1. Introduction
Generative AI (genAI) has rapidly advanced as a powerful tool to synthesize new digital content, including images, text, and music [
1,
2]. Although these models have achieved remarkable success in generating high-quality visuals for artistic and commercial use, their application to scientific imaging presents significant challenges. In particular, generating accurate images of scientific phenomena that were not represented in the training data often results in hallucinations [
3] or misrepresentations of fundamental physical and biological principles [
4]. Such failures can result in visually convincing but scientifically implausible outputs, potentially propagating misconceptions, contributing poor images to training sets, and hindering scientific progress [
5,
6].
This article investigates generative image modeling within two primary subdomains: text-to-image and image-to-image generation. We begin with a comprehensive overview of recent key developments, followed by an in-depth discussion of how leading architectures such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Diffusion Models have revolutionized areas reliant on image analysis. Particular emphasis is placed on their applications in scientific contexts, where precision, fidelity, and interpretability are paramount. Thus, we discuss strategies and methodologies for the verification and validation of synthetic images.
The main contributions of this paper are:
Detailed analysis of generative methods for text-to-image and image-to-image synthesis, with emphasis on scientific relevance.
Comparative evaluation of generative architectures, highlighting their capabilities and limitations across multiple scientific domains and material types.
Critical discussion of current challenges and future directions, including pathways for verifying and validating the scientific integrity of synthetic images.
2. Background
Image-generating models have become a prevalent area of research in recent years, fueled by advances in both algorithm design and hardware capabilities. Early efforts focused on conventional data-augmentation techniques such as rigid-body transformations [
7], but the field has since evolved toward more sophisticated approaches, including the development of foundational models [
8].
To illustrate the accelerating interest in image generation,
Figure 1 presents publication trends over the past decade, using data from Dimensions [
9]. After remaining steady in the early 2010s, the number of publications began to rise sharply around 2017. This growth reflects a convergence of factors: breakthroughs in generative algorithms, expanded access to large-scale datasets, and the proliferation of high-performance computing resources. Given this pace of innovation, it is key to critically assess the applicability and limitations of these models, particularly within scientific imaging contexts.
During the earlier phase of this acceleration, Generative Adversarial Networks (GANs) dominated the field, especially in image synthesis tasks. The significant increase in the number of publications can be attributed to specific breakthroughs that both enabled and inspired future work in Image Generation. Key breakthroughs in 2017 and 2018 significantly advanced GAN performance, yielding state-of-the-art (SOTA) results. For example, Pix2Pix [
10] introduced conditional adversarial networks for image-to-image translation, enabling the model to learn mappings from input to output images using paired datasets. CycleGAN [
11] further extended this approach by allowing image translation from unpaired data, a key feature for real-world applications where aligned datasets are scarce or unavailable. These innovations laid the foundation for powerful image manipulation tools, such as style transfer and background replacement.
Introduced in 2018, StyleGAN [
12] redefined the field by introducing an alternative generator architecture that enabled unprecedented control over the latent space, allowing for fine-grained manipulation of image attributes. This shift brought significant improvements in visual quality and consistency. A year later, transformers [
13] entered the generative space with SAGAN (Self-attention GAN) [
14], which introduced self-attention layers into both the generator and discriminator, allowing the models to account for long-range dependencies in the image. Building on this, BigGAN scaled up GANs substantially, resulting in higher-resolution outputs with greater diversity, albeit with a corresponding increase in computational demands.
The year 2020 marked the emergence of Diffusion Models as competitive alternatives to GANs. Initially introduced by Sohl-Dickstein et al. [
15], these models iteratively add and remove noise from images in a learned forward-reverse process, achieving state-of-the-art results on high-resolution tasks and rivaling the performance of top GANs. In parallel, transformer-based architectures, originally designed for language modeling [
13], began to influence vision research, particularly with Vision Transformer (ViT), which reframed image classification by treating image patches as input tokens, similarly to natural language processing [
13]. Building upon this work, Ho et al. create their Denoising Diffusion Probabilistic Models (DDPM) [
16], which formulate new strategies for training and sampling from Diffusion Models. This resulted in SOTA performance compared to other Diffusion Models, and similar performance to SOTA GANs on higher-resolution images.
Transformers also fueled advances in text-to-image generation. In 2021, OpenAI introduced DALL-E [
17], a transformer-based model that synthesized coherent and often whimsical images from textual prompts. This marked a turning point in multimodal generation, further bolstered by the release of CLIP [
18], a model trained to align text and images in a shared embedding space. These tools laid the groundwork for the next generation of models, including Google’s Imagen, released in 2022, which used a diffusion-based approach to generate photorealistic images from text [
19]. OpenAI followed with DALL-E 2, incorporating CLIP to improve semantic alignment between text and image [
20]. Stability AI’s release of Stable Diffusion further democratized access by making high-performing text-to-image Diffusion Models open-source.
Progress continued into 2023, with OpenAI’s DALL-E 3, which introduced improved training methods and data alignment strategies, enhancing the accuracy and consistency of text-to-image synthesis [
21]. At the same time, major tech companies integrated generative AI into user-facing products. Microsoft embedded DALL-E-based models into its Designer and Image Creator platforms, making advanced image-generation tools more accessible to non-experts [
22]. Meanwhile, Meta developed the Segment Anything Model (SAM) [
23], a zero-shot image segmentation model that expanded the toolkit for image manipulation and interactive generation, also enabling new applications in energy sciences [
24].
In 2024, text-to-image and image-to-image synthesis models became even more refined. Google advanced its Imagen family with improvements in photorealism and semantic parsing. Meta enhanced its Emu architecture, optimizing for speed and quality and experimenting with hybrid models that combine diffusion processes and VAEs [
25,
26,
27]. OpenAI continued to iterate on the DALL-E line, focusing on higher fidelity and incorporating LLM-based refinements. Anthropic also entered the field, exploring visual generation in conjunction with its Claude model, while Microsoft expanded its ecosystem integrations for generative design tools.
So far, 2025 has continued the trend of Diffusion Models dominating the landscape of image generation. Recent advancements have further enhanced the capabilities of Diffusion Models for both image synthesis [
28] and super-resolution [
29]. In particular, breakthrough applications have emerged in scientific imaging, for example, models in [
30] demonstrated a promising generative approach for dehazing satellite images.
Today, Diffusion Models dominate the generative image landscape, often operating in latent spaces defined by VAEs for greater efficiency. Although GANs remain relevant in niche tasks such as upscaling and style transfer, Diffusion Models now serve as the foundation for most text-to-image and image-to-image systems. A defining trend across recent developments is the integration of large language models (LLMs), which enhance generative fidelity by better interpreting prompts and guiding image synthesis. As these technologies continue to mature, understanding their mathematical foundations, computational requirements, and potential pitfalls is critical, especially when applying them to scientific image generation, where precision and trustworthiness are mandatory.
This paper describes key generative architectures (
Section 3,
Section 4 and
Section 5), highlighting their underlying mathematical foundations, computational demands, and prevalent challenges in scientific image generation.
Section 6 explains the Experimental Setup, including a comparative analysis on the generative methods and a summary on the selected models and APIs for image generation. Subsequently,
Section 7 details the metrics for the verification and validation protocols applied to selected models, and discusses the experimental results using each of the selected models against energy-centric scientific data (
Figure 2). Finally,
Section 8 summarizes the results and discusses capabilities and limitations across datasets and
Section 9 draws conclusions about this investigation and future directions.
3. Key Generative Architecture: Variational Auto-Encoder (VAE)
First introduced in 2013, the Variational Auto-Encoder (VAE) [
31] is a type of generative neural network capable of learning a probability distribution over a set of data points without labels. It learns to encode input data into a lower-dimensional latent space and decode it back to the original image space by sampling latents, while ensuring the latent representations follow a known probability distribution.
A VAE is a latent-variable model with an intractable posterior distribution, which prevents direct likelihood evaluation. Instead, it approximates the posterior using variational inference. This means that the VAE must optimize a lower bound on the likelihood because marginalizing over the latent space is intractable. Intuitively, latent variables (LVs) provide a more compact representation of the data by capturing its underlying structure. More formally, they are the result of transforming data points into a continuous, lower-dimensional space that reveals the essential features of the observed data.
Throughout this paper, we denote vectors using boldface (e.g., , , ). In the context of VAEs, let D be the dimensionality of the observed data, then represents the observed data (e.g., images), and represents a latent variable, where typically d is the dimension of each latent variables and .
Mathematically, given a data point drawn from an unknown distribution , and a latent variable from a prior , the following relationships hold:
is the prior distribution over LVs;
is the marginal distribution (model goal, intractable to compute directly);
is the likelihood or decoder, parametrized by , mapping latents to data points ;
is the joint distribution of data points and latent variables;
is the posterior distribution (approximated during training), which describes that can be produced by .
The generative process in VAEs consists of sampling a latent variable from the prior distribution
, then generating a data sample from the conditional distribution
. During inference, given a data point
, the posterior
is needed to sample a latent variable
that captures the underlying representation of
(see
Figure 3). However, since the true posterior
is intractable, VAEs instead use a variational approximation
, parametrized by
, typically implemented as the encoder network.
To find the parameters of the marginal distribution
, we can apply gradient descent, which translates into computing the following (non-tractable gradient):
The goal of variational inference is to approximate the intractable posterior distribution
with a tractable explicit distribution
, known as variational posterior (see
Figure 4, encoder block). Here, the parameters
represent the parameters of the generative model (decoder), while
corresponds to the parameters of the inference model (encoder). By using this approximation, Bayesian inference can be reformulated as an optimization problem [
32]. Specifically, training involves minimizing the Kullback–Leibler (KL) divergence between
and the true posterior
, defined as:
Sampling directly from the variational posterior distribution
is non-differentiable, preventing gradient backpropagation during training. To address this, Kingma and Welling [
31] introduced a reparameterization trick, which transforms the sampling step into a differentiable operation. Specifically, instead of directly sampling the distribution parameterized by mean
and standard deviation
, the latent variables are obtained by adding parameter-independent noise
drawn from a standard normal distribution, enabling gradient computations:
where
, which is independent of the network parameters. The new
is now a deterministic function of
,
, and
. Since
and
are outputs of the neural network, we can now backpropagate through them. That way instead of learning
directly, the network learns
and
to shape the latent distribution and sampling occurs outside of the computational graph (with
), making it possible to compute gradients and optimize the VAE via gradient descent.
Once the prior distribution is defined, the generative process (decoder) of the VAE consists of the following steps (see
Figure 4, decoder block):
Sample latent variable ;
Compute parameters through the decoder network;
Generate a data point by sampling from .
The training objective of the VAE is to maximize the Evidence Lower Bound (ELBO), equivalently formulated as maximize the following loss function:
The first term of this equation, known as the reconstruction error, quantifies how well the decoder reconstructs the input data from the latent representation . The second term measures the KL divergence between the variational posterior and the prior , encouraging the latent space produced by the encoder to remain regularized, continuous, and consistent with the prior assumptions.
β-VAE
The
β-VAE (Beta-Variational Autoencoder) is a modification of the standard Variational Autoencoder (VAE) presented in 2017 [
33], and that introduces a weighting adjustable factor
to control the trade-off between reconstruction fidelity and the disentanglement of the learned latent representations. In contrast with standard VAEs,
-VAE modifies this objective by scaling the KL term with a hyperparameter
. When
, the model is encouraged to learn more disentangled and factorized latent representations at the cost of some reconstruction accuracy. This is particularly useful in unsupervised learning where interpretability of latent factors is important. The objective function of this model is similar to Equation (
4) with the additional
factor:
Using -VAE is particularly beneficial when focusing on learning interpretable, disentangled and structured latent representations. Such representations allow better analysis, manipulation and control of the latent space and independent generative factors (e.g., shape, size, orientation).
4. Key Generative Architecture: Generative Adversarial Networks (GANs)
The Generative Adversarial Network (GAN), introduced in 2014 [
34,
35], represents a major advance in generative learning. GANs comprise two competing neural networks: a generator and a discriminator, where the generator aims to produce synthetic data, and the discriminator attempts to distinguish between real data and synthetic data (see
Figure 5).
Formally, GAN training involves solving a min-max adversarial optimization problem, described as follows:
The generator maps random noise (also called latents and where is the prior over the latents) to the data distribution and outputs the synthetic image in the shape of a 1D-vector . The stochasticity given by this random sampling will provide a non-deterministic output, which is how the model creates diversity in the generation process. The goal here is to fool the discriminator and minimize , which amounts to maximizing the discriminator’s error in classifying the generated images as fake.
The discriminator takes as input a real and synthetic image (generated by the generator) and outputs the probability that the image comes from the real data distribution or not. The goal here is to maximize the loss function or the probability that it correctly classifies real and fake images.
This adversarial process drives both the generator and the discriminator to improve, resulting in high-quality synthetic data. In addition, the fact that the generator is only trained to fool the discriminator makes this Vanilla GAN model unsupervised. The goal of the GAN is to solve the min-max game or adversarial game between the generator and the discriminator with the following objective function and optimization problem:
where
is the probability that
is real,
is the generated sample, and thus
is the probability that the generated image given latent
is real.
One of the most common limitations of GANs is the so-called mode collapse problem where the generator fails to accurately represent the pixel space of all possible outputs. This issue is common in high-resolution images, where too many fine-scale features must be captured. In that case, the generator gets stuck in a parameter setting with a similar level of noise that can consistently fool the discriminator and only captures a subset of the real data distribution. It then fails to produce diversity in its outputs and collapses to producing only a few types of synthetic samples.
4.1. Conditional GAN (CGAN)
As an extension of the Vanilla GAN, the Conditional GAN was introduced in 2014 [
36], and uses conditional information (image or text) to guide the generation process. The CGAN performs conditioning generation by feeding information to both the generator and the discriminator (see
Figure 6).
The generator
takes as input random noise
, and the conditional embedding
and learns to generate data given this condition, whereas the discriminator
learns to classify real and fake images by checking that condition
is met. The updated conditional min-max optimization function becomes:
4.2. Deep Convolutional GAN (DCGAN)
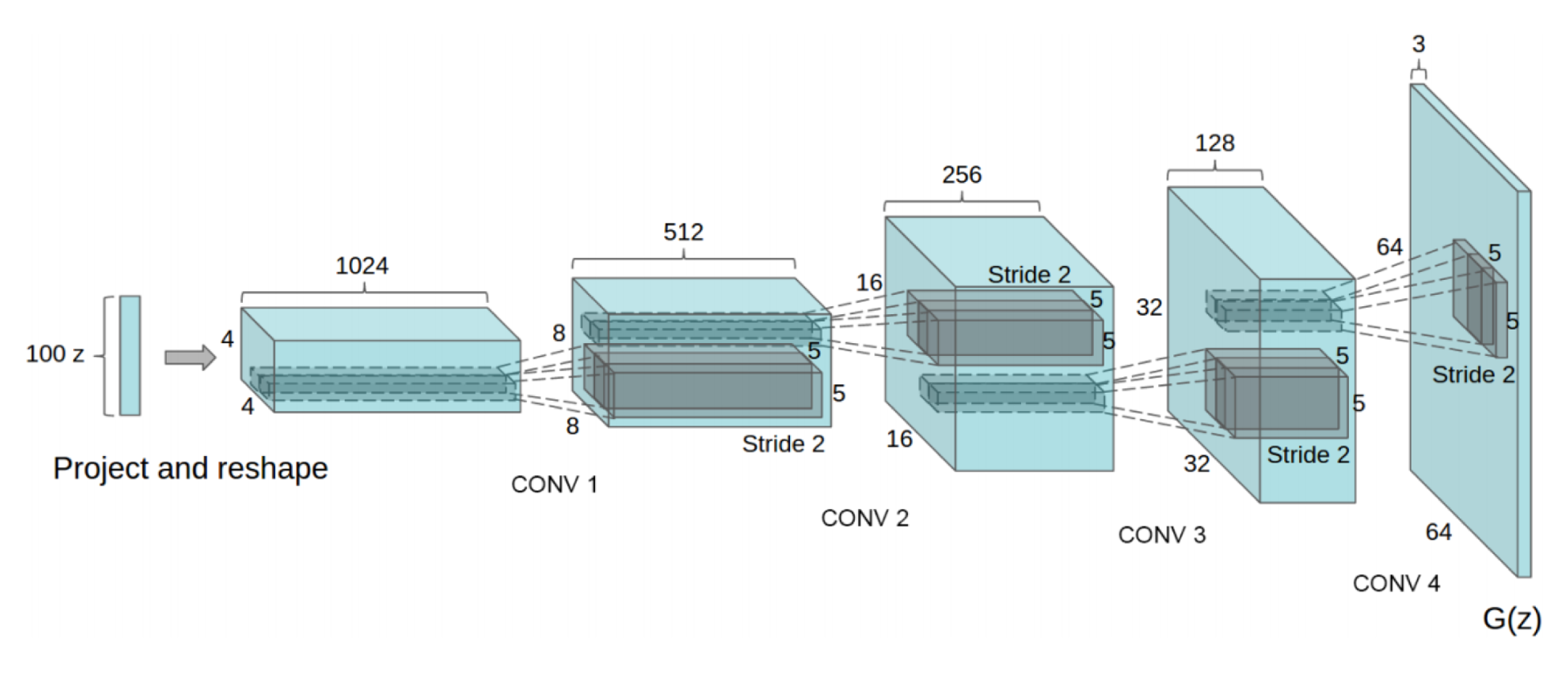
Following the initial development of GANs, various architectures emerged, notably Deep Convolutional Generative Adversarial Networks (DCGANs) introduced by Radford et al. in 2015 [
37], which extended the foundational GAN framework. While the Vanilla GAN architecture contains downsampling and upsampling layers with ReLU activations and a sigmoid activation for the discriminator, this variant of the GAN is made of strided convolution layers in both the Discriminator and the Generator (as illustrated in
Figure 7), along with batch normalization layers, and LeakyReLU activation functions. This architecture is adapted to small-size images such as RGB inputs of shape
(3,64,64) and struggles with high-resolution images.
4.3. Architectural Innovations Derived from CGAN and DCGAN
4.3.1. Pix2Pix
Pix2Pix is a type of Conditional GAN framework introduced in 2017 by Isola et al. [
10], which learns a mapping from an input image
and random noise vector
to a target image
, using a U-Net [
38]-based generator
G and a convolution-based discriminator
D (called PatchGAN). The adversarial loss encourages the generator to produce outputs that are indistinguishable from real images, conditioned on the input:
In addition to the adversarial loss, Pix2Pix introduces a reconstruction loss based on the
distance between the generated image and the ground truth, which encourages the generator to produce images that are structurally close to the target:
The total objective for the generator combines both losses:
where
is a hyperparameter that controls the relative importance of the
loss.
4.3.2. CycleGAN
CycleGAN is a generative model designed in 2017 [
11], for unpaired image-to-image translation. It learns to translate images from one domain
X (e.g., horses) to another domain
Y (e.g., zebras) without requiring paired training examples.
The model consists of two generators and two discriminators (see
Figure 8) and is defined by the following structure:
Figure 8.
(
a) CycleGAN architecture containing two mapping functions F and G and two associated adversarial discriminators
and
. (
b) Forward cycle-consistency loss:
. (
c) Backward cycle-consistency loss:
, where blue dots referring to outputs of domain X and red dots referring to outputs of domain Y. Source: [
11].
Figure 8.
(
a) CycleGAN architecture containing two mapping functions F and G and two associated adversarial discriminators
and
. (
b) Forward cycle-consistency loss:
. (
c) Backward cycle-consistency loss:
, where blue dots referring to outputs of domain X and red dots referring to outputs of domain Y. Source: [
11].
Each generator is trained with a standard GAN loss.
The
full objective combines both adversarial and cycle consistency losses:
where
is a hyperparameter controlling the importance of the cycle consistency loss. CycleGAN thus enables high-quality, unpaired image-to-image translation through adversarial learning and cyclic reconstruction. For more details on the explicit loss formulation, see
Appendix A.
4.3.3. StyleGAN
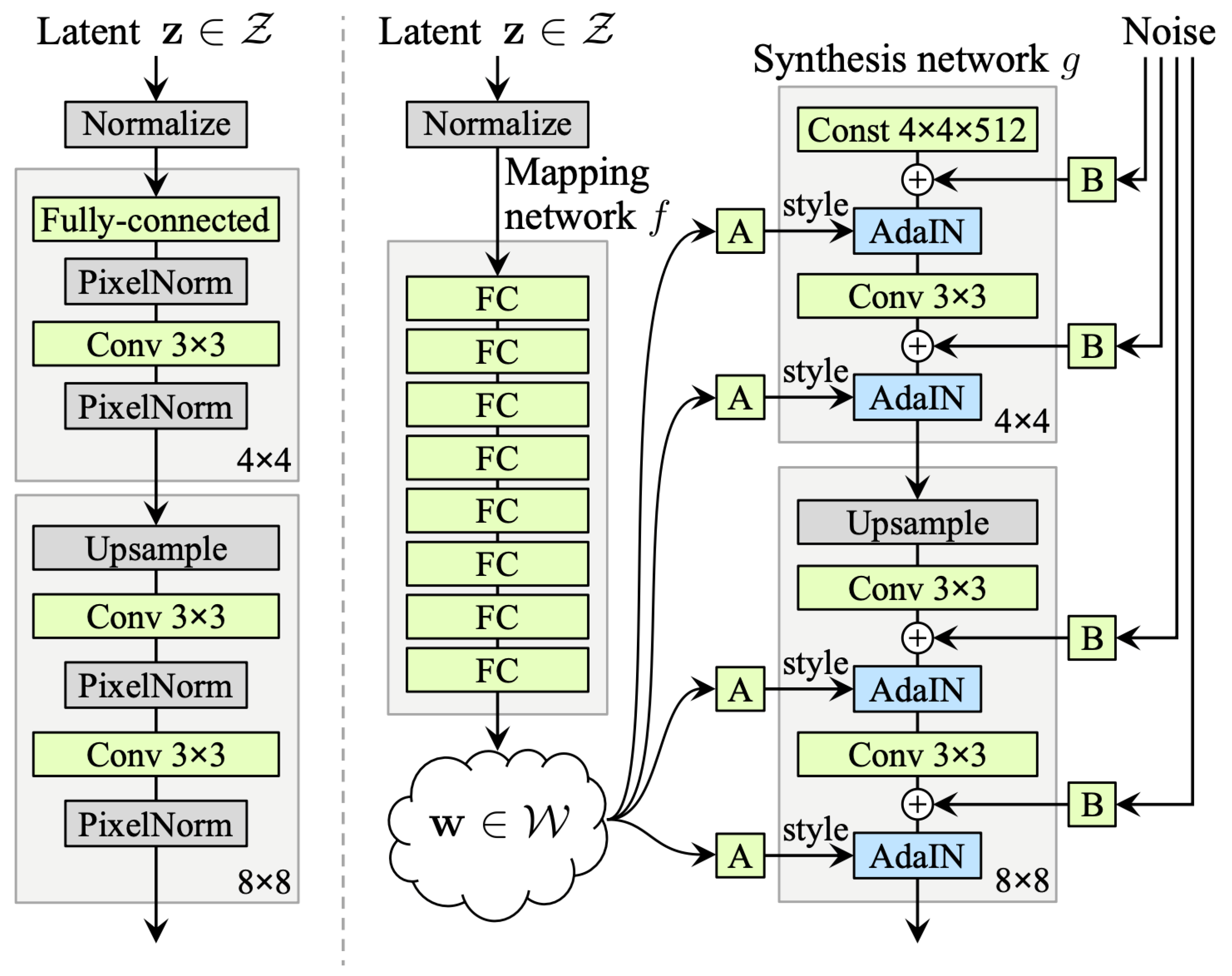
StyleGAN (Style-Based Generative Adversarial Network) is a type of GAN that was introduced by NVIDIA in 2018 [
12] and was initially applied to image face synthesis. It relies on style-based architecture with convolutional layers. This new GAN architecture allows control over different aspects of the image by learning high-level features without supervision and stochastic variation (random noise) in the synthetic images (fine-scale attributes such as eyes and hair).
Let
be a latent variable, input of the generator. Then as illustrated on the right side of
Figure 9,
is mapped through multiple fully connected (FC) layers and outputs a vector
which will be an intermediate representation fed to each convolutional block, through Adaptive Instance Normalization (AdaIN) that normalizes feature maps separately. Gaussian noise is then added to the feature maps after each convolutional layer, which allows conservation of global aspects.
The StyleGAN generator architecture enables precise control over image synthesis through scale-specific style modifications.
By leveraging a mapping network and affine transformations, the model samples styles from a learned distribution, while the synthesis network constructs an image by integrating these styles. Crucially, each style’s influence remains localized within the network and adjusting a subset of styles primarily alters corresponding aspects of the image. This localization effect arises from the AdaIN mechanism. Before applying style-based transformations, AdaIN standardizes each channel by enforcing a zero mean and unit variance. Only afterward does it introduce new scales and biases dictated by the style parameters. Because this process eliminates dependence on the original feature statistics, each style exclusively governs a single convolution before the next AdaIN operation takes over. This sequential modulation allows for fine-grained and independent control over different levels of the generated image.
The discriminator in StyleGAN is a standard Convolutional Neural Network (CNN) designed to distinguish between real and generated images.
4.3.4. GigaGAN
GANs were the traditional choice for text-to-image generation until the release of large Diffusion Models such as DALL-E, Imagen, and Stable Diffusion. These new Diffusion Models have parameters on the scale of billions, while the SOTA GAN model had only 75 million parameters. The disparity in image quality was attributed to the massive gap in parameter counts. GigaGAN was able to create a scalable architecture that far exceeds the size of previous GAN models and has competitive performance to Diffusion Models while being orders of magnitude faster [
39]. GigaGAN is a private model whose results were published by Adobe in 2023. While there is a community implementation [
40] of the work presented in [
39], there have been no other attempts to make a publicly available version of this model to test at the time of writing this paper. Although the results of the paper are promising, training the model from scratch to recreate the capabilities and testing on scientific images are beyond the scope of this paper.
4.3.5. Other GAN-Based Models
StackGAN [
41] and Attention GAN (AttnGAN) [
42] are notable Conditional GAN architectures that have significantly advanced the field of conditional image generation. StackGAN introduced a hierarchical approach, generating low-resolution images and iteratively refining them to high-resolution outputs. AttnGAN innovated with attention mechanisms (see explanation of
attention mechanisms in
Section 5.2.1), allowing the model to selectively attend to specific words or phrases in the text description when generating the corresponding image regions. Progressive GAN [
43] and BigGAN [
44] are two other influential models that significantly advanced image generation. Progressive GAN grows the generator and discriminator networks gradually, from low to high resolution, starting with tiny images (e.g., 4 × 4) and incrementally adding layers to reach resolutions such as 1024 × 1024. This strategy stabilizes training and allows the model to learn coarse features before fine details. In contrast, BigGAN focuses on scaling up model size and dataset complexity. It introduces class-conditional generation with large batch sizes and deep architectures, enabling the production of high-fidelity, diverse images across 1000 ImageNet categories. BigGAN employs techniques such as the truncation trick to balance the trade-off between image quality and diversity. In this method, instead of sampling noise vectors
z from the full standard normal distribution
, the samples are clipped or resampled to lie within a certain range closer to the mean. This limits extreme values, which tends to improve image fidelity at the cost of reduced variability.
Table 1 summarizes the discussion about GAN models, showcasing their diverse architectures and applications, from early convolutional models like DCGAN to modern style-based approaches such as StyleGAN and GigaGAN. While early models focused on simple image generation and translation, later advancements incorporated techniques like cycle consistency (CycleGAN), attention mechanisms (AttnGAN), and multi-stage refinement (StackGAN) to improve conditional generation and overcome common limitations like mode collapse and low resolution.
5. Key Generative Architecture: Diffusion Models
In thermodynamics, diffusion refers to the spontaneous flow of particles from regions of high concentration to regions of low concentration, ultimately moving the system toward a state of equilibrium. In statistics, the concept of diffusion draws a similar analogy: it describes the process of transforming a complex data distribution
into a simpler, predefined distribution
over the same domain. Formally, this is achieved via a first transformation
such that:
Describing this analogy in terms of entropy provides additional insight: both in thermodynamics and in statistics, diffusion involves an increase in disorder or uncertainty in the forward direction. That is, a structured, high-information (low-entropy) distribution is progressively mapped to an unstructured, high-entropy distribution (e.g., isotropic Gaussian noise).
The second transformation reverses this stochastic process, reducing entropy and gradually transforming samples from the simple distribution back into samples from . These two mappings constitute the forward process (diffusion) and the reverse process (denoising generation), which together form the foundation of diffusion-based generative models.
Diffusion Models, now producing SOTA high-fidelity and diverse images, have evolved from the initial work of Sohl-Dickstein et al. in 2015 [
15], to the significantly impactful Denoising Diffusion Probabilistic Models (DDPM) by Ho et al. in 2020 [
16]. Diffusion Models differ from previous generative models as they decompose the image-generation process through small denoising steps. They take an input image
and gradually add Gaussian noise (forward process). The second part of the network (reverse process or sampling process), consists of removing the noise to obtain new data (see
Figure 10).
The forward process consists of a Markov chain of T steps, where Gaussian noise is incrementally added to an input image to produce noisy latent variables of the same dimensionality. The variance of added noise is controlled by a schedule , often linear or cosine.
During training, a neural network approximates the reverse transitions
using Gaussian parameterization. The objective is to minimize the negative log-likelihood, which is estimated via the Evidence Lower Bound (ELBO):
where:
is the reconstruction term;
quantifies how close the noisy latent is to a standard Gaussian;
measures the gap between the true reverse process and the learned denoising model.
The reverse model is typically implemented as a U-Net conditioned on timestep embeddings and trained using a mean squared error loss between the true and predicted noise. A simplified version of the training loss, used in DDPM training, is derived that enables the model to predict the noise
added at each timestep
t, rather than directly reconstructing
.
For a complete derivation of the forward and reverse processes, we refer the reader to
Appendix B.
The model is typically implemented using a U-Net with residual blocks, group normalization, and self-attention. The timestep t is embedded (e.g., using a cosine embedding) and injected into each residual block.
5.1. Score-Based Generative Models
Score-Based Diffusion Models (SBDMs) are a class of Diffusion Models proposed by [
46,
47] that combine score functions (gradient of the log probability density function) and Langevin dynamics (iterative process where we draw samples from a distribution based only on its score function, as illustrated in
Figure 11). The gradient of the log probability density function, also called the score function, is the mathematical tool that allows generative models to transform random noise into realistic data by following the estimated directions where the data probability density grows most.
This approach builds on the principle of score-modeling and score-matching [
48], enabling the training of deep neural networks to approximate the score of complex, high-dimensional data distributions. Unlike methods such as Variational Autoencoders (VAEs), which require a tractable normalizing constant, or Generative Adversarial Networks (GANs), which rely on adversarial training, score-based modeling bypasses both constraints. Instead of modeling the probability density function
directly, a neural network
is trained to approximate its score function
by minimizing the following training objective:
Once the score-based model is trained and
is obtained, the next step consists in generating samples using a Langevin Dynamics Markov chain Monte Carlo (MCMC) procedure by starting from an arbitrary prior distribution and iterating the following update (for
):
where
. When the step size
and the number of iterations
, the distribution of
obtained from this procedure converges to a sample from
under some regularity conditions. In practice, the error is negligible when
is sufficiently small and
K is sufficiently large.
5.1.1. Noise Conditional Score Networks (NCSN)
While Langevin dynamics can sample
using the approximated score function, directly estimating
is difficult and imprecise: the estimated score functions are usually inaccurate in low-density regions, where few data points are available and as a result, the quality of the data sampled using Langevin dynamics is poor. To address this, one solution consists in learning score functions at various noise levels, which can be achieved by perturbing the data with multiple scales of Gaussian noise [
46]. Therefore, given the data distribution
, we perturb it with Gaussian noise
where
and
to obtain a noise-perturbed distribution:
which we can draw samples from by sampling
and computing
, where
. Finally we train a network
, known as the Noise Conditional Score-Based Network (NCSN), to estimate the score function
. The training objective is a weighted sum of Fisher divergences for all noise levels:
Similarly to the previous section, once we obtain , we can apply the Langevin Dynamics MCMC procedure to sample new data points.
5.1.2. Score-Based Diffusion Through Stochastic Differential Equations (SDE)
Song et al. [
46,
47] unify Noise Conditional Score Networks (NCSNs) and Denoising Diffusion Probabilistic Models (DDPMs) by introducing a continuous-time generative model based on stochastic differential equations (SDEs). In contrast to perturbing data with a discrete set of noise levels, they define a continuous-time diffusion process
, which gradually transforms data into a tractable noise distribution. This forward process, going from an input image
to random noise
as in
Figure 12, is governed by a fixed reversible SDE with no learnable parameters:
where:
is the state at time t;
is a vector valued function called the drift function, and is always of the form ;
is a real-valued function corresponding to the diffusion coefficient;
is a standard Wiener process (Brownian motion with infinitesimal white noise).
Figure 12.
Score-based generative modeling through SDE by transforming input data to a noise distribution through a continuous-time SDE and reversing the process using the score function of the distribution at each intermediate time step. Source: [
47].
Figure 12.
Score-based generative modeling through SDE by transforming input data to a noise distribution through a continuous-time SDE and reversing the process using the score function of the distribution at each intermediate time step. Source: [
47].
To determine the specific forms of
and
, two commonly used noise schedules are presented in [
47] (and originally in [
16,
46]). A full derivation of these formulations can be found in
Appendix C.
Let
denote
, i.e., the state of the process at time
t, and
. The marginal distribution
is then obtained by integrating the perturbation kernels over
(Equation (
13) of [
49]):
where
is Gaussian and defined in
Appendix C.
The next step consists in learning a time-dependent score function
. Since the true score function,
is intractable, it is approximated using the score neural network
. Then, using the identity:
we train the score network
to match
on average over samples
.
This gives rise to training the model by minimizing the Continuous-Time Weighted Score-Matching Loss:
where:
is the score network approximating ;
is the transition kernel of the forward SDE;
is a weighting function over time (often noise-dependent);
is the uniform distribution over the time interval .
Once the score-based model is trained, it is possible to generate new samples by computing the well-defined reverse SDE, under appropriate regularity conditions (e.g., those from Anderson’s theorem [
50]):
where
is a standard Wiener process evolving backward in time, and
denotes the marginal density of
. Since
is not analytically available, it is learned via a time-dependent score network
.
The Euler–Maruyama method is the default solver used in early works, such as Song et al. [
47], where it is employed to approximate the reverse-time SDE during the sampling process. Subsequent improvements led to the adoption of higher-order solvers. For instance, Karras et al. [
49] explore the design space of noise schedules and use Heun’s method, a second-order stochastic Runge–Kutta scheme, for improved sampling quality.
Song et al. [
47] also propose the probability flow ODE which shares the same marginal distributions
as the corresponding SDE:
This formulation allows deterministic sampling from the generative model using numerical ODE solvers. Ultimately, the choice between VP and VE formulations depends on the modeling objective: VP provides controlled noise injection allowing likelihood estimation and discrete-time training, while VE supports direct score-based generation from unbounded priors with flexible noise scales.
Alternatives to score-based modeling, such as flow matching [
51], propose training neural fields to match velocity fields derived from optimal transport, providing another pathway for continuous-time generative modeling. Compared to autoregressive models, which generate data sequentially and have shown promise in scalable image synthesis [
52], score-based and flow-based approaches enable parallel sampling and have opened new avenues for efficient and high-fidelity generation.
5.1.3. Conditional Image Generation with Guided Diffusion and Classifier Guidance
Similarly to the CGAN, an important extension of the Diffusion Model is the
Guided diffusion model that enables conditional image generation via classifier gradients. It was introduced by Dhariwal et al. [
53] when looking for a way to trade off diversity for image fidelity and were inspired by class-conditional generative models that rely on class label conditioning. In the paper [
53], the model adds conditioning information
at each diffusion step: Dhariwal et al. train a separate classifier
on noisy images at timestep
t denoted by
, and then use gradients
to guide the diffusion sampling process towards an arbitrary class label
. As discussed in the previous section, score-based Diffusion Models generate samples by predicting the score function
of the target distribution.
Let us first define
using Bayes rules and gradient computations:
Then, by adding a guidance weight term
s to the classifier score term
to control the sharpness of the distribution (closeness to label
in the generation process), they define a new guided conditional score
using the previous formulation at each timestep t:
where:
is the standard diffusion score;
is the classifier guidance term;
s is a scaling coefficient controlling the strength of guidance.
Based on the original mean
and variance
, classifier guidance modifies the mean to:
At each reverse diffusion step
t, sampling is performed using the perturbed mean
and the covariance
:
This formulation explicitly uses both the Diffusion Model’s learned dynamics and the classifier’s gradient signal to steer the sampling process toward samples that are more likely to belong to class
(Algorithm 1, source: [
53]).
| Algorithm 1 Classifier guided diffusion sampling, given a diffusion model , classifier , and gradient scale s |
- 1:
Input: class label y, gradient scale s - 2:
sample from - 3:
for all t from T to 1 do - 4:
- 5:
sample from - 6:
end for - 7:
return
|
The intuition behind this approach is the following:
If the classifier assigns a high probability to class for a given noisy image , it means is on the right track.
If the classifier assigns a low probability, the guidance term nudges in a direction that increases , pushing the sample towards a more likely image.
We can underline that higher guidance weights s enforce more alignment with classifier predictions but may reduce diversity, whereas a lower guidance weights allows more diversity but might not enforce class constraints strongly.
Classifier guidance is commonly used in models such as GLIDE [
54] and Imagen [
55], making text-to-image generation more controllable.
5.1.4. Conditional Image Generation with Guided Diffusion and Classifier Free-Guidance
Classifier-free guidance, proposed by Ho et al. [
56], allows for enhanced control in Diffusion Models by eliminating the need for separate classifiers. Instead of relying on a separate classifier, which increases training complexity and introduces potential bias, classifier-free guidance trains the Diffusion Model to directly learn and combine conditional and unconditional distributions during inference, streamlining the process. In other words, the authors train a conditional Diffusion Model
and an unconditional model
as a single neural network. Based on Equations (
29) and (
30), classifier-free guidance linearly combines the score estimates of conditional and unconditional models, which leads to the following formula:
This approach is advantageous compared to the previous one as it trains a single model to guide the diffusion process and can take different types of conditional data such as text embeddings. We will see that many models rely on classifier free-guidance especially when training on multimodal data.
5.2. Stable Diffusion
5.2.1. Attention Mechanisms
Attention is based on the idea that we should look at all the different words of a sequence at the same time and learn to
pay attention to the correct ones depending on the task in which we are interested. Attention mechanisms, introduced by Vaswani et al. in [
13], can be defined as attention of the same sequence, where, instead of looking for an input–ouput sequence association, we look for probability scores between the elements of the sequence.
The attention mechanism computes a weighted representation of a set of values based on a set of queries and keys , where n is the sequence length, is the key and query dimensionality, and is the value dimensionality.
Self-Attention. Self-attention is a special case where the queries, keys, and values come from the same sequence. The scaled dot-product attention is defined as:
where:
are the query, key, and value matrices, respectively;
is the dimensionality of each query and key vector;
The dot product produces pairwise similarity scores between all tokens in the sequence.
The softmax operation normalizes each row to a probability distribution over keys such that for a vector
, then:
This mechanism allows each token to attend to all other tokens, including itself, weighted by their learned importance (a token is a vector representation of a discrete input unit: in NLP, tokens represent words or sub-words whereas in vision models, an image is split into patches, each flattened and projected into a vector which form a sequence input to vision transformer models).
Multi-head Attention. Instead of computing attention once, multi-head attention projects the queries, keys, and values
h times using learnable weight matrices and computes attention in parallel across
h different heads. For each head
:
where:
, , are learnable projection matrices for the i-th head;
Typically, , so the concatenation of h heads gives the original embedding size.
The outputs of all heads are concatenated and projected through another learnable matrix
:
where
Concat denotes the concatenation of the outputs from the
h individual attention heads along the feature dimension, resulting in a single tensor of shape
, where
T is the sequence length and
is the dimensionality of each head’s output. This concatenated tensor is then linearly projected back to
via
. This formulation allows the model to jointly attend to information from different representation subspaces at different positions, enriching the learned representation of each token. The design choice to keep the final output dimensionality equal to
ensures compatibility with residual connections and layer stacking in transformer architectures.
Cross-Attention. Cross-attention extends the self-attention mechanism to allow one sequence (the
query source) to attend to another sequence (the
key-value source). It was introduced in [
57] and is particularly important in tasks such as text-to-image generation and text-guided image editing, where the model must condition the output (e.g., an image) on an auxiliary input (e.g., a text prompt). In such settings, the image decoder learns to respond to text embeddings, allowing semantic concepts of the prompt to directly influence the visual output. Modulating the attention maps—by replacing, augmenting, or re-weighting them—enables precise control over spatial layout, geometry, and semantic content of the generated image. Let:
be the matrix of query vectors derived from the image decoder (e.g., latent image tokens).
be the key and value matrices derived from the text encoder (e.g., token embeddings), where m is the length of the text sequence and d is the embedding dimensionality.
The cross-attention operation is defined as:
where:
contains the pairwise dot-product similarities between image queries and text keys;
The softmax normalizes each row to a probability distribution over the m text tokens;
The result is a matrix of size , where each image token is a weighted combination of the text values.
This mechanism enables each spatial or latent position in the image representation to condition its generation on the most relevant tokens from the text prompt. As illustrated in
Figure 13, this mechanism enables:
Semantic alignment: which ensures that visual elements in the output image correspond to the content described in the text;
Layout preservation: which, by manipulating specific attention maps (e.g., for a token t), ensures that spatial structure from a reference image can be preserved during editing;
Prompt-based control: which allows for targeted edits or enhancements when replacing or modifying words in the prompt (which can trigger attention shifts in the image decoder).
Figure 13.
Cross-attention mechanisms. (
Top) Visual and textual embeddings are combined through cross-attention layers that generate spatial attention maps for each text token. (
Bottom) The spatial arrangement and geometry of the generated image are guided by the attention maps from a source image. This approach allows various editing tasks to be performed solely by modifying the textual prompt. When replacing a word in the prompt, we insert the source image’s attention maps
, replacing the target image maps
, to maintain the original spatial layout. Conversely, when adding a new phrase, we only incorporate the attention maps related to the unchanged part of the prompt. Additionally, the semantic influence of a word can be enhanced or reduced by re-weighting its corresponding attention map. Source: [
57].
Figure 13.
Cross-attention mechanisms. (
Top) Visual and textual embeddings are combined through cross-attention layers that generate spatial attention maps for each text token. (
Bottom) The spatial arrangement and geometry of the generated image are guided by the attention maps from a source image. This approach allows various editing tasks to be performed solely by modifying the textual prompt. When replacing a word in the prompt, we insert the source image’s attention maps
, replacing the target image maps
, to maintain the original spatial layout. Conversely, when adding a new phrase, we only incorporate the attention maps related to the unchanged part of the prompt. Additionally, the semantic influence of a word can be enhanced or reduced by re-weighting its corresponding attention map. Source: [
57].
Attention mechanisms are a foundational component in language models such as GPT and BERT, where they helps capture contextual relationships within text, and in vision models (e.g., Vision Transformer (ViT) and Diffusion Transformers (DiT in
Section 5.4)), where they model spatial relationships between image patches. In generative models such as Stable Diffusion (next
Section 5.2.2), self-attention is used within the UNet architecture to enable global spatial dependencies across the image representation. Multi-head attention extends self-attention by enabling the model to project the input into multiple attention heads, each learning to focus on different aspects or subspaces of the data. This mechanism is central to transformer architectures and is used in both text and vision transformers, including generative models such as DALL-E and StyleGAN-T, where diverse and nuanced relationships need to be captured simultaneously across different parts of the input.
Cross-attention, in contrast, involves interactions between different modalities or sequences, where one set of tokens (queries) attends to another set (keys and values). This is crucial in conditional image-generation tasks. For instance, in DALL-E 2 (see
Section 5.3) and DALL-E 3, cross-attention allows image representations to attend to text embeddings, enabling coherent image synthesis from textual prompts. Similarly, Stable Diffusion incorporates cross-attention in its denoising network to condition the image-generation process on language inputs.
5.2.2. Latent Diffusion Models (LDMs)
Latent Diffusion Models (LDMs) are yet another innovative extension of Diffusion Models [
19]. Instead of applying the diffusion on a high-dimensional input (namely pixel or image space), we project the input image into a smaller latent space and apply diffusion with the obtained latents as inputs. The authors of [
19] propose to use an encoder network to encode the input into a latent representation and apply the forward process to this latent vector. Then the reverse process is the same as a standard diffusion process with a U-Net to generate new data, which are then reconstructed by a decoder network (see
Figure 14). Therefore, given a pre-trained VAE encoder
, which maps an image
to a latent representation
, the diffusion process is applied in the latent space. The training objective for the Latent Diffusion Model (LDM) is defined as:
where the noisy latent
is generated via the forward diffusion process:
and where:
is the latent code of input image ;
is standard Gaussian noise;
t is a timestep sampled uniformly from ;
is the learnable parameter;
is the model’s prediction of the noise.
Figure 14.
Diagram of the Latent Diffusion Model (LDM) architecture where the input image is encoded into a latent vector
through an encoder
, which will be the input to the forward diffusion process. The denoising U-Net
utilizes cross-attention layers to process key, query and value pairs (Q, K, V). This setup includes conditioning information through elements such as semantic maps, text and images to guide the transformation back to pixel space using the decoder block
. Source: [
45].
Figure 14.
Diagram of the Latent Diffusion Model (LDM) architecture where the input image is encoded into a latent vector
through an encoder
, which will be the input to the forward diffusion process. The denoising U-Net
utilizes cross-attention layers to process key, query and value pairs (Q, K, V). This setup includes conditioning information through elements such as semantic maps, text and images to guide the transformation back to pixel space using the decoder block
. Source: [
45].
Stable Diffusion can also be conditioned, in particular, using classifier-free guidance by adding conditional embeddings such as image features or text descriptions using a text encoder (e.g., CLIP’s text encoder) to steer the generation process.
5.3. Models Combining Diffusion Based Architectures and Transformers
5.3.1. InstructPix2Pix
Figure 15 illustrates InstructPix2Pix, yet another relevant CGAN-based generative model introduced in 2022 [
58] based on the Pix2Pix model [
10]. InstructPix2Pix utilizes both LLMs and Diffusion Models by creating a training set consisting of pairs of images and an edit prompt to bridge one image to another. This generated dataset is then used to train a model to generate the resulting images from the input image and edit prompt. Although the dataset is generated, the resulting model is able to generalize and edit input images with arbitrary edit prompts.
5.3.2. DALL-E and DALL-E 2
The first version of DALL-E, introduced by OpenAI in 2021 [
59], is a generative model that generates visual outputs given a text description. Training is carried out using a text-image pairs dataset. The architecture of DALL-E is based on a discrete Variational Autoencoder also called a Vector Quantized Variational Autoencoder (VQ-VAE) [
60], which maps the input images to image tokens (the VAE mentioned in the section above uses a continuous latent space whereas the (VQ-VAE) uses a discrete latent space). The image and text tokens are concatenated and fed as a single embedding into the network. DALL-E uses an autoregressive transformer (generate one token at a time) to model the joint distribution of text-image pairs (GPT-like Transformer). These generated tokens are converted back into an image via the VQ-VAE decoder. During inference, the target caption is tokenized and concatenated to the output of the (VQ-VAE) and fed to the transformer decoder, which will generate a synthetic image. However, DALL-E showed some limitations due to the discrete tokenization that led to a loss of fine details and lower resolution (256 × 256 images).
A modified version of DALL-E presented as DALL-E 2 in 2022 [
61] overcomes these challenges and allows for more complex text inputs, better prompt understanding and more realistic and coherent images. It can also manage high-resolution images, and proposes in-painting (image editing) and out-painting (extending images beyond original borders). The network components of DALL-E 2 varies from DALL-E: instead of a discrete VAE (VQ-VAE), the model uses a Latent Diffusion Model (LDM) as well as a CLIP-based Prior (CLIP: Contrastive Language-Image Pre-training model) that converts text prompts into image embeddings.
CLIP, first introduced by OpenAI in 2021 [
62], is a classifier that targets the Natural Language for Visual Reasoning issue by classifying an image into a label (text description of the image) based on its context. It learns to associate images and text descriptions in a shared latent space. In fact, CLIP uses a contrastive learning approach: given text-image pairs, the model learns to maximize the similarity between matching pairs while maximizing the similarity between mismatched pairs.
This is done by encoding both images and text into vector embeddings using an image encoder network with a text encoder network (see
Figure 16,
left side). The model is trained on large-scale datasets of text-image pairs, enabling it to generalize well to zero-shot learning tasks, meaning it can understand and classify images based on natural language descriptions without task-specific fine-tuning. CLIP’s ability to create meaningful text-image embeddings makes it useful for image-generation application such as DALL-E 2. As illustrated in
Figure 17, DALL-E 2 first transforms a text prompt into a CLIP image embedding
using a CLIP prior model
where:
Once the CLIP embedding is obtained, it is passed to a latent Diffusion Model to generate a synthetic image in a lower-dimensional latent space using a pre-trained VAE.
Figure 16.
CLIP architecture: CLIP model simultaneously trains an image encoder and a text encoder to correctly match pairs of (image, text) examples within a batch during training. During testing, the trained text encoder produces a zero-shot linear classifier by embedding the names or descriptions of the classes in the target dataset. Source: [
62].
Figure 16.
CLIP architecture: CLIP model simultaneously trains an image encoder and a text encoder to correctly match pairs of (image, text) examples within a batch during training. During testing, the trained text encoder produces a zero-shot linear classifier by embedding the names or descriptions of the classes in the target dataset. Source: [
62].
Figure 17.
Overview of the DALL-E 2 (or unCLIP) architecture:
Above the dotted line is illustrated the CLIP training process, which develops a joint representation space for both text and images.
Below the dotted line is the text-to-image-generation pipeline: a CLIP text embedding is first given as input to an autoregressive or diffusion prior to generate an image embedding, which is then used to condition a diffusion decoder that creates the final image. The CLIP model remains frozen during the training of the prior and the decoder. Source: [
61].
Figure 17.
Overview of the DALL-E 2 (or unCLIP) architecture:
Above the dotted line is illustrated the CLIP training process, which develops a joint representation space for both text and images.
Below the dotted line is the text-to-image-generation pipeline: a CLIP text embedding is first given as input to an autoregressive or diffusion prior to generate an image embedding, which is then used to condition a diffusion decoder that creates the final image. The CLIP model remains frozen during the training of the prior and the decoder. Source: [
61].
5.3.3. ControlNET
ControlNET was introduced in 2023 [
63] and presents an auxiliary network that mirrors U-Net in Stable Diffusion but is conditioned on additional structural guidance (e.g., depth maps, edge maps, or poses). It works by injecting guidance at multiple stages of the U-Net via a set of trainable convolutional layers. These layers receive the conditioning input (e.g., Canny edges) and propagate structured features into the diffusion process, ensuring that the generated image adheres to the input structure while maintaining generative creativity. The guidance information is processed through a zero-convolution module (a 1 × 1 convolution initialized to zero) to ensure smooth integration with the Diffusion Model without destabilizing its pretrained weights.
ControlNET enhances Stable Diffusion by incorporating additional conditioning inputs to guide the image generation process.
5.3.4. Stable unCLIP
Stable unCLIP [
64] is a variant of latent Diffusion Models that conditions on CLIP image embeddings in addition to text prompts, enabling effective text-guided image variation and editing tasks. It builds upon the Latent Diffusion Models framework introduced by Rombach et al. [
65], extending it to support image-conditioned generation through the use of CLIP embeddings.
Instead of using a text encoder (like OpenAI DALL-E 2’s CLIP or T5) to encode prompts, it takes a CLIP ViT-L/14 image embedding and injects it into the diffusion process as a form of semantic prior. The architecture remains similar to Stable Diffusion, where the U-Net operates in the latent space, guided by the CLIP embedding through cross-attention layers. Additionally, Stable unCLIP employs a learned projection network that maps CLIP image embeddings to Stable Diffusion’s latent space, allowing image variations to be generated without requiring explicit textual guidance. Unlike text-to-image models, which primarily rely on cross-attention with text tokens, Stable unCLIP leverages direct latent conditioning, allowing for greater abstraction in the generated images and for the production of image and text-guided variations at (768 × 768) resolution.
5.3.5. DiffEdit
First introduced in the paper [
66], DiffEdit enhances Stable Diffusion by introducing a mask prediction network that determines which areas of an image should be edited before running the diffusion process. As illustrated in
Figure 18, the key innovation here is the dual forward pass through the U-Net:
First pass: the input image is diffused (noised through forward process) and then denoised using the target text prompt. This provides a preliminary reconstruction of what the model thinks the target image should look like.
Mask prediction: the difference between the original image and the first-pass reconstruction is computed using a learned discrepancy function, identifying which areas should be modified.
Second pass (final editing): the identified areas are selectively resampled in the latent space while keeping the unmasked regions frozen, ensuring that only relevant changes are applied.
Figure 18.
DiffEdit model diagram: first step consists in adding noise to the input image and then denoising it twice—once conditioned on the query text and once conditioned on a reference text (or unconditionally). The differences in the denoising results are used to generate a mask. In the second step, the input image is encoded using DDIM to estimate its latent representation. Finally, in the third step, DDIM decoding is performed conditioned on the text query, with the inferred mask guiding the replacement of the background pixels with values obtained from the encoding process at the corresponding timestep. Source: [
66].
Figure 18.
DiffEdit model diagram: first step consists in adding noise to the input image and then denoising it twice—once conditioned on the query text and once conditioned on a reference text (or unconditionally). The differences in the denoising results are used to generate a mask. In the second step, the input image is encoded using DDIM to estimate its latent representation. Finally, in the third step, DDIM decoding is performed conditioned on the text query, with the inferred mask guiding the replacement of the background pixels with values obtained from the encoding process at the corresponding timestep. Source: [
66].
The core architecture remains that of Stable Diffusion’s latent U-Net, but it incorporates a dynamically computed mask that modifies how noise is applied across different spatial regions. The mask-guided approach prevents unnecessary edits, making it ideal for controlled inpainting and localized modifications.
This approach also ensures that only targeted areas are modified, preserving the rest of the image.
5.3.6. LEDITS++
Introduced in the paper [
67], the model LEDITS++ builds upon Stable Diffusion’s latent U-Net while integrating two key additional components: edge-preserving conditioning and CLIP-based semantic guidance. During inference, a source image is first processed to extract its edge representation (typically using a Canny edge detector). These edges are then used as a constraint in the U-Net’s latent space via feature injection layers, which act similarly to ControlNET but with a focus on structural similarity rather than strict adherence to the input. Simultaneously, a CLIP-guided latent optimization step ensures that generated outputs match a target text description while still respecting the original image’s edge structure. The U-Net’s cross-attention mechanism is modified to incorporate both CLIP text embeddings and edge constraints, allowing the Diffusion Model to transform images while preserving spatial features.
5.4. Diffusion Transformers (DiT)
One of the most recent diffusion-based models is the Diffusion Transformer (DiT) proposed in [
68], which is an architecture that combines the principles of Diffusion Models and transformer models and that generates high-quality synthetic images. It leverages the iterative denoising process inherent in Diffusion Models while utilizing the powerful representation learning capabilities of transformers for improved sample generation. The authors in [
68] replace the U-Net backbone, in the LDM model, by a neural network called a Transformer [
13]. Transformers are a class of models based on self-attention mechanisms, and they have been proven to excel in tasks involving sequential data (like language processing). They work by attending to all input tokens at once and using multi-head self-attention to process the input efficiently.
In the context of a Diffusion Transformer (see
Figure 19), the input to the transformer is typically a set of tokens or features (e.g., image patches, sequence tokens), and self-attention helps the model attend to dependencies across all tokens to capture long-range relationships. In the reverse process of the Diffusion Model, the transformer network is responsible for predicting the noise at each step, conditioned on the noisy data. For example, given the noisy image at time step
t, the transformer can model long-range spatial dependencies across the image patches (or sequence tokens) and generate a clean image at the next step:
where:
Figure 19.
Diffusion Transformer (DiT) architecture: on the left, conditional latent DiT models are trained, where the input latent is divided into patches and processed through multiple DiT blocks. On the right, the DiT blocks include various configurations of standard transformer components that integrate conditioning through methods such as adaptive layer normalization, cross-attention, and additional input tokens. Among these, adaptive layer normalization proves to be the most effective. Source: [
68].
Figure 19.
Diffusion Transformer (DiT) architecture: on the left, conditional latent DiT models are trained, where the input latent is divided into patches and processed through multiple DiT blocks. On the right, the DiT blocks include various configurations of standard transformer components that integrate conditioning through methods such as adaptive layer normalization, cross-attention, and additional input tokens. Among these, adaptive layer normalization proves to be the most effective. Source: [
68].
DALL-E 3
DALL-E 3 [
21] represents the latest advancement in OpenAI’s series of text-to-image generative models, significantly improving the visual fidelity and prompt adherence compared to its predecessor. This model integrates a large-scale language model (GPT-4) with a diffusion-based image-generation pipeline, allowing it to better understand complex textual descriptions and generate images that align closely with the given prompts. DALL-E 3 incorporates an end-to-end approach where the language and image-generation components are deeply coupled, which enhances the model’s ability to faithfully render nuanced details from the text prompt, resulting in higher semantic alignment and image quality.
Although DALL-E 3 uses diffusion-based generation techniques and transformer architectures, it is not explicitly based on the DiT (Diffusion Transformer) architecture. DiTs replace the conventional U-Net backbone in Diffusion Models with pure transformer architectures and achieve strong results in class-conditional image-generation benchmarks such as ImageNet. The key distinction lies in the design objectives: DiT focuses primarily on architectural efficiency and improved Diffusion Model backbones, whereas DALL-E 3 emphasizes the integration of advanced language understanding (via GPT-4) with diffusion to enhance prompt fidelity and user control in image synthesis. Based on that, DALL-E 3 overcomes DALL-E 2’s limitations in handling highly complex prompts by tightly coupling language and image generation through GPT-4 guidance, resulting in more faithful and contextually rich image outputs.
Table 2 summarizes and compares the previously discussed Diffusion and Transformer-based models, highlighting the strengths and limitations of each architecture. While the computational complexity of Diffusion Models can vary depending on architectural choices and implementation details, it is possible to provide a general characterization. The theoretical time complexity can be expressed as:
Training: , and Sampling: , where:
S is the number of training samples (or batch size);
T is the number of sampling steps required to generate an output;
N is the number of pixels in the input image;
is an architecture-dependent exponent, typically for convolutional networks such as U-Nets, and for Transformer-based models.
This formulation highlights the key computational scaling properties of Diffusion Models, showing that their cost increases linearly with the number of training examples or sampling iterations, and either linearly or quadratically with image resolution, depending on the model architecture used.
Table 2.
Comparison of Diffusion Models categorized by methodology, including conditional and latent-guided variants.
Table 2.
Comparison of Diffusion Models categorized by methodology, including conditional and latent-guided variants.
| Model | Type | Transformer | Pros | Cons |
|---|
| Basic Diffusion Models (DM) [15,16] | Denoising Diffusion Probabilistic Models (DDPM) | No | Simple and stable training; high-quality, diverse outputs. | Slow sampling due to many denoising steps. |
| Score-Based Generative Models [46] | Score Matching (e.g., SMLD) | No | Theoretically grounded; aligns with likelihood-based training. | High compute; limited control and flexibility. |
| NCSN [46] | Noise-Conditional Score Networks | No | Trains score functions at multiple noise scales; enables image synthesis from noise. | Requires careful training; lacks intuitive conditioning. |
| Score-Based Diffusion (SDE) [47] | SDE-based (continuous-time) diffusion | No | Flexible noise schedules; supports fast sampling via ODE solvers. | Complex math; needs denoising score models. |
| Guided Diffusion [53,69] | Classifier or Classifier-Free Guidance | No | Enables conditional generation with control (class, text, layout, etc.). | Can bias or degrade image quality at high guidance scales. |
| InstructPix2Pix [58] | Conditional + Guided Diffusion | No | Instruction-guided image editing; strong alignment with user intent. | Requires prompt quality; editing is often limited to style/content described. |
| ControlNet [63] | Conditional + Guided Diffusion | No | Adds structural control (edges, pose, depth, etc.) to diffusion; high precision. | Heavy model; requires control input (Canny, pose, etc.). |
| DiffEdit [66] | Masked Conditional Diffusion | No | Local editing with mask guidance; leaves background untouched. | Sensitive to mask boundaries; limited generalization. |
| LEDITS++ [67] | Localized Conditional Diffusion | No | High-fidelity edits from prompts + structure; state-of-the-art for controllable editing. | Still under research; complex training and model merging. |
| Stable Diffusion (v1) [65] | Latent Diffusion + Classifier-Free Guidance | No | Efficient and scalable; text-to-image from latent space; open-source. | Harder to train than pixel-space models; prompt sensitivity. |
| Stable UnCLIP [64] | Latent Diffusion + Image Embedding Conditioned | No | Leverages image embeddings; better reconstruction from reference image. | Reduced diversity; limited to CLIP-space control. |
| DALL-E 1 [59] | Transformer-based + Discrete Diffusion Decoder | Yes; Autoregressive token generation | Combines VQ-VAE and transformer priors; end-to-end text-to-image. | Coarse outputs; training is complex. |
| DALL-E 2 [61] | Diffusion Decoder + CLIP Guidance | Yes; Maps text embeddings to image embeddings | High-fidelity images from text; CLIP-based guidance improves alignment. | Prone to prompt leakage or repetition; less open. |
| DALL-E 3 [21] | Transformer-based Diffusion Model | Yes; Semantic alignment, layout planning and concept binding | Best alignment with complex text; enhanced prompt following. | Closed source; requires Azure/OpenAI backend. |
6. Experimental Setup
6.1. Methods for Comparative Analysis
We define a set of metrics to evaluate the general performance of a model family in image generation. Image quality refers to the level of detail in the generated image. A model with high image quality strictly adheres to the imposed restrictions placed on it while maintaining a high level of detail, and absence of artifacts. A model with low image quality consistently generates images with large amounts of noise and/or artifacts and incoherent features [
70]. A model’s diversity refers to its range of potential outputs. A model with high diversity can produce a wide spectrum of images while maintaining a constant image quality. A model with low diversity can only generate images in a narrow range with constant image quality [
71]. Leaving this narrow range can lead to significant and rapid decreases in image quality. Controllability refers to the ease with which one can guide the image-generation process with some additional input. For example, if one wanted to generate variations of an image, they could condition the model with an input image to help shape the generated output. A highly controllable model can take into account additional user input, understand the underlying features, and apply those features to the generated image. Training stability refers to the model’s ability to reliably and smoothly converge over the training process.
Within the scope of generative models for image synthesis, Diffusion Models stand out for their ability to produce the highest quality images, often surpassing GANs, which also generate sharp visuals but may not achieve the same level of detail as diffusion-based approaches. VAEs, on the other hand, tend to yield blurrier images, indicating a trade-off in image fidelity. When it comes to diversity, both GANs and Diffusion Models excel at generating a wide variety of outputs, while VAEs can struggle with high variability, limiting their performance in certain applications. In terms of controllability, Diffusion Models offer the most significant level of control over the generation process, allowing for precise adjustments, whereas GANs provide moderate to high control that can vary based on specific architectural choices. However, VAEs exhibit limited tractability, making them less suitable for applications requiring fine-tuned image generation. Lastly, in terms of training stability, VAEs and Diffusion Models are generally more stable during the training process, reducing the likelihood of issues, while GANs often face challenges related to instability and mode collapse, which can hinder their performance and diversity [
72].
Table 3 summarizes aspects about image quality, diversity, controllability and training stability.
Scientific images can present details at different scales and in high-resolution as they are often acquired using advanced instruments, e.g., microscopes. In order to generate valuable synthetic images to augment scientific datasets, image quality is expected to be higher than in other domains, such as art. For example, MRI (Magnetic Resonance Imaging) scans of human brains [
73] must be both detailed and expressly go through the HIPAA (Health Insurance Portability and Accountability Act) guidelines. The ability to generate brain scans with synthetic MRI represents an invaluable opportunity to create more diverse datasets from a few “approved” images, which could be used by researchers to train models [
74,
75,
76]. The challenge with scientific image generation lies in the Controllability or controlling their generation since pre-existent models are typically trained on data dissimilar to specialized imagery such as microscopy data. If one were to just condition on a single cross-section on a standard GAN or Diffusion Model, then the results would likely be suboptimal. Alternatively, training a model from scratch would require a large dataset, which is actually the motivation for using image generation in the first place. Gathering sufficient amounts of data from experimental settings is often difficult, and sometimes impossible, but without the sufficient quantity to minimize bias and reach convergence during training, the models can be useless. Considering the aforementioned strengths, Diffusion Models are expected to exhibit optimal performance in the synthesis of scientific imagery, as they address each of these criteria.
6.2. Selected Models and APIs for Image Generation
To systematically evaluate contemporary generative approaches, we categorize our selected models into three functional domains: (1) image generation from noise or textual input, (2) image translation and semantic variation, and (3) image inpainting with masked guidance. This structure allows us to compare and contrast models not only by task type, but also by underlying architecture—spanning GANs, diffusion-based models, and transformer-based architectures. Our selection aims to provide a representative and balanced overview of the current generative modeling landscape.
(1) Image Generation from Noise or Textual Prompts. This category includes models that generate images from random noise or from scratch using language-based prompts. We study DCGAN and StyleGAN, and DALL-E 2 and DALL-E 3 as state-of-the-art transformer-based text-to-image models. DCGAN serves as a classical baseline, illustrating stable GAN training and low-resolution synthesis. In contrast, StyleGAN showcases advanced GAN capabilities, producing high-resolution, photorealistic images with fine-grained latent space control, which is key for disentangled representation learning. On the transformer side, DALL-E 2 and DALL-E 3 represent autoregressive and diffusion-based text-to-image architectures that operate on powerful image-text joint embeddings. We will refer to these models as DALL-E 2 (generation) and DALL-E 3 (generation), respectively. This category collectively enables us to examine unconditional and prompt-based generation, as well as architectural differences in sampling and representation.
(2) Image Translation and Semantic Variation. Here, we examine models that take an existing image as input and produce a semantically modified version, often guided by language or structural conditioning. This includes diffusion-based models like Stable unCLIP, LEDITS++, and InstructPix2Pix, as well as the transformer-conditioned diffusion framework ControlNet. Stable unCLIP and LEDITS++ translate an input image based on a target prompt, enabling semantic transformations while preserving content. InstructPix2Pix focuses on instruction-driven edits (e.g., "make circles larger"), demonstrating strong alignment with natural language commands. ControlNet adds an extra layer of structure by introducing a secondary conditioning input such as edge maps or segmentation masks (in our use case, the model uses the Canny edges, i.e., the structural cues, to guide full image generation). Its hybrid design enables spatial control combined with textual semantics. We also evaluate DALL-E 2 (variation mode) which creates semantic variations by taking an input image without prompt guidance and to which we will refer to as DALL-E 2 (variation). This category allows us to probe the boundaries of controllability, latent consistency, and editing capacity in diffusion and transformer-enhanced pipelines.
(3) Image Inpainting with Masked Edits. In this final group, the models specialize in localized image editing, where masked regions of an image are filled in, based on surrounding context and semantic prompts. We consider DiffEdit, a diffusion-based mask-aware model, and the DALL-E 2 (edit mode), which supports guided inpainting and to which we will refer to as DALL-E 2 (edit). DiffEdit automatically detects editable regions by contrasting source and target prompts and generating semantic masks, which are refined using a diffusion-based denoising process. DALL-E 2 (edit) allows manual masks and natural language prompts to guide the regeneration of masked areas, ensuring contextual coherence and semantic alignment. These models illustrate the utility of combining image structure and language semantics for fine-grained editing tasks, and they offer insight into localized sampling capabilities within generative frameworks.
Table 4 summarizes models from all three major generative families: GANs (DCGAN, StyleGAN), Diffusion Models (Stable unCLIP, DiffEdit, InstructPix2Pix, ControlNet, LEDITS++), and transformer-based models (DALL-E 2 and 3). By spanning the full range of synthesis tasks, our study provides a comprehensive assessment of how different architectures approach image generation, transformation, and inpainting. This comparative framework enables a deeper understanding of trade-offs in fidelity, controllability, and semantic alignment across model classes.
Regarding computational complexity, Diffusion Models have slower sampling speeds than GANs, but recent advances such as Denoising Diffusion Implicit Models (DDIM) and progressive distillation are helping mitigate runtime while preserving output quality [
77].
7. Experiments with genAI for Scientific Images
Our experiments consist of using experimental images acquired at LBNL facilities and running a variety of genAI algorithms that aim to mimic key properties present in each of those sets. Datasets range from objects with thin regular structures (fibers) to irregular filaments (roots), to bulk materials (rocks), enabling access to the performance of generative tasks across the spectrum of intensities, textures, sizes, and shapes.
Both the
rocks and
fibers datasets are microCT images acquired at the LBNL synchrotron beamline with energies between 10 and 45 keV, with a 1% bandpass, CCD camera Cooke PCO 4000, Kodak chip with 4008 × 2672 pixels, 14 bit, 9 micron square pixels. The image slices come from reconstructions of the parallel beam projection data [
78].
Fibers: These images come from high-resolution imaging, achieved using synchrotron X-ray radiation to probe the fiber structure and integrity, enabling characterization at the micrometer scale. The reconstructed samples from the parallel-beam projection data are image stacks. These samples are composed of Ceramic Matrix Composites (CMCs), a class of materials engineered to enhance toughness and high-temperature performance compared to monolithic ceramics. This enhancement is achieved by incorporating reinforcement fibers within the ceramic matrix. The interplay between these fibers and the matrix, along with the behavior of the interfaces between them, dictates the overall mechanical properties and the material’s degradation pathways under load [
79]. We will refer to this dataset as the
CMC dataset, which contains 937 high-resolution images of shape (2560,2560).
Figure 20 summarizes the experimental results using the selected methods in
Table 4.
Roots: This dataset consists of slices scanned by an automated robotic system called EcoBOT that enables high-throughput scanning of plants in hydroponic systems known as EcoFABs. EcoBOT scans roots using a professional-grade EPSON Perfection V850 Pro scanner for image acquisition. This scanner provides exceptional precision and quality for various media, including paper sheets. Key features include a dual high-resolution lens system (up to 6400 dpi for photos, documents, and 35 mm film/slides) [
80]. We will refer to this dataset as the
EcoFAB dataset, which counts 375 high-resolution images of shape (2039,3000).
Figure 21 shows the experimental results.
Rocks: This dataset comprises microCT scans from samples containing large sediment grains from the Hanford DOE contaminated nuclear site. These sediment grains are contained within a tube, and individual image slices exhibit a visually distinct contrast between the solid grains and the pore space. This dataset has been used for benchmarking segmentation algorithms that separate the pore space from the grains [
81]. This is complicated by the presence of reconstruction artifacts, specifically ring artifacts resulting from the back-projection algorithm. Although the inherent contrast between solid and pore space is good, these artifacts introduce streaks that make segmentation difficult. We will refer to this dataset as the
Rocks dataset, which counts 502 high-resolution images of shape (1813,1830).
Figure 22 presents the experimental results.
Figure 20.
Comparison of image-generation models for the fiber dataset. DCGAN was trained on root images resized to (64,64). DALL-E 2 and DALL-E 3 perform zero-shot image generation from text prompts such as x-ray image of a composite material with deformed circles as cross-sections.
Figure 20.
Comparison of image-generation models for the fiber dataset. DCGAN was trained on root images resized to (64,64). DALL-E 2 and DALL-E 3 perform zero-shot image generation from text prompts such as x-ray image of a composite material with deformed circles as cross-sections.
Figure 21.
Comparison of image-generation models for the root dataset. DCGAN was trained on root images resized to (64,64). DALL-E 2 and DALL-E 3 perform zero-shot image generation from text prompts such as microscopy image of entangled plant root in hydroponic system.
Figure 21.
Comparison of image-generation models for the root dataset. DCGAN was trained on root images resized to (64,64). DALL-E 2 and DALL-E 3 perform zero-shot image generation from text prompts such as microscopy image of entangled plant root in hydroponic system.
Figure 22.
Comparison of image-generation models for the root dataset. DCGAN was trained on rock images resized to (64,64). DALL-E 2 and DALL-E 3 perform zero-shot image generation from text prompts such as microCT scan of rock sample containing large grains.
Figure 22.
Comparison of image-generation models for the root dataset. DCGAN was trained on rock images resized to (64,64). DALL-E 2 and DALL-E 3 perform zero-shot image generation from text prompts such as microCT scan of rock sample containing large grains.
In these experiments, GAN-based models were trained from scratch for each dataset, whereas diffusion-based models were used purely for inference in their pre-trained state without any task-specific fine-tuning. While high-fidelity outputs were not expected under these conditions, the objective was to assess the baseline performance of state-of-the-art image-generation models when applied to scientific imagery. These inference-only evaluations targeted models that accept either a text prompt (commonly utilized for image editing tasks), an input image, or both. For inference models, between 1 to 3 output images were generated per input, resulting in approximately 1000 to 2000 total images per model. In contrast, for GAN-based models trained from scratch, the number of outputs was directly controlled to generate a similar volume of approximately 2000 images. The dataset comprised a diverse set of scientific images, each accompanied by descriptive metadata. For models constrained to fixed input resolutions, cropped regions of the original images were used to maintain visual fidelity.
In terms of HPC resources,
Table 5 provides a comparative summary of computational resources, runtime efficiency, and dataset characteristics for all selected generative models applied to all three image types (CMC, EcoFAB and Rocks). Each table details the model category, GPU configuration, average compiling or inference time, and the number and resolution of images processed. In particular, DCGAN and StyleGAN were trained on each dataset type downsampled or cropped to the appropriate resolutions, whereas API-based models, including DALL-E-based models, were used to perform inference for each high-resolution images. All computations were performed using NVIDIA A100 GPUs. Together, those tables offer insight into the scalability, efficiency, and deployment context of different generative approaches across diverse scientific imaging domains.
7.1. Quantitative and Qualitative Results
Verification and validation (V&V) are critical to ensuring the reliability of generative AI models, especially in scientific domains where hallucinations, dataset biases, and lack of ground truth can lead to misleading outputs. Verification focuses on whether the model meets formal specifications, including unit testing and performance benchmarking. Validation assesses whether generated content aligns with real-world phenomena, often relying on both expert judgment and quantitative metrics. SSIM (Structural Similarity Index) evaluates image similarity based on luminance and structural consistency, offering interpretable scores for low-level fidelity. LPIPS (Learned Perceptual Image Patch Similarity) uses deep neural network embeddings to assess perceptual realism, capturing textural and semantic similarity. FID (Fréchet Inception Distance) compares the distribution of real and generated image features, quantifying global realism and diversity. CLIPScore measures semantic alignment between images and text prompts in a joint embedding space, which makes it particularly relevant for prompt-based generation. SSIM and LPIPS operate on image pairs, offering localized evaluations, while FID and CLIPScore evaluate entire image sets. Together, these metrics capture complementary aspects of quality, enabling robust assessment of generative performance. When combined with domain-specific priors and expert validation, they provide a rigorous foundation for the responsible use of GenAI in science. Further information about these metrics are available in
Appendix D.
Across the three datasets, we observed that pairwise metrics such as SSIM and LPIPS are not fully representative for unconditional generative models like DCGAN, StyleGAN, and text-to-image models such as DALL-E 2 and DALL-E 3. In fact, these models generate images without direct input-output pairs, making structural and perceptual similarity comparisons, with unrelated reference images, less meaningful. Consequently, for these unconditional models, we primarily rely on FID, which assesses the overall distributional similarity and image realism more robustly. In contrast, for pairwise inference models—ControlNet, LEDITS++, DiffEdit, InstructPix2Pix, Stable unCLIP, DALL-E 2 (edit) and DALL-E 2 (variation)—that produce outputs directly conditioned a specific input image, we evaluate performance using the full set of metrics (SSIM, LPIPS, FID, and CLIPScore) to capture both structural fidelity and perceptual quality. This combined evaluation framework ensures a fair and informative comparison tailored to each model’s generation paradigm.
7.2. Results on CMC Dataset
The quantitative evaluation of generative models on the CMC dataset (
Figure 20), presented in
Table 6, reveals clear differences in performance across architectures. Among all models, DiffEdit, DALL-E 2 (edit), and LEDITS++ deliver the best visual results (results in bold in
Table 6), consistent with their strong SSIM, low LPIPS, and low FID scores. DiffEdit notably preserves structural elements, such as the circular fiber boundary, while making targeted edits, reflecting high fidelity and realism. LEDITS++ also maintains structure but introduces a stylized, drawn aesthetic that, while perceptually consistent, sacrifices photorealism.
In contrast, text-to-image DALL-E 2 and 3 (custom prompts), ControlNet, Stable unCLIP, and InstructPix2Pix produce the least realistic outputs. These models often distort key features or generate incoherent and unrealistic edits, which aligns with their poorer LPIPS and FID scores. Interestingly, InstructPix2Pix reports high SSIM but performs poorly visually, indicating it may preserve low-level structure while failing semantically.
CLIPScores are low across all multimodal models—even those generating good images—likely due to CLIP’s poor alignment with scientific image domains like microCT imaging. This underscores the need for domain-adapted embedding models or additional task-specific evaluation metrics. Overall, the combined metrics and visual assessments highlight the strengths of targeted editing models like DiffEdit and the limitations of general-purpose text-to-image systems in scientific contexts.
7.3. Results on EcoFAB Dataset
Table 7 presents each evaluation metric and gives insight on each model’s generative performance for the EcoFAB dataset (
Figure 21). These quantitative results reveal a complex relationship between metric performance and visual quality for this particular set of images. Although DiffEdit reports the best overall scores—highest SSIM, lowest LPIPS, and lowest FID—its outputs are visually flawed, introducing unnatural black or RGB artifacts on the root structure. This highlights a limitation of conventional metrics, which reward structural similarity even when semantic fidelity is compromised. In contrast, StyleGAN produced the most realistic textures and plausible images, despite lower SSIM and higher LPIPS, though its color palette appeared slightly muted. DALL-E 2 (edit) yielded visually convincing edits, closely aligned with the prompts, though it occasionally exaggerated root branching beyond what is biologically plausible.
Text-to-image models like DALL-E 2 and 3 (custom prompts) underperformed both numerically and visually, often generating images unrelated to the target domain, explaining their poor FID and misaligned CLIPScores. Similarly, models such as ControlNet, Stable unCLIP, and InstructPix2Pix failed to preserve the spatial structure or semantics of the original images, despite moderate scores in some metrics. This mismatch between metrics and actual utility further underscores the limitations of general-purpose evaluation tools like CLIPScore, particularly in scientific domains like EcoFAB, where domain-specific structure and realism are critical.
7.4. Results on Rocks Dataset
The quantitative evaluation on the Rocks dataset (
Figure 22), presented in
Table 8, reveals diverse model performances with clear strengths and weaknesses. DALL-E 2 (edit) achieves the best overall balance, exhibiting high SSIM, low LPIPS, and low FID, indicating strong structural preservation, perceptual similarity, and semantic alignment. Visually, it produces realistic edits that maintain the original image’s content well. DiffEdit scores well on metrics but visually shows minimal structural changes, preserving the input almost identically while introducing some minor unrealistic artifacts, highlighting a disconnection between metric scores and meaningful edits. LEDITS++ offers strong perceptual quality and realism with low FID and LPIPS, though it exhibits slight stylization, suggesting some deviation from strict realism. StyleGAN generates realistic textures, as reflected in its favorable FID.
Conversely, InstructPix2Pix performs poorly visually, introducing many unrealistic colored artifacts, despite moderate quantitative metrics. DALL-E 2 (variation) generates visually realistic images but fails to maintain the original input structure, which reduces its applicability for structure-sensitive tasks. Similarly, Stable unCLIP exhibits weak structural and perceptual consistency with inputs, resulting in poor visual fidelity and moderate metric performance. Models like ControlNet and DALL-E 3 (custom prompt) also struggle to preserve input semantics and produce plausible outputs.
Overall, the results highlight that while editing-focused models like DALL-E 2 (edit) provide the best combination of realism and semantic alignment, many generative models still face challenges preserving fine structural details, especially in domain-specific scientific images.
8. Summary and Discussion
The quantitative and qualitative evaluation of GAN-based and diffusion-based generative models across three scientific datasets—CMC, EcoFAB, and Rocks—reveals consistent trends in model performance and challenges specific to scientific image generation. Editing-focused Diffusion Models such as DiffEdit, DALL-E 2 (edit), and LEDITS++, in terms or quantitative results, consistently achieve the best balance of structural fidelity, perceptual quality, and semantic alignment, as reflected in strong SSIM, low LPIPS, and favorable FID scores. However, visual inspection highlights limitations even in top performers: DiffEdit often preserves input structures almost identically but introduces minor unrealistic artifacts, while LEDITS++ shows stylized but less photorealistic outputs.
GAN-based models like StyleGAN generate realistic textures and plausible images, yet their metrics (SSIM, LPIPS) may not fully capture their performance due to the lack of direct input-output pairing, highlighting the limitations of pairwise similarity metrics in unconditional generation scenarios. Notably, models that emphasize realism over diversity, such as StyleGAN or editing models like DALL-E 2 (edit), seem particularly well-suited for applications like slice interpolation or volumetric reconstruction, where generating structurally consistent intermediate slices is essential.
Text-to-image models, including DALL-E 2 and DALL-E 3 with custom prompts, generally underperform both numerically and visually, frequently producing outputs that stray from the target domain or fail to preserve input structure and follow prompt instruction or description. Similarly, models such as ControlNet, Stable unCLIP, and InstructPix2Pix struggle to maintain semantic and spatial consistency, resulting in incoherent or artifact-laden outputs despite sometimes moderate metric scores. In fact, high SSIM or CLIPScores do not always correlate with visual realism or meaningful edits in scientific contexts, indicating a need for domain-adapted evaluation metrics.
The experimental outcomes are primarily shaped by the inherent strengths and limitations of each generative model architecture when applied to scientific image synthesis. Diffusion Models excel in image quality, controllability, and training stability, which allows them to produce highly detailed and structurally faithful images across diverse scientific datasets. Meanwhile, GAN-based models generate sharp and realistic visuals with notable diversity, but often struggle in stability and sometimes lack structural consistency in scientific contexts due to limited controllability and the absence of explicit conditioning mechanisms. Text-to-image models face challenges in scientific applications as their language and vision encoders are typically trained on general content, leading to issues such as semantic drift and poor retention of domain-specific details, which in turn affect output fidelity despite occasionally favorable quantitative metrics. Collectively, these outcomes reflect the broader theoretical understanding that model architecture, controllability, and training objectives directly translate to performance trade-offs in scientific image generation, especially regarding detail preservation, diversity, and alignment with user intent or specialized scientific features.
Despite some success, these generative models sometimes fail to capture domain-specific scientific fidelity due to fundamental limitations in their multi-modal architecture. In text to image and instruction-based models (which in this case includes models such as DALL-E 2, Stable unCLIP, ControlNet and InstructPix2Pix), the CLIP-based text-encoders or similar text encoders are originally trained on web images and lack tuning to scientific language and scientific visual details. In that sense, such misalignment lead to poor semantic guidance, where prompts referencing domain-specific features (e.g., “microCT slice”, “plant roots”, or “composite material”) are either misinterpreted or ignored during generation, resulting in outputs that deviate from scientifically accurate representations. This is called semantic drift, where generated images follow the form of the prompt without maintaining scientific accuracy and fidelity.
Similarly, in image-to-image models, the visual encoders are typically pretrained on natural image datasets (e.g., ImageNet) and not adapted to scientific domains like microCT or high-resolution images of biological components. As a result, they fail to capture or prioritize fine-grained, structurally meaningful details that are essential in scientific imaging tasks—such as cellular boundaries, mineral textures, or biological symmetries. This lack of domain-specific training undermines the model’s ability to generate or edit content with the necessary precision, even when quantitative scores appear adequate.
These challenges can be potentially mitigated through targeted fine-tuning strategies or by leveraging reinforcement learning techniques such as Reinforcement Learning with Human Feedback (RLHF) to better align generative models with domain-specific structural and semantic requirements. Additionally, integrating domain-specific prompt alignment methods, for example, leveraging contrastive learning between scientific image features and tailored textual descriptors, can improve semantic guidance during generation. Methods like Prompt Tuning with Domain-Adaptive Embeddings—where embeddings are adapted or learned specifically on scientific datasets—could enable models to better interpret and generate relevant content from specialized prompts.
Overall, while diffusion-based editing models currently set the benchmark for generating scientifically meaningful images, advancing fine-tuning strategies and developing domain-specific alignment mechanisms will be necessary to overcome existing limitations and enhance multi-modal generative AI performance for scientific image synthesis, in particular in application areas such as materials science imaging.
Building upon the success of generative Diffusion Models in biomedical imaging, ranging from AdaDiff’s ability to overcome domain shifts in MRI reconstruction [
82] to unsupervised domain adaptation frameworks for multi-organ segmentation [
83], our work takes a complementary approach. Instead of using yet another biomedical dataset, we explore the untapped potential of these methods in energy-centric science. This allows us to investigate their performance and adaptability in a new domain characterized by unique challenges like modality heterogeneity, fine-scale structures, and data scarcity, particularly given the limited to no representation of this data over the web.
9. Conclusions and Future Directions
The future of text-to-image and image-to-image technologies promises significant advancements, with profound implications across diverse fields, notably scientific data analysis. We can anticipate continuous refinements in Diffusion Models, leading to hyper-realistic image generation coupled with increasingly granular control over specific attributes and detail. The expectation is that AI models will enable deeper understanding of contextual relationships, and the production of more nuanced and precise visual representations. Additionally, ongoing optimization of algorithms and hardware will yield faster generation times and reduced computational costs, while cloud-based platforms and mobile applications could democratize access to these technologies. A significant trend is the rapid progression of light-weight multimodal models [
84,
85], with potential improvements in quality and coherence, particularly taking advantage of high-performance computer systems. Finally, AI will increasingly personalize image generation, learning individual user preferences to produce highly tailored visual outputs.
The impact of these technologies on scientific data analysis, particularly with scarce image sets from specialized instruments, will be transformative. AI-driven data augmentation promises to enable the generation of synthetic data to supplement limited datasets, enhancing the training of machine learning models for critical tasks like image segmentation and object detection. In addition, AI will translate abstract scientific data into intuitive visual representations, facilitating the identification of patterns and trends in fields such as genomics and materials science. By generating visual representations of potential scenarios, AI will assist scientists in formulating hypotheses and designing experiments, such as simulating molecular interactions or astronomical phenomena. AI can also be used to identify and rectify errors in scientific images, improving the accuracy and reliability of data analysis. Furthermore, AI will encourage increased collaboration by creating easily understandable visual representations of data for various scientific audiences.
Despite the immense potential, challenges remain. AI models can inherit biases from training data, leading to inaccurate results, which requires careful attention to dataset representativeness. The “black box” nature of some AI models poses challenges to interpretability, requiring efforts to develop more transparent models for scientific applications. Crucially, validation of AI-generated results against experimental data and established scientific principles is essential, especially when dealing with scarce datasets, to ensure the responsible and successful application of these powerful tools.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}