Realistic Dynamic Numerical Phantom for MRI of the Upper Vocal Tract


Abstract
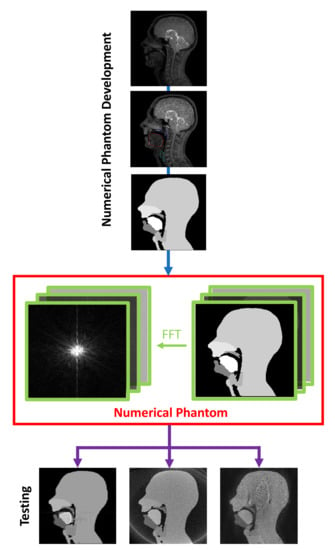
1. Introduction
1.1. Upper Vocal Tract and Dynamic Imaging Rationale
1.2. Overview of Dynamic and rtMRI: Sequences and Acquisition Strategies
1.3. Need for Optimisation and the Use of Phantoms
1.4. Aim of This Work
2. Materials and Methods
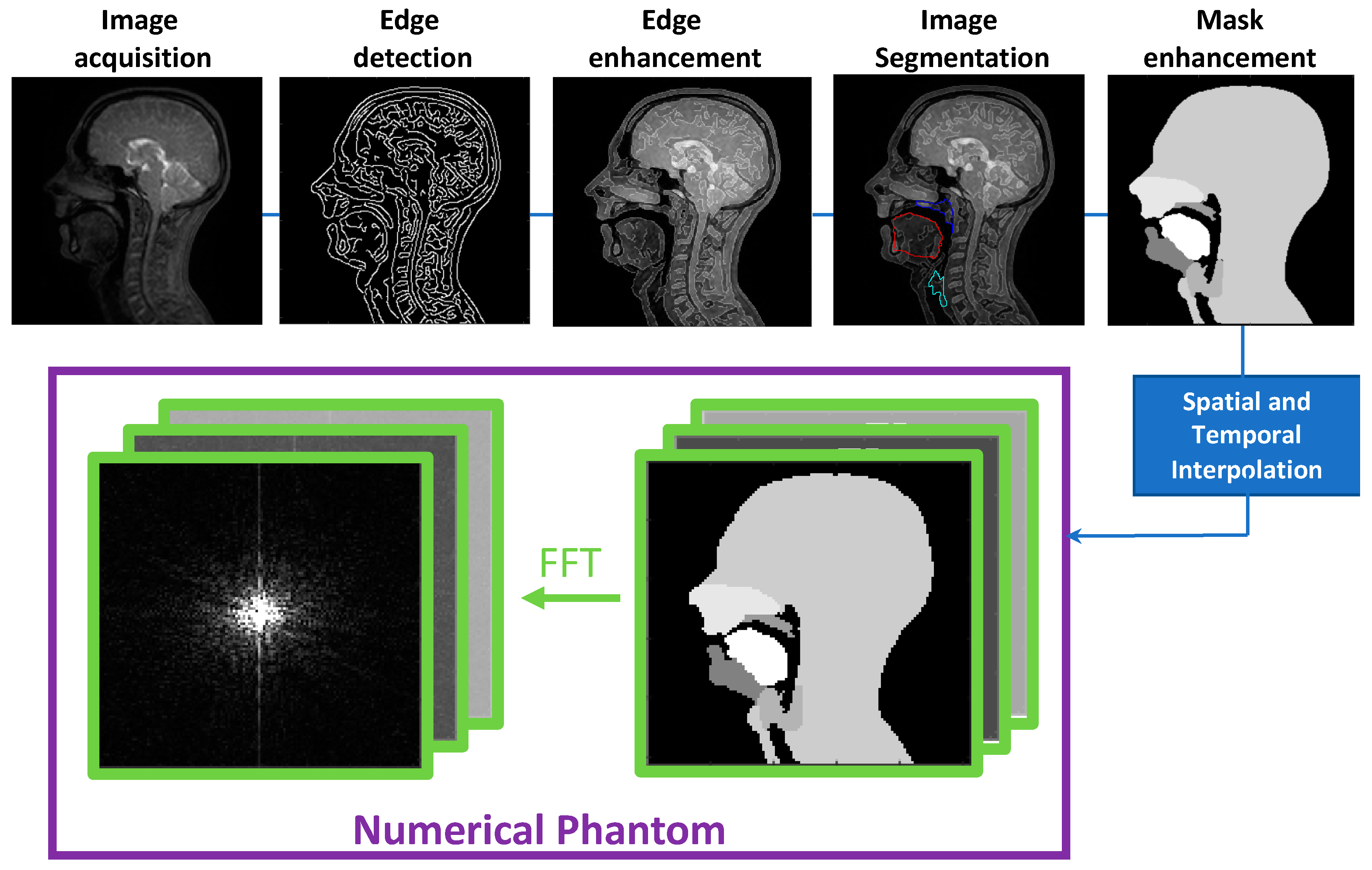
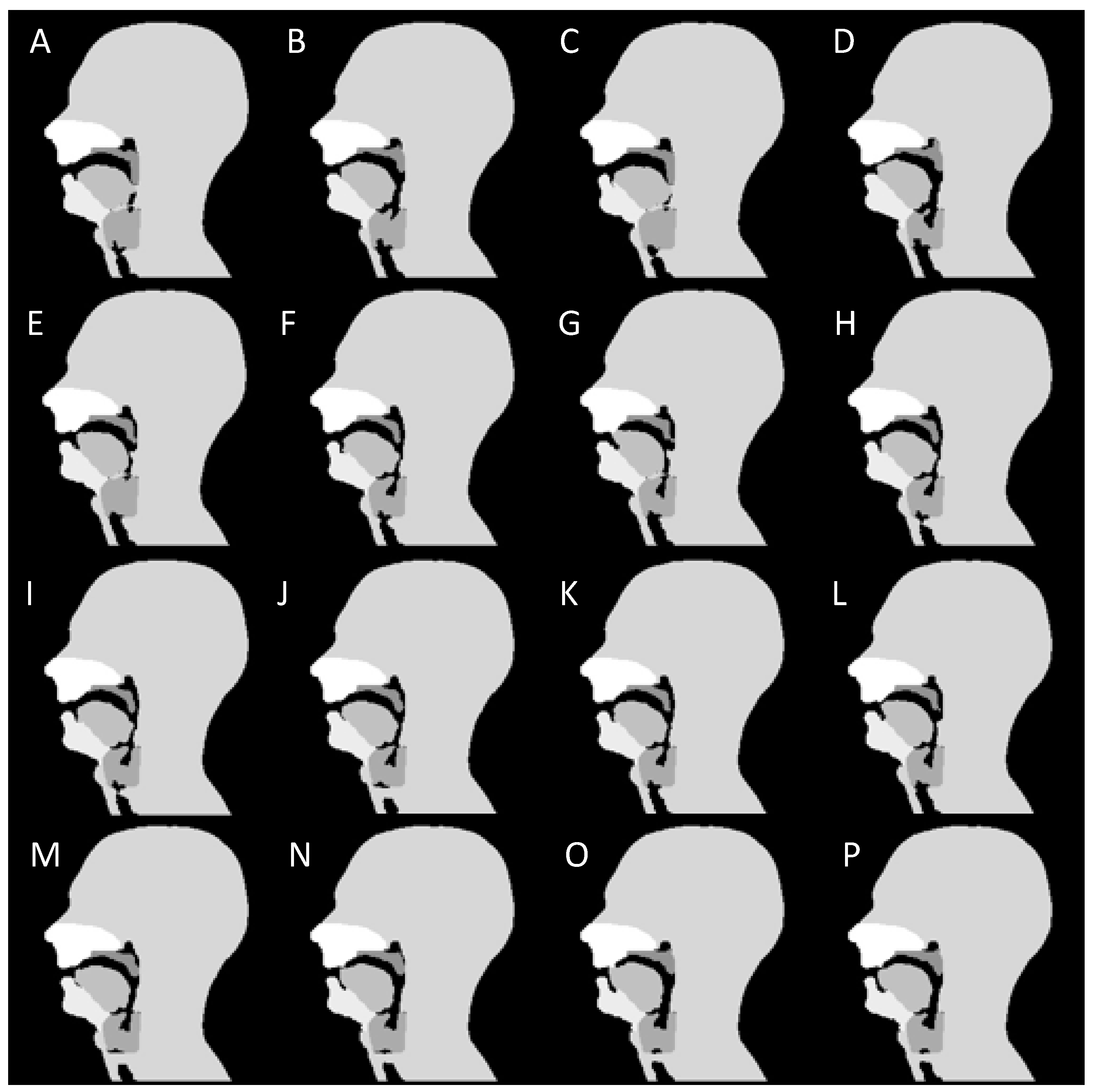
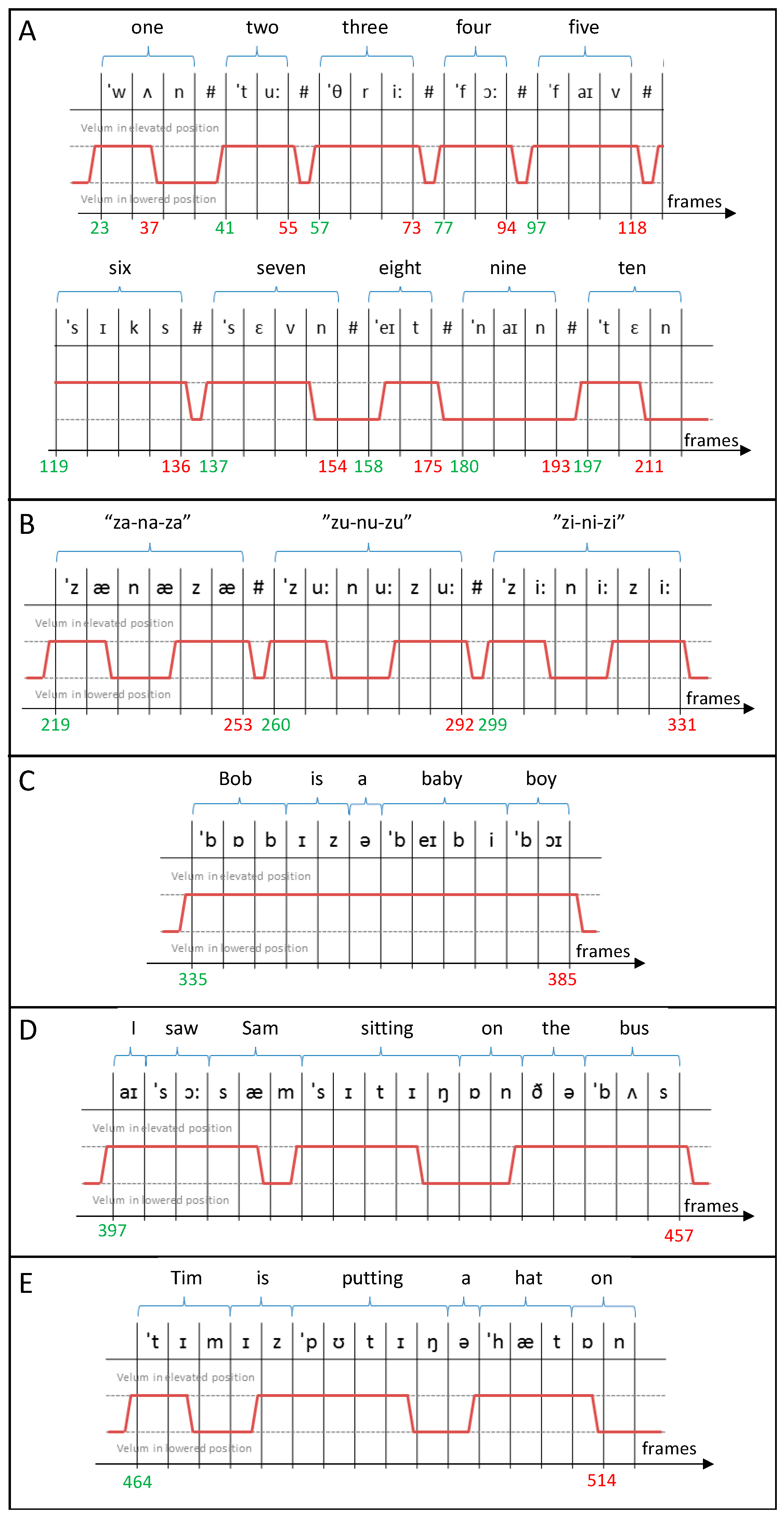
2.1. Numerical Phantom Development
- (1)
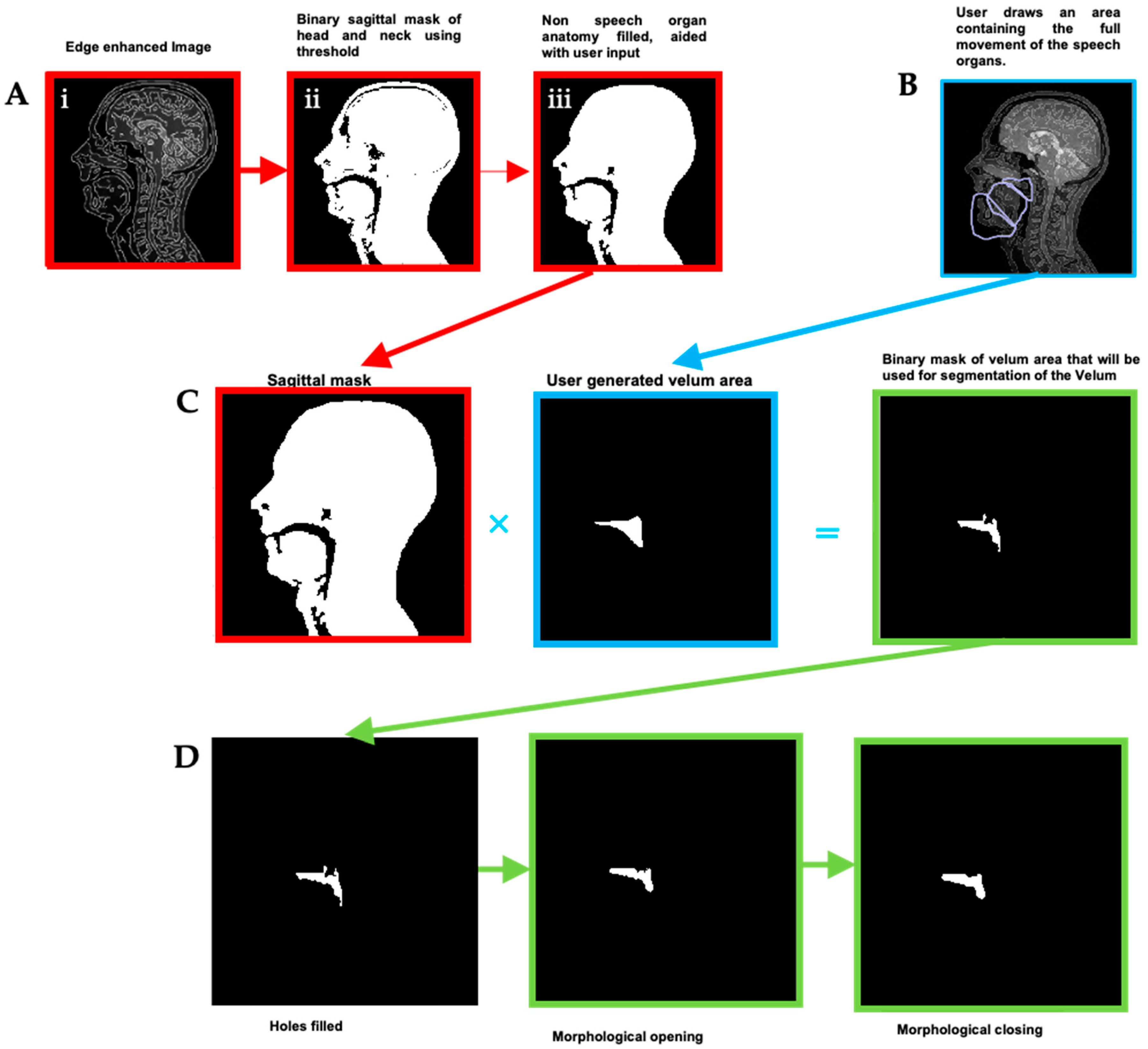
- Binary masks of the whole head with the vocal and speech organs visible were created using thresholding from the heads and some user input to ensure the upper respiratory tract remains distinct but that regions with zero value are filled in non-speech organs.
- (2)
- Manually select a region containing each speech articulator. It must be sufficiently large to allow for a full range of movement of an organ of interest (such as the velum or tongue) and is outlined directly onto the image.
- (3)
- Automatically segment and create a mask for each organ of interest at each time point, using the Hadamard product of the head mask and organ of interest mask at each time point, an example for the velum can be seen in Figure 3. This results in binary masks for each of the speech organs of interest for each frame in the original dynamic image set.
2.2. Numerical Phantom Testing
2.2.1. Cartesian and Non-Cartesian k-Space Trajectories
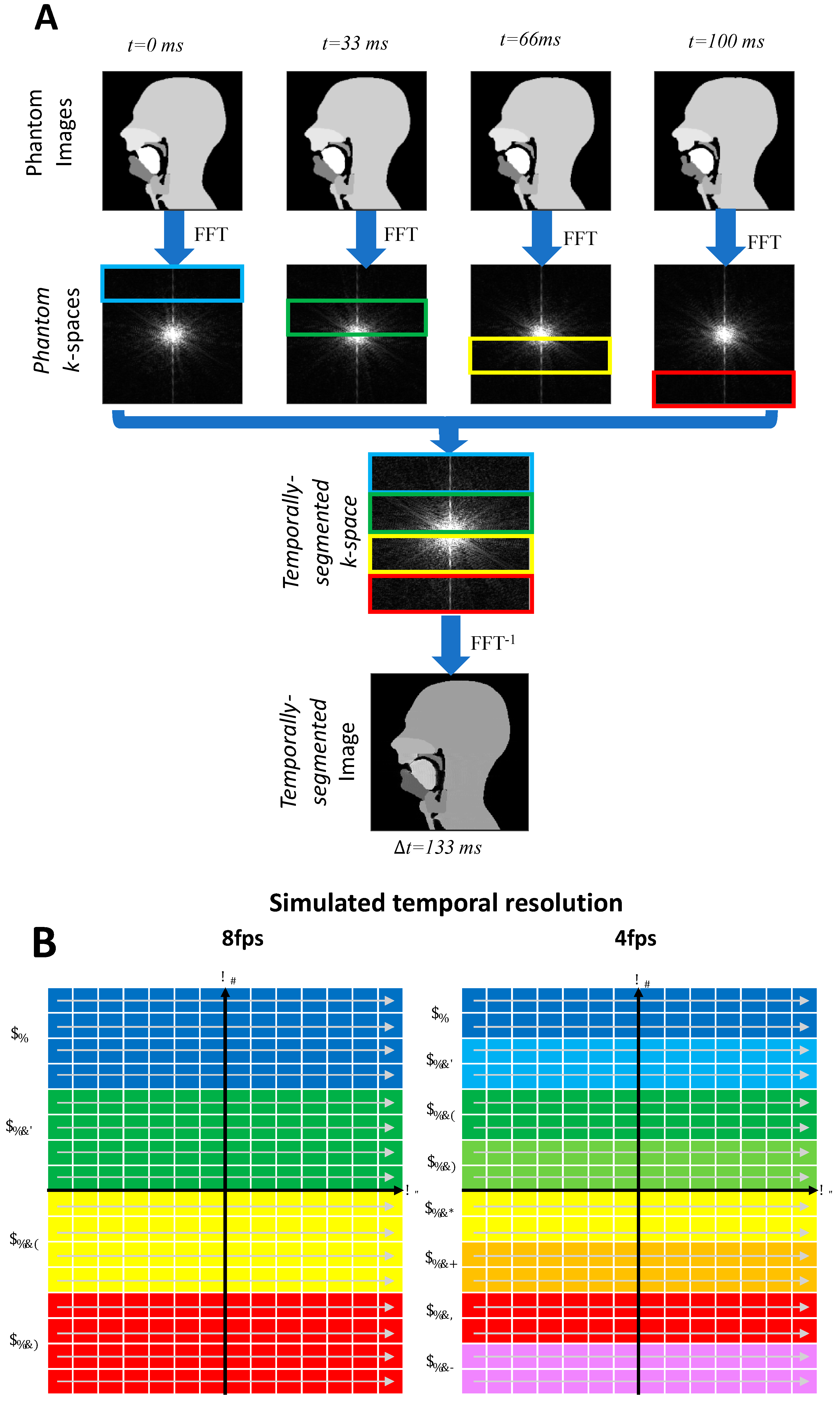
2.2.2. Simulating Lower Frame Rates
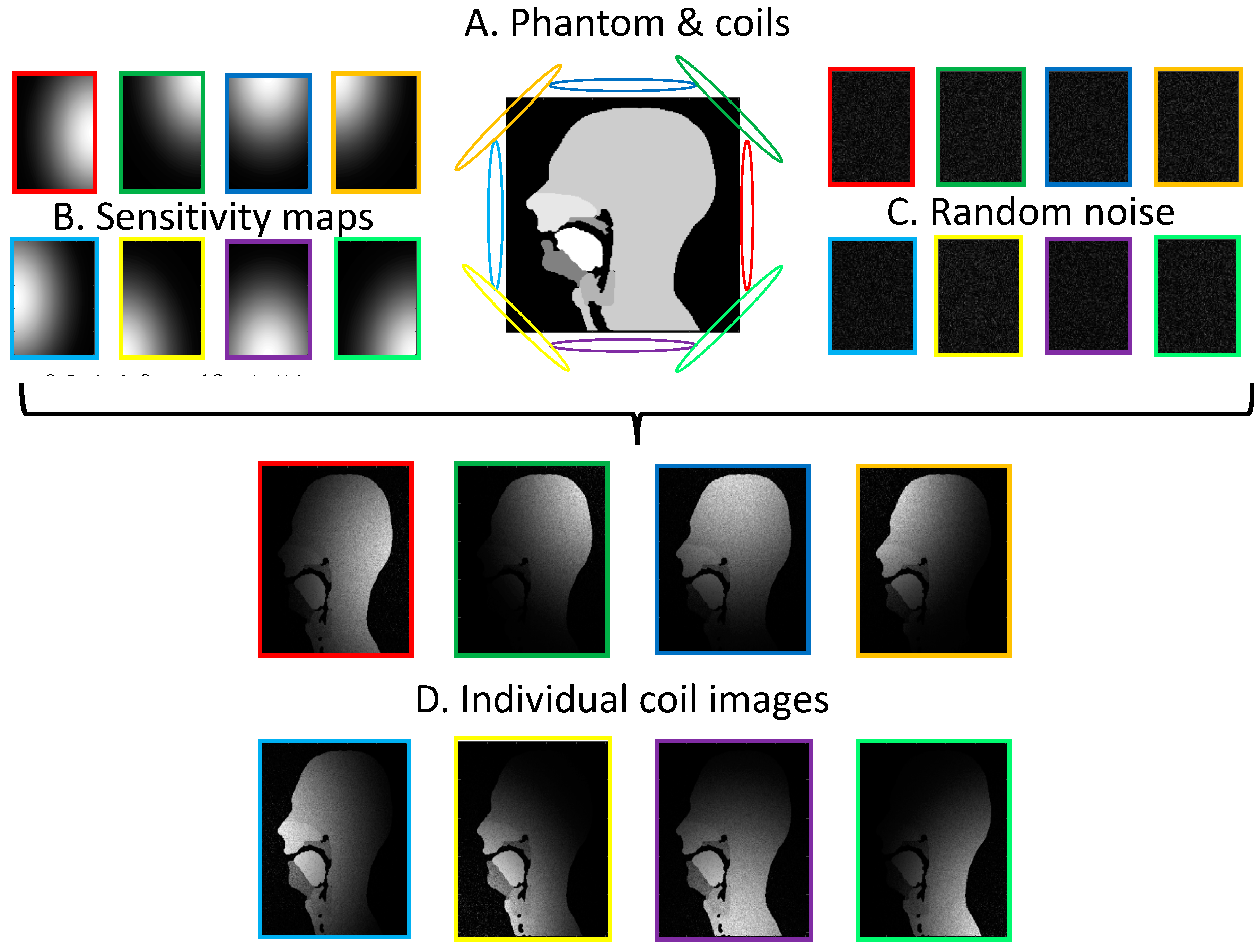
2.2.3. Parallel Imaging Simulations
3. Results and Discussion
3.1. Phantom Development
3.2. Cartesian, Radial and Spiral Trajectories
3.3. Lower Frame Rates
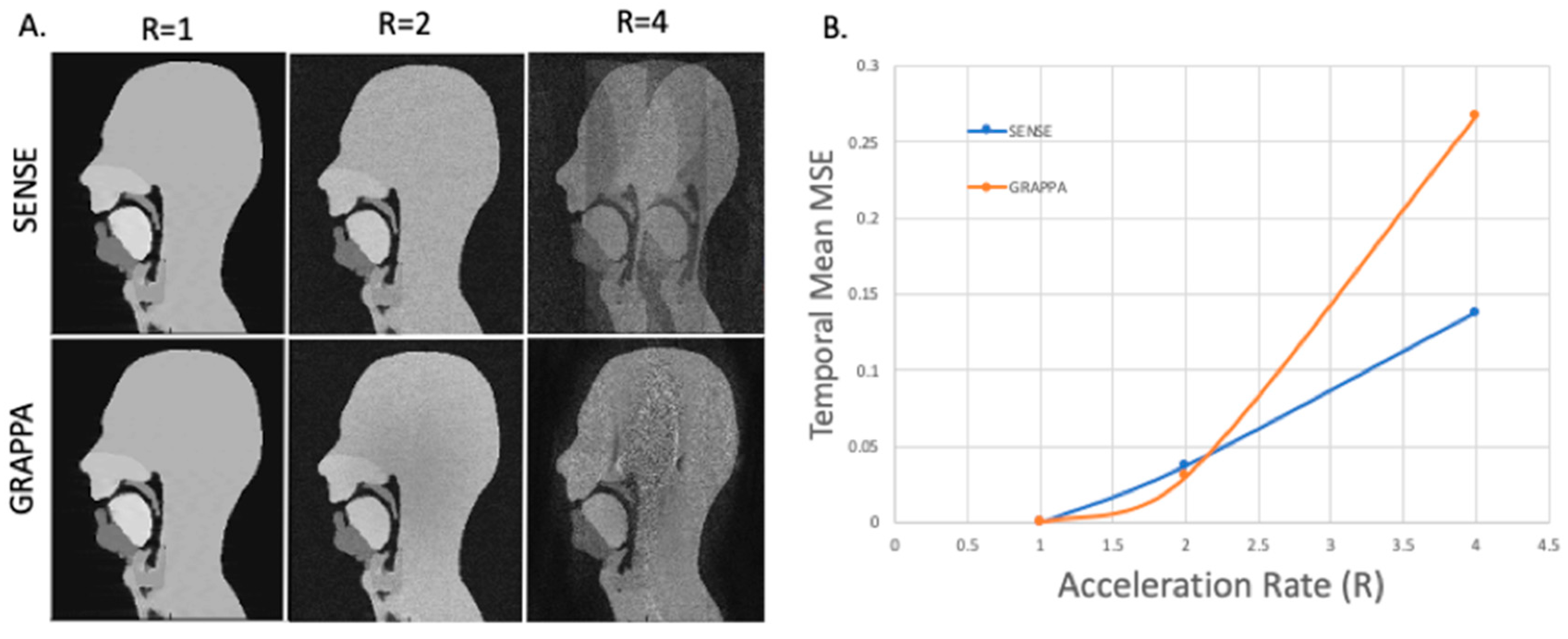
3.4. GRAPPA and SENSE Reconstructions
4. Conclusions and Possible Directions for Future Work
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fry, D.B. The Physics of Speech (Cambridge Textbooks in Linguistics); Cambridge University Press: Cambridge, UK, 1979. [Google Scholar] [CrossRef]
- Lacroix, A. Speech Production-Physics, Models and Prospective Applications. In Proceedings of the 2nd International Symposium on Image and Signal Processing and Analysis ISPA 2001. In conjunction with 23rd International Conference on Information Technology Interfaces, Pula, Croatia, 19–21 June 2001; p. 3. [Google Scholar] [CrossRef]
- Scott, A.D.; Wylezinska, M.; Birch, M.J.; Miquel, M.E. Speech MRI: Morphology and Function. Phys. Medica 2014, 30, 604–618. [Google Scholar] [CrossRef] [PubMed]
- Lingala, S.G.; Sutton, B.P.; Miquel, M.E.; Nayak, K.S. Recommendations for Real-time Speech MRI. J. Magn. Reson. Imaging 2016, 43, 28–44. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Kim, Y.-C.; Proctor, M.I.; Narayanan, S.S.; Nayak, K.S. Dynamic 3-D Visualization of Vocal Tract Shaping during Speech. IEEE Trans. Med. Imaging 2012, 32, 838–848. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Fu, M.; Barlaz, M.S.; Holtrop, J.L.; Perry, J.L.; Kuehn, D.P.; Shosted, R.K.; Liang, Z.; Sutton, B.P. High-frame-rate Full-vocal-tract 3D Dynamic Speech Imaging. Magn. Reson. Med. 2017, 77, 1619–1629. [Google Scholar] [CrossRef] [PubMed]
- Ramanarayanan, V.; Tilsen, S.; Proctor, M.; Töger, J.; Goldstein, L.; Nayak, K.S.; Narayanan, S. Analysis of Speech Production Real-Time MRI. Comput. Speech Lang. 2018, 52, 1–22. [Google Scholar] [CrossRef]
- Lim, Y.; Zhu, Y.; Lingala, S.G.; Byrd, D.; Narayanan, S.; Nayak, K.S. 3D Dynamic MRI of the Vocal Tract during Natural Speech. Magn. Reson. Med. 2019, 81, 1511–1520. [Google Scholar] [CrossRef]
- Isaieva, K.; Laprie, Y.; Odille, F.; Douros, I.K.; Felblinger, J.; Vuissoz, P.-A. Measurement of Tongue Tip Velocity from Real-Time MRI and Phase-Contrast Cine-MRI in Consonant Production. J. Imaging 2020, 6, 31. [Google Scholar] [CrossRef]
- Benítez, A.; Ramanarayanan, V.; Goldstein, L.; Narayanan, S.S. A Real-Time MRI Study of Articulatory Setting in Second Language Speech. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Carey, D.; Miquel, M.E.; Evans, B.G.; Adank, P.; McGettigan, C. Vocal Tract Images Reveal Neural Representations of Sensorimotor Transformation during Speech Imitation. Cereb. Cortex 2017, 27, 3064–3079. [Google Scholar] [CrossRef]
- Echternach, M.; Burk, F.; Burdumy, M.; Traser, L.; Richter, B. Morphometric Differences of Vocal Tract Articulators in Different Loudness Conditions in Singing. PLoS ONE 2016, 11, e0153792. [Google Scholar] [CrossRef]
- Echternach, M.; Sundberg, J.; Arndt, S.; Markl, M.; Schumacher, M.; Richter, B. Vocal Tract in Female Registers—A Dynamic Real-Time MRI Study. J. Voice 2010, 24, 133–139. [Google Scholar] [CrossRef]
- Echternach, M.; Sundberg, J.; Markl, M.; Richter, B. Professional Opera Tenors’ Vocal Tract Configurations in Registers. Folia Phoniatr. Logop. 2010, 62, 278–287. [Google Scholar] [CrossRef] [PubMed]
- Iltis, P.W.; Schoonderwaldt, E.; Zhang, S.; Frahm, J.; Altenmüller, E. Real-Time MRI Comparisons of Brass Players: A Methodological Pilot Study. Hum. Mov. Sci. 2015, 42, 132–145. [Google Scholar] [CrossRef] [PubMed]
- Schumacher, M.; Schmoor, C.; Plog, A.; Schwarzwald, R.; Taschner, C.; Echternach, M.; Richter, B.; Spahn, C. Motor Functions in Trumpet Playing—A Real-Time MRI Analysis. Neuroradiology 2013, 55, 1171–1181. [Google Scholar] [CrossRef] [PubMed]
- Greene, M.C.L. The Voice and Its Disorders, 4th ed.; Lippincott Co.: Philadelphia, PA, USA, 1980. [Google Scholar]
- Pauloski, B.R.; Logemann, J.A.; Rademaker, A.W.; McConnel, F.M.S.; Heiser, M.A.; Cardinale, S.; Shedd, D.; Lewin, J.; Baker, S.R.; Graner, D.; et al. Speech and Swallowing Function After Anterior Tongue and Floor of Mouth Resection With Distal Flap Reconstruction. J. Speech Lang. Hear. Res. 1993, 36, 267–276. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, J.J. Chaotic Vibrations of a Vocal Fold Model with a Unilateral Polyp. J. Acoust. Soc. Am. 2004, 115, 1266–1269. [Google Scholar] [CrossRef]
- Kosowski, T.R.; Weathers, W.M.; Wolfswinkel, E.M.; Ridgway, E.B. Cleft Palate. Semin. Plast. Surg. 2012, 26, 164–169. [Google Scholar] [CrossRef]
- Wyatt, R.; Sell, D.; Russell, J.; Harding, A.; Harland, K.; Albery, L. Cleft Palate Speech Dissected: A Review of Current Knowledge and Analysis. Br. J. Plast. Surg. 1996, 49, 143–149. [Google Scholar] [CrossRef]
- Boschi, V.; Catricalà, E.; Consonni, M.; Chesi, C.; Moro, A.; Cappa, S.F. Connected Speech in Neurodegenerative Language Disorders: A Review. Front. Psychol. 2017, 8, 269. [Google Scholar] [CrossRef]
- Atik, B.; Bekerecioglu, M.; Tan, O.; Etlik, O.; Davran, R.; Arslan, H. Evaluation of Dynamic Magnetic Resonance Imaging in Assessing Velopharyngeal Insufficiency during Phonation. J. Craniofac. Surg. 2008, 19, 566–572. [Google Scholar] [CrossRef]
- Drissi, C.; Mitrofanoff, M.; Talandier, C.; Falip, C.; Le Couls, V.; Adamsbaum, C. Feasibility of Dynamic MRI for Evaluating Velopharyngeal Insufficiency in Children. Eur. Radiol. 2011, 21, 1462–1469. [Google Scholar] [CrossRef]
- Miquel, M.E.; Freitas, A.C.; Wylezinska, M. Evaluating Velopharyngeal Closure with Real-Time MRI. Pediatr. Radiol. 2015, 45, 941–942. [Google Scholar] [CrossRef] [PubMed]
- Perry, J.L.; Mason, K.; Sutton, B.P.; Kuehn, D.P. Can Dynamic MRI Be Used to Accurately Identify Velopharyngeal Closure Patterns? Cleft Palate-Craniofacial J. 2018, 55, 499–507. [Google Scholar] [CrossRef] [PubMed]
- Olthoff, A.; Zhang, S.; Schweizer, R.; Frahm, J. On the Physiology of Normal Swallowing as Revealed by Magnetic Resonance Imaging in Real Time. Gastroenterol. Res. Pract. 2014, 2014, 493174. [Google Scholar] [CrossRef] [PubMed]
- Kumar, K.V.V.; Shankar, V.; Santosham, R. Assessment of Swallowing and Its Disorders—A Dynamic MRI Study. Eur. J. Radiol. 2013, 82, 215–219. [Google Scholar] [CrossRef]
- Mills, N.; Lydon, A.; Davies-Payne, D.; Keesing, M.; Geddes, D.T.; Mirjalili, S.A. Imaging the Breastfeeding Swallow: Pilot Study Utilizing Real-time MRI. Laryngoscope Investig. Otolaryngol. 2020, 5, 572–579. [Google Scholar] [CrossRef]
- Hartl, D.M.; Kolb, F.; Bretagne, E.; Bidault, F.; Sigal, R. Cine-MRI Swallowing Evaluation after Tongue Reconstruction. Eur. J. Radiol. 2010, 73, 108–113. [Google Scholar] [CrossRef]
- Ha, J.; Sung, I.; Son, J.; Stone, M.; Ord, R.; Cho, Y. Analysis of Speech and Tongue Motion in Normal and Post-Glossectomy Speaker Using Cine MRI. J. Appl. Oral Sci. 2016, 24, 472–480. [Google Scholar] [CrossRef]
- Zu, Y.; Narayanan, S.S.; Kim, Y.-C.; Nayak, K.; Bronson-Lowe, C.; Villegas, B.; Ouyoung, M.; Sinha, U.K. Evaluation of Swallow Function after Tongue Cancer Treatment Using Real-Time Magnetic Resonance Imaging: A Pilot Study. JAMA Otolaryngol. Neck Surg. 2013, 139, 1312–1319. [Google Scholar] [CrossRef]
- Nishimura, S.; Tanaka, T.; Oda, M.; Habu, M.; Kodama, M.; Yoshiga, D.; Osawa, K.; Kokuryo, S.; Miyamoto, I.; Kito, S. Functional Evaluation of Swallowing in Patients with Tongue Cancer before and after Surgery Using High-Speed Continuous Magnetic Resonance Imaging Based on T2-Weighted Sequences. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2018, 125, 88–98. [Google Scholar] [CrossRef]
- Kane, A.A.; Butman, J.A.; Mullick, R.; Skopec, M.; Choyke, P. A New Method for the Study of Velopharyngeal Function Using Gated Magnetic Resonance Imaging. Plast. Reconstr. Surg. 2002, 109, 472–481. [Google Scholar] [CrossRef]
- Shinagawa, H.; Ono, T.; Honda, E.-I.; Masaki, S.; Shimada, Y.; Fujimoto, I.; Sasaki, T.; Iriki, A.; Ohyama, K. Dynamic Analysis of Articulatory Movement Using Magnetic Resonance Imaging Movies: Methods and Implications in Cleft Lip and Palate. Cleft Palate-Craniofacial J. 2005, 42, 225–230. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Honda, K.; Maeda, S. Stroboscopic-Cine MRI Study of the Phasing between the Tongue and the Larynx in the Korean Three-Way Phonation Contrast. J. Phon. 2005, 33, 1–26. [Google Scholar] [CrossRef]
- Dietz, B.; Fallone, B.G.; Wachowicz, K. Nomenclature for Real-Time Magnetic Resonance Imaging. Magn. Reson. Med. 2019, 81, 1483–1484. [Google Scholar] [CrossRef] [PubMed]
- Nayak, K.S. Response to Letter to the Editor: “Nomenclature for Real-Time Magnetic Resonance Imaging”. Magn. Reson. Med. 2019, 82, 525–526. [Google Scholar] [CrossRef] [PubMed]
- Freitas, A.C.; Ruthven, M.; Boubertakh, R.; Miquel, M.E. Real-Time Speech MRI: Commercial Cartesian and Non-Cartesian Sequences at 3T and Feasibility of Offline TGV Reconstruction to Visualise Velopharyngeal Motion. Phys. Medica 2018, 46, 96–103. [Google Scholar] [CrossRef]
- Lingala, S.G.; Zhu, Y.; Kim, Y.-C.; Toutios, A.; Narayanan, S.; Nayak, K.S. A Fast and Flexible MRI System for the Study of Dynamic Vocal Tract Shaping. Magn. Reson. Med. 2017, 77, 112–125. [Google Scholar] [CrossRef]
- Uecker, M.; Zhang, S.; Voit, D.; Karaus, A.; Merboldt, K.; Frahm, J. Real-time MRI at a Resolution of 20 Ms. NMR Biomed. 2010, 23, 986–994. [Google Scholar] [CrossRef]
- Kim, Y.-C.; Narayanan, S.S.; Nayak, K.S. Flexible Retrospective Selection of Temporal Resolution in Real-Time Speech MRI Using a Golden-Ratio Spiral View Order. Magn. Reson. Med. 2011, 65, 1365–1371. [Google Scholar] [CrossRef][Green Version]
- Iltis, P.W.; Frahm, J.; Voit, D.; Joseph, A.A.; Schoonderwaldt, E.; Altenmüller, E. High-Speed Real-Time Magnetic Resonance Imaging of Fast Tongue Movements in Elite Horn Players. Quant. Imaging Med. Surg. 2015, 5, 374–381. [Google Scholar] [CrossRef]
- Arendt, C.T.; Eichler, K.; Mack, M.G.; Leithner, D.; Zhang, S.; Block, K.T.; Berdan, Y.; Sader, R.; Wichmann, J.L.; Gruber-Rouh, T.; et al. Comparison of Contrast-Enhanced Videofluoroscopy to Unenhanced Dynamic MRI in Minor Patients Following Surgical Correction of Velopharyngeal Dysfunction. Eur. Radiol. 2020. [Google Scholar] [CrossRef]
- Beer, A.J.; Hellerhoff, P.; Zimmermann, A.; Mady, K.; Sader, R.; Rummeny, E.J.; Hannig, C. Dynamic Near-real-time Magnetic Resonance Imaging for Analyzing the Velopharyngeal Closure in Comparison with Videofluoroscopy. J. Magn. Reson. Imaging 2004, 20, 791–797. [Google Scholar] [CrossRef] [PubMed]
- Akin, E.; Sayin, M.Ö.; Karaçay, Ş.; Bulakbaşi, N. Real-Time Balanced Turbo Field Echo Cine-Magnetic Resonance Imaging Evaluation of Tongue Movements during Deglutition in Subjects with Anterior Open Bite. Am. J. Orthod. Dentofac. Orthop. 2006, 129, 24–28. [Google Scholar] [CrossRef] [PubMed]
- Scott, A.D.; Boubertakh, R.; Birch, M.J.; Miquel, M.E. Towards Clinical Assessment of Velopharyngeal Closure Using MRI: Evaluation of Real-Time MRI Sequences at 1.5 and 3 T. Br. J. Radiol. 2012, 85, e1083–e1092. [Google Scholar] [CrossRef] [PubMed]
- Narayanan, S.S.; Alwan, A.A. A Nonlinear Dynamical Systems Analysis of Fricative Consonants. J. Acoust. Soc. Am. 1995, 97, 2511–2524. [Google Scholar] [CrossRef]
- NessAiver, M.S.; Stone, M.; Parthasarathy, V.; Kahana, Y.; Paritsky, A. Recording High Quality Speech during Tagged Cine-MRI Studies Using a Fiber Optic Microphone. J. Magn. Reson. Imaging An Off. J. Int. Soc. Magn. Reson. Med. 2006, 23, 92–97. [Google Scholar] [CrossRef]
- Clément, P.; Hans, S.; Hartl, D.M.; Maeda, S.; Vaissière, J.; Brasnu, D. Vocal Tract Area Function for Vowels Using Three-Dimensional Magnetic Resonance Imaging. A Preliminary Study. J. Voice 2007, 21, 522–530. [Google Scholar] [CrossRef]
- Scott, A.D.; Boubertakh, R.; Birch, M.J.; Miquel, M.E. Adaptive Averaging Applied to Dynamic Imaging of the Soft Palate. Magn. Reson. Med. 2013, 70, 865–874. [Google Scholar] [CrossRef]
- Schmitt, F.; Stehling, M.K.; Turner, R. Echo-Planar Imaging: Theory, Technique and Application; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Poustchi-Amin, M.; Mirowitz, S.A.; Brown, J.J.; McKinstry, R.C.; Li, T. Principles and Applications of Echo-Planar Imaging: A Review for the General Radiologist. Radiographics 2001, 21, 767–779. [Google Scholar] [CrossRef]
- Anagnostara, A.; Stoeckli, S.; Weber, O.M.; Kollias, S.S. Evaluation of the Anatomical and Functional Properties of Deglutition with Various Kinetic High-speed MRI Sequences. J. Magn. Reson. Imaging An Off. J. Int. Soc. Magn. Reson. Med. 2001, 14, 194–199. [Google Scholar] [CrossRef]
- Fu, M.; Zhao, B.; Carignan, C.; Shosted, R.K.; Perry, J.L.; Kuehn, D.P.; Liang, Z.; Sutton, B.P. High-resolution Dynamic Speech Imaging with Joint Low-rank and Sparsity Constraints. Magn. Reson. Med. 2015, 73, 1820–1832. [Google Scholar] [CrossRef]
- Niebergall, A.; Zhang, S.; Kunay, E.; Keydana, G.; Job, M.; Uecker, M.; Frahm, J. Real-time MRI of Speaking at a Resolution of 33 Ms: Undersampled Radial FLASH with Nonlinear Inverse Reconstruction. Magn. Reson. Med. 2013, 69, 477–485. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Block, K.T.; Frahm, J. Magnetic Resonance Imaging in Real Time: Advances Using Radial FLASH. J. Magn. Reson. Imaging 2010, 31, 101–109. [Google Scholar] [CrossRef] [PubMed]
- Freitas, A.C.; Wylezinska, M.; Birch, M.J.; Petersen, S.E.; Miquel, M.E. Comparison of Cartesian and Non-Cartesian Real-Time MRI Sequences at 1.5 T to Assess Velar Motion and Velopharyngeal Closure during Speech. PLoS ONE 2016, 11, e0153322. [Google Scholar] [CrossRef] [PubMed]
- Lim, Y.; Lingala, S.G.; Narayanan, S.S.; Nayak, K.S. Dynamic Off-resonance Correction for Spiral Real-time MRI of Speech. Magn. Reson. Med. 2019, 81, 234–246. [Google Scholar] [CrossRef]
- Feng, X.; Blemker, S.S.; Inouye, J.; Pelland, C.M.; Zhao, L.; Meyer, C.H. Assessment of Velopharyngeal Function with Dual-planar High-resolution Real-time Spiral Dynamic MRI. Magn. Reson. Med. 2018, 80, 1467–1474. [Google Scholar] [CrossRef]
- Baert, A.L. Parallel Imaging in Clinical MR Applications; Springer Science & Business Media: Berlin, Germany, 2007. [Google Scholar]
- Pruessmann, K.P.; Weiger, M.; Scheidegger, M.B.; Boesiger, P. SENSE: Sensitivity Encoding for Fast MRI. Magn. Reson. Med. 1999, 42, 952–962. [Google Scholar] [CrossRef]
- Griswold, M.A.; Jakob, P.M.; Heidemann, R.M.; Nittka, M.; Jellus, V.; Wang, J.; Kiefer, B.; Haase, A. Generalized Autocalibrating Partially Parallel Acquisitions (GRAPPA). Magn. Reson. Med. 2002, 47, 1202–1210. [Google Scholar] [CrossRef]
- Lingala, S.G.; Zhu, Y.; Lim, Y.; Toutios, A.; Ji, Y.; Lo, W.; Seiberlich, N.; Narayanan, S.; Nayak, K.S. Feasibility of Through-time Spiral Generalized Autocalibrating Partial Parallel Acquisition for Low Latency Accelerated Real-time MRI of Speech. Magn. Reson. Med. 2017, 78, 2275–2282. [Google Scholar] [CrossRef]
- Freitas, A.C.; Ruthven, M.; Boubertakh, R.; Miquel, M.E. Improved Real-Time MRI to Visualise Velopharyngeal Motion during Speech Using Accelerated Radial through-Time GRAPPA. Magn. Reson. Mater. Phys. Biol. Med. 2017, 30, S17–S18. [Google Scholar] [CrossRef]
- Ruthven, M.; Freitas, A.C.; Boubertakh, R.; Miquel, M.E. Application of Radial GRAPPA Techniques to Single-and Multislice Dynamic Speech MRI Using a 16-channel Neurovascular Coil. Magn. Reson. Med. 2019, 82, 948–958. [Google Scholar] [CrossRef]
- Sinko, K.; Czerny, C.; Jagsch, R.; Baumann, A.; Kulinna-Cosentini, C. Dynamic 1.5-T vs 3-T True Fast Imaging with Steady-State Precession (TrueFISP)-MRI Sequences for Assessment of Velopharyngeal Function. Dentomaxillofacial Radiol. 2015, 44, 20150028. [Google Scholar] [CrossRef] [PubMed]
- El Banoby, T.M.Y.; Hamza, F.A.; Elshamy, M.I.; Ali, A.M.A.; Abdelmonem, A.A. Role of Static MRI in Assessment of Velopharyngeal Insufficiency. Pan Arab J. Rhinol. 2020, 10, 21. [Google Scholar] [CrossRef]
- Swailes, N.E.; MacDonald, M.E.; Frayne, R. Dynamic Phantom with Heart, Lung, and Blood Motion for Initial Validation of MRI Techniques. J. Magn. Reson. Imaging 2011, 34, 941–946. [Google Scholar] [CrossRef] [PubMed]
- Dieringer, M.A.; Hentschel, J.; de Quadros, T.; von Knobelsdorff-Brenkenhoff, F.; Hoffmann, W.; Niendorf, T.; Schulz-Menger, J. Design, Construction, and Evaluation of a Dynamic MR Compatible Cardiac Left Ventricle Model. Med. Phys. 2012, 39, 4800–4806. [Google Scholar] [CrossRef] [PubMed]
- Shulman, M.; Cho, E.; Aasi, B.; Cheng, J.; Nithiyanantham, S.; Waddell, N.; Sussman, D. Quantitative Analysis of Fetal Magnetic Resonance Phantoms and Recommendations for an Anthropomorphic Motion Phantom. Magn. Reson. Mater. Phys. Biol. Med. 2019, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Wissmann, L.; Santelli, C.; Segars, W.P.; Kozerke, S. MRXCAT: Realistic Numerical Phantoms for Cardiovascular Magnetic Resonance. J. Cardiovasc. Magn. Reson. 2014, 16, 63. [Google Scholar] [CrossRef]
- Duchateau, N.; Sermesant, M.; Delingette, H.; Ayache, N. Model-Based Generation of Large Databases of Cardiac Images: Synthesis of Pathological Cine MR Sequences from Real Healthy Cases. IEEE Trans. Med. Imaging 2017, 37, 755–766. [Google Scholar] [CrossRef]
- Wang, C.; Yin, F.-F.; Segars, W.P.; Chang, Z.; Ren, L. Development of a Computerized 4-D MRI Phantom for Liver Motion Study. Technol. Cancer Res. Treat. 2017, 16, 1051–1059. [Google Scholar] [CrossRef]
- Lo, W.; Chen, Y.; Jiang, Y.; Hamilton, J.; Grimm, R.; Griswold, M.; Gulani, V.; Seiberlich, N. Realistic 4D MRI Abdominal Phantom for the Evaluation and Comparison of Acquisition and Reconstruction Techniques. Magn. Reson. Med. 2019, 81, 1863–1875. [Google Scholar] [CrossRef]
- Basil, V.R.; Turner, A.J. Iterative Enhancement: A Practical Technique for Software Development. IEEE Trans. Softw. Eng. 1975, 4, 390–396. [Google Scholar] [CrossRef]
- Ruthven, M.; Freitas, A.C.; Keevil, S.; Miquel, M.E. Real-Time Speech MRI: What Is the Optimal Temporal Resolution for Clinical Velopharyngeal Closure Assessment? Proc. Int. Soc. Magn. Reson. Med. 2016, 24, 208. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Fessler, J.A. On NUFFT-Based Gridding for Non-Cartesian MRI. J. Magn. Reson. 2007, 188, 191–195. [Google Scholar] [CrossRef] [PubMed]
- Pinoli, J.-C. Mathematical Foundations of Image Processing and Analysis, Volume 2; John Wiley & Sons: Hoboken, NJ, USA, 2014; Volume 2. [Google Scholar]
- Liu, F.; Block, W.F.; Kijowski, R.; Samsonov, A. MRiLab: Fast Realistic MRI Simulations Based on Generalized Exchange Tissue Model. IEEE Trans. Med Imaging 2016. [Google Scholar] [CrossRef]
- Pruessmann, K.P. Encoding and Reconstruction in Parallel MRI. NMR Biomed. 2006, 19, 288–299. [Google Scholar] [CrossRef] [PubMed]
- Uecker, M.; Tamir, J.I.; Ong, F.; Lustig, M. The BART Toolbox for Computational Magnetic Resonance Imaging; ISMRM: Concord, CA, USA, 2016. [Google Scholar]
- Bresch, E.; Narayanan, S. Region Segmentation in the Frequency Domain Applied to Upper Airway Real-Time Magnetic Resonance Images. IEEE Trans. Med. Imaging 2008, 28, 323–338. [Google Scholar] [CrossRef]
- Raeesy, Z.; Rueda, S.; Udupa, J.K.; Coleman, J. Automatic Segmentation of Vocal Tract MR Images. In Proceedings of the 2013 IEEE 10th International Symposium on Biomedical Imaging, San Francisico, CA, USA, 7–11 April 2013; pp. 1328–1331. [Google Scholar] [CrossRef]
- Kim, J.; Kumar, N.; Lee, S.; Narayanan, S. Enhanced Airway-Tissue Boundary Segmentation for Real-Time Magnetic Resonance Imaging Data. In Proceedings of the International Seminar on Speech Production ISSP, Cologne, Germany, 5–8 May 2014; pp. 222–225. [Google Scholar]
- Silva, S.; Teixeira, A. Unsupervised Segmentation of the Vocal Tract from Real-Time MRI Sequences. Comput. Speech Lang. 2015, 33, 25–46. [Google Scholar] [CrossRef]
- Wylezinska, M.; Pinkstone, M.; Hay, N.; Scott, A.D.; Birch, M.J.; Miquel, M.E. Impact of Orthodontic Appliances on the Quality of Craniofacial Anatomical Magnetic Resonance Imaging and Real-Time Speech Imaging. Eur. J. Orthod. 2015, 37, 610–617. [Google Scholar] [CrossRef]
- Valliappan, C.A.; Kumar, A.; Mannem, R.; Karthik, G.R.; Ghosh, P.K. An Improved Air Tissue Boundary Segmentation Technique for Real Time Magnetic Resonance Imaging Video Using SegNet. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brightin, UK, 12–17 May 2019; pp. 5921–5925. [Google Scholar] [CrossRef]
- Valliappan, C.A.; Mannem, R.; Ghosh, P.K. Air-Tissue Boundary Segmentation in Real-Time Magnetic Resonance Imaging Video Using Semantic Segmentation with Fully Convolutional Networks. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 3132–3136. [Google Scholar] [CrossRef]
- Mannem, R.; Ghosh, P.K. Air-Tissue Boundary Segmentation in Real Time Magnetic Resonance Imaging Video Using a Convolutional Encoder-Decoder Network. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5941–5945. [Google Scholar] [CrossRef]
- Somandepalli, K.; Toutios, A.; Narayanan, S.S. Semantic Edge Detection for Tracking Vocal Tract Air-Tissue Boundaries in Real-Time Magnetic Resonance Images. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 631–635. [Google Scholar] [CrossRef]
- Labrunie, M.; Badin, P.; Voit, D.; Joseph, A.A.; Frahm, J.; Lamalle, L.; Vilain, C.; Boe, L.-J. Automatic Segmentation of Speech Articulators from Real-Time Midsagittal MRI Based on Supervised Learning. Speech Commun. 2018, 99, 27–46. [Google Scholar] [CrossRef]
- Hebbar, S.A.; Sharma, R.; Somandepalli, K.; Toutios, A.; Narayanan, S. Vocal Tract Articulatory Contour Detection in Real-Time Magnetic Resonance Images Using Spatio-Temporal Context. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7354–7358. [Google Scholar] [CrossRef]
- Erattakulangara, S.; Lingala, S.G. Airway Segmentation in Speech MRI Using the U-Net Architecture. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1887–1890. [Google Scholar]
- Barron, J.L.; Fleet, D.J.; Beauchemin, S.S. Performance of Optical Flow Techniques. Int. J. Comput. Vis. 1994, 12, 43–77. [Google Scholar] [CrossRef]
- Rueckert, D.; Sonoda, L.I.; Hayes, C.; Hill, D.L.G.; Leach, M.O.; Hawkes, D.J. Nonrigid Registration Using Free-Form Deformations: Application to Breast MR Images. IEEE Trans. Med. Imaging 1999, 18, 712–721. [Google Scholar] [CrossRef]
- Sven. Interpmask—Interpolate (Tween) Logical Masks. MATLAB Central File Exchange 2014. Available online: https://uk.mathworks.com/matlabcentral/fileexchange/46429-interpmask-interpolate-tween-logical-masks (accessed on 25 June 2020).
- Zhang, S.; Olthoff, A.; Frahm, J. Real-time Magnetic Resonance Imaging of Normal Swallowing. J. Magn. Reson. Imaging 2012, 35, 1372–1379. [Google Scholar] [CrossRef] [PubMed]
- Pearson, W.G., Jr.; Zumwalt, A.C. Visualising Hyolaryngeal Mechanics in Swallowing Using Dynamic MRI. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2014, 2, 208–216. [Google Scholar] [CrossRef] [PubMed]
- Olthoff, A.; Joseph, A.A.; Weidenmüller, M.; Riley, B.; Frahm, J. Real-Time MRI of Swallowing: Intraoral Pressure Reduction Supports Larynx Elevation. NMR Biomed. 2016, 29, 1618–1623. [Google Scholar] [CrossRef]
- Zastrow, E.; Davis, S.K.; Lazebnik, M.; Kelcz, F.; Van Veen, B.D.; Hagness, S.C. Development of Anatomically Realistic Numerical Breast Phantoms with Accurate Dielectric Properties for Modeling Microwave Interactions with the Human Breast. IEEE Trans. Biomed. Eng. 2008, 55, 2792–2800. [Google Scholar] [CrossRef] [PubMed]
- Patch, S.K. K-Space Data Preprocessing for Artifact Reduction in MR Imaging. Multidimens. Image Process. Anal. Disp. RSNA Categ. Course Diagn. Radiol. Pysics 2005, 73–87. Available online: https://cpb-us-w2.wpmucdn.com/sites.uwm.edu/dist/f/106/files/2016/04/RSNA05-ul73r5.pdf (accessed on 25 June 2020).
- Buonocore, M.H.; Gao, L. Ghost Artifact Reduction for Echo Planar Imaging Using Image Phase Correction. Magn. Reson. Med. 1997, 38, 89–100. [Google Scholar] [CrossRef]
- Reeder, S.B.; Atalar, E.; Bolster Jr, B.D.; McVeigh, E.R. Quantification and Reduction of Ghosting Artifacts in Interleaved Echo-planar Imaging. Magn. Reson. Med. 1997, 38, 429–439. [Google Scholar] [CrossRef]
- Zeng, H.; Constable, R.T. Image Distortion Correction in EPI: Comparison of Field Mapping with Point Spread Function Mapping. Magn. Reson. Med. 2002, 48, 137–146. [Google Scholar] [CrossRef]
- Bluemke, D.A.; Boxerman, J.L.; Atalar, E.; McVeigh, E.R. Segmented K-Space Cine Breath-Hold Cardiovascular MR Imaging: Part 1. Principles and Technique. AJR. Am. J. Roentgenol. 1997, 169, 395–400. [Google Scholar] [CrossRef]
- Deshmane, A.; Gulani, V.; Griswold, M.A.; Seiberlich, N. Parallel MR Imaging. J. Magn. Reson. Imaging 2012, 36, 55–72. [Google Scholar] [CrossRef]
- Ferreira, P.; Gatehouse, P.; Firmin, D. Myocardial First-Pass Perfusion Imaging with Hybrid-EPI: Frequency-Offsets and Potential Artefacts. J. Cardiovasc. Magn. Reson. 2012, 14, 44. [Google Scholar] [CrossRef] [PubMed]
- Toutios, A.; Lingala, S.G.; Vaz, C.; Kim, J.; Esling, J.H.; Keating, P.A.; Gordon, M.; Byrd, D.; Goldstein, L.; Nayak, K.S. Illustrating the Production of the International Phonetic Alphabet Sounds Using Fast Real-Time Magnetic Resonance Imaging. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 2428–2432. [Google Scholar] [CrossRef]
- Huang, F. Technique for Parallel MRI Imaging (Kt Grappa). U.S. Patents 20060050981A1, 9 March 2006. [Google Scholar]
- Tsao, J.; Boesiger, P.; Pruessmann, K.P. K-t BLAST and K-t SENSE: Dynamic MRI with High Frame Rate Exploiting Spatiotemporal Correlations. Magn. Reson. Med. 2003, 50, 1031–1042. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frame Rate (fps) | Number of Coils | Calibration Lines | R | Lines Sampled | MSE (%) | Velum & Tongue Discernible? | Aliasing Artefacts | |||
|---|---|---|---|---|---|---|---|---|---|---|
| GRAPPA | SENSE | GRAPPA | SENSE | GRAPPA | SENSE | |||||
| 2 | 2 | 10 | 2 | 128 | 14.01 | 4.09 | Yes | Yes | Yes | No |
| 4 | 10 | 2 | 128 | 5.37 | 3.82 | Yes | Yes | Yes | No | |
| 8 | 10 | 2 | 128 | 4.13 | 2.46 | Yes | Yes | Yes | No | |
| 8 | 20 | 2 | 128 | 3.19 | 2.45 | Yes | Yes | No | No | |
| 8 | 40 | 2 | 128 | 2.91 | 2.46 | Yes | Yes | No | No | |
| 4 | 2 | 10 | 2 | 128 | 14.00 | 4.27 | Yes | Yes | Yes | No |
| 4 | 10 | 2 | 128 | 5.79 | 4.06 | Yes | Yes | Yes | No | |
| 8 | 10 | 2 | 128 | 4.65 | 2.62 | Yes | Yes | Yes | No | |
| 8 | 20 | 2 | 128 | 3.35 | 2.62 | Yes | Yes | No | No | |
| 8 | 40 | 2 | 128 | 3.062 | 2.62 | Yes | Yes | No | No | |
| 8 | 2 | 10 | 2 | 128 | 14.16 | 4.35 | Yes | Yes | Yes | No |
| 4 | 10 | 2 | 128 | 6.26 | 4.19 | Yes | Yes | Yes | No | |
| 8 | 10 | 2 | 128 | 4.82 | 2.72 | Yes | Yes | Yes | No | |
| 8 | 20 | 2 | 128 | 3.45 | 2.72 | Yes | Yes | No | No | |
| 8 | 40 | 2 | 128 | 3.17 | 2.73 | Yes | Yes | No | No | |
| 15 | 2 | 10 | 2 | 128 | 15.10 | 4.56 | Yes | Yes | Yes | No |
| 4 | 10 | 2 | 128 | 7.40 | 4.45 | Yes | Yes | Yes | No | |
| 8 | 10 | 2 | 128 | 6.59 | 3.01 | Yes | Yes | Yes | No | |
| 8 | 20 | 2 | 128 | 3.75 | 3.01 | Yes | Yes | No | No | |
| 8 | 40 | 2 | 128 | 3.46 | 3.01 | Yes | Yes | No | No | |
| 8 | 20 | 4 | 64 | 92.69 | 26.66 | Yes | No | Yes | Yes | |
| 8 | 40 | 4 | 64 | 13.78 | 26.66 | Yes | Yes | Yes | Yes | |
| 8 | 20 | 8 | 32 | 64.41 | 35.44 | No | No | Yes | Yes | |
| 8 | 40 | 8 | 32 | >99 | 35.41 | No | No | Yes | Yes | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin, J.; Ruthven, M.; Boubertakh, R.; Miquel, M.E. Realistic Dynamic Numerical Phantom for MRI of the Upper Vocal Tract. J. Imaging 2020, 6, 86. https://doi.org/10.3390/jimaging6090086
Martin J, Ruthven M, Boubertakh R, Miquel ME. Realistic Dynamic Numerical Phantom for MRI of the Upper Vocal Tract. Journal of Imaging. 2020; 6(9):86. https://doi.org/10.3390/jimaging6090086
Chicago/Turabian StyleMartin, Joe, Matthieu Ruthven, Redha Boubertakh, and Marc E. Miquel. 2020. "Realistic Dynamic Numerical Phantom for MRI of the Upper Vocal Tract" Journal of Imaging 6, no. 9: 86. https://doi.org/10.3390/jimaging6090086
APA StyleMartin, J., Ruthven, M., Boubertakh, R., & Miquel, M. E. (2020). Realistic Dynamic Numerical Phantom for MRI of the Upper Vocal Tract. Journal of Imaging, 6(9), 86. https://doi.org/10.3390/jimaging6090086