
Underwater Image Enhancement Using a Diffusion Model with Adversarial Learning


Abstract
1. Introduction
- We introduce an adversarial diffusion model for underwater image enhancement, named ALDiff-UIE. It employs a diffusion model as the generator to produce high-quality images through its iterative denoising steps and utilizes a discriminator to evaluate and provide adversarial feedback to refine the generated images. The diffusion model guides the generation of local details, while feedback from the discriminator enhances global features, resulting in more globally consistent and visually realistic generated images.
- We developed a multi-scale dynamic-windowed attention mechanism, designed to effectively extract features at multiple scales and implement self-attention within windows along both vertical and horizontal dimensions. This mechanism incorporates an agent strategy that optimizes the process of capturing and integrating information while reducing computational complexity.
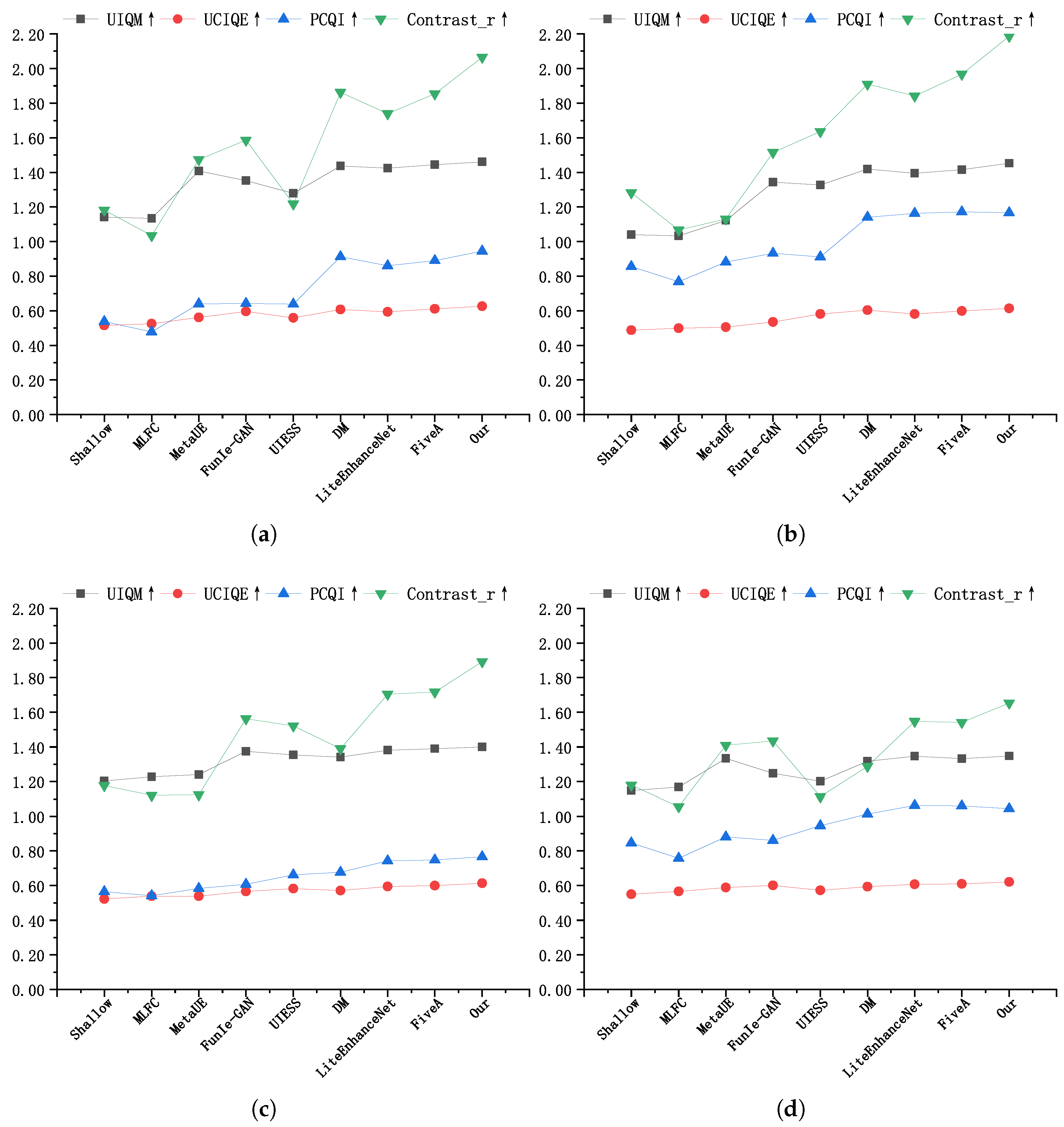
- The comprehensive experimental results demonstrate that the proposed method significantly enhances image details and contrast. Across various standard evaluation metrics, the proposed method shows substantial performance improvement, further validating its effectiveness in the field of underwater image enhancement.
2. Related Work
2.1. Traditional Methods
2.2. Data-Driven-Based Methods
3. Proposed Method
3.1. Diffusion Model-Based Generator
3.1.1. Multi-Scale Dynamic-Windowed Attention Module
3.1.2. Objective
| Algorithm 1 ALDiff-UIE Training and Inference |
Require: Paired dataset , noise schedule Ensure: Trained generator and discriminator
|
4. Experiments
4.1. Implementation Details
4.2. Qualitative Comparisons
4.3. Quantitative Comparisons
4.4. Ablation Study
- woMDWA: Removing the multi-scale dynamic-windowed attention mechanism from the proposed model to investigate its key role in the image enhancement task.
- woDIS: Removing the discriminator from the proposed model to evaluate its impact on the overall model performance.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alsakar, Y.M.; Sakr, N.A.; El-Sappagh, S.; Abuhmed, T.; Elmogy, M. Underwater image restoration and enhancement: A comprehensive review of recent trends, challenges, and applications. Vis. Comput. 2025, 41, 3735–3783. [Google Scholar] [CrossRef]
- Raveendran, S.; Patil, M.D.; Birajdar, G.K. Underwater image enhancement: A comprehensive review, recent trends, challenges and applications. Artif. Intell. Rev. 2021, 54, 5413–5467. [Google Scholar] [CrossRef]
- Cong, X.; Zhao, Y.; Gui, J.; Hou, J.; Tao, D. A comprehensive survey on underwater image enhancement based on deep learning. arXiv 2024, arXiv:2405.19684. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 28th International Conference on Neural Information Processing Systems(NIPS’14), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Zhang, W.; Cui, B.; Yang, M.H. Diffusion models: A comprehensive survey of methods and applications. ACM Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, T.; Zhang, W. Underwater vision enhancement technologies: A comprehensive review, challenges, and recent trends. Appl. Intell. 2023, 53, 3594–3621. [Google Scholar] [CrossRef]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater Single Image Color Restoration Using Haze-Lines and a New Quantitative Dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2822–2837. [Google Scholar] [CrossRef]
- Muniraj, M.; Dhandapani, V. Underwater image enhancement by combining color constancy and dehazing based on depth estimation. Neurocomputing 2021, 460, 211–230. [Google Scholar] [CrossRef]
- Li, Z. Physics-based Underwater Image Enhancement. In Proceedings of the 2023 IEEE 6th International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 23–25 September 2023; pp. 1020–1024. [Google Scholar] [CrossRef]
- Li, C.Y.; Guo, J.C.; Cong, R.M.; Pang, Y.W.; Wang, B. Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, C.; Sun, B.; Yan, X.; Chen, M. A novel multi-scale fusion framework for detail-preserving low-light image enhancement. Inf. Sci. 2021, 548, 378–397. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, T.; Dong, J.; Yu, H. Underwater image enhancement via extended multi-scale Retinex. Neurocomputing 2017, 245, 1–9. [Google Scholar] [CrossRef]
- Zhuang, P.; Li, C.; Wu, J. Bayesian retinex underwater image enhancement. Eng. Appl. Artif. Intell. 2021, 101, 104171. [Google Scholar] [CrossRef]
- Wu, S.; Luo, T.; Jiang, G.; Yu, M.; Xu, H.; Zhu, Z.; Song, Y. A two-stage underwater enhancement network based on structure decomposition and characteristics of underwater imaging. IEEE J. Ocean. Eng. 2021, 46, 1213–1227. [Google Scholar] [CrossRef]
- Jiang, J.; Ye, T.; Bai, J.; Chen, S.; Chai, W.; Jun, S.; Liu, Y.; Chen, E. Five A+ Network: You Only Need 9K Parameters for Underwater Image Enhancement. arXiv 2023, arXiv:2305.08824. [Google Scholar]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Khandouzi, A.; Ezoji, M. Coarse-to-fine underwater image enhancement with lightweight CNN and attention-based refinement. J. Vis. Commun. Image Represent. 2024, 99, 104068. [Google Scholar] [CrossRef]
- Liu, X.; Gao, Z.; Chen, B.M. MLFcGAN: Multilevel feature fusion-based conditional GAN for underwater image color correction. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1488–1492. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Zhang, D.; Wu, C.; Zhou, J.; Zhang, W.; Li, C.; Lin, Z. Hierarchical attention aggregation with multi-resolution feature learning for GAN-based underwater image enhancement. Eng. Appl. Artif. Intell. 2023, 125, 106743. [Google Scholar] [CrossRef]
- Chaurasia, D.; Chhikara, P. Sea-Pix-GAN: Underwater image enhancement using adversarial neural network. J. Vis. Commun. Image Represent. 2024, 98, 104021. [Google Scholar] [CrossRef]
- Gao, Z.; Yang, J.; Zhang, L.; Jiang, F.; Jiao, X. TEGAN: Transformer Embedded Generative Adversarial Network for Underwater Image Enhancement. Cogn. Comput. 2024, 16, 191–214. [Google Scholar] [CrossRef]
- Ren, T.; Xu, H.; Jiang, G.; Yu, M.; Zhang, X.; Wang, B.; Luo, T. Reinforced swin-convs transformer for simultaneous underwater sensing scene image enhancement and super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4209616. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef]
- Khan, R.; Mishra, P.; Mehta, N.; Phutke, S.S.; Vipparthi, S.K.; Nandi, S.; Murala, S. Spectroformer: Multi-Domain Query Cascaded Transformer Network for Underwater Image Enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 1454–1463. [Google Scholar]
- Shen, Z.; Xu, H.; Luo, T.; Song, Y.; He, Z. UDAformer: Underwater image enhancement based on dual attention transformer. Comput. Graph. 2023, 111, 77–88. [Google Scholar] [CrossRef]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2256–2265. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Lu, S.; Guan, F.; Zhang, H.; Lai, H. Underwater image enhancement method based on denoising diffusion probabilistic model. J. Vis. Commun. Image Represent. 2023, 96, 103926. [Google Scholar] [CrossRef]
- Tang, Y.; Kawasaki, H.; Iwaguchi, T. Underwater Image Enhancement by Transformer-based Diffusion Model with Non-uniform Sampling for Skip Strategy. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 5419–5427. [Google Scholar]
- Shi, X.; Wang, Y.G. CPDM: Content-Preserving Diffusion Model for Underwater Image Enhancement. arXiv 2024, arXiv:2401.15649. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Dong, C.; Cai, W. Learning A Physical-aware Diffusion Model Based on Transformer for Underwater Image Enhancement. arXiv 2024, arXiv:2403.01497. [Google Scholar]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Wang, S.; Ma, K.; Yeganeh, H.; Wang, Z.; Lin, W. A patch-structure representation method for quality assessment of contrast changed images. IEEE Signal Process. Lett. 2015, 22, 2387–2390. [Google Scholar] [CrossRef]
- Tsai, D.Y.; Lee, Y.; Matsuyama, E. Information entropy measure for evaluation of image quality. J. Digit. Imaging 2008, 21, 338–347. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Fu, X.; Cao, X. Underwater image enhancement with global–local networks and compressed-histogram equalization. Signal Process. Image Commun. 2020, 86, 115892. [Google Scholar] [CrossRef]
- Zhang, Z.; Yan, H.; Tang, K.; Duan, Y. MetaUE: Model-based Meta-learning for Underwater Image Enhancement. arXiv 2023, arXiv:2303.06543. [Google Scholar]
- Chen, Y.W.; Pei, S.C. Domain Adaptation for Underwater Image Enhancement via Content and Style Separation. IEEE Access 2022, 10, 90523–90534. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, S.; An, D.; Li, D.; Zhao, R. LiteEnhanceNet: A lightweight network for real-time single underwater image enhancement. Expert Syst. Appl. 2024, 240, 122546. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wang, W. A fusion adversarial underwater image enhancement network with a public test dataset. arXiv 2019, arXiv:1906.06819. [Google Scholar]
- Islam, M.J.; Edge, C.; Xiao, Y.; Luo, P.; Mehtaz, M.; Morse, C.; Enan, S.S.; Sattar, J. Semantic segmentation of underwater imagery: Dataset and benchmark. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 1769–1776. [Google Scholar]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Hautiere, N.; Tarel, J.P.; Aubert, D.; Dumont, E. Blind contrast enhancement assessment by gradient ratioing at visible edges. Image Anal. Stereol. 2008, 27, 87–95. [Google Scholar] [CrossRef]
- Korhonen, J.; You, J. Peak signal-to-noise ratio revisited: Is simple beautiful? In Proceedings of the 2012 Fourth International Workshop on Quality of Multimedia Experience, Melbourne, VIC, Australia, 5–7 July 2012; pp. 37–38. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Yang, Y.; Ming, J.; Yu, N. Color image quality assessment based on CIEDE2000. Adv. Multimed. 2012, 2012, 273723. [Google Scholar] [CrossRef]
- Guo, C.; Wu, R.; Jin, X.; Han, L.; Zhang, W.; Chai, Z.; Li, C. Underwater ranker: Learn which is better and how to be better. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 702–709. [Google Scholar]
- Huang, S.; Wang, K.; Liu, H.; Chen, J.; Li, Y. Contrastive semi-supervised learning for underwater image restoration via reliable bank. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18145–18155. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Methods | Figure 3 | Figure 4 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (I) | (II) | (III) | (IV) | (I) | (II) | (III) | (IV) | ||
| UCIQE ↑ | Shallow [39] | 0.535 | 0.616 | 0.448 | 0.391 | 0.535 | 0.458 | 0.497 | 0.448 |
| MLFCGAN [19] | 0.550 | 0.628 | 0.455 | 0.382 | 0.550 | 0.504 | 0.483 | 0.407 | |
| MetaUE [40] | 0.565 | 0.637 | 0.519 | 0.555 | 0.565 | 0.503 | 0.526 | 0.452 | |
| FUnIE [20] | 0.579 | 0.613 | 0.494 | 0.548 | 0.579 | 0.519 | 0.561 | 0.485 | |
| UIESS [41] | 0.592 | 0.652 | 0.585 | 0.615 | 0.592 | 0.514 | 0.589 | 0.560 | |
| DM [31] | 0.626 | 0.658 | 0.570 | 0.530 | 0.626 | 0.475 | 0.621 | 0.561 | |
| LiteEnhanceNet [42] | 0.615 | 0.646 | 0.585 | 0.504 | 0.615 | 0.542 | 0.629 | 0.545 | |
| FiveA [16] | 0.622 | 0.639 | 0.604 | 0.586 | 0.622 | 0.560 | 0.632 | 0.603 | |
| Proposed | 0.649 | 0.638 | 0.607 | 0.621 | 0.649 | 0.579 | 0.639 | 0.592 | |
| PCQI ↑ | Shallow [39] | 0.602 | 0.504 | 0.556 | 0.529 | 0.602 | 0.987 | 0.797 | 0.744 |
| MLFCGAN [19] | 0.539 | 0.433 | 0.467 | 0.489 | 0.539 | 0.972 | 0.665 | 0.581 | |
| MetaUE [40] | 0.729 | 0.587 | 0.631 | 0.888 | 0.729 | 1.020 | 0.834 | 0.827 | |
| FUnIE [20] | 0.667 | 0.737 | 0.718 | 0.344 | 0.732 | 0.945 | 0.771 | 0.999 | |
| UIESS [41] | 0.650 | 0.453 | 0.676 | 0.924 | 0.650 | 1.165 | 0.902 | 0.821 | |
| DM [31] | 0.886 | 0.717 | 0.960 | 0.970 | 0.886 | 1.094 | 1.111 | 1.306 | |
| LiteEnhanceNet [42] | 0.948 | 0.817 | 1.031 | 0.997 | 0.948 | 1.246 | 1.222 | 1.246 | |
| FiveA [16] | 0.959 | 0.766 | 1.098 | 1.137 | 0.959 | 1.235 | 1.250 | 1.302 | |
| Proposed | 0.976 | 0.936 | 1.237 | 1.283 | 0.976 | 1.276 | 1.324 | 1.343 | |
| Entropy ↑ | Shallow [39] | 7.490 | 7.139 | 6.831 | 6.147 | 7.490 | 7.406 | 7.051 | 7.030 |
| MLFCGAN [19] | 7.579 | 7.147 | 6.997 | 6.443 | 7.579 | 7.496 | 7.192 | 7.255 | |
| MetaUE [40] | 7.607 | 7.391 | 7.048 | 7.306 | 7.607 | 7.233 | 7.051 | 6.999 | |
| FUnIE [20] | 7.689 | 7.301 | 7.107 | 7.312 | 7.689 | 7.403 | 7.357 | 7.392 | |
| UIESS [41] | 7.667 | 7.225 | 7.400 | 7.346 | 7.667 | 7.429 | 7.413 | 7.370 | |
| DM [31] | 7.847 | 7.479 | 7.484 | 7.123 | 7.847 | 7.541 | 7.673 | 7.533 | |
| LiteEnhanceNet [42] | 7.849 | 7.525 | 7.694 | 7.008 | 7.849 | 7.694 | 7.685 | 7.490 | |
| FiveA [16] | 7.876 | 7.589 | 7.750 | 7.461 | 7.876 | 7.767 | 7.733 | 7.774 | |
| Proposed | 7.889 | 7.530 | 7.751 | 7.658 | 7.889 | 7.859 | 7.876 | 7.772 | |
| Metrics | Methods | Figure 5 | Figure 6 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (I) | (II) | (III) | (IV) | (I) | (II) | (III) | (IV) | ||
| UCIQE ↑ | Shallow [39] | 0.487 | 0.544 | 0.556 | 0.357 | 0.399 | 0.544 | 0.618 | 0.471 |
| MLFCGAN [19] | 0.533 | 0.568 | 0.564 | 0.379 | 0.402 | 0.590 | 0.651 | 0.500 | |
| MetaUE [40] | 0.480 | 0.541 | 0.557 | 0.358 | 0.414 | 0.564 | 0.623 | 0.489 | |
| FUnIE [20] | 0.533 | 0.568 | 0.564 | 0.379 | 0.402 | 0.590 | 0.651 | 0.500 | |
| UIESS [41] | 0.544 | 0.579 | 0.583 | 0.421 | 0.478 | 0.587 | 0.656 | 0.539 | |
| DM [31] | 0.492 | 0.551 | 0.552 | 0.447 | 0.496 | 0.566 | 0.632 | 0.581 | |
| LiteEnhanceNet [42] | 0.559 | 0.599 | 0.620 | 0.452 | 0.487 | 0.577 | 0.661 | 0.534 | |
| FiveA [16] | 0.576 | 0.601 | 0.630 | 0.537 | 0.578 | 0.577 | 0.671 | 0.554 | |
| Proposed | 0.582 | 0.616 | 0.635 | 0.558 | 0.583 | 0.578 | 0.692 | 0.617 | |
| PCQI ↑ | Shallow [39] | 0.550 | 0.693 | 0.678 | 0.252 | 0.632 | 0.940 | 0.744 | 0.953 |
| MLFCGAN [19] | 0.509 | 0.626 | 0.660 | 0.188 | 0.534 | 0.833 | 0.584 | 0.827 | |
| MetaUE [40] | 0.594 | 0.797 | 0.749 | 0.359 | 0.917 | 0.978 | 0.879 | 0.999 | |
| FUnIE [20] | 0.667 | 0.737 | 0.718 | 0.344 | 0.732 | 0.945 | 0.771 | 0.999 | |
| UIESS [41] | 0.757 | 0.828 | 0.759 | 0.473 | 0.981 | 0.903 | 0.787 | 0.984 | |
| DM [31] | 0.611 | 0.890 | 0.815 | 0.661 | 1.151 | 0.973 | 1.014 | 1.047 | |
| LiteEnhanceNet [42] | 0.922 | 1.108 | 0.949 | 0.694 | 1.219 | 1.069 | 0.947 | 1.072 | |
| FiveA [16] | 0.941 | 1.070 | 0.933 | 0.882 | 1.322 | 1.068 | 1.029 | 1.061 | |
| Proposed | 1.079 | 1.140 | 1.097 | 0.955 | 1.390 | 1.111 | 1.076 | 1.033 | |
| Entropy ↑ | Shallow [39] | 7.183 | 7.674 | 7.747 | 6.828 | 7.364 | 7.539 | 7.090 | 7.459 |
| MLFCGAN [19] | 7.314 | 7.692 | 7.772 | 6.737 | 7.302 | 7.491 | 6.979 | 7.033 | |
| MetaUE [40] | 7.197 | 7.540 | 7.652 | 6.850 | 7.295 | 7.555 | 7.114 | 7.285 | |
| FUnIE [20] | 7.543 | 7.686 | 7.794 | 7.119 | 7.467 | 7.615 | 7.308 | 7.474 | |
| UIESS [41] | 7.532 | 7.629 | 7.732 | 6.331 | 7.062 | 7.446 | 7.338 | 7.522 | |
| DM [31] | 7.168 | 7.606 | 7.665 | 6.473 | 7.009 | 7.513 | 7.191 | 7.643 | |
| LiteEnhanceNet [42] | 7.666 | 7.787 | 7.883 | 6.876 | 7.154 | 7.663 | 7.715 | 7.525 | |
| FiveA [16] | 7.723 | 7.771 | 7.864 | 7.276 | 7.514 | 7.597 | 7.541 | 7.686 | |
| Proposed | 7.846 | 7.826 | 7.907 | 7.418 | 7.633 | 7.799 | 7.853 | 7.602 | |
| Methods | Params (M) | Testing per Image (s) |
|---|---|---|
| Shallow [39] | 7.40 M | 0.05 |
| MLFCGAN [19] | 565.6 M | 0.06 |
| MetaUE [40] | 24.42 M | 0.49 |
| FUnIE [20] | 7.02 M | 0.135 |
| UIESS [41] | 4.26 M | 0.006 |
| DM [31] | 10 M | 0.16 |
| LiteEnhanceNet [42] | 1.64 M | 0.114 |
| FiveA [16] | 0.01 M | 0.03 |
| Proposed | 65.59 M | 22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, X.; Chen, X.; Sui, Y.; Wang, Y.; Zhang, J. Underwater Image Enhancement Using a Diffusion Model with Adversarial Learning. J. Imaging 2025, 11, 212. https://doi.org/10.3390/jimaging11070212
Ding X, Chen X, Sui Y, Wang Y, Zhang J. Underwater Image Enhancement Using a Diffusion Model with Adversarial Learning. Journal of Imaging. 2025; 11(7):212. https://doi.org/10.3390/jimaging11070212
Chicago/Turabian StyleDing, Xueyan, Xiyu Chen, Yixin Sui, Yafei Wang, and Jianxin Zhang. 2025. "Underwater Image Enhancement Using a Diffusion Model with Adversarial Learning" Journal of Imaging 11, no. 7: 212. https://doi.org/10.3390/jimaging11070212
APA StyleDing, X., Chen, X., Sui, Y., Wang, Y., & Zhang, J. (2025). Underwater Image Enhancement Using a Diffusion Model with Adversarial Learning. Journal of Imaging, 11(7), 212. https://doi.org/10.3390/jimaging11070212