1. Introduction
Traffic signs are an essential component of the infrastructure that enables the safe movement of all road users, including drivers, passengers, cyclists, and pedestrians. They provide unambiguous instructions and warnings that facilitate the prevention of accidents and reduce the risk of injuries or fatalities. It should be noted, however, that this only applies to traffic signs that are intact, correctly oriented, and undamaged. Due to the large number of traffic signs, manually inspecting, localizing, and constantly monitoring them is almost impossible. In Germany alone, for instance, the official traffic sign catalog lists a total of 1134 different traffic signs [
1]. These include danger signs, regulatory signs, and direction signs, which are further complemented by traffic devices and additional signs. The estimated number of traffic signs on German roads is approximately 20 million [
2]. This equates to one sign every 24 m along the entire street network of 830,000 km [
3].
The automatic detection and segmentation of traffic signs has the potential to enhance the efficiency of the process of ensuring correctness. To solve these vision tasks, deep learning is the current state-of-the-art approach [
4]. Traditionally, training robust models for such tasks requires an extensive amount of annotated data, especially in terms of the diversity of traffic signs. The collection of data is both time-consuming and costly. Recent advances in large foundation models such as BERT, DALL-E, and GPT [
5] offer a promising solution to this challenge by using knowledge already acquired from these foundation models for such specific downstream tasks [
5]. Thus, the need for large additional training data can be minimized, because fine-tuning often requires only a limited amount of data or specific guidance. This study explores the application of pre-trained foundation models using
Meta’s Segment Anything Model (SAM) [
6]. SAM is a transformer-based foundation model developed for semantic segmentation. The use of the transformer model architecture enables more meaningful models to be created in less time through parallel training [
5]. A large amount of training data utilized for pre-training the SAM improves the model’s capabilities in the field of computer vision. The primary purpose of this study is to assess whether the SAM can maintain its performance despite being trained on a significantly reduced dataset, thereby lowering the barriers for subtasks and making them more accessible and cost-effective. The performance of the foundation model is evaluated in comparison to a leading architecture in the field of traffic sign segmentation.
The architecture of the SAM consists of an image encoder, prompt encoder, and mask decoder. Its heavyweight image encoder is based on a vision transformer (ViT) [
7] architecture and extracts the input image features into image embeddings. The prediction depends on an input that is provided as a prompt. This prompt may take the form of one or more points, a bounding box, a mask, or text. The prompt is processed by the prompt encoder [
6]. The lightweight mask decoder is designed for interactive real-time mask prediction. Several studies have modified the model to align with their specific research objectives. These include studies on remote sensing applications [
8,
9,
10], shadows [
11,
12], food [
13], web pages [
14], oil spills [
15], and camouflaged objects [
16]. SAM fine-tuning has a particular focus on medical image segmentation [
17,
18,
19,
20,
21] due to the limited availability of data in this field. In general, updating all parameters of the SAM is a time-consuming process. Consequently, numerous studies have focused their efforts on parameter-efficient fine-tuning [
17]. They employed the use of adapter modules, which are positioned between the encoder transformer layers [
11,
18]. Subsequently, the adapter, prompt encoder, and mask decoder are fine-tuned on specific data. A significant limitation of the SAM is the dependency of segmentation on prompt input. For this particular task, it is necessary to adapt the SAM for the purpose of automatic traffic sign segmentation. One concept for automatic mask prediction is the use of the automatic mask generation pipeline [
6], which employs a large grid of points as a prompt. However, the automatic mask generation pipeline is not suitable for productive use due to its long calculation time. For instance, in the context of SAM automation, there are approaches for developing a prompt generator, which generates prompts for the prompt encoder [
10,
22,
23,
24]. Another variant employs learnable embeddings as prompts [
24].
In this work, the original SAM image encoder is combined with two distinct decoders to determine whether there is an influence of a decoder of the foundation model, which only contains 1% of all the model parameters. In addition to the original mask decoder (referred to as SAM-Fine-ViT
H), a decoder containing convolutional layers (referred to as SAM-Conv-ViT
H) is used. One significant drawback of the powerful SAM encoder is its long processing time, which is a consequence of the considerable number of parameters involved. Consequently, a parameter-distilled encoder version ViT
T [
25], created based on knowledge distillation to enhance performance, is employed. It is an opportune moment to consider whether the tiny version would yield comparable results, even with limited training data. The heavyweight image encoder has consequently been replaced with the tiny image encoder, while only the decoder has undergone fine-tuning. The decoder also contains convolutional layers (referred to as SAM-Conv-ViT
T).
Given the importance of traffic sign recognition for autonomous driving systems, as well as urban mobile mapping for maintenance planning or accident prevention, the field is widely covered in the scientific literature. However, in this field, the dominant approach is the use of convolutional neural networks (CNNs) [
26,
27,
28,
29,
30,
31,
32]. In contrast to object detection, semantic segmentation of traffic signs is a relatively underrepresented field. References [
33,
34,
35,
36,
37,
38] demonstrate that the Faster R-CNN model is a widely used tool for the detection of traffic signs, with the model achieving highly satisfactory results. In addition to the Faster R-CNN model, its extension, the Mask R-CNN model is used, as it also enables instance segmentation [
39,
40]. One of the few studies on sign segmentation uses a fully connected network [
27]. Another approach [
41] employs traffic sign recognition through segmentation with a specially developed SegU-Net, a fully connected network, that represents a combination of Seg-Net [
42], and U-Net [
43]. In 2022, an initial approach was implemented to investigate the use of ViT for traffic sign recognition [
44]. It was found that the tested CNNs outperformed the ViT architecture. However, these were pre-trained compared to the transformer architectures. The publication points out the advantages of the ViT in terms of its shorter training duration. Another paper comparing the feature extraction of CNNs with that of ViT [
45] demonstrates that the original ViT models are outperformed in the detection of advanced CNNs. Nevertheless, when a ViT is employed as a backbone model in the context of detection and compared to CNN backbone models, the ViT models demonstrate superior performance [
46]. The three models, which are based on the SAM architecture, are evaluated and compared to the Mask R-CNN architecture as a well-established and leading framework for traffic sign segmentation.
In this study, we investigate the adaptability of foundation models to a specific task with minimal additional training data. Our contributions can be summarized as follows:
A comparative evaluation between a state-of-the-art architecture provides for a specific task and a foundation model, focusing on their performance with reduced training data.
Two distinct decoders applied to the same large-scale encoder are compared, examining their impact on model performance.
The effects of knowledge distillation from foundation models are examined in the context of training data reduction.
The results are evaluated against multiple benchmark datasets, ensuring the robustness, reliability, and generalizability of our findings.
Model performance is measured based on the intersection over union (IoU), precision–recall, and their segmentation ability on an instance basis.
The main documentation is structured in two sections:
Section 2 considers the structures of the four implemented architectures, while
Section 3 presents the results of the implementation. In
Section 2, the implementation details are provided, including descriptions of the data preprocessing steps, the hyperparameter selection process, and the training setup. The datasets used are described in detail in
Section 3, followed by the presentation of segmentation results on different datasets. Additionally, the impact of training data reduction is analyzed, considering the IoU and precision–recall metric and presenting instance-level segmentation results. The results are interpreted in
Section 4 and summarized in
Section 5.
2. Methods
For implementation, the pre-trained ViT
H (huge) encoder is employed. The architectural structure enables the encoder to be used independently. During preprocessing, the image is scaled to
pixels and encoded into
with 256 feature maps [
6]. For automated use, the prompt encoder is completely removed, so the prompt tokens that correspond to the output of the prompt encoder are replaced by learnable embeddings. The number of model parameters that are frozen and fine-tuned during training, along with their respective performance, is presented in
Table 1. The performance is quantified in terms of floating-point operations per second (FLOPS) using an NVIDIA A100 SXM4 80GB GPU with an input tensor of dimensions 1024 × 1024 × 3.
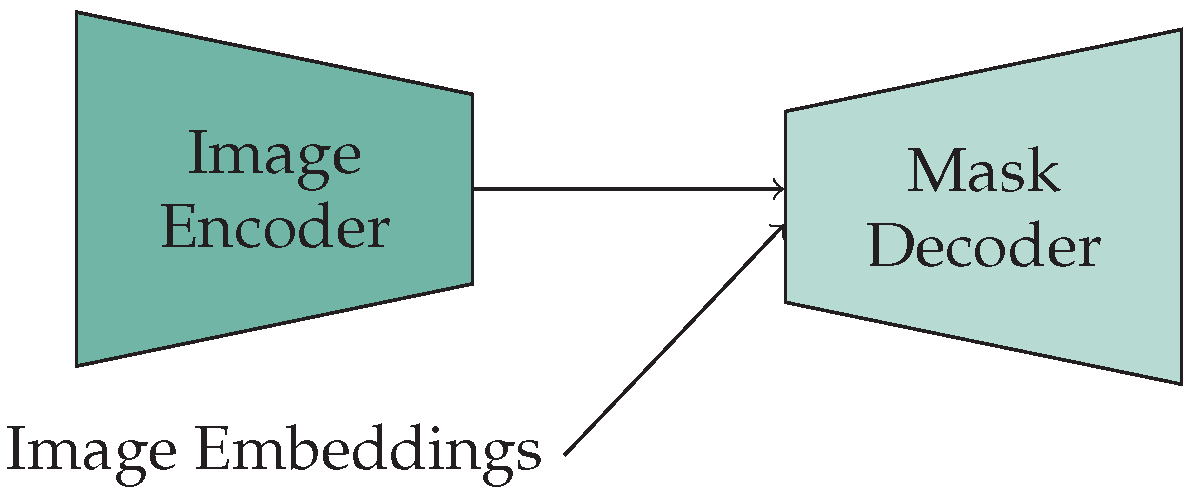
For SAM-Fine-ViT
H, the originally designed lightweight decoder is utilized (
Figure 1). It initially processes the embeddings with a transformer, and subsequently with 2D transposed convolutions, to increase the image size to
. The transposed convolution employs a
kernel with a stride of two, which doubles the resolution and reduces the number of feature maps to a quarter. After a transposed convolution, layer normalization follows. The output of the up-scaling step is employed after a multilayer perceptron to generate the masks and the IoU token.
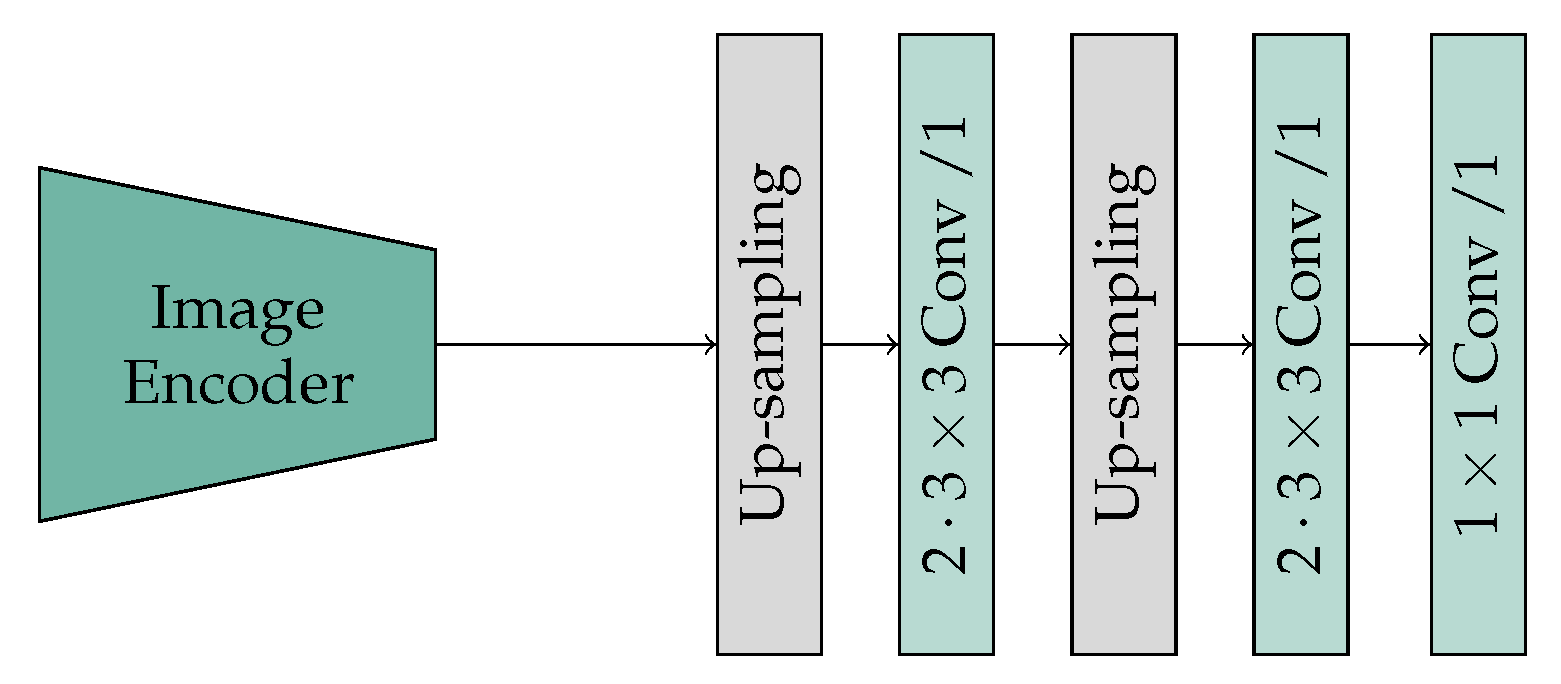
The decoder of SAM-Conv-ViT corresponds to the final two up-sampling steps, which combine an up-sampling and convolution layer, of the ascending path of the U-Net implementation [
43]. The initial step of the ViT patch-embedding process involves cropping image patches to a size of 16 × 16. Consequently, no encoding information is stored, and no skip connections can be used. Following the up-sampling, which doubles the size of the output and halves the number of feature maps, a subsequent double convolution is then applied (
Figure 2). A simple parameter-efficient bilinear interpolation is employed for up-sampling. The convolution is performed with a
kernel, a stride of one, and a zero-padding of one, and it is supplemented by batch normalization and the rectified linear unit (ReLU) activation function. Finally, 64 feature maps with a resolution of
remain, which are then processed into a binary mask by a
convolution layer.
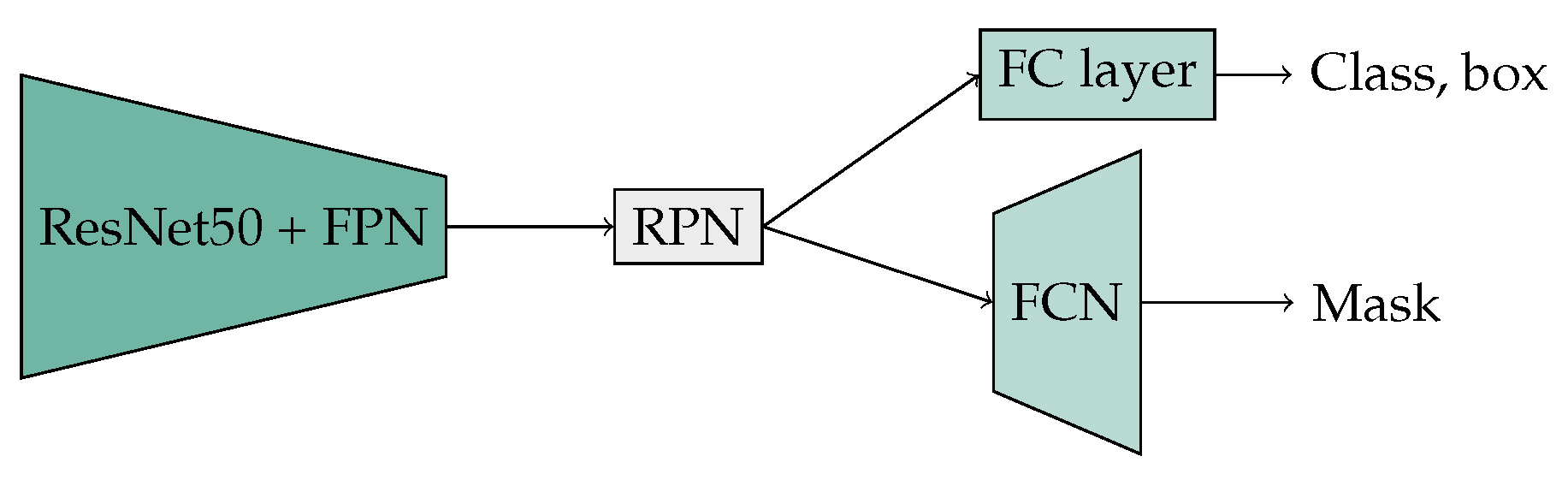
In accordance with reference [
47], the Mask R-CNN implementation (
Figure 3) employs a ResNet50 backbone model for feature extraction, extended by a feature pyramid network (FPN) [
48]. The FPN employs hierarchical processing of image information at four different resolutions. This approach is advantageous for the recognition of traffic signs, as these are often very small. In ResNet50, residual blocks derived from convolution operations with
,
, and
kernels with a stride of one were employed. To enhance the extraction of features, a ResNet50 pre-trained on the COCO dataset was utilized. The weights of the initial layer of a ResNet50 are frozen for the training process. This layer is typically responsible for processing fundamental features, such as edges and simple shapes, which are frequently useful in numerous image-recognition tasks. Based on the output of the encoder, a region proposal network (RPN) is used to predict potential bounding boxes, from which smaller feature maps are formed. A small fully convolutional network (FCN) is added to the architecture as a decoder for the pixel-based prediction of the binary mask. Additionally, a fully connected (FC) layer has been included to provide the necessary classification capabilities.
Implementation Details
The decoders are subjected to fine-tuning on a dataset for traffic sign segmentation, while the encoder parameters (or a subset of them in the case of Mask R-CNN) are held constant throughout the training process. In the preprocessing step, the input images are scaled to the dimensions required by the architectures. Additionally, the red, green, and blue (RGB) values of the images are normalized with the average RGB and standard deviation (SD) values of images used for training the SAM and Mask R-CNN. The SAM encoder architecture requires an image size of , while the output mask of the decoder is . For Mask R-CNN, an input and output image size of is employed.
To enhance the robustness and generalizability of architectures, the utilization of data augmentation for road images in the context of traffic sign recognition has a beneficial impact on the outcomes [
38,
39]. In this study, a series of functions, including brightness, contrast, rotation, distortion, blurring, and noise, were employed for data augmentation in the context of street scenes. The images have been adjusted to handle different lighting situations, varying camera settings and perspectives, and environmental influences such as motion blurring caused by high travel speeds. For the implementation, the data augmentation functions of torchvision, a library from PyTorch [
49], and albumentation [
50] are used.
The segmentation models are trained using an equal-weighted combination of the Dice and Binary Cross-Entropy loss functions. This approach is particularly well-suited for data sets with an imbalanced class distribution and for small objects [
51]. Additionally, the Adam optimization algorithm [
52] is employed. An initial learning rate of 0.1 (for all SAM models) and 0.001 (for Mask R-CNN) is scheduled based on the publication by Loshchilov et al. (2017) [
53]. The approach employs the cosine annealing warm restarts function, which periodically repeats the descending part of the cosine function. The training phase was conducted using a maximum of five hundred epochs, but the process was terminated prematurely when the validation metric reached a stable point or began to decline. All models were trained on an NVIDIA A100 SXM4 80 GB GPU with a batch size of eight, which aligns with the maximum available resources of the working memory. The implementation is carried out in Python using the PyTorch [
49] framework.
4. Discussion
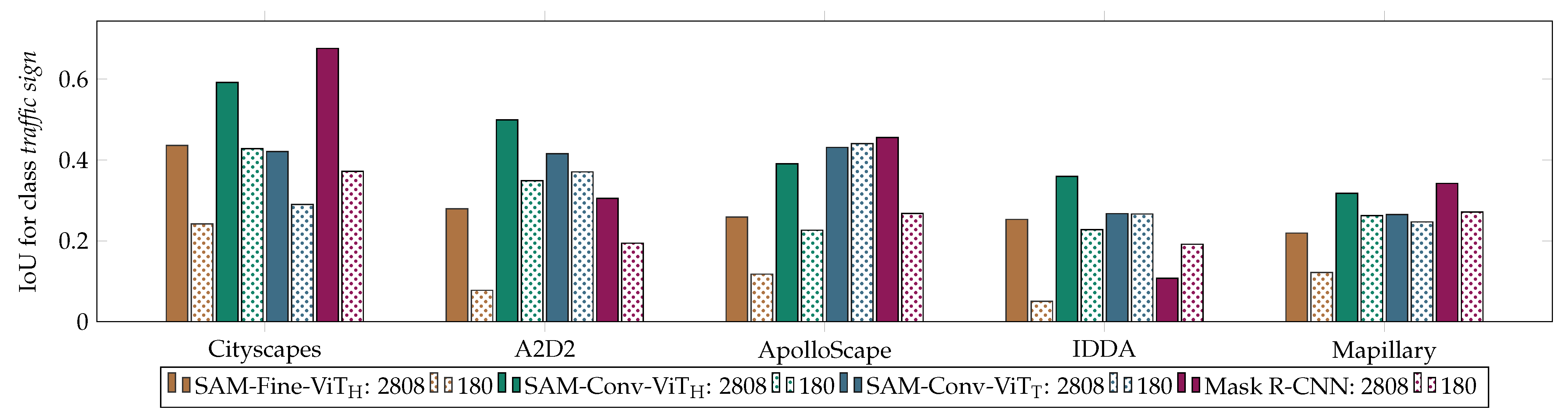
The segmentation of traffic signs is challenging due to their variability in shape, color, and small size. Across different model architectures, the number of detected signs is low. The smaller the size of the traffic signs, the lower the recognition rate. Among the models evaluated, the one with the greatest number of parameters, SAM-Conv-ViTH, exhibited the highest overall performance, followed by Mask R-CNN and SAM-Conv-ViTT. As expected, all the models demonstrated the highest prediction accuracy on the Cityscapes dataset due to its use for optimization. Mask R-CNN, which serves as the benchmark leading model, achieved the best results on the Cityscapes dataset. However, there are limitations to its adaptability to different datasets. In contrast, SAM-Conv-ViTH outperforms Mask R-CNN in accuracy across all datasets. Similarly, SAM-Conv-ViTT delivers less-impressive results overall but demonstrates the most consistent performance across different datasets. The models with a robust encoder indicate superior generalization capabilities. The analysis shows that SAM-Conv-ViTH demonstrates better segmentation accuracy than SAM-Fine-ViTH. It can be concluded that the decoder of the foundation model has a notable impact, despite comprising only 1% of the parameters. The SAM-Fine decoder was initially developed as a lightweight decoder to enable real-time mask prediction based on a prompt. However, it became evident that this decoder was not suitable for the task of traffic sign segmentation.
With limited training data, Mask R-CNN, behind SAM-Fine-ViTH, exhibits the most pronounced performance reduction. The results of the training data reduction indicate that SAM-Conv-ViTH demonstrates better robustness to smaller training datasets compared to Mask R-CNN. This is due to the greater number of pre-trained parameters, which are more relevant when training data are limited. SAM-Conv-ViTT benefits from knowledge distillation, showing superior generalization capabilities even with fewer parameters and demonstrating no decrease in accuracy when the training data are reduced. However, the precision–recall observation demonstrates noteworthy outcomes. Mask R-CNN exhibits a minimal reduction over the entire threshold spectrum. Contrary to expectations, SAM-Conv-ViTH shows the highest reduction over the precision–recall curve, suggesting that extensive pre-training is not essential for this task. The curve observation is more meaningful than considering a single IoU threshold at 0.75.
Instance-level observations indicate that SAM-Conv-ViT
H is more effective at identifying sign instances, whereas the Mask R-CNN model demonstrates superior performance in terms of correct segmentation. A correlation is identified between the encoder and the quantity of recognized masks, as well as between the decoder and the quality of the masks. Although SAM-Conv-ViT
T once again underperformed compared to SAM-Conv-ViT
H and Mask R-CNN when trained on the entire dataset, it demonstrated a clear advantage in terms of data reduction, exhibiting no decrease in accuracy. The main issue with the foundation model, as with the others, is the low detection rate, particularly for smaller signs. The process of down-sampling employed by the encoder resulted in the loss of certain image details, particularly those of a smaller scale. The effective performance of Mask R-CNN can be explained using an FPN, which processes images at varying resolutions and predicts sharp-edged masks without interpolation. In contrast, SAM-Conv-ViT
H relies on interpolation, leading to curved edges in the segmentation masks (
Figure A1). The effects of interpolation on the quality of mask prediction are particularly pronounced in the case of small objects, such as traffic signs. To improve the segmentation ability of the SAM, a high-quality version of the SAM, HQ-SAM [
59], has been developed. However, HQ-SAM does not outperform the original SAM in the case of small objects measuring less than 1024 pixels. For the Cityscapes dataset, for example, this means approximately 67% of the traffic signs fall into this category. Consequently, this area was not investigated further in this study.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}