
E-InMeMo: Enhanced Prompting for Visual In-Context Learning †

 , ,
, ,  , , and
, , and
Abstract
1. Introduction
- We introduce a new strategy to apply learnable prompt directly to the in-context pair, with strong robustness.
- We remove the need for resizing the in-context pairs, and thus reducing trainable parameters from 69,840 to 27,540.
- We validate E-InMeMo’s consistent outperformance across diverse datasets, including natural and medical images. Furthermore, we present comprehensive experiments to highlight E-InMeMo’s robustness and generalizability.
2. Related Work
2.1. In-Context Learning
2.2. Learnable Prompting
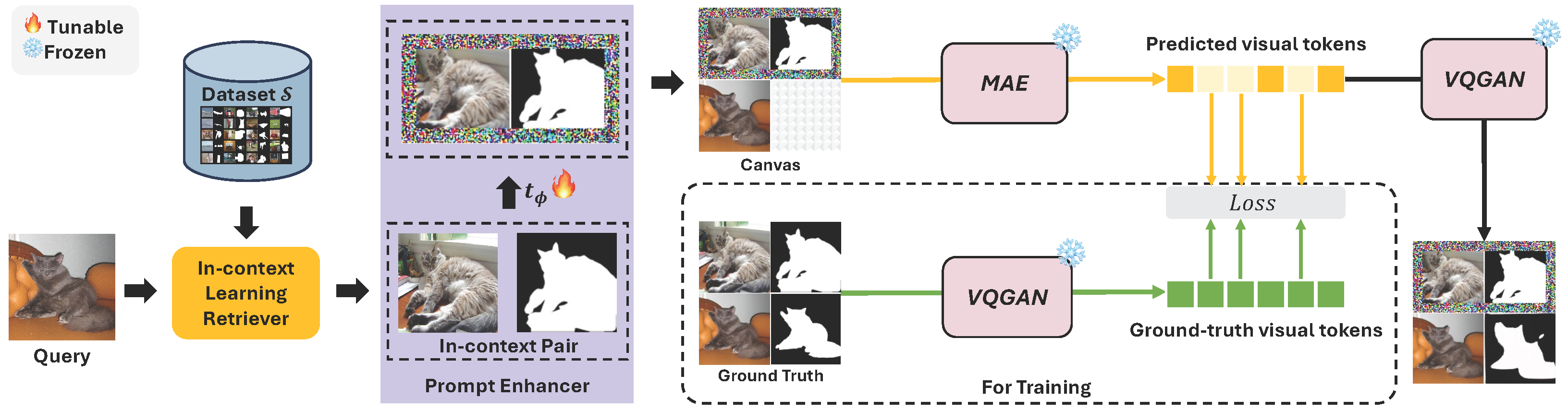
3. Method
3.1. Preliminary: MAE-VQGAN
3.2. Overview of E-InMeMo
3.3. In-Context Learning Retriever
3.4. Prompt Enhancer
3.5. Prediction
3.6. Training
3.7. Interpretation
4. Experiments
4.1. Experimental Setup
- Random [15] means randomly retrieves in-context pairs from the training set.
- UnsupPR [16] uses CLIP as the feature extractor to retrieve in-context pairs based on features after the classification header.
- SupPR [16] introduces contrastive learning to develop a similarity metric for in-context pair selection.
- SCS [65] proposes a stepwise context search method to adaptively search the well-matched in-context pairs based on a small yet rich candidate pool.
- Partial2Global [66] proposes a transformer-based list-wise ranker and ranking aggregator to approximately identify the global optimal in-context pair.
- Prompt-SelF [18] applies an ensemble of eight different prompt arrangements, combined using a pre-defined threshold of voting strategy.
- FMLR (CLIP) means to utilizes CLIP as the feature extractor for feature-map- level retrieval.
- FMLR (DINOv2) utilizes DINOv2 as the feature extractor for feature-map-level retrieval.
4.2. Comparison with State-of-the-Art
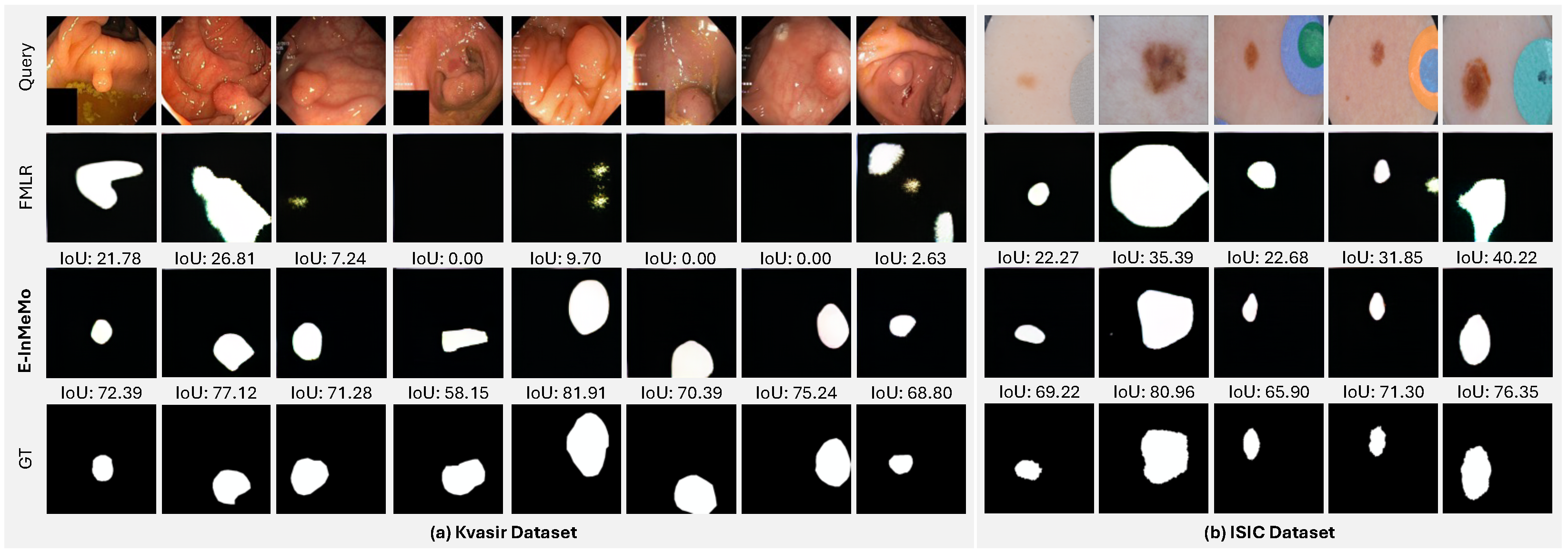
4.3. Results on Medical Datasets
4.4. Domain Shifts Analysis
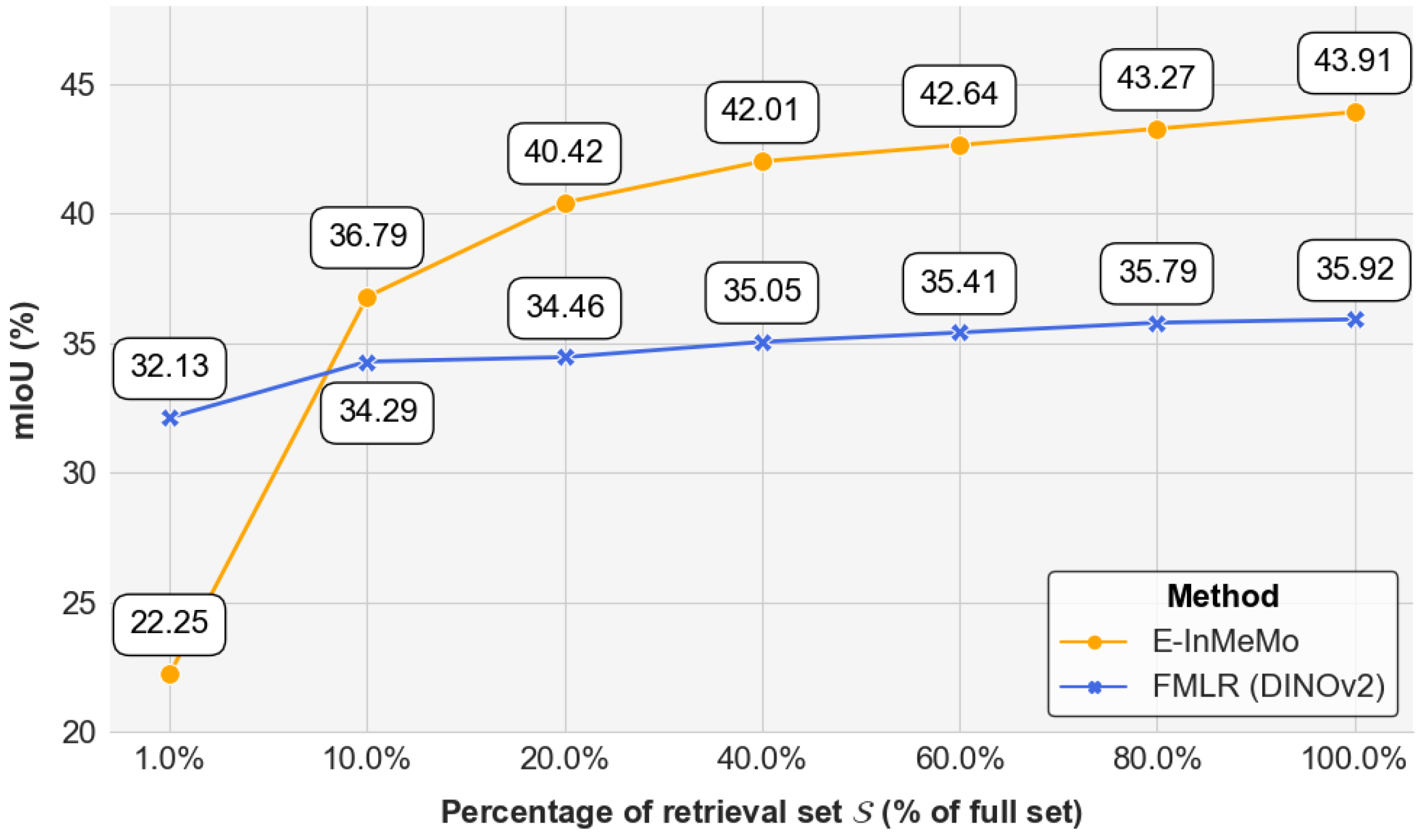
4.5. Further Analyses on E-InMeMo
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- GPT-4o. Available online: https://openai.com/index/hello-gpt-4o/ (accessed on 21 February 2025).
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Rubin, O.; Herzig, J.; Berant, J. Learning to retrieve prompts for in-context learning. arXiv 2021, arXiv:2112.08633. [Google Scholar]
- Gonen, H.; Iyer, S.; Blevins, T.; Smith, N.A.; Zettlemoyer, L. Demystifying prompts in language models via perplexity estimation. arXiv 2022, arXiv:2212.04037. [Google Scholar]
- Wu, Z.; Wang, Y.; Ye, J.; Kong, L. Self-adaptive in-context learning. arXiv 2022, arXiv:2212.10375. [Google Scholar]
- Sorensen, T.; Robinson, J.; Rytting, C.M.; Shaw, A.G.; Rogers, K.J.; Delorey, A.P.; Khalil, M.; Fulda, N.; Wingate, D. An information-theoretic approach to prompt engineering without ground truth labels. arXiv 2022, arXiv:2203.11364. [Google Scholar]
- Honovich, O.; Shaham, U.; Bowman, S.R.; Levy, O. Instruction induction: From few examples to natural language task descriptions. arXiv 2022, arXiv:2205.10782. [Google Scholar]
- Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N.A.; Khashabi, D.; Hajishirzi, H. Self-instruct: Aligning language model with self generated instructions. arXiv 2022, arXiv:2212.10560. [Google Scholar]
- Min, S.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Noisy channel language model prompting for few-shot text classification. arXiv 2021, arXiv:2108.04106. [Google Scholar]
- Zhang, J.; Yoshihashi, R.; Kitada, S.; Osanai, A.; Nakashima, Y. VASCAR: Content-Aware Layout Generation via Visual-Aware Self-Correction. arXiv 2024, arXiv:2412.04237. [Google Scholar]
- Wang, B.; Chang, J.; Qian, Y.; Chen, G.; Chen, J.; Jiang, Z.; Zhang, J.; Nakashima, Y.; Nagahara, H. DiReCT: Diagnostic Reasoning for Clinical Notes via Large Language Models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024; Volume 37, pp. 74999–75011. [Google Scholar]
- Bar, A.; Gandelsman, Y.; Darrell, T.; Globerson, A.; Efros, A. Visual prompting via image inpainting. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 25005–25017. [Google Scholar]
- Zhang, Y.; Zhou, K.; Liu, Z. What Makes Good Examples for Visual In-Context Learning? In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2023; Volume 36, pp. 17773–17794. [Google Scholar]
- Wang, X.; Wang, W.; Cao, Y.; Shen, C.; Huang, T. Images speak in images: A generalist painter for in-context visual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6830–6839. [Google Scholar]
- Sun, Y.; Chen, Q.; Wang, J.; Wang, J.; Li, Z. Exploring Effective Factors for Improving Visual In-Context Learning. arXiv 2023, arXiv:2304.04748. [Google Scholar] [CrossRef] [PubMed]
- Bahng, H.; Jahanian, A.; Sankaranarayanan, S.; Isola, P. Exploring visual prompts for adapting large-scale models. arXiv 2022, arXiv:2203.17274. [Google Scholar]
- Chen, A.; Yao, Y.; Chen, P.Y.; Zhang, Y.; Liu, S. Understanding and improving visual prompting: A label-mapping perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 19133–19143. [Google Scholar]
- Oh, C.; Hwang, H.; Lee, H.y.; Lim, Y.; Jung, G.; Jung, J.; Choi, H.; Song, K. BlackVIP: Black-Box Visual Prompting for Robust Transfer Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 24224–24235. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.N. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 709–727. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Elsayed, G.F.; Goodfellow, I.; Sohl-Dickstein, J. Adversarial reprogramming of neural networks. arXiv 2018, arXiv:1806.11146. [Google Scholar]
- Neekhara, P.; Hussain, S.; Du, J.; Dubnov, S.; Koushanfar, F.; McAuley, J. Cross-modal adversarial reprogramming. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2427–2435. [Google Scholar]
- Zhang, J.; Wang, B.; Li, L.; Nakashima, Y.; Nagahara, H. Instruct me more! random prompting for visual in-context learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2024; pp. 2597–2606. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Wu, Z.; Chang, B.; Sun, X.; Xu, J.; Sui, Z. A survey for in-context learning. arXiv 2022, arXiv:2301.00234. [Google Scholar]
- Liu, J.; Shen, D.; Zhang, Y.; Dolan, B.; Carin, L.; Chen, W. What Makes Good In-Context Examples for GPT-3? arXiv 2021, arXiv:2101.06804. [Google Scholar]
- Lu, Y.; Bartolo, M.; Moore, A.; Riedel, S.; Stenetorp, P. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. arXiv 2021, arXiv:2104.08786. [Google Scholar]
- Winston, P.H. Learning and reasoning by analogy. Communications of the ACM 1980, 23, 689–703. [Google Scholar] [CrossRef]
- Sun, T.; Shao, Y.; Qian, H.; Huang, X.; Qiu, X. Black-box tuning for language-model-as-a-service. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 20841–20855. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Min, S.; Lewis, M.; Zettlemoyer, L.; Hajishirzi, H. Metaicl: Learning to learn in context. arXiv 2021, arXiv:2110.15943. [Google Scholar]
- Kim, H.J.; Cho, H.; Kim, J.; Kim, T.; Yoo, K.M.; Lee, S.g. Self-generated in-context learning: Leveraging auto-regressive language models as a demonstration generator. arXiv 2022, arXiv:2206.08082. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 24824–24837. [Google Scholar]
- Press, O.; Zhang, M.; Min, S.; Schmidt, L.; Smith, N.A.; Lewis, M. Measuring and narrowing the compositionality gap in language models. arXiv 2022, arXiv:2210.03350. [Google Scholar]
- An, S.; Lin, Z.; Fu, Q.; Chen, B.; Zheng, N.; Lou, J.G.; Zhang, D. How Do In-Context Examples Affect Compositional Generalization? arXiv 2023, arXiv:2305.04835. [Google Scholar]
- Hosseini, A.; Vani, A.; Bahdanau, D.; Sordoni, A.; Courville, A. On the compositional generalization gap of in-context learning. arXiv 2022, arXiv:2211.08473. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A visual language model for few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 23716–23736. [Google Scholar]
- Bai, Y.; Geng, X.; Mangalam, K.; Bar, A.; Yuille, A.L.; Darrell, T.; Malik, J.; Efros, A.A. Sequential modeling enables scalable learning for large vision models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 22861–22872. [Google Scholar]
- Wang, X.; Zhang, X.; Cao, Y.; Wang, W.; Shen, C.; Huang, T. Seggpt: Towards segmenting everything in context. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 1130–1140. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Pfeiffer, J.; Kamath, A.; Rücklé, A.; Cho, K.; Gurevych, I. AdapterFusion: Non-destructive task composition for transfer learning. arXiv 2020, arXiv:2005.00247. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2790–2799. [Google Scholar]
- Zhang, R.; Han, J.; Liu, C.; Gao, P.; Zhou, A.; Hu, X.; Yan, S.; Lu, P.; Li, H.; Qiao, Y. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv 2023, arXiv:2303.16199. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Wang, J.; Li, J.; Wu, W.; Sun, M. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv 2021, arXiv:2108.02035. [Google Scholar]
- Tsai, Y.Y.; Chen, P.Y.; Ho, T.Y. Transfer learning without knowing: Reprogramming black-box machine learning models with scarce data and limited resources. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 9614–9624. [Google Scholar]
- Chen, S.; Ge, C.; Tong, Z.; Wang, J.; Song, Y.; Wang, J.; Luo, P. Adaptformer: Adapting vision transformers for scalable visual recognition. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 16664–16678. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar]
- Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. Clip-adapter: Better vision-language models with feature adapters. Int. J. Comput. Vis. 2024, 132, 581–595. [Google Scholar] [CrossRef]
- Tsao, H.A.; Hsiung, L.; Chen, P.Y.; Liu, S.; Ho, T.Y. Autovp: An automated visual prompting framework and benchmark. arXiv 2023, arXiv:2310.08381. [Google Scholar]
- Han, X.; Zhao, W.; Ding, N.; Liu, Z.; Sun, M. Ptr: Prompt tuning with rules for text classification. AI Open 2022, 3, 182–192. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 16000–16009. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12873–12883. [Google Scholar]
- Shaban, A.; Bansal, S.; Liu, Z.; Essa, I.; Boots, B. One-shot learning for semantic segmentation. arXiv 2017, arXiv:1709.03410. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; De Lange, T.; Johansen, D.; Johansen, H.D. Kvasir-seg: A segmented polyp dataset. In Proceedings of the International Conference on Multimedia Modeling, Daejeon, Republic of Korea, 5–8 January 2020; pp. 451–462. [Google Scholar]
- Yue, G.; Xiao, H.; Xie, H.; Zhou, T.; Zhou, W.; Yan, W.; Zhao, B.; Wang, T.; Jiang, Q. Dual-constraint coarse-to-fine network for camouflaged object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 3286–3298. [Google Scholar] [CrossRef]
- Gutman, D.; Codella, N.C.; Celebi, E.; Helba, B.; Marchetti, M.; Mishra, N.; Halpern, A. Skin lesion analysis toward melanoma detection: A challenge at the international symposium on biomedical imaging (ISBI) 2016, hosted by the international skin imaging collaboration (ISIC). arXiv 2016, arXiv:1605.01397. [Google Scholar]
- Zhong, J.; Tian, W.; Xie, Y.; Liu, Z.; Ou, J.; Tian, T.; Zhang, L. PMFSNet: Polarized multi-scale feature self-attention network for lightweight medical image segmentation. Comput. Methods Programs Biomed. 2025, 108611. [Google Scholar] [CrossRef] [PubMed]
- Suo, W.; Lai, L.; Sun, M.; Zhang, H.; Wang, P.; Zhang, Y. Rethinking and Improving Visual Prompt Selection for In-Context Learning Segmentation. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 18–35. [Google Scholar]
- Xu, C.; Liu, C.; Wang, Y.; Yao, Y.; Fu, Y. Towards Global Optimal Visual In-Context Learning Prompt Selection. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024; Volume 37, pp. 74945–74965. [Google Scholar]
- Rakelly, K.; Shelhamer, E.; Darrell, T.; Efros, A.; Levine, S. Conditional networks for few-shot semantic segmentation. In Proceedings of the International Conference on Learning Representations Workshop, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain generalization: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4396–4415. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seg. (mIoU) | Det. | |||||
|---|---|---|---|---|---|---|
| Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean | (mIoU) | |
| Meta-learning | ||||||
| OSLSM [59] | 33.60 | 55.30 | 40.90 | 33.50 | 40.80 | - |
| co-FCN [67] | 36.70 | 50.60 | 44.90 | 32.40 | 41.10 | - |
| In-context learning | ||||||
| Random [15] | 28.66 | 30.21 | 27.81 | 23.55 | 27.56 | 25.45 |
| UnsupPR [16] | 34.75 | 35.92 | 32.41 | 31.16 | 33.56 | 26.84 |
| SupPR [16] | 37.08 | 38.43 | 34.40 | 32.32 | 35.56 | 28.22 |
| SCS [65] | - | - | - | - | 35.00 | - |
| Partial2Global [66] | 38.81 | 41.54 | 37.25 | 36.01 | 38.40 | 30.66 |
| prompt-SelF [18] | 42.48 | 43.34 | 39.76 | 38.50 | 41.02 | 29.83 |
| FMLR (CLIP) | 35.69 | 37.24 | 33.98 | 33.13 | 35.01 | 27.27 |
| FMLR (DINOv2) | 36.48 | 37.41 | 35.03 | 34.77 | 35.92 | 27.18 |
| InMeMo [28] | 41.65 | 47.68 | 42.43 | 40.80 | 43.14 | 43.21 |
| E-InMeMo (Ours) | 42.82 | 46.97 | 43.00 | 42.83 | 43.91 | 44.22 |
| Kvasir (mIoU) | ISIC | ||||||
|---|---|---|---|---|---|---|---|
| Method | Fold-0 | Fold-1 | Fold-2 | Fold-3 | Fold-4 | Mean | (mIoU) |
| Random [15] | 37.79 | 33.98 | 35.72 | 32.33 | 32.51 | 34.47 | 62.43 |
| UnSupPR [16] | 39.71 | 39.99 | 41.02 | 35.90 | 37.54 | 38.83 | 68.78 |
| SupPR [16] | 41.16 | 40.94 | 41.58 | 38.53 | 36.33 | 39.71 | 68.76 |
| FMLR (CLIP) | 41.17 | 40.91 | 40.49 | 39.40 | 37.01 | 39.80 | 70.77 |
| FMLR (DINOv2) | 45.70 | 42.25 | 44.85 | 43.25 | 39.94 | 43.20 | 70.12 |
| E-InMeMo | 53.04 | 50.04 | 53.96 | 54.47 | 45.97 | 51.50 | 76.13 |
| Domain Setting | Method | Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean |
|---|---|---|---|---|---|---|
| Pascal → Pascal | FMLR (DINOv2) | 36.48 | 37.41 | 35.03 | 34.77 | 35.92 |
| E-InMeMo | 42.82 | 46.97 | 43.00 | 42.83 | 43.91 | |
| COCO → Pascal | FMLR (DINOv2) | 34.43 | 34.06 | 32.60 | 33.31 | 33.60 |
| E-InMeMo | 41.28 | 42.26 | 40.97 | 41.18 | 41.42 |
| Combination | Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean |
|---|---|---|---|---|---|
| E-InMeMo variant | |||||
| I | 42.28 | 44.86 | 41.10 | 43.24 | 42.87 |
| Q | 40.71 | 43.32 | 39.97 | 40.01 | 41.01 |
| I & Q | 39.92 | 44.01 | 39.68 | 40.12 | 40.93 |
| I & L (E-InMeMo) | 42.82 | 46.97 | 43.00 | 42.83 | 43.91 |
| Padding Size | Para. | Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean |
|---|---|---|---|---|---|---|
| 5 | 9,780 | 41.31 | 47.12 | 41.37 | 41.14 | 42.73 |
| 10 | 18,960 | 43.59 | 47.86 | 41.46 | 42.65 | 43.89 |
| 15 (E-InMeMo) | 27,540 | 42.82 | 46.97 | 43.00 | 42.83 | 43.91 |
| 20 | 35,520 | 39.23 | 42.81 | 37.77 | 41.06 | 40.22 |
| 25 | 42,900 | 42.22 | 45.96 | 37.96 | 39.72 | 41.47 |
| 30 | 49,680 | 31.53 | 40.62 | 36.10 | 39.26 | 36.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wang, B.; Liu, H.; Li, L.; Nakashima, Y.; Nagahara, H. E-InMeMo: Enhanced Prompting for Visual In-Context Learning. J. Imaging 2025, 11, 232. https://doi.org/10.3390/jimaging11070232
Zhang J, Wang B, Liu H, Li L, Nakashima Y, Nagahara H. E-InMeMo: Enhanced Prompting for Visual In-Context Learning. Journal of Imaging. 2025; 11(7):232. https://doi.org/10.3390/jimaging11070232
Chicago/Turabian StyleZhang, Jiahao, Bowen Wang, Hong Liu, Liangzhi Li, Yuta Nakashima, and Hajime Nagahara. 2025. "E-InMeMo: Enhanced Prompting for Visual In-Context Learning" Journal of Imaging 11, no. 7: 232. https://doi.org/10.3390/jimaging11070232
APA StyleZhang, J., Wang, B., Liu, H., Li, L., Nakashima, Y., & Nagahara, H. (2025). E-InMeMo: Enhanced Prompting for Visual In-Context Learning. Journal of Imaging, 11(7), 232. https://doi.org/10.3390/jimaging11070232