Abstract
In the context of sensor-based data analysis, the compensation of image artifacts is a challenge. When the structures of interest are not clearly visible in an image, algorithms that can cope with artifacts are crucial for obtaining the desired information. Thereby, the high variation of artifacts, the combination of different types of artifacts, and their similarity to signals of interest are specific issues that have to be considered in the analysis. Despite the high generalization capability of deep learning-based approaches, their recent success was driven by the availability of large amounts of labeled data. Therefore, the provision of comprehensive labeled image data with different characteristics of image artifacts is of importance. At the same time, applying deep neural networks to problems with low availability of labeled data remains a challenge. This work presents a data-centric augmentation approach based on generative adversarial networks that augments the existing labeled data with synthetic artifacts generated from data not present in the training set. In our experiments, this augmentation leads to a more robust generalization in segmentation. Our method does not need additional labeling and does not lead to additional memory or time consumption during inference. Further, we find it to be more effective than comparable augmentations based on procedurally generated artifacts and the direct use of real artifacts. Building upon the improved segmentation results, we observe that our approach leads to improvements of 22% in the F1-score for an evaluated detection problem. Having achieved these results with an example sensor, we expect increased robustness against artifacts in future applications.
1. Introduction
A key goal of image analysis is to automatically extract information contained in an image using a suitable algorithm [1]. The devices used for image acquisition are usually based on either charge-coupled device (CCD) sensors [2] or complementary metal–oxide–semiconductor (CMOS) sensors [3]. Although the specific properties of recording techniques differ, all types induce artifacts caused by the process of capturing images [4].
We refer to all image signal components as artifacts that are not intended to be part of an image. These artifacts impede an automatic or human evaluation of recorded images, especially when they are similar to signals of interest, which can cause them to be falsely recognized as such. Artifacts should compromise the analysis of images as little as possible. Therefore, methods to reduce the influence of artifacts on an image are of particular interest [5]. The effects causing artifacts are called disturbances. These include, for example, instabilities of the used recording devices and other connected electronics, environmental influence, or flaws in the preprocessing software.
Artifacts are visually recognizable in a variety of shapes and intensities. Table 1 shows common artifact types occurring in sensor images, their sources, and algorithmic example methods which can be used to reduce these artifacts. The set of example artifacts can be divided into correlated and uncorrelated signals. Uncorrelated artifacts, also called random noises, are characterized by the absence of clear, detectable structures. Often, they originate from the sensor instruments themselves due to electronic instabilities or environmental influence [4,6,11]. Artifacts that show recognizable structures in the temporal, the spatial, or both dimensions are referred to as correlated. In distinction to random noise, these are also called structured noise [40,41]. In terms of their temporal behavior, most of the correlated and the uncorrelated artifacts are temporally changing, making them difficult to detect and reduce. Besides the determined differences of artifact types, it is worth noting that in practice, a signal does not only contain a single type of artifact but combinations of them.

Table 1.
Overview of common artifact types in sensor images, their properties, sources, and examples for algorithmic reduction methods. Correlated artifacts are also called structured noise, and uncorrelated artifacts are called unstructured. Temporally changing artifacts can vary in each frame.
Image-related tasks like classification, segmentation, and object detection are increasingly solved using deep learning [42,43,44]. This holds, in particular, for the field of sensor imaging. Examples include astronomical imaging [45], autonomous driving [46], fluorescence microscopy [47], X-ray [48], magnetic resonance (MR) [49], computed tomography (CT) [50], and histological imaging [51]. While access to an arbitrarily large amount of data could be used to form all possible combinations of signals of interest and artifact signals during training, a common problem is the limited availability of data, particularly in medical imaging tasks [52]. It is caused by high time and material costs for recording examples and intensified by data privacy restrictions that create further hurdles for the data collection [52]. Additionally, the annotation of images can be a time-consuming task requiring experts’ review [52]. For deep learning methods in sensor image analysis, it is therefore particularly desirable to develop approaches that deal with very limited data availability during the training stage.
As an example of a sensor affected by different disturbances, Section 3 describes the Plasmon-Assisted Microscopy of Nano-Objects (PAMONO) sensor, which has been the subject of several research questions [53,54,55,56] and served as a starting point for the research presented in this paper. It is affected by disturbances during image acquisition, resulting in varying artifact characteristics, for which some are shown in Figure 1. Therefore, it offers a well-suited data basis to evaluate methods for increased robustness against artifacts.

Figure 1.
Example images extracted from different datasets recorded with the Plasmon-Assisted Microscopy of Nano-Objects (PAMONO) sensor after preprocessing and the application of dynamic contrast enhancement. Different dominating types of artifacts presented in Table 1 can be perceived. Random noise artifacts are present in each recorded image but vary in their intensities with differing environmental influences. (a) Washed out line artifact. (b) Dominant background noise with temporal brightness inconsistencies in an image region on the right. (c) Dominating higher frequency wave artifact with a center near the visible region. (d) Dominating lower frequency wave artifact with visible origin.
Motivated by the observation above, we propose a data-centric approach that aims at increasing the robustness of learning methods against image artifacts. We use the term data-centric to describe that only training data is modified to maximize the performance of a learning procedure. At the same time, the existing model does not change. There is no deceleration or change in memory requirements during inference as only the learned weights are adjusted. We present an approach based on generative adversarial networks (GANs) [57], which overlays images with realistic but synthetically generated artifacts during the training of a segmentation network. The GAN is trained with real images containing only artifacts and learns to generate an arbitrary number of new artifact images. We do not need additional annotations for our approach. As an example for our method, we evaluate our GAN approach on PAMONO sensor data. We find that the effect of artifacts on a segmentation task is reduced significantly. We also show that the GAN approach is superior to alternative, non-learning approaches in the evaluated segmentation task. For comparison, we employ a procedural generation of combined wave artifacts based on qualitative observations and the direct use of real artifact images from recorded datasets.
The structure of this paper is as follows. Section 2 mentions related methods for reducing artifacts in image signals and popular methods for generating synthetic images. Section 3 details the PAMONO sensor and its recorded data as the basis for evaluating the presented approaches. Section 4.1 describes our approach for an overlay composed of realistic but synthetic artifact patterns utilizing the StyleGAN2-ADA [58] architecture. For direct comparison, Section 4.2 and Section 4.3 present methods for overlaying training images with real artifacts and the procedural generation of combined waves, respectively. We present the integration of our approach into experiments and the considered metrics in Section 5. The results are compared and discussed in Section 6. In the end, we give suggestions for future work in Section 7.
2. State of the Art
For the task of artifact reduction, examples for methods related to specific types of artifacts can be found in Table 1. It includes traditional as well as machine learning approaches. An overview focusing particularly on deep learning-based methods for image artifact removal is provided by Tian et al. [9]. It covers a wide range of approaches and structures them based on their methodological similarities. There are various traditional approaches such as Gaussian, median and bilateral filters [7,8], homomorphic filtering [13], methods based on physical models [25], morphological filters [30], Fourier- and wavelet-based filtering [10]. An early application of convolutional networks for image denoising was published by Jain and Seung [59]. The proposed strategy introduced a specific artifact removal network that outputs a clean image with reduced artifacts [59]. Since this learning strategy demonstrated its potential to reduce various artifacts, further work has followed this approach [60,61,62]. Disadvantages of these methods include an introduction of additional computational costs, additional memory requirements, and in some cases, the need for clean images without artifacts.
A different approach improves the robustness of an existing model against artifacts using augmentation methods [63]. The related methods are applied to an existing model by modifying or expanding training data during the optimization process. Since these methods only change data but not architectures, we refer to them as data-centric. This characteristic has the advantage that the methods can be applied during training and do not require the modification of an existing algorithm. Various methods for augmentation show drawbacks making them undesirable as they focus on uncorrelated noise [63], assume perfect artifacts [15], or rely on hand-crafted definitions for creating correlated artifacts [64]. In addition, reference images are rarely exploited. Reference images can be acquired without objects of interest and therefore contain only background and artifacts. They contain valuable information, especially for tasks with low data availability. We developed our approach to address these shortcomings. We exploit reference images and use both correlated and uncorrelated artifacts.
Cubuk et al. [65] proposed AutoAugment, a method to learn sequences of augmentations from a set of parametrized operations to improve the training process for an underlying network. As our approach is comparable to an augmentation operation within AutoAugment, the methods do not form alternatives but are combinable.
For tasks with low availability of labeled training data, various approaches augment existing data with synthetic images using GANs [66,67,68,69,70]. For example, Frid-Adar et al. [66] use a GAN to synthesize new images for CT scan data of liver lesions. Han et al. [67] follow a similar objective by generating synthetic brain MR images. Sandfort et al. [68] employ a CycleGAN [71] to expand a dataset of CT scans with synthetic images. Hee et al. [69] use a conditional GAN to generate brain metastases at desired locations in synthetic MR images. The mentioned methods do not use reference images but only images containing signals of interest. In contrast to that, our approach also uses reference images to take advantage of this information.
For GANs, as state of the art for image synthesis, recent developments show that they can be trained even with very limited amounts of data [58]. Driven by these findings, we make use of a StyleGAN2-ADA network [58] to generate realistic artifacts, which we use for the augmentation of existing training data.
3. PAMONO Sensor Image Streams
The following explanations characterize the images recorded with the Plasmon-Assisted Microscopy of Nano-Objects (PAMONO) sensor [53]. Since each recording of the device shows different types of dominant artifacts, this data serves as the basis for our evaluation.
The PAMONO sensor employs the effect of surface plasmon resonance (SPR) [72] to make individual nanoparticles visible as bright spots on preprocessed images. These spots become more difficult to detect with an increasing quantity or intensity of artifacts in the images. This functionality enables the use as a rapid test for the presence of viruses and virus-like particles (VLPs) and for counting nanoparticles in a sample [73]. The sensor visualizes particles of interest using a gold foil with an antibody coating on one side. The foil is attached to a flow cell containing a liquid sample, while the opposite side reflects a laser beam directed towards it. When specific particles in a sample attach to the antibody coating, the reflective properties of the gold foil change at this region, and the particles become visible in the reflected signal. This setup provides indirect imaging for the downstream detection of nano-sized objects. Further explanations of the technical aspects and application scenarios, such as detecting viruses, can be found in the literature [53,54,55,56]. While a high degree of reliability is essential for detecting nanoparticles, recording with the PAMONO sensor is prone to disturbances originating from its high sensitivity to changes in the nanometer scale, temperature dependence, sensitivity to external impacts, and contaminations of the analyzed samples [74]. This results in random noises originating from the electronics and the environment, wave and line artifacts resulting from air bubbles and dirt particles in a sample, and significant global and local brightness differences due to environmental changes or the preprocessing. In addition, local damages of the coated gold can introduce line artifacts and fixed pattern noises. Therefore, an applied segmentation approach must cope with different types of artifacts. Figure 1 shows example images gathered with the PAMONO sensor containing different characteristics of artifacts. The intensities and occurring types can change for each experiment and also during one recording. Since tests with particles involve high material costs, the availability of the related images is low. In contrast, reference images showing only background and artifacts can be provided more efficiently. This property and the occurrence of various artifacts make the data acquired with the PAMONO sensor a well-suited example for evaluating our approach.
4. Methods
For increasing the robustness against artifacts in the analysis of sensor images, we formally introduce our method. We assume an image at a discrete timestep t originating from a data stream from the set of all image streams to be composed of different signals in an additive signal model
for . The signal consists of a particle signal , a background , which is constant for all positions within a single image, a correlated artifact signal , and uncorrelated artifacts .
Both artifact components can contain values outside of . For this work, we use images , which are already preprocessed with a sliding window method presented in previous work [56]. This preprocessing enhances the visibility of particle signals using temporal information for each image pixel and a dynamic contrast enhancement afterward. Figure 1 shows example images for different datasets and timesteps t where predominates with different artifact characteristics in each image. The goal here is to highlight all image positions containing a particle. Therefore, we want to find a function
to realize a semantic segmentation [75] to learn a mapping
from images onto a binary segmentation map. In order for f to achieve good results on a multitude of different datasets , a broad set of artifacts has to be handled. Our approach expands a low-artifact data basis by augmenting the training data with additional artifacts. We make use of datasets without particles of interest so that a contained image can be written as
Such images can be created without the need for test objects and serve as a basis for learning realistic characteristics of artifact patterns.
Having identified that wave-like artifacts are a factor that can heavily disturb detection methods, we also developed a method to generate wave-like artifacts directly to prepare the trained network towards being robust against possible correlated artifacts. This method serves as a basis for comparison to the presented GAN-based approach.
4.1. Artifact Overlays Based on Synthetic Artifacts
From an abstract perspective, we overlay an image containing object signals of interest with a composite synthetic noise signal to optimize a segmentation model. Figure 2 shows an overview of this procedure. The upper part of the system shows the learning of artifact characteristics from images without object signals. Tiles are extracted from a recorded image and used for training a GAN. The GAN learns to generate new tiles, which are then combined into an artifact image. The lower part shows the overlay of a recording with a composition of generated artifact tiles.
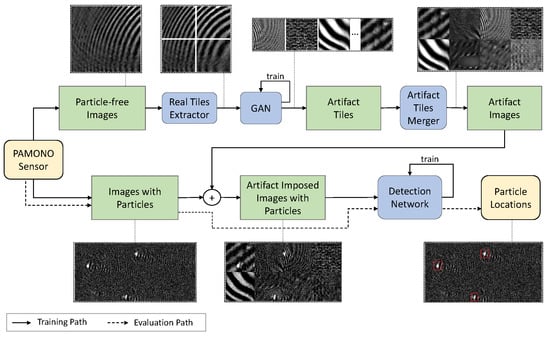
Figure 2.
Schematic representation of overlaying training images with generative adversarial network (GAN)-generated artifacts from composite tiles. The PAMONO sensor is used to record samples without particles of interest (upper part) and samples including such particles (lower part) for the training process. The trained detection model is then used to search for particles in images where their presence is unknown. Dashed arrows show the path of images in the evaluation process, while solid arrows represent the path of images in the training process. The images in dotted boxes visualize the single steps by examples. The yellow boxes illustrate start and end of the pipeline, green boxes represent data and blue boxes mark algorithms.
In detail, we augment each training image with structured artifacts and uncorrelated artifacts . We combine both types to a single artifact signal
and use it to create an augmented image
Figure 3 shows an example of such an overlay.

Figure 3.
Example combination of artifacts according to Equation (6). A training image I with little correlated artifacts is augmented with wave artifacts to expand the present artifact patterns. The combination of artifacts is noted as .
In order to extract artifact signals from an image, we solve the assumed signal model of Equation (4) for artifact components
Since we are only interested in the contained artifact signals, we use images without particle signals. Therefore, the only remaining unknown signal is the constant background signal. We assume that the artifact and noise signals are zero-centered. Consequently, we approximate the background as the mean intensity value
of the full image. The artifact signal can be formulated as
for further use as an overlay. With these artifacts, the original images from a dataset can be augmented according to Equation (6).
Despite the reduced costs of producing images without involving particles for real artifact tiles, the available images are still limited. In order to have access to an unlimited stream of new and distinct artifacts, we propose the synthetic generation of new images . With this, we can provide an arbitrary number of synthetic but realistic-looking artifact patterns. Currently, the state-of-the-art method for image synthesis are generative adversarial networks (GANs) [58]. GANs use a generator model G to mimic the distribution of a set of real images optimized with feedback from a discriminator model D. The discriminator is optimized to distinguish between real and synthetic images. As the input for training the GAN, we use real images from a dataset . In this work, we employ StyleGAN2-ADA [58], which is specifically designed for optimization with limited data. After optimizing the generative network, the generator function is used to create an arbitrary number of new artifact images.
The generated artifacts can be smaller than the original image . In this case, larger artifact images can be composed of multiple smaller ones. A set of artifact tiles
is generated where each artifact tile is extracted from a synthetically generated image with side lengths v and w. The tiles are then composed to a single artifact
which has the needed size. For each training image, a new set is dynamically generated.
4.2. Real Artifacts as Overlays
For a direct comparison, we apply real artifacts directly to the training images instead of applying synthetic artifacts. To create overlays from recorded data directly, we modify the set of artifacts to not originate from the GAN but from random cutouts from real images. We make use of non-annotated images which do not contain signals of objects of interest but are still affected by artifacts. Unlike in the GAN-based approach, the available data is directly limited by the original set of input images. This allows a meaningful comparison of the effects of learned artifacts with the direct utilization of real artifacts.
4.3. Procedurally Generated Artifact Signals
We present another approach for generating artifact patterns which is based on the procedural generation of artifacts in an attempt to simulate real artifacts in the form of imperfect waves superimposed over an image. In our observations, we found sine waves to be suitable approximations for actually recorded artifacts. These calculations are rules-based and can be varied using random parameter values.
Given an image I with side lengths X and Y, waves are generated and added to this image for training. For a single sine wave centered around point = , we determine the amplitude
at every image position using a frequency parameter , a phase shift and a distance
We observed that the intensities of waves in an image are often not constant over the entire surface, so a term
is included to add a fading effect starting from an independant center point from which the intensity decreases with a rate . This term is applied to the original wave function h to receive a single fading wave
Finally, all waves are composed and added to the image I to simulate a combination
of different vanishing waves by using sets of wave centers , fade centers , frequency parameters , phase shifts , and fade rates . The influence of the waves in the resulting image is controlled via the wave strength factor . The parameter values for each wave are randomly chosen from a restricted interval. Figure 4 shows examples of randomly generated wave artifacts added to a low artifact image. The resulting wave artifacts approximate the visual appearance of real artifacts with parameters drawn from a manually defined interval.

Figure 4.
An (a) input image and (b–d) examples of randomly generated wave artifacts.
Although it is possible to find fitting intervals that result in a distribution similar to real artifacts, a procedural generation of artifacts requires the manual definition of the generating function and manual tuning to the artifact characteristics at hand.
5. Experiments
We evaluate our GAN-based method by applying it to image streams recorded with the PAMONO sensor that is described in Section 3. Individual image streams show different artifacts, so it offers a well-suited opportunity to evaluate this approach. The goal is to find a model that solves the segmentation of particles, as formulated in Section 4. Particles should be easily distinguishable from other image parts in the resulting segmentation, so we employ a blob detection based on Difference of Gaussians (DoG) [76] features for particle detection. To focus the evaluation on the augmentations only, we employ a plain 5-layer U-Net [77] with 16 filters in the first layer. We make no changes to this architecture during our experiments and only conduct changes for the data itself. In this way, we can evaluate the effectiveness of our proposed approach and compare it directly to the other introduced methods. This provides a concrete implementation of the abstract detection network shown in Figure 2. The different approaches are compared to each other based on correctly detected nanoparticles.
We utilize the dice loss [78] in combination with the Adam [79] optimizer to train the U-Net. An initial learning rate of is halved after every 15 epochs with no improvement in the dice loss for designated validation datasets. We end the training after 30 epochs with no improvement. For this work, 23 annotated image streams containing particles of interest provide 30,782 images in total. Only one of these datasets with low intensities of artifacts and well visible particle regions containing 500 images is used for training. We employ five datasets as validation data. The remaining datasets are used as test data after the training is completed.
Due to the preprocessing, each particle contained in the image streams can be seen not only on one but on several frames. We connect the particle locations on individual images to traces afterward. This means that sufficiently overlapping regions on consecutive frames are combined to one particle, which is especially important for counting particles to determine the viral load in a sample [56].
For measuring run times, an Nvidia Geforce GTX 1080 GPU is used. Random cutouts with side lengths of 128 pixels from 1157 images originating from a single reference image stream are used for training the GAN. About 5 GB of video memory are allocated. Using a batch size of 16, around 38 h are needed for training a StyleGAN2-ADA network consisting of a generator part with parameters and a discriminator part with parameters. The training times for the U-Net lie between 90 min with no augmentation and up to 360 min for the GAN-based augmentations. For better comparability, the same dataset for training the GAN is used for overlaying images with real artifacts.
To compare the GAN-approach also to a direct and simple augmentation we apply a variation of image sizes relative to the sizes of particle regions in the samples. For each training dataset the median surface of annotated particle regions in the dataset is calculated to determine the overall minimum size
and the maximum size analogously. The median operator is used to determine sizes within a dataset in order to compensate for possible outliers caused by manual annotation. By restricting the random factor used to scale both sides of an image separately to
for a dataset , the scaled images cover the range of particle sizes seen as plausible based on the available annotations. In each training step the side lengths u and v of a training image are scaled by a factor to and . Since this approach presents a simple strategy that has proven useful in combination with more complex approaches in preliminary tests, it is also applied in the case of procedural wave generation, real artifact overlays, and GAN-based overlays.
For each evaluated configuration of augmentations, we consider two measures. The first measure is the F1-score [80]
of particle traces which uses the number of true positives (), false positives (), and false negatives () to indicate the extent to which the predicted traces and the annotations match. A predicted trace is seen as matching if its bounding box overlaps significantly with the box of an annotated trace. As two overlapping predictions can both be seen as true positives when overlapping with one annotated trace, this measure focuses on the accuracy of particle locations instead of matching trace counts.
The second measure is the count exactness [56]
which compares the number of predicted traces with the number of annotated traces . As the count exactness does not consider where the single traces are located, false positives and false negatives can misleadingly balance each other out. Nevertheless, it is a simple and practice-oriented measure that is especially of interest in real use case scenarios, where an expert can interpret this information based on domain knowledge. In PAMONO sensor data, the determined particle count could be compared to expected concentrations of virus particles related to an infection of interest.
We execute each training configuration three times to reduce the effect of outliers. The model with the median F1-score is selected for evaluating all presented metrics. We compare the proposed GAN-based approach in Table 2 with the alternatives based on F1-scores and count exactness values related to particle traces. The results vary heavily for different datasets depending on the intensities and prevalent types of artifacts in the contained images. Therefore, we also show results for datasets split into different groups of artifacts. A comparison broken down by the qualitative type of dominant artifacts is given in Table 3.
Table 2.
F1-score and count exactness values measured after training with the presented augmentation methods. The best results are written in bold.
Table 3.
F1-score (F1) and count exactness (CE) values for samples containing particles of interest after training with different augmentation methods broken down by dominant artifact types. The best results are written in bold.
We also compare the approaches using the binary distinction between samples containing particles of interest and samples free of them. The exact particle counts and locations are less relevant here. Instead, an effective separation between these two groups is sought, for which a low number of false positives in particle-free samples is essential. Results for samples of this type are conducted in Table 4, and the counts of predicted particles per image are compared for models trained with the different approaches. For this purpose, 12 particle-free datasets with 10,384 images in total showing diverse artifact types and intensities are analyzed.
Table 4.
Number of falsely predicted particles (FP) per image for datasets containing no particles of interest measured after training with different augmentation methods. The best results are written in bold.
6. Discussion
Aiming at high robustness of a learned segmentation against imaging artifacts, our approach using GANs to generate synthetic artifacts shows to be the most effective. Compared to the version with no augmentation, as shown in Table 2, this approach yields improvements of 22% in the F1-score, 26% in the average count exactness, and even greater improvements in the related minimum values. Table 3 shows that the results improve more with stronger visible artifacts and correlation within these. The GAN approach increases the F1-score by 63% and the average count exactness by 61% for datasets with wave-like artifacts. In the task of searching for particles in particle-free samples, this approach improves the average number of false positive particle traces from to per image, with the dataset performing the worst, only having false-positive traces per image.
Comparing the GAN-based approach with extracting artifacts directly from images, the span between the worst and best values is smaller. The augmentation by superimposing wave artifacts based on a hand-crafted, procedural function is approximately on par with the augmentation with real artifacts when considering average scores. However, minimum values show a slight improvement, which indicates greater stability of the detection after the appropriate training. The real and the procedurally generated artifacts improve the F1-score by 14% compared to the training without augmentations. This shows that the model benefits significantly from augmentation with correlated artifacts. Viewing the results in Table 2, it is noticeable that direct augmentation, representing the random size augmentation based on the particle sizes present in the training dataset, does not improve the F1-score and the count exactness for datasets containing particles. Compared to the basic version without augmentation, there is even a slight deterioration in the F1-score. If the evaluation is expanded to the datasets not containing particles of interest, the impression is different. Table 4 shows that the average rate of false positives per image can be reduced by 94.5% by just applying direct size augmentations.
All in all, the augmentation by overlaying with artifacts generated by our GAN-based approach achieves the most significant improvements, both in the average and minimum values. The increase of the minimum values can be seen as better robustness against artifacts that do not occur in the training data. At the same time, despite the increased training time, the advantage of not having to define and adjust a function description by hand can be noted. This shows that the GAN-based generation of artifact images for data augmentation can be a worthwhile improvement to classic augmentations in image analysis. This holds especially when the exact artifact patterns can only be described with great effort, for example, when the application environment of the used sensor changes frequently while a lack of training data makes the determination difficult.
7. Outlook
Since our approach showed to be capable of increasing the robustness of a spatial learning system against image artifacts, the exploitation of temporal correlations can be investigated. In image data streams, objects of interest and artifact patterns are time-dependent in most cases, so generating time-consistent artifacts could further improve the results for a downstream task. It needs to be considered that, while the complexity of the generation task increases, fewer spatiotemporal training samples can be formed from a set of images. Despite the potential problems, evaluating a generation approach incorporating the temporal dimension can further increase the robustness of a downstream, spatiotemporal image analysis. Our approach demonstrates that it mitigates the effects of artifacts in images of the PAMONO sensor. Further work should evaluate this method for images from other sensors. The approach has the potential to be applied to other sensors with little customization.
Author Contributions
A.R. and K.W. conducted the investigation, development and design of methodology, analyzed literature and wrote the paper. K.W. curated the data. F.W. supervised the process and reviewed the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported by the German Research Association (DFG) within the Collaborative Research Centre 876 SFB 876 “Providing Information by Resource-Constrained Data Analysis”, projects B2 and B4. URL: http://sfb876.tu-dortmund.de (accessed on 5 October 2021).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Example datasets with samples containing particles of interest and samples without such particles can be found at https://graphics-data.cs.tu-dortmund.de/docs/publications/panomo/ (accessed on 5 October 2021).
Acknowledgments
We want to thank the Leibniz Institute for Analytical Sciences-ISAS-e.V., especially Victoria Shpacovitch and Roland Hergenröder for recording the PAMONO sensor data used for our studies.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chan, T.F.; Shen, J. Image Processing and Analysis: Variational, PDE, Wavelet, and Stochastic Methods; SIAM: Philadelphia, PA, USA, 2005. [Google Scholar]
- Lesser, M. Charge-Coupled Device (CCD) Image Sensors. In High Performance Silicon Imaging, 2nd ed.; Woodhead Publishing Series in Electronic and Optical Materials; Durini, D., Ed.; Woodhead Publishing: Sawston, UK, 2020; Chapter 3; pp. 75–93. [Google Scholar] [CrossRef]
- Choubey, B.; Mughal, W.; Gouveia, L. CMOS Circuits for High-Performance Imaging. In High Performance Silicon Imaging, 2nd ed.; Woodhead Publishing Series in Electronic and Optical Materials; Durini, D., Ed.; Woodhead Publishing: Sawston, UK, 2020; Chapter 5; pp. 119–160. [Google Scholar] [CrossRef]
- Konnik, M.; Welsh, J. High-Level Numerical Simulations of Noise in CCD and CMOS Photosensors: Review and Tutorial. arXiv 2014, arXiv:1412.4031. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image Denoising: Can Plain Neural Networks Compete with BM3D? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2392–2399. [Google Scholar] [CrossRef]
- Tian, H. Noise Analysis in CMOS Image Sensors. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2000. [Google Scholar]
- Arce, G.R.; Bacca, J.; Paredes, J.L. Nonlinear Filtering for Image Analysis and Enhancement. In Handbook of Image and Video Processing, 2nd ed.; Bovik, A., Ed.; Communications, Networking and Multimedia; Academic Press: Cambridge, MA, USA, 2005; Chapter 3.2; pp. 109–132. [Google Scholar] [CrossRef]
- Zhang, M.; Gunturk, B. Compression Artifact Reduction with Adaptive Bilateral Filtering. Proc. SPIE 2009, 7257. [Google Scholar] [CrossRef]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep Learning on Image Denoising: An Overview. arXiv 2020, arXiv:1912.13171. [Google Scholar] [CrossRef]
- Münch, B.; Trtik, P.; Marone, F.; Stampanoni, M. Stripe and Ring Artifact Removal With Combined Wavelet—Fourier Filtering. Opt. Express 2009, 17, 8567–8591. [Google Scholar] [CrossRef]
- Charles, B. Image Noise Models. In Handbook of Image and Video Processing, 2nd ed.; Bovik, A., Ed.; Communications, Networking and Multimedia; Academic Press: Cambridge, MA, USA, 2005; Chapter 4.5; pp. 397–409. [Google Scholar] [CrossRef]
- Boitard, R.; Cozot, R.; Thoreau, D.; Bouatouch, K. Survey of Temporal Brightness Artifacts in Video Tone Mapping. HDRi 2014: Second International Conference and SME Workshop on HDR Imaging. 2014, Volume 9. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.646.1334&rep=rep1&type=pdf (accessed on 5 October 2021).
- Mustafa, W.A.; Khairunizam, W.; Yazid, H.; Ibrahim, Z.; Shahriman, A.; Razlan, Z.M. Image Correction Based on Homomorphic Filtering Approaches: A Study. In Proceedings of the International Conference on Computational Approach in Smart Systems Design and Applications (ICASSDA), Kuching, Malaysia, 15–17 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Delon, J.; Desolneux, A. Stabilization of Flicker-Like Effects in Image Sequences through Local Contrast Correction. SIAM J. Imaging Sci. 2010, 3, 703–734. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, X.; Wang, S.; Cheng, C.; Huang, Y.; Yang, K.; Li, Y. BLNet: A Fast Deep Learning Framework for Low-Light Image Enhancement with Noise Removal and Color Restoration. arXiv 2021, arXiv:2106.15953. [Google Scholar]
- Rashid, S.; Lee, S.Y.; Hasan, M.K. An Improved Method for the Removal of Ring Artifacts in High Resolution CT Imaging. EURASIP J. Adv. Signal Process. 2012, 2012, 93. [Google Scholar] [CrossRef]
- Hoff, M.; Andre, J.; Stewart, B. Artifacts in Magnetic Resonance Imaging. In Image Principles, Neck, and the Brain; Saba, L., Ed.; Taylor & Francis Ltd.: Abingdon, UK, 2016; pp. 165–190. [Google Scholar] [CrossRef]
- Lv, X.; Ren, X.; He, P.; Zhou, M.; Long, Z.; Guo, X.; Fan, C.; Wei, B.; Feng, P. Image Denoising and Ring Artifacts Removal for Spectral CT via Deep Neural Network. IEEE Access 2020, 8, 225594–225601. [Google Scholar] [CrossRef]
- Liu, J.; Liu, D.; Yang, W.; Xia, S.; Zhang, X.; Dai, Y. A Comprehensive Benchmark for Single Image Compression Artifact Reduction. IEEE Trans. Image Process. 2020, 29, 7845–7860. [Google Scholar] [CrossRef]
- Vo, D.T.; Nguyen, T.Q.; Yea, S.; Vetro, A. Adaptive Fuzzy Filtering for Artifact Reduction in Compressed Images and Videos. IEEE Trans. Image Process. 2009, 18, 1166–1178. [Google Scholar] [CrossRef][Green Version]
- Kırmemiş, O.; Bakar, G.; Tekalp, A.M. Learned Compression Artifact Removal by Deep Residual Networks. arXiv 2018, arXiv:1806.00333. [Google Scholar]
- Xu, Y.; Gao, L.; Tian, K.; Zhou, S.; Sun, H. Non-Local ConvLSTM for Video Compression Artifact Reduction. arXiv 2019, arXiv:1910.12286. [Google Scholar]
- Xu, Y.; Zhao, M.; Liu, J.; Zhang, X.; Gao, L.; Zhou, S.; Sun, H. Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and Frequency Domain Information. arXiv 2021, arXiv:2105.14962. [Google Scholar]
- Stankiewicz, O.; Lafruit, G.; Domański, M. Multiview Video: Acquisition, Processing, Compression, and Virtual View Rendering. In Academic Press Library in Signal Processing; Chellappa, R., Theodoridis, S., Eds.; Academic Press: Cambridge, MA, USA, 2018; Volume 6, Chapter 1; pp. 3–74. [Google Scholar] [CrossRef]
- Drap, P.; Lefèvre, J. An Exact Formula for Calculating Inverse Radial Lens Distortions. Sensors 2016, 16, 807. [Google Scholar] [CrossRef] [PubMed]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Del Gallego, N.P.; Ilao, J.; Cordel, M. Blind First-Order Perspective Distortion Correction Using Parallel Convolutional Neural Networks. Sensors 2020, 20, 4898. [Google Scholar] [CrossRef]
- Lagendijk, R.L.; Biemond, J. Basic Methods for Image Restoration and Identification. In Handbook of Image and Video Processing, 2nd ed.; Bovik, A., Ed.; Communications, Networking and Multimedia; Academic Press: Cambridge, MA, USA, 2005; Chapter 3.5; pp. 167–181. [Google Scholar] [CrossRef]
- Merchant, F.A.; Bartels, K.A.; Bovik, A.C.; Diller, K.R. Confocal Microscopy. In Handbook of Image and Video Processing, 2nd ed.; Bovik, A., Ed.; Communications, Networking and Multimedia; Academic Press: Cambridge, MA, USA, 2005; Chapter 10.9; pp. 1291–1309. [Google Scholar] [CrossRef]
- Maragos, P. 3.3—Morphological Filtering for Image Enhancement and Feature Detection. In Handbook of Image and Video Processing, 2nd ed.; Bovik, A., Ed.; Communications, Networking and Multimedia; Academic Press: Cambridge, MA, USA, 2005; pp. 135–156. [Google Scholar] [CrossRef]
- He, D.; Cai, D.; Zhou, J.; Luo, J.; Chen, S.L. Restoration of Out-of-Focus Fluorescence Microscopy Images Using Learning-Based Depth-Variant Deconvolution. IEEE Photonics J. 2020, 12, 1–13. [Google Scholar] [CrossRef]
- Xu, G.; Liu, C.; Ji, H. Removing Out-of-Focus Blur From a Single Image. arXiv 2018, arXiv:1808.09166. [Google Scholar]
- Lesser, M. Charge Coupled Device (CCD) Image Sensors. In High Performance Silicon Imaging; Durini, D., Ed.; Woodhead Publishing: Sawston, UK, 2014; Chapter 3; pp. 78–97. [Google Scholar] [CrossRef]
- Bigas, M.; Cabruja, E.; Forest, J.; Salvi, J. Review of CMOS Image Sensors. Microelectron. J. 2006, 37, 433–451. [Google Scholar] [CrossRef]
- Guan, J.; Lai, R.; Xiong, A.; Liu, Z.; Gu, L. Fixed Pattern Noise Reduction for Infrared Images Based on Cascade Residual Attention CNN. Neurocomputing 2020, 377, 301–313. [Google Scholar] [CrossRef]
- Yang, L.; Liu, S.; Salvi, M. A Survey of Temporal Antialiasing Techniques. Comput. Graph. Forum 2020, 39, 607–621. [Google Scholar] [CrossRef]
- Vasconcelos, C.; Larochelle, H.; Dumoulin, V.; Roux, N.L.; Goroshin, R. An Effective Anti-Aliasing Approach for Residual Networks. arXiv 2020, arXiv:2011.10675. [Google Scholar]
- Zhong, Z.; Zheng, Y.; Sato, I. Towards Rolling Shutter Correction and Deblurring in Dynamic Scenes. arXiv 2021, arXiv:2104.01601. [Google Scholar]
- Zhuang, B.; Tran, Q.H.; Ji, P.; Cheong, L.F.; Chandraker, M. Learning Structure-And-Motion-Aware Rolling Shutter Correction. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–21 June 2019; pp. 4546–4555. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Broaddus, C.; Krull, A.; Weigert, M.; Schmidt, U.; Myers, G. Removing Structured Noise with Self-Supervised Blind-Spot Networks. In Proceedings of the IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 159–163. [Google Scholar] [CrossRef]
- He, Z. Deep Learning in Image Classification: A Survey Report. In Proceedings of the 2nd International Conference on Information Technology and Computer Application (ITCA), Guangzhou, China, 18–20 December 2020; pp. 174–177. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2001.05566. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Teimoorinia, H.; Kavelaars, J.J.; Gwyn, S.D.J.; Durand, D.; Rolston, K.; Ouellette, A. Assessment of Astronomical Images Using Combined Machine-Learning Models. Astron. J. 2020, 159, 170. [Google Scholar] [CrossRef]
- Li, P.; Chen, X.; Shen, S. Stereo R-CNN based 3D Object Detection for Autonomous Driving. arXiv 2019, arXiv:1902.09738. [Google Scholar]
- Caicedo, J.C.; Roth, J.; Goodman, A.; Becker, T.; Karhohs, K.W.; Broisin, M.; Molnar, C.; McQuin, C.; Singh, S.; Theis, F.J.; et al. Evaluation of Deep Learning Strategies for Nucleus Segmentation in Fluorescence Images. Cytom. Part A 2019, 95, 952–965. [Google Scholar] [CrossRef] [PubMed]
- Çallı, E.; Sogancioglu, E.; van Ginneken, B.; van Leeuwen, K.G.; Murphy, K. Deep Learning for Chest X-Ray Analysis: A Survey. Med. Image Anal. 2021, 72, 102125. [Google Scholar] [CrossRef] [PubMed]
- Lundervold, A.S.; Lundervold, A. An Overview of Deep Learning in Medical Imaging Focusing on MRI. Z. Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef]
- Kulathilake, K.A.S.H.; Abdullah, N.A.; Sabri, A.Q.M.; Lai, K.W. A Review on Deep Learning Approaches for Low-Dose Computed Tomography Restoration. Complex Intell. Syst. 2021. [Google Scholar] [CrossRef]
- Srinidhi, C.L.; Ciga, O.; Martel, A.L. Deep Neural Network Models for Computational Histopathology: A Survey. Med. Image Anal. 2021, 67, 101813. [Google Scholar] [CrossRef] [PubMed]
- Puttagunta, M.; Ravi, S. Medical Image Analysis Based on Deep Learning Approach. Multimed. Tools Appl. 2021. [Google Scholar] [CrossRef] [PubMed]
- Lenssen, J.E.; Shpacovitch, V.; Siedhoff, D.; Libuschewski, P.; Hergenröder, R.; Weichert, F. A Review of Nano-Particle Analysis with the PAMONO-Sensor. Biosens. Adv. Rev. 2017, 1, 81–100. [Google Scholar]
- Lenssen, J.E.; Toma, A.; Seebold, A.; Shpacovitch, V.; Libuschewski, P.; Weichert, F.; Chen, J.J.; Hergenröder, R. Real-Time Low SNR Signal Processing for Nanoparticle Analysis with Deep Neural Networks. In International Conference on Bio-Inspired Systems and Signal Processing (BIOSIGNALS); SciTePress: Funchal, Portugal, 2018. [Google Scholar]
- Yayla, M.; Toma, A.; Chen, K.H.; Lenssen, J.E.; Shpacovitch, V.; Hergenröder, R.; Weichert, F.; Chen, J.J. Nanoparticle Classification Using Frequency Domain Analysis on Resource-Limited Platforms. Sensors 2019, 19, 4138. [Google Scholar] [CrossRef] [PubMed]
- Wüstefeld, K.; Weichert, F. An Automated Rapid Test for Viral Nanoparticles Based on Spatiotemporal Deep Learning. In Proceedings of the IEEE Sensors, Rotterdam, The Netherlands, 25–28 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Jabbar, A.; Li, X.; Omar, B. A Survey on Generative Adversarial Networks: Variants, Applications, and Training. arXiv 2020, arXiv:2006.05132. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training Generative Adversarial Networks With Limited Data. arXiv 2020, arXiv:2006.06676. [Google Scholar]
- Jain, V.; Seung, S. Natural Image Denoising With Convolutional Networks. Adv. Neural Inf. Process. Syst. 2008, 21, 769–776. [Google Scholar]
- Andina, D.; Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep Image Prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9446–9454. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning Enriched Features for Real Image Restoration and Enhancement. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 492–511. [Google Scholar]
- Gu, S.; Rigazio, L. Towards Deep Neural Network Architectures Robust to Adversarial Examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Zhao, Y.; Ossowski, J.; Wang, X.; Li, S.; Devinsky, O.; Martin, S.P.; Pardoe, H.R. Localized Motion Artifact Reduction on Brain MRI Using Deep Learning With Effective Data Augmentation Techniques. arXiv 2020, arXiv:2007.05149. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies from Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 113–123. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-Based Synthetic Medical Image Augmentation for Increased CNN Performance in Liver Lesion Classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef]
- Han, C.; Rundo, L.; Araki, R.; Nagano, Y.; Furukawa, Y.; Mauri, G.; Nakayama, H.; Hayashi, H. Combining Noise-to-Image and Image-to-Image GANs: Brain MR Image Augmentation for Tumor Detection. IEEE Access 2019, 7, 156966–156977. [Google Scholar] [CrossRef]
- Sandfort, V.; Yan, K.; Pickhardt, P.J.; Summers, R.M. Data Augmentation Using Generative Adversarial Networks (CycleGAN) To Improve Generalizability in CT Segmentation Tasks. Sci. Rep. 2019, 9, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Han, C.; Murao, K.; Noguchi, T.; Kawata, Y.; Uchiyama, F.; Rundo, L.; Nakayama, H.; Satoh, S. Learning More With Less: Conditional PGGAN-Based Data Augmentation for Brain Metastases Detection Using Highly-Rough Annotation on MR Images. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 119–127. [Google Scholar]
- Han, C.; Kitamura, Y.; Kudo, A.; Ichinose, A.; Rundo, L.; Furukawa, Y.; Umemoto, K.; Li, Y.; Nakayama, H. Synthesizing Diverse Lung Nodules Wherever Massively: 3D Multi-Conditional GAN-Based CT Image Augmentation for Object Detection. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Québec City, QC, Canada, 16–19 September 2019; pp. 729–737. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Liang, A.; Liu, Q.; Wen, G.; Jiang, Z. The Surface-Plasmon-Resonance Effect of Nanogold/Silver and Its Analytical Applications. TrAC Trends Anal. Chem. 2012, 37, 32–47. [Google Scholar] [CrossRef]
- Shpacovitch, V.; Sidorenko, I.; Lenssen, J.E.; Temchura, V.; Weichert, F.; Müller, H.; Überla, K.; Zybin, A.; Schramm, A.; Hergenröder, R. Application of the PAMONO-sensor for Quantification of Microvesicles and Determination of Nano-particle Size Distribution. Sensors 2017, 17, 244. [Google Scholar] [CrossRef]
- Siedhoff, D. A Parameter-Optimizing Model-Based Approach to the Analysis of Low-SNR Image Sequences for Biological Virus Detection. Ph.D. Thesis, TU Dortmund, Dortmund, Germany, 2016. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Marr, D.; Hildreth, E. Theory of Edge Detection. Proc. R. Soc. Lond. Ser. B 1980, 207, 187–217. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. arXiv 2016, arXiv:1606.04797. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In AI 2006: Advances in Artificial Intelligence; Sattar, A., Kang, B.H., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1015–1021. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).