Attention-Based Fully Gated CNN-BGRU for Russian Handwritten Text


Abstract
1. Introduction
- Handwritten samples (forms) of keywords in Kazakh and Russian (Areas, Cities, Village, etc.).
- Handwritten Kazakh and Russian Cyrillic alphabet.
- Handwritten samples (Forms) of poems in Russian.
2. Related Work
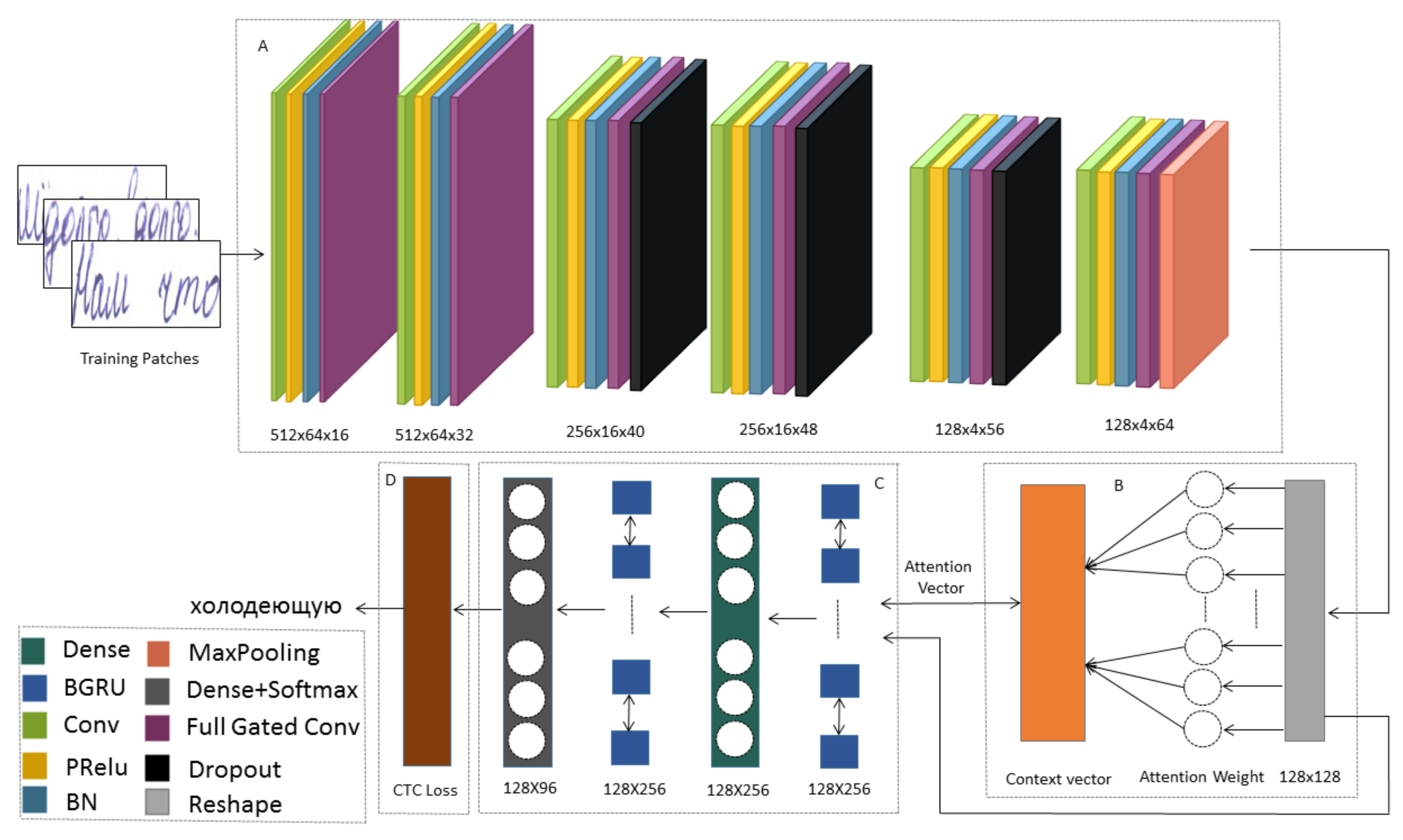
3. Proposed Model
- Preprocessing such as Resize with padding (1024 × 128), Illumination Compensation, and Deslant Cursive Images is performed. We then convert the raw data into a hierarchical data format (HDF5) files; this conversation helps us provide fast loading of the data.
- Extract characteristics by using the CNN layers.
- Bahdanau attention mechanism that makes the model pay attention to the inputs and relates them to the output.
- The map features sequence by BGRU.
- Calculate the loss function Connectionist Temporal Classification (CTC) [32].
- Decode the output into the text format and perform post-processing to improve the final text.
3.1. Image Preprocessing
3.2. Model
3.2.1. Encoder
Convolutional Blocks
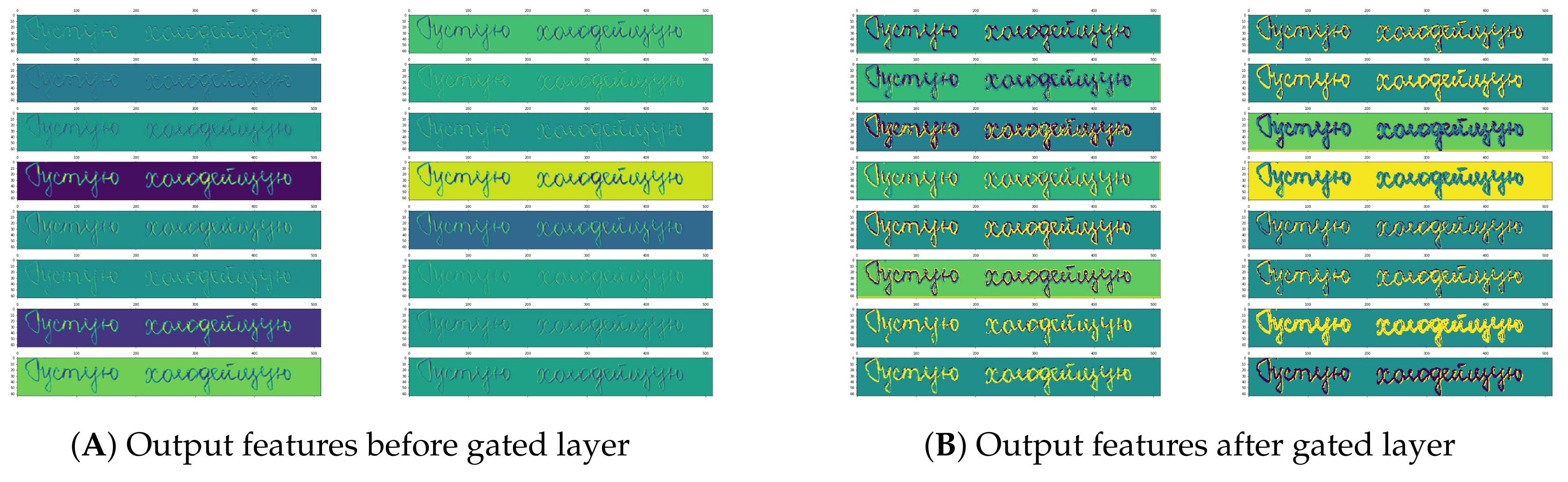
Gated Convolutional Layer
3.2.2. Decoder
3.2.3. Attention Mechanism
3.2.4. Connectionist Temporal Classification(CTC)
4. Experiment Setup
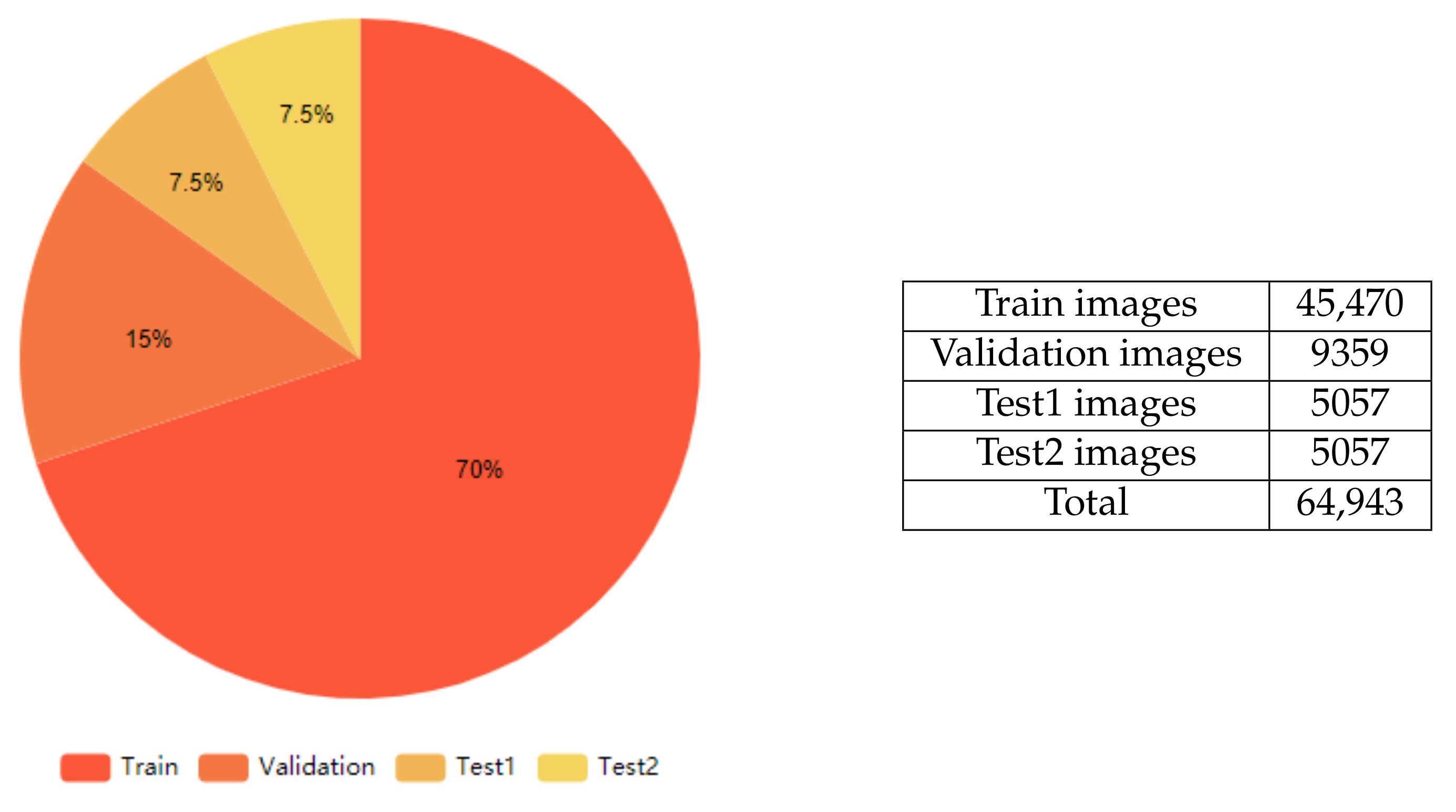
4.1. Data
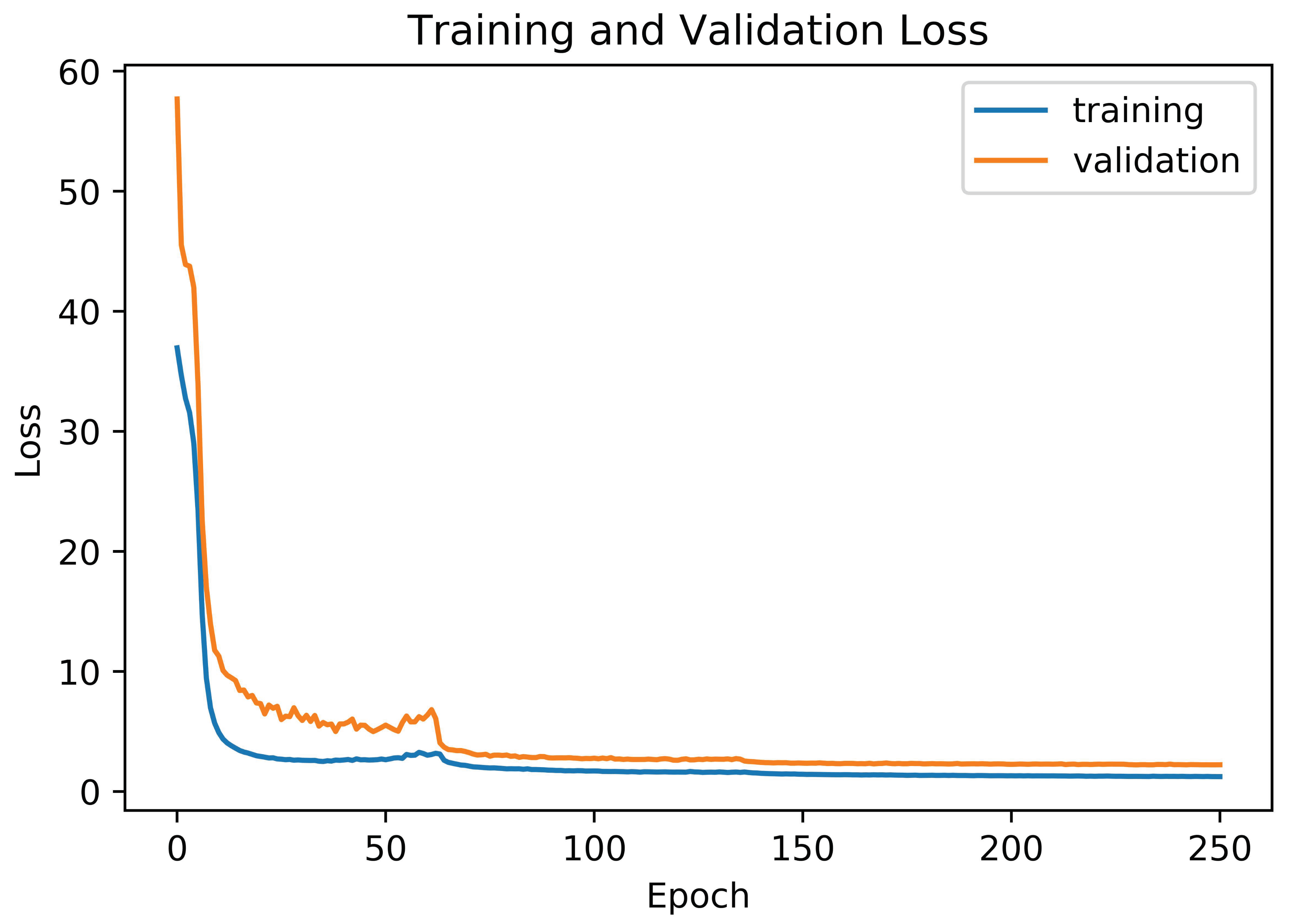
4.2. Training
5. Result
5.1. Experiments
5.2. Comparison with State-of-the-Art on HKR Dataset
- Initialization Randomness, such as weights.
- Regularization randomness, such as dropout.
- Randomness in layers, like embedding of words.
- Optimization randomness, such as stochastic optimization.
5.3. Experimental Evaluation on HKR dataset
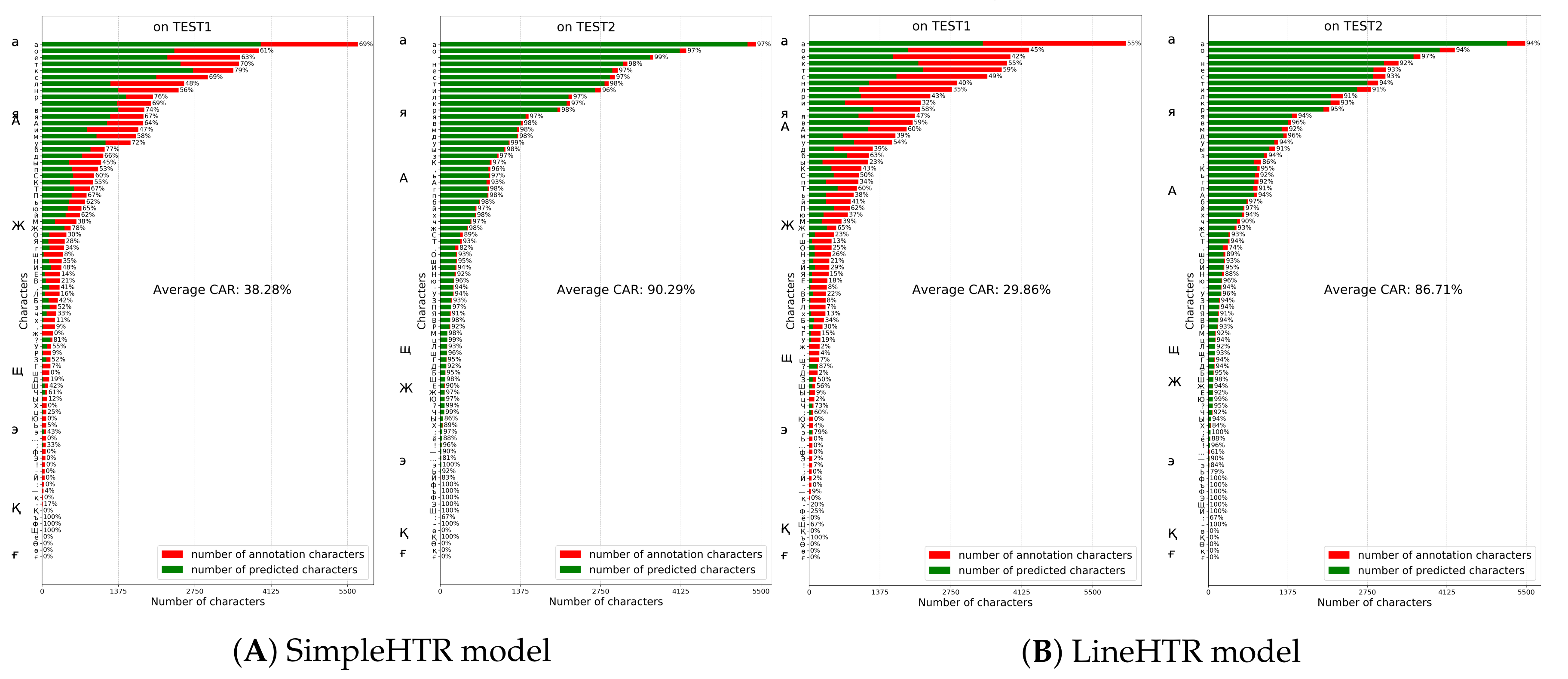
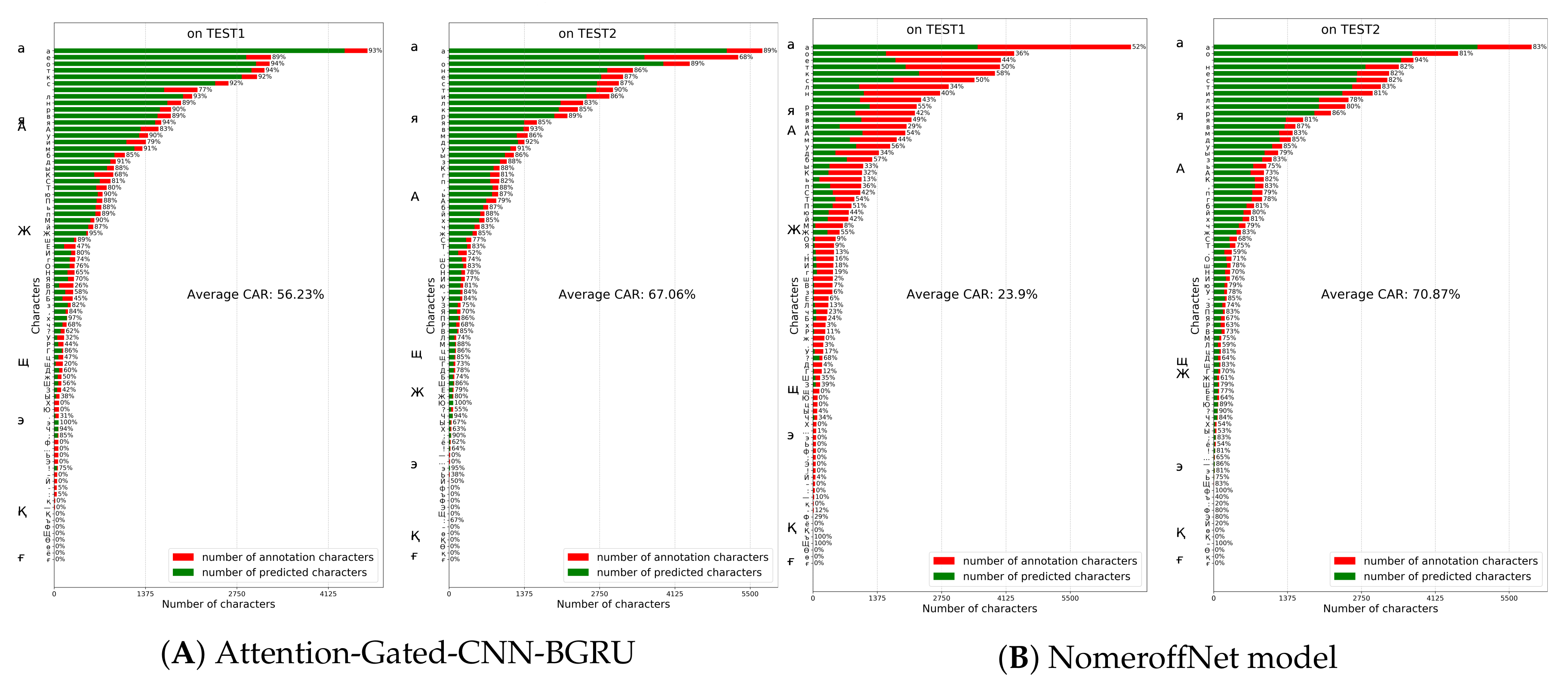
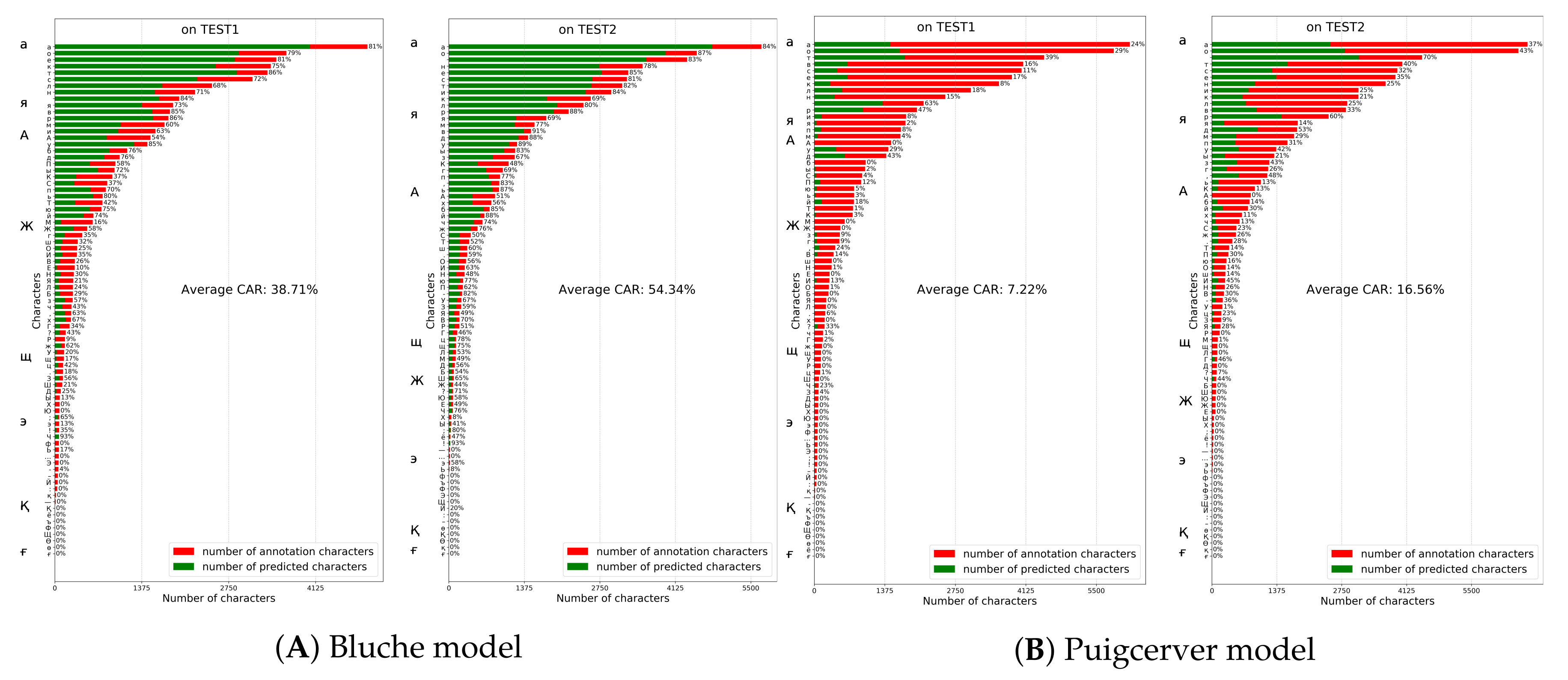
5.4. Comparison with Other Models on HKR Dataset Using Character Accuracy Rates
5.5. Comparison with Other Datasets
5.6. Data Augmentation and Batch Normalization
5.7. Experimental Evaluation on Other Datasets
5.8. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bunke, H.; Roth, M.; Schukat-Talamazzini, E. Off-line cursive handwriting recognition using hidden markov models. Pattern Recognit. 1995, 28, 139–1413. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE ASSP Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Lee, K.F.; Hon, H.W.; Hwang, M.Y.; Huang, X. Speech recognition using Hidden Markov Models: A CMU perspective. Speech Commun. 1990, 9, 497–508. [Google Scholar] [CrossRef]
- Caesar, T.; Gloger, J.; Kaltenmeier, A.; Mandler, E. Recognition of handwritten word images by statistical methods. In Proceedings of the International Workshop on Frontiers in Handwriting Recognition, Buffalo, NY, USA, 25–27 May 1993; pp. 409–416. [Google Scholar]
- Mohamed, M.; Gader, P. Handwritten word recognition using segmentation-free hidden Markov modeling and segmentation-based dynamic programming techniques. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 548–554. [Google Scholar] [CrossRef]
- Chen, M.Y.; Kundu, A.; Zhou, J. Off-line handwritten word recognition using a hidden Markov model type stochastic network. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 481–496. [Google Scholar]
- Gilloux, M.; Leroux, M.; Bertille, J.M. Strategies for cursive script recognition using hidden Markov models. Mach. Vis. Appl. 1995, 8, 197–205. [Google Scholar] [CrossRef]
- Graves, A.; Liwicki, M.; Bunke, H.; Schmidhuber, J.; Fernández, S. Unconstrained On-line Handwriting Recognition with Recurrent Neural Networks. In Advances in Neural Information Processing Systems 20; Platt, J.C., Koller, D., Singer, Y., Roweis, S.T., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2008; pp. 577–584. [Google Scholar]
- Voigtlaender, P.; Doetsch, P.; Ney, H. Handwriting Recognition with Large Multidimensional Long Short-Term Memory Recurrent Neural Networks. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 228–233. [Google Scholar]
- Liwicki, M.; Graves, A.; Fernández, S.; Bunke, H.; Schmidhuber, J. A novel approach to on-line handwriting recognition based on bidirectional long short-term memory networks. In Proceedings of the 9th International Conference on Document Analysis and Recognition, ICDAR 2007, Parana, Brazil, 23–26 September 2007. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Abdallah, A.; Kasem, M.; Hamada, M.A.; Sdeek, S. Automated Question-Answer Medical Model Based on Deep Learning Technology. In Proceedings of the 6th International Conference on Engineering & MIS 2020 (ICEMIS’20); Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 4634–4643. [Google Scholar]
- Hamada, M.A.; Sultanbek, K.; Alzhanov, B.; Tokbanov, B. Sentimental text processing tool for Russian language based on machine learning algorithms. In Proceedings of the 5th International Conference on Engineering and MIS, Astana, Kazakhstan, 6–8 June 2019; pp. 1–6. [Google Scholar]
- Chorowski, J.K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 577–585. [Google Scholar]
- Bluche, T.; Louradour, J.; Messina, R. Scan, attend and read: End-to-end handwritten paragraph recognition with mdlstm attention. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1050–1055. [Google Scholar]
- Kang, L.; Toledo, J.I.; Riba, P.; Villegas, M.; Fornés, A.; Rusinol, M. Convolve, attend and spell: An attention-based sequence-to-sequence model for handwritten word recognition. In German Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 459–472. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Nurseitov, D.; Bostanbekov, K.; Kurmankhojayev, D.; Alimova, A.; Abdallah, A. HKR For Handwritten Kazakh & Russian Database. arXiv 2020, arXiv:2007.03579. [Google Scholar]
- El-Yacoubi, A.; Gilloux, M.; Sabourin, R.; Suen, C.Y. An HMM-based approach for off-line unconstrained handwritten word modeling and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 752–760. [Google Scholar] [CrossRef]
- Bunke, H.; Bengio, S.; Vinciarelli, A. Offline recognition of unconstrained handwritten texts using HMMs and statistical language models. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 709–720. [Google Scholar] [CrossRef] [PubMed]
- Gorbe-Moya, J.; Boquera, S.E.; Zamora-Martínez, F.; Bleda, M.J.C. Handwritten Text Normalization by using Local Extrema Classification. PRIS 2008, 8, 164–172. [Google Scholar] [CrossRef]
- Bengio, Y. A connectionist approach to speech recognition. In Advances in Pattern Recognition Systems Using Neural Network Technologies; World Scientific: Singapore, 1993; pp. 3–23. [Google Scholar] [CrossRef]
- Graves, A.; Liwicki, M.; Bunke, H.; Schmidhuber, J.; Fernández, S. Unconstrained on-line handwriting recognition with recurrent neural networks. In Proceedings of the ADvances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–11 November 2008; pp. 577–584. [Google Scholar]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hannun, A.Y.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep Speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 843–852. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Gupta, A.; Srivastava, M.; Mahanta, C. Offline handwritten character recognition using neural network. In Proceedings of the 2011 IEEE International Conference on Computer Applications and Industrial Electronics (ICCAIE), Penang, Malaysia, 4–7 December 2011; pp. 102–107. [Google Scholar]
- Bianne-Bernard, A.L.; Menasri, F.; Mohamad, R.A.H.; Mokbel, C.; Kermorvant, C.; Likforman-Sulem, L. Dynamic and contextual information in HMM modeling for handwritten word recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2066–2080. [Google Scholar] [CrossRef]
- Bluche, T.; Messina, R. Gated convolutional recurrent neural networks for multilingual handwriting recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 646–651. [Google Scholar]
- Moysset, B.; Bluche, T.; Knibbe, M.; Benzeghiba, M.F.; Messina, R.; Louradour, J.; Kermorvant, C. The A2iA multi-lingual text recognition system at the second Maurdor evaluation. In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Crete Island, Greece, 1–4 September 2014; pp. 297–302. [Google Scholar]
- Puigcerver, J. Are multidimensional recurrent layers really necessary for handwritten text recognition? In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 67–72. [Google Scholar]
- Wang, Z.R.; Du, J.; Wang, J.M. Writer-aware CNN for parsimonious HMM-based offline handwritten Chinese text recognition. Pattern Recognit. 2020, 100, 107102. [Google Scholar] [CrossRef]
- Ly, N.T.; Nguyen, C.T.; Nakagawa, M. An Attention-Based End-to-End Model for Multiple Text Lines Recognition in Japanese Historical Documents. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 629–634. [Google Scholar] [CrossRef]
- Kang, L.; Toledo, J.I.; Riba, P.; Villegas, M.; Fornés, A.; Rusiñol, M. Convolve, Attend and Spell: An Attention-based Sequence-to-Sequence Model for Handwritten Word Recognition. In Pattern Recognition; Brox, T., Bruhn, A., Fritz, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 459–472. [Google Scholar]
- Chowdhury, A.; Vig, L. An efficient end-to-end neural model for handwritten text recognition. arXiv 2018, arXiv:1807.07965. [Google Scholar]
- Wang, Z.; Liu, J.C. Translating math formula images to LaTeX sequences using deep neural networks with sequence-level training. Int. J. Doc. Anal. Recognit. (IJDAR) 2020, 1–13. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Hochreiter, S. The Vanishing Gradient Problem during Learning Recurrent Neural Nets and Problem Solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Hinton, G.; Srivastava, N.; Swersky, K. Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited On 2012, 14. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Frinken, V.; Bunke, H. Continuous Handwritten Script Recognition. In Handbook of Document Image Processing and Recognition; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
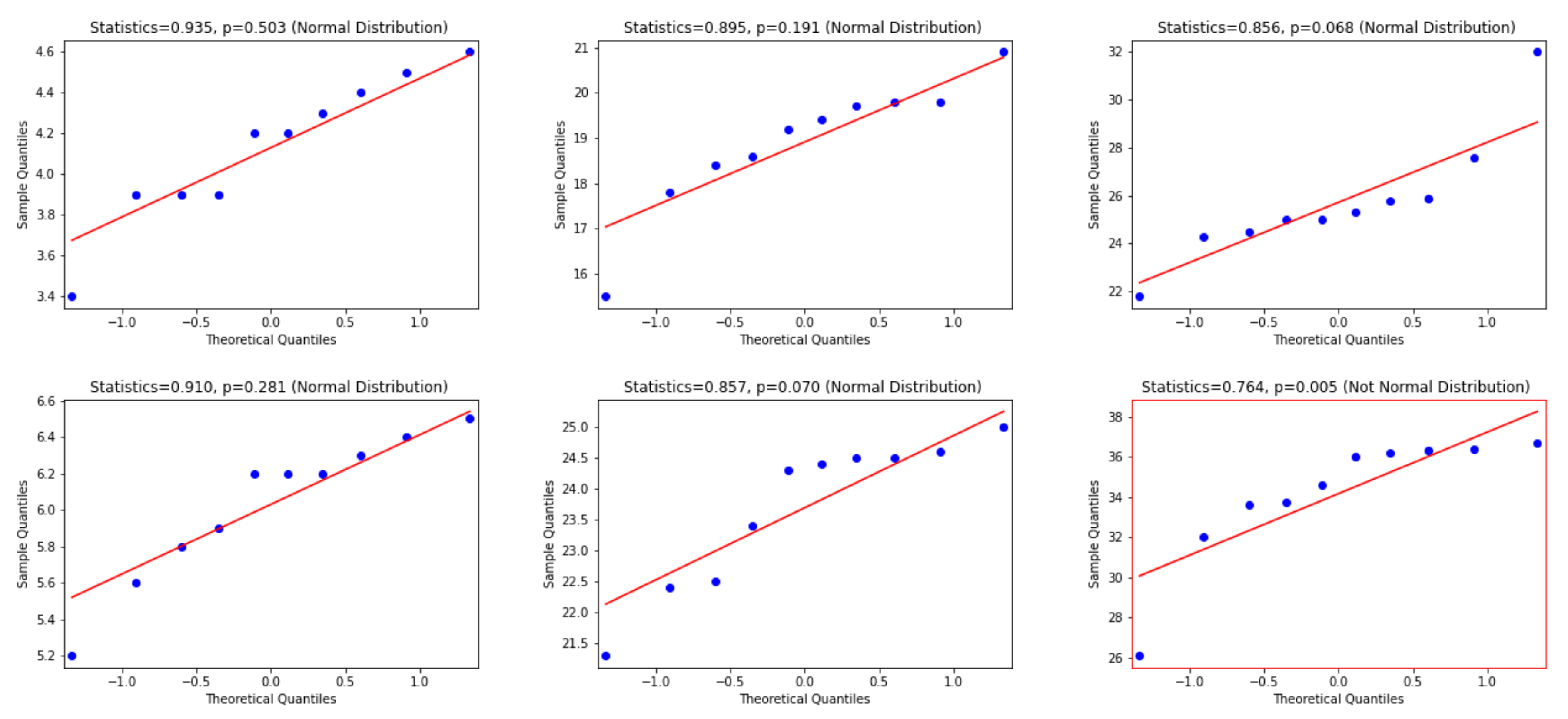
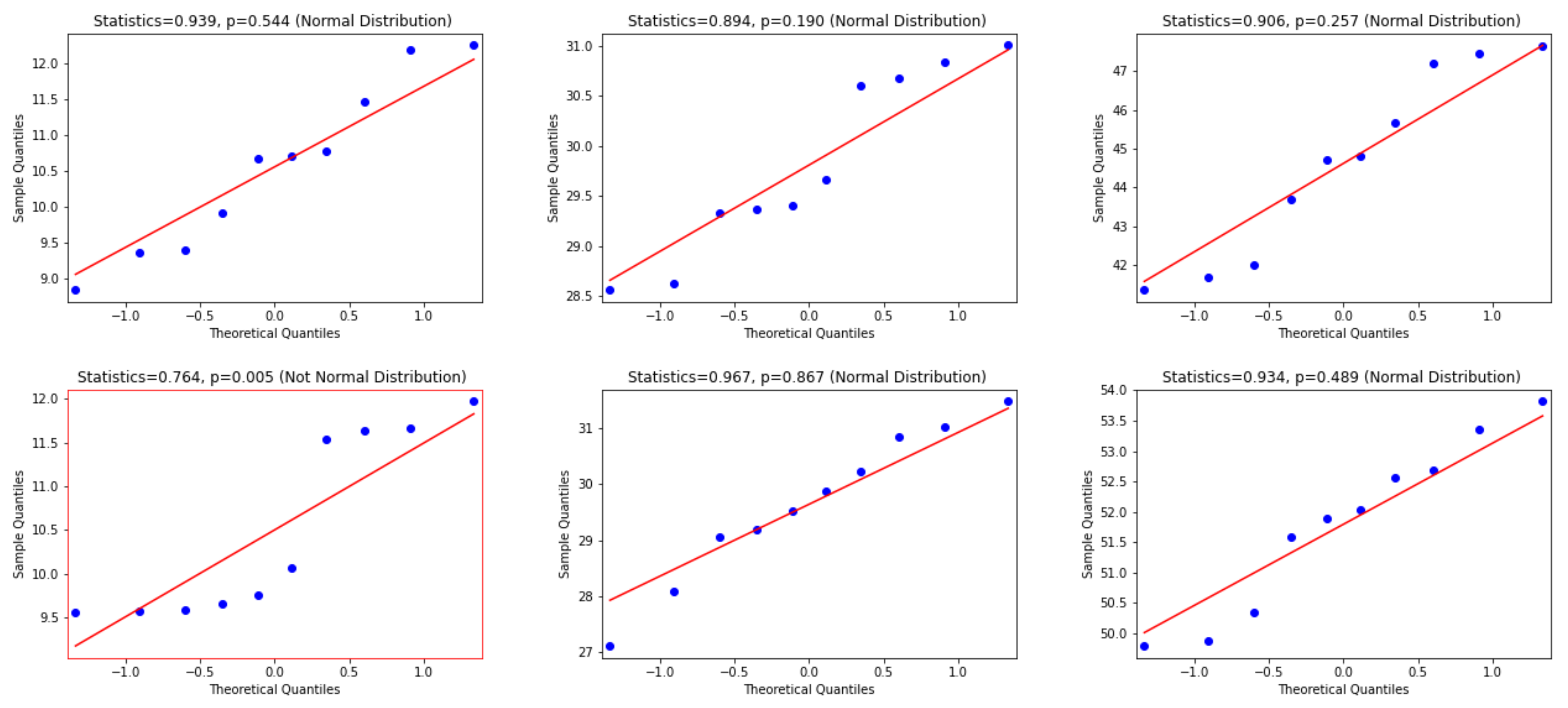
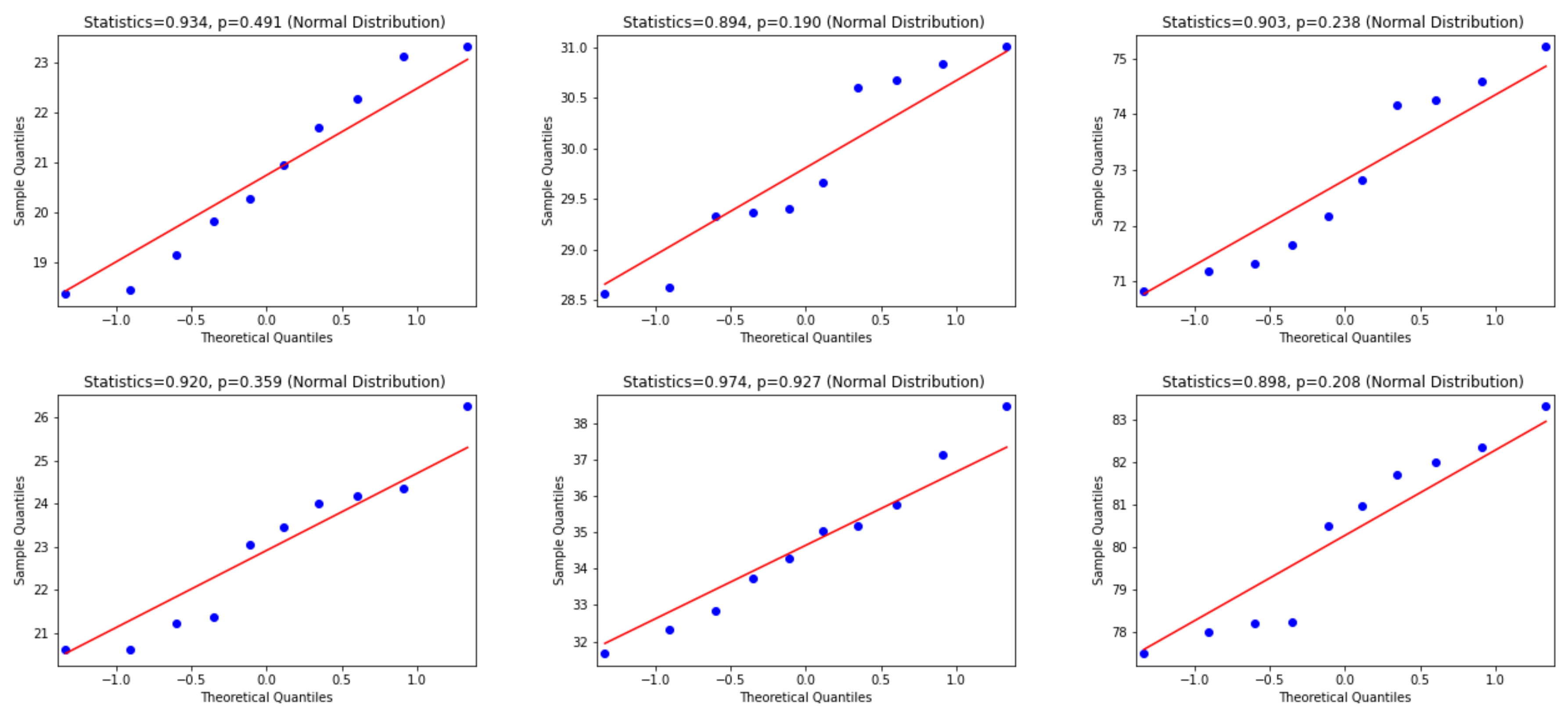
- Wilk, M.B.; Gnanadesikan, R. Probability plotting methods for the analysis for the analysis of data. Biometrika 1968, 55, 1–17. [Google Scholar] [CrossRef]
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- D’agostino, R.B.; Belanger, A.R.B.D., Jr. A Suggestion for Using Powerful and Informative Tests of Normality. Am. Stat. 1990, 44, 316–321. [Google Scholar] [CrossRef]
- Davison, A.C.; Hinkley, D.V. Bootstrap Methods and Their Application; Number 1; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Wilcoxon, F. Individual Comparisons by Ranking Methods. In Breakthroughs in Statistics: Methodology and Distribution; Kotz, S., Johnson, N.L., Eds.; Springer New York: New York, NY, USA, 1992; pp. 196–202. [Google Scholar] [CrossRef]
- Nurseitov, D.; Bostanbekov, K.; Kanatov, M.; Alimova, A.; Abdallah, A.; Abdimanap, G. Classification of Handwritten Names of Cities and Handwritten Text Recognition using Various Deep Learning Models. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 934–943. [Google Scholar] [CrossRef]
- Bostanbekov, K.; Tolegenov, R.; Abdallah, A. Character Accuracy Rate. Available online: https://github.com/abdoelsayed2016/CAR (accessed on 20 November 2020).
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef]
- Scheidl, H. Handwritten Text Recognition in Historical Documents; Technische Universität Wien: Vienna, Austria, 2018. [Google Scholar]
- Lâm, H.T. Line-Level Handwritten Text Recognition with TensorFlow. 2018. Available online: https://github.com/lamhoangtung/LineHTR (accessed on 11 May 2020).
- Nomeroff Net. Automatic Numberplate Recognition System. Version 0.3.1. Available online: https://nomeroff.net.ua/ (accessed on 11 May 2020).
- The leading platform for entire computer vision lifecycle. Available online: https://supervise.ly/ (accessed on 20 November 2020).
- Marti, U.V.; Bunke, H. The IAM-database: An English sentence database for offline handwriting recognition. Int. J. Doc. Anal. Recognit. 2002, 5, 39–46. [Google Scholar] [CrossRef]
- Fischer, A.; Frinken, V.; Fornés, A.; Bunke, H. Transcription alignment of Latin manuscripts using hidden Markov models. In Proceedings of the 2011 Workshop on Historical Document Imaging and Processing, Beijing, China, 16–17 September 2011; pp. 29–36. [Google Scholar]
- Gatos, B.; Louloudis, G.; Causer, T.; Grint, K.; Romero, V.; Sánchez, J.A.; Toselli, A.H.; Vidal, E. Ground-truth production in the transcriptorium project. In Proceedings of the 2014 11th IAPR International Workshop on Document Analysis Systems, Tours, France, 7–10 April 2014; pp. 237–241. [Google Scholar]
- Fischer, A.; Keller, A.; Frinken, V.; Bunke, H. Lexicon-free handwritten word spotting using character HMMs. Pattern Recognit. Lett. 2012, 33, 934–942. [Google Scholar] [CrossRef]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A novel connectionist system for unconstrained handwriting recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 855–868. [Google Scholar] [CrossRef] [PubMed]
- Almazán, J.; Gordo, A.; Fornés, A.; Valveny, E. Word spotting and recognition with embedded attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2552–2566. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Wu, Y.; Yin, F.; Liu, C.L. Simultaneous script identification and handwriting recognition via multi-task learning of recurrent neural networks. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 525–530. [Google Scholar]
- Pham, V.; Bluche, T.; Kermorvant, C.; Louradour, J. Dropout improves recurrent neural networks for handwriting recognition. In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Crete Island, Greece, 1–4 September 2014; pp. 285–290. [Google Scholar]
- Krishnan, P.; Dutta, K.; Jawahar, C. Word spotting and recognition using deep embedding. In Proceedings of the 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 1–6. [Google Scholar]
- Sueiras, J.; Ruiz, V.; Sanchez, A.; Velez, J.F. Offline continuous handwriting recognition using sequence to sequence neural networks. Neurocomputing 2018, 289, 119–128. [Google Scholar] [CrossRef]
- Perez, F.; Vasconcelos, C.; Avila, S.; Valle, E. Data augmentation for skin lesion analysis. In OR 2.0 Context-Aware Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin Image Analysis; Springer: Berlin/Heidelberg, Germany, 2018; pp. 303–311. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Test1 | Test2 | Params | ||||
|---|---|---|---|---|---|---|---|
| CER (in %) | WER (in %) | SER (in %) | CER (in %) | WER (in %) | SER (in %) | ||
| Attention-Gated-CNN-BGRU | 4.13 | 18.91 | 25.72 | 6.31 | 23.69 | 35.16 | 885K |
| [3.4–4.6] | [15.5–20.9] | [21.8–32.0] | [5.2–6.4] | [21.3–25.0] | [32.0–36.7] | ||
| Bluche [35] | 728K | ||||||
| [8.35–13.1] | [26.9–31.6] | [40.3–48.2] | [9.5–12.2] | [29.45–31.8] | [49.5–55.8] | ||
| Puigcerver [37] | 9.6M | ||||||
| [17.78–23.87] | [31.57–38.84] | [69.56–75.85] | [20.31–26.73] | [31.6–39.2] | [77.2–83.3] | ||
| Input | Label | Prediction |
|---|---|---|
 | Густую холодеющую | Густую холодеюую |
 | ЖАМБЫЛЬСКАЯ | ЖаМбЫЛСКАЯ |
 | Еще не появившиеся | Еице не появившс |
 | А встретятся | А встретятся |
 | ТУРКЕСТАН | Туркестан |
 | Отеген батыра | Отеген батыра |
 | Качар | Качар |
 | Колхозницы | Колхозницы |
 | молодость прошла! | молодость прошла ! |
 | Павлодарская | Павлодарская |
 | Жаркент | Жаркент |
 | Байконыр | Байконыр |
| Model | Test1 | Test2 | Params | ||||
|---|---|---|---|---|---|---|---|
| CER (in %) | WER (in %) | SER (in %) | CER (in %) | WER (in %) | SER (in %) | ||
| Attention model | 4.13 | 18.91 | 25.27 | 6.31 | 23.69 | 35.16 | 885K |
| Without Attention | 9.5 | 37.7 | 46.1 | 11.4 | 41.1 | 49.4 | 823K |
| Without GRU | 23.5 | 76.4 | 83.6 | 19.5 | 61.6 | 80.8 | 296K |
| Model | Test1 | Test2 | |||||
|---|---|---|---|---|---|---|---|
| CER | WER | SER | CER | WER | SER | ||
| Attention-Gated-CNN-BGRU—Bluche | t-test | −14.36 | −20.38 | −13.64 | −12.29 | −9.70 | −23.69 |
| p-value | 1.63 × 10 | 7.66 × 10 | 2.56 × 10 | 6.23 × 10 | 4.60 × 10 | 2.02 × 10 | |
| Attention-Gated-CNN-BGRU—Puigcerver | t-test | −27.03 | −26.85 | −43.74 | −27.39 | −12.51 | −70.11 |
| p-value | 6.26 × 10 | 6.66 × 10 | 8.51 × 10 | 5.57 × 10 | 5.397 × 10 | 1.23 × 10 | |
| Model | IAM | Saint Gall | Washington | Bentham | ||||
|---|---|---|---|---|---|---|---|---|
| CER (in %) | WER (in %) | CER (in %) | WER (in %) | CER (in %) | WER (in %) | CER (in %) | WER (in %) | |
| Graves [64] | - | - | - | - | - | - | ||
| Almazan [65] | - | - | - | - | - | - | ||
| Chen [66] | 11.15 | - | - | - | - | - | - | |
| Pham [67] | 10.80 | 35.10 | - | - | - | - | - | - |
| Krishnanet [68] | 9.78 | 32.89 | - | - | - | - | - | - |
| Chowdhury [41] | 8.10 | 16.70 | - | - | - | - | - | - |
| Jorge Sueiras [69] | 6.20 | 12.70 | - | - | - | - | - | - |
| Lei Kang [40] | 6.88 | 17.45 | - | - | - | - | - | - |
| Puigcerver [37] | 8.20 | 25.0 | 12.5 | 36.9 | 20.6 | 35.6 | 7.2 | 20.3 |
| Bluche [35] | 6.96 | 18.89 | 8.13 | 25.78 | 12.78 | 23.15 | 7.81 | 20.93 |
| Attention-Gated-CNN-BGRU | 5.79 | 15.85 | 7.25 | 23.0 | 8.70 | 21.50 | 6.10 | 18.20 |
| Method | Description | |
|---|---|---|
| 1 | Saturation, Contrast, and Brightness | To modify saturation, contrast, and brightness, we sampled random factors from a uniform distribution of [0.7, 1.3]. |
| 2 | Saturation, Contrast, Brightness, and Hue | As shown in 1, but also the hue is shifted by a value sampled from a uniform distribution of [−0.1, 0.1]. |
| 3 | Affine and Scaling | Rotate the image by up to 90, shear by up to 20, and scale the area by [0:8; 1:2]. New pixels are filled symmetrically at edges. |
| 4 | Flips | Randomly flip the images horizontally and/or vertically. |
| 5 | Random Crops | Randomly crop the original image. The crop has 0.4–1.0 of the original image, and 3/4–4/3 of the original aspect ratio. |
| 6 | Random Erasing | Fill part of the image (area up to 30% of the original image) with random noise. The transformation is applied with a probability of 0.5. |
| 6 | Erosion and Dilation | gray-scale erosion with 5%, and dilation with 5%. |
| Model | IAM | Saint Gall | Washington | Bentham | ||||
|---|---|---|---|---|---|---|---|---|
| CER (in %) | WER (in %) | CER (in %) | WER (in %) | CER (in %) | WER (in %) | CER (in %) | WER (in %) | |
| Puigcerver | 5.97 ± 0.06 | 13.73 ± 0.17 | 9.15 ± 0.06 | 25.37 ± 0.15 | 14.29 ± 0.09 | 24.87 ± 0.19 | 5.65 ± 0.07 | 16.75 ± 0.18 |
| Bluche | 4.94 ± 0.07 | 11.19 ± 0.19 | 7.01 ± 0.04 | 21.87 ± 0.15 | 9.90 ± 0.07 | 18.95 ± 0.18 | 5.40 ± 0.06 | 15.82 ± 0.15 |
| Attention-Gated-CNN-BGRU | 3.23 ± 0.03 | 9.21 ± 0.11 | 4.47 ± 0.05 | 19.21 ± 0.12 | 5.32 ± 0.06 | 15.87 ± 0.14 | 4.73 ± 0.04 | 11.18 ± 0.13 |
| Model | IAM | Saint Gall | Washington | Bentham | |||||
|---|---|---|---|---|---|---|---|---|---|
| CER | WER | CER | WER | CER | WER | CER | WER | ||
| Attention-Gated-CNN-BGRU—Bluche | t-test | −80.26 | −44.08 | −164.48 | −94.58 | −465.65 | −74.68 | −54.84 | −129.43 |
| p-value | 3.65 × 10 | 7.94 × 10 | 5.76 × 10 | 8.36 × 10 | 4.94 × 10 | 6.99 × 10 | 1.12 × 10 | 4.98 × 10 | |
| Attention-Gated-CNN-BGRU—Puigcerver | t-test | −150.39 | −96.58 | −819.12 | −221.11 | −488.43 | −257.28 | −71.33 | −125.74 |
| p-value | 1.29 × 10 | 6.93 × 10 | 3.06 × 10 | 4.02 × 10 | 3.21 × 10 | 1.03 × 10 | 1.05 × 10 | 6.46 × 10 | |
| Exp | Test1 | Test2 | Seed | Time | ||||
|---|---|---|---|---|---|---|---|---|
| CER (in %) | WER (in %) | SER (in %) | CER (in %) | WER (in %) | SER (in %) | |||
| 1 | 1234 | 3 days, 2:52:28 | ||||||
| 2 | 50 | 2 days, 22:22:27 | ||||||
| 3 | 70 | 4 days, 14:32:49 | ||||||
| 4 | 1225 | 7 days, 1:46:26 | ||||||
| 5 | 80 | 5 days, 0:13:21 | ||||||
| 6 | 500 | 3 days, 12:50:51 | ||||||
| 7 | 2000 | 2 days, 10:50:32 | ||||||
| 8 | 1334 | 2 days, 22:36:42 | ||||||
| 9 | 800 | 4 days, 6:15:17 | ||||||
| 10 | 150 | 5 days, 4:52:44 | ||||||
| mean | 4.13 | 18.91 | 25.72 | 60.30 | 23.69 | 35.16 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdallah, A.; Hamada, M.; Nurseitov, D. Attention-Based Fully Gated CNN-BGRU for Russian Handwritten Text. J. Imaging 2020, 6, 141. https://doi.org/10.3390/jimaging6120141
Abdallah A, Hamada M, Nurseitov D. Attention-Based Fully Gated CNN-BGRU for Russian Handwritten Text. Journal of Imaging. 2020; 6(12):141. https://doi.org/10.3390/jimaging6120141
Chicago/Turabian StyleAbdallah, Abdelrahman, Mohamed Hamada, and Daniyar Nurseitov. 2020. "Attention-Based Fully Gated CNN-BGRU for Russian Handwritten Text" Journal of Imaging 6, no. 12: 141. https://doi.org/10.3390/jimaging6120141
APA StyleAbdallah, A., Hamada, M., & Nurseitov, D. (2020). Attention-Based Fully Gated CNN-BGRU for Russian Handwritten Text. Journal of Imaging, 6(12), 141. https://doi.org/10.3390/jimaging6120141