Investigating the Performance of Generative Adversarial Networks for Prostate Tissue Detection and Segmentation

 ,
, 
Abstract
1. Introduction
- to incorporate three data augmentation schemes (super-pixel, noise addition and moving mean) to increase the amount of data in the training set;
- to train three models including U-Net, cGAN and cycleGAN with limited amount of training data and compensate it by using the augmented training data
- to compare their robustness on the publicly available prostate MRI dataset (completely unseen samples collected from different institution) and our clinically collected prostate multi-parametric MRI dataset (collected from the same institution).
2. Methodology
2.1. Datasets
2.2. Augmentation Schemes
2.2.1. Super-Pixel (SP) Approach
2.2.2. Gaussian Noise Addition (GNA) Approach
2.2.3. Moving Mean (MM) Approach
2.3. The Deep Learning Frameworks
2.3.1. U-Net
2.3.2. Conditional GAN (cGAN)
2.3.3. CycleGAN
2.4. Training
2.5. Post-Processing
2.6. Evaluation Metrics
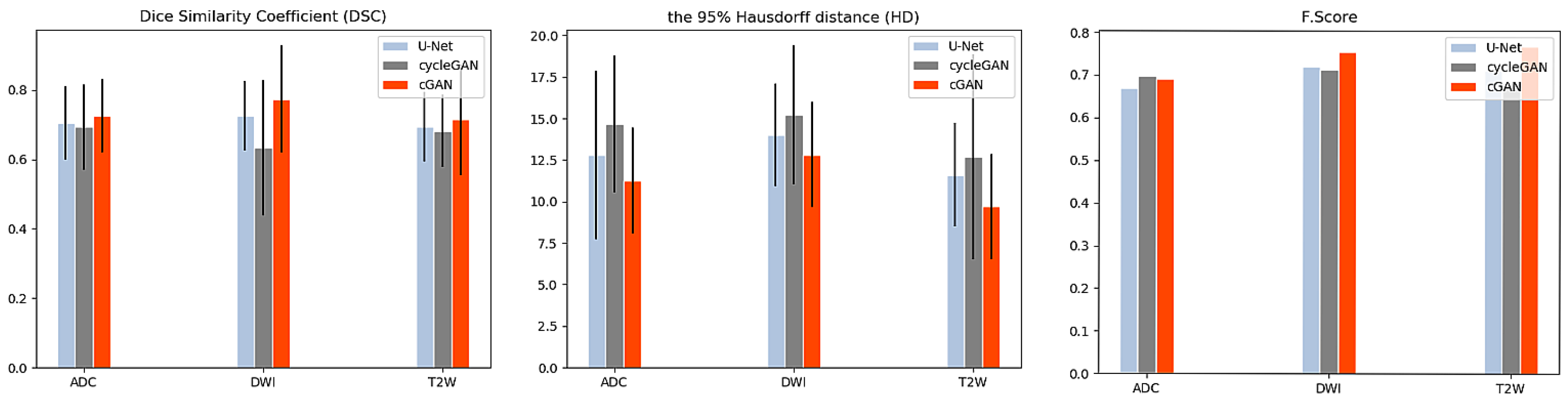
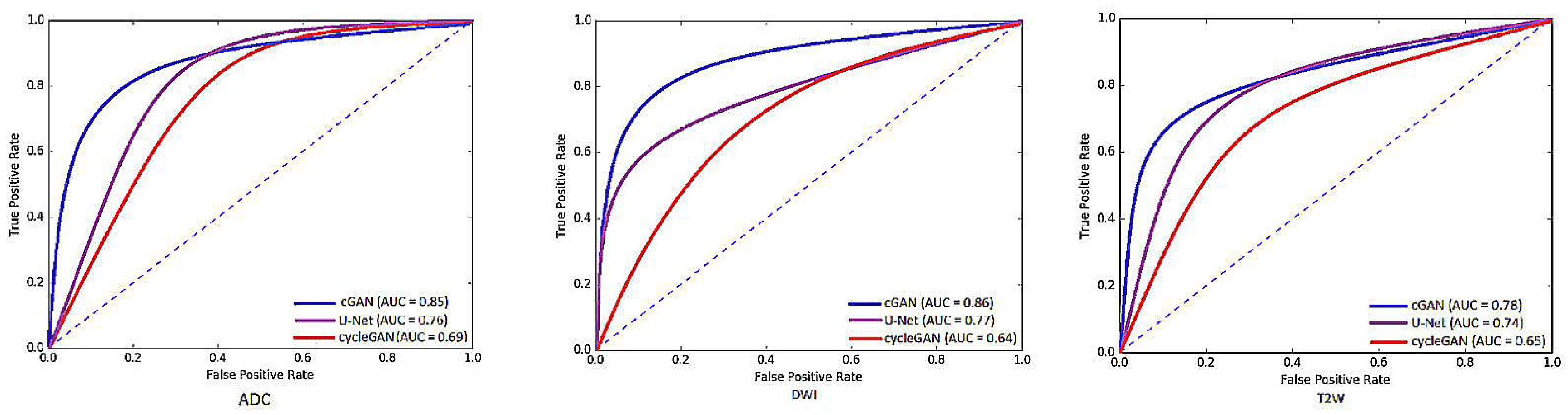
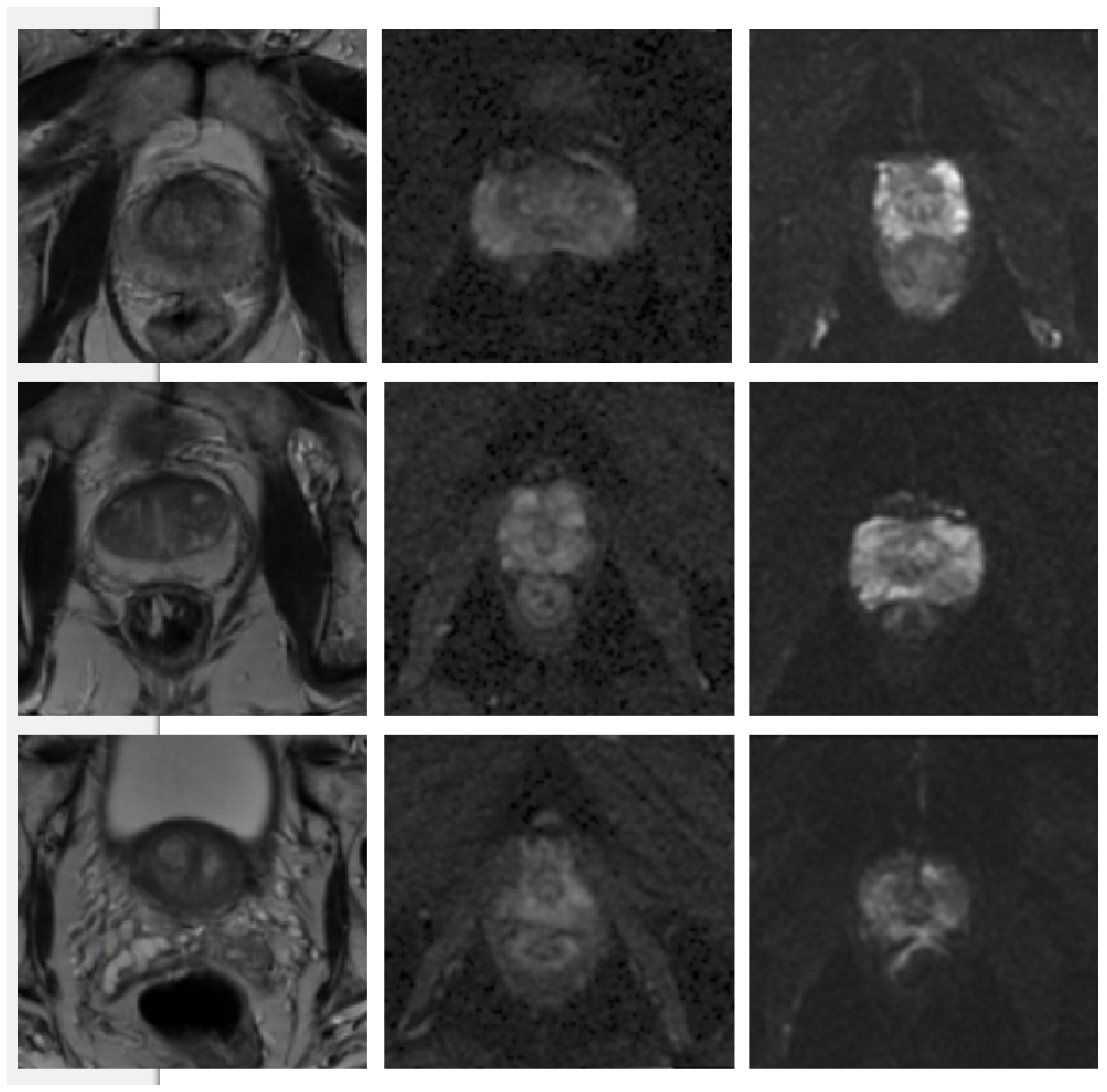
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


References
- Cancer-Research-UK. Prostate Cancer Statistics. 2018. Available online: https://www.cancerresearchuk.org/health-professional/cancer-statistics/statistics-by-cancer-type/prostate-cancer (accessed on 20 April 2020).
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CAA Cancer Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed]
- Stanzione, A.; Ponsiglione, A.; Di Fiore, G.A.; Picchi, S.G.; Di Stasi, M.; Verde, F.; Petretta, M.; Imbriaco, M.; Cuocolo, R. Prostate Volume Estimation on MRI: Accuracy and Effects of Ellipsoid and Bullet-Shaped Measurements on PSA Density. Acad. Radiol. 2020. [Google Scholar] [CrossRef] [PubMed]
- Grall, A.; Hamidinekoo, A.; Malcolm, P.; Zwiggelaar, R. Using a conditional Generative Adversarial Network (cGAN) for Prostate Segmentation. In Medical Image Understanding and Analysis (MIUA); Springer: Berlin, Germany, 2019; Volume 1065, pp. 15–25. [Google Scholar]
- Zhu, Y.; Williams, S.; Zwiggelaar, R. Computer technology in detection and staging of prostate carcinoma: A review. Med. Image Anal. 2006, 10, 178–199. [Google Scholar] [CrossRef] [PubMed]
- Cuocolo, R.; Cipullo, M.B.; Stanzione, A.; Ugga, L.; Romeo, V.; Radice, L.; Brunetti, A.; Imbriaco, M. Machine learning applications in prostate cancer magnetic resonance imaging. Eur. Radiol. Exp. 2019, 3, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Cuocolo, R.; Cipullo, M.B.; Stanzione, A.; Romeo, V.; Green, R.; Cantoni, V.; Ponsiglione, A.; Ugga, L.; Imbriaco, M. Machine learning for the identification of clinically significant prostate cancer on MRI: A meta-analysis. Eur. Radiol. 2020, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Comelli, A.; Stefano, A.; Coronnello, C.; Russo, G.; Vernuccio, F.; Cannella, R.; Salvaggio, G.; Lagalla, R.; Barone, S. Radiomics: A New Biomedical Workflow to Create a Predictive Model. In Annual Conference on Medical Image Understanding and Analysis; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1248, pp. 280–293. [Google Scholar]
- Zhu, Q.; Du, B.; Turkbey, B.; Choyke, P.L.; Yan, P. Deeply-supervised CNN for prostate segmentation. In Proceedings of the 2017 International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017; pp. 178–184. [Google Scholar]
- Yu, L.; Yang, X.; Chen, H.; Qin, J.; Heng, P.A. Volumetric convnets with mixed residual connections for automated prostate segmentation from 3D MR images. In Proceedings of the Thirty-First Association for the Advancement of Artificial Intelligence (AAAI) Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 17, pp. 35–73. [Google Scholar]
- Guo, Y.; Gao, Y.; Shen, D. Deformable MR prostate segmentation via deep feature learning and sparse patch matching. IEEE Trans. Med Imaging 2015, 35, 1077–1089. [Google Scholar] [CrossRef] [PubMed]
- Liao, S.; Gao, Y.; Oto, A.; Shen, D. Representation learning: A unified deep learning framework for automatic prostate MR segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8150, pp. 254–261. [Google Scholar]
- Kohl, S.; Bonekamp, D.; Schlemmer, H.P.; Yaqubi, K.; Hohenfellner, M.; Hadaschik, B.; Radtke, J.P.; Maier-Hein, K. Adversarial networks for the detection of aggressive prostate cancer. arXiv 2017, arXiv:1702.08014. [Google Scholar]
- Zabihollahy, F.; Schieda, N.; Krishna Jeyaraj, S.; Ukwatta, E. Automated segmentation of prostate zonal anatomy on T2-weighted (T2W) and apparent diffusion coefficient (ADC) map MR images using U-Nets. Med. Phys. 2019, 46, 3078–3090. [Google Scholar] [CrossRef] [PubMed]
- Cheng, R.; Lay, N.S.; Roth, H.R.; Turkbey, B.; Jin, D.; Gandler, W.; McCreedy, E.S.; Pohida, T.J.; Pinto, P.A.; Choyke, P.L.; et al. Fully automated prostate whole gland and central gland segmentation on MRI using holistically nested networks with short connections. J. Med. Imaging 2019, 6, 024007. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yang, L.; Zheng, H.; Liang, P.; Mangold, C.; Loreto, R.G.; Hughes, D.P.; Chen, D.Z. SPDA: Superpixel-based Data Augmentation for Biomedical Image Segmentation. arXiv 2019, arXiv:1903.00035. [Google Scholar]
- Tian, Z.; Liu, L.; Zhang, Z.; Fei, B. Superpixel-based segmentation for 3D prostate MR images. IEEE Trans. Med. Imaging 2015, 35, 791–801. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Greenshields, I.R. A nonlocal maximum likelihood estimation method for Rician noise reduction in MR images. IEEE Trans. Med. Imaging 2008, 28, 165–172. [Google Scholar]
- Chen, G.; Zhang, P.; Wu, Y.; Shen, D.; Yap, P.T. Denoising magnetic resonance images using collaborative non-local means. Neurocomputing 2016, 177, 215–227. [Google Scholar] [CrossRef] [PubMed]
- Cadzow, J.A.; Wilkes, D.M.; Peters, R.A.; Li, X. Image Texture synthesis-by-analysis using moving-average models. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 1110–1122. [Google Scholar] [CrossRef]
- Turkbey, B.; Rosenkrantz, A.B.; Haider, M.A.; Padhani, A.R.; Villeirs, G.; Macura, K.J.; Tempany, C.M.; Choyke, P.L.; Cornud, F.; Margolis, D.J.; et al. Prostate imaging reporting and data system version 2.1: 2019 update of prostate imaging reporting and data system version 2. Eur. Urol. 2019, 76, 340–351. [Google Scholar] [CrossRef] [PubMed]
- Junker, D.; Steinkohl, F.; Fritz, V.; Bektic, J.; Tokas, T.; Aigner, F.; Herrmann, T.R.; Rieger, M.; Nagele, U. Comparison of multiparametric and biparametric MRI of the prostate: Are gadolinium-based contrast agents needed for routine examinations? World J. Urol. 2019, 37, 691–699. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. Segan: Adversarial network with multi-scale l 1 loss for medical image segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef]
- Sonn, G.A.; Fan, R.E.; Ghanouni, P.; Wang, N.N.; Brooks, J.D.; Loening, A.M.; Daniel, B.L.; To’o, K.J.; Thong, A.E.; Leppert, J.T. Prostate magnetic resonance imaging interpretation varies substantially across radiologists. Eur. Urol. Focus 2019, 5, 592–599. [Google Scholar] [CrossRef]
- Litjens, G.; Toth, R.; van de Ven, W.; Hoeks, C.; Kerkstra, S.; van Ginneken, B.; Vincent, G.; Guillard, G.; Birbeck, N.; Zhang, J.; et al. Evaluation of prostate segmentation algorithms for MRI: The PROMISE12 challenge. Med. Image Anal. 2014, 18, 359–373. [Google Scholar] [CrossRef] [PubMed]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| cGAN Model | cycleGAN Model | ||||||
|---|---|---|---|---|---|---|---|
| Modality | Training Dataset | DSC | F.Score | DSC | F.Score | ||
| ADC | Raw | 0.715 ± 0.106 | 11.24 ± 2.07 | 0.692 | 0.693 ± 0.12 | 14.67 ± 7.02 | 0.697 |
| Raw + GNA | 0.802 ± 0.03 | 8.35 ± 2.12 | 0.807 | 0.759 ± 0.16 | 11.97 ± 5.62 | 0.796 | |
| Raw + SP | 0.786 ± 0.16 | 9.83 ± 8.11 | 0.759 | 0.710 ± 0.34 | 12.54 ± 6.31 | 0.772 | |
| Raw + MM | 0.763 ± 0.18 | 10.87 ± 6.80 | 0.782 | 0.735 ± 0.60 | 12.71 ± 6.00 | 0.726 | |
| Raw+SP+MM+GNA | 0.681 ± 0.25 | 12.56 ± 3.47 | 0.673 | 0.663 ± 0.18 | 14.96 ± 9.51 | 0.694 | |
| T2W | Raw | 0.701 ± 0.24 | 10.69 ± 4.02 | 0.761 | 0.689 ± 0.12 | 12.68 ± 4.67 | 0.682 |
| Raw + GNA | 0.789 ± 0.12 | 8.59 ± 2.26 | 0.804 | 0.704 ± 0.40 | 10.17 ± 3.67 | 0.701 | |
| Raw + SP | 0.720 ± 0.23 | 11.87 ± 5.00 | 0.71 | 0.748 ± 0.20 | 9.66 ± 4.28 | 0.749 | |
| Raw + MM | 0.713 ± 0.83 | 10.04 ± 3.84 | 0.642 | 0.713± 0.87 | 12.54 ± 4.19 | 0.719 | |
| Raw+SP+MM+GNA | 0.682 ± 0.45 | 11.87 ± 7.00 | 0.663 | 0.670± 0.76 | 13.02 ± 6.26 | 0.670 | |
| DWI | Raw | 0.764 ± 0.25 | 12.82 ± 9.89 | 0.754 | 0.633 ± 0.29 | 15.20 ± 8.06 | 0.714 |
| Raw + GNA | 0.787 ± 0.14 | 11.74 ± 5.22 | 0.795 | 0.729 ± 0.10 | 10.18 ± 7.04 | 0.730 | |
| Raw + SP | 0.765 ± 0.12 | 11.78 ± 8.27 | 0.802 | 0.702 ± 0.15 | 12.43 ± 3.96 | 0.766 | |
| Raw + MM | 0.825 ± 0.24 | 9.59 ± 2.12 | 0.838 | 0.761 ± 0.17 | 10.17 ± 2.16 | 0.784 | |
| Raw+SP+MM+GNA | 0.746 ± 0.17 | 11.93 ± 4.03 | 0.714 | 0.696 ± 0.13 | 11.16 ± 1.62 | 0.704 | |
| Reference | Deep Learning Base Methodology | Dataset | HD (mm) | DSC |
|---|---|---|---|---|
| Zhu et al. [9] | deeply-supervised CNN | National Cancer Institute, NIH, USA | - | 0.885 |
| Yu et al. [10] | Volumetric ConvNets | MICCAI PROMISE12 | 5.41 | 0.864 |
| Guo et al. [11] | deep feature learning & sparse patch matching | University of Chicago Hospital | 7.43 ± 2.82 pix | 0.87 ± 4.0 |
| Liao et al. [12] | stacked independent subspace analysis network | University of Chicago Hospital | 8.2 ± 2.5 | 0.86 ± 2.2 |
| Kohl et al. [13] | a simple generative model | National Center for Tumor Diseases, Germany | - | 0.41 ± 0.28 |
| Grall et al. [4] | conditional generative adversarial model | Norfolk&Norwich University Hospital | 6.58 ± 3.00 | 0.73 ± 0.16 |
| U-Net model used in this work | U-Net model | our private dataset (Section 2.1) | 6.11 ± 1.49 | 0.76 ± 0.10 |
| cycleGAN model used in this work | unpaired image-to-image translation(cycleGAN) | our private dataset (Section 2.1) | 6.63 ± 2.94 | 0.73 ± 0.20 |
| cGAN model used in this work | conditional GAN model | our private dataset (Section 2.1) | 5.90 ± 3.59 | 0.789 ± 0.12 |
| U-Net model used in this work | U-Net model | MICCAI PROMISE12 | 10.07 ± 0.95 pix | 0.72 ± 0.03 |
| cycleGAN model used in this work | unpaired image-to-image translation (cycleGAN) | MICCAI PROMISE12 | 11.02 ± 2.65 pix | 0.70 ± 3.41 |
| cGAN model used in this work | conditional GAN model | MICCAI PROMISE12 | 9.30 ± 2.6 pix | 0.757 ± 2.18 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cem Birbiri, U.; Hamidinekoo, A.; Grall, A.; Malcolm, P.; Zwiggelaar, R. Investigating the Performance of Generative Adversarial Networks for Prostate Tissue Detection and Segmentation. J. Imaging 2020, 6, 83. https://doi.org/10.3390/jimaging6090083
Cem Birbiri U, Hamidinekoo A, Grall A, Malcolm P, Zwiggelaar R. Investigating the Performance of Generative Adversarial Networks for Prostate Tissue Detection and Segmentation. Journal of Imaging. 2020; 6(9):83. https://doi.org/10.3390/jimaging6090083
Chicago/Turabian StyleCem Birbiri, Ufuk, Azam Hamidinekoo, Amélie Grall, Paul Malcolm, and Reyer Zwiggelaar. 2020. "Investigating the Performance of Generative Adversarial Networks for Prostate Tissue Detection and Segmentation" Journal of Imaging 6, no. 9: 83. https://doi.org/10.3390/jimaging6090083
APA StyleCem Birbiri, U., Hamidinekoo, A., Grall, A., Malcolm, P., & Zwiggelaar, R. (2020). Investigating the Performance of Generative Adversarial Networks for Prostate Tissue Detection and Segmentation. Journal of Imaging, 6(9), 83. https://doi.org/10.3390/jimaging6090083