

Development of Deep Learning Models for Real-Time Thoracic Ultrasound Image Interpretation


Abstract
1. Introduction
- Additional swine data curation was implemented for a more robust dataset compared to previous studies.
- The filtering methods of the dataset were designed from the results of image preprocessing and analysis to correct data distribution shifts.
- A multi-class DL CNN was developed and optimized to classify ultrasound images as uninjured, HTX, or PTX.
- The model performance was evaluated with real-time data captures to highlight how the advancements improved performance when compared to previous studies.
2. Related Work
3. Materials and Methods
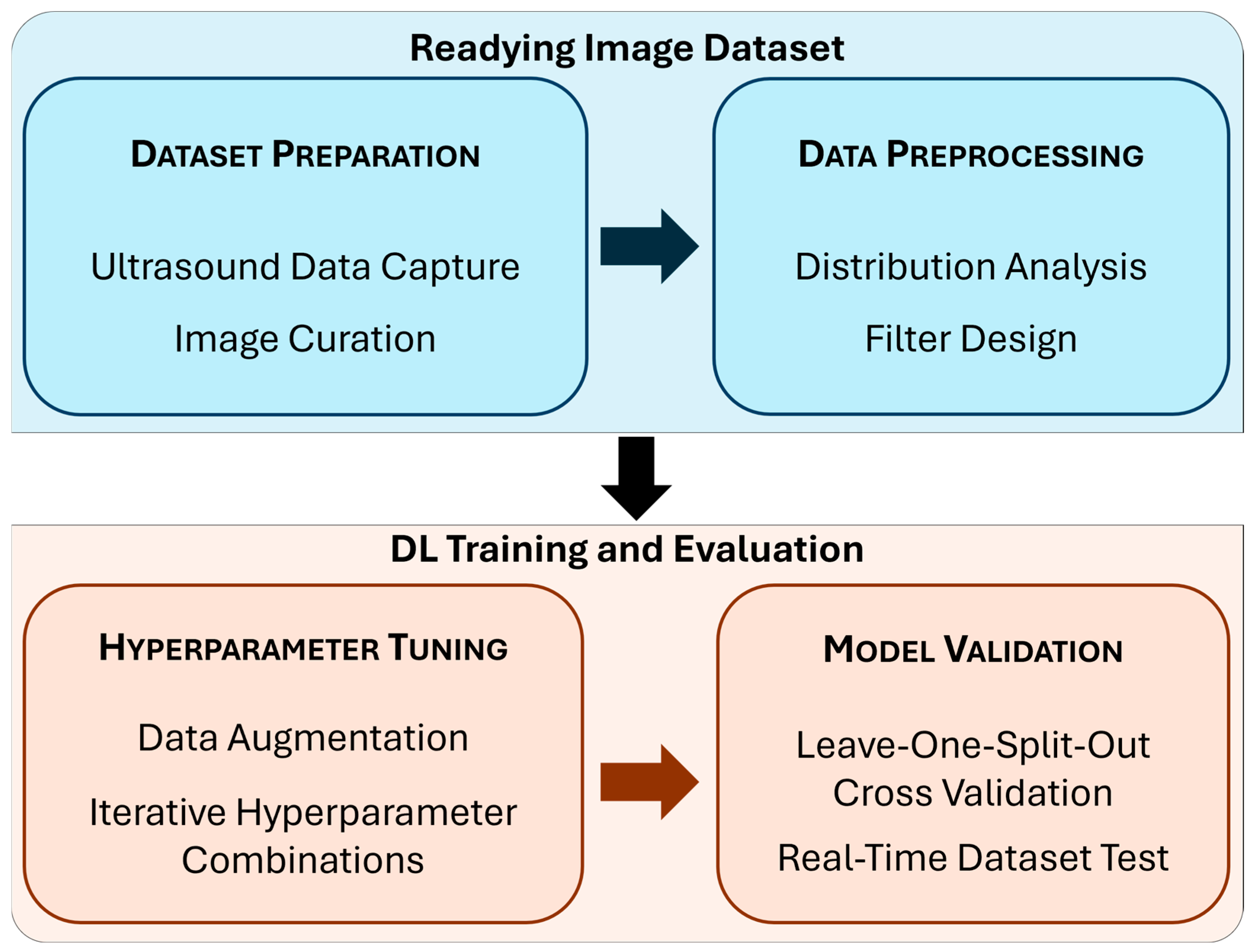
3.1. Readying the Image Dataset
3.1.1. Dataset Preparation
3.1.2. Data Preprocessing
3.2. DL Model Training and Evaluation
3.2.1. Hyperparameter Tuning
3.2.2. Real-Time Testing
4. Results
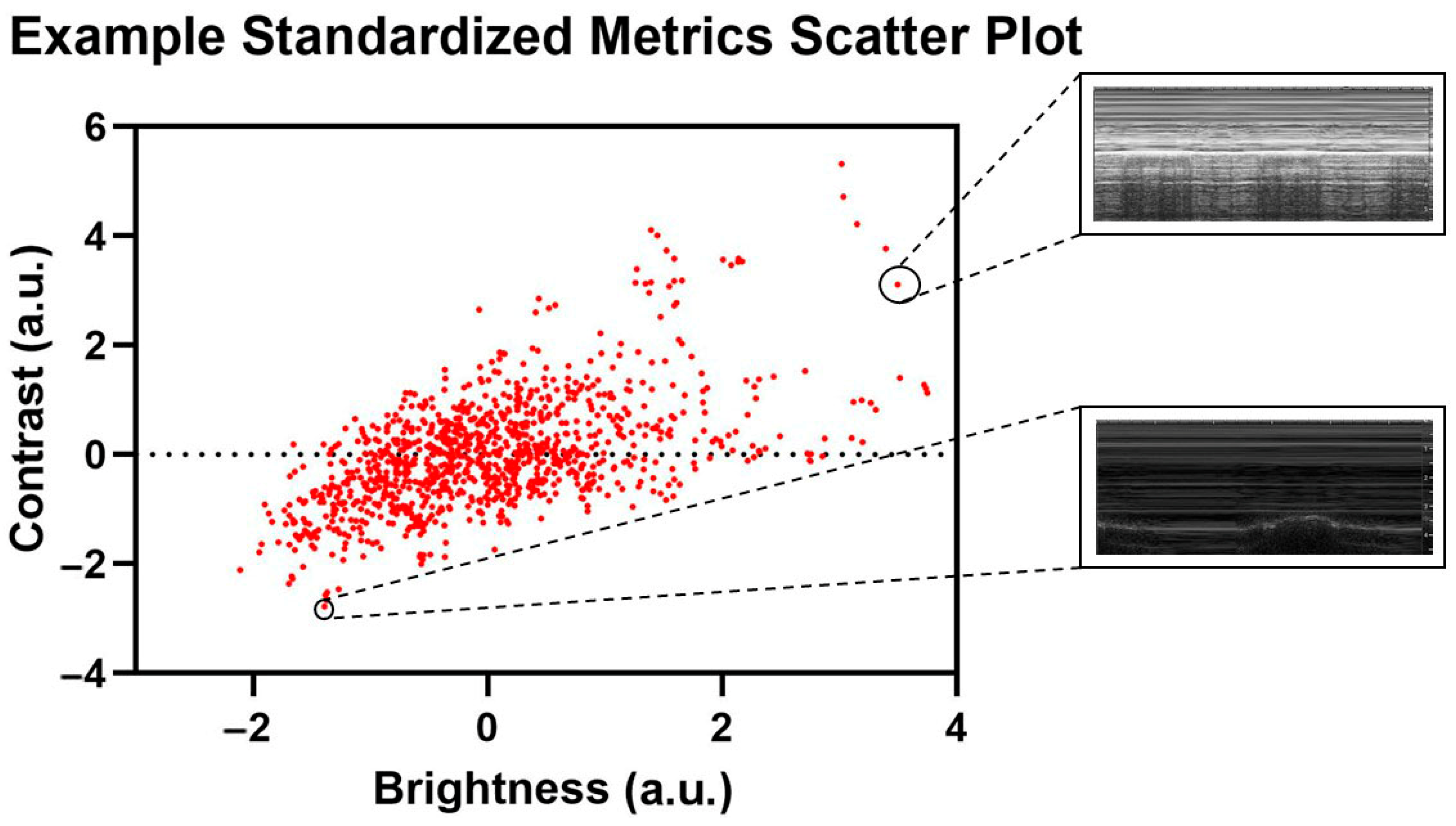
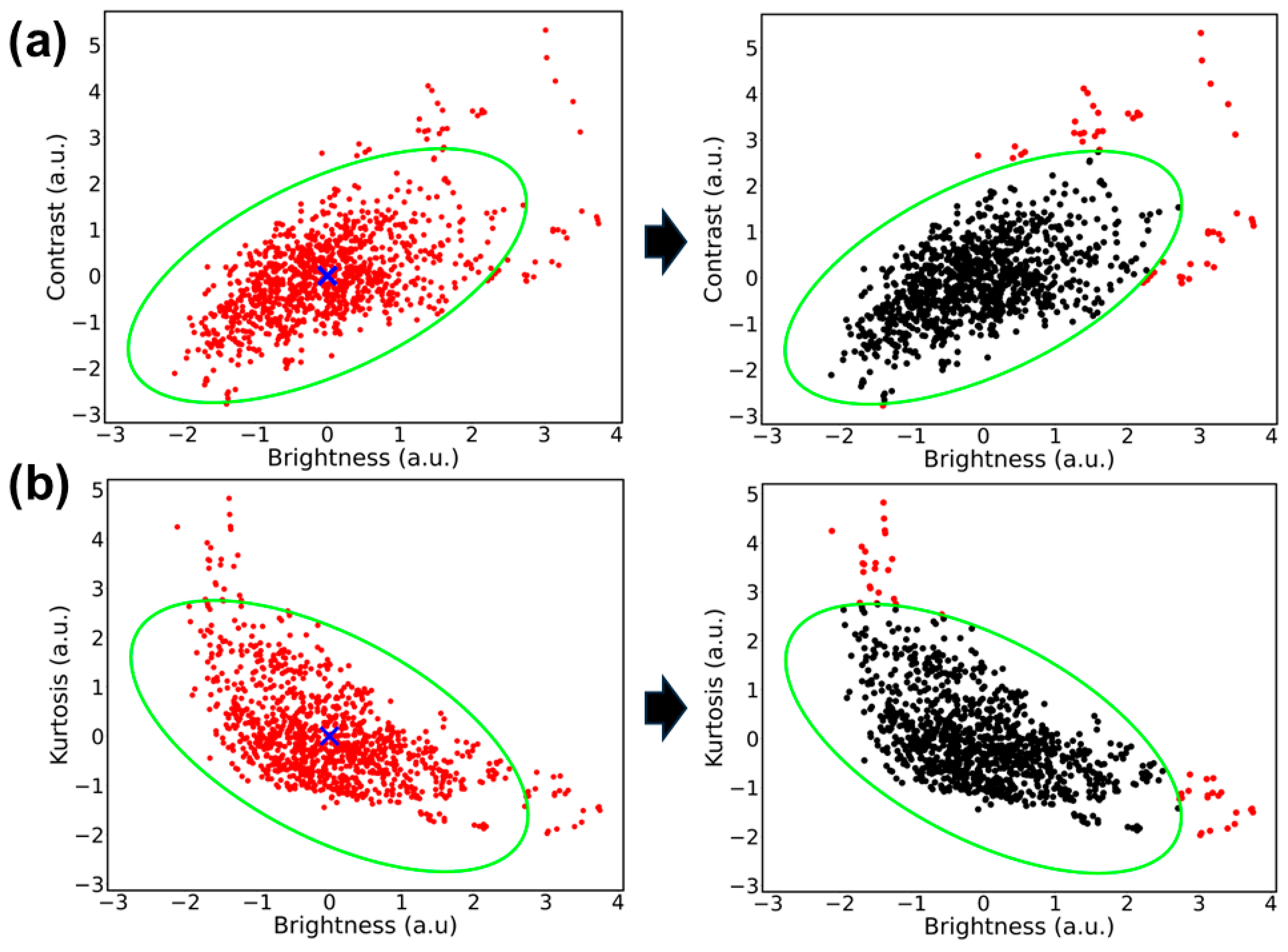
4.1. Cluster Analysis Results
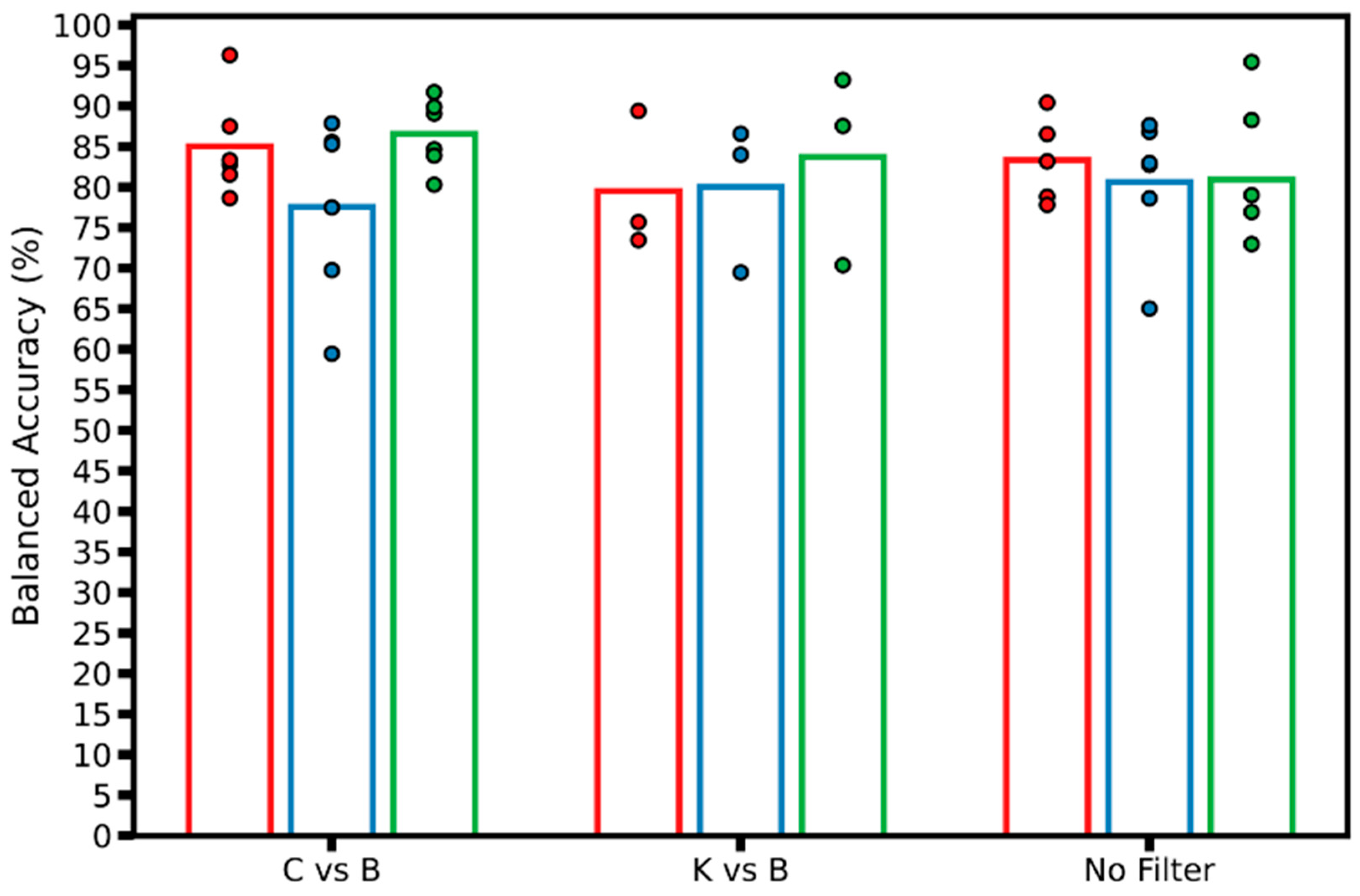
4.2. AI Model Development
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, L.; DeCara, J.M. Point-of-Care Ultrasound. Curr. Cardiol. Rep. 2020, 22, 149. [Google Scholar] [CrossRef]
- Ivey, K.M.; White, C.E.; Wallum, T.E.; Aden, J.K.; Cannon, J.W.; Chung, K.K.; McNeil, J.D.; Cohn, S.M.; Blackbourne, L.H. Thoracic Injuries in US Combat Casualties: A 10-Year Review of Operation Enduring Freedom and Iraqi Freedom. J. Trauma. Acute Care Surg. 2012, 73, S514–S519. [Google Scholar] [CrossRef]
- Townsend, S.; Lasher, W. The U.S. Army in Multi-Domain Operations 2028; U.S. Army: Arlington County, VA, USA, 2018. [Google Scholar]
- Dubecq, C.; Dubourg, O.; Morand, G.; Montagnon, R.; Travers, S.; Mahe, P. Point-of-Care Ultrasound for Treatment and Triage in Austere Military Environments. J. Trauma. Acute Care Surg. 2021, 91, S124–S129. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Wang, Y.; Yang, X.; Lei, B.; Liu, L.; Li, S.X.; Ni, D.; Wang, T. Deep Learning in Medical Ultrasound Analysis: A Review. Engineering 2019, 5, 261–275. [Google Scholar] [CrossRef]
- Wang, Z. Deep Learning in Medical Ultrasound Image Segmentation: A Review. arXiv 2020, arXiv:2002.07703. [Google Scholar]
- Hernandez Torres, S.I.; Ruiz, A.; Holland, L.; Ortiz, R.; Snider, E.J. Evaluation of Deep Learning Model Architectures for Point-of-Care Ultrasound Diagnostics. Bioengineering 2024, 11, 392. [Google Scholar] [CrossRef]
- Hernandez Torres, S.I.; Holland, L.; Winter, T.; Ortiz, R.; Amezcua, K.-L.; Ruiz, A.; Thorpe, C.R.; Snider, E.J. Real-Time Deployment of Ultrasound Image Interpretation AI Models for Emergency Medicine Triage Using a Swine Model. Technologies 2025, 13, 29. [Google Scholar] [CrossRef]
- Yu, H.; Yang, L.T.; Zhang, Q.; Armstrong, D.; Deen, M.J. Convolutional Neural Networks for Medical Image Analysis: State-of-the-Art, Comparisons, Improvement and Perspectives. Neurocomputing 2021, 444, 92–110. [Google Scholar] [CrossRef]
- Xie, H.; Yang, D.; Sun, N.; Chen, Z.; Zhang, Y. Automated Pulmonary Nodule Detection in CT Images Using Deep Convolutional Neural Networks. Pattern Recognit. 2019, 85, 109–119. [Google Scholar] [CrossRef]
- Shen, W.; Zhou, M.; Yang, F.; Yu, D.; Dong, D.; Yang, C.; Zang, Y.; Tian, J. Multi-Crop Convolutional Neural Networks for Lung Nodule Malignancy Suspiciousness Classification. Pattern Recognit. 2017, 61, 663–673. [Google Scholar] [CrossRef]
- Boccatonda, A. Emergency Ultrasound: Is It Time for Artificial Intelligence? J. Clin. Med. 2022, 11, 3823. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Fischetti, C.; Guy, M.; Hsu, E.; Fox, J.; Young, S.D. Artificial Intelligence (AI) Applications for Point of Care Ultrasound (POCUS) in Low-Resource Settings: A Scoping Review. Diagnostics 2024, 14, 1669. [Google Scholar] [CrossRef] [PubMed]
- Sonko, M.L.; Arnold, T.C.; Kuznetsov, I.A. Machine Learning in Point of Care Ultrasound. POCUS J. 2022, 7, 78–87. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.-T.; Ooyang, C.-H.; Liao, C.-H.; Kang, S.-C. Applications of Deep Learning in Trauma Radiology: A Narrative Review. Biomed. J. 2025, 48, 100743. [Google Scholar] [CrossRef]
- Diaz-Escobar, J.; Ordóñez-Guillén, N.E.; Villarreal-Reyes, S.; Galaviz-Mosqueda, A.; Kober, V.; Rivera-Rodriguez, R.; Rizk, J.E.L. Deep-Learning Based Detection of COVID-19 Using Lung Ultrasound Imagery. PLoS ONE 2021, 16, e0255886. [Google Scholar] [CrossRef]
- Huang, S.; Yang, J.; Fong, S.; Zhao, Q. Artificial Intelligence in the Diagnosis of COVID-19: Challenges and Perspectives. Int. J. Biol. Sci. 2021, 17, 1581. [Google Scholar] [CrossRef]
- Kim, K.; Macruz, F.; Wu, D.; Bridge, C.; McKinney, S.; Al Saud, A.A.; Sharaf, E.; Sesic, I.; Pely, A.; Danset, P.; et al. Point-of-Care AI-Assisted Stepwise Ultrasound Pneumothorax Diagnosis. Phys. Med. Biol. 2023, 68, 205013. [Google Scholar] [CrossRef]
- Montgomery, S.; Li, F.; Funk, C.; Peethumangsin, E.; Morris, M.; Anderson, J.T.; Hersh, A.M.; Aylward, S. Detection of Pneumothorax on Ultrasound Using Artificial Intelligence. J. Trauma. Acute Care Surg. 2023, 94, 379–384. [Google Scholar] [CrossRef]
- Hannan, D.; Nesbit, S.C.; Wen, X.; Smith, G.; Zhang, Q.; Goffi, A.; Chan, V.; Morris, M.J.; Hunninghake, J.C.; Villalobos, N.E.; et al. MobilePTX: Sparse Coding for Pneumothorax Detection Given Limited Training Examples. Proc. AAAI Conf. Artif. Intell. 2023, 37, 15675–15681. [Google Scholar] [CrossRef]
- Hernandez Torres, S.I.; Holland, L.; Edwards, T.H.; Venn, E.C.; Snider, E.J. Deep Learning Models for Interpretation of Point of Care Ultrasound in Military Working Dogs. Front. Vet. Sci. 2024, 11, 1374890. [Google Scholar] [CrossRef]
- Snider, E.J.; Hernandez-Torres, S.I.; Boice, E.N. An Image Classification Deep-Learning Algorithm for Shrapnel Detection from Ultrasound Images. Sci. Rep. 2022, 12, 8427. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- McLachlan, G.J. Mahalanobis Distance. Resonance 1999, 4, 20–26. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Keskar, N.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. arXiv 2016, arXiv:1609.04836. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Yaseen, M. What Is YOLOv8: An In-Depth Exploration of the Internal Features of the Next-Generation Object Detector. arXiv 2024, arXiv:2408.15857. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-Cam: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Agnihotri, A.; Batra, N. Exploring Bayesian Optimization. Distill 2020, 5, e26. [Google Scholar] [CrossRef]
- Frazier, P.I. A Tutorial on Bayesian Optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]
- Fiedler, H.C.; Prager, R.; Smith, D.; Wu, D.; Dave, C.; Tschirhart, J.; Wu, B.; Berlo, B.V.; Malthaner, R.; Arntfield, R. Automated Real-Time Detection of Lung Sliding Using Artificial Intelligence: A Prospective Diagnostic Accuracy Study. Chest 2024, 166, 362–370. [Google Scholar] [CrossRef]
- Jaščur, M.; Bundzel, M.; Malík, M.; Dzian, A.; Ferenčík, N.; Babič, F. Detecting the Absence of Lung Sliding in Lung Ultrasounds Using Deep Learning. Appl. Sci. 2021, 11, 6976. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filter | Weighted Loss | Validation Patience | Weighted Decay | Balanced Accuracy AVG (%) | Balanced Accuracy STD (%) | Global Accuracy AVG (%) | Global Accuracy STD (%) |
|---|---|---|---|---|---|---|---|
| No Filter | None | None | None | 88.17 | 7.05 | 86.63 | 7.97 |
| No Filter | None | 10 | None | 84.64 | 4.14 | 84.64 | 5.08 |
| No Filter | Balanced | None | None | 76.86 | 8.91 | 76.86 | 10.91 |
| No Filter | Balanced | 10 | None | 79.64 | 4.72 | 79.64 | 5.79 |
| No Filter | Balanced | 10 | 1 × 10−4 | 80.8 | 4.85 | 80.67 | 6.04 |
| No Filter | Balanced | 10 | 1 × 10−5 | 79.7 | 4.76 | 79.7 | 5.83 |
| C vs. B | None | None | None | 82.89 | 2.16 | 87.8 | 0.95 |
| C vs. B | None | 10 | None | 79.55 | 14.32 | 81.16 | 7.6 |
| C vs. B | Balanced | None | None | 80.27 | 3.15 | 75.34 | 5.85 |
| C vs. B | Balanced | 10 | None | 86.75 | 2.47 | 84.96 | 11.29 |
| C vs. B | Balanced | 10 | 1 × 10−4 | 78.39 | 6.18 | 78.75 | 12.91 |
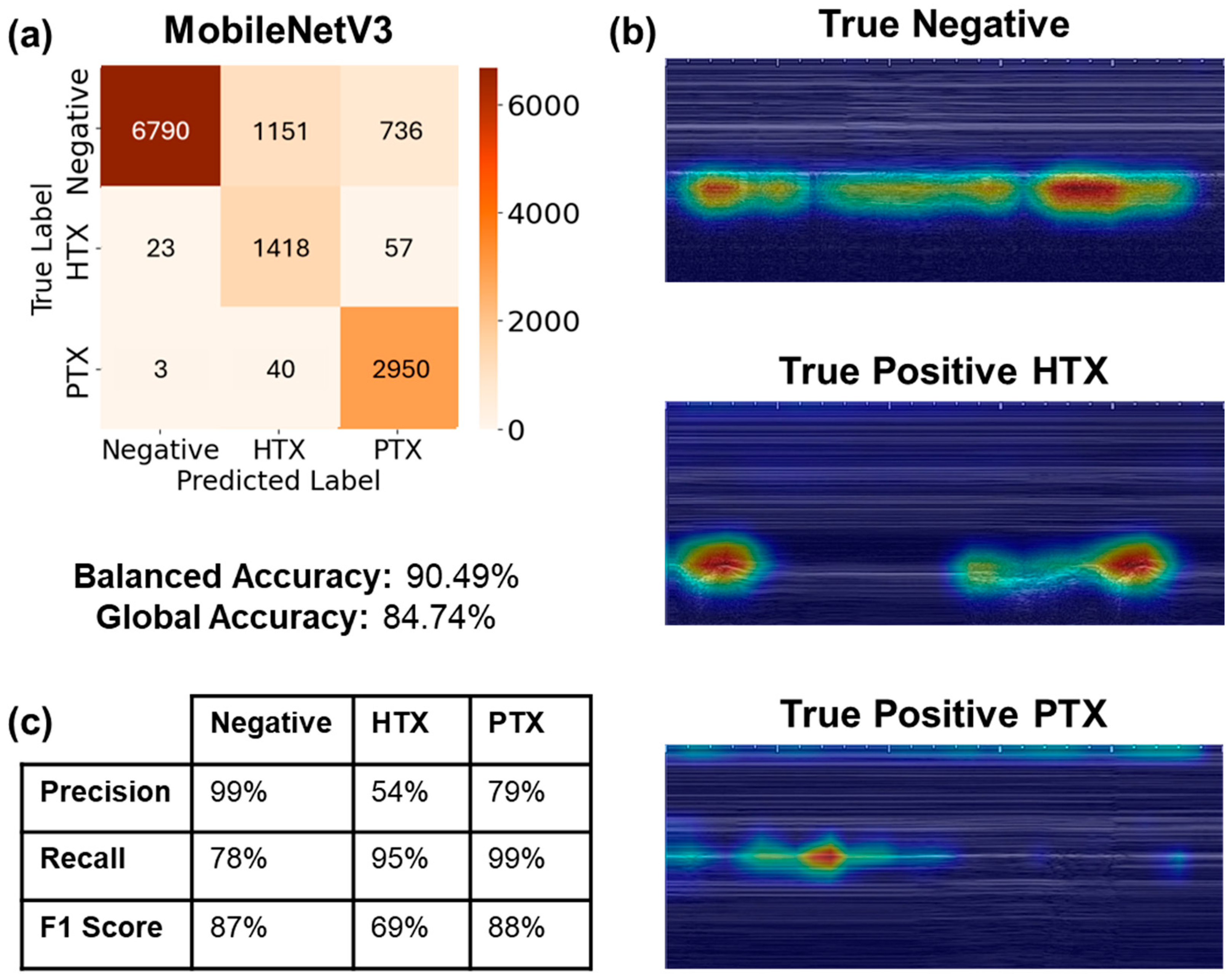
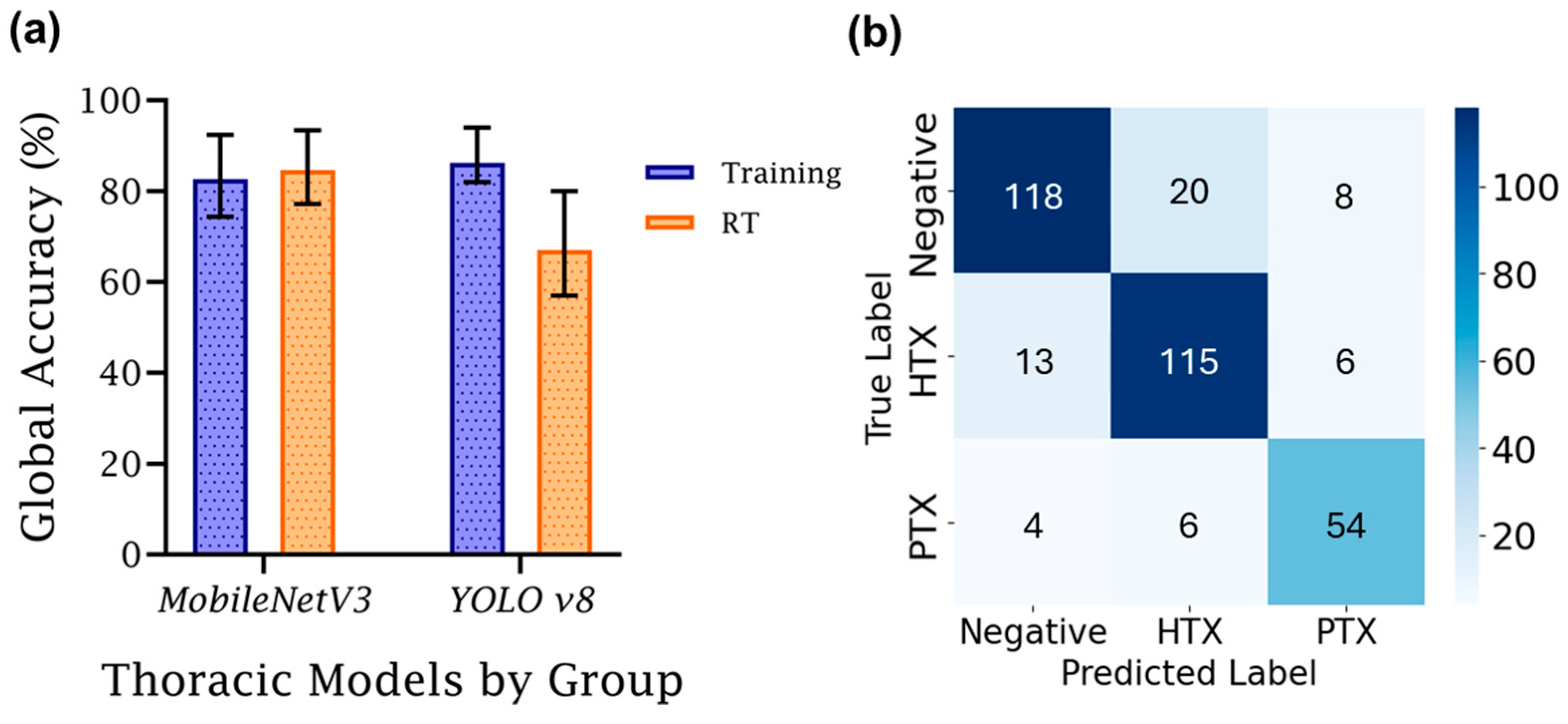
| C vs. B | Balanced | 10 | 1 × 10−5 | 90.49 | 4.51 | 84.74 | 8.18 |
| K vs. B | None | None | None | 85.17 | 7.23 | 84.87 | 3.05 |
| K vs. B | Balanced | 10 | None | 81.26 | 8 | 81.26 | 9.8 |
| K vs. B | Balanced | 10 | 1 × 10−5 | 76.83 | 7.75 | 81.15 | 12.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruiz, A.J.; Hernández Torres, S.I.; Snider, E.J. Development of Deep Learning Models for Real-Time Thoracic Ultrasound Image Interpretation. J. Imaging 2025, 11, 222. https://doi.org/10.3390/jimaging11070222
Ruiz AJ, Hernández Torres SI, Snider EJ. Development of Deep Learning Models for Real-Time Thoracic Ultrasound Image Interpretation. Journal of Imaging. 2025; 11(7):222. https://doi.org/10.3390/jimaging11070222
Chicago/Turabian StyleRuiz, Austin J., Sofia I. Hernández Torres, and Eric J. Snider. 2025. "Development of Deep Learning Models for Real-Time Thoracic Ultrasound Image Interpretation" Journal of Imaging 11, no. 7: 222. https://doi.org/10.3390/jimaging11070222
APA StyleRuiz, A. J., Hernández Torres, S. I., & Snider, E. J. (2025). Development of Deep Learning Models for Real-Time Thoracic Ultrasound Image Interpretation. Journal of Imaging, 11(7), 222. https://doi.org/10.3390/jimaging11070222