Detecting Morphing Attacks through Face Geometry Features



Abstract
1. Introduction
- We conduct an extensive experimental campaign to assess the effectiveness of landmark-based geometric features for the pairs. This includes adopting different training/testing conditions to encourage a sufficiently high variability between training and testing sets in terms of source datasets and subject characteristics and to better assess the generalization abilities of the detectors. A corpus of images belonging to different source datasets has been constructed, which represents a wider and more diverse benchmark with respect to previous studies in this direction [13,14].
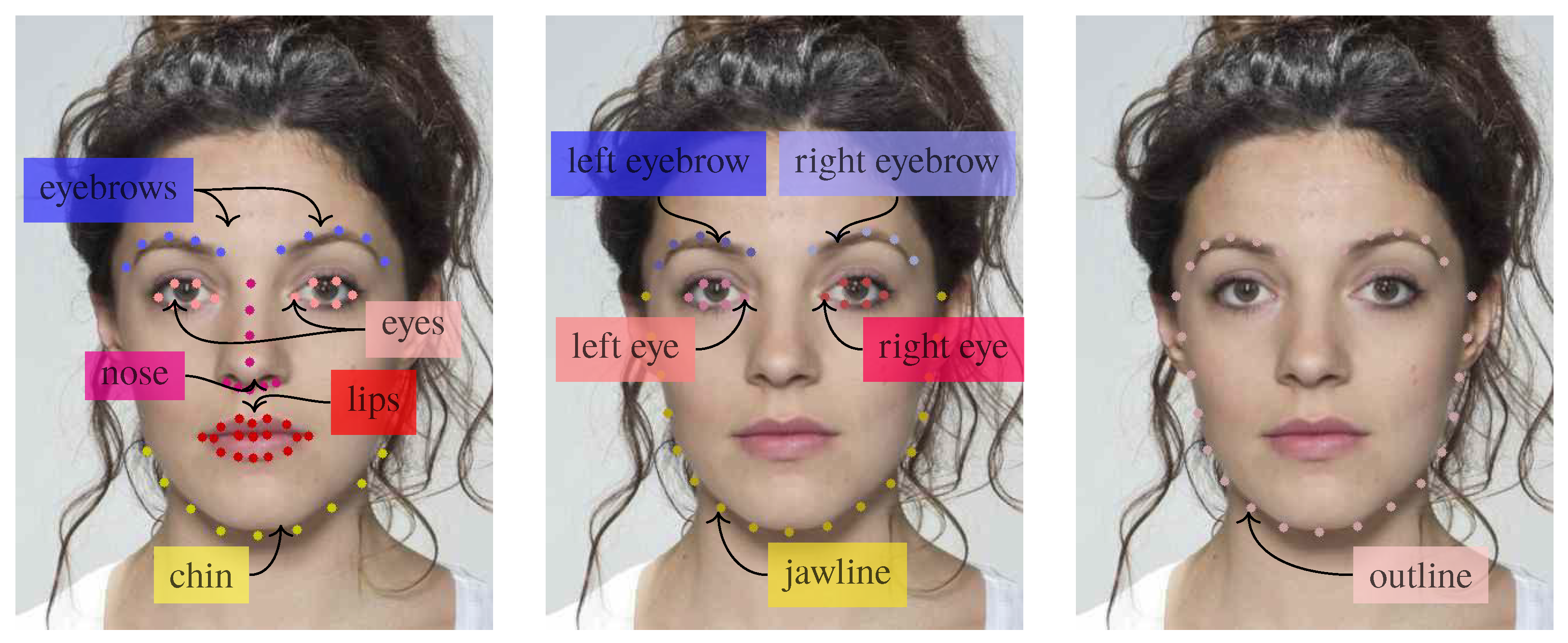
- We identify the more relevant face areas for morphing detection through an ablation study on semantically related groups of landmarks, thus gaining insights on the face locations where more discriminative patterns can be found.
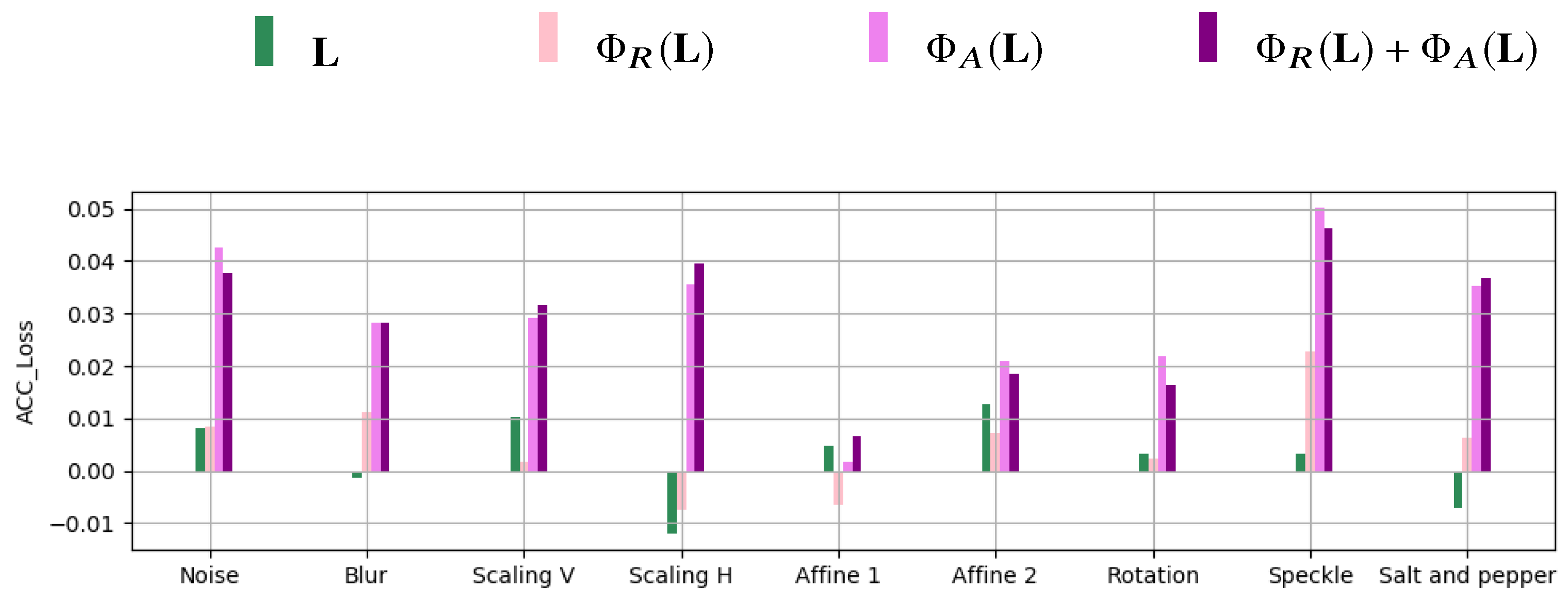
- We evaluate the effect of noise sources that can typically affect the image pairs in realistic scenarios, revealing that the performance of the proposed detectors against unseen processing in the training tests are largely preserved. This confirms the advantage of geometric-based method of being stable against common image alterations, as opposed to texture-based approaches.
2. Related Work
2.1. Creation of Morphed Faces
2.2. Single-Image Detectors
2.3. Differential Detectors
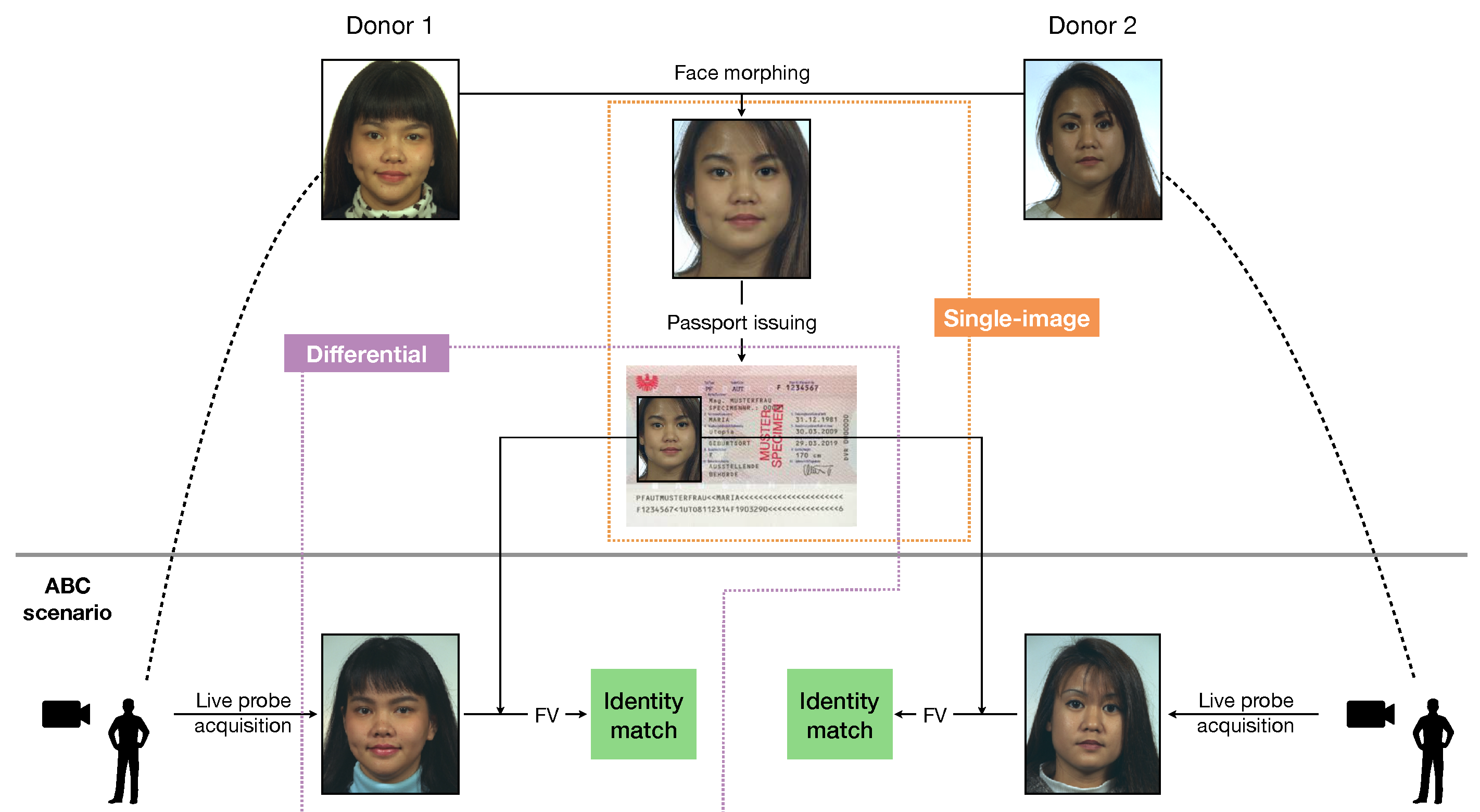
3. Detection Framework
- Bona fide pairs: the eMRTD contains a genuine face image of the physical subject.
- Attacked pairs: the eMRTD contains a morphed face image of which physical subject is a donor.
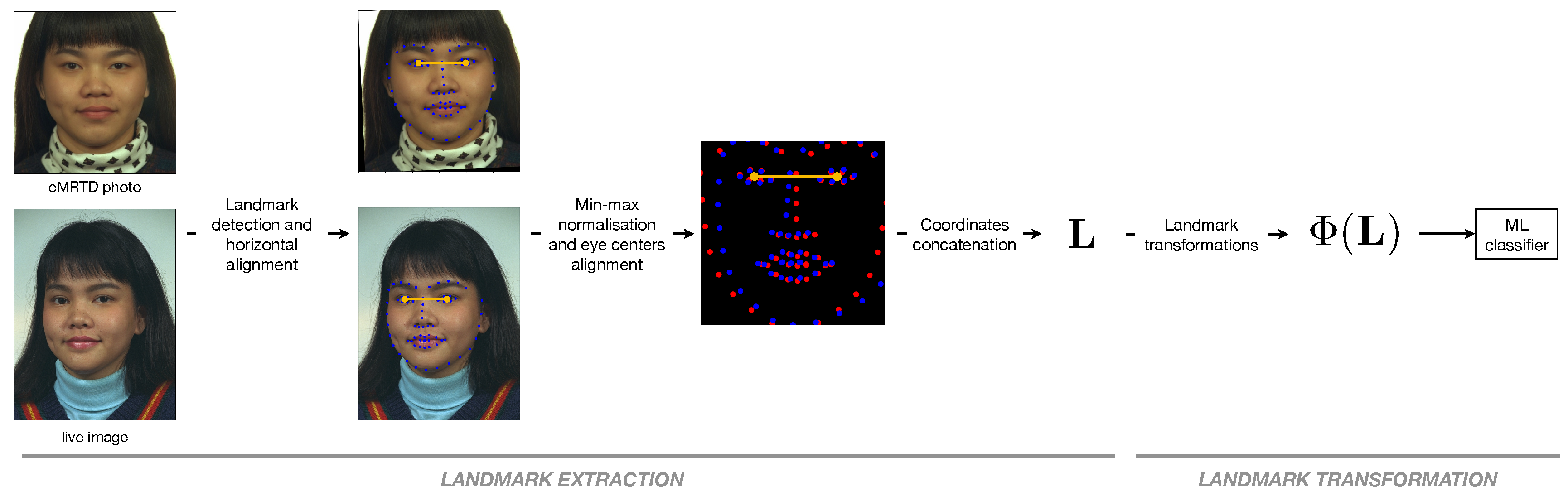
3.1. Landmark Extraction
3.2. Landmark Transformations
3.2.1. Anthropometry-Based Features
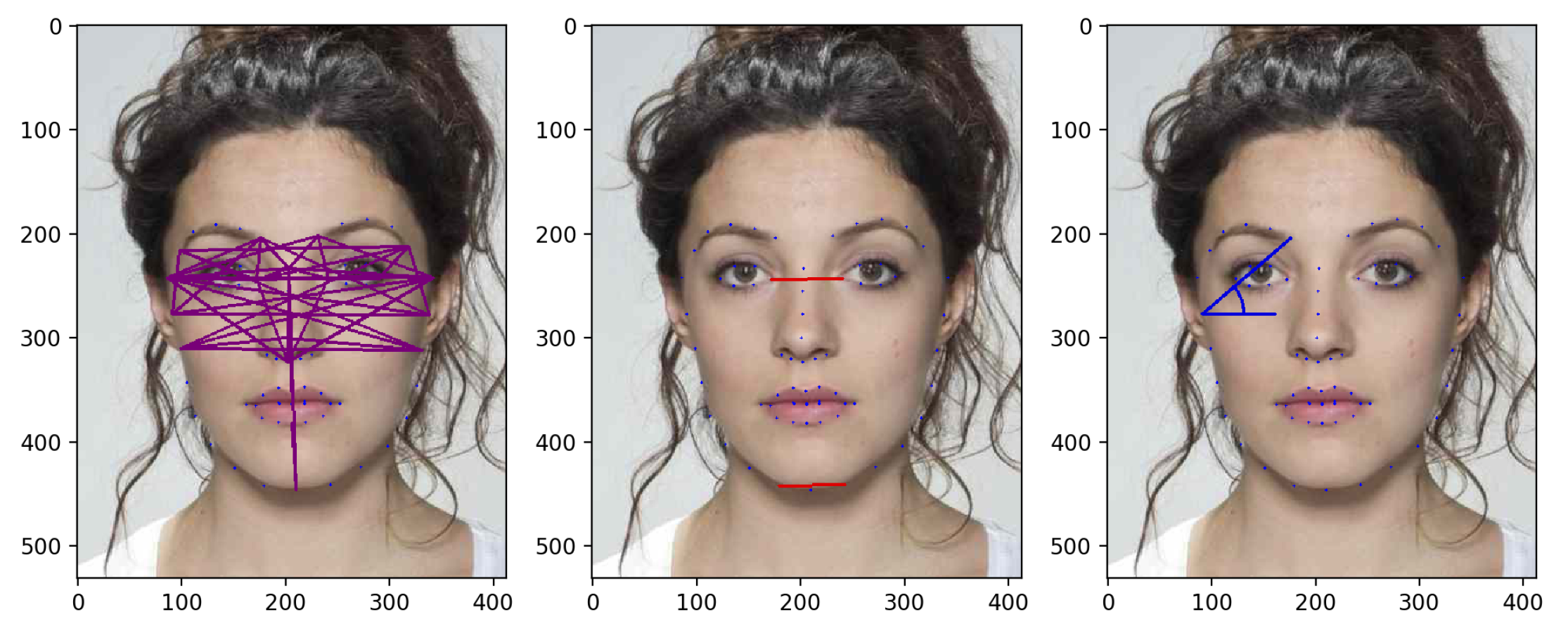
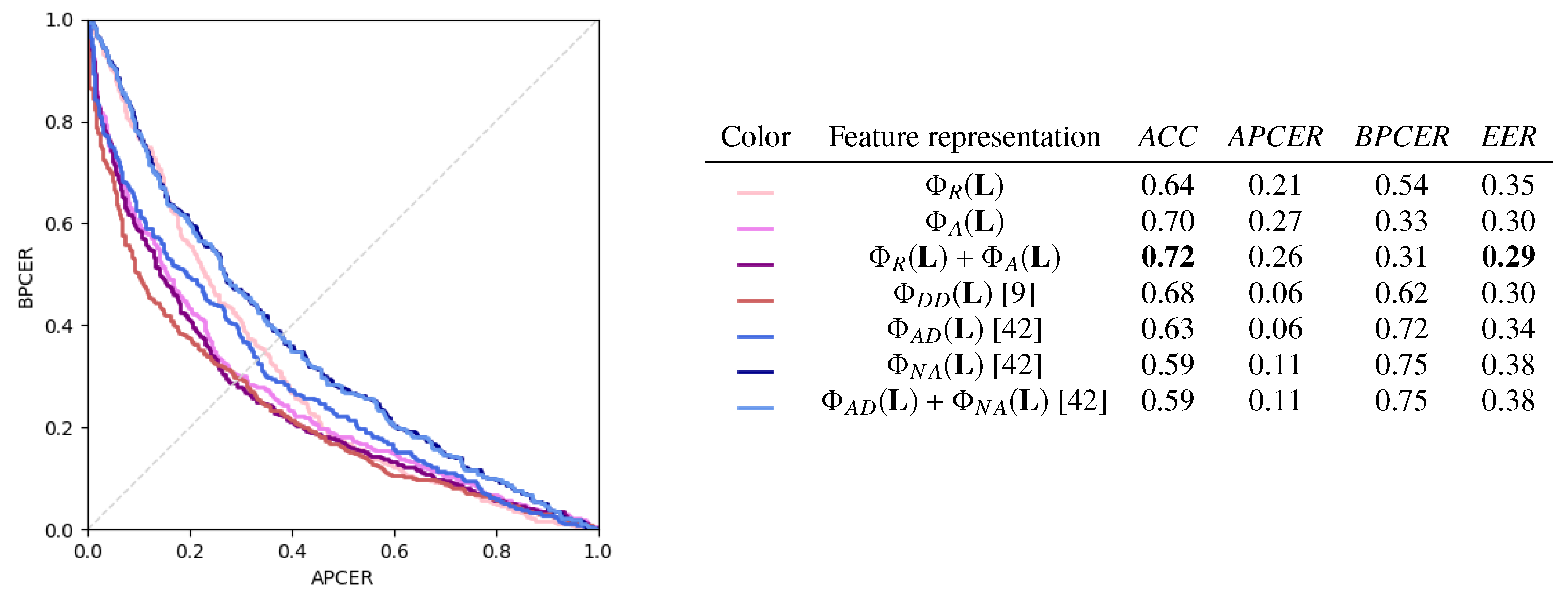
- Ratios (): for each face, we consider 47 pairs of landmarks and compute the distance between them, as depicted in (Figure 5, left). Those landmarks are selected as highly involved in the morphing process and less sensitive to slight expression variations. Then, those distances are divided individually by the two benchmark distances depicted in red in (Figure 5, middle) and chosen so that they are reliably detected and relatively stable through the morphing process, according to the approach proposed in [36]. Those 94 ratio values from each face are then concatenated, resulting in a feature vector of size 188.
- Angles (): we take the 47 distances and the 2 benchmark distances used for transformation. The angle between each of these distances and the horizontal line are then computed for the two faces (see Figure 5, right) and stored in a vector, resulting into a feature vector of size .
- Ratios+Angles (): in this case, and are simply concatenated, the size of the feature vector being .
3.2.2. Previously Proposed Landmark-Based Features
- Directed Distances (): proposed in [13], the transformation yields a 136-dimensional vector containing shifting patterns between corresponding landmarks in the two faces.
- All Distances and Neighbour Angles (): the approach in [14] leads to two transformations: calculates a 2278-dimensional feature vector based on distances between all extracted landmarks of a face image; only considers angle differences between neighbouring landmarks and yields a 68-dimensional feature vector.
4. Experimental Results
4.1. Experimental Setup
- Bona-fide pairs:
- -
- AR: 472 pairs formed starting from images in the AR dataset [37]. For every subject, pictures taken in two different acquisitions and distinct poses are available. We selected the 2 available frontal facing images where the face shows neutral expressions from both sessions and paired them with each other.
- -
- REPLAY: 140 pairs formed from frames extracted from the Replay dataset [38], which was originally proposed to benchmark detectors of face spoofing attacks.
- -
- Attacked pairs:
- -
- -
- APCER (Attack Presentation Classification Error Rate): ratio of attacked pairs erroneously classified as bona fide pairs;
- BPCER (Bona fide Presentation Classification Error Rate): ratio of bona fide pairs erroneously classified as attacked pairs;
- ACC (Accuracy): fraction of image pairs that are correctly classified (either as bona-fide or attacked)
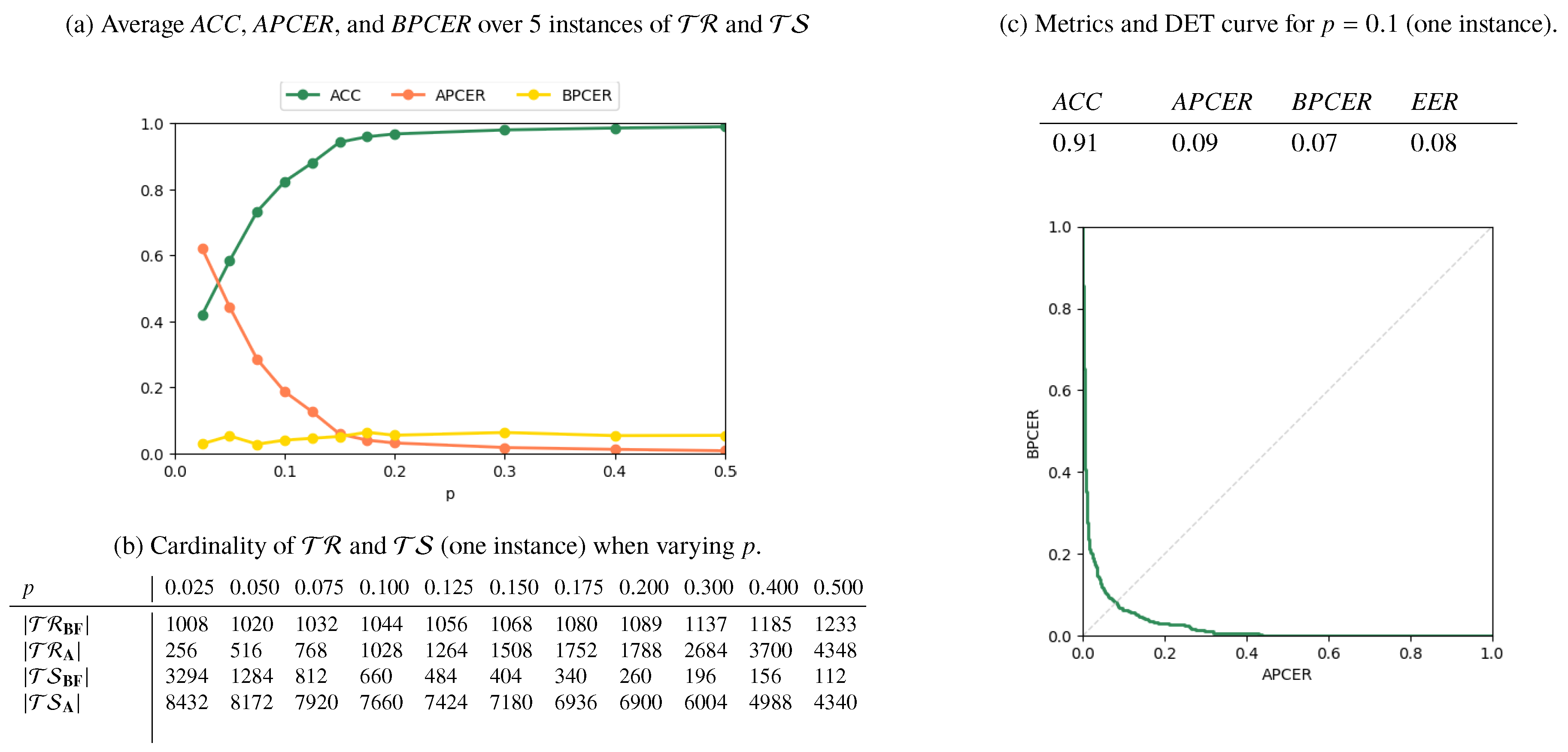
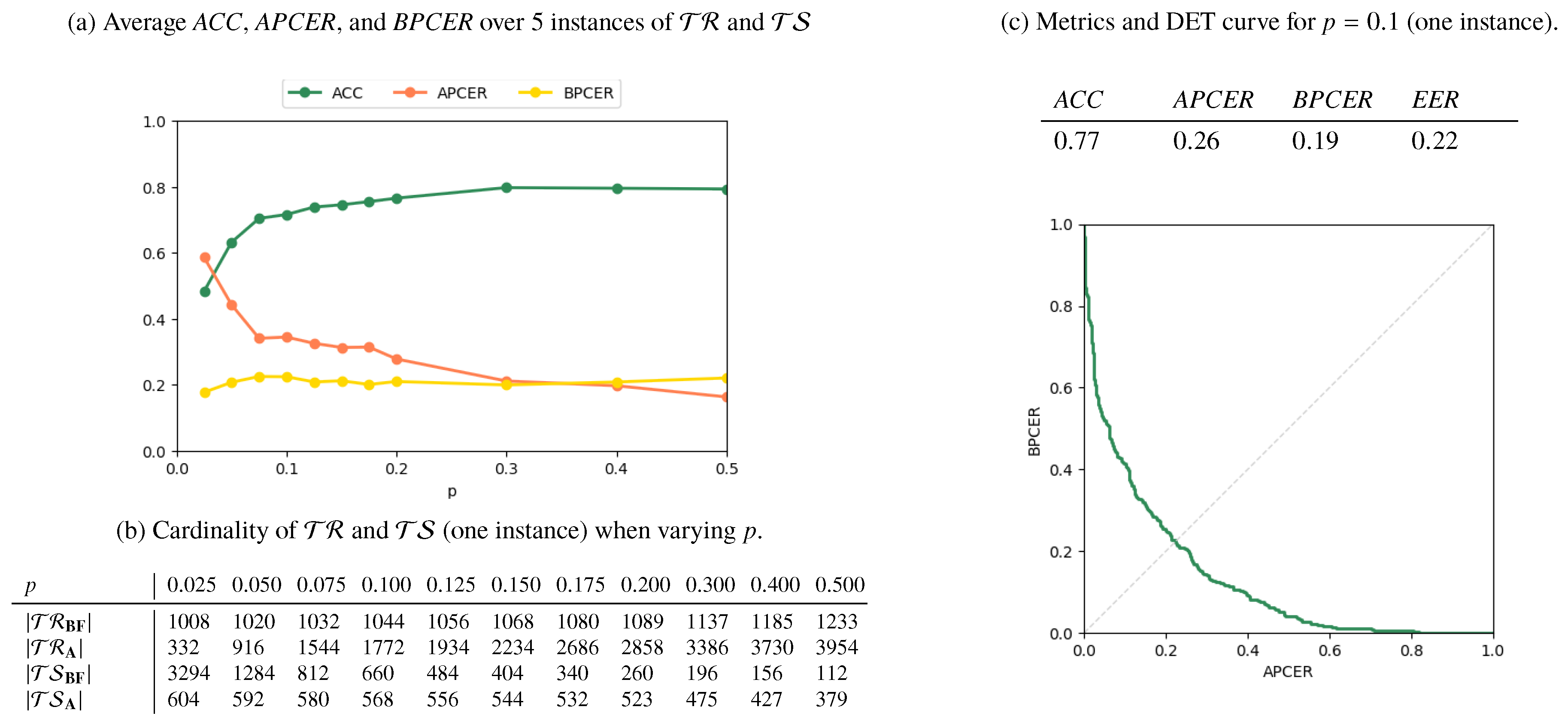
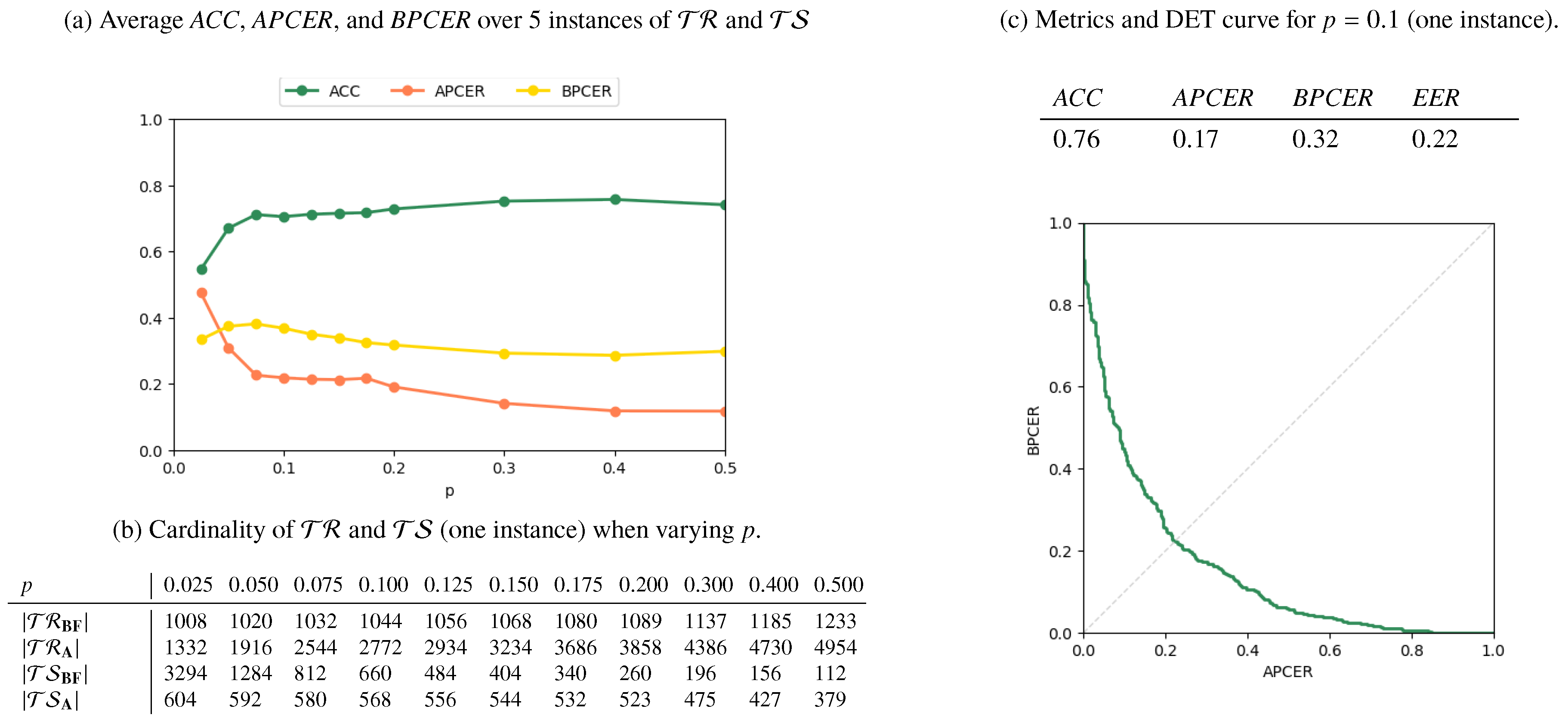
4.2. Full Landmark Set
- a fraction p of the subjects appearing in are randomly chosen;
- all the pairs in which depict any of these subjects in one or both images or as donors of a morphed fac, are stored in
- the remaining pairs in are stored in
4.3. Ablation Study
4.4. Comparison of Landmark Transformations
4.5. Robustness to Processing Operations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; BMVA Press: Durham, UK, 2015; pp. 41.1–41.12. [Google Scholar]
- Balaban, S. Deep learning and face recognition: The state of the art. In Proceedings Volume 9457 Biometric and Surveillance Technology for Human and Activity Identification XII; SPIE: Bellingham, WA, USA, 2015. [Google Scholar] [CrossRef]
- Neubert, T.; Kraetzer, C.; Dittmann, J. A Face Morphing Detection Concept with a Frequency and a Spatial Domain Feature Space for Images on eMRTD. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Paris, France, 3–5 July 2019; pp. 95–100. [Google Scholar]
- Ferrara, M.; Franco, A.; Maltoni, D. The magic passport. In Proceedings of the IEEE International Joint Conference on Biometrics, 2014, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Biometix Pty Ltd. New Face Morphing Dataset (for Vulnerability Research). 2018. Available online: http://www.biometix.com/2017/09/18/new-face-morphing-dataset-for-vulnerability-research/ (accessed on 1 December 2019).
- Makrushin, A.; Neubert, T.; Dittmann, J. Automatic Generation and Detection of Visually Faultless Facial Morphs. In Proceedings of the Internation Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Porto, Portugal, 27 February–1 March 2017; pp. 39–50. [Google Scholar] [CrossRef]
- Scherhag, U.; Rathgeb, C.; Busch, C. Performance variation of morphed face image detection algorithms across different datasets. In Proceedings of the 2018 International Workshop on Biometrics and Forensics (IWBF), Sassari, Italy, 7–8 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Pasquini, C.; Schöttle, P.; Böhme, R.; Boato, G.; Pèrez-Gonzàlez, F. Forensics of High Quality and Nearly Identical JPEG Image Recompression. In Proceedings of the ACM Information Hiding and Multimedia Security Workshop, Vigo, Spain, 20–22 June 2016; pp. 11–21. [Google Scholar]
- Shang, S.; Kong, X. Printer and Scanner Forensics. In Handbook of Digital Forensics of Multimedia Data and Devices; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2015; Chapter 10; pp. 375–410. [Google Scholar]
- Pasquini, C.; Böhme, R. Information-Theoretic Bounds for the Forensic Detection of Downscaled Signals. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1928–1943. [Google Scholar] [CrossRef]
- Neubert, T.; Makrushin, A.; Hildebrandt, M.; Krätzer, C.; Dittmann, J. Extended StirTrace benchmarking of biometric and forensic qualities of morphed face images. IET Biom. 2018, 7, 325–332. [Google Scholar] [CrossRef]
- Scherhag, U.; Rathgeb, C.; Busch, C. Morph Detection from Single Face Image: A Multi-Algorithm Fusion Approach. In Proceedings of the 2018 2Nd International Conference on Biometric Engineering and Applications; ICBEA ’18; ACM: New York, NY, USA, 2018; pp. 6–12. [Google Scholar] [CrossRef]
- Damer, N.; Boller, V.; Wainakh, Y.; Boutros, F.; Terhörst, P.; Braun, A.; Kuijper, A. Detecting Face Morphing Attacks by Analyzing the Directed Distances of Facial Landmarks Shifts. In Pattern Recognition; Brox, T., Bruhn, A., Fritz, M., Eds.; Springer International Publishing: Berlin, Germany, 2019; pp. 518–534. [Google Scholar]
- Scherhag, U.; Budhrani, D.; Gomez-Barrero, M.; Busch, C. Detecting Morphed Face Images Using Facial Landmarks. In Image and Signal Processing; Springer International Publishing: Cham, Switzerland, 2018; pp. 444–452. [Google Scholar] [CrossRef]
- Scherhag, U.; Rathgeb, C.; Merkle, J.; Breithaupt, R.; Busch, C. Face Recognition Systems Under Morphing Attacks: A Survey. IEEE Access 2019, 7, 23012–23026. [Google Scholar] [CrossRef]
- FaceMorpher. Available online: https://github.com/stheakanath/facemorpher (accessed on 27 July 2020).
- FaceMorpher Luxand. Available online: https://www.luxand.com/facemorpher/ (accessed on 27 July 2020).
- Damer, N.; Saladié, A.M.; Braun, A.; Kuijper, A. MorGAN: Recognition Vulnerability and Attack Detectability of Face Morphing Attacks Created by Generative Adversarial Network. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Los Angeles, CA, USA, 22–25 October 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Venkatesh, S.; Zhang, H.; Ramachandra, R.; Raja, K.B.; Damer, N.; Busch, C. Can GAN Generated Morphs Threaten Face Recognition Systems Equally as Landmark Based Morphs?-Vulnerability and Detection. In Proceedings of the IEEE International Workshop on Biometrics and Forensics (IWBF), Porto, Portugal, 29–30 April 2020; pp. 1–6. [Google Scholar]
- Scherhag, U.; Rathgeb, C.; Busch, C. Towards Detection of Morphed Face Images in Electronic Travel Documents. In Proceedings of the 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 187–192. [Google Scholar] [CrossRef]
- Wandzik, L.; Kaeding, G.; Garcia, R.V. Morphing Detection Using a General- Purpose Face Recognition System. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1012–1016. [Google Scholar]
- Jassim, S.; Asaad, A. Automatic Detection of Image Morphing by Topology-based Analysis. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1007–1011. [Google Scholar]
- Rashid, R.D.; Asaad, A.; Jassim, S. Topological data analysis as image steganalysis technique. In Proceedings of the Mobile Multimedia/Image Processing, Security, and Applications, Bellingham, WA, USA, 16–17 April 2018; Volume 10668, pp. 103–111. [Google Scholar]
- Kraetzer, C.; Makrushin, A.; Neubert, T.; Hildebrandt, M.; Dittmann, J. Modeling Attacks on Photo-ID Documents and Applying Media Forensics for the Detection of Facial Morphing. In Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, Philadelphia, PA, USA, 20–21 June 2017; IH&MMSec ’17. ACM: New York, NY, USA, 2017; pp. 21–32. [Google Scholar] [CrossRef]
- Debiasi, L.; Rathgeb, C.; Scherhag, U.; Uhl, A.; Busch, C. PRNU Variance Analysis for Morphed Face Image Detection. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Los Angeles, CA, USA, 22–25 October 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Scherhag, U.; Debiasi, L.; Rathgeb, C.; Busch, C.; Uhl, A. Detection of Face Morphing Attacks Based on PRNU Analysis. IEEE Trans. Biom. Behav. Identity Sci. 2019, 1, 302–317. [Google Scholar] [CrossRef]
- Makrushin, A.; Kraetzer, C.; Neubert, T.; Dittmann, J. Generalized Benford’s Law for Blind Detection of Morphed Face Images. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, 20–22 June 2018; pp. 49–54. [Google Scholar] [CrossRef]
- Seibold, C.; Hilsmann, A.; Eisert, P. Reflection Analysis for Face Morphing Attack Detection. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1022–1026. [Google Scholar]
- Seibold, C.; Samek, W.; Hilsmann, A.; Eisert, P. Detection of Face Morphing Attacks by Deep Learning. In Digital Forensics and Watermarking; Kraetzer, C., Shi, Y.Q., Dittmann, J., Kim, H.J., Eds.; Springer International Publishing: Berlin, Germany, 2017; pp. 107–120. [Google Scholar]
- Raghavendra, R.; Raja, K.B.; Venkatesh, S.; Busch, C. Transferable Deep-CNN Features for Detecting Digital and Print-Scanned Morphed Face Images. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1822–1830. [Google Scholar] [CrossRef]
- Ferrara, M.; Franco, A.; Maltoni, D. Face Demorphing. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1008–1017. [Google Scholar] [CrossRef]
- Peng, F.; Zhang, L.; Long, M. FD-GAN: Face-demorphing generative adversarial network for restoring accomplice’s facial image. IEEE Access 2019, 7, 75122–75131. [Google Scholar] [CrossRef]
- Scherhag, U.; Rathgeb, C.; Merkle, J.; Busch, C. Deep Face Representations for Differential Morphing Attack Detection. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3625–3639. [Google Scholar] [CrossRef]
- Farkas, L.G.; Munro, I.R. Anthropometric facial proportions in medicine. Am. J. Orthod. Dentofac. Orthop. 1987, 92, 522. [Google Scholar]
- Gupta, S.; Markey, M.; Bovik, A.C. Anthropometric 3D Face Recognition. Int. J. Comput. Vis. 2010, 90, 331–349. [Google Scholar] [CrossRef]
- Shi, J.; Samal, A.; Marx, D. How Effective Are Landmarks and Their Geometry for Face Recognition? Comput. Vis. Image Underst. 2006, 102, 117–133. [Google Scholar] [CrossRef]
- Martinez, A.; Benavente, R. The AR Face Database. Tech. Rep. CVC Tech. Rep. 1998. Available online: http://www2.ece.ohio-state.edu/~aleix/ARdatabase.html (accessed on 1 March 2020).
- Chingovska, I.; Anjos, A.; Marcel, S. On the Effectiveness of Local Binary Patterns in Face Anti-spoofing. In Proceedings of the International Conference of Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 6–7 September 2012. [Google Scholar]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.; Hawk, S.; Knippenberg, A. Presentation and validation of the Radboud Face Database. Cogn. Emot. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Peer, P. CVL Face Database. 2010. Available online: http://lrv.fri.uni-lj.si/facedb.html (accessed on 1 March 2020).
- Kasiński, A.; Florek, A.; Schmidt, A. The PUT face database. Image Process. Commun. 2008, 13, 59–64. [Google Scholar]
- Thomaz, C.; Giraldi, G. A new ranking method for Principal Components Analysis and its application to face image analysis. Image Vis. Comput. 2010, 28, 902–913. [Google Scholar] [CrossRef]
- Ma, D.; Correll, J.; Wittenbrink, B. The Chicago face database: A free stimulus set of faces and norming data. Behav. Res. Methods 2015, 47. [Google Scholar] [CrossRef] [PubMed]
- AMSL Face Morph Image Data Set. 2018. Available online: https://omen.cs.uni-magdeburg.de/disclaimer/index.php (accessed on 1 December 2019).
- Phillips, P.J.; Moon, H.; Rizvi, S.A.; Rauss, P.J. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Dabouei, A.; Soleymani, S.; Dawson, J.M.; Nasrabadi, N.M. Fast Geometrically-Perturbed Adversarial Faces. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AMSL-only | ||||
| FERET-only | ||||
| Mixed |
| Model | ACC | APCER | BPCER | Average Training Time per p | Average Prediction Time per Pair |
|---|---|---|---|---|---|
| RBF SVM | min | s | |||
| 1D CNN | min | s |
| Feature Representation | ACC | APCER | BPCER | EER |
|---|---|---|---|---|
| Name | Description |
|---|---|
| Noise | Additive Gaussian noise with |
| Blur | Blurring with normalized box filter |
| Scaling V | Downscaling the vertical dimension by 1–2% |
| Scaling H | Downscaling the horizontal dimension by 1–2% |
| Affine 1 | Applying small offsets to three selected landmarks and the corresponding affine transform to the whole image |
| Affine 2 | Applying a small offset to one selected landmark and the corresponding affine transform to the whole image |
| Rotation | Rotating the image by % degrees |
| Speckle | Multiplicative noise |
| Salt and pepper | Punctual noise on 4% of pixels |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Autherith, S.; Pasquini, C. Detecting Morphing Attacks through Face Geometry Features. J. Imaging 2020, 6, 115. https://doi.org/10.3390/jimaging6110115
Autherith S, Pasquini C. Detecting Morphing Attacks through Face Geometry Features. Journal of Imaging. 2020; 6(11):115. https://doi.org/10.3390/jimaging6110115
Chicago/Turabian StyleAutherith, Stephanie, and Cecilia Pasquini. 2020. "Detecting Morphing Attacks through Face Geometry Features" Journal of Imaging 6, no. 11: 115. https://doi.org/10.3390/jimaging6110115
APA StyleAutherith, S., & Pasquini, C. (2020). Detecting Morphing Attacks through Face Geometry Features. Journal of Imaging, 6(11), 115. https://doi.org/10.3390/jimaging6110115