
Self-Supervised Multi-Task Learning for the Detection and Classification of RHD-Induced Valvular Pathology


Abstract
1. Introduction
- a heavy reliance on echocardiographic features for diagnosis;
- a distinction between “definite” and “borderline” RHD to allow for more nuanced assessments;
- a focus on abnormalities of the mitral and aortic valves, which are most commonly affected by RHD;
- and the use of standardized measurements and criteria to enhance consistency in diagnosis.
2. Materials and Methods
2.1. Dataset Description
- Unlabelled Subset: used for self-supervised pre-training, it included 920 unlabelled static images (with resolutions from 640 × 480 to 836 × 583 pixels) and 832 videos (640 × 480 pixels, 1–4 s, 30/60 fps), yielding 37,117 frames, totalling 38,037 images.
- Labelled Subset: used for supervised fine-tuning, it comprised 21 labelled static images and 20 videos (640 × 480 pixels, ~4 s, 30/60 fps), with 2634 frames extracted, totalling 2655 images. These were annotated for view, condition, and severity.
2.2. Data Labelling Application
- Structured Annotation Drop-Down Options (WHF 2012 Informed): the application provided a drop-down option for inputting various image attributes. It was meticulously designed to capture the key echocardiographic features emphasized by the WHF 2012 guidelines. The metadata options included:
- Echocardiographic Views: users could select from a range of standard views, each providing a distinct perspective on cardiac anatomy and function. The options included:
- o
- Parasternal long axis (PLAX)
- o
- Parasternal short axis (PSAX)
- o
- Apical four chamber (A4C)
- o
- Subcostal
- o
- Suprasternal
- o
- Apical two chamber
- o
- Apical three chamber
- o
- Doppler
Correctly identifying the view was essential for accurate diagnosis, as different views reveal different cardiac structures (e.g., the mitral valve is best visualized in the PLAX and A4C views).- Valve Thickness: users could determine the thickness of the valve leaflets, a key feature assessed in the WHF 2012 criteria. The options were:
- o
- Thick
- o
- Not thick
- o
- Not applicable
- Colour: The presence of colour in an echocardiogram usually indicates the direction and speed of blood flow.
- RHD Conditions: users could select one or more RHD-associated conditions based on the features they observe in the image where applicable. The available options included:
- o
- Mitral valve prolapse
- o
- Mitral valve regurgitation
- o
- Aortic valve regurgitation
- o
- Pulmonary valve regurgitation
- o
- Tricuspid valve regurgitation
- o
- Aortic valve stenosis
- o
- Mitral valve stenosis
- o
- Pulmonary valve stenosis
- o
- Tricuspid valve stenosis
- o
- Not applicable
The WHF 2012 guidelines emphasize the assessment of mitral and aortic valve abnormalities, although other valves may also be affected.- RHD Severity: users could label the severity of RHD according to the WHF 2012 criteria. The options included:
- o
- Definite RHD
- o
- Borderline RHD
- o
- Normal
- o
- Not applicable
- Comments: a free-text comments box was provided for each image, allowing the annotators to describe any additional observations, unusual features, or uncertainty about the assigned labels. This allowed for more nuanced information to be gathered about the images or videos.
- Progress Bar: a progress bar, as seen in Figure 3 above, was present to indicate the user’s annotation progress, motivating users to complete the labelling task.
- Database Integration: the application seamlessly integrates with a MySQL database, enabling the efficient storage, retrieval, and management of annotated data.
2.3. Data Preprocessing and Augmentation
- Image Resizing: images were resized to a consistent size of [224 × 224] to ensure uniform input to the models.
- Pixel Intensity Normalisation: pixel intensities were normalised to a range of 0–1 to improve model performance and prevent bias due to variations in image brightness.
- Grayscale Conversion: images were converted to grayscale to reduce computational complexity and potentially improve model robustness to variations in colour.
- Random cropping: randomly cropping image sections to create variations in the field of view.
- Horizontal flipping: randomly flipping images horizontally to augment the dataset with mirrored versions.
- Random rotations: rotating images by random angles within the range of [−15 to 15 degrees] to introduce rotational variations.
- Brightness/contrast adjustments: adjusted brightness and contrast within the range of [−0.2 to 0.2] to simulate variations in imaging conditions.
- Padding: to protect patient privacy when handling medical images, especially patient information around the images, padding was used. By padding the area containing patient information with a constant value, the aspect ratio of the images was maintained, and shearing was avoided.
2.4. Self-Supervised Learning
2.4.1. SimCLR Implementation
- Early layers: detect edges and textures (e.g., heart chamber boundaries).
- Middle layers: recognize shapes (e.g., valves, myocardium).
- Final layers: capture complex spatial relationships such as blood flow patterns.
- View classification (e.g., apical four chamber, parasternal long axis)
- RHD condition detection (e.g., mitral regurgitation, aortic stenosis)
- RHD severity assessment (e.g., borderline RHD/definite RHD)
2.4.2. DINOv2 Implementation
- Divides the image into 16 × 16 patches (e.g., splitting a 224 × 224 image into 196 patches).
- Flattens each patch into a 1D vector and adds positional embeddings to retain spatial context.
- Processes patches through transformer layers that use self-attention mechanisms. Self-attention allows the model to weigh relationships between all patches simultaneously—for example, linking a valve patch to adjacent blood flow patterns. The output is a 768-dimensional feature vector (Figure 6, Block 4) encoding global image context.
- Student network: updated via gradient descent to predict the teacher’s output.
- Teacher network: a slowly updated version of the student (using exponential moving averages).
- General patterns from self-supervised pre-training (e.g., cardiac anatomy).
- Task-specific signals from fine-tuning (e.g., severity thresholds).
2.5. Multitask Learning
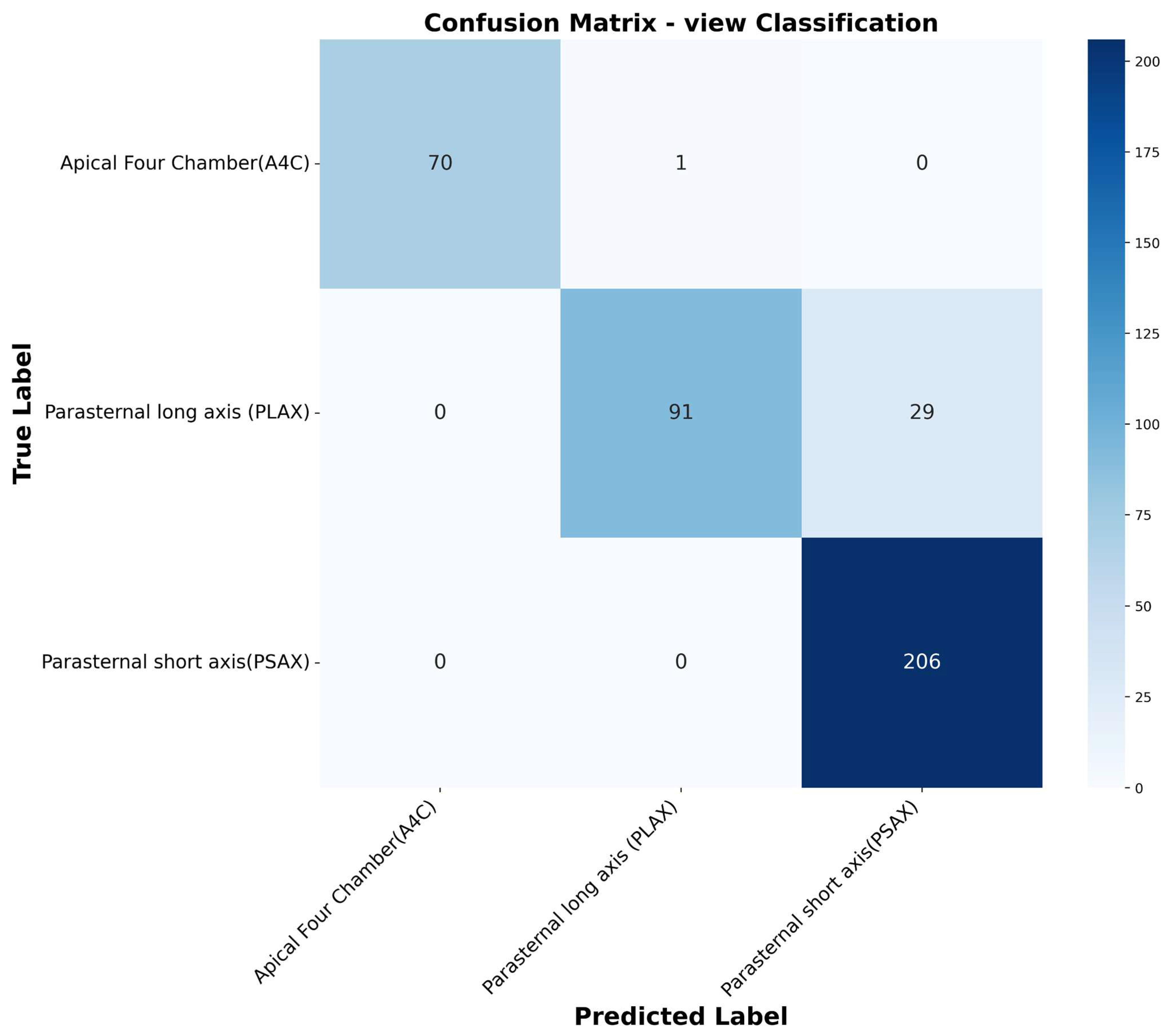
- View classification: the model learns to identify three different echocardiographic views, i.e., the parasternal long axis, parasternal short axis, and apical four chamber. This ensures proper image acquisition angles in real life.
- Condition detection: using the same encoded features, the model identifies various heart valve conditions indicative of RHD, such as mitral valve regurgitation and aortic valve regurgitation.
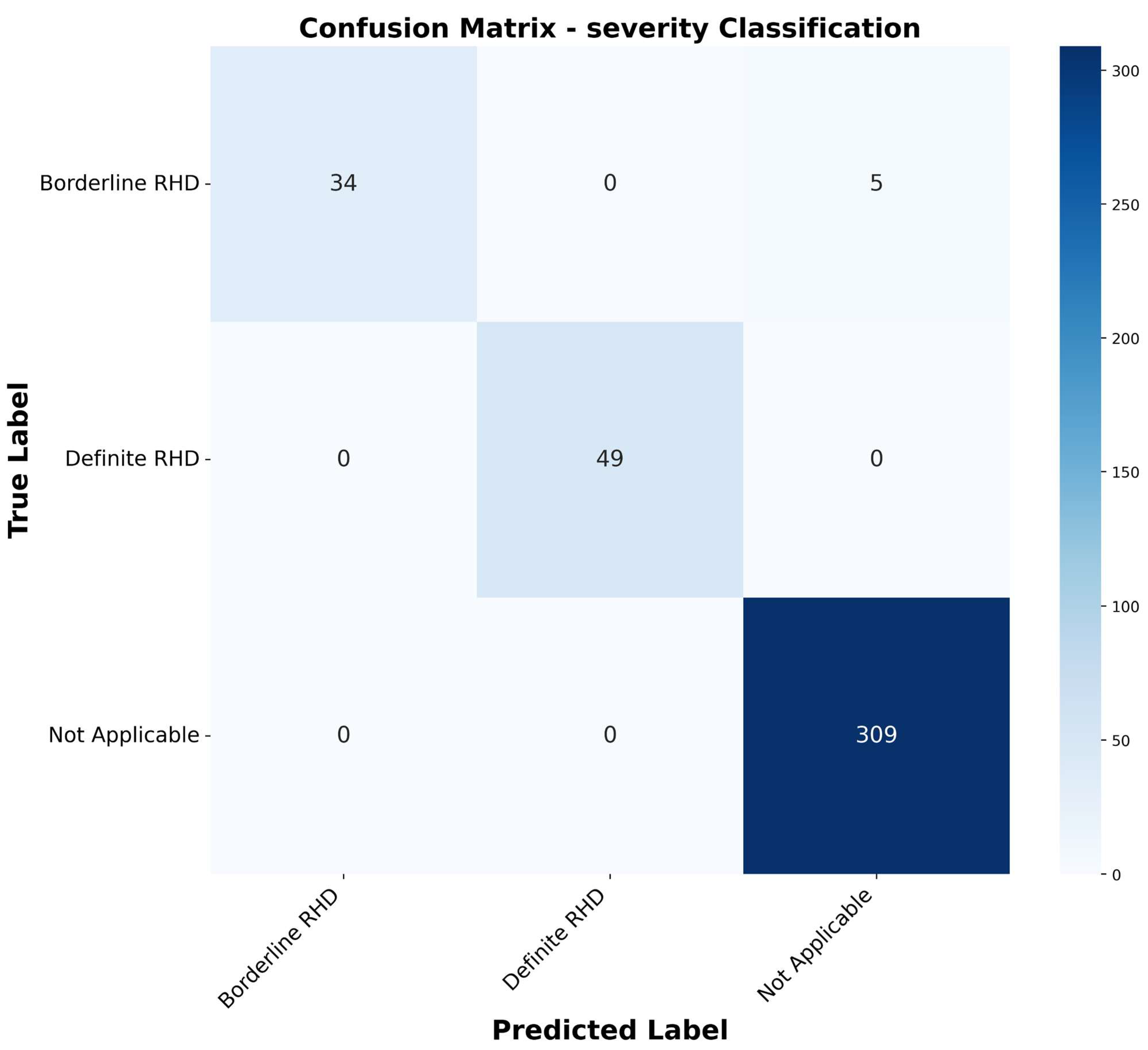
- Severity assessment: the third task determines the severity levels of RHD. It could be borderline or definite RHD.
- L is the cross-entropy loss;
- M is the number of classes;
- is the binary indicator (0 or 1) of whether class c is the true class for the sample;
- is the predicted probability that the sample belongs to class c.
2.6. Evaluation Metrics
- Accuracy: the performance of correctly classified images offering a general measure of predictive performance [29].
- Precision: the ratio of true positive predictions to total predicted positives, reflecting the accuracy of positive classifications.
- Recall: the ratio of true positive predictions to actual positives, indicating the model’s ability to detect all positive cases.
- F1 Score: the harmonic mean of precision and recall, providing a balanced metric that is particularly valuable for imbalanced datasets [29].
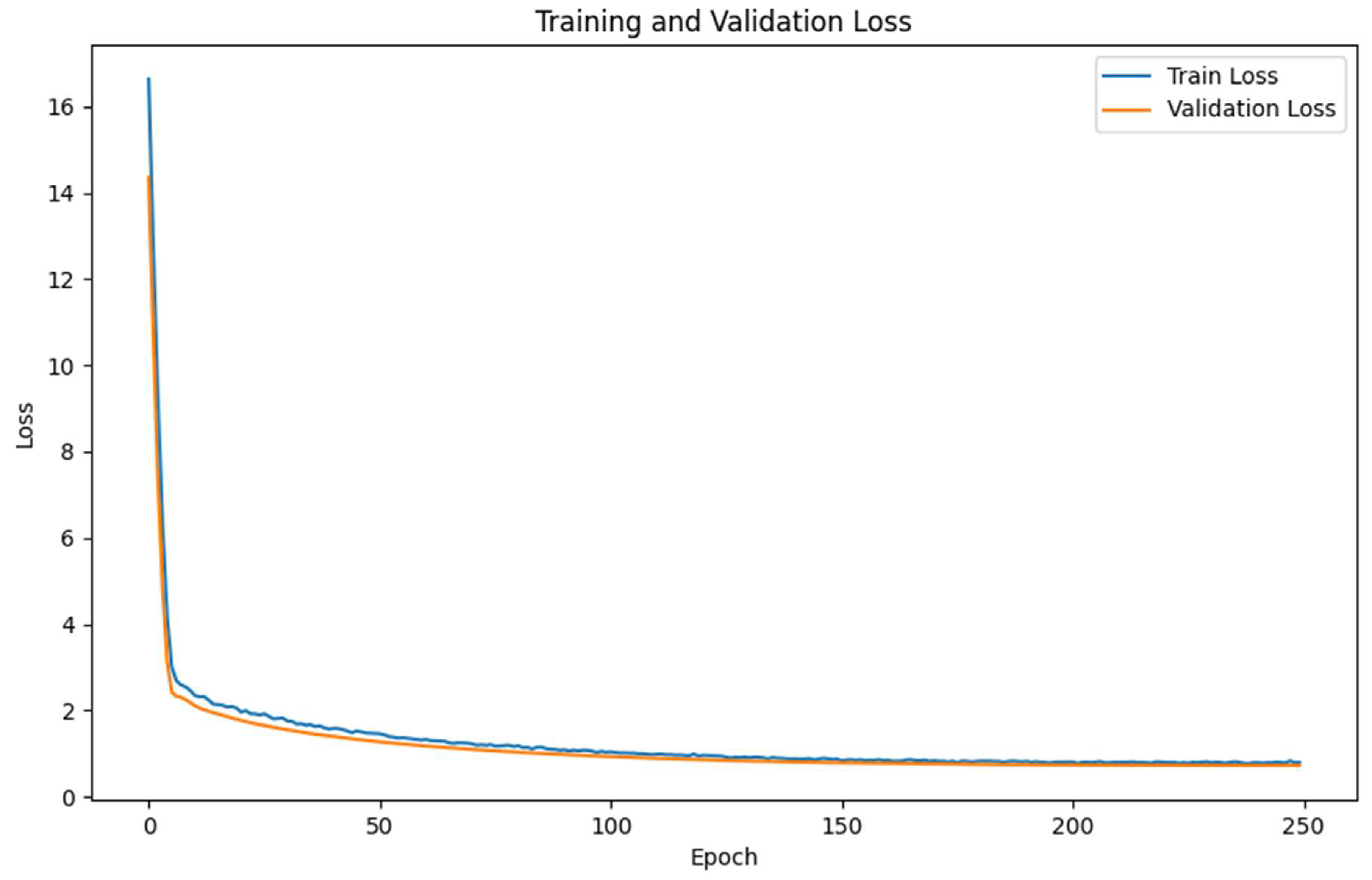
3. Results
3.1. Labelling Application
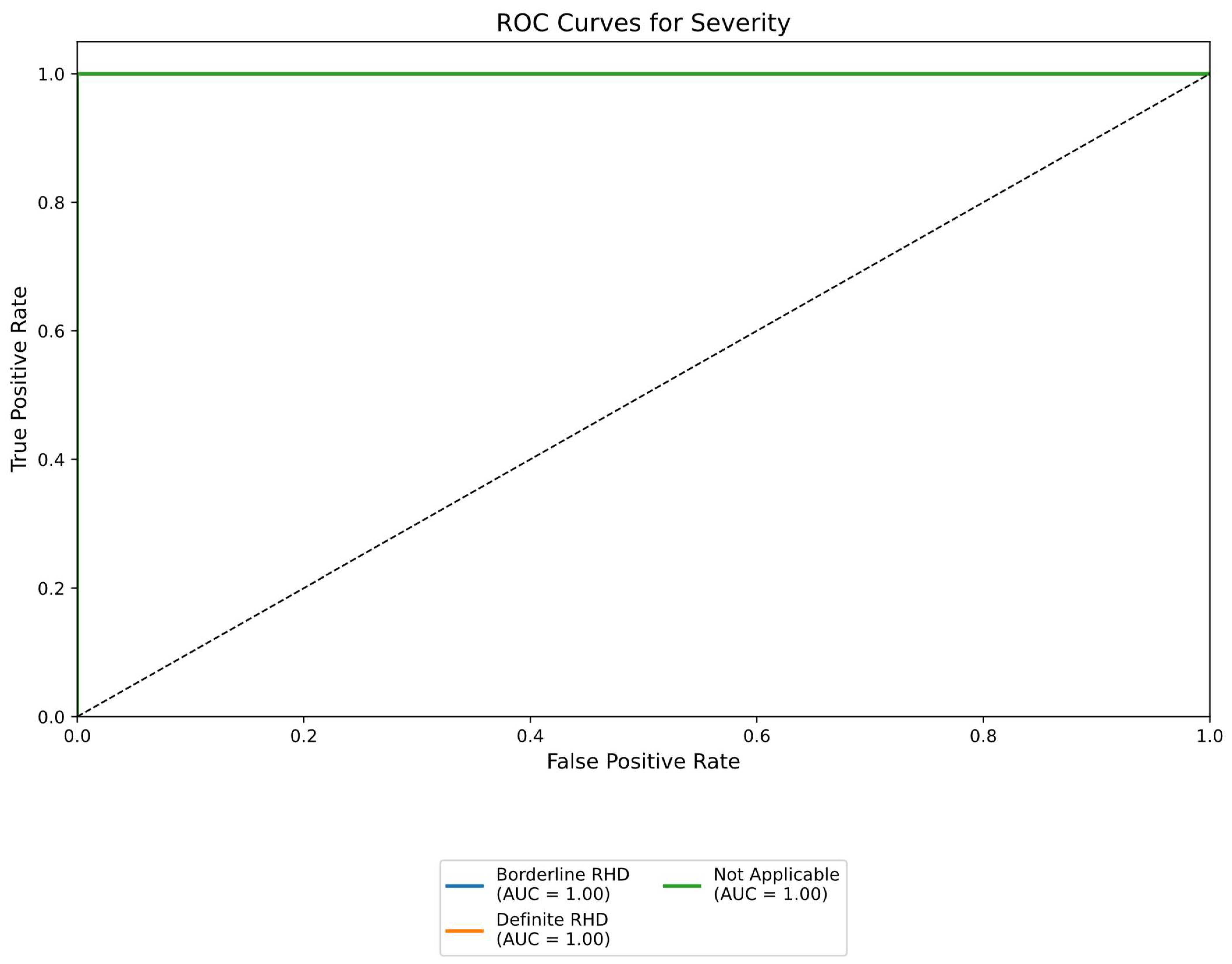
3.2. Classification
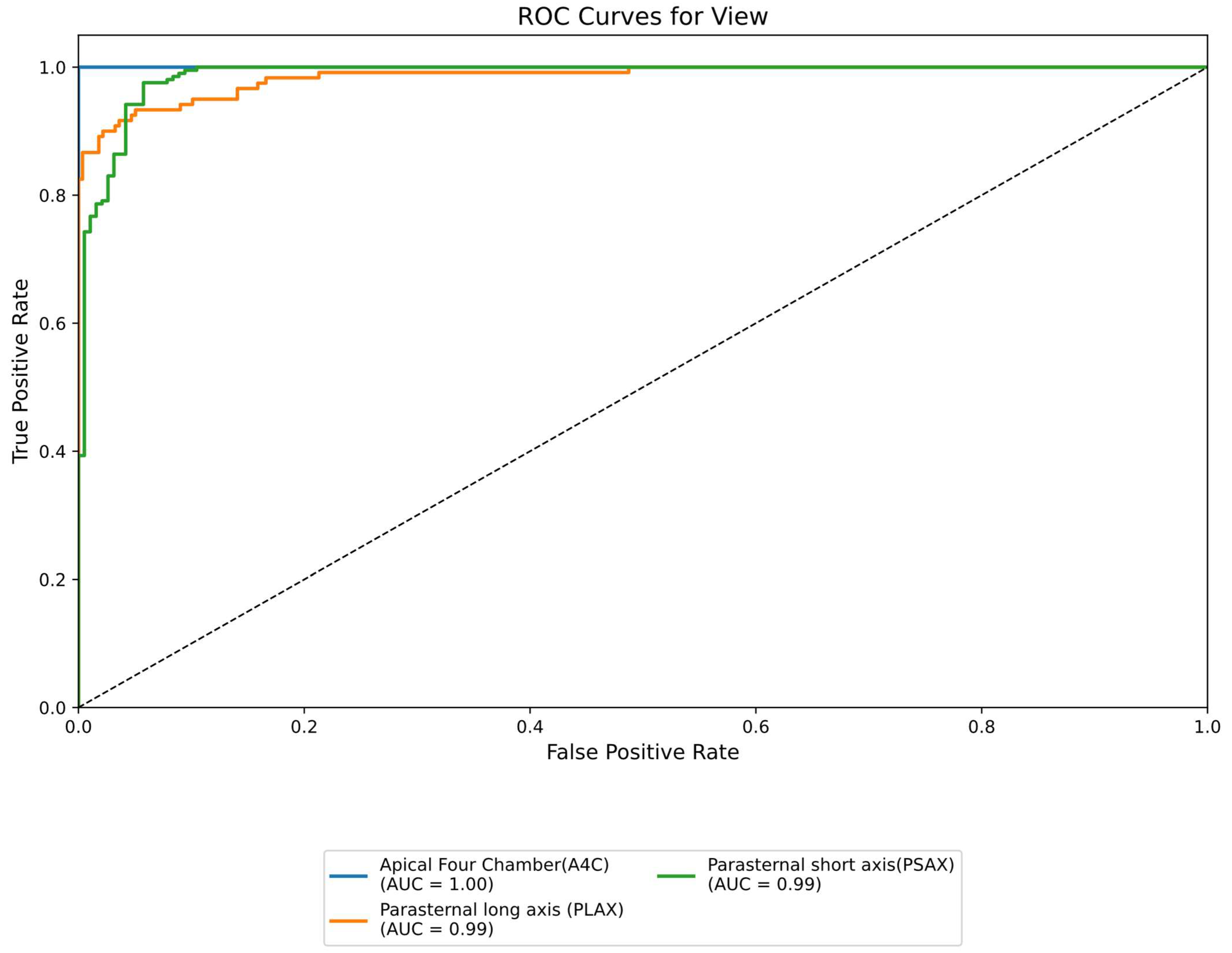
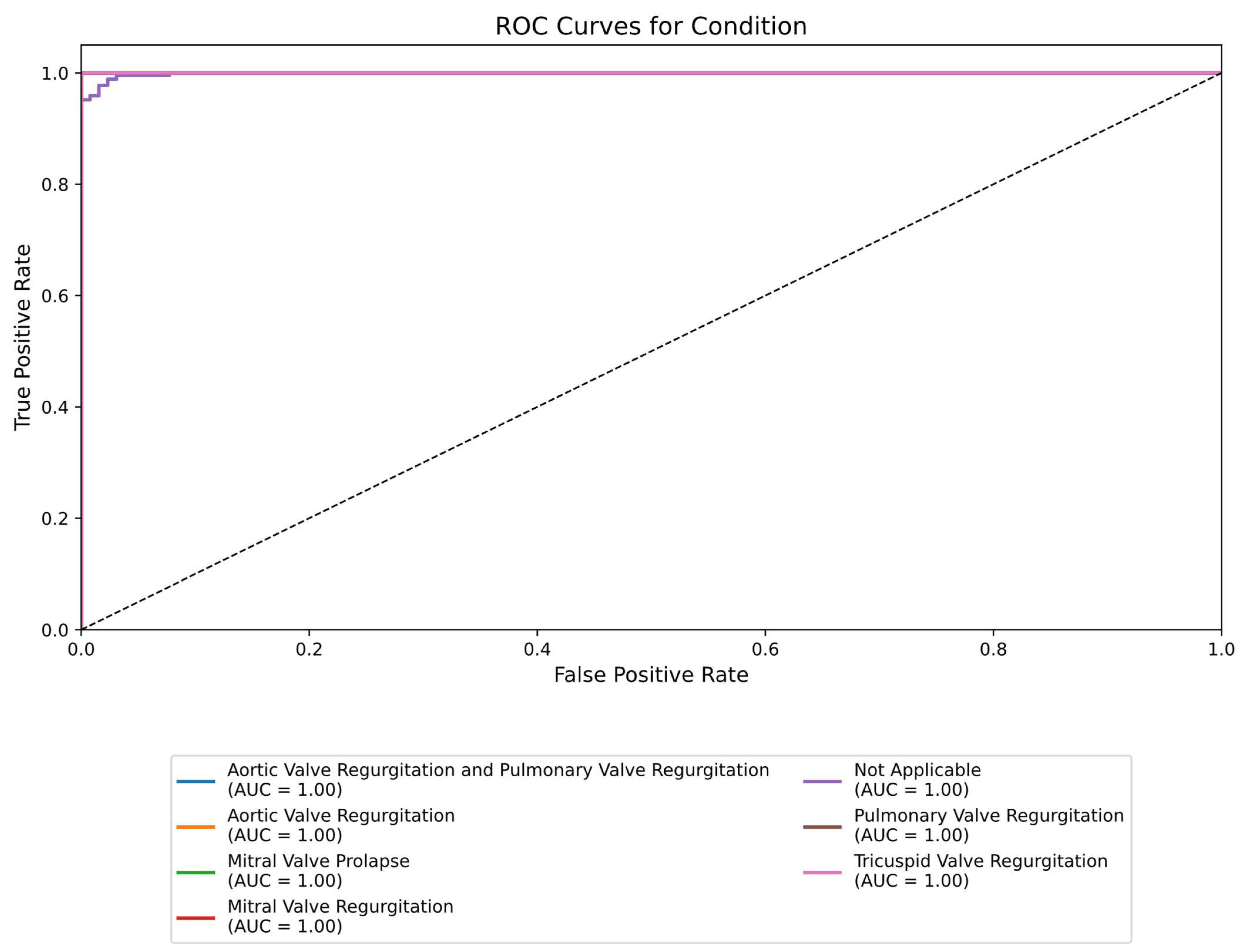
3.3. Performance Metrics Comparison
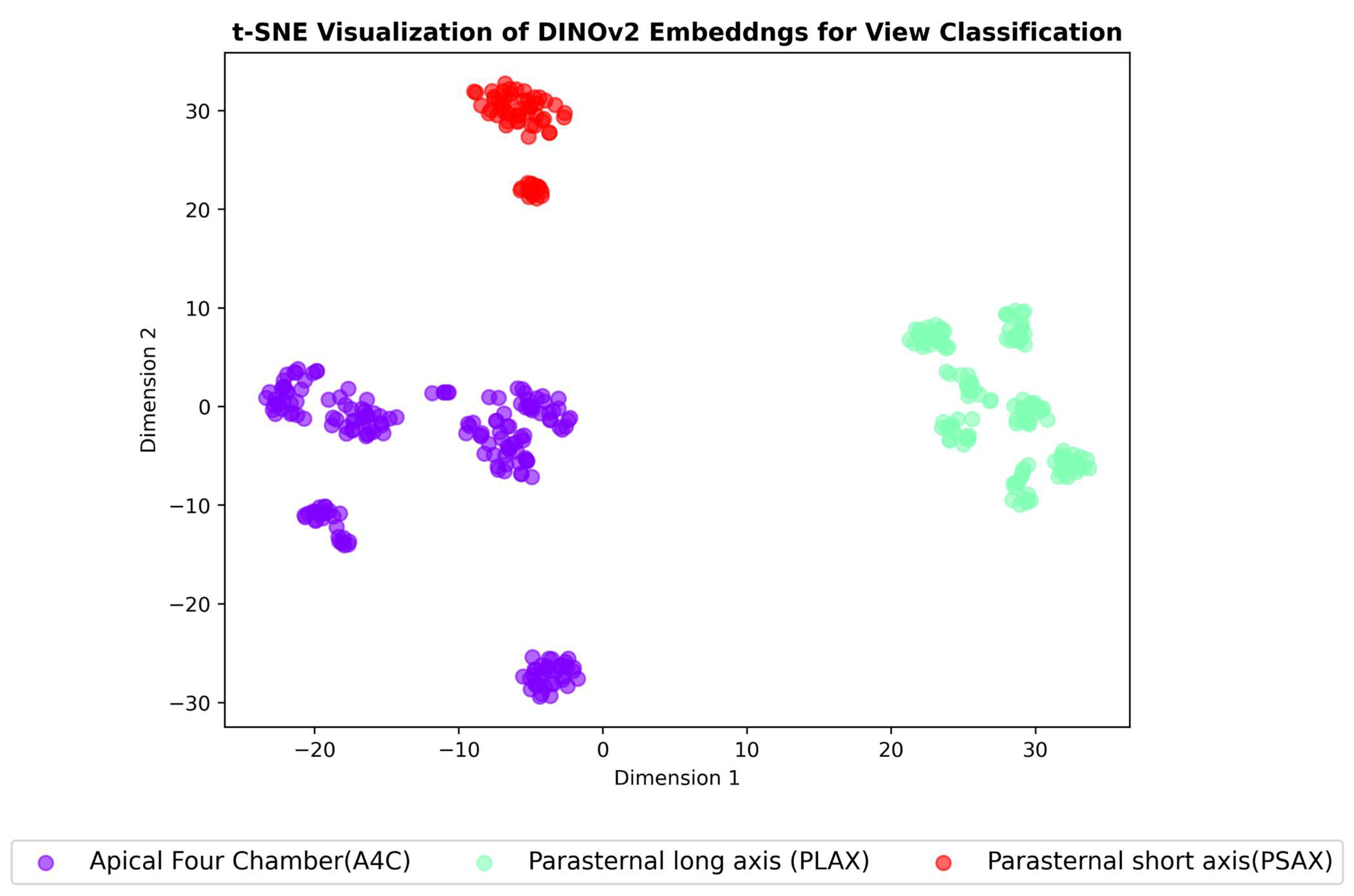
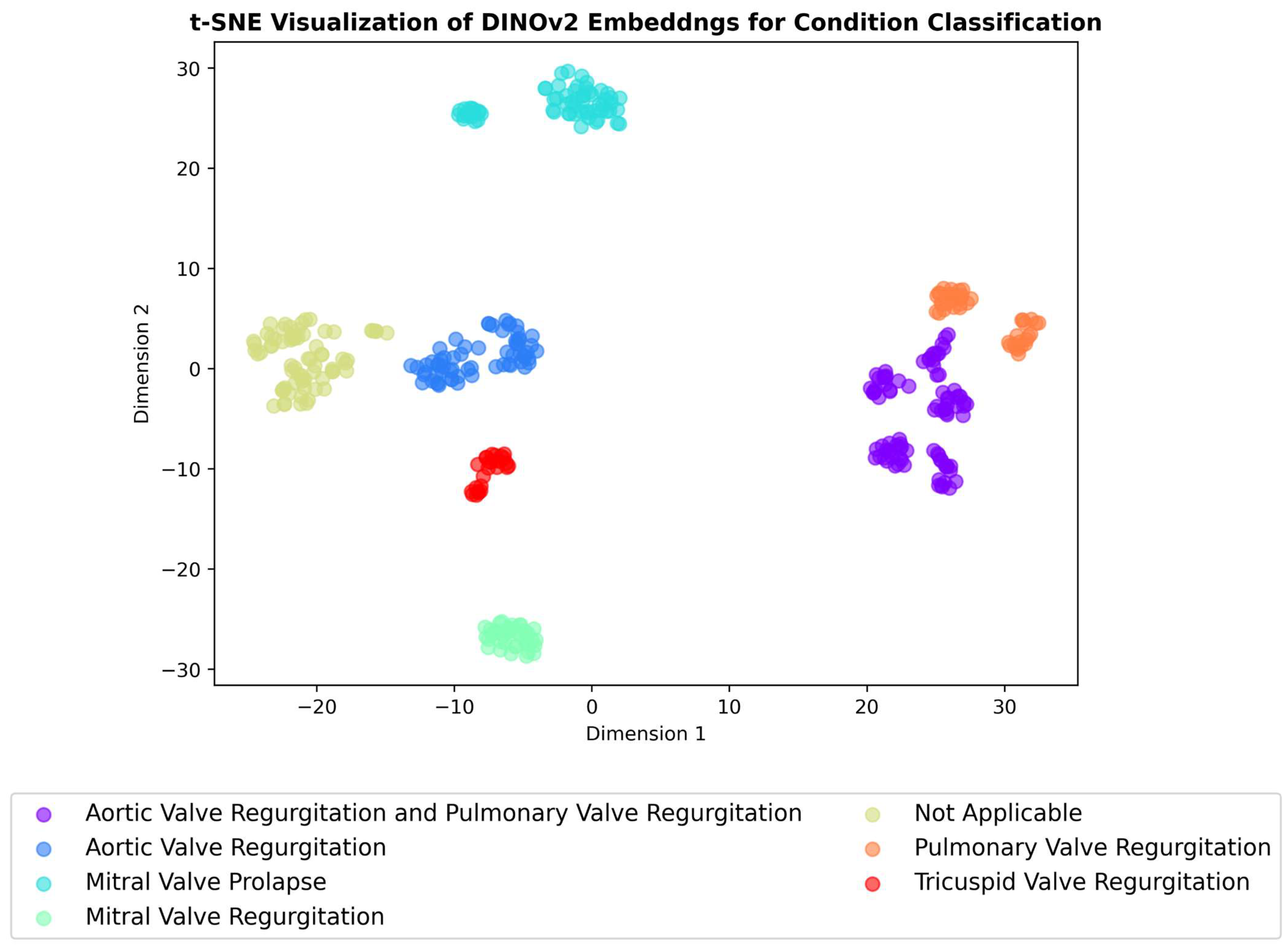
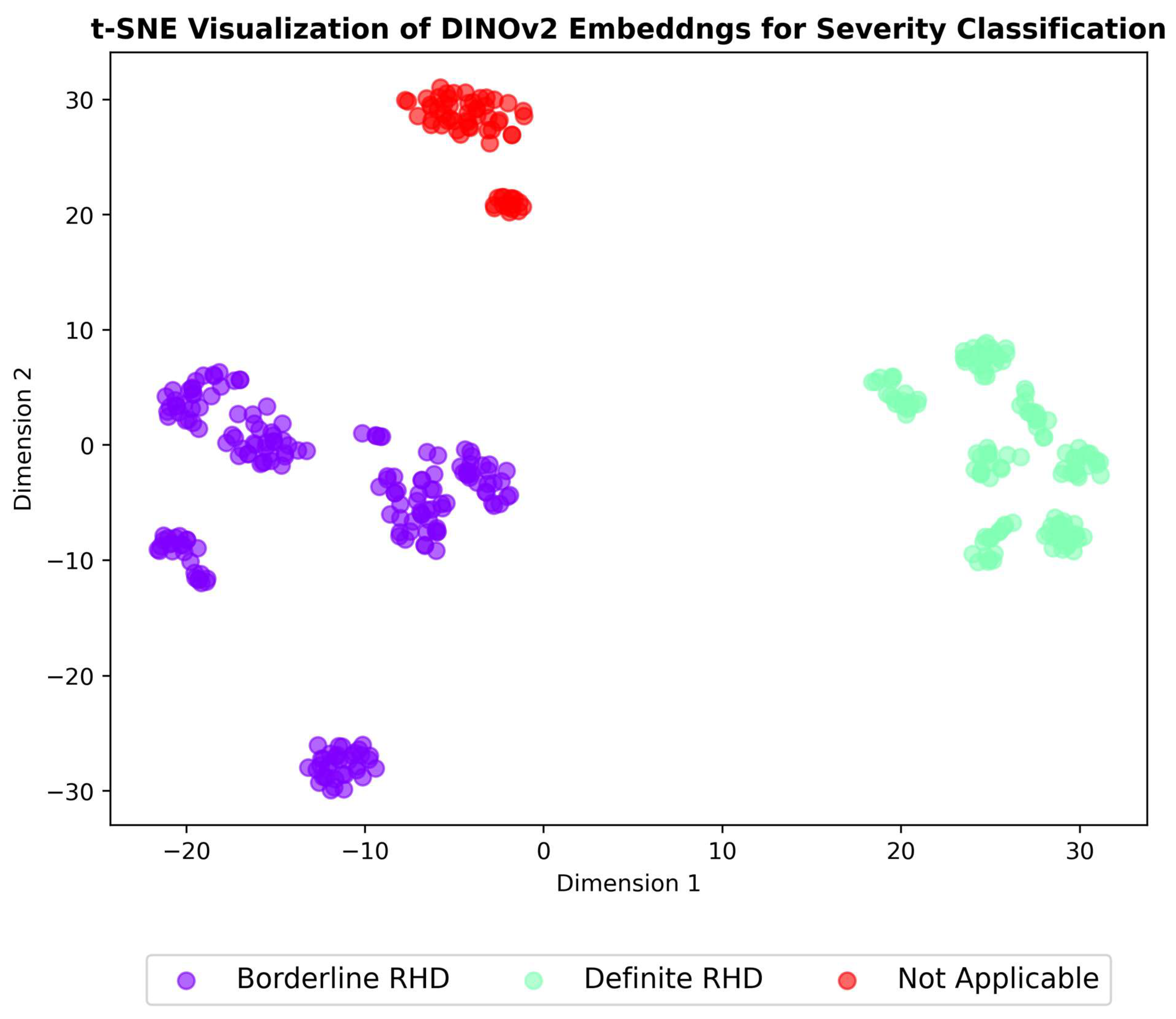
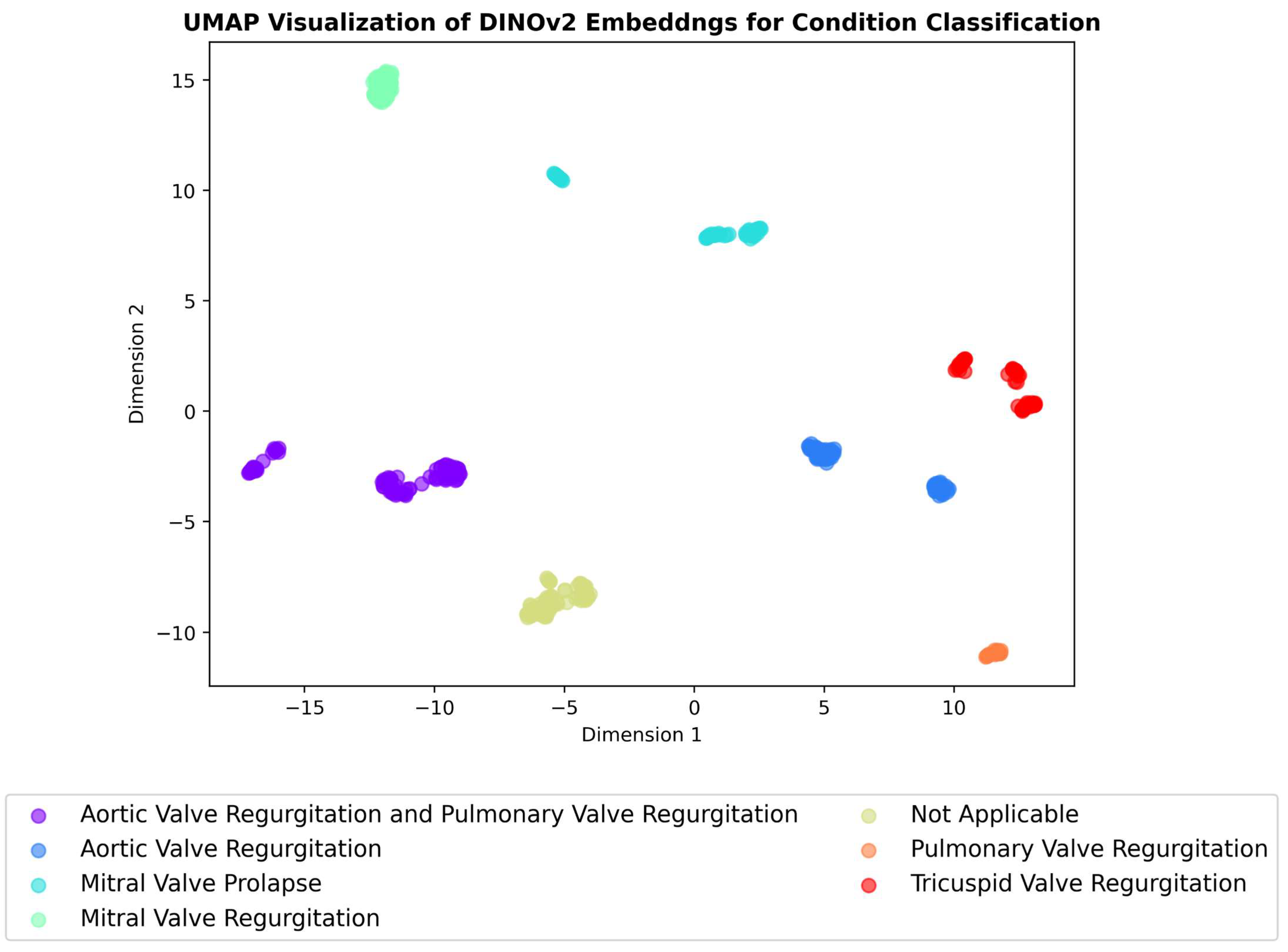
3.4. Embeddings Visualisation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B

Appendix C
Appendix D
References
- Chillo, P.; Mutagaywa, R.; Nkya, D.; Njelekela, M.; Kwesigabo, G.; Kahabuka, F.; Kerry, V.; Kamuhabwa, A. Sub-clinical rheumatic heart disease (RHD) detected by hand-held echocardiogram in children participating in a school-based RHD prevention program in Tanzania. BMC Cardiovasc. Disord. 2023, 23, 155. [Google Scholar] [CrossRef]
- Ali, S.; Beaton, A.; Ndagire, E.; Alhag, L. Silent Acute Rheumatic Fever Unmasked by Using Handheld Echocardiography for Febrile Children Presenting in a Rheumatic Heart Disease–Endemic Area. J. Pediatr. 2024, 268, 113954. [Google Scholar] [CrossRef] [PubMed]
- Liang, Y.; Yu, D.; Lu, Q.; Zheng, Y.; Yang, Y. The rise and fall of acute rheumatic fever and rheumatic heart disease: A mini review. Front. Cardiovasc. Med. 2023, 10, 1183606. [Google Scholar] [CrossRef] [PubMed]
- Asfaw, T. Prevalence of rheumatic heart disease in Ethiopia: A systematic review and meta-analysis. SAGE Open Med. 2023, 11, 20503121231169389. [Google Scholar] [CrossRef] [PubMed]
- Bennett, J.; Moreland, N.J.; Oliver, J.; Crane, J.; Williamson, D.A.; Sika-Paotonu, D.; Harwood, M.; Upton, A.; Smith, S.; Carapetis, J.; et al. Understanding group A streptococcal pharyngitis and skin infections as causes of rheumatic fever: Protocol for a prospective disease incidence study. BMC Infect. Dis. 2019, 19, 633. [Google Scholar] [CrossRef]
- Mebrahtom, G.; Hailay, A.; Aberhe, W.; Zereabruk, K.; Haile, T. Rheumatic Heart Disease in East Africa: A Systematic Review and Meta-Analysis. Int. J. Rheumatol. 2023, 2023, 8834443. [Google Scholar] [CrossRef]
- Baker, M.G.; Masterson, M.Y.; Shung-King, M.; Beaton, A.; Bowen, A.C.; Bansal, G.P.; Carapetis, J.R. Research priorities for the primordial prevention of acute rheumatic fever and rheumatic heart disease by modifying the social determinants of health. BMJ Glob. Health 2023, 8 (Suppl. 9), e012467. [Google Scholar] [CrossRef]
- Reményi, B.; Wilson, N.; Steer, A.; Ferreira, B.; Kado, J.; Kumar, K.; Lawrenson, J.; Maguire, G.; Marijon, E.; Mirabel, M.; et al. World Heart Federation criteria for echocardiographic diagnosis of rheumatic heart disease—An evidence-based guideline. Nat. Rev. Cardiol. 2012, 9, 297–309. [Google Scholar] [CrossRef]
- Rwebembera, J.; Marangou, J.; Mwita, J.C.; Mocumbi, A.O.; Mota, C.; Okello, E.; Nascimento, B.; Thorup, L.; Beaton, A.; Kado, J.; et al. 2023 World Heart Federation guidelines for the echocardiographic diagnosis of rheumatic heart disease. Nat. Rev. Cardiol. 2024, 21, 250–263. [Google Scholar] [CrossRef]
- Topçu, S.; Uçar, T. Echocardiographic Screening of Rheumatic Heart Disease: Current Concepts and Challenges. Turk. Arch. Pediatr. 2024, 59, 3–12. [Google Scholar] [CrossRef]
- Peck, D.; Rwebembera, J.; Nakagaayi, D.; Minja, N.W.; Ollberding, N.J.; Pulle, J.; Klein, J.; Adams, D.; Martin, R.; Koepsell, K.; et al. The Use of Artificial Intelligence Guidance for Rheumatic Heart Disease Screening by Novices. J. Am. Soc. Echocardiogr. 2023, 36, 724–732. [Google Scholar] [CrossRef] [PubMed]
- Edwards, L.A.; Feng, F.; Iqbal, M.; Fu, Y.; Sanyahumbi, A.; Hao, S.; McElhinney, D.B.; Ling, X.B.; Sable, C.; Luo, J. Machine learning for pediatric echocardiographic mitral regurgitation detection. J. Am. Soc. Echocardiogr. 2023, 36, 96–104. [Google Scholar] [CrossRef]
- Brown, K.; Roshanitabrizi, P.; Rwebembera, J.; Okello, E.; Beaton, A.; Linguraru, M.G.; Sable, C.A. Using Artificial Intelligence for Rheumatic Heart Disease Detection by Echocardiography: Focus on Mitral Regurgitation. J. Am. Heart Assoc. 2024, 13, e031257. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.-C.; Pareek, A.; Jensen, M.; Lungren, M.P.; Yeung, S.; Chaudhari, A.S. Self-supervised learning for medical image classification: A systematic review and implementation guidelines. npj Digit. Med. 2023, 6, 74. [Google Scholar] [CrossRef]
- Ding, C.; Wu, C. Self-Supervised Learning for Biomedical Signal Processing: A Systematic Review on ECG and PPG Signals. medRxiv 2024. [Google Scholar] [CrossRef]
- Holste, G.; Oikonomou, E.K.; Mortazavi, B.J.; Coppi, A.; Faridi, K.F.; Miller, E.J.; Forrest, J.K.; McNamara, R.L.; Ohno-Machado, L.; Yuan, N.; et al. Severe aortic stenosis detection by deep learning applied to echocardiography. Eur. Heart J. 2023, 44, 4592–4604. [Google Scholar] [CrossRef]
- Krishnamoorthy, R.; Agrawal, A.; Agarwal, P. Self-Supervised Representation Learning for Diagnosis of Cardiac Abnormalities on Echocardiograms. In Proceedings of the 2024 International Conference on Optimization Computing and Wireless Communication (ICOCWC), Debre Tabor, Ethiopia, 29–30 January 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Holste, G.; Oikonomou, E.K.; Mortazavi, B.J.; Wang, Z.; Khera, R. Efficient deep learning-based automated diagnosis from echocardiography with contrastive self-supervised learning. Commun. Med. 2024, 4, 133. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, B.; Bunting, K.V.; Brind, D.; Thorley, A.; Karwath, A.; Lu, W.; Zhou, D.; Wang, X.; Mobley, A.R.; et al. Development of Automated Neural Network Prediction for Echocardiographic Left ventricular Ejection Fraction. arXiv 2024, arXiv:2403.12152. [Google Scholar] [CrossRef]
- Liu, Z.; Kainth, K.; Zhou, A.; Deyer, T.W.; Fayad, Z.A.; Greenspan, H.; Mei, X. A review of self-supervised, generative, and few-shot deep learning methods for data-limited magnetic resonance imaging segmentation. NMR Biomed. 2024, 37, e5143. [Google Scholar] [CrossRef]
- Fadnavis, S.; Parmar, C.; Emaminejad, N.; Cerna, A.U.; Malik, A.; Selej, M.; Mansi, T.; Dunnmon, P.; Yardibi, T.; Standish, K.; et al. EchoFM: A View-Independent Echocardiogram Model for the Detection of Pulmonary Hypertension. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2024, Proceedings of the 27th International Conference, Marrakesh, Morocco, 6–10 October 2024; Linguraru, M.G., Dou, Q., Feragen, A., Giannarou, S., Glocker, B., Lekadir, K., Schnabel, J.A., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 253–263. [Google Scholar] [CrossRef]
- Jacob, A.J.; Borgohain, I.; Chitiboi, T.; Sharma, P.; Comaniciu, D.; Rueckert, D. Towards a vision foundation model for comprehensive assessment of Cardiac MRI. arXiv 2024, arXiv:2410.01665. [Google Scholar] [CrossRef]
- Kim, S.; Ren, H.; Charton, J.; Hu, J.; Gonzalez, C.A.M.; Khambhati, J.; Cheng, J.; DeFrancesco, J.; A Waheed, A.; Marciniak, S.; et al. Assessment of valve regurgitation severity via contrastive learning and multi-view video integration. Phys. Med. Biol. 2024, 69, 045020. [Google Scholar] [CrossRef]
- Liu, Z.; Alavi, A.; Li, M.; Zhang, X. Self-Supervised Contrastive Learning for Medical Time Series: A Systematic Review. Sensors 2023, 23, 4221. [Google Scholar] [CrossRef] [PubMed]
- Hu, R.; Chen, J.; Zhou, L. Spatiotemporal self-supervised representation learning from multi-lead ECG signals. Biomed. Signal Process. Control 2023, 84, 104772. [Google Scholar] [CrossRef]
- Le, D.; Truong, S.; Brijesh, P.; Adjeroh, D.A.; Le, N. sCL-ST: Supervised Contrastive Learning With Semantic Transformations for Multiple Lead ECG Arrhythmia Classification. IEEE J. Biomed. Health Inform. 2023, 27, 2818–2828. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar] [CrossRef]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv 2024, arXiv:2304.07193. [Google Scholar] [CrossRef]
- An, J.; Li, W.; Bai, Y.; Chen, H.; Zhao, G.; Cai, Q.; Gao, Z. MTECC: A Multitask Learning Framework for Esophageal Cancer Analysis. IEEE Trans. Artif. Intell. 2024, 5, 6739–6751. [Google Scholar] [CrossRef]
- Azizi, S.; Mustafa, B.; Ryan, F.; Beaver, Z.; Freyberg, J.; Deaton, J.; Loh, A.; Karthikesalingam, A.; Kornblith, S.; Chen, T.; et al. Big Self-Supervised Models Advance Medical Image Classification. arXiv 2021, arXiv:2101.05224v2. [Google Scholar] [CrossRef]
- Wu, Y.; Zeng, D.; Wang, Z.; Shi, Y.; Hu, J. Distributed Contrastive Learning for Medical Image Segmentation. arXiv 2022, arXiv:2208.03808. [Google Scholar] [CrossRef]
- Wang, W.-C.; Ahn, E.; Feng, D.; Kim, J. A Review of Predictive and Contrastive Self-supervised Learning for Medical Images. Mach. Intell. Res. 2023, 20, 483–513. [Google Scholar] [CrossRef]
- Charton, J.; Ren, H.; Kim, S.; Gonzalez, C.M.; Khambhati, J.; Cheng, J.; DeFrancesco, J.; Waheed, A.; Marciniak, S.; Mour, F.; et al. Multi-task Learning for Hierarchically-Structured Images: Study on Echocardiogram View Classification. In Simplifying Medical Ultrasound, Proceedings of the 4th International Workshop, ASMUS 2023, Vancouver, BC, Canada, 8 October 2023; Springer: Cham, Switzerland, 2023; pp. 185–194. [Google Scholar] [CrossRef]
- Ahmadi Amiri, S.N. Detection and Severity Assessment of Aortic Stenosis Using Machine Learning. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 2023. Available online: https://open.library.ubc.ca/soa/cIRcle/collections/ubctheses/24/items/1.0433730 (accessed on 4 October 2023).
- Wang, Y.; Huang, H.; Rudin, C.; Shaposhnik, Y. Understanding How Dimension Reduction Tools Work: An Empirical Approach to Deciphering t-SNE, UMAP, TriMap, and PaCMAP for Data Visualization. J. Mach. Learn. Res. 2021, 22, 1–73. [Google Scholar]
- Damrich, S.; Böhm, J.N.; Hamprecht, F.A.; Kobak, D. From $t$-SNE to UMAP with contrastive learning. arXiv 2023, arXiv:2206.01816. [Google Scholar] [CrossRef]
- Mittal, M.; Praveen, G.; Guru, P.; Devadas, R.M.; Ambreen, L.; Kumar, V. Dimensionality Reduction Using UMAP and TSNE Technique. In Proceedings of the 2024 Second International Conference on Advances in Information Technology (ICAIT), Chikkamagaluru, India, 24–27 July 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Orlov, A.; Akhmetshin, T.; Horvath, D.; Marcou, G.; Varnek, A. From High Dimensions to Human Comprehension: Exploring Dimensionality Reduction for Chemical Space Visualization. ChemRxiv 2024. [Google Scholar] [CrossRef]
- Draganov, A.; Dohn, S. Relating tSNE and UMAP to Classical Dimensionality Reduction. arXiv 2024, arXiv:2306.11898. [Google Scholar] [CrossRef]
- Ali, M.; Choudhary, J.; Kasbe, T. A hybrid model for data visualization using linear algebra methods and machine learning algorithm. Indones. J. Electr. Eng. Comput. Sci. 2024, 33, 463–475. [Google Scholar] [CrossRef]
- Holste, G.; Oikonomou, E.K.; Mortazavi, B.J.; Coppi, A.; Faridi, K.F.; Miller, E.J.; Forrest, J.K.; McNamara, R.L.; Ohno-Machado, L.; Yuan, N.; et al. Automated detection of severe aortic stenosis using single-view echocardiography: A self-supervised ensemble learning approach. medRxiv 2022. [Google Scholar] [CrossRef]
- Sangha, V.; Khunte, A.; Holste, G.; Mortazavi, B.J.; Wang, Z.; Oikonomou, E.K.; Khera, R. Biometric Contrastive Learning for Data-Efficient Deep Learning from Electrocardiographic Images. medRxiv 2023. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filename | Colour | Echo View | Thickness | Condition | Severity | |
|---|---|---|---|---|---|---|
| a | 10.38.47 hrs __[0005903].jpeg | NO COLOUR | Parasternal long axis (PLAX) | Thick | Not applicable | Definite RHD |
| b | 10.39.22 hrs __[0005905].mp4 | COLOUR | Parasternal long axis (PLAX) | Not thick | Aortic valve regurgitation | Borderline RHD |
| c | 10.40.10 hrs __[0005906].jpeg | COLOUR | Parasternal long axis (PLAX) | Not applicable | Mitral valve regurgitation | Normal |
| d | 10.40.15 hrs __[0005907].mp4 | NO COLOUR | Parasternal short axis (PSAX) | Not applicable | Mitral valve prolapse | Not applicable |
| View Classification | ||
|---|---|---|
| Class | Numerical Encoding | Number of Samples |
| Apical Four Chamber (A4C) | 0 | 483 |
| Parasternal Long Axis (PLAX) | 1 | 724 |
| Parasternal Short Axis (PSAX) | 2 | 1448 |
| Condition Classification | ||
| Class | Numerical Encoding | Number of Samples |
| Aortic Valve Regurgitation | 0 | 121 |
| Aortic Valve Regurgitation, Pulmonary Valve Regurgitation | 1 | 121 |
| Mitral Valve Prolapse | 2 | 241 |
| Mitral Valve Regurgitation | 3 | 121 |
| Not Applicable | 4 | 1809 |
| Pulmonary Valve Regurgitation | 5 | 121 |
| Tricuspid Valve Regurgitation | 6 | 121 |
| Severity Classification | ||
| Class | Numerical Encoding | Number of Samples |
| Borderline RHD | 0 | 242 |
| Definite RHD | 1 | 241 |
| Not Applicable | 2 | 2172 |
| Metric | Task | SimCLR | DINOv2 |
|---|---|---|---|
| Accuracy | View | 0.99 | 0.92 |
| Condition | 0.92 | 0.98 | |
| Severity | 0.96 | 0.99 | |
| Precision | View | 0.99 | 0.93 |
| Condition | 0.92 | 0.98 | |
| Severity | 0.97 | 0.98 | |
| Recall | View | 0.99 | 0.92 |
| Condition | 0.92 | 0.98 | |
| Severity | 0.97 | 0.98 | |
| F1 score | View | 0.99 | 0.92 |
| Condition | 0.92 | 0.98 | |
| Severity | 0.96 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mugambi, L.; wa Maina, C.; Zühlke, L. Self-Supervised Multi-Task Learning for the Detection and Classification of RHD-Induced Valvular Pathology. J. Imaging 2025, 11, 97. https://doi.org/10.3390/jimaging11040097
Mugambi L, wa Maina C, Zühlke L. Self-Supervised Multi-Task Learning for the Detection and Classification of RHD-Induced Valvular Pathology. Journal of Imaging. 2025; 11(4):97. https://doi.org/10.3390/jimaging11040097
Chicago/Turabian StyleMugambi, Lorna, Ciira wa Maina, and Liesl Zühlke. 2025. "Self-Supervised Multi-Task Learning for the Detection and Classification of RHD-Induced Valvular Pathology" Journal of Imaging 11, no. 4: 97. https://doi.org/10.3390/jimaging11040097
APA StyleMugambi, L., wa Maina, C., & Zühlke, L. (2025). Self-Supervised Multi-Task Learning for the Detection and Classification of RHD-Induced Valvular Pathology. Journal of Imaging, 11(4), 97. https://doi.org/10.3390/jimaging11040097