
Toward Unbiased High-Quality Portraits through Latent-Space Evaluation



Abstract
1. Introduction
- The extension of DaVinciFace portraits to evaluate its capability to generate portraits for different social categories in the style of the Renaissance genius Leonardo da Vinci, and the demonstration of the effectiveness of latent space to support this goal.
- A qualitative and quantitative analysis of a significant number of portraits to provide clear evidence of the effectiveness of our methodology in using DaVinciFace to create high-quality and realistic portraits in terms of diversity of facial features (e.g., beard, hair color, and skin tone).
- Analyzing user feedback collected via a survey on the performance of DaVinciFace using a scale of identity vs style trade-off settings, including subjects with diversity regarding gender, race, and age. Where a high tolerance for the loss of identity features is observed in general to preserve more style features.
2. Related Work
3. Methodology
3.1. DaVinciFace Application
3.2. Parameter Setting
3.3. Survey Design
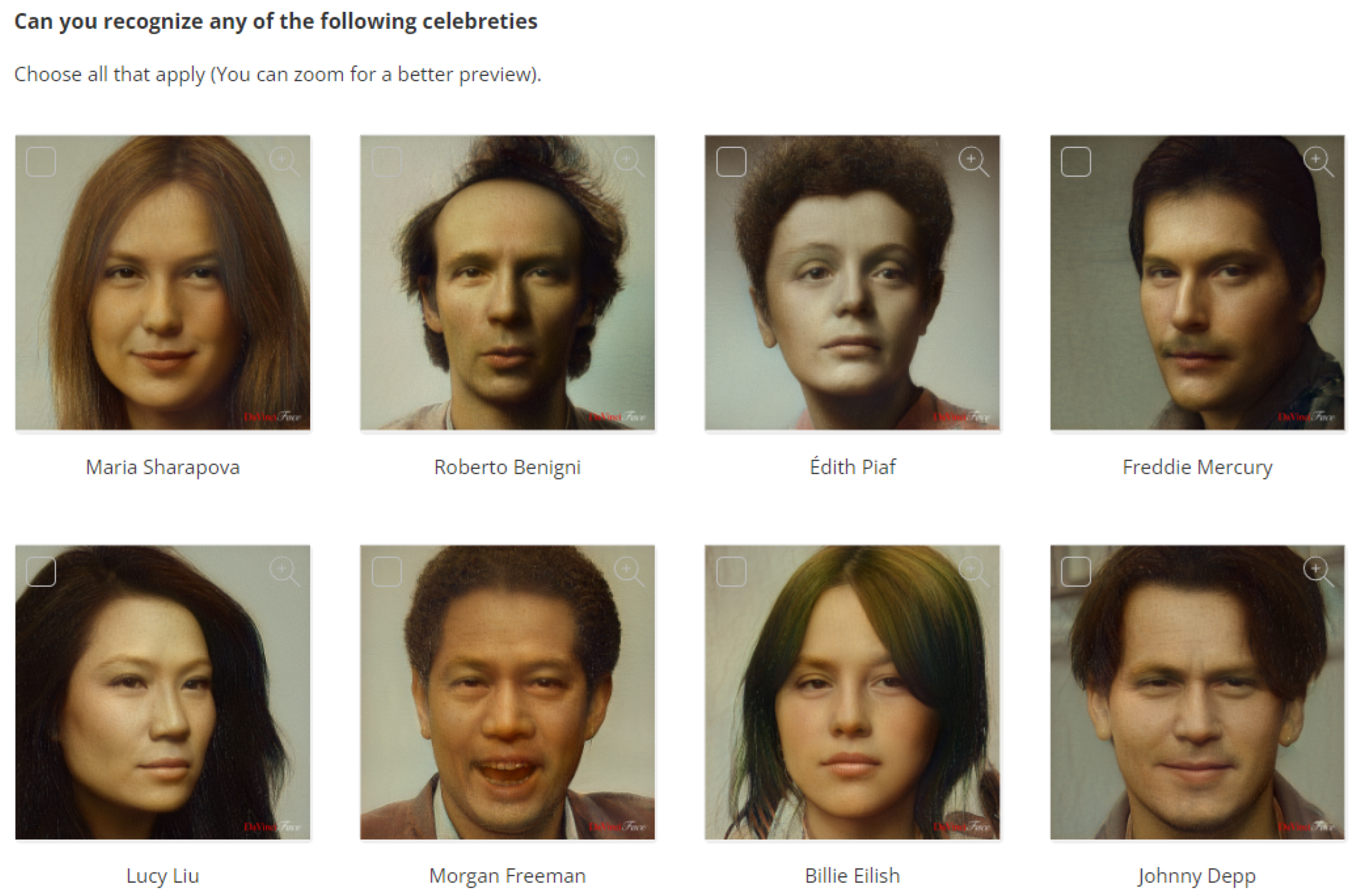
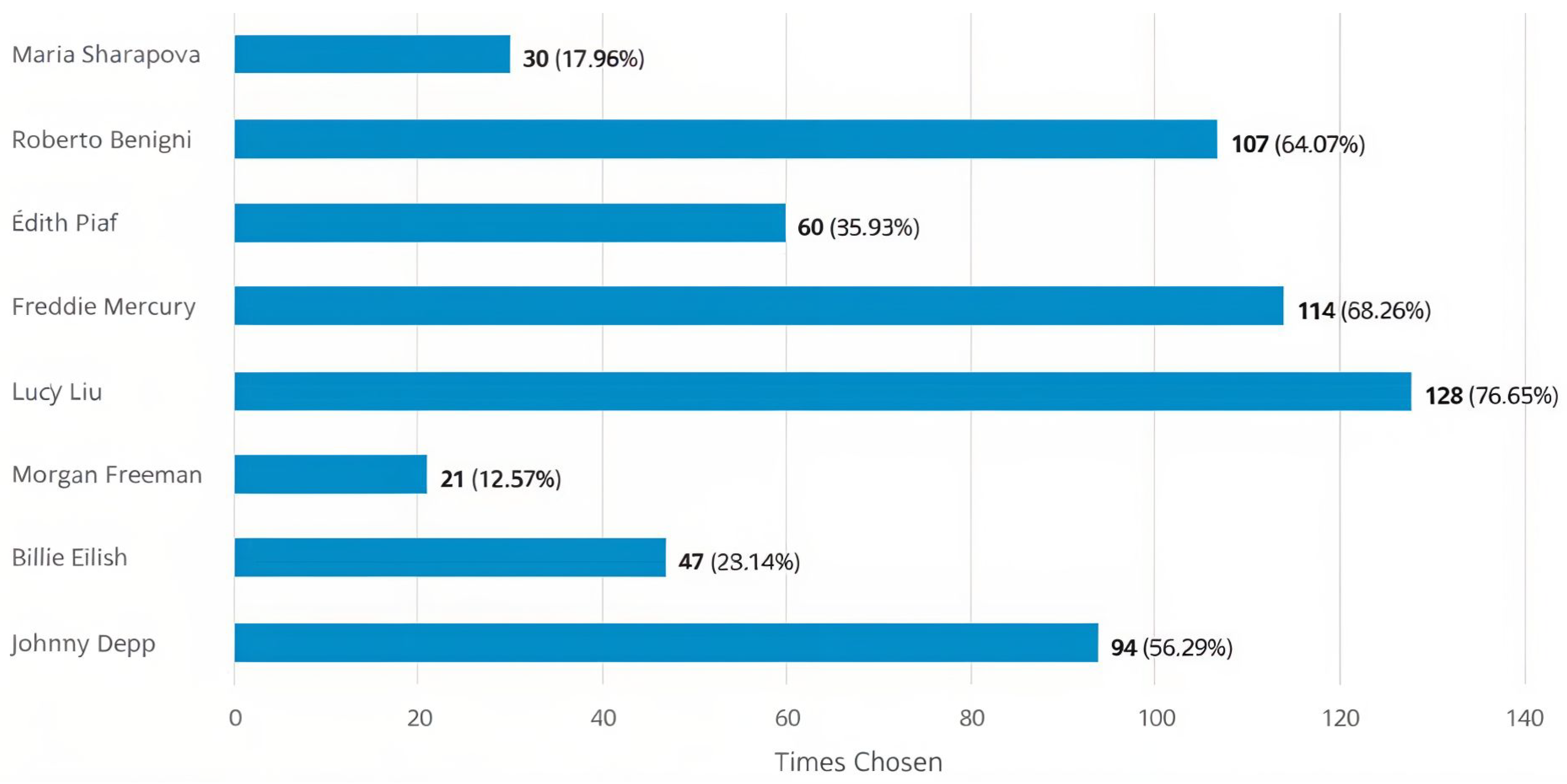
- To address RQ1, the survey presents portraits of celebrities with the default settings and asks participants to select those they can recognize. By asking the user to select all recognized celebrity portraits, we can measure identity preservation in the default settings. However, the use of celebrities in a particular domain may influence the recognition of the celebrity itself. We selected eight celebrities from different fields and social characteristics, namely Maria Sharapova, Roberto Benigni, Edith Piaf, Freddie Mercury, Lucy Liu, Morgan Freeman, Billie Eilish, and Johnny Depp (see Figure 5).
- To address RQ2, the survey presents different portraits created with different settings for the selected subjects, using the original image as a reference. By asking the user to select the best portraits, we can identify the best settings for the trade-off between style and identity preservation. We selected eight subjects (see Table 2), including four different celebrities with different fields and social characteristics (namely Monica Bellucci, Luciano Pavarotti, G-Dragon, and Barack Obama) and four other test cases (an example is shown in Figure 6).
- Instrumentation: In designing this survey, we conducted a pilot survey with 19 participants to help us determine the extent to which the questionnaire was understandable and complete. Participants had the opportunity to give their feedback on the questionnaire in terms of wording, clarity, and presentation.
- Selection of participants: Participants took part in the survey voluntarily.
- Maturation: Risks of fatigue or boredom were not considered as the average completion time was 3:44 min.
- The representativeness of the participant population was ensured by sending the survey to all users of the DaVinciFace.
4. Results
4.1. Dataset and Latent Representations
- Human face detection: using a pre-trained model on the FFHQ dataset available on paperswithcode.com/dataset/ffhq (accessed on 14 May 2022) that extracts the most distinct face in the image;
- Centering and cropping the detected face in a square frame with the dimensions .
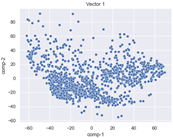
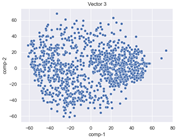
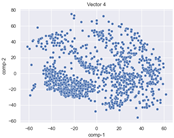
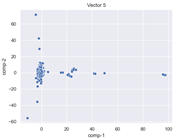
4.2. Dimensionality Reduction and Density Calculation
4.3. The Effect of Sparse Vectors
4.4. Survey Results
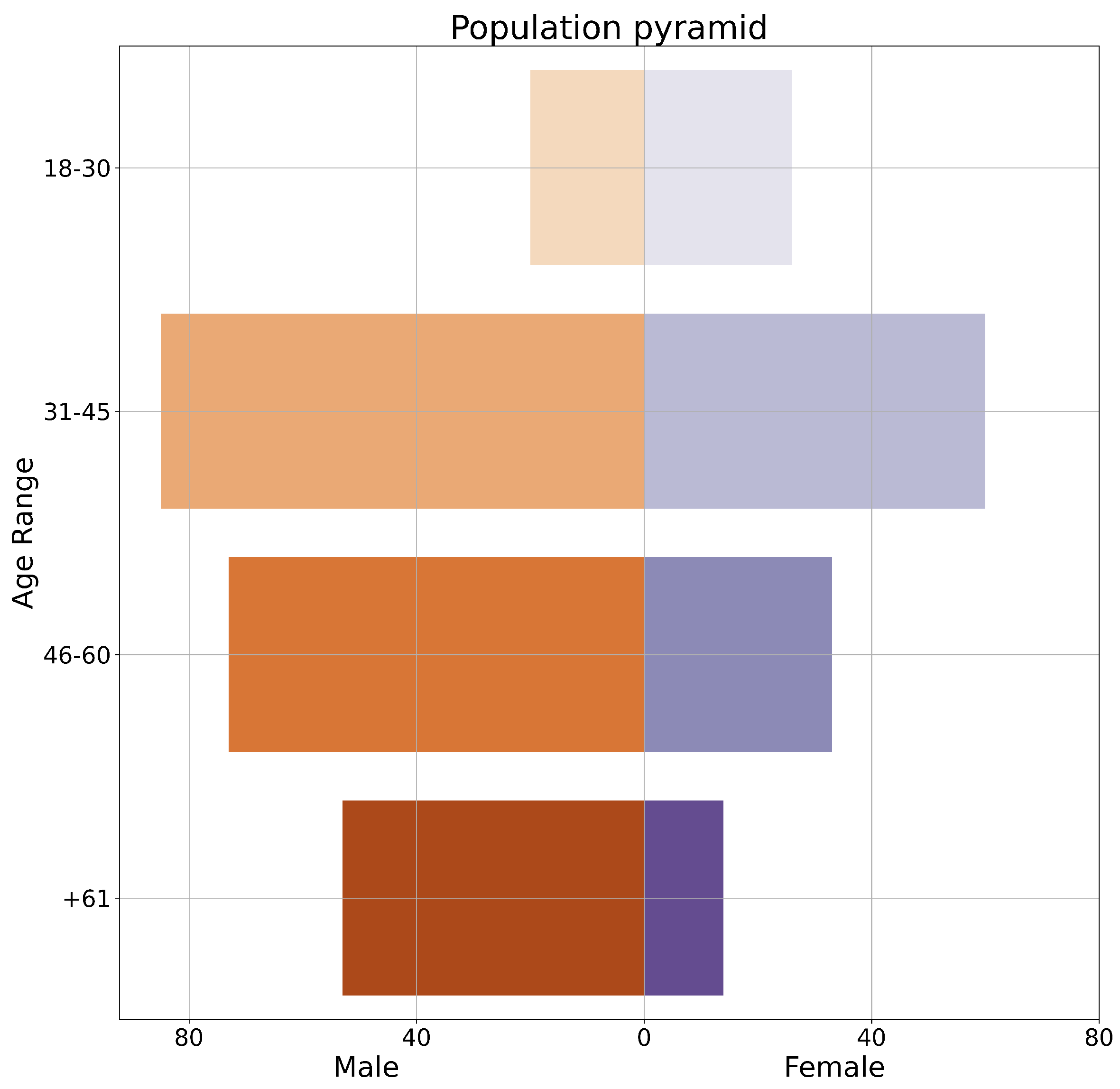
- Gender perspective, out of 360 responses: 224 (62.22%) are men, 129 (35.83%) are women and 7 (1.94%) preferred not to answer.
- Age perspective: Out of 360 responses, 39.44% of participants belong to the age group (31–45), followed by 28.89% in the age group (46–60), 18.33% are older than 61 and 13.33% are younger than 30.
- Art-related background: Most users are interested in art (56.82%), followed by people not related or are not interested in art (21.17%), while professional artists and art students represent 16.71% and 5.29% respectively.
- For G-Dragon, two other groups chose option (a), and the majority chose option (b);
- For Barack Obama, all other groups chose option (c), and the majority chose option (d);
- For test case 1, two other groups chose option (b), and the majority chose option (a).
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GANs | generative adversarial networks |
| VAEs | variational autoencoder |
| ISOMAP | isometric mapping |
| t-SNE | t-distributed stochastic neighbor embedding |
| UMAP | uniform manifold approximation and projection |
| AI | artificial intelligence |
References
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Arvanitidis, G.; Hansen, L.K.; Hauberg, S. Latent space oddity: On the curvature of deep generative models. arXiv 2017, arXiv:1710.11379. [Google Scholar]
- Connor, M.; Rozell, C. Representing closed transformation paths in encoded network latent space. Proc. Aaai Conf. Artif. Intell. 2020, 34, 3666–3675. [Google Scholar] [CrossRef]
- Donoho, D.L.; Grimes, C. Image manifolds which are isometric to Euclidean space. J. Math. Imaging Vis. 2005, 23, 5–24. [Google Scholar] [CrossRef]
- Smith, A.L.; Asta, D.M.; Calder, C.A. The geometry of continuous latent space models for network data. Stat. Sci. Rev. J. Inst. Math. Stat. 2019, 34, 428. [Google Scholar] [CrossRef] [PubMed]
- Mukherjee, S.; Asnani, H.; Lin, E.; Kannan, S. Clustergan: Latent space clustering in generative adversarial networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; 2019; Volume 33, pp. 4610–4617. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Liao, Y.; Bartler, A.; Yang, B. Anomaly detection based on selection and weighting in latent space. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 409–415. [Google Scholar]
- Liu, X.; Zou, Y.; Kong, L.; Diao, Z.; Yan, J.; Wang, J.; Li, S.; Jia, P.; You, J. Data augmentation via latent space interpolation for image classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 728–733. [Google Scholar]
- Fetty, L.; Bylund, M.; Kuess, P.; Heilemann, G.; Nyholm, T.; Georg, D.; Löfstedt, T. Latent space manipulation for high-resolution medical image synthesis via the StyleGAN. Z. FÜR Med. Phys. 2020, 30, 305–314. [Google Scholar] [CrossRef] [PubMed]
- Gat, I.; Lorberbom, G.; Schwartz, I.; Hazan, T. Latent space explanation by intervention. Proc. Aaai Conf. Artif. Intell. 2022, 36, 679–687. [Google Scholar] [CrossRef]
- Lin, E.; Lin, C.H.; Lane, H.Y. Relevant applications of generative adversarial networks in drug design and discovery: Molecular de novo design, dimensionality reduction, and de novo peptide and protein design. Molecules 2020, 25, 3250. [Google Scholar] [CrossRef] [PubMed]
- Park, S.W.; Ko, J.S.; Huh, J.H.; Kim, J.C. Review on generative adversarial networks: Focusing on computer vision and its applications. Electronics 2021, 10, 1216. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://openai.com/index/language-unsupervised/ (accessed on 27 June 2024).
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Asperti, A.; Evangelista, D.; Loli Piccolomini, E. A survey on variational autoencoders from a green AI perspective. Comput. Sci. 2021, 2, 301. [Google Scholar] [CrossRef]
- Balasubramanian, M.; Schwartz, E.L. The isomap algorithm and topological stability. Science 2002, 295, 7. [Google Scholar] [CrossRef] [PubMed]
- Cetinic, E.; She, J. Understanding and creating art with AI: Review and outlook. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Ploennigs, J.; Berger, M. Ai art in architecture. Civ. Eng. 2023, 2, 8. [Google Scholar] [CrossRef]
- Zylinska, J. AI Art Machine Visions and Warped Dreams; Open Humanities Press: London, UK, 2020. [Google Scholar]
- Grba, D. Deep else: A critical framework for ai art. Digital 2022, 2, 1–32. [Google Scholar] [CrossRef]
- Hong, J.W.; Curran, N.M. Artificial intelligence, artists, and art: Attitudes toward artwork produced by humans vs. artificial intelligence. Acm Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–16. [Google Scholar] [CrossRef]
- Jiang, H.H.; Brown, L.; Cheng, J.; Khan, M.; Gupta, A.; Workman, D.; Hanna, A.; Flowers, J.; Gebru, T. AI Art and its Impact on Artists. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, Montreal, QC, Canada, 8–10 August 2023; pp. 363–374. [Google Scholar]
- Latikka, R.; Bergdahl, J.; Savela, N.; Oksanen, A. AI as an Artist? A Two-Wave Survey Study on Attitudes Toward Using Artificial Intelligence in Art. Poetics 2023, 101, 101839. [Google Scholar] [CrossRef]
- Almhaithawi, D.; Bellini, A.; Cuomo, S. Exploring Latent Space Using a Non-linear Dimensionality Reduction Algorithm for Style Transfer Application. In Proceedings of the European Conference on Advances in Databases and Information Systems, Turin, Italy, 5–8 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 277–286. [Google Scholar]
- Xu, Z.; Wilber, M.; Fang, C.; Hertzmann, A.; Jin, H. Learning from multi-domain artistic images for arbitrary style transfer. arXiv 2018, arXiv:1805.09987. [Google Scholar]
- Prabhumoye, S.; Tsvetkov, Y.; Salakhutdinov, R.; Black, A.W. Style transfer through back-translation. arXiv 2018, arXiv:1804.09000. [Google Scholar]
- Shaban, M.T.; Baur, C.; Navab, N.; Albarqouni, S. Staingan: Stain style transfer for digital histological images. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (Isbi 2019), Venice, Italy, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 953–956. [Google Scholar]
- Ruder, M.; Dosovitskiy, A.; Brox, T. Artistic style transfer for videos and spherical images. Int. J. Comput. Vis. 2018, 126, 1199–1219. [Google Scholar] [CrossRef]
- Figueira, A.; Vaz, B. Survey on synthetic data generation, evaluation methods and GANs. Mathematics 2022, 10, 2733. [Google Scholar] [CrossRef]
- Laino, M.E.; Cancian, P.; Politi, L.S.; Della Porta, M.G.; Saba, L.; Savevski, V. Generative adversarial networks in brain imaging: A narrative review. J. Imaging 2022, 8, 83. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Zhang, H.; Xu, X.; Zhang, Z.; Yan, S. Collocating clothes with generative adversarial networks cosupervised by categories and attributes: A multidiscriminator framework. IEEE Trans. Neural Networks Learn. Syst. 2019, 31, 3540–3554. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Du, C.; He, H. Semi-supervised cross-modal image generation with generative adversarial networks. Pattern Recognit. 2020, 100, 107085. [Google Scholar] [CrossRef]
- Wu, A.N.; Stouffs, R.; Biljecki, F. Generative Adversarial Networks in the built environment: A comprehensive review of the application of GANs across data types and scales. Build. Environ. 2022, 223, 109477. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Kammoun, A.; Slama, R.; Tabia, H.; Ouni, T.; Abid, M. Generative Adversarial Networks for face generation: A survey. Acm Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Wong, A.D. BLADERUNNER: Rapid Countermeasure for Synthetic (AI-Generated) StyleGAN Faces. arXiv 2022, arXiv:2210.06587. [Google Scholar]
- Khoo, B.; Phan, R.C.W.; Lim, C.H. Deepfake attribution: On the source identification of artificially generated images. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1438. [Google Scholar] [CrossRef]
- Abdal, R.; Qin, Y.; Wonka, P. Image2stylegan: How to embed images into the stylegan latent space? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4432–4441. [Google Scholar]
- Liu, K.; Cao, G.; Zhou, F.; Liu, B.; Duan, J.; Qiu, G. Towards disentangling latent space for unsupervised semantic face editing. IEEE Trans. Image Process. 2022, 31, 1475–1489. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Yang, C.; Tang, X.; Zhou, B. InterFaceGAN: Interpreting the Disentangled Face Representation Learned by GANs. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2004–2018. [Google Scholar] [CrossRef] [PubMed]
- Tahiroğlu, K.; Kastemaa, M.; Koli, O. Ganspacesynth: A hybrid generative adversarial network architecture for organising the latent space using a dimensionality reduction for real-time audio synthesis. In Proceedings of the Conference on AI Music Creativity, Graz, Austria, 18–22 July 2021. [Google Scholar]
- Zhu, J.; Zhao, D.; Zhang, B.; Zhou, B. Disentangled inference for GANs with latently invertible autoencoder. Int. J. Comput. Vis. 2022, 130, 1259–1276. [Google Scholar] [CrossRef]
- Jørgensen, M.; Hauberg, S. Isometric gaussian process latent variable model for dissimilarity data. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 5127–5136. [Google Scholar]
- Velliangiri, S.; Alagumuthukrishnan, S.; Thankumar Joseph, S.I. A review of dimensionality reduction techniques for efficient computation. Procedia Comput. Sci. 2019, 165, 104–111. [Google Scholar] [CrossRef]
- Shen, J.; Wang, R.; Shen, H.W. Visual exploration of latent space for traditional Chinese music. Vis. Informatics 2020, 4, 99–108. [Google Scholar] [CrossRef]
- Crecchi, F.; Bacciu, D.; Biggio, B. Detecting adversarial examples through nonlinear dimensionality reduction. arXiv 2019, arXiv:1904.13094. [Google Scholar]
- Tasoulis, S.; Pavlidis, N.G.; Roos, T. Nonlinear dimensionality reduction for clustering. Pattern Recognit. 2020, 107, 107508. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Becht, E.; McInnes, L.; Healy, J.; Dutertre, C.A.; Kwok, I.W.; Ng, L.G.; Ginhoux, F.; Newell, E.W. Dimensionality reduction for visualizing single-cell data using UMAP. Nat. Biotechnol. 2019, 37, 38–44. [Google Scholar] [CrossRef] [PubMed]
- Castaneda, J.; Jover, A.; Calvet, L.; Yanes, S.; Juan, A.A.; Sainz, M. Dealing with gender bias issues in data-algorithmic processes: A social-statistical perspective. Algorithms 2022, 15, 303. [Google Scholar] [CrossRef]
- Pagano, T.P.; Loureiro, R.B.; Lisboa, F.V.; Peixoto, R.M.; Guimarães, G.A.; Cruz, G.O.; Araujo, M.M.; Santos, L.L.; Cruz, M.A.; Oliveira, E.L.; et al. Bias and unfairness in machine learning models: A systematic review on datasets, tools, fairness metrics, and identification and mitigation methods. Big Data Cogn. Comput. 2023, 7, 15. [Google Scholar] [CrossRef]
- Alshareef, N.; Yuan, X.; Roy, K.; Atay, M. A study of gender bias in face presentation attack and its mitigation. Future Internet 2021, 13, 234. [Google Scholar] [CrossRef]
- Berta, M.; Vacchetti, B.; Cerquitelli, T. GINN: Towards Gender InclusioNeural Network. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4119–4126. [Google Scholar]
- Bhargava, S.; Forsyth, D. Exposing and correcting the gender bias in image captioning datasets and models. arXiv 2019, arXiv:1912.00578. [Google Scholar]
- Schwemmer, C.; Knight, C.; Bello-Pardo, E.D.; Oklobdzija, S.; Schoonvelde, M.; Lockhart, J.W. Diagnosing gender bias in image recognition systems. Socius 2020, 6, 2378023120967171. [Google Scholar] [CrossRef] [PubMed]
- An, J.; Huang, S.; Song, Y.; Dou, D.; Liu, W.; Luo, J. Artflow: Unbiased image style transfer via reversible neural flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 862–871. [Google Scholar]
- Georgopoulos, M.; Oldfield, J.; Nicolaou, M.A.; Panagakis, Y.; Pantic, M. Mitigating demographic bias in facial datasets with style-based multi-attribute transfer. Int. J. Comput. Vis. 2021, 129, 2288–2307. [Google Scholar] [CrossRef]
- La Quatra, M.; Greco, S.; Cagliero, L.; Cerquitelli, T. Inclusively: An AI-Based Assistant for Inclusive Writing. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Turin, Italy, 18–22 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 361–365. [Google Scholar]
- Tejeda-Ocampo, C.; López-Cuevas, A.; Terashima-Marin, H. Improving deep interactive evolution with a style-based generator for artistic expression and creative exploration. Entropy 2020, 23, 11. [Google Scholar] [CrossRef] [PubMed]
- Amini, A.; Soleimany, A.P.; Schwarting, W.; Bhatia, S.N.; Rus, D. Uncovering and mitigating algorithmic bias through learned latent structure. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 289–295. [Google Scholar]
- Rai, A.; Ducher, C.; Cooperstock, J.R. Improved attribute manipulation in the latent space of stylegan for semantic face editing. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–16 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 38–43. [Google Scholar]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Corno, F.; De Russis, L.; Sáenz, J.P. On the challenges novice programmers experience in developing IoT systems: A survey. J. Syst. Softw. 2019, 157, 110389. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Portraits |  |  |  |  |  |  |
| Default Settings of DaVinciFace |  |  |  |  |  |  |
| Monica Bellucci | Luciano Pavarotti | G-Dragon | Barack Obama |
 |  |  |  |
| Test Case 1 | Test Case 2 | Test Case 3 | Test Case 4 |
 |  |  |  |
| Vector 0 | Vector 1 | Vector 2 |
|---|---|---|
 |  |  |
| Vector 3 | Vector 4 | Vector 5 |
 |  |  |
| Vector 6 | Vector 7 | Vector 8 |
 |  |  |
| Vector 9 | Vector 10 | Vector 11 |
 |  |  |
| Vector 12 | Vector 13 | Vector 14 |
 |  |  |
| Vector 15 | Vector 16 | Vector 17 |
 |  |  |
| Vector 0 | Vector 1 | Vector 2 |
|---|---|---|
 |  |  |
| Vector 3 | Vector 4 | Vector 5 |
 |  |  |
| Vector 6 | Vector 7 | Vector 8 |
 |  |  |
| Vector 9 | Vector 10 | Vector 11 |
 |  |  |
| Vector 12 | Vector 13 | Vector 14 |
 |  |  |
| Vector 15 | Vector 16 | Vector 17 |
 |  |  |
| Vector 0 | Vector 1 | Vector 2 | Vector 3 | Vector 4 | Vector 5 |
|---|---|---|---|---|---|
| 39.43 | 49.18 | 45.37 | 49.73 | 48.80 | 5.89 |
| Vector 6 | Vector 7 | Vector 8 | Vector 9 | Vector 10 | Vector 11 |
| 5.42 | 7.02 | 35.96 | 6.36 | 10.95 | 6.17 |
| Vector 12 | Vector 13 | Vector 14 | Vector 15 | Vector 16 | Vector 17 |
| 23.92 | 11.70 | 26.86 | 23.45 | 19.30 | 18.95 |
| Subject | Default settings | +Vector 8 | +Vector 9 | +Vector 10 | +Vector 11 |
|---|---|---|---|---|---|
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |
 |  |  |  |  |  |  |
|---|---|---|---|---|---|---|
 |  |  |  |  |  |  |
| Subject | Description 1 | Total Responses | Option a (Default) | Option b (+Vector 8) | Option c (+Vector 10) | Option d (+Vector 11) |
|---|---|---|---|---|---|---|
| Monica Bellucci | Woman, Brunette | 343 | 67.93% | 10.79% | 9.62% | 11.66% |
| Luciano Pavarotti | Bearded man, Caucasian | 349 | 43.84% | 23.78% | 15.19% | 17.19% |
| G-Dragon | Man, Asian | 346 | 35.84% | 38.15% | 13.01% | 13.01% |
| Barack Obama | Man, African | 350 | 26% | 16.57% | 28.57% | 28.86% |
| Test case 1 | Bearded man, Caucasian | 346 | 31.21% | 25.43% | 22.83% | 20.52% |
| Test case 2 | Woman, blonde | 352 | 45.74% | 11.65% | 23.30% | 19.32% |
| Test case 3 | Woman, African | 167 | 30.54% | 31.14% | 18.56% | 19.76% |
| Test case 4 | Woman, Brunette | 167 | 57.49% | 20.96% | 10.78% | 10.78% |
| Art-Related | Monica | Luciano | G-Dragon | Barack | Test Case 1 | Test Case 2 | Test Case 3 | Test Case 4 |
|---|---|---|---|---|---|---|---|---|
| Professional artist | a (65%) | a (43%) | a (43%) | c (37%) | a (32%) | a (49%) | c (31%) | a (45%) |
| Art student | a (61%) | a (58%) | b (44%) | c (32%) | b (56%) | a (37%) | b (50%) | a (70%) |
| Interested in art | a (72%) | a (44%) | b (41%) | d (32%) | a (32%) | a (47%) | a (39%) | a (59%) |
| Not related to art | a ( 64%) | a (37%) | a (38%) | c (34%) | b (32%) | a (41%) | b (33%) | a (60%) |
| Gender | Monica | Luciano | G-Dragon | Barack | Test Case 1 | Test Case 2 | Test Case 3 | Test Case 4 |
|---|---|---|---|---|---|---|---|---|
| Female | a (72%) | a (52%) | a (39%) | a (28%) | a (29%) | a (53%) | a (40%) | a (64%) |
| Male | a (66%) | a (39%) | b (37%) | d (30%) | a (32%) | a (42%) | b (31%) | a (53%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almhaithawi, D.; Bellini, A.; Cerquitelli, T. Toward Unbiased High-Quality Portraits through Latent-Space Evaluation. J. Imaging 2024, 10, 157. https://doi.org/10.3390/jimaging10070157
Almhaithawi D, Bellini A, Cerquitelli T. Toward Unbiased High-Quality Portraits through Latent-Space Evaluation. Journal of Imaging. 2024; 10(7):157. https://doi.org/10.3390/jimaging10070157
Chicago/Turabian StyleAlmhaithawi, Doaa, Alessandro Bellini, and Tania Cerquitelli. 2024. "Toward Unbiased High-Quality Portraits through Latent-Space Evaluation" Journal of Imaging 10, no. 7: 157. https://doi.org/10.3390/jimaging10070157
APA StyleAlmhaithawi, D., Bellini, A., & Cerquitelli, T. (2024). Toward Unbiased High-Quality Portraits through Latent-Space Evaluation. Journal of Imaging, 10(7), 157. https://doi.org/10.3390/jimaging10070157