Image Features Based on Characteristic Curves and Local Binary Patterns for Automated HER2 Scoring †


Abstract
1. Introduction
2. Materials and Methods
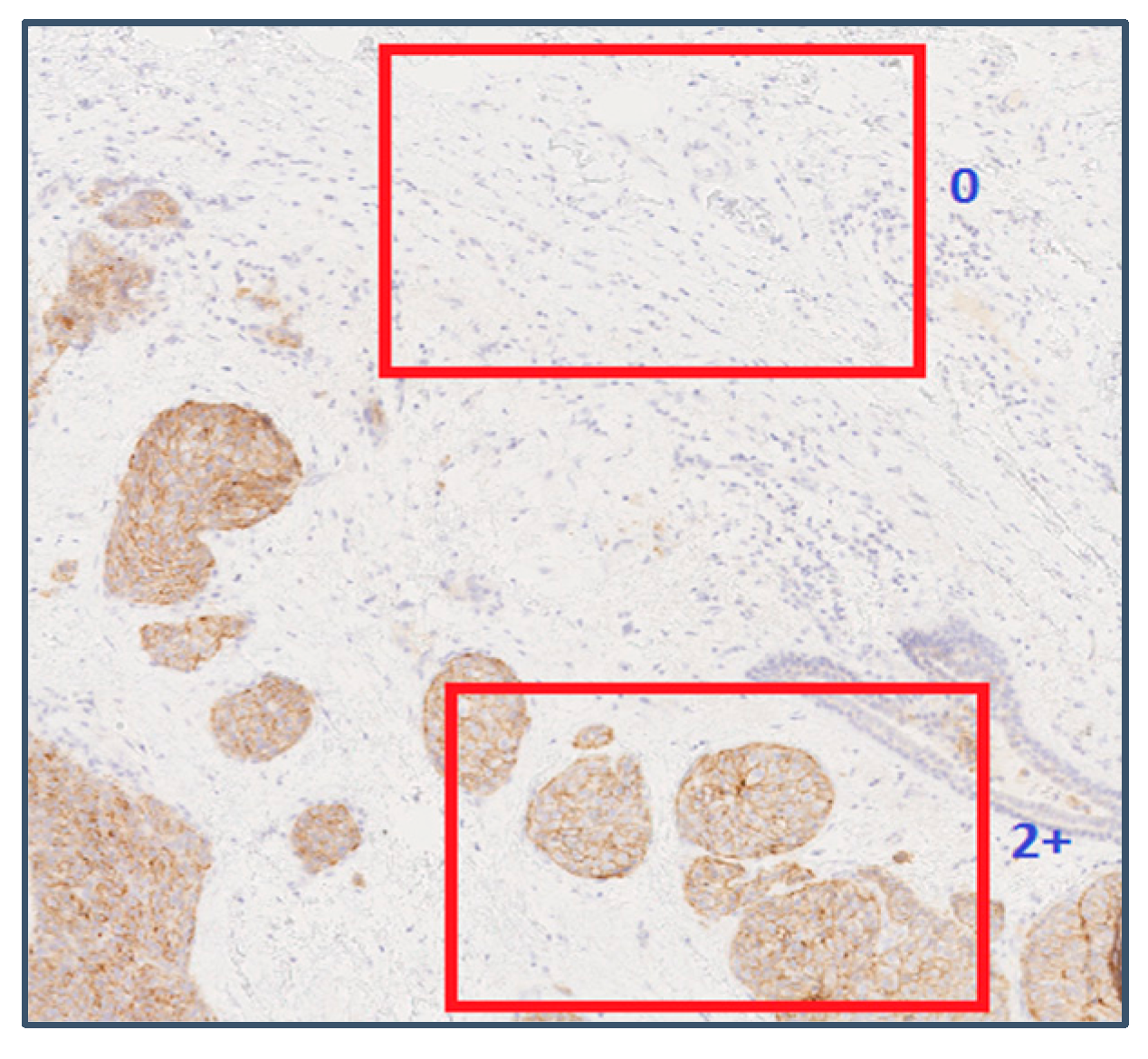
2.1. HER2 Assessment
2.2. Dataset
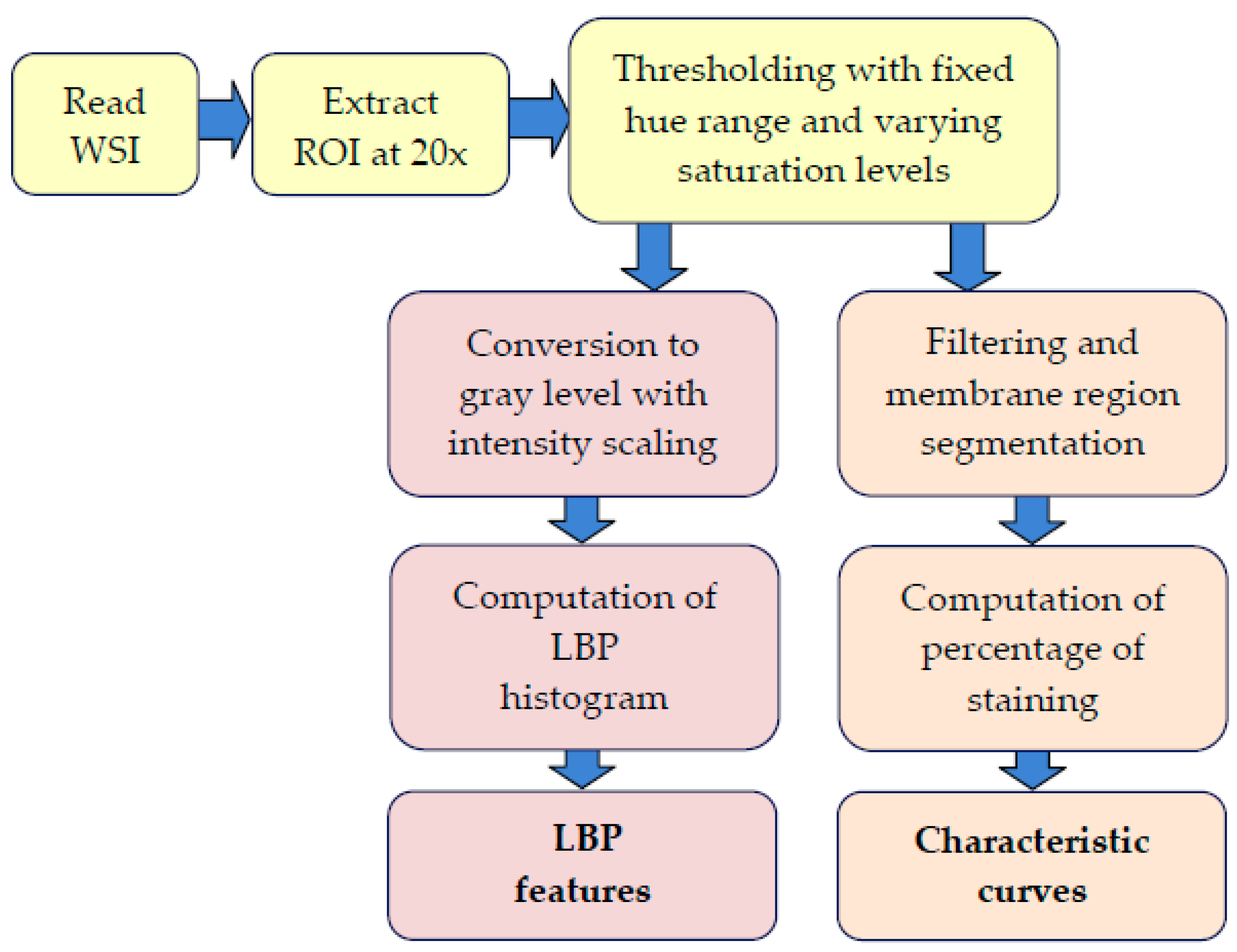
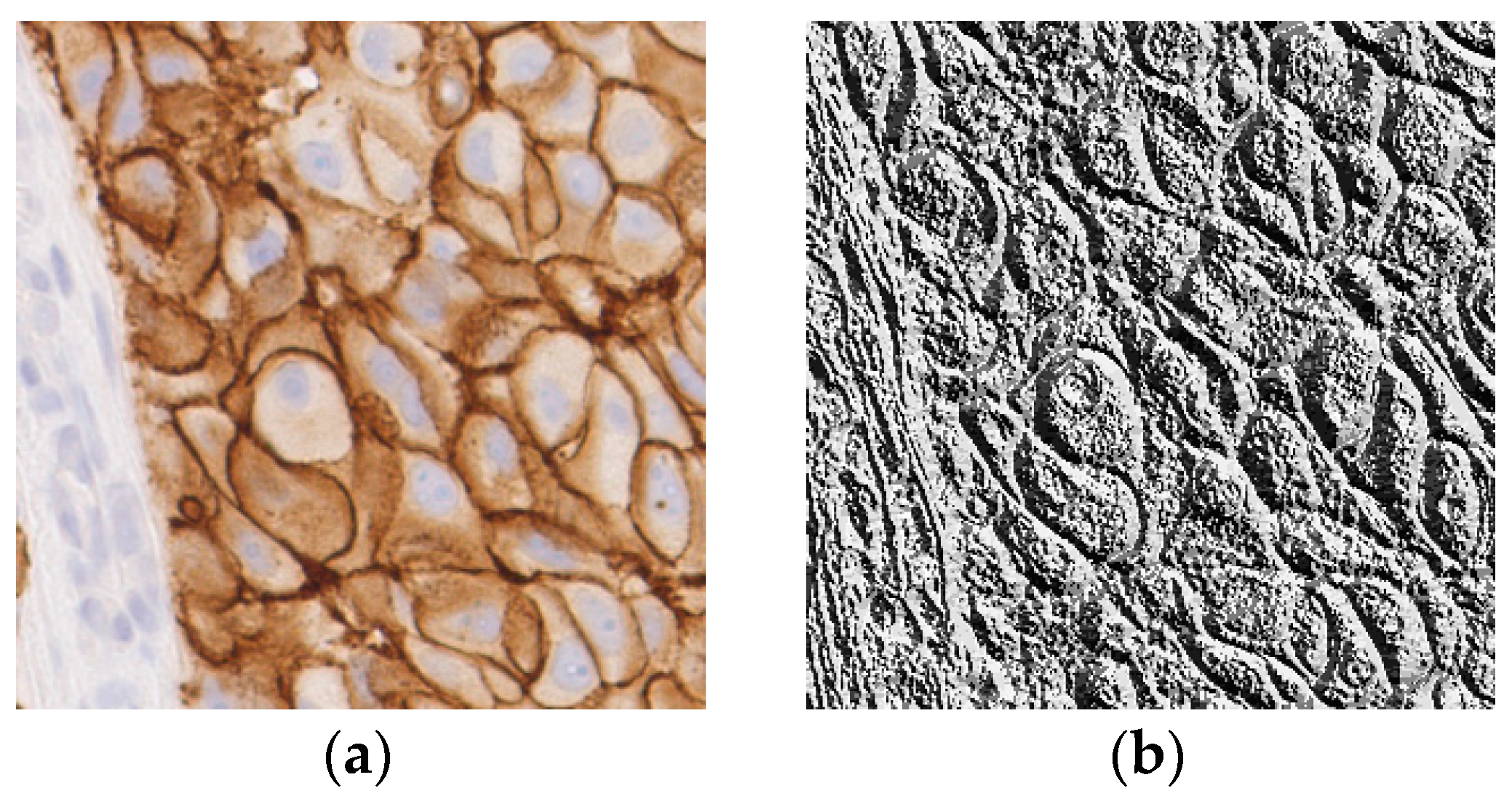
2.3. Processing Stages
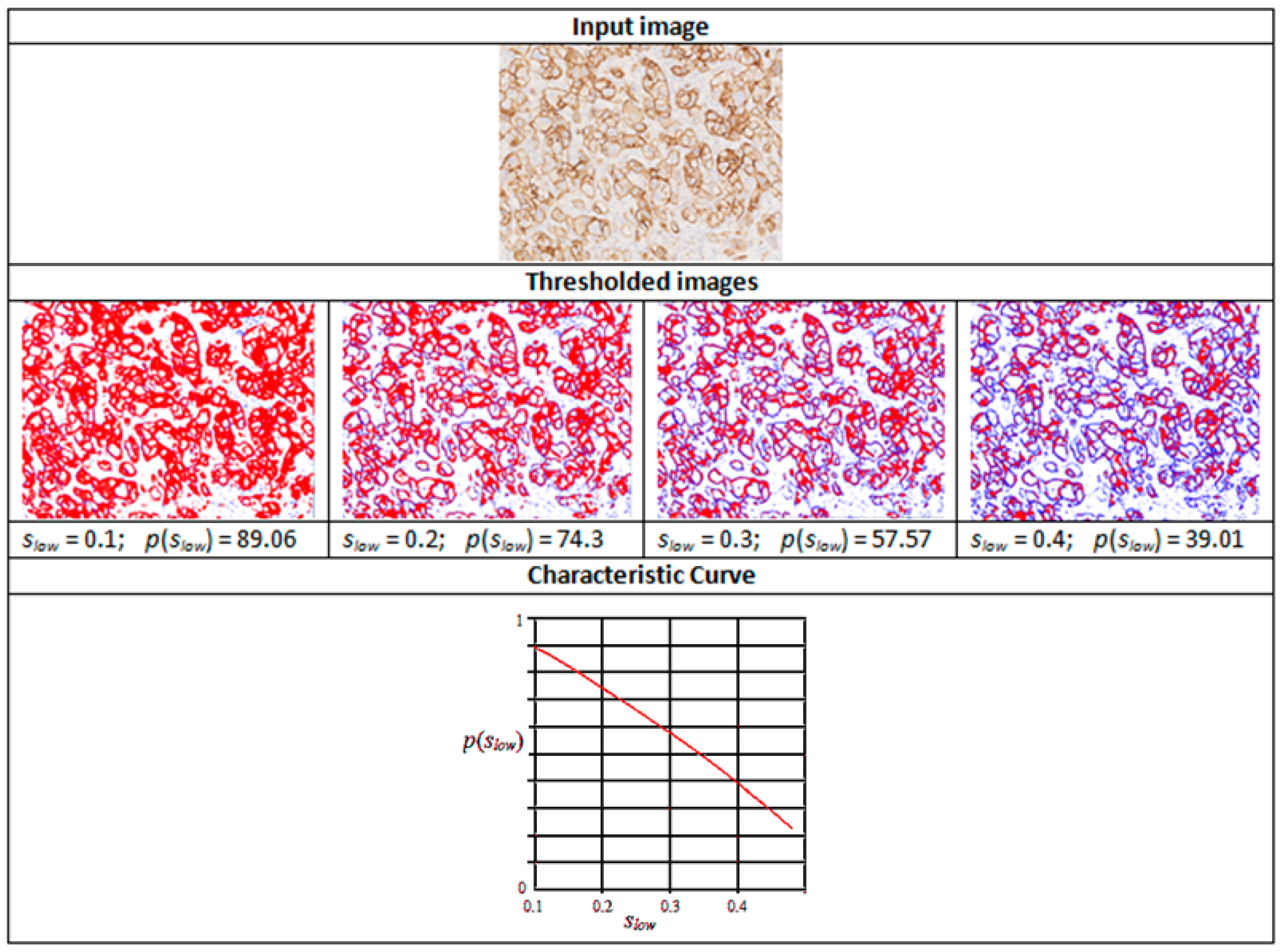
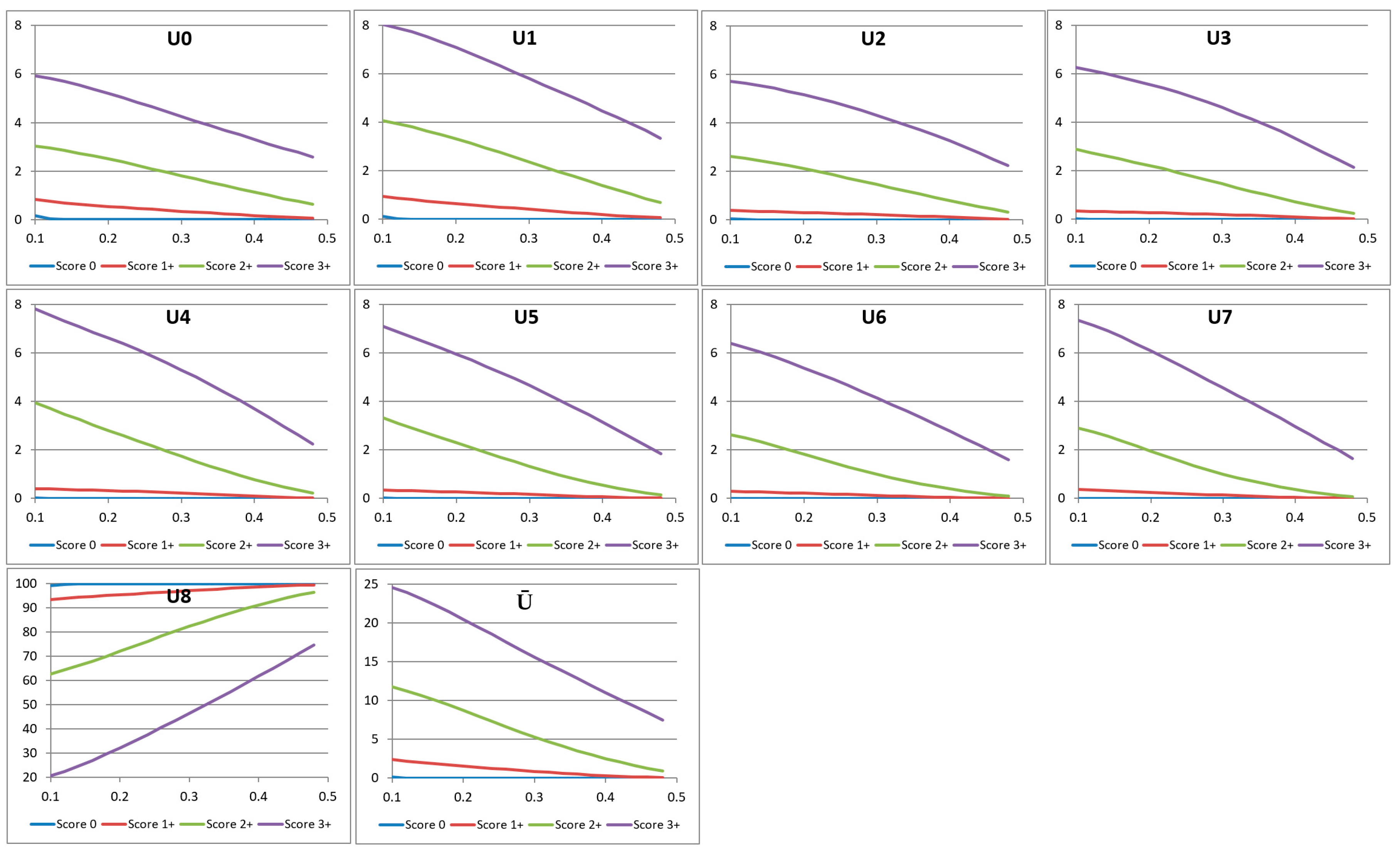
3. Characteristic Curves
s > slow
v1 ≤ v < v2,
- If z0 (=p(0.1)) <10%, then the whole curve lies below 10%, and the score is 0
- Else if zn−1 (=p(0.5)) >30%, then the whole curve lies above 30%, and the score is 3+
- Else if 10% ≤ z0 (=p(0.1)) <40% and p(0.2) <15%, the score is 1+
- Else if p(0.4) <15%, then the score is 2+
- Else, the score is 3+
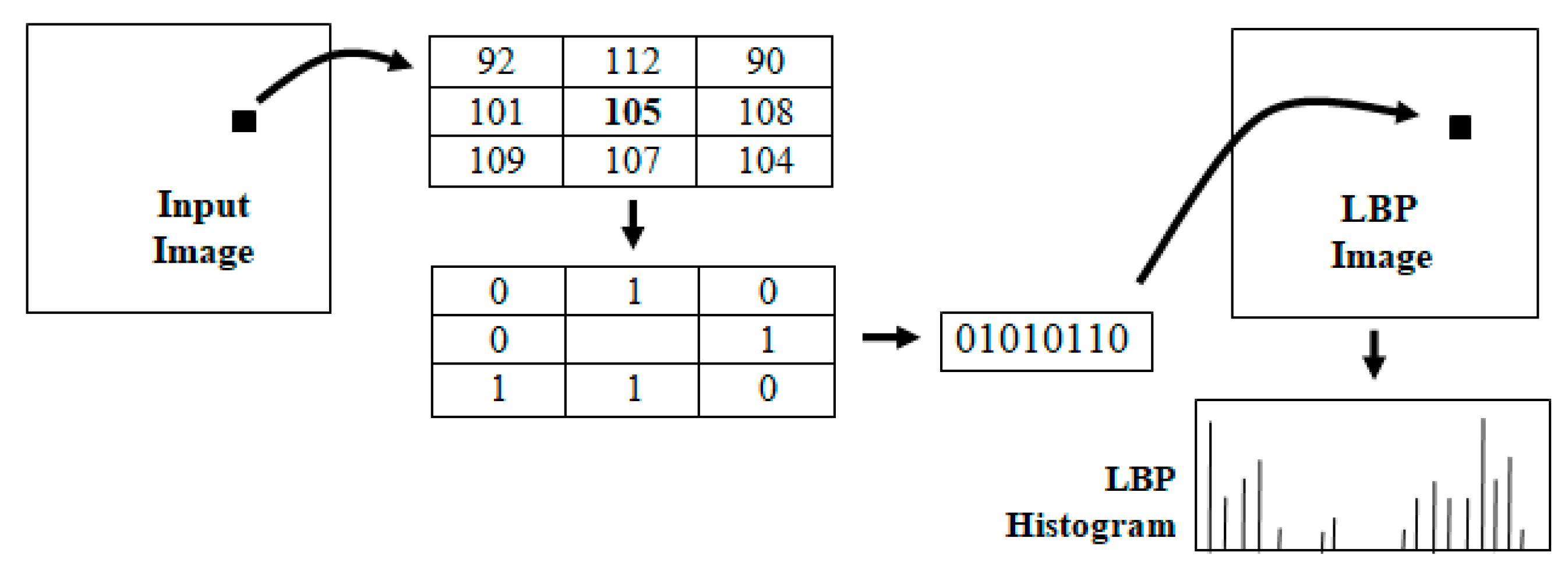
4. Local Binary Patterns
4.1. LBP Computation
4.2. Rotation-Invariant Uniform LBP
4.3. uLBP Feature Curves
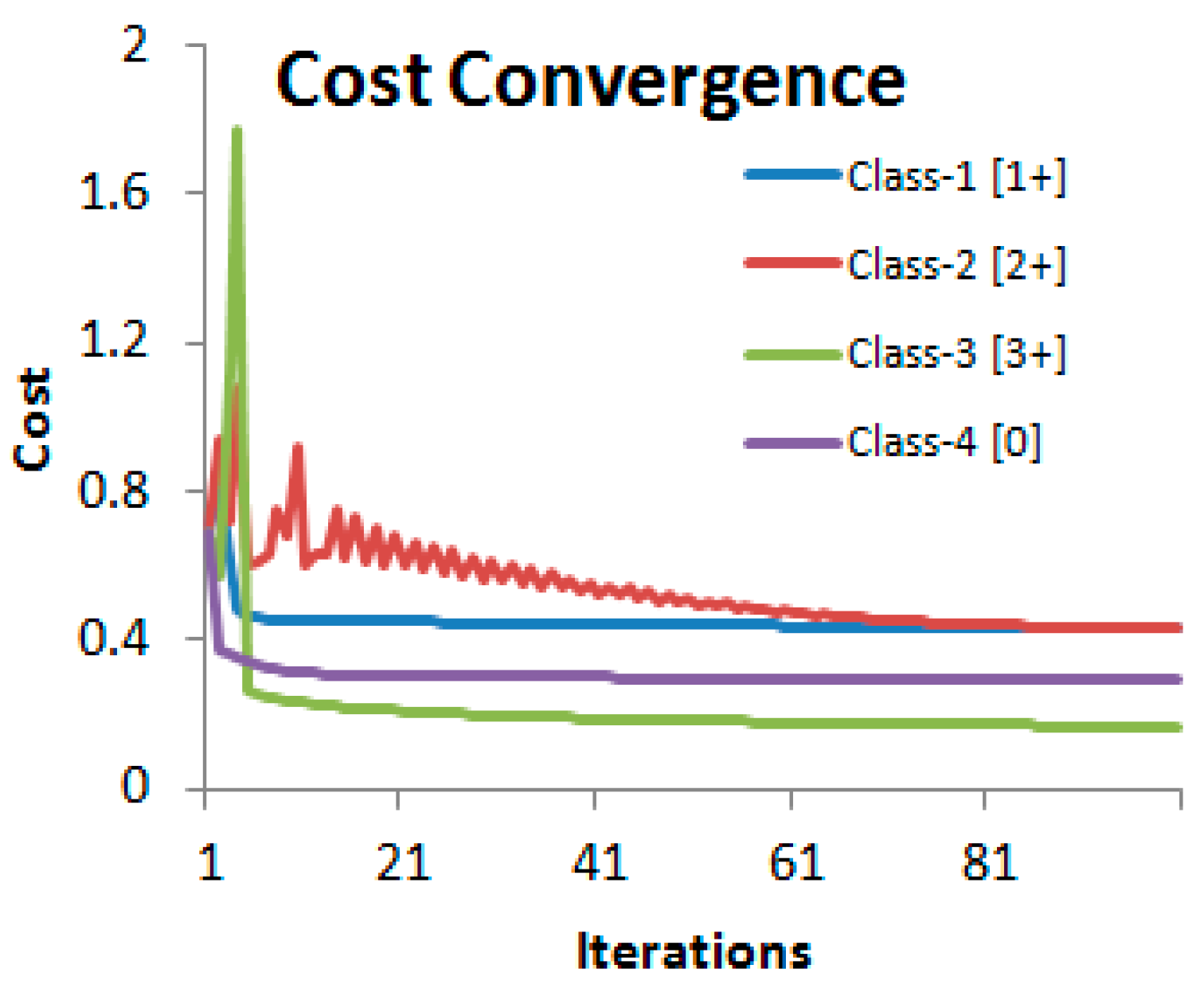
5. HER2 Classification and Scoring
6. Experimental Results and Analysis
7. Conclusions and Future Work
Acknowledgments
Conflicts of Interest
References
- Hicks, D.G.; Schiffhauer, L. Standardized assessment of the Her2 status in breast cancer by immunohistochemistry. Lab. Med. 2015, 42, 459–467. [Google Scholar] [CrossRef]
- Rakha, E.A.; Pinder, S.E.; Bartlett, J.M.; Ibrahim, M.; Starczynski, J.; Carder, P.J.; Provenzano, E.; Hanby, A.; Hales, S.; Lee, A.H.; et al. Updated UK recommendations for HER2 assessment in breast cancer. J. Clin. Pathol. 2015, 68, 93–99. [Google Scholar] [CrossRef] [PubMed]
- Gavrielides, M.A.; Gallas, B.D.; Lenz, P.; Badano, A.; Hewitt, S.M. Observer variability in the interpretation of HER2 immunohistochemical expression with unaided and computer aided digital microscopy. Arch. Pathol. Lab. Med. 2011, 135, 233–242. [Google Scholar] [CrossRef] [PubMed]
- Akbar, S.; Jordan, L.B.; Purdie, C.A.; Thompson, A.M.; McKenna, S.J. Comparing computer-generated and pathologist-generated tumour segmentations for immunohistochemical scoring of breast tissue microarrays. Br. J. Cancer 2015, 113, 1075–1080. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, P.W.; Bankhead, P.; Wang, Y.; Hutchinson, R.; Kieran, D.; McArt, D.G.; James, J.; Salto-Tellez, M. Digital pathology and image analysis in tissue biomarker research. Methods 2014, 70, 59–73. [Google Scholar] [CrossRef] [PubMed]
- Farahani, N.; Parwani, A.V.; Pantanowitz, L. Whole slide imaging in pathology: Advantages, limitations and emerging perspectives. Pathol. Lab. Med. Int. 2015, 7, 23–33. [Google Scholar] [CrossRef]
- Ghaznavi, F.; Evan, A.; Madabhushi, A.; Feldman, M. Digital imaging in pathology: Whole-slide imaging and beyond. Annu. Rev. Pathol. Mech. Dis. 2013, 8, 31–59. [Google Scholar] [CrossRef] [PubMed]
- Razavi, S.; Hatipoglu, G.; Yalcin, H. Automatically diagnosing HER2 amplification status for breast cancer patients using large FISH images. In Proceedings of the 25th Signal Processing and Communications Applications Conference, Antalya, Turkey, 15–18 May 2017; pp. 1–4. [Google Scholar]
- Department of Computer Science, University of Warwick: Her2 Scoring Contest. Available online: http://www2.warwick.ac.uk/fac/sci/dcs/research/combi/research/bic/her2contest/ (accessed on 15 November 2016).
- Department of Computer Science, University of Warwick: Her2 Contest Results. Available online: http://www2.warwick.ac.uk/fac/sci/dcs/research/combi/research/bic/her2contest/outcome (accessed on 15 November 2016).
- Qaiser, T.; Mukherjee, A.; Reddy Pb, C.; Munugoti, S.D.; Tallam, V.; Pitkäaho, T.; Lehtimäki, T.; Naughton, T.; Berseth, M.; Pedraza, A.; et al. Her2 Challenge Contest: A detailed assessment of Her2 scoring algorithms and man vs machine in whole slide images of breast cancer tissues. Histopathology 2018, 72, 227–238. [Google Scholar] [CrossRef] [PubMed]
- Mukundan, R. A Robust Algorithm for Automated Her2 Scoring in Breast Cancer Histology Slides Using Characteristic Curves. In Medical Image Understanding and Analysis; Communications in Computer and Information Science; Valdés Hernández, M., González-Castro, V., Eds.; Springer: Cham, Switzerland, 2017; Volume 723, pp. 386–397. [Google Scholar]
- Pietikainen, M.; Zhao, G.; Hadid, A.; Ahonen, T. Computer Vision Using Local Binary Patterns; Springer: London, UK, 2011; ISBN 978-0-85729-748-8. [Google Scholar]
- Goode, A.; Gilbert, B.; Harkes, J.; Jukie, D.; Satyanarayanan, M. OpenSlide: A vendor-neutral software foundation for digital pathology. J. Pathol. Inform. 2013, 4. [Google Scholar] [CrossRef]
- Livanos, G.; Zervakis, M.; Giakos, G.C. Automated analysis of immunohistochemical images based on curve evolution approaches. In Proceedings of the IEEE Conference of Imaging Systems and Techniques, Beijing, China, 22–23 October 2013; pp. 112–115. [Google Scholar]
- Sørensen, L.; Shaker, S.B.; de Bruijne, M. Quantitative analysis of pulmonary emphysema using local binary patterns. IEEE Trans. Med. Imaging 2010, 29, 559–569. [Google Scholar] [CrossRef] [PubMed]
- Morales, S.; Engan, K.; Naranjo, V.; Colomer, A. Detection of diabetic retinopathy and age-related macular degeneration from fundus images through local binary patterns and random forests. In Proceedings of the IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 4838–4842. [Google Scholar]
- Sarwinda, D.; Bustamam, A. Detection of Alzheimer’s disease using advanced local binary pattern from hippocampus and whole brain of MR images. In Proceedings of the International Joint Conference on Neural Networks, Vancouver, BC, Canada, 24–29 July 2016; pp. 5051–5056. [Google Scholar]
- Tiwari, A.K.; Pachori, R.B.; Kanhangad, V.; Panigrahi, B.K. Automated diagnosis of epilepsy using key-point based local binary pattern of EEG signals. IEEE J. Biomed. Health Inform. 2017, 21, 888–896. [Google Scholar] [CrossRef] [PubMed]
- Urdal, J.; Engan, K.; Kvikstad, V.; Janssen, E.A.M. Prognostic prediction of histopathological images by local binary patterns and RUSBoost. In Proceedings of the 25th European Signal Processing Conference, Kos, Greece, 2 September 2017; pp. 2349–2353. [Google Scholar]
- Sigirci, I.O.; Albayrak, A.; Bilgin, G. Detection of mitotic cells using completed local binary pattern in histopathological images. In Proceedings of the 23rd Signal Processing and Communications Applications Conference, Malatya, Turkey, 16–19 May 2015; pp. 1078–1081. [Google Scholar]
- Zhang, H.; Chen, Z.; Chi, Z.; Fu, H. Hierarchical local binary pattern for branch retinal vein occlusion recognition with fluorescein angiography images. Electron. Lett. 2014, 50, 1902–1904. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Watt, J.; Borhani, R.; Katsaggelos, A.K. Machine Learning Refined: Foundations, Algorithms and Applications, 1st ed.; Cambridge Uniersity Press: Cambridge, UK, 2016; ISBN 978-1107123526. [Google Scholar]
- Keay, T.; Conway, C.M.; O’Flaherty, N.; Hewitt, S.M.; Shea, K.; Gavrielides, M.A. Reproducibility in the automated quantitative assessment of HER2/neu for breast cancer. J. Pathol. Inform. 2013, 4. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HER2 Score | Assessment | Staining Pattern |
|---|---|---|
| 0 | Negative | No staining is observed, or membrane staining is observed in less than 10% of tumor cells |
| 1+ | Negative | A faint/barely perceptible membrane staining is detected in greater than 10% of tumor cells. The cells exhibit incomplete membrane staining. |
| 2+ | Weakly Positive | A weak to moderate membrane staining is observed in greater than 10% of tumor cells. |
| 3+ | Positive | A strong complete membrane staining is observed in greater than 10% of tumor cells. |
| Training Set | Test Set | ||
|---|---|---|---|
| Ground Truth HER2 Score | Number of WSIs | Contest-1 No. of WSIs | Contest-2 No. of WSIs |
| 0 | 13 | 28 | 6 |
| 1+ | 13 | ||
| 2+ | 13 | ||
| 3+ | 13 | ||
| Total | 52 | ||
| Number of 1’s | Byte Values | |||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | |||||||
| 1 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| 2 | 3 | 6 | 12 | 24 | 48 | 96 | 192 | 129 |
| 3 | 7 | 14 | 28 | 56 | 112 | 224 | 193 | 131 |
| 4 | 15 | 30 | 60 | 120 | 240 | 225 | 195 | 135 |
| 5 | 31 | 62 | 124 | 248 | 241 | 227 | 199 | 143 |
| 6 | 63 | 126 | 252 | 249 | 243 | 231 | 207 | 159 |
| 7 | 127 | 254 | 253 | 251 | 247 | 239 | 223 | 191 |
| 8 | 255 | |||||||
| HER2 Score | Predicted | Accuracy = 88.46% | |||||
|---|---|---|---|---|---|---|---|
| 0 | 1+ | 2+ | 3+ | Precision | Recall | ||
| Actual | 0 | 37 | 2 | 0 | 0 | 0.86 | 0.95 |
| 1+ | 6 | 29 | 4 | 0 | 0.83 | 0.74 | |
| 2+ | 0 | 4 | 34 | 1 | 0.87 | 0.87 | |
| 3+ | 0 | 0 | 1 | 38 | 0.97 | 0.97 | |
| HER2 Score | Predicted | Accuracy = 83.3% | |||||
|---|---|---|---|---|---|---|---|
| 0 | 1+ | 2+ | 3+ | Precision | Recall | ||
| Actual | 0 | 37 | 2 | 0 | 0 | 0.80 | 0.95 |
| 1+ | 8 | 24 | 7 | 0 | 0.75 | 0.61 | |
| 2+ | 1 | 6 | 31 | 1 | 0.79 | 0.79 | |
| 3+ | 0 | 0 | 1 | 38 | 0.97 | 0.97 | |
| HER2 Score | Predicted | Accuracy = 90.38% | |||||
|---|---|---|---|---|---|---|---|
| 0 | 1+ | 2+ | 3+ | Precision | Recall | ||
| Actual | 0 | 38 | 1 | 0 | 0 | 0.86 | 0.97 |
| 1+ | 5 | 31 | 3 | 0 | 0.86 | 0.79 | |
| 2+ | 1 | 4 | 33 | 1 | 0.92 | 0.85 | |
| 3+ | 0 | 0 | 0 | 39 | 0.98 | 1.00 | |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukundan, R. Image Features Based on Characteristic Curves and Local Binary Patterns for Automated HER2 Scoring. J. Imaging 2018, 4, 35. https://doi.org/10.3390/jimaging4020035
Mukundan R. Image Features Based on Characteristic Curves and Local Binary Patterns for Automated HER2 Scoring. Journal of Imaging. 2018; 4(2):35. https://doi.org/10.3390/jimaging4020035
Chicago/Turabian StyleMukundan, Ramakrishnan. 2018. "Image Features Based on Characteristic Curves and Local Binary Patterns for Automated HER2 Scoring" Journal of Imaging 4, no. 2: 35. https://doi.org/10.3390/jimaging4020035
APA StyleMukundan, R. (2018). Image Features Based on Characteristic Curves and Local Binary Patterns for Automated HER2 Scoring. Journal of Imaging, 4(2), 35. https://doi.org/10.3390/jimaging4020035