Slant Removal Technique for Historical Document Images

Abstract
1. Introduction
- Angle-frequency approach: Down-strokes are first located based on such criteria as the minimum vertical extent or velocity. Next, the angle of the local ink direction is measured at these locations and the resulting angles are agglomerated in a histogram. From this histogram, the slant angle is determined. This is a one-step procedure.
- Repeated-shearing approach: This method is based on the assumption that the projection of dark pixels is maximized along an axis parallel to the slant angle. The basic principle is to repeatedly shear images of individual text lines, varying the shear angle, and optimizing the vertical projection of dark pixels. This approach is clearly more time consuming, but proves more accurate, as indicated by its popularity.
- the TrigraphSlant database [18] (the only available database for slant estimation),
- a synthetic printed database where slants are fully determined.
- To the best of our knowledge, this is the first time that a slant removal technique is proposed, able to be applied to the entire page, without requiring text line or word segmentation.
- It does not generate extra noise, due to line and/or word segmentation that would remain in the page after slant removal, which is accomplished by shifting the entire page uniformly and ensuring text homogeneity. Most of the existed techniques apply to ideal databases, like IAM-DB (Figure 1) that is appropriately made for line and word segmentation. In the case of historical documents (Figure 2), the final result would be full of dots and strokes because of the segmentation.
- Instructions are given over the best application to document page, after detailed results.
2. Materials and Methods
2.1. Slant Detection Algorithm
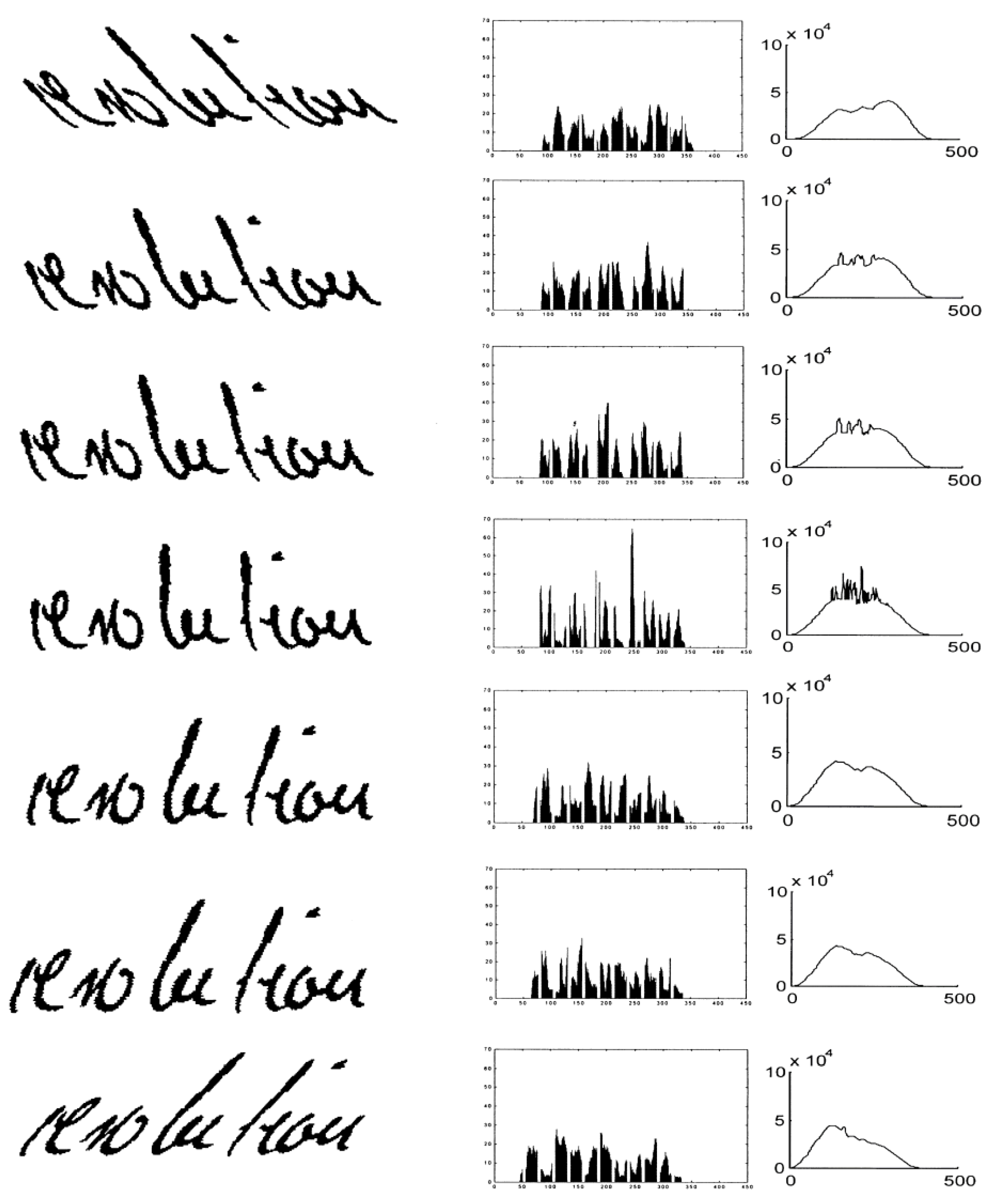
- The word image is artificially slanted to both, left and right, under different slant detection angles. The maximum slant angle is approximately 45 degrees and the slant angle step depends on the height of the text image.
- For each of the extracted word images, the vertical projection profile is calculated.
- The WVD is calculated for all the above projected profiles.
- The curves of maximum intensity of the WVDs are extracted, just by keeping the maximum value of each curve of the space-frequency distribution, for the specific slant.
- The curve of maximum intensity with the greatest peak, corresponding to the projected profile with the most intense alternations is selected.
- The corresponding word image is selected as the most non-slanted word.
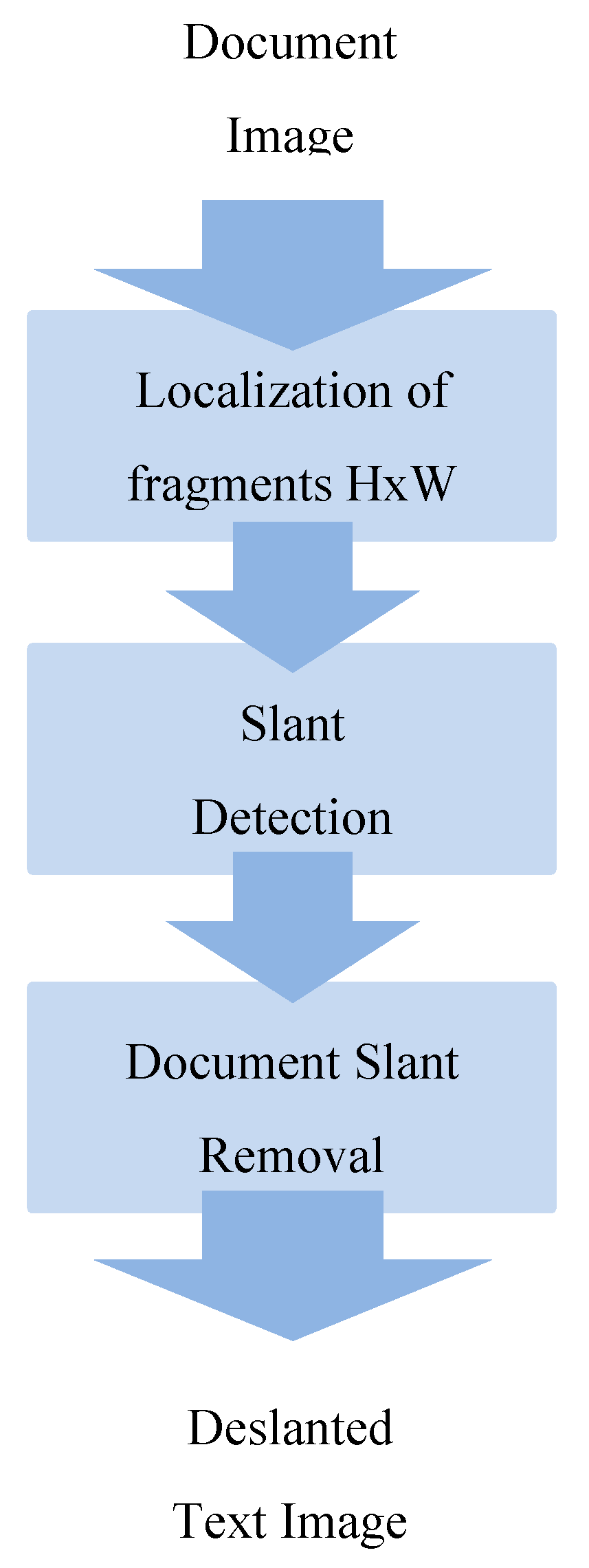
2.2. Proposed Slant Removal Technique
- The text ratio R in the window;
- The amount M of the fragments in use;
- The height H of the window;
- The width W of the window.
- The main body height detection [22], since it does not require line or word segmentation;
- The slant detection procedure. Once the M fragments have been selected (Figure 5), the slant detection algorithm [9], described in Section 2, is applied and the slant angles are detected, one per fragment. The maximum and minimum slant angles are ignored as possible outliers, while slant is defined as the detected slant of the page. The entire document page is then corrected according to the slant angle by shifting each pixel so thatwhere (x0, y0) defines the initial position of the pixel and (xf, yf) is the final pixel position.
3. Results
- The TrigraphSlant database (DB) [18], in order to perform tests on a renowned DB for slant. However, in this DB each writer was asked to write two pages of his natural slant and two of force slants. Only the natural slant documents were used here (see Experimental Results).
- The George Washington DB [19], in order to perform tests on a renowned DB of historical documents.
- The BH2M: the Barcelona Historical Handwritten Marriages database [20], in order to perform tests on a second DB of historical documents.
- The Print DB: printed documents with artificial slant, in order to check the accuracy of the technique. Moreover, since all the rest do not guarantee the existence of all the possible slants, special care was taken to include all possible slants, including 0 (no slant).
3.1. TrigraphSlant DB
3.2. George Washington DB
3.3. BH2M DB
3.4. PrintDB
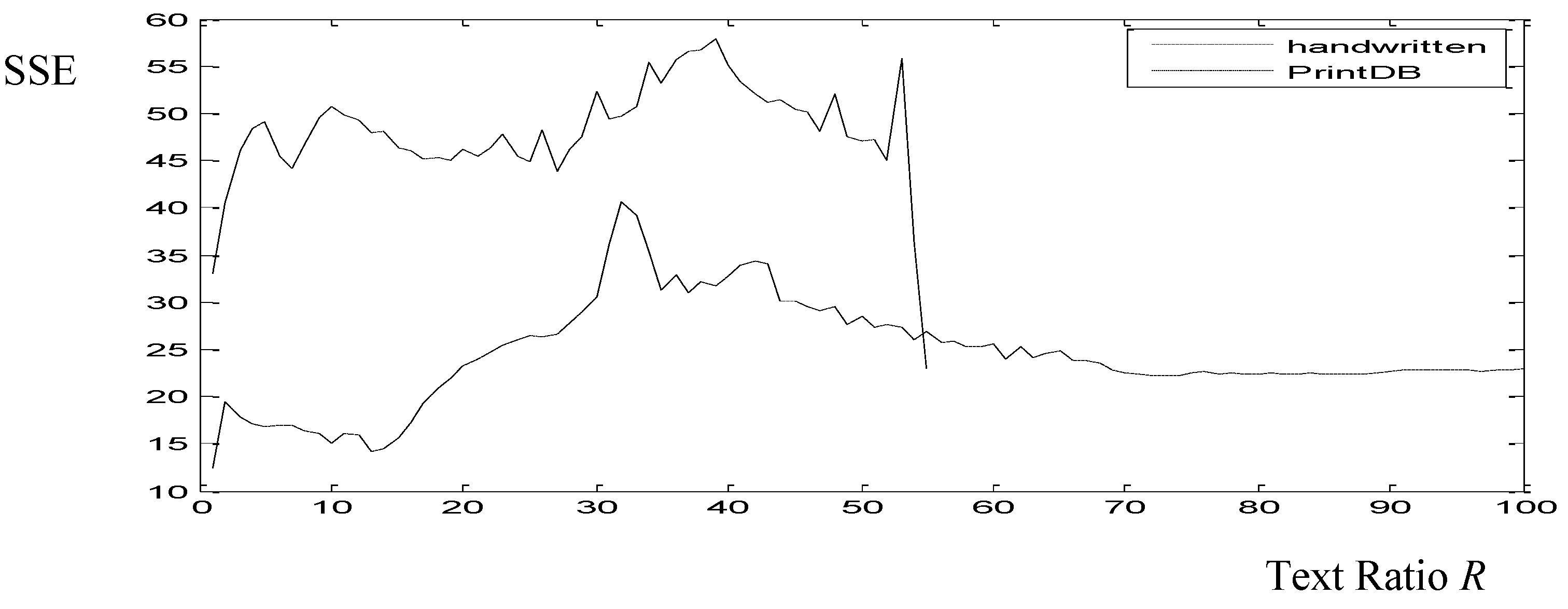
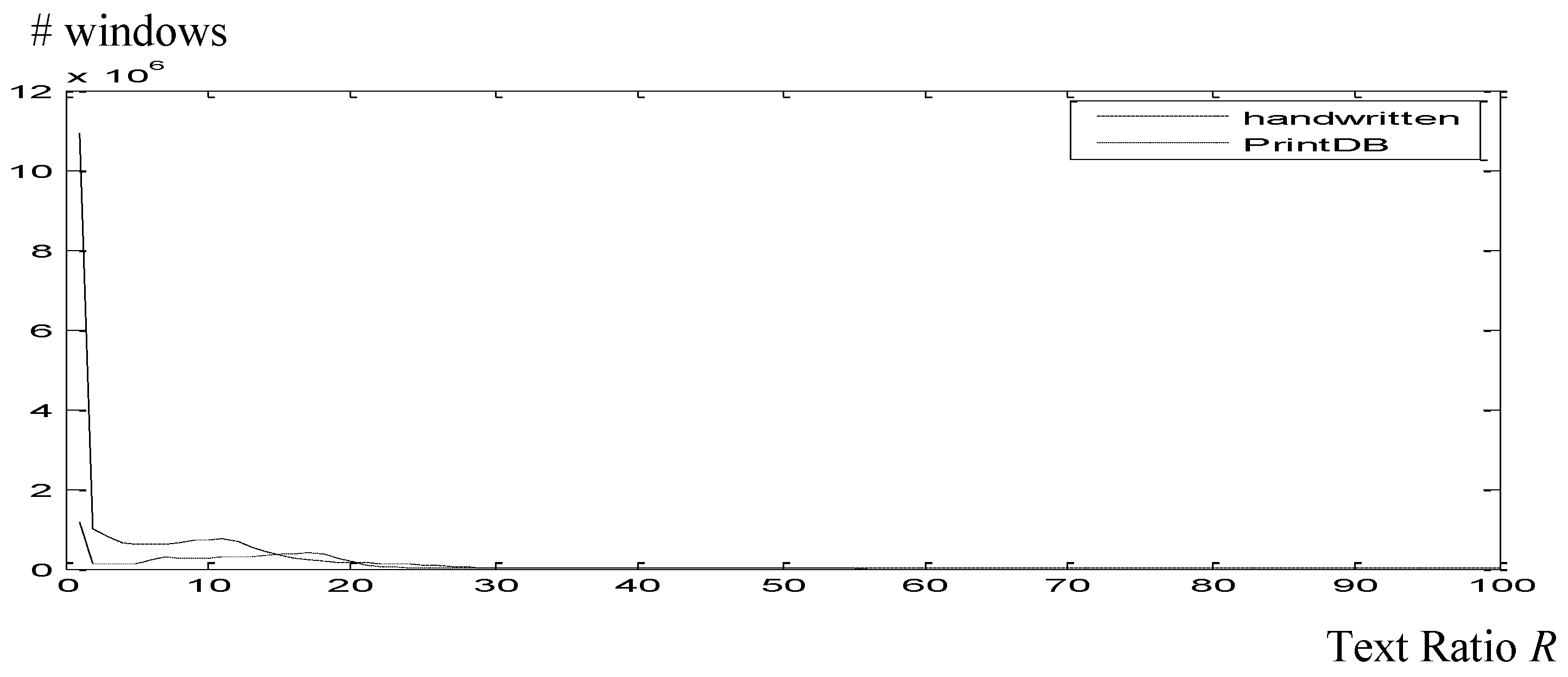
3.5. Set-Up of the Text Ratio R Parameter
3.6. Set-Up of the Height H of the Window
3.7. Set-Up of the Width W of the Window
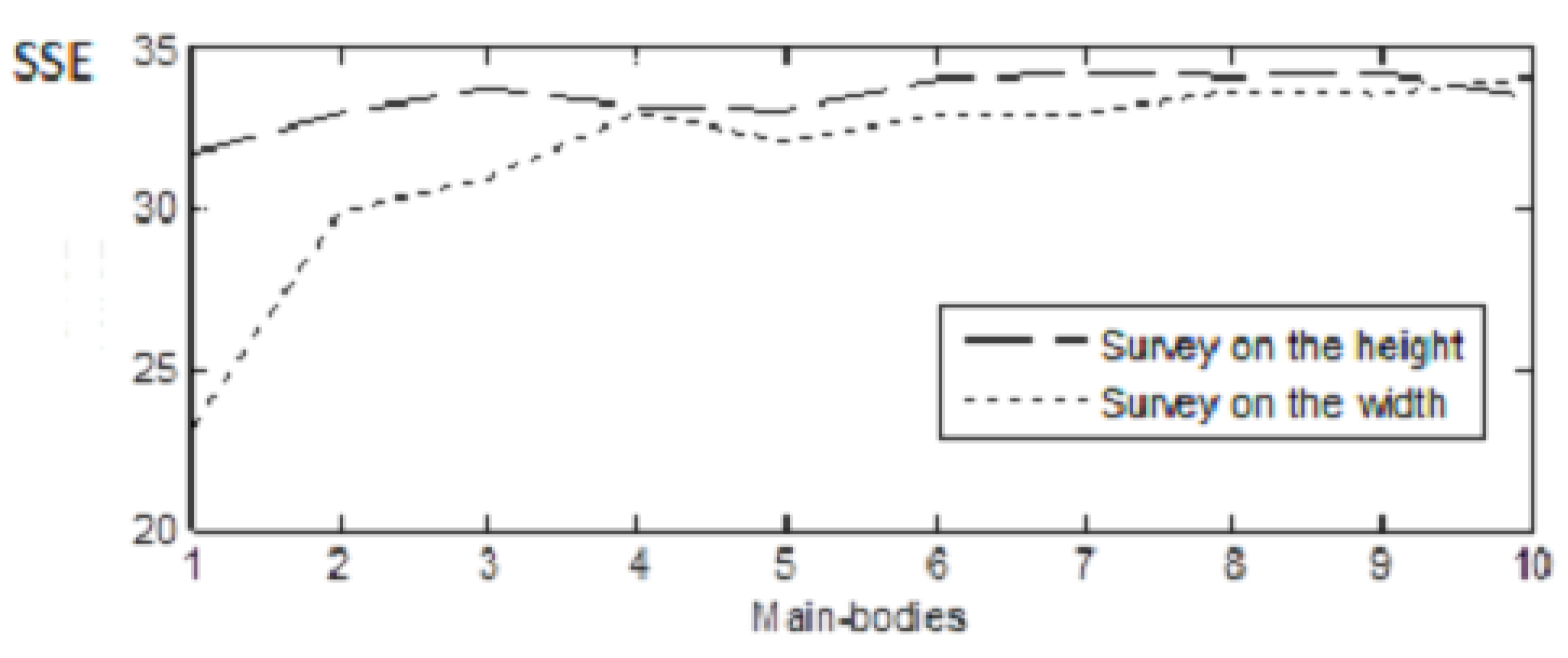
3.8. Set-Up of the Number M of Fragments to Use
- Four fragments, mean of the fragments: SSE on the evaluation set 563
- Five fragments, mean of the fragments: SSE on the evaluation set 513
- Five fragments, median of the fragments: SSE on the evaluation set 509
3.9. Experimental Results on the Databases
- In the TrigraphSlant, the writing is modern and not as uniform as in the historical documents. When examined by human estimators, a standard deviation of 2.45 was observed.
- George Washington DB of historical documents is more uniform.
- BH2M presents more density which made our character main body size algorithm fail more times.
- PrintDB includes printed text that is artificially slanted, and therefore is uniform.
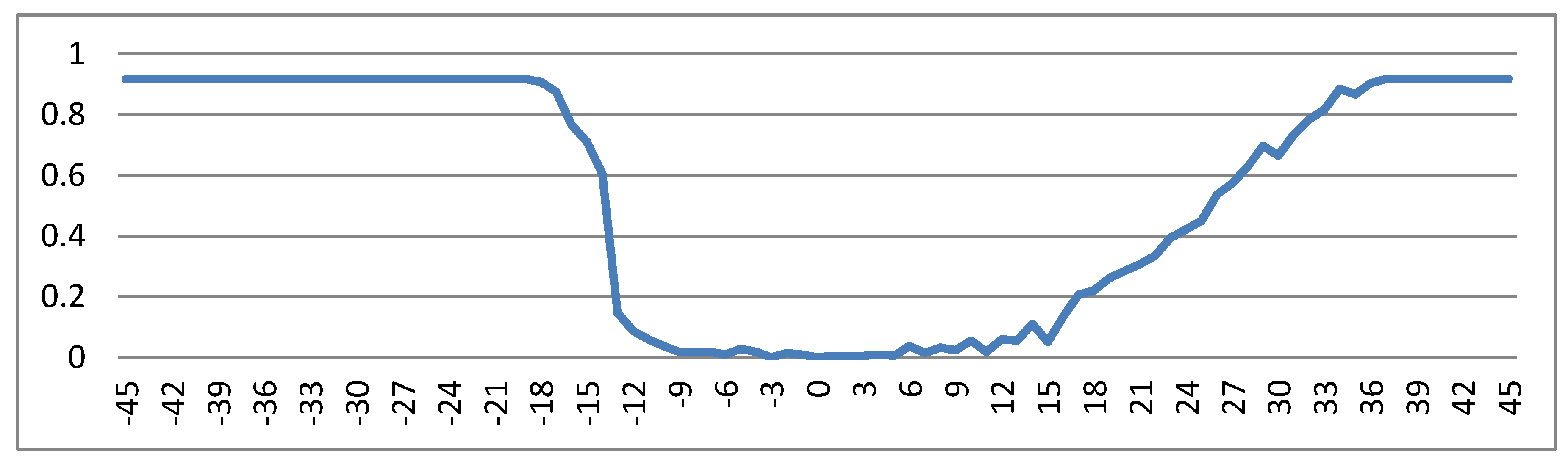
- We present in the following experiments in order to evaluate the improvement brought by our slant detection and removal technique on document analysis and recognition tasks. We thus conduct recognition experiments on printed documents with an OCR, and word spotting experiments on handwritten documents, before and after slant removal. The recognition results for the handwriting of our databases were a failure, due to having historical documents or/and languages other than English. For the PrintDB database, in Figure 13, the character error rate vs. the artificial slant are shown, as obtained by a commercial OCR system (Adobe Acrobat).
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Parvez, T.M.; Sabri, A.M. Arabic handwriting recognition using structural and syntactic pattern attributes. Pattern Recognit. 2013, 46, 141–154. [Google Scholar] [CrossRef]
- José, A.R.-S.; Perronnin, F. Handwritten word-spotting using hidden Markov models and universal vocabularies. Pattern Recognit. 2009, 42, 2106–2116. [Google Scholar]
- Brink, A.A.; Niels, R.M.J.; van Batenburg, R.A.; van den Heuvel, C.E.; Schomaker, L.R.B. Towards robust writer verification by correcting unnatural slant. Pattern Recognit. Lett. 2011, 32, 449–457. [Google Scholar] [CrossRef]
- Bozinovic, R.; Srihari, S. Off-line cursive script word recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 68–83. [Google Scholar] [CrossRef]
- Kim, G.; Govindaraju, V. A lexicon driven approach to handwritten word recognition for real-time applications. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 366–379. [Google Scholar]
- Shridar, M.; Kimura, F. Handwritten address interpretation using word recognition with and without lexicon. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Vancouver, BC, Canada, 22–25 October 1995; Volume 3, pp. 2341–2346. [Google Scholar]
- Papandreou, A.; Gatos, B. Word slant estimation using non-horizontal character parts and core-region information. In Proceedings of the 10th IAPR International Workshop on Document Analysis Systems (DAS 2012), Gold Coast, QLD, Australia, 27–29 March 2012; pp. 307–311. [Google Scholar]
- Alessandro, V.; Luettin, J. A new normalization technique for cursive handwritten words. Pattern Recognit. Lett. 2001, 22, 1043–1050. [Google Scholar]
- Kavallieratou, E.; Fakotakis, N.; Kokkinakis, G. Slant estimation algorithm for OCR systems. Pattern Recognit. 2001, 34, 2515–2522. [Google Scholar] [CrossRef]
- Britto, A., Jr.; Sabourin, R.; Lethelier, E.; Bortolozzi, F.; Suen, C. Improvement handwritten numeral string recognition by slant normalization and contextual information. In Proceedings of the 7th International Workshop on Frontiers in Handwriting Recognition, Amsterdam, The Netherlands, 11–13 September 2000; pp. 323–332. [Google Scholar]
- Ding, Y.; Kimura, F.; Miyake, Y.; Shridhar, M. Accuracy improvement of slant estimation for handwritten words. In Proceedings of the International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000; Volume 4, pp. 527–530. [Google Scholar]
- Ding, Y.; Ohyama, W.; Kimura, F.; Shridhar, M. Local slant estimation for handwritten English words. In Proceedings of the 9th International Workshop on Frontiers in Handwriting Recognition (IWFHR), Kokubunji, Tokyo, Japan, 26–29 October 2004; pp. 328–333. [Google Scholar]
- Bertolami, R.; Uchida, S.; Zimmermann, M.; Bunke, H. Non-uniform slant correction for handwritten text line recognition. In Proceedings of the 9th International Conference on Document Analysis and Recognition, Parana, Brazil, 23–26 September 2007; pp. 18–22. [Google Scholar]
- Taira, E.; Uchida, S.; Sakoe, H. Non-uniform slant correction for handwritten word recognition. IEICE Trans. Inf. Syst. 2004, E87-D, 1247–1253. [Google Scholar]
- Seiichi, U.; Eiji, T.; Hiroaki, S. Non uniform slant correction using dynamic programming. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Seattle, WA, USA, 10–13 September 2001. [Google Scholar]
- Ziaratban, M.; Faez, K. Non-uniform slant estimation and correction for Farsi/Arabic handwritten words. Int. J. Doc. Anal. Recognit. (IJDAR) 2009, 12, 249–267. [Google Scholar] [CrossRef]
- Kavallieratou, E. A slant removal technique for document page. In Proceedings of the IS&T/SPIE Electronic Imaging, San Francisco, CA, USA, 3–6 February 2013. [Google Scholar]
- Available online:. Available online: http://www.unipen.org/trigraphslant.html (accessed on 14 May 2018).
- Lavrenko, V.; Rath, T.M.; Manmatha, R. Holistic word recognition for handwritten historical documents. In Proceedings of the International Workshop on Document Image Analysis for Libraries (DIAL), Palo Alto, CA, USA, 23–24 January 2004; pp. 278–287. [Google Scholar]
- Fernández-Mota, D.; Almazán, J.; Cirera, N.; Fornés, A.; Lladós, J. Bh2m: The barcelona historical, handwritten marriages database. In Proceedings of the 2014 22nd International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 256–261. [Google Scholar]
- Claasen, T.A.; Mecklenbrauker, W.F. The Wigner distribution: A tool for time-frequency signal analysis. Phillips J. Res 1980, 35(Pts 1, 2 and 3), 217–250, 276–300, 372–389. [Google Scholar]
- Diamantatos, P.; Verras, V.; Kavallieratou, E. Detecting main body size in document images. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 1160–1164. [Google Scholar]
- Zeeuw, F. Slant Correction Using Histograms. Ph.D. Thesis, Artifical Intelligence, University of Groningen, Groningen, The Netherlands, 2006. [Google Scholar]
- Papandreou, A.; Gatos, B. Slant estimation and core-region detection for handwritten Latin words. Pattern Recognit. Lett. 2014, 35, 16–22. [Google Scholar]
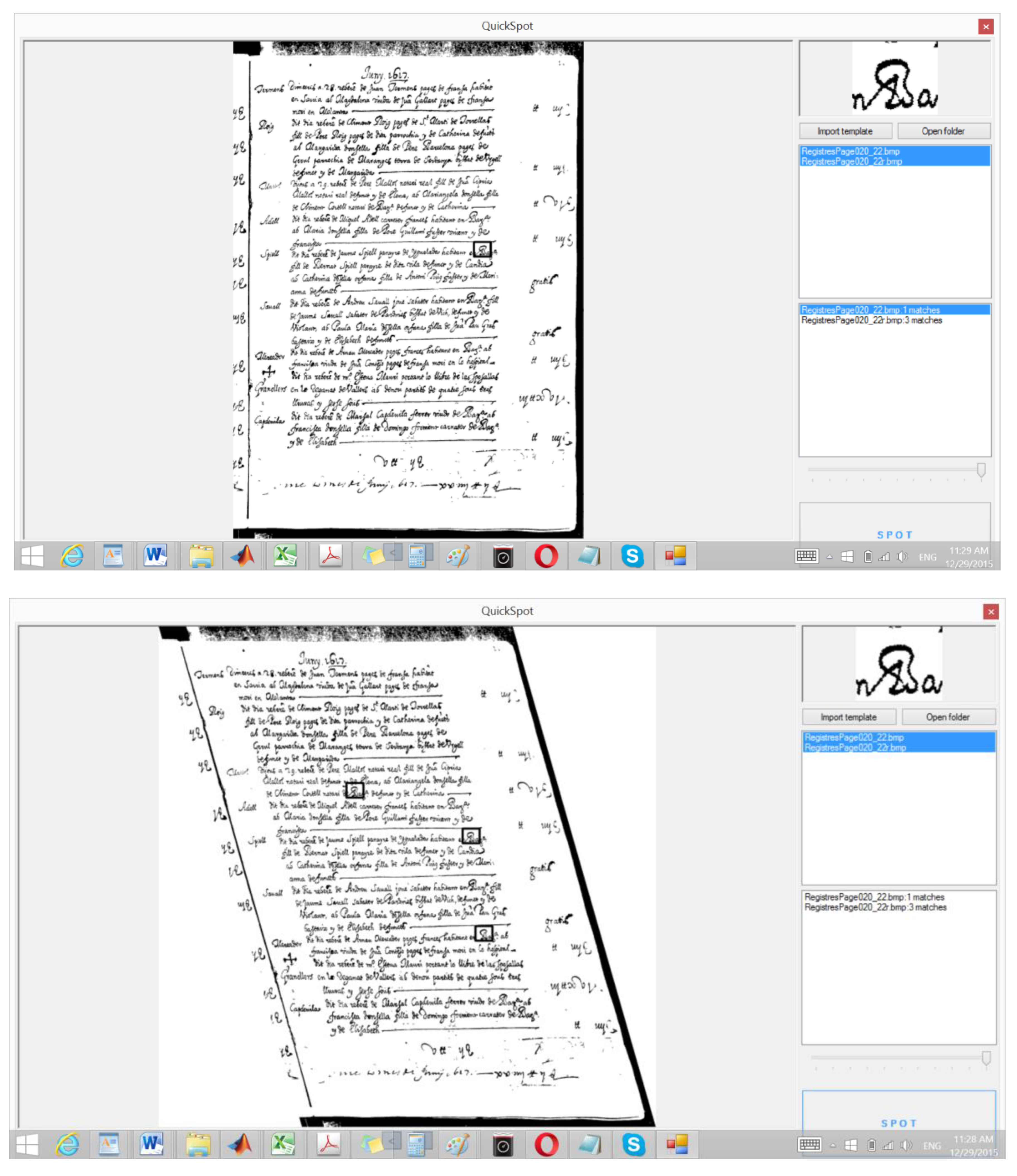
- Vasilopoulos;N.;Kavallieratou, E. A classification-free word-spotting system. In Proceedings of the IS&T/SPIE Electronic Imaging. International Society for Optics and Photonics, San Francisco, CA, USA, 3–6 February 2013. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kavallieratou, E.; Likforman-Sulem, L.; Vasilopoulos, N. Slant Removal Technique for Historical Document Images. J. Imaging 2018, 4, 80. https://doi.org/10.3390/jimaging4060080
Kavallieratou E, Likforman-Sulem L, Vasilopoulos N. Slant Removal Technique for Historical Document Images. Journal of Imaging. 2018; 4(6):80. https://doi.org/10.3390/jimaging4060080
Chicago/Turabian StyleKavallieratou, Ergina, Laurence Likforman-Sulem, and Nikos Vasilopoulos. 2018. "Slant Removal Technique for Historical Document Images" Journal of Imaging 4, no. 6: 80. https://doi.org/10.3390/jimaging4060080
APA StyleKavallieratou, E., Likforman-Sulem, L., & Vasilopoulos, N. (2018). Slant Removal Technique for Historical Document Images. Journal of Imaging, 4(6), 80. https://doi.org/10.3390/jimaging4060080