
Evaluation of 2D-/3D-Feet-Detection Methods for Semi-Autonomous Powered Wheelchair Navigation




Abstract
:1. Introduction
2. Related Works
3. Methodology
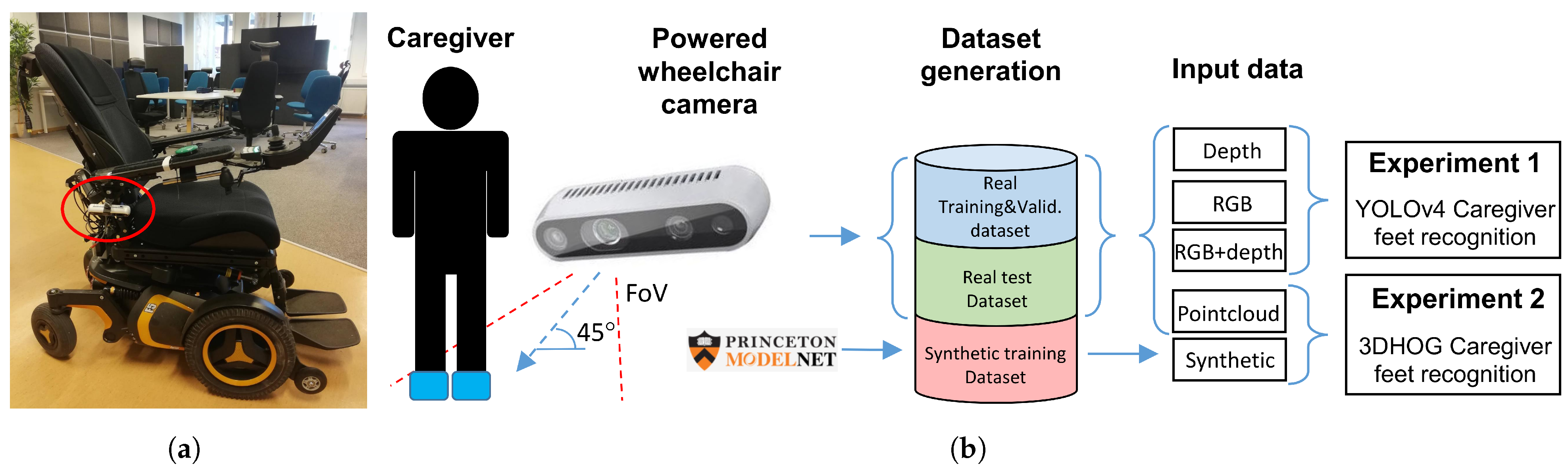
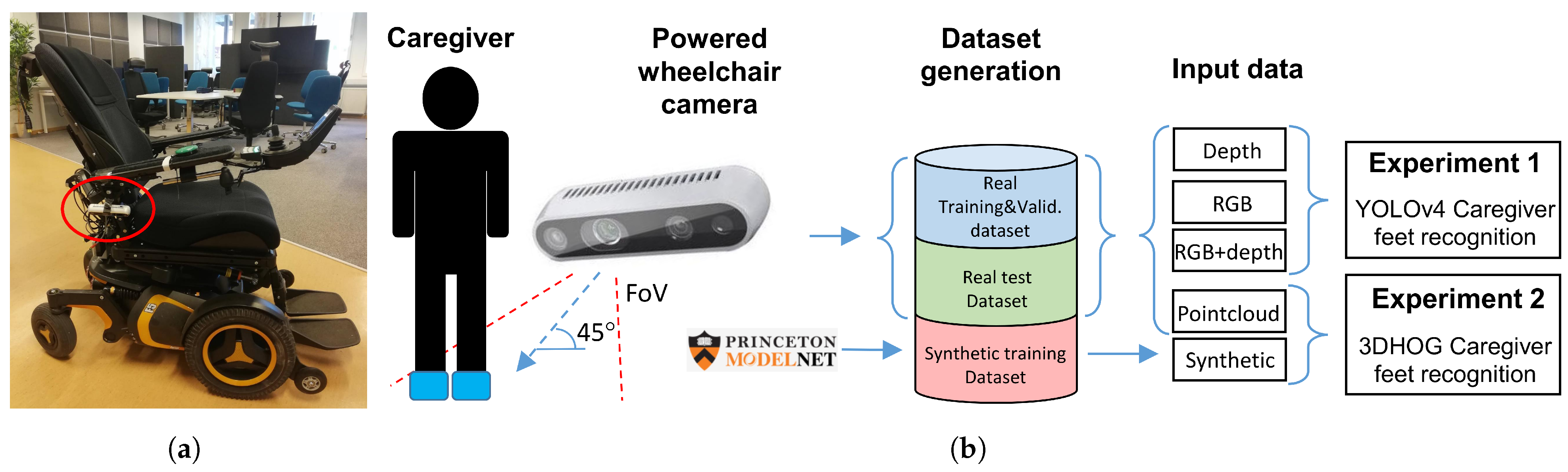
3.1. Application Description
3.2. Experiments Definition
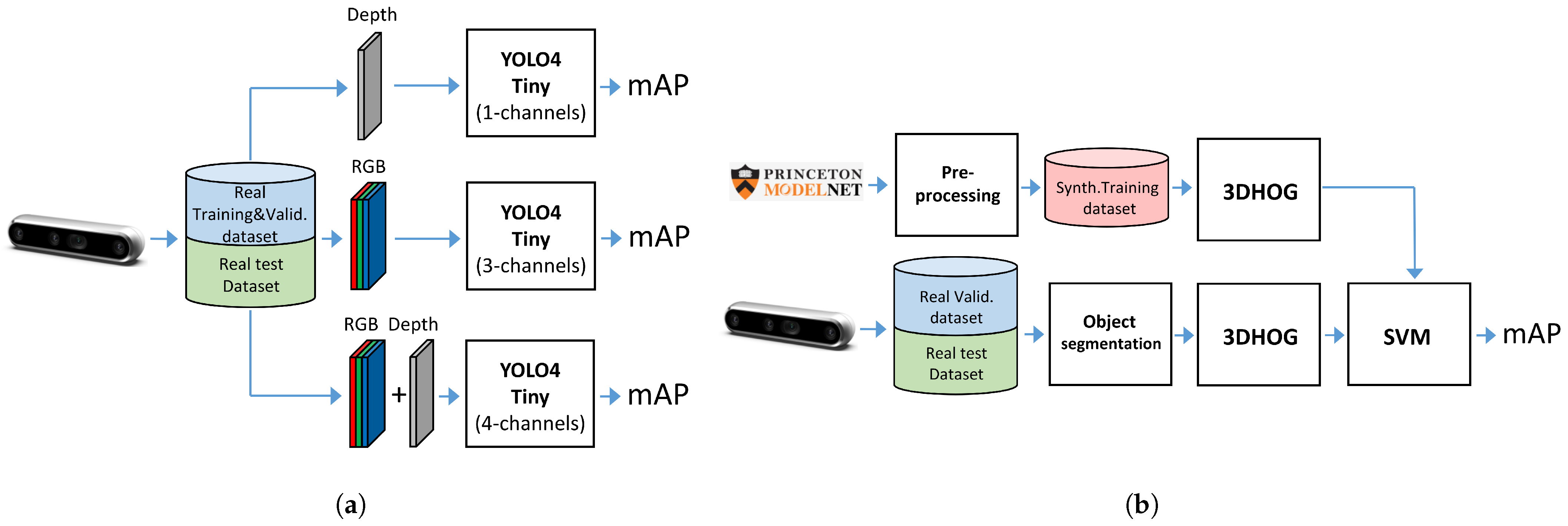
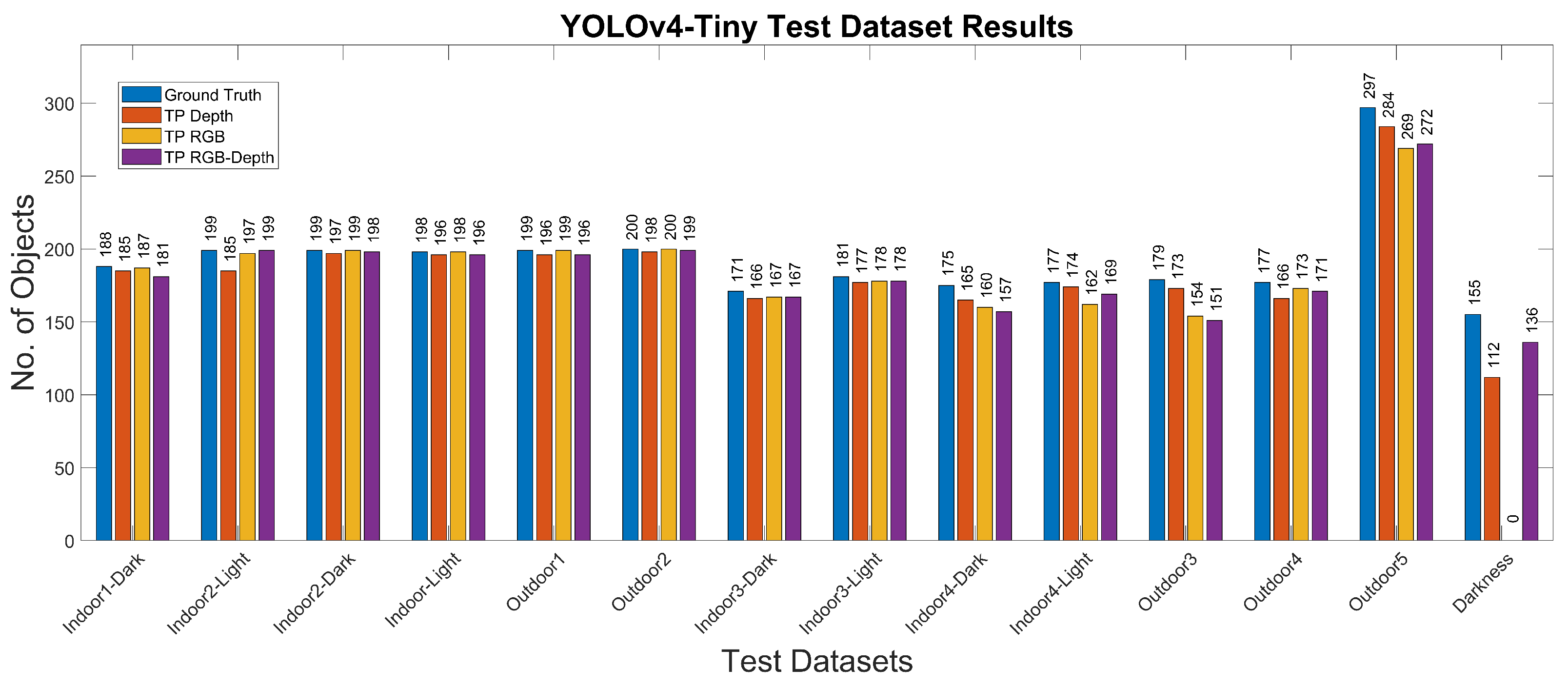
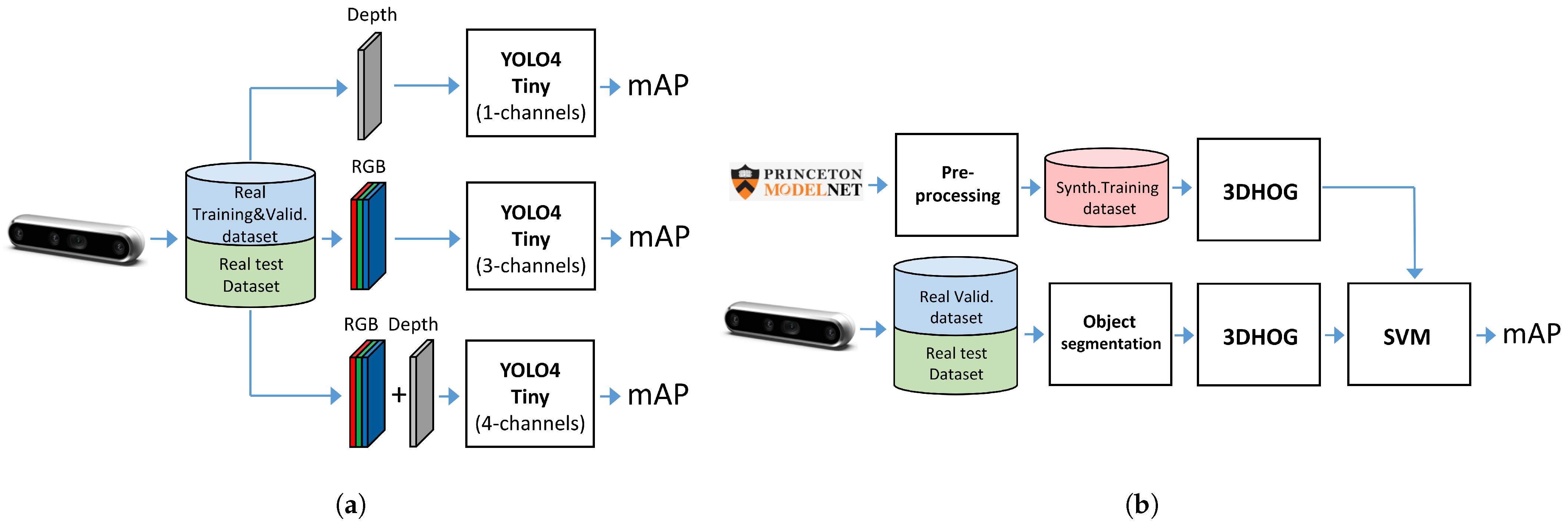
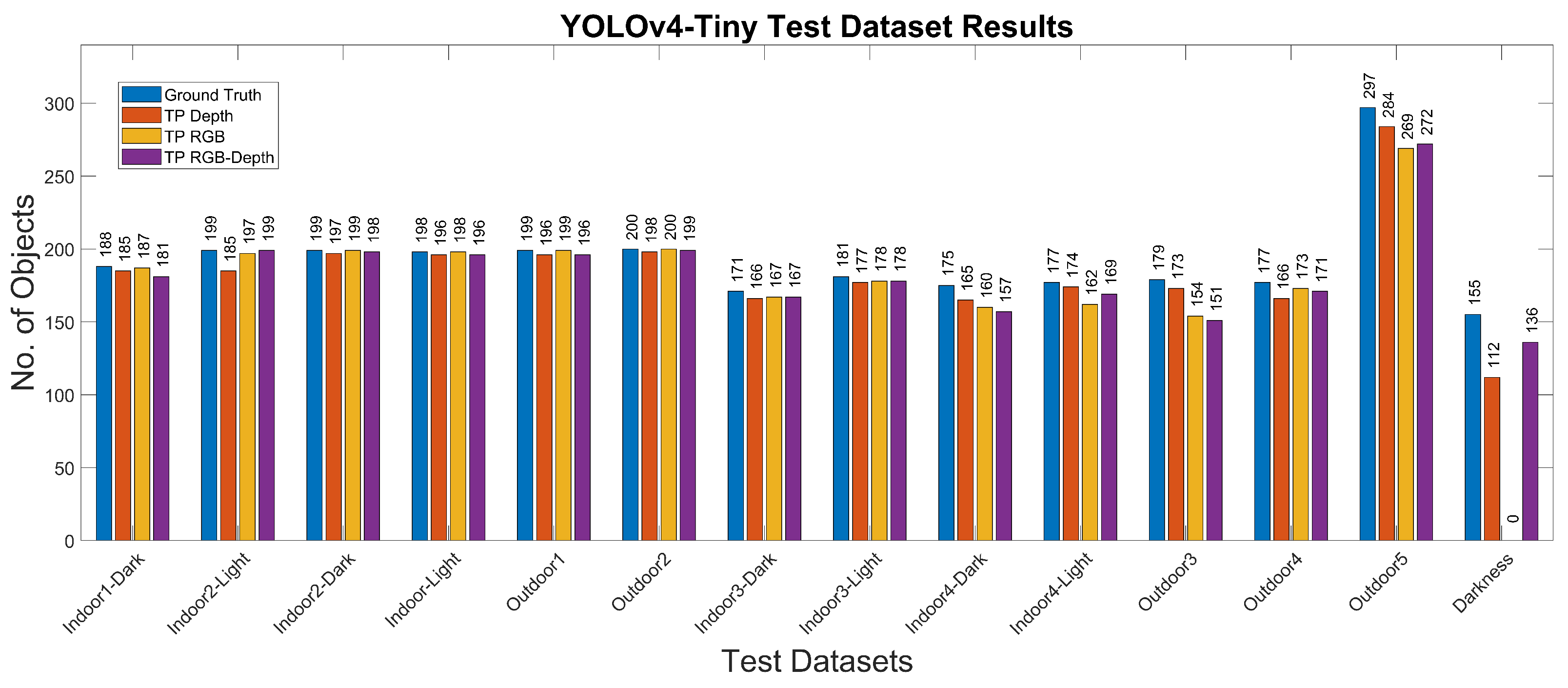
- Experiment 1: We used the Miun-Feet custom dataset of images captured by a depth camera for training, validation and test in combination with a YOLOv4-Tiny-based approach for object recognition. We evaluated the different camera output formats in terms of Mean Average Precision (mAP). Therefore, as camera outputs, we use: (1) the depth channel (1 channel), (2) the visual RGB channels (3 channels), and finally, (3) a combination of RGB and depth (4 channels) to recognize the caregiver’s feet walking next to the PW, Figure 3a.
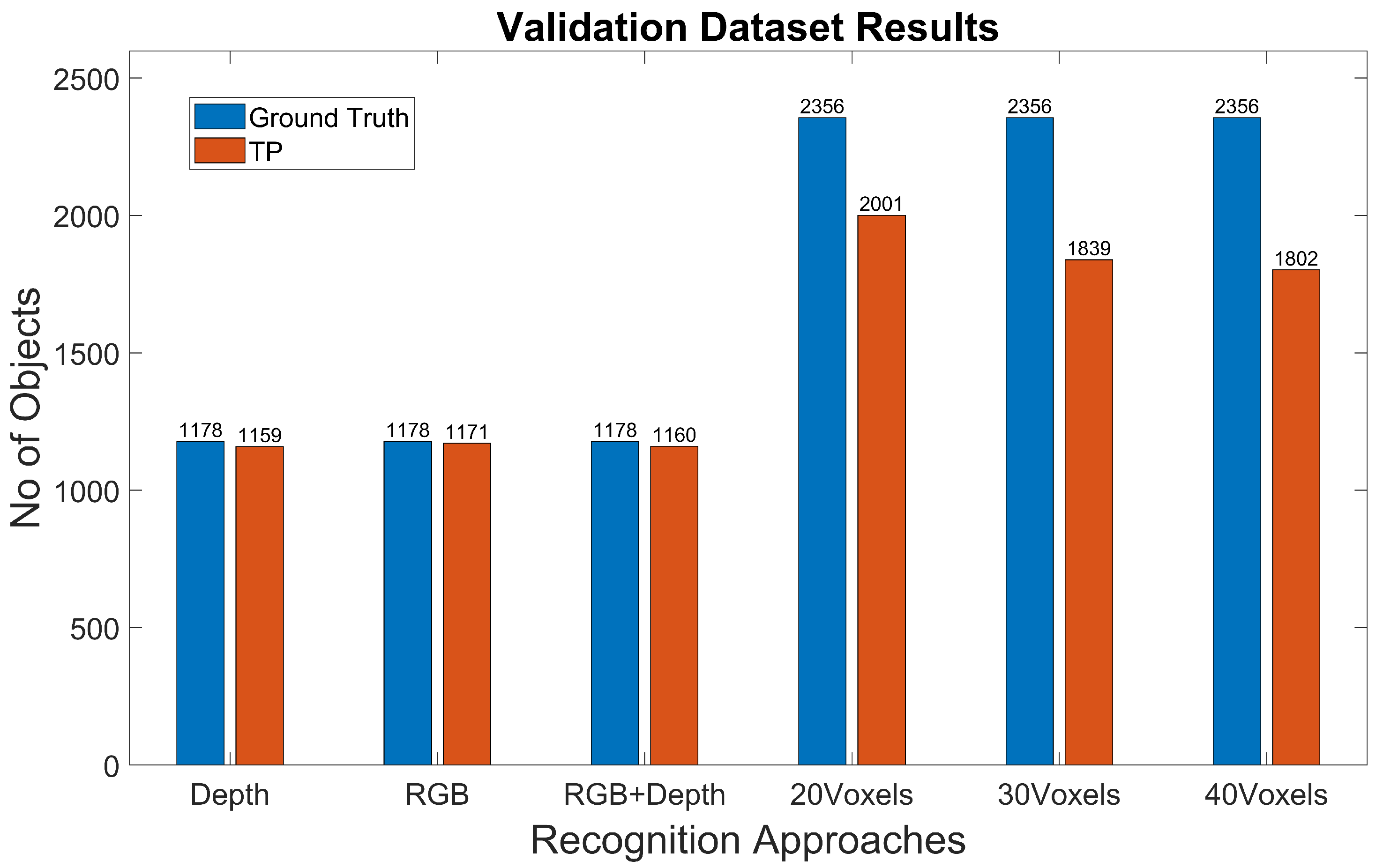
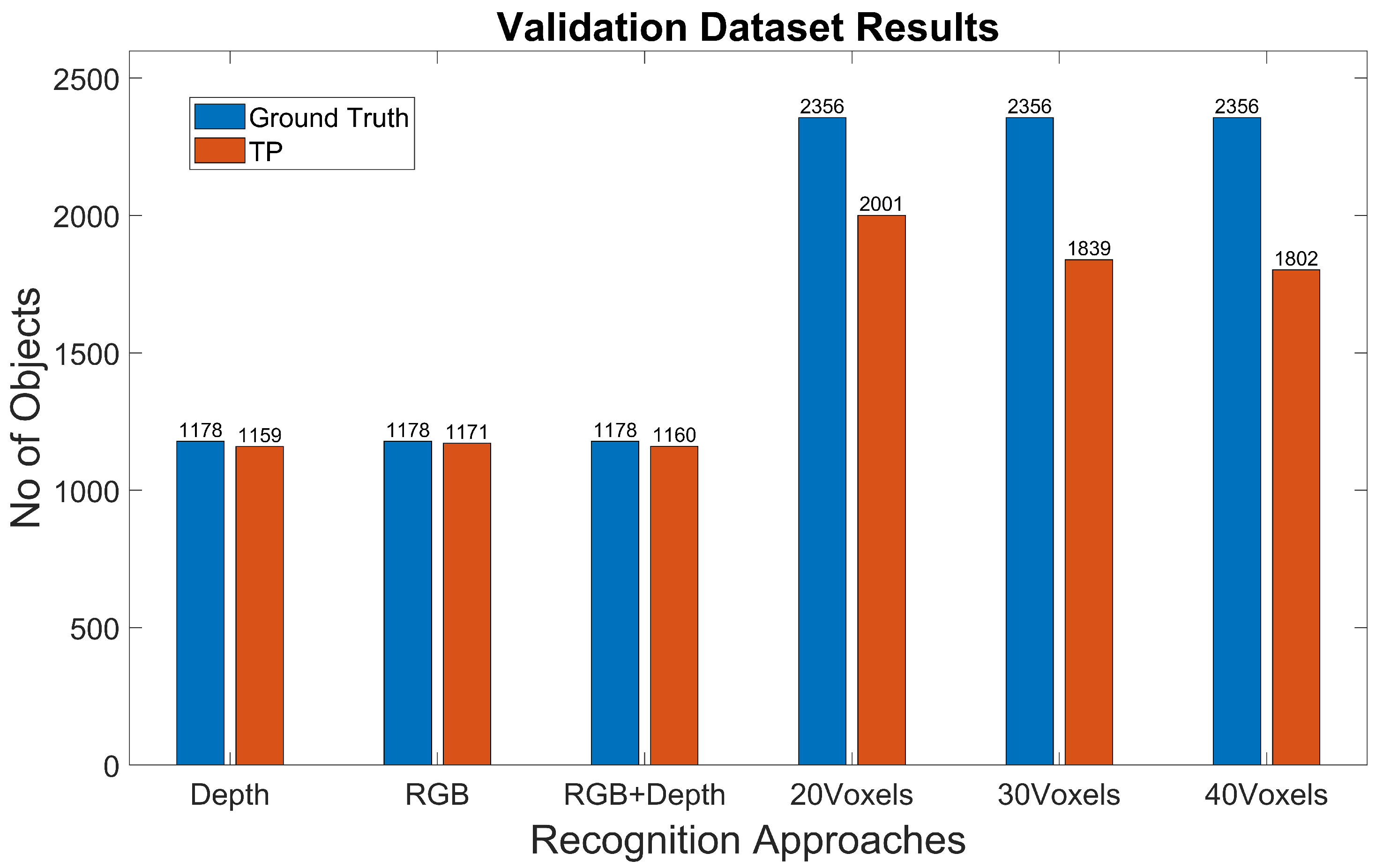
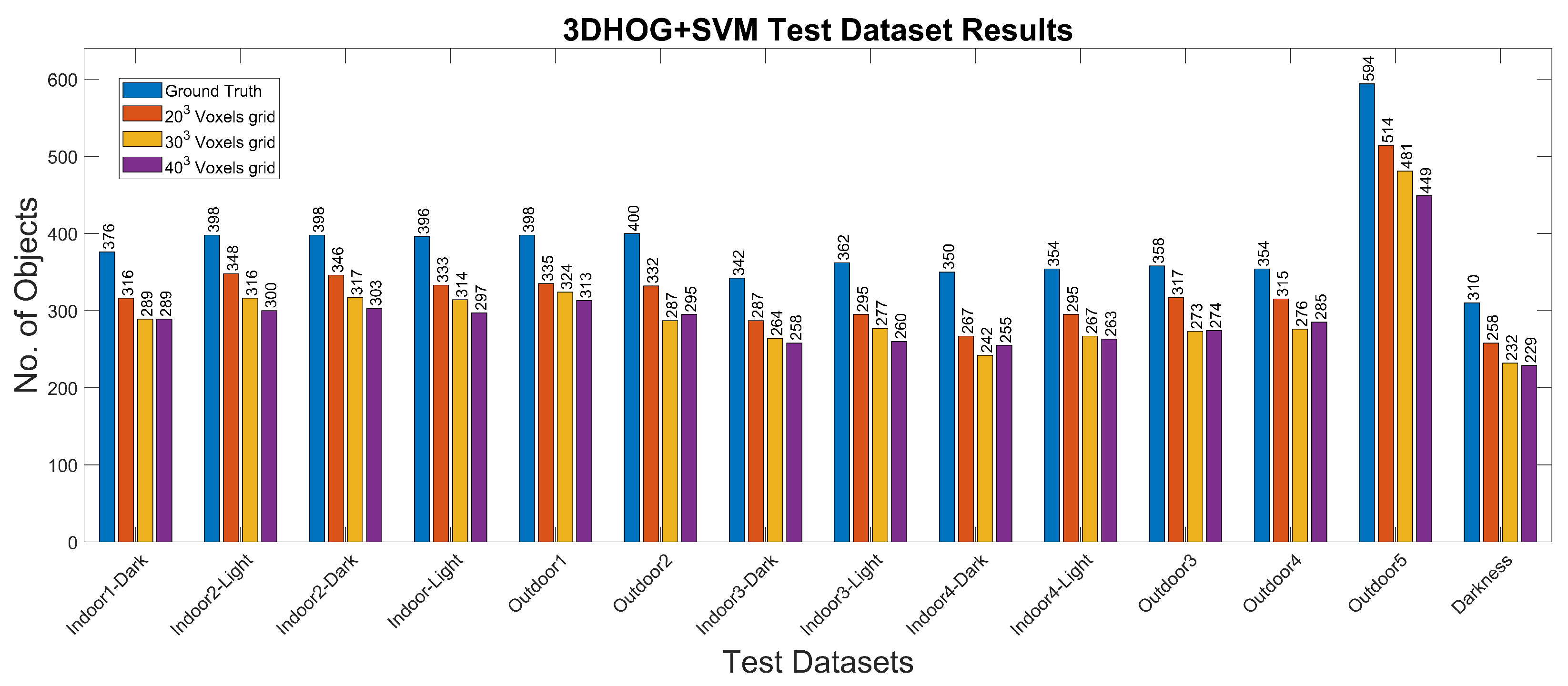
- Experiment 2: We used a synthetic dataset of objects segmented from the Modelnet40 dataset [16] for training and validation and the Miun-Feet dataset used in Experiment 1 for testing. We evaluated a hand-crafted approach based on the 3DHOG in terms of mAP. See Figure 3b for the voxel grid resolutions of , and Voxels.
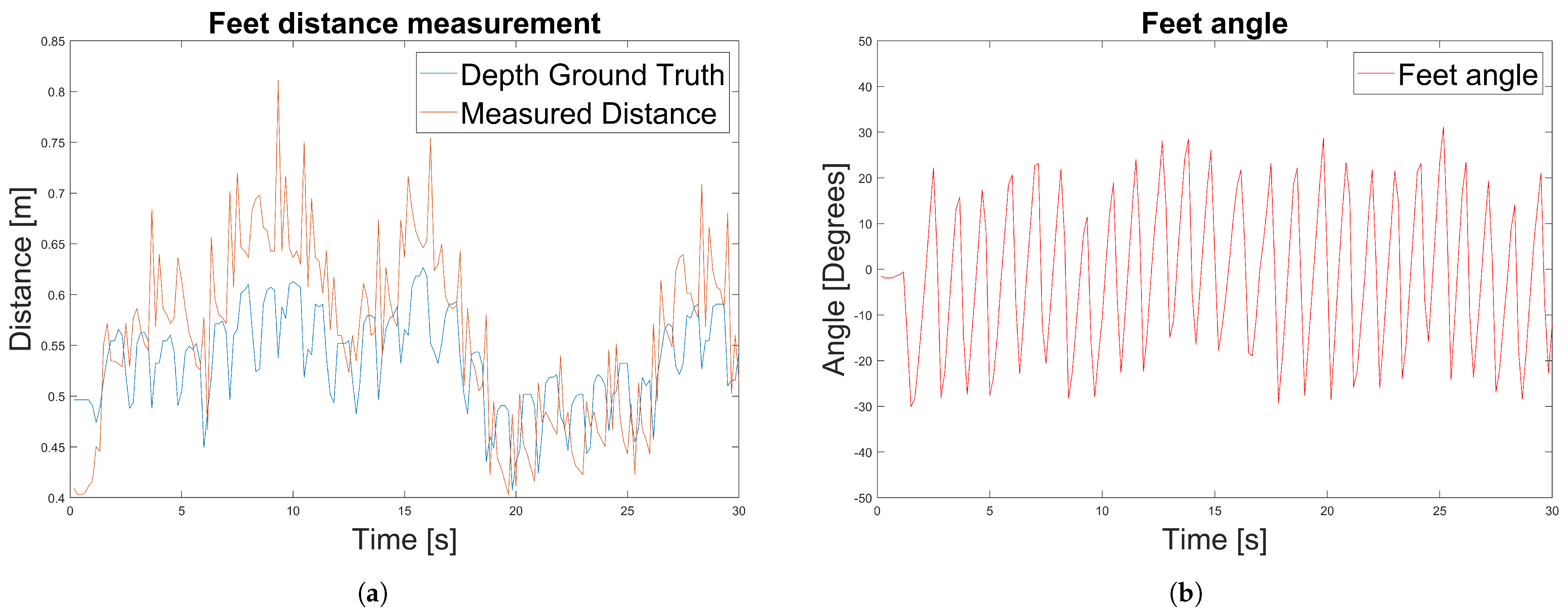
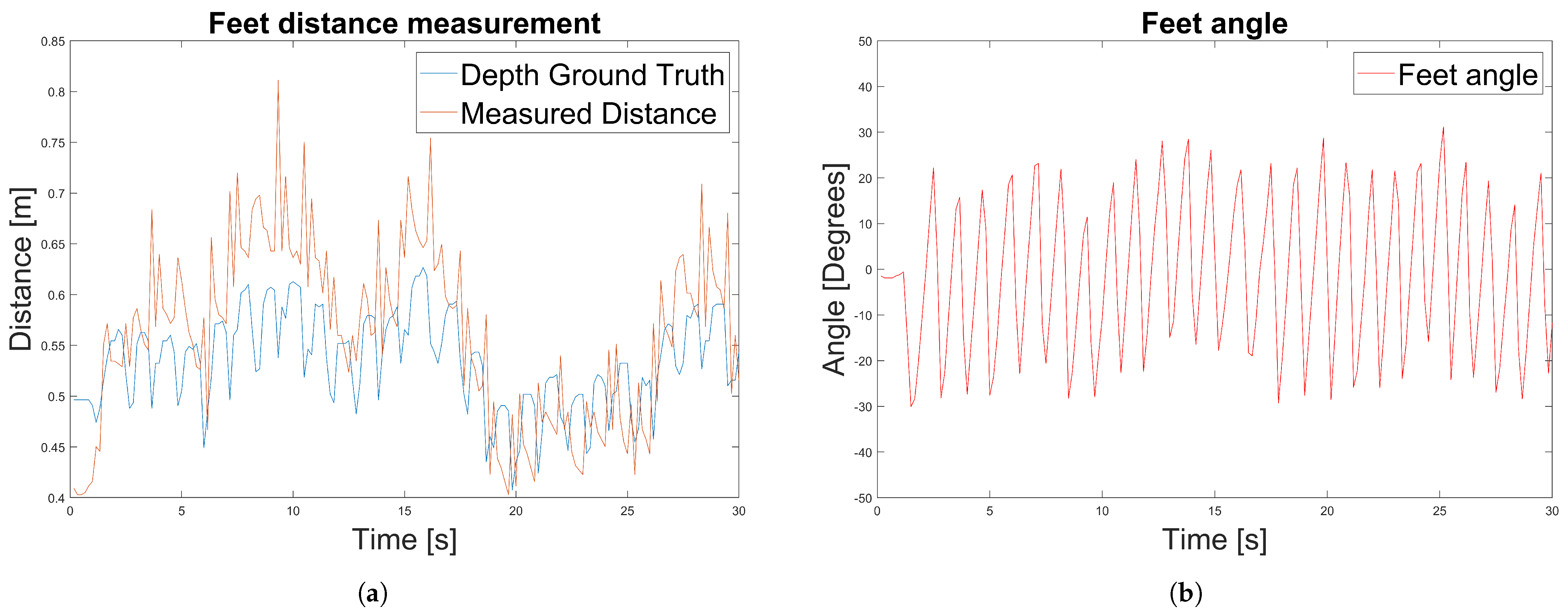
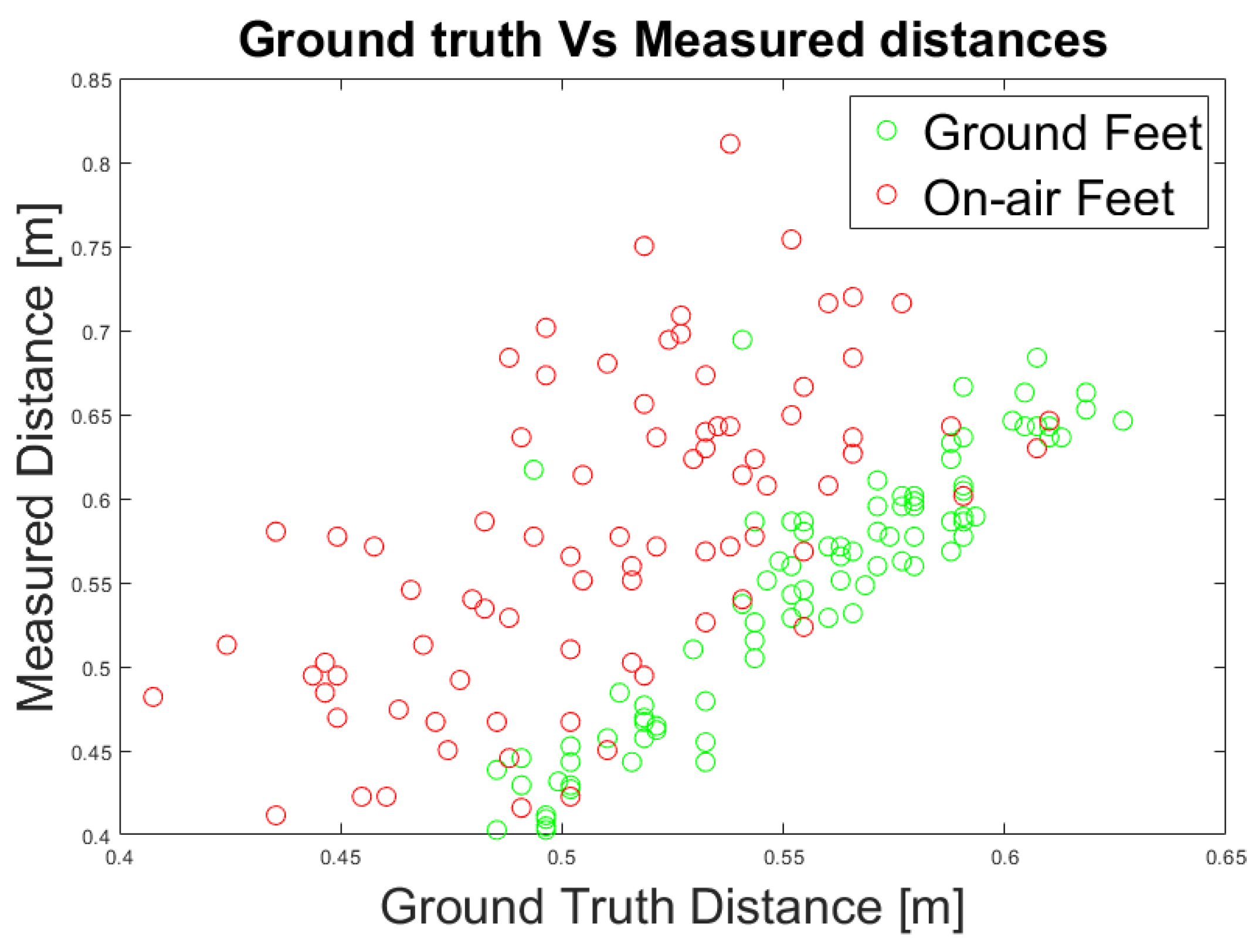
- Experiment 3: We propose an alternative method to measure the relative distance and angle of the caregiver beside a PW using the RGB camera output. We compared the results with respect to the ground truth data measured by the depth camera.
3.3. Miun-Feet Dataset Construction
- RGB frames: Visual data frames (3 channels);
- Depth frames: Depth map image that includes true distances measurements from the camera for each pixel value (1 channel);
- RGB-D frames: 4-channels image that stacked visual frames (3 channels) and depth frames;
- Point cloud: Unstructured 3D data representation.
3.4. Synthetic Dataset Generation
- (1) Frontal projection: the depth camera does not capture the data the object itself obscures. Therefore, it is necessary to compute the frontal projection of each synthetic object with respect to the camera angle and remove the occluded data.
- (2) Dataset augmentation: The 3DHOG object descriptor is sensitive to the rotation. Thus, we perform dataset augmentation by rotating each synthetic object along the X-axis (0,15,30) degrees, the Y-axis (0,15,30) degrees and the Z-axis (0,30,60) degrees, giving a total of 27 rotations per synthetic object.
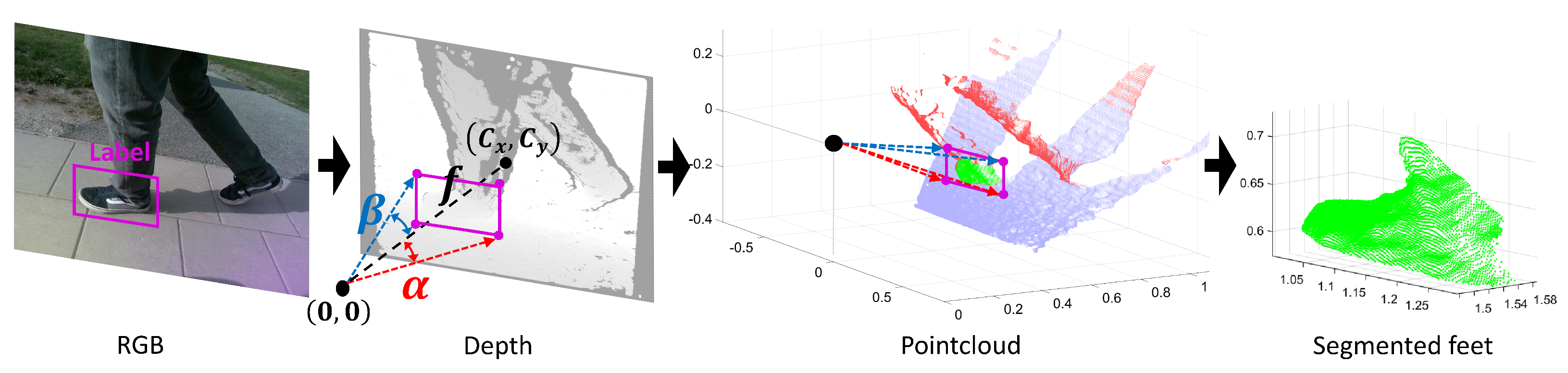
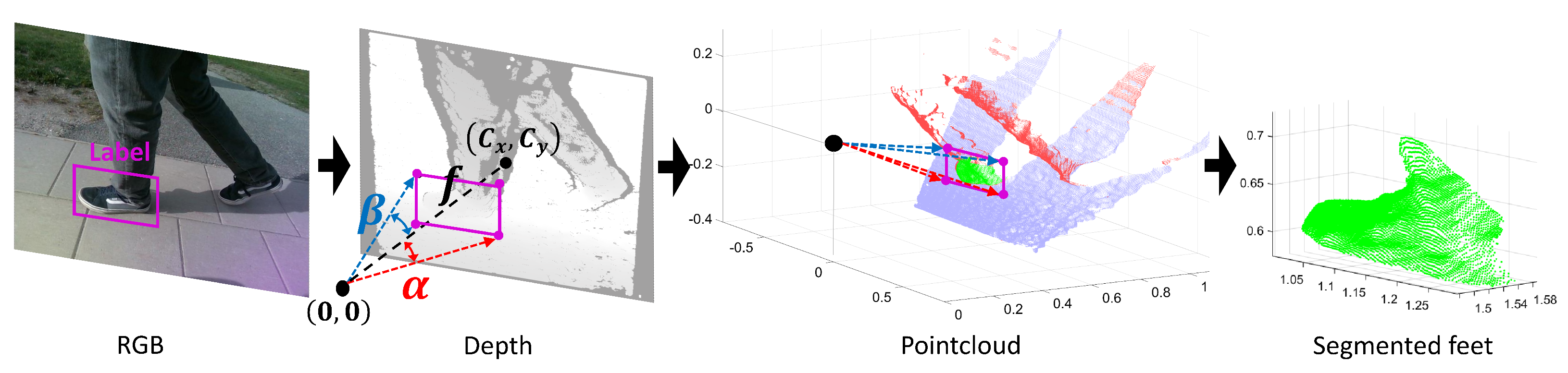
3.5. Point Cloud Object Segmentation
3.6. YOLOv4-Tiny Approach
3.7. 3DHOG Approach
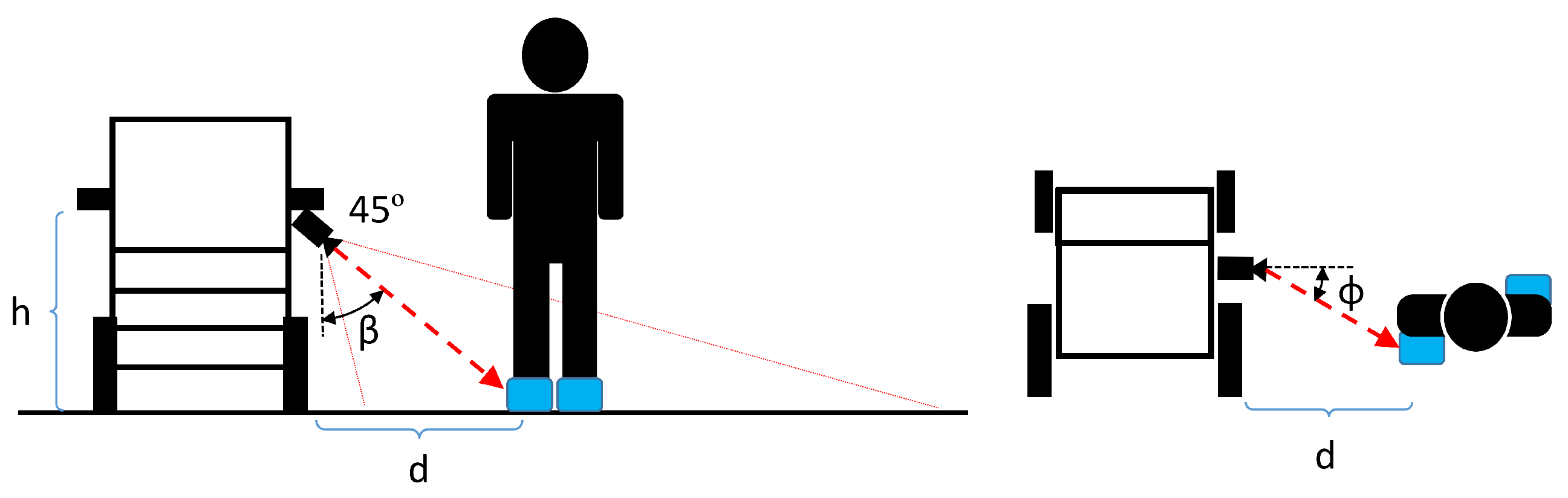
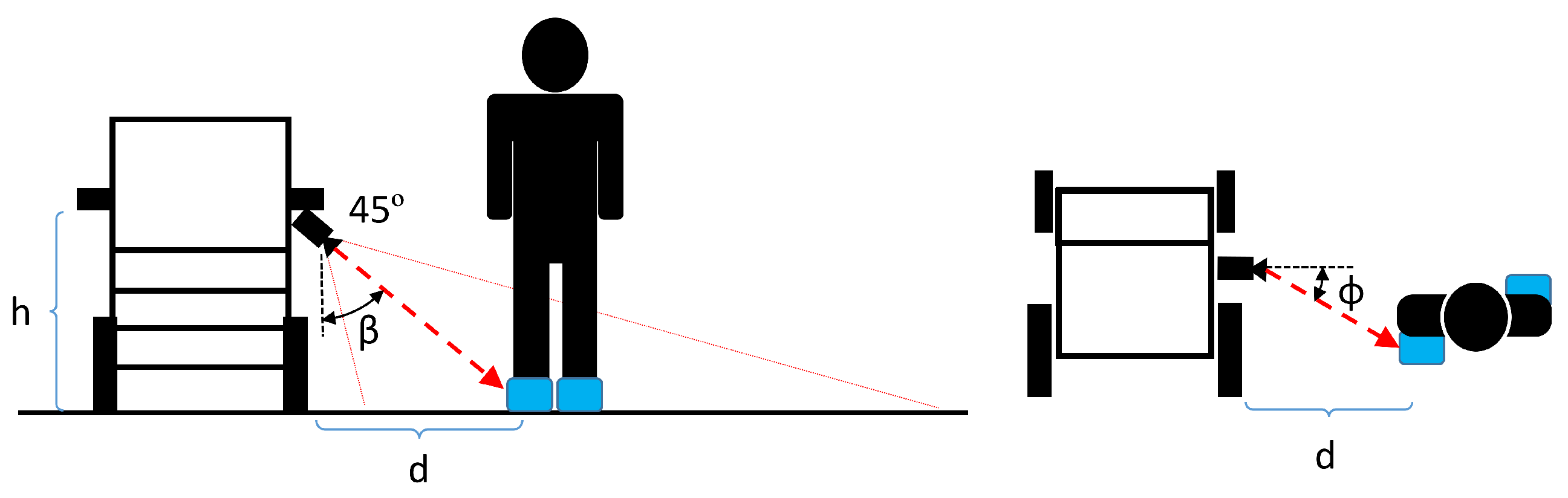
3.8. Caregiver Distance and Angle Computation
4. Results and Analysis
4.1. Experiment 1. YOLOv4-Tiny
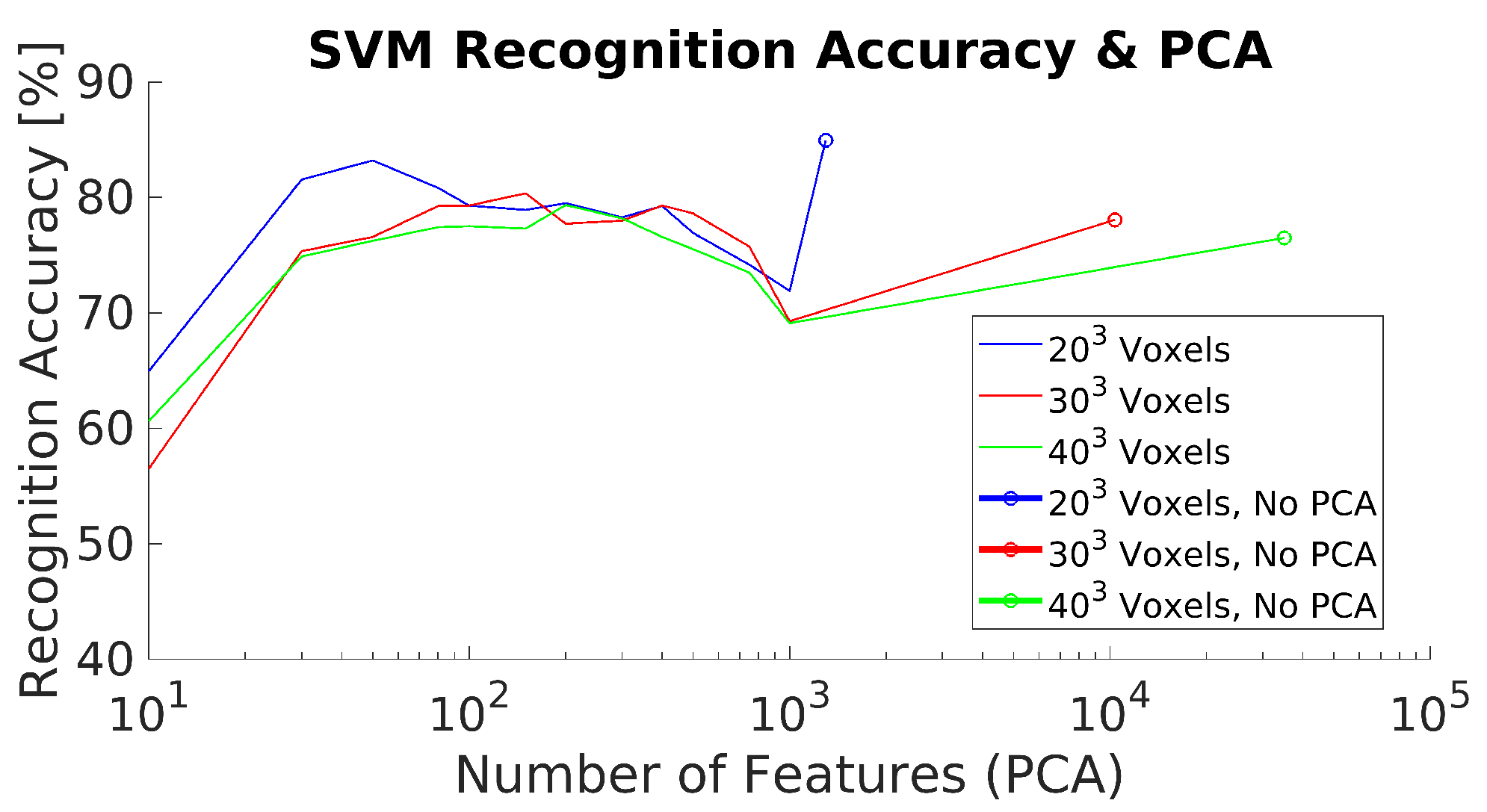
4.2. Experiment 2: 3DHOG Approach
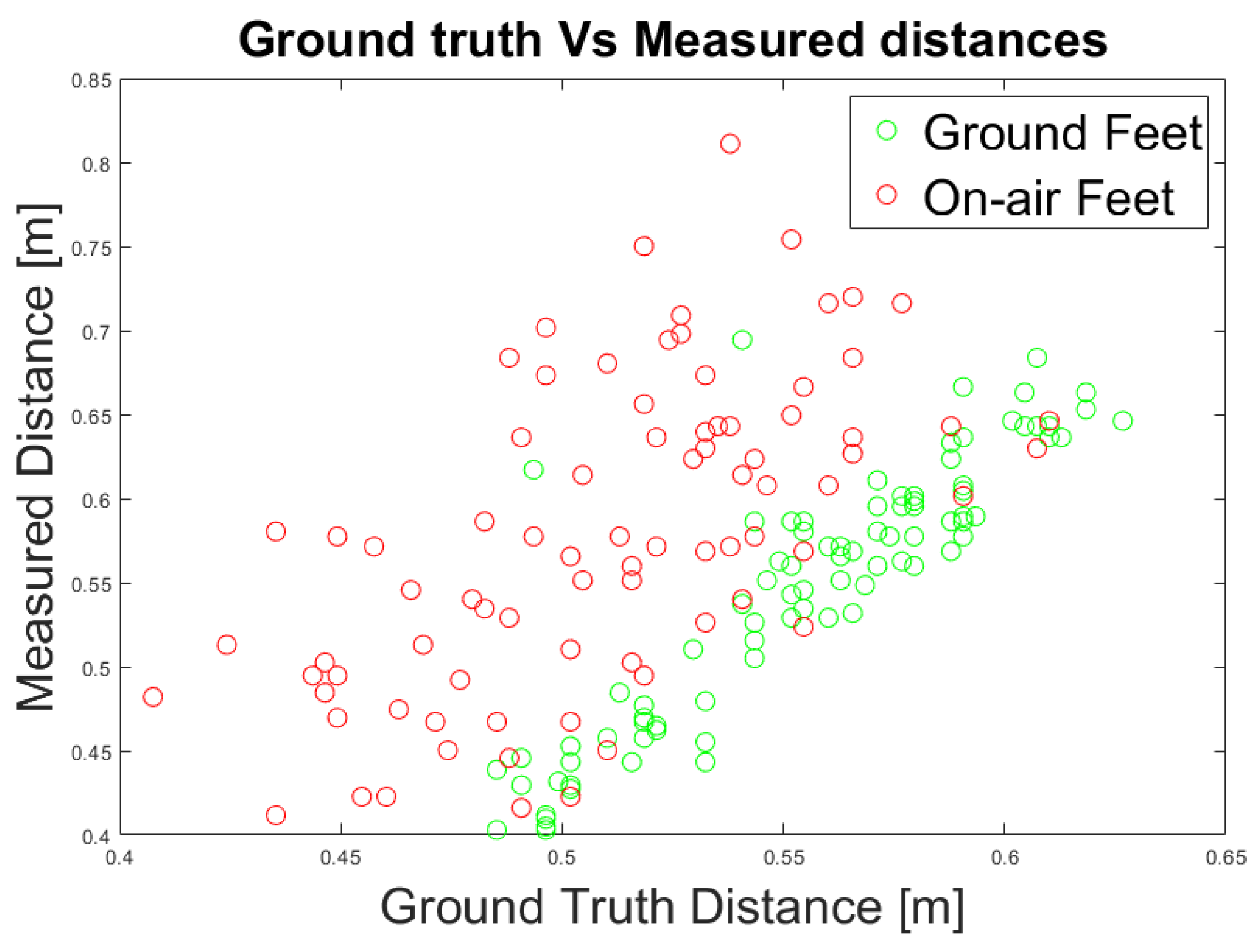
4.3. Experiment 3: Caregiver’s Distance and Angle Computation
5. Discussion
Evaluation of the Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kristiansen, L. Wanting a Life in Decency!—A Qualitative Study from Experienced Electric Wheelchairs Users’ perspective. Open J. Nurs. 2018, 8, 419–433. [Google Scholar] [CrossRef] [Green Version]
- Vilar, C.; Thörnberg, B.; Krug, S. Evaluation of Embedded Camera Systems for Autonomous Wheelchairs. In Proceedings of the 5th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS), Crete, Greece, 3–5 May 2019; pp. 76–85. [Google Scholar] [CrossRef]
- Dupre, R.; Argyriou, V. 3D Voxel HOG and Risk Estimation. In Proceedings of the International Conference on Digital Signal Processing (DSP), Singapore, 21–24 July 2015; pp. 482–486. [Google Scholar]
- Vilar, C.; Krug, S.; Thornberg, B. Processing chain for 3D histogram of gradients based real-time object recognition. Int. J. Adv. Robot. Syst. 2020, 18, 13. [Google Scholar] [CrossRef]
- Vilar, C.; Krug, S.; O’Nils, M. Realworld 3d object recognition using a 3d extension of the hog descriptor and a depth camera. Sensors 2021, 21, 910. [Google Scholar] [CrossRef]
- Xiong, M.; Hotter, R.; Nadin, D.; Patel, J.; Tartakovsky, S.; Wang, Y.; Patel, H.; Axon, C.; Bosiljevac, H.; Brandenberger, A.; et al. A Low-Cost, Semi-Autonomous Wheelchair Controlled by Motor Imagery and Jaw Muscle Activation. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 2180–2185. [Google Scholar] [CrossRef]
- Kader, M.A.; Alam, M.E.; Jahan, N.; Bhuiyan, M.A.B.; Alam, M.S.; Sultana, Z. Design and implementation of a head motion-controlled semi-autonomous wheelchair for quadriplegic patients based on 3-axis accelerometer. In Proceedings of the 2019 22nd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Subramanian, M.; Songur, N.; Adjei, D.; Orlov, P.; Faisal, A.A. A.Eye Drive: Gaze-based semi-autonomous wheelchair interface. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 5967–5970. [Google Scholar] [CrossRef]
- Grewal, H.S.; Jayaprakash, N.T.; Matthews, A.; Shrivastav, C.; George, K. Autonomous wheelchair navigation in unmapped indoor environments. In Proceedings of the 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Grewal, H.; Matthews, A.; Tea, R.; George, K. LiDAR-based autonomous wheelchair. In Proceedings of the 2017 IEEE Sensors Applications Symposium (SAS), Glassboro, NJ, USA, 13–15 March 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Li, Z.; Xiong, Y.; Zhou, L. ROS-Based Indoor Autonomous Exploration and Navigation Wheelchair. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; Volume 2, pp. 132–135. [Google Scholar] [CrossRef]
- Kobayashi, Y.; Suzuki, R.; Kuno, Y. Robotic wheelchair with omni-directional vision for moving alongside a caregiver. In Proceedings of the IECON 2012—38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012; pp. 4177–4182. [Google Scholar] [CrossRef]
- Kobayashi, T.; Chugo, D.; Yokota, S.; Muramatsu, S.; Hashimoto, H. Design of personal mobility motion based on cooperative movement with a companion. In Proceedings of the 2015 6th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Gyor, Hungary, 19–21 October 2015; pp. 165–170. [Google Scholar] [CrossRef]
- Motokucho, T.; Oda, N. Vision-based human-following control using optical flow field for power assisted wheelchair. In Proceedings of the 2014 IEEE 13th International Workshop on Advanced Motion Control (AMC), Yokohama, Japan, 14–16 March 2014; pp. 266–271. [Google Scholar] [CrossRef]
- He, Y.; Chen, S.; Yu, H.; Yang, T. A cylindrical shape descriptor for registration of unstructured point clouds from real-time 3D sensors. J. Real-Time Image Process. 2020, 18, 261–269. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Aleman, J.; Monjardin Hernandez, H.S.; Orozco-Rosas, U.; Picos, K. Autonomous navigation for a holonomic drive robot in an unknown environment using a depth camera. Opt. Photonics Inf. Process. XIV 2020, 11509, 1. [Google Scholar] [CrossRef]
- Tabib, W.; Goel, K.; Yao, J.; Boirum, C.; Michael, N. Autonomous Cave Surveying with an Aerial Robot. IEEE Trans. Robot. 2020, 1–17. [Google Scholar] [CrossRef]
- Papazov, C.; Haddadin, S.; Parusel, S.; Krieger, K.; Burschka, D. Rigid 3D geometry matching for grasping of known objects in cluttered scenes. Int. J. Robot. Res. 2012, 31, 538–553. [Google Scholar] [CrossRef]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J.; Kwok, N. A Comprehensive Performance Evaluation of 3D Local Feature Descriptors. Int. J. Comput. Vis. 2015, 116. [Google Scholar] [CrossRef]
- Bayramoglu, N.; Alatan, A.A. Shape index SIFT: Range image recognition using local features. In Proceedings of the International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 352–355. [Google Scholar] [CrossRef]
- Tang, K.; Member, S.; Song, P.; Chen, X. 3D Object Recognition in Cluttered Scenes with Robust Shape Description and Correspondence Selection. IEEE Access 2017, 5, 1833–1845. [Google Scholar] [CrossRef]
- Salti, S.; Tombari, F.; Stefano, L.D. SHOT: Unique signatures of histograms for surface and texture description q. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, Y.; Cao, Z. Aligning 2.5D Scene Fragments with Distinctive Local Geometric Features. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 714–729. [Google Scholar] [CrossRef]
- Johnson, A.E.; Hebert, M. Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 433–449. [Google Scholar] [CrossRef] [Green Version]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D recognition and pose using the viewpoint feature histogram. In Proceedings of the IEEE/RSJ 2010 International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D registration. In Proceedings of the International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar] [CrossRef]
- Wohlkinger, W.; Vincze, M. Ensemble of shape functions for 3D object classification. In Proceedings of the International Conference on Robotics and Biomimetics (ROBIO), Karon Beach, Thailand, 7–11 December 2011; pp. 2987–2992. [Google Scholar]
- Domenech, J.F.; Escalona, F.; Gomez-Donoso, F.; Cazorla, M. A Voxelized Fractal Descriptor for 3D Object Recognition. IEEE Access 2020, 8, 161958–161968. [Google Scholar] [CrossRef]
- Tao, W.; Hua, X.; Yu, K.; Chen, X.; Zhao, B. A Pipeline for 3-D Object Recognition Based on Local Shape Description in Cluttered Scenes. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1–16. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. arXiv 2017, arXiv:cs.CV/1711.06396. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. FoldingNet: Point Cloud Auto-Encoder via Deep Grid Deformation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 206–215. [Google Scholar] [CrossRef] [Green Version]
- Kanezaki, A.; Matsushita, Y.; Nishida, Y. RotationNet: Joint Object Categorization and Pose Estimation Using Multiviews from Unsupervised Viewpoints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5010–5019. [Google Scholar] [CrossRef] [Green Version]
- Liu, A.A.; Zhou, H.; Nie, W.; Liu, Z.; Liu, W.; Xie, H.; Mao, Z.; Li, X.; Song, D. Hierarchical multi-view context modelling for 3D object classification and retrieval. Inf. Sci. 2021, 547, 984–995. [Google Scholar] [CrossRef]
- Simon, M.; Milz, S.; Amende, K.; Gross, H.M. Complex-YOLO: Real-time 3D Object Detection on Point Clouds. arXiv 2018, arXiv:cs.CV/1803.06199. [Google Scholar]
- Qi, S.; Ning, X.; Yang, G.; Zhang, L.; Long, P.; Cai, W.; Li, W. Review of multi-view 3D object recognition methods based on deep learning. Displays 2021, 69, 102053. [Google Scholar] [CrossRef]
- Takahashi, M.; Moro, A.; Ji, Y.; Umeda, K. Expandable YOLO: 3D Object Detection from RGB-D Images. CoRR 2020, abs/2006.14837. [Google Scholar]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor Semantic Segmentation using depth information. arXiv 2013, arXiv:cs.CV/1301.3572. [Google Scholar]
- Rahman, M.M.; Tan, Y.; Xue, J.; Lu, K. RGB-D object recognition with multimodal deep convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 991–996. [Google Scholar] [CrossRef]
- Morales, Y.; Kanda, T.; Hagita, N. Walking Together: Side-by-Side Walking Model for an Interacting Robot. J. Hum.-Robot Interact. 2014, 3, 50–73. [Google Scholar] [CrossRef]
- Kobayashi, T.; Chugo, D.; Yokota, S.; Muramatsu, S.; Hashimoto, H. A driving assistance for a powered wheelchair with a walking partner. In Proceedings of the 2016 IEEE International Conference on Industrial Technology (ICIT), Taipei, Taiwan, 14–17 March 2016; pp. 1866–1871. [Google Scholar] [CrossRef]
- Udsatid, P.; Niparnan, N.; Sudsang, A. Human position tracking for side by side walking mobile robot using foot positions. In Proceedings of the 2012 IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 11–14 December 2012; pp. 1374–1378. [Google Scholar] [CrossRef]
- © Intel Corporation. Available online: https://www.intelrealsense.com/depth-camera-d455 (accessed on 29 November 2021).
- Torr, P.H.S.; Zisserman, A. MLESAC: A new robust estimator with application to estimating image geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:cs.CV/2004.10934. [Google Scholar]
- Ma, L.; Chen, Y.; Zhang, J. Vehicle and Pedestrian Detection Based on Improved YOLOv4-tiny Model. J. Phys. Conf. Ser. 2021, 1920, 012034. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Vilar, C.; Krug, S.; Thornberg, B. Rotational Invariant Object Recognition for Robotic Vision. In 3rd International Conference on Automation, Control and Robots ( ICACR); ACM: Prague, Czech Republic, 2019; pp. 1–6. [Google Scholar]
- Sowmya, V.; Radha, R. Heavy-Vehicle Detection Based on YOLOv4 featuring Data Augmentation and Transfer-Learning Techniques. J. Phys. Conf. Ser. 2021, 1911, 012029. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot Object Detection via Feature Reweighting. arXiv 2019, arXiv:cs.CV/1812.01866. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration preset | High density |
| Frame Resolution | 640 × 480 pixels |
| Aligned RGB and Depth streams | Yes |
| Frame Rate | 6 fps |
| Exposure | 156 ms Auto |
| Active lighting power | Maximum |
| Scenario | Placement | Background | Light Conditions | Exposure | Shoes Model |
|---|---|---|---|---|---|
| Indoor1-Dark | Tunnel corridor | Tiles/wall | Low light | 156 ms | 1–5 |
| Indoor1-Light | Tunnel corridor | Tiles/wall | LED lighting | 156 ms | 1–5 |
| Indoor2-Dark | University corridor | Hall | Low light | 156 ms | 1–5 |
| Indoor2-Light | University corridor | Hall | LED lighting | 156 ms | 1–5 |
| Outdoor1 | Pedestrian asphalt | Road | Sunny | Auto | 1–5 |
| Outdoor2 | Pedestrian tiles | Grass | Sunny | Auto | 1–5 |
| Indoor3-Dark | Tunnel corridor | Tiles/wall | Low light | 156 ms | 6–8 |
| Indoor3-Light | Tunnel corridor | Tiles/wall | LED lighting | 156 ms | 6–8 |
| Indoor4-Dark | University corridor | Hall | Low light | 156 ms | 6–8 |
| Indoor4-Light | University corridor | Hall | LED lighting | 156 ms | 6–8 |
| Outdoor3 | Pedestrian asphalt | Road | Sunny | Auto | 6–8 |
| Outdoor4 | Pedestrian tiles | Grass | Sunny | Auto | 6–8 |
| Outdoor5 | Pedestrian tiles | Bikes parking | Sunny | Auto | 6–8 |
| Darkness | Laboratory | Wall/chairs | Darkness | 156 ms | 6–8 |
| Scenarios | |||||||
|---|---|---|---|---|---|---|---|
| Dataset | Indoor1-Dark (Feet/Empty) | Indoor1-Light (Feet/Empty) | Indoor2-Dark Feet/Empty | Indoor2-Light(Feet/Empty) | Outdoor1 (Feet/Empty) | Outdoor2 (Feet/Empty) | Total (Feet/Empty) |
| Training | 500/500 | 500/500 | 500/500 | 500/500 | 500/500 | 500/500 | 3000/3000 |
| Validation | 100/100 | 100/100 | 100/100 | 100/100 | 100/100 | 100/100 | 600/600 |
| YOLOv4-Tiny | 3DHOG | |||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | No.Frames | No.Empty | No.Obj. | Dataset | No.Feet | No.Others | Total Obj. | |
| Training | Real | 3000 | 3000 | 5880 | Synthetic | 50 × 27 | 1350 | 2700 |
| Validation | Real | 600 | 600 | 1178 | Real | 1178 | 1178 | 2356 |
| Test: | ||||||||
| Indoor1-Dark | Real | 100 | 100 | 188 | Real | 188 | 188 | 376 |
| Indoor1-Light | Real | 100 | 100 | 199 | Real | 199 | 199 | 398 |
| Indoor2-Dark | Real | 100 | 100 | 199 | Real | 199 | 199 | 398 |
| Indoor2-Light | Real | 100 | 100 | 188 | Real | 188 | 188 | 376 |
| Indoor3-Dark | Real | 90 | 90 | 171 | Real | 171 | 171 | 342 |
| Indoor3-Light | Real | 90 | 90 | 181 | Real | 181 | 181 | 362 |
| Indoor4-Dark | Real | 90 | 90 | 175 | Real | 175 | 175 | 350 |
| Indoor4-Light | Real | 90 | 90 | 177 | Real | 177 | 177 | 354 |
| Outdoor1 | Real | 100 | 100 | 199 | Real | 199 | 199 | 398 |
| Outdoor2 | Real | 100 | 100 | 200 | Real | 199 | 200 | 400 |
| Outdoor3 | Real | 90 | 90 | 179 | Real | 179 | 179 | 358 |
| Outdoor4 | Real | 90 | 90 | 177 | Real | 177 | 177 | 354 |
| Outdoor5 | Real | 150 | 150 | 297 | Real | 297 | 297 | 594 |
| Darkness | Real | 80 | 80 | 155 | Real | 155 | 155 | 310 |
| Batch size | 64 |
| Sub-division | 24 |
| Width | 640 |
| Height | 480 |
| Channels | 1(Depth), 3(RGB), 4(RGB-D) |
| Momentum | 0.9 |
| Decay | 0.0005 |
| Max.batch | 2000 |
| Burn in | 500 |
| Steps | 1800, 1900 |
| Scales | 0.1, 0.1 |
| Anchors | (10,14), (23,27) (37,58), (81,82) (135,169), (344,319) |
| Voxel Grid | |||
|---|---|---|---|
| 1 | 8 | 27 | |
| 8 | 8 | 8 | |
| 1296 | 10,368 | 34,992 |
| Parameter | Value |
|---|---|
| 18 | |
| 9 | |
| 6 | |
| 2 | |
| 2 |
| Method | Test Cases | ||||||
|---|---|---|---|---|---|---|---|
| Validation mAP(%) | Indoor1-Dark mAP(%) | Indoor1-Light mAP(%) | Indoor2-DarkmAP(%) | Indoor2-Light mAP(%) | Outdoor1 mAP(%) | Outdoor2 mAP(%) | |
| Depth (1CH) | 99.24 | 99.33 | 100 | 99.46 | 99.88 | 99.91 | 99.19 |
| RGB (3CH) | 99.83 | 99.98 | 100 | 100 | 99.78 | 100 | 100 |
| RGB-D (4CH) | 99.52 | 99.82 | 100 | 99.96 | 99.97 | 99.83 | 99.85 |
| 3DHOG, Voxels | 84.93 | 84.04 | 87.44 | 86.93 | 84.09 | 84.17 | 83 |
| 3DHOG, Voxels | 78.06 | 76.86 | 79.40 | 79.65 | 79.29 | 81.41 | 71.75 |
| 3DHOG, Voxels | 76.49 | 76.86 | 75.38 | 76.13 | 75.00 | 78.64 | 73.75 |
| Method | Additional Test Cases | |||||||
|---|---|---|---|---|---|---|---|---|
| Indoor3-Dark mAP(%) | Indoor3-Light mAP(%) | Indoor4-Dark mAP(%) | Indoor4-Light mAP(%) | Outdoor3 mAP(%) | Outdoor4 mAP(%) | Outdoor5 mAP(%) | Darkness mAP(%) | |
| Depth (1CH) | 98.66 | 99.39 | 96.45 | 98.78 | 99.10 | 97.61 | 99.17 | 97.68 |
| RGB (3CH) | 99.33 | 99.99 | 97.63 | 98.50 | 96.15 | 99.32 | 96.70 | 0 |
| RGB-D (4CH) | 98.83 | 99.88 | 95.46 | 97.58 | 98.64 | 95.92 | 96.23 | 94.98 |
| 3DHOG, Voxels | 83.92 | 81.49 | 76.29 | 83.33 | 88.55 | 88.98 | 86.53 | 83.23 |
| 3DHOG, Voxels | 77.19 | 76.52 | 69.14 | 75.42 | 76.26 | 77.97 | 80.98 | 74.84 |
| 3DHOG, Voxels | 75.44 | 71.82 | 72.86 | 74.29 | 76.54 | 80.51 | 75.59 | 73.87 |
| All Feet | Ground Feet | |
|---|---|---|
| RMSE (m) | 0.077 | 0.035 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giménez, C.V.; Krug, S.; Qureshi, F.Z.; O’Nils, M. Evaluation of 2D-/3D-Feet-Detection Methods for Semi-Autonomous Powered Wheelchair Navigation. J. Imaging 2021, 7, 255. https://doi.org/10.3390/jimaging7120255
Giménez CV, Krug S, Qureshi FZ, O’Nils M. Evaluation of 2D-/3D-Feet-Detection Methods for Semi-Autonomous Powered Wheelchair Navigation. Journal of Imaging. 2021; 7(12):255. https://doi.org/10.3390/jimaging7120255
Chicago/Turabian StyleGiménez, Cristian Vilar, Silvia Krug, Faisal Z. Qureshi, and Mattias O’Nils. 2021. "Evaluation of 2D-/3D-Feet-Detection Methods for Semi-Autonomous Powered Wheelchair Navigation" Journal of Imaging 7, no. 12: 255. https://doi.org/10.3390/jimaging7120255
APA StyleGiménez, C. V., Krug, S., Qureshi, F. Z., & O’Nils, M. (2021). Evaluation of 2D-/3D-Feet-Detection Methods for Semi-Autonomous Powered Wheelchair Navigation. Journal of Imaging, 7(12), 255. https://doi.org/10.3390/jimaging7120255