
Historical Manuscripts Analysis: A Deep Learning System for Writer Identification Using Intelligent Feature Selection with Vision Transformers


 ,
,  ,
, 
Abstract
1. Introduction
- -
- Document preprocessing: Initially, we employ techniques such as denoising and binarization to enhance the quality of manuscript images. This step involves reducing noise and standardizing document representations to establish a robust foundation for subsequent analysis.
- -
- Feature detection: Following preprocessing, we identify and extract meaningful features from the documents. This enables us to characterize distinct handwriting styles and patterns associated with individual writers. Here, we introduce novel feature selection strategies tailored to the nuances of historical manuscript analysis, aiming to capture the intrinsic variability present in handwritten texts.
- -
- Classification: In the final stage, we integrate vision transformers into our writer identification pipeline. Leveraging their self-attention mechanisms, we capture long-range dependencies and contextual information within manuscript images. This allows us to surpass the limitations of traditional convolutional architectures and achieve superior performance in writer identification tasks.
- -
- Introduction of a novel approach combining intelligent feature detection techniques and vision transformers, resulting in an efficient system for automated writer identification in historical manuscripts with high accuracy.
- -
- We employed effective preprocessing techniques to obtain clean and denoised data, addressing the challenge of limited writing samples by efficiently augmenting our dataset.
- -
- Additionally, we utilized automatic keypoints detection combined with k-means clustering to avoid manual region-of-interest selection, ensuring a good distribution of regions throughout the image and minimizing redundancies and irrelevant information.
- -
- Through a comprehensive comparative analysis, we evaluated the performance of our proposed system against state-of-the-art methods, justifying our methodological choices and demonstrating the effectiveness of our approach across various experimentation scenarios.
2. Related Works
3. Materials and Methods
3.1. Dataset
3.2. Preprocessing
3.2.1. Image Denoising
- Preserving Edges: Bilateral filtering excels in preserving edges within historical scripts, which is essential for maintaining the integrity and legibility of the text during the denoising process. By retaining edge information, the filter ensures that important structural features of the script are not lost, thus aiding in accurate classification.
- Artifact Reduction: Ink traces, worn papers, and other artifacts commonly found in historical manuscripts are effectively reduced through bilateral filtering. By mitigating noise and unwanted elements, such as stains or creases, the filter enhances the clarity of the script, leading to improved classification accuracy.
- Enhancing Feature Extraction: The denoising capabilities of bilateral filtering result in clearer script images, facilitating more efficient feature extraction during subsequent classification stages. By reducing noise and enhancing contrast, the filter enables algorithms to extract meaningful features from the script, which are crucial for accurate writer identification.
3.2.2. Binarization
- ▪
- and are the variances of the background and foreground classes, respectively.
- ▪
- and are the probabilities of occurrence of the background and foreground classes, respectively.
3.3. Features Detection
3.3.1. Features from Accelerated Segment Test (FAST)
3.3.2. Clustering and Patch Extraction
- -
- represents the objective function, and it quantifies the overall quality of the clustering.
- -
- K is the number of clusters that you want to divide your data into.
- -
- n is the total number of data points.
- -
- represents the i-th data point in the j-th cluster.
- -
- is the centroid (mean) of the j-th cluster.
- -
- calculates the squared Euclidean distance between data point and the centroid of cluster j.
- image_height and image_width refer to the dimensions of the original manuscript image.
- patch_height and patch_width represent the fixed size of each patch used as input to the vision transformer model.
- The image is divided uniformly into these smaller patches, with no overlap.
- The product of the two ratios gives the total number of patches K, which are then treated as input tokens in the transformer architecture.
| Algorithm 1. Keypoint-Guided Patch Extraction from Historical Manuscript Images |
| Input: image (grayscale manuscript image) patch_height, patch_width (desired patch size) keypoint_detector (e.g., FAST) Output: patches[] (list of extracted image patches) 1. Preprocess the image: a. Apply bilateral filtering for denoising b. Apply Otsu’s thresholding (optional for clarity) 2. Detect keypoints: keypoints = keypoint_detector(image) 3. Compute the number of clusters: K = (image_height // patch_height) × (image_width // patch_width) 4. Convert keypoints to coordinates: points = [kp.pt for kp in keypoints] 5. Apply K-means clustering: clusters = KMeans(n_clusters=K).fit(points) 6. For each cluster center: a. Center a patch of size (patch_height × patch_width) around the cluster center b. Ensure the patch remains within image bounds c. Extract the patch and append to patches[] 7. Return patches[] |
3.4. Training
3.4.1. Vision Transformer (Vit)
- ▪
- ViTs utilize self-attention mechanisms to compute attention scores between tokens, determining their importance in relation to each other. This attention mechanism facilitates the aggregation of information from all regions of the manuscript simultaneously, enabling effective feature learning across the entire image.
- Q (Query), K (Key), and V (Value) are matrices derived from the input patches (tokens) through learned linear projections.
- computes the similarity between each query and all keys, indicating how much focus each token should place on others.
- is a scaling factor (with dkd_kdk being the dimension of the key vectors) that prevents extremely large dot-product values which could push the softmax function into regions with very small gradients.
- softmax normalizes the similarity scores into attention weights.
- The result is multiplied by V (Value) to generate a weighted sum of values, producing context-aware representations for each input token.
- ▪
- Moreover, ViTs incorporate multiple layers of self-attention modules, each followed by feedforward neural networks (FFNs), to process and refine the learned features. These FFNs introduce non-linear transformations, enhancing the model’s capacity to capture intricate patterns and nuances present in historical manuscripts.
- ▪
- In our system, we integrate positional encodings into the token embeddings to inject spatial information into the model. This ensures that the ViT architecture can differentiate between tokens representing different spatial locations within the manuscript, further enhancing its ability to understand the structural layout of the text.
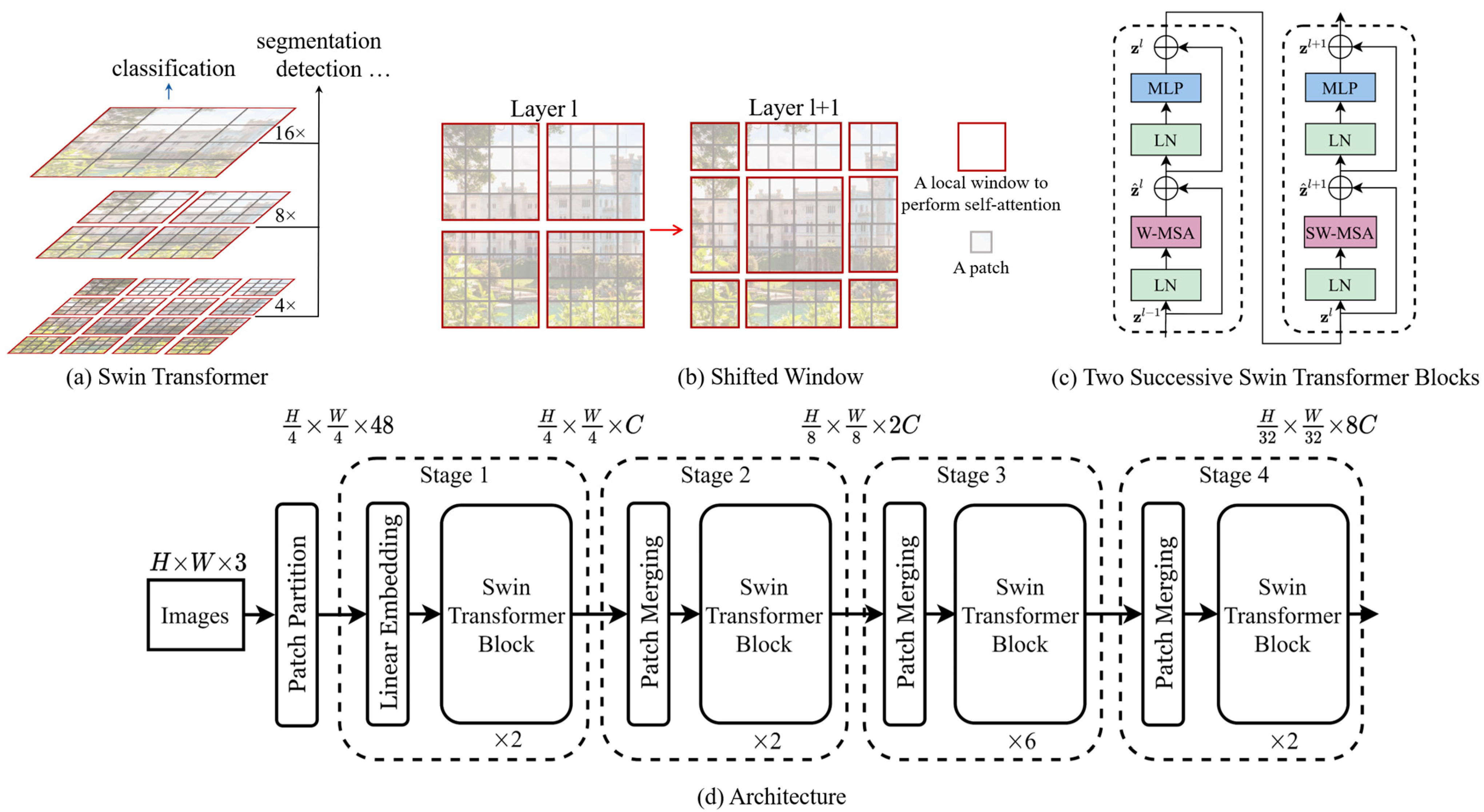
3.4.2. Shifted Windows Transformer (Swin)
3.4.3. Data Efficient Image Transformer (DeiT)
4. Experiments and Results
4.1. Model Hyperparameters
4.2. Impact of Preprocessing
- Baseline Phase: In the initial phase, no preprocessing techniques were applied, and the images were solely resized to match the model’s input dimensions. This served as a baseline to gauge the model’s performance without any additional preprocessing.
- Random Patch Extraction: The subsequent phase involved extracting random patches of uniform dimensions from the images. Unlike the baseline approach, which resized entire images, this strategy randomly sampled patches, introducing variability and diversity into the experiment.
- Preprocessing: In the final phase, patches were extracted based on regions of interest detection. Keypoints were identified using the FAST detector, followed by centroid extraction through k-means clustering. This meticulous process ensured that patches were selected from regions specifically adorned with text, enhancing the relevance of extracted features for writer identification.
4.3. Impact of Patch Size
- ◦
- 150 × 150 Patches: Using smaller patches of size 150 × 150 pixels yielded moderate identification performance, with a Top-1 accuracy of 55.25%, Top-5 accuracy of 78.16%, and Top-10 accuracy of 86.06%. This suggests that while smaller patches may capture finer details, they may also lack sufficient contextual information for accurate writer identification.
- ◦
- 224 × 224 Patches: Increasing the patch size to 224 × 224 pixels resulted in improved identification performance across all metrics. The Top-1 accuracy increased to 66.79%, with the Top-5 accuracy at 84.98% and Top-10 accuracy at 90.45%. This suggests that larger patches provide a better balance between capturing detailed features and preserving contextual information.
- ◦
- 550 × 550 Patches: Optimal identification performance was achieved with patches of size 550 × 550 pixels. The system achieved its highest accuracy, with a Top-1 accuracy of 79.02%, Top-5 accuracy of 88.83%, and Top-10 accuracy of 91.46%. This indicates that patches of this size effectively capture both detailed features and contextual information, facilitating more accurate writer identification.
- ◦
- 750 × 750 Patches: Using larger patches of size 750 × 750 pixels led to a slight decrease in identification performance compared to the optimal patch size. The Top-1 accuracy dropped to 59.54%, with the Top-5 accuracy at 76.98% and Top-10 accuracy at 81.39%. This suggests that larger patches may introduce more irrelevant information or dilute the importance of key features, leading to reduced accuracy.
4.4. Model Selection
4.5. Final System Results
- Highly similar handwriting styles between different writers, especially in short texts.
- Degraded or low-contrast manuscript images, where noise overwhelms distinguishing features.
- Sparse keypoint distributions in pages with limited handwriting content, leading to insufficient patch diversity.
4.6. Performance Comparison
4.7. Limitations and Future Work
5. Conclusions
- -
- Preprocessing: Our approach begins with preprocessing the historical manuscripts, involving bilateral filtering for denoising and Otsu thresholding for binarization. These techniques enhance the quality of the documents, preparing them for subsequent feature extraction.
- -
- Feature Detection: We utilize the FAST method to detect keypoints within the manuscripts, followed by clustering using k-means. This process facilitates the extraction of regions of interest in the form of patches with uniform sizes, optimizing feature representation for classification.
- -
- Classification: The extracted patches are then classified using vision transformer architectures, including VIT, Swin, and Deit. These deep learning models effectively classify the patches based on learned features, enabling accurate writer identification.
- -
- The effectiveness of our preprocessing techniques in enhancing the quality of historical manuscripts.
- -
- The efficacy of our intelligent feature selection method in extracting informative regions from the documents.
- -
- The superior performance of vision transformer architectures in classifying manuscript patches compared to traditional methods.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Siddiqi, I.; Vincent, N. Text independent writer recognition using redundant writing patterns with contour-based orientation and curvature features. Pattern Recognit. 2010, 43, 3853–3865. [Google Scholar] [CrossRef]
- Ghiasi, G.; Safabakhsh, R. Offline Text-Independent Writer Identification Using Codebook and Efficient Code Extraction Methods. Image Vis. Comput. 2013, 31, 379–391. [Google Scholar] [CrossRef]
- Fiel, S.; Sablatnig, R. Writer identification and writer retrieval using the Fisher vector on visual vocabularies. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 545–549. [Google Scholar]
- Abdi, M.N.; Khemakhem, M. A model-based approach to offline textindependent Arabic writer identification and verification. Pattern Recognit. 2015, 48, 1890–1903. [Google Scholar] [CrossRef]
- Bennour, A.; Djeddi, C.; Gattal, A.; Siddiqi, I.; Mekhaznia, T. Handwriting based writer recognition using implicit shape codebook. Forensic Sci. Int. 2019, 301, 91–100. [Google Scholar] [CrossRef]
- Fiel, S.; Hollaus, F.; Gau, M.; Sablatnig, R. Writer identification on historical Glagolitic documents. In Document Recognition and Retrieval XXI; SPIE: Bellingham, WA, USA, 2014; Volume 9021, pp. 9–18. [Google Scholar]
- Fecker, D.; Asit, A.; Märgner, V.; El-Sana, J.; Fingscheidt, T. Writer identification for historical arabic documents. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; IEEE: New York, NY, USA, 2014; pp. 3050–3055. [Google Scholar]
- Asi, A.; Abdalhaleem, A.; Fecker, D.; Märgner, V.; El-Sana, J. On writer identification for Arabic historical manuscripts. Int. J. Doc. Anal. Recognit. 2017, 20, 173–187. [Google Scholar] [CrossRef]
- Gattal, A.; Djeddi, C.; Siddiqi, I.; Al-Maadeed, S. Writer Identification on Historical Documents using Oriented Basic Image Features. In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 369–373. [Google Scholar] [CrossRef]
- Gattal, A.; Djeddi, C.; Abbas, F.; Siddiqi, I.; Bouderah, B. A new method for writer identification based on historical documents. J. Intell. Syst. 2023, 32, 20220244. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995; Volume 3361. [Google Scholar]
- Javidi, M.; Jampour, M. A deep learning framework for text-independent writer identification. Eng. Appl. Artif. Intell. 2020, 95, 103912. [Google Scholar] [CrossRef]
- Xing, L.; Qiao, Y. Deepwriter: A multi-stream deep CNN for text-independent writer identification. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; IEEE: New York, NY, USA, 2016; pp. 584–589. [Google Scholar]
- Semma, A.; Hannad, Y.; Siddiqi, I.; Djeddi, C.; El Kettani, M.E.Y. Writer identification using deep learning with fast keypoints and harris corner detector. Expert Syst. Appl. 2021, 184, 115473. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Nguyen, C.T.; Ino, T.; Indurkhya, B.; Nakagawa, M. Text-independent writer identification using convolutional neural network. Pattern Recognit. Lett. 2019, 121, 104–112. [Google Scholar] [CrossRef]
- Rehman, A.; Naz, S.; Razzak, M.I.; Hameed, I.A. Automatic visual features for writer identification: A deep learning approach. IEEE Access 2019, 7, 17149–17157. [Google Scholar] [CrossRef]
- Cilia, N.D.; De Stefano, C.; Fontanella, F.; Marrocco, C.; Molinara, M.; Di Freca, A.S. An end-to-end deep learning system for medieval writer identification. Pattern Recognit. Lett. 2020, 129, 137–143. [Google Scholar] [CrossRef]
- Chammas, M.; Makhoul, A.; Demerjian, J.; Dannaoui, E. A deep learning based system for writer identification in handwritten Arabic historical manuscripts. Multimed. Tools Appl. 2022, 81, 30769–30784. [Google Scholar] [CrossRef]
- Chammas, M.; Makhoul, A.; Demerjian, J.; Dannaoui, E. An End-to-End deep learning system for writer identification in handwritten Arabic manuscripts. Multimed. Tools Appl. 2023, 83, 54569–54589. [Google Scholar] [CrossRef]
- Bennour, A.; Boudraa, M.; Siddiqi, I.; Al-Sarem, M.; Al-Shaby, M.; Ghabban, F. A deep learning framework for historical manuscripts writer identification using data-driven features. Multimed. Tools Appl. 2024, 83, 80075–80101. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2010, arXiv:2010.11929. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Manzari, O.N.; Ahmadabadi, H.; Kashiani, H.; Shokouhi, S.B.; Ayatollahi, A. MedViT: A robust vision transformer for generalized medical image classification. Comput. Biol. Med. 2023, 157, 106791. [Google Scholar] [CrossRef]
- Bhojanapalli, S.; Chakrabarti, A.; Glasner, D.; Li, D.; Unterthiner, T.; Veit, A. Understanding robustness of transformers for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10231–10241. [Google Scholar]
- Yu, S.; Ma, K.; Bi, Q.; Bian, C.; Ning, M.; He, N.; Li, Y.; Liu, H.; Zheng, Y. Mil-vt: Multiple instance learning enhanced vision transformer for fundus image classification. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–1 October 2021; Proceedings, Part VIII 24; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 45–54. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Boudraa, M.; Bennour, A.; Mekhaznia, T.; Alqarafi, A.; Marie, R.R.; Al-Sarem, M.; Dogra, A. Revolutionizing Historical Document Analysis: A Deep Learning Approach with Intelligent Feature Extraction for Script Classification. Acta Inform. Pragensia 2024, 13, 251–272. [Google Scholar] [CrossRef]
- Bennour, A.; Boudraa, M.; Ghabban, F. HeritageScript: A cutting-edge approach to historical document script classification with CNN and vision transformer architectures. Intell. Decis. Technol. 2024, preprint. [Google Scholar] [CrossRef]
- Boudraa, M.; Bennour, A.; Al-Sarem, M.; Ghabban, F.; Bakhsh, O.A. Contribution to historical document dating: A hybrid approach employing hand-crafted features with vision transformers. Digit. Signal Process. 2024, 149, 104477. [Google Scholar] [CrossRef]
- Fiel, S.; Kleber, F.; Diem, M.; Christlein, V.; Louloudis, G.; Nikos, S.; Gatos, B. Icdar2017 competition on historical document writer identification (historical-wi). In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: New York, NY, USA, 2017; Volume 1, pp. 1377–1382. [Google Scholar]
- Paris, S.; Kornprobst, P.; Tumblin, J.; Durand, F. Bilateral filtering: Theory and applications. Found. Trends® Comput. Graph. Vis. 2009, 4, 1–73. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: New York, NY, USA, 2011; pp. 2564–2571. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 105–119. [Google Scholar] [CrossRef]
- Jin, X.; Han, J. K-Means Clustering. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar]
- Lai, S.; Zhu, Y.; Jin, L. Encoding pathlet and SIFT features with bagged VLAD for historical writer identification. IEEE Trans Inf. Forensics Secur. 2020, 15, 3553–3566. [Google Scholar] [CrossRef]
- Jordan, S.; Seuret, M.; Král, P.; Lenc, L.; Martínek, J.; Wiermann, B.; Schwinger, T.; Maier, A.; Christlein, V. Re-ranking for writer identification and writer retrieval. In International Workshop on Document Analysis Systems; Springer: Cham, Switzerland, 2020; pp. 572–586. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features-Detector | Time (Seconds) | Keypoints Number |
|---|---|---|
| FAST | 0.00001 | 3876 |
| SIFT | 0.2449 | 15,156 |
| ORB | 1.78 | 500 |
| Learning Rate | Optimizer | Top-1 | Top-5 | Top-10 |
|---|---|---|---|---|
| 0.01 | Adam | 0.92 | 3.71 | 7.43 |
| 0.001 | Adam | 26.51 | 51.39 | 62.36 |
| 0.01 | SGD | 79.02 | 88.83 | 91.46 |
| 0.001 | SGD | 61.83 | 79.81 | 86.34 |
| Experiment | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| Without Preprocessing (Only resizing) | 17.53 | 31.07 | 35.93 |
| Random patches | 59.84 | 77.17 | 83.54 |
| With preprocessing | 79.02 | 88.83 | 91.46 |
| Patches Size | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| 150 × 150 | 55.25 | 78.16 | 86.06 |
| 224 × 224 | 66.79 | 84.98 | 90.45 |
| 550 × 550 | 79.02 | 88.83 | 91.46 |
| 750 × 750 | 59.54 | 76.98 | 81.39 |
| Model | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| Vit-Ti | 72.85 | 86.72 | 89.46 |
| Vit-S | 79.02 | 88.83 | 91.46 |
| Vit-B | 73.27 | 86.51 | 89.35 |
| DeiT-S | 75.75 | 87.46 | 89.99 |
| Swin-S | 80.50 | 90.04 | 91.83 |
| Optimizer | Learning Rate | Batch Size | Patch Size | Model | Top-1 | Top-5 | Top-10 |
|---|---|---|---|---|---|---|---|
| SGD | 0.01 | 32 | 550 × 550 | Swin-s | 90.59 | 94.08 | 94.57 |
| Study | Top-1 | Top-10 | |
|---|---|---|---|
| Proposed method | 90.59 | 94.57 | |
| Harris + CNN | [20] | 85.2 | 93.6 |
| VLAD-encoded CNN features | [32] | 88.9 | 93.8 |
| SIFT and pathlet features with bagged-VLAD | [39] | 90.1 | - |
| VLAD-encoded CNN features with reranking | [40] | 89.43 | - |
| Moment-based distance features matching | [8] | 78.75 | 91.08 |
| Combined basic image features | [9] | 77.39 | - |
| OBIF | [32] | 76.4 | - |
| SRS-LBP | 67.0 | 80.1 | |
| SIFT + NBNN | 67.1 | 80.2 | |
| CoHinge features | 76.1 | 85.8 | |
| AngU-Net + R-SIFT | 48 | 92 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boudraa, M.; Bennour, A.; Nahas, M.; Marie, R.R.; Al-Sarem, M. Historical Manuscripts Analysis: A Deep Learning System for Writer Identification Using Intelligent Feature Selection with Vision Transformers. J. Imaging 2025, 11, 204. https://doi.org/10.3390/jimaging11060204
Boudraa M, Bennour A, Nahas M, Marie RR, Al-Sarem M. Historical Manuscripts Analysis: A Deep Learning System for Writer Identification Using Intelligent Feature Selection with Vision Transformers. Journal of Imaging. 2025; 11(6):204. https://doi.org/10.3390/jimaging11060204
Chicago/Turabian StyleBoudraa, Merouane, Akram Bennour, Mouaaz Nahas, Rashiq Rafiq Marie, and Mohammed Al-Sarem. 2025. "Historical Manuscripts Analysis: A Deep Learning System for Writer Identification Using Intelligent Feature Selection with Vision Transformers" Journal of Imaging 11, no. 6: 204. https://doi.org/10.3390/jimaging11060204
APA StyleBoudraa, M., Bennour, A., Nahas, M., Marie, R. R., & Al-Sarem, M. (2025). Historical Manuscripts Analysis: A Deep Learning System for Writer Identification Using Intelligent Feature Selection with Vision Transformers. Journal of Imaging, 11(6), 204. https://doi.org/10.3390/jimaging11060204