Deep Learning-Based Crowd Scene Analysis Survey

 , ,
, , 
Abstract
1. Introduction
- surveying deep learning-based methods for crowd scenes analysis,
- reviewing available crowd scene datasets, and
- proposing crowd divergence (CD) for an accurate evaluation of crowd scenes analysis methods
2. Crowd Counting
2.1. Traditional Computer Vision Methods
2.1.1. Detection-Based Approaches
2.1.2. Regression-Based Approaches
2.1.3. Density Estimation-Based Approaches
2.2. Deep Learning Approaches
3. Crowd Action Recognition
3.1. Traditional Computer Vision Methods
3.2. Deep Learning Approaches
4. Crowd Scene Datasets
5. Crowd Divergence (CD)
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Musse, S.R.; Thalmann, D. A model of human crowd behavior: Group inter-relationship and collision detection analysis. In Computer Animation and Simulation’97; Springer: Berlin/Heidelberg, Germany, 1997; pp. 39–51. [Google Scholar]
- Watkins, J. Preventing a Covid-19 Pandemic. 2020. Available online: https://www.bmj.com/content/368/bmj.m810.full (accessed on 8 May 2012).
- Jarvis, N.; Blank, C. The importance of tourism motivations among sport event volunteers at the 2007 world artistic gymnastics championships, stuttgart, germany. J. Sport Tour. 2011, 16, 129–147. [Google Scholar] [CrossRef]
- Da Matta, R. Carnivals, Rogues, and Heroes: An Interpretation of the Brazilian Dilemma; University of Notre Dame Press Notre Dame: Notre Dame, IN, USA, 1991. [Google Scholar]
- Winter, T. Landscape, memory and heritage: New year celebrations at angkor, cambodia. Curr. Issues Tour. 2004, 7, 330–345. [Google Scholar] [CrossRef]
- Peters, F.E. The Hajj: The Muslim Pilgrimage to Mecca and the Holy Places; Princeton University Press: Princeton, NJ, USA, 1996. [Google Scholar]
- Cui, X.; Liu, Q.; Gao, M.; Metaxas, D.N. Abnormal detection using interaction energy potentials. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20 June 2011; pp. 3161–3167. [Google Scholar]
- Mehran, R.; Moore, B.E.; Shah, M. A streakline representation of flow in crowded scenes. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 439–452. [Google Scholar]
- Benabbas, Y.; Ihaddadene, N.; Djeraba, C. Motion pattern extraction and event detection for automatic visual surveillance. J. Image Video Process. 2011, 7, 163682. [Google Scholar] [CrossRef]
- Chow, W.K.; Ng, C.M. Waiting time in emergency evacuation of crowded public transport terminals. Saf. Sci. 2008, 46, 844–857. [Google Scholar] [CrossRef]
- Sime, J.D. Crowd psychology and engineering. Saf. Sci. 1995, 21, 1–14. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? a new look at signal fidelity measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In Proceedings of the 19th International Conference on Pattern Recognition (ICPR 2008), Tampa, FL, USA, 8 December 2008; pp. 1–4. [Google Scholar]
- Brox, T.; Bruhn, A.; Papenberg, N.; Weickert, J. High accuracy optical flow estimation based on a theory for warping. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2004; pp. 25–36. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Computer Vision and Pattern Recognition, CVPR 2005, San Diego, CA, USA, June 20 2005; Volume 1, pp. 886–893. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Detection of multiple, partially occluded humans in a single image by bayesian combination of edgelet part detectors. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17 October 2005; Volume 1, pp. 90–97. [Google Scholar]
- Ali, S.; Shah, M. A lagrangian particle dynamics approach for crowd flow segmentation and stability analysis. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 22 June 2007; pp. 1–6. [Google Scholar]
- Sabzmeydani, P.; Mori, G. Detecting pedestrians by learning shapelet features. In Proceedings of the Computer Vision and Pattern Recognition (CVPR’07), Minneapolis, MN, USA, 17 June 2007; pp. 1–8. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Gall, J.; Yao, A.; Razavi, N.; Van Gool, L.; Lempitsky, V. Hough forests for object detection, tracking, and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2188–2202. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J.; Snow, D. Detecting pedestrians using patterns of motion and appearance. Int. J. Comput. Vis. 2005, 63, 153–161. [Google Scholar] [CrossRef]
- Zhang, T.; Jia, K.; Xu, C.; Ma, Y.; Ahuja, N. Partial occlusion handling for visual tracking via robust part matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24 June 2014; pp. 1258–1265. [Google Scholar]
- Kilambi, P.; Ribnick, E.; Joshi, A.J.; Masoud, O.; Papanikolopoulos, N. Estimating pedestrian counts in groups. Comput. Vis. Image Underst. 2008, 110, 43–59. [Google Scholar] [CrossRef]
- Whitt, W. Stochastic-Process Limits: An Introduction to Stochastic-Process Limits and Their Application to Queues; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Ge, W.; Collins, R.T. Marked point processes for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20 June 2009; pp. 2913–2920. [Google Scholar]
- Chatelain, F.; Costard, A.; Michel, O.J. A bayesian marked point process for object detection: Application to muse hyperspectral data. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22 May 2011; pp. 3628–3631. [Google Scholar]
- Juan, A.; Vidal, E. Bernoulli mixture models for binary images. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 26–26 August 2004; Volume 3, pp. 367–370. [Google Scholar]
- Zhao, T.; Nevatia, R.; Wu, B. Segmentation and tracking of multiple humans in crowded environments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1198–1211. [Google Scholar] [CrossRef]
- Geyer, C.J. Markov Chain Monte Carlo Maximum Likelihood; Interface Foundation of North America: Fairfax Station, VA, USA, 1991. [Google Scholar]
- Bouwmans, T.; Silva, C.; Marghes, C.; Zitouni, M.S.; Bhaskar, H.; Frelicot, C. On the role and the importance of features for background modeling and foreground detection. Comput. Sci. Rev. 2018, 28, 26–91. [Google Scholar] [CrossRef]
- Tuceryan, M.; Jain, A.K. Texture analysis. In Handbook of Pattern Recognition and Computer Vision; World Scientific: Singapore, 1993; pp. 235–276. [Google Scholar]
- Mikolajczyk, K.; Zisserman, A.; Schmid, C. Shape rEcognition With Edge-Based Features. 2003. Available online: https://hal.inria.fr/inria-00548226/ (accessed on 11 September 2020).
- Hwang, J.W.; Lee, H.S. Adaptive image interpolation based on local gradient features. IEEE Signal Process. Lett. 2004, 11, 359–362. [Google Scholar] [CrossRef]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008), Anchorage, AK, USA, 24 June 2008; pp. 1–7. [Google Scholar]
- Paragios, N.; Ramesh, V. A mrf-based approach for real-time subway monitoring. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8 December 2001. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. In Proceedings of the British Machine Vision Conference; BMVA Press: Surrey, UK, 2012; Volume 1, p. 3. [Google Scholar] [CrossRef]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23 June 2013; pp. 2547–2554. [Google Scholar]
- Vu, T.H.; Osokin, A.; Laptev, I. Context-aware cnns for person head detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7 December 2015; pp. 2893–2901. [Google Scholar]
- Lindeberg, T. Scale Invariant Feature Transform. 2012. Available online: https://www.diva-portal.org/smash/get/diva2:480321/FULLTEXT02 (accessed on 11 September 2020).
- Li, S.Z. Markov Random Field Modeling in Computer Vision; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning to count objects in images. In Advances in Neural Information Processing Systems, Proceedings of the Neural Information Processing Systems 2010, Vancouver, BC, Canada, 6 December 2010; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2010; pp. 1324–1332. [Google Scholar]
- Loy, C.C.; Chen, K.; Gong, S.; Xiang, T. Crowd counting and profiling: Methodology and evaluation. In Modeling, Simulation and Visual Analysis of Crowds; Springer: Berlin/Heidelberg, Germany, 2013; pp. 347–382. [Google Scholar]
- Teo, C.H.; Vishwanthan, S.; Smola, A.J.; Le, Q.V. Bundle methods for regularized risk minimization. J. Mach. Learn. Res. 2010, 11, 311–365. [Google Scholar]
- Goffin, J.L.; Vial, J.P. Convex nondifferentiable optimization: A survey focused on the analytic center cutting plane method. Optim. Methods Softw. 2002, 17, 805–867. [Google Scholar] [CrossRef]
- Pham, V.Q.; Kozakaya, T.; Yamaguchi, O.; Okada, R. Count forest: Co-voting uncertain number of targets using random forest for crowd density estimation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 3–17 December 2015; pp. 3253–3261. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomforest. News 2002, 2, 18–22. [Google Scholar]
- Sirmacek, B.; Reinartz, P. Automatic crowd density and motion analysis in airborne image sequences based on a probabilistic framework. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–11 November 2011; pp. 898–905. [Google Scholar]
- Scaillet, O. Density estimation using inverse and reciprocal inverse gaussian kernels. Nonparametric Stat. 2004, 16, 217–226. [Google Scholar] [CrossRef]
- Cha, S.H. Comprehensive survey on distance/similarity measures between probability density functions. City 2007, 1, 1. [Google Scholar]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized mlp architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep people counting in extremely dense crowds. In Proceedings of the 23rd ACM International Conference on Multimedia; ACM: New York, NY, USA, 2015; pp. 1299–1302. [Google Scholar]
- Fu, M.; Xu, P.; Li, X.; Liu, Q.; Ye, M.; Zhu, C. Fast crowd density estimation with convolutional neural networks. Eng. Appl. Artif. Intell. 2015, 43, 81–88. [Google Scholar] [CrossRef]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; LeCun, Y. Pedestrian detection with unsupervised multi-stage feature learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, Portland, OR, USA, 23–28 June 2013; pp. 3626–3633. [Google Scholar]
- Sun, Z.; Wang, Y.; Tan, T.; Cui, J. Improving iris recognition accuracy via cascaded classifiers. IEEE Trans. Syst. Man Cybern. Part Appl. Rev. 2005, 35, 435–441. [Google Scholar] [CrossRef]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 4681–4690. [Google Scholar]
- Shen, Z.; Xu, Y.; Ni, B.; Wang, M.; Hu, J.; Yang, X. Crowd counting via adversarial cross-scale consistency pursuit. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake Cite, UT, USA, 18–22 June 2018; pp. 5245–5254. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Onoro-Rubio, D.; López-Sastre, R.J. Towards perspective-free object counting with deep learning. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 615–629. [Google Scholar]
- Liu, N.; Long, Y.; Zou, C.; Niu, Q.; Pan, L.; Wu, H. Adcrowdnet: An attention-injective deformable convolutional network for crowd understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3225–3234. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Caesars Palace, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 589–597. [Google Scholar]
- Oh, M.H.; Olsen, P.A.; Ramamurthy, K.N. Crowd counting with decomposed uncertainty. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; pp. 11799–11806. [Google Scholar]
- Amirgholipour, S.; He, X.; Jia, W.; Wang, D.; Liu, L. PDANet: Pyramid Density-aware Attention Net for Accurate Crowd Counting. arXiv Preprint 2020, arXiv:2001.05643. [Google Scholar]
- Liu, L.; Qiu, Z.; Li, G.; Liu, S.; Ouyang, W.; Lin, L. Crowd counting with deep structured scale integration network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October 2019; pp. 1774–1783. [Google Scholar]
- Reddy, M.K.K.; Hossain, M.; Rochan, M.; Wang, Y. Few-shot scene adaptive crowd counting using meta-learning. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2814–2823. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-aware crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, June 16 2019; pp. 5099–5108. [Google Scholar]
- Andersson, M.; Rydell, J.; Ahlberg, J. Estimation of crowd behavior using sensor networks and sensor fusion. In Proceedings of the 12th International Conference on Information Fusion, Seattle, WA, USA, 6–9 July 2009; pp. 396–403. [Google Scholar]
- Beal, M.J.; Ghahramani, Z.; Rasmussen, C.E. The infinite hidden markov model. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002; pp. 577–584. [Google Scholar]
- Siva, P.; Xiang, T. Action detection in crowd. In Proceedings of the British Machine Vision Conference (BMVC), Aberystwyth, Wales, UK, 31 August–3 September 2010; pp. 1–11. [Google Scholar]
- Li, B.; Yu, S.; Lu, Q. An improved k-nearest neighbor algorithm for text categorization. arXiv 2003, arXiv:cs/0306099. [Google Scholar]
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 21 November 2012; pp. 1–6. [Google Scholar]
- Shao, J.; Loy, C.C.; Kang, K.; Wang, X. Slicing convolutional neural network for crowd video understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5620–5628. [Google Scholar]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Attribute recognition by joint recurrent learning of context and correlation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 531–540. [Google Scholar]
- Lazaridis, L.; Dimou, A.; Daras, P. Abnormal behavior detection in crowded scenes using density heatmaps and optical flow. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 3–7 September 2018; pp. 2060–2064. [Google Scholar]
- You, Q.; Jiang, H. Action4d: Online action recognition in the crowd and clutter. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11857–11866. [Google Scholar]
- Ke, Y.; Sukthankar, R.; Hebert, M. Event detection in crowded videos. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Setubal, Portugal, 8–11 March 2007; pp. 1–8. [Google Scholar]
- Kliper-Gross, O.; Hassner, T.; Wolf, L. The action similarity labeling challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 615–621. [Google Scholar] [CrossRef]
- Deng, Y.; Luo, P.; Loy, C.C.; Tang, X. Pedestrian attribute recognition at far distance. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 789–792. [Google Scholar]
- Rabiee, H.; Haddadnia, J.; Mousavi, H.; Kalantarzadeh, M.; Nabi, M.; Murino, V. Novel dataset for fine-grained abnormal behavior understanding in crowd. In Proceedings of the 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 95–101. [Google Scholar]
- Péteri, R.; Fazekas, S.; Huiskes, M.J. Dyntex: A comprehensive database of dynamic textures. Pattern Recognit. Lett. 2010, 31, 1627–1632. [Google Scholar] [CrossRef]
- Fazekas, S.; Amiaz, T.; Chetverikov, D.; Kiryati, N. Dynamic texture detection based on motion analysis. Int. J. Comput. Vis. 2009, 82, 48. [Google Scholar] [CrossRef]
- Ghanem, B.; Ahuja, N. Maximum margin distance learning for dynamic texture recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 223–236. [Google Scholar]
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Georgiou, T.T.; Lindquist, A. Kullback-leibler approximation of spectral density functions. IEEE Trans. Inf. Theory 2003, 49, 2910–2917. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Shang, C.; Ai, H.; Bai, B. End-to-end crowd counting via joint learning local and global count. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1215–1219. [Google Scholar]
- Chen, K.; Gong, S.; Xiang, T.; Change Loy, C. Cumulative attribute space for age and crowd density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23 June 2013; pp. 2467–2474. [Google Scholar]
- Wang, Y.; Zou, Y. Fast visual object counting via example-based density estimation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3653–3657. [Google Scholar]
- Xu, B.; Qiu, G. Crowd density estimation based on rich features and random projection forest. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), New York, NY, USA, 7–9 March 2016; pp. 1–8. [Google Scholar]
- Boominathan, L.; Kruthiventi, S.S.; Babu, R.V. Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the 24th ACM International Conference on Multimedia; ACM: New York, NY, USA, 2016; pp. 640–644. [Google Scholar]
- Walach, E.; Wolf, L. Learning to count with cnn boosting. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 660–676. [Google Scholar]
- Kumagai, S.; Hotta, K.; Kurita, T. Mixture of counting cnns: Adaptive integration of cnns specialized to specific appearance for crowd counting. arXiv 2017, arXiv:1703.09393. [Google Scholar]
- Marsden, M.; McGuinness, K.; Little, S.; O’Connor, N.E. Fully convolutional crowd counting on highly congested scenes. arXiv 2016, arXiv:1612.00220. [Google Scholar]
- Kang, D.; Ma, Z.; Chan, A.B. Beyond counting: Comparisons of density maps for crowd analysis tasks—Counting, detection, and tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1408–1422. [Google Scholar] [CrossRef]
- Sheng, B.; Shen, C.; Lin, G.; Li, J.; Yang, W.; Sun, C. Crowd counting via weighted vlad on a dense attribute feature map. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1788–1797. [Google Scholar] [CrossRef]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching convolutional neural network for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 4031–4039. [Google Scholar]










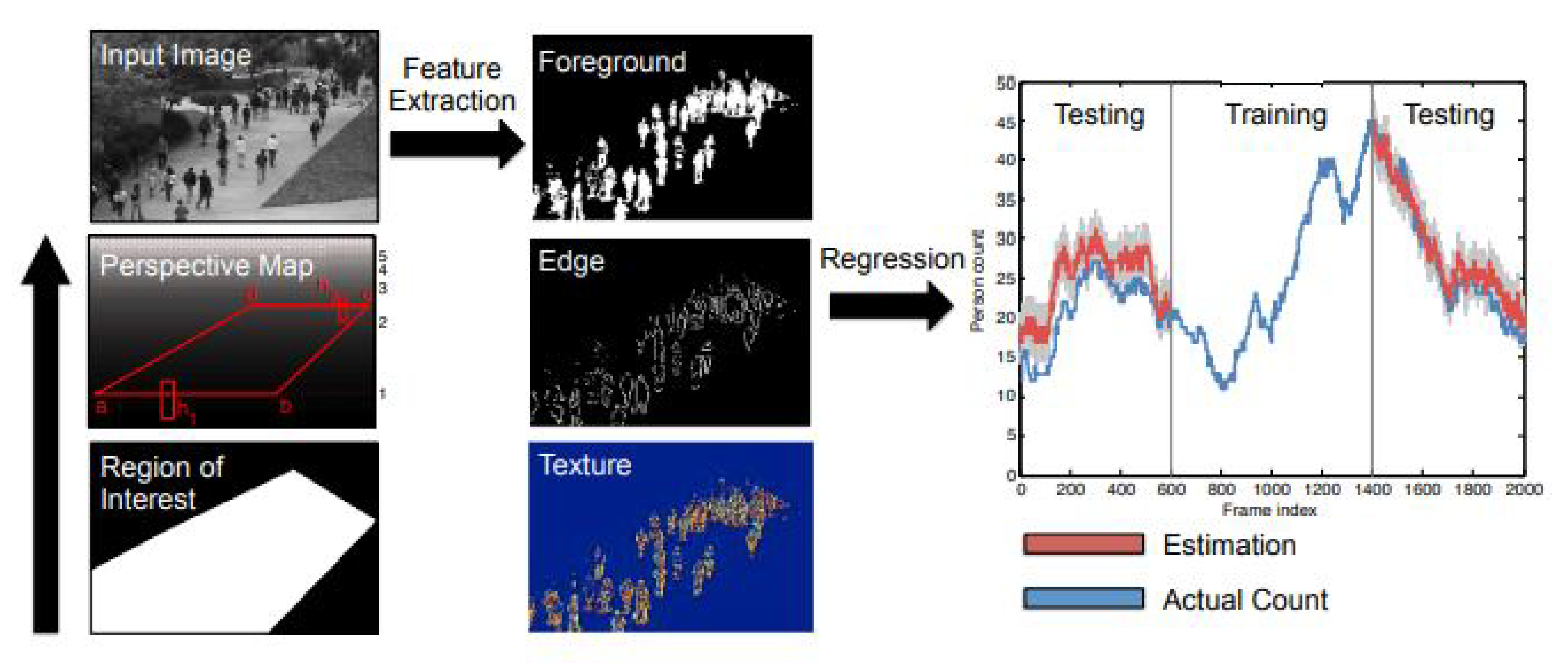{kind=link}
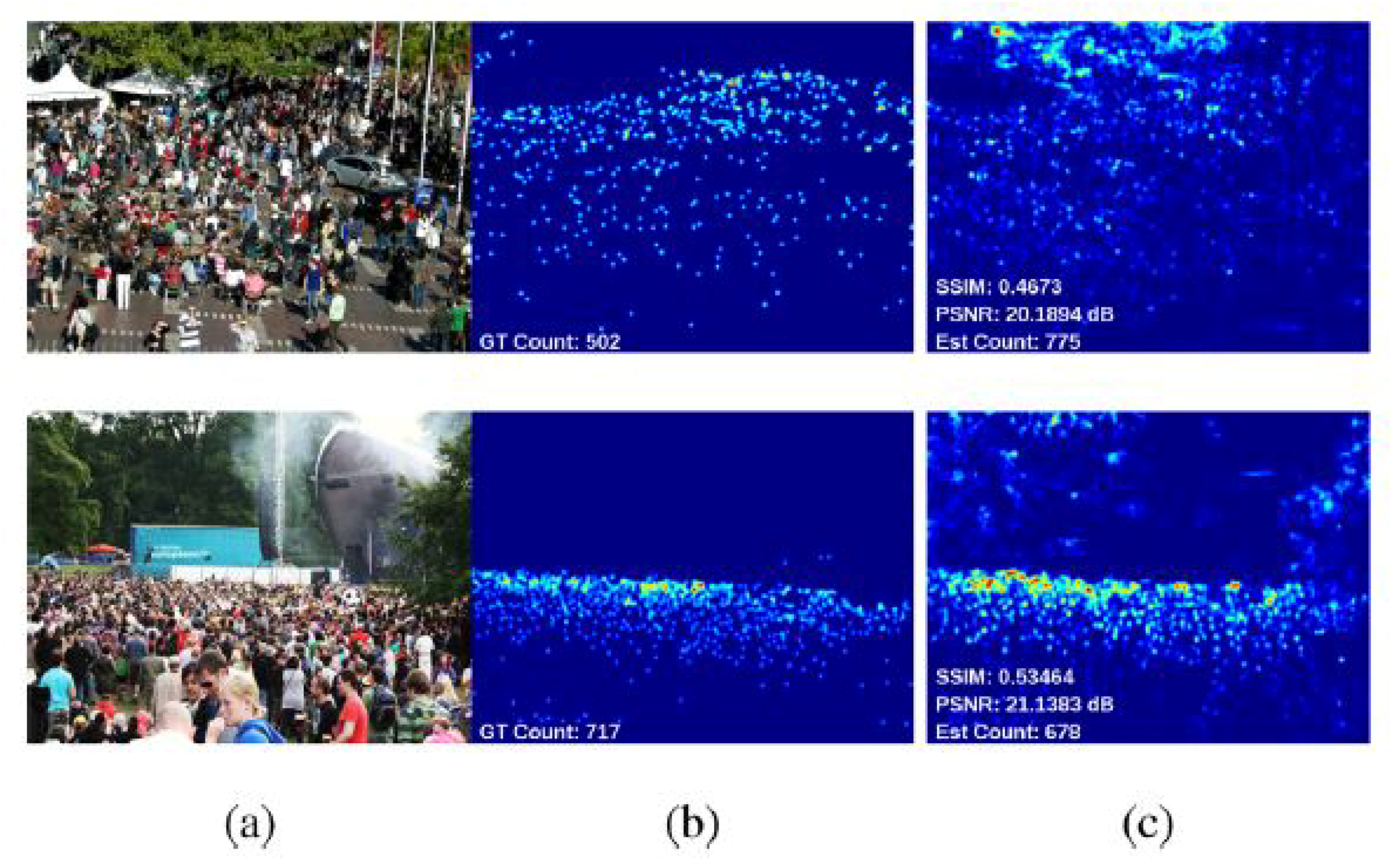{kind=link}
{kind=link}
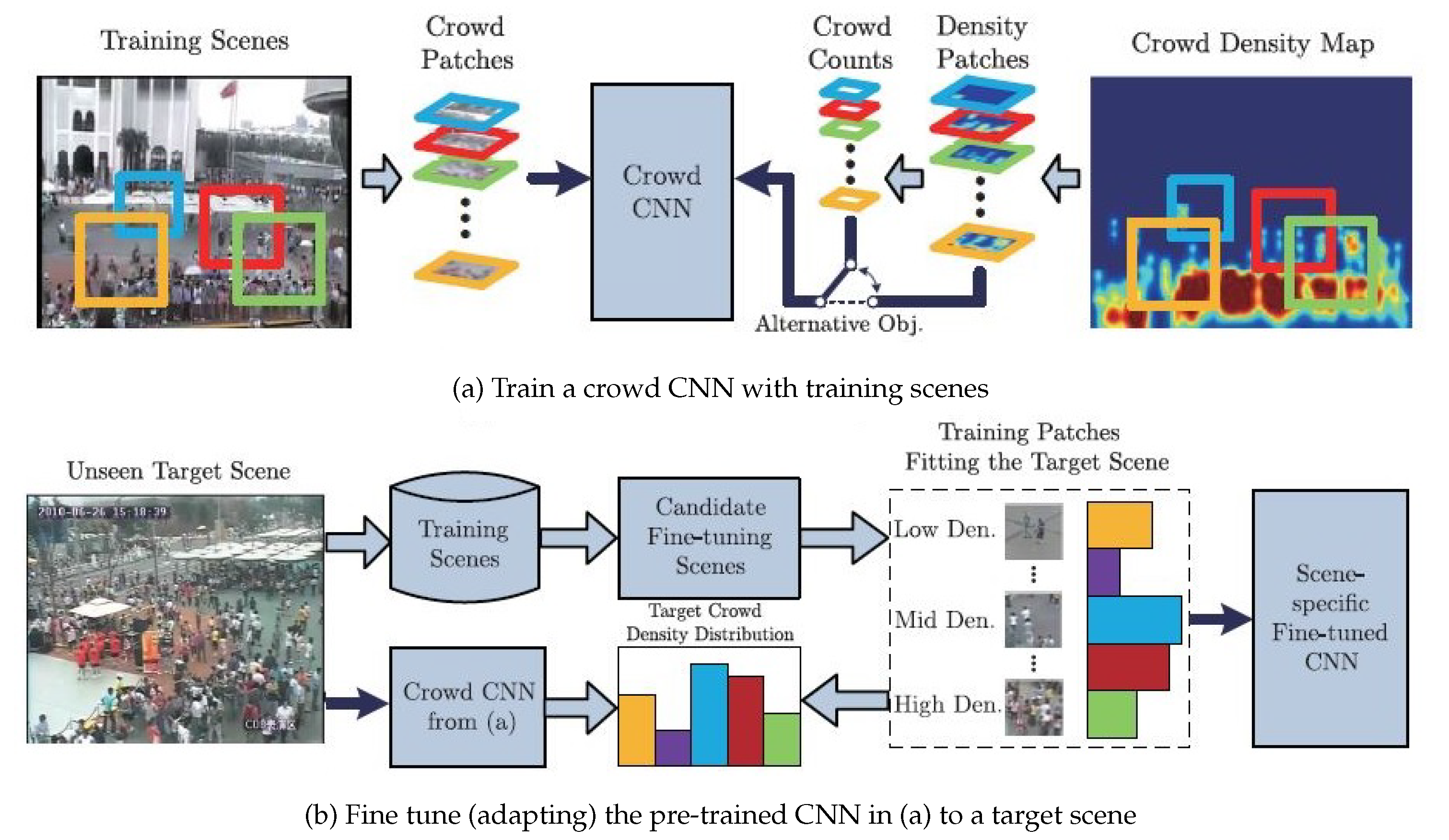{kind=link}
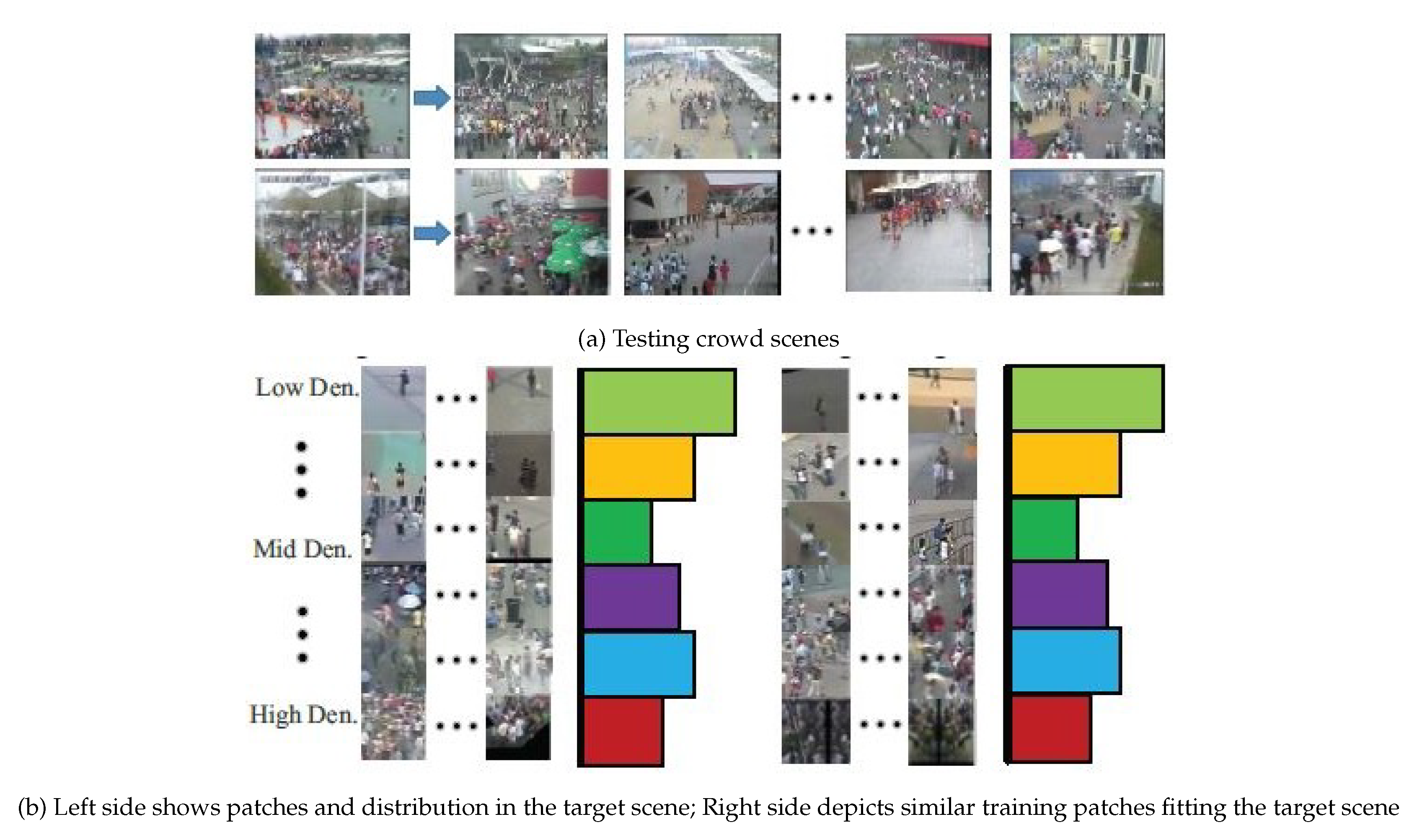{kind=link}
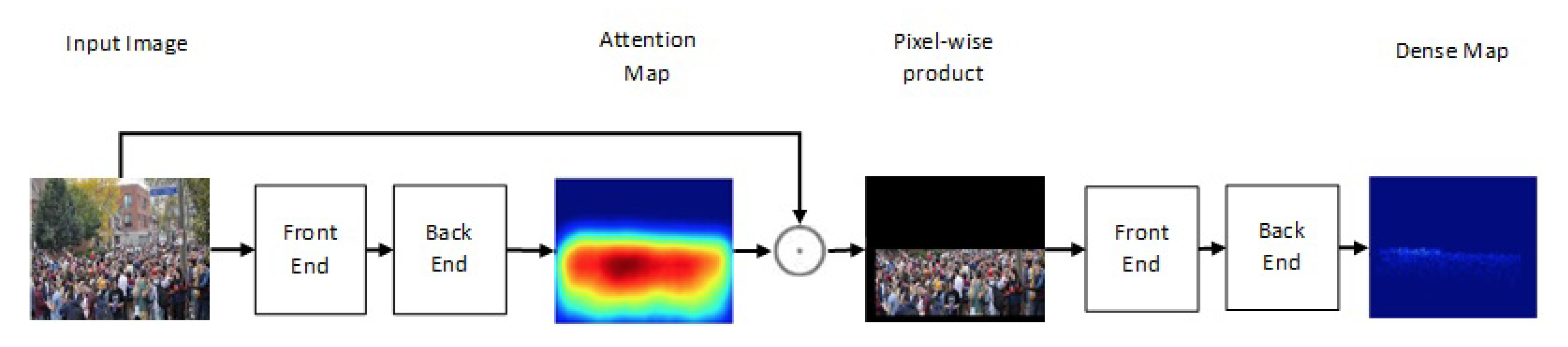{kind=link}
{kind=link}
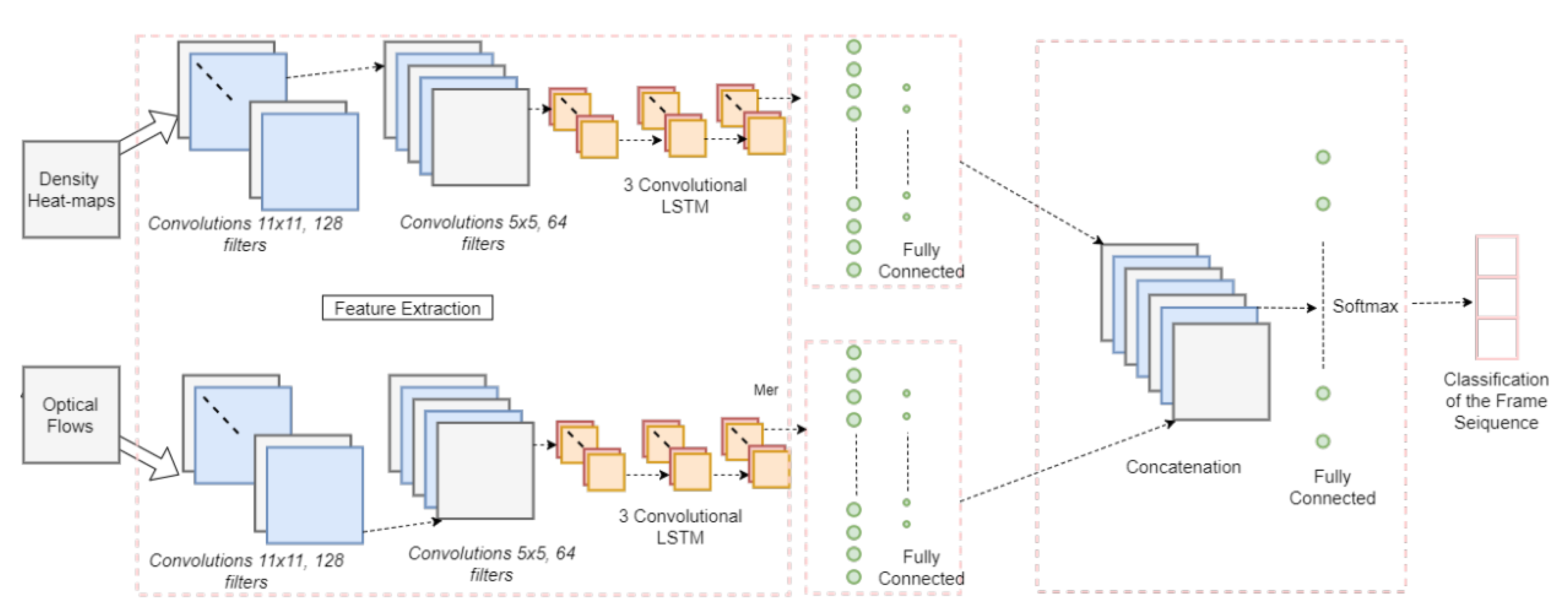{kind=link}
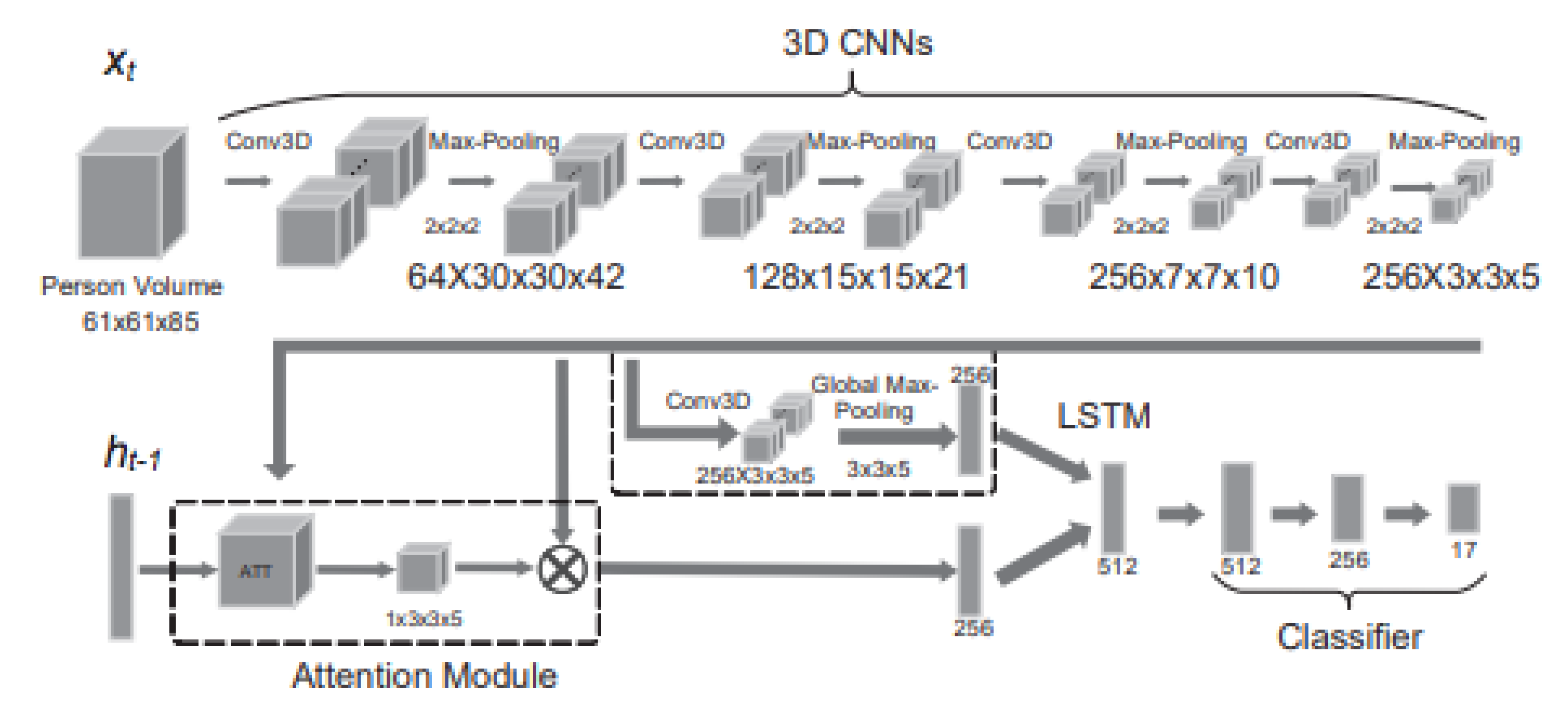{kind=link}
| Traditional Counting Approaches | What They do | Pros and Cons |
|---|---|---|
| Detection-based Approaches | Use detectors to detect people’s heads and/or shoulders in the crowd scene | Reasonable results but fail in very crowded scenes and scenes with heavy occlusion |
| Regression-based Approaches | Low-level feature extraction and regression modeling | Good results but lack spatial information as they are based on global count |
| Density Estimation-based Approaches | Map input crowd image to its corresponding density map | Use spatial information to reduce counting errors |
| Method | Dataset | Underlying Technique |
|---|---|---|
| [72] | Street | Hidden Markov Model |
| [74] | CMU action detection dataset [81] | 3D searching window with discriminative classifier |
| [76] | ASLAN [82] | statistics of how flow-vector magnitudes with SVM |
| [77] | WWW Crowd Dataset | CNN with xy-slices |
| [78] | PETA [83] | LTSM CNN |
| [79] | [84] | CNN with heat map and optical flow |
| [80] | 4D action recognition dataset [80] | CNN for 4D model |
| Dataset | No. of Images | Resolution | Min | Ave | Max | Total Count |
|---|---|---|---|---|---|---|
| UCSD [39] | 2000 | 158 × 238 | 11 | 25 | 46 | 49,885 |
| Mall [41] | 2000 | 320 × 240 | 13 | - | 53 | 62,325 |
| UCF_CC_50 [42] | 50 | Varied | 94 | 1279 | 4543 | 63,974 |
| WorldExpo’10 [60] | 3980 | 576 × 720 | 1 | 50 | 253 | 199,923 |
| ShanghaiTech Part A [66] | 482 | Varied | 33 | 501 | 3139 | 241,677 |
| ShanghaiTech Part B [66] | 716 | 768 × 1024 | 9 | 123 | 578 | 88,488 |
| Ref. | Dataset | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UCSD | Mall | UCF CC 50 | WorldExpo ’10 | Shanghai Tech-A | Shanghai Tech-B | |||||||
| MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | |
| [42] | 468.0 | 590.3 | ||||||||||
| [92] | 2.07 | 6.86 | 3.43 | 17.07 | ||||||||
| [46] | 1.7 | 493.4 | 487.1 | |||||||||
| [50] | 1.61 | 4.40 | 2.5 | 10.0 | ||||||||
| [93] | 1.98 | 1.82 | 2.74 | 2.10 | ||||||||
| [94] | 1.90 | 6.01 | 3.22 | 15.5 | ||||||||
| [60] | 1.60 | 3.31 | 467.0 | 498.5 | 12.9 | 181.8 | 277.7 | 32.0 | 49.8 | |||
| [95] | 452.5 | |||||||||||
| [66] | 1.07 | 1.35 | 377.6 | 509.1 | 11.6 | 110.2 | 173.2 | 26.4 | 41.3 | |||
| [96] | 1.10 | 2.01 | 364.4 | |||||||||
| [64] | 333.7 | 425.2 | ||||||||||
| [91] | 270.3 | 11.7 | ||||||||||
| [97] | 2.75 | 13.4 | 361.7 | 493.3 | ||||||||
| [98] | 338.6 | 424.5 | 126.5 | 173.5 | 23.76 | 33.12 | ||||||
| [99] | 1.12 | 2.06 | 406.2 | 404.0 | 13.4 | |||||||
| [100] | 2.86 | 13.0 | 2.41 | 9.12 | ||||||||
| [12] | 322.8 | 341.4 | 101.3 | 152.4 | 20.0 | 31.1 | ||||||
| [101] | 1.62 | 2.10 | 318.1 | 439.2 | 9.4 | 90.4 | 135.0 | 21.6 | 33.4 | |||
| [62] | 1.04 | 1.35 | 291.0 | 404.6 | 2.8 | 75.7 | 102.7 | 17.2 | 27.4 | |||
| [65] | 0.98 | 1.25 | 257.1 | 363.5 | 8.5 | 68.5 | 107.5 | 9.3 | 16.9 | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elbishlawi, S.; Abdelpakey, M.H.; Eltantawy, A.; Shehata, M.S.; Mohamed, M.M. Deep Learning-Based Crowd Scene Analysis Survey. J. Imaging 2020, 6, 95. https://doi.org/10.3390/jimaging6090095
Elbishlawi S, Abdelpakey MH, Eltantawy A, Shehata MS, Mohamed MM. Deep Learning-Based Crowd Scene Analysis Survey. Journal of Imaging. 2020; 6(9):95. https://doi.org/10.3390/jimaging6090095
Chicago/Turabian StyleElbishlawi, Sherif, Mohamed H. Abdelpakey, Agwad Eltantawy, Mohamed S. Shehata, and Mostafa M. Mohamed. 2020. "Deep Learning-Based Crowd Scene Analysis Survey" Journal of Imaging 6, no. 9: 95. https://doi.org/10.3390/jimaging6090095
APA StyleElbishlawi, S., Abdelpakey, M. H., Eltantawy, A., Shehata, M. S., & Mohamed, M. M. (2020). Deep Learning-Based Crowd Scene Analysis Survey. Journal of Imaging, 6(9), 95. https://doi.org/10.3390/jimaging6090095