Image Processing Technique and Hidden Markov Model for an Elderly Care Monitoring System



Abstract
:1. Introduction
- Develop a monitoring system that provides a visual understanding of a person’s situation and can judge whether the state is abnormal or normal based on video data acquired using a simple and affordable RGB camera;
- Develop an individualized and modified statistical analysis on each of the extracted features, providing trustworthy information, not only on the definite moment of a fall, but also on the period of a fall;
- Develop an efficient way of using a Hidden Markov Model (HMM) for the detailed detection of sequential abnormal and normal states for the person being monitored.
2. Related Works
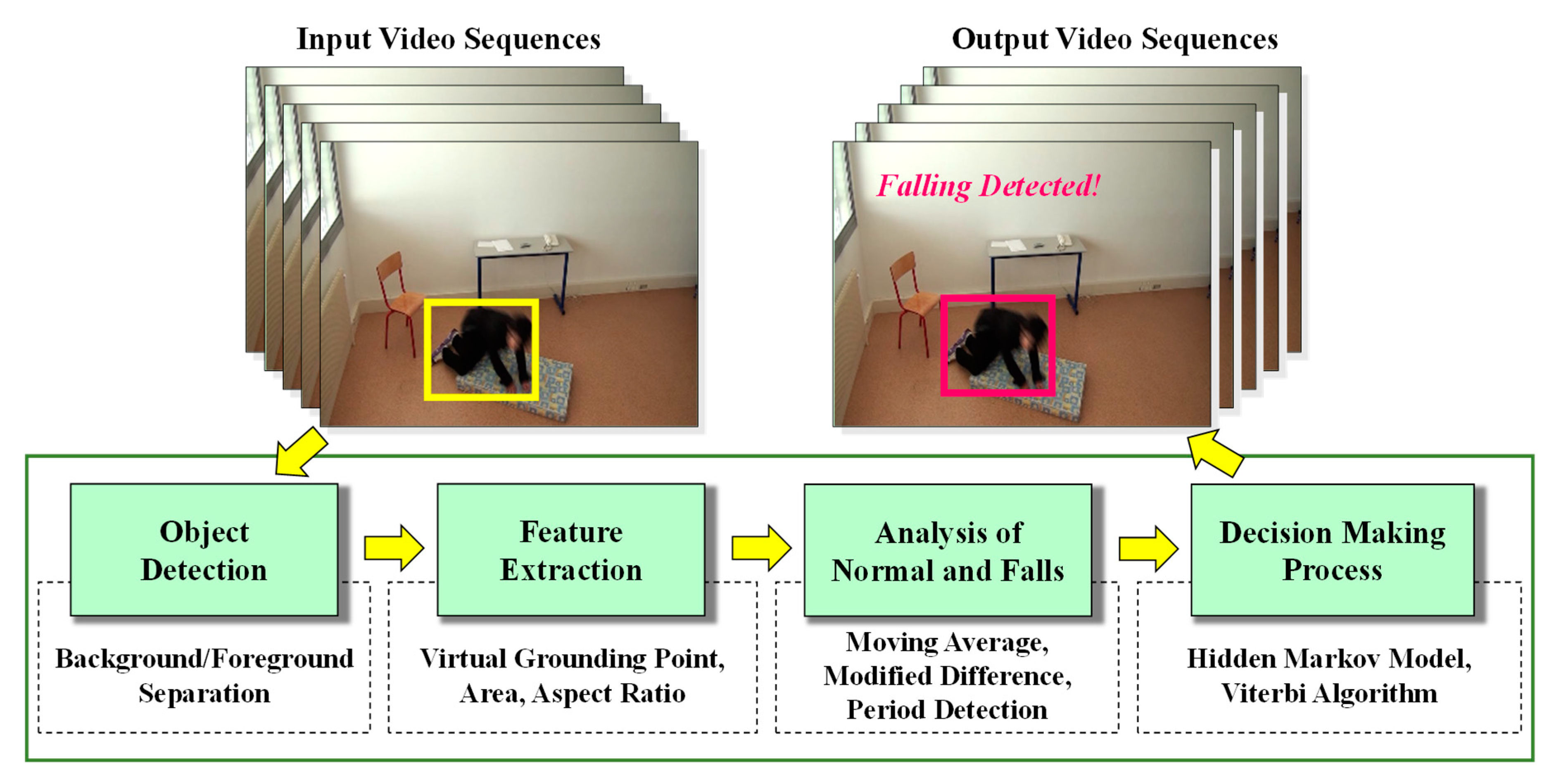
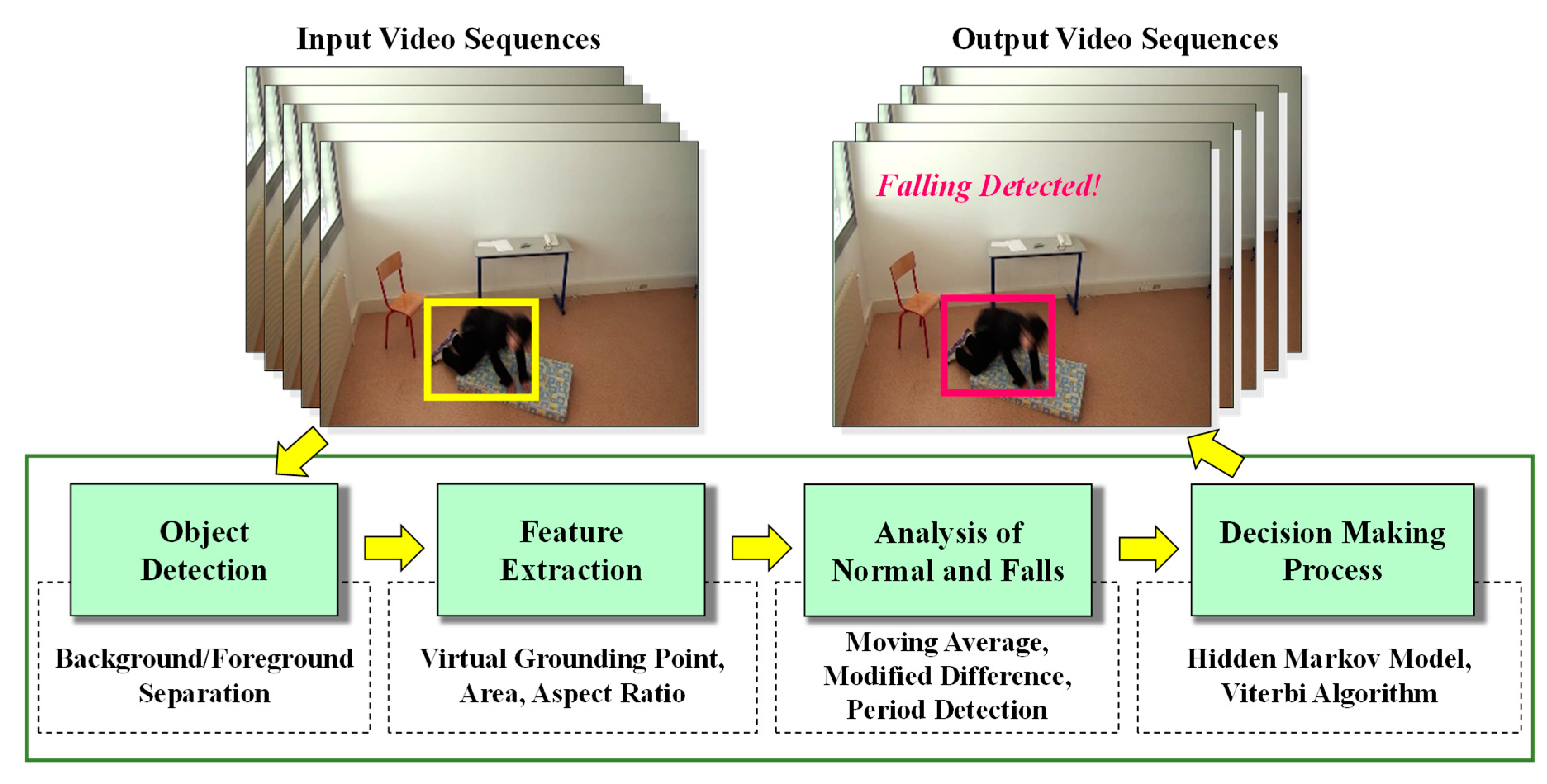
3. Proposed Architecture of the System
3.1. Object Detection
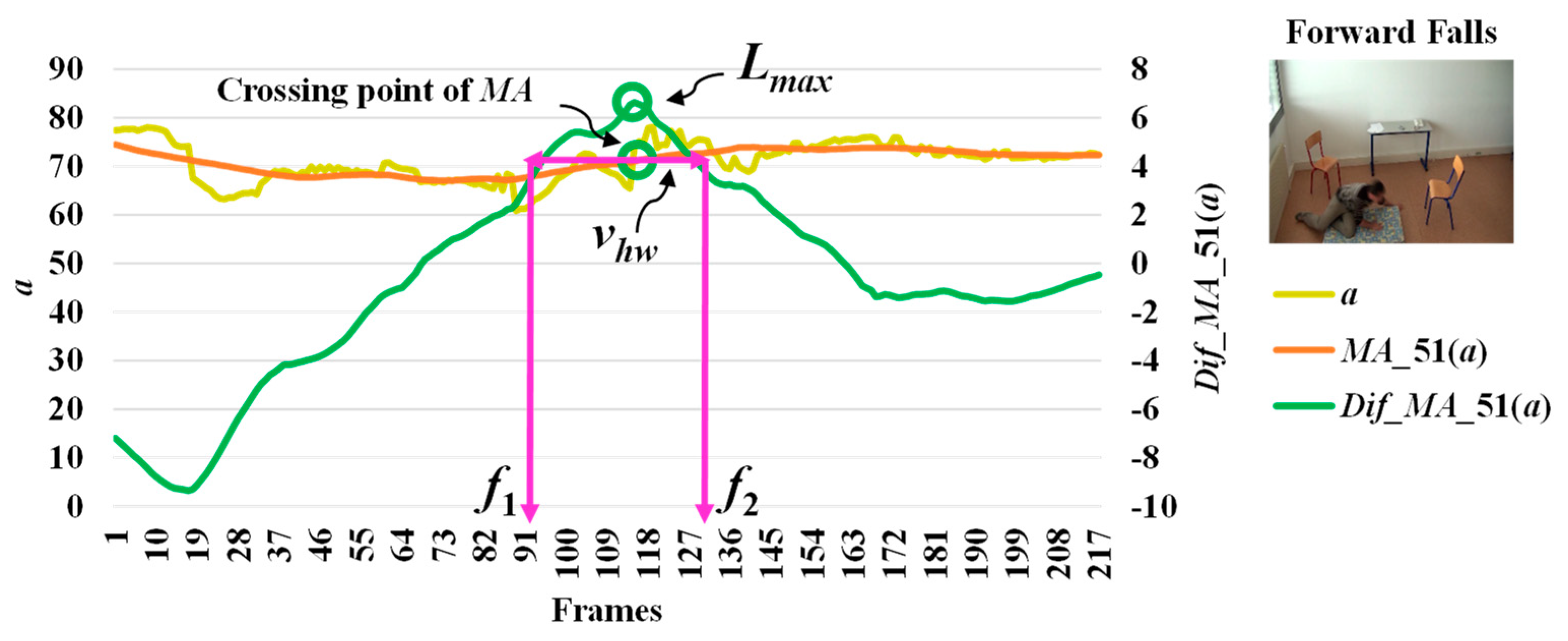
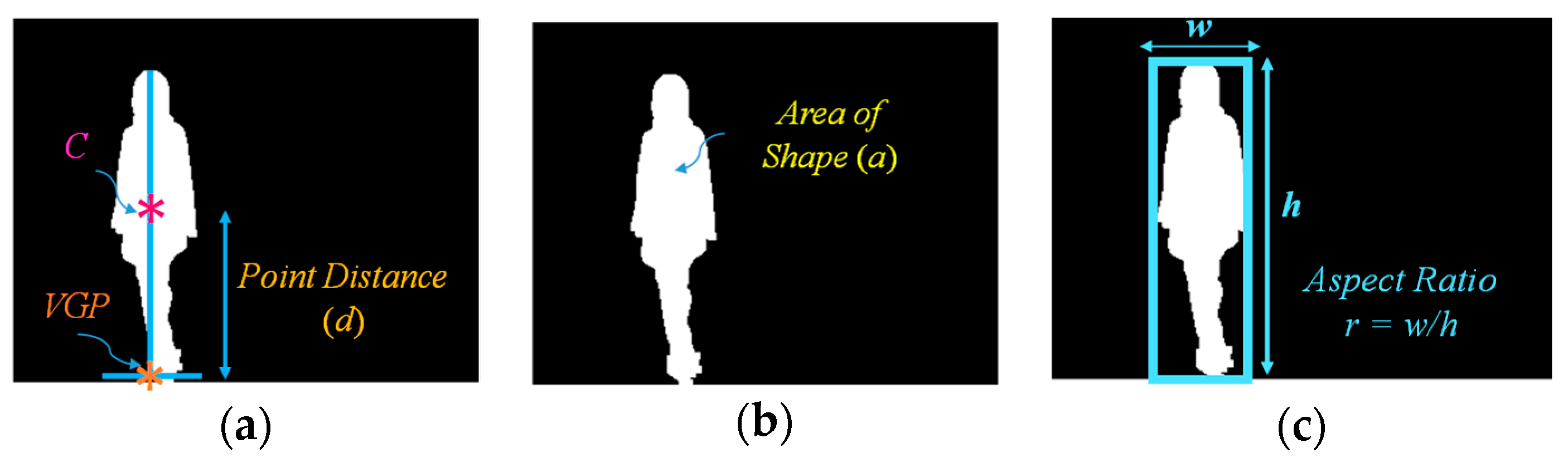
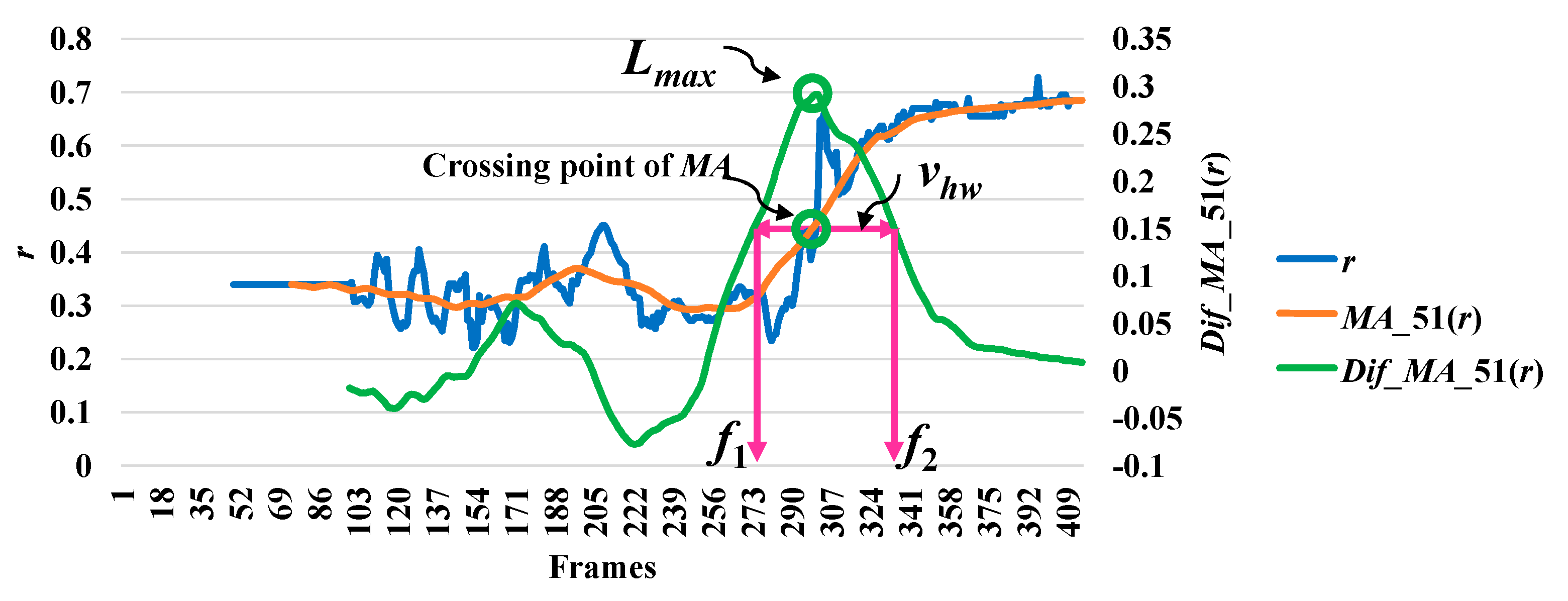
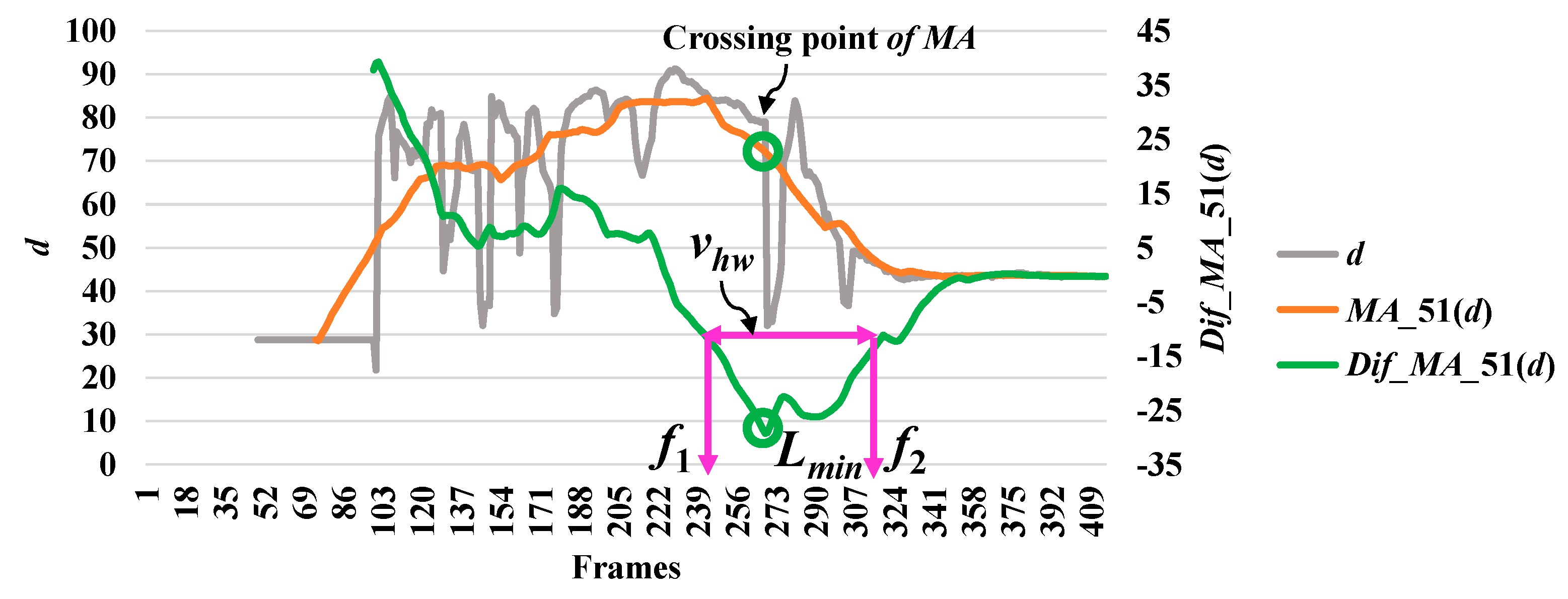
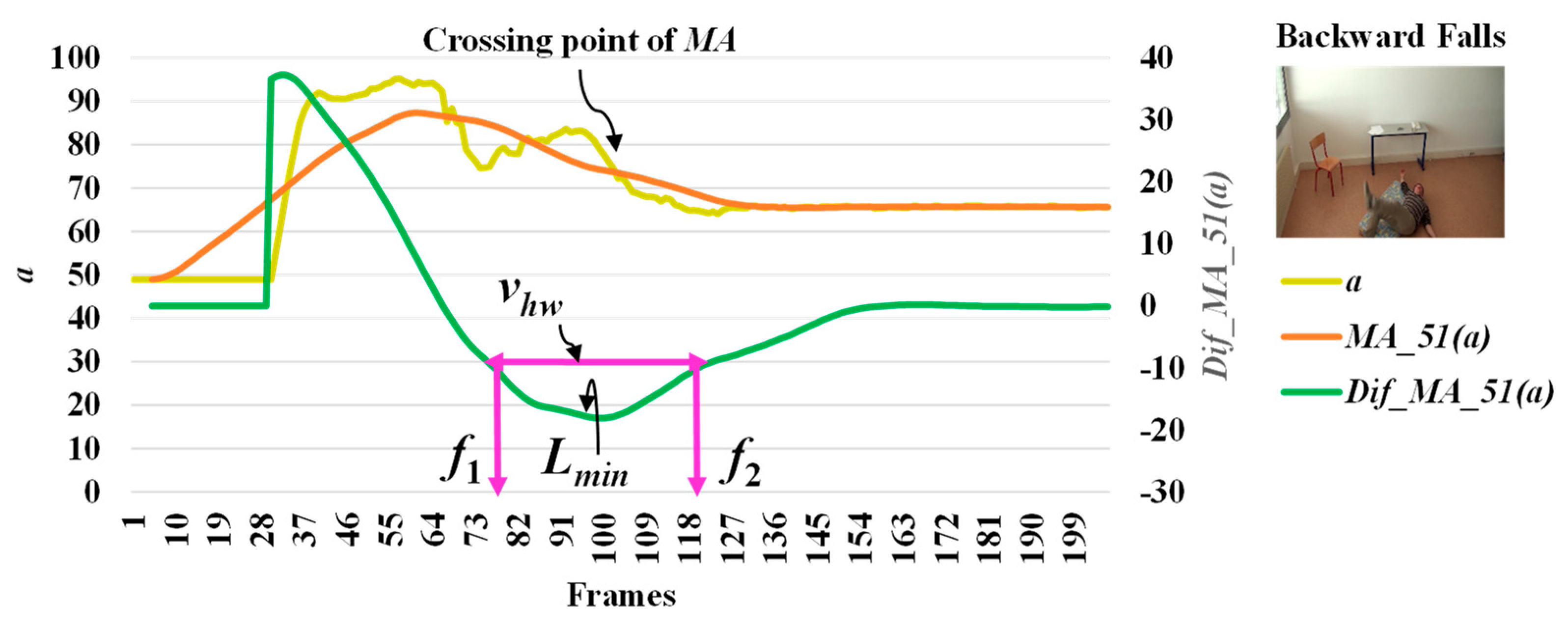
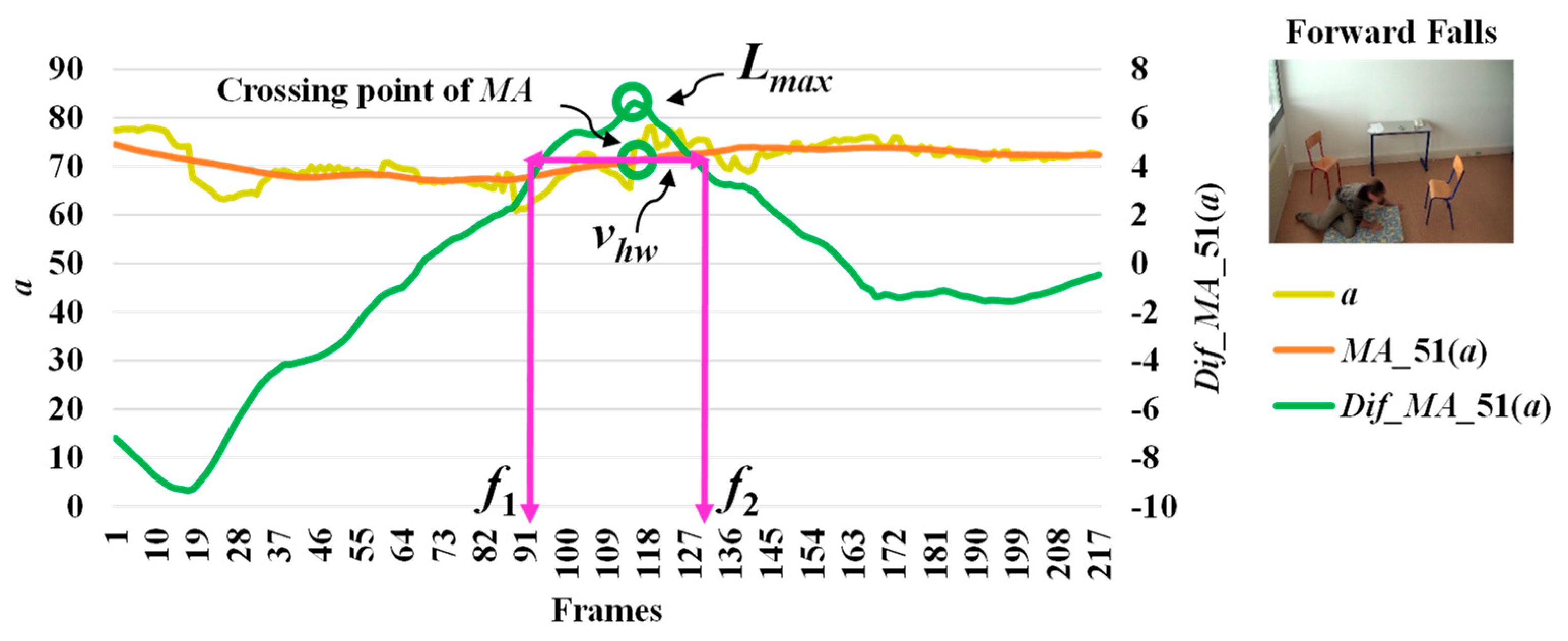
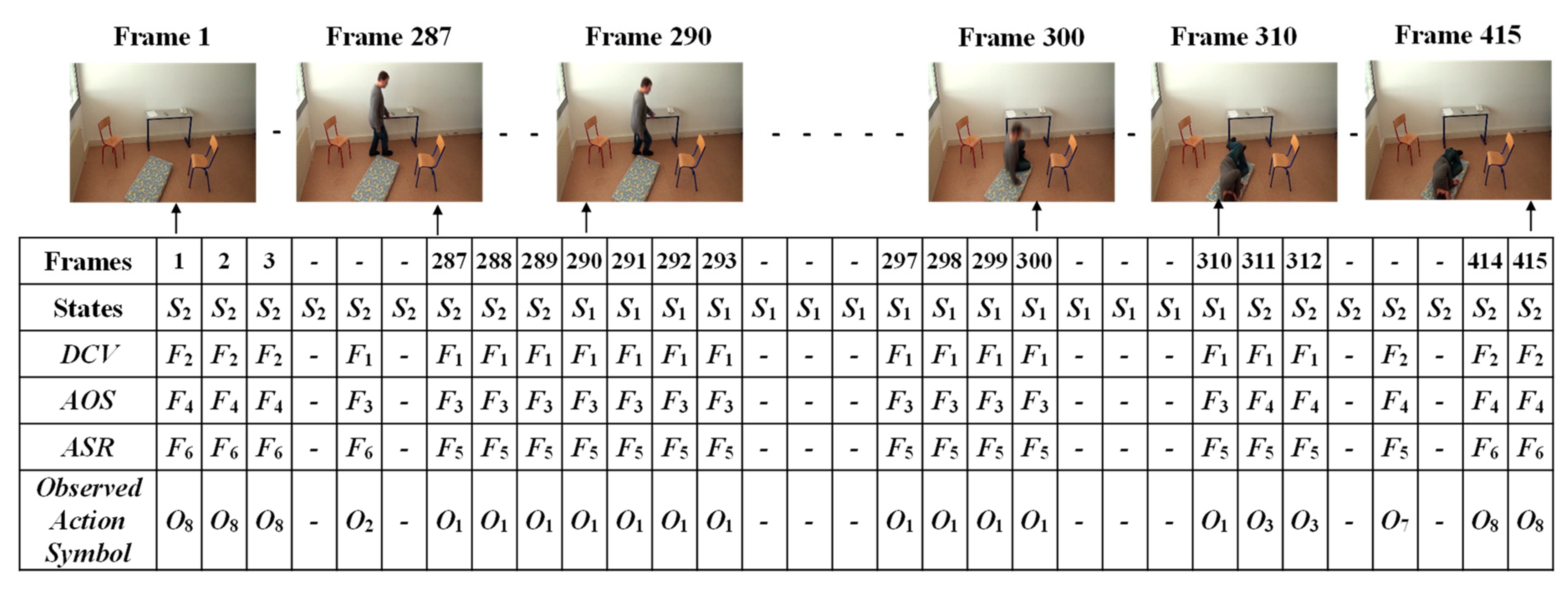
3.2. Feature Extraction
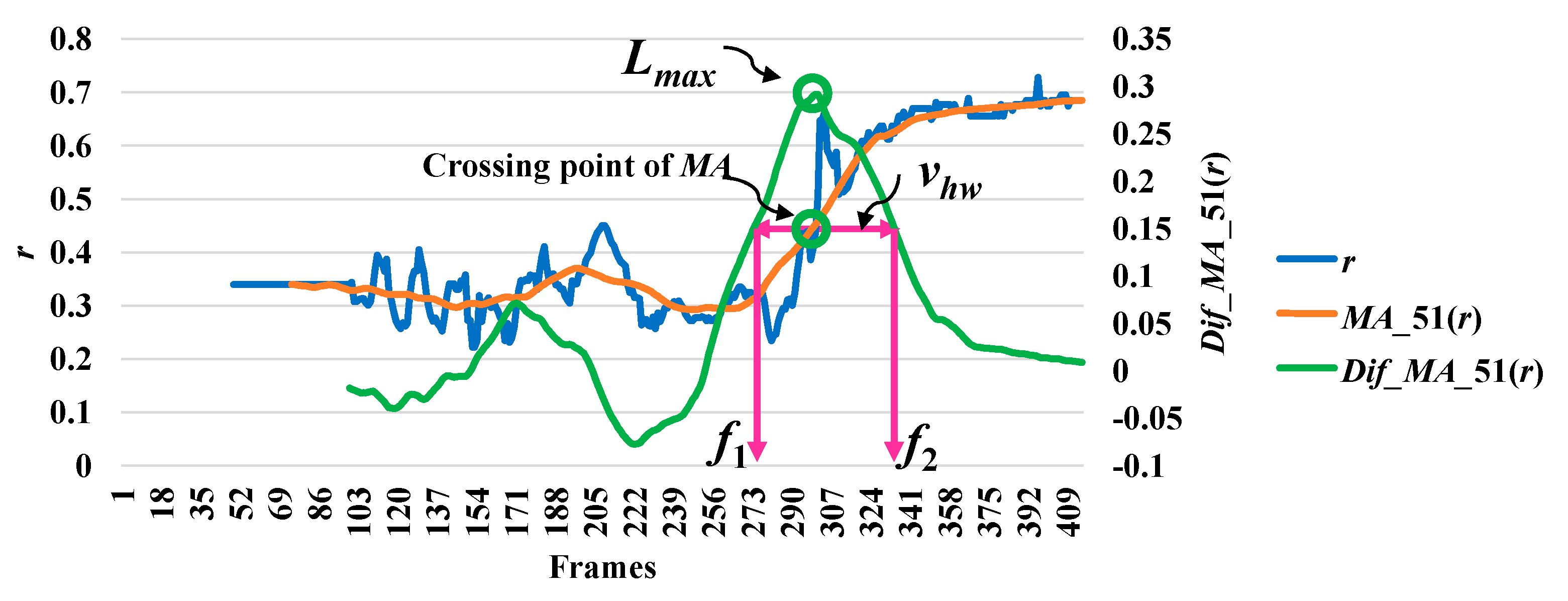
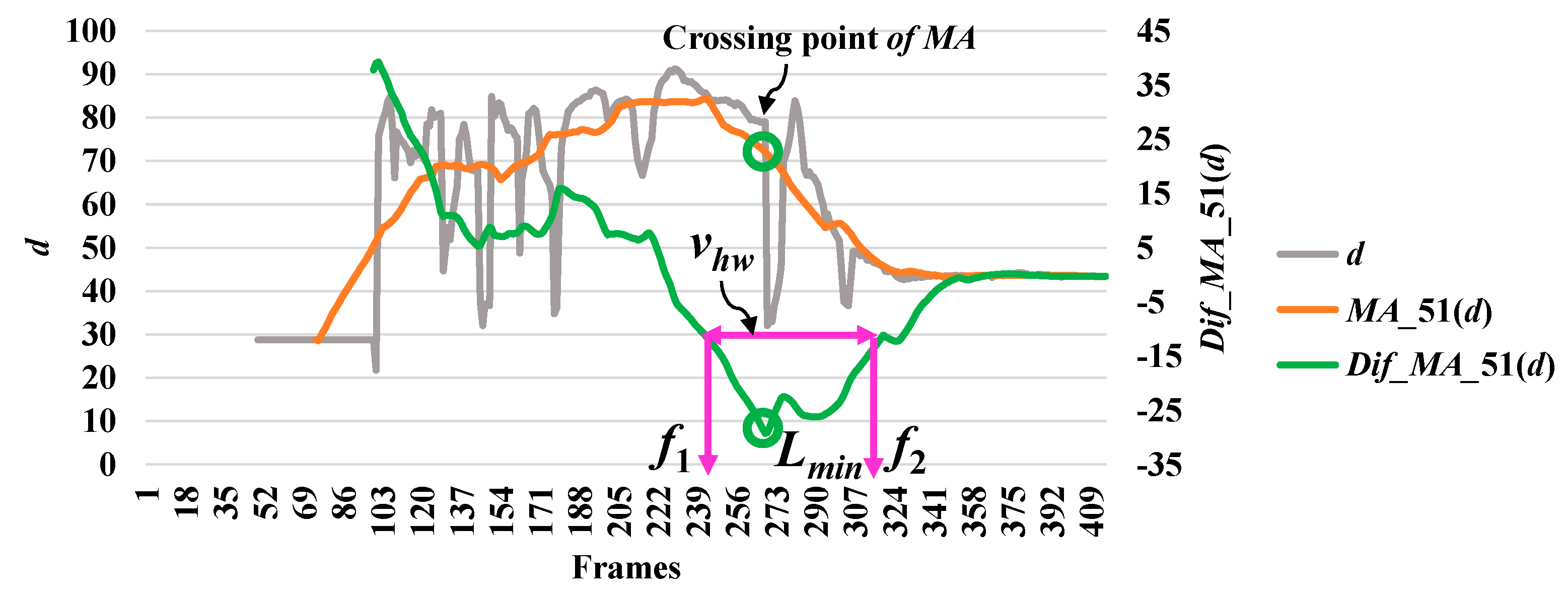
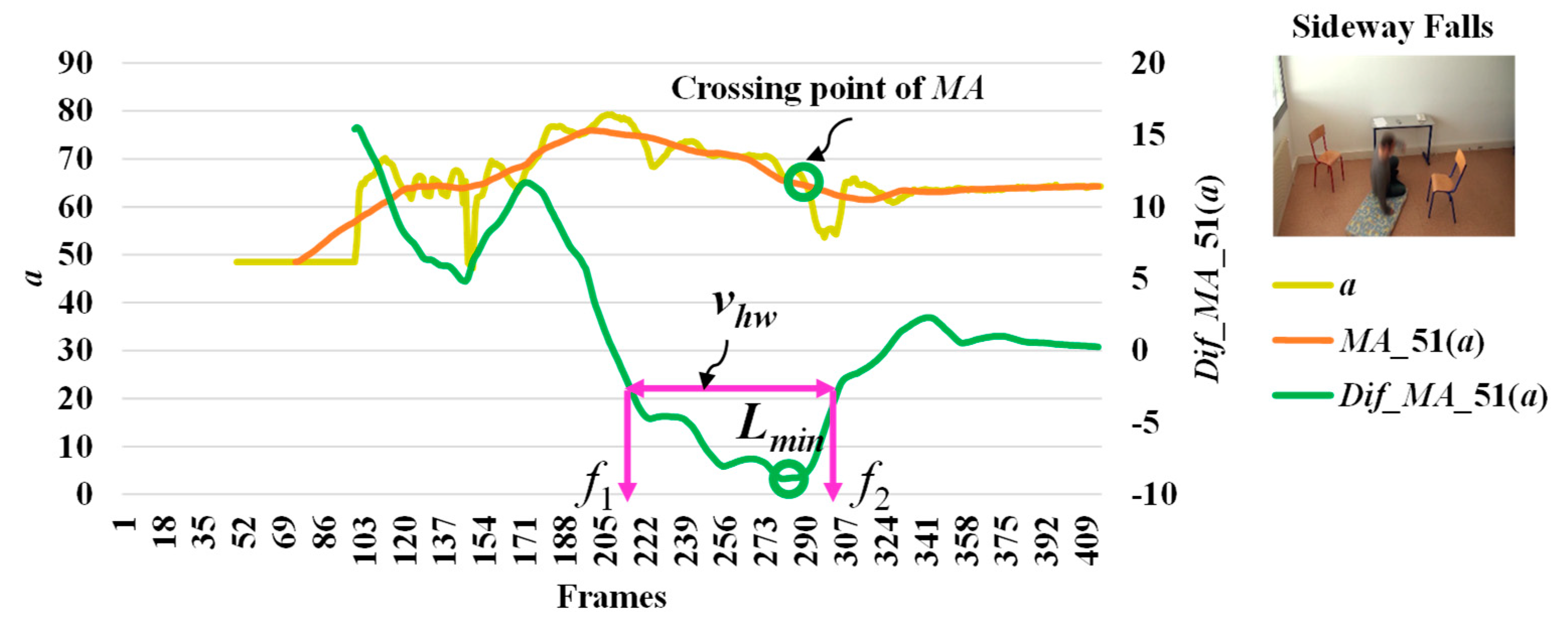
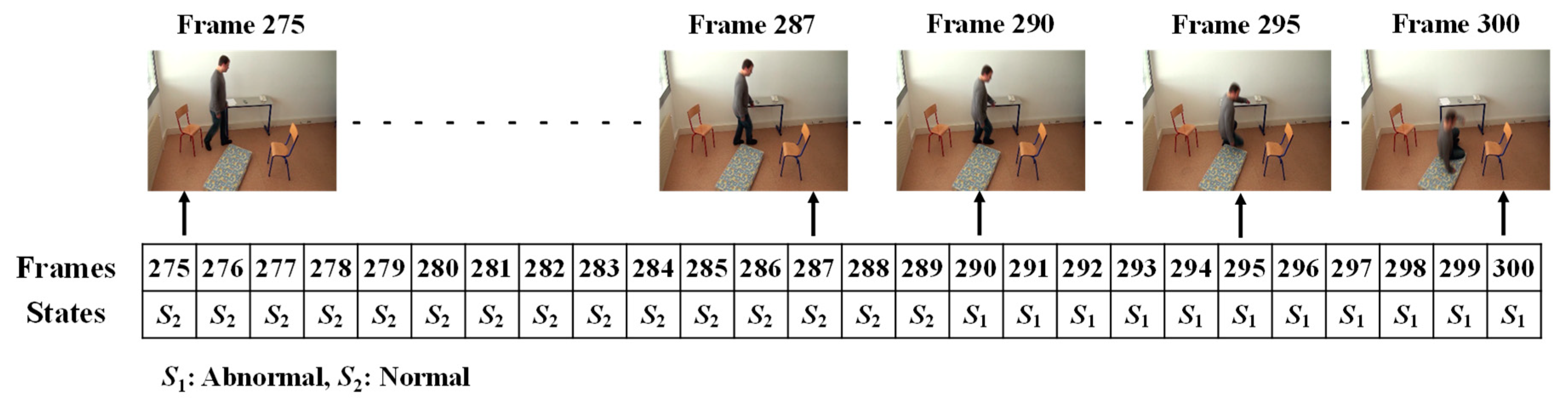
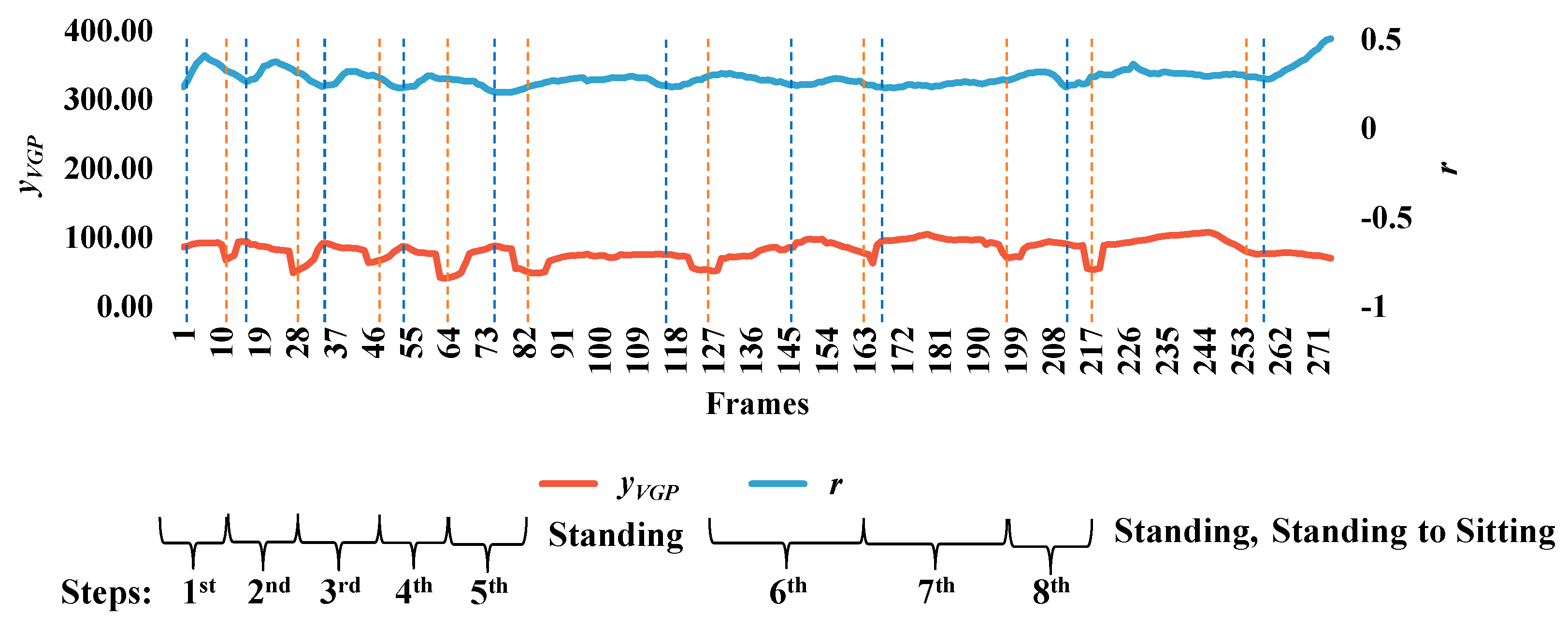
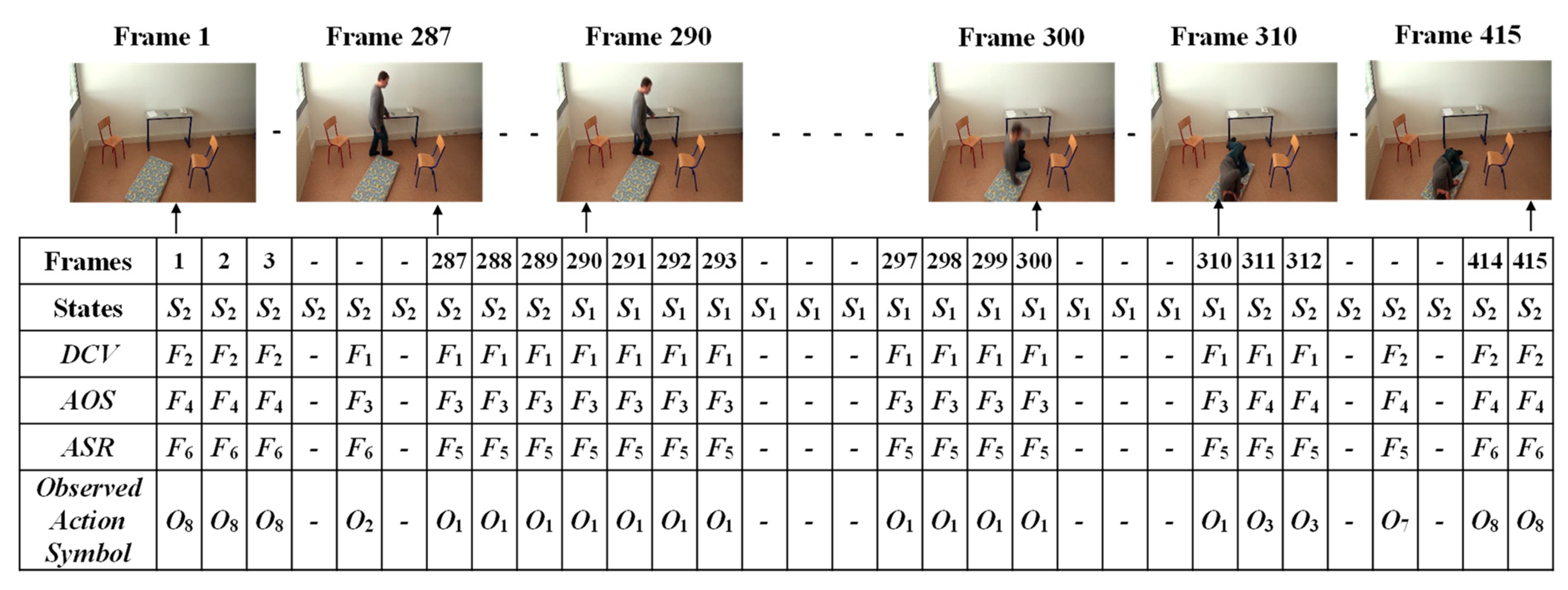
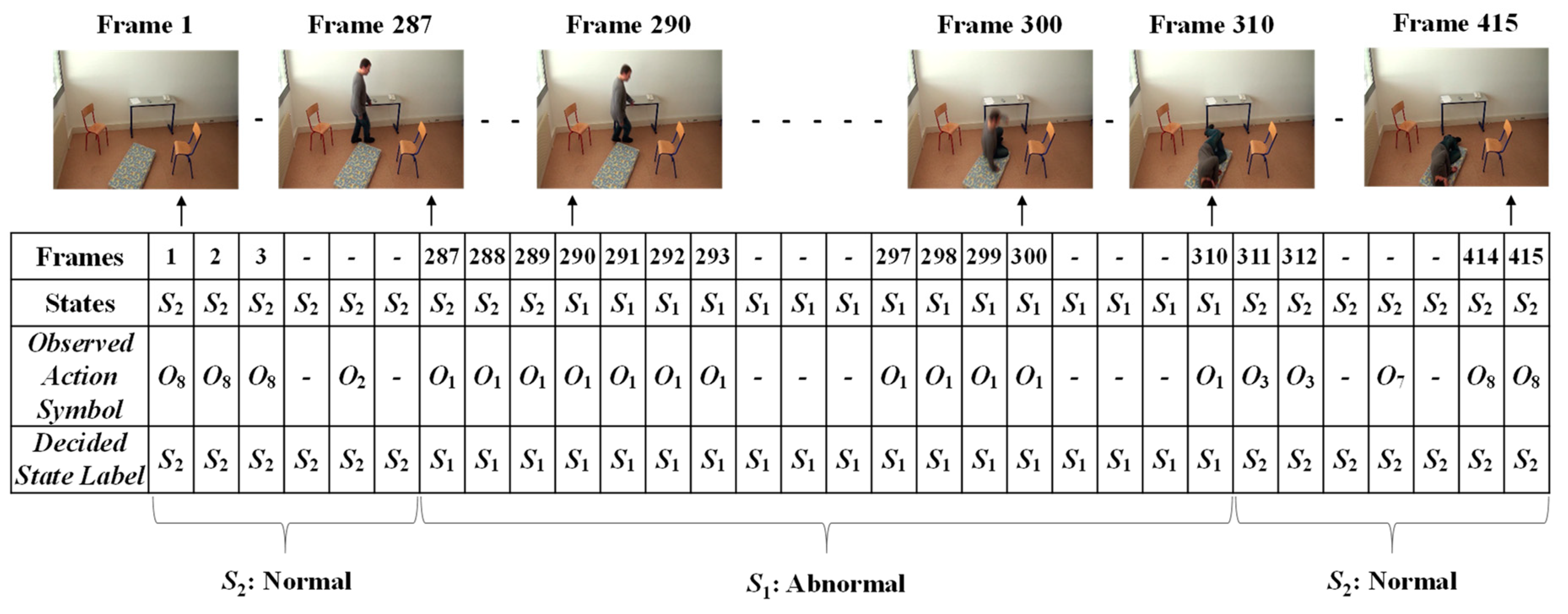
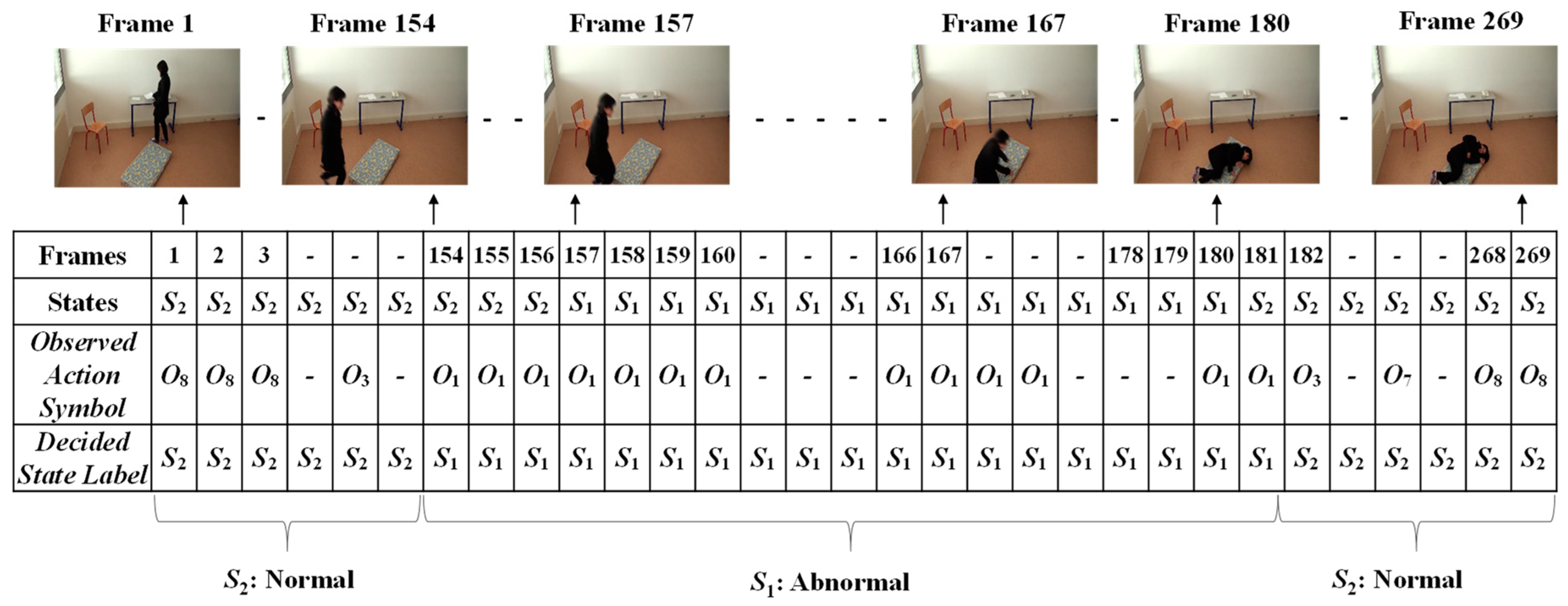
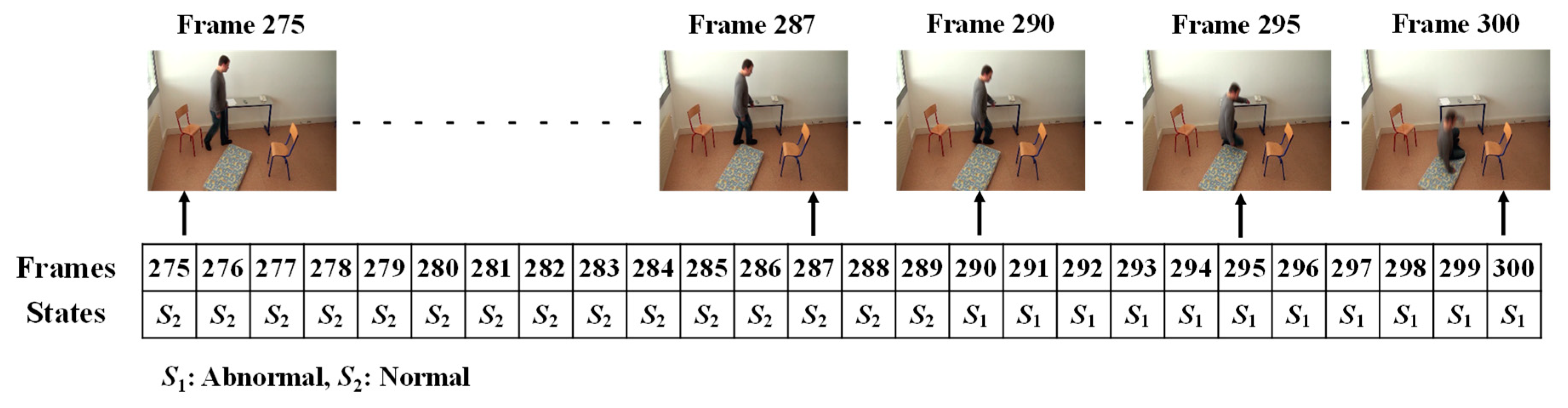
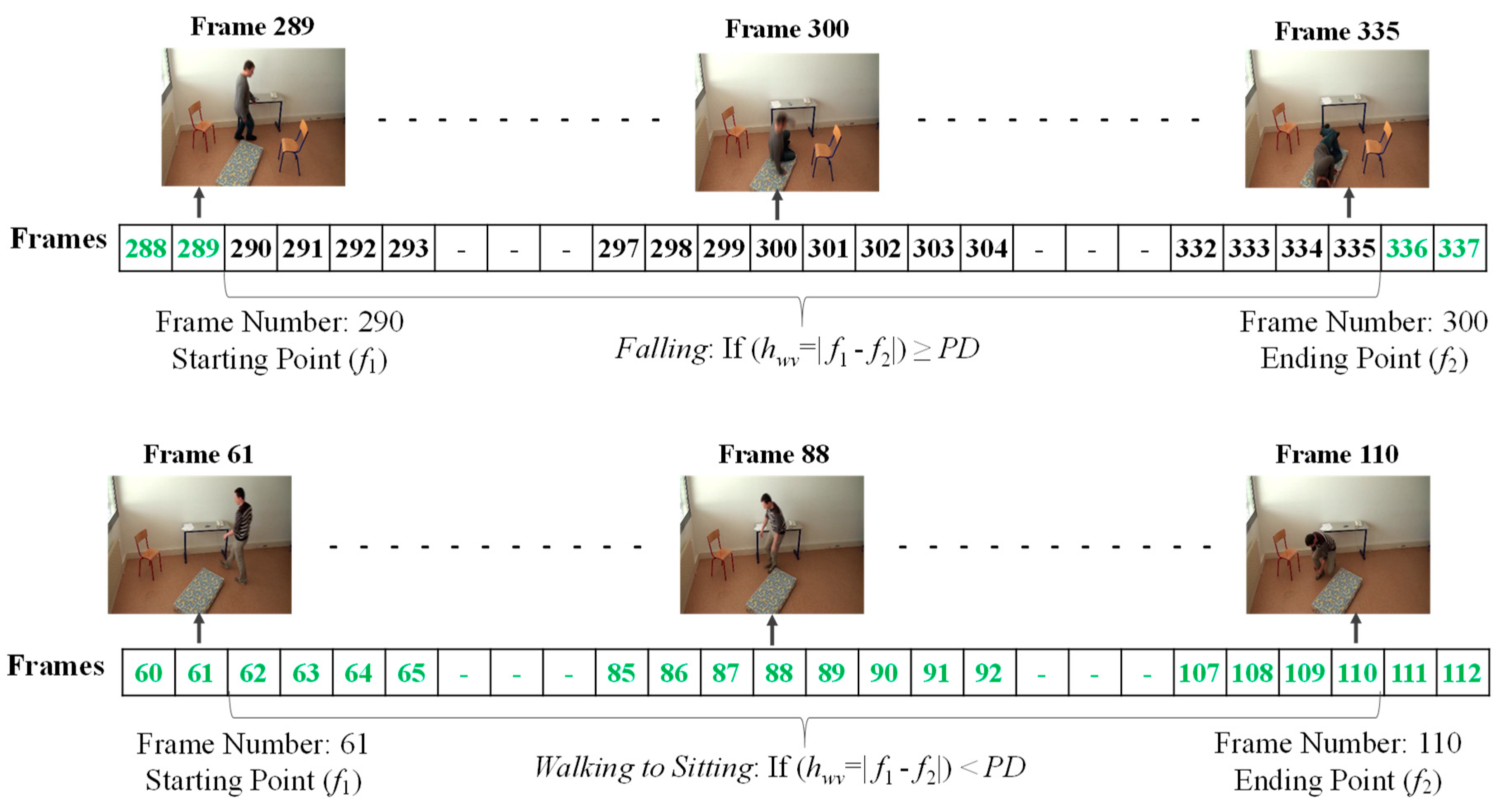
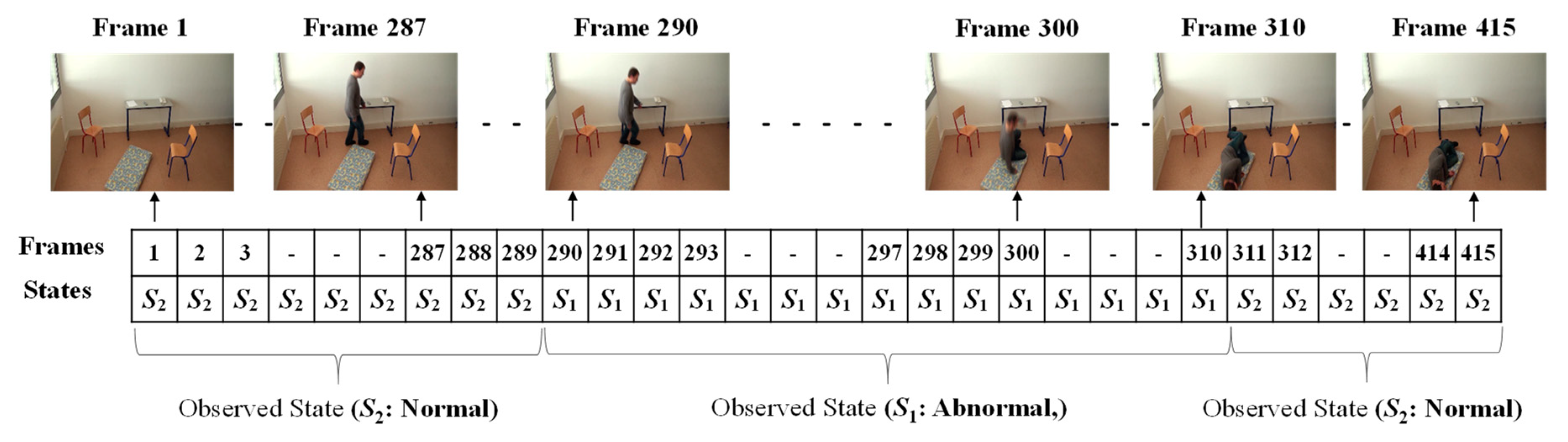
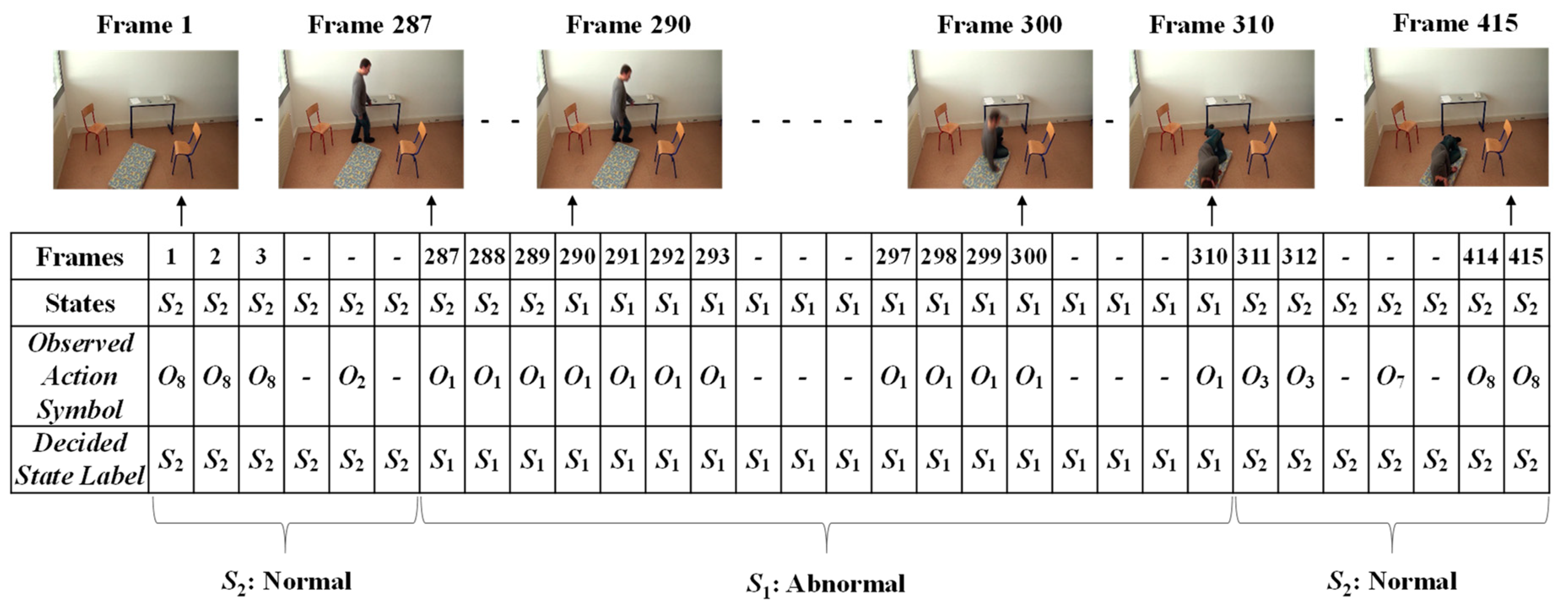
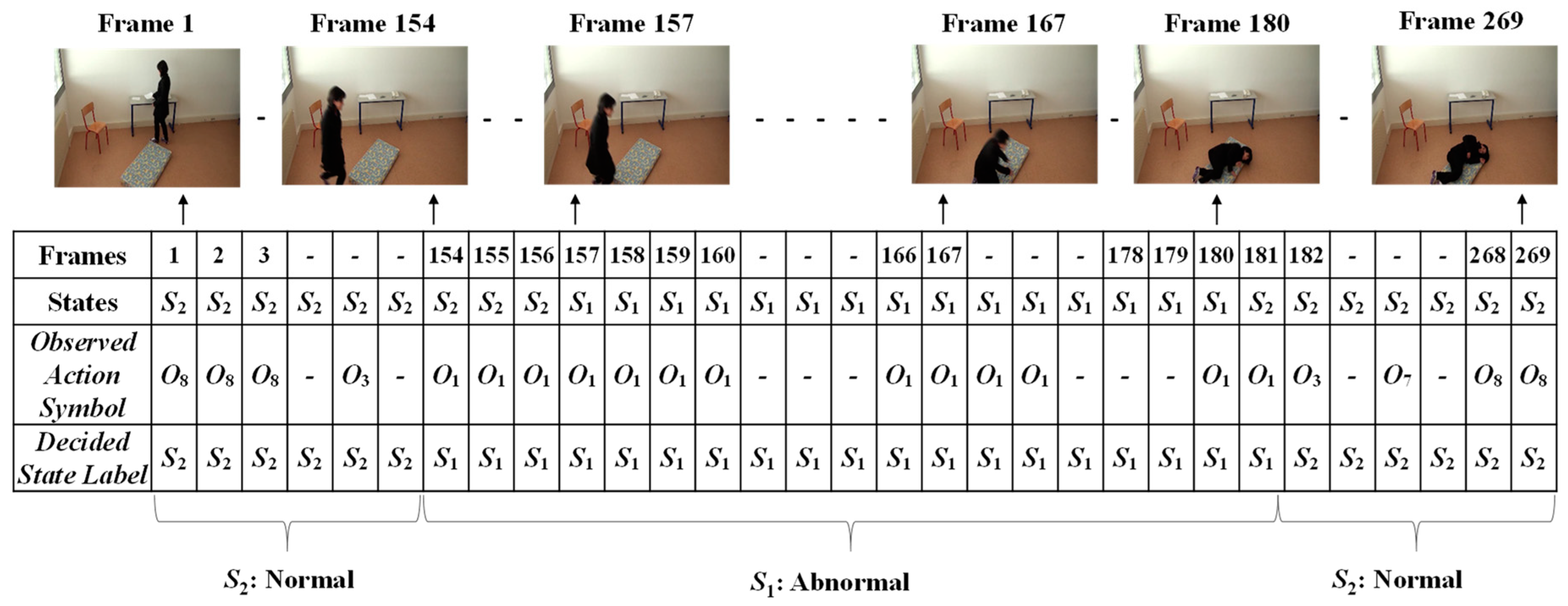
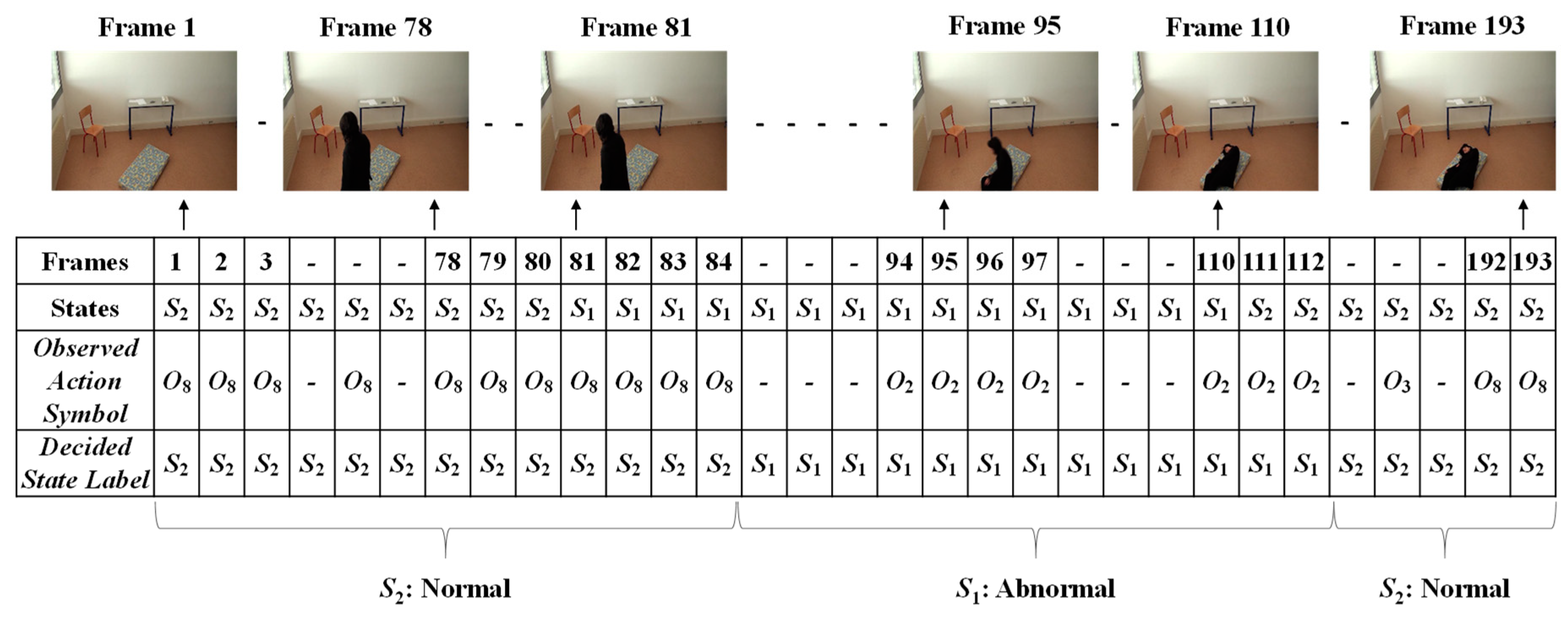
3.3. Analysis of Abnormal and Normal Events
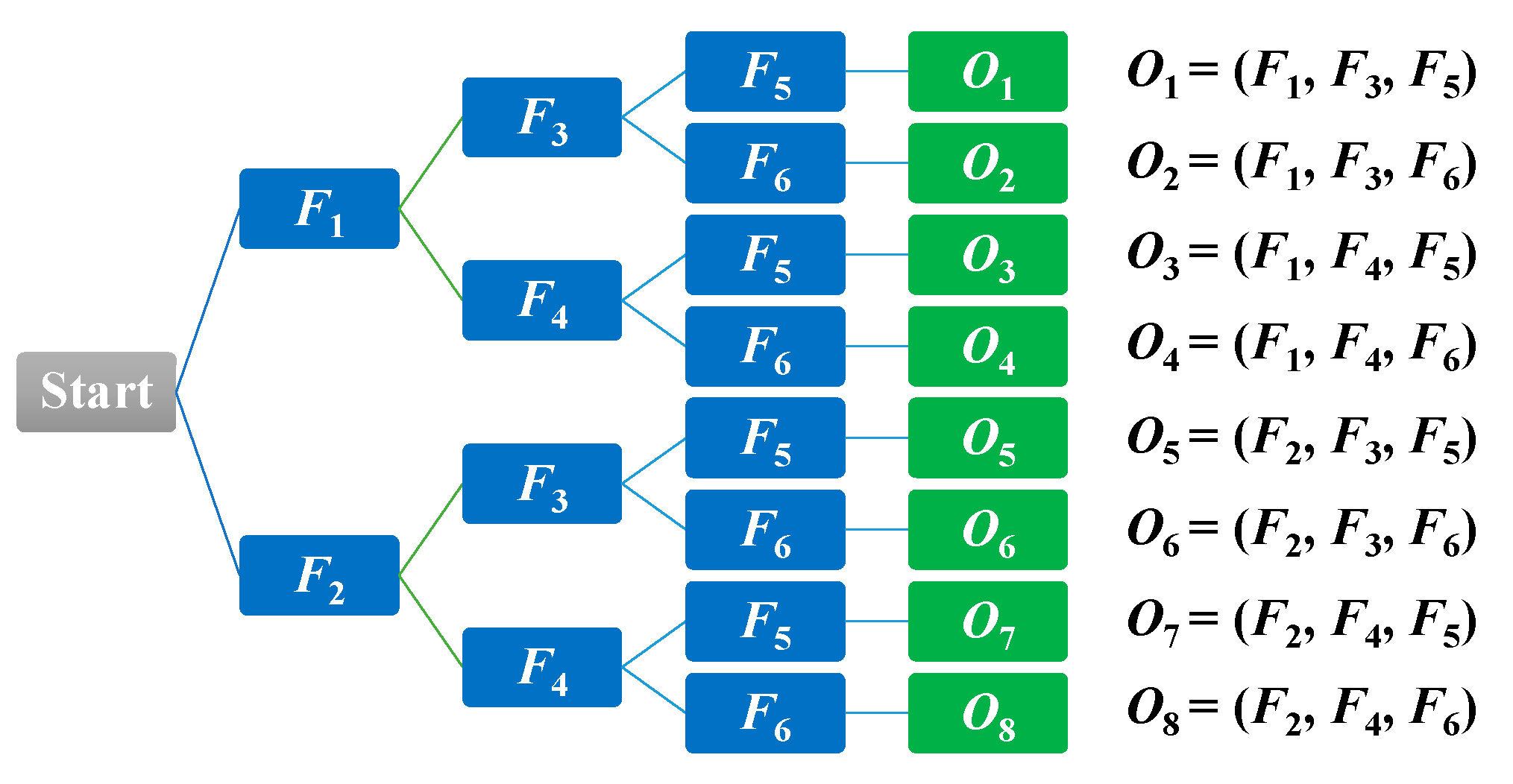
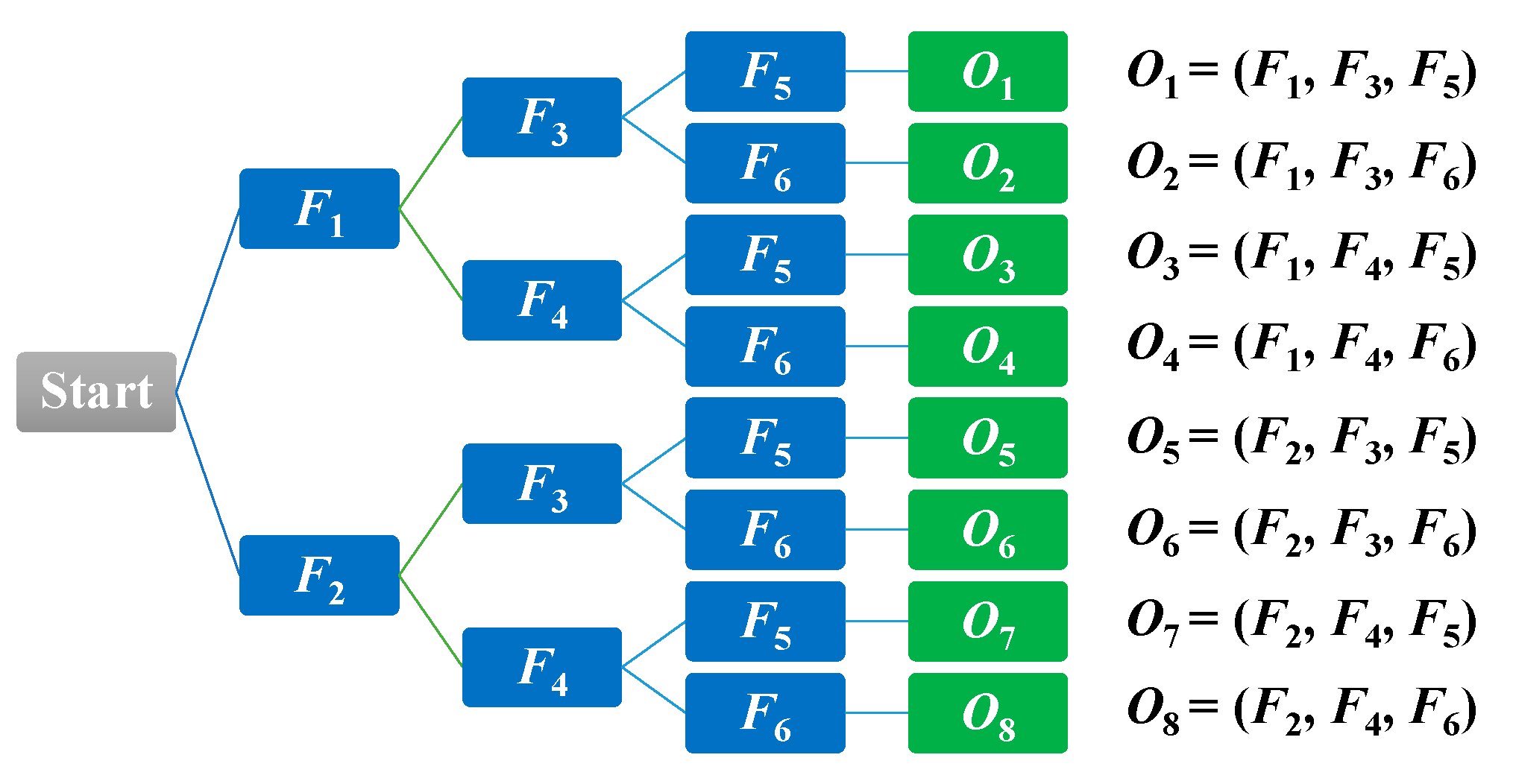
3.4. Decision-Making Rules
4. Experiments
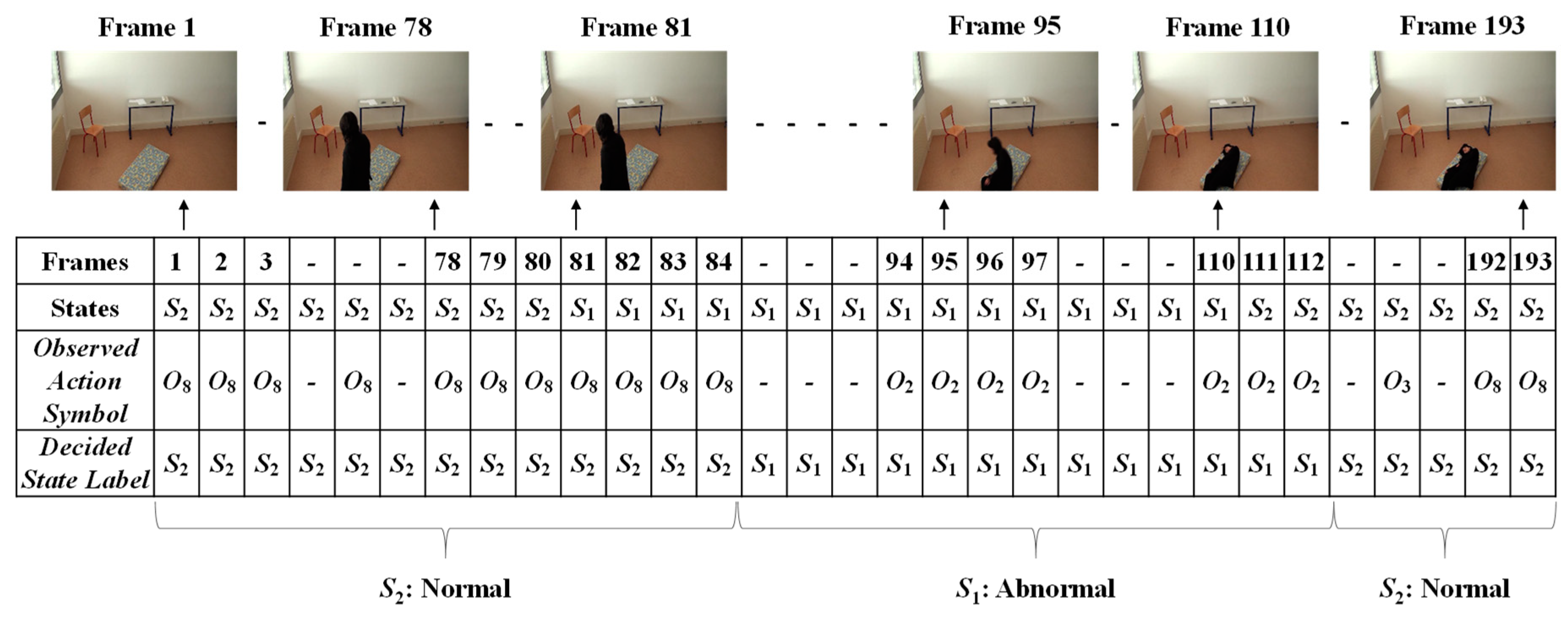
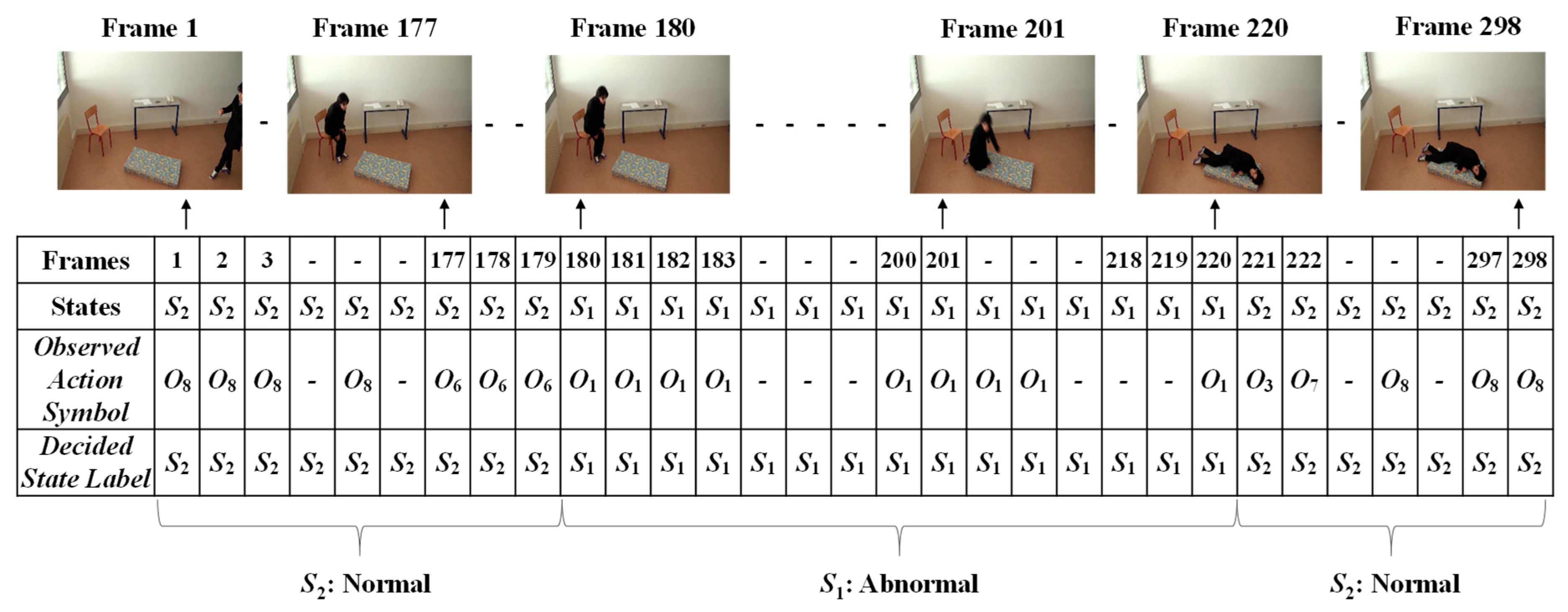
4.1. The Dataset
4.2. Experimental Results
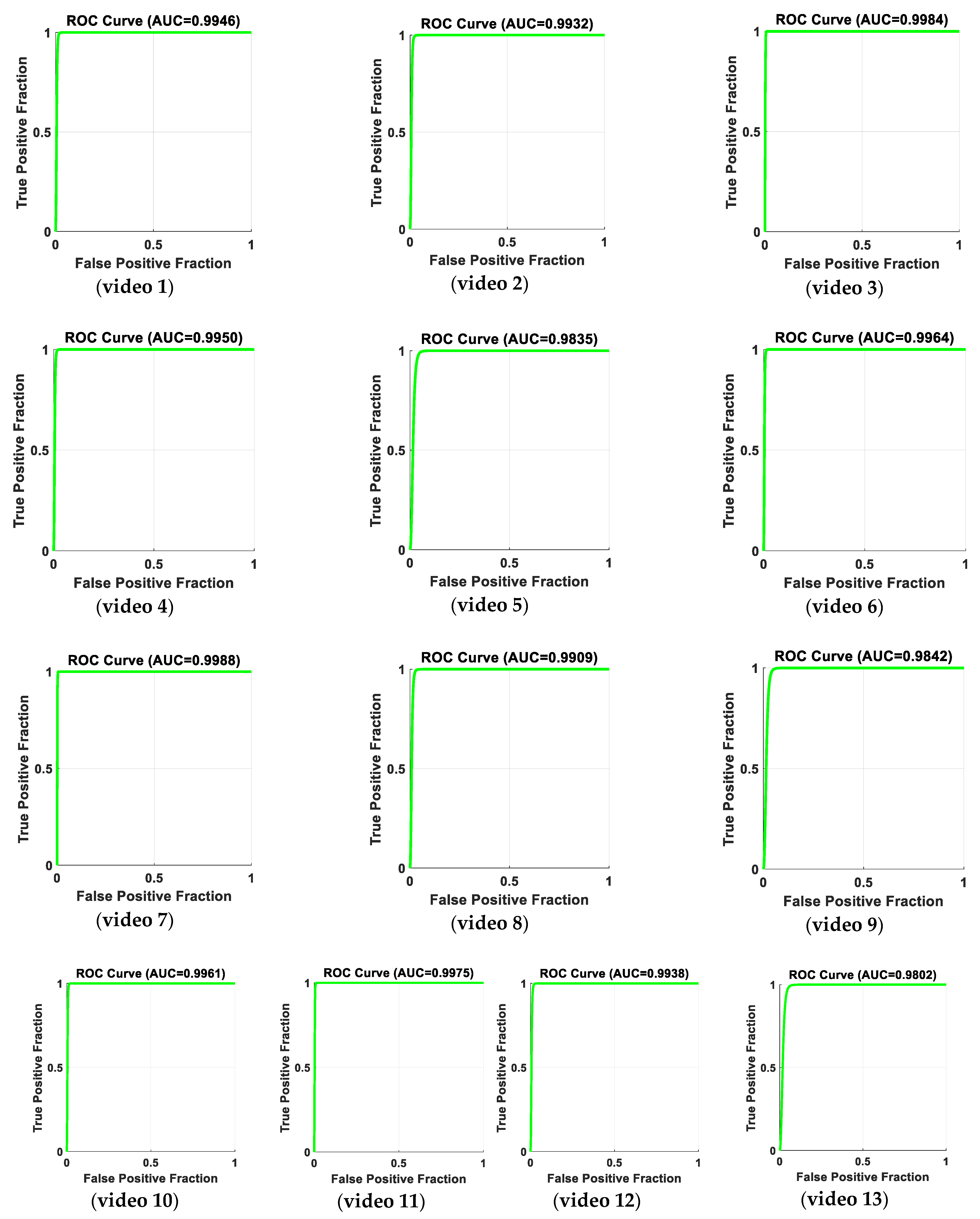
4.3. Performance Evaluation of the Proposed Approach
- Detected Abnormal State (As1): A video frame represents an abnormal state, and is correctly classified as “Positive Abnormal”;
- Undetected Abnormal State (As2): A video frame represents an abnormal state, and is incorrectly classified as “Negative Normal”;
- Normal State (Ns1): A video frame does not represent an abnormal state, and is correctly classified as “Negative Normal”;
- Mis-detected Normal State (Ns2): A video frame does not represent an abnormal state, and is incorrectly classified as “Positive Abnormal”.
4.4. Comparative Studies of the Merits and Demerits of Our Proposed System
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- World Health Organization Regional Office for Europe. Healthy Ageing: Policy. Available online: http://www.euro.who.int/en/health-topics/Life-stages/healthy-ageing/policy (accessed on 13 December 2018).
- Lindemann, U.; Hock, A.; Stuber, M.; Keck, W.; Becker, C. Evaluation of a fall detector based on accelerometers: A pilot study. Med. Boil. Eng. 2005, 43, 548–551. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.-C.; Chiang, C.-Y.; Lin, P.-Y.; Chou, Y.-C.; Kuo, I.-T.; Huang, C.-N.; Chan, C.-T. Development of a Fall Detecting System for the Elderly Residents. In Proceedings of the 2008 2nd International Conference on Bioinformatics and Biomedical Engineering, Shanghai, China, 16–18 May 2008; pp. 1359–1362. [Google Scholar]
- Bagalà, F.; Becker, C.; Cappello, A.; Chiari, L.; Aminian, K.; Hausdorff, J.M.; Zijlstra, W.; Klenk, J. Evaluation of Accelerometer-Based Fall Detection Algorithms on Real-World Falls. PLoS ONE 2012, 7, e37062. [Google Scholar] [CrossRef] [Green Version]
- Mathie, M.J.; Coster, A.C.F.; Lovell, N.H.; Celler, B.G. Accelerometry: Providing an integrated, practical method for long-term, ambulatory monitoring of human movement. Physiol. Meas. 2004, 25, R1–R20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rimminen, H.; Lindström, J.; Linnavuo, M.; Sepponen, R. Detection of falls among the elderly by a floor sensor using the electric near field. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1475–1476. [Google Scholar] [CrossRef] [PubMed]
- Abbate, S.; Avvenuti, M.; Bonatesta, F.; Cola, G.; Corsini, P.; Vecchio, A. A smartphone-based fall detection system. Pervasive Mob. Comput. 2012, 8, 883–899. [Google Scholar] [CrossRef]
- Albert, M.V.; Kording, K.; Herrmann, M.; Jayaraman, A. Fall Classification by Machine Learning Using Mobile Phones. PLoS ONE 2012, 7, e36556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mao, A.; Ma, X.; He, Y.; Luo, J. Highly Portable, Sensor-Based System for Human Fall Monitoring. Sensors 2017, 17, 2096. [Google Scholar] [CrossRef] [Green Version]
- Chaccour, K.; Darazi, R.; El Hassani, A.H.; Andres, E. From Fall Detection to Fall Prevention: A Generic Classification of Fall-Related Systems. IEEE Sens. J. 2017, 17, 812–822. [Google Scholar] [CrossRef]
- Sugimoto, M.; Zin, T.T.; Takashi, T.; Shigeyoshi, N. Robust Rule-Based Method for Human Activity Recognition. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2011, 11, 37–43. [Google Scholar]
- De Miguel, K.; Brunete, A.; Hernando, M.; Gambao, E. Home Camera-Based Fall Detection System for the Elderly. Sensors 2017, 17, 2864. [Google Scholar] [CrossRef] [Green Version]
- Htun, S.N.N.; Zin, T.T.; Hama, H. Virtual Grounding Point Concept for Detecting Abnormal and Normal Events in Home Care Monitoring Systems. Appl. Sci. 2020, 10, 3005. [Google Scholar] [CrossRef]
- Rougier, C.; Meunier, J.; St-Arnaud, A.; Rousseau, J. Fall Detection from Human Shape and Motion History Using Video Surveillance. In Proceedings of the 21st International Conference on Advanced Information Networking and Applications Workshops (AINAW’07), Niagara Falls, ON, Canada, 21–23 May 2007; pp. 875–880. [Google Scholar] [CrossRef]
- Rougier, C.; St-Arnaud, A.; Rousseau, J.; Meunier, J. Video Surveillance for Fall Detection. In Video Surveillance; IntechOpen: London, UK, 3 February 2011. [Google Scholar] [CrossRef] [Green Version]
- Kishanprasad, G.; Prachi, M. Indoor Human Fall Detection System Based on Automatic Vision Using Computer Vision and Machine Learning Algorithms. J. Eng. Sci. Technol. 2018, 13, 2587–2605. [Google Scholar]
- Lotfi, A.; Albawendi, S.; Powell, H.; Appiah, K.; Langensiepen, C. Supporting Independent Living for Older Adults; Employing a Visual Based Fall Detection Through Analysing the Motion and Shape of the Human Body. IEEE Access 2018, 6, 70272–70282. [Google Scholar] [CrossRef]
- Suad, G.A. Automated Human Fall Recognition from Visual Data. Ph.D. Thesis, Nottingham Trent University, Nottingham, UK, February 2019; pp. 1–160. [Google Scholar]
- Htun, S.N.N.; Zin, T.T. Motion History and Shape Orientation Based Human Action Analysis. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 754–755. [Google Scholar]
- Yong, H.; Meng, D.; Zuo, W.; Zhang, K. Robust Online Matrix Factorization for Dynamic Background Subtraction. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1726–1740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marki, N.; Perazzi, F.; Wang, O.; Sorkine-Hornung, A. Bilateral Space Video Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 743–751. [Google Scholar]
- Htun, S.N.N.; Zin, T.T.; Hama, H. Human Action Analysis Using Virtual Grounding Point and Motion History. In Proceedings of the 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech), Kyoto, Japan, 10–12 March 2020; pp. 249–250. [Google Scholar]
- Núñez-Marcos, A.; Azkune, G.; Arganda-Carreras, I. Vision-Based Fall Detection with Convolutional Neural Networks. Wirel. Commun. Mob. Comput. 2017, 2017, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Minjie, H.; Yibing, N.; Shiguo, L. Falls Prediction Based on Body Keypoints and Seq2Seq Architecture. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshop), Seoul, Korea, 27–28 October 2019; pp. 1251–1259. [Google Scholar] [CrossRef]
- Amandine, D.; François, C. Automatic Fall Detection System with a RGB-D Camera using a Hidden Markov Model. In Proceedings of the ICOST-11th International Conference on Smart Homes and Health Telematics, Singapore, 19–21 June 2013; pp. 259–266. [Google Scholar] [CrossRef] [Green Version]
- Triantafyllou, D.; Krinidis, S.; Ioannidis, D.; Metaxa, I.; Ziazios, C.; Tzovaras, D. A Real-time Fall Detection System for Maintenance Activities in Indoor Environments—This work has been partially supported by the European Commission through the project HORIZON 2020-INNOVATION ACTIONS (IA)-636302-SATISFACTORY. IFAC-PapersOnLine 2016, 49, 286–290. [Google Scholar] [CrossRef]
- Daniel, J.; James, H.M. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 3rd ed.; Stanford University: Stanford, CA, USA, 16 October 2019. [Google Scholar]
- Le2i Fall Detection Dataset. Available online: http://le2i.cnrs.fr/Fall-detection-Dataset?lang=fr (accessed on 27 February 2013).
- Cattaneo, C.; Mainetti, G.; Sala, R. The Importance of Camera Calibration and Distortion Correction to Obtain Measurements with Video Surveillance Systems. J. Phys. Conf. Ser. 2015, 658, 012009. [Google Scholar] [CrossRef] [Green Version]



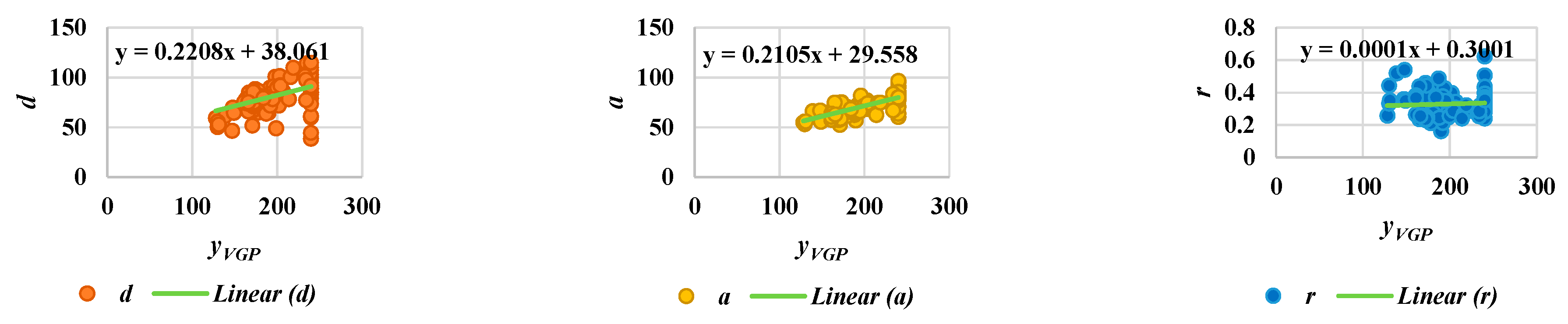



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
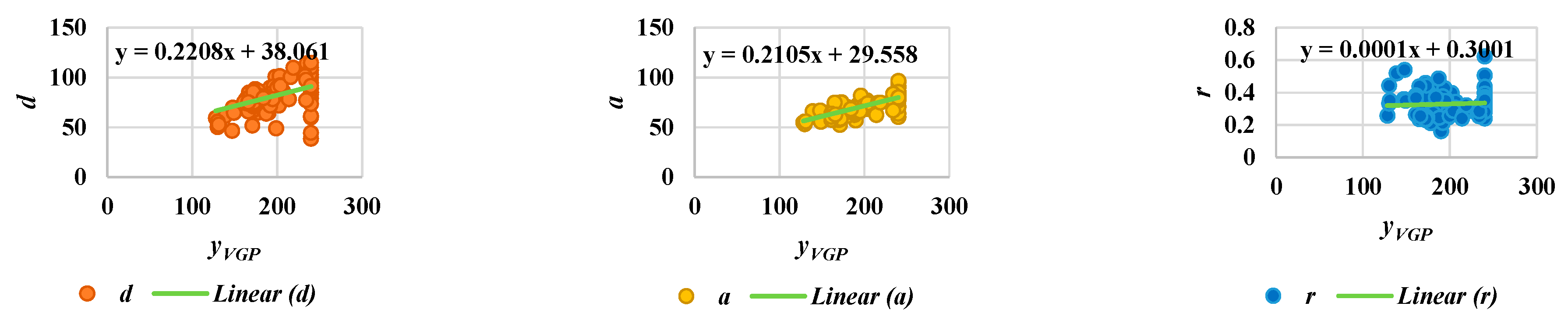{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Videos | Precision (%) | Recall (%) | Accuracy (%) | Specificity (%) | NPV (%) |
|---|---|---|---|---|---|
| 1 | 100 | 100 | 100 | 96.88 | 96.88 |
| 2 | 100 | 100 | 100 | 96.07 | 96.09 |
| 3 | 100 | 86.66 | 98.32 | 99.04 | 97.17 |
| 4 | 100 | 100 | 100 | 97.07 | 97.06 |
| 5 | 100 | 100 | 100 | 90.40 | 90.40 |
| 6 | 82.98 | 97.50 | 99.76 | 97.89 | 97.63 |
| 7 | 98.04 | 100 | 100 | 99.36 | 99.36 |
| 8 | 100 | 100 | 100 | 94.70 | 94.70 |
| 9 | 100 | 83.33 | 97.41 | 90.80 | 99.09 |
| 10 | 100 | 100 | 100 | 97.72 | 97.72 |
| 11 | 100 | 100 | 100 | 98.54 | 98.54 |
| 12 | 100 | 100 | 100 | 96.38 | 96.38 |
| 13 | 100 | 100 | 100 | 88.48 | 88.48 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Htun, S.N.N.; Zin, T.T.; Tin, P. Image Processing Technique and Hidden Markov Model for an Elderly Care Monitoring System. J. Imaging 2020, 6, 49. https://doi.org/10.3390/jimaging6060049
Htun SNN, Zin TT, Tin P. Image Processing Technique and Hidden Markov Model for an Elderly Care Monitoring System. Journal of Imaging. 2020; 6(6):49. https://doi.org/10.3390/jimaging6060049
Chicago/Turabian StyleHtun, Swe Nwe Nwe, Thi Thi Zin, and Pyke Tin. 2020. "Image Processing Technique and Hidden Markov Model for an Elderly Care Monitoring System" Journal of Imaging 6, no. 6: 49. https://doi.org/10.3390/jimaging6060049
APA StyleHtun, S. N. N., Zin, T. T., & Tin, P. (2020). Image Processing Technique and Hidden Markov Model for an Elderly Care Monitoring System. Journal of Imaging, 6(6), 49. https://doi.org/10.3390/jimaging6060049