Abstract
Nonmydriatic retinal fundus images often suffer from quality issues and artifacts due to ocular or systemic comorbidities, leading to potential inaccuracies in clinical diagnoses. In recent times, deep learning methods have been widely employed to improve retinal image quality. However, these methods often require large datasets and lack robustness in clinical settings. Conversely, the inherent stability and adaptability of traditional unsupervised learning methods, coupled with their reduced reliance on extensive data, render them more suitable for real-world clinical applications, particularly in the limited data context of high noise levels or a significant presence of artifacts. However, existing unsupervised learning methods encounter challenges such as sensitivity to noise and outliers, reliance on assumptions like cluster shapes, and difficulties with scalability and interpretability, particularly when utilized for retinal image enhancement. To tackle these challenges, we propose a novel robust PCA (RPCA) method with low-rank sparse decomposition that also integrates affine transformations , weighted nuclear norm, and the norms, aiming to overcome existing method limitations and to achieve image quality improvement unseen by these methods. We employ the weighted nuclear norm to assign weights to singular values to each retinal images and utilize the norm to eliminate correlated samples and outliers in the retinal images. Moreover, is employed to enhance retinal image alignment, making the new method more robust to variations, outliers, noise, and image blurring. The Alternating Direction Method of Multipliers (ADMM) method is used to optimally determine parameters, including , by solving an optimization problem. Each parameter is addressed separately, harnessing the benefits of ADMM. Our method introduces a novel parameter update approach and significantly improves retinal image quality, detecting cataracts, and diabetic retinopathy. Simulation results confirm our method’s superiority over existing state-of-the-art methods across various datasets.
1. Introduction
Estimating genuine low-rank components from corrupted high dimensional images is a significant advancement in health applications, particularly in biomedical image processing. Leveraging these inherent low-rank characteristics in biomedical image processing is crucial for transforming a wide array of real-world health-related applications, fostering substantial progress and innovation in the field. Among these, image enhancement has garnered significant attention from researchers, particularly in fields such as cataract diagnosis [1,2,3,4], cancer detection [5], retinal enhancement [6,7,8,9], medical image segmentation [10,11,12], scene categorization [13], crime detection [14], sparse coding [15], image denoising [16], communications and computational imaging [17], computer vision [18], and retinal disease detection [19,20] such as glaucoma [21,22]. However, the existing methods encounter significant challenges such as image blurring, noise, and corruptions in biomedical imaging.
Nowadays, deep learning methods have been widely applied to biomedical image processing for medical diagnosis [23,24]. An example is the deep hybrid network low-light image enhancement approach via a unified network with two different streams to capture the global content and the salient structures of the clear image [25]. Yet, this method requires a large volume of training data and storage to process millions of parameters. A hybrid retinal image enhancement algorithm was proposed by [26] for detecting diabetic retinopathy and improving the low quality, using the deep learning model. However, this method is computationally expensive and lacks robustness when the percentage of noise level in images is high. To improve poor-quality retinal fundus images, a simple but effective end-to-end unsupervised learning framework was proposed by [7]. Moreover, Zhu et al. (2023) [27] introduced an unpaired image-to-image translation method for converting low-quality images into their high-quality counterparts. Similarly, Liu et al. (2022) [28] proposed the pyramid constraint to create a degradation-invariant supervised learning enhancement network (PCE-Net). This approach reduces the need for clinical data and effectively enhances the hidden intrinsic dataset. However, challenges still persist in clinical scenarios. To address the challenges of uneven illumination, blurring, and various anomalies, in enhancing retinal images, Liu and Huang [29] introduced a combined approach for improving low-quality retinal images and segmenting blood vessels, utilizing a diffusion model for both tasks [30]. Furthermore, Oh et al. (2023) [31] introduced a novel retina image enhancement framework using scattering transform. This framework entails training an enhancement model that relies on paired images to convert low-quality images into their high-quality counterparts. However, these methods lack generalization on data outside of the training set and encounter problems with mode collapse with the GAN-based unsupervised method, including difficulties in optimizing the parameters. Additionally, deep learning methods via a new frontier of machine learning require more training [32], which takes more computational time [33,34], and have poor real-world clinical generalizability, limiting their practicality in medical imaging [35,36]. Moreover, deep learning models are often considered black boxes, lacking the interpretability crucial for clinical acceptance [37,38]. Hence, it is essential to consider traditional unsupervised machine learning methods to enhance the quality of retinal images.
To overcome the drawbacks of the deep learning methods, unsupervised learning methods have been proposed for retinal image processing [39]. For instance, a contrast-limited adaptive histogram equalization (CLAHE) method was proposed by [40], and a histogram equalization method (HEM) incorporating a tunable parameter was proposed by [41]. However, these methods fail to maintain image quality, often resulting in excessive blurring of the edges. In an effort to enhance retinal image quality, researchers have proposed the low-light image enhancement method (LLIEM). This innovative approach incorporates multi-resolution branches to gain a deeper understanding of diverse levels of local and global context through distinct streams as outlined in reference [42]. However, this method suffers loss of information and semantic content. The machine learning technique was proposed by [43] for retinal image enhancement and glaucoma detection—review and perspective—and a hybrid image enhancement algorithm (HIEA) was developed by [44], which incorporates a median filter for image denoising and is also time consuming. Although these methods do not require training datasets, they lack robustness in high-dimensional medical images with noisy data. To enhance the low-quality of images, a spatial domain filtering method incorporated with the norm by [45] and a new approach proposed by [46] suggest detecting microaneurysms by considering grey-scale transformations that reduce spatial dependence between images as in [47]. Gao et al. (2019) [48] applied adaptive retinal mechanisms to enhance fundus images as demonstrated by [49,50]. To enhance the quality of retinal images, several methods [51] have been proposed. However, these approaches require explicit training data and exhibit more computational complexity.
Recently, Jiang et al. (2023) [52] proposed an event-based low-illumination image enhancement technique. However, these methods lack the ability to accurately estimate the true underlying objects and reduce nonexistent blurring when enhancing the low-quality color fundus images. This affects diagnostic accuracy and hinders their direct application to fundus images. Given the constraints of conventional unsupervised learning techniques, there is a compelling need to introduce a novel method capable of robust generalization and effective noise handling in high-dimensional and complex image datasets.
To address the limitations of unsupervised learning methods in terms of robustness, interpretability, and computational efficiency for various imaging tasks, numerous methods have been developed ever since the epoch-making emergence of Robust Principal Component Analysis (RPCA) by [53,54]. These methods, proposed by [53], and a myriad of other methods [55,56], proposed to enhance the quality of images through robust low-rank-sparse image representation. For instance, Wright et al. (2009) and Kopriva et al. (2016) [57,58] demonstrated the potential of low-rank matrix approximation to enhance the quality of images. However, the full benefits of these techniques have yet to be extensively explored in the realm of biomedical imaging. In this regard, the low-rank approximation model [59,60,61] has been explored with great success in natural image recovery. The ADMM approach is employed to iteratively update optimization variables, similar to the work of [61,62,63]. However, while the performance of these methods appears promising, the methods assign the same singular values to different images, which affects the performance in complex and highly correlated images. Similarly, tensor low-rank representation (TLLR) for image denoising was proposed by [64], while [8,65] proposed sparse rank-constrained learning and its application for medical image grading. However, they fail to denoise highly correlated images, as they do not consider the and norms, which undermines the method’s performance.
Despite its theoretical foundation and practical efficacy, the RPCA methodology put forth by [9,53,61,62,64,66] fails to differentiate between singular values in image data, employing a uniform approach to regularization across all singular values. This approach leads to an inaccurate estimation of the low-rank component of image data [53,67,68]. To overcome this issue, this paper proposes a novel RPCA method by adding , and norms. To be robust against the adverse effects, the new method combines , and norms for a better biomedical image processing. To reduce the misalignment problem in retinal image recovery, affine transformations are incorporated to render more accurate robust image enhancement. Our method benefits from the weighted nuclear norm, a norm which assigns varying weights to different retinal images through singular value decomposition, enhancing its adaptability and effectiveness. In this paper, an alternative novel method is proposed which is robust to the selection of different EyeQ and cataract images taken from the Kaggale datasets. The ADMM technique is considered, and a new set of equations is formed to estimate the optimization parameters and affine transformations in an iterative process. The simulation results demonstrate that the proposed method outperforms state-of-the-art techniques for enhancing retinal images on certain popular available datasets.
The key contributions of this paper can be summarized as follows.
(1) In this paper, we proposed a novel RPCA that integrates affine transformations to iteratively and accurately estimate the low-rank component from highly complicated retinal images. This work incorporates affine transformations to rectify distorted or misaligned retinal images, aiming to achieve improved quality. As a result of incorporating affine transformation, a new updated parameter is achieved. To tackle the computational load, all parameters are individually solved using ADMM and then updated iteratively in a round-robin manner.
(2) The novel approach aims to enhance robustness against diverse adverse effects, such as measurement noise, image blurring, and artifacts by integrating the previously unexplored and norms in retinal imaging enhancement techniques. In this work, the norm is employed to assign weights to singular values for each retinal image, providing essential adaptability for scenarios where specific features or dimensions need emphasis during decomposition. Additionally, the norm is utilized to effectively eliminate correlated samples and outliers within complex retinal images, and it enables denoising, feature highlighting, and artifact removal from retinal images, resulting in clearer and more informative images, beneficial for medical diagnosis and analysis.
(3) The developed method is efficiently solved using the ADMM approach iteratively, ensuring robustness and effectiveness in addressing the complexities of retinal image enhancement.
(4) The method’s effectiveness is demonstrated through extensive simulations with multiple retinal images, showing improved image quality by addressing degradation factors such as cataract, glaucoma and diabetic retinopathy in human eyes.
(5) This work not only proposes a novel RPCA method but also aims to draw scholars’ attention to the development of low-rank image representation techniques in retinal, cataract, and cancer imaging, with the goal of reducing anomalies for improved clinical diagnosis in biomedical image processing, an aspect that has not been extensively explored in previous methods, highlighting the potential for advancements in this field.
This paper is structured as follows. Section 2 discusses the novel method of RPCA with and norms. We further explain the parameter estimation in the optimization techniques. Section 3 describes the nature of the dataset considered for medical image analysis. Section 4 presents the results of medical image analysis using visualization and numerical analysis. Section 5 provides some discussions and concluding remarks to summarize the paper.
2. Methods
Within this section, we describe the development of the new method for retinal image enhancement.
2.1. RPCA with and Norms
One of the major drawbacks of the existing methods, such as [53,69], is their inefficiency in adequately eliminating outliers and noise, and detecting cataracts, glaucoma, and diseases during biomedical image enhancement in human eyes. To overcome this limitation, the subsequent section introduces a pioneering approach for enhancing retinal images and also detecting cataracts and glaucoma.
2.2. The and Norms Method
Consider n low-quality retinal images, , denoting the width and height of the images as w and h, respectively, with c representing the number of channels (e.g., “c = 3” for an RGB image).
Each of these retinal images depicts identical objects and exhibits high correlation with one another. Often, these images are marred by issues such as image blurring due to various adverse annoying effects. Then, it is possible to stack these images into a matrix: , as such used to denote the vectorization operators for the purpose of stacking images. As such, the original images can be further decomposed [70,71], where is a clean low-rank or enhanced image, and denotes a sparse error matrix incurred by outliers or corruptions. The RPCA by [53], which decomposes highly corrupted retinal images as low-rank, can name enhanced image and anomalies as sparse in the form of optimization techniques given by
where , denoting the nuclear norm of the low-rank component matrix , indicates the singular values of , is the norm given by , and is the Lagrangian multiplier.
Typically, are usually not well matched, leading to imprecision in the low-rank-sparse decomposition of retinal images after mitigating adverse effects.
To address this, drawing inspiration from [72], we consider to substantially misaligned retinal images to achieve well-transformed images , where o indicates the transforming operator. Then, by stacking these transformed retinal images into a matrix, we achieve . Since the solution of is intractable due to the nature of the nonlinearity issue, we have to further linearize . Solving for the parameters related to the constraints is intractable as a result of the nonlinearity issue. To overcome this obstacle, we proceed under the assumption that the alterations induced by these affine transformations are minor, and an initial is already available.
Then, we make a linearization to by taking the first-order-Taylor-approximation as ; as such, is denoting a transformed image, with p being the number of variables, represents the Jacobian of the i-th retinal images with respect to , and is the standard basis for . Thus, by adding to , is changed to as in [62,72,73].
To make the proposed method more resilient and robust to noise and outliers, occlusions, blurring and artifacts, the norms are incorporated by combining the into the norm, which is employed to manifest the sparsity and the low-rank properties that are regarded as the enhanced retinal images. Also, we transform images and consider the suggested by [74] to tackle the misalignment problem and highly correlated samples between images. Moreover, the regularizer is taken into account as the rotational invariant of the norm and it captures the collinearity between retinal images which is preferred to overcome and address the lack of robustness due to outliers and anomalies [75].
To boost the performance of the proposed method, and tackle the drawbacks of the nuclear norm [53,59,60,62], the norm is incorporated to assign weights to singular values in retinal images as demonstrated in [76,77,78]. Subsequently, the overall problem can be formulated as an optimization problem as follows
where , is the weight given by , where is representing a constant, n is the number of similar retinal images in , is used to reduce the complexity of dividing by zero, and denotes the singular value of a matrix [76], then the norm can be given by which denotes the norm of which denotes the norm of [60,62], and and denote the Lagrangian multiplier and regularization parameter, respectively.
2.3. Parameter Estimation
To solve (2), we delve into the augmented Lagrangian function, characterized by:
where denotes the Lagrangian multiplier, denotes the penalty parameter, and . By utilizing an augmented Lagrange multiplier alongside an adaptive penalty as proposed in [79,80], (3) can be reformulated as:
Directly solving (4) poses significant computational challenges; thus, we opt for iteratively updating the parameters alternately using the ADMM method [62,81].
Firstly, to update , we fix and as constant, so , updated by
k is an index representing an iteration. By ignoring all parameters as a constant , Equation (5) can be rewritten as
Problem (6) is equivalent to the weighted nuclear norm minimization (WNNM) problem [76,81,82], and the closed-form solution of the WNNM operator is given by
where is given by and where , and C are small constants and .
Secondly, to update , we keep and as constants, then is updated by
from which , Equation (8), is reduced as
By considering the lemma as in [83] as constants, the optimal parameter of the i-th column of , is given by
where , and is denoting the Euclidean norm. Next, to optimize , and are considered fixed, and then is given by
Consider all other parameters independent of as constant, from which we can obtain
Solving (12) by considering the thresholds operator as in [72], we can achieve an optimal parameter given by
where denotes the Moore–Penrose pseudoinverse of [84]. Following the same procedure as above, the Lagrangian multiplier is updated through
Similarly, the regularization parameter is updated through
where is a carefully selected constant and is an adjustable parameter that influences the convergence of the proposed method. The remaining parameters are updated independently while keeping all other variables fixed.
As we invoked with affine transformation, we also achieved a new updating parameter . To make the new method easy to understand, the pseudocode is given in Algorithm 1.
| Algorithm 1 ADMM for RPCA with and norms. |
| Output Data Matrix , , , , , |
| While not converged Do |
| Update: using (7) |
| Update: using (10) |
| Update: using (13) |
| Update: using (14) |
| Update: using (15) |
| End while |
| Outputs: ,, |
In this paper, we evaluate the performance of the new method first using statistical measures through peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM). We further verify the generalizability of the proposed method using the Pearson correlation coefficient (PCC) and Visual Information Fidelity (VIF) index based on on EyeQ, Kaggle, and High-Resolution Fundus (HRF) retinal image datasets, each containing its own degraded and ground truth images. In each experimental simulation, we first consider the degraded retinal images, then apply the new method to these images to achieve enhanced images. Next, we compare the enhanced images obtained through the proposed method with the ground truth. Finally, we compare the robustness of our method with existing methods. All experimental simulations are performed in MATLAB. Additionally, we consider regularization parameters, including , and . For an easy understanding of the procedure of the proposed method, we support with the diagrammatic image representation shown in Figure 1.
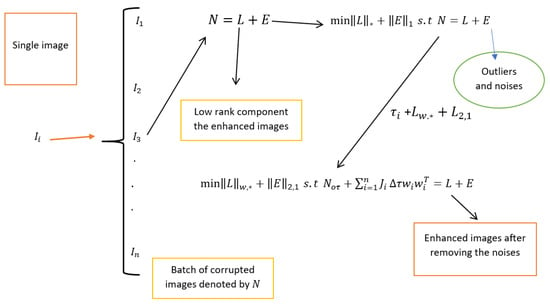
Figure 1.
Flowchart of the robust PCA for retinal image decomposition.
2.4. Numerical Evaluation Criterion
The two popular criteria mainly used as quantitative evaluation indicators are the peak signal-to-noise ratio (PSNR) [85] and the structural similarity index measure (SSIM) [86,87].
The quality of retinal image enhancement by the proposed method is also validated using SSIM [86,87], which is given by
where , , are the mean and variance of the ground truth and enhanced retinal images.
The Pearson correlation coefficient PCC [88] between the ground truth image f and the enhanced image is given by:
where:
The Visual Information Fidelity (VIF) [89] index between the ground truth image f and the enhanced image is given by:
where is the i-th block of the ground truth image f, is the i-th block of the enhanced image , is the variance of the -th block of the ground truth image f, is the variance of the difference between the i-th block of the ground truth and enhanced images, and is the noise variance in the i-th block of the ground truth image.
3. Datasets
In this section, three various retinal image datasets are used to evaluate the performance of the new method described in Section 2.2. The first dataset is the Eye Quality (EyeQ) retinal images which is taken from https://github.com/HzFu/EyeQ (accessed on 16 June 2024). To see the effectiveness of the new method, we used two independent datasets (both the training and testing images). The second dataset consists of retinal images infected with cataracts and glaucoma taken from the https://www.kaggle.com/datasets/jr2ngb/cataractdataset Kaggle dataset (accessed on 16 June 2024). The third dataset is taken from the High-Resolution Fundus (HRF) Image Database https://www5.cs.fau.de/research/data/fundus-images/ (accessed on 16 June 2024). We conducted comprehensive simulations across scenarios where ground truth, considered clean images, were available (full-reference assessment) for three distinct datasets to validate the generalizability of our method.
To see the efficacy of the new approach, we compared it with several existing approaches. Specifically, we considered HEM by [41], HIEA by [44], LLIE by [42], and one low-rank sparse method, TLLR by [64]. The methods we compared our proposed approach with are HEM by [41], TLLR by [64], LLIE by [42], and HIEA by [44]. In the upcoming subsections, we will delve into the datasets utilized, the numerical evaluation criteria employed, and the findings from our medical image analyses.
3.1. EyeQ Retinal Image Data
The Eye Quality (EyeQ) Assessment Dataset is a re-annotated subset of the EyePACS dataset, created for fundus image quality evaluation. The EyeQ dataset [7,90,91] consists of 28,480 training and 15,128 testing retinal images. The original retinal image dataset is manually labeled into three quality levels: good, usable, and reject. First, we considered 10 in low-quality images from the training dataset and 10 from the testing images, which are independent of the training dataset, to see the effectiveness of a novel approach in enhancing the low-quality images. This dataset encompasses the ground truth and degraded images, where the ground truth refers to the normal high-quality retinal images, while the degraded images, also called the low-quality retinal images, are simulated from the ground truth using light disturbance, image blurring, and retinal artifacts as outlined in [7,90,91]. The first two experiments predominantly focus on retinal image enhancement considering 10 true color degraded retinal images with a size of pixels from the training dataset, while the second has a size of pixels from the testing set; we considered this to assess the performance of the proposed method through visualization and numerical analysis.
3.2. Kaggle Cataract Retinal Image Data
The Kaggle dataset is another commonly used resource for evaluating the performance of the proposed method described in Section 2.1. The EyePACS dataset on Kaggle contains high-resolution retinal images used for cataract and other eye disease research. It includes thousands of annotated images, supporting diagnostic algorithm development. This dataset aids advancements in automated disease detection. Researchers use EyePACS to improve cataract diagnosis and eye care. This dataset contains retinal images that show symptoms of cataracts, glaucoma, and other diseases affecting human eyes. The cataract retinal images used for this analysis are taken from https://www.kaggle.com/datasets/jr2ngb/cataractdataset dataset (accessed on 16 June 2024), which consists of approximately 3500. The main focus of the final simulation results relies on the cataract retinal images, each having a size of 2464 × 1632 pixels.
3.3. High-Resolution Fundus Retinal Image Data
To verify the performance of the proposed method, we also considered the High-Resolution Fundus (HRF) dataset, a meticulously curated collection of retinal images tailored for developing and evaluating algorithms in medical image analysis. This dataset has three subjects: the first is the normal retinal images, the second is the retinal images infected with glaucoma, and the last one is retinal images with diabetic retinopathy, each with dimensions of 3304 × 2336 pixels. Its objective is to advance ophthalmology by considering high-quality images. It is also essential in the implementation of the new development of methods for detecting retinal diseases like diabetic retinopathy, macular degeneration, and glaucoma. The dataset includes 45 images, with 15 healthy retinas, 15 with diabetic retinopathy, and 15 with glaucoma. The high resolution of these images enables the precise identification of critical features such as blood vessels, optic discs, and lesions, which are essential for detecting conditions like diabetic retinopathy, glaucoma, and age-related macular degeneration. By utilizing the HRF dataset, we were able to implement the performance of the novel method compared with the state-of-the-art methods, enhancing our understanding of retinal diseases and advancing the development of automated diagnostic tools. The summary of all the datasets considered for retinal image data analysis is provided in Table 1.

Table 1.
Characteristics of retinal image datasets.
4. Results
In this section, we aim to present experimental simulations of the new method compared with state-of-the-art methods such as HEM [41], TLLR [64], LLIE [42], and HIEA [44]. Initially, we conducted retinal image analysis using both the testing and training datasets. Subsequently, we attempted to simulate enhancement based on cataract retinal images. Finally, we conducted experimental simulations based on HRF diabetic retinopathy images.
4.1. Degraded Retinal Image Data Analysis
First, we conduct simulations on degraded retinal images taken from the training dataset as in [7,90,91]. In this experiment, 10 degraded retinal images with size pixels are considered. As a visualization, some of the improved retinal images based on the above methods are given in Figure 2, in which our novel method, shown in Figure 2e, better enhances the degraded retinal images as compared to the state-of-the-art methods [41,42,44,64]. The values of the PSNR and SSIM based on the individual images are illustrated in Figure 3, from which we note that the new approach is relatively better to improve the low-quality individual original retinal images. To validate the performance of the proposed method, we employ PSNR and SSIM. HIEA [44] has better performance than HEM, shown by [41], as HIEA [44] requires a median filter, which was employed for image denoising, which boosts the effectiveness of the new approach as compared with LLIE developed by [42]. This result resembles the results given in Table 2, and further confirms that the new method is more resilient to the degradation factors, which means that the new approach outperformed the four competitors in all evaluation metrics.

Figure 2.
Degraded retinal image enhancement (training dataset): (a) HEM [41]; (b) TLLR [64]; (c) LLIE [42]; (d) HIEA [44]; (e) ours; (f) degraded image, and (g) ground truth.

Figure 3.
PSNRs and SSIMs obtained from the ground truth and enhanced images (training retinal degraded retinal images) computed by HEM [41] (blue color); TLLR [64] (green color); LLIE [42] (magenta color); HIEA [44] (red color) and ours (black color).
Table 2.
Comparison of methods by PSNR and SSIM (training dataset).
Furthermore, we incorporate 10 degraded images from the EyeQ test dataset, which has been commonly referenced in prior studies [7,90,91], to simulate additional light interference, image blurring, and artifacts.
We check the performance of the proposed method to enhance the degraded images through visualization and numerical measures using the PSNR and SSIM between the degraded low-quality images and their high-quality counterparts. As illustrated, Figure 4e shows some visual images enhanced by the proposed method compared with existing methods. These images demonstrate that the proposed method significantly enhances degraded retinal images, bringing them closer to the ground truth. The enhanced images exhibit clearer visual quality by effectively removing light disturbance, image blurring, and retinal artifacts. To further verify the performance of the new approach based on individual retinal images, we compare it using the PSNR and SSIM with existing methods as shown in Figure 5. LLIE [42] outperforms HEA [41] by considering multi-resolution branches for a better understanding of different levels of local and global context, thus mitigating the influence of outliers and noise. HIEA [44] surpasses all three existing methods, as it is a hybrid algorithm incorporating a median filter for image denoising. Figure 4e demonstrates that the new method achieves the best performance [41,42,44,64]. The summary values of the PSNR and SSIM for ten retinal images achieved by the proposed method along with existing methods are shown in Table 3. From this table, we can see that HIEA by [44] produces the second-best performance. This aligns with the results presented in Figure 4 and further justifies that the proposed method better enhances the degraded retinal images as compared with existing methods. The summary values of the PSNR and SSIM for ten retinal images achieved by the proposed method along with existing methods is given in Table 3, from which we can observe that HIEA by [44] produces the second-best performance. The performance of the proposed method is evaluated, taking more retinal images, and it is confirmed that the performance is better than the existing methods. This is because HIEA combines median filtering to reduce variation and combines it with deep learning to minimize the norm of the sparse error. We can also observe from Table 3 that the new approach still outperforms all existing methods. It achieves this by including affine transformations and utilizing the and norms to render more robust degraded retinal image recovery. The visual enhancement of degraded retinal images shown in Figure 4e and Figure 5 is more consistent with the numerical evaluation analysis provided in Table 3. This is because the new method incorporates a set of affine transformations and employs the and norms to simultaneously align and enhance the retinal images. This enables the new method to reduce the influences of outliers, heavy sparse noise, occlusions, light transmission issues, image blurring, retinal artifacts, and illuminations.
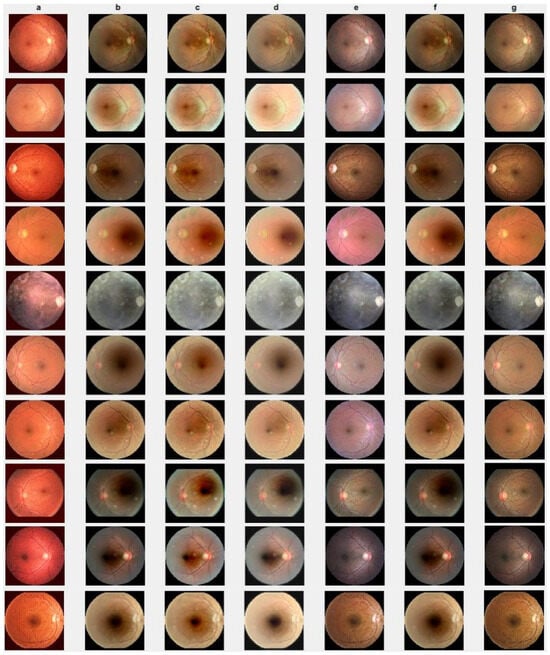
Figure 4.
Degraded retinal image enhancement (testing dataset): (a) HEM by [41]; (b) TLLR by [64]; (c) LLIE by [42]; (d) HIEA by [44]; (e) ours; (f) degraded image, and (g) ground truth.
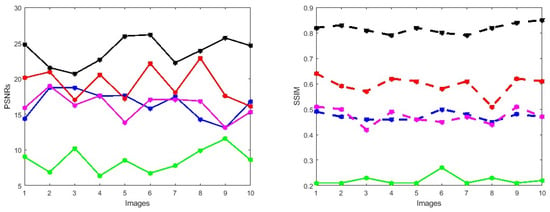
Figure 5.
PSNRs and SSIMs obtained from the ground truth and enhanced images (testing retinal degraded retinal images) computed by HEM [41] (blue color); TLLR [64] (green color); LLIE [42] (magenta color); HIEA [44] (red color) and ours (black color).
Next, we also conduct simulations on a more challenging set of 40 large samples of low-quality degraded retinal images with size , sourced from [7,90,91], to verify the performance of the proposed method in enhancing these retinal images as shown in Figure 6e, demonstrating superior performance compared to existing methods. We also verify the effectiveness of the proposed method by taking 40 retinal images and confirm that the new method is better compared to the baselines, both through visualization and numerical analysis. Subsequently, the comparison of PSNRs and SSIMs is summarized in Table 4, revealing that LLIE [42] outperforms HEM [41] and TLLR [64]. Meanwhile, our proposed method outperforms the existing methods due to its incorporation of affine transformations, and norms. Statistically, the proposed method demonstrates superiority over the other four competitors [41,42,44,64] in terms of PSNR and SSIM as shown in Table 4. The PSNRs and SSIMs for individual images are given in Figure 7, indicating that the performance of the proposed method surpasses that of the existing methods. This improvement is attributed to the incorporation of affine transformation and and norms to further denoise the degraded retinal images.
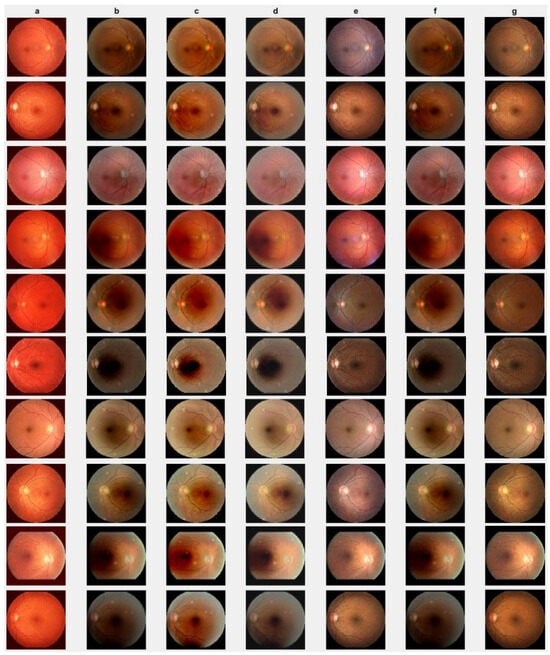
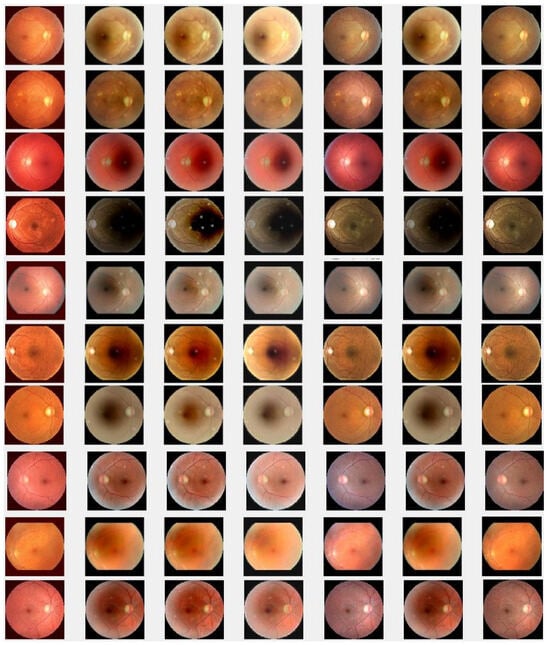
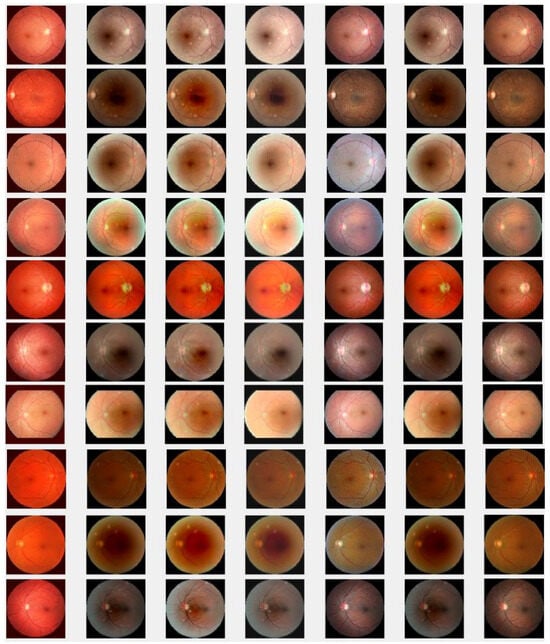
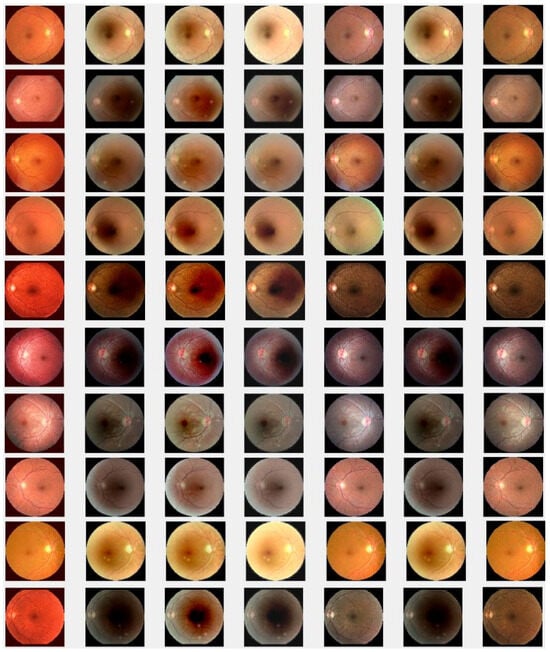
Figure 6.
Degraded retinal image enhancement (training dataset): (a) HEM [41]; (b) TLLR [64]; (c) LLIE [42]; (d) HIEA [44]; (e) ours; (f) degraded image and (g) ground truth.
Table 4.
Comparison of methods by the PSNR and SSIM (testing dataset).
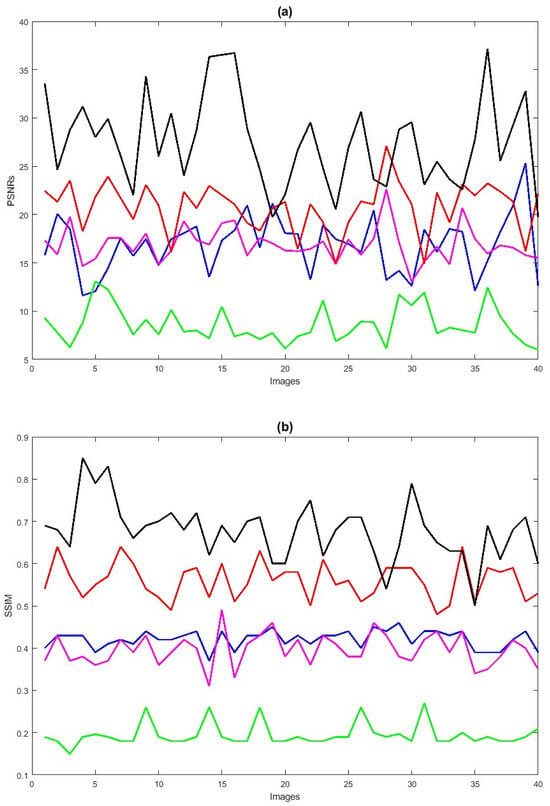
Figure 7.
PSNRs (a) and SSIMs (b) vs. degraded 40 retinal images. HEM [41] (blue color); TLLR [64] (green color); LLIE [42] (magenta color); HIEA [44] (red color); ours (black color).
Table 3.
Comparison of methods by the PSNR and SSIM (ground truth and enhanced images).

Figure 8.
Cataract infected low-quality retinal image enhancement: (a) HEM [41]; (b) TLLR [64]; (c) LLIE [42]; (d) HIEA [44]; (e) ours; (f) degraded image, and (g) ground truth.
4.2. Cataract Retinal Image Data Analysis
In this section, we present the results of the proposed method compared with existing methods [41,42,44,64] based on more challenging and high-dimensional cataract retinal images from the Kaggle dataset. In this simulation, 10 retinal images with cataract with size of 2464 × 1632 are considered. The visualization results show that the proposed method performs better in enhancing ten retinal images infected with cataracts, closely aligning with the ground truth as depicted in Figure 8e. To evaluate the performance of the proposed method compared with existing methods for individual retinal images, we compute PSNRs and SSIMs, from which we observe that the proposed method outperforms in enhancing cataract retinal images as depicted in the third row of Figure 9. The result of Table 3 is consistent with the results shown in image visualization. This improvement is attributed to the proposed method considering , and the and norms. This is consistent with the results in Table 3, and further confirms that the proposed method is more resilient to outliers and heavy sparse noise.
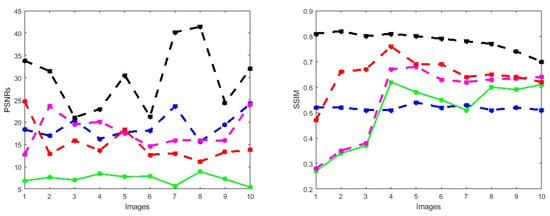
Figure 9.
PSNRs and SSIMs obtained from the ground truth and enhanced images (cataract retinal images) computed by HEM [41] (blue color); TLLR [64] (green color); LLIE [42] (magenta color); HIEA [44] (red color) and ours (black color).
4.3. HRF Image Database
To further verify the performance of the new method, we also considered a complicated and high-dimensional dataset infected with various diabetic retinal images, with each having a size of 3304 × 1632 pixels, for which the visualization results are displayed in Figure 10. The result achieved by the novel method shown in Figure 10e is better in enhancing the quality of the diabetic retinal images compared with the state-of-the-art methods. This result is more consistent with the numerical simulations given in Table 5. The individual results using PSNRs, SSIMs, PCCs and VIFs are illustrated in Figure 11, in which the performance achieved by the proposed method is better compared to the existing methods.
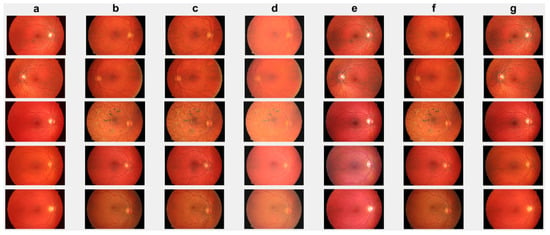
Figure 10.
Diabetic retinopathy retinal image: (a) HEM by [41]; (b) TLLR by [64]; (c) LLIE by [42]; (d) HIEA by [44]; (e) ours; (f) degraded image and (g) ground truth.
Table 5.
Comparison of methods by the PSNR, SSIM, PCC and VIF based on HRF dataset.
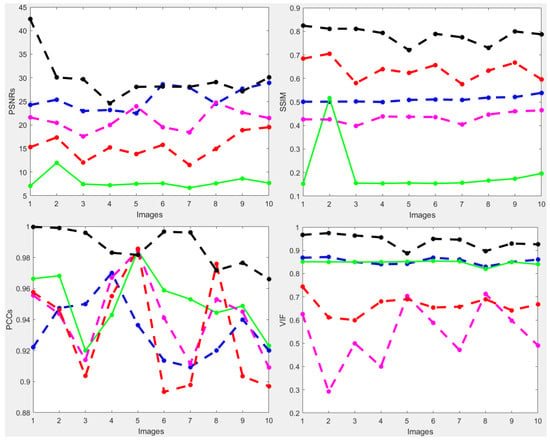
Figure 11.
PSNRs and SSIMs obtained from the ground truth and enhanced images (HRF diabetic retinopathy) (first row). The values of PCCs and VIFs obtained from the ground truth and enhanced images (HRF diabetic retinopathy) (second row) computed by HEM [41] (blue color); TLLR [64] (green color); LLIE [42] (magenta color); HIEA [44] (red color) and ours (black color).
5. Discussion and Conclusions
This work is dedicated to the enhancement of retinal images by the RPCA method [53,54] through , and affine transformation, aimed at improving their robustness. The development of these approaches represents a significant contribution to the field of statistics in imaging, particularly in the realm of high-dimensional medical images. Existing methods, as referenced in [53,54], often lack robustness in the presence of gross errors and outliers within high-dimensional retinal images. In response to this challenge, this article presents a novel method developed to address these issues head on.
In this paper, we propose a novel method for enhancing low-quality retinal images, which is crucial for detecting cataracts and diabetic diseases in human eyes. To ensure robustness against anomalies such as light disturbances, image blurring, and retinal artifacts, the proposed new method combines , and and norms into RPCA, thereby advancing the existing optimization techniques. The proposed method for enhancing low-quality retinal images is a multifaceted approach that integrates several mathematical frameworks to address the common challenges encountered in retinal imaging. The incorporation of , and norms into Robust Principal Component Analysis (RPCA) represents a sophisticated novel strategy to enhance the robustness of the image processing algorithm.
The utilization of for image alignment through Taylor series expansion and Jacobian transformation provides a novel application of geometric principles in the context of retinal image processing. By iteratively updating the warp parameters, this technique aims to mitigate misalignments induced by factors such as eye movement or imaging artifacts. Moreover, the introduction of the norm serves to address sparse adverse effects within the retinal images, leveraging sparse regularization to effectively handle noise and outliers. This norm contributes to the alignment of retinal images by minimizing the impact of correlated samples and promoting consistency across the dataset. The incorporation of the weighted nuclear norm, denoted by , introduces a nuanced approach to singular value regularization, where weights are assigned to individual singular values based on their significance in the image processing context. By assigning appropriate weights, this technique aims to preserve important features while suppressing noise and irrelevant variations, thereby enhancing the fidelity of the reconstructed images.
The validation of this proposed new method on two widely used public datasets demonstrates its efficacy in real-world scenarios and provides empirical evidence of its superiority over existing methods. The comparative evaluation highlights the potential of this new method to significantly enhance the quality of retinal images, which is crucial for accurate disease detection and diagnosis.
As future research, this work can be extended to incorporate truncated weighted nuclear norm regularization for image denoising and its integration into Tensor RPCA. By extending the proposed new method to handle more complex data structures and incorporating additional regularization parameters, this work has the potential to enhance the quality of the retinal image processing over the baselines.
Author Contributions
Conceptualization, H.T.L. and D.-G.C.; methodology, H.T.L., D.-G.C., K.C., Y.W. and W.Z; software, H.T.L.; validation, H.T.L., D.-G.C., K.C., Y.W. and W.Z.; formal analysis, H.T.L.; writing—original draft preparation, H.T.L.; editing, D.-G.C., K.C., Y.W. and W.Z.; visualization, H.T.L., D.-G.C., K.C., Y.W. and W.Z.; supervision, D.-G.C., K.C. and Y.W.; funding acquisition, D.-G.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by South Africa National Research Foundation (NRF) and South Africa Medical Research Council (SAMRC) (South Africa DST-NRF-SAMRC SARChI Research Chair in Biostatistics, Grant number 114613).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Applicable.
Acknowledgments
The authors express their gratitude to the editor and anonymous reviewers for their careful review of the manuscript and thoughtful comments. Their suggestions, including the recommendation to add more simulations, have significantly enhanced the readability and quality of this work.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MDPI | Multidisciplinary Digital Publishing Institute |
| ADMM | Alternating Direction Method of Multipliers |
| CLAHE | Contrast Limited Adaptive Histogram Equalization |
| LLIEM | Low Light Image Enhancement Method |
| RPCA | Robust Principal Component Analysis |
| PSNRs | Peak Signal-to-Noise Ratio |
| SSIMs | Structural Similarity Index |
| EyeQ | Eye Quality |
| HIEA | Hybrid Image Enhancement Algorithm |
| WNNM | Weighted Nuclear Norm Minimization |
| TLLR | Tensor Low-Rank Representation |
| VIF | Visual Information Fidelity |
| PCC | Pearson correlation coefficient |
References
- Pratap, T.; Kokil, P. Deep neural network based robust computer-aided cataract diagnosis system using fundus retinal images. Biomed. Signal Process. Control 2021, 70, 102–985. [Google Scholar] [CrossRef]
- Devi, Y.A.S.; Kamsali, M.C. Retinal Image Contrast Enhancement through Pixel Collaboration in Spatial Domain. Int. J. Intell. Eng. Syst. 2022, 15, 500â. [Google Scholar]
- Gonzalez-Amador, E.; Arines, J.; Charlón, P.; Garcia-Porta, N.; Abraldes, M. Improvement of retinal images affected by cataracts. Photonics 2022, 9, 251. [Google Scholar] [CrossRef]
- Ren, K.C.; Longdan, W.; Minjie, G.G.; Chen, Q. An improved U-net based retinal vessel image segmentation method. Heliyon 2022, 8, 10. [Google Scholar] [CrossRef] [PubMed]
- Singh, V.; Verma, N.K.; Cui, Y. Type-2 fuzzy PCA approach in extracting salient features for molecular cancer diagnostics and prognostics. IEEE Trans. Nanobioscience 2019, 18, 482–489. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, I.; Ma, J.; Shaheed, K. A hybrid proposed fundus image enhancement framework for diabetic retinopathy. Algorithms 2019, 12, 14. [Google Scholar] [CrossRef]
- Zhu, W.; Qiu, P.; Farazi, M.; Nandakumar, K.; Dumitrascu, O.M.; Wang, Y. Optimal transport guided unsupervised learning for enhancing low-quality retinal images. In Proceedings of the IEEE 20th International Symposium on Biomedical Imaging (ISBI), Cartagena, Colombia, 17–21 April 2023; pp. 1–5. [Google Scholar]
- Fu, Y.; Wang, W.; Wang, C. Image change detection method based on RPCA and low-rank decomposition. In Proceedings of the 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 9412–9417. [Google Scholar]
- Baghaie, A.; D’souza, R.M.; Yu, Z. Sparse and low rank decomposition based batch image alignment for speckle reduction of retinal OCT images. In Proceedings of the 12th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 226–230. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2nd medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Cheng, J.; Xu, Y.; Wong, D.W.K.; Liu, J.; Cao, X. Joint optic disc and cup segmentation based on multi-label deep network and polar transformation. IEEE Trans. Med. Imaging 2018, 37, 1597–1605. [Google Scholar] [CrossRef]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; Van Ginnek, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Yang, J.; Yu, K.; Gong, Y.; Huang, T. Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1794–1801. [Google Scholar]
- Agarwal, S.; Roth, D. Learning a sparse representation for object detection. In Proceedings of the Computer Vision—ECCV 2002: 7th European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; Volume 23, pp. 113–127. [Google Scholar]
- Li, J.; Gsaxner, C.; Pepe, A.; Schmalstieg, D.; Kleesiek, J.; Egger, J. Sparse convolutional neural networks for medical image analysis. TechRxiv 2023. [Google Scholar] [CrossRef]
- Bindhya, P.; Jegan, C.; Raj, V. A Review on Methods of Enhancement And Denoising in Retinal Fundus Images. Int. J. Comput. Sci. Eng. 2020, 8, 1–9. [Google Scholar]
- Ashanand; Kaur, M. Retinal Image Enhancement for Detection of Medical Complications. Smart Energy Adv. Power Technol. Sel. Proc. ICSEAPT 2022, 2, 667–694. [Google Scholar]
- Zhang, R.; Nie, F.; Li, X.; Wei, X. Feature selection with multi-view data: A survey. Inf. Fusion 2019, 50, 158–167. [Google Scholar] [CrossRef]
- Lakshminarayanan, V.; Kheradfallah, H.; Sarkar, A.; Jothi Balaji, J. Automated detection and diagnosis of diabetic retinopathy: A comprehensive survey. J. Imaging 2021, 7, 165. [Google Scholar] [CrossRef] [PubMed]
- Dumitrascu, O.M.; Zhu, W.; Qiu, P.; Nandakumar, K.Y. Automated Retinal Imaging Analysis for Alzheimers Disease Screening. In Proceedings of the IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Chicago, IL, USA, 30 March–2 April 2011. [Google Scholar]
- Lenka, S.; Lazarus, M.Z.; Behera, S.R. Glaucoma Detection Based on Specularity Removal Low Rank Model from Retinal Fundus Images. ECTI Trans. Comput. Inf. Technol. 2023, 17, 330–342. [Google Scholar]
- Singh, L.K.; Pooja, G.; Hitendra, K.M.; Bhadoria, R.S. An enhanced deep image model for glaucoma diagnosis using feature-based detection in retinal fundus. Med. Biol. Eng. Comput. 2021, 59, 333–353. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Zhao, Y.; Yap, P.; Schönlieb, C.; Frangi, A.F. Guest Editorial Special Issue on Geometric Deep Learning in Medical Imaging. IEEE Trans. Med. Imaging 2023, 42, 332–335. [Google Scholar] [CrossRef]
- Alom, M.Z.; Yakopcic, C.; Hasan, M.; Taha, T.M.; Asari, V.K. Recurrent residual U-Net for medical image segmentation. J. Med. Imaging 2019, 6, 014006. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Ma, L.; Xu, Q.; Xu, X.; Cao, X.; Du, J.; Yang, M. Low-light image enhancement via a deep hybrid network. IEEE Trans. Image Process. 2019, 28, 4364–4375. [Google Scholar] [CrossRef]
- Abbood, S.H.; Hamed, H.N.A.; Rahim, M.S.M.; Rehman, A.S.T.; Bahaj, S.A. Hybrid retinal image enhancement algorithm for diabetic retinopathy diagnostic using deep learning model. IEEE Access 2022, 10, 73079–73086. [Google Scholar] [CrossRef]
- Zhu, W.; Qiu, P.; Dumitrascu, O.M.; Sobczak, J.M.; Farazi, M.Y.Z.; Nandakumar, K.; Wang, Y. OTRE: Where optimal transport guided unpaired image-to-image translation meets regularization by enhancing. In Proceedings of the International Conference on Information Processing in Medical Imaging, San Carlos de Bariloche, Argentina, 18–23 June 2023; pp. 415–427. [Google Scholar]
- Liu, H.; Li, H.; Fu, H.; Xiao, R.; Gao, Y.; Hu, Y.; Liu, J. Degradation-invariant enhancement of fundus images via pyramid constraint network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 507–516. [Google Scholar]
- Liu, F.; Huang, W. ESDiff: A joint model for low-quality retinal image enhancement and vessel segmentation using a diffusion model. Biomed. Opt. Express 2023, 14, 6563–6578. [Google Scholar] [CrossRef] [PubMed]
- Kushol, R.; Kabir, M.H.; Abdullah-Al-Wadud, M.; Islam, M.S. Retinal blood vessel segmentation from fundus image using an efficient multiscale directional representation technique Bendlets. Math. Biosci. Eng. 2020, 17, 7751–7771. [Google Scholar] [CrossRef] [PubMed]
- Oh, E.J.; Hwang, Y.; Han, Y.; Choi, T.; Lee, G.; Kim, W.H. TaeRESToring Clarity: Unpaired Retina Image Enhancement Using Scattering Transform. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Volume 14, pp. 470–480. [Google Scholar]
- Wang, G.; Ye, J.C.; Mueller, K.; Fessler, J.A. Image reconstruction is a new frontier of machine learning. IEEE Trans. Med. Imaging 2018, 37, 1289–1296. [Google Scholar] [CrossRef] [PubMed]
- Albattah, W.; Nawaz, M.; Javed, A.; Masood, M.; Albahli, S. A novel deep learning method for detection and classification of plant diseases. Complex Intell. Syst. 2022, 37, 1–18. [Google Scholar] [CrossRef]
- Aurangzeb, K.; Alharthi, R.S.; Haider, S.I.; Alhussein, M. An efficient and light weight deep learning model for accurate retinal vessels segmentation. IEEE Access 2022, 11, 23107–23118. [Google Scholar] [CrossRef]
- Harine, M.; Kumar, A.; Gopinath, P.; Sasikala, S. Fundus Image Enhancement Using Hybrid Deep Learning Approaches. In Proceedings of the 1st International Conference on Innovations in High Speed Communication and Signal Processing, Bhopal, India, 4–5 March 2023; pp. 347–352. [Google Scholar]
- Goutam, B.; Hashmi, M.F.; Geem, Z.W.; Bokde, N.D. A comprehensive review of deep learning strategies in retinal disease diagnosis using fundus images. IEEE Trans. Med. Imaging 2022, 10, 57796–57823. [Google Scholar] [CrossRef]
- Valente, J.; António, J.; Mora, C.; Jardim, S. Developments in image processing using deep learning and reinforcement learning. J. Imaging 2023, 9, 207. [Google Scholar] [CrossRef] [PubMed]
- Fan, F.; Xiong, J.; Li, M.; Wang, G. On interpretability of artificial neural networks: A survey. IEEE Trans. Radiat. Plasma Med. Sci. 2021, 5, 741–760. [Google Scholar] [CrossRef]
- Soomro, T.A.; Afifi, A.J.; Shah, A.A.; Soomro, S.; Baloch, G.A.; Zheng, L.; Yin, M.; Gao, J. Impact of image enhancement technique on CNN model for retinal blood vessels segmentation. IEEE Access 2019, 7, 158183–158197. [Google Scholar] [CrossRef]
- He, Y.; Zheng, Y.; Zhao, Y.; Ren, Y.; Lian, J.; Gee, J. Retinal image denoising via bilateral filter with a spatial kernel of optimally oriented line spread function. Comput. Math. Methods Med. 2017, 2017, 1769834. [Google Scholar] [CrossRef]
- Singh, N.; Kaur, L.; Singh, K. Histogram equalization techniques for enhancement of low radiance retinal images for early detection of diabetic retinopathy. Eng. Sci. Technol. Int. J. 2019, 22, 736–745. [Google Scholar] [CrossRef]
- Singh, A.; Chougule, A.; Narang, P.; Chamola, V.; Yu, F.R. Low-light image enhancement for UAVs with multi-feature fusion deep neural networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Barros, D.M.; Moura, J.C.; Freire, C.R.; Taleb, A.C.; Valentim, R.A.; Morais, P.S. Machine learning applied to retinal image processing for glaucoma detection: Review and perspective. Biomed. Eng. Online 2020, 19, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Xian, Y.; Zhao, G.; Wang, C.; Chen, X.; Dai, Y. A Novel Hybrid Retinal Blood Vessel Segmentation Algorithm for Enlarging the Measuring Range of Dual-Wavelength Retinal Oximetry. Photonics 2023, 10, 722. [Google Scholar] [CrossRef]
- Kandpal, A.; Jain, N. Retinal image enhancement using edge-based texture histogram equalization. In Proceedings of the International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 27–28 February 2020; pp. 477–482. [Google Scholar]
- Rosas-Romero, R.; Martínez-Carballido, J.; Hernández-Capistrán, J.; Uribe-Valencia, L.J. A method to assist in the diagnosis of early diabetic retinopathy: Image processing applied to detection of microaneurysms in fundus images. Comput. Med. Imaging Graph. 2015, 44, 41–53. [Google Scholar] [CrossRef] [PubMed]
- Foracchia, M.; Grisan, E.; Ruggeri, A. Luminosity and contrast normalization in retinal images. Med. Image Anal. 2005, 9, 179–190. [Google Scholar] [CrossRef] [PubMed]
- Gao, S.; Zhang, M.; Zhao, Q.; Zhang, X.; Li, Y. Underwater image enhancement using adaptive retinal mechanisms. Med. Image Anal. 2019, 28, 5580–5595. [Google Scholar] [CrossRef] [PubMed]
- Setiawan, A.W.; Mengko, T.R.; Santoso, O.S.; Suksmono, A.B. Color retinal image enhancement using CLAHE. In Proceedings of the International Conference on ICT for Smart Society, Bandung, Indonesia, 13–14 June 2013; pp. 1–3. [Google Scholar]
- Joshi, G.D.; Sivaswamy, J. Colour retinal image enhancement based on domain knowledge. In Proceedings of the IEEE Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 591–598. [Google Scholar]
- Wang, S.; Jin, K.; Lu, H.; Cheng, C.; Ye, J.; Qian, D. Human visual system-based fundus image quality assessment of portable fundus camera photographs. IEEE Trans. Med. Imaging 2015, 35, 1046–1055. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, Y.; Li, S.; Zhang, Y.; Zhao, M.; Gao, Y. Event-based low-illumination image enhancement. IEEE Trans. Multimed. 2023, 26, 1920–1931. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 1–37. [Google Scholar] [CrossRef]
- Li, R.; Pan, J.; Si, Y.; Yan, B.; Hu, Y.; Qin, H. Specular reflections removal for endoscopic image sequences with adaptive-RPCA decomposition. IEEE Trans. Med. Imaging 2019, 39, 328–340. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Yang, C.; Zhao, H.; Yu, W. Low-rank modeling and its applications in image analysis. ACM Comput. Surv. 2014, 47, 1–33. [Google Scholar] [CrossRef]
- Hamlomo, S.; Atemkeng, M.; Brima, Y.; Nunhokee, C.; Baxter, J. Advancing Low-Rank and Local Low-Rank Matrix Approximation in Medical Imaging: A Systematic Literature Review and Future Directions. arXiv 2024, arXiv:2402.14045. [Google Scholar]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Advances in Neural Information Processing Systems 22 (NIPS 2009); Curran Associates, Inc.: Red Hook, NY, USA, 2009; Volume 22, Available online: https://papers.nips.cc/paper_files/paper/2009/hash/c45147dee729311ef5b5c3003946c48f-Abstract.html (accessed on 16 June 2024).
- Kopriva, I.; Shi, F.; Chen, X. Enhanced low-rank+ sparsity decomposition for speckle reduction in optical coherence tomography. J. Biomed. Opt. 2016, 21, 076008. [Google Scholar] [CrossRef]
- Likassa, H.T.; Fang, W.H.; Chuang, Y. Modified robust image alignment by sparse and low rank decomposition for highly linearly correlated data. In Proceedings of the 3rd International Conference on Intelligent Green Building and Smart Grid, Yilan, Taiwan, 22–25 April 2018; pp. 1–4. [Google Scholar]
- Likassa, H.T.; Xian, W.; Tang, X. New robust regularized shrinkage regression for high-dimensional image recovery and alignment via affine transformation and tikhonov regularizationa. Int. J. Math. Math. Sci. 2020, 2020, 1286909. [Google Scholar] [CrossRef]
- Likassa, H.T.; Xia, Y.; Gotu, B. An Efficient New Robust PCA Method for Joint Image Alignment and Reconstruction via the Norms and Affine Transformation. Sci. Program. 2022, 2022, 5682492. [Google Scholar] [CrossRef]
- Likassa, H.T.; Fang, W.; Leu, J. Robust image recovery via affine transformation and L2,1 norm. IEEE Access 2019, 7, 125011–125021. [Google Scholar] [CrossRef]
- Wahlberg, B.; Boyd, S.; Annergren, M.; Wang, Y. An ADMM algorithm for a class of total variation regularized estimation problems. IFAC Proc. Vol. 2012, 45, 83–88. [Google Scholar] [CrossRef]
- Zhou, P.; Lu, C.; Feng, J.; Lin, Z.; Yan, S. Tensor low-rank representation for data recovery and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1718–1732. [Google Scholar] [CrossRef]
- Cheng, J. Sparse range-constrained learning and its application for medical image grading. IEEE Trans. Med. Imaging 2018, 37, 2729–27382. [Google Scholar] [CrossRef]
- Gao, Q.; Zhang, P.; Xia, W.; Xie, D.; Gao, X.; Tao, D. Enhanced tensor RPCA and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2133–2140. [Google Scholar] [CrossRef] [PubMed]
- Gong, W.; Xu, W.; Wu, L.; Xie, X.; Cheng, Z. Intrinsic image sequence decomposition using low-rank sparse model. IEEE Access 2018, 7, 4024–4030. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Y.; Wang, S.; Liu, Y.; Hu, Y.; Chen, L.; Chen, H. Global Weighted Tensor Nuclear Norm for Tensor Robust Principal Component Analysis. arXiv 2022, arXiv:2209.14084. [Google Scholar]
- Likassa, H.T.; Fang, W.H. Robust regression for image alignment via subspace recovery techniques. In Proceedings of the 2018 VII International Conference on Network, Communication and Computing, Maui, HI, USA, 5–8 March 2018; pp. 288–293. [Google Scholar]
- Lin, Z.; Chen, M.; Ma, Y. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv 2010, arXiv:1009.5055. [Google Scholar]
- Liu, G.; Lin, Z.; Yu, Y. Robust subspace segmentation by low-rank representation. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 663–670. [Google Scholar]
- Peng, Y.; Ganesh, A.; Wright, J.; Xu, W.; Ma, Y. RASL: Robust alignment by sparse and low-rank decomposition for linearly correlated images. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2233–2246. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Shen, H.; Li, Y.; Tang, X.; Wang, F.; Kleinsteuber, M.; Murphey, Y.L. Reconstructible nonlinear dimensionality reduction via joint dictionary learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 175–189. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Li, Y.; Shen, H.; Xiang, W.; Murphey, Y.L. Joint learning sparsifying linear transformation for low-resolution image synthesis and recognition. Pattern Recognit. 2017, 68, 412–424. [Google Scholar] [CrossRef]
- Bouwmans, T.; Sobral, A.; Javed, S.; Jung, S.K.; Zahzah, E.H. Decomposition into low-rank plus additive matrices for background/foreground separation: A review for a comparative evaluation with a large-scale dataset. Comput. Sci. Rev. 2017, 23, 1–71. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Zhou, Y.; Dou, Y. Double weighted RPCA denoising algorithm for color images. In Proceedings of the IEEE 4th International Conference on Computer and Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1670–1674. [Google Scholar]
- Xu, Z.; Lu, Y.; Wu, J.; He, R.; Wu, S.; Xie, S. Adaptive weighted robust principal component analysis. In Proceedings of the 15th IEEE Conference on Industrial Electronics and Applications, Kristiansand, Norway, 9–13 November 2020; pp. 19–24. [Google Scholar]
- Subbarao, R.; Meer, P. Beyond RANSAC: User independent robust regression. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshop, Seattle, WA, USA, 14–19 June 2020; p. 101. [Google Scholar]
- Sawatzky, A.; Xu, Q.; Schirra, C.O.; Anastasio, M.A. Proximal ADMM for multi-channel image reconstruction in spectral X-ray CT. IEEE Trans. Med. Imaging 2014, 33, 1657–1668. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Gu, S.; Xie, Q.; Meng, D.; Zuo, W.; Feng, X.; Zhang, L. Weighted nuclear norm minimization and its applications to low level vision. Int. J. Comput. Vis. 2017, 121, 183–208. [Google Scholar] [CrossRef]
- Yang, J.; Yin, W.; Zhang, Y.; Wang, Y. A fast algorithm for edge-preserving variational multichannel image restoration. SIAM J. Imaging Sci. 2009, 2, 569–592. [Google Scholar] [CrossRef]
- Courrieu, P. Fast computation of Moore-Penrose inverse matrices. arXiv 2008, arXiv:0804.4809. [Google Scholar]
- Edelstein, W.; Glover, G.; Hardy, C.; Redington, R. The intrinsic signal-to-noise ratio in NMR imaging. Magn. Reson. Med. 1986, 3, 604–618. [Google Scholar] [CrossRef] [PubMed]
- Pérez, J.; Espinosa, J.; Vázquez, C.; Mas, D. Retinal image quality assessment through a visual similarity index. J. Mod. Opt. 2013, 60, 544–550. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Pal, M.N.; Banerjee, M. Evaluation of effectiveness of image enhancement techniques with application to retinal fundus images. In Proceedings of the 2020 4th International Conference on Computational Intelligence and Networks (CINE), Kolkata, India, 27–29 February 2020; Volume 58, pp. 1–37. [Google Scholar]
- Kuo, T.Y.; Su, P.C.; Tsai, C.M. Improved visual information fidelity based on sensitivity characteristics of digital images. J. Vis. Commun. Image Represent. 2016, 40, 76–84. [Google Scholar] [CrossRef]
- Shen, Z.; Fu, H.; Shen, J.; Shao, L. Modeling and enhancing low-quality retinal fundus images. IEEE Trans. Med. Imaging 2020, 40, 996–1006. [Google Scholar] [CrossRef]
- Fu, H.; Wang, B.; Shen, J.; Cui, S.; Xu, Y.; Liu, J.; Shao, L. Evaluation of retinal image quality assessment networks in different color-spaces. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; pp. 48–56. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).