A Survey of Computer Vision Methods for 2D Object Detection from Unmanned Aerial Vehicles






Abstract
1. Introduction
- an update of dominant literature aiming at performing object detection from UAV and aerial views;
- a taxonomy for the UAV based on the computer vision point of view, that considers how the same problem can drastically change when it is observed from a different perspective;
- a critical discussion of the actual state of the art, with particular attention to the impact of deep learning.
2. Background on UAVs
2.1. Sensors On-Board UAVs
- RGB cameras are passive sensors that capture the intensity information of the visual spectrum of light of the observed scene, using three different channels, i.e., Red, Green, and Blue. Main issues when mounted on-board of the UAV are the vehicle speed or sudden burst that can cause blur and noise in the image. At this purpose, global shutter cameras, with the peculiarity that the entire area of the image is scanned simultaneously instead of a scanning across the scene (either vertically or horizontally) as for the rolling shutter counterpart, are usually preferred [23]. Grayscale cameras provide only one single channel with the average intensity information of the visual spectrum of light of the observed scene.
- Event-based cameras, e.g., Dynamic Vision Sensor (DVS) in particular, are well-suited for the analysis of motion in real time motion, presenting higher temporal resolution and sensitivity to light and low latency. Recently, it has been used on-board of UAVs [24]. Their output, anyway, is not composed by classic intensity imaging, but from a sequence of asynchronous events, thus the necessity for further research and the design of new image processing pipelines is very actual topic [25].
- Thermal cameras are passive sensors that capture the infrared radiation emitted by all objects with a temperature above absolute zero (thermal radiation). If their application fields were initially limited to surveillance and night vision for military purposes, their recent drop in price opened up a broad field of applications [26]. In fact, thermal imaging can eliminate the illumination problems of normal grayscale and RGB cameras, providing a precise solution in all the domains where life must be detected and tracked, and UAV does not represent an exception [27].
- 3D Cameras can capture the scene providing color as well as 3D information. Presently, the three dominant technologies to build such cameras are stereo vision, time-of-flight (ToF) and structured light. For instance, commercial stereo cameras, i.e., the Stereolab ZED camera (https://www.stereolabs.com/), have been used for the UAV object detection problem [28]. Anyway, they are mostly based on triangulation, thus the presence of texture in the image is necessary to infer the depth information. With recent technological advancements, relatively small and low-cost off-the-shelf depth sensors based on structured light-like Microsoft Kinect ((https://developer.microsoft.com/en-us/windows/kinect/) [29]), ASUS Xtion Pro Live ((https://www.asus.com/us/3D-Sensor/Xtion_PRO_LIVE/) [30]) have been employed for object detection in UAV operations. Anyway, the aforementioned sensors are based on structured light, implying that they are sensitive to optical interference from the environment, thus more suited for indoor applications or controlled environments [31]. Finally, ToF cameras obtain the distance between the camera and the object, by measuring the time taken by projected infrared light to travel from the camera, bounce off the object surface, and return back to the sensor. They are becoming cheaper but are vulnerable to ambient light and UAV movements. Furthermore, they offer lower resolution than RGB sensors.
- LiDARs (Light Detection and Ranging), are active sensors that measure distances by hitting the target with laser light and measuring the reflection with a transducer. In former times, LiDARs were too large, heavy and costly to be used on-board UAVs, nevertheless, the recent advances on solid-state technologies, with examples as Ouster LiDARs (https://ouster.com/), have considerably reduced their size, weight, and cost, turning them into a growing popular choice on-board UAVs.
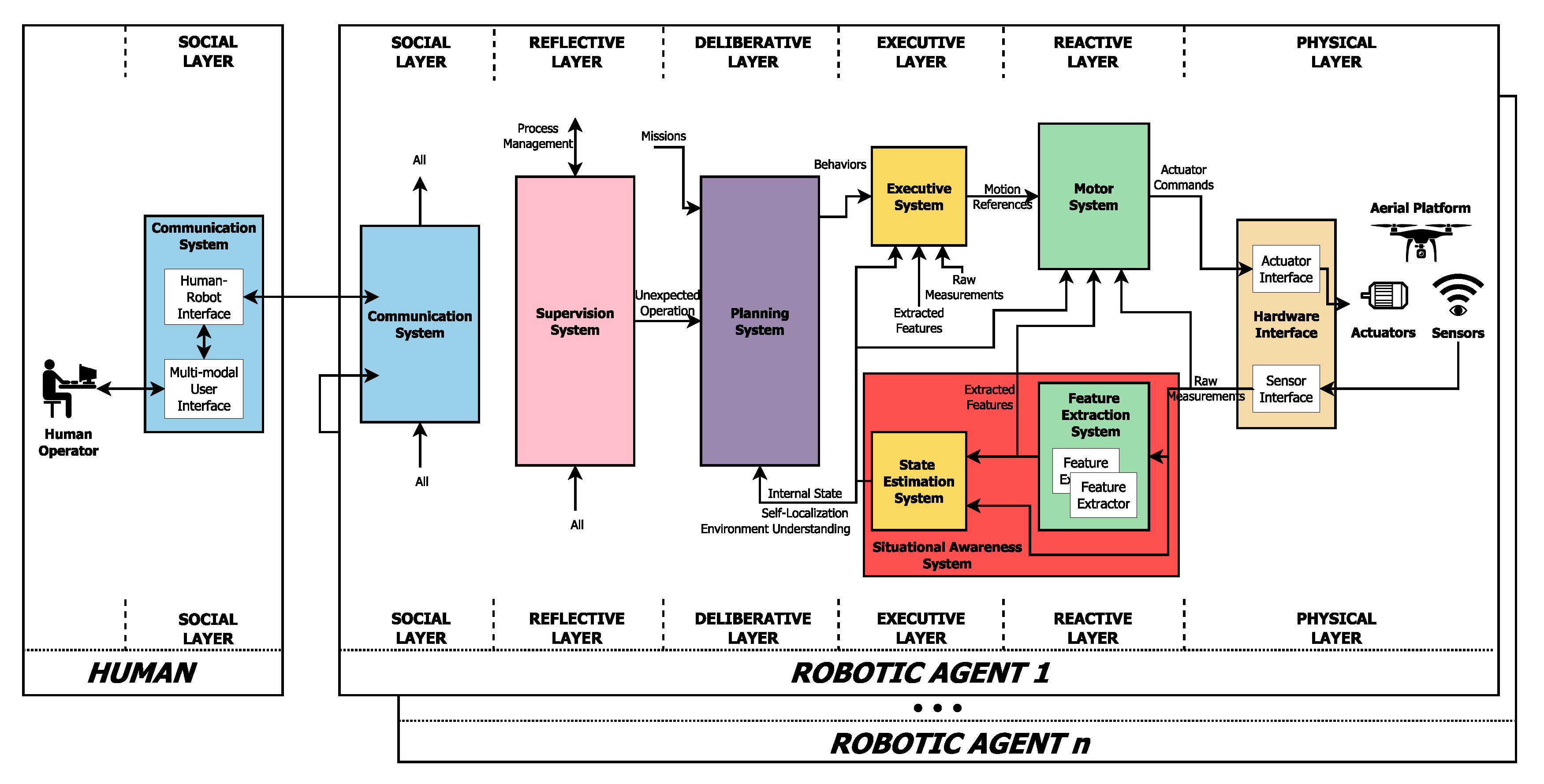
2.2. Autonomous Operation of UAVs: Situational Awareness
- Path planning or obstacle avoidance: consist on the generation of collision-free trajectories and motion commands based on the available knowledge of the existing obstacles of the environment [36]. Although it can be based on pure metric maps [43], its performance can be increased when having semantic information such as the kind of objects of the environment [44,45].

3. Definitions and Proposed Taxonomy
- Eye level view: this category corresponds to a flying height between 0 and 5 m.
- Low and medium heights: 5–120 m. It represents the interval with the majority of commercial and industrial applications. Its upper bound has also been fixed according to the EU rules and procedures for the operation of unmanned aircraft (https://eur-lex.europa.eu/eli/reg_impl/2019/947/oj).
- Aerial Imaging: ≥120 m. It corresponds to elevated heights for whom usually special permissions are required to capture data, and/or satellite imaging.
4. Object Detection Architectures
- R-CNN [65] (2014) is a two-stage object detector that introduced the search for possible object locations (region proposals) in the image using a selective search; for each proposal, the features were extracted separately by the network, at the cost of high computational load.
- Faster R-CNN [66] (2015) increased speed of R-CNN taking the entire image as input instead of using a CNN for each region proposals introducing RoI pooling layers, improving both accuracy and speed.
- Mask R-CNN [67] (2017) extended Faster R-CNN, adding a branch for predicting also the object mask in parallel with the bounding box recognition.
- YOLO [68] (2016) is a one-step object detector that drastically improving computing speed. Like Faster R-CNN, YOLO uses a single feature map to detect objects, but the image is divided into a grid where the objects are searched. From the first version of YOLO, many further improvements have been proposed, leading to different YOLO versions [69].
- Feature Pyramid Network (FPN) [70] (2017) has turned out to be fundamental for the correct identification of objects at different scales. This concept has been proposed numerous times along with light or more radical modifications since its publication so that it can be considered to be a structural component of modern object detectors. Pointedly, in the original FPN version, a top-down path is linked with lateral connections with the usual bottom-up feed-forward pathway to output multi-scale prediction in correspondence to the multi-resolution feature maps.
- SqueezeNet [71] introduces a new building block, called the fire module, which is composed by a convolutional layer to reduce the number of channels with the minimum number of parameters (hence the name squeeze) followed by a mix of and convolutions forming the expand block that increases again the depth dimension. Additionally, this module is combined with the design decision of delayed down-sampling, by which the feature maps resolution is decreased later in the network to improve accuracy.
- SqueezeNext represents an upgrade of the aforementioned network [72]: the authors reduce the depth to a quarter by using two bottleneck layers. Furthermore, through a separable convolution, they swipe over the width and the height of the feature maps in other two consecutive layers before expanding again the channels with a convolution. Finally, a skip connection is added to learn a residual with respect to the initial values.
- ShuffleNet [73] makes use of group convolution in the bottleneck layer to reduce the number of parameters. Noticing that the output would depend only on one group of input channels group convolutions, a mechanism to break this relation is under the form of a shuffling operation, which is feasible by simply rearranging the order of the output tensor dimensions. Nevertheless,
- Ma et al. [74] argue that the memory access cost of the group convolution would surpass the benefits of the reduced floating points operations (FLOPS) version, and consequently, proposed a second version of the shufflenet architecture based on empirically established guidelines to reduce computation time. In this regard, with ShuffleNetV2, the authors introduce the channel split operator that branches the initial channels in two equal parts, one of which remains as identity and is concatenated at the end to restore the total number of channels. Hence, the group convolutions are substituted with normal point-wise convolutions and the channel shuffle operation of the original model is replicated after the concatenation of the two branches to allow information exchange.
- MobileNet [75] is built upon the concept of depthwise separable convolutions, first introduced by [76] and popularised by the Xception network [77]. This computation module consists of one first layer of kernels that operates on each input channel independently, the depth-wise convolution, followed by a second, the point-wise, that combines the intermediate feature maps through a convolution. Additionally, MobileNet has a hyperparameter, named width multiplier, to control the number of output channel at the end of each block and the total number of parameters.
- MobileNetV2 [78] adds linear bottleneck layers at the end of the separable convolutions to create what the authors call inverted residual block since the skip connection with the identity feature maps is performed when the network shrinks the number of channels. The intuition of the authors is that ReLU non-linearity can preserve the information manifold contained in the channels when it lies in a low-dimensional subspace of the input.
- Neural Architecture Search (NAS) is a novel prolific field whose purpose is to use search algorithms, usually either Reinforcement Learning or Evolutionary optimization methods, to find a combination of modules that obtains an optimal trade-off between latency and accuracy. For instance, the optimization metric could be specified in the form of a Pareto multi-objective function as demonstrated in MnasNet [79]. FBNet [80], ChamNet [81], and MobilenetV3 [82] are other examples of successive contributions to mobile network architecture search. The reader can refer to [83,84] for a thorough analysis of this technique.
- EfficientNet [85] improves the ability of manually tuning the model complexity letting the users choose the desired trade-off between efficiency and accuracy. Pointedly, the authors propose a compound scaling hyperparameter that tunes the network depth, i.e., the number of layers or blocks, the width, i.e., the number of channels, and the input image size, which influences the inner feature maps’ resolution, all at once in an optimal way. This scaling method follows from the observation that the network’s dimensions are not independently influencing the latency-accuracy trade-off. Finally, this novel scaling concept is applied to a baseline network found by taking advantage of the multi-objective optimization and search space specified in MnasNet.
- Parameter Pruning is a technique principally meant to reduce the memory footprint of a neural network by reducing the redundant connections. In general, single weights, group of neurons, or whole convolutional filter can be removed improving also the inference time. As a side-effect, this operation impacts the accuracy of the model, thus requiring an iterative process composed of pruning and network re-tuning steps. Additionally, the resulting models are generally sparse and require specialized hardware and software to not lose the advantage over the unpruned dense counterparts.
- Quantization cuts the number of multiply-adds operations and the memory storage by changing the number of bits used to represent weights. Since 16, 8, or 4 bits are more commonly used, for the special case of 1-bit quantization we refer to weight binarization. Additionally, weight sharing is a related concept that indicates the technique of clustering groups of weights that fall into an interval and to assign them a single common value.
- Knowledge Distillation has the objective of transferring the knowledge embodied into large state-of-the-art models to lighter networks, which would have the advantage of retaining the generalization capabilities while being faster. This technique can be coupled with quantization where a “teacher” network would use full-precision representation for the weights and the lighter “student” network is, for example, binarized. However, applying this method to tasks other than image classification, where the compressed model learns to mimic the class logits from the teacher, is more challenging. In this regard, the work in Chen et al. [88] shows how to generalize this technique to object detection by exploiting the teacher regression loss relative to the bounding boxes’ coordinates as an upper bound.
- Low-rank Factorization replaces weight matrices with a smaller dimensional version using matrix factorization algorithms. For instance, Singular Value Decomposition can be applied to perform a low-rank factorization that approximate the original model parameters by retaining the top k eigenvalues of the weight matrix.
5. Eye Level View
5.1. Human-Drone Interaction
5.2. Indoor Navigation
5.3. Datasets
6. Low and Medium Heights
6.1. Search and Rescue
6.2. Crowd Analysis and Monitoring
6.3. Datasets
7. Aerial Imaging
7.1. Vehicle Detection
7.2. Maps Labelling–Semantic Land Classification
7.3. Datasets
8. Discussion
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| FAST | Features from Accelerated Segment Test |
| FPN | Feature Pyramid Network |
| GCS | Ground Control Station |
| GPS | Global Positioning System |
| GPU | Graphics Processing Unit |
| IMU | Inertial Measurement Unit |
| INS | Inertial Navigation System |
| LiDAR | Light Detection and Ranging |
| LSH | Locality-Sensitive Hashing |
| mAP | mean Average Precision |
| ReLU | Rectified Linear Unit |
| RP | Relaxed Precision |
| RPA | Remotely Piloted Aircraft |
| RPAS | Remotely Piloted Aerial System |
| UAV | Unmanned Aerial Vehicle |
| UAS | Unmanned Aerial System |
References
- Walia, K. VTOL UAV Market 2025 Research Report—Industry Size & Share; Value Market Research: Maharashtra, India, 2019. [Google Scholar]
- PricewaterhouseCoopers (PwC). Skies without Limits–Drones-Taking the UK’s Economy to New Heights; PwC: London, UK, 2018. [Google Scholar]
- Undertaking, S.J. European Drones Outlook Study—Unlocking the Value for Europe; SESAR: Brussels, Belgium, 2016. [Google Scholar]
- Valavanis, K.P. Advances in Unmanned Aerial Vehicles: State of the Art and the Road to Autonomy; Springer Science & Business Media: Cham, Switzerland, 2008; Volume 33. [Google Scholar]
- Lu, Y.; Xue, Z.; Xia, G.S.; Zhang, L. A survey on vision-based UAV navigation. Geo-Spat. Inf. Sci. 2018, 21, 21–32. [Google Scholar] [CrossRef]
- Kanellakis, C.; Nikolakopoulos, G. Survey on computer vision for UAVs: Current developments and trends. J. Intell. Robot. Syst. 2017, 87, 141–168. [Google Scholar] [CrossRef]
- Roberts, L.G. Machine perception of three-dimensional soups. Mass. Inst. Technol. 1963, 2017. [Google Scholar]
- Papert, S.A. The Summer Vision Project; Massachusetts Institute of Technology: Cambridge, MA, USA, 1966. [Google Scholar]
- Al-Kaff, A.; Martin, D.; Garcia, F.; de la Escalera, A.; Armingol, J.M. Survey of computer vision algorithms and applications for unmanned aerial vehicles. Expert Syst. Appl. 2018, 92, 447–463. [Google Scholar] [CrossRef]
- Zhao, J.; Xiao, G.; Zhang, X.; Bavirisetti, D.P. A Survey on Object Tracking in Aerial Surveillance. In Proceedings of the International Conference on Aerospace System Science and Engineering, Shanghai, China, 31 July–2 August 2018; pp. 53–68. [Google Scholar]
- Xu, Y.; Pan, L.; Du, C.; Li, J.; Jing, N.; Wu, J. Vision-based uavs aerial image localization: A survey. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, Seattle, WA, USA, 6 November 2018; pp. 9–18. [Google Scholar]
- Carrio, A.; Sampedro, C.; Rodriguez-Ramos, A.; Campoy, P. A review of deep learning methods and applications for unmanned aerial vehicles. J. Sensors 2017, 2017, 1–13. [Google Scholar] [CrossRef]
- Nikolakopoulos, K.G.; Soura, K.; Koukouvelas, I.K.; Argyropoulos, N.G. UAV vs classical aerial photogrammetry for archaeological studies. J. Archaeol. Sci. Rep. 2017, 14, 758–773. [Google Scholar] [CrossRef]
- Hoskere, V.; Park, J.W.; Yoon, H.; Spencer Jr, B.F. Vision-based modal survey of civil infrastructure using unmanned aerial vehicles. J. Struct. Eng. 2019, 145, 04019062. [Google Scholar] [CrossRef]
- Karantanellis, E.; Marinos, V.; Vassilakis, E.; Christaras, B. Object-Based Analysis Using Unmanned Aerial Vehicles (UAVs) for Site-Specific Landslide Assessment. Remote Sens. 2020, 12, 1711. [Google Scholar] [CrossRef]
- Tsokos, A.; Kotsi, E.; Petrakis, S.; Vassilakis, E. Combining series of multi-source high spatial resolution remote sensing datasets for the detection of shoreline displacement rates and the effectiveness of coastal zone protection measures. J. Coast. Conserv. 2018, 22, 431–441. [Google Scholar] [CrossRef]
- Valavanis, K.P.; Vachtsevanos, G.J. Handbook of Unmanned Aerial Vehicles; Springer: Cham, Switzerland, 2015; Volume 1, pp. 83–91. [Google Scholar]
- Commission Directive (EU) 2019/514 of 14 March 2019 Amending Directive 2009/43/EC of the European Parliament and of the Council as Regards the List of Defence-Related Products (Text with EEA Relevance). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=uriserv:OJ.L_.2019.089.01.0001.01.ENG (accessed on 17 July 2020).
- Siciliano, B.; Khatib, O. Springer Handbook of Robotics; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Commission Implementing Regulation (EU) 2019/947 of 24 May 2019 on the Rules and Procedures for the Operation of Unmanned Aircraft (Text with EEA Relevance). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:02019R0947-20200606 (accessed on 17 July 2020).
- Cuerno-Rejado, C.; García-Hernández, L.; Sánchez-Carmona, A.; Carrio, A.; Sánchez-López, J.L.; Campoy, P. Historical Evolution of the Unmanned Aerial Vehicles to the Present. DYNA 2016, 91, 282–288. [Google Scholar]
- Dalamagkidis, K. Classification of UAVs. In Handbook of Unmanned Aerial Vehicles; Valavanis, K.P., Vachtsevanos, G.J., Eds.; Springer: Dordrecht, The Netherlands, 2015; pp. 83–91. [Google Scholar] [CrossRef]
- Baca, T.; Stepan, P.; Saska, M. Autonomous landing on a moving car with unmanned aerial vehicle. In Proceedings of the 2017 European Conference on Mobile Robots (ECMR), Paris, France, 6–8 September 2017; pp. 1–6. [Google Scholar]
- Mitrokhin, A.; Fermüller, C.; Parameshwara, C.; Aloimonos, Y. Event-based moving object detection and tracking. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Afshar, S.; Ralph, N.; Xu, Y.; Tapson, J.; Schaik, A.v.; Cohen, G. Event-based feature extraction using adaptive selection thresholds. Sensors 2020, 20, 1600. [Google Scholar] [CrossRef] [PubMed]
- Gade, R.; Moeslund, T.B. Thermal cameras and applications: A survey. Mach. Vis. Appl. 2014, 25, 245–262. [Google Scholar] [CrossRef]
- Portmann, J.; Lynen, S.; Chli, M.; Siegwart, R. People detection and tracking from aerial thermal views. In Proceedings of the 2014 IEEE international conference on robotics and automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 1794–1800. [Google Scholar]
- Ramon Soria, P.; Arrue, B.C.; Ollero, A. Detection, location and grasping objects using a stereo sensor on uav in outdoor environments. Sensors 2017, 17, 103. [Google Scholar] [CrossRef] [PubMed]
- Mashood, A.; Noura, H.; Jawhar, I.; Mohamed, N. A gesture based kinect for quadrotor control. In Proceedings of the 2015 International Conference on Information and Communication Technology Research (ICTRC), Abu Dhabi, UAE, 17–19 May 2015; pp. 298–301. [Google Scholar]
- Yu, Y.; Wang, X.; Zhong, Z.; Zhang, Y. ROS-based UAV control using hand gesture recognition. In Proceedings of the 2017 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 6795–6799. [Google Scholar]
- Shao, L.; Han, J.; Kohli, P.; Zhang, Z. Computer Vision and Machine Learning with RGB-D Sensors; Springer: Cham, Switzerland, 2014; Volume 20. [Google Scholar]
- Hall, D.L.; McMullen, S.A. Mathematical Techniques in Multisensor Data Fusion; Artech House: Norwood, MA, USA, 2004. [Google Scholar]
- Sanchez-Lopez, J.L.; Arellano-Quintana, V.; Tognon, M.; Campoy, P.; Franchi, A. Visual marker based multi-sensor fusion state estimation. IFAC-PapersOnLine 2017, 50, 16003–16008. [Google Scholar] [CrossRef]
- Sanchez-Lopez, J.L.; Molina, M.; Bavle, H.; Sampedro, C.; Fernández, R.A.S.; Campoy, P. A multi-layered component-based approach for the development of aerial robotic systems: The aerostack framework. J. Intell. Robot. Syst. 2017, 88, 683–709. [Google Scholar] [CrossRef]
- Endsley, M.R. Toward a theory of situation awareness in dynamic systems. Hum. Factors 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Rosinol, A.; Gupta, A.; Abate, M.; Shi, J.; Carlone, L. 3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans. arXiv 2020, arXiv:2002.06289. [Google Scholar]
- Bavle, H.; De La Puente, P.; How, J.P.; Campoy, P. VPS-SLAM: Visual Planar Semantic SLAM for Aerial Robotic Systems. IEEE Access 2020, 8, 60704–60718. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, L.; Shen, P.; Wei, W.; Zhu, G.; Song, J. Semantic SLAM based on object detection and improved octomap. IEEE Access 2018, 6, 75545–75559. [Google Scholar] [CrossRef]
- Manzoor, S.; Joo, S.H.; Rocha, Y.G.; Lee, H.U.; Kuc, T.Y. A Novel Semantic SLAM Framework for Humanlike High-Level Interaction and Planning in Global Environment. In Proceedings of the 1st International Workshop on the Semantic Descriptor, Semantic Modeling and Mapping for Humanlike Perception and Navigation of Mobile Robots toward Large Scale Long-Term Autonomy (SDMM1), Macau, China, 4–8 November 2019. [Google Scholar]
- Sanchez-Lopez, J.L.; Sampedro, C.; Cazzato, D.; Voos, H. Deep learning based semantic situation awareness system for multirotor aerial robots using LIDAR. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 899–908. [Google Scholar]
- Sanchez-Lopez, J.L.; Castillo-Lopez, M.; Voos, H. Semantic situation awareness of ellipse shapes via deep learning for multirotor aerial robots with a 2D LIDAR. In Proceedings of the 2020 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 9–12 June 2020; pp. 1–10. [Google Scholar]
- Lin, Y.; Saripalli, S. Sampling-based path planning for UAV collision avoidance. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3179–3192. [Google Scholar] [CrossRef]
- Sanchez-Lopez, J.L.; Wang, M.; Olivares-Mendez, M.A.; Molina, M.; Voos, H. A real-time 3d path planning solution for collision-free navigation of multirotor aerial robots in dynamic environments. J. Intell. Robot. Syst. 2019, 93, 33–53. [Google Scholar] [CrossRef]
- Castillo-Lopez, M.; Ludivig, P.; Sajadi-Alamdari, S.A.; Sanchez-Lopez, J.L.; Olivares-Mendez, M.A.; Voos, H. A Real-Time Approach for Chance-Constrained Motion Planning With Dynamic Obstacles. IEEE Robot. Autom. Lett. 2020, 5, 3620–3625. [Google Scholar] [CrossRef]
- Pestana, J.; Sanchez-Lopez, J.L.; Saripalli, S.; Campoy, P. Computer vision based general object following for gps-denied multirotor unmanned vehicles. In Proceedings of the 2014 American Control Conference, Portland, OR, USA, 4–6 June 2014; pp. 1886–1891. [Google Scholar]
- Pestana, J.; Sanchez-Lopez, J.L.; Campoy, P.; Saripalli, S. Vision based gps-denied object tracking and following for unmanned aerial vehicles. In Proceedings of the 2013 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Linköping, Sweden, 21–26 October 2013; pp. 1–6. [Google Scholar]
- Koga, Y.; Miyazaki, H.; Shibasaki, R. A Method for Vehicle Detection in High-Resolution Satellite Images that Uses a Region-Based Object Detector and Unsupervised Domain Adaptation. Remote Sens. 2020, 12, 575. [Google Scholar] [CrossRef]
- Redding, J.D.; McLain, T.W.; Beard, R.W.; Taylor, C.N. Vision-based target localization from a fixed-wing miniature air vehicle. In Proceedings of the 2006 American Control Conference, Minneapolis, MN, USA, 14–16 June 2006; p. 6. [Google Scholar]
- Semsch, E.; Jakob, M.; Pavlicek, D.; Pechoucek, M. Autonomous UAV surveillance in complex urban environments. In Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Milan, Italy, 15–18 September 2009; Volume 2, pp. 82–85. [Google Scholar]
- Nikolic, J.; Burri, M.; Rehder, J.; Leutenegger, S.; Huerzeler, C.; Siegwart, R. A UAV system for inspection of industrial facilities. In Proceedings of the 2013 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2013; pp. 1–8. [Google Scholar]
- Sankey, T.; Donager, J.; McVay, J.; Sankey, J.B. UAV lidar and hyperspectral fusion for forest monitoring in the southwestern USA. Remote Sens. Environ. 2017, 195, 30–43. [Google Scholar] [CrossRef]
- Cazzato, D.; Olivares-Mendez, M.A.; Sanchez-Lopez, J.L.; Voos, H. Vision-Based Aircraft Pose Estimation for UAVs Autonomous Inspection without Fiducial Markers. In Proceedings of the IECON 2019—45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; Volume 1, pp. 5642–5648. [Google Scholar]
- Andreopoulos, A.; Tsotsos, J.K. 50 years of object recognition: Directions forward. Comput. Vis. Image Underst. 2013, 117, 827–891. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Ponce, J.; Hebert, M.; Schmid, C.; Zisserman, A. Toward Category-Level Object Recognition; Springer: Cham, Switzerland, 2007; Volume 4170. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Wang, R.; Xu, J.; Han, T.X. Object instance detection with pruned Alexnet and extended training data. Signal Process. Image Commun. 2019, 70, 145–156. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I-I. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Zhao, S.; Keutzer, K. Squeezenext: Hardware-aware neural network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1638–1647. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sifre, L. Rigid-Motion Scattering for Image Classification. Ph.D. Thesis, École Polytechnique, Palaiseau, France, 2014. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10734–10742. [Google Scholar]
- Dai, X.; Zhang, P.; Wu, B.; Yin, H.; Sun, F.; Wang, Y.; Dukhan, M.; Hu, Y.; Wu, Y.; Jia, Y.; et al. Chamnet: Towards efficient network design through platform-aware model adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11398–11407. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 1314–1324. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. arXiv 2018, arXiv:1808.05377. [Google Scholar]
- Wistuba, M.; Rawat, A.; Pedapati, T. A survey on neural architecture search. arXiv 2019, arXiv:1905.01392. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. A survey of model compression and acceleration for deep neural networks. arXiv 2017, arXiv:1710.09282. [Google Scholar]
- Choudhary, T.; Mishra, V.; Goswami, A.; Sarangapani, J. A comprehensive survey on model compression and acceleration. Artif. Intel. Rev. 2020, 1–43. [Google Scholar] [CrossRef]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2017; pp. 742–751. [Google Scholar]
- Al-Kaff, A.; García, F.; Martín, D.; De La Escalera, A.; Armingol, J.M. Obstacle detection and avoidance system based on monocular camera and size expansion algorithm for UAVs. Sensors 2017, 17, 1061. [Google Scholar] [CrossRef]
- Lv, Q.; Josephson, W.; Wang, Z.; Charikar, M.; Li, K. Multi-probe LSH: Efficient indexing for high-dimensional similarity search. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 950–961. [Google Scholar]
- Hesch, J.A.; Roumeliotis, S.I. A direct least-squares (DLS) method for PnP. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 383–390. [Google Scholar]
- Aguilar, W.G.; Luna, M.A.; Moya, J.F.; Abad, V.; Parra, H.; Ruiz, H. Pedestrian detection for UAVs using cascade classifiers with meanshift. In Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 30 January–1 February 2017; pp. 509–514. [Google Scholar]
- De Smedt, F.; Hulens, D.; Goedemé, T. On-board real-time tracking of pedestrians on a UAV. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–8. [Google Scholar]
- Peng, X.Z.; Lin, H.Y.; Dai, J.M. Path planning and obstacle avoidance for vision guided quadrotor UAV navigation. In Proceedings of the 2016 12th IEEE International Conference on Control and Automation (ICCA), Kathmandu, Nepal, 1–3 June 2016; pp. 984–989. [Google Scholar]
- McGuire, K.; De Croon, G.; De Wagter, C.; Tuyls, K.; Kappen, H. Efficient optical flow and stereo vision for velocity estimation and obstacle avoidance on an autonomous pocket drone. IEEE Robot. Autom. Lett. 2017, 2, 1070–1076. [Google Scholar] [CrossRef]
- Lee, J.; Wang, J.; Crandall, D.; Šabanović, S.; Fox, G. Real-time, cloud-based object detection for unmanned aerial vehicles. In Proceedings of the 2017 First IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 10–12 April 2017; pp. 36–43. [Google Scholar]
- Smolyanskiy, N.; Kamenev, A.; Smith, J.; Birchfield, S. Toward low-flying autonomous MAV trail navigation using deep neural networks for environmental awareness. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4241–4247. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Schmidhuber, J.; Huber, R. Learning to generate artificial fovea trajectories for target detection. Int. J. Neural Syst. 1991, 2, 125–134. [Google Scholar] [CrossRef]
- Loquercio, A.; Maqueda, A.I.; Del-Blanco, C.R.; Scaramuzza, D. Dronet: Learning to fly by driving. IEEE Robot. Autom. Lett. 2018, 3, 1088–1095. [Google Scholar] [CrossRef]
- Dai, X.; Mao, Y.; Huang, T.; Qin, N.; Huang, D.; Li, Y. Automatic Obstacle Avoidance of Quadrotor UAV via CNN-based Learning. Neurocomputing 2020, 402, 346–358. [Google Scholar] [CrossRef]
- Wojciechowska, A.; Frey, J.; Sass, S.; Shafir, R.; Cauchard, J.R. Collocated human-drone interaction: Methodology and approach strategy. In Proceedings of the 2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Daegu, Korea, 11–14 March 2019; pp. 172–181. [Google Scholar]
- Monajjemi, M.; Bruce, J.; Sadat, S.A.; Wawerla, J.; Vaughan, R. UAV, do you see me? Establishing mutual attention between an uninstrumented human and an outdoor UAV in flight. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 3614–3620. [Google Scholar]
- Karjalainen, K.D.; Romell, A.E.S.; Ratsamee, P.; Yantac, A.E.; Fjeld, M.; Obaid, M. Social drone companion for the home environment: A user-centric exploration. In Proceedings of the 5th International Conference on Human Agent Interaction, Bielefeld, Germany, 17–20 October 2017; pp. 89–96. [Google Scholar]
- Arroyo, D.; Lucho, C.; Roncal, S.J.; Cuellar, F. Daedalus: A sUAV for human-robot interaction. In Proceedings of the 2014 ACM/IEEE International Conference on Human-Robot Interaction, Bielefeld, Germany, 3–6 March 2014; pp. 116–117. [Google Scholar]
- Cauchard, J.R.; Zhai, K.Y.; Spadafora, M.; Landay, J.A. Emotion encoding in human-drone interaction. In Proceedings of the 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Christchurch, New Zealand, 7–10 March 2016; pp. 263–270. [Google Scholar]
- Leo, M.; Carcagnì, P.; Mazzeo, P.L.; Spagnolo, P.; Cazzato, D.; Distante, C. Analysis of Facial Information for Healthcare Applications: A Survey on Computer Vision-Based Approaches. Information 2020, 11, 128. [Google Scholar] [CrossRef]
- Perera, A.G.; Wei Law, Y.; Chahl, J. UAV-GESTURE: A dataset for UAV control and gesture recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chéron, G.; Laptev, I.; Schmid, C. P-cnn: Pose-based cnn features for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3218–3226. [Google Scholar]
- Fernandez, R.A.S.; Sanchez-Lopez, J.L.; Sampedro, C.; Bavle, H.; Molina, M.; Campoy, P. Natural user interfaces for human-drone multi-modal interaction. In Proceedings of the 2016 International Conference on Unmanned Aircraft Systems (ICUAS), Arlington, VA, USA, 7–10 June 2016; pp. 1013–1022. [Google Scholar]
- Bruce, J.; Perron, J.; Vaughan, R. Ready—aim—fly! hands-free face-based HRI for 3D trajectory control of UAVs. In Proceedings of the 2017 14th Conference on Computer and Robot Vision (CRV), Edmonton, AB, Canada, 16–19 May 2017; pp. 307–313. [Google Scholar]
- Nagi, J.; Giusti, A.; Di Caro, G.A.; Gambardella, L.M. Human control of UAVs using face pose estimates and hand gestures. In Proceedings of the 2014 9th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Bielefeld, Germany, 3–6 March 2014; pp. 1–2. [Google Scholar]
- Nagi, J.; Giusti, A.; Gambardella, L.M.; Di Caro, G.A. Human-swarm interaction using spatial gestures. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 3834–3841. [Google Scholar]
- Obaid, M.; Kistler, F.; Kasparavičiūtė, G.; Yantaç, A.E.; Fjeld, M. How would you gesture navigate a drone? A user-centered approach to control a drone. In Proceedings of the 20th International Academic Mindtrek Conference, Tampere, Finland, 17–18 October 2016; pp. 113–121. [Google Scholar]
- Cauchard, J.R.; E, J.L.; Zhai, K.Y.; Landay, J.A. Drone & me: An exploration into natural human-drone interaction. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 361–365. [Google Scholar]
- Davis, N.; Pittaluga, F.; Panetta, K. Facial recognition using human visual system algorithms for robotic and UAV platforms. In Proceedings of the 2013 IEEE Conference on Technologies for Practical Robot Applications (TePRA), Woburn, MA, USA, 22–23 April 2013; pp. 1–5. [Google Scholar]
- Nousi, P.; Tefas, A. Discriminatively trained autoencoders for fast and accurate face recognition. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Athens, Greece, 25–27 August 2017; pp. 205–215. [Google Scholar]
- Hsu, H.J.; Chen, K.T. Face recognition on drones: Issues and limitations. In Proceedings of the First Workshop on Micro Aerial Vehicle Networks, Systems, and Applications for Civilian Use, Florence, Italy, 18 May 2015; pp. 39–44. [Google Scholar]
- Li, Y.; Scanavino, M.; Capello, E.; Dabbene, F.; Guglieri, G.; Vilardi, A. A novel distributed architecture for UAV indoor navigation. Transp. Res. Procedia 2018, 35, 13–22. [Google Scholar] [CrossRef]
- Mori, T.; Scherer, S. First results in detecting and avoiding frontal obstacles from a monocular camera for micro unmanned aerial vehicles. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1750–1757. [Google Scholar]
- Hamledari, H.; McCabe, B.; Davari, S. Automated computer vision-based detection of components of under-construction indoor partitions. Autom. Constr. 2017, 74, 78–94. [Google Scholar] [CrossRef]
- Loquercio, A.; Kaufmann, E.; Ranftl, R.; Dosovitskiy, A.; Koltun, V.; Scaramuzza, D. Deep drone racing: From simulation to reality with domain randomization. IEEE Trans. Robot. 2019, 36, 1–14. [Google Scholar] [CrossRef]
- Hsu, H.J.; Chen, K.T. DroneFace: An open dataset for drone research. In Proceedings of the 8th ACM on Multimedia Systems Conference, Taipei, Taiwan, 20–23 June 2017; pp. 187–192. [Google Scholar]
- Kalra, I.; Singh, M.; Nagpal, S.; Singh, R.; Vatsa, M.; Sujit, P. Dronesurf: Benchmark dataset for drone-based face recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–7. [Google Scholar]
- Perera, A.G.; Law, Y.W.; Chahl, J. Drone-Action: An Outdoor Recorded Drone Video Dataset for Action Recognition. Drones 2019, 3, 82. [Google Scholar] [CrossRef]
- Leo, M.; Furnari, A.; Medioni, G.G.; Trivedi, M.; Farinella, G.M. Deep learning for assistive computer vision. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8311–8320. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density Map Guided Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 28 March 2020; pp. 190–191. [Google Scholar]
- Zhou, J.; Vong, C.M.; Liu, Q.; Wang, Z. Scale adaptive image cropping for UAV object detection. Neurocomputing 2019, 366, 305–313. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Zhang, P.; Zhong, Y.; Li, X. SlimYOLOv3: Narrower, faster and better for real-time UAV applications. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhao, H.; Zhou, Y.; Zhang, L.; Peng, Y.; Hu, X.; Peng, H.; Cai, X. Mixed YOLOv3-LITE: A lightweight real-time object detection method. Sensors 2020, 20, 1861. [Google Scholar] [CrossRef]
- Pedoeem, J.; Huang, R. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Jabari, S.; Fathollahi, F.; Zhang, Y. Application of Sensor Fusion to Improve Uav Image Classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 153. [Google Scholar] [CrossRef]
- Ki, M.; Cha, J.; Lyu, H. Detect and avoid system based on multi sensor fusion for UAV. In Proceedings of the 2018 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 17–19 October 2018; pp. 1107–1109. [Google Scholar]
- Półka, M.; Ptak, S.; Kuziora, Ł. The use of UAV’s for search and rescue operations. Procedia Eng. 2017, 192, 748–752. [Google Scholar] [CrossRef]
- Tijtgat, N.; Van Ranst, W.; Goedeme, T.; Volckaert, B.; De Turck, F. Embedded real-time object detection for a UAV warning system. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2110–2118. [Google Scholar]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Lygouras, E.; Gasteratos, A.; Tarchanidis, K.; Mitropoulos, A. ROLFER: A fully autonomous aerial rescue support system. Microprocess. Microsyst. 2018, 61, 32–42. [Google Scholar] [CrossRef]
- Lygouras, E.; Santavas, N.; Taitzoglou, A.; Tarchanidis, K.; Mitropoulos, A.; Gasteratos, A. Unsupervised Human Detection with an Embedded Vision System on a Fully Autonomous UAV for Search and Rescue Operations. Sensors 2019, 19, 3542. [Google Scholar] [CrossRef]
- Sun, J.; Li, B.; Jiang, Y.; Wen, C.y. A camera-based target detection and positioning UAV system for search and rescue (SAR) purposes. Sensors 2016, 16, 1778. [Google Scholar] [CrossRef]
- Ahmed, A.; Nagai, M.; Tianen, C.; Shibasaki, R. UAV based monitoring system and object detection technique development for a disaster area. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 373–377. [Google Scholar]
- Doherty, P.; Rudol, P. A UAV search and rescue scenario with human body detection and geolocalization. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Gold Coast, Australia, 2–6 December 2007; pp. 1–13. [Google Scholar]
- Rudol, P.; Doherty, P. Human body detection and geolocalization for UAV search and rescue missions using color and thermal imagery. In Proceedings of the 2008 IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2008; pp. 1–8. [Google Scholar]
- Motlagh, N.H.; Bagaa, M.; Taleb, T. UAV-based IoT platform: A crowd surveillance use case. IEEE Commun. Mag. 2017, 55, 128–134. [Google Scholar] [CrossRef]
- Qazi, S.; Siddiqui, A.S.; Wagan, A.I. UAV based real time video surveillance over 4G LTE. In Proceedings of the 2015 International Conference on Open Source Systems & Technologies (ICOSST), Florence, Italy, 16–17 May 2015; pp. 141–145. [Google Scholar]
- Gu, J.; Su, T.; Wang, Q.; Du, X.; Guizani, M. Multiple moving targets surveillance based on a cooperative network for multi-UAV. IEEE Commun. Mag. 2018, 56, 82–89. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep people counting in extremely dense crowds. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1299–1302. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Almagbile, A. Estimation of crowd density from UAVs images based on corner detection procedures and clustering analysis. Geo-Spat. Inf. Sci. 2019, 22, 23–34. [Google Scholar] [CrossRef]
- Bansal, A.; Venkatesh, K. People counting in high density crowds from still images. arXiv 2015, arXiv:1507.08445. [Google Scholar]
- Shami, M.B.; Maqbool, S.; Sajid, H.; Ayaz, Y.; Cheung, S.C.S. People counting in dense crowd images using sparse head detections. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2627–2636. [Google Scholar] [CrossRef]
- Basalamah, S.; Khan, S.D.; Ullah, H. Scale driven convolutional neural network model for people counting and localization in crowd scenes. IEEE Access 2019, 7, 71576–71584. [Google Scholar] [CrossRef]
- Huynh, V.S.; Tran, V.H.; Huang, C.C. Iuml: Inception U-Net Based Multi-Task Learning For Density Level Classification And Crowd Density Estimation. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3019–3024. [Google Scholar]
- Chandra, R.; Bhattacharya, U.; Bera, A.; Manocha, D. DensePeds: Pedestrian Tracking in Dense Crowds Using Front-RVO and Sparse Features. arXiv 2019, arXiv:1906.10313. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition loss for counting, density map estimation and localization in dense crowds. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 532–546. [Google Scholar]
- Singh, A.; Patil, D.; Omkar, S. Eye in the sky: Real-time Drone Surveillance System (DSS) for violent individuals identification using ScatterNet Hybrid Deep Learning network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1629–1637. [Google Scholar]
- Perera, A.G.; Law, Y.W.; Ogunwa, T.T.; Chahl, J. A Multiviewpoint Outdoor Dataset for Human Action Recognition. IEEE Trans. Hum. Mach. Syst. 2020. [Google Scholar] [CrossRef]
- Tripathi, G.; Singh, K.; Vishwakarma, D.K. Convolutional neural networks for crowd behaviour analysis: A survey. Vis. Comput. 2019, 35, 753–776. [Google Scholar] [CrossRef]
- Bour, P.; Cribelier, E.; Argyriou, V. Crowd behavior analysis from fixed and moving cameras. In Multimodal Behavior Analysis in the Wild; Elsevier: Amsterdam, The Netherlands, 2019; pp. 289–322. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 445–461. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Ling, H.; Hu, Q.; Nie, Q.; Cheng, H.; Liu, C.; Liu, X.; et al. Visdrone-det2018: The vision meets drone object detection in image challenge results. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhu, P.; Du, D.; Wen, L.; Bian, X.; Ling, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-VID2019: The Vision Meets Drone Object Detection in Video Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 227–235. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning social etiquette: Human trajectory understanding in crowded scenes. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 549–565. [Google Scholar]
- Bozcan, I.; Kayacan, E. AU-AIR: A Multi-Modal Unmanned Aerial Vehicle Dataset for Low Altitude Traffic Surveillance. Available online: http://xxx.lanl.gov/abs/2001.11737 (accessed on 3 August 2020).
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Hirzer, M.; Beleznai, C.; Roth, P.M.; Bischof, H. Person re-identification by descriptive and discriminative classification. In Proceedings of the Scandinavian Conference on Image Analysis, Ystad, Sweden, 23–27 May 2011; pp. 91–102. [Google Scholar]
- Layne, R.; Hospedales, T.M.; Gong, S. Investigating open-world person re-identification using a drone. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 225–240. [Google Scholar]
- Kumar, S.; Yaghoubi, E.; Das, A.; Harish, B.; Proença, H. The P-DESTRE: A Fully Annotated Dataset for Pedestrian Detection, Tracking, Re-Identification and Search from Aerial Devices. arXiv 2020, arXiv:2004.02782. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Patt. Anal. Mach. Intel. 2020. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Zheng, K.; Wei, M.; Sun, G.; Anas, B.; Li, Y. Using vehicle synthesis generative adversarial networks to improve vehicle detection in remote sensing images. ISPRS Int. J. Geo-Inf. 2019, 8, 390. [Google Scholar] [CrossRef]
- Lin, H.; Zhou, J.; Gan, Y.; Vong, C.M.; Liu, Q. Novel Up-scale Feature Aggregation for Object Detection in Aerial Images. Neurocomputing 2020, 411, 364–374. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed]
- Cheng, H.Y.; Weng, C.C.; Chen, Y.Y. Vehicle detection in aerial surveillance using dynamic Bayesian networks. IEEE Trans. Image Process. 2011, 21, 2152–2159. [Google Scholar] [CrossRef] [PubMed]
- Gleason, J.; Nefian, A.V.; Bouyssounousse, X.; Fong, T.; Bebis, G. Vehicle detection from aerial imagery. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2065–2070. [Google Scholar]
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 3286–3293. [Google Scholar]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Vehicle detection in satellite images by hybrid deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Sommer, L.W.; Schuchert, T.; Beyerer, J. Fast deep vehicle detection in aerial images. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 311–319. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Liu, K.; Mattyus, G. Fast multiclass vehicle detection on aerial images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 210–223. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road extraction from high-resolution remote sensing imagery using refined deep residual convolutional neural network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Pesaresi, M.; Amason, K. Classification and feature extraction for remote sensing images from urban areas based on morphological transformations. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1940–1949. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R. A multiple conditional random fields ensemble model for urban area detection in remote sensing optical images. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3978–3988. [Google Scholar] [CrossRef]
- Kovács, A.; Szirányi, T. Improved harris feature point set for orientation-sensitive urban-area detection in aerial images. IEEE Geosci. Remote Sens. Lett. 2012, 10, 796–800. [Google Scholar] [CrossRef]
- Harris, C.G.; Stephens, M. A combined corner and edge detector. In Alvey Vision Conference; University of Manchester: Manchester, UK, 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Manno-Kovacs, A.; Sziranyi, T. Orientation-selective building detection in aerial images. ISPRS J. Photogramm. Remote Sens. 2015, 108, 94–112. [Google Scholar] [CrossRef]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imaging 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Hayrapetyan, N.; Hakobyan, R.; Poghosyan, A.; Gabrielyan, V. Border Surveillance Using UAVs with Thermal Camera. In Meeting Security Challenges Through Data Analytics and Decision Support; IOS Press: Amsterdam, The Netherlands, 2016; pp. 219–225. [Google Scholar]
- Byerlay, R.A.; Nambiar, M.K.; Nazem, A.; Nahian, M.R.; Biglarbegian, M.; Aliabadi, A.A. Measurement of land surface temperature from oblique angle airborne thermal camera observations. Int. J. Remote Sens. 2020, 41, 3119–3146. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A large contextual dataset for classification, detection and counting of cars with deep learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 785–800. [Google Scholar]
- Andriluka, M.; Roth, S.; Schiele, B. People-tracking-by-detection and people-detection-by-tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Liew, C.F.; Yairi, T. Companion Unmanned Aerial Vehicles: A Survey. arXiv 2020, arXiv:2001.04637. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Taxonomy | Method | Object Detection Network | Metric (mAP) | Objects Size | Dataset |
|---|---|---|---|---|---|
| Eye Level | [89] (2017) | handcrafted features | 97.4% | 8500–200,000 pixels | own data |
| [92] (2017) | handcrafted features | 76.97% Sensitivity | - | CICTE-PeopleDetection | |
| Eye Level/Low-Medium | [124] (2019) | Tiny Face | 96.5% Precision | 5–25 pixels inter eye | DroneSURF active |
| [142] (2019) | Tiny YOLOV3 | 67% | - | Swimmers | |
| [142] (2019) | SSD MobileNetV2 | 21% | |||
| Low-Medium | [165] (2019) | CornerNet | 17.41% | 3–355,432 pixels | Visdrone test |
| [165] (2019) | Light-Head R-CNN | 16.53% | |||
| [165] (2019) | FPN | 16.51% | |||
| [167] (2018) | R-FCN | 34.35% | 29–131,803 pixels | UAVDT | |
| [167] (2018) | SSD | 33.62% | |||
| [167] (2018) | Faster R-CNN | 22.32% | |||
| [169] (2020) | Tiny YOLOV3 | 30.22% | 9–2,046,720 pixels | AU-AIR | |
| [169] (2020) | SSDLite MobileNetV2 | 19.50% | |||
| Aerial | [183] (2017) | Fast R-CNN | 95.2% | 12.5 cmpp | VEDAI 1024 |
| [183] (2017) | Fast R-CNN | 91.4% | 15 cmpp | DLR 3K | |
| [184] (2017) | AVPN + R-CNN | 87.81% | |||
| [178] (2017) | Hyper R-CNN | 89.2% | |||
| [186] (2015) | AlexNet + SVM | 94.5% | 15 cmpp | Google Earth aerial images | |
| [189] (2018) | deep residual U-Net | 91.87% RP (roads) | 1.2 mpp | URBAN | |
| [191] (2019) | RDRCNN + post proc. | 99.9% (roads) | |||
| [197] (2016) | CNN | 92.30% (buildings) |
| Dataset | Taxonomy | Task | Heights Range | # Images | Resolution | Notes |
|---|---|---|---|---|---|---|
| CICTE-PeopleDetection [92] | Eye Level | Pedestrian Detection | 2.3–5 m | 43K+ | emulates UAV with videos from 100 surveillance cameras | |
| DroneSURF [124] | Eye Level/Low-Medium | Face Detection and Recognition | n.d. | 411K+ | DJI Phantom 4; 58 subjects with more than 786K face annotations | |
| Swimmers [142] | Eye Level/Low-Medium | People (Swimmers) Detection | n.d. | 9000 | mix of labeled internet pictures with images from a UAV flying over the sea shore | |
| UAV123 [163] | Low-Medium | Object Detection and Tracking | 5–25 m | 110K+ | additional scenes taken from a simulation from Unreal4 Game Engine | |
| Visdrone [164] | Low-Medium | Object Detection | various heights | 8599 | wide-range of flight height and viewpoint; huge number of labeled bounding boxes (540K) | |
| UAVDT [167] | Low-Medium | Object Detection | 10–70+ m | 80K | labeled weather conditions; wide-range of flight height; 3 camera views | |
| P-DESTRE [173] | Low-Medium | Pedestrian Detection, Tracking and Re-Identification | 5.5–6.7 m | n.d. | DJI Phantom 4; 269 identities with 16 biometrics labels | |
| Stanford Campus [168] | Low-Medium | Object Tracking and Trajectory Forecasting | ~80 m | 920K+ | 3DR SOLO; annotated interactions between targets and space | |
| AU-AIR [169] | Low-Medium | Object Detection | 10–30 m | 32K+ | Parrot Bepop2; multi-modal, contains GPS, Altitude, Velocity, IMU, and Time | |
| DOTA [200] | Aerial | Object Detection | n.d. | 2806 | – | collected from Google Earth and other aerial photography platforms; 15 object categories, from vehicles to field types and buildings |
| DLR 3K [185] | Aerial | Vehicle Detection | 1000+ m | 20 | DLR 3K camera system: three Canon 1Ds Mark II on-board of Dornier DO 228 or a Cessna 208B Grand Caravan; only 3418 cars and 54 trucks labels | |
| VEDAI [201] | Aerial | Vehicle Detection | n.d. | 1210 | , | collected from Utah AGRC (http://gis.utah.gov/) aerial photography set; RGB plus near infrared channel; 9 vehicle classes |
| DIOR [175] | Aerial | Object Detection | n.d. | 23K+ | collected from Google Earth; labeled with 20 object categories | |
| COWC [202] | Aerial | Car Detection | n.d. | 388K+ | six aerial photography sets from different regions in the world (Germany, New Zealand, USA, Canada); more than 30k unique cars annotated | |
| URBAN [188] | Aerial | Buildings and Roads Detection | n.d. | 1322 | mostly urban and suburban areas and buildings of all sizes, including individual houses and garages |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cazzato, D.; Cimarelli, C.; Sanchez-Lopez, J.L.; Voos, H.; Leo, M. A Survey of Computer Vision Methods for 2D Object Detection from Unmanned Aerial Vehicles. J. Imaging 2020, 6, 78. https://doi.org/10.3390/jimaging6080078
Cazzato D, Cimarelli C, Sanchez-Lopez JL, Voos H, Leo M. A Survey of Computer Vision Methods for 2D Object Detection from Unmanned Aerial Vehicles. Journal of Imaging. 2020; 6(8):78. https://doi.org/10.3390/jimaging6080078
Chicago/Turabian StyleCazzato, Dario, Claudio Cimarelli, Jose Luis Sanchez-Lopez, Holger Voos, and Marco Leo. 2020. "A Survey of Computer Vision Methods for 2D Object Detection from Unmanned Aerial Vehicles" Journal of Imaging 6, no. 8: 78. https://doi.org/10.3390/jimaging6080078
APA StyleCazzato, D., Cimarelli, C., Sanchez-Lopez, J. L., Voos, H., & Leo, M. (2020). A Survey of Computer Vision Methods for 2D Object Detection from Unmanned Aerial Vehicles. Journal of Imaging, 6(8), 78. https://doi.org/10.3390/jimaging6080078