
Evaluating Super-Resolution Models in Biomedical Imaging: Applications and Performance in Segmentation and Classification



Abstract
1. Introduction
2. Related Work
2.1. Deep Learning-Based Super-Resolution Techniques
2.2. Super-Resolution in Medical Imaging
2.3. Evaluation Metrics for Super-Resolution
- Segmentation accuracy measures how well SR-enhanced images improve the performance of downstream segmentation tasks, often evaluated using the Dice coefficient or Intersection over Union (IoU) [25].
- Classification metrics assess the impact of SR on diagnostic accuracy; commonly used metrics include area under the curve (AUC) and F1 score [26].
3. Methodology
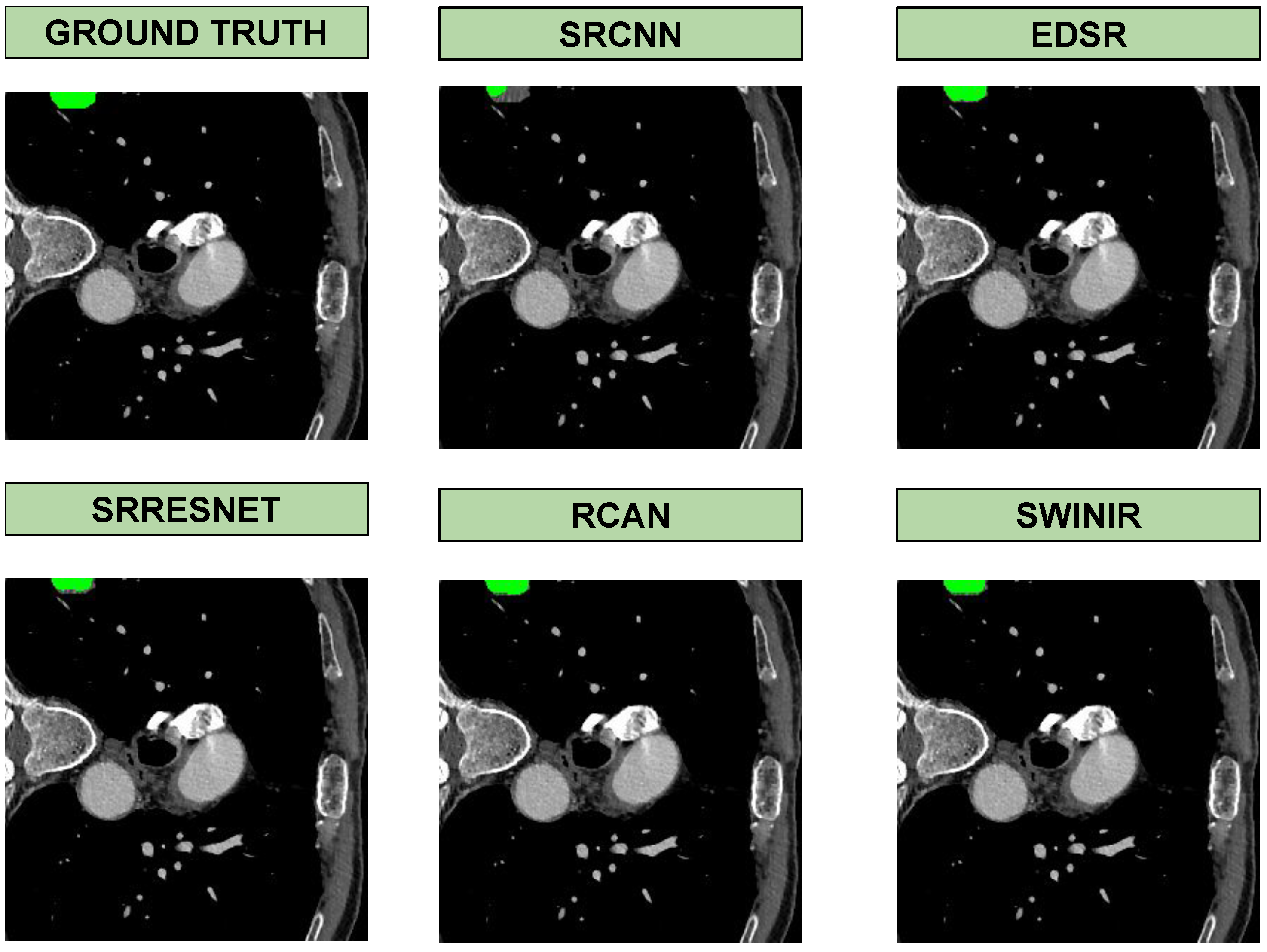
3.1. Super-Resolution Networks
- SRCNN (Super-Resolution Convolutional Neural Network): One of the pioneering models for super-resolution, SRCNN utilizes a shallow convolutional architecture to learn end-to-end mappings from low-resolution to high-resolution images. Despite its simplicity, SRCNN demonstrates significant improvements in image quality, making it a foundational model in the field [27].
- EDSR (Enhanced Deep Residual Networks for Single Image Super-Resolution): EDSR, an extension of the ResNet architecture, optimizes super-resolution tasks by removing batch normalization layers and enhancing the performance of residual blocks. This model achieves higher PSNR and SSIM scores than traditional residual networks, making it particularly effective at preserving fine details in medical images [2].
- SRResNet: Introduced alongside the SRGAN framework, SRResNet is designed to improve image resolution using deep residual blocks. This model focuses on enhancing structural details without introducing artifacts, proving effective in medical imaging where the preservation of structural integrity is crucial [11].
- RCAN (Residual Channel Attention Network): RCAN utilizes channel attention mechanisms to adaptively rescale feature maps, enhancing important details while suppressing less relevant information. This approach is particularly useful in medical imaging, where fine-grained details can be critical for diagnosis [12].
- SwinIR (Swin Transformer for Image Restoration): SwinIR leverages the Swin Transformer architecture, employing window-based attention mechanisms to capture both local and global features. This model excels in enhancing resolution while maintaining computational efficiency, making it a suitable choice for high-resolution medical imaging tasks [21].
3.2. Evaluation of Classification
3.3. Evaluation of Segmentation
4. Experiments
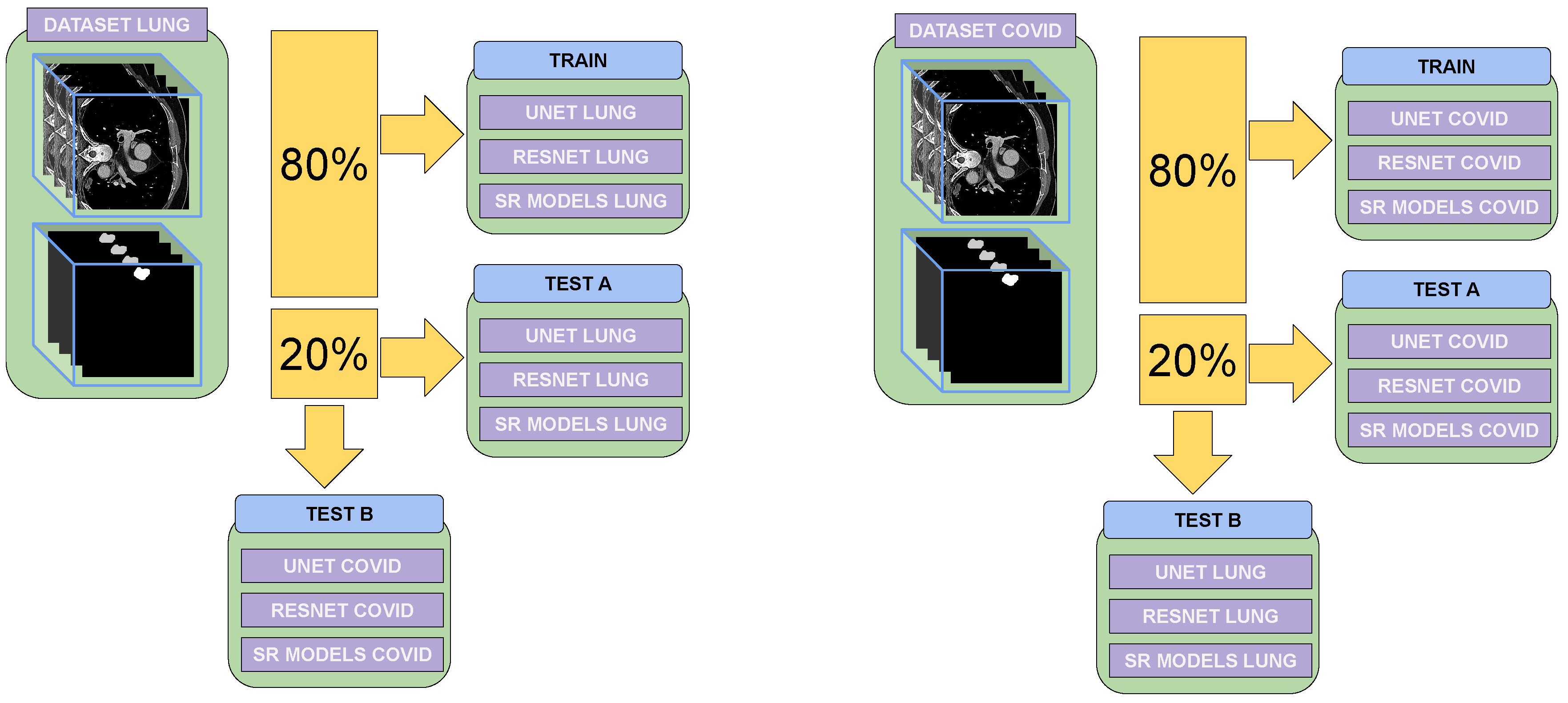
4.1. Datasets
4.2. Image Preprocessing
4.3. Tests Performed
- Visual Metrics: These metrics assess image quality using indicators such as PSNR and SSIM. PSNR measures the ratio between the maximum possible power of a signal and the power of noise affecting its representation, providing an objective assessment of the fidelity of the reconstructed image. SSIM, on the other hand, evaluates the structural similarity between the original and reconstructed images, focusing on luminance, contrast, and structure.
- Functional Metrics: These metrics focus on improvements or error ratios in specific tasks, such as segmentation and classification. For example, they evaluate whether super-resolution enhances accuracy in delineating regions of interest in segmentation tasks or improves classification predictions for disease diagnosis.
- Training and Testing on the Same Dataset: The model was trained on a specific dataset and tested on images from the same dataset. This approach helped to determine how well the model generalized within a controlled environment and served as a baseline for comparison.
- Training and Testing on Different Datasets: The model was trained on one dataset and tested on a different dataset. This evaluated the model’s robustness and its ability to generalize across diverse data distributions, which are crucial for real-world applications.
5. Results
5.1. Segmentation Results
5.2. Classification Results
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Izonin, I.; Tkachenko, R.; Peleshko, D.; Rak, T.; Batyuk, D. Learning-Based Image Super-Resolution Using Weight Coefficients of Synaptic Connections. In Proceedings of the 2015 Xth International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 14–17 September 2015; pp. 25–29. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Li, R.; Xiao, C.; Huang, Y.; Hassan, H.; Huang, B. Deep Learning Applications in Computed Tomography Images for Pulmonary Nodule Detection and Diagnosis: A Review. Diagnostics 2022, 12, 298. [Google Scholar] [CrossRef] [PubMed]
- Umehara, K.; Ota, J.; Ishida, T. Application of Super-Resolution Convolutional Neural Network for Enhancing Image Resolution in Chest CT. J. Digit. Imaging 2018, 31, 441–450. [Google Scholar] [PubMed]
- Georgescu, M.I.; Ionescu, R.; Miron, A.I.; Savencu, O.; Ristea, N.C.; Verga, N.; Khan, F. Multimodal Multi-Head Convolutional Attention with Various Kernel Sizes for Medical Image Super-Resolution. arXiv 2022, arXiv:2204.04218. [Google Scholar]
- Li, Y.; Sixou, B.; Peyrin, F. A Review of the Deep Learning Methods for Medical Images Super Resolution Problems. IRBM 2021, 42, 120–133. [Google Scholar] [CrossRef]
- Gevaert, O.; Xu, J.; Hoang, C.; Leung, A.; Xu, Y.; Quon, A.; Rubin, D.; Napel, S.; Plevritis, S. Non-Small Cell Lung Cancer: Identifying Prognostic Imaging Biomarkers by Leveraging Public Gene Expression Microarray Data–Methods and Preliminary Results. Radiology 2012, 264, 387–396. [Google Scholar] [CrossRef] [PubMed]
- Napel, S. NSCLC Radiogenomics: Initial Stanford Study of 26 Cases; The Cancer Imaging Archive: Bethesda, MD, USA, 2014. [Google Scholar]
- Bakr, S.; Gevaert, O.; Echegaray, S.; Ayers, K.; Zhou, M.; Shafiq, M.; Zheng, H.; Benson, J.; Zhang, W.; Leung, A.; et al. A Radiogenomic Dataset of Non-Small Cell Lung Cancer. Sci. Data 2018, 5, 180160. [Google Scholar] [CrossRef]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. In SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Deka, B.; Datta, S.; Mullah, H.; Hazarika, S. Diffusion-weighted and spectroscopic MRI super-resolution using sparse representations. Biomed. Signal Process. Control 2020, 60, 101941. [Google Scholar] [CrossRef]
- Amoros, M.; Curado, M.; Vicent, J.F. CTextureFusion: Advanced Texture Transfer with Multi-head Attention for Improving Lung CT Super Resolution. Proceedings of International Conference on Pattern Recognition 2024, Kalkota, India, 1 December 2024; pp. 96–111. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S. Deep Learning for Image Super-Resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3365–3387. [Google Scholar] [PubMed]
- Zhang, Z.; Wang, Z.; Lin, Z.; Qi, H. Image Super-Resolution by Neural Texture Transfer. arXiv 2019, arXiv:1903.00834. [Google Scholar]
- Xiang, R.; Yang, H.; Yan, Z.; Mohamed Taha, A.; Xu, X.; Wu, T. Super-Resolution Reconstruction of GOSAT CO2 Products Using Bicubic Interpolation. Geocarto Int. 2022, 37, 15187–15211. [Google Scholar] [CrossRef]
- Higaki, T.; Nakamura, Y.; Tatsugami, F.; Nakaura, T.; Awai, K. Improvement of Image Quality at CT and MRI Using Deep Learning. Jpn. J. Radiol. 2019, 37, 73–80. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Loy, C.; Qiao, Y.; Tang, X. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. Available online: https://github.com/xinntao/ESRGAN (accessed on 16 January 2025).
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Montreal, QC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar] [CrossRef]
- Xu, L.; Zeng, X.; Huang, Z.; Li, W.; Zhang, H. Low-Dose Chest X-Ray Image Super-Resolution Using Generative Adversarial Nets with Spectral Normalization. Biomed. Signal Process. Control 2020, 55, 101600. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, Z.; Liao, G.; Yuan, K. Csrgan: Medical Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the ISBI Workshops 2020—International Symposium on Biomedical Imaging Workshops, Iowa City, IA, USA, 4 April 2020; pp. 1–5. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Pawar, K.; Ekanayake, M.; Pain, C.; Zhong, S.; Egan, G. Deep Learning for Image Enhancement and Correction in Magnetic Resonance Imaging—State-of-the-Art and Challenges. J. Digit. Imaging 2022, 36, 204–230. [Google Scholar] [PubMed]
- Loizidou, K.; Elia, R.; Pitris, C. Computer-Aided Breast Cancer Detection and Classification in Mammography: A Comprehensive Review. Comput. Biol. Med. 2023, 153, 106554. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. Available online: http://mmlab.ie.cuhk.edu.hk/ (accessed on 16 January 2025).
- Ma, J.; Ge, C.; Wang, Y.; An, X.; Gao, J.; Yu, Z.; Zhang, M.; Liu, X.; Deng, X.; Cao, S.; et al. COVID-19 CT Lung and Infection Segmentation Dataset. 2020. Available online: https://doi.org/10.5281/zenodo.3757476 (accessed on 10 November 2024).

{kind=link}
{kind=link}
{kind=link}
| Model | Training Data | Test Data | Dice Score | IoU Score |
|---|---|---|---|---|
| No Super-Resolution | – | COVID | 0.6921 | 0.5276 |
| SRCNN | Task06-Lung | COVID | 0.5551 | 0.4076 |
| EDSR | Task06-Lung | COVID | 0.6485 | 0.4817 |
| SRResNet | Task06-Lung | COVID | 0.6710 | 0.5063 |
| RCAN | Task06-Lung | COVID | 0.6248 | 0.4560 |
| SwinIR | Task06-Lung | COVID | 0.6856 | 0.5260 |
| SRCNN | COVID | COVID | 0.6703 | 0.4677 |
| EDSR | COVID | COVID | 0.7220 | 0.6171 |
| SRResNet | COVID | COVID | 0.7115 | 0.6295 |
| RCAN | COVID | COVID | 0.6328 | 0.4642 |
| SwinIR | COVID | COVID | 0.8054 | 0.6647 |
| No Super-Resolution | – | Task06-Lung | 0.7121 | 0.5966 |
| SRCNN | Task06-Lung | Task06-Lung | 0.7308 | 0.6371 |
| EDSR | Task06-Lung | Task06-Lung | 0.6888 | 0.5935 |
| SRResNet | Task06-Lung | Task06-Lung | 0.6797 | 0.5880 |
| RCAN | Task06-Lung | Task06-Lung | 0.6454 | 0.5562 |
| SwinIR | Task06-Lung | Task06-Lung | 0.6921 | 0.6001 |
| SRCNN | COVID | Task06-Lung | 0.7343 | 0.6415 |
| EDSR | COVID | Task06-Lung | 0.7497 | 0.6533 |
| SRResNet | COVID | Task06-Lung | 0.7468 | 0.6547 |
| RCAN | COVID | Task06-Lung | 0.6812 | 0.5905 |
| SwinIR | COVID | Task06-Lung | 0.7017 | 0.6062 |
| Model | Training Data | Test Data | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|
| No Super-Resolution | – | COVID | 0.9509 | 0.9643 | 0.9024 | 0.9621 |
| SRCNN | Task06-Lung | COVID | 0.9109 | 0.9633 | 0.8824 | 0.9211 |
| EDSR | Task06-Lung | COVID | 0.9554 | 0.9825 | 0.9412 | 0.9614 |
| SRResNet | Task06-Lung | COVID | 0.9406 | 0.9652 | 0.9328 | 0.9487 |
| RCAN | Task06-Lung | COVID | 0.9505 | 0.9739 | 0.9412 | 0.9573 |
| SwinIR | Task06-Lung | COVID | 0.9406 | 0.9421 | 0.9580 | 0.9500 |
| SRCNN | COVID | COVID | 0.9109 | 0.9633 | 0.8824 | 0.9211 |
| EDSR | COVID | COVID | 0.9554 | 0.9825 | 0.9412 | 0.9614 |
| SRResNet | COVID | COVID | 0.9406 | 0.9652 | 0.9328 | 0.9487 |
| RCAN | COVID | COVID | 0.9505 | 0.9739 | 0.9412 | 0.9573 |
| SwinIR | COVID | COVID | 0.9406 | 0.9421 | 0.9580 | 0.9500 |
| No Super-Resolution | – | Task06-Lung | 0.9589 | 0.9621 | 0.6421 | 0.9621 |
| SRCNN | Task06-Lung | Task06-Lung | 0.9525 | 0.9677 | 0.5263 | 0.7518 |
| EDSR | Task06-Lung | Task06-Lung | 0.9593 | 0.9459 | 0.6140 | 0.7447 |
| SRResNet | Task06-Lung | Task06-Lung | 0.9542 | 0.9167 | 0.5789 | 0.7097 |
| RCAN | Task06-Lung | Task06-Lung | 0.9593 | 0.8837 | 0.6667 | 0.7600 |
| SwinIR | Task06-Lung | Task06-Lung | 0.9610 | 0.9677 | 0.6667 | 0.7677 |
| SRCNN | COVID | Task06-Lung | 0.9559 | 1.0000 | 0.5439 | 0.7045 |
| EDSR | COVID | Task06-Lung | 0.9168 | 1.0000 | 0.1404 | 0.2462 |
| SRResNet | COVID | Task06-Lung | 0.9100 | 1.0000 | 0.0702 | 0.1311 |
| RCAN | COVID | Task06-Lung | 0.9338 | 0.6406 | 0.7193 | 0.6777 |
| SwinIR | COVID | Task06-Lung | 0.9525 | 0.9677 | 0.5263 | 0.6818 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amoros, M.; Curado, M.; Vicent, J.F. Evaluating Super-Resolution Models in Biomedical Imaging: Applications and Performance in Segmentation and Classification. J. Imaging 2025, 11, 104. https://doi.org/10.3390/jimaging11040104
Amoros M, Curado M, Vicent JF. Evaluating Super-Resolution Models in Biomedical Imaging: Applications and Performance in Segmentation and Classification. Journal of Imaging. 2025; 11(4):104. https://doi.org/10.3390/jimaging11040104
Chicago/Turabian StyleAmoros, Mario, Manuel Curado, and Jose F. Vicent. 2025. "Evaluating Super-Resolution Models in Biomedical Imaging: Applications and Performance in Segmentation and Classification" Journal of Imaging 11, no. 4: 104. https://doi.org/10.3390/jimaging11040104
APA StyleAmoros, M., Curado, M., & Vicent, J. F. (2025). Evaluating Super-Resolution Models in Biomedical Imaging: Applications and Performance in Segmentation and Classification. Journal of Imaging, 11(4), 104. https://doi.org/10.3390/jimaging11040104