
Novel Texture Feature Descriptors Based on Multi-Fractal Analysis and LBP for Classifying Breast Density in Mammograms




Abstract
1. Introduction
2. Materials and Methods
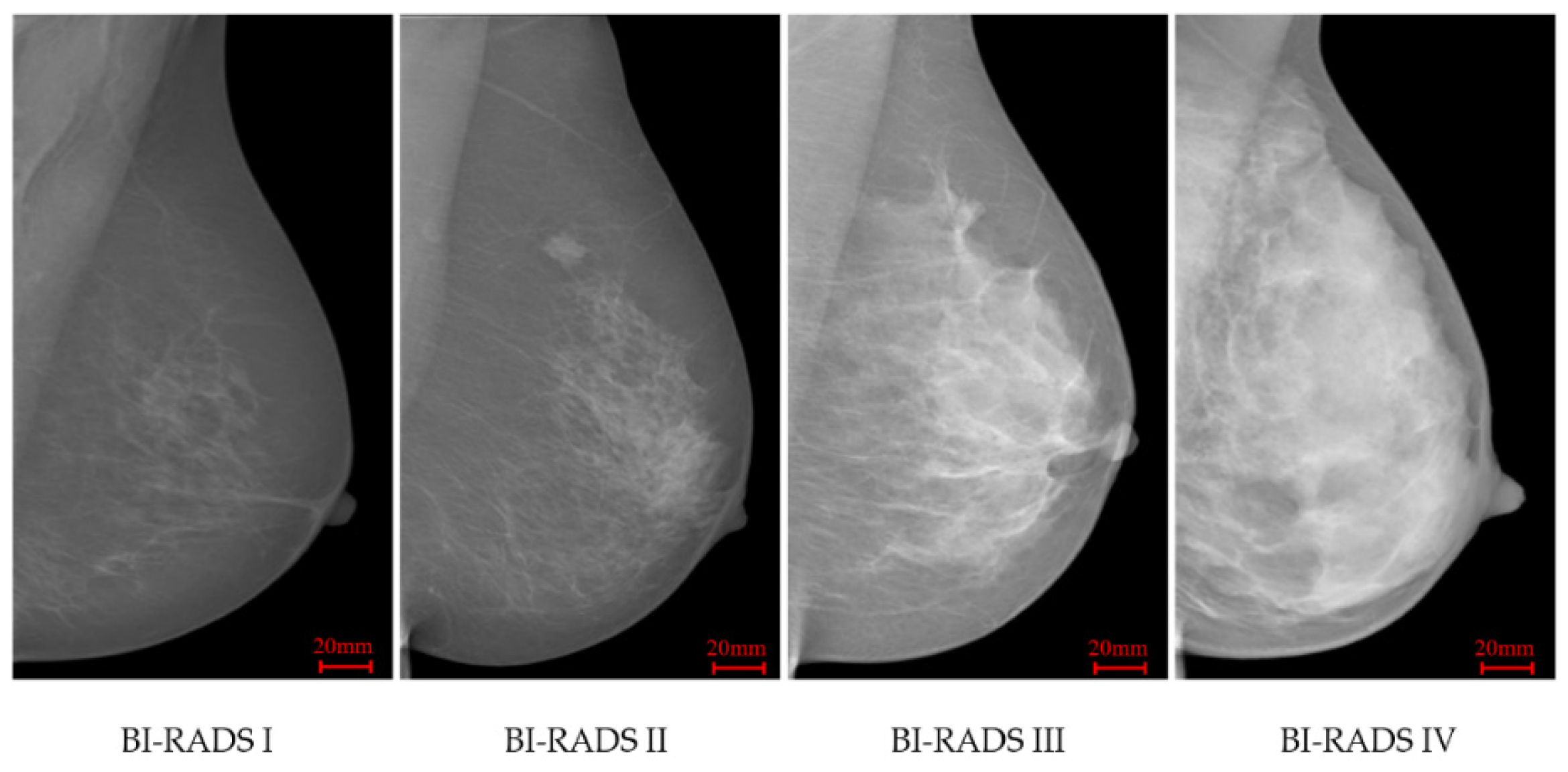
2.1. Breast Density Classification
2.2. Dataset
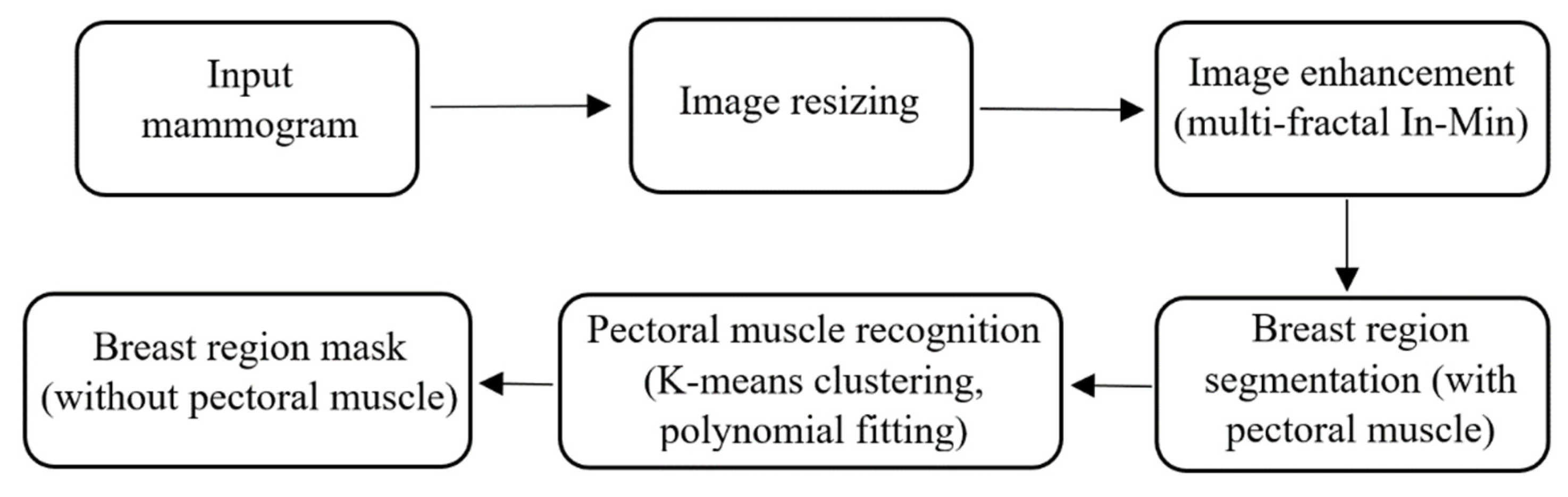
2.3. Processing Stages
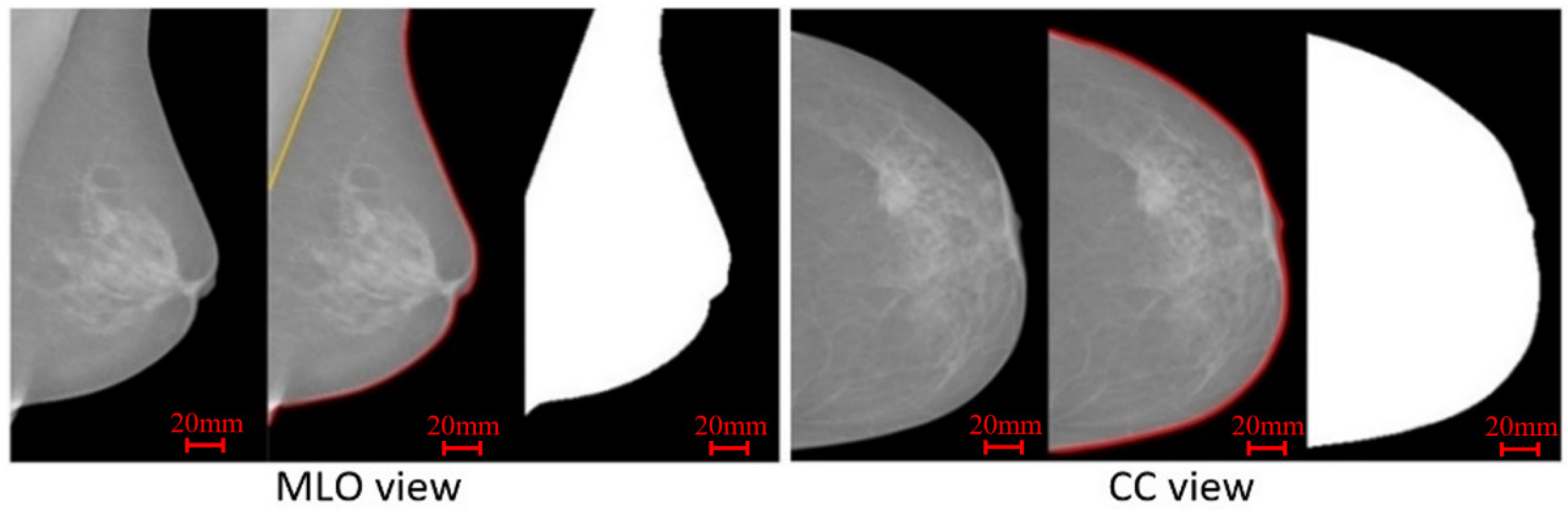
2.4. Mammogram Pre-Processing
3. Feature Extraction
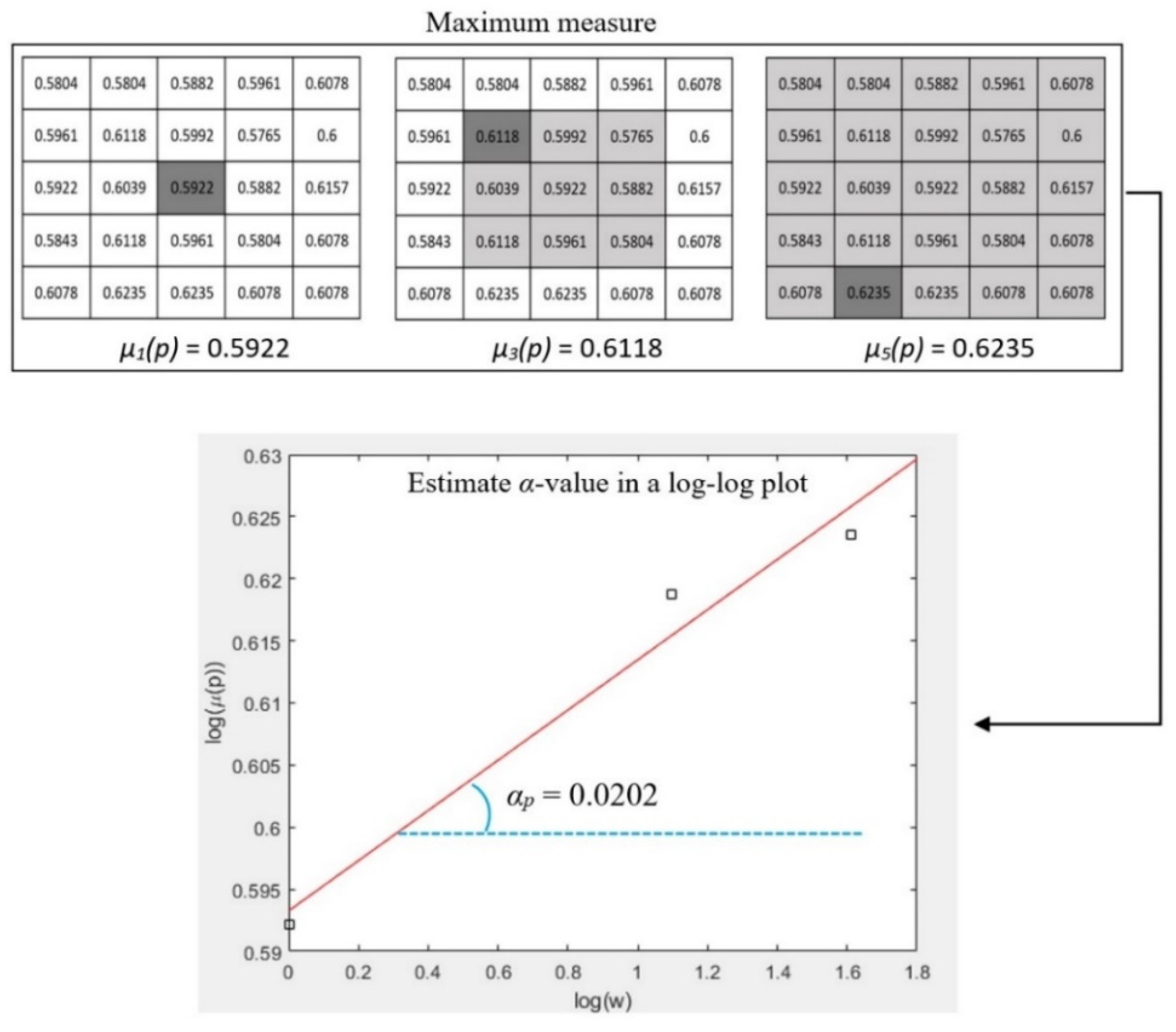
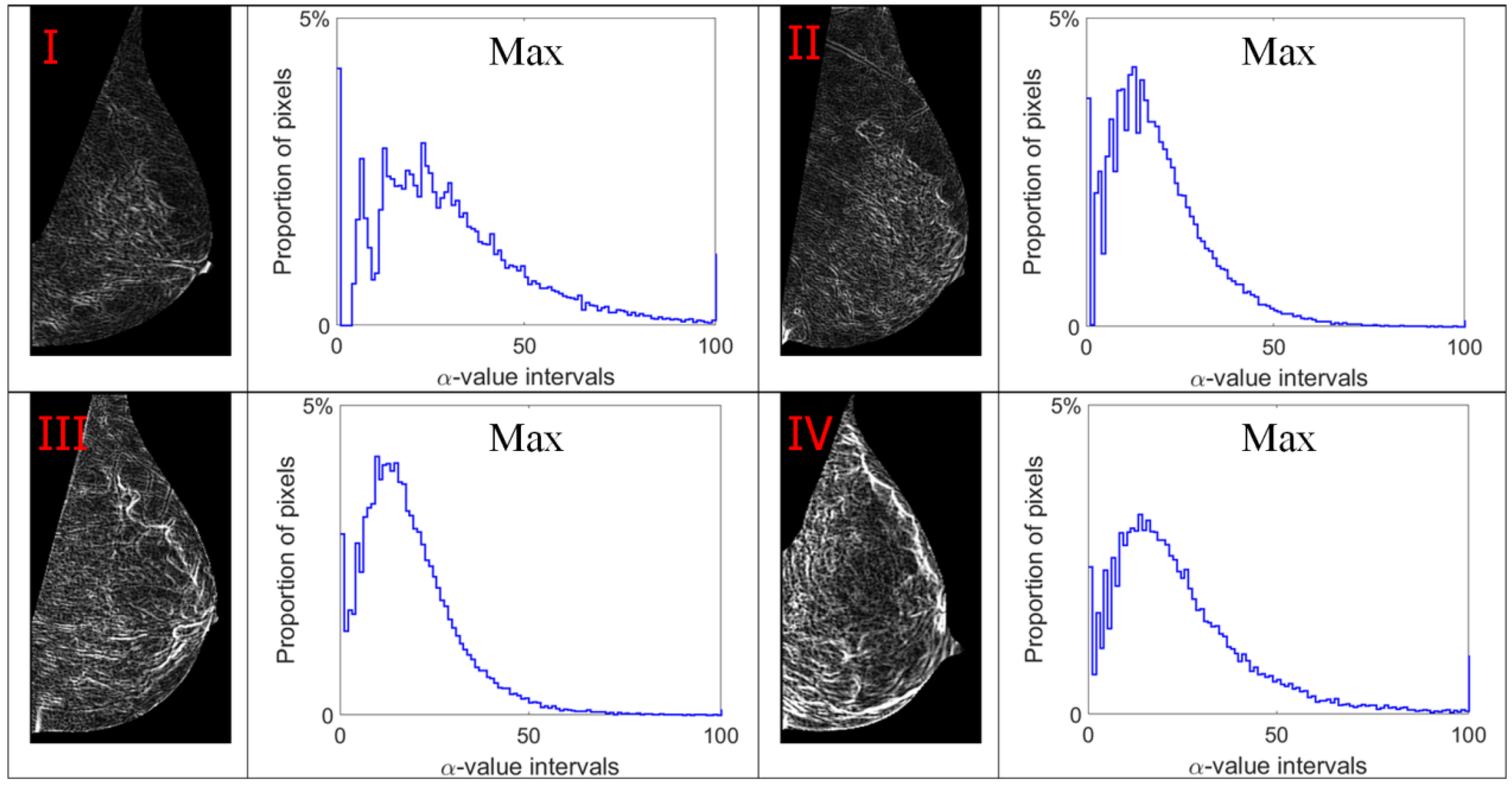
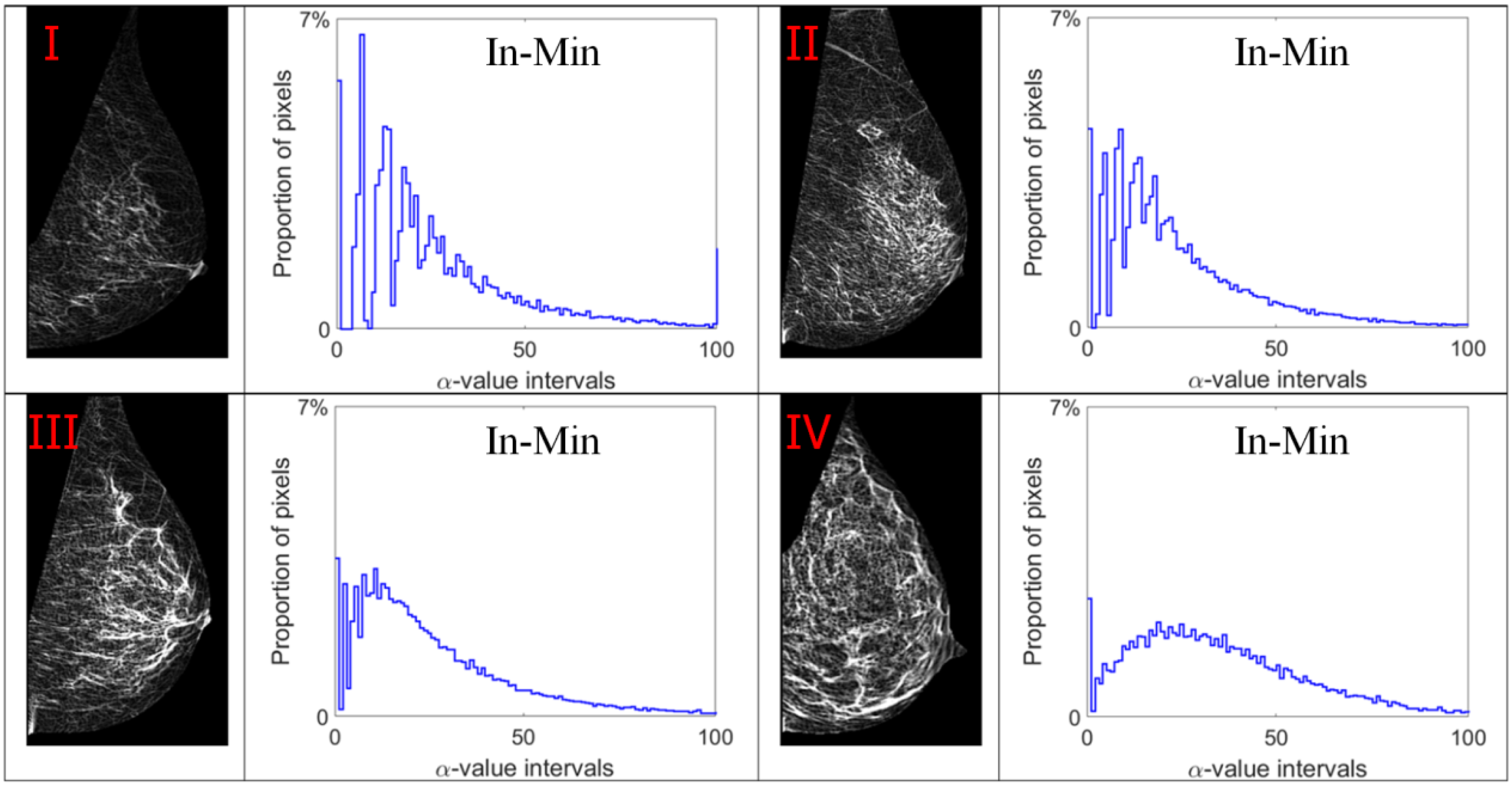
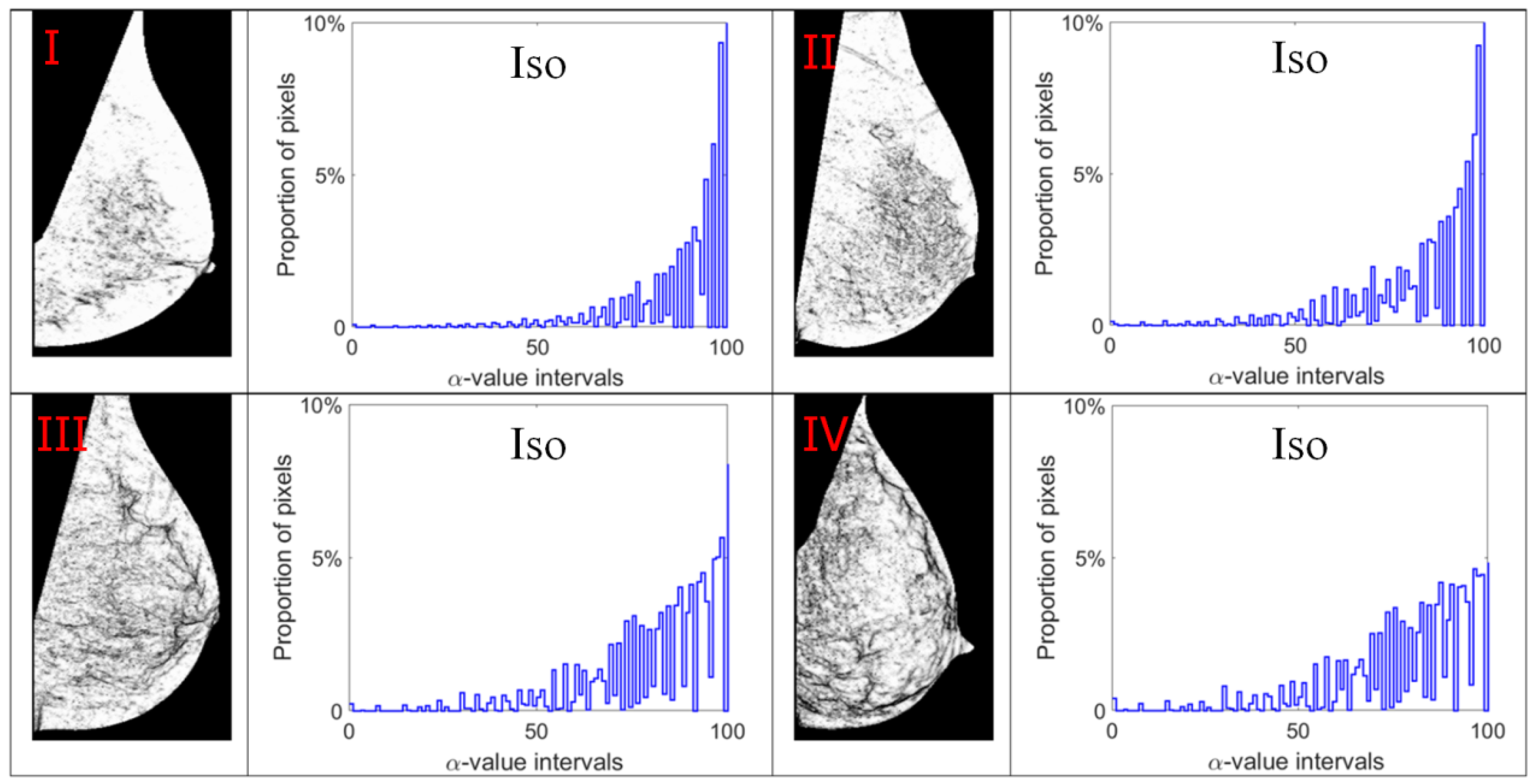
3.1. Multi-Fractal Analysis
3.2. Alpha Image and Texture Features
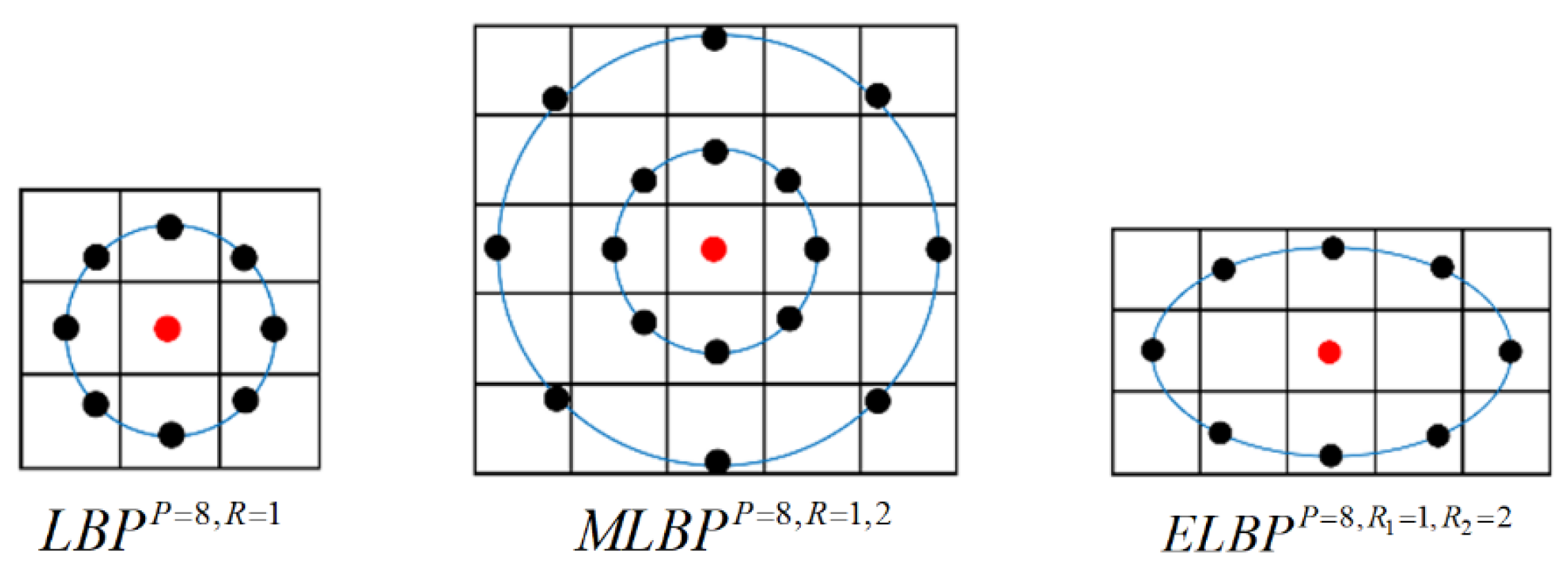
3.3. Local Binary Patterns
3.4. Feature Descriptor with Concatenated Texture Features
4. Feature Selection
4.1. Principal Components Analysis
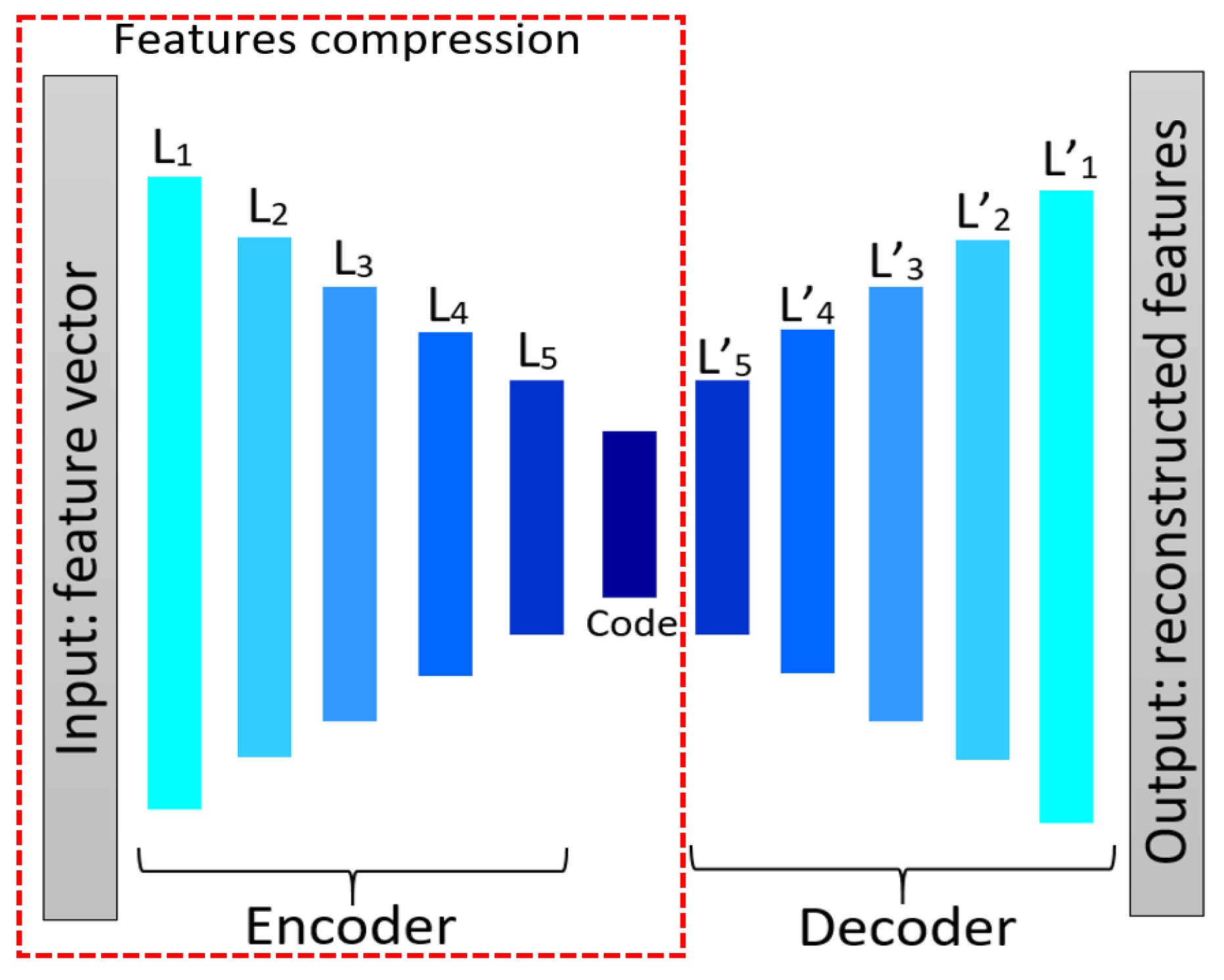
4.2. Autoencoder Network
4.3. Classification
5. Experiments and Result Analysis
5.1. Classification Results Using Multi-Fractal Features
5.2. Classification Results Using LBP Features
5.3. Classification Results Using Cascaded Features
5.4. Effect of Feature Selection
5.5. Results Comparison and Discussion
- (1)
- For the LBP and its variants, we can see that the use of a different neighbourhood topologies (i.e., elliptical vs. circular) can improve the classification performance, which is consistent with the conclusion in [25]: the extracted anisotropic texture information have the potential in distinguishing objects. However, the MLBP which collects texture information from two different neighbourhood areas makes the improvement more evident. This indicates that for the breast density classification which is a very challenging task due to the heterogeneous texture patterns of breast tissue, capturing more (richer) texture features from different local regions can lead to the improvement of the classification performance.
- (2)
- The results in Table 2 lead to the following observations regarding multi-fractal features. The Iso measure produces a better classification result than the other measures. The reason for this can be ascribed to fact that the Max and In-Min measures consider only one pixel information (the maximum or the minimum intensity value) when computing the singularity coefficient (i.e., α-value), and fails to collect the image information from the other pixels within the local region.
- (3)
- From the results in Table 4 and Table 6, we can see that the use of the combined feature descriptor improves the classification accuracy significantly, which also indicates that the texture features extracted from the MLBP and multi-fractal methods are different. The feature sets collected by the two different methods can be considered as complementary to each other.
- (4)
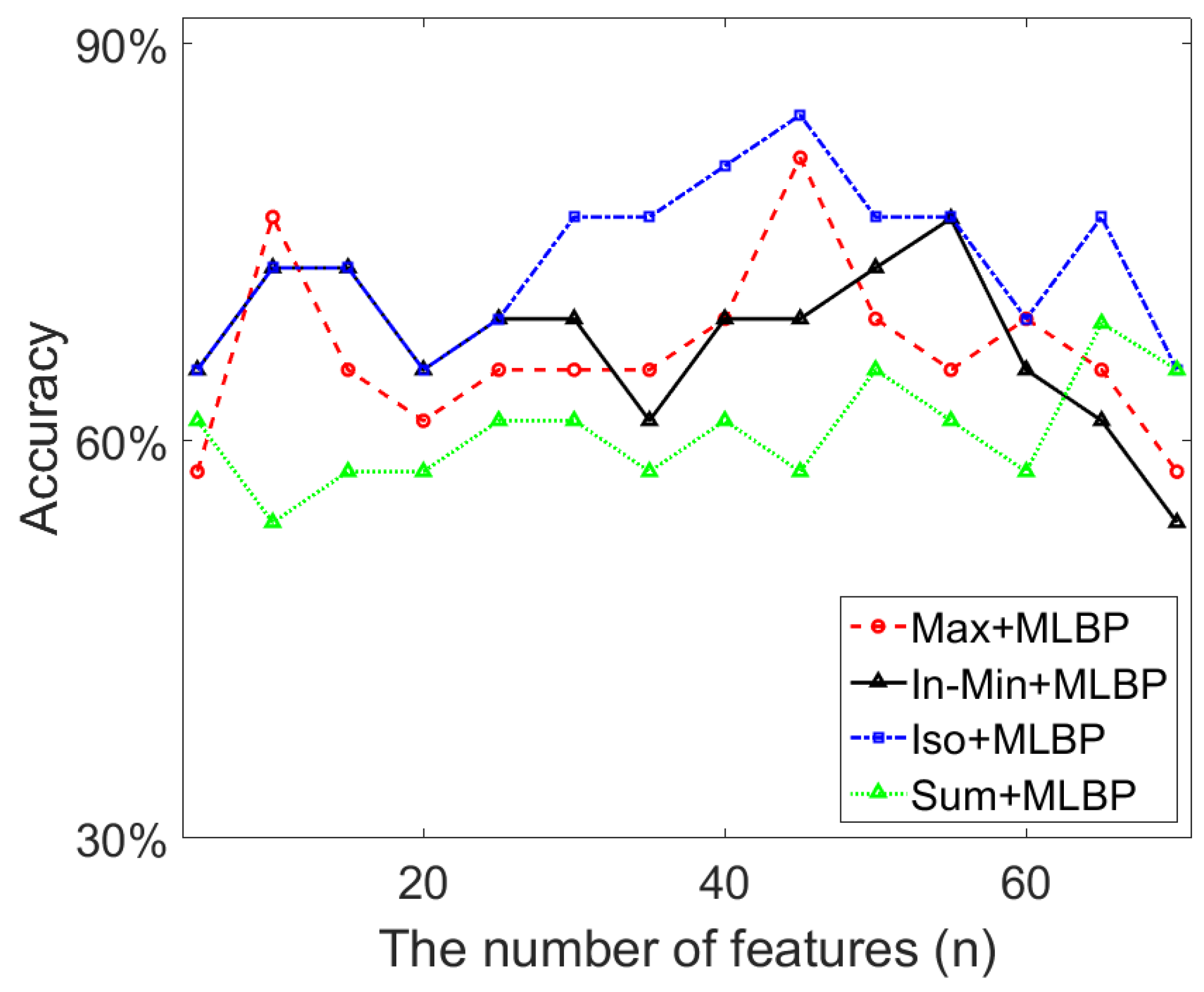
- As shown in Section 5.4, the combination of different texture features produce a bigger feature space which contains redundant features that do not help distinguish the breast density related characteristics between different categories. Results in Figure 14 show that the classification accuracy can even be lower than using the individual feature set if the concatenated features are not selected properly, which demonstrate the importance of removing the redundant features and the necessity of using the feature selection scheme.
- (5)
- Even though BI-RADS uses four density categories, sometimes, breast density is discussed with binary labels of low density (fatty and sparsely dense, or BI-RADS I and II) and high density (heterogeneously and extremely dense, or BI-RADS III and IV) [7]. We conduct the binary classification using the Iso+MLBP descriptor which produces the best four-category classification results in our experiments. Table 7 shows the binary classification results. Although the texture features extracted by the multi-fractal Iso method and the MLBP provide desirable binary classification accuracies (89.2% and 91.9%), the joint feature descriptor Iso+MLBP shows a more powerful representation capability for image features, with a higher classification performance of 92.9% obtained. These observations are consistent with the results obtained in four-category classification work and demonstrates the robustness of the proposed feature descriptor.
6. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kallenberg, M.; Petersen, K.; Nielsen, M.; Ng, A.Y.; Diao, P.; Igel, C.; Vachon, C.M.; Holland, K.; Winkel, R.R.; Karssemeijer, N.; et al. Unsupervised deep learning applied to breast density segmentation and mammographic risk scoring. IEEE Trans. Med. Imaging 2016, 35, 1322–1331. [Google Scholar] [CrossRef] [PubMed]
- Boyd, N.F.; Byng, J.W.; Jong, R.A.; Fishell, E.K.; Little, L.E.; Miller, A.B.; Lockwood, G.A.; Tritchler, D.L.; Yaffe, M.J. Quantitative Classification of Mammographic Densities and Breast Cancer Risk: Results from the Canadian National Breast Screening Study. J. Natl. Cancer Inst. 1995, 87, 670–675. [Google Scholar] [CrossRef]
- Kerlikowske, K.; Cook, A.J.; Buist, D.S.; Cummings, S.R.; Vachon, C.; Vacek, P.; Miglioretti, D.L. Breast Cancer Risk by Breast Density, Menopause, and Postmenopausal Hormone Therapy Use. J. Clin. Oncol. 2010, 28, 3830–3837. [Google Scholar] [CrossRef]
- McLean, K.E.; Stone, J. Role of breast density measurement in screening for breast cancer. Climacteric 2018, 21, 214–220. [Google Scholar] [CrossRef]
- Wolfe, J.N. Risk for breast cancer development determined by mammographic parenchymal pattern. Cancer 1976, 37, 2486–2492. [Google Scholar] [CrossRef]
- Sickles, E.A.; D’Orsi, C.J.; Bassett, L.W.; Appleton, C.M.; Berg, W.A.; Burnside, E.S.; Feig, S.A.; Gavenonis, S.C.; Newell, M.S.; Trinh, M.M. ACR BI-RADS® Mammography. In ACR BI-RADS® Atlas, Breast Imaging Reporting and Data System; American College of Radiology: Reston, VA, USA, 2013. [Google Scholar]
- Muštra, M.; Grgic, M.; Delač, K. Breast Density Classification Using Multiple Feature Selection. Automatika 2012, 53, 362–372. [Google Scholar] [CrossRef]
- Huo, C.W.; Chew, G.L.; Britt, K.; Ingman, W.; A Henderson, M.; Hopper, J.L.; Thompson, E.W. Mammographic density—a review on the current understanding of its association with breast cancer. Breast Cancer Res. Treat. 2014, 144, 479–502. [Google Scholar] [CrossRef] [PubMed]
- Jeffers, A.M.; Sieh, W.; Lipson, J.A.; Rothstein, J.H.; McGuire, V.; Whittemore, A.S.; Rubin, D.L. Breast Cancer Risk and Mammographic Density Assessed with Semiautomated and Fully Automated Methods and BI-RADS. Radiology 2017, 282, 348–355. [Google Scholar] [CrossRef] [PubMed]
- Oliver, A.; Tortajada, M.; Lladó, X.; Freixenet, J.; Ganau, S.; Tortajada, L.; Vilagran, M.; Sentis, M.; Martí, R. Breast Density Analysis Using an Automatic Density Segmentation Algorithm. J. Digit. Imaging 2015, 28, 604–612. [Google Scholar] [CrossRef] [PubMed]
- Subashini, T.; Ramalingam, V.; Palanivel, S. Automated assessment of breast tissue density in digital mammograms. Comput. Vis. Image Underst. 2010, 114, 33–43. [Google Scholar] [CrossRef]
- Qu, Y.; Fu, Q.; Shang, C.; Deng, A.; Zwiggelaar, R.; George, M.; Shen, Q. Fuzzy-rough assisted refinement of image processing procedure for mammographic risk assessment. Appl. Soft Comput. 2020, 91, 106230. [Google Scholar] [CrossRef]
- Li, S.; Wei, J.; Chan, H.-P.; Helvie, M.A.; Roubidoux, M.A.; Lu, Y.; Zhou, C.; Hadjiiski, L.M.; Samala, R.K. Computer-aided assessment of breast density: Comparison of supervised deep learning and feature-based statistical learning. Phys. Med. Biol. 2017, 63, 025005. [Google Scholar] [CrossRef] [PubMed]
- Tzikopoulos, S.D.; Mavroforakis, M.E.; Georgiou, H.V.; Dimitropoulos, N.; Theodoridis, S. A fully automated scheme for mammographic segmentation and classification based on breast density and asymmetry. Comput. Methods Programs Biomed. 2011, 102, 47–63. [Google Scholar] [CrossRef] [PubMed]
- Muhimmah, I.; Zwiggelaar, R. Mammographic density classification using multiresolution histogram information. In Proceedings of the International Special Topic Conference on Information Technology in Biomedicine, Ioannina, Greece, 26–28 October 2006; pp. 26–28. [Google Scholar]
- Chen, Z.; Denton, E.; Zwiggelaar, R. Local feature based mammographic tissue pattern modelling and breast density classification. In Proceedings of the 2011 4th International Conference on Biomedical Engineering and Informatics (BMEI), Shanghai, China, 15–17 October 2011. [Google Scholar]
- George, M.; Rampun, A.; Denton, E.; Zwiggelaar, R. Mammographic ellipse modelling towards birads density classification. In Proceedings of the 13th International Workshop on Breast Imaging IWDM, Malmö, Sweden, 19–22 June 2016; pp. 423–430. [Google Scholar]
- Zheng, Y.; Keller, B.M.; Ray, S.; Wang, Y.; Conant, E.F.; Gee, J.C.; Kontos, D. Parenchymal texture analysis in digital mammography: A fully automated pipeline for breast cancer risk assessment. Med. Phys. 2015, 42, 4149–4160. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, A.A.; Berg, W.A.; Peng, H.; Luo, Y.; Jankowitz, R.C.; Wu, S. A deep learning method for classifying mammographic breast density categories. Med. Phys. 2018, 45, 314–321. [Google Scholar] [CrossRef] [PubMed]
- Berg, W.A.; Campassi, C.; Langenberg, P.; Sexton, M.J. Breast Imaging Reporting and Data System: Inter- and intraobserver variability in feature analysis and final assessment. AJR Am. J. Roentgenol. 2000, 174, 1769–1777. [Google Scholar] [CrossRef]
- Ahn, C.K.; Heo, C.; Jin, H.; Kim, J.H. A novel deep learning-based approach to high accuracy breast density estimation in digital mammography. In Proceedings of the SPIE Medical Imaging 2017: Computer-Aided Diagnosis, Orlando, FL, USA, 11–16 February 2017; Volume 10134. [Google Scholar] [CrossRef]
- Lee, J.; Nishikawa, R.M. Automated mammographic breast density estimation using a fully convolutional network. Med. Phys. 2018, 45, 1178–1190. [Google Scholar] [CrossRef]
- Hamidinekoo, A.; Denton, E.; Rampun, A.; Honnor, K.; Zwiggelaar, R. Deep learning in mammography and breast histology, an overview and future trends. Med. Image Anal. 2018, 47, 45–67. [Google Scholar] [CrossRef] [PubMed]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- George, M.; Zwiggelaar, R. Comparative Study on Local Binary Patterns for Mammographic Density and Risk Scoring. J. Imaging 2019, 5, 24. [Google Scholar] [CrossRef] [PubMed]
- Tan, X.; Triggs, W. Enhanced Local Texture Feature Sets for Face Recognition Under Difficult Lighting Conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [CrossRef]
- Rampun, A.; Morrow, P.; Scotney, B.; Winder, J. Breast density classification using local ternary patterns in mammo-grams. In Proceedings of the Image Analysis and Recognition 14th International Conference, ICIAR 2017, Montreal, QC, Canada, 5–7 July 2017; pp. 463–470. [Google Scholar] [CrossRef]
- Nanni, L.; Lumini, A.; Brahnam, S. Local binary patterns variants as texture descriptors for medical image analysis. Artif. Intell. Med. 2010, 49, 117–125. [Google Scholar] [CrossRef] [PubMed]
- Rampun, A.; Scotney, B.W.; Morrow, P.J.; Wang, H.; Winder, J. Breast Density Classification Using Local Quinary Patterns with Various Neighbourhood Topologies. J. Imaging 2018, 4, 14. [Google Scholar] [CrossRef]
- Rampun, A.; Morrow, P.J.; Scotney, B.W.; Wang, H. Breast density classification in mammograms: An investigation of encoding techniques in binary-based local patterns. Comput. Biol. Med. 2020, 122, 103842. [Google Scholar] [CrossRef]
- Ibrahim, M.; Mukundan, R. Multifractal Techniques for Emphysema Classification in Lung Tissue Images. In Proceedings of the 3rd International Conference on Future Bioengineering (ICFB), Kuala Lumpur, Malaysia, 6–7 December 2019; pp. 115–119. [Google Scholar]
- Reljin, I.; Reljin, B.; Pavlovic, I.; Rakocevic, I. Multifractal analysis of gray-scale images. In Proceedings of the 2000 10th Mediterranean Electrotechnical Conference. Information Technology and Electrotechnology for the Mediterranean Countries. Proceedings. MeleCon 2000, Lemesos, Cyprus, 29–31 May 2000; Volumes 1–3, pp. 490–493. [Google Scholar]
- Xue, Y.; Bogdan, P. Reliable Multi-Fractal Characterization of Weighted Complex Networks: Algorithms and Implications. Sci. Rep. 2017, 7, 1–22. [Google Scholar] [CrossRef]
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J. INbreast: Toward a Full-field Digital Mammographic Database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef]
- Muštra, M.; Grgic, M.; Rangayyan, R. Review of recent advances in segmentation of the breast boundary and the pectoral muscle in mammograms. Med. Biol. Eng. Comput. 2015, 54, 1003–1024. [Google Scholar] [CrossRef] [PubMed]
- Slavkovic-Ilic, M.; Gavrovska, A.; Milivojević, M.; Reljin, I.; Reljin, B.; Marijeta, S.-I.; Ana, G.; Milan, M.; Irini, R.; Branimir, R. Breast region segmentation and pectoral muscle removal in mammograms. Telfor J. 2016, 8, 50–55. [Google Scholar] [CrossRef]
- Falconer, K. Random Fractals. Fractal Geometry: Mathematical Foundations and Applications; Second Chichester; John Wiley & Sons: London, UK, 2005. [Google Scholar]
- Hyvarinen, A.; Karhunen, J.; Oja, E. Independent Component Analysis; John Wiley & Sons: New York, NY, USA, 2001. [Google Scholar]
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Bai, J.; Dai, X.; Wu, Q.; Xie, L. Limited-view CT Reconstruction Based on Autoencoder-like Generative Adversarial Networks with Joint Loss. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018. [Google Scholar]
- Du, S.; Liu, C.; Xi, L. A Selective Multiclass Support Vector Machine Ensemble Classifier for Engineering Surface Classification Using High Definition Metrology. J. Manuf. Sci. Eng. 2015, 137, 011003. [Google Scholar] [CrossRef]
- Li, H.; Mukundan, R.; Boyd, S. Robust Texture Features for Breast Density Classification in Mammograms. In Proceedings of the 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 454–459. [Google Scholar] [CrossRef]
- Sreedevi, S.; Sherly, E. A Novel Approach for Removal of Pectoral Muscles in Digital Mammogram. Procedia Comput. Sci. 2015, 46, 1724–1731. [Google Scholar] [CrossRef]
- Rampun, A.; López-Linares, K.; Morrow, P.J.; Scotney, B.W.; Wang, H.; Ocaña, I.G.; Maclair, G.; Zwiggelaar, R.; Ballester, M.A.G.; Macía, I. Breast pectoral muscle segmentation in mammograms using a modified holistically-nested edge detection network. Med Image Anal. 2019, 57, 1–17. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Related Parameters |
|---|---|
| Multi-fractal analysis |
|
| LBP | 1. (R = 2, P = 8) |
| MLBP | 1. (R1 = 2, R2 = 4, P = 8) |
| ELBP | 1. (R1 = 1, P1 = 8), (R2 = 4, P2 = 8) |
| Autoencoder network |
|
| SVM classifier | For grid-searching:
|
| BI-RADS | Predicted (Max) | Accuracy = 63.3% | BI-RADS | Predicted (In-Min) | Accuracy = 59.7% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I | II | III | IV | Recall | I | II | III | IV | Recall | ||||
| Actual | I | 113 | 8 | 11 | 4 | 83% | Actual | I | 98 | 16 | 18 | 4 | 72% |
| II | 49 | 51 | 44 | 2 | 35% | II | 38 | 65 | 39 | 4 | 45% | ||
| III | 20 | 1 | 73 | 5 | 74% | III | 18 | 8 | 65 | 8 | 66% | ||
| IV | 2 | 0 | 4 | 22 | 79% | IV | 5 | 0 | 7 | 16 | 57% | ||
| BI-RADS | Predicted (Iso) | Accuracy = 73.8% | BI-RADS | Predicted (Sum) | Accuracy = 55.3% | ||||||||
| I | II | III | IV | Recall | I | II | III | IV | Recall | ||||
| Actual | I | 119 | 9 | 5 | 3 | 88% | Actual | I | 88 | 21 | 25 | 2 | 65% |
| II | 24 | 91 | 26 | 5 | 62% | II | 41 | 69 | 36 | 0 | 47% | ||
| III | 15 | 5 | 72 | 7 | 73% | III | 21 | 10 | 59 | 9 | 60% | ||
| IV | 0 | 1 | 7 | 20 | 71% | IV | 1 | 5 | 12 | 10 | 36% | ||
| BI-RADS | Predicted (LBP) | Accuracy = 70.9% | BI-RADS | Predicted (ELBP) | Accuracy = 72.1% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I | II | III | IV | Recall | I | II | III | IV | Recall | ||||
| Actual | I | 127 | 0 | 9 | 0 | 93% | Actual | I | 125 | 5 | 6 | 0 | 92% |
| II | 48 | 69 | 29 | 0 | 47% | II | 49 | 68 | 29 | 0 | 47% | ||
| III | 16 | 3 | 80 | 0 | 81% | III | 11 | 3 | 83 | 2 | 84% | ||
| IV | 0 | 0 | 14 | 14 | 50% | IV | 0 | 0 | 9 | 19 | 68% | ||
| BI-RADS | Predicted (MLBP) | Accuracy = 73.3% | |||||||||||
| Actual | I | II | III | IV | Recall | ||||||||
| I | 129 | 3 | 4 | 0 | 95% | ||||||||
| II | 50 | 72 | 24 | 0 | 49% | ||||||||
| III | 11 | 2 | 85 | 1 | 86% | ||||||||
| IV | 1 | 0 | 13 | 14 | 50% | ||||||||
| BI-RADS | Predicted (Max + MLBP) | Accuracy = 81.4% | BI-RADS | Predicted (In-Min + MLBP) | Accuracy = 76.8% | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I | II | III | IV | Recall | I | II | III | IV | Recall | ||||
| Actual | I | 130 | 2 | 3 | 1 | 96% | Actual | I | 129 | 3 | 3 | 1 | 95% |
| II | 36 | 95 | 15 | 0 | 65% | II | 32 | 88 | 25 | 1 | 60% | ||
| III | 10 | 2 | 84 | 3 | 85% | III | 14 | 4 | 73 | 8 | 74% | ||
| IV | 1 | 0 | 3 | 24 | 86% | IV | 1 | 0 | 3 | 24 | 86% | ||
| BI-RADS | Predicted (Iso + MLBP) | Accuracy = 84.6% | BI-RADS | Predicted (In-Min + MLBP) | Accuracy = 68.9% | ||||||||
| I | II | III | IV | Recall | I | II | III | IV | Recall | ||||
| Actual | I | 128 | 5 | 2 | 1 | 94% | Actual | I | 107 | 10 | 14 | 5 | 79% |
| II | 18 | 108 | 19 | 1 | 74% | II | 40 | 76 | 30 | 0 | 52% | ||
| III | 8 | 1 | 84 | 6 | 85% | III | 11 | 4 | 76 | 8 | 77% | ||
| IV | 0 | 0 | 2 | 26 | 93% | IV | 1 | 1 | 3 | 23 | 82% | ||
| The Number of Hidden Layers | Feature Number | Classification Accuracy |
|---|---|---|
| 5 | 128 | 72.9% |
| 7 | 128 | 75.2% |
| 9 | 64 | 77.2% |
| 11 | 64 | 80.7% |
| 13 | 32 | 76.2% |
| 15 | 16 | 69.1% |
| CA (%) | AUC (%) | Kappa | F1 | p-Value | |
|---|---|---|---|---|---|
| LBP | 70.9 | 85.6 ± 3.6 | 0.58 | 0.72 | <10−4 |
| ELBP | 72.1 | 86.9 ± 2.8 | 0.59 | 0.73 | <10−4 |
| MLBP | 73.3 | 87.2 ± 2.9 | 0.60 | 0.74 | 0.015 |
| Multi-fractal (Max) | 63.3 | 80.1 ± 4.4 | 0.41 | 0.63 | 0.001 |
| Multi-fractal (In-Min) | 59.7 | 78.3 ± 3.5 | 0.34 | 0.60 | <10−4 |
| Multi-fractal (Iso) | 73.8 | 87.4 ± 4.1 | 0.60 | 0.74 | 0.002 |
| Multi-fractal (Sum) | 55.3 | 77.1 ± 4.5 | 0.31 | 0.55 | 0.001 |
| Iso+MLBP | 84.6 | 95.3 ± 3.1 | 0.79 | 0.85 | − |
| Binary Categories | Predicted (MLBP) | Accuracy = 91.9% | Binary Categories | Predicted (Iso) | Accuracy = 89.2% | ||||
|---|---|---|---|---|---|---|---|---|---|
| Low Density | High Density | Recall | Low Density | High Density | Recall | ||||
| Actual | Low density | 259 | 23 | 92% | Actual | Low density | 253 | 29 | 90% |
| High density | 10 | 117 | 92% | High density | 15 | 112 | 88% | ||
| Binary categories | Predicted (Iso + MLBP) | Accuracy = 92.9% | |||||||
| Low Density | High Density | Recall | |||||||
| Actual | Low density | 262 | 20 | 93% | |||||
| High density | 9 | 118 | 93% | ||||||
| Image Feature | The Number of Features | The Number of Test Images | Classification Accuracy (%) |
|---|---|---|---|
| LQP(Ellipse) [29] | Over 200 | 206 | 82.02% |
| LQP(Circle) [29] | Around 100 | 206 | Under 80% |
| LBP | 256 | 409 | 70.9% |
| ELBP | 256 | 409 | 72.1% |
| MLBP | 512 | 409 | 73.3% |
| Multi-fractal (Max) | 100 | 409 | 63.3% |
| Multi-fractal (In-Min) | 100 | 409 | 59.7% |
| Multi-fractal (Iso) | 100 | 409 | 73.8% |
| Multi-fractal (Sum) | 100 | 409 | 55.3% |
| Max+MLBP | 45 | 409 | 81.4% |
| In-Min+MLBP | 55 | 409 | 76.8% |
| Iso+MLBP | 45 | 409 | 84.6% |
| Sum+MLBP | 65 | 409 | 68.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Mukundan, R.; Boyd, S. Novel Texture Feature Descriptors Based on Multi-Fractal Analysis and LBP for Classifying Breast Density in Mammograms. J. Imaging 2021, 7, 205. https://doi.org/10.3390/jimaging7100205
Li H, Mukundan R, Boyd S. Novel Texture Feature Descriptors Based on Multi-Fractal Analysis and LBP for Classifying Breast Density in Mammograms. Journal of Imaging. 2021; 7(10):205. https://doi.org/10.3390/jimaging7100205
Chicago/Turabian StyleLi, Haipeng, Ramakrishnan Mukundan, and Shelley Boyd. 2021. "Novel Texture Feature Descriptors Based on Multi-Fractal Analysis and LBP for Classifying Breast Density in Mammograms" Journal of Imaging 7, no. 10: 205. https://doi.org/10.3390/jimaging7100205
APA StyleLi, H., Mukundan, R., & Boyd, S. (2021). Novel Texture Feature Descriptors Based on Multi-Fractal Analysis and LBP for Classifying Breast Density in Mammograms. Journal of Imaging, 7(10), 205. https://doi.org/10.3390/jimaging7100205