
Comparative Analysis of Deep Learning Architectures for Macular Hole Segmentation in OCT Images: A Performance Evaluation of U-Net Variants


 , , and
, , and
Abstract
1. Introduction
2. Background
2.1. Related Work
2.2. Selection of Models for Segmentation
3. Methodology
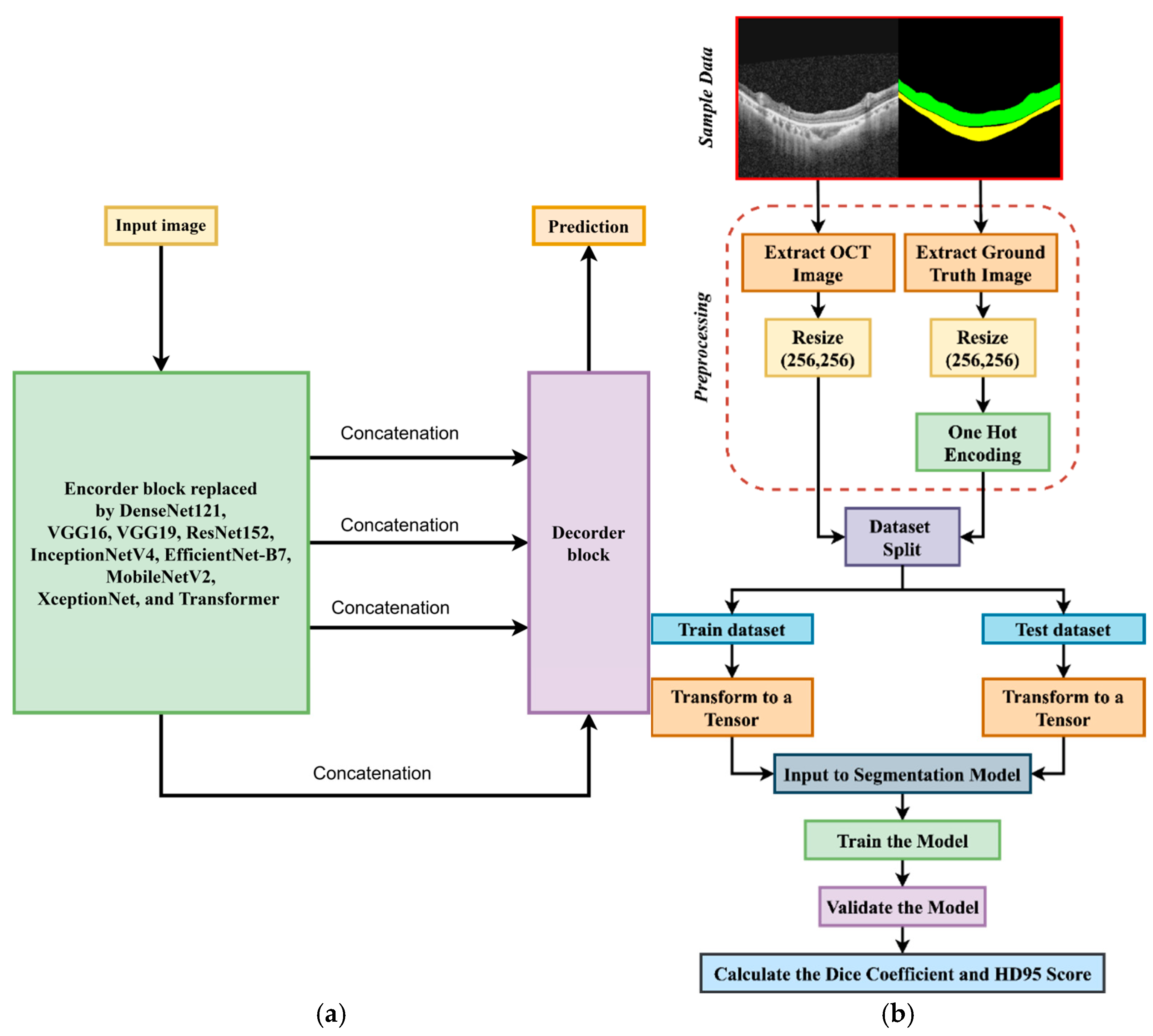
3.1. Data Acquisition
3.2. Preprocessing
3.3. Workflow of This Study
3.4. Training Process
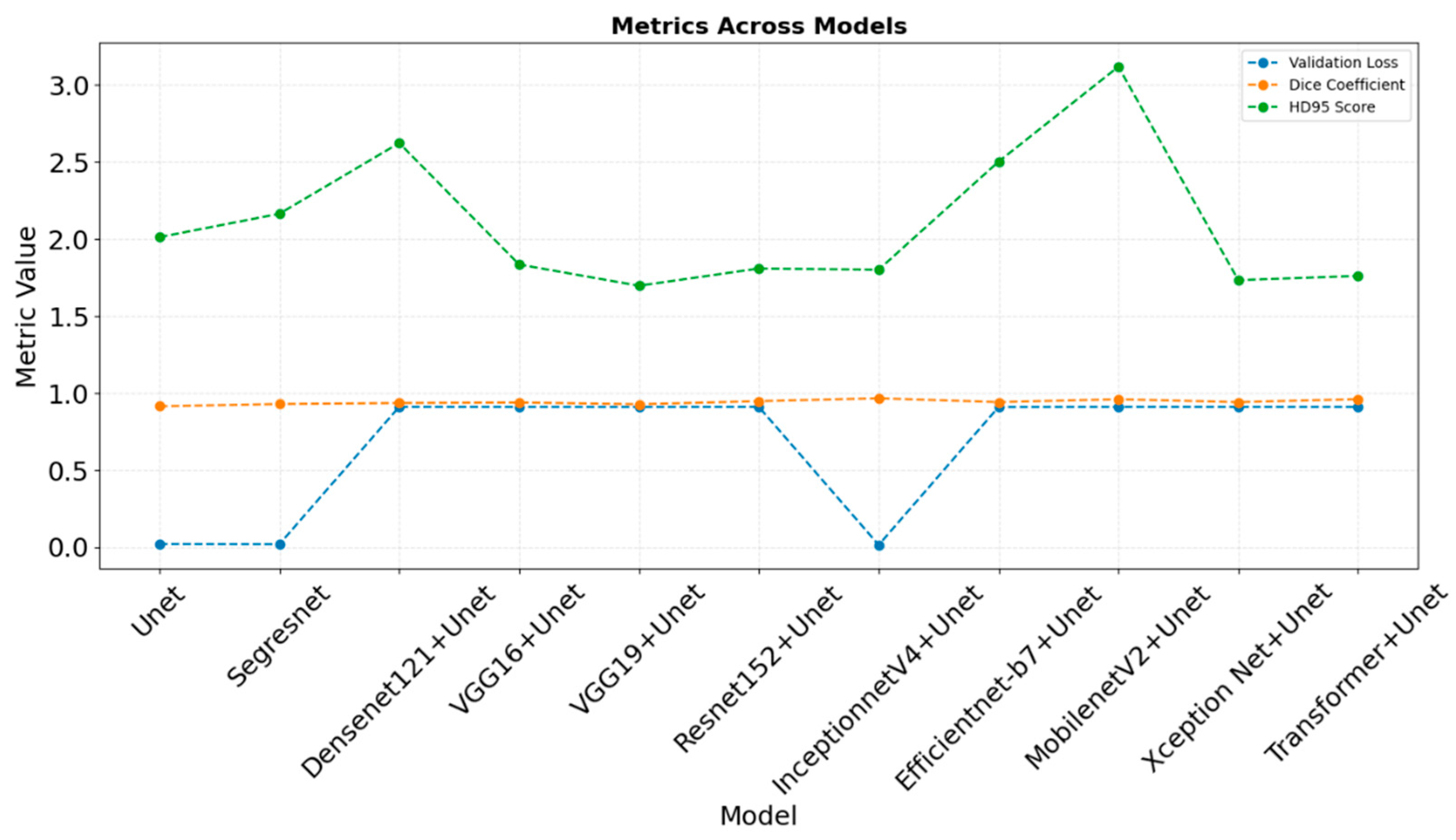
3.5. Evaluation Metrics
- Dice Coefficient (Dice Similarity Coefficient or DSC)
- Harsdorf Distance at 95th percentile (HD95 Score)
- Forward Distance: For each point , compute the minimum distance to any point :
- Reverse Distance: For each point , compute the minimum distance to any point :
- Combine Distances: Collect all minimum distances:
- Compute 95th Percentile: Find the 95th percentile of D:
4. Experiments and Results
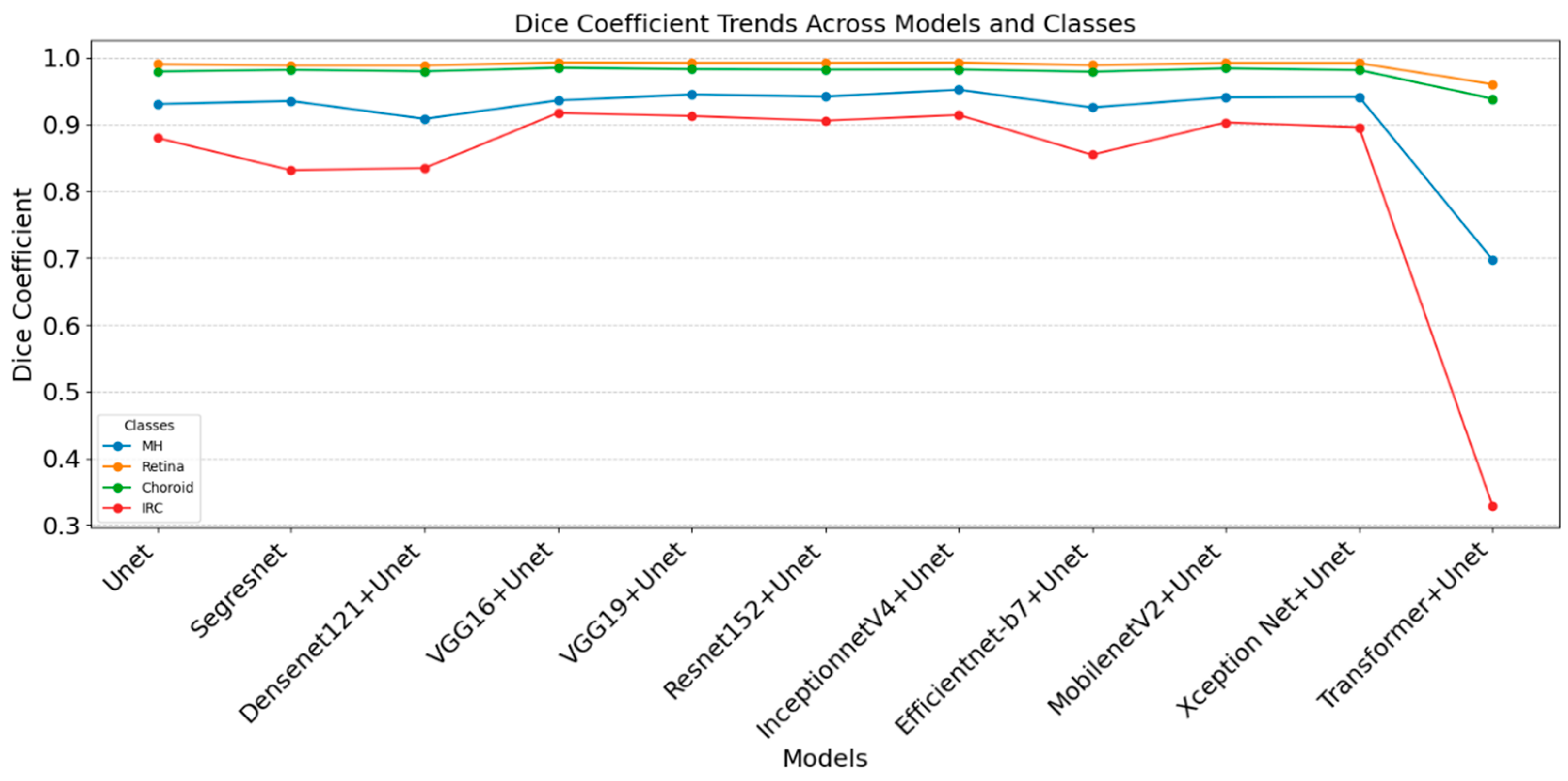
4.1. Comparative Analysis of Evaluation Metrices Across the Classes
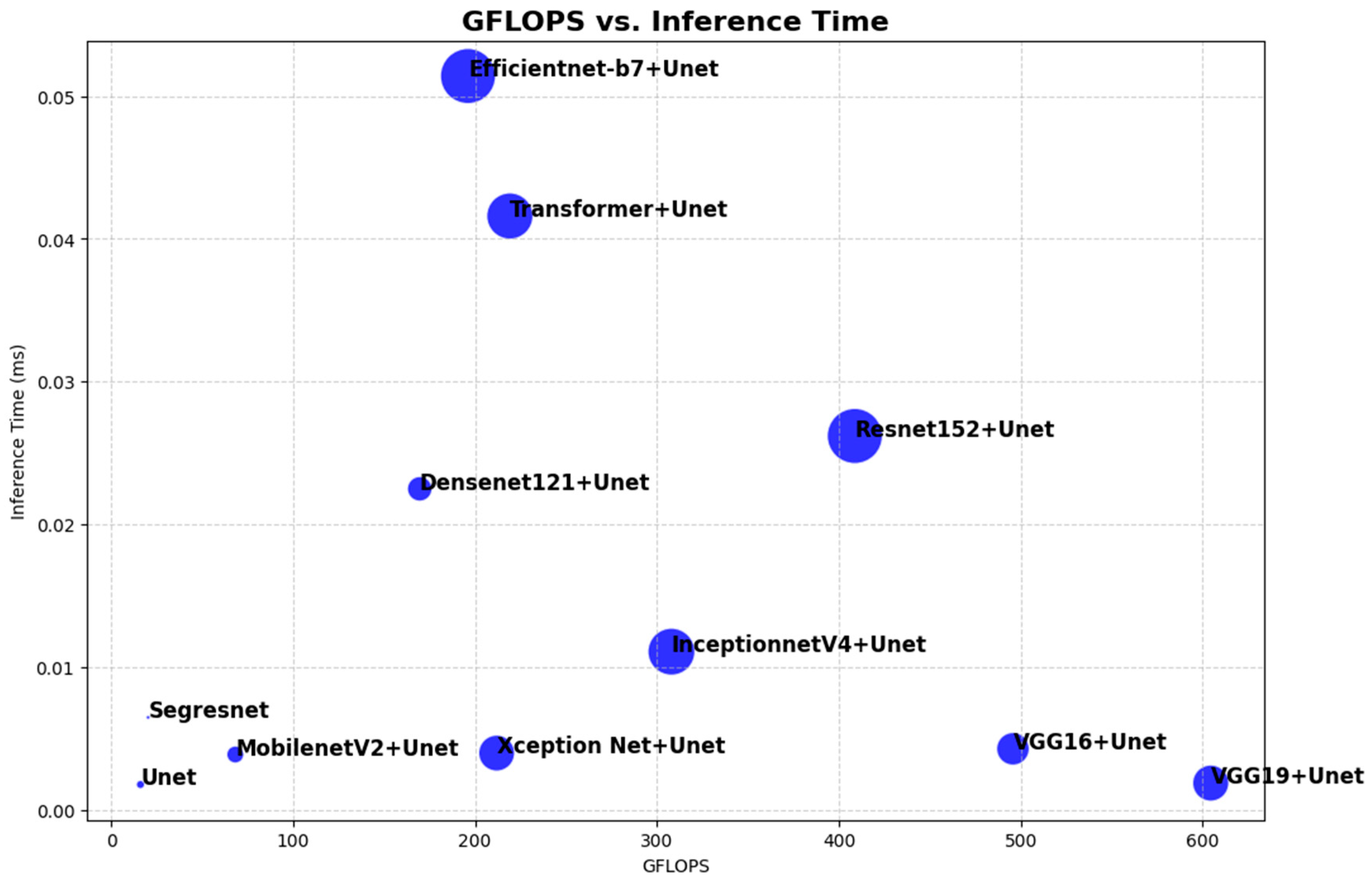
4.2. Comparative Analysis of Computational Resources
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, X.; Huang, J.; Zhao, K.; Zhang, T.; Li, Z.; Yue, C.; Chen, W.; Wang, R.; Chen, X.; Zhang, Q.; et al. SASAN: Spectrum-Axial Spatial Approach Networks for Medical Image Segmentation. IEEE Trans. Med. Imaging 2024, 43, 3044–3056. [Google Scholar] [CrossRef] [PubMed]
- Sampath Kumar, A.; Schlosser, T.; Langner, H.; Ritter, M.; Kowerko, D. Improving OCT Image Segmentation of Retinal Layers by Utilizing a Machine Learning Based Multistage System of Stacked Multiscale Encoders and Decoders. Bioengineering 2023, 10, 1177. [Google Scholar] [CrossRef] [PubMed]
- Niu, S.; Xing, R.; Gao, X.; Liu, T.; Chen, Y. A Fine-to-Coarse-to-Fine Weakly Supervised Framework for Volumetric SD-OCT Image Segmentation. IET Comput. Vis. 2023, 17, 123–134. [Google Scholar] [CrossRef]
- Garcia-Marin, Y.F.; Alonso-Caneiro, D.; Fisher, D.; Vincent, S.J.; Collins, M.J. Patch-Based CNN for Corneal Segmentation of AS-OCT Images: Effect of the Number of Classes and Image Quality upon Performance. Comput. Biol. Med. 2023, 152, 106342. [Google Scholar] [CrossRef]
- Fang, J.; Xing, A.; Chen, Y.; Zhou, F. SeqCorr-EUNet: A Sequence Correction Dual-Flow Network for Segmentation and Quantification of Anterior Segment OCT Image. Comput. Biol. Med. 2024, 171, 108143. [Google Scholar] [CrossRef]
- Li, S.; Ma, F.; Yan, F.; Dong, X.; Guo, Y.; Meng, J.; Liu, H. SFNet: Spatial and Frequency Domain Networks for Wide-Field OCT Angiography Retinal Vessel Segmentation. J. Biophotonics 2024, 18, e202400420. [Google Scholar] [CrossRef] [PubMed]
- Fazekas, B.; Aresta, G.; Lachinov, D.; Riedl, S.; Mai, J.; Schmidt-Erfurth, U.; Bogunović, H. SD-LayerNet: Robust and Label-Efficient Retinal Layer Segmentation via Anatomical Priors. Comput. Methods Programs Biomed. 2025, 261, 108586. [Google Scholar] [CrossRef]
- Wang, Y.; Dan, R.; Luo, S.; Sun, L.; Wu, Q.; Li, Y.; Chen, X.; Yan, K.; Ye, X.; Yu, D. AMSC-Net: Anatomy and Multi-Label Semantic Consistency Network for Semi-Supervised Fluid Segmentation in Retinal OCT. Expert. Syst. Appl. 2024, 249, 123496. [Google Scholar] [CrossRef]
- Ji, Z.; Ma, X.; Leng, T.; Rubin, D.L.; Chen, Q. Mirrored X-Net: Joint Classification and Contrastive Learning for Weakly Supervised GA Segmentation in SD-OCT. Pattern Recognit. 2024, 153, 110507. [Google Scholar] [CrossRef]
- Chen, Q.; Zeng, L.; Lin, C. A Deep Network Embedded with Rough Fuzzy Discretization for OCT Fundus Image Segmentation. Sci. Rep. 2023, 13, 328. [Google Scholar] [CrossRef] [PubMed]
- Sheeba, T.M.; Albert Antony Raj, S.; Anand, M. Analysis of Various Image Segmentation Techniques on Retinal OCT Images. In Proceedings of the 2023 Third International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 2–4 February 2023; pp. 716–721. [Google Scholar] [CrossRef]
- Liu, J.; Yan, S.; Lu, N.; Yang, D.; Lv, H.; Wang, S.; Zhu, X.; Zhao, Y.; Wang, Y.; Ma, Z.; et al. Automated Retinal Boundary Segmentation of Optical Coherence Tomography Images Using an Improved Canny Operator. Sci. Rep. 2022, 12, 1412. [Google Scholar] [CrossRef] [PubMed]
- Diao, S.; Yin, Z.; Chen, X.; Li, M.; Zhu, W.; Mateen, M.; Xu, X.; Shi, F.; Fan, Y. Two-Stage Adversarial Learning Based Unsupervised Domain Adaptation for Retinal OCT Segmentation. Med. Phys. 2024, 51, 5374–5385. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Li, J.; Wang, J.; Li, R.; Gu, K.; Liu, B. DiffusionDCI: A Novel Diffusion-Based Unified Framework for Dynamic Full-Field OCT Image Generation and Segmentation. IEEE Access 2024, 12, 37702–37714. [Google Scholar] [CrossRef]
- Niu, Z.; Deng, Z.; Gao, W.; Bai, S.; Gong, Z.; Chen, C.; Rong, F.; Li, F.; Ma, L. FNeXter: A Multi-Scale Feature Fusion Network Based on ConvNeXt and Transformer for Retinal OCT Fluid Segmentation. Sensors 2024, 24, 2425. [Google Scholar] [CrossRef] [PubMed]
- Su, W.; Zhili, H.; Zixuan, W.; Qiyong, L.; Jinsong, L. MAPI-Net: A Context and Location Fusion Network for Multi-Lesion Segmentation in Intravascular OCT. Biomed. Signal Process. Control. 2024, 96, 106559. [Google Scholar] [CrossRef]
- Ye, X.; He, S.; Zhong, X.; Yu, J.; Yang, S.; Shen, Y.; Chen, Y.; Wang, Y.; Huang, X.; Shen, L. OIMHS: An Optical Coherence Tomography Image Dataset Based on Macular Hole Manual Segmentation. Sci. Data 2023, 10, 769. [Google Scholar] [CrossRef] [PubMed]
- Cao, G.; Peng, Z.; Wu, Y.; Zhou, Z. Retinal OCT Image Layer Segmentation Based on Attention Mechanism. In Proceedings of the 2023 8th International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 23–25 November 2023; pp. 205–209. [Google Scholar] [CrossRef]
- Liu, X.; Ding, Y. A Feature Pyramid Fusion Network Based on Dynamic Perception Transformer for Retinal OCT Biomarker Image Segmentation. In Neural Information Processing; Luo, B., Cheng, L., Wu, Z.-G., Li, H., Li, C., Eds.; Springer Nature Singapore: Singapore, 2024; Volume 1964, pp. 114–124. [Google Scholar] [CrossRef]
- Kumar Vupparaboina, K.; Chandra Bollepalli, S.; Ibrahim, M.N.; Selvam, A.; Vaishnavi Kurakula, S.; Mohammed, A.R.; Mayer, N.; Sahel, J.-A.; Chhablani, J. Protecting Privacy While Improving Choroid Layer Segmentation in OCT Images: A GAN-Based Image Synthesis Approach; SSRN: Rochester, NY, USA, 2024; Available online: https://ssrn.com/abstract=4705376 (accessed on 3 March 2024).
- Xiao, Z.; Du, M.; Liu, J.; Sun, E.; Zhang, J.; Gong, X.; Chen, Z. EA-UNet Based Segmentation Method for OCT Image of Uterine Cavity. Photonics 2023, 10, 73. [Google Scholar] [CrossRef]
- Kugelman, J.; Alonso-Caneiro, D.; Read, S.A.; Vincent, S.J.; Collins, M.J. Enhancing OCT Patch-Based Segmentation with Improved GAN Data Augmentation and Semi-Supervised Learning. Neural Comput. Appl. 2024, 36, 18087–18105. [Google Scholar] [CrossRef]
- Montazerin, M.; Sajjadifar, Z.; Khalili Pour, E.; Riazi-Esfahani, H.; Mahmoudi, T.; Rabbani, H.; Movahedian, H.; Dehghani, A.; Akhlaghi, M.; Kafieh, R. Livelayer: A Semi-Automatic Software Program for Segmentation of Layers and Diabetic Macular Edema in Optical Coherence Tomography Images. Sci. Rep. 2021, 11, 13794. [Google Scholar] [CrossRef] [PubMed]
- Alex, V.; Motevasseli, T.; Freeman, W.R.; Jayamon, J.A.; Bartsch, D.U.G.; Borooah, S. Assessing the Validity of a Cross-Platform Retinal Image Segmentation Tool in Normal and Diseased Retina. Sci. Rep. 2021, 11, 21784. [Google Scholar] [CrossRef] [PubMed]
- Cao, G.; Zhou, Z.; Wu, Y.; Peng, Z.; Yan, R.; Zhang, Y.; Jiang, B. GCN-Enhanced Spatial-Spectral Dual-Encoder Network for Simultaneous Segmentation of Retinal Layers and Fluid in OCT Images. Biomed. Signal Process Control 2024, 98, 106702. [Google Scholar] [CrossRef]
- Hao, J.; Li, H.; Lu, S.; Li, Z.; Zhang, W. General Retinal Layer Segmentation in OCT Images via Reinforcement Constraint. Comput. Med. Imaging Graph. 2025, 120, 102480. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; le Yu, X.; Yao, H.; Jin, Y.; Lin, K.; Shi, C.; Cheng, H.; Lin, Z.; Jiang, J.; Gao, H.; et al. ScLNet: A Cornea with Scleral Lens OCT Layers Segmentation Dataset and New Multi-Task Model. Heliyon 2024, 10, e33911. [Google Scholar] [CrossRef] [PubMed]
- Geetha, A.; Carmel Sobia, M.; Santhi, D.; Ahilan, A. DEEP GD: Deep Learning Based Snapshot Ensemble CNN with EfficientNet for Glaucoma Detection. Biomed. Signal Process Control 2025, 100, 106989. [Google Scholar] [CrossRef]
- Tanthanathewin, R.; Wongrattanapipat, W.; Khaing, T.T.; Aimmanee, P. Automatic Exudate and Aneurysm Segmentation in OCT Images Using UNET++ and Hyperreflective-Foci Feature Based Bagged Tree Ensemble. PLoS ONE 2024, 19, e0304146. [Google Scholar] [CrossRef] [PubMed]
- Ndipenoch, N.; Miron, A.; Li, Y. Performance Evaluation of Retinal OCT Fluid Segmentation, Detection, and Generalization Over Variations of Data Sources. IEEE Access 2024, 12, 31719–31735. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Methodology | Findings |
|---|---|---|
| Huang et al. [1] SASAN | Combines spectral and spatial features for retinal OCT segmentation. | Improved retinal layer delineation and segmentation reliability. |
| Sampath Kumar et al. [2] Multistage Approach | EfficientNet, ResNet, and Attention U-Net for noisy, low-contrast OCT images. | Significant accuracy improvement; reduced noise impact. |
| Niu et al. [3] 3D-GDH algorithm | Weakly supervised framework with 3D-GDH algorithm for pseudo-labeling. | Reduced annotation needs while maintaining accuracy. |
| Niu et al. [4] Patch-based CNN Classifier | Trains CNNs (VGG16, ResNet50) on patches for corneal layer segmentation. | Enhanced segmentation accuracy; aids in corneal disease diagnosis. |
| Fang et al. [5] SeqCorr-EUNet | Combines U-Net and EfficientNet for anterior segment OCT segmentation. | Outperformed prior methods with superior accuracy. |
| Li et al. [6] SFNet | Combines spatial-frequency domains. | Achieved state-of-the-art accuracy, improves early vascular disease detection. |
| Fazekas et al. [7] SD-LayerNet | Semi-supervised segmentation leverages sparse labels, topology prediction. | Boosts cross-dataset robustness, label efficiency, and retinal disease management. |
| Wang et al. [8] AMSC-Net | Semi-supervised fluid segmentation, uses consistency losses for enhancement. | Achieves 73.95% Dice with 5% labeled data, clinical usefulness. |
| Ji et al. [9] Mirrored X-Net | Uses weak supervision, anisotropic downsampling, contrastive module. | Improved feature extraction, better class differentiation in GA segmentation. |
| Chen et al. [10] Rough Fuzzy Discretization | Adds rough fuzzy logic to deep learning for noisy OCT segmentation. | Increased segmentation robustness and accuracy. |
| Sheeba et al. [11] K-means Clustering | Applies clustering techniques with Wiener filter preprocessing. | High accuracy; minimized MSE and maximized PSNR. |
| Liu et al. [12] Canny operator | An improved algorithm that adds a multi-point boundary search step based on the original method and adjusts the convolution kernel. | Beneficial for use alone or in combination with other methods in initial boundary detection. |
| Diao et al. [13] Two-stage Adversarial Learning | Domain adaptation via adversarial learning for OCT datasets. | Enhanced cross-dataset segmentation performance. |
| Yang et al. [14] DiffusionDCI | Dual Semantic Diffusion Model for generating and segmenting DCI with cross-attention. | Accurate segmentation and high-fidelity image generation. |
| Niu et al. [15] FNeXter | Combines ConvNeXt, Transformer, spatial attention for fluid segmentation. | Outperforms state-of-the-art methods in retinal OCT fluid segmentation. |
| Su et al. [16] MAPI-Net | Uses multi-scale features and location fusion for plaque segmentation. | Outperforms comparison models, aids cardiovascular disease research and diagnosis. |
| S. He et al. [17] OIMHS Dataset | Released dataset for macular hole segmentation in OCT images. | Provided a benchmark for training and evaluation. |
| Cao et al. [18] Transformer-based Attention | Transformer-based attention for retinal OCT segmentation. | Improved feature extraction and accuracy. |
| Liu et al. [19] Feature Pyramid Fusion Network | Multiscale features with Dynamic Perception Transformer for biomarker segmentation. | Robust accuracy; outperformed traditional methods. |
| Liu et al. [20] GAN-based Privacy Approach | Uses GANs to synthesize privacy-preserving OCT images. | Balanced privacy and segmentation performance. |
| Xiao et al. [21] EA-UNet Adaptation | Adapted EA-UNet for uterine cavity segmentation from retinal OCT data. | Demonstrated model flexibility for diverse imaging tasks. |
| Kugelman et al. [22] Conditional StyleGAN2 | GAN-based augmentation, semi-supervised learning for enhanced segmentation. | Improves accuracy with sparse data, aids medical imaging research. |
| Montazerin et al. [23] Livelayer | Dijkstra’s Shortest Path First (SPF) algorithm and the Livewire function together with some preprocessing operations on the segmented images. | Detailed layer segmentation and fluid localization with reduced manual effort. |
| Alex et al. [24] Comparing automated retinal layer segmentation | Retinal segmentation compared proprietary and cross-platform software against manual grading and layer volumes. | Cross-platform software excels in specific layer segmentation and correlates well with manual standards. |
| Cao et al. [25] GD-Net | Uses FFT encoder, graph convolution for segmentation. | Achieves accuracy, cross-dataset generalization, aids Macular Edema diagnosis. |
| Hao et al. [26] General segmentation method | Improved decoder, attention mechanisms, focal loss for segmentation. | Excels on five datasets, aids ocular disease diagnosis, research. |
| Cao et al. [27] ScLNet | Deep learning for scleral lens, corneal, TFR segmentation. | Surpasses state-of-the-art methods, achieves high segmentation accuracy. |
| Geetha et al. [28] DEEP GD | CCRS ECNN, EfficientNetB4, Aquila optimization | Achieves 99.35% accuracy, outperforms existing glaucoma detection methods. |
| Tanthanathewin et al. [29] Method based on U-Net++ | U-Net++ with adaptive thresholding, bagged tree classifiers for segmentation. | Achieved 87.0% F1-score, outperforms binary thresholding, watershed methods. |
| Ndipenoch et al. [30] Algorithm comparison | Reviewed nnUNet, SAMedOCT, IAUNet_SPP_CL on RETOUCH dataset. | nnUNet_RASPP achieves best fluid segmentation. |
| Work | Dice Coefficient | Dataset |
|---|---|---|
| Huang et al. [1] | 93.53 ± 17.35 | OIMHS DATASET |
| Sampath Kumar et al. [2] | 82.25 ± 0.74% | Duke SD-OCT |
| Li et al. [6] | 83.85 | Retinal Vessels Images in OCTA (REVIO) dataset |
| 76.7 | ROSE: A Retinal OCT Angiography Vessel Segmentation Dataset and New Model | |
| 82.85 | OCTA—500 | |
| Wang et al. [8] | 73.95% | Private dataset |
| Chen et al. [10] | 0.97 | Private dataset |
| Yang et al. [14] | 0.8302 | DCI dataset |
| Niu et al. [15] | 82.33 ± 0.46 | RETOUCH |
| Cao et al. [18] | 0.845 | DUKE DME |
| Liu et al. [19] | 80.23 | Local biomarker dataset |
| Cao et al. [25] | 0.839 | DUKE DME |
| 0.826 | Peripapillary OCT | |
| 0.872 | RETOUCH | |
| Hao et al. [26] | 82.64 | MGU dataset |
| 87.42 | DUKE | |
| 91.95 | NR206 | |
| 94.32 | OCTA500 | |
| 89.55 | Private dataset | |
| Cao et al. [27] | 96.50% | Private dataset |
| Ndipenoch et al. [30] | 82.3% | RETOUCH |
| Model | MH | Retina | Choroid | IRC |
|---|---|---|---|---|
| U-Net | nan | 1.32069862 | 1.95789254 | nan |
| Segresnet | nan | 1.5654013 | 1.5654013 | nan |
| Densenet121 + U-Net | nan | 1.96263492 | 2.11148545 | nan |
| VGG16 + U-Net | nan | 1.05933894 | 1.7365639 | nan |
| VGG19 + U-Net | nan | 1.06198439 | 1.90753952 | nan |
| Resnet152 + U-Net | nan | 1.09918057 | 1.77921848 | nan |
| InceptionnetV4 + U-Net | nan | 1.0417409 | 1.81851334 | nan |
| Efficientnet-b7 + U-Net | nan | 2.1089202 | 3.18990847 | nan |
| MobilenetV2 + U-Net | nan | 1.88089567 | 3.71487823 | nan |
| Xception Net + U-Net | nan | 1.11548322 | 1.89977866 | nan |
| Transformer + U-Net | nan | 15.29405853 | 6.77490137 | nan |
| Original | 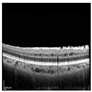 | 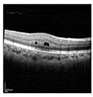 | 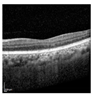 | 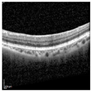 |  |
| Ground truth |  | 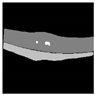 |  |  |  |
| U-Net | 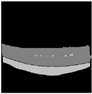 | 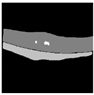 |  |  |  |
| Segresnet | 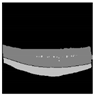 |  |  |  |  |
| Densenet121 + U-Net |  | 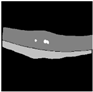 |  |  |  |
| VGG16 + U-Net | 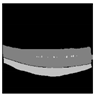 | 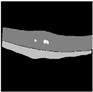 |  |  |  |
| VGG19 + U-Net |  |  |  |  |  |
| Resnet152 + U-Net | 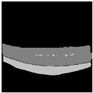 | 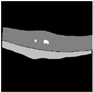 |  |  |  |
| InceptionnetV4 + U-Net | 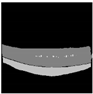 |  |  |  |  |
| Efficientnet-b7 + U-Net | 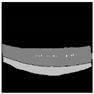 |  |  |  |  |
| MobilenetV2 + U-Net |  |  |  |  |  |
| Xception Net + U-Net | 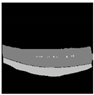 | 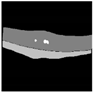 |  |  |  |
| Transformer + U-Net |  |  |  |  |  |
| Model | GFLOPS | Number of Parameters | GPU Memory Usage | Inference Time per Batch (Batch Size = 20) |
|---|---|---|---|---|
| U-Net | 16.13 | 1,626,796 | 261.51 MB | 0.0018 s |
| Segresnet | 20.34 | 395,157 | 276.61 MB | 0.0065 s |
| Densenet121 + U-Net | 169.63 | 13,608,213 | 1021.69 MB | 0.0225 s |
| VGG16 + U-Net | 495.70 | 23,748,821 | 1568.32 MB | 0.0043 s |
| VGG19 + U-Net | 604.41 | 29,058,517 | 1644.84 MB | 0.0019 s |
| Resnet152 + U-Net | 408.78 | 67,157,461 | 1857.09 MB | 0.0262 s |
| InceptionnetV4 + U-Net | 307.98 | 48,792,501 | 1544.98 MB | 0.0111 s |
| Efficientnet-b7 + U-Net | 196.17 | 67,095,909 | 1942.01 MB | 0.0514 s |
| MobilenetV2 + U-Net | 68.25 | 6,629,525 | 726.39 MB | 0.0039 s |
| Xception Net + U-Net | 211.92 | 28,769,981 | 1195.59 MB | 0.0040 s |
| Transformer + U-Net | 219.18 | 47,353,429 | 1391.86 MB | 0.0416 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herath, H.M.S.S.; Yasakethu, S.L.P.; Madusanka, N.; Yi, M.; Lee, B.-I. Comparative Analysis of Deep Learning Architectures for Macular Hole Segmentation in OCT Images: A Performance Evaluation of U-Net Variants. J. Imaging 2025, 11, 53. https://doi.org/10.3390/jimaging11020053
Herath HMSS, Yasakethu SLP, Madusanka N, Yi M, Lee B-I. Comparative Analysis of Deep Learning Architectures for Macular Hole Segmentation in OCT Images: A Performance Evaluation of U-Net Variants. Journal of Imaging. 2025; 11(2):53. https://doi.org/10.3390/jimaging11020053
Chicago/Turabian StyleHerath, H. M. S. S., S. L. P. Yasakethu, Nuwan Madusanka, Myunggi Yi, and Byeong-Il Lee. 2025. "Comparative Analysis of Deep Learning Architectures for Macular Hole Segmentation in OCT Images: A Performance Evaluation of U-Net Variants" Journal of Imaging 11, no. 2: 53. https://doi.org/10.3390/jimaging11020053
APA StyleHerath, H. M. S. S., Yasakethu, S. L. P., Madusanka, N., Yi, M., & Lee, B.-I. (2025). Comparative Analysis of Deep Learning Architectures for Macular Hole Segmentation in OCT Images: A Performance Evaluation of U-Net Variants. Journal of Imaging, 11(2), 53. https://doi.org/10.3390/jimaging11020053