
Discretization of Learned NETT Regularization for Solving Inverse Problems



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Reconstruction with Learned Regularizers
- (T1)
- Choose a family of desired reconstructions .
- (T2)
- For some , construct undesired reconstructions .
- (T3)
- Choose a class of functions (networks) .
- (T4)
- Determine with .
- (T5)
- Define with for some .
1.2. Discrete NETT
1.3. Outline
2. Convergence Analysis
2.1. Well-Posedness
- (W1)
- , are Banach spaces, reflexive, weakly sequentially closed.
- (W2)
- The distance measure satisfies
- (a)
- .
- (b)
- .
- (c)
- .
- (d)
- .
- (e)
- is weakly sequentially lower semi-continuous (wslsc).
- (W3)
- is proper and wslsc.
- (W4)
- is weakly sequentially continuous.
- (W5)
- is nonempty and bounded.
- (W6)
- is a sequence of subspaces of .
- (W7)
- is a family of weakly sequentially continuous .
- (W8)
- is a family of proper wslsc regularizers .
- (W9)
- is nonempty and bounded.
- (a)
- .
- (b)
- Let with and consider .
- has at least one weak accumulation point.
- Every weak accumulation point is a minimizer of .
- (c)
- The statements in (a),(b) also hold for in place of ,
2.2. Convergence
- (C1)
- with .
- (C2)
- .
- (C3)
- .
- (C4)
- .
- (a)
- has a weakly convergent subsequence
- (b)
- The weak limit of is an -minimizing solution of .
- (c)
- , where is the weak limit of .
- (d)
- If the -minimizing solution of is unique, then .
2.3. Convergence Rates
- (R1)
- Items (C1), (C2) hold.
- (R2)
- .
- (R3)
- .
- (R4)
- is Gâteaux differentiable at
- (R5)
- There exist a concave, continuous, strictly increasing with and such that for all
3. Application to a Limited Data Problem in PAT
3.1. Discrete Forward Operator
3.2. Discrete NETT
| Algorithm 1: NETT optimization. |
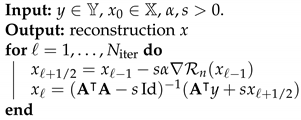 |
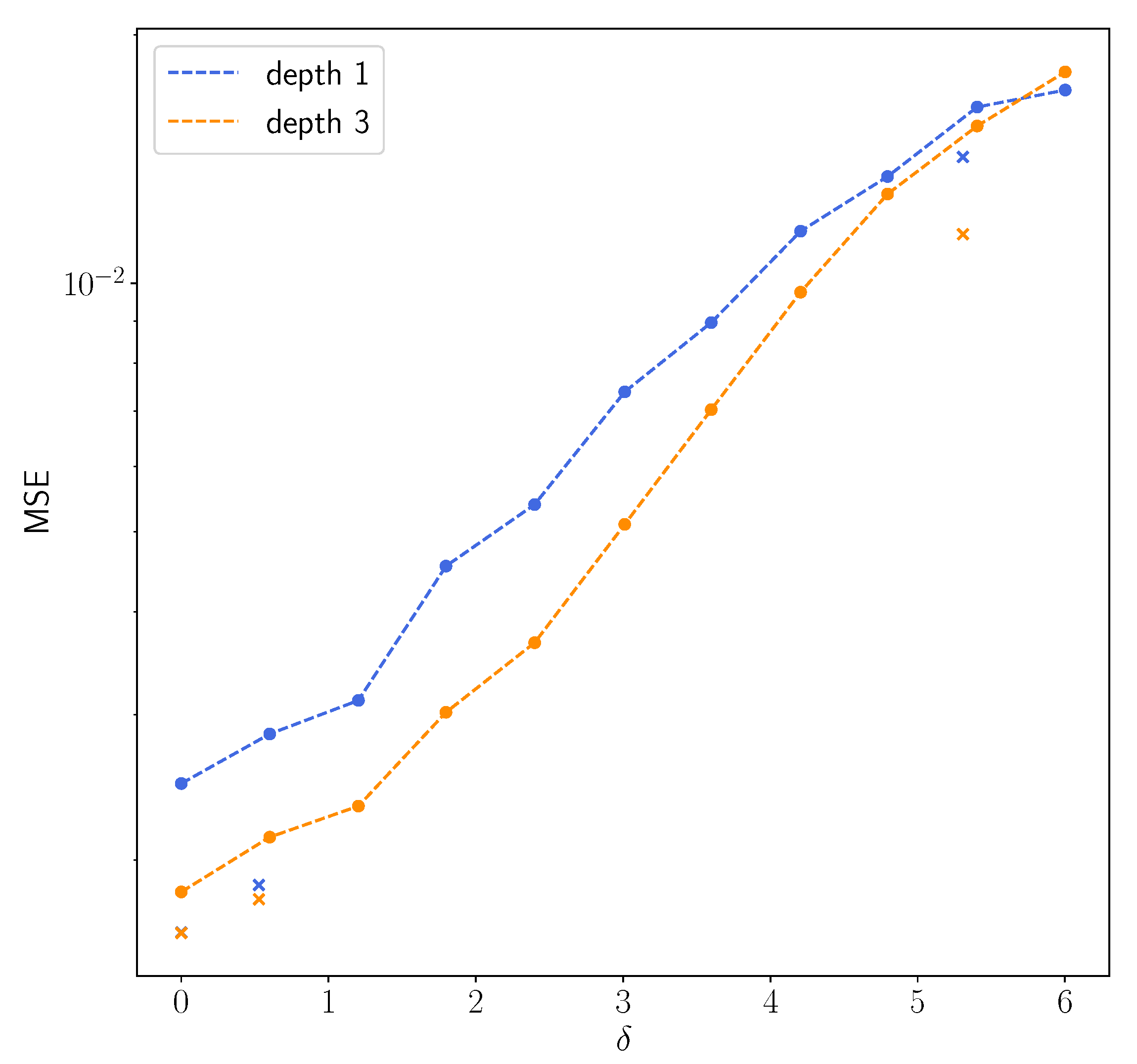
3.3. Numerical Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Engl, H.W.; Hanke, M.; Neubauer, A. Regularization of Inverse Problems. In Mathematics and Its Applications; Kluwer Academic Publishers Group: Dordrecht, The Netherlands, 1996; Volume 375. [Google Scholar]
- Scherzer, O.; Grasmair, M.; Grossauer, H.; Haltmeier, M.; Lenzen, F. Variational methods in imaging. In Applied Mathematical Sciences; Springer: New York, NY, USA, 2009; Volume 167. [Google Scholar]
- Natterer, F.; Wübbeling, F. Mathematical Methods in Image Reconstruction. In Monographs on Mathematical Modeling and Computation; SIAM: Philadelphia, PA, USA, 2001; Volume 5. [Google Scholar]
- Zhdanov, M.S. Geophysical Inverse Theory and Regularization Problems; Elsevier: Amsterdam, The Netherlands, 2002; Volume 36. [Google Scholar]
- Morozov, V.A. Methods for Solving Incorrectly Posed Problems; Springer: New York, NY, USA, 1984. [Google Scholar]
- Tikhonov, A.N.; Arsenin, V.Y. Solutions of Ill-Posed Problems; John Wiley & Sons: Washington, DC, USA, 1977. [Google Scholar]
- Ivanov, V.K.; Vasin, V.V.; Tanana, V.P. Theory of Linear Ill-Posed Problems and Its Applications, 2nd ed.; Inverse and Ill-posed Problems Series; VSP: Utrecht, The Netherlands, 2002. [Google Scholar]
- Grasmair, M. Generalized Bregman distances and convergence rates for non-convex regularization methods. Inverse Probl. 2010, 26, 115014. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Schwab, J.; Antholzer, S.; Haltmeier, M. NETT: Solving inverse problems with deep neural networks. Inverse Probl. 2020, 36, 065005. [Google Scholar] [CrossRef] [Green Version]
- Obmann, D.; Nguyen, L.; Schwab, J.; Haltmeier, M. Sparse ℓq-regularization of Inverse Problems Using Deep Learning. arXiv 2019, arXiv:1908.03006. [Google Scholar]
- Obmann, D.; Nguyen, L.; Schwab, J.; Haltmeier, M. Augmented NETT regularization of inverse problems. J. Phys. Commun. 2021, 5, 105002. [Google Scholar] [CrossRef]
- Haltmeier, M.; Nguyen, L.V. Regularization of Inverse Problems by Neural Networks. arXiv 2020, arXiv:2006.03972. [Google Scholar]
- Lunz, S.; Öktem, O.; Schönlieb, C.B. Adversarial Regularizers in Inverse Problems; NIPS: Montreal, QC, Canada, 2018; pp. 8507–8516. [Google Scholar]
- Mukherjee, S.; Dittmer, S.; Shumaylov, Z.; Lunz, S.; Öktem, O.; Schönlieb, C.B. Learned convex regularizers for inverse problems. arXiv 2020, arXiv:2008.02839. [Google Scholar]
- Adler, J.; Öktem, O. Solving ill-posed inverse problems using iterative deep neural networks. Inverse Probl. 2017, 33, 124007. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, H.K.; Mani, M.P.; Jacob, M. MoDL: Model-based deep learning architecture for inverse problems. IEEE Trans. Med. Imaging 2018, 38, 394–405. [Google Scholar] [CrossRef]
- de Hoop, M.V.; Lassas, M.; Wong, C.A. Deep learning architectures for nonlinear operator functions and nonlinear inverse problems. arXiv 2019, arXiv:1912.11090. [Google Scholar]
- Kobler, E.; Klatzer, T.; Hammernik, K.; Pock, T. Variational networks: Connecting variational methods and deep learning. In Proceedings of the German Conference on Pattern Recognition, Basel, Switzerland, 12–15 September 2017; Springer: Cham, Switzerland, 2017; pp. 281–293. [Google Scholar]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. Deep ADMM-Net for Compressive Sensing MRI. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 10–18. [Google Scholar]
- Shang, Y. Subspace confinement for switched linear systems. Forum Math. 2017, 29, 693–699. [Google Scholar] [CrossRef]
- Romano, Y.; Elad, M.; Milanfar, P. The little engine that could: Regularization by denoising (RED). SIAM J. Imaging Sci. 2017, 10, 1804–1844. [Google Scholar] [CrossRef]
- Pöschl, C.; Resmerita, E.; Scherzer, O. Discretization of variational regularization in Banach spaces. Inverse Probl. 2010, 26, 105017. [Google Scholar] [CrossRef]
- Pöschl, C. Tikhonov Regularization with General Residual Term. Ph.D. Thesis, University of Innsbruck, Innsbruck, Austria, 2008. [Google Scholar]
- Tikhonov, A.N.; Leonov, A.S.; Yagola, A.G. Nonlinear ill-posed problems. In Applied Mathematics and Mathematical Computation; Translated from the Russian; Chapman & Hall: London, UK, 1998; Volumes 1, 2 and 14. [Google Scholar]
- Kruger, R.; Lui, P.; Fang, Y.; Appledorn, R. Photoacoustic ultrasound (PAUS)—Reconstruction tomography. Med. Phys. 1995, 22, 1605–1609. [Google Scholar] [CrossRef]
- Paltauf, G.; Nuster, R.; Haltmeier, M.; Burgholzer, P. Photoacoustic tomography using a Mach-Zehnder interferometer as an acoustic line detector. Appl. Opt. 2007, 46, 3352–3358. [Google Scholar] [CrossRef]
- Matej, S.; Lewitt, R.M. Practical considerations for 3-D image reconstruction using spherically symmetric volume elements. IEEE Trans. Med. Imaging 1996, 15, 68–78. [Google Scholar] [CrossRef] [PubMed]
- Schwab, J.; Pereverzyev, S., Jr.; Haltmeier, M. A Galerkin least squares approach for photoacoustic tomography. SIAM J. Numer. Anal. 2018, 56, 160–184. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Schoonover, R.W.; Su, R.; Oraevsky, A.; Anastasio, M.A. Discrete Imaging Models for Three-Dimensional Optoacoustic Tomography Using Radially Symmetric Expansion Functions. IEEE Trans. Med. Imaging 2014, 33, 1180–1193. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Su, R.; Oraevsky, A.A.; Anastasio, M.A. Investigation of iterative image reconstruction in three-dimensional optoacoustic tomography. Phys. Med. Biol. 2012, 57, 5399. [Google Scholar] [CrossRef] [PubMed]
- Acar, R.; Vogel, C.R. Analysis of bounded variation penalty methods for ill-posed problems. Inverse Probl. 1994, 10, 1217. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Antholzer, S.; Haltmeier, M.; Schwab, J. Deep learning for photoacoustic tomography from sparse data. Inverse Probl. Sci. Eng. 2019, 27, 987–1005. [Google Scholar] [CrossRef] [Green Version]
- Antholzer, S.; Schwab, J.; Bauer-Marschallinger, J.; Burgholzer, P.; Haltmeier, M. NETT regularization for compressed sensing photoacoustic tomography. In Proceedings of the Photons Plus Ultrasound: Imaging and Sensing 2019, San Francisco, CA, USA, 3–6 February 2019; Volume 10878, p. 108783B. [Google Scholar]
- Combettes, P.L.; Pesquet, J.C. Proximal splitting methods in signal processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2011; pp. 185–212. [Google Scholar]
- Paszke, A.; Gross, S. PyTorch: An Imperative Style, High-Performance Deep Learning Library; NIPS: Montreal, QC, Canada, 2018; pp. 8024–8035. [Google Scholar]
- Hornik, K. Some new results on neural network approximation. Neural Netw. 1993, 6, 1069–1072. [Google Scholar] [CrossRef]
- Barron, A.R. Approximation and estimation bounds for artificial neural networks. Mach. Learn. 1994, 14, 115–133. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Antholzer, S.; Haltmeier, M. Discretization of Learned NETT Regularization for Solving Inverse Problems. J. Imaging 2021, 7, 239. https://doi.org/10.3390/jimaging7110239
Antholzer S, Haltmeier M. Discretization of Learned NETT Regularization for Solving Inverse Problems. Journal of Imaging. 2021; 7(11):239. https://doi.org/10.3390/jimaging7110239
Chicago/Turabian StyleAntholzer, Stephan, and Markus Haltmeier. 2021. "Discretization of Learned NETT Regularization for Solving Inverse Problems" Journal of Imaging 7, no. 11: 239. https://doi.org/10.3390/jimaging7110239
APA StyleAntholzer, S., & Haltmeier, M. (2021). Discretization of Learned NETT Regularization for Solving Inverse Problems. Journal of Imaging, 7(11), 239. https://doi.org/10.3390/jimaging7110239