2. Related Works
Currently, efficient and secure facial recognition is an important guarantee for online identity verification. Faced with various scenarios, many researchers have studied and improved facial recognition technology. Srivastava G et al. [
5]. proposed a modern data-driven marketing approach based on facial recognition and neuromarketing. The uniqueness of this study lies in providing the latest review of neuromarketing and facial recognition marketing, filling a gap that has not been fully studied in these two fields. Komagal E et al. [
6]. proposed a student engagement analysis method based on facial expressions. In this method, multiple faces in a classroom were detected quickly and accurately through the You Only Look Once (YOLO) detector, and a robust constrained local model integration method was adopted to provide feature location for the occluded faces themselves. The system is capable of identifying behavioral activities such as concentration, non-concentration, daydreaming, napping, playing with personal items, and talking to students behind. Chen et al. [
7]. proposed a lightweight face recognition algorithm to reduce the complexity of the facial feature extraction network in response to the problem of excessive parameters and computational load in facial recognition applications. The algorithm was implemented and optimized on the Jetson Nano embedded platform, enabling the face recognition system to achieve precise and real-time deployment. The system takes 37 milliseconds to complete the entire facial detection and recognition and has good robustness against complex backgrounds and illumination changes. Zhang W et al. [
8]. proposed a facial expression recognition algorithm based on an improved residual neural network for the problems of network performance degradation and feature information loss in facial expression recognition. By achieving high recognition accuracy on two public datasets, the problems of reduced network performance and insufficient feature information were effectively solved. Xiao et al. [
9]. found that deep cell NNs are susceptible to adversarial patch attacks. To address the security issues of face recognition models based on deep NNs, they proposed an adversarial patch model on regularized low-dimensional data manifolds. It used facial features as adversarial perturbations. After pre-training, it exhibited better transferability compared to other similar facial recognition models and also had certain advantages in recognition accuracy.
Shang L et al. [
10]. proposed a unified uncertainty modeling and face recognition (FR) framework to address data uncertainty in the face recognition process. This framework adjusted the learning intensity of clean and noisy samples to improve data perception ability, showing higher performance than other models and advantages in construction cost. Due to COVID-19, wearing masks has posed challenges for face recognition. In response, Hariri W [
11]. developed a method based on occlusion removal and deep learning features, which removed occluded parts and focused on extracting features of the eyes and forehead for classification using multi-layer perceptrons. This method demonstrated a higher recognition rate and reliability compared to advanced techniques. Qiu H et al. [
12]. introduced a new end-to-end deep neural network model to address the recognition of occluded facial images, extracting damaged features through deep convolution and using dynamic simulation for recovery, achieving significant success on datasets like Megaface Challenge 1 and showing promise for general FR applications. Zhang L et al. [
13]. found that different regions of the human face impact recognition and proposed an attention-aware facial recognition model based on deep neural networks and reinforcement learning, which utilized attention and feature networks and achieved good results in public facial verification databases, thus confirming its feasibility. Terhörst P et al. [
14]. highlighted the significant impact of facial recognition on key decisions, summarizing the effects of 47 attributes on two mainstream FR systems. They proposed an improved approach to FR technology, demonstrating its effectiveness in reducing bias.
Zhang K et al. [
15]. addressed the blur problem in image restoration by proposing a comprehensive literature review on deep learning image deblurring methods, discussing common causes of image blur, baseline datasets, performance indicators, and various problem representations. They classified and reviewed convolutional neural network (CNN) methods in detail based on architecture, loss functions, and applications. To tackle the challenges of spatial and temporal feature modeling due to video blur from camera shake or target motion, they introduced a deblurring network (DBLRNet) that utilizes 3D convolution for improved video deblurring performance. They further integrated DBLRNet into a generative adversarial network (GAN) architecture, employing a combination of content loss and adversarial loss for efficient training. Experimental results demonstrated that this GAN approach achieved state-of-the-art performance on two standard benchmark datasets [
16]. Their work highlighted that deep learning methods, particularly CNNs, offer new solutions for deblurring by effectively capturing spatial and temporal features, enhancing feature extraction through 3D convolution. The integration of DBLRNet into the GAN framework also showcased the potential for improved blurry image recovery, using adversarial training to optimize image quality while reducing the degradation of fine-grained features that is often inherent in traditional models. To sum up, current research mostly focuses on a single technology or method, such as convolutional neural networks (CNNs), but lacks a comparative analysis of the effectiveness of different technologies in dynamic environments to illustrate the necessity of adversarial learning. Furthermore, most studies have failed to explore the limitations faced in dealing with blurred images and occlusions, which seriously affect recognition accuracy. Therefore, in order to alleviate the problem of low recognition accuracy in the case of blurred images and occlusion, this research introduces a GAN and combines deblurring processing, aiming to enhance the recognition ability of facial features in complex scenes, improve the accuracy and robustness of face recognition, and cope with increasingly complex domain challenges.
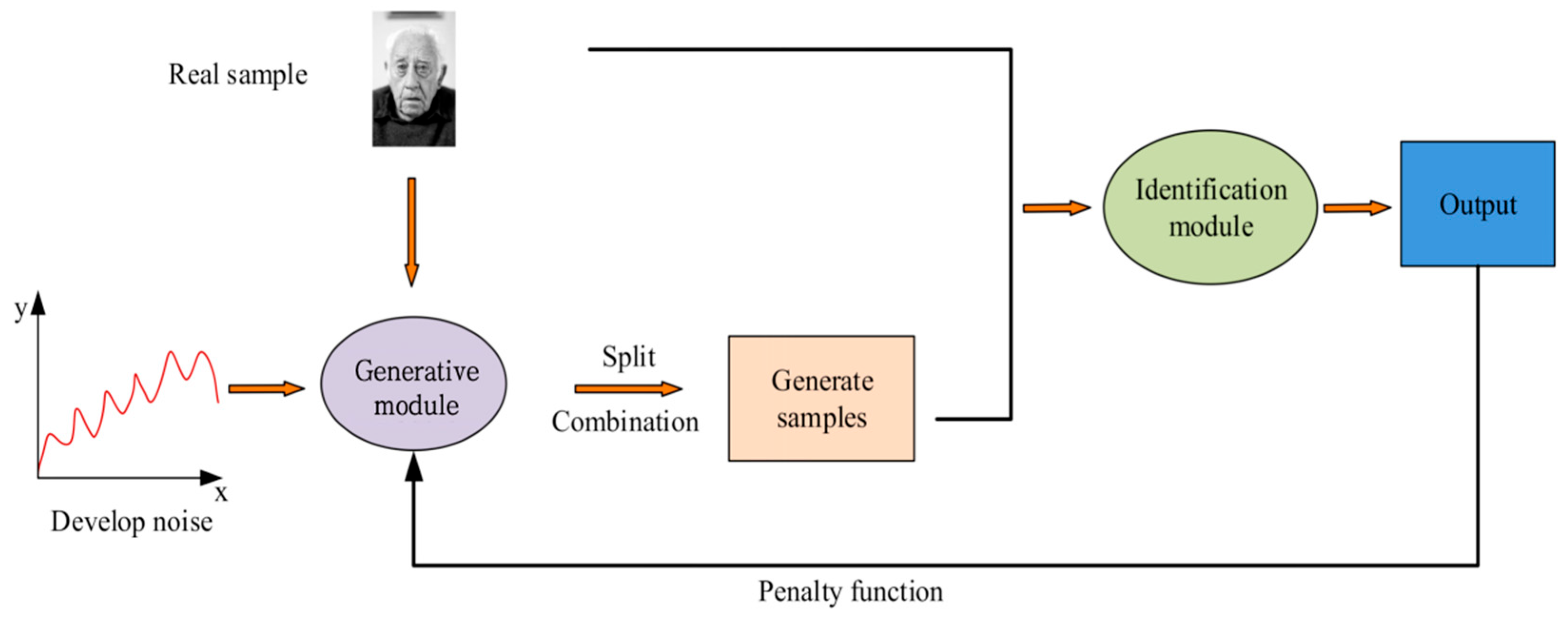
4. Performance Verification of Adversarial Learning Face Recognition Model with Fusion Deblurring Processing
The device used was a desktop computer with 16GB of running memory, i7-13700K CPU, and a GeForce GTX 470 graphics card. The system resource was Windows 10. The software resource was JavaSE. The datasets used for training and testing included YTF, IMDB WIKI, and WiderFace. YTF is a large-scale video dataset for facial recognition and verification, consisting primarily of facial images from YouTube videos. The dataset consists of 3,000 video clips of 341 different identities, each with a different number of facial images and their expressions, poses, and shooting angles, giving the dataset significant advantages in terms of diversity and complexity. YTF is particularly suitable for evaluating the performance of facial recognition algorithms in dynamic scenes and non-static states, while demonstrating the challenges of facial blurring, lighting changes, and occlusion in video. Imdb-wiki is a massive facial dataset, collected by both IMDB and WIKI, containing more than 500,000 facial images and covering multiple age groups and genders. The images are primarily used for age estimation and gender classification studies, and the labels included in the dataset make it suitable for training and testing multiple facial recognition and analysis models. WiderFace is a dataset dedicated to face detection that contains 32,203 images covering faces in a variety of complex scenarios, especially those taken in natural environments. There are more than 400,000 face instances labeled in this dataset, which includes a variety of facial gestures, occlusion degree, and lighting conditions, making the evaluation of algorithm performance more challenging and practical. When conducting model training and validation using datasets such as YTF, IMDB-WIKI and WiderFace, attention should be paid to potential dataset bias issues. For example, there may be insufficient representation of age, gender or race in the datasets, resulting in a decline in the model’s recognition ability among certain populations. Furthermore, the differences in image quality, acquisition conditions, and environmental diversity may also affect the robustness of the model. To address these biases, the research adopted data augmentation strategies, such as incorporating techniques like rotation, scaling, and color transformation during the training process to increase the diversity of samples. Moreover, cross-validation was conducted by fusing different datasets, thereby enhancing the generalization ability and fairness of the model.
In this research, the implementation details of the model included multiple important hyperparameter settings and the arrangement of the training cycle to ensure the optimization of its performance. Hyperparameters such as the learning rate, batch size, and the network structure of the generator and discriminator were all strictly adjusted. The learning rate was set to an initial value of 0.0002, and a dynamic adjustment strategy was adopted to adapt to different training stages. The batch size was set to 64 to balance computational efficiency and the rate of loss convergence. The training cycle was set at 50 cycles. Each cycle included real-time validation for the YTF, IMDB-WIKI and WiderFace datasets to ensure that the model can provide timely feedback and adjust the strategy during the training process to avoid overfitting. Meanwhile, data augmentation techniques, such as random cropping and rotation, were also introduced to increase the diversity of training samples, thereby further enhancing the generalization ability and robustness of the model.
To verify the region selection, segmentation, and recognition performance of this model, this study randomly selected a facial image as the input for DE-I-GAN. In
Figure 6, the effectiveness of the DE-I-GAN model in facial localization and segmentation is demonstrated. By inputting specific facial images, the model can accurately identify the positions of facial feature points such as eyes, nose and mouth, indicating its strong adaptability in dynamic and complex scenes. Compared with I-GAN and GAN, DE-I-GAN significantly improves the positioning accuracy of feature points, reflecting the effectiveness of its optimization strategy for blurred and dynamic image problems.
Facial recognition requires real-time implementation, so the model recognition speed must be very fast. To test the DE-I-GAN recognition speed, this study used I-GAN and GAN as controls. A total of 100 images with 720 × 720, 360 × 360, and 180 × 180 pixels each were selected as inputs from WiderFace and IMDB-WIKI.
Figure 7 records the average output time required by DE-I-GAN, I-GAN and GAN when processing the same image size. The results show that DE-I-GAN exhibits shorter processing times than I-GAN and GAN when dealing with 720 × 720, 360 × 360, and 180 × 180-pixel images, which are 70.01 s, 60.26 s, and 47.16 s, respectively. This indicates that DE-I-GAN has made significant progress in optimizing computational efficiency and is more suitable for scenarios that require rapid response and real-time processing. In contrast, there is no significant difference in the response time between I-GAN and GAN under the same conditions, indicating the deficiency in their training strategies. Therefore, DE-I-GAN not only improves the recognition accuracy, but also increases the processing speed, making it more capable of meeting the requirements of practical applications.
To verify the deblurring effect of DE-I-GAN, images with blur parameters of 0.8 and 0.4 in the YTF dataset were selected as inputs in
Figure 8.
Figure 8 provides a comparison of DE-I-GAN, I-GAN, and GAN in terms of deblurring. For the image with a blurring parameter of 0.8, the blurring degree of the output image of DE-I-GAN is reduced to 0.173, which is significantly better than 0.226 (I-GAN) and 0.360 (GAN). When the blurring parameter is 0.4, the blurring degree output by DE-I-GAN is also relatively low, indicating that it has a stronger deblurring ability under high blurring conditions. This result emphasizes the effectiveness of the DE-I-GAN-integrated deblurring technology, enabling the recovery of relatively clear facial feature information even when the input image quality is poor.
In
Figure 9, the ROC curve shows the true positive case rate and false positive case rate of different models on the YTF dataset. The ROC curve of DE-I-GAN rapidly approached a 100% true positive case rate, demonstrating its high sensitivity and accuracy in recognizing facial images. In contrast, the curves of I-GAN and GAN show a relatively slow upward trend, indicating that their responses are not rapid enough when processing face images with background interference or blurriness. This further verifies the superiority demonstrated by DE-I-GAN in dynamic scenes.
Figure 10 shows the varied relationship between the training time and accuracy of DE-I-GAN, I-GAN and GAN on the WiderFace and IMDB-WIKI datasets. In the WiderFace dataset, DE-I-GAN can converge rapidly, and the accuracy rate eventually reaches 81.06%, which is significantly higher than the results of the other two models. This indicates that DE-I-GAN achieves a better classification performance while maintaining a lower training time. In IMDB-WIKI, although the convergence time of DE-I-GAN is slightly longer than that of I-GAN, its accuracy rate still remains at 79.77, demonstrating the stronger stability and consistency of the model. Overall, DE-I-GAN demonstrates higher training efficiency and recognition ability, indicating that it has broader prospects in practical applications.
In
Figure 11, the recall rates of each model on the YTF dataset are compared in detail. The results show that the average recall rate of DE-I-GAN is 87.40%, which is significantly higher than that of I-GAN and GAN. This high recall rate means that DE-I-GAN has a relatively high success rate in recognizing facial features, thereby reducing the probability of missed detection, and is suitable for application scenarios with high requirements for recognition accuracy. In contrast, the recall rates of I-GAN and GAN are relatively low, reflecting their insufficient identification ability in complex environments. This result further indicates the advantages of DE-I-GAN under dynamic and fuzzy conditions and is suitable for practical application fields such as monitoring and security.
Figure 12 shows the F1 value performance of DE-I-GAN, I-GAN, and GAN during the training process, which were tested on the WiderFace and IMDB-WIKI datasets, respectively. The F1 value of DE-I-GAN outperformed other control models on both datasets, reaching 96.17% on WiderFace. The increase in the F1 value shows that DE-I-GAN achieved a better balance between precision and recall, demonstrating its superior overall performance in complex facial recognition tasks.
Table 1 verifies the validity of each component of the model through ablation experiments. The basic GAN model performed inadequately in fuzzy image processing (with an average recall rate of 70.35% and an F1 value of 80.11%). The indicators improved after the introduction of the improved GAN (recall rate 74.10%, F1 value 84.20%). The performance was significantly enhanced after combining the feature pyramid (recall rate 80.55%, F1 value 90.32%). After adding the deblurring technology, the indicators continued to improve (recall rate 82.05%, F1 value 92.18%). The complete model (feature pyramid + deblurring + improved GAN) achieved the optimal effect. The average recall rate was 87.40%; the accuracy rates of IMDB-WIKI/WiderFace reached 81.06%/79.77%, respectively; and the F1 value was 96.17%, which proved that the synergy of each component was significant. Among them, the feature pyramid and deblurring technology made a key contribution to the performance improvement. To further verify the feasibility of the proposed method, a comparative analysis was conducted between the Dual Variational Generative Face (DVG-Face) model and the Adaptive Robust Face (ARFace). The experiment selected a high-resolution deblurring dataset. The sample pixels of the dataset were 720×1280, and it was used to test dynamic blur restoration. The evaluation indicators include peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), floating-point operation cost (FLOPs), memory usage, deblurring computing cost (proportion of additional FLOPs), and interceptor analysis (convergence time). The specific results are shown in
Table 2.
Table 2 presents the feasibility analysis results of different models on high-resolution deblurring datasets. Through comparison, DE-I-GAN achieved a peak signal-to-noise ratio (PSNR) of 29.7 ± 0.3 dB, significantly higher than 28.1 ± 0.4 dB of DVG-Face and 25.6 ± 0.5 dB of ARFace, indicating that DE-I-GAN has more advantages in image quality. Meanwhile, in the structural similarity index (SSIM), the 0.921 of DE-I-GAN is also superior to the other two models, further indicating its effectiveness in preserving the image structure. In terms of performance indicators, although the floating-point operation capacity (FLOPs) of DE-I-GAN is 45.2 G (which is lower than 68.7 G of DVG-Face but higher than 52.4 G of ARFace), the memory usage of 3.8 GB is also less than that of DVG-Face (5.2 GB) and ARFace (4.5 GB). It is worth noting that the proportion of additional FLOPs of DE-I-GAN is 0.15%, which is relatively low, demonstrating its efficiency in terms of the cost of deblurring computing. Finally, its convergence time of 8.2 h is also superior to the 12.5 h of DVG-Face and the 10.1 h of ARFace, highlighting the advantages of DE-I-GAN in overall training and execution efficiency. These results indicate that DE-I-GAN exhibits stronger throughput capacity and a superior image-processing effect in the dynamic blur restoration task, providing strong support for its feasibility in practical applications. To test the effect of this research method in solving the global optimal constraint, this study introduced the genetic algorithm (GA) and the particle swarm optimization algorithm (PSO) for comparison. The results are shown in
Table 3.
Table 3 shows the influence of different optimization algorithms on the model effect. When the batch size of the original DE-I-GAN model was 32, the PSNR was 29.7 ± 0.3 dB, the SSIM was 0.921, and the convergence time was 8.2 h. After introducing the genetic algorithm (GA), when the batch size of the GA-DE-I-GAN model was 64, the PSNR increased to 32.5 ± 0.2 dB, the SSIM rose to 0.935, and the convergence time shortened to 6.5 h, showing a significant performance improvement. In contrast, the PSO-DE-I-GAN optimized by particle swarm optimization (PSO) has a PSNR of 31.7 ± 0.4 dB and an SSIM of 0.925 when the batch size is 56. Although it performs well, it does not achieve the effect of GA-DE-I-GAN. The results show that the introduction of GA and PSO optimization algorithms effectively improves the model performance and convergence ability.
Overall, the proposed model has high detection accuracy and stable F1 and can also achieve ideal results in the processing of blurred images. Therefore, it has a promoting effect on the development of fuzzy facial recognition and has a positive impact on the development of the facial recognition industry.
In the experimental results presented above, the research method addresses the issues of traditional GAN gradient vanishing and mode collapse by accelerating the generator’s convergence during training. This significantly enhances the quality of the generated output images and prevents the variance from diminishing due to the discriminator’s strength. After the training, the diversity and realism of the generated images are improved, and data samples that are close to reality can be generated more effectively. Aiming to alleviate the problem of poor fuzzy image processing, a defuzzy processing module is introduced, which focuses on improving the quality of fuzzy images. The test results show that on the YTF dataset, the model can significantly enhance the recognition rate of fuzzy images, and the accuracy of images with a high degree of fuzziness can be significantly improved after processing.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}