1. Introduction
Images and videos undergo several transformations from capture to display in various formats. The key to transferring these contents over networks lies in the design of image/video analysis and processing algorithms that can simultaneously tackle two opposing goals: (1) The ability to handle potentially massive content sizes (e.g., 8 K video); while (2) achieving the results in a timely fashion (e.g., near real time) on practical computing hardware. One such analysis application is the field of image and video quality assessment (QA), which deals with automated techniques of scoring the quality of images/videos in a manner that is in agreement with the quality perceived by a human consumer. Perceptual QA algorithms fill a critical role in determining what is acceptable quality and what is unacceptable from a human visual perspective. Indeed, such algorithms have proved useful for the design and evaluation of many applications (e.g., [
1,
2,
3,
4,
5]).
Over the last decade, the field of image and video QA has seen enormous growth in research activity, particularly in the design of new QA algorithms for improved
quality predictions, with particular growth over the last five years (see, e.g., [
1,
2,
3,
4,
5,
6,
7,
8]; see also [
9] for a recent review). However, an equally important, though much less pursued topic of QA research is in regards to
computational performance. Many existing QA algorithms have been designed from the outset to sacrifice or even completely neglect the use of perceptual models in order to achieve runtime practicality (e.g., [
1,
10,
11,
12,
13] all use fast, but perceptually inaccurate multiscale decompositions); whereas other algorithms forgo runtime practicality to achieve higher perceptual accuracy (e.g., [
14,
15]). Thus, an urgent and crucial task for QA research is to investigate ways of achieving practical runtimes without sacrificing the prediction accuracy and robustness afforded by proper perceptual modeling.
One method of achieving large performance gains would be to implement the algorithms on a graphics processing unit (GPU). Using GPUs for general-purpose computational tasks (termed GPGPU) leverages the parallelism of GPUs with programing models, such as CUDA and open computing language (OpenCL). Generally, the types of problems that are well-suited for a GPU implementation are ones which can be decomposed into an algorithmic form that exposes a large amount of data-level parallelism. Furthermore, if a specific computational problem can be decomposed into an algorithmic structure that exposes both data- and task-level parallelism, then multiple GPUs can be used to gain even greater performance benefits.
The use of the GPU for acceleration of
general image/video analysis and processing has emerged as a recent thrust for attaining fast results without sacrificing accuracy on traditionally time- and/or memory-prohibitive applications. For example, for image-domain-warping [
16], Wang et al. investigated the use of the GPU as a solution for achieving real-time results on the otherwise extremely intensive task of view synthesis. For video encoding, Momcilovic et al. [
17] present not only GPU acceleration, but multi-GPU acceleration on a heterogeneous system, with a speedup of 8.5× over a multi-core CPU version. Zhang et al. describe GPU acceleration using CUDA for 3D full-body motion tracking in real time [
18]. The main research challenge in these and related applications is how to research and design efficient data-level parallelism strategies: What parts to offload to the GPU, what parts to keep on the CPU, and how to minimize data transfer between the two. As the size of multimedia content continues to grow at an astounding rate, researchers and practitioners must be aware of parallelism and data-transfer strategies, and ideally apply this knowledge during the algorithm-design stages. To this end, in this paper, we address the issue of GPU acceleration of the perceptual and statistical processing stages used in QA, in the hopes to inform the design, implementation, and deployment of future multimedia QA systems.
Perceptual QA algorithms, in particular, should be prime candidates for a GPU implementation due to the fact that their underlying models attempt to mimic arrays of visual neurons, which also operate in a massively parallel fashion. Furthermore, many perceptual models employ multiple independent stages, which are candidates for task-level parallelization. However, as demonstrated in previous studies [
19,
20,
21,
22], the need to transfer data to and from the GPU’s dynamic random-access memory (DRAM) gives rise to performance degradation due to memory bandwidth bottlenecks. This memory bandwidth bottleneck is commonly the single largest limiting factor in the use of GPUs for image and video processing applications. The specific impacts of this bottleneck on a GPU/multi-GPU implementation of a perceptual QA algorithm has yet to be investigated.
To address this issue, in this paper, we implement and analyze the Most Apparent Distortion (MAD) [
14] image QA (IQA) algorithm, which is highly representative of a modern perceptual IQA algorithm that can potentially gain massive computational performance improvements using GPUs. MAD has consistently been reported to be among the very best full-reference IQA algorithms in terms of prediction accuracy (see, e.g., [
23]). Furthermore, the underlying perceptual models used in MAD have been used for other applications such as for video QA [
24] and for digital watermarking [
25]. However, MAD employs relatively extensive perceptual modeling which imposes a large runtime that prohibits its widespread adoption into real-time applications. MAD exhibits both levels of parallelism which potentially allows for large performance gains from a multi-GPU implementation.
Here, we analyze the potential performance gains and bottlenecks between single- and multiple-GPU implementations of MAD using Nvidia’s Compute Unified Device Architecture (CUDA; Nvidia Corporation, Santa Clara, CA, USA). As we will demonstrate, it is possible for the perceptual modeling to achieve near-real-time performance using a single-GPU CUDA implementation that parallelizes the modeled neural responses and neural interactions, in a manner not unlike the parallel structure of the primary visual cortex. We further demonstrate that by using three GPUs, and by placing the task-parallel sections of the algorithm on separate GPUs, an even larger performance gain can be realized, though care must be taken to mask the latency in inter-GPU and GPU-CPU memory transfers (see [
26,
27] for related masking strategies).
In our previous related work [
28], we compared the timings of naive vs. optimized C++ ports of MAD, and vs. using a Matlab-based GPU implementation of only the log-Gabor decomposition. Although significant speedups were obtained relative to the naive implementation, the use of the GPU contributed only a 1.6×–1.8× speedup over the CPU-based optimizations, which is reasonable considering only the log-Gabor decomposition was deployed on the GPU, and considering the fact that it was a Matlab-based GPU port. Later, in [
22], for CPU-only implementations of six QA algorithms (including MAD), a hotspot analysis was performed to identify sections of code that were performance bottlenecks, and a microarchitectural analysis was performed to identify the underlying causes of these bottlenecks. In the current manuscript, the key novelties compared to our prior work are as follows: (1) we implemented all of MAD in CUDA, thereby allowing analyses of all of the stages (detection, appearance, memory transfers); (2) we tested three different GPUs to examine the effects of different GPU architectures; (3) we further analyzed the differences between using a single GPU vs. parallelizing MAD across three GPUs (multi-GPU implementation) to investigate how the results scale with the number of GPUs; and (4) finally, we performed a microarchitectural analysis of the key bottleneck kernel (the CUDA kernel which computes the various local statistics) to gain insight into and inform future implementations about the GPU memory infrastructure usage.
The main contributions of this work are as follows. First, we demonstrate how to map highly representative perceptual models (from MAD, but used in many IQA algorithms) onto different GPU architectures. The main research challenge for this task is to properly and timely allocate different threads to accomplish different paralleled image processing steps within an algorithm, while simultaneously considering the various bottlenecks due to memory transfers. Second, we identify and analyze the bottlenecks by using both the CUDA profiler and a microarchitectural analysis. Based on this investigation, we propose some software and hardware solutions that can potentially alleviate the bottlenecks that allow the algorithm to run in near real time. For example, it is common to observe irregular memory accesses on the GPU arising from an exorbitant number of transactions and global memory accesses to the off-chip DRAM. Via our microarchitectural analysis, we identify the CUDA kernel with the largest bottleneck, and we propose the use of a shared memory feature provided by the NVIDIA GPU to resolve the bottleneck and improve performance. Finally, we provide a similar mapping strategy and preliminary investigation of the perceptual models on a multi-GPU setting. We run the same CUDA code on three different NVIDIA GPUs (Titan Black, Tesla K40 and GTX 960). It can be observed that the runtime of the algorithm is greatly reduced even though the number of memory transfers across the GPUs has increased.
This paper is organized as follows:
Section 2 provides a brief review of related work on efforts to accelerate IQA algorithms and/or its underlying computations.
Section 3 provides an overview of MAD and details of its original implementation. In
Section 4, we provide details of our CUDA implementation of MAD. In
Section 5, we present a performance analysis of the implementation tested on various GPUs. General conclusions are provided in
Section 6.
3. Description of the MAD Algorithm
As mentioned in
Section 2, MAD is a full-reference IQA algorithm which models two distinct perceptual strategies: QA based on visual detection, and QA based on visual appearance. In this subsection, we describe the various stages of MAD in terms of: (1) the objective(s) of each stage; (2) how the objective(s) are estimated via signal-processing-based analyses; (3) and how the analyses were implemented in Matlab/C++. The goal of this description is to provide a background and context for later comparison with the CUDA implementation.
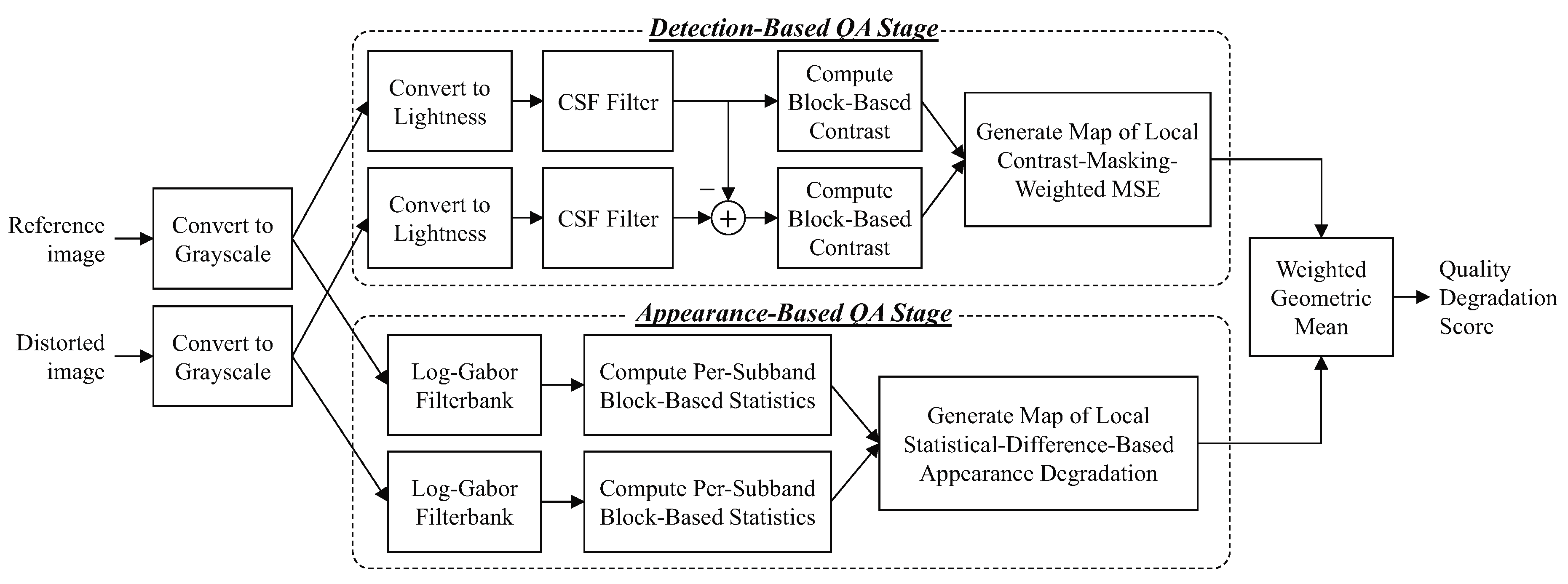
Figure 1 shows a block diagram of MAD’s stages. MAD takes as input two RGB images: a distorted image and its corresponding reference image. Only the luminance information is used, and thus the RGB images are converted to grayscale versions via the pointwise conversion
, where
R,
G,
B denote the RGB values and
X denotes the resulting grayscale value. In the original Matlab implementation of MAD, this conversion was performed via the
rgb2gray function.
The detection stage, represented in the top portion in
Figure 1, first converts the images into the lightness domain, then filters the images with a contrast sensitivity function (CSF) filter, and then local block-based statistics are extracted and compared to create a detection-based quality degradation map. In the appearance stage, represented in the lower portion of
Figure 1, each image is first decomposed into 20 log-Gabor subbands (5 scales × 4 orientations), then block-based subband statistics are computed and compared for corresponding subbands of the reference and distorted images, and then these block-based statistical differences are merged across bands to create an appearance-based quality degradation map. Finally, the detection-based and appearance-based maps are each collapsed into a scalar quantity, and then the two resulting scalars are then combined into a final quality (degradation) score via a weighted geometric mean.
The following subsections provide details of the implementations of these stages in the original Matlab/C++ versions.
3.1. Visual Detection Stage
As argued in [
14], when the amount of distortion is relatively low (i.e., when the distorted image would generally judge to be of high quality), some of the distortions are in the near-threshold regime, and thus the human visual system (HVS) judges quality based on visual detection of the distortions. Thus, the objective of the visual detection stage in MAD is to determine which distortions are visible, and then to perform QA based on these visible distortions. To estimate the visibilities of the distortions, MAD employs a block-based contrast masking measure; this yields a map indicating the local visibility of the distortion in each block. QA is then performed by using local mean squared error (MSE) between the reference and distorted images weighted by the masking map.
In the original Matlab version of MAD, the visual detection stage was implemented as shown in Listing 1.
First, each pixel of reference and distorted images are sent through a pointwise scaling and power function with an exponent of 2.2/3. The scaling and power of 2.2 converts the pixel values into luminance values (assuming an sRGB display). The power of 1/3 provides a basic account of brightness perception (termed “relative lightness” in [
14]). The scaling is performed by direct multiplication; the power function is performed via a lookup table.
Next, the HVS’s frequency dependence of contrast sensitivity (CSF function) is modeled by using a lowpass filter. This filter is defined in the frequency domain, and it is applied to both the reference image and the error image via multiplication in the frequency domain. For the original Matlab implementation, the fft2 and ifft2 functions were used to perform the forward and inverse 2D discrete Fourier transforms (DFTs); for the C++ port, the ooura FFT library was used.
Next, a visibility map is created based on a basic measure of contrast masking. The RMS contrast of each
block of the reference image is compared to the RMS contrast of the distortions (errors) in the corresponding
block of the distorted image. The corresponding block in the visibility map is assigned an “error visibility” value that is larger for lower contrast reference blocks containing higher contrast distortion (and vice-versa). Note that the standard deviation used in computing the RMS contrast is the modified version defined in [
14] as the minimum of the four standard deviations of the
sub-blocks of each
block. Also note that overlapping blocks are used; neighboring
blocks are positioned
and/or
pixels away. For this visibility map, C++ code was used in both the original Matlab implementation (MEX file) and the C++ port.
| Listing 1 Pseudocode of MAD’s Visual Detection Stage |
- 1:
procedureVisualDetectionQA - 2:
Inputs and Output: - 3:
- 4:
- 5:
- 6:
Convert Images to Lightness: - 7:
- 8:
- 9:
- 10:
- 11:
Apply CSF Filter: - 12:
- 13:
imgref)CSF - 14:
imgerr)CSF - 15:
Build Visibility MapV: - 16:
for each 16x16 block , do - 17:
- 18:
- 19:
// RMS contrast of mask - 20:
// RMS contrast of error - 21:
- 22:
end for - 23:
Compute Quality Degradation Score: - 24:
- 25:
// LMSE via 2D convolution (imfilter) - 26:
- 27:
end procedure
|
The output of the visual detection stage is a scalar, , denoting the overall quality degradation estimate due to visual detection of distortions. As shown in Listing 1, is given as the RMS value of the product of the visibility map and a map of local MSE between the reference and distorted images (following lightness conversion and CSF filtering) measured by using the error image.
3.2. Visual Appearance Stage
When the amount of distortion is relatively high, MAD advocates the use of a different strategy for QA, one based not on visual detection, but on visual appearance. In this visual appearance stage, MAD employs a log-Gabor filterbank to model a set of visual neurons at each location and at various scales. QA is then performed based on local statistical differences between the modeled neural responses to reference image and the modeled neural responses to the distorted image.
In the original Matlab version of MAD, the visual detection stage was implemented as shown in Listing 2.
First, the images are subjected to a log-Gabor filterbank of five scales (center radial spatial frequencies) and four orientations (0, 45, 90, and 135 degrees). This filterbank is designed to mimic an array of linear visual neurons, and thus the centers and bandwidths of the passbands have been selected to approximate the cortical responses of the mammalian visual system. The log-Gabor frequency responses are constructed in the 2D DFT domain, and the filtering is applied via frequency-domain filtering. As shown in Listing 1, the filtering results in 20 subbands for the reference image and 20 subbands for the distorted image , each set indexed by scale index s and orientation index o. Again, in Matlab, the fft2 and ifft2 functions were used to perform the forward and inverse 2D DFTs; the ooura FFT library was used for the C++ port.
| Listing 2 Pseudocode of MAD’s Visual Appearance Stage |
- 1:
procedureVisualAppearanceQA - 2:
Inputs and Output: - 3:
- 4:
- 5:
- 6:
Create and Apply Log-Gabor Filters: - 7:
for scale do - 8:
// (0, 45, 90, 270 degrees) - 9:
for orientation do - 10:
- 11:
// simulated neural response matrices - 12:
imgref)Gs,o - 13:
imgdst)Gs,o - 14:
end for - 15:
end for - 16:
Compute Response Differences (Appearance Changes): - 17:
for scale do - 18:
- 19:
// (0, 45, 90, 270 degrees) - 20:
for orientation do - 21:
for each block , do - 22:
- 23:
- 24:
- 25:
- 26:
// appearance change @ (i, j) - 27:
- 28:
end for - 29:
end for - 30:
end for - 31:
Compute Quality Degradation Score: - 32:
- 33:
end procedure
|
Next, each pair of subbands (reference and distorted) is divided into blocks, and basic sample statistics (standard deviation, skewness, kurtosis) are computed for each block. These statistics measured for the reference image’s block are compared to the corresponding statistics measured from the co-located block of the distorted image to quantify the appearance change for that location, scale, and orientation (). MAD uses a simple sum of absolute differences between the reference and distorted statistics for the computation of . These values are then summed across scale and orientation to generate a single map denoting local degradations in appearance. Again, overlapping blocks are used, with and/or pixels away.
The output of the visual appearance stage is a scalar, , denoting the overall quality degradation estimate due to degradations in visual appearance. As shown in Listing 1, is given as the root mean square (RMS) value of the product of the visibility map and a map of local MSE between the reference and distorted images (following lightness conversion and CSF filtering).
3.3. Overall MAD Score
The overall MAD score is determined based on the following adaptive combination of the
and
,
where the adaptive weight
is chosen to give more weight to
if the image is in the high-quality regime, and more weight to
if the image is in the low-quality regime. The value of
is computed by using a sigmoidal function of
(see [
14]).
4. CUDA Implementation of MAD
In this section, we describe our GPU-based implementation of MAD, which uses separate CUDA kernels for all fully data-parallel operations.
4.1. CPU Tasks: Loading Images; Computing Overall Quality
The reference and distorted images are first read into the computer’s RAM (the host memory), then converted to grayscale on the CPU, and then converted into linearized single-precision arrays on the CPU. These steps are performed by using the OpenCV library.
The single-precision arrays are then copied to the GPU’s RAM by transferring the data across the PCIexpress (PCIe) bus. For the single-GPU evaluations, in order to minimize latency introduced by PCIe memory traffic, we performed this transfer from the host memory to the GPU memory only once during the beginning of the program. As described previously, and as demonstrated in similar studies [
20,
22], transferring data to and from the GPU memory creates a performance bottleneck which can result in a latency that can obviate the performance gains. For the multi-GPU evaluation, the arrays were also transferred to each GPU only once at the beginning; however, a considerable number of inter-GPU transfers were required, as discussed later in
Section 5.3.
MAD’s detection and appearance stages are computed on the GPU as discussed next. However, because MAD can optionally provide to the end-user the detection-based and appearance-based maps (in addition to the scalar quality scores), we transferred the maps from the GPU back to the CPU, where the maps were collapsed and the individual and overall quality scores were computed. These map transfers can be eliminated in practice if only the scalar scores are sufficient for a particular QA application.
4.2. Visual Detection Stage in CUDA
All fully data-parallel operations in our CUDA implementation are performed by individual kernel functions, which are executed such that each CUDA thread performs the kernel-defined operation on a separate pixel of the input image.
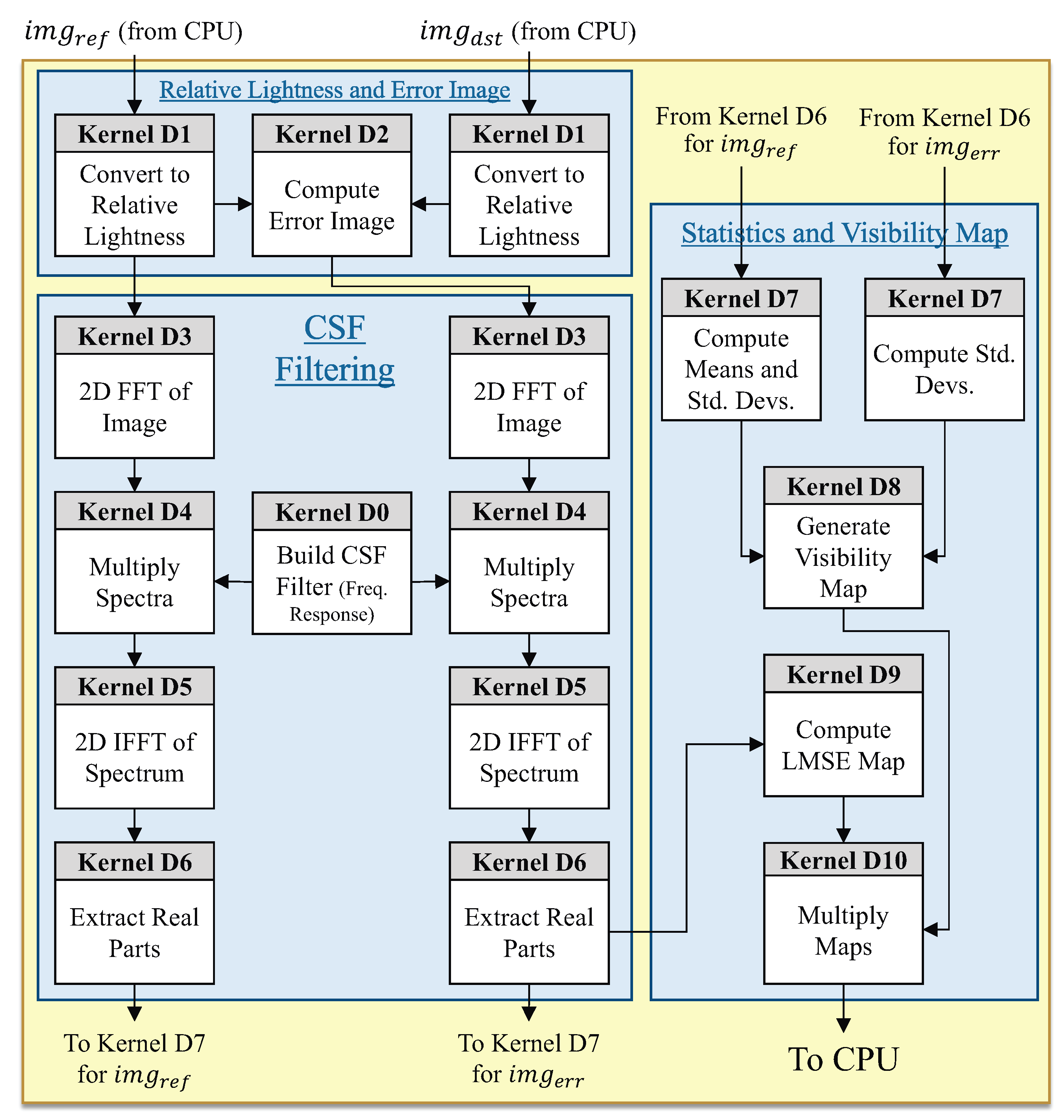
Figure 2 shows the specific breakdown of how the detection stage was implemented on the GPU via eleven CUDA kernels (Kernels D0-D10).
The relative lightness conversion and CSF filtering are performed by Kernels D0-D6:
Kernel D0 constructs the CSF filter’s frequency response (Line 12 of Listing 1).
Kernel D1 maps the images into the relative lightness domain (Lines 7–9).
Kernel D2 computes the error image (Line 10).
Kernel D3 computes the 2D DFT (via the cuFFT library) to obtain each image’s spectrum (Lines 13,14).
Kernel D4 performs multiplication of each image’s spectrum with the CSF frequency response (Lines 13,14).
Kernel D5 computes the 2D inverse DFT (via the cuFFT library) to transform the images back into the spatial domain (Lines 13–14).
Kernel D6 extracts the real part of the inverse FFT to avoid roundoff-induced imaginary values (Lines 13,14).
The statistics, visibility map, LMSE map, and final detection-based map are computed by Kernels D7–D10:
Kernel D7 computes the means and standard deviations of the blocks (Lines 17,18).
Kernel D8 computes and compares the blocks’ contrasts to generate the distortion visibility map (Lines 19–21).
Kernel D9 computes the local MSE map from the error image (Lines 24,25).
Kernel D10 computes the product of the visibility map and the local MSE map (Line 26).
The final detection-based map (visibility-weighted local MSE map from Kernel D10) is transferred back across the PCIe bus to the CPU, where the final detection-based quality degradation estimate is computed.
4.3. Visual Appearance Stage in CUDA
The visual appearance stages was also implemented by using separate kernels for all fully data-parallel operations; the kernel functions are executed such that each CUDA thread performs the kernel-defined operation on a separate pixel of the input image.
Figure 3 shows the specific breakdown of how the appearance stage was implemented on the GPU via six CUDA kernels (Kernels A0-A6).
Kernel A0 computes the 2D DFT of the image via the cuFFT library (fft in Lines 12,13 of Listing 2).
Kernel A1 builds the frequency response of its log-Gabor filter (Line 10).
Kernel A2 pointwise multiplies its filter’s frequency response with the image’s spectrum that has been cached in GPU memory (Lines 12,13).
Kernel A3 performs the inverse 2D DFT via the cuFFT library (ifft in Lines 12,13).
Kernel A4 takes the magnitude of each complex-valued entry in the response (Lines 22–24).
Kernel A5 computes three matrices for each subband; each matrix contains the standard deviations, skewnesses, and kurtoses of the 16x16 subband blocks (Lines 22–24).
Kernel A6 computes the appearance-based quality degradation map (Line 32).
The frequency response of each of the 20 distinct filters are constructed in the DFT domain in a separate instance of Kernel A1. Because each element of the frequency response is independent of all other elements, we implemented the construction of all frequency response values in separate threads where each overall filter is created by the execution of a 4D CUDA kernel with total threads; i.e., the kernel is executed as a 2D grid where each thread block within the grid is composed of a 2D collection of threads. The size of the grid was and the size of the thread blocks were independent of the size of the input image.
The images are then filtered with each of the log-Gabor filters in Kernel A3, which performs pointwise complex multiplication between each filter instance and the images spectra, which has been stored in global device (GPU) memory after the FFT operation is applied to it in Kernel A0.
After each image has been processed through the filterbank, Kernel A4 performs an inverse FFT for each corresponding log-Gabor subband. The result of the image passing through the filterbank is a set of 20 complex values subbands. The imaginary component is a result of the odd filter and the real component is a result of the even filter.
Next, in Kernel A5, a set of three statistical matrices (one matrix each for standard deviation, skewness, and kurtosis) from each of the 20 filtered images is computed. Due to the overlapping blocks (shift of the sliding window by four pixels between successive blocks), the size of each statistical matrices is .
The set of 60 statistical matrices from the processed reference image are compared against the 60 statistical matrices from the filterbank processing of the distorted image in Kernel A6 to produce the appearance-based quality degradation map. This map is transferred back across the PCIe bus to the CPU, where the final appearance-based quality degradation estimate is computed.
5. Results and Analysis
We evaluated the GPU-based implementation on three systems containing a variety of Nvidia GPUs. Here, we report and discuss the runtime performances.
All performance timings for the GPU-based implementations were performed by using Nvidia’s Nsight profiler. For the test images, we used the CSIQ database [
14]. As documented in [
22], the semantic category of the reference image did not have a significant effect on MAD’s runtime; however, a minor effect was observed for different distortion types and amounts. Thus, we used two reference images, all six distortion types, and two levels of distortion (high and low) for each type. In a follow-up verification experiment (for Evaluation 1 only), we used all images from the IVC database [
60].
5.1. Evaluation 1: Overall and Per-Kernel Performance
The primary test system consisted of a modern desktop computer with an Intel Core i7 processor (Intel Corporation, Santa Clara, CA, USA) and three Nvidia GPUs (two GeForce Titans and one Tesla K40; all use the Kepler GK110 GPU architecture). The details of the primary test system are shown in
Table 1. For the primary single-GPU experiment, we used one of the Titans (labeled GPU 2 in
Table 1). For the follow-up secondary single-GPU experiment (IVC database), we used a separate system containing a Tesla K40 GPU (labeled as System 2 presented later in
Section 5.2).
The results of the performance analysis of the primary single-GPU implementation are shown in
Table 2. The results of the follow-up verification performance analysis of the secondary single-GPU implementation (IVC database) are shown in
Table 3. All single-GPU kernels were executed in a task-serial fashion. Because the subsections of the algorithm did not have any overlap in computation, we were able to easily compute the ratio of the overall time spent on the different subsections vs. the overall runtime of the complete algorithm. Overall, going from a CPU-based implementation to a GPU-based implementation results in a significant speedup. The C++ version required approximately 960 ms, whereas the CUDA version required approximately 40 ms, which is a 24× speedup. The follow-up experiment confirmed these same general per-stage and overall trends (843 ms down to 55 ms), though with a lesser 15× overall speedup due to the lower-spec K40 GPU used in the latter experiment.
A runtime of 40 ms would allow MAD to operate at 25 frames/sec in a video application, which can be considered near-real-time performance, with the caveat that our experiments consider only images. Our implementation is expected to scale linearly to larger image sizes, but a formal analysis of this is a topic of future investigation.
Please note that the GPU version of the code is not a simplification nor an approximation of the MAD algorithm. Both the CPU and GPU results yield the same numerical results for practical purposes (differences of less than between the CPU and GPU versions of the MAD quality scores).
5.1.1. Per-Kernel Performance on the Detection Stage
Table 4 displays the runtimes of all constituent kernels on the primary test system. The first 11 rows of
Table 4 show the runtimes of the individual kernels for MAD’s detection stage. In the detection stage, Kernel D1, which maps the image to the relative lightness domain, performs a scaling of each pixel value by a constant
k and then exponentiates the result by the power 2.2/3. This operation achieves the exponentiation through the use the
pow function from the CUDA Math library. Kernel D1 is one of the fastest-performing kernels in our program. This kernel, along with Kernels D3, D4, D6, and D10, all are composed of standard arithmetic operations with no control flow (e.g., no
if/
else statements). The lack of control flow ensures there is minimal thread divergence in these kernels. Thread divergence occurs when threads within the same warp (group of 32 threads) take different paths of execution, which causes all threads in the warp to wait on the completion of the slowest-performing thread.
The forward and inverse FFTs, which are used in Kernels D3 and D5, exhibit relatively good performance in regards to runtime. Their fast execution is expected because the CUDA FFT library we utilized, called cuFFT, is based on the popular FFTW library [
61]; and, as in FFTW, calls to CUDA’s FFT function autonomously fine-tune their implementation details based on the hardware on which they are executed.
Kernels D7 and D8 are the worst-performing kernels in the detection stage. We attribute the poor performance of Kernel D7, which is the kernel that performs the detection-based statistical computations, to the redundant computations in our specific implementation. The integral image technique is currently being explored to reduce the number of operations performed in this kernel. Kernel D8, which computes the local MSE between the reference and distorted image, performs a large number of control flow logic. It is likely that the large amount of control flow gives rise to undesired thread divergence. We are currently investigating potential reformulations of the specific algorithm used in this kernel to exploit more parallelism to avoid the suspected thread divergence.
5.1.2. Per-Kernel Performance on the Appearance Stage
The lower seven rows of
Table 4 show the runtimes of the individual kernels for MAD’s appearance stage. The appearance stage consumes the majority of the overall runtime. The primary reason for the relatively massive runtime of this section is simply that the filterbank is itself massive in regards to the number of computations of the overall algorithm. Each filter in the pair of filterbanks (one filterbank each for the reference and distorted images) is composed of 20 different filtering sections, which are represented as the individual columns as shown in
Figure 4.
Kernels A2 and A4 are expected to have good runtime performance due to their lack of control flow. Indeed, the data in
Table 4 support this expectation; Kernels A2 and A4 are the fastest-performing kernels in this stage of the algorithm.
Because the coefficients of the 20 different log-Gabor filters are only dependent on the dimensions of the input image, and not on the image’s actual pixel data, we initially attempted to precompute these filter coefficients. However, we found that it was far more advantageous to simply compute the coefficients at the time of their use in the filterbank, as opposed to retrieving the coefficient values from global memory. We suspect that the pre-computational process gave rise to poor spatial locality (i.e., the filter coefficients were stored further away from the actual computations performed), thus eliminating the expected performance gain.
The key conclusions from this experiment are as follows. Exploiting the parallel hardware paths in a GPU through a CUDA-based implementation of MAD leads to a 24× speedup, and a runtime of 40 ms. A deeper look on a per-kernel basis reveals that computation of the local MSE map (Kernel D9) takes the most time in the detection stage and the computation of block-based statistics (Kernel A5) takes the most time in the appearance stage. We believe the use of shared memory to perform local computation within the blocks in on-chip SRAM would alleviate this bottleneck. Just as performing computation in a block-based fashion to exploit the memory hierarchy is critical to good performance on modern CPUs [
62] utilization of the memory hierarchy on GPUs is also a critical, but relatively advanced, optimization technique. Thus, a detailed understanding of the memory system in the GPU is essential to further improve performance.
5.2. Evaluation 2: Performances on Different GPUs
Next, we investigated the effects that GPUs with different architectures/capabilities might have on the runtimes. For this evaluation, we ran the code on two additional systems, the details of which are provided in
Table 5. The setup listed in
Table 5 as System 1 was the same system used in the previous section (Evaluation 1); we have repeated its specifications here for convenience. System 2 used an Nvidia Tesla K40, which is a high-end GPU designed primarily for scientific computation. System 3 used an Nvidia GTX 960 GPU, which is designed primarily for gaming.
The results of this evaluation are shown in
Table 6, which shows the overall runtime as well as the runtimes of the specific stages of MAD. Before discussing the observed execution times, it is important to note the differences in the hardware configuration and capabilities of the three GPUs; these specifications are shown in
Table 7.
GPUs are considered to be highly threaded, many-core processors that provide a very large computational throughput. This large throughput can be used to hide unavoidable memory latencies by utilizing the GPU’s ability to execute a very large number of threads. The large memory bandwidth can also be used to hide memory latency. The achieved performance, therefore, depends on the parallelism exploited by the algorithm, the effectiveness of latency hiding, and the utilization of multiprocessors (occupancy) [
63]. Based on the results in
Table 6, observe that our CUDA implementation exhibits better performance and a shorter runtime on the Titan than on the GTX 960. This observation indicates that the implementation is effective in scaling related to cores: The Titan has 2688 cores and the GTX 960 has 1024 cores.
In our current CUDA implementation, most kernels launch as more than 200,000 concurrent threads for the specific dataset used for our experiment. One of the limiting factors of the number of threads that can be executed simultaneously is the overall number of cores on the GPU. The maximum number of threads that can be executing at any given time is the same as the number of cores on the GPU. Therefore, the larger runtime on the GTX 960 can be attributed to its fewer number of cores. The speedup can as well be attributed to the minimal use of inter-thread communication in our implementation. Code that depends on the communication of data between threads requires explicit synchronization, which often increases overall runtime. As can be seen in
Table 6, the latency of memory transfers across the PCIe memory bus on the Titan is 1.8× of that on the Tesla, and 1.2× of that on the GTX 960. Approximately 2% of the overall runtime is spent on PCIe memory transfer on the Titan.
On the GeForce line of Nvidia GPUs (Titan Black and GTX 960), cudaMalloc (the function call used to allocate GPU memory in the CUDA programming model) not only allocates the memory on the GPU, but also initializes the contents to zero, which emulates the C-language calloc function. However, on the Tesla line of Nvidia GPUs (Tesla K40), cudaMalloc simply allocates the memory on the GPU, leaving garbage data in the allotted memory, emulating the C-language malloc function. This necessitates additional cudaMemcpy calls to initialize the memory allocated on the Tesla K40 to avoid garbage values.
The key conclusions from this experiment are as follows. First, we observe the CUDA implementation of MAD is robust and works well on three GPUs with different internal architectures and capabilities. Second, the CUDA implementation exploits parallelism effectively on all these GPUs without any modification to the code, because the performance scales with the number of cores, as opposed to the frequency at which the cores operate.
5.3. Evaluation 3: Performance on a Multi-GPU System
In this section we analyze the runtime performance when simultaneously utilizing all of the GPUs on System 1. In general, the most straightforward method of utilizing multiple GPUs is to divide the task-independent portions of an algorithm among the different GPUs. MAD’s detection and appearance stages do not share any information until the final computation of the quality score; thus, these two stages are easily performed on separate GPUs. The appearance stage can be further decomposed into a largely task-parallel structure by observing that the subbands produced from filtering the reference and distorted images with the log-Gabor filters are not needed together until computing the difference map. Together, the filterbank and the statistics extracted from each subband consume the majority of the overall runtime. Therefore, implementing each of the two filterbanks, and subsequent statistics extractions, on separate GPUs in parallel has the potential to significantly reduce overall runtime.
Thus, we performed the detection stage on one GPU (System 1’s GPU 1: Tesla K40c), and the two filterbanks were placed on the remaining two GPUs (System 1’s GPU 2 and GPU 3: Titan Black). We chose to perform the detection stage on GPU 1 because this stage requires only three memory transfers: two 1 MB transfers from the host to copy the image data onto the GPU, and one transfer to copy the detection-based statistical difference map back to the host upon completion of the detection stage. Because GPU 1 used a PCIe 2.0 bus, the three memory transfers were able to occur in parallel to the computation on the other two GPUs.
We placed each of the two filterbanks and each subsection’s statistical extraction on neighboring GPUs. The 20 individual sections of the filterbank and their subsequent statistical extraction for each image were performed in parallel on GPU 2 and GPU 3, respectively. We then collected all of the statistical matrices onto GPU 2, and performed the difference map computation. Due to the need to collect all the statistical data from both filterbanks together to compute the difference map, we had to perform a memory transfer between GPU 2 and GPU 3 by using the host as an intermediary. Upon completion of the detection stage and appearance stage, we copied their maps back to the host memory to collapse the maps and calculate the final quality score on the CPU.
The requirement of using the host memory as a buffer forced us to perform a large number of memory transfers across the PCIe bus. In the single-GPU implementation, we only used two 1 MB data transfers at the beginning of the program to get the image data to the GPU, and two 1 MB transfers back to the CPU to collapse and combine the statistical difference maps. Decomposing the filterbank into task-parallel sections, as previously described, causes the number of data transfers across the PCIe bus to increase to 126 memory transfers.
The results of the performance analysis of the multi-GPU implementation are shown in
Table 8. A 1.4× speedup is observed in the overall execution time. While an ideal speedup going from one GPU to three GPUs would be 3×, the somewhat lower 1.4× speedup is not surprising. As explained in the preceding paragraphs, a large number of memory transfers (126) were necessary to facilitate task-parallelism, and these would have resulted in a significant slowdown had we not been able to overlap the memory transfers with computation.
This brief study on parallelizing MAD across three GPUs provides two important lessons for attempting to implement a highly parallel version of MAD or other similar programs on multi-GPU-based high-performance nodes. One, division of tasks between the GPUs should be as clean as possible, as communication, data transfer and synchronization will reduce the gains obtained from parallelization. Two, in the event that certain data-bound dependencies exist and require data transfers across GPUs, sub-partitioning such that a data transfer can be parallelized with computation, is highly recommended.
5.4. Evaluation 4: Microarchitectural Analysis of Kernel A5
Finally, we performed a deeper investigation of Kernel A5, the current bottleneck, from the point of view of resource usage. Because Kernel A5 consumes a large portion of the overall runtime, it is pertinent to investigate its interaction with the underlying hardware. This experiment was performed on System 2 described in
Table 5.
As described in
Section 3, Kernel A5 computes the local statistics (mean, skewness, kurtosis, and standard deviation) of each block via a sliding window using a block size 16 × 16. The specific details of how this kernel was implemented are as follows:
Every thread declares a 1D array of 256 elements.
Each thread gathers the 16 × 16 data from the global memory and stores the data in the threads designated local memory space.
Each thread then computes the sample mean from these 256 elements via a 1D traversal.
Using the mean an additional 1D traversal is used to calculate the standard deviation, skewness, and kurtosis.
The calculated values are scattered across the corresponding memory locations in global memory.
In the K40 hardware, there are 64 active warps per streaming multiprocessor (SM). Specifically, the active warps/SM = (number of warps/block) × (number of active blocks/SM) = 8 × 8 = 64 active warps/SM. Hence, a kernel capable of spanning 64 active warps at any point in execution will give a theoretical occupancy of 100%. However, the runtime statistics for Kernel A5 given by the Nsight profiler revealed an average occupancy of only 51.4% occupancy, indicating that only half the number of active warps, 32 as opposed to 64, were used. This finding can be attributed to the kernel launch parameters.
Specifically, Kernel A5 is launched with a grid configuration of and a block configuration of . Hence, the total number of threads = 8 × 8 × 16 × 16 = 16,384. The number of warps = total number of threads/number of threads in a warp = 16384/32 = 512. The total number of active warps supported = 64 × number of SM on the GPU = 64 × 15 = 960. Thus, in this configuration, the theoretical value of achieved occupancy = 512/960 = 53.33%, and our implementation achieved close to that value.
To further evaluate the development process guided by the profiler, we thus profiled Kernel A5 in terms of memory bandwidth. The memory bandwidth is the rate at which data is read or written from the memory. On a GPU, the bandwidth depends on efficient usage of the memory subsystem, which involves L1/shared memory, L2 cache, device memory, and system memory (via PCIe). Since there are many components in the memory subsystem, we performed separate profiling to collect data from the corresponding subsystem. Memory statistics were collected from:
Global: Profiling of memory operations to the global memory, with a specific focus on the communication between SMs and L2 cache.
Local: Profiling of memory operations to the local memory, with a specific focus on the communication between the SMs and the L1 cache.
Cache: Profiling of communication between L1 cache/texture cache and L2 cache for all memory operations.
Buffers: Profiling of communication between L2 cache and device memory and system memory.
Figure 5 shows the results of this analysis, which are discussed in the following subsections. Note that the memory statistics of atomics, texture, and shared memory were not collected because our current implementation does not use those features.
5.4.1. Memory Statistics—Global
Global device memory can be accessed through two different data paths. Data traffic can go through L2 and/or L1, and read-only global memory access can alternatively go through the read-only data cache/texture cache.
Figure 5 shows that cached loads use the L1 cache or texture cache as well as L2 cache, whereas uncached loads uses only the L2 cache.
On the Tesla K40, the L1 cache line size is 128 bytes. Memory accesses that are cached in both L1 and L2 are serviced with a 128-byte cache line size. Memory accesses that are cached only in L2 are serviced with 32-byte cache line size. This scheme is designed to reduce over-fetch, for instance, in case of scatter memory operations.
A warp in execution accessing device memory (load or store assembly instructions), coalesces the memory accesses of all the threads (32 threads share a program counter) in a warp into one or more of these memory transactions depending on the size of the word accessed by each thread as well as the distribution of the memory addresses across the threads. If all the threads within a warp perform random strides, coalescing gets disturbed, resulting in 32 different accesses in a warp.
Figure 5 shows the average number of L1 and L2 transactions required per executed global memory instruction, separately for load and store operations; lower numbers are better. Ideally, there should be just one transaction for a 4-byte access (32 threads × 4 bytes = 128-byte cache line), and two transactions for an 8-byte access (32 threads × 8 bytes = 256 bytes; 2 cache lines) access.
A memory “request” is an instruction, which accesses memory, and a “transaction” is the movement of a unit of data between two regions of memory. As shown in
Figure 5, 129,024 load requests are made in Kernel A5, resulting in 2,256,000 transactions. Each of the requests are 4-byte requests (float). Hence, the number of transactions for a load = 2,256,000/129,024 = 17.485, and the number of transactions for a store = 23,625/1512 = 15.625.
5.4.2. Memory Statistics—Local
Local memory is called local to define its scope from the programmer’s perspective, i.e., it is not global or shared across threads. However, its physical manifestation depends on how much local memory a thread requests. Ideally, if a thread requests only as much memory as can fit in the registers, then the local memory is physically local as well, and accesses are fast. On the other hand, if the requested memory exceeds register capacity, then in a process called spilling, the memory is allocated on the much slower device DRAM. Arrays that are declared in the kernel are automatically saved in global memory. In addition, if there are not enough registers to accommodate all auto variables (register spilling), the variables are saved in local memory.
Every thread can use maximum of 32 registers. If a kernel uses more than 32 registers, then the data gets spilled over to the local memory. Every thread executed in Kernel A5 declares a local storage of 256 elements. The launch configuration of the kernel has 256 threads per block. The total local memory needed by a block = 256 threads × 256 elements per thread × 4-byte each = 262,144 bytes = 256 KB. The on-chip memory of an SM in the Tesla K40 is of size 48 KB. Hence, the register spill gets carried over to global memory, resulting in poor performance because global memory incurs a 200–400 cycle latency.
5.4.3. Memory Statistics—Caches
On Nvidia GPUs, there are three data caches: L1, L2 and texture/read-only. If the data is present in both L1 and L2, 128-byte cache line transactions occur; otherwise 32-byte transactions occur. If the data block is cached in both L2 and L1, and if every thread in a warp accesses a 4-byte value from random sparse locations that miss in L1 cache, each thread will give rise to one 128-byte L1 transaction and four 32-byte L2 transactions. This scenario will cause the load instruction to reissue 32 times more than the case in which the values were adjacent and cache-aligned. Here, the cache hit rate is very low because, by default on the Tesla K40, L1 is not used for load/store purposes.
In summary, the key observation from this microarchitectural analysis of Kernel A5 is that algorithms/programs that target the memory hierarchy of CPUs work poorly with the GPU memory infrastructure. Indeed, GPUs are designed to mostly stream data, while CPU caches are built to capture temporal locality, i.e., reuse data. A second important observation is that it is crucial to understand the concept of warps, and the fact that 32 threads in a warp can access 32 data elements in a single load or store as long as they are contiguous. Thus, when designing CUDA kernels, the programmer must carefully choose the dimensions such that threads in a warp do not access non-contiguous memory. A third observation is that it is important to limit the amount of data that a thread tries to access, because any access that exceeds the 32 registers will result in register spilling, which is an expensive operation.
Overall, this microarchitectural analysis reveals that the default settings for compilation leave the code unoptimized, resulting in millions of unnecessary transfers between device DRAM and the caches. In order to achieve better performance, additional studies on the memory usage are required, and future designs should attempt to reduce the traffic between on-chip and off-chip memories (see [
64] for some initial steps).
6. Conclusions
Obtaining performance gains through GPGPU solutions is an attractive area of research. In this paper, we have proposed, analyzed, and discussed a GPU-based implementation of a top-performing perceptual QA algorithm (MAD). Our results demonstrated that going from a CPU-based implementation to a GPU-based implementation resulted in a 15×-24× speedup, resulting in a near-real-time version of MAD that is not an approximation of the original version. Our CUDA implementation was also shown to port well to GPUs with different architectures and capabilities. Our results also demonstrated that obtaining performance gains from utilizing multiple GPUs is a challenging problem with higher potential performance gains; the challenge lies in decomposing the computations into a largely task-parallel algorithmic form. If data must be communicated between the tasks placed on separate GPUs, the memory bandwidth bottleneck can prohibit potential gains. To accommodate for the limited PCIe bandwidth, an appropriate strategy must be formulated and tailored to the problem and particular microarchitectural resources of the GPUs.
One of the broader conclusions from this work is that obtaining performance gains through GPU solutions, especially when utilizing multiple GPUs, requires an understanding of the underlying architecture of the hardware, including the CPU, GPU, and their associated memory hierarchies and bus bandwidths. Although programming APIs, such as CUDA, strive to free the programmer from this burden, they have not yet accomplished this goal.
The second conclusion that can be drawn from this work is that a large number of computational problems can hide the latency introduced by asynchronous memory transfers in the manner proposed in this work. The strategy we found to be best suited for a problem that requires many memory transfers, was to overlap computation with asynchronous memory transfers. Thus, we highly recommend considering this technique for image and video quality assessment algorithms.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}