

Interpretation of AI-Generated vs. Human-Made Images


Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Stimuli
2.3. Variables
2.3.1. Dependent Variables
2.3.2. Independent Variables
2.4. Data Acquisition
2.5. Data Analysis
3. Results
3.1. Source Identification
3.1.1. Human Portraits
3.1.2. Landscapes
3.1.3. Everyday Scenes
3.1.4. Detailed Objects
3.2. Realism
3.2.1. Human Portraits
3.2.2. Landscapes
3.2.3. Everyday Scenes
3.2.4. Detailed Objects
3.3. Credibility
3.3.1. Human Portraits
3.3.2. Landscapes
3.3.3. Everyday Scenes
3.3.4. Detailed Objects
4. Discussion
5. Conclusions
6. Limitations
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANOVA | Analysis of Variance |
| GAN | Generative Adversarial Network |
Appendix A

{kind=link}
{kind=link}
| Topic | Type of Tool | Original Prompt/Text in Spanish | Translation into English |
|---|---|---|---|
| Human portrait 1 | Human-made (Freepik) | Retrato mujer latina sonriente. | Portrait of a smiling Latina woman. |
| AI-generated (Midjourney, DALL·E 3, and Firefly) | Crea una imagen tipo fotografía realista de una mujer blanca sonriente, una oreja se ve y la otra está cubierta por su cabello oscuro largo, ojos cafés, fotografía en primer plano, exterior, enfoque en ella. Está vestida con un suéter blanco y una chaqueta blanca. | Create a realistic photo-like image of a smiling white woman, one ear visible and the other covered by her long dark hair and brown eyes, close-up, outdoor photography, focus on her. She is wearing a white sweater and a white jacket. | |
| Human portrait 2 | Human-made (Freepik) | Retrato hombre negro de noche. | Portrait of a black man at night. |
| AI-generated (Midjourney, DALL·E 3, and Firefly) | Fotografía contrapicada de un hombre negro con camisa negra, pensativo. | Low angle photograph of a black man wearing a black shirt, thoughtful. | |
| Landscapes 1 | Human-made (Freepik) | Paisaje costero al atardecer. | Coastal landscape at sunset. |
| AI-generated (Midjourney, DALL·E 3, and Firefly) | Fotografía cálida de una playa tropical, el mar con palmeras de coco en el momento de la salida del sol. | Warm photograph of a tropical beach, the sea with coconut palm trees at sunrise. | |
| Landscapes 1 | Human-made (Freepik) | Bosque en otoño. | Forest in autumn. |
| AI-generated (Midjourney, DALL·E 3, and Firefly) | Fotografía de un bosque en otoño, donde hay muchas hojas son naranjas y el sol se ve al fondo. | Photograph of a forest in autumn, where there are many orange leaves, and the sun can be seen in the background. | |
| Everyday scenes 1 | Human-made (Freepik) | Reunión de trabajo en una sala, una persona está exponiendo. | Business meeting in a room, one person is speaking. |
| AI-generated (Midjourney, DALL·E 3, and Firefly) | Fotografía de cuatro personas que están en una reunión de trabajo en una sala. | Photograph of four people in a work meeting in a room. | |
| Everyday scenes 2 | Human-made (Freepik) | Padres e hijos cocinando en casa. | Parents and children cooking at home. |
| AI-generated (Midjourney, DALL·E 3, and Firefly) | Fotografía de padres e hijos cocinando galletas en casa. | Photograph of parents and children baking cookies at home. | |
| Detailed objects 1 | Human-made (Freepik) | Bicicleta vintage en un taller de reparación. | Vintage bicycle in a repair shop. |
| AI-generated (Midjourney, DALL·E 3, and Firefly) | Primer plano detallado de una bicicleta vintage en un taller de reparación. | Detailed close-up of a vintage bicycle in a repair shop. | |
| Detailed objects 2 | Human-made (Freepik) | Plano detalle de un girasol. | Close-up of a sunflower. |
| AI-generated (Midjourney, DALL·E 3, and Firefly) | Plano detalle de un girasol. | Close-up of a sunflower. |
References
- Tigre Moura, F.; Castrucci, C.; Hindley, C. Artificial Intelligence Creates Art? An Experimental Investigation of Value and Creativity Perceptions. J. Creat. Behav. 2023, 57, 534–549. [Google Scholar] [CrossRef]
- Savadjiev, P.; Chong, J.; Dohan, A.; Vakalopoulou, M.; Reinhold, C.; Paragios, N.; Gallix, B. Demystification of AI-Driven Medical Image Interpretation: Past, Present and Future. Eur. Radiol. 2019, 29, 1616–1624. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Chen, E.; Banerjee, O.; Topol, E.J. AI in Health and Medicine. Nat. Med. 2022, 28, 31–38. [Google Scholar] [CrossRef] [PubMed]
- Rao, V.M.; Hla, M.; Moor, M.; Adithan, S.; Kwak, S.; Topol, E.J.; Rajpurkar, P. Multimodal Generative AI for Medical Image Interpretation. Nature 2025, 639, 888–896. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Lungren, M.P. The Current and Future State of AI Interpretation of Medical Images. N. Engl. J. Med. 2023, 388, 1981–1990. [Google Scholar] [CrossRef]
- Hartmann, J.; Exner, Y.; Domdey, S. The Power of Generative Marketing: Can Generative AI Create Superhuman Visual Marketing Content? Int. J. Res. Mark. 2025, 42, 13–31. [Google Scholar] [CrossRef]
- Quan, H.; Li, S.; Zeng, C.; Wei, H.; Hu, J. Big Data and AI-Driven Product Design: A Survey. Appl. Sci. 2023, 13, 9433. [Google Scholar] [CrossRef]
- Papia, E.-M.; Kondi, A.; Constantoudis, V. Entropy and Complexity Analysis of AI-Generated and Human-Made Paintings. Chaos Solitons Fractals 2023, 170, 113385. [Google Scholar] [CrossRef]
- Ostmeyer, J.; Schaerf, L.; Buividovich, P.; Charles, T.; Postma, E.; Popovici, C. Synthetic Images Aid the Recognition of Human-Made Art Forgeries. PLoS ONE 2024, 19, e0295967. [Google Scholar] [CrossRef]
- Ha, A.Y.J.; Passananti, J.; Bhaskar, R.; Shan, S.; Southen, R.; Zheng, H.; Zhao, B.Y. Organic or Diffused: Can We Distinguish Human Art from AI-Generated Images? In Proceedings of the 2024 ACM SIGSAC Conference on Computer and Communications SEcurity (CCS’24), Salt Lake City, UT, USA, 14–18 October 2024. [Google Scholar] [CrossRef]
- Lotze, M.; Scheler, G.; Tan, H.-R.M.; Braun, C.; Birbaumer, N. The Musician’s Brain: Functional Imaging of Amateurs and Professionals during Performance and Imagery. Neuroimage 2003, 20, 1817–1829. [Google Scholar] [CrossRef]
- Gaser, C.; Schlaug, G. Brain Structures Differ between Musicians and Non-Musicians. J. Neurosci. 2003, 23, 9240–9245. [Google Scholar] [CrossRef]
- Muraskin, J.; Dodhia, S.; Lieberman, G.; Garcia, J.O.; Verstynen, T.; Vettel, J.M.; Sherwin, J.; Sajda, P. Brain Dynamics of Post-Task Resting State Are Influenced by Expertise: Insights from Baseball Players. Hum. Brain Mapp. 2016, 37, 4454–4471. [Google Scholar] [CrossRef] [PubMed]
- Maguire, E.A.; Woollett, K.; Spiers, H.J. London Taxi Drivers and Bus Drivers: A Structural MRI and Neuropsychological Analysis. Hippocampus 2006, 16, 1091–1101. [Google Scholar] [CrossRef] [PubMed]
- Maguire, E.A.; Gadian, D.G.; Johnsrude, I.S.; Good, C.D.; Ashburner, J.; Frackowiak, R.S.; Frith, C.D. Navigation-Related Structural Change in the Hippocampi of Taxi Drivers. Proc. Natl. Acad. Sci. USA 2000, 97, 4398–4403. [Google Scholar] [CrossRef] [PubMed]
- Andreu-Sánchez, C.; Martín-Pascual, M.Á.; Gruart, A.; Delgado-García, J.M. Eyeblink Rate Watching Classical Hollywood and Post-Classical MTV Editing Styles, in Media and Non-Media Professionals. Sci. Rep. 2017, 7, 43267. [Google Scholar] [CrossRef]
- Andreu-Sánchez, C.; Martín-Pascual, M.Á.; Gruart, A.; Delgado-García, J.M. Beta-Band Differences in Primary Motor Cortex between Media and Non-Media Professionals When Watching Motor Actions in Movies. Front. Neurosci. 2023, 17, 1204809. [Google Scholar] [CrossRef]
- Andreu-Sánchez, C.; Martín-Pascual, M.Á.; Gruart, A.; Delgado-García, J.M. The Effect of Media Professionalization on Cognitive Neurodynamics During Audiovisual Cuts. Front. Syst. Neurosci. 2021, 1, 598383. [Google Scholar] [CrossRef]
- Andreu-Sánchez, C.; Ngel Martín-Pascual, M.; Gruart, A.; Delgado-García, J.M. Looking at Reality versus Watching Screens: Media Professionalization Effects on the Spontaneous Eyeblink Rate. PLoS ONE 2017, 12, e0176030. [Google Scholar] [CrossRef]
- Meyer, R. “Platform Realism”. AI Image Synthesis and the Rise of Generic Visual Content. Transbordeur 2025, 9, 1–18. [Google Scholar] [CrossRef]
- Andreu-Sánchez, C.; Martín-Pascual, M.Á. Representación Visual y Diversidad En La Inteligencia Artificial. In Patrimonio y Competencias Digitales en la Sociedad Hiperconectada y Participativa; Dykinson: Madrid, Spain, 2024; pp. 129–143. [Google Scholar]
- Fletcher, J. Deepfakes, Artificial Intelligence, and Some Kind of Dystopia: The New Faces of Online Post-Fact Performance. Theatre J. 2018, 70, 455–471. [Google Scholar] [CrossRef]
- Khodabakhsh, A.; Ramachandra, R.; Busch, C. Subjective Evaluation of Media Consumer Vulnerability to Fake Audiovisual Content. In Proceedings of the 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), Belin, Germany, 5 June 2019; pp. 1–6. [Google Scholar]
- Engel-Hermann, P.; Skulmowski, A. Appealing, but Misleading: A Warning against a Naive AI Realism. AI Ethics 2025, 5, 3407–3413. [Google Scholar] [CrossRef]
- Goring, S.; Ramachandra Rao, R.R.; Merten, R.; Raake, A. Analysis of Appeal for Realistic AI-Generated Photos. IEEE Access 2023, 11, 38999–39012. [Google Scholar] [CrossRef]
- Moshel, M.L.; Robinson, A.K.; Carlson, T.A.; Grootswagers, T. Are You for Real? Decoding Realistic AI-Generated Faces from Neural Activity. Vis. Res. 2022, 199, 108079. [Google Scholar] [CrossRef]
- McCabe, D.P.; Castel, A.D. Seeing Is Believing: The Effect of Brain Images on Judgments of Scientific Reasoning. Cognition 2008, 107, 343–352. [Google Scholar] [CrossRef]
- Cukurova, M.; Luckin, R.; Kent, C. Impact of an Artificial Intelligence Research Frame on the Perceived Credibility of Educational Research Evidence. Int. J. Artif. Intell. Educ. 2020, 30, 205–235. [Google Scholar] [CrossRef]
- Khan, A.W.; Mishra, A. AI Credibility and Consumer-AI Experiences: A Conceptual Framework. J. Serv. Theory Pract. 2024, 34, 66–97. [Google Scholar] [CrossRef]
- Jung, J.; Song, H.; Kim, Y.; Im, H.; Oh, S. Intrusion of Software Robots into Journalism: The Public’s and Journalists’ Perceptions of News Written by Algorithms and Human Journalists. Comput. Hum. Behav. 2017, 71, 291–298. [Google Scholar] [CrossRef]
- Mirbabaie, M.; Stieglitz, S. Do You Trust an AI-Journalist? A Credibility Analysis of News Content with AI-Authorship. In Proceedings of the ECIS 2021 Research Papers, Marrakesh, Morocco, 14–16 June 2021; pp. 1–15. [Google Scholar]
- Passos, L.A.; Jodas, D.; Costa, K.A.P.; Souza Júnior, L.A.; Rodrigues, D.; Del Ser, J.; Camacho, D.; Papa, J.P. A Review of Deep Learning-Based Approaches for Deepfake Content Detection. Expert Syst. 2024, 41, e13570. [Google Scholar] [CrossRef]
- Komali, L.; Jyothsna Malika, S.; Satya, A.; Kumari, K.M.; Nikhita, V.; Sri Naga, C.; Vardhani, S. Detection of Fake Images Using Deep Learning. Tanz 2024, 19, 134–140. [Google Scholar]
- Singh, B.; Sharma, D.K. Predicting Image Credibility in Fake News over Social Media Using Multi-Modal Approach. Neural Comput. Appl. 2022, 34, 21503–21517. [Google Scholar] [CrossRef]
- Fernández, Ó.B. The Baroque Definition of the Real in Descartes in Light of Suárezian Metaphysics. An. Semin. Hist. Filos. 2022, 39, 203–213. [Google Scholar] [CrossRef]
- Rodríguez-Fernández, M.M.; Martínez-Fernández, V.A.; Juanatey-Boga, Ó. Credibility of Online Press: A Strategy for Distinction and Audience Generation. Prof. Inf. 2020, 29, 1–18. [Google Scholar] [CrossRef]
- Kar, S.K.; Bansal, T.; Modi, S.; Singh, A. How Sensitive Are the Free AI-Detector Tools in Detecting AI-Generated Texts? A Comparison of Popular AI-Detector Tools. Indian J. Psychol. Med. 2025, 47, 275–278. [Google Scholar] [CrossRef]
- Andreu-Sánchez, C.; Martín-Pascual, M.Á. Fake Images of the SARS-CoV-2 Coronavirus in the Communication of Information at the Beginning of the First COVID-19 Pandemic. Prof. Inf. 2020, 29, e290309. [Google Scholar] [CrossRef]
- Andreu-Sánchez, C.; Martín-Pascual, M.Á. The Attributes of the Images Representing the SARS-CoV-2 Coronavirus Affect People’s Perception of the Virus. PLoS ONE 2021, 16, e0253738. [Google Scholar] [CrossRef]
- Andreu-Sánchez, C.; Martín-Pascual, M.Á. Scientific Illustrations of SARS-CoV-2 in the Media: An Imagedemic on Screens. Humanit Soc. Sci. Commun. 2022, 9, 1–6. [Google Scholar] [CrossRef]
- Doss, C.; Mondschein, J.; Shu, D.; Wolfson, T.; Kopecky, D.; Fitton-Kane, V.A.; Bush, L.; Tucker, C. Deepfakes and Scientific Knowledge Dissemination. Sci. Rep. 2023, 13, 13429. [Google Scholar] [CrossRef]
- Lim, W.M. Fact or Fake? The Search for Truth in an Infodemic of Disinformation, Misinformation, and Malinformation with Deepfake and Fake News. J. Strateg. Mark. 2023, 1–37. [Google Scholar] [CrossRef]
- Rademacher, P.; Lengyel, J.; Cutrell, E.; Whitted, T. Measuring the Perception of Visual Realism in Images. In Proceedings of the Rendering Techniques 2001. EGSR 2001. Eurographics; Gortler, S.J., Myszkowski, K., Eds.; Springer: Vienna, Austria, 2011; pp. 235–247. [Google Scholar]
- Xue, S.; Agarwala, A.; Dorsey, J.; Rushmeier, H. Understanding and Improving the Realism of Image Composites. ACM Trans. Graph. 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Snow, J.C.; Culham, J.C. The Treachery of Images: How Realism Influences Brain and Behavior. Trends Cogn. Sci. 2021, 25, 506–519. [Google Scholar] [CrossRef]
- Kim, J.; Merrill, K.; Xu, K.; Kelly, S. Perceived Credibility of an AI Instructor in Online Education: The Role of Social Presence and Voice Features. Comput. Hum. Behav. 2022, 136, 107383. [Google Scholar] [CrossRef]
- Cupchik, G.C. Emotion in Aesthetics: Reactive and Reflective Models. Poetics 1994, 23, 177–188. [Google Scholar] [CrossRef]
- Leder, H.; Belke, B.; Oeberst, A.; Augustin, D. A Model of Aesthetic Appreciation and Aesthetic Judgments. Br. J. Psychol. 2004, 95, 489–508. [Google Scholar] [CrossRef]
- Dykstra, S.W. The Artist’s Intentions and the Intentional Fallacy in Fine Arts Conservation. J. Am. Inst. Conserv. 1996, 35, 197–218. [Google Scholar] [CrossRef]
- Silvia, P.J. Emotional Responses to Art: From Collation and Arousal to Cognition and Emotion. Rev. Gen. Psychol. 2005, 9, 342–357. [Google Scholar] [CrossRef]
- Leder, H.; Nadal, M. Ten Years of a Model of Aesthetic Appreciation and Aesthetic Judgments: The Aesthetic Episode—Developments and Challenges in Empirical Aesthetics. Br. J. Psychol. 2014, 105, 443–464. [Google Scholar] [CrossRef] [PubMed]
- Chan, K.-H.; Im, S.-K.; Ke, W. Variable-Depth Convolutional Neural Network for Text Classification. In Neural Information Processing; Springer: Bangkok, Thailand, 2020; Volume 5, pp. 685–692. [Google Scholar]
- Li, Y.; Wang, Y.; Yang, X.; Im, S.K. Speech Emotion Recognition Based on Graph-LSTM Neural Network. EURASIP J. Audio Speech Music Process 2023, 40, 1–10. [Google Scholar] [CrossRef]
- Kirk, U.; Skov, M.; Schram Christensen, M.; Nygaard, N. Brain Correlates of Aesthetic Expertise: A Parametric FMRI Study. Brain Cogn 2008, 69, 306–315. [Google Scholar] [CrossRef]
- Brunyé, T.T.; Carney, P.A.; Allison, K.H.; Shapiro, L.G.; Weaver, D.L.; Elmore, J.G. Eye Movements as an Index of Pathologist Visual Expertise: A Pilot Study. PLoS ONE 2014, 9, e103447. [Google Scholar] [CrossRef]
- Hill, N.; Schneider, W. Brain Changes in the Development of Expertise: Neuroanatomical and Neurophysiological Evidence about Skill-Based Adaptations. In The Cambridge Handbook of Expertise and Expert Performance; Ericksson, K.A., Charness, N., Feltovich, P.J., Hoffman, R.R., Eds.; Cambridge University Press: Cambridge, UK, 2006; pp. 653–682. ISBN 9780511816796. [Google Scholar]

| AI-Generated Images | Human-Made Images | |||
|---|---|---|---|---|
| Topic | Midjourney | Dalle-e 3 (Bing) | Firefly | Freepik |
| Human portraits | 2 | 2 | 2 | 2 |
| Landscapes | 2 | 2 | 2 | 2 |
| Everyday scenes | 2 | 2 | 2 | 2 |
| Detailed objects | 2 | 2 | 2 | 2 |
| Original Source | ||
|---|---|---|
| AI-Generated Images (N = 3864) | Human-Made Images (N = 1288) | |
| Classified as AI-generated images | 2360 (61.08%) | 280 (21.74%) |
| Classified as human-made images | 1504 (38.92%) | 1008 (78.26%) |
| Original Source | ||
|---|---|---|
| AI-Generated Images (N = 966) | Human-Made Images (N = 322) | |
| Classified as AI-generated images | 525 (54.35%) | 65 (20.19%) |
| Classified as human-made images | 441 (45.65%) | 257 (79.81%) |
| Original Source | ||
|---|---|---|
| AI-Generated Images (N = 966) | Human-Made Images (N = 322) | |
| Classified as AI-generated images | 635 (65.74%) | 102 (31.68%) |
| Classified as human-made images | 331 (34.26%) | 220 (68.32%) |
| Original Source | ||
|---|---|---|
| AI-Generated Images (N = 966) | Human-Made Images (N = 322) | |
| Classified as AI-generated images | 608 (62.94%) | 64 (19.88%) |
| Classified as human-made images | 359 (37.16%) | 257 (79.81%) |
| Original Source | ||
|---|---|---|
| AI-Generated Images (N = 966) | Human-Made Images (N = 322) | |
| Classified as AI-generated images | 592 (61.28%) | 49 (15.22%) |
| Classified as human-made images | 375 (38.82%) | 272 (84.47%) |
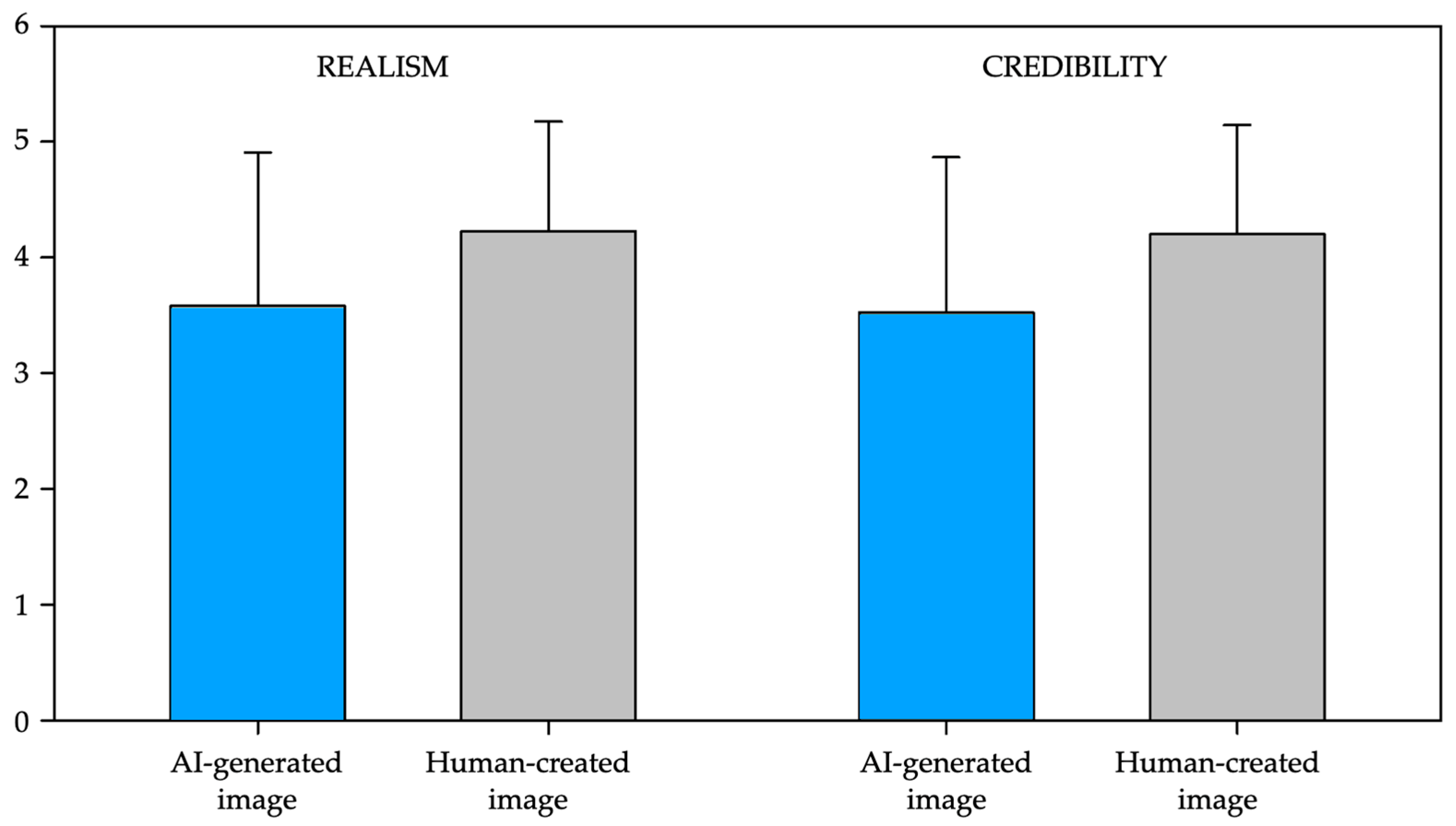
| Realism (Mean ± SD) | |||
|---|---|---|---|
| AI-generated images | 3.58 ± 1.326 | Visual professionals | 3.5 ± 1.37 |
| Non-visual professionals | 3.3 ± 1.39 | ||
| Human-made images | 4.224 ± 0.949 | Visual professionals | 4.43 ± 0.76 |
| Non-visual professionals | 4.1 ± 1.05 | ||
| Credibility (Mean ± SD) | |||
|---|---|---|---|
| AI-generated images | 3.527 ± 1.338 | Visual professionals | 3.47 ± 1.34 |
| Non-visual professionals | 3.29 ± 1.37 | ||
| Human-made images | 4.199 ± 0.944 | Visual professionals | 3.78 ± 1.25 |
| Non-visual professionals | 4.08 ± 1.03 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Velásquez-Salamanca, D.; Martín-Pascual, M.Á.; Andreu-Sánchez, C. Interpretation of AI-Generated vs. Human-Made Images. J. Imaging 2025, 11, 227. https://doi.org/10.3390/jimaging11070227
Velásquez-Salamanca D, Martín-Pascual MÁ, Andreu-Sánchez C. Interpretation of AI-Generated vs. Human-Made Images. Journal of Imaging. 2025; 11(7):227. https://doi.org/10.3390/jimaging11070227
Chicago/Turabian StyleVelásquez-Salamanca, Daniela, Miguel Ángel Martín-Pascual, and Celia Andreu-Sánchez. 2025. "Interpretation of AI-Generated vs. Human-Made Images" Journal of Imaging 11, no. 7: 227. https://doi.org/10.3390/jimaging11070227
APA StyleVelásquez-Salamanca, D., Martín-Pascual, M. Á., & Andreu-Sánchez, C. (2025). Interpretation of AI-Generated vs. Human-Made Images. Journal of Imaging, 11(7), 227. https://doi.org/10.3390/jimaging11070227