 98.2% | 96.8% | |
| Top 10 | 8.2% | 97.9% | 80.0% | 98.5% | 97.1% | |
| S3 | Top 1 | 5.4% | 93.1% | 65.7% | 98.0% | 90.2% |
| Top 5 | 14.3% | 96.1% | 82.4% | 98.0% | 95.1% | |
| Top 10 | 21.4% | 97.1% | 86.3% | 98.0% | 96.1% | |
| DCT + LLE | pHash | aHash | dHash | wHash | ||
|---|---|---|---|---|---|---|
| S1 | Top 1 | 0.3% | 83.8% | 51.3% | 82.8% | 82.3% |
| Top 5 | 0.5% | 85.5% | 64.5% | 84.0% | 86.5% | |
| Top 10 | 0.5% | 86.3% | 70.0% | 85.5% | 87.5% | |
| S2 | Top 1 | 0.3% | 93.5% | 57.4% | 92.1% | 92.4% |
| Top 5 | 0.6% | 94.7% | 73.8% | 93.5% | 96.5% | |
| Top 10 | 0.9% | 95.3% | 80.9% | 94.7% | 97.1% | |
| S3 | Top 1 | 0.0% | 96.1% | 76.5% | 94.1% | 91.2% |
| Top 5 | 0.0% | 96.1% | 84.3% | 96.1% | 96.1% | |
| Top 10 | 0.0% | 96.1% | 88.2% | 98.0% | 96.1% | |
References
- Ishiyama, R.; Takahashi, T.; Kudo, Y. Individual recognition based on the fingerprint of things expands the applications of IoT. NEC Tech. J. 2016, 11, 1–5. [Google Scholar]
- Wigger, B.; Meissner, T.; Förste, A.; Jetter, V.; Zimmermann, A. Using unique surface patterns of injection moulded plastic components as an image based Physical Unclonable Function for secure component identification. Sci. Rep. 2018, 8, 4738. [Google Scholar] [CrossRef]
- Ishiyama, R.; Kudo, Y.; Takahashi, T.; Kooper, M.; Makino, K.; Abbink, D.; Nl, D. Medicine Tablet Authentication Using “Fingerprints” of Ink-Jet Printed Characters. In Proceedings of the 2019 IEEE International Conference on Industrial Technology (ICIT), Melbourne, VIC, Australia, 13–15 February 2019. [Google Scholar]
- Al-alem, F.; Alsmirat, M.A.; Al-Ayyoub, M. On the road to the Internet of Biometric Things: A survey of fingerprint acquisition technologies and fingerprint databases. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–6. [Google Scholar]
- Wang, X.; Gao, L.; Mao, S. CSI Phase Fingerprinting for Indoor Localization With a Deep Learning Approach. IEEE Internet Things J. 2016, 3, 1113–1123. [Google Scholar] [CrossRef]
- WHO. Global Surveillance and Monitoring System for Substandard and Falsified Medical Products; World Health Organization: Geneva, Switzerland, 2017; ISBN 978-92-4-151342-5. [Google Scholar]
- Behner, P.; Hecht, M.L.; Wahl, F. Fighting counterfeit pharmaceuticals: New defenses for an underestimated and growing menace. Retrieved Dec. 2017, 12, 2017. [Google Scholar]
- Juels, A. RFID security and privacy: A research survey. IEEE J. Sel. Areas Commun. 2006, 24, 381–394. [Google Scholar] [CrossRef]
- Chen, C.H.; Lin, I.C.; Yang, C.C. NFC Attacks Analysis and Survey. In Proceedings of the 2014 Eighth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Birmingham, UK, 2–4 July 2014; pp. 458–462. [Google Scholar]
- Costa, V.; Sousa, A.; Reis, A. Cork as a Unique Object: Device, Method, and Evaluation. Appl. Sci. 2018, 8, 2150. [Google Scholar] [CrossRef]
- Rührmair, U.; Devadas, S.; Koushanfar, F. Security Based on Physical Unclonability and Disorder. In Introduction to Hardware Security and Trust; Springer: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Pappu, R.; Recht, B.; Taylor, J.; Gershenfeld, N. Physical one-way functions. Science 2002, 297, 2026–2030. [Google Scholar] [CrossRef]
- Rührmair, U.; Holcomb, D.E. PUFs at a glance. In Proceedings of the 2014 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 24–28 March 2014; pp. 1–6. [Google Scholar]
- Brzuska, C.; Fischlin, M.; Schröder, H.; Katzenbeisser, S. Physically Uncloneable Functions in the Universal Composition Framework BT—Advances in Cryptology—CRYPTO 2011; Rogaway, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 51–70. [Google Scholar]
- Costa, V.; Sousa, A.; Reis, A. Preventing wine counterfeiting by individual cork stopper recognition using image processing technologies. J. Imaging 2018, 4, 54. [Google Scholar] [CrossRef]
- Di Martino, F.; Loia, V.; Perfilieva, I.; Sessa, S. An image coding/decoding method based on direct and inverse fuzzy transforms. Int. J. Approx. Reason. 2008, 48, 110–131. [Google Scholar] [CrossRef]
- Gupta, M.; Kumar Garg, D. Analysis of Image Compression Algorithm Using DCT. Int. J. Eng. Res. Appl. 2012, 2, 515–521. [Google Scholar]
- Ito, I. A New Pseudo-Spectral Method Using the Discrete Cosine Transform. J. Imaging 2020, 6, 15. [Google Scholar] [CrossRef]
- Robinson, J.; Kecman, V. Combining support vector machine learning with the discrete cosine transform in image compression. IEEE Trans. Neural Netw. 2003, 14, 950–958. [Google Scholar] [CrossRef]
- Ridder, D.; Duin, R. Locally Linear Embedding For Classification. In Artificial Neural Networks and Neural Information Processing—ICANN/ICONIP 2003; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Tang, Z.; Lao, H.; Zhang, X.; Liu, K. Robust image hashing via DCT and LLE. Comput. Secur. 2016, 62, 133–148. [Google Scholar] [CrossRef]
- Xizhi, Z. The Application of Wavelet Transform in Digital Image Processing. In Proceedings of the 2008 International Conference on MultiMedia and Information Technology, Three Gorges, China, 30–31 December 2008; pp. 326–329. [Google Scholar]
- Ramos, R.; Valdez-Salas, B.; Zlatev, R.; Schorr Wiener, M.; Bastidas Rull, J.M. The Discrete Wavelet Transform and Its Application for Noise Removal in Localized Corrosion Measurements. Int. J. Corros. 2017, 2017, 7925404. [Google Scholar] [CrossRef]
- Xiong, Z.; Ramchandran, K. Chapter 18—Wavelet Image Compression. In The Essential Guide to Image Processing; Bovik, A., Ed.; Academic Press: Boston, MA, USA, 2009; pp. 463–493. ISBN 978-0-12-374457-9. [Google Scholar]
- Kehtarnavaz, N. Chapter 7—Frequency Domain Processing. In Digital Signal Processing System Design, 2nd ed.; Kehtarnavaz, N., Ed.; Academic Press: Burlington, VT, USA, 2008; pp. 175–196. ISBN 978-0-12-374490-6. [Google Scholar]
- Dargham, J.A.; Chekima, A.; Moung, E.; Omatu, S. Radon transform for face recognition. Artif. Life Robot. 2010, 15, 359–362. [Google Scholar] [CrossRef]
- Beatty, J. The Radon Transform and Medical Imaging; CBMS-NSF Regional Conference Series in Applied Mathematics; SIAM: Philadelphia, PA, USA, 2014. [Google Scholar]
- Lefbvre, F.; Macq, B.; Legat, J.-D. Rash: Radon soft hash algorithm. In Proceedings of the 2002 11th European Signal Processing Conference, Toulouse, France, 3–6 September 2002; Volume 1. [Google Scholar]
- Ou, Y.; Rhee, K.H. A key-dependent secure image hashing scheme by using Radon transform. In Proceedings of the 2009 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Kanazawa, Japan, 7–9 January 2009; pp. 595–598. [Google Scholar]
- Santosh, K.C.; Lamiroy, B.; Wendling, L. DTW-radon-based shape descriptor for pattern recognition. Int. J. Pattern Recognit. Artif. Intell. 2013, 27, 1350008. [Google Scholar] [CrossRef]
- Van Ginkel, M.; Luengo Hendriks, C.; Van Vliet, L. A Short Introduction to the Radon and Hough Transforms and How They Relate to Each Other; Delft University of Technology: Delft, The Netherlands, 2004. [Google Scholar]
- Bailey, D.; Chang, Y.; Le Moan, S. Analysing Arbitrary Curves from the Line Hough Transform. J. Imaging 2020, 6, 26. [Google Scholar] [CrossRef]
- Du, L.; Ho, A.T.S.; Cong, R. Perceptual hashing for image authentication: A survey. Signal Process. Image Commun. 2020, 81, 115713. [Google Scholar] [CrossRef]
- Yan, C.; Pun, C. Multi-Scale Difference Map Fusion for Tamper Localization Using Binary Ranking Hashing. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2144–2158. [Google Scholar] [CrossRef]
- Qin, C.; Hu, Y.; Yao, H.; Duan, X.; Gao, L. Perceptual Image Hashing Based on Weber Local Binary Pattern and Color Angle Representation. IEEE Access 2019, 7, 45460–45471. [Google Scholar] [CrossRef]
- Qin, C.; Sun, M.; Chang, C.-C. Perceptual hashing for color images based on hybrid extraction of structural features. Signal Process. 2018, 142, 194–205. [Google Scholar] [CrossRef]
- Pun, C.-M.; Yan, C.-P.; Yuan, X.-C. Robust image hashing using progressive feature selection for tampering detection. Multimed. Tools Appl. 2018, 77, 11609–11633. [Google Scholar] [CrossRef]
- Sun, R.; Zeng, W. Secure and robust image hashing via compressive sensing. Multimed. Tools Appl. 2014, 70, 1651–1665. [Google Scholar] [CrossRef]
- Liu, H.; Xiao, D.; Xiao, Y.; Zhang, Y. Robust image hashing with tampering recovery capability via low-rank and sparse representation. Multimed. Tools Appl. 2016, 75, 7681–7696. [Google Scholar] [CrossRef]
- Srivastava, M.; Siddiqui, J.; Ali, M.A. Robust image hashing based on statistical features for copy detection. In Proceedings of the 2016 IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics Engineering (UPCON), Varanasi, India, 9–11 December 2016; pp. 490–495. [Google Scholar]
- Huang, Z.; Liu, S. Robustness and Discrimination Oriented Hashing Combining Texture and Invariant Vector Distance. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1389–1397. [Google Scholar]
- Jiang, C.; Pang, Y. Perceptual image hashing based on a deep convolution neural network for content authentication. J. Electron. Imaging 2018, 27, 043055. [Google Scholar] [CrossRef]
- Costa, V. Vision Methods to Find Uniqueness Within a Class of Objects [University of Porto]. 2019. Available online: https://hdl.handle.net/10216/119624 (accessed on 5 March 2021).
- Costa, V.; Sousa, A.; Reis, A. CBIR for a wine anti-counterfeiting system using imagery from cork stoppers. In Proceedings of the 2018 13th Iberian Conference on Information Systems and Technologies (CISTI), Cáceres, Spain, 13–16 June 2018; pp. 1–6. [Google Scholar]
- Jafari-Khouzani, K.; Soltanian-Zadeh, H. Radon transform orientation estimation for rotation invariant texture analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1004–1008. [Google Scholar] [CrossRef] [PubMed]
- Hejazi, M.R.; Shevlyakov, G.; Ho, Y. Modified Discrete Radon Transforms and Their Application to Rotation-Invariant Image Analysis. In Proceedings of the 2006 IEEE Workshop on Multimedia Signal Processing, Victoria, BC, Canada, 3–6 October 2006; pp. 429–434. [Google Scholar]












| Section 2 | Parameter Designation | Value |
|---|---|---|
| Section 2.1 | Image size | 512 |
| Section 2.2 | Lowpass filtering window size | 3 |
| Section 2.2 | Standard deviation | 8 |
| Section 2.3 | Rad. Minimum limit value | 230 |
| Section 2.3 | Rad. Maximum limit value | 260 |
| Section 2.3 | Center min. Limit value | 230 |
| Section 2.3 | Center max. Limit value | 280 |
| Section 2.4 | Clip value | 0.03 |
| Section 2.5 | B (N = 64-bit hash code) | 64 |
| Section 2.5 | B (N = 256-bit hash code) | 32 |
| Section 2.5 | B (N = 1024-bit hash code) | 16 |
| Section 2.6 | K (N = 64-bit hash code) | 15 |
| Section 2.6 | Dmax (N = 64-bit hash code) | 40 |
| Section 2.6 | K (N = 256-bit hash code) | 42 |
| Section 2.6 | Dmax (N = 256-bit hash code) | 42 |
| Section 2.6 | K (N = 1024-bit hash code) | 400 |
| Section 2.6 | Dmax (N = 1024-bit hash code) | 450 |
| Step 1 | Step 2 | Step 3 | Step 5 | ||||
|---|---|---|---|---|---|---|---|
| μ (s) | σ (s) | μ (s) | σ (s) | μ (s) | σ (s) | μ (s) | σ (s) |
| 0.0243 | 0.0131 | 0.8178 | 0.0765 | 7.8382 | 0.4197 | 0.0035 | 0.0065 |
| 64-bit | 256-bit | 1024-bit | ||||
|---|---|---|---|---|---|---|
| μ (s) | σ (s) | μ (s) | σ (s) | μ (s) | σ (s) | |
| pHash | 0.0079 | 0.0250 | 0.0076 | 0.0192 | 0.0113 | 0.0252 |
| aHash | 0.0071 | 0.0377 | 0.0113 | 0.0732 | 0.0086 | 0.0156 |
| wHash | 0.0774 | 0.0235 | 0.1010 | 0.0420 | 0.1330 | 0.6917 |
| dHash | 0.0041 | 0.0057 | 0.0050 | 0.0108 | 0.0065 | 0.0055 |
| DCT + LLE | 17.3090 | 1.9727 | 19.4306 | 0.5628 | 274.3112 | 83.3862 |
| Method | Literature [44], CBIR (ms) | Current Work, Hashing (ms) | Ratio |
|---|---|---|---|
| Average of Comparing Time | 9.6 | 0.241 | 39.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fitas, R.; Rocha, B.; Costa, V.; Sousa, A. Design and Comparison of Image Hashing Methods: A Case Study on Cork Stopper Unique Identification. J. Imaging 2021, 7, 48. https://doi.org/10.3390/jimaging7030048
Fitas R, Rocha B, Costa V, Sousa A. Design and Comparison of Image Hashing Methods: A Case Study on Cork Stopper Unique Identification. Journal of Imaging. 2021; 7(3):48. https://doi.org/10.3390/jimaging7030048
Chicago/Turabian StyleFitas, Ricardo, Bernardo Rocha, Valter Costa, and Armando Sousa. 2021. "Design and Comparison of Image Hashing Methods: A Case Study on Cork Stopper Unique Identification" Journal of Imaging 7, no. 3: 48. https://doi.org/10.3390/jimaging7030048
APA StyleFitas, R., Rocha, B., Costa, V., & Sousa, A. (2021). Design and Comparison of Image Hashing Methods: A Case Study on Cork Stopper Unique Identification. Journal of Imaging, 7(3), 48. https://doi.org/10.3390/jimaging7030048