Overview and Empirical Analysis of ISP Parameter Tuning for Visual Perception in Autonomous Driving

Abstract
1. Introduction
2. Background
2.1. Related Work on ISP Impact and Tuning
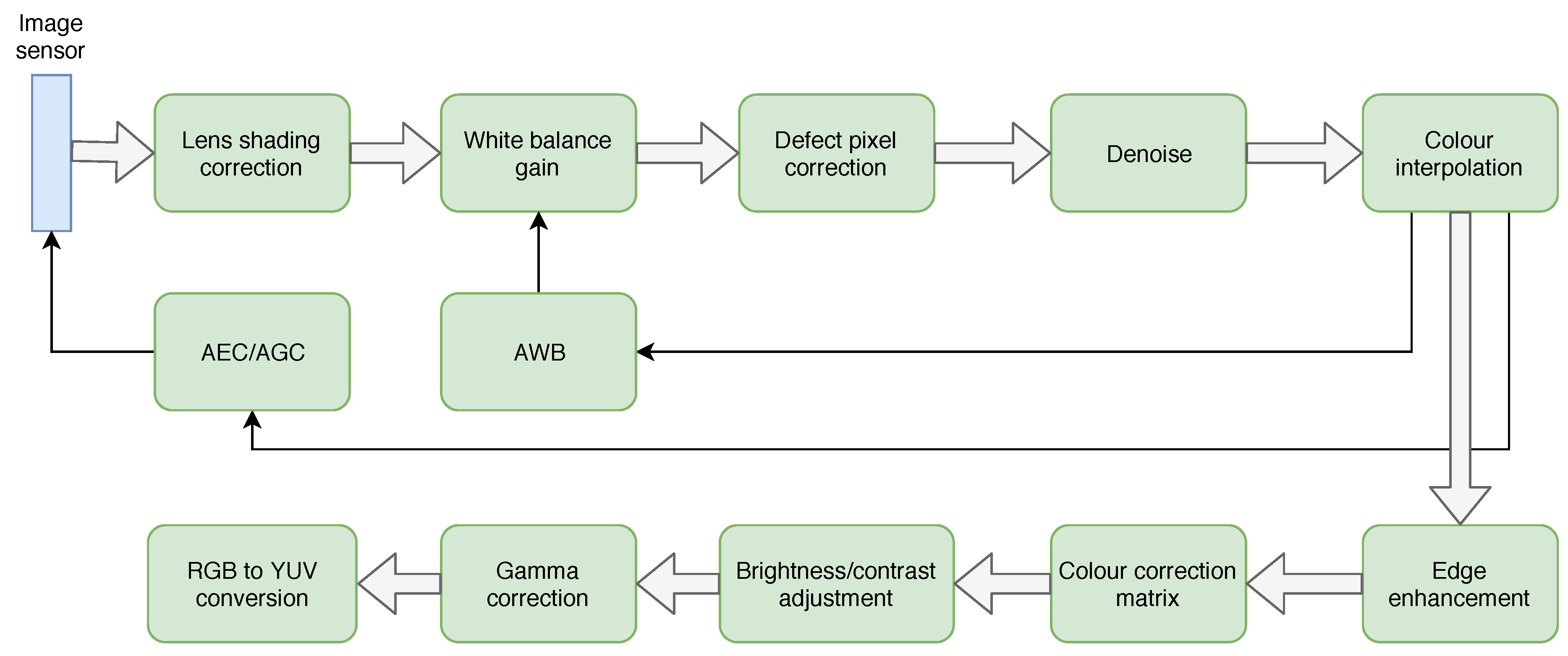
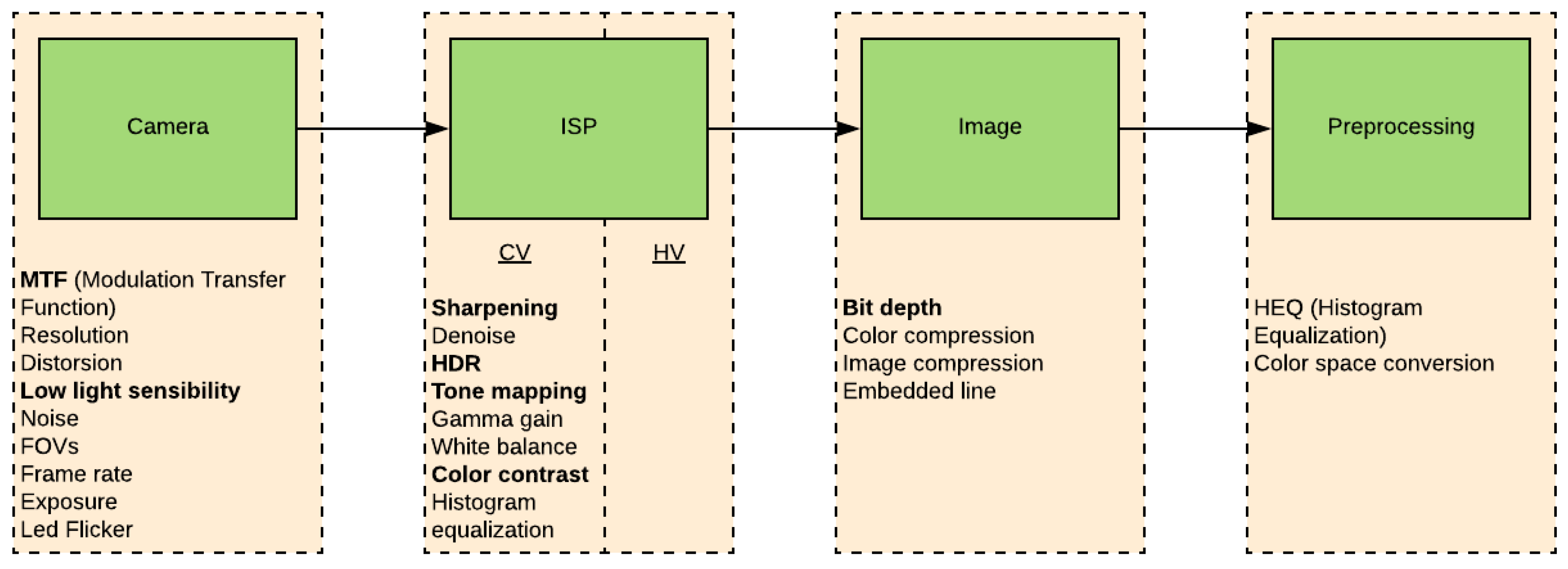
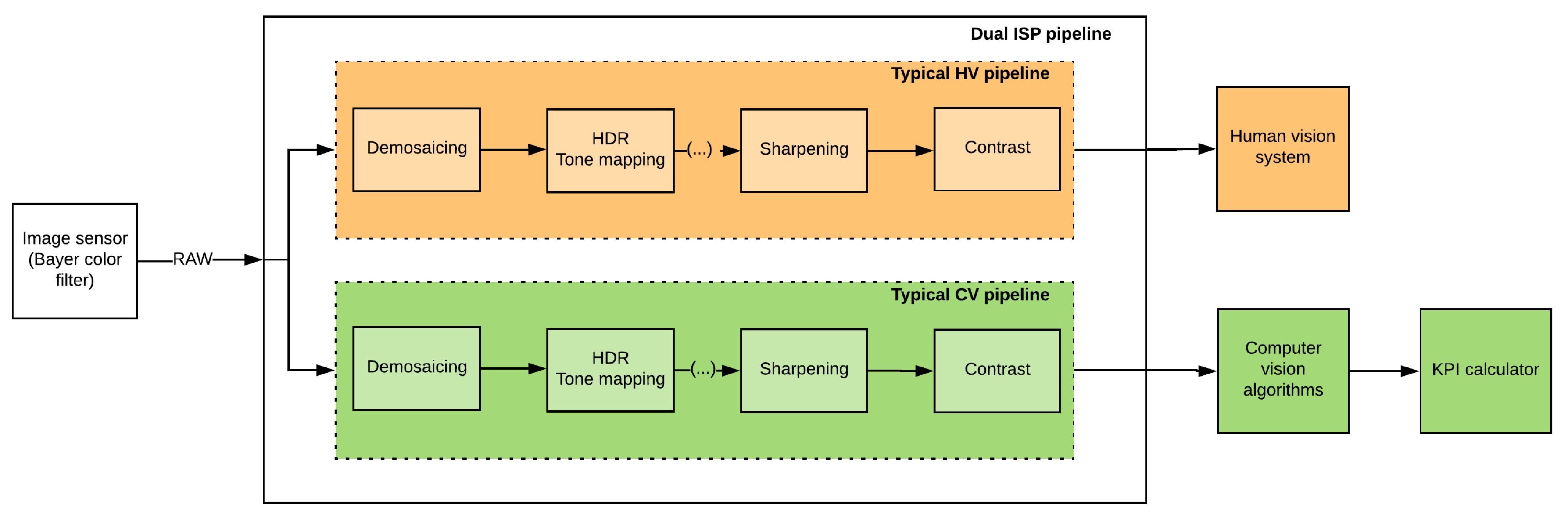
2.2. Overview of ISP Architectures
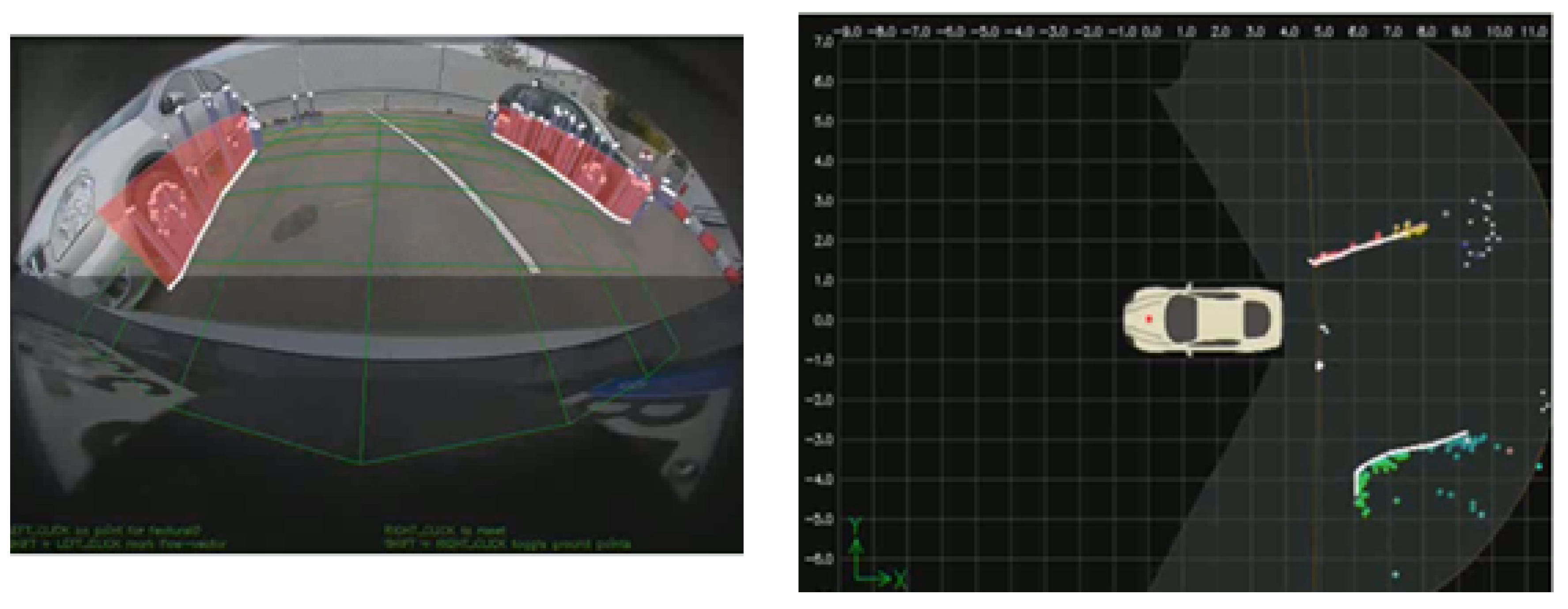
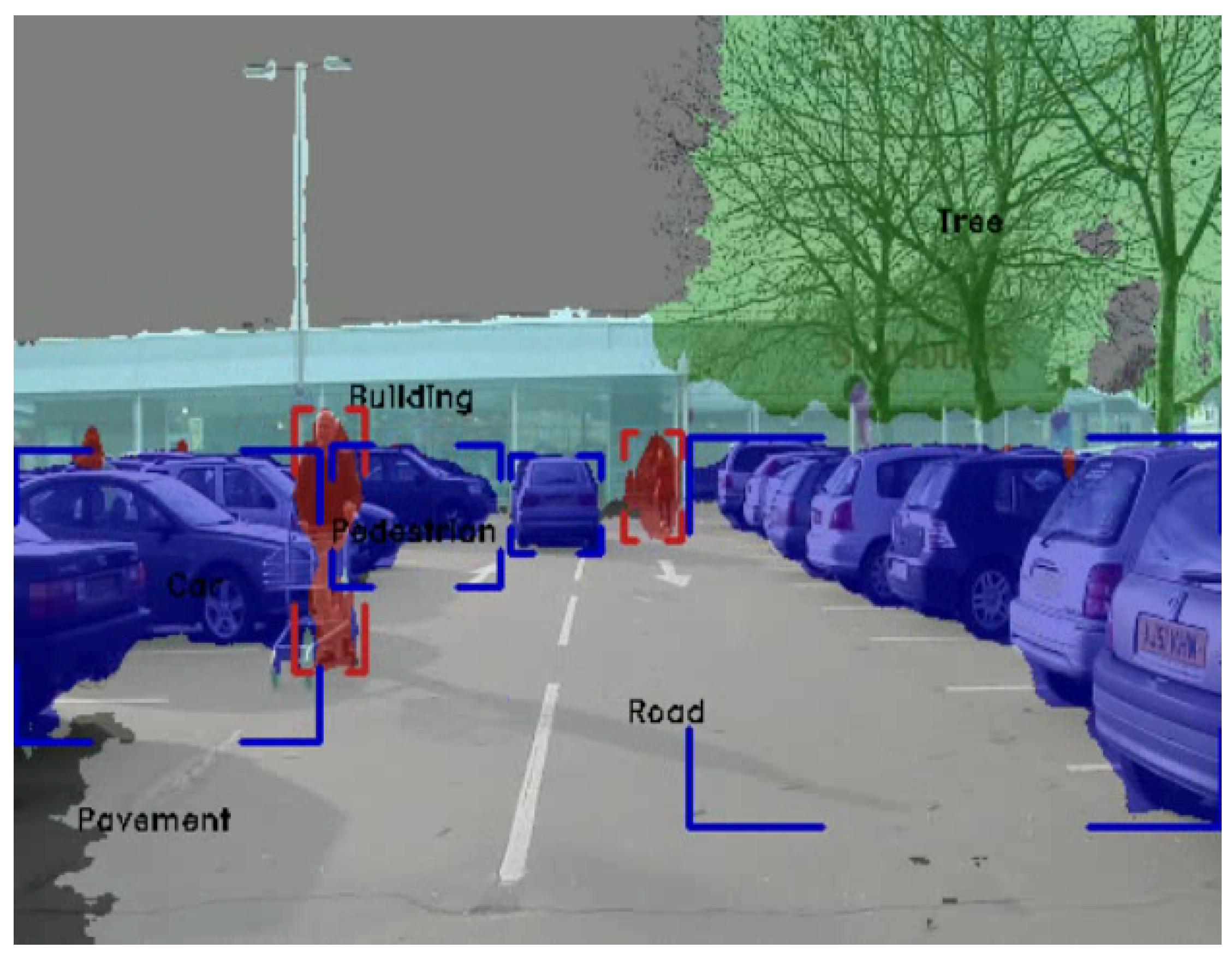
2.3. Computer Vision Algorithms for Automotive Applications
2.3.1. Classical Computer Vision
2.3.2. Deep Learning
2.4. Discussion
3. Empirical Analysis of Image Processing Parameters’ Impact on Computer Vision Algorithms
3.1. Overall Methodology and Test Settings
3.1.1. Test Setup
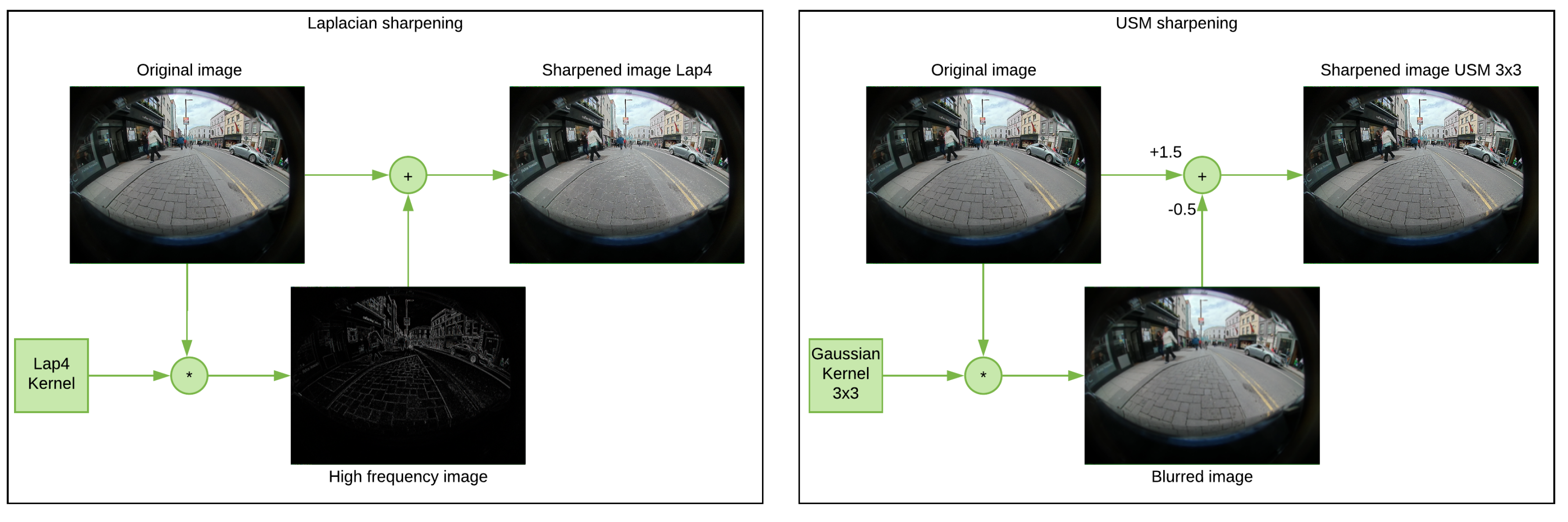
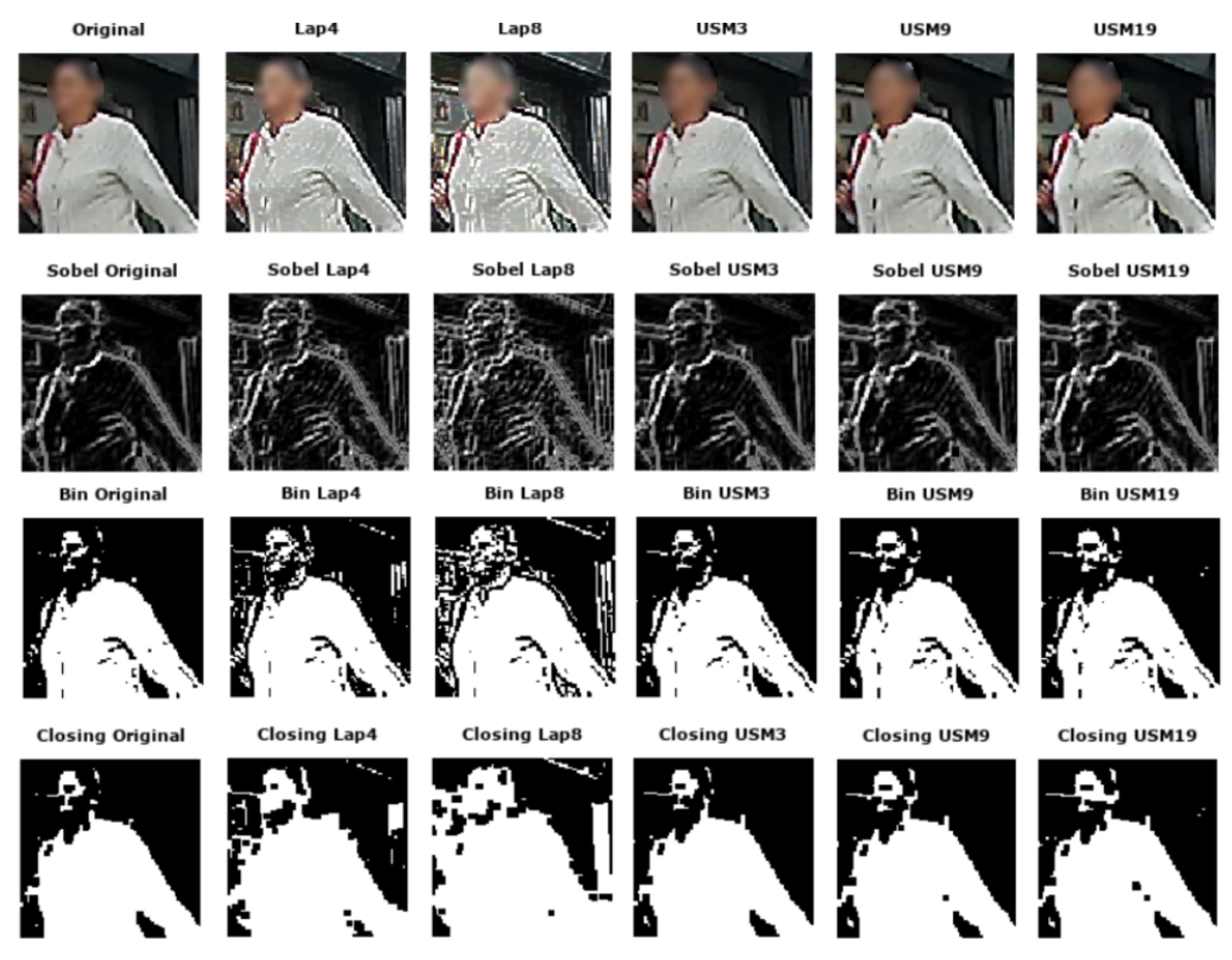
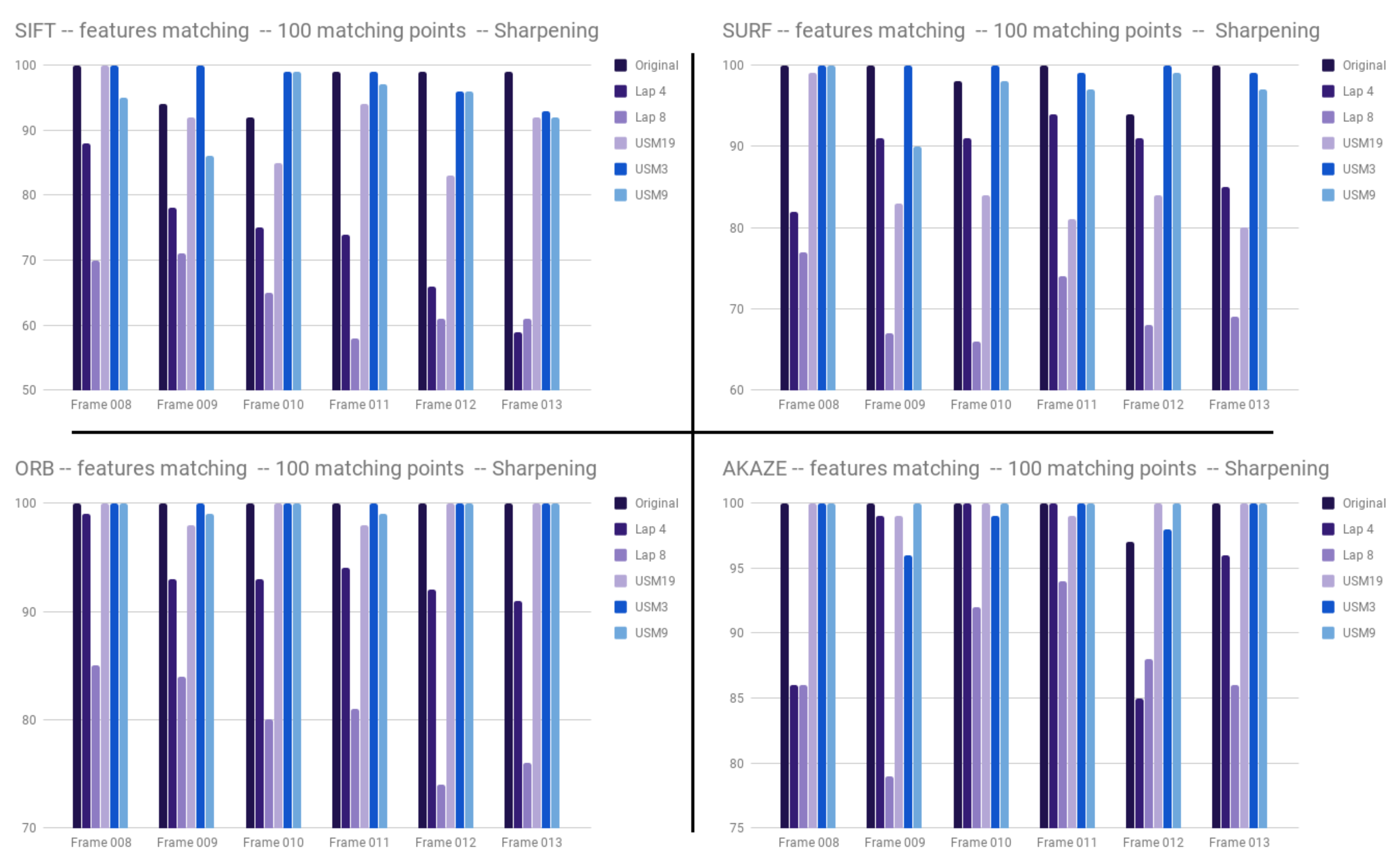
3.1.2. Sharpening
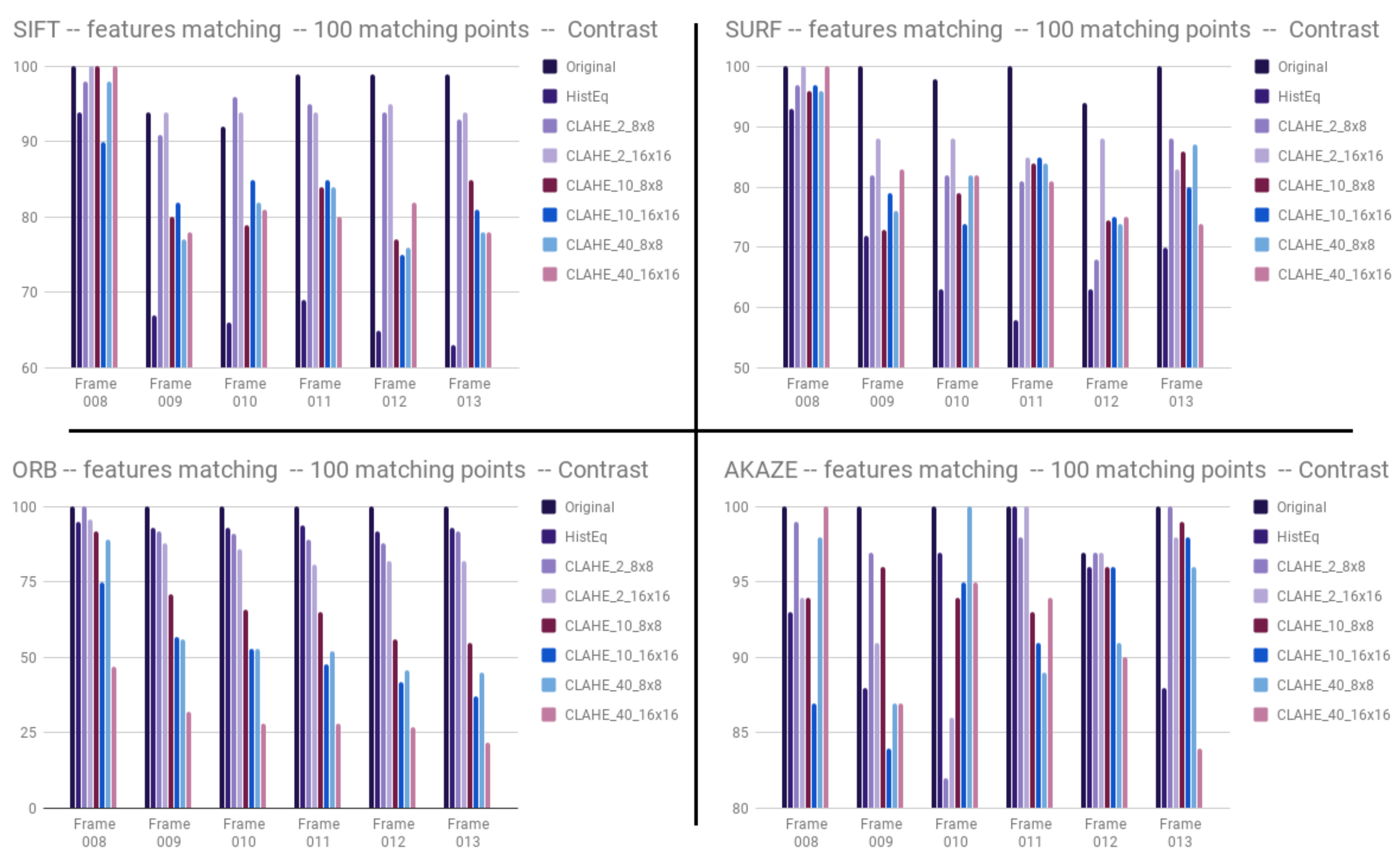
3.1.3. Contrast
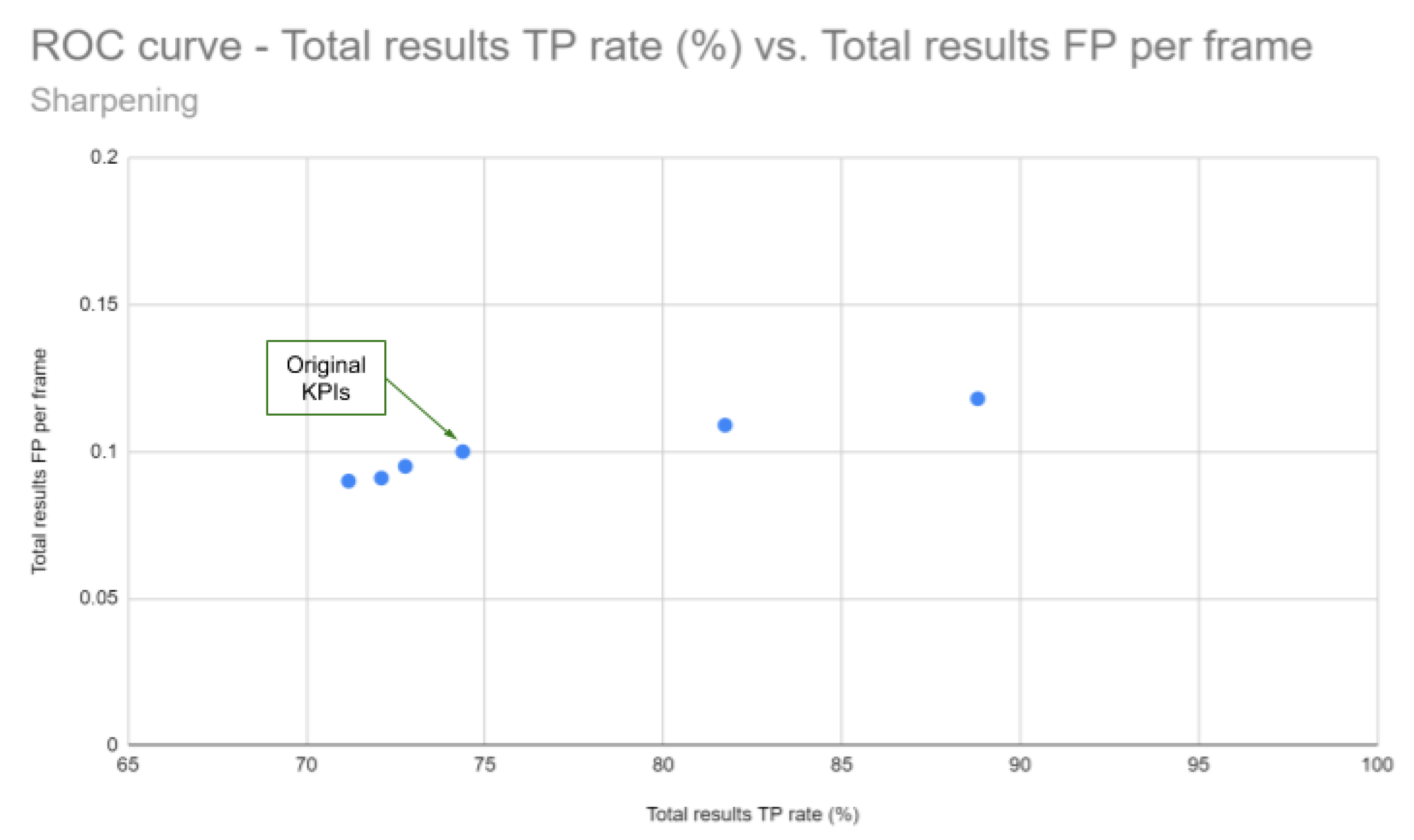
3.2. Sharpening and Contrast’s Filters Tuning
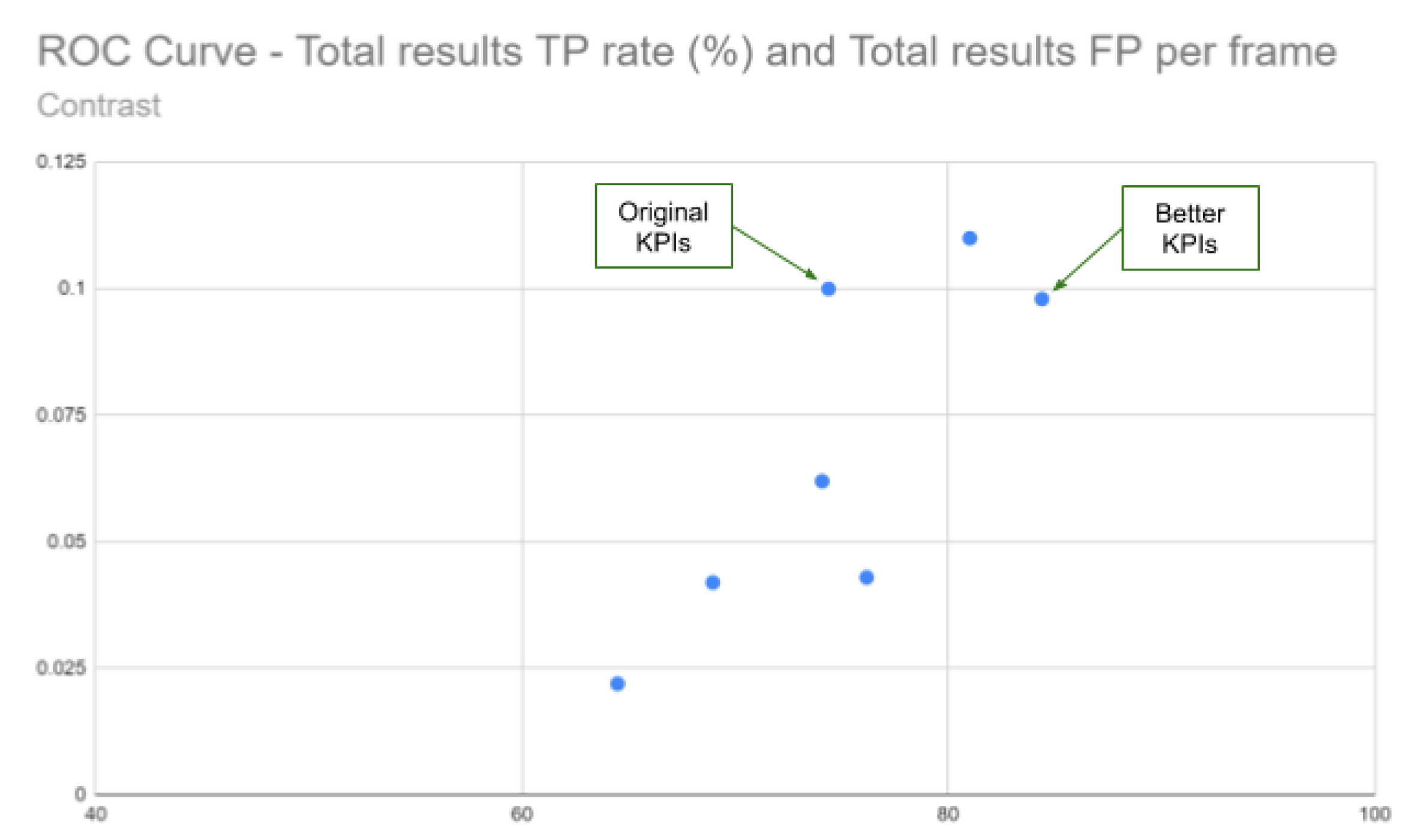
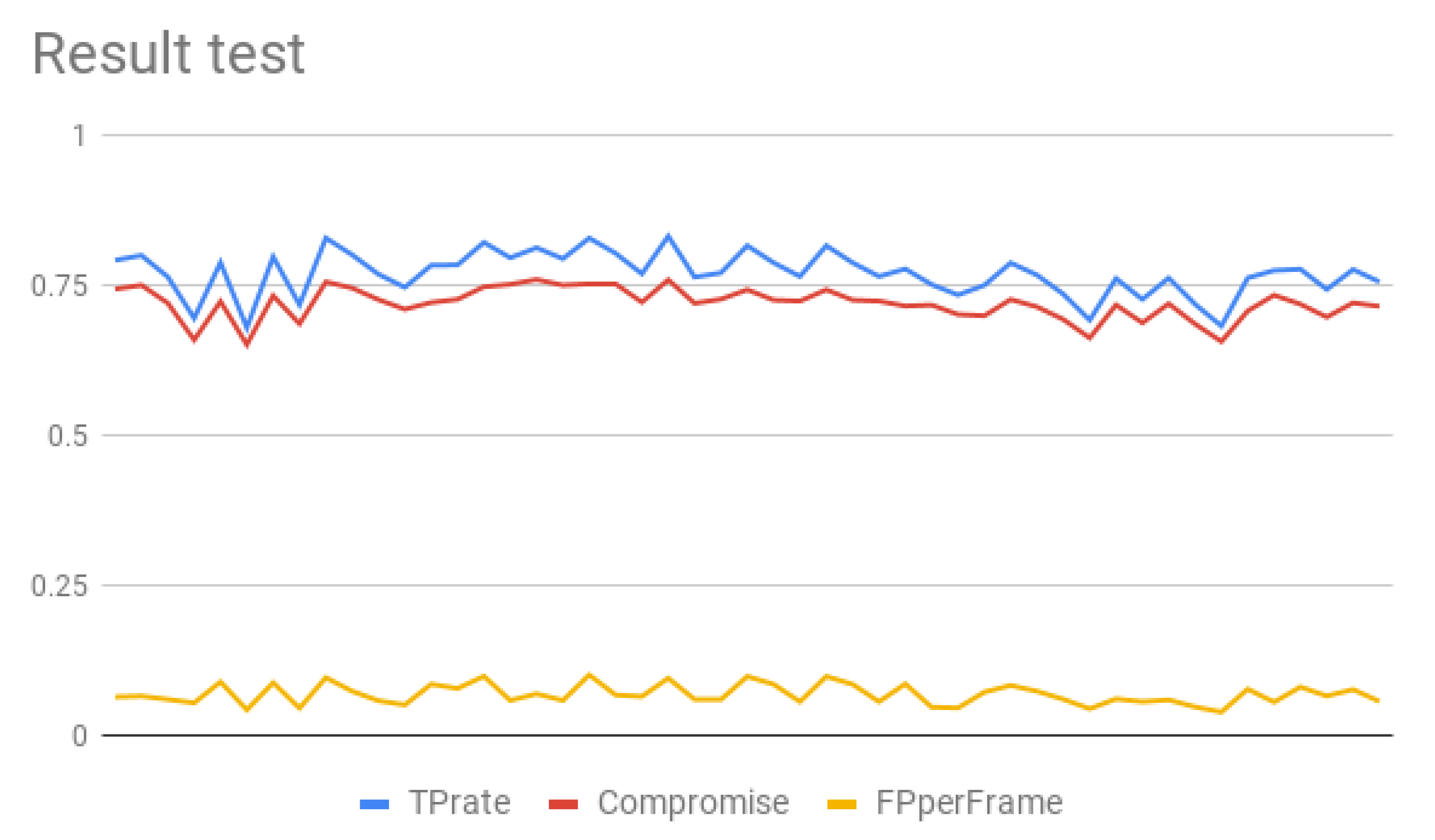
3.3. Discussion
4. Future Work: Specialized ISP for Computer Vision
4.1. Tuning Algorithms
One ISP vs. Dual ISP
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AD | Autonomous Driving |
| ADAS | Advanced Driving Assistance System |
| ADC | Analog-to-Digital Conversion |
| AHE | Adaptive Histogram Equalization |
| AKAZE | Accelerated-KAZE |
| AWB | Auto White Balance |
| BRIEF | Binary Robust Independent Elementary Features |
| CLAHE | Contrast Limited Adaptive Histogram Equalization |
| CNN | Convolutional Neural Networks |
| CV | Computer Vision |
| DL | Deep Learning |
| DoG | Difference-of-Gaussian |
| FAST | Features from Accelerated Segment Test |
| FOV | Field Of View |
| FUN | Fidelity, Utility and Naturalness |
| HDR | High Dynamic Range |
| HE | Histogram Equalization |
| HOG | Histogram of Oriented Gradients |
| HV | Human Vision |
| ISP | Image Signal Processing/Processor/Processed, depending on context |
| KPI | Key Performance Indicators |
| LoG | Laplacian-of-Gaussian |
| LBP | Local Binary Patterns |
| MSE | Mean Square Error |
| MTF | Modulation Transfer Function |
| OEM | Original Equipment Manufacturer (in our context, the car manufacturers) |
| ORB | Oriented FAST and Rotated BRIEF |
| PD | Pedestrian Detection |
| RANSAC | RANdom SAmple Consensus |
| R-CNN | Regional-CNN |
| RGB | Additive color model in which the primary additive colours are red, green and blue |
| SfM | Structure of Motion |
| SIFT | Scale-Invariant Feature Transform |
| SLAM | Simultaneous Localization And Mapping |
| SMAC | Sequential Model-based Algorithm Configuration |
| SNR | Signal-to-Noise Ratio |
| SoC | System on Chip |
| SSIM | Structural SIMilarity |
| SURF | Speeded Up Robust Features |
| SVM | Support Vector Machine |
| TOF | Time Of Flight |
| TOPS | Tera Operations Per Second |
| USB | Universal Serial Bus |
| USM | Unsharp Masking |
| YUV | Colour space in terms of one luma (Y) and two chrominance (UV) components |
References
- Bovik, A.C. Automatic prediction of perceptual image and video quality. Proc. IEEE 2013, 101, 2008–2024. [Google Scholar]
- ITU-R Study Group. BT.500: Methodology for the Subjective Assessment of the Quality of Television Pictures; International Telecommunications Union: Geneva, Switzerland, 2012. [Google Scholar]
- ITU-T Study Group. P.910: Subjective Video Quality Assessment Methods for Multimedia Applications; International Telecommunications Union: Geneva, Switzerland, 2008. [Google Scholar]
- Hertel, D.W.; Chang, E. Image quality standards in automotive vision applications. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 404–409. [Google Scholar]
- Winterlich, A.; Zlokolica, V.; Denny, P.; Kilmartin, L.; Glavin, M.; Jones, E. A saliency weighted no-reference perceptual blur metric for the automotive environment. In Proceedings of the 2013 Fifth International Workshop on Quality of Multimedia Experience (QoMEX), Klagenfurt am Wörthersee, Austria, 3–5 July 2013; pp. 206–211. [Google Scholar]
- Heimberger, M.; Horgan, J.; Hughes, C.; McDonald, J.; Yogamani, S. Computer vision in automated parking systems: Design, implementation and challenges. Image Vis. Comput. 2017, 68, 88–101. [Google Scholar] [CrossRef]
- Johnson, J. Analysis of image forming systems. Image Intensifier Symposium, AD220160; Warfare Electrical Engineering Department, U.S. Army Research and Development Laboratoires: Ft. Belvoir, VA, USA, 1958; pp. 244–273. [Google Scholar]
- Velichko, S. Intelligent Sensors For Autonomous Driving. In Proceedings of the Automotive Forum of International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 17–21 February 2019; Volume 62. [Google Scholar]
- Gomez, A. ISP Optimization for ML/CV Automotive Applications. In Proceedings of the AutoSens Conference, Detroit, MI, USA, 14–16 May 2019. [Google Scholar]
- Somayaji, M. Tuning Image Processing Pipelines for Automotive Use. In Proceedings of the AutoSens Conference, Detroit, MI, USA, 14–16 May 2019. [Google Scholar]
- Yahiaoui, L.; Hughes, C.; Horgan, J.; Deegan, B.; Denny, P.; Yogamani, S. Optimization of ISP parameters for object detection algorithms. In Proceedings of the Electronic Imaging, Autonomous Vehicles and Machines Conference, Burlingame, CA, USA, 13–17 January 2019; pp. 44-1–44-8. [Google Scholar]
- Denny, P.; Jones, E.; Glavin, M.; Hughes, C.; Deegan, B. Imaging for the Automotive Environment. In Handbook of Visual Display Technology; Chen, J., Cranton, W., Fihn, M., Eds.; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Girod, B. What’s wrong with mean-squared error? Digital Images and Human Vision; Watson, A.B., Ed.; MIT Press: Cambridge, MA, USA, 1993; pp. 207–220. [Google Scholar]
- Eskicioglu, A.; Fisher, P. Image quality meaures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef]
- Mannos, J.; Sakrison, D. The effects of a visual fidelity criterion on the encoding of images. IEEE Trans. Inf. Theory 1974, 4, 525–536. [Google Scholar] [CrossRef]
- Eckert, M.; Bradley, A. Perceptual quality metrics applied to still image compression. Signal Process. 1998, 70, 177–200. [Google Scholar] [CrossRef]
- Wang, Z.; Bovick, A. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 1–14. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.; Bovik, A. Multiscale structural similarity for image quality assessment. In Proceedings of the Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Sheikh, H.; Bovik, A.; DeVeciana, G. An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Trans. Image Process. 2005, 14, 2117–2128. [Google Scholar] [CrossRef]
- Sheikh, H.; Bovik, A. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef]
- Chandler, D.; Hemami, S. A wavelet-based visual signal-to-noise ratio for natural images. IEEE Trans. Image Process. 2007, 16, 2284–2298. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 649–666. [Google Scholar]
- Moorthy, A.; Bovik, A. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Moorthy, A.; Bovik, A. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Kingdom, F.; Prins, N. Psychophysics: A Practical Introduction, 2nd ed.; Academic Press: Cambridge, MA, USA, 2016. [Google Scholar] [CrossRef]
- Lu, Z.L.; Dosher, B. Visual Psychophysics: From Laboratory to Theory; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- RichardWebster, B.; Anthony, S.E.; Scheirer, W.J. PsyPhy: A Psychophysics Driven Evaluation Framework for Visual Recognition. IEEE Trans. Pat. Anal. Mach. Intel. 2019, 41, 2280–2286. [Google Scholar] [CrossRef] [PubMed]
- Winterlich, A.; Denny, P.; Kilmartin, L.; Glavin, M.; Jones, E. Performance optimization for pedestrian detection on degraded video using natural scene statistics. J. Electron. Imaging 2014, 23, 061114. [Google Scholar] [CrossRef]
- Pezzementi, Z.; Tabor, T.; Yim, S.; Chang, J.; Drozd, B.; Guttendorf, D.; Wagner, M.; Koopman, P. Putting image manipulations in context: Robustness testing for safe perception. In Proceedings of the IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Philadelphia, PA, USA, 6–8 August 2018. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evolut. Comput. 2019. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Buckler, M.; Jayasuriya, S.; Sampson, A. Reconfiguring the imaging pipeline for computer vision. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 206, p. 12. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Blasinski, H.; Farrell, J.; Lian, T.; Liu, Z.; Wandell, B. Optimizing Image Acquisition Systems for Autonomous Driving. In Proceedings of the Electronic Imaging, Photography, Mobile, and Immersive Imaging Conference, Burlingame, CA, USA, 28 January–1 February 2018; pp. 161-1–161-7. [Google Scholar]
- Young, I.T. Shading correction: compensation for illumination and sensor inhomogeneities. Curr. Protoc. Cytom. 2001, 14, 2–11. [Google Scholar]
- Yung-Cheng Liu, W.H.C.; Chen, Y.Q. Automatic white balance for digital still camera. IEEE Trans. Consum. Electron. 1995, 41, 460–466. [Google Scholar] [CrossRef]
- SangHyun Park, G.K.; Jeon, J. The method of auto exposure control for low-end digital camera. In Proceedings of the 11th International Conference on Advanced Communication Technology, Phoenix Park, Korea, 15–18 February 2009; Volume 3, pp. 1712–1714. [Google Scholar]
- Fowler, K.R. Automatic gain control for image-intensified camera. IEEE Trans. Instrum. Meas. 2004, 53, 1057–1064. [Google Scholar] [CrossRef]
- Yuan, X.; He, P.; Zhu, Q.; Bhat, R.R.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neur. Net. Lear. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed]
- Yoo, Y.; Lee, S.D.; Choe, W.; Kim, C.Y. CMOS image sensor noise reduction method for image signal processor in digital cameras and camera phones. In Proceedings of the Digital Photography, San Jose, CA, USA, 20 February 2007. [Google Scholar]
- Losson, O.; Macaire, L.; Yang, Y. Comparison of Color Demosaicing Methods. Adv. Imag. Electron. Phys. 2010, 162, 173–265. [Google Scholar] [CrossRef]
- Takahashi, K.; Monno, Y.; Tanaka, M.; Okutomi, M. Effective color correction pipeline for a noisy image. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4002–4006. [Google Scholar]
- Morris, T. Computer Vision and Image Processing; Palgrave Macmillan Ltd.: London, UK, 2004. [Google Scholar]
- Horgan, J.; Hughes, C.; McDonald, J.; Yogamani, S. Vision-based driver assistance systems: Survey, taxonomy and advances. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Las Palmas, Spain, 15–18 September 2015; pp. 2032–2039. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Tareen, S.A.K.; Saleem, Z. A comparative analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–10. [Google Scholar]
- Tang, Z.; Boukerche, A. An Improved Algorithm for Road Markings Detection with SVM and ROI Restriction: Comparison with a Rule-Based Model. In Proceedings of the International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Li, L.; Luo, W.; Wang, K. Lane Marking Detection and Reconstruction with Line-Scan Imaging Data. Sensors 2018, 18, 1635. [Google Scholar] [CrossRef] [PubMed]
- Jung, H.G.; Kim, D.S.; Yoon, P.J.; Kim, J. Parking slot markings recognition for automatic parking assist system. In Proceedings of the 2006 IEEE Intelligent Vehicles Symposium, Tokyo, Japan, 13–15 June 2006; pp. 106–113. [Google Scholar]
- Liu, Y.C.; Lin, K.Y.; Chen, Y.S. Bird’s-eye view vision system for vehicle surrounding monitoring. In Proceedings of the International Conference on Robot Vision (RobVis), Auckland, New Zealand, 18–20 February 2008; pp. 207–218. [Google Scholar]
- Jung, H.G.; Kim, D.S.; Yoon, P.J.; Kim, J. Structure Analysis Based Parking Slot Marking Recognition For Semi-Automatic Parking System. In Proceedings of the Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition, Hong Kong, China, 17–19 August 2006; pp. 384–393. [Google Scholar]
- Su, B.; Lu, S. A System for Parking Lot Marking Detection. In Proceedings of the Pacific-Rim Conference on Multimedia (PCM), Kuching, Malaysia, 1–4 December 2014; pp. 268–273. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Chavan, A.; Yogamani, S.K. Real-time DSP implementation of pedestrian detection algorithm using HOG features. In Proceedings of the 12th International Conference on ITS Telecommunications, Taipei, Taiwan, 5–8 November 2012; pp. 352–355. [Google Scholar]
- Siam, M.; Gamal, M.; Abdel-Razek, M.; Yogamani, S.; Jagersand, M. RTSeg: Real-time semantic segmentation comparative study. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1603–1607. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. arXiv 2016, arXiv:1612.01925. [Google Scholar]
- Siam, M.; Mahgoub, H.; Zahran, M.; Yogamani, S.; Jagersand, M.; El-Sallab, A. Modnet: Motion and appearance based moving object detection network for autonomous driving. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2859–2864. [Google Scholar]
- Kumar, V.R.; Milz, S.; Witt, C.; Simon, M.; Amende, K.; Petzold, J.; Yogamani, S.; Pech, T. Monocular fisheye camera depth estimation using sparse lidar supervision. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2853–2858. [Google Scholar]
- Milz, S.; Arbeiter, G.; Witt, C.; Abdallah, B.; Yogamani, S. Visual SLAM for Automated Driving: Exploring the Applications of Deep Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 8–22 June 2018; pp. 247–257. [Google Scholar]
- Uricar, M.; Krizek, P.; Sistu, G.; Yogamani, S. SoilingNet: Soiling Detection on Automotive Surround-View Cameras. In Proceedings of the IEEE Intelligent Transportation Systems Conference, Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Sistu, G.; Leang, I.; Chennupati, S.; Milz, S.; Yogamani, S.; Rawashdeh, S. NeurAll: Towards a Unified Model for Visual Perception in Automated Driving. In Proceedings of the IEEE Intelligent Transportation Systems Conference, Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Valada, A.; Oliveira, G.L.; Brox, T.; Burgard, W. Deep Multispectral Semantic Scene Understanding of Forested Environments using Multimodal Fusion. In Proceedings of the International Symposium on Experimental Robotics (ISER), Tokyo, Japan, 3–6 October 2016. [Google Scholar]
- Bonanni, T.M.; Pennisi, A.; Bloisi, D.; Iocchi, L.; Nardi, D. Human-robot collaboration for semantic labeling of the environment. In Proceedings of the 3rd Workshop on Semantic Perception, Mapping and Exploration, Anchorage, AL, USA, 3 May 2013. [Google Scholar]
- Vineet, V.; Miksik, O.; Lidegaard, M.; Nießner, M.; Golodetz, S.; Prisacariu, V.A.; Kähler, O.; Murray, D.W.; Izadi, S.; Perez, P.; et al. Incremental Dense Semantic Stereo Fusion for Large-Scale Semantic Scene Reconstruction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Kundu, A.; Li, Y.; Dellaert, F.; Li, F.; Rehg, J.M. Joint semantic segmentation and 3d reconstruction from monocular video. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 703–718. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]
- Zhu, W.; Xie, X. Adversarial deep structural networks for mammographic mass segmentation. arXiv 2016, arXiv:1612.05970. [Google Scholar]
- Miksik, O.; Vineet, V.; Lidegaard, M.; Prasaath, R.; Nießner, M.; Golodetz, S.; Hicks, S.L.; Pérez, P.; Izadi, S.; Torr, P.H. The semantic paintbrush: Interactive 3d mapping and recognition in large outdoor spaces. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 3317–3326. [Google Scholar]
- Siam, M.; Elkerdawy, S.; Jagersand, M.; Yogamani, S. Deep semantic segmentation for automated driving: Taxonomy, roadmap and challenges. In Proceedings of the IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–8. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Farabet, C.; Couprie, C.; Najman, L.; Lecun, Y. Scene Parsing with Multiscale Feature Learning, Purity Trees, and Optimal Covers. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, Scotland, 26 June–1 July 2012; pp. 1857–1864. [Google Scholar]
- Grangier, D.; Bottou, L.; Collobert, R. Deep convolutional networks for scene parsing. In Proceedings of the ICML 2009 Deep Learning Workshop, Montreal, QC, Canada, 14–18 June 2009; Volume 3. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Qi, G.J. Hierarchically Gated Deep Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2267–2275. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2462–2470. [Google Scholar]
- Ummenhofer, B.; Zhou, H.; Uhrig, J.; Mayer, N.; Ilg, E.; Dosovitskiy, A.; Brox, T. DeMoN: Depth and motion network for learning monocular stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5038–5047. [Google Scholar]
- Borkar, T.S.; Karam, L.J. DeepCorrect: Correcting DNN models against image distortions. IEEE Trans. Image Process. 2019, 28, 6022–6034. [Google Scholar] [CrossRef] [PubMed]
- Dodge, S.F.; Karam, L.J. Understanding How Image Quality Affects Deep Neural Networks. In Proceedings of the International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Winterlich, A.; Hughes, C.; Kilmartin, L.; Glavin, M.; Jones, E. An oriented gradient based image quality metric for pedestrian detection performance evaluation. Signal Process. Image Commun. 2015, 31. [Google Scholar] [CrossRef]
- Yahiaoui, L.; Horgan, J.; Yogamani, S.; Hughes, C.; Deegan, B. Impact Analysis and Tuning Strategies for Camera Image Signal Processing Parameters in Computer Vision. In Proceedings of the Irish Machine Vision and Image Processing Conference (IMVIP), Belfast, UK, 29–31 August 2018. [Google Scholar]
- Shrivakshan, G.; Chandrasekar, C. A Comparison of various Edge Detection Techniques used in Image Processing. Int. J. Comput. Sci. Issues 2012, 9, 269–276. [Google Scholar]
- Haralick, R.M.; Sternberg, S.R.; Zhuang, X. Image Analysis Using Mathematical Morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 532–550. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE Features. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 214–227. [Google Scholar]
- Alcantarilla, P.F.; Nuevo, J.; Bartoli, A. Fast Explicit Diffusion for Accelerated Features in Nonlinear Scale Spaces. IEEE Trans. Patt. Anal. Mach. Intell. 2013, 34, 1281–1298. [Google Scholar]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vision Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Diamond, S.; Sitzmann, V.; Boyd, S.; Wetzstein, G.; Heide, F. Dirty pixels: Optimizing image classification architectures for raw sensor data. arXiv 2017, arXiv:1701.06487. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2951–2959. [Google Scholar]
- Blau, Y.; Michaeli, T. The Perception-Distortion Tradeoff. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6228–6237. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original (KPI) | Lap4 (KPI) | Lap8 (KPI) | USM3 (KPI) | USM9 (KPI) | USM19 (KPI) | |
|---|---|---|---|---|---|---|
| Total results | ||||||
| TP rate (%) | 74.38 | 81.73 | 88.81 | 72.1 | 71.18 | 72.77 |
| Total results | ||||||
| FP per frame | 0.1 | 0.109 | 0.118 | 0.091 | 0.090 | 0.095 |
| Original (KPI) | CLAHE 2_8 (KPI) | CLAHE 2_16 (KPI) | CLAHE 10_8 (KPI) | CLAHE 10_16 (KPI) | CLAHE 40_8 (KPI) | CLAHE 40_16 (KPI) | |
|---|---|---|---|---|---|---|---|
| Total results | |||||||
| TP rate (%) | 74.38 | 81.01 | 84.39 | 74.08 | 76.17 | 68.95 | 64.48 |
| Total results | |||||||
| FP per frame | 0.1 | 0.11 | 0.098 | 0.062 | 0.043 | 0.042 | 0.022 |
| Original | Best Config (by ) | Best Config (by ) | |
|---|---|---|---|
| 0.7451 | 0.7589 | 0.7595 | |
| 0.7869 | 0.83 | 0.81 | |
| 0.055 | 0.095 | 0.069 |
| Best Config (by ) | Best Config (by ) | |
|---|---|---|
| Lap | Lap4 | Lap8 |
| clipLimit | 2 | 2 |
| tileSize | 8 × 8 | 8 × 8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yahiaoui, L.; Horgan, J.; Deegan, B.; Yogamani, S.; Hughes, C.; Denny, P. Overview and Empirical Analysis of ISP Parameter Tuning for Visual Perception in Autonomous Driving. J. Imaging 2019, 5, 78. https://doi.org/10.3390/jimaging5100078
Yahiaoui L, Horgan J, Deegan B, Yogamani S, Hughes C, Denny P. Overview and Empirical Analysis of ISP Parameter Tuning for Visual Perception in Autonomous Driving. Journal of Imaging. 2019; 5(10):78. https://doi.org/10.3390/jimaging5100078
Chicago/Turabian StyleYahiaoui, Lucie, Jonathan Horgan, Brian Deegan, Senthil Yogamani, Ciarán Hughes, and Patrick Denny. 2019. "Overview and Empirical Analysis of ISP Parameter Tuning for Visual Perception in Autonomous Driving" Journal of Imaging 5, no. 10: 78. https://doi.org/10.3390/jimaging5100078
APA StyleYahiaoui, L., Horgan, J., Deegan, B., Yogamani, S., Hughes, C., & Denny, P. (2019). Overview and Empirical Analysis of ISP Parameter Tuning for Visual Perception in Autonomous Driving. Journal of Imaging, 5(10), 78. https://doi.org/10.3390/jimaging5100078