Text/Non-Text Separation from Handwritten Document Images Using LBP Based Features: An Empirical Study

Abstract
:1. Introduction
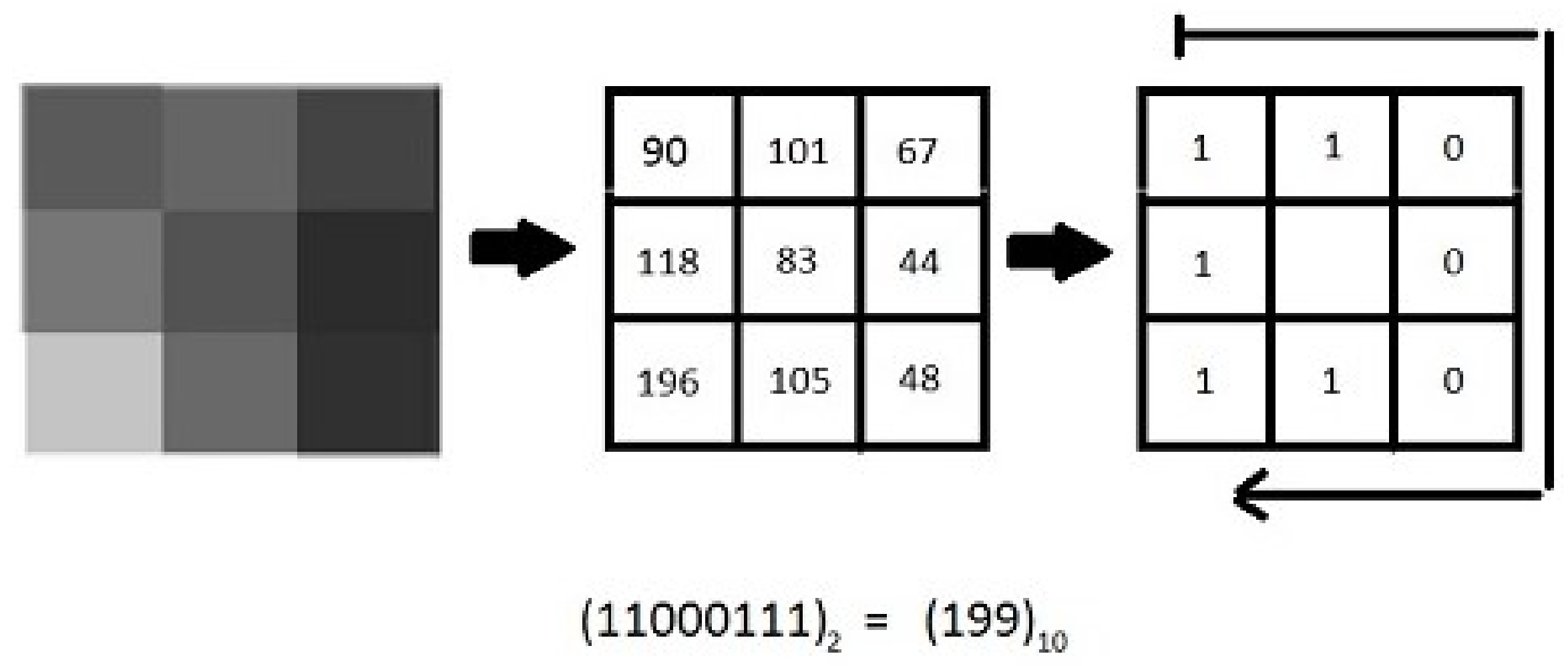
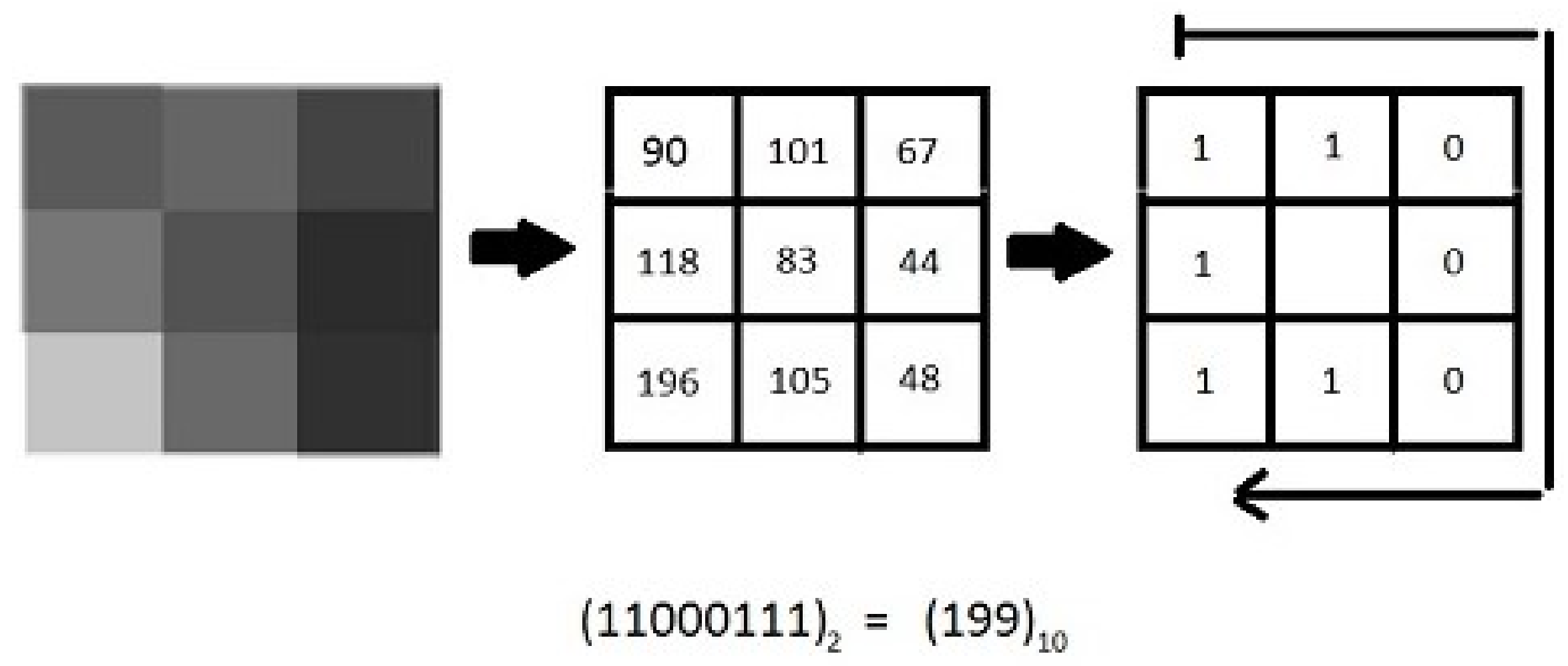
- We have given a detailed analysis of how accurately features extracted by different variants of the LBP operator from handwritten document images help in differentiating text components from non-text ones, which is one of the most challenging research areas in the domain of document image processing. For that purpose, we have considered five variants of LBP [21], namely, the basic LBP [22], improved LBP [23], rotation invariant LBP [22], uniform LBP [22], and rotation invariant and uniform LBP [22].
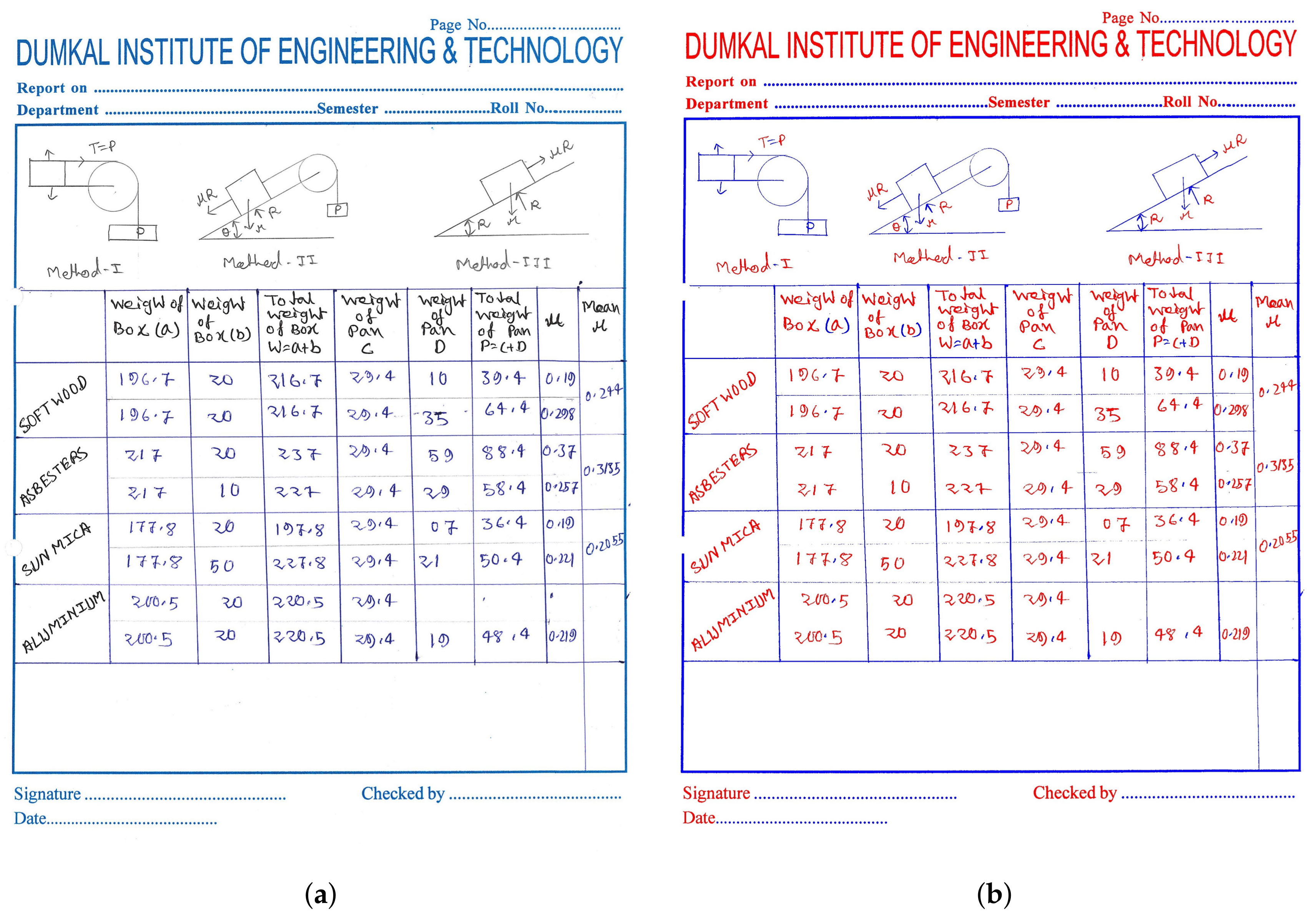
- The contents of the dataset, used here for evaluation, have complex text and non-text components as well as variations in terms of scripts, as we have considered both Bangla and English texts. In addition to that, some of the documents have handwritten as well as printed texts.
- We have also made a minor alteration to robust LBP [24] in order to develop robust and uniform LBP. A method to determine the appropriate threshold value used in this variant of LBP for handwritten documents has also been proposed.
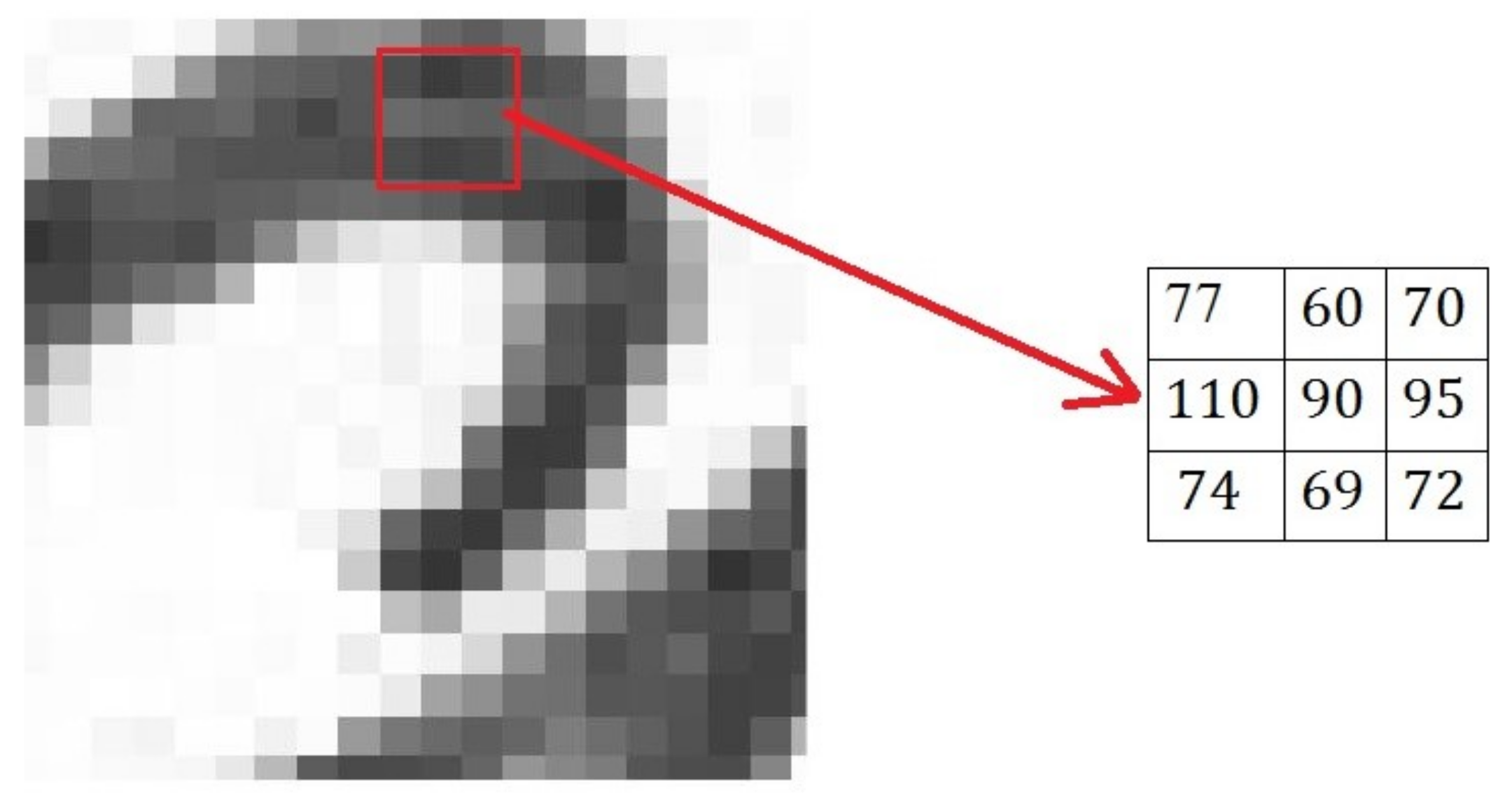
2. Local Binary Patterns and Its Variants
2.1. Improved LBP (ILBP)
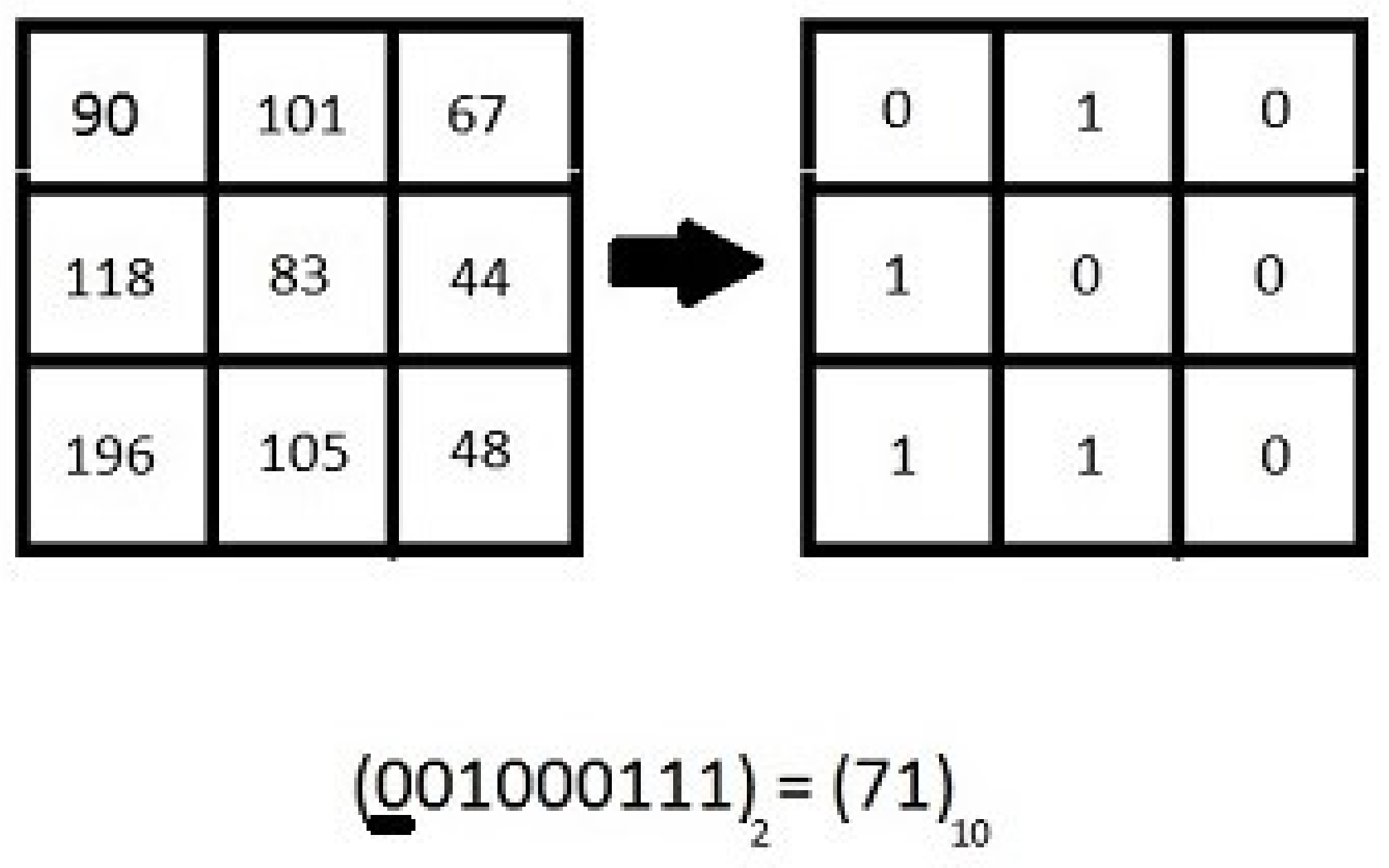
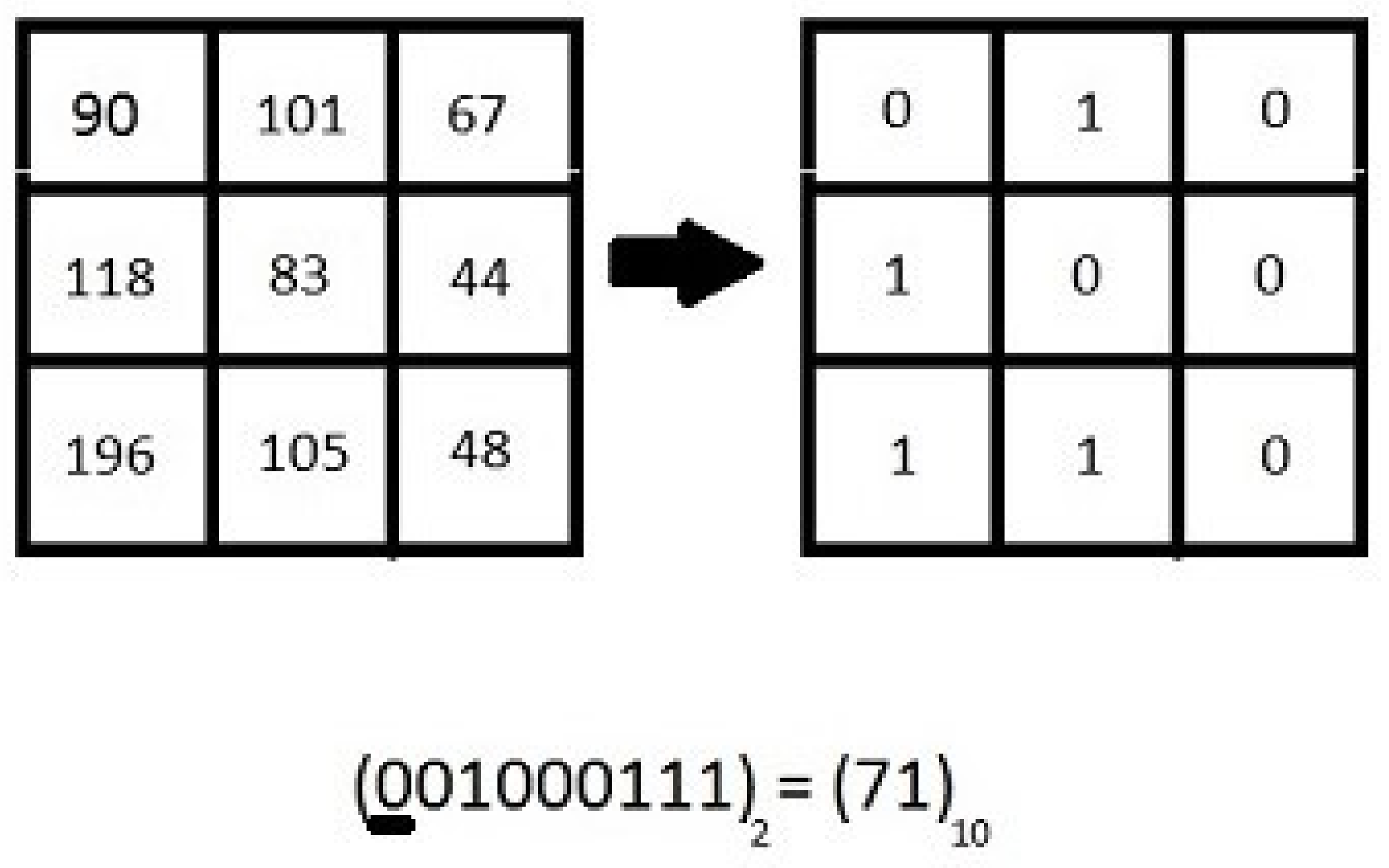
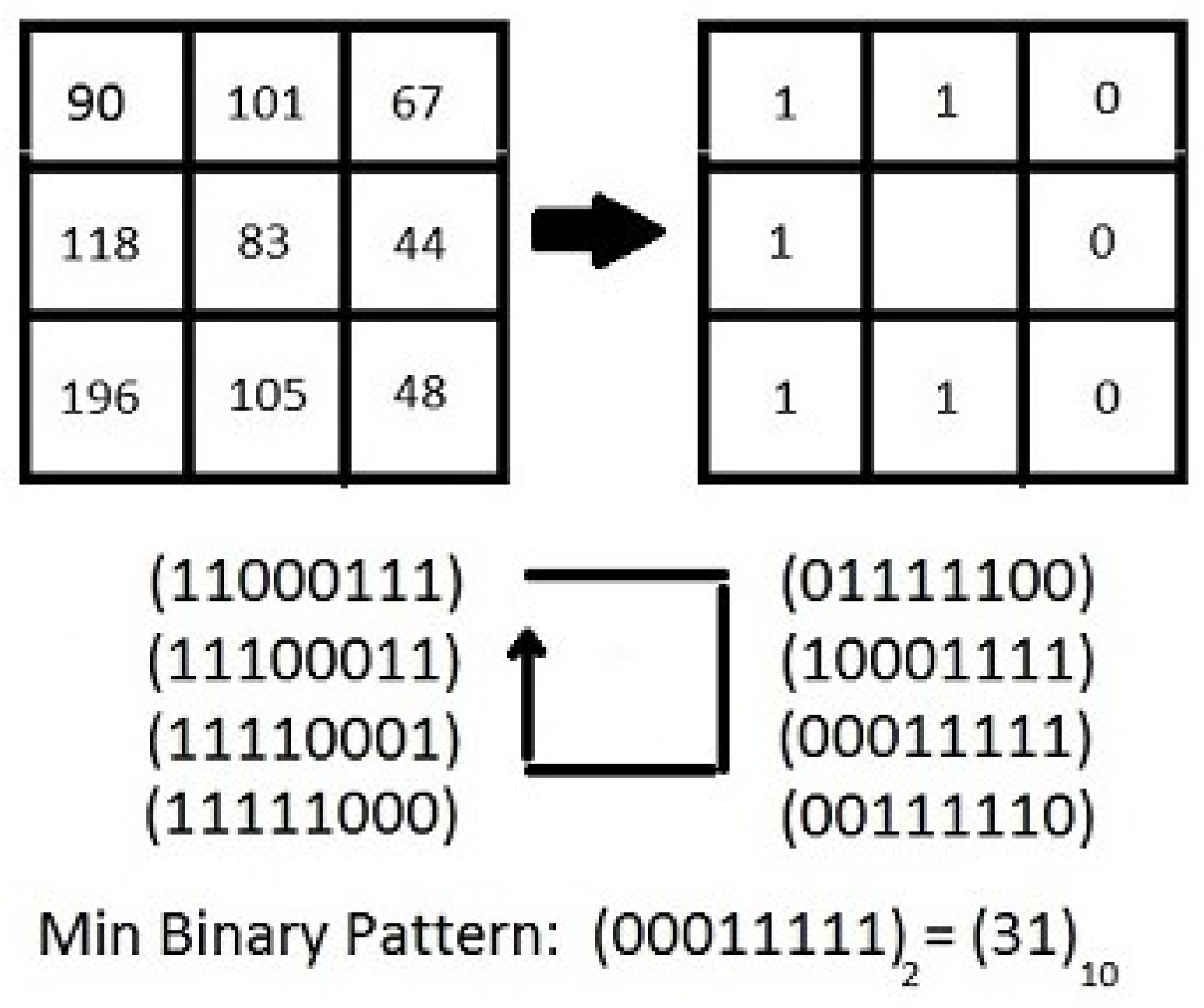
2.2. Rotation Invariant LBP (RILBP)
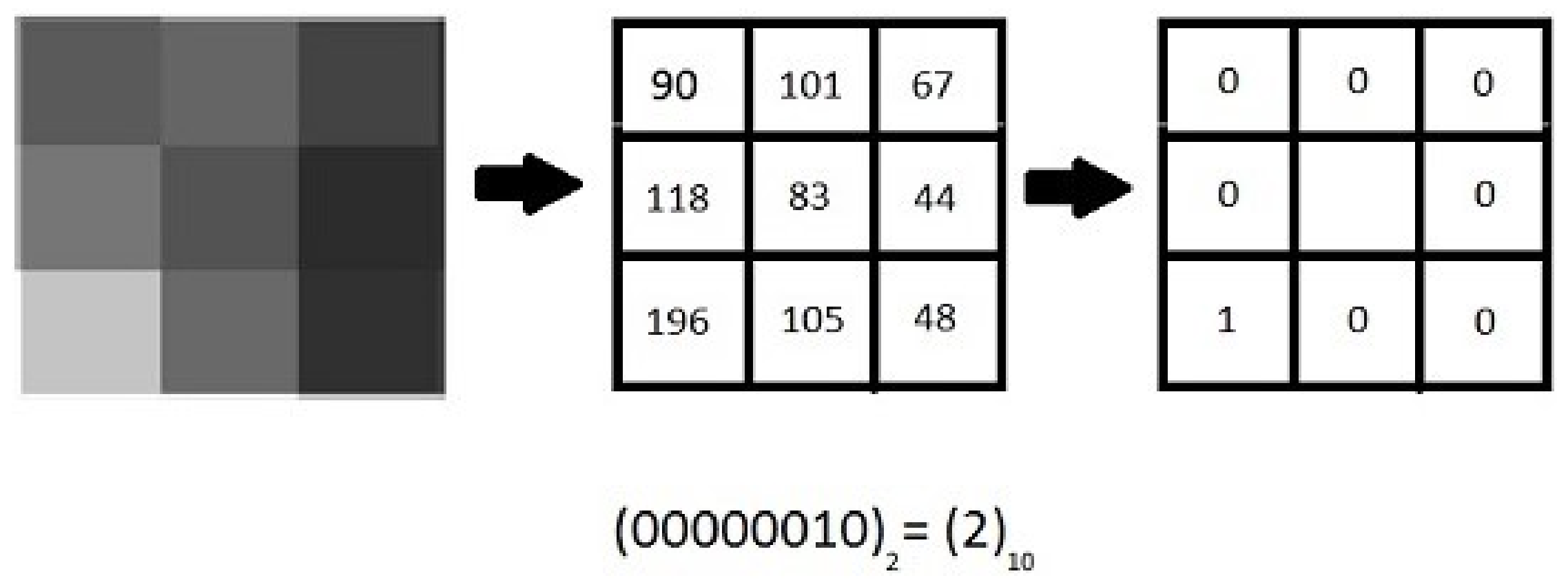
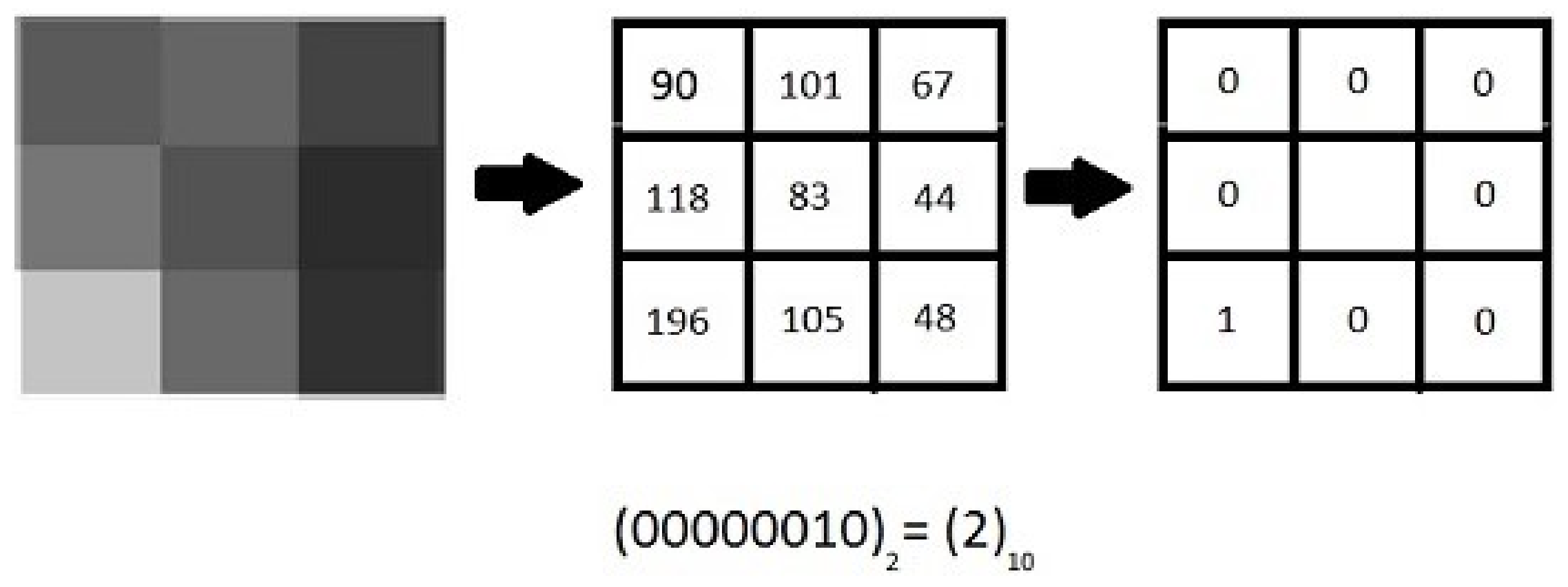
2.3. Uniform LBP (ULBP)
2.4. Rotation Invariant and Uniform LBP (RIULBP)
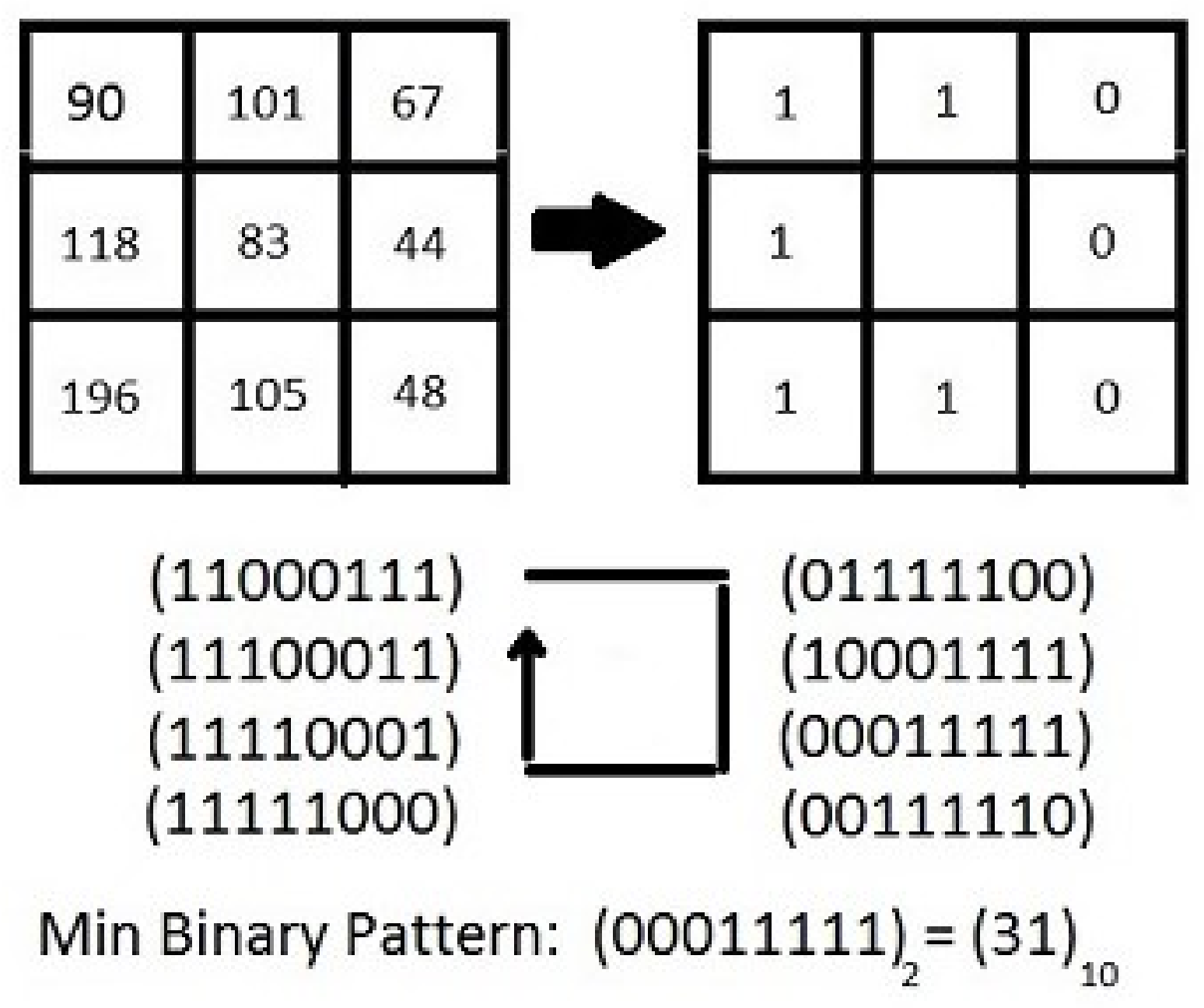
2.5. Robust and Uniform LBP (RULBP)
2.5.1. Idea of ‘Uniform Pattern’
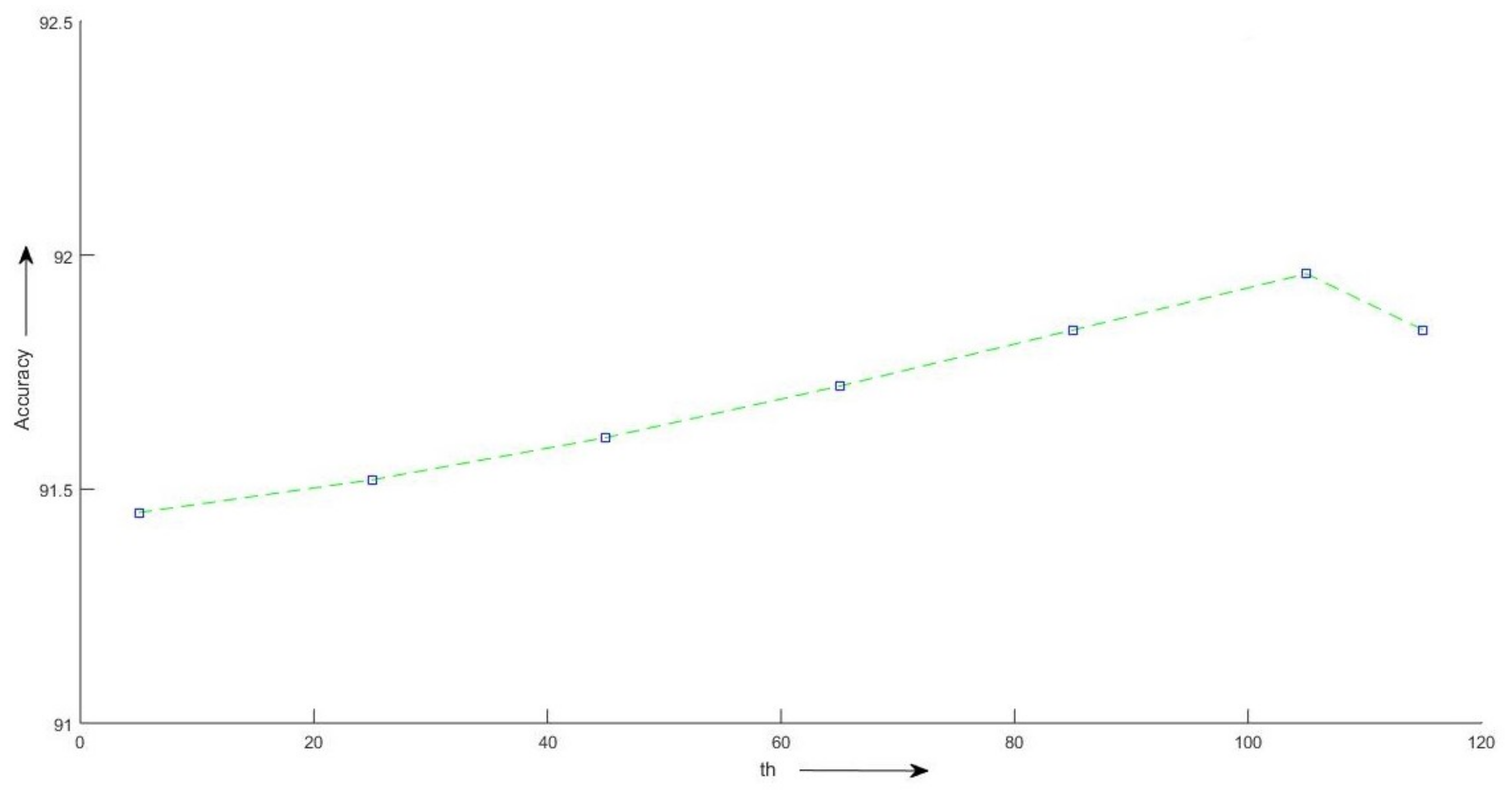
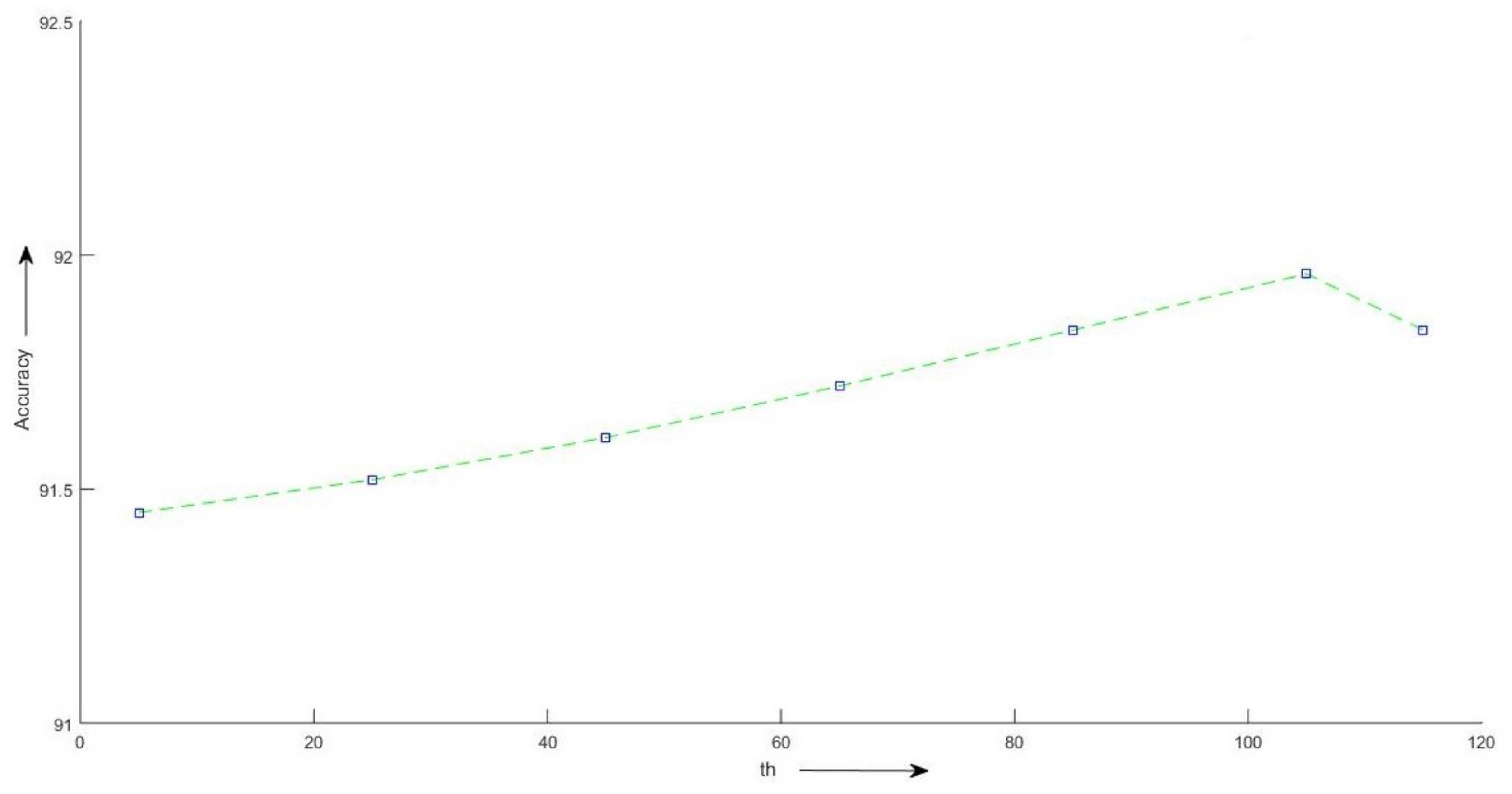
2.5.2. Selecting the Value of th
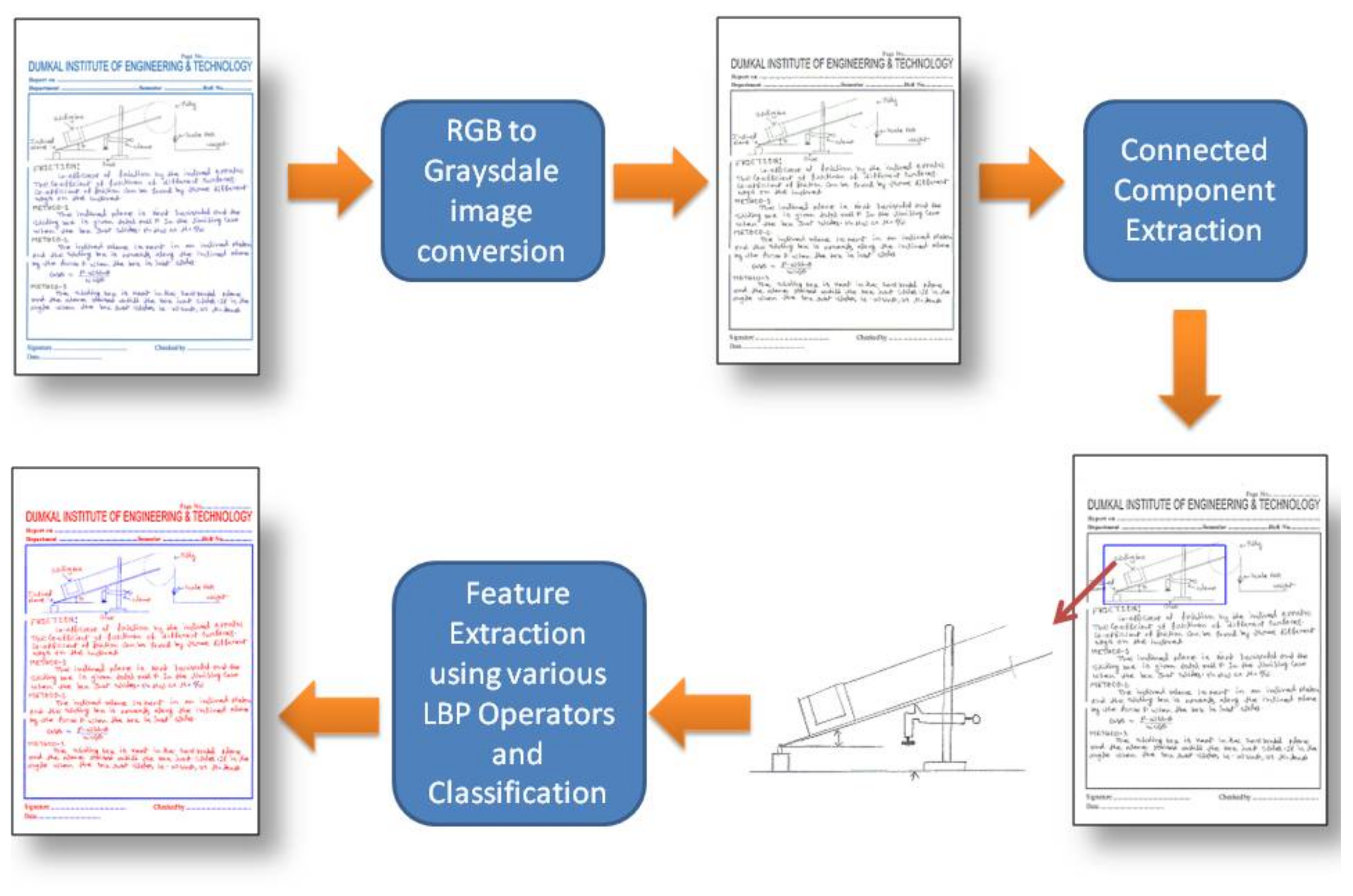
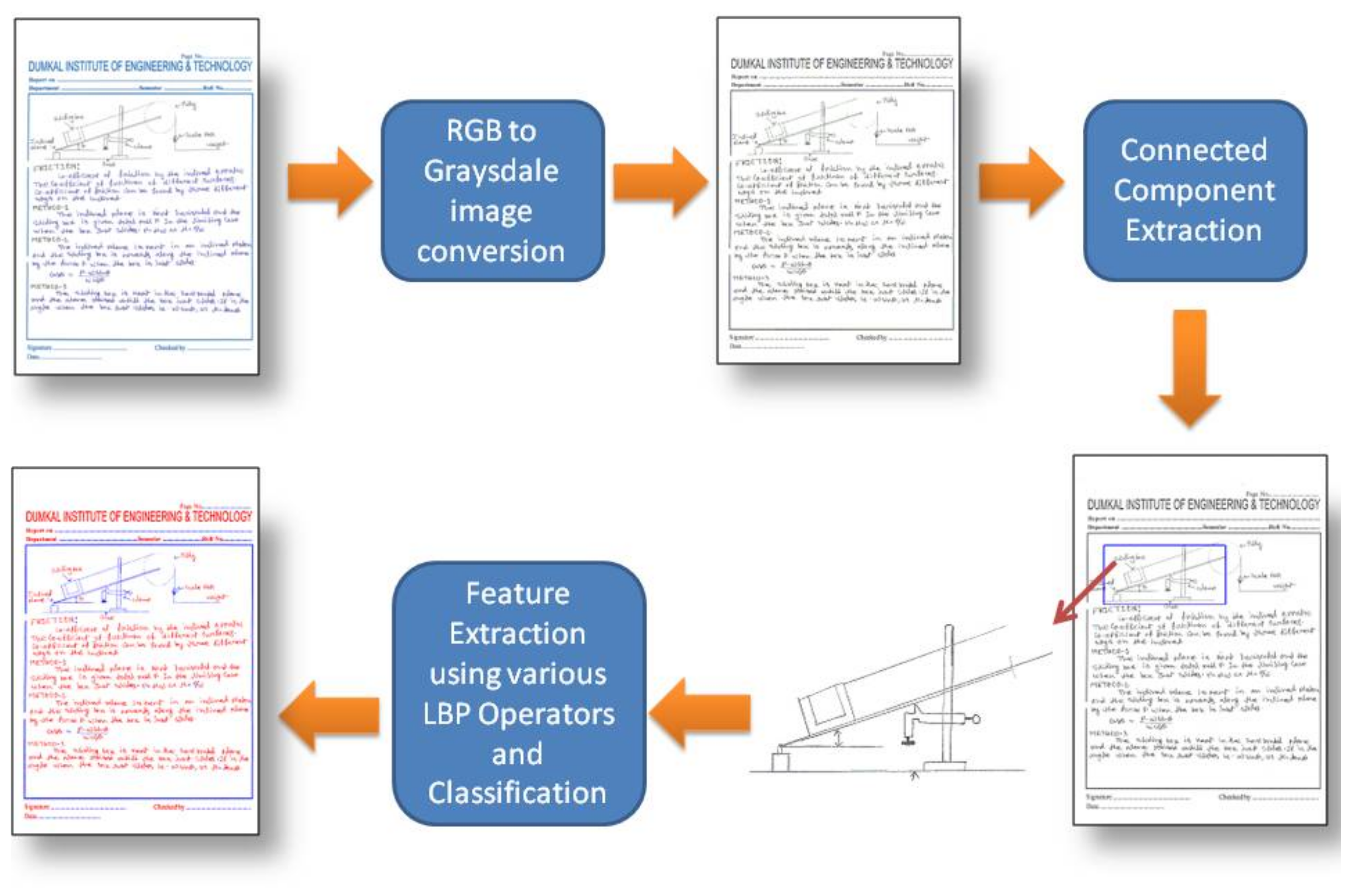
3. Method
4. Experimental Setup
4.1. Database Preparation
4.2. Classifiers
4.3. Performance Metrics
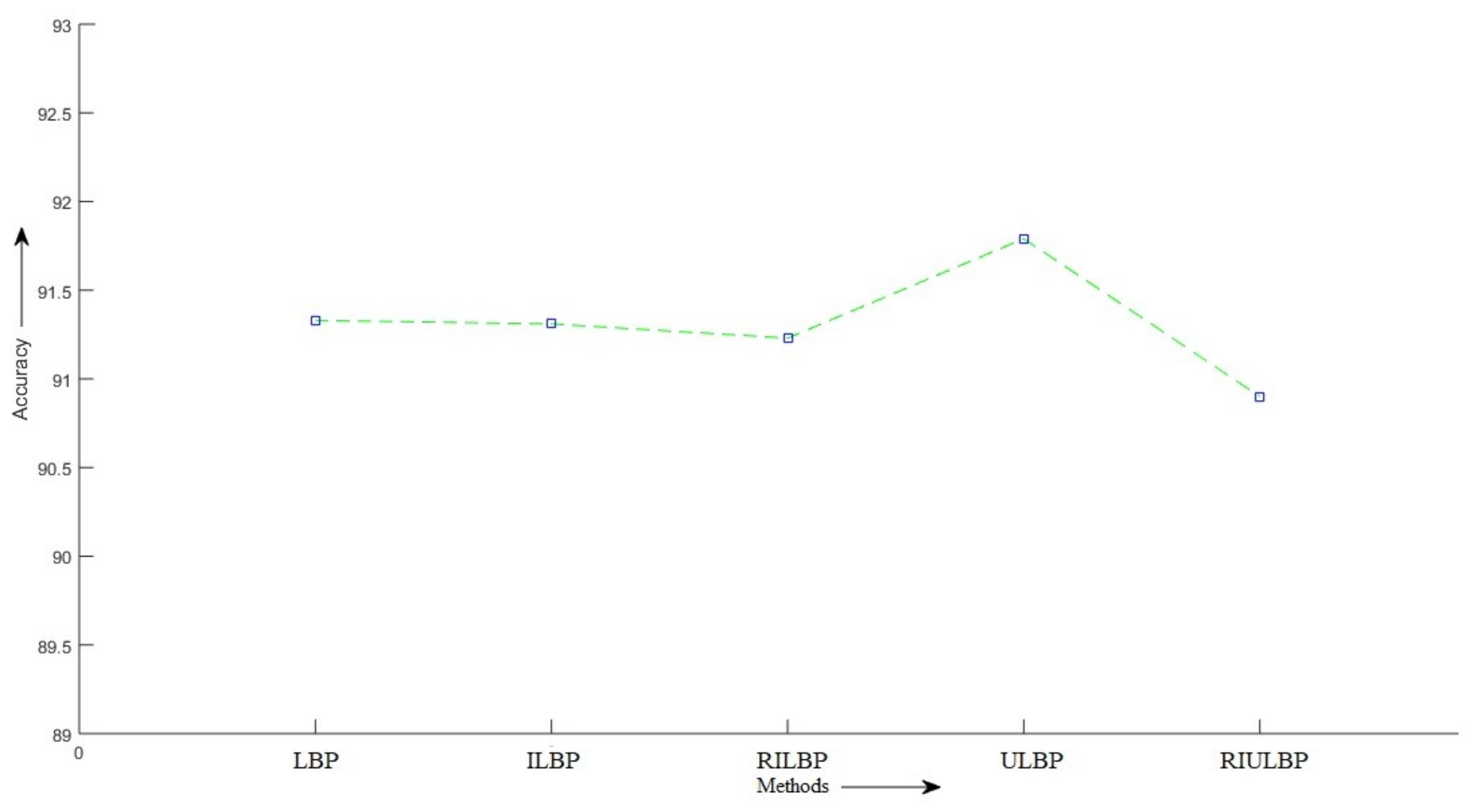
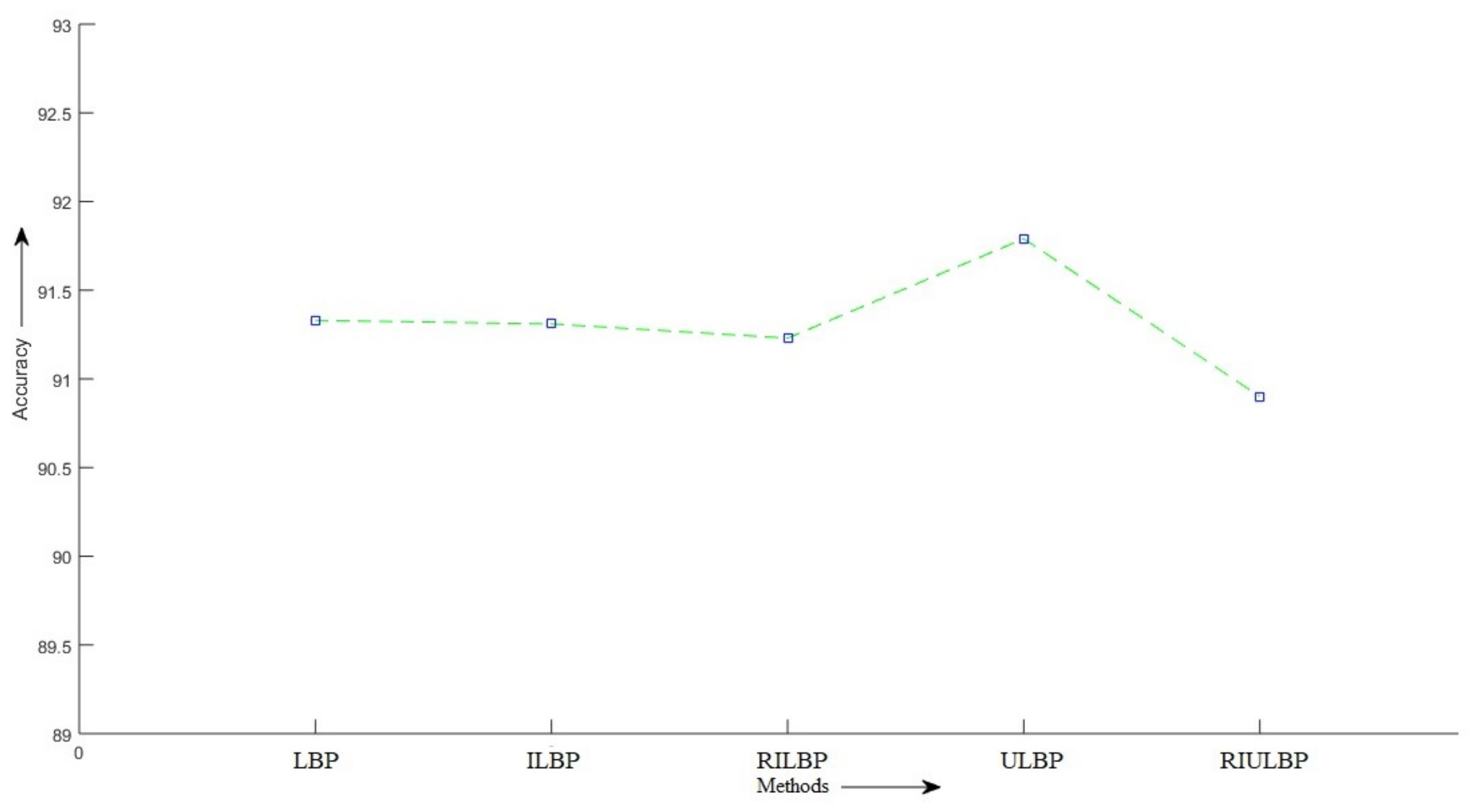
5. Experimental Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| LBP | Local Binary Pattern |
| GLCM | Gray-Level Co-Occurrence Matrix |
| CC | Connected Components |
| BB | Bounding Box |
| ILBP | Improved Local Binary Pattern |
| RILBP | Rotation Invariant Local Binary Pattern |
| ULBP | Uniform Local Binary Pattern |
| RIULBP | Rotation Invariant Uniform Local Binary Pattern |
| RULBP | Robust Uniform Local Binary Pattern |
| NB | Naive Bayes |
| MLP | Multilayer Perceptron |
| SMO | Sequential Minimal Optimization |
| k-NN | k-Nearest Neighbors |
| RF | Random Forest |
References
- Santosh, K.C.; Wendling, L. Character recognition based on non-linear multi-projection profiles measure. Front. Comput. Sci. 2015, 9, 678–690. [Google Scholar] [CrossRef]
- Santosh, K.C.; Iwata, E. Stroke-Based Cursive Character Recognition. In Advances in Character Recognition; InTechOpen: London, UK, 2012; Chapter 10. [Google Scholar]
- Santosh, K.C.; Nattee, C.; Lamiroy, B. Relative Positioning Of Stroke-based Clustering: A New Approach To Online Handwritten Devnagari Character Recognition. Int. J. Image Graph. 2012, 12, 1250016. [Google Scholar] [CrossRef]
- Oyedotun, O.K.; Khashman, A. Document segmentation using textural features summarization and feedforward neural network. Appl. Intell. 2016, 45, 198–212. [Google Scholar] [CrossRef]
- Le, V.P.; Nayef, N.; Visani, M.; Ogier, J.-M.; De Tran, C. Text and non-text segmentation based on connected component features. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; Volume 45, pp. 1096–1100. [Google Scholar]
- Tran, T.-A.; Na, I.-S.; Kim, S.-H. Separation of Text and Non-text in Document Layout Analysis using a Recursive Filter. KSII Trans. Internet Inf. Syst. 2015, 9, 4072–4091. [Google Scholar]
- Sarkar, R.; Moulik, S.; Das, N.; Basu, S.; Nasipuri, M.; Kundu, M. Suppression of non-text components in handwritten document images. In Proceedings of the 2011 International Conference on Image Information Processing (ICIIP), Shimla, India, 3–5 November 2011; pp. 1–7. [Google Scholar]
- Bhowmik, S.; Sarkar, R.; Nasipuri, M. Text and Non-text Separation in Handwritten Document Images Using Local Binary Pattern Operator. In International Conference on Intelligent Computing and Communication; Springer: Singapore, 2017; pp. 507–515. [Google Scholar]
- Santosh, K.C. g-DICE: Graph mining-based document information content exploitation. Int. J. Doc. Anal. Recognit. IJDAR 2015, 18, 337–355. [Google Scholar] [CrossRef]
- Santosh, K.C. Complex and Composite Graphical Symbol Recognition and Retrieval: A Quick Review. In International Conference on Recent Trends in Image Processing and Pattern Recognition; Springer: Singapore, 2016. [Google Scholar]
- Vil’kin, A.M.; Safonov, I.V.; Egorova, M.A. Algorithm for segmentation of documents based on texture features. Pattern Recognit. Image Anal. 2013, 23, 153–159. [Google Scholar] [CrossRef]
- Park, H.C.; Ok, S.Y.; Cho, H. Word extraction in text/graphic mixed image using 3-dimensional graph model. In Proceedings of the ICCPOL, Tokushima, Japan, 24–26 March 1999; Volume 99, pp. 171–176. [Google Scholar]
- Shih, F.Y.; Chen, S.-S. Adaptive document block segmentation and classification. IEEE Trans. Syst. Man Cybern. Part B 1996, 26, 797–802. [Google Scholar] [CrossRef] [PubMed]
- Antonacopoulos, A.; Ritchings, T.R.; De Tran, C. Representation and classification of complex-shaped printed regions using white tiles. In Proceedings of the Third International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 2, pp. 1132–1135. [Google Scholar]
- Pintus, R.; Yang, Y.; Rushmeier, H. ATHENA: Automatic text height extraction for the analysis of text lines in old handwritten manuscripts. J. Comput. Cult. Herit. 2015, 8, 1. [Google Scholar] [CrossRef]
- Yang, Y.; Pintus, R.; Gobbetti, E.; Rushmeier, H. Automatic single page-based algorithms for medieval manuscript analysis. J. Comput. Cult. Herit. 2017, 10, 9. [Google Scholar] [CrossRef]
- Garz, A.; Sablatnig, R.; Diem, M. Layout analysis for historical manuscripts using sift features Document. In Proceedings of the 2011 International Conference on Document Analysis and Recognition (ICDAR), Beijing, China, 18–21 September 2011. [Google Scholar]
- Garz, A.; Sablatnig, R.; Diem, M. Using Local Features for Efficient Layout Analysis of Ancient Manuscripts. In Proceedings of the European Signal Processing Conference, Barcelona, Spain, 29 Auguat–2 September 2011; pp. 1259–1263. [Google Scholar]
- Wang, D.; Nihari, S.N. Classification of newspaper image blocks using texture analysis. Comput. Vis. Graph. Image Process 1989, 47, 327–352. [Google Scholar] [CrossRef]
- Belaïd, A.; Santosh, K.C.; d’Andecy, V.P. Handwritten and Printed Text Separation in Real Document. arXiv, 2013; arXiv:1303.4614. [Google Scholar]
- Nanni, L.; Lumini, A.; Brahnam, S. Survey on LBP based texture descriptors for image classification. Expert Syst. Appl. 2012, 39, 3634–3641. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Jin, H.; Liu, Q.; Lu, H.; Tong, X. Face detection using improved LBP under Bayesian framework. In Proceedings of the Third International Conference on Image and Graphics (ICIG), Hong Kong, China, 18–20 December 2004; pp. 306–309. [Google Scholar]
- Heikkila, M.; Pietikainen, M. A texture-based method for modeling the background and detecting moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 657–662. [Google Scholar] [CrossRef] [PubMed]
- Harwood, D.; Ojala, T.; Pietikäinen, M.; Kelman, S.; Davis, L. Texture classification by center-symmetric auto-correlation, using Kullback discrimination of distributions. Pattern Recognit. Lett. 1995, 16, 1–10. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Das, B.; Bhowmik, S.; Saha, A.; Sarkar, R. An Adaptive Foreground-Background Separation Method for Effective Binarization of Document Images. In Eighth International Conference on Soft Computing and Pattern Recognition; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. The WEKA Workbench. Online Appendix for Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Sah, K.A.; Bhowmik, S.; Malakar, S.; Sarkar, R.; Kavallieratou, E.; Vasilopoulos, N. Text and non-text recognition using modified HOG descriptor. In Proceedings of the IEEE Calcutta Conference (CALCON), Kolkata, India, 2–3 December 2017. [Google Scholar] [CrossRef]
- Obaidullah, S.M.; Santosh, K.C.; Halder, C.; Das, N.; Roy, K. Automatic Indic script identification from handwritten documents: Page, block, line and word-level approach. Int. J. Mach. Learn. Cyber 2017, 1–20. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Parameters with Values |
|---|---|
| NB | • Batch size: 100 |
| • Normal distribution for numeric attributes | |
| MLP | • Learning Rate for the back propagation algorithm: 0.3 |
| • Momentum Rate: 0.2 | |
| • Number of epochs to train through: 500 | |
| • Learning Rate: 0.3 | |
| SMO | • Complexity constant C: 1 |
| • Tolerance Parameter: 1.0 × 10−3 | |
| • Epsilon for round-off error: 1.0 × 10−12 | |
| • The random number seed: 1 | |
| K-NN | • K: 1 |
| • Batch size: 100 | |
| RF | • Batch size: 100 |
| • Minimum number of instances per leaf: 1 | |
| • Minimum numeric class variance proportion of train variance for split: 1.0 × 10−3 | |
| • The maximum depth of the tree: unlimited |
| Feature | Feature Dimension | Classifier | Precision | Recall | F-Measure | Accuracy (in %) |
|---|---|---|---|---|---|---|
| NB | 0.802 | 0.771 | 0.774 | 77.08 | ||
| MLP | 0.529 | 0.54 | 0.534 | 54.04 | ||
| LBP | 256 | SMO | 0.892 | 0.889 | 0.889 | 88.87 |
| K-NN | 0.856 | 0.851 | 0.852 | 85.12 | ||
| RF | 0.914 | 0.913 | 0.913 | 91.33 | ||
| NB | 0.82 | 0.764 | 0.767 | 76.41 | ||
| MLP | 0.386 | 0.621 | 0.476 | 62.13 | ||
| ILBP | 511 | SMO | 0.862 | 0.858 | 0.859 | 85.84 |
| K-NN | 0.852 | 0.845 | 0.847 | 84.5 | ||
| RF | 0.913 | 0.913 | 0.912 | 91.31 | ||
| NB | 0.831 | 0.802 | 0.805 | 80.18 | ||
| MLP | 0.908 | 0.907 | 0.905 | 90.66 | ||
| RILBP | 36 | SMO | 0.889 | 0.886 | 0.887 | 88.62 |
| K-NN | 0.882 | 0.882 | 0.882 | 88.19 | ||
| RF | 0.912 | 0.912 | 0.912 | 91.23 | ||
| NB | 0.862 | 0.857 | 0.858 | 85.65 | ||
| MLP | 0.912 | 0.912 | 0.912 | 91.22 | ||
| ULBP | 59 | SMO | 0.891 | 0.888 | 0.889 | 88.8 |
| KNN | 0.901 | 0.901 | 0.901 | 90.13 | ||
| RF | 0.918 | 0.918 | 0.917 | 91.79 | ||
| NB | 0.859 | 0.855 | 0.856 | 85.52 | ||
| MLP | 0.907 | 0.907 | 0.906 | 90.71 | ||
| RIULBP | 10 | SMO | 0.888 | 0.886 | 0.887 | 88.58 |
| KNN | 0.886 | 0.886 | 0.886 | 88.62 | ||
| RF | 0.909 | 0.909 | 0.908 | 90.9 |
| Feature Dimension | Threshold (th) | Precision | Recall | F-Measure | Accuracy in % |
|---|---|---|---|---|---|
| 5 | 0.915 | 0.915 | 0.914 | 91.45 | |
| 25 | 0.915 | 0.915 | 0.915 | 91.52 | |
| 45 | 0.916 | 0.916 | 0.915 | 91.61 | |
| 59 | 65 | 0.917 | 0.917 | 0.917 | 91.72 |
| 85 | 0.919 | 0.918 | 0.918 | 91.84 | |
| 105 | 0.920 | 0.920 | 0.919 | 91.96 | |
| 115 | 0.919 | 0.918 | 0.918 | 91.84 |
| Method | NB | MLP | SMO | KNN | RF |
|---|---|---|---|---|---|
| RULBP | 50.38 | 90.78 | 88.62 | 90.20 | 91.96 |
| GLCM | 77.92 | 90.22 | 87.21 | 87.70 | 90.90 |
| HOG | 36.22 | 80.46 | 72.61 | 88.89 | 91.42 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghosh, S.; Lahiri, D.; Bhowmik, S.; Kavallieratou, E.; Sarkar, R. Text/Non-Text Separation from Handwritten Document Images Using LBP Based Features: An Empirical Study. J. Imaging 2018, 4, 57. https://doi.org/10.3390/jimaging4040057
Ghosh S, Lahiri D, Bhowmik S, Kavallieratou E, Sarkar R. Text/Non-Text Separation from Handwritten Document Images Using LBP Based Features: An Empirical Study. Journal of Imaging. 2018; 4(4):57. https://doi.org/10.3390/jimaging4040057
Chicago/Turabian StyleGhosh, Sourav, Dibyadwati Lahiri, Showmik Bhowmik, Ergina Kavallieratou, and Ram Sarkar. 2018. "Text/Non-Text Separation from Handwritten Document Images Using LBP Based Features: An Empirical Study" Journal of Imaging 4, no. 4: 57. https://doi.org/10.3390/jimaging4040057