
Automatic Switching of Electric Locomotive Power in Railway Neutral Sections Using Image Processing


Abstract
1. Introduction
2. Related Literature for Object Detection in the Railway Industry
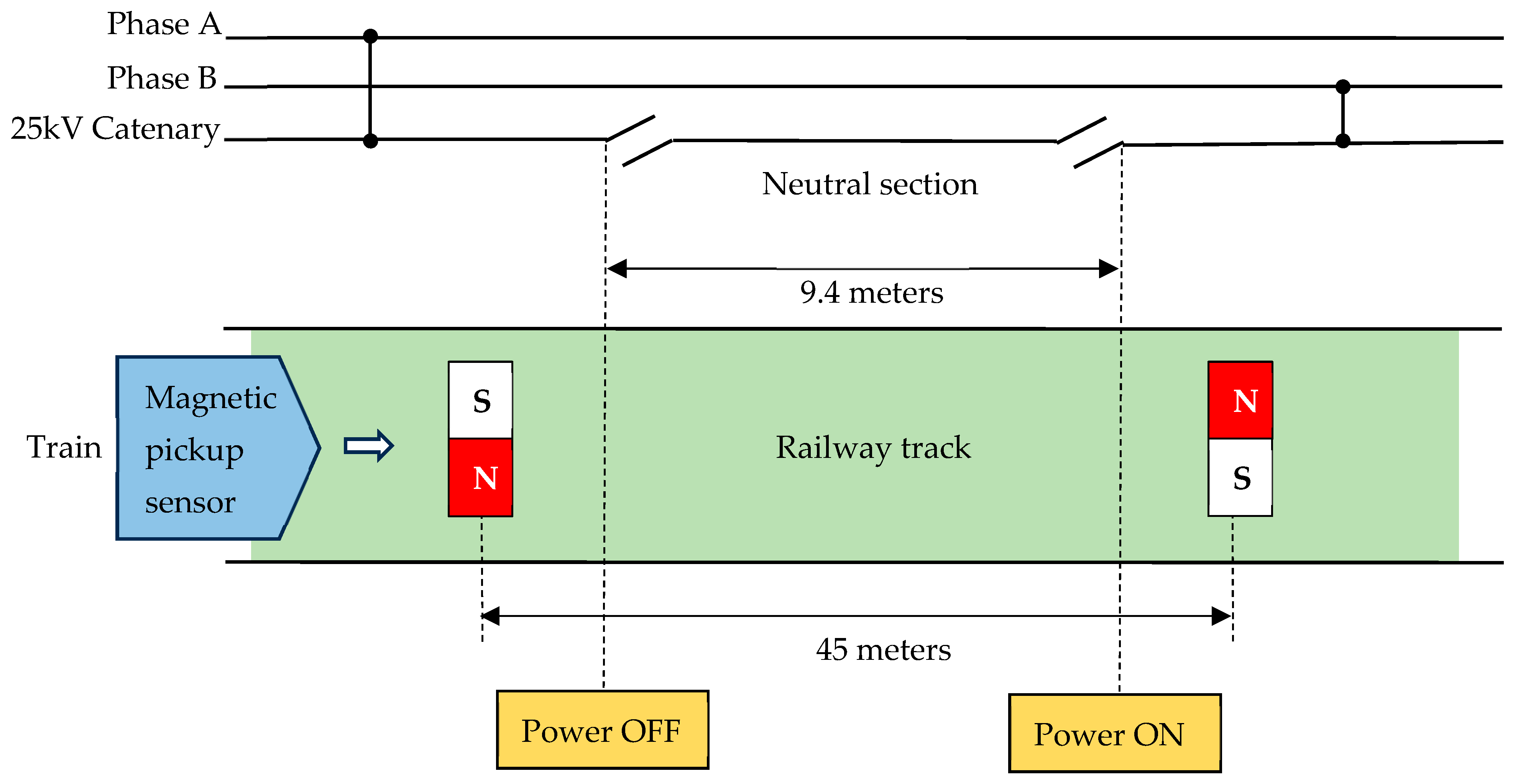
- We suggest the replacement of the conventional electro-mechanical system used for switching traction supplies with a computer-based vision system. The advantage of such a system would be that it would reduce maintenance costs and enhance the reliability of the system. Visual detection has the potential for high accuracy and rapid automation.
- The introduction of visual markers along the railway line as triggers for NS would enable precise and automated control of the vacuum circuit breakers within the locomotive.
- Employing the Circular Hough Transform shape detection for image segmentation enhances the accuracy of locating the markers in the captured images.
- The implementation of image classification using a Histogram of Orientation Gradient technique and training a Liner Support Vector Machine algorithm for target image classification are novel approaches in this context.
3. Methodology for Neutral Switching Using Image Detection
3.1. Image Acquisition
3.2. Image Pre-Processing
3.2.1. RGB to Greyscale Conversion
3.2.2. Bilateral Noise Filter
- : Original image value at pixel position .
- : Filtered image value at pixel position .
- : Spatial and range weights of the neighboring pixel .
- : Coordinate of the neighbouring pixel to be filtered.
- : Coordinate of the current pixel to be filtered.
- : Window centered in , so defines another pixel.
- : Spatial Gaussian weighting (for smoothing).
- : Range Gaussian weighting (preserves contours).
| Algorithm 1. Image conversion and filtering |
| Input: Greyscale marker images Output: Grayscale noise-filtered images
|
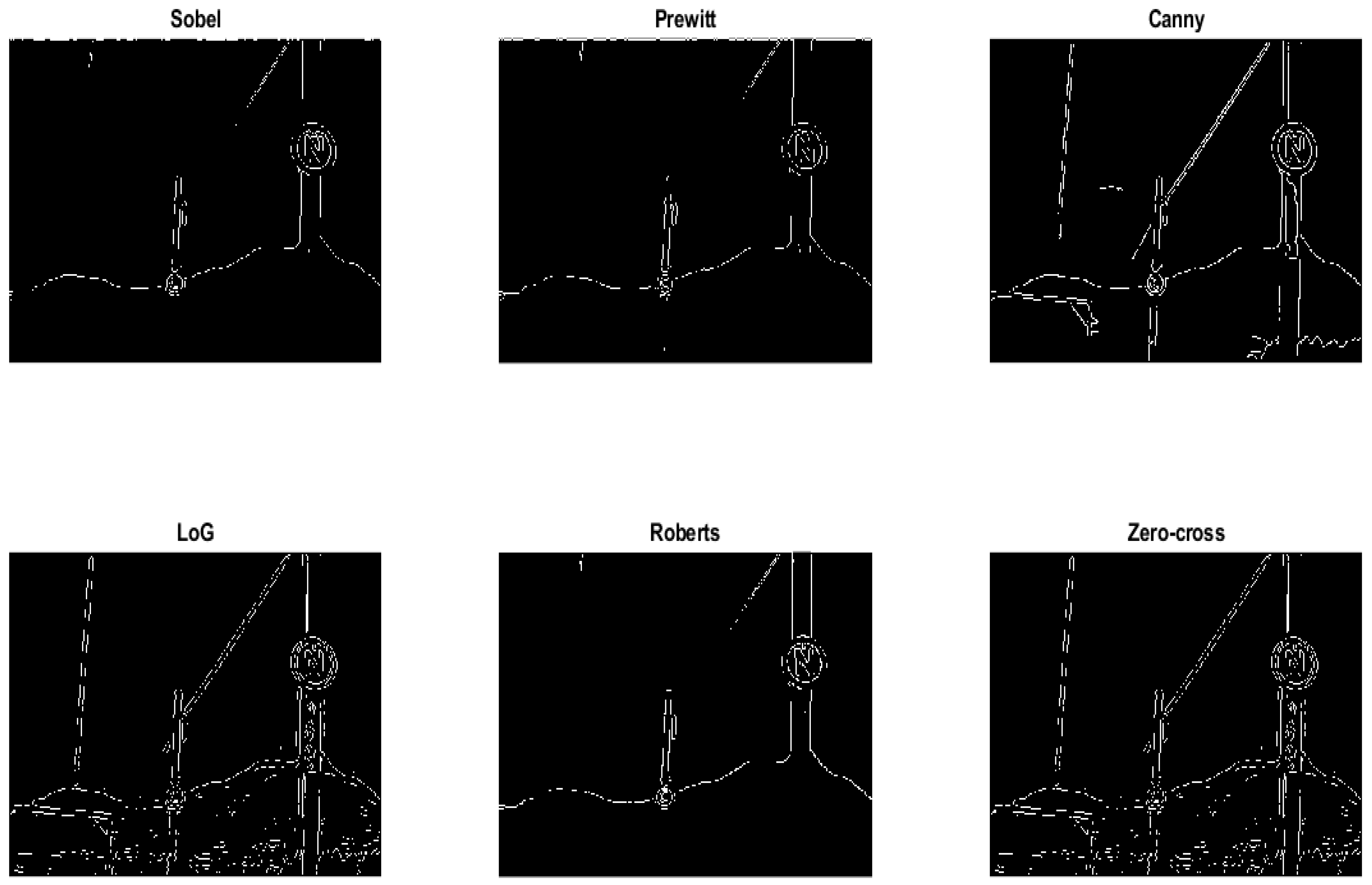
3.3. Edge Detection Using the Sobel Operator
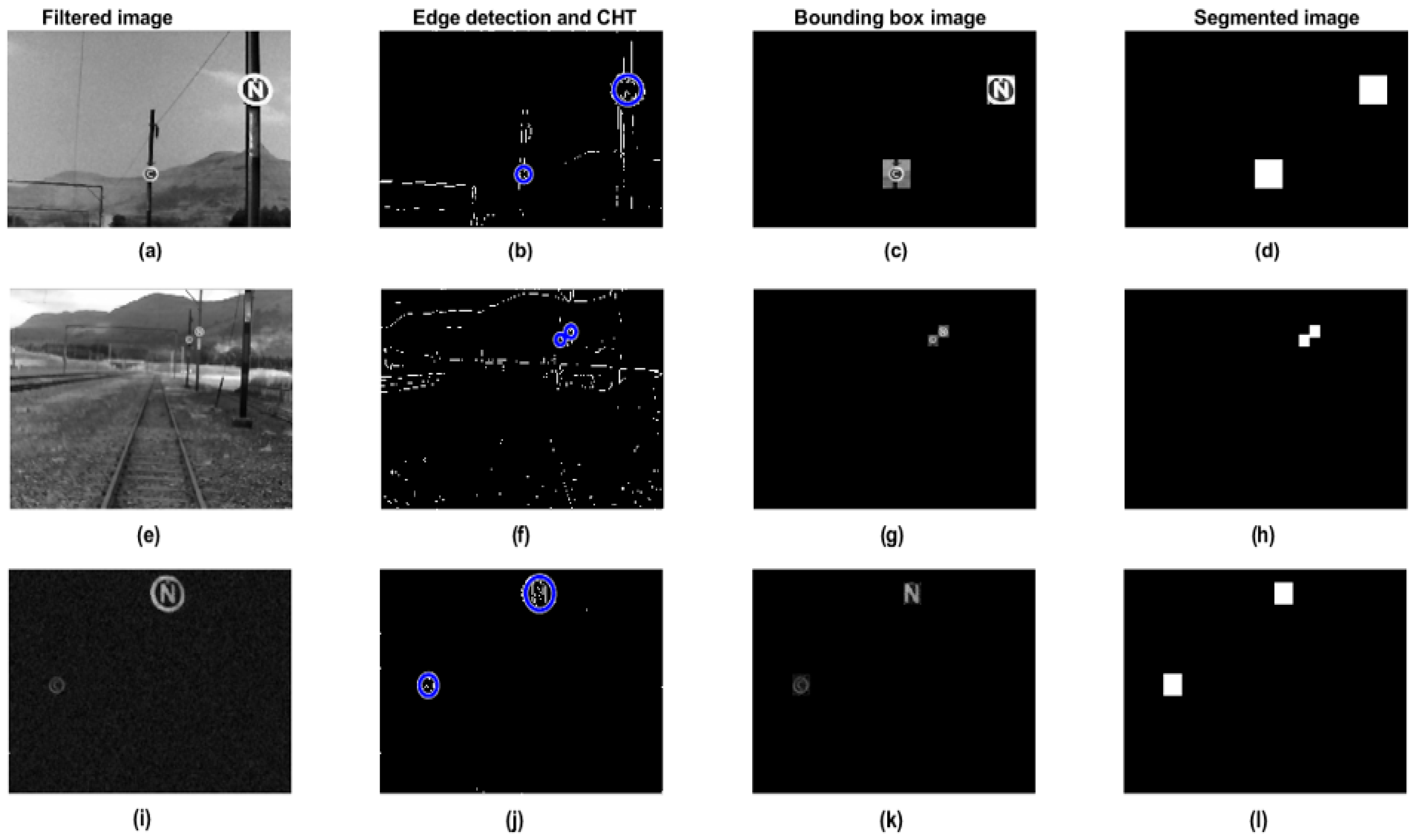
3.4. Locating the Region of Interest
| Algorithm 2. Segmentation an RoI extraction |
| Input: Greyscale noise-filtered images (Algorithm 1) Output: Cropped images with OoI’s (markers)
|
3.5. Image Feature Extraction
- The features allow for a more robust image when subjected to variations in illumination and shading.
- They are relatively invariant to small translations and rotations, which makes them suitable for marker classification in different orientations or positions.
- Unique information about marker edges and corners is inherently encoded.
- Finally, they are computationally efficient when compared to other methods, which would allow for efficient real-time implementation in an embedded system.
| Algorithm 3. Feature extraction using HOG |
| Input: Cropped images (Algorithm 2) Output: Concatenated feature vector
|
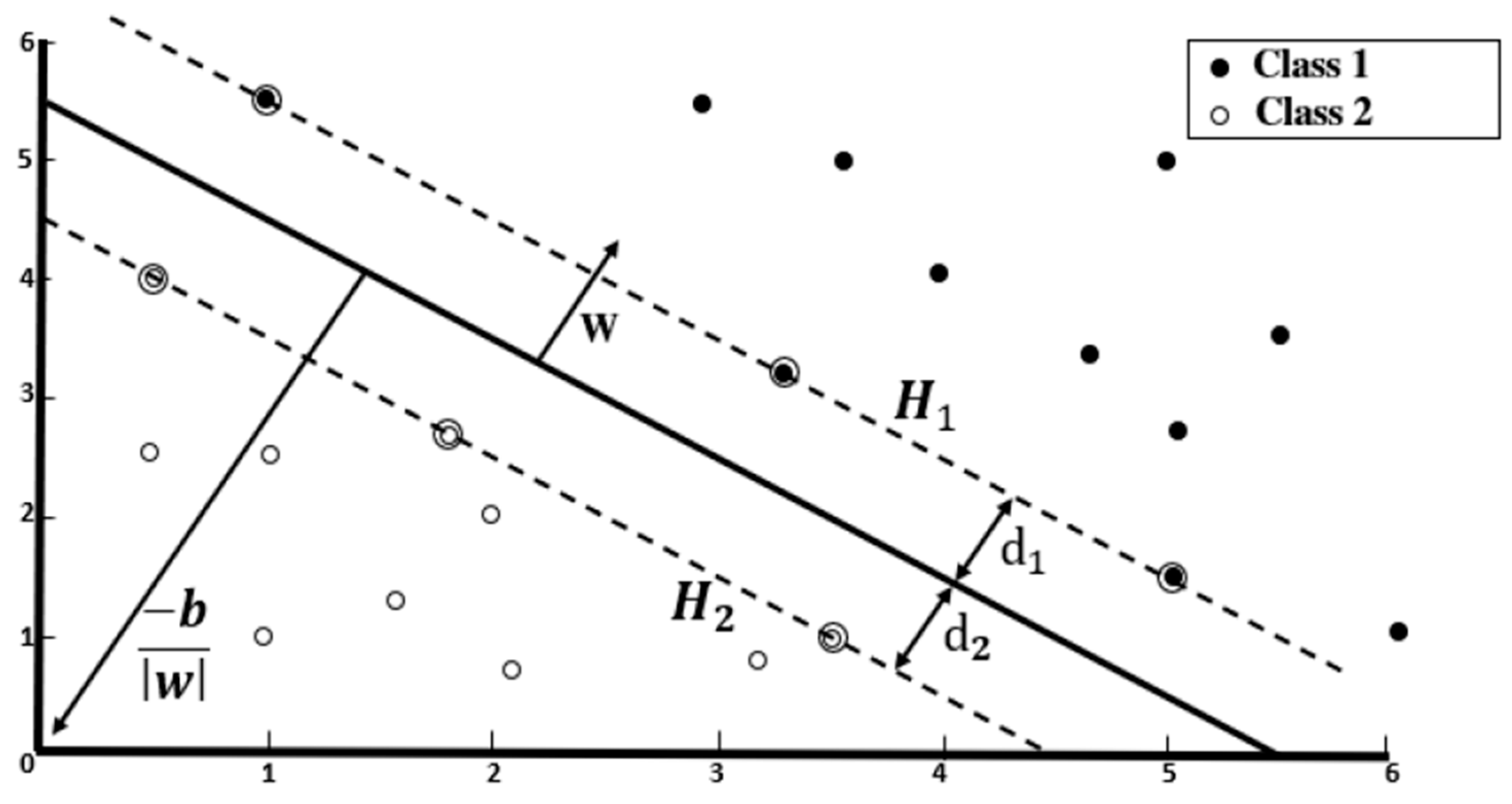
3.6. Image Classification
| Algorithm 4. Image classification training using LSVM |
| Input: Training and Validation BoF (Algorithm 3) Output: Class label for each BoF
|
4. Results
4.1. Optimal Parameter Selection for the Bilateral Filter
4.2. Comparison of Edge Detection Operators
4.3. Image Classification Results
4.3.1. Evaluation Metric
4.3.2. LSVM Model Performance
4.3.3. Efficacy of the System Performance
5. Conclusions and Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Han, Z.; Liu, S.; Gao, S. An automatic system for China high-speed multiple unit train running through neutral section with electric load. In Proceedings of the 2010 Asia-Pacific Power and Energy Engineering Conference, Chengdu, China, 28–31 March 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–3. [Google Scholar]
- Ran, W.; Zheng, T.Q.; Li, X.; Liu, B. Research on power electronic switch system used in the auto-passing neutral section with electric load. In Proceedings of the 2011 International Conference on Electrical Machines and Systems, Beijing, China, 20–23 August 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–4. [Google Scholar]
- Mcineka, C.T. Autonomous Switching of Electric Locomotives in Neutral Sections. 2023. Available online: https://hdl.handle.net/10321/4881 (accessed on 1 January 2023).
- Chen, D.; Pan, M.; Tian, W.; Yang, W. Automatic neutral section passing control device based on image recognition for electric locomotives. In Proceedings of the 2010 IEEE International Conference on Imaging Systems and Techniques, Thessaloniki, Greece, 1–2 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 385–388. [Google Scholar]
- Mcineka, C.T.; Reddy, S. Automatic Switching of Electric Locomotives in Neutral Sections. In Proceedings of the Conference on Information Communications Technology and Society (ICTAS), Durban, South Africa, 10–11 March 2021; pp. 97–102. [Google Scholar] [CrossRef]
- Mcineka, C.T.; Pillay, N. Machine Learning Classifiers Based on HoG Features Extracted from Locomotive Neutral Section Images. In Proceedings of the 2022 International Conference on Engineering and Emerging Technologies (ICEET), Kuala Lumpur, Malaysia, 27–28 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer vision for autonomous vehicles: Problems, datasets and state of the art. Found. Trends Comput. Graph. Vis. 2020, 12, 1–308. [Google Scholar] [CrossRef]
- Nassu, B.T.; Ukai, M. Automatic recognition of railway signs using SIFT features. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 348–354. [Google Scholar]
- Mikrut, S.; Mikrut, Z.; Moskal, A.; Pastucha, E. Detection and recognition of selected class railway signs. Image Process. Commun. 2014, 19, 83. [Google Scholar] [CrossRef]
- Ristić-Durrant, D.; Franke, M.; Michels, K. A review of vision-based on-board obstacle detection and distance estimation in railways. Sensors 2021, 21, 3452. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Zhang, X.; Damiani, L.; Giribone, P.; Revetria, R.; Ronchetti, G. Transportation Safety Improvements Through Video Analysis: An Application of Obstacles and Collision Detection Applied to Railways and Roads. In Transactions on Engineering Technologies, Proceedings of the 25th International Multi Conference of Engineers and Computer Scientists, Hong Kong, 15–17 March 2017; Springer: Singapore, 2018; pp. 1–15. [Google Scholar]
- Ross, R. Vision-based track estimation and turnout detection using recursive estimation. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1330–1335. [Google Scholar]
- Maire, F.; Bigdeli, A. Obstacle-free range determination for rail track maintenance vehicles. In Proceedings of the 2010 11th International Conference on Control Automation Robotics & Vision, Singapore, 7–10 December 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2172–2178. [Google Scholar]
- Qi, Z.; Tian, Y.; Shi, Y. Efficient railway tracks detection and turnouts recognition method using HOG features. Neural Comput. Appl. 2013, 23, 245–254. [Google Scholar] [CrossRef]
- Yu, M.; Yang, P.; Wei, S. Railway obstacle detection algorithm using neural network. AIP Conf. Proc. 2018, 1967, 040017. [Google Scholar]
- Kapoor, R.; Goel, R.; Sharma, A. Deep learning based object and railway track recognition using train mounted thermal imaging system. J. Comput. Theor. Nanosci. 2020, 17, 5062–5071. [Google Scholar] [CrossRef]
- Ye, T.; Wang, B.; Song, P.; Li, J. Automatic railway traffic object detection system using feature fusion refine neural network under shunting mode. Sensors 2018, 18, 1916. [Google Scholar] [CrossRef] [PubMed]
- Ye, T.; Zhang, X.; Zhang, Y.; Liu, J. Railway traffic object detection using differential feature fusion convolution neural network. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1375–1387. [Google Scholar] [CrossRef]
- Ristić-Durrant, D.; Haseeb, M.A.; Banić, M.; Stamenković, D.; Simonović, M.; Nikolić, D. SMART on-board multi-sensor obstacle detection system for improvement of rail transport safety. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2022, 236, 623–636. [Google Scholar] [CrossRef]
- Ye, T.; Zhang, Z.; Zhang, X.; Zhou, F. Autonomous railway traffic object detection using feature-enhanced single-shot detector. IEEE Access 2020, 8, 145182–145193. [Google Scholar] [CrossRef]
- Chernov, A.; Butakova, M.; Guda, A.; Shevchuk, P. Development of intelligent obstacle detection system on railway tracks for yard locomotives using CNN. In Dependable Computing-EDCC 2020 Workshops, Proceedings of the AI4RAILS, DREAMS, DSOGRI, SERENE 2020, Munich, Germany, 7–10 September 2020; Proceedings 16; Springer International Publishing: Cham, Switzerland, 2020; pp. 33–43. [Google Scholar]
- Haseeb, M.A.; Guan, J.; Ristic-Durrant, D.; Gräser, A. DisNet: A novel method for distance estimation from monocular camera. In Proceedings of the 10th Planning, Perception and Navigation for Intelligent Vehicles (PPNIV18), IROS, Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Karagiannis, G.; Olsen, S.; Pedersen, K. Deep learning for detection of railway signs and signals. In Advances in Computer Vision, Proceedings of the 2019 Computer Vision Conference (CVC), Las Vegas, NV, USA, 25–26 April 2019; Springer International Publishing: Cham, Switzerland, 2020; Volume 943, pp. 1–15. [Google Scholar]
- Staino, A.; Suwalka, A.; Mitra, P.; Basu, B. Real-time detection and recognition of railway traffic signals using deep learning. J. Big Data Anal. Transp. 2022, 4, 57–71. [Google Scholar] [CrossRef]
- Li, B.; Wu, S.; Wang, Z.; Chen, X.; Shi, L.; Tan, S. Railway track circuit signal state check using object detection. J. Phys. Conf. Ser. 2020, 1486, 042018. [Google Scholar] [CrossRef]
- Fayyaz, M.A.B.; Johnson, C. Object detection at level crossing using deep learning. Micromachines 2020, 11, 1055. [Google Scholar] [CrossRef] [PubMed]
- Sikora, P.; Malina, L.; Kiac, M.; Martinasek, Z.; Riha, K.; Prinosil, J.; Jirik, L.; Srivastava, G. Artificial intelligence-based surveillance system for railway crossing traffic. IEEE Sens. J. 2020, 21, 15515–15526. [Google Scholar] [CrossRef]
- Mehta, S.; Patel, A.; Mehta, J. CCD or CMOS Image sensor for photography. In Proceedings of the International Conference on Communications and Signal Processing (ICCSP), Melmaruvathur, India, 2–4 April 2015; pp. 0291–0294. [Google Scholar] [CrossRef]
- Saravanan, C. Color Image to Grayscale Image Conversion. In Proceedings of the Second International Conference on Computer Engineering and Applications, Bali, Indonesia, 19–21 March 2010; pp. 196–199. [Google Scholar] [CrossRef]
- Kaur, S. Noise Types and Various Removal Techniques. Int. J. Adv. Res. Electron. Commun. Eng. (IJARECE) 2015, 4, 226–230. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Chi Qin, L.A.I.; Teoh, S.S. An efficient method of HOG feature extraction using selective histogram bin and PCA feature reduction. Adv. Electr. Comput. Eng. 2016, 16, 101–108. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kernel Function | Kernel Scale | Kernel Offset | Box Constraint Level | Cross Validation Folds |
|---|---|---|---|---|
| Linear | ‘auto’ | 0 | 1 | 2 and 5 |
| Gaussian Weighing | Correlation of the Original Image versus the Filtered Image (%) | Time (msec) | |
|---|---|---|---|
| 1 * | 10 | 99.33 | 2.70 |
| 30 | 99.37 | 2.88 | |
| 100 | 99.41 | 2.75 | |
| 300 | 99.43 | 2.75 | |
| 650.25 * | 99.43 | 2.62 | |
| 3 | 10 | 99.36 | 12.37 |
| 30 | 99.42 | 11.37 | |
| 100 | 99.46 | 12.76 | |
| 300 | 99.39 | 10.73 | |
| 650.25 | 99.26 | 12.76 | |
| 10 | 10 | 99.36 | 389.52 |
| 30 | 99.41 | 412.96 | |
| 100 | 99.41 | 444.07 | |
| 300 | 99.43 | 368.09 | |
| 650.25 | 98.75 | 326.18 | |
| Actual image | Predicted image | |||
| Close ‘C’ | Negative ‘I’ | Open ‘N’ | ||
| Close ‘C’ | TP | FP | FP | |
| Negative ‘I’ | FN | TP | FN | |
| Open ‘N’ | FN | FN | TP | |
| Cell Size | Precision (%) | Recall (%) | F1 Score (%) | |
|---|---|---|---|---|
| Two-fold cross-validation | [2 × 2] | 93.60 | 88.79 | 91.13 |
| [4 × 4] | 96.43 | 98.63 | 97.52 | |
| [8 × 8] | 96.79 | 95.91 | 96.35 | |
| [16 × 16] | 95.67 | 91.28 | 93.43 | |
| Five-fold cross-validation | [2 × 2] | 95.96 | 98.17 | 97.05 |
| [4 × 4] | 97.77 | 98.21 | 97.99 | |
| [8 × 8] | 99.09 | 96.89 | 97.98 | |
| [16 × 16] | 97.16 | 92.76 | 94.91 |
| Classifier | Training Accuracy (%) | Validation Accuracy (%) | Prediction Speed (Objects/Second) |
|---|---|---|---|
| DT (CART) | 75.4 | 80.7 | 72 |
| DT (ID3) | 74.1 | 77.1 | 73 |
| LDA | 94.7 | 92.8 | 78 |
| QDA | 85.1 | 81.9 | 71 |
| Naïve Bayes | 85.1 | 81.9 | 26 |
| LSVM | 93.4 | 94.0 | 75 |
| QSVM | 93.9 | 94.0 | 68 |
| CSVM | 93.0 | 92.8 | 74 |
| AdaBoost | 57.5 | 57.8 | 68 |
| CNN | 90.8 | 90.4 | 82 |
| K-NN (2) * | 82.0 | 80.7 | 13 |
| K-NN (10) * | 84.6 | 80.7 | 14 |
| K-NN (20) * | 83.3 | 90.4 | 12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mcineka, C.T.; Pillay, N.; Moorgas, K.; Maharaj, S. Automatic Switching of Electric Locomotive Power in Railway Neutral Sections Using Image Processing. J. Imaging 2024, 10, 142. https://doi.org/10.3390/jimaging10060142
Mcineka CT, Pillay N, Moorgas K, Maharaj S. Automatic Switching of Electric Locomotive Power in Railway Neutral Sections Using Image Processing. Journal of Imaging. 2024; 10(6):142. https://doi.org/10.3390/jimaging10060142
Chicago/Turabian StyleMcineka, Christopher Thembinkosi, Nelendran Pillay, Kevin Moorgas, and Shaveen Maharaj. 2024. "Automatic Switching of Electric Locomotive Power in Railway Neutral Sections Using Image Processing" Journal of Imaging 10, no. 6: 142. https://doi.org/10.3390/jimaging10060142
APA StyleMcineka, C. T., Pillay, N., Moorgas, K., & Maharaj, S. (2024). Automatic Switching of Electric Locomotive Power in Railway Neutral Sections Using Image Processing. Journal of Imaging, 10(6), 142. https://doi.org/10.3390/jimaging10060142