1. Introduction
In autonomous driving applications, road object segmentation is a fundamental task that enables self-driving vehicles to perceive and understand their surroundings, ensuring safe and efficient navigation [
1]. Accurate segmentation is essential for autonomous vehicles to operate and navigate without the need for human interaction in dynamic driving environments [
2]. As autonomous driving technology advances, the demand for robust and reliable segmentation models will increase, as road object segmentation is considered a basis for other autonomous driving tasks, such as road object classification, recognition, and tracking [
3]. However, autonomous vehicles still require an accurate segmentation model as the current state of road object segmentation technology is not ideal, and autonomous vehicle perception systems continue to suffer from limitations such as sensor constraints, resolution, susceptibility to adverse weather conditions (e.g., rain and fog), occlusions, and variations in illumination conditions [
4], all of which complicate the segmentation process and compromise the accuracy and reliability of captured road information.
Most of the previously proposed models for image segmentation rely on deep learning techniques [
5,
6,
7] and were often trained and tested in specific scene environments with limited variability. These models may demonstrate strong performance in specific scenarios but often struggle to generalize to diverse road conditions, weather variations, and lighting changes. Moreover, they may be limited in their ability to handle the wide range of object types and road environments encountered in real-world driving scenarios. This inherent limitation of traditional supervised approaches poses significant challenges for autonomous driving systems, which demand highly robust and adaptable object perception in constantly evolving environments.
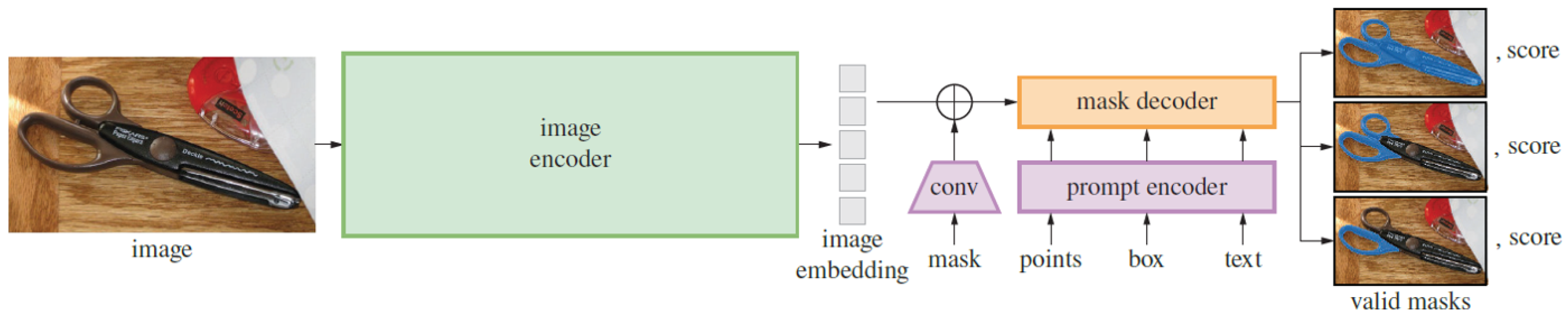
Efforts to eliminate the limitations of existing models have led to the development of Large Vision Models (LVMs), which represent a big leap for computer vision tasks. These models are specially developed to tackle complicated visual tasks by employing deep neural network architectures trained on large-scale datasets. These large models, called foundation models, serve as the building blocks for various vision tasks and provide a solid starting point for further advancements [
8]. One of the notable foundation models in computer vision is the Segment Anything Model (SAM), which is considered the first foundation model for image segmentation [
9]. The SAM foundation model was trained on a large-scale dataset, enabling powerful zero-shot transfer learning and flexible prompting. The SAM has demonstrated strong performance in a wide range of segmentation tasks, and it does not require retraining for specific tasks; instead, it adapts swiftly to a new downstream task [
9].
Despite its advantages, the SAM’s performance in road object segmentation remains largely unexplored. As the SAM has been pretrained on general image datasets, its generalization ability may be limited when applied to specific data sources, such as road object data under varying conditions, including weather, illumination, or crowd density. The SAM has been evaluated in multiple domains, including medical [
10,
11], urban planning [
12], and mobility infrastructure [
13]; each domain presents unique challenges that can affect its accuracy. Given the unique challenges of road object segmentation, such as the need to adapt to changing environments, including dynamic road environments, illumination, and occlusion, it is essential to evaluate the SAM’s ability to handle these tasks effectively. With the SAM’s unprecedented generalization capabilities and its potential to circumvent the extensive retraining burden of traditional models, understanding its direct applicability to the complex and safety-critical domain of road object segmentation is paramount. Consequently, its inherent zero-shot generalization for diverse road object segmentation remains largely unexplored in a comprehensive manner, and the unique challenges it faces in this domain are not yet well defined, representing a critical gap in assessing its immediate utility and limitations for autonomous perception.
Researchers have begun to explore the SAM’s performance in autonomous driving contexts; for instance, the authors of [
14] investigated the SAM’s performance in self-driving tasks under specific adverse weather conditions. However, our study distinguishes itself from previous work by providing a comprehensive zero-shot evaluation across a wider array of diverse road scenes and varying environmental conditions (beyond just specific weather types, e.g., varied illumination, crowd density, and geographical locations). Crucially, we also explicitly define and characterize the specific challenges that the SAM faces in road object segmentation in this unprompted configuration, an aspect not thoroughly detailed in prior evaluations such as [
14]. This foundational zero-shot analysis offers unique insights into the SAM’s intrinsic capabilities before any specialized adaptations. While domain-specific adaptations of the SAM, such as MedSAM [
15] and GeoSAM [
13], have been proposed for other domains, this study focused on evaluating the SAM in a zero-shot setting without explicit prompts in order to establish a clear performance baseline for road object segmentation without task-specific enhancements. We aimed to fill a key research gap by comprehensively evaluating the SAM’s performance in the domain of road object segmentation and by rigorously identifying the challenges it faces in diverse road scenarios. We utilized the “Segment Everything” mode, which allows the SAM to automatically generate masks for all potential objects in a scene, without requiring specific object prompts. This approach is particularly suitable for dynamic environments such as road scenes, where the diversity of objects and constant changes make prompt-based segmentation impractical. We thoroughly evaluated the SAM on the KITTI [
16], BDD100K [
17], and Mapillary Vistas [
18] datasets with varying weather, illumination, and complex road conditions. This evaluation involved a quantitative analysis using standard segmentation metrics alongside qualitative analysis to identify specific challenges. We believe that our findings will be valuable to researchers and developers working on autonomous driving and other road scene understanding applications, guiding future research and development efforts to improve the SAM’s performance and robustness in complex road environments.
The contributions of this study are summarized as follows:
This study presents the pioneering comprehensive evaluation of the Segment Anything Model (SAM) specifically for road object segmentation, with an assessment of its performance across diverse road environmental conditions (occlusion, illumination variations, weather conditions).
This work highlights the specific challenges faced by the SAM in achieving the effective segmentation of road objects under these various environmental conditions, underscoring limitations crucial for its applicability in autonomous driving scenarios.
A thorough quantitative evaluation was conducted using five established evaluation metrics—Mean Intersection over Union (mIoU), Recall, Precision, F1 Score, and Highest IoU—to provide a robust understanding of the SAM’s strengths and weaknesses, complemented by qualitative evidence for visualizing these segmentation challenges.
The SAM’s generalizability and reliability were verified by evaluating it on three publicly available road object datasets that encompass a wide range of real-world road scenarios: KITTI, BDD100K, and Mapillary Vistas.
Valuable insights are provided by identifying specific challenges and providing a detailed quantitative analysis, which can guide future research toward targeted enhancements to improve the accuracy and robustness of the SAM in this critical domain.
The remainder of this paper is organized as follows:
Section 2 provides a review of related work on image segmentation.
Section 3 details the methodology employed for evaluating the SAM in road object segmentation, encompassing the datasets and experimental setup.
Section 4 presents the quantitative and qualitative results obtained from our comprehensive evaluation, and
Section 5 discusses the challenges encountered by the SAM in road object segmentation and suggests recommendations for future research. Finally,
Section 6 concludes the paper.
2. Related Work
Image segmentation is one of the most fundamental research areas in computer vision. It has consistently attracted significant attention from researchers, as it serves as the foundation for pattern recognition and image understanding [
3]. Various methods have been developed for image segmentation, with these approaches evolving and improving over time. Traditional segmentation techniques primarily focused on processing individual images, with notable examples including edge detection [
19], graph theory [
20], and clustering [
21]. However, these early methods had several limitations, such as sensitivity to noise, the need for manual parameter tuning, difficulties in extracting high-level semantic information, and challenges in handling complex images. These limitations motivated a significant shift toward deep learning approaches.
Over the past several years, deep learning approaches, particularly Convolutional Neural Networks (CNNs), have been widely applied to overcome the limitations of traditional methods in image segmentation. The Fully Convolutional Network (FCN) proposed by Long et al. [
22] is considered a pioneering work that enabled pixel-level classification for semantic segmentation by converting classification probabilities into spatial feature maps. FCNs modify standard CNNs by replacing fully connected layers with convolutional layers [
22]. Numerous advances building upon the FCN architecture have been made to better understand spatial relationships and extract features at different levels of detail, aiming for more accurate and efficient segmentation in complex visual scenes. For example, Convolutional Autoencoders (CAEs) [
5,
6] have often been employed for more efficient dimensionality reduction, making models more suitable for real-time applications. The authors of [
6] proposed a hybrid model that combined PSPNet and EfficientNet to create a super-light architecture.
Beyond these initial efforts to increase efficiency, significant advancements have also focused on robust multi-scale feature representation to handle objects of varying sizes in different contexts by using Feature Pyramid Networks (FPNs) to extract multi-scale features for better segmentation results. FPNs achieve this by combining high-level semantic information with low-level detailed features to construct strong semantic features at different scales. For instance, in [
23], multiple predictions at different resolutions were proposed to enhance the segmentation of small objects and narrow structures. Similarly, MPNet [
24] contains a multi-scale prediction module where pairs of adjacent features are combined for three parallel predictions, with an integrated Atrous Spatial Pyramid Pooling (ASPP) module providing further multi-scale contextual information. Other architectural advancements, such as RGPNet [
25], proposed an asymmetric encoder–decoder structure with an adapter module to refine features and improve gradient flow. The authors of [
5] applied CAEs in conjunction with FPNs to extract hierarchical features from images and also incorporated a bottleneck residual network to reduce computational complexity. Building upon such efforts to improve computational efficiency for resource-constrained environments, various lightweight architectures have emerged. These include the Shared Feature Reuse Segmentation (SFRSeg) model [
26], which focuses on shared feature reuse and context mining. Similarly, in [
27], the authors tackle the challenge of real-time performance by proposing an efficient Short-Term Dense Bottleneck (SDB) module and a parallel shallow branch for precise localization. AGLNet [
28], in turn, is based on a lightweight encoder–decoder architecture that specifically aims for efficiency while also incorporating a multi-scale context through attention mechanisms.
Another significant direction in semantic segmentation is the use of dilated convolutions in the DeepLab series and its variants to enlarge the receptive field while maintaining spatial resolution. For example, DeepLabV3+ was integrated with the rapid shift superpixel segmentation technique in [
2]. Moreover, the authors of [
7] modified the DeepLabV3+ framework by incorporating ASPP for more effective multi-scale feature extraction. More recently, attention mechanisms have also been explored to enhance segmentation performance, as seen in DCN-Deeplabv3+ [
29], which improves semantic segmentation by involving dual-attention modules based on the Deeplabv3+ network.
Despite the significant progress achieved by deep learning models in image segmentation, inherent limitations persist. A major challenge lies in the fact that most existing approaches are trained and tested on the same dataset, severely restricting their ability to generalize effectively across diverse environments and scenarios. Furthermore, these segmentation models are typically constrained by dataset-specific learning and predefined classes, which limits their adaptability to novel or unseen object categories.
Table 1 summarizes the performance of various state-of-the-art models that use deep learning approaches for semantic segmentation benchmarks, illustrating current capabilities and inherent challenges in generalization across diverse environments.
Through efforts to overcome these challenges and enhance generalization, the field has witnessed the emergence of Large Vision Models (LVMs), leveraging extensive training on massive datasets to learn more broadly applicable visual representations. A notable LVM that has gained significant prominence, particularly in image segmentation due to its training on a vast and diverse image collection, is the Segment Anything Model (SAM) [
9]. Introduced as the first foundation model specifically for image segmentation, the SAM has an exceptional ability to generate precise segmentation masks for natural images and provides a flexible zero-shot segmentation framework. Numerous studies have been conducted to evaluate the SAM’s performance as an initial step in identifying its strengths and limitations in various domains, including medical imaging [
30,
31], urban environments [
12], and remote scene imagery [
32].
In the medical domain, multiple studies have evaluated the zero-shot segmentation performance of the SAM in various tasks and image modalities [
30,
31,
32,
33,
34]. For instance, the authors of [
30] assessed the SAM’s ability to segment polyps in colonoscopy images and found that it struggled to accurately delineate the often-blurred boundaries between polyps and surrounding tissues. Similarly, the researchers in [
33] evaluated the SAM in segmenting medical lesions and other different modalities, and they concluded that its segmentation results did not surpass those of state-of-the-art methods in these areas. To further broaden the evaluation, the authors of [
31,
34] adopted a broader approach, assessing the SAM’s performance with diverse medical image modalities (MRI, CT, X-ray, ultrasound, PET) and various anatomical structures using different prompting strategies. Meanwhile, in [
34], the authors constructed a large, multi-modal medical image dataset encompassing 84 object categories to thoroughly assess the SAM’s strengths and weaknesses with different modalities. Moreover, the researchers in [
32] evaluated the SAM on various image types, including medical images, remote scene images, and RGB images, focusing on the relationship between perturbations and model vulnerabilities.
Beyond the medical domain, several other studies have also evaluated the SAM’s segmentation performance in other specialized areas, with remote sensing (RS) imagery analysis being a prominent area. For instance, the researchers in [
35] evaluated the SAM’s segmentation performance with different remote sensing modalities (airborne images and satellite images) at varying resolutions. Their observations indicated that, while the SAM’s performance shows promise, it is significantly influenced by the applied prompt and the spatial resolution of the imagery. Lower-resolution images presented a challenge for the SAM in accurately defining boundaries between adjacent objects. Similarly, the authors of [
12] proposed using the SAM to delineate green areas in urban and agricultural landscapes from RS images. The model encountered several challenges, notably difficulties in precisely segmenting urban green belts and complex urban environments characterized by a mixture of various features. Furthermore, the study suggested that large-sized RS images presented computational challenges, potentially due to the overwhelming amount of feature information.
Whereas the aforementioned studies focused on medical and remote sensing imagery, other research has explored the SAM’s capabilities using standard RGB images. For example, in [
36], the authors assessed the SAM for traffic sign segmentation, comparing it against Mask R-CNN using diverse datasets and training data amounts. Their findings indicated that while the SAM did not surpass Mask R-CNN in accuracy, a modified SAM incorporating convolutional layers demonstrated improved generalization. The research also explored the influence of different decoders and analyzed instance-level segmentation, underscoring the SAM’s potential for efficient adaptation in autonomous driving applications.
Consequently, the collective results from these evaluations in various domains indicate an inconsistency in the performance of the SAM. It performs well in certain image modalities or with some objects while struggling with others. This variability appears to be influenced by factors such as the type of chosen prompt, object size, the clarity of boundaries, image complexity, intensity differences, and image resolution. Overall, the aforementioned studies demonstrate that applying the SAM directly in different domains has revealed limitations due to visual differences between these domain-specific images and the natural images on which the SAM was trained. Notably, despite the extensive evaluation of the SAM in domains such as medical imaging and remote sensing, to the best of our knowledge, there is a lack of specific studies dedicated to evaluating the SAM’s performance for road object segmentation under diverse real-world conditions. Based on the results of evaluations in other domains, several studies have focused on adapting the SAM to address these challenges and enhance its performance, aiming to improve its ability to handle domain-specific complexities and its robustness in difficult segmentation tasks.
Numerous studies in the medical domain have attempted to adapt the SAM to enhance its segmentation performance for diverse image modalities. For instance, notable work in this direction is presented in [
10,
15], with a researcher in [
15] introducing the MedSAM model, which was adapted by fine-tuning the SAM on a large-scale medical image segmentation dataset containing 1,570,263 image–mask pairs in 10 imaging modalities and with over 30 cancer types. Although MedSAM demonstrated improved performance over the original SAM, challenges remained, particularly in segmenting vessel-like branching structures, where the suggestions of the bounding box were ambiguous. Similarly, the study in [
10] proposed SAM-Med2D, an adapted version of the SAM tailored for 2D medical image segmentation. This adaptation involved fine-tuning the SAM using a large dataset of 4.6 million medical images and 19.7 million corresponding masks. To integrate medical domain knowledge without retraining the entire model, adapter modules were added to each transformer block of the image encoder. This adaptation technique improved the SAM’s performance and enabled it to generalize better across a variety of medical imaging modalities.
Despite the promise of these adaptations, many still rely heavily on prompt engineering to define Regions of Interest (ROIs), which can be labor-intensive and costly, particularly when working with large datasets and multiple classes. To address this challenge, several studies have explored auto-prompting mechanisms aimed at enhancing the SAM’s performance. In [
11], the researchers integrated YOLOv8 with the SAM and HQ-SAM to enhance ROI segmentation using different medical imaging modalities. YOLOv8 is effective in identifying bounding boxes around ROIs, while the SAM offers advantages in handling ambiguous regions and providing real-time mask estimates. The integration of YOLOv8 with the SAM and HQ-SAM improves both segmentation accuracy and efficiency. Meanwhile, in [
37], the Uncertainty Rectified Segment Anything Model (UR-SAM) framework was proposed to enhance the robustness and reliability of auto-prompting. This approach utilizes prompt augmentation to generate multiple bounding box prompts, producing varied segmentation output. The framework then estimates segmentation uncertainty and applies uncertainty rectification to improve model performance, particularly in challenging medical image segmentation tasks.
In the domain of remote sensing imagery, adaptations of the SAM have been made to tackle the unique challenges associated with geographical segmentation. For example, GeoSAM [
13] was developed to enhance the SAM’s segmentation capabilities for mobility infrastructure such as sidewalks and roads in geographical images. The SAM faced difficulties in segmenting these objects due to issues such as texture blending, narrow features, and occlusions. To overcome these challenges, GeoSAM adapts the mask decoder using parameter-efficient techniques, resulting in more accurate segmentation of mobility infrastructure without the need for human intervention. Similarly, in [
38], the authors employed a fine-tuning strategy for the SAM to improve the segmentation of water bodies, such as lakes and rivers, in RS images. This approach eliminated the need for a prompt encoder, reducing human interaction, by adding learned embeddings to each image feature, which were then supplied to the mask decoder to predict low-resolution masks. As a result of this adaptation, the SAM’s performance was improved compared to deep learning approaches, but with higher computational costs.
Based on a review of the existing literature, it is evident that, while numerous studies have evaluated and adapted the SAM for various domains, its performance in segmenting road objects, particularly under the diverse and dynamic conditions typical of road environments, remains unclear. In a previous study [
14], initial attempts were made to apply the SAM in the autonomous driving domain under different weather conditions, including rain, snow, and fog. However, the authors did not perform a comprehensive analysis of how the SAM handles segmenting road objects when subjected to different factors, such as different illumination levels, different types of roads, and occlusions. Consequently, the specific challenges that the SAM encounters in accurately segmenting road objects in real-world scenarios are still largely undefined and require further exploration. In this study, we aimed to directly address this critical gap by conducting a comprehensive evaluation of the SAM’s ability to segment road objects under complex, real-world conditions. We assessed its performance in various challenging scenarios, meticulously identifying its strengths and limitations in handling the intricacies inherent in road environments.
5. Challenges and Recommendations
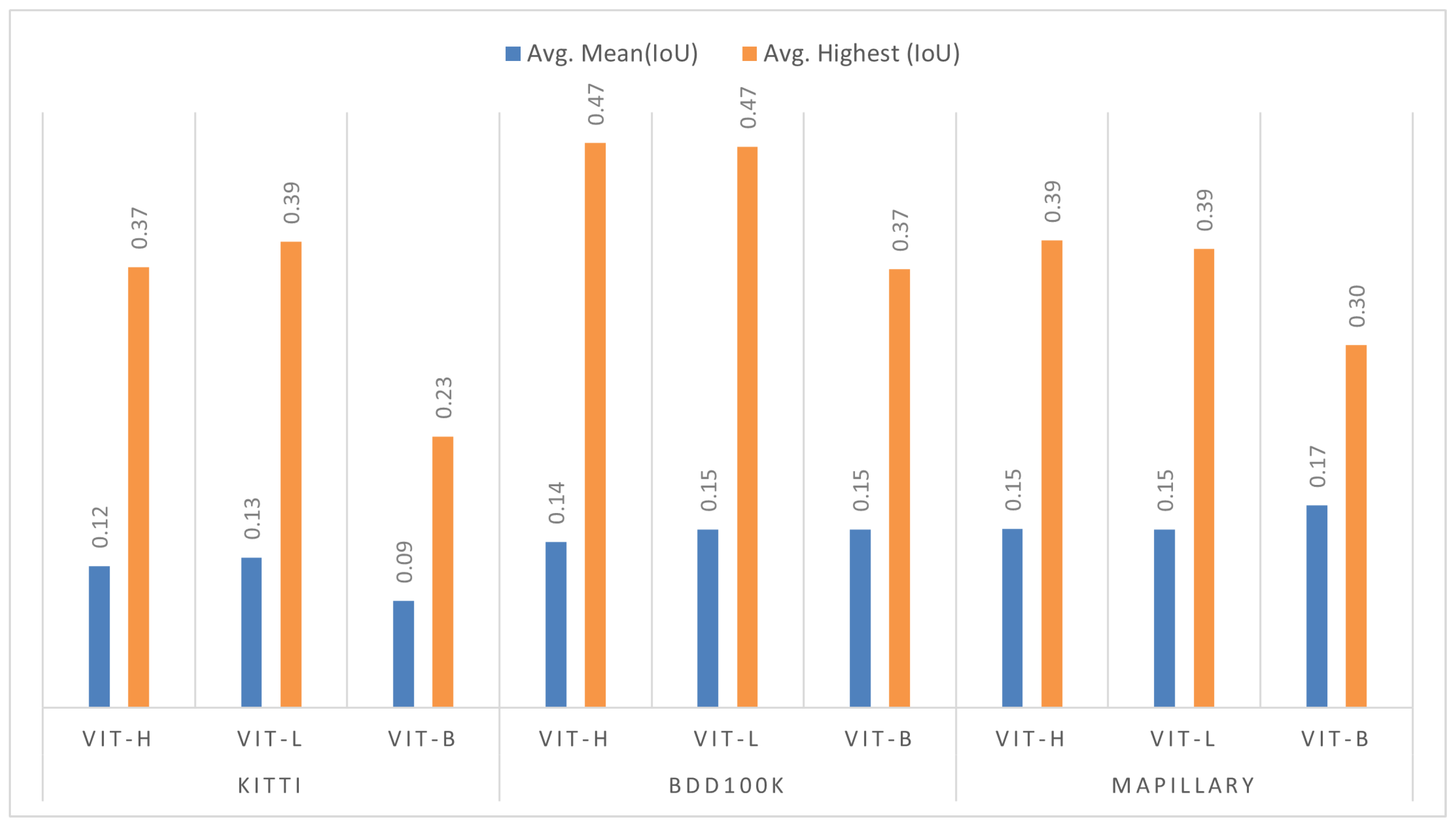
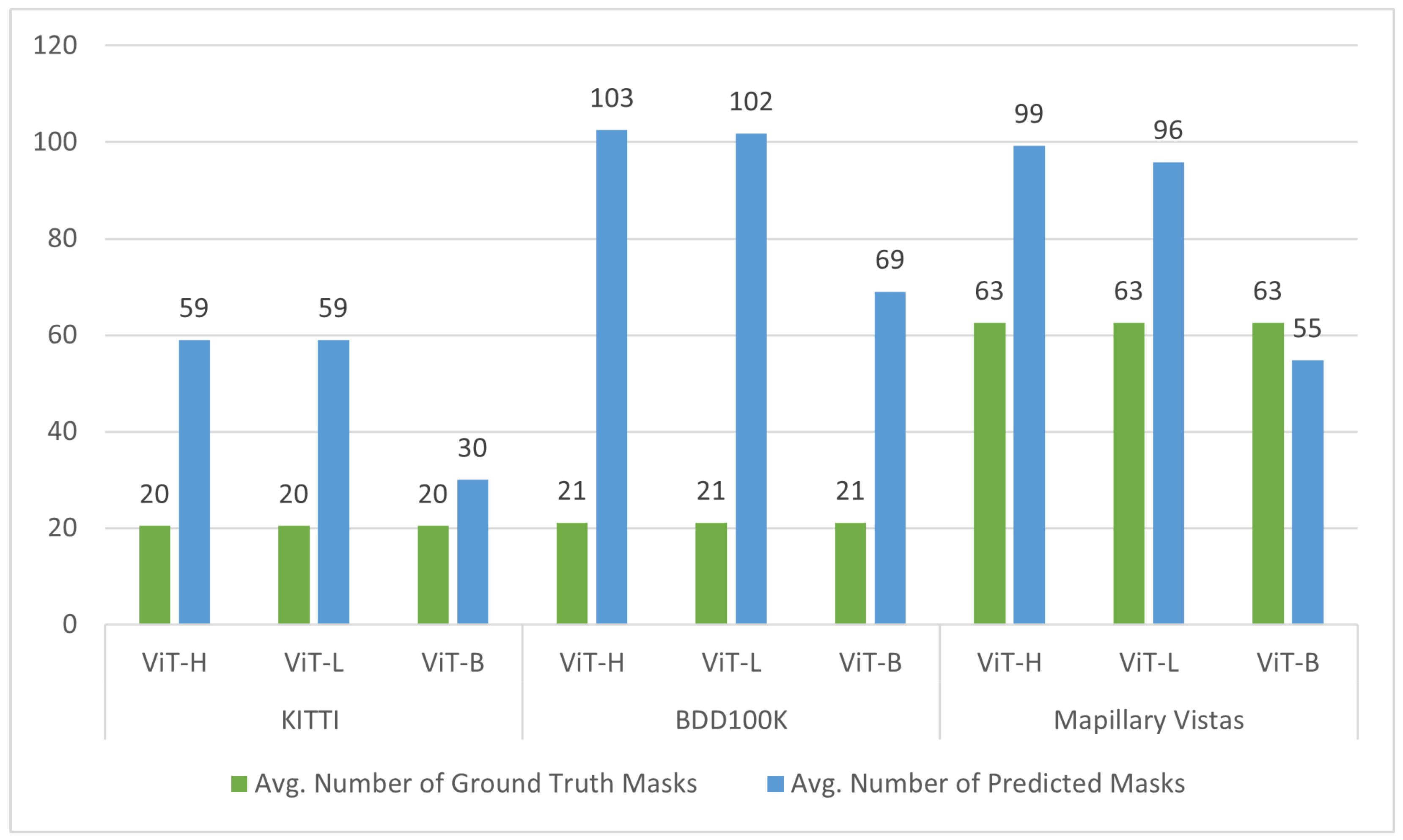
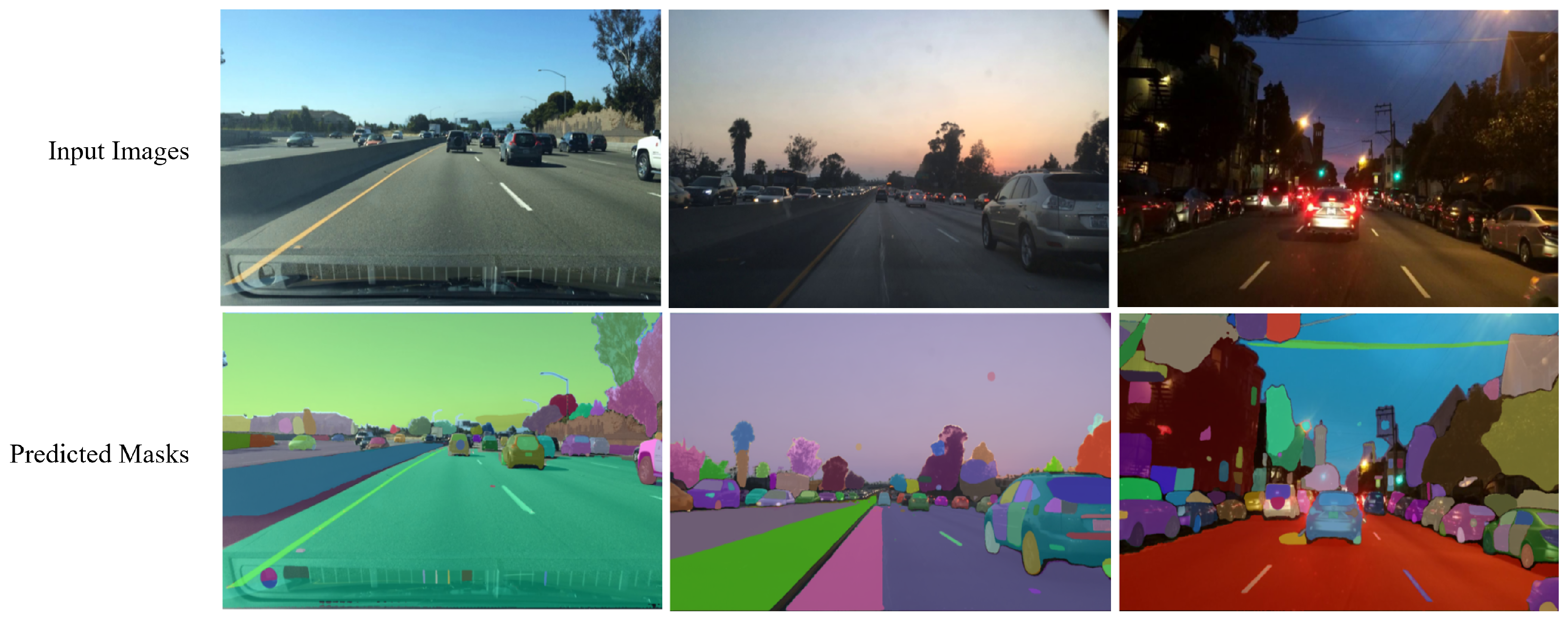
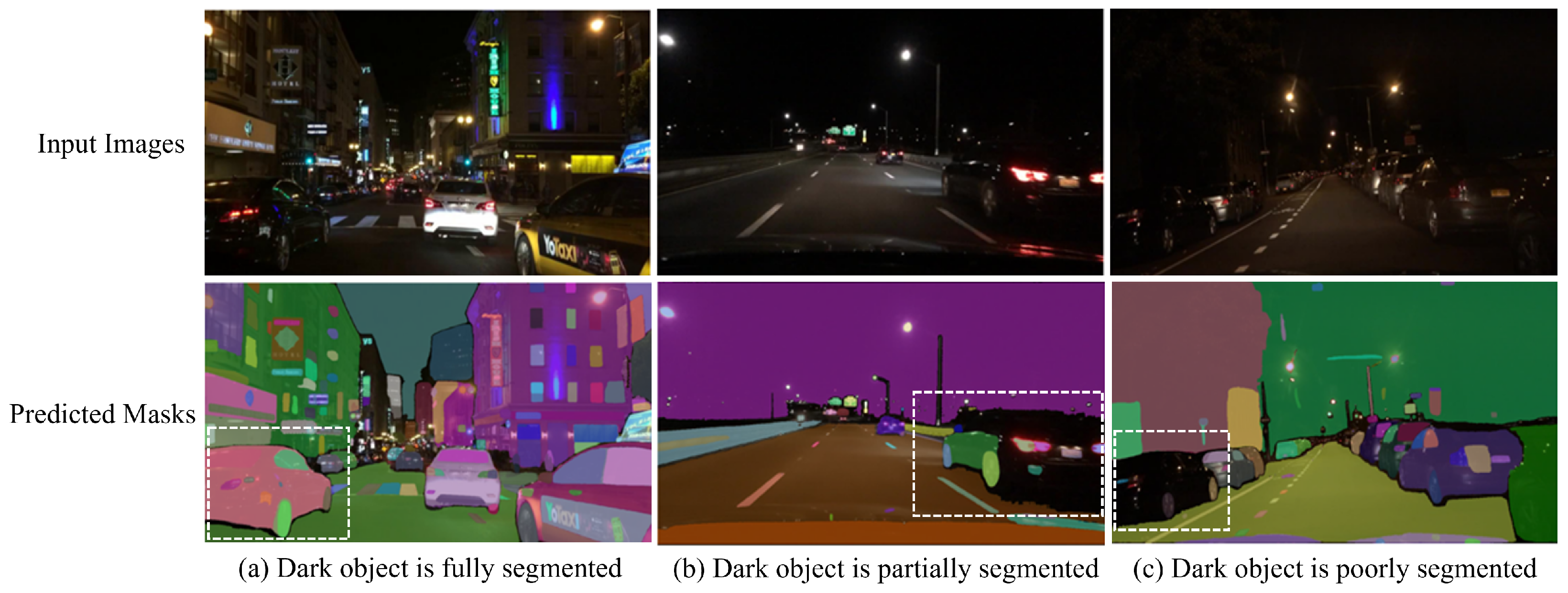
Our comprehensive evaluation of the SAM for zero-shot road object segmentation, conducted without explicit prompts, revealed several key challenges that hinder its accurate and robust performance. Firstly, we observed a crucial trade-off between segmentation accuracy and computational efficiency across different ViT backbones (ViT-H, ViT-L, ViT-B). While larger backbones (ViT-H and ViT-L) generally yielded superior segmentation quality, their increased processing demands pose challenges for real-time autonomous driving systems, where low latency and precise perception are critical for safety, contrasting with the faster inference but reduced accuracy of ViT-B. Secondly, the inherent use of the “Segment Everything” mode resulted in significant over-segmentation, leading to a relatively low overall Mean IoU across all backbones. This issue was often exacerbated by the finer details captured by larger ViTs, which generated more masks. Furthermore, the SAM’s segmentation performance significantly correlated with object size, demonstrating greater segmentation proficiency with larger objects while struggling with smaller ones, particularly those affected by occlusion and background clutter. Finally, the model exhibited significant sensitivity to prevalent environmental factors in road scenes, including shadows, reflections (which it often failed to differentiate from actual objects), and adverse weather and illumination conditions, where rain introduced visual noise, further hindering performance. Moreover, the SAM struggled with border ambiguity, failing to accurately delineate object boundaries for closely positioned or overlapping road objects.
Building upon the insights gained from this evaluation of the SAM’s performance for road object segmentation, future research should explore strategies to overcome the identified challenges and enhance its applicability in real-world road scenarios. We propose the following key recommendations: Firstly, a key direction for future research involves significantly enhancing the SAM’s segmentation performance and robustness in real-world autonomous driving scenarios. This can be approached in two ways: (1) improving the model’s robustness to challenging road scene conditions, such as adverse weather, lighting variations, ambiguous object boundaries, and varying object sizes, through domain adaptation strategies such as fine-tuning on diverse road scene datasets or auto-prompt engineering. Since other studies have enhanced the SAM’s performance through fine-tuning and auto-prompt engineering in other domains, such as medical and remote sensing imagery, these techniques hold great potential for improving its robustness and accuracy in autonomous driving scenarios; (2) developing efficient post-processing techniques to address current limitations such as over-segmentation issues, pushing performance beyond established baselines (30.7–51.8%) [
23,
24,
25,
26,
27,
28,
29]. Such a comprehensive approach will significantly improve the SAM’s flexibility and applicability across varied road environments. Secondly, addressing the significant computational demands of the SAM is paramount for its real-time applicability in autonomous systems. Future work should focus on exploring model optimization techniques, the development of lightweight SAM architectures, and hardware acceleration, which will be critical to achieving the high frame rates required for real-time autonomous perception. Thirdly, targeted investigations are needed to improve SAM’s performance on small and complex road objects, potentially through architectural modifications or specialized training strategies. Finally, to comprehensively benchmark the SAM’s practical utility, future studies should conduct quantitative performance comparisons with established state-of-the-art supervised segmentation models. Such comparisons, particularly after the domain-specific fine-tuning or sophisticated prompt engineering of the SAM, are essential for understanding its competitive standing relative to models specifically optimized for road object segmentation. These recommended research directions will be fundamental to enhancing the SAM’s foundational capabilities, transforming it into a robust and reliable solution for real-time road scene understanding in autonomous vehicles.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}