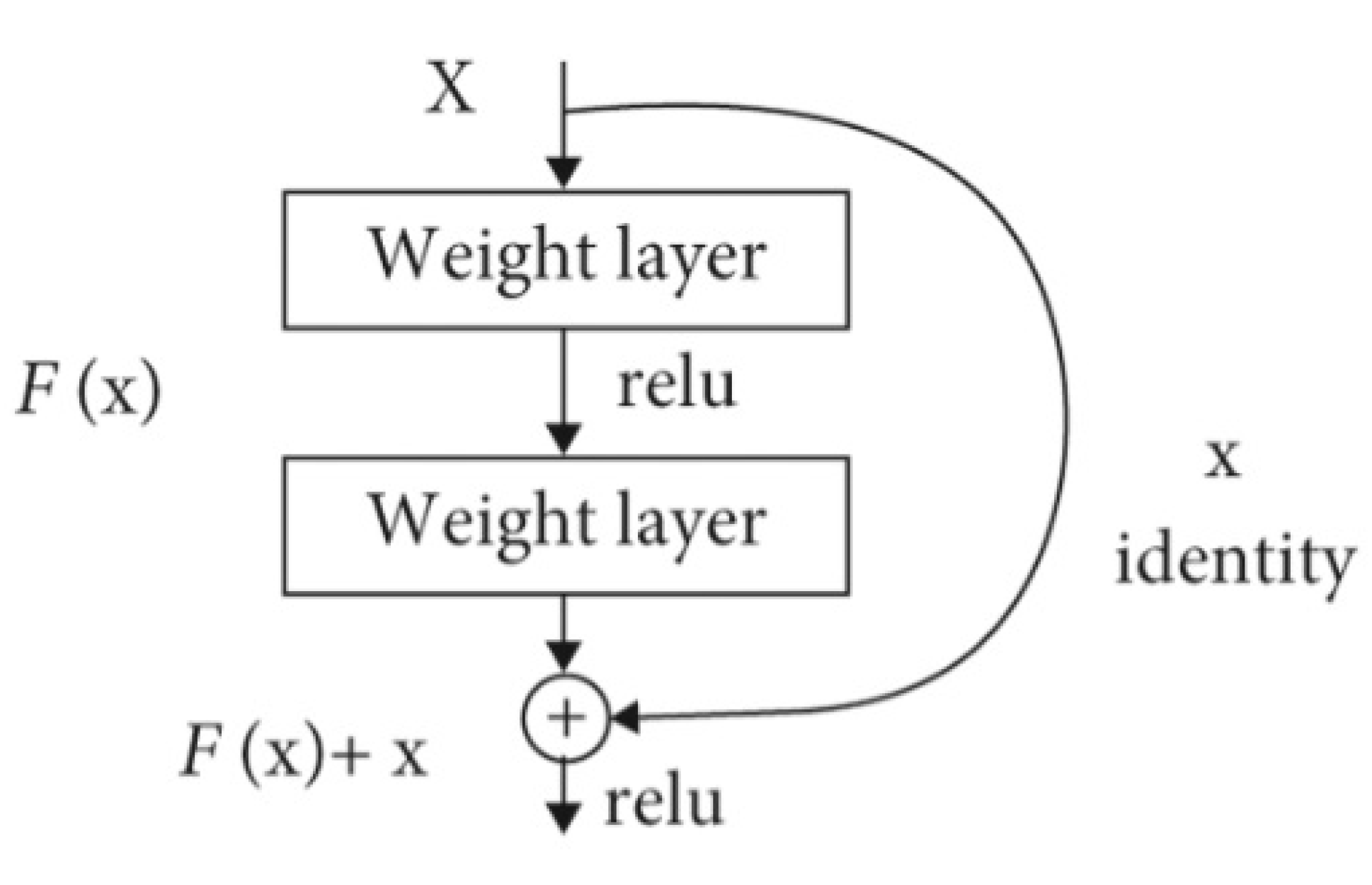
Figure 1.
ResNet50 shortcut.
Figure 1.
ResNet50 shortcut.
Figure 2.
The right panel shows the extracted RGB patches and the left panel shows its corresponding masks.
Figure 2.
The right panel shows the extracted RGB patches and the left panel shows its corresponding masks.
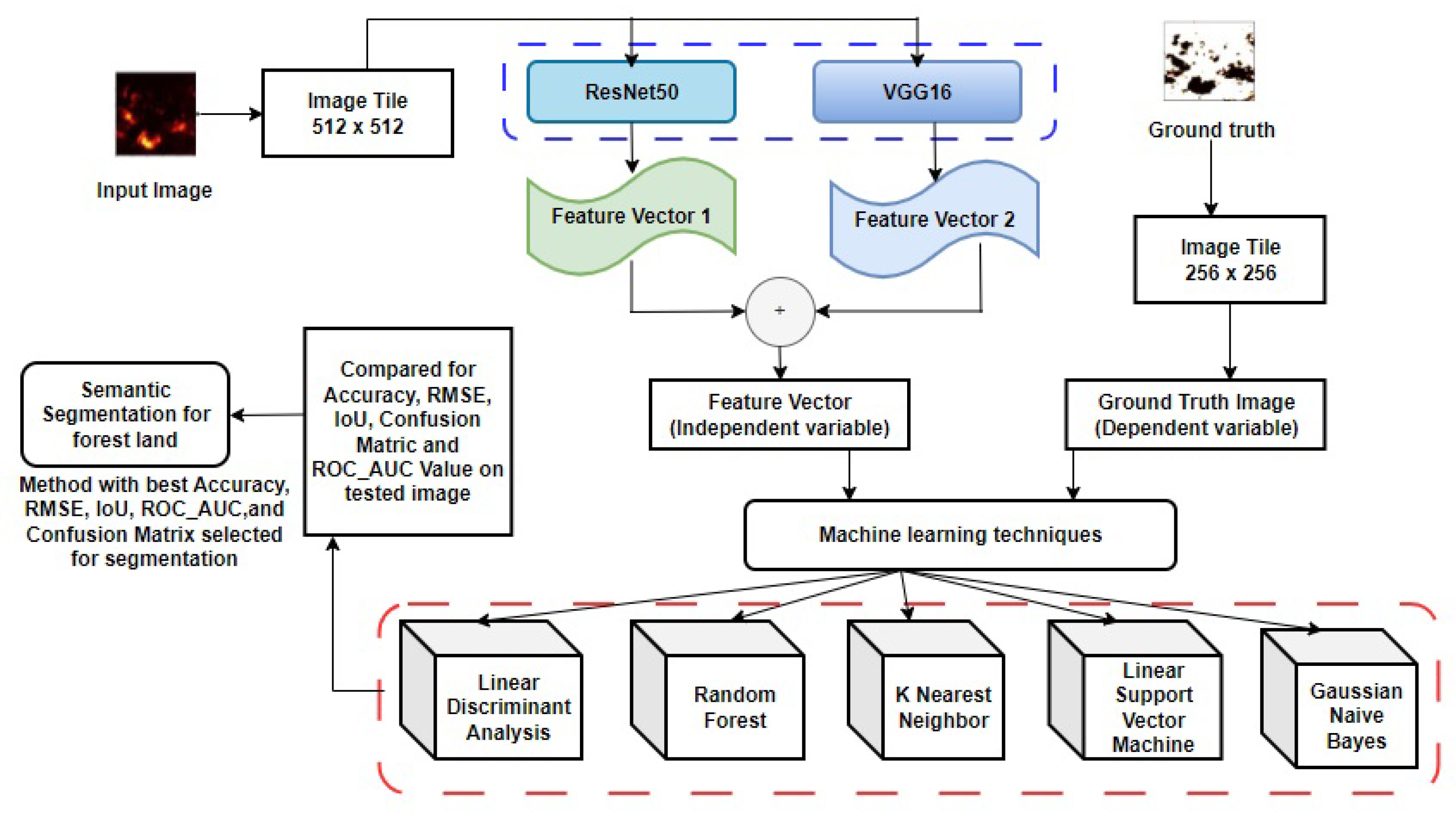
Figure 3.
Segmentation framework model with all traditional machine learning classifiers.
Figure 3.
Segmentation framework model with all traditional machine learning classifiers.
Figure 4.
Set of features produced by VGG16 model.
Figure 4.
Set of features produced by VGG16 model.
Figure 5.
Set of features produced by ResNet50 model.
Figure 5.
Set of features produced by ResNet50 model.
Figure 6.
Composite set of features produced by VGG16 and ResNet50.
Figure 6.
Composite set of features produced by VGG16 and ResNet50.
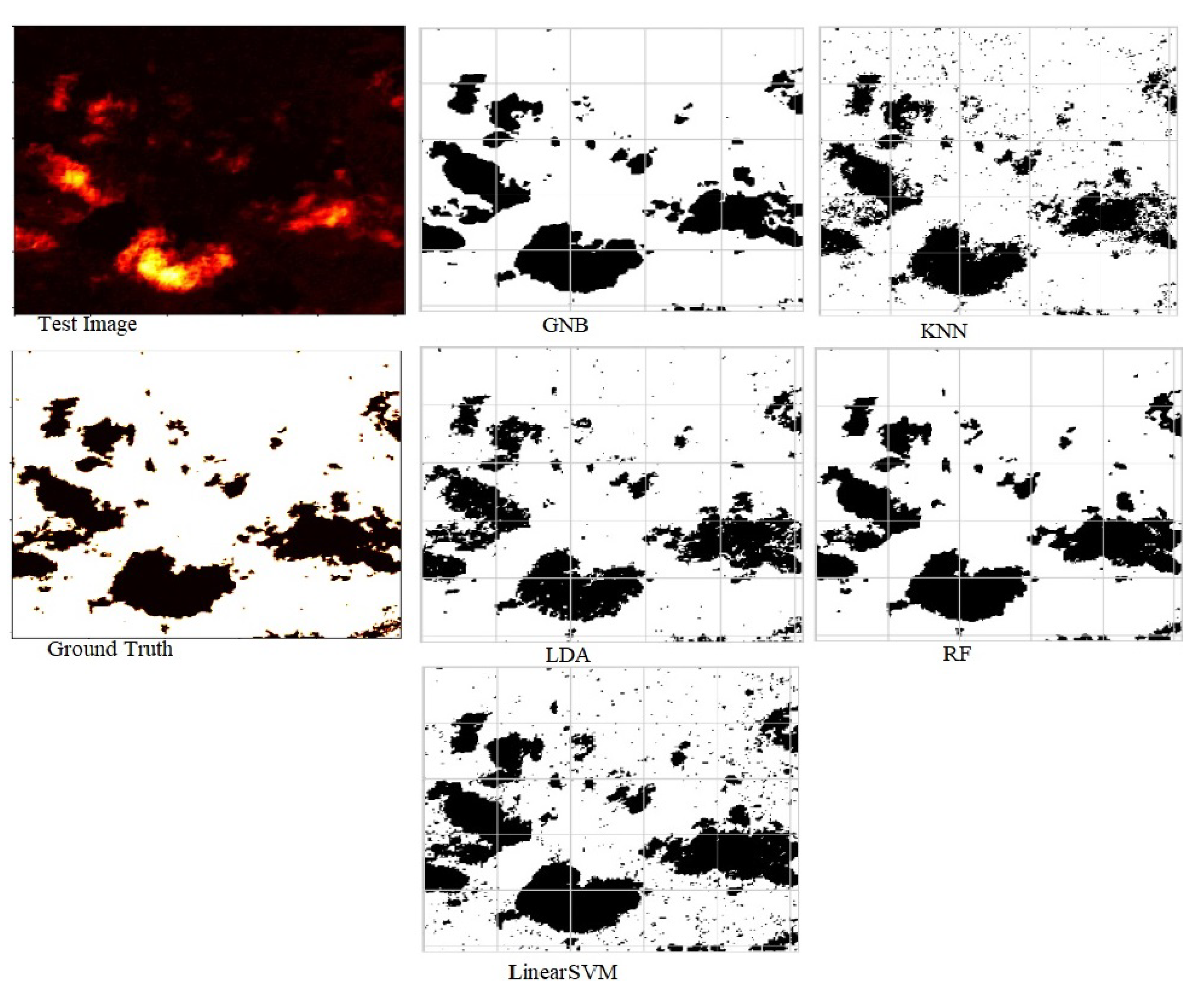
Figure 7.
Predicted segmentation results by RF, LDA, GNB, kNN, and LinearSVM with the ensembled approach.
Figure 7.
Predicted segmentation results by RF, LDA, GNB, kNN, and LinearSVM with the ensembled approach.
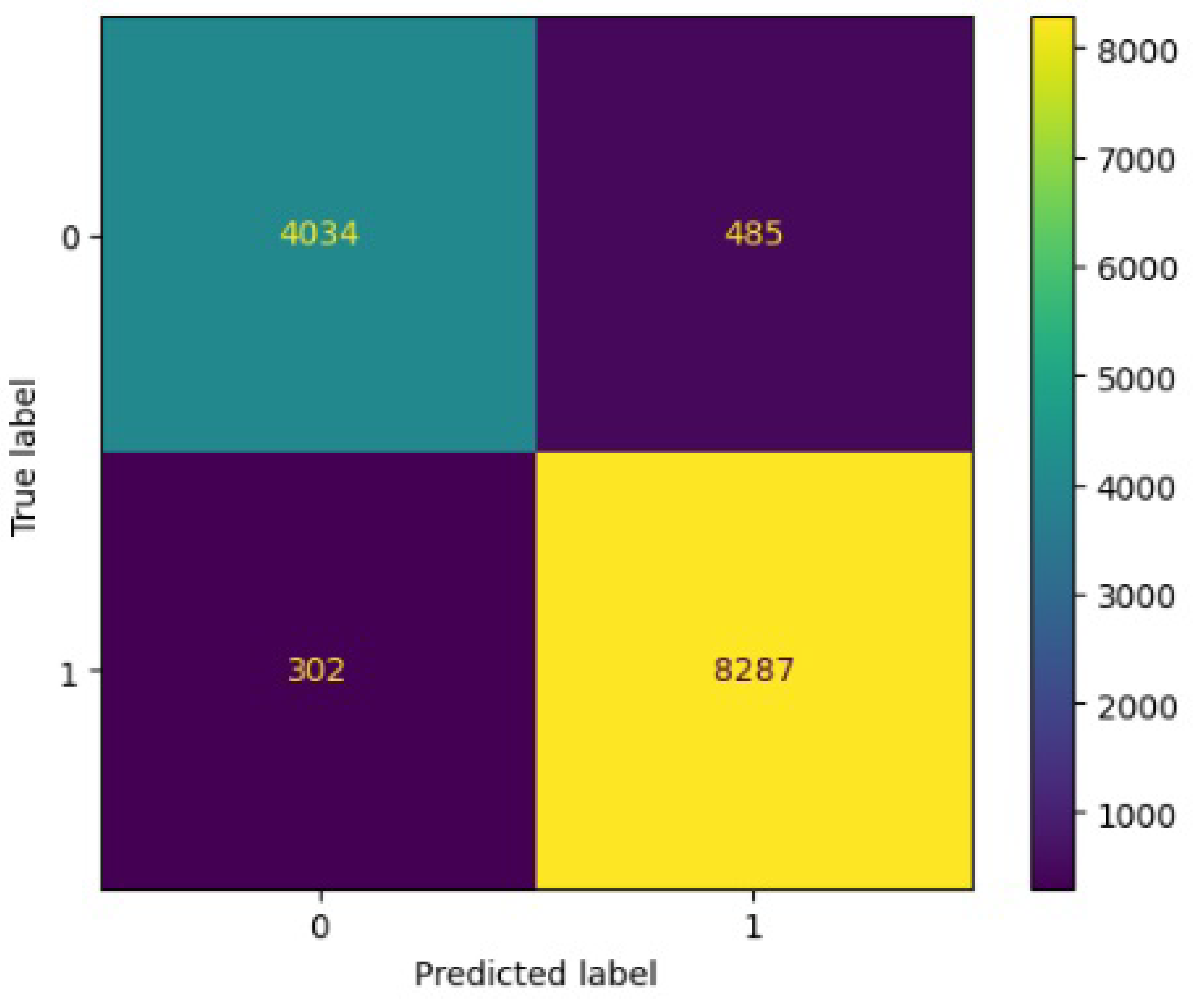
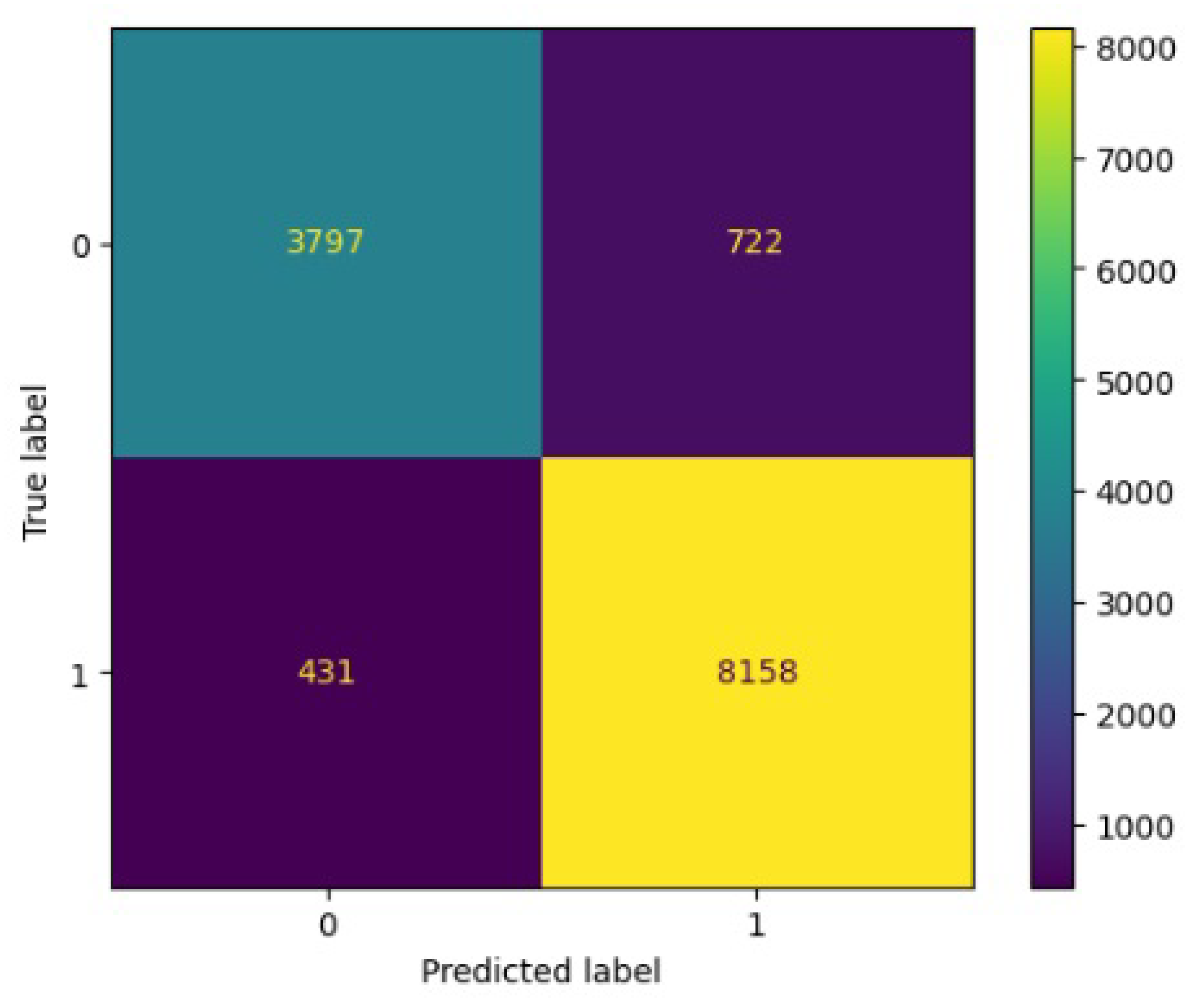
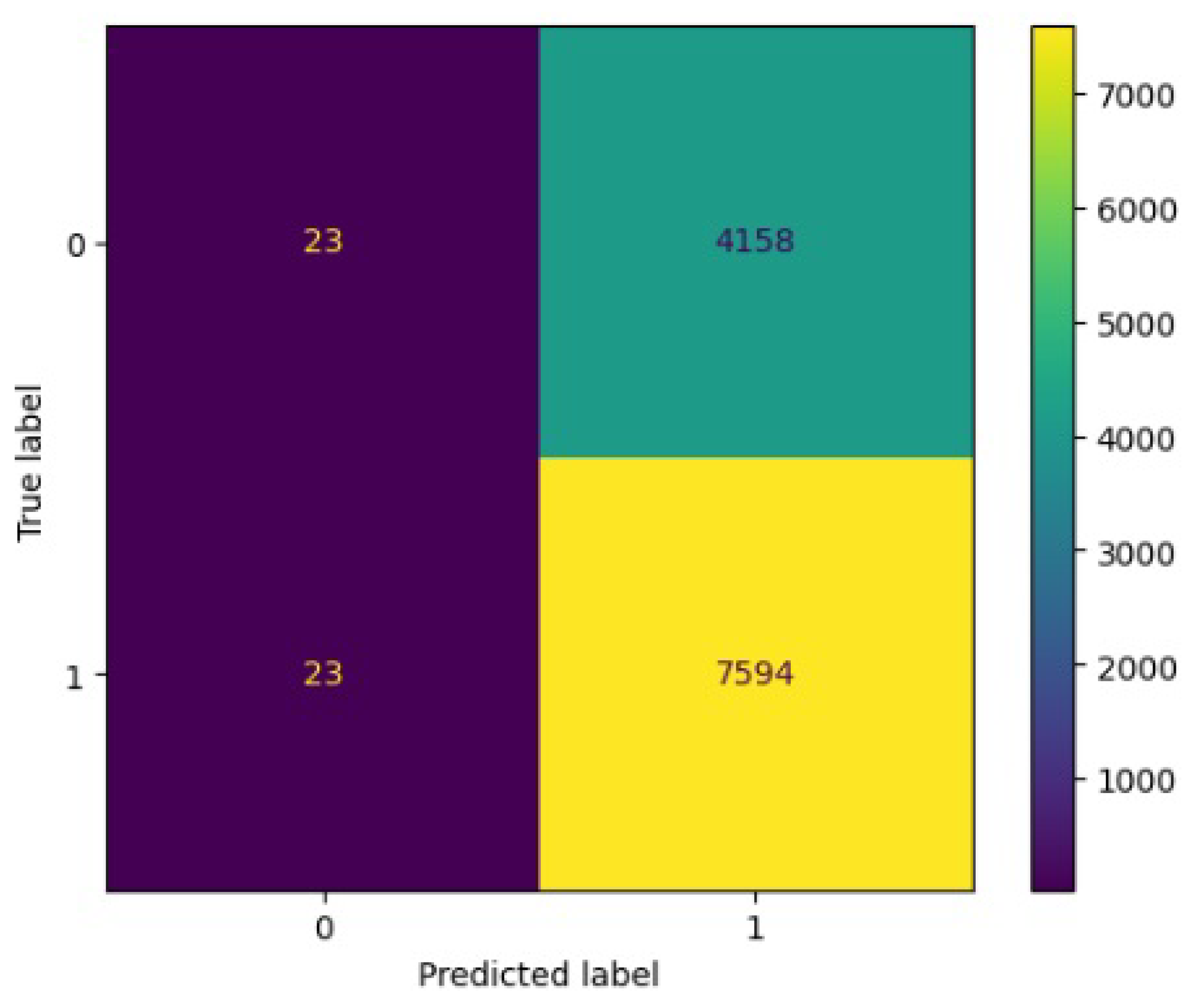
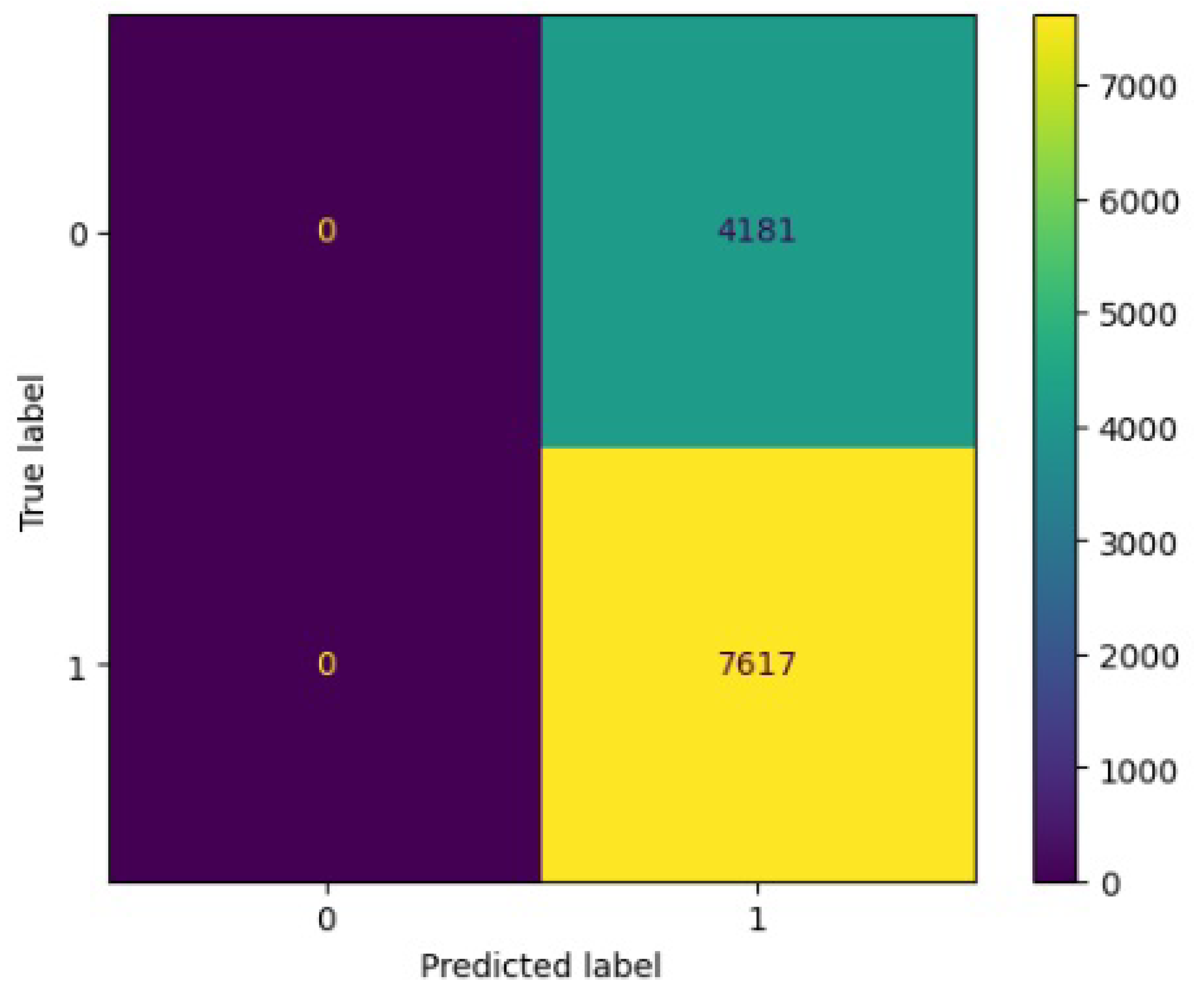
Figure 8.
Confusion matrix results for RF.
Figure 8.
Confusion matrix results for RF.
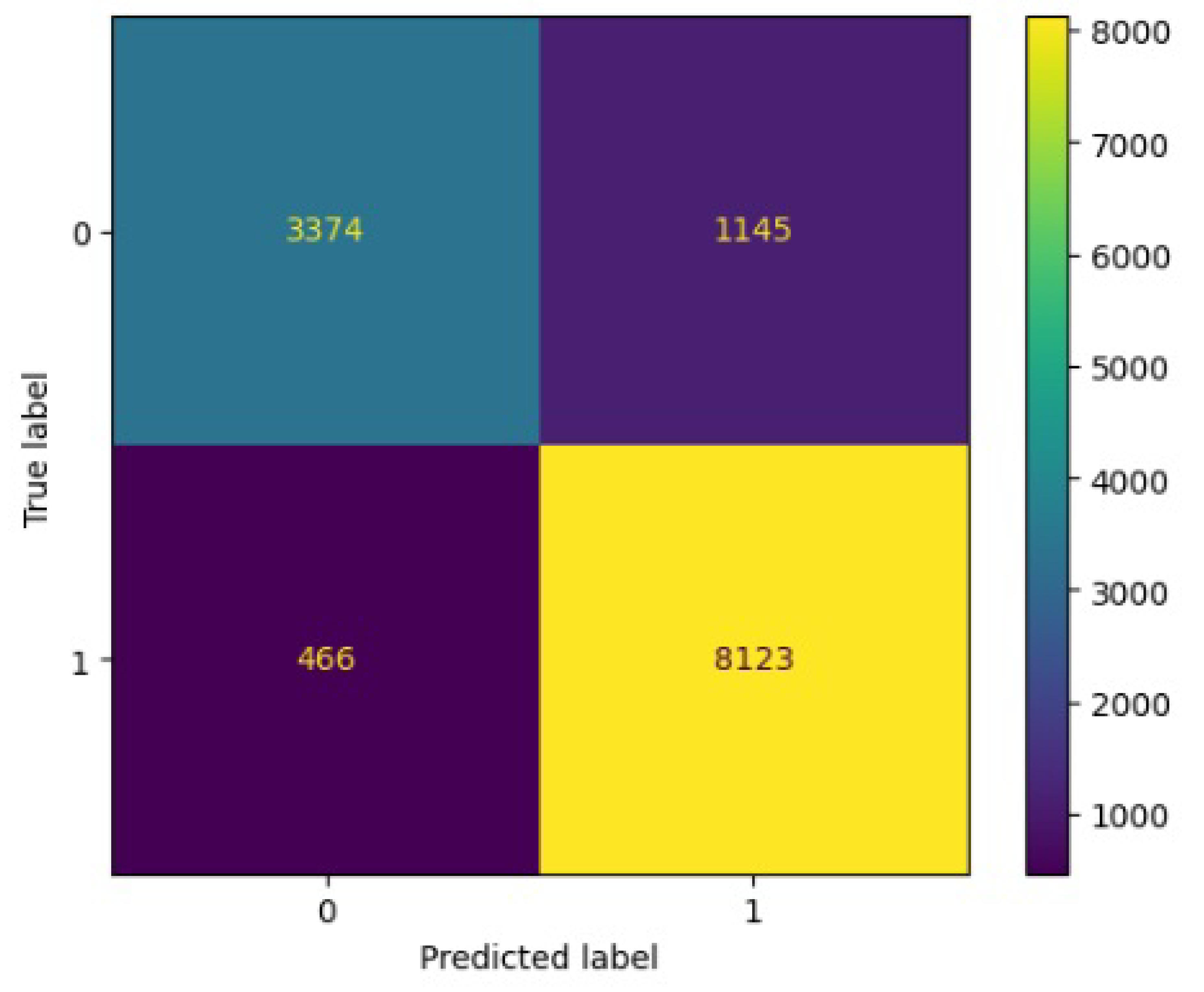
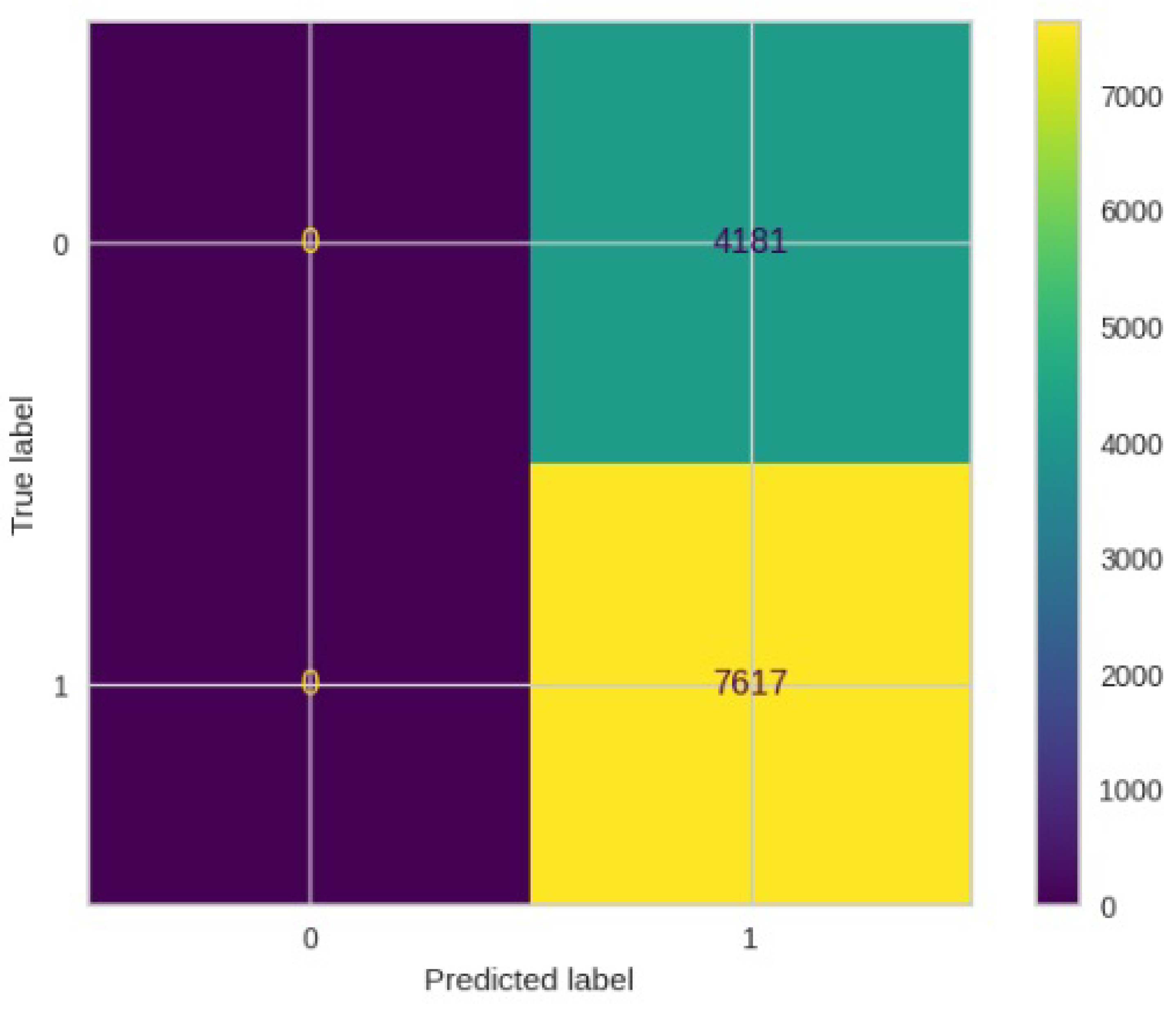
Figure 9.
Confusion matrix results for LinearSVM.
Figure 9.
Confusion matrix results for LinearSVM.
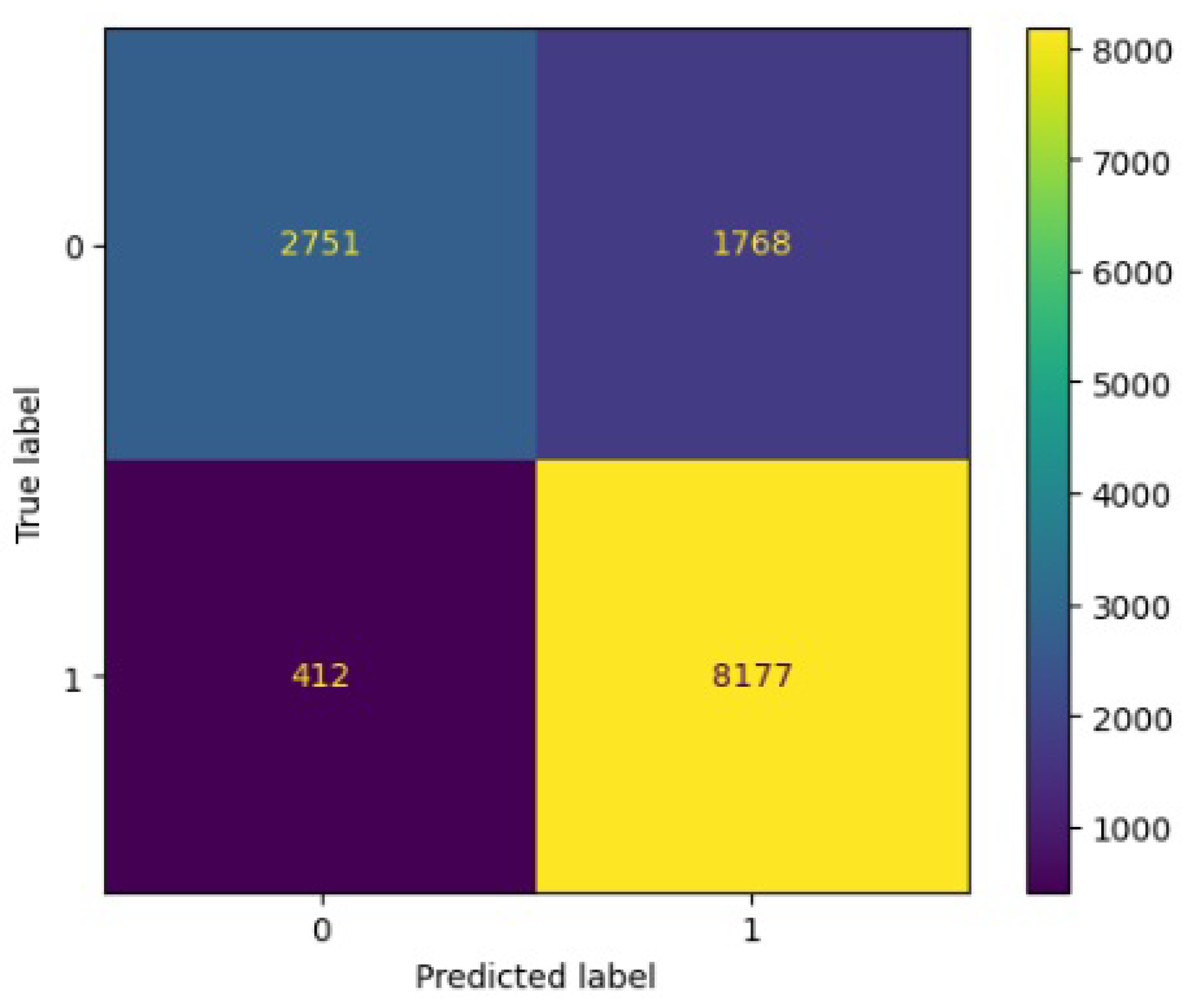
Figure 10.
Confusion matrix results for LDA.
Figure 10.
Confusion matrix results for LDA.
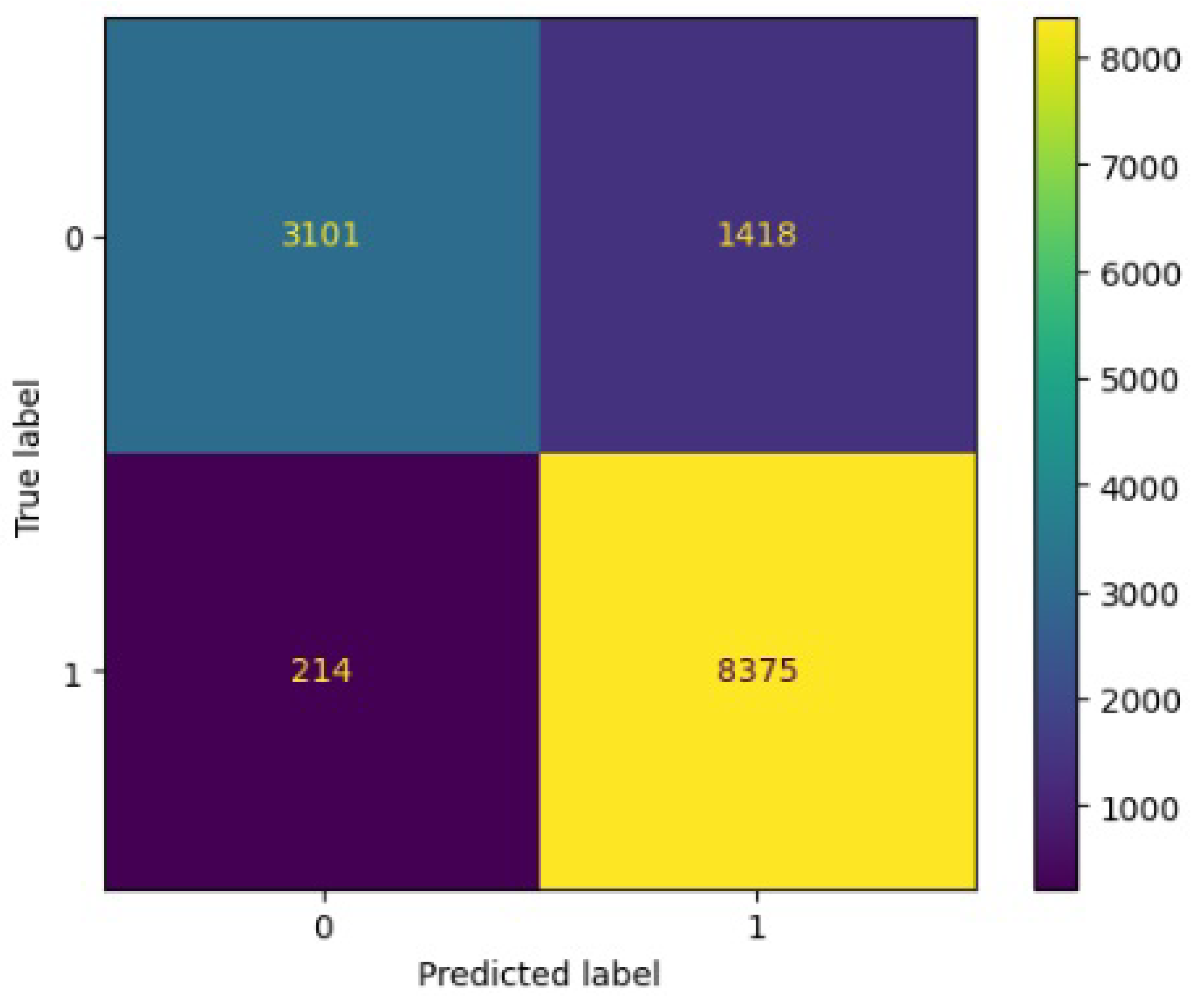
Figure 11.
Confusion matrix results for KNN.
Figure 11.
Confusion matrix results for KNN.
Figure 12.
Confusion matrix results for GNB.
Figure 12.
Confusion matrix results for GNB.
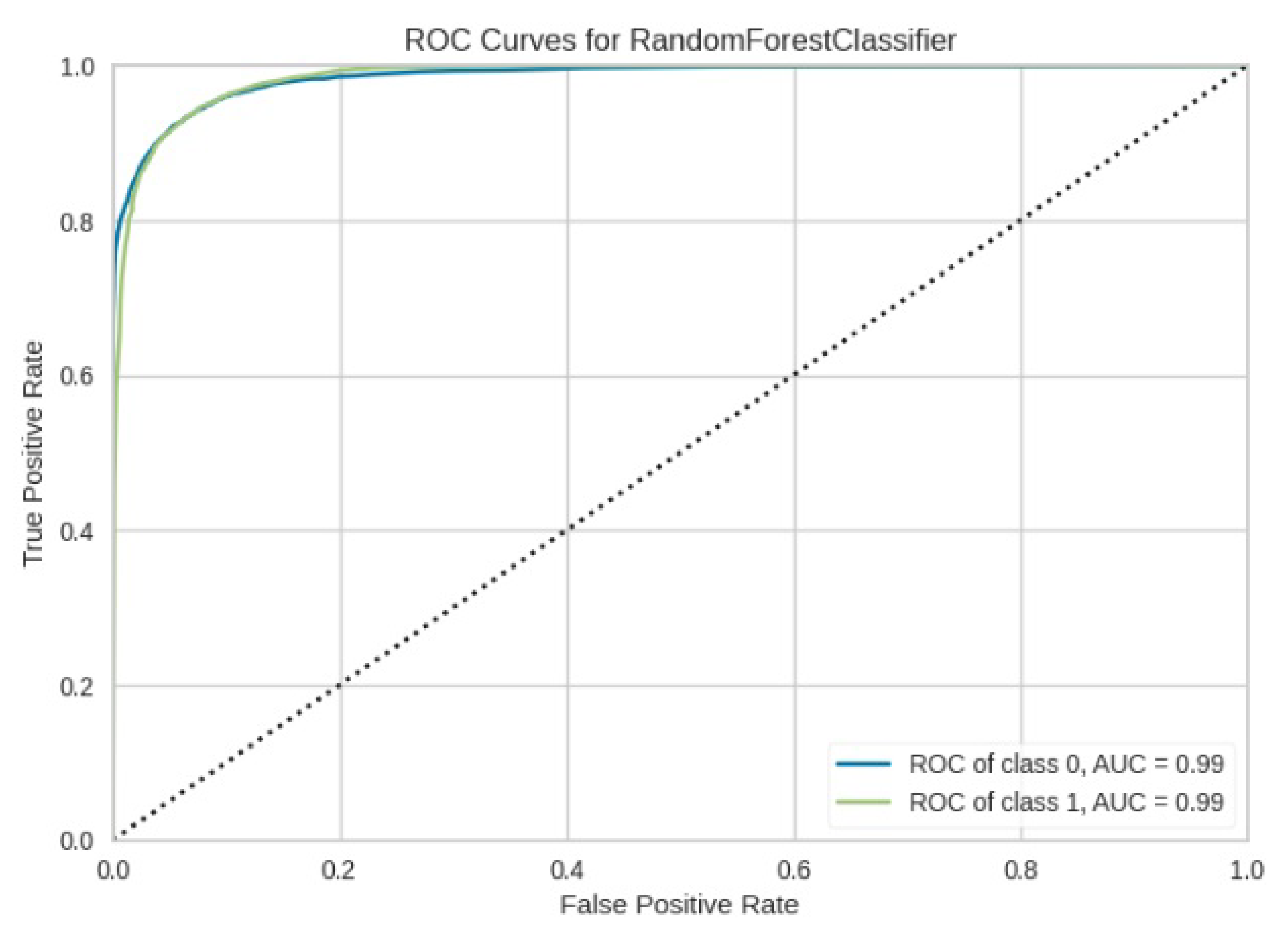
Figure 13.
ROC curve for RF.
Figure 13.
ROC curve for RF.
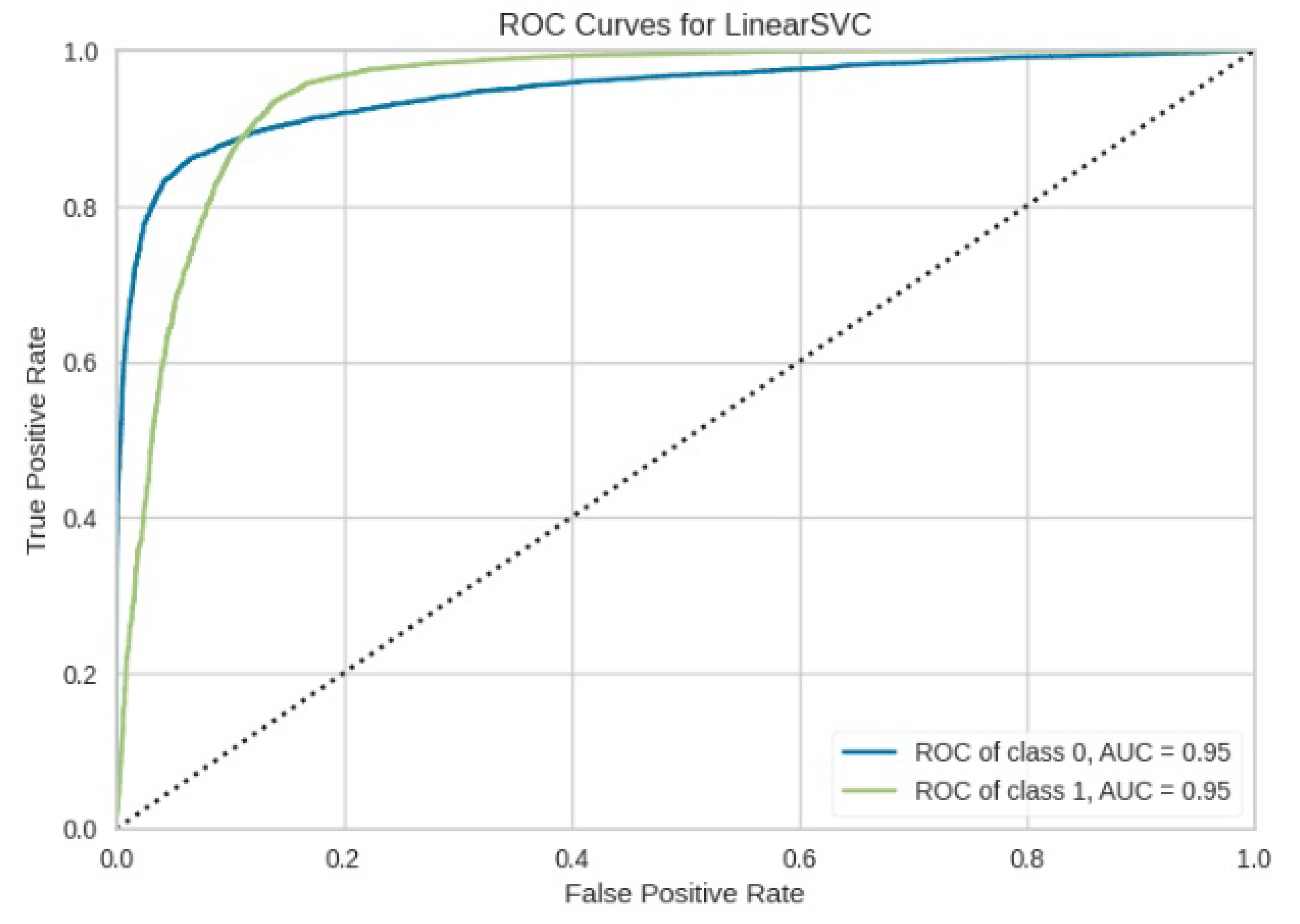
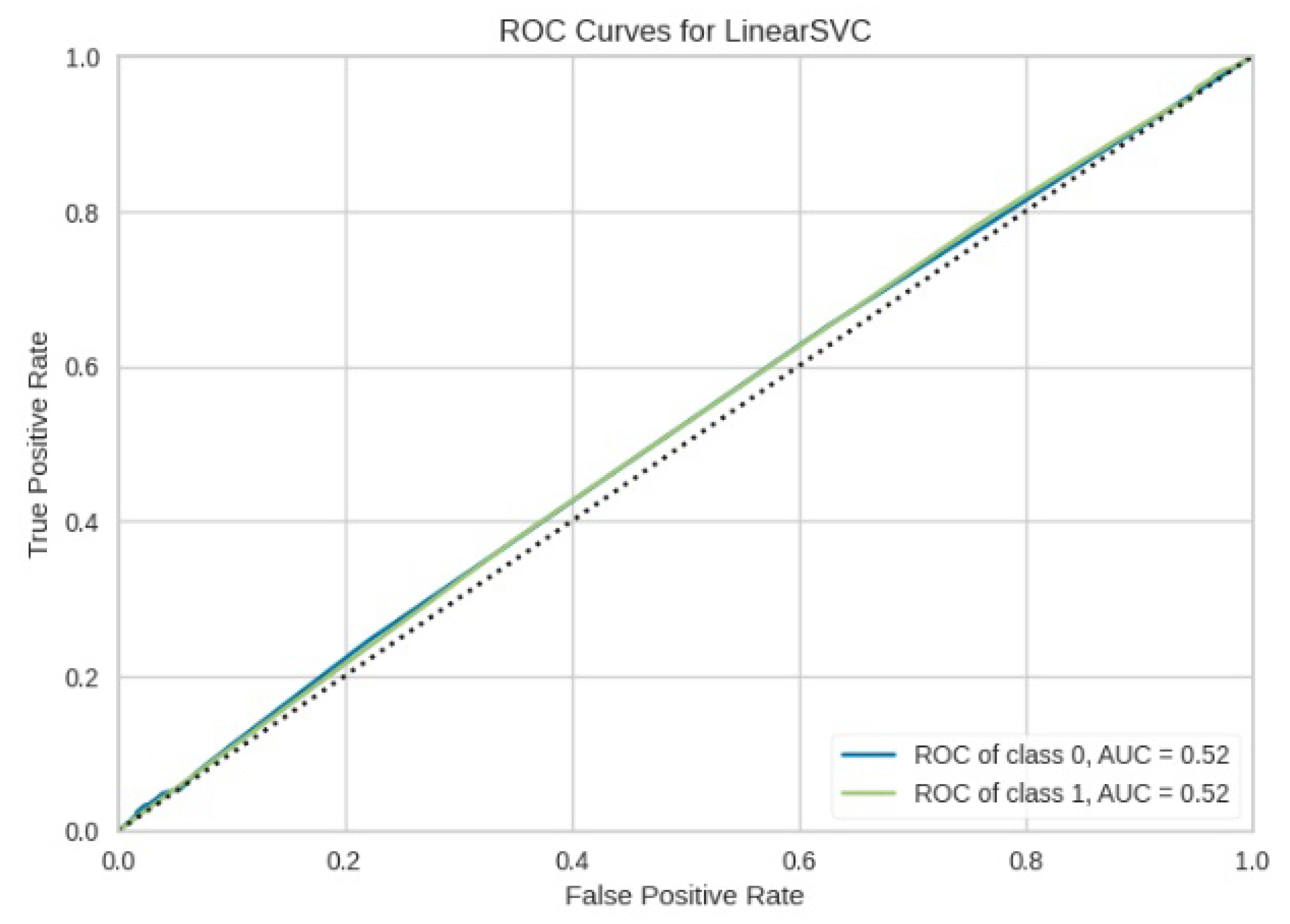
Figure 14.
ROC curve for LinearSVM.
Figure 14.
ROC curve for LinearSVM.
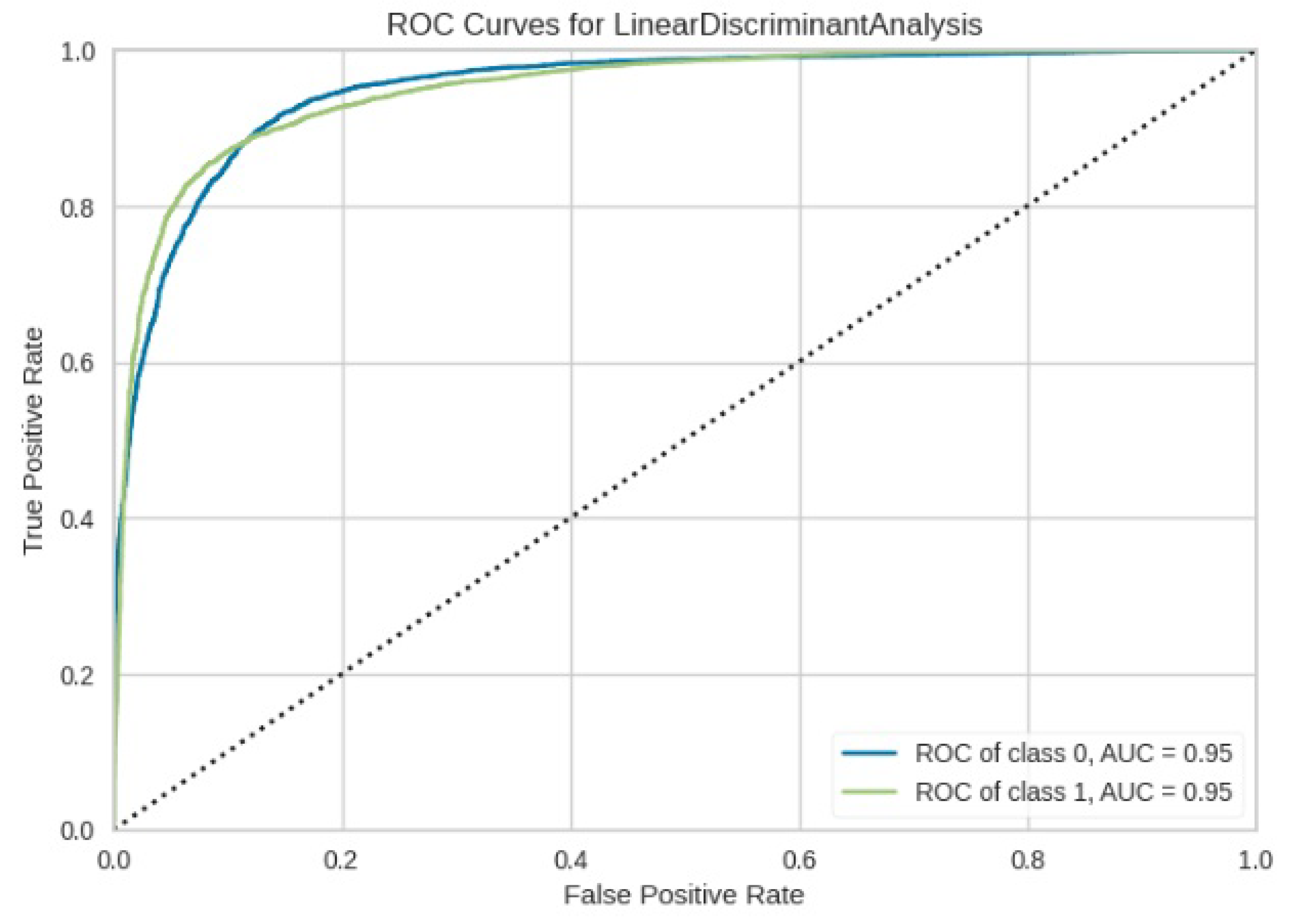
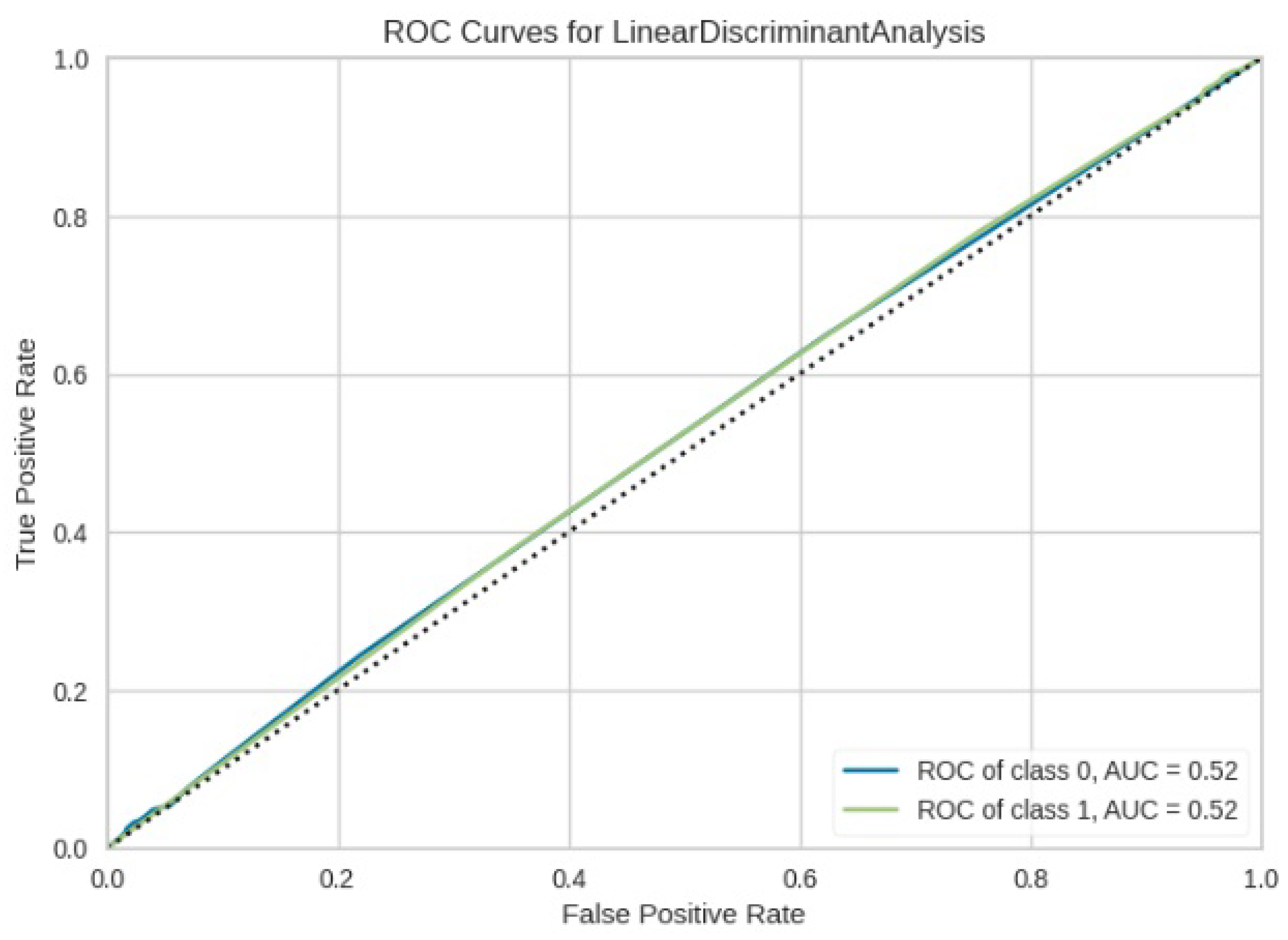
Figure 15.
ROC curve for LDA.
Figure 15.
ROC curve for LDA.
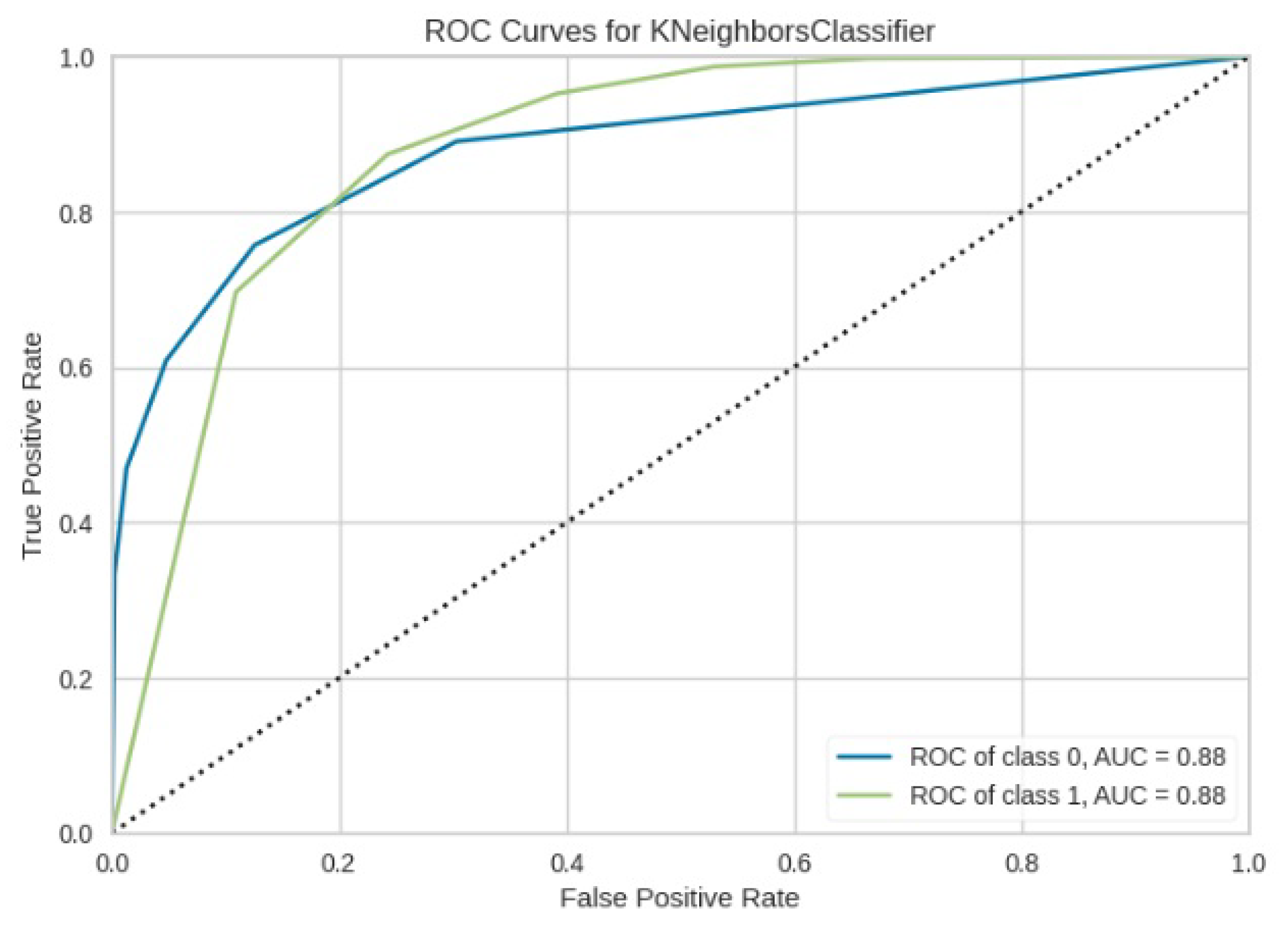
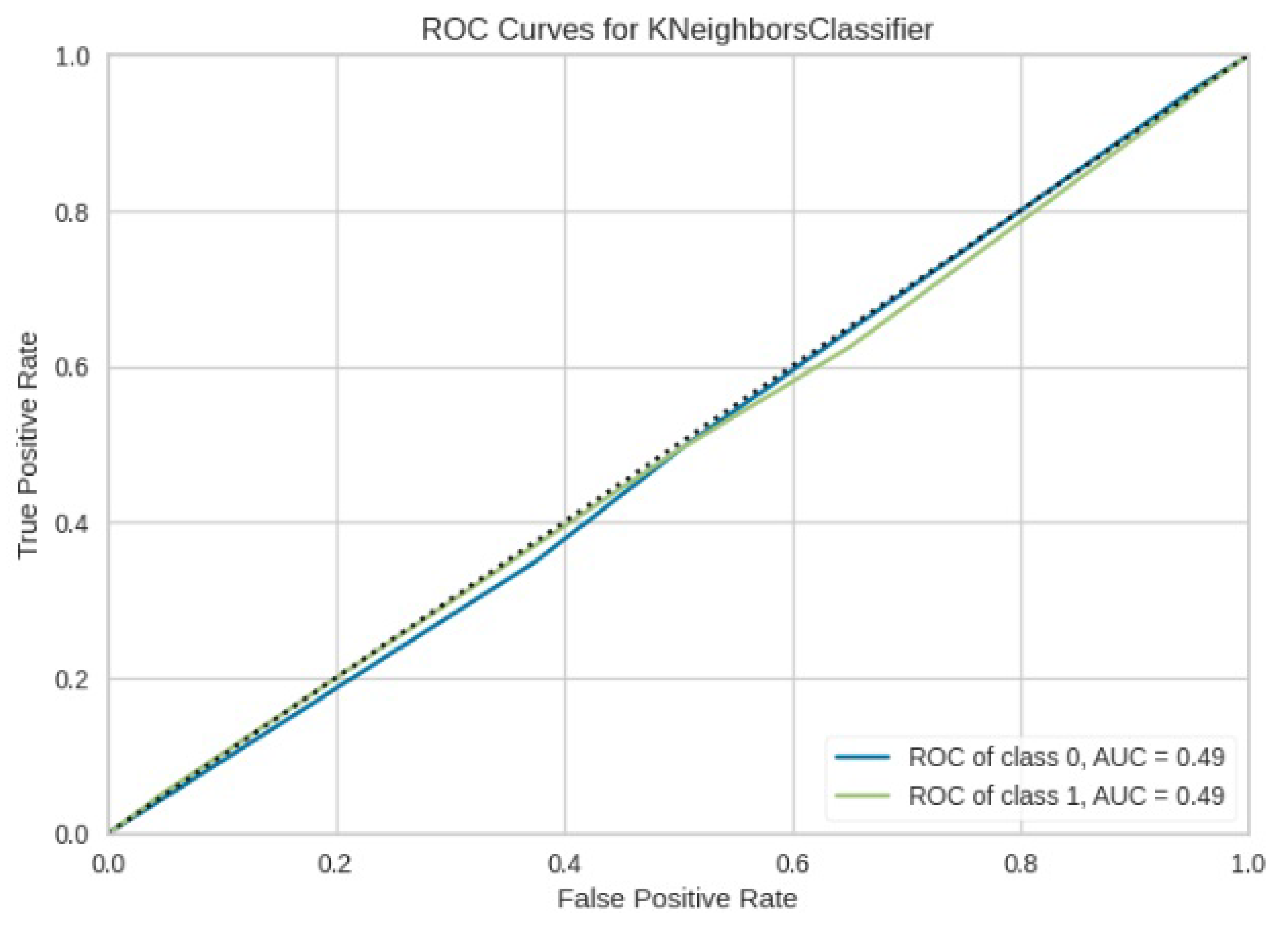
Figure 16.
ROC curve for KNN.
Figure 16.
ROC curve for KNN.
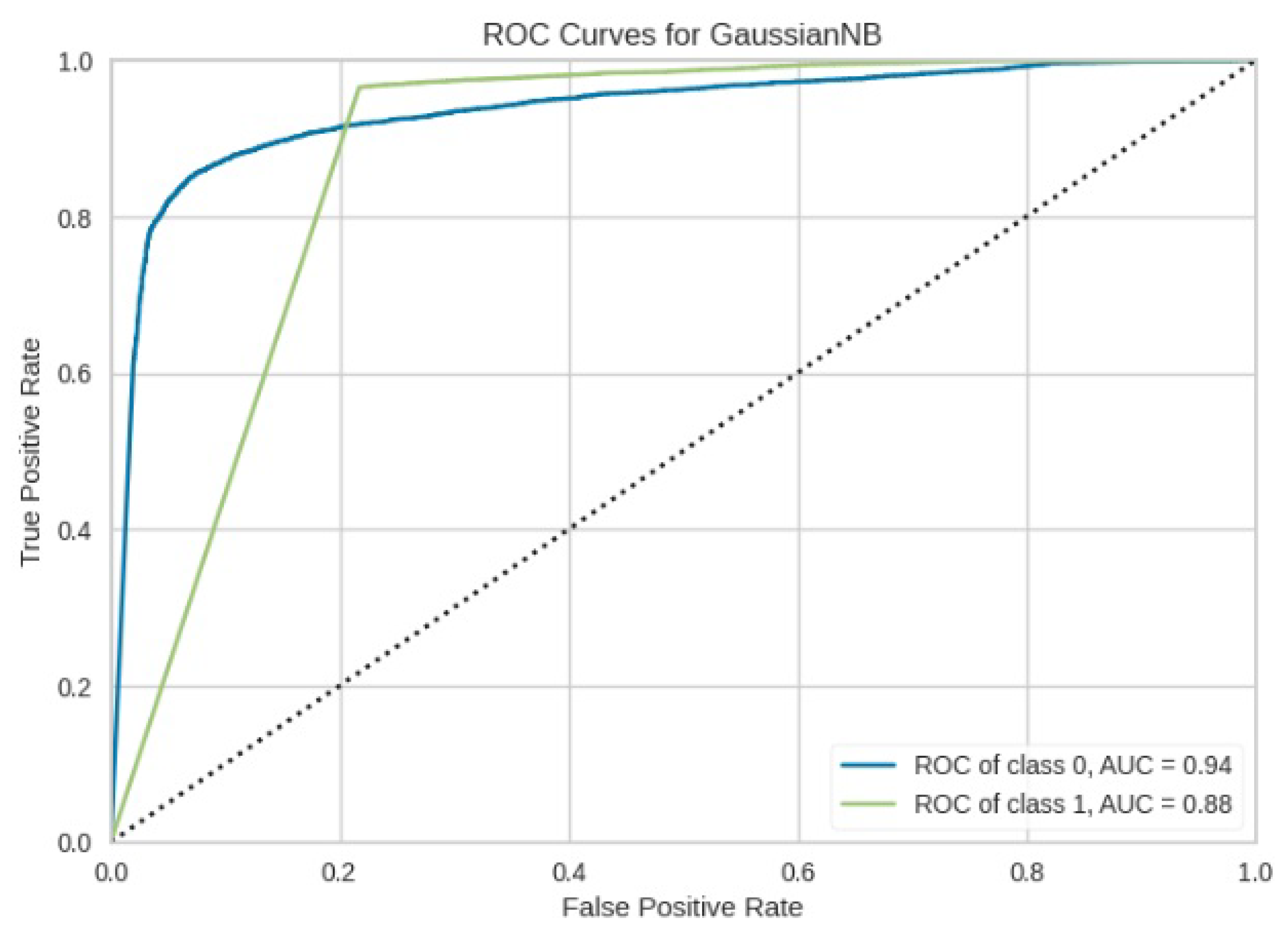
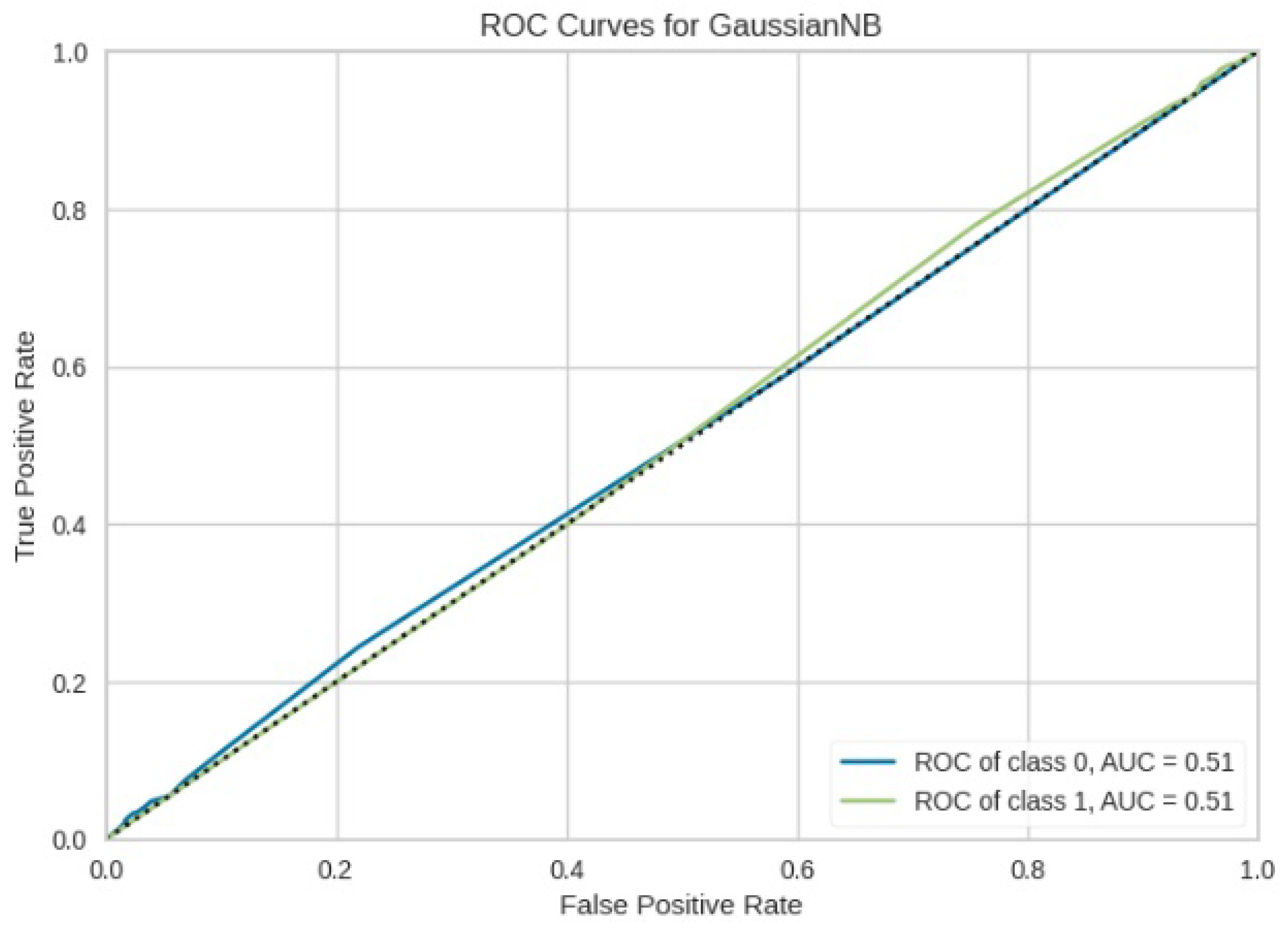
Figure 17.
ROC curve for GNB.
Figure 17.
ROC curve for GNB.
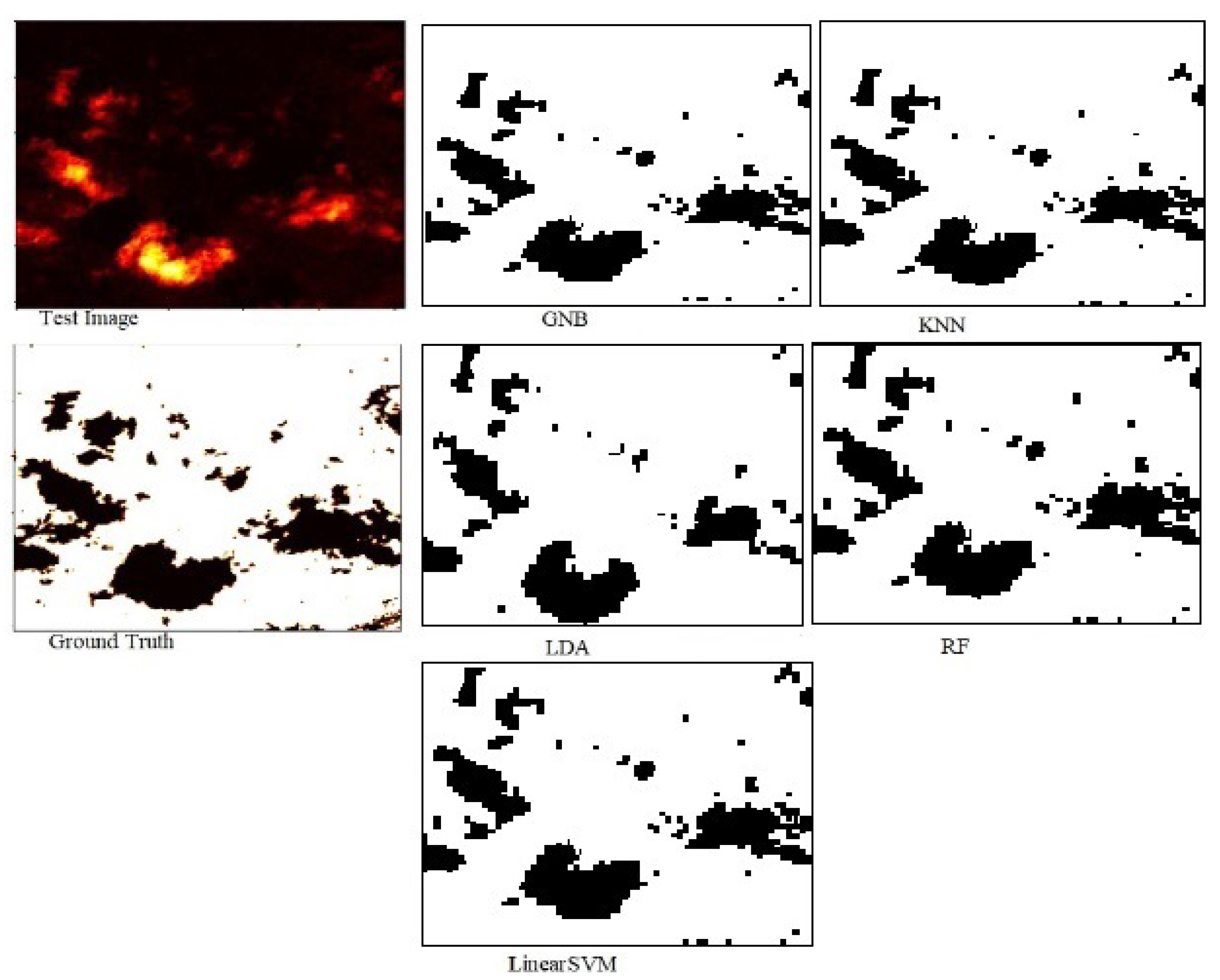
Figure 18.
Segmentation of test image with respect to RF, LinearSVM, LDA, GNB, and kNN without the deep learning.
Figure 18.
Segmentation of test image with respect to RF, LinearSVM, LDA, GNB, and kNN without the deep learning.
Figure 19.
Confusion matrix results for RF without the deep learning.
Figure 19.
Confusion matrix results for RF without the deep learning.
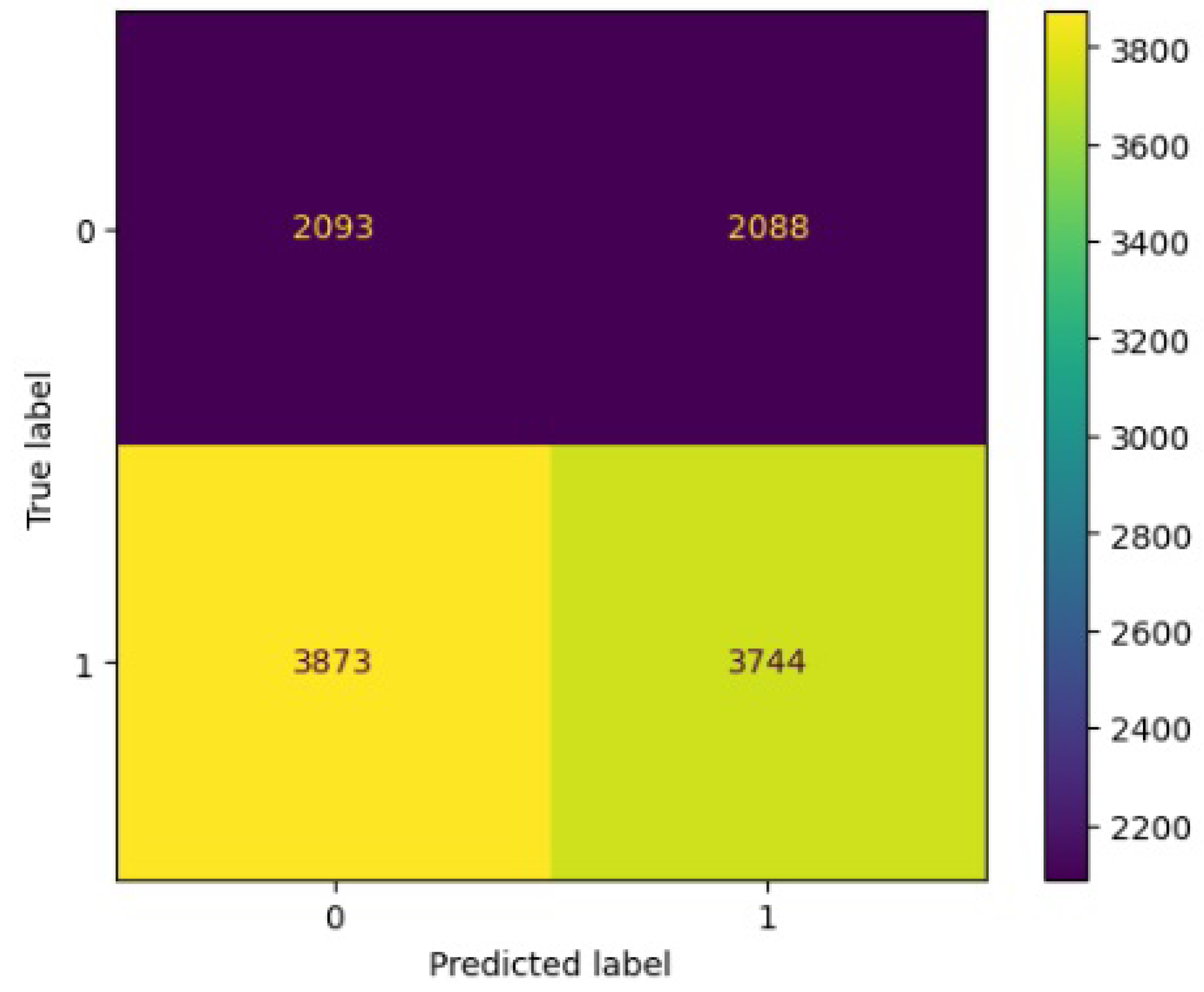
Figure 20.
Confusion matrix results for LinearSVM without the deep learning.
Figure 20.
Confusion matrix results for LinearSVM without the deep learning.
Figure 21.
Confusion matrix results for LDA without the deep learning.
Figure 21.
Confusion matrix results for LDA without the deep learning.
Figure 22.
Confusion matrix results for KNN without the deep learning.
Figure 22.
Confusion matrix results for KNN without the deep learning.
Figure 23.
Confusion matrix results for GNB without the deep learning.
Figure 23.
Confusion matrix results for GNB without the deep learning.
Figure 24.
ROC Curve results for RF without the deep learning.
Figure 24.
ROC Curve results for RF without the deep learning.
Figure 25.
ROC Curve results for LinearSVM without the deep learning.
Figure 25.
ROC Curve results for LinearSVM without the deep learning.
Figure 26.
ROC Curve results for LDA without the deep learning.
Figure 26.
ROC Curve results for LDA without the deep learning.
Figure 27.
ROC Curve results for KNN without the deep learning.
Figure 27.
ROC Curve results for KNN without the deep learning.
Figure 28.
ROC Curve results for GNB without the deep learning.
Figure 28.
ROC Curve results for GNB without the deep learning.
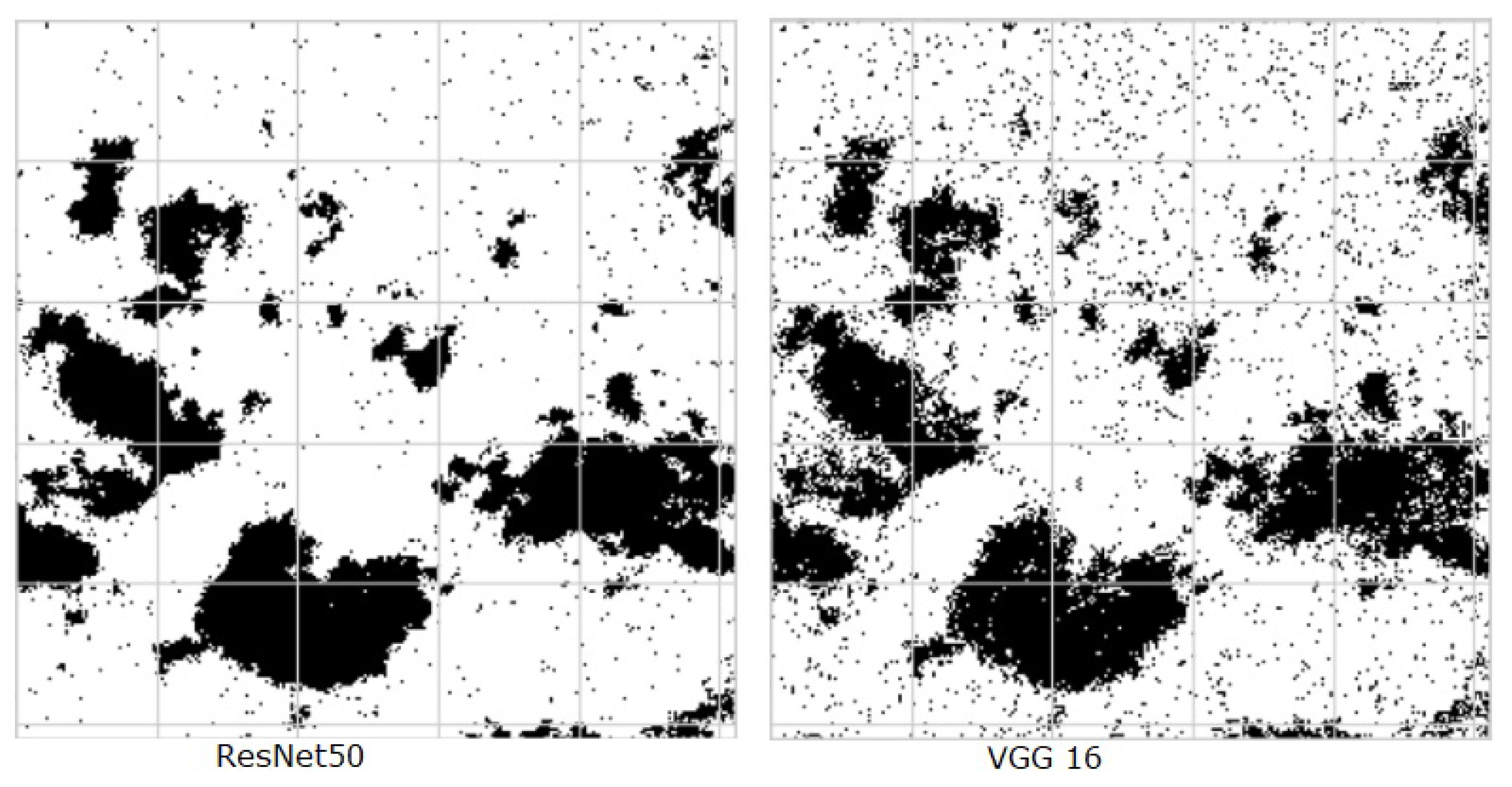
Figure 29.
Predicted segmentation results by ResNet50 and VGG16 models.
Figure 29.
Predicted segmentation results by ResNet50 and VGG16 models.
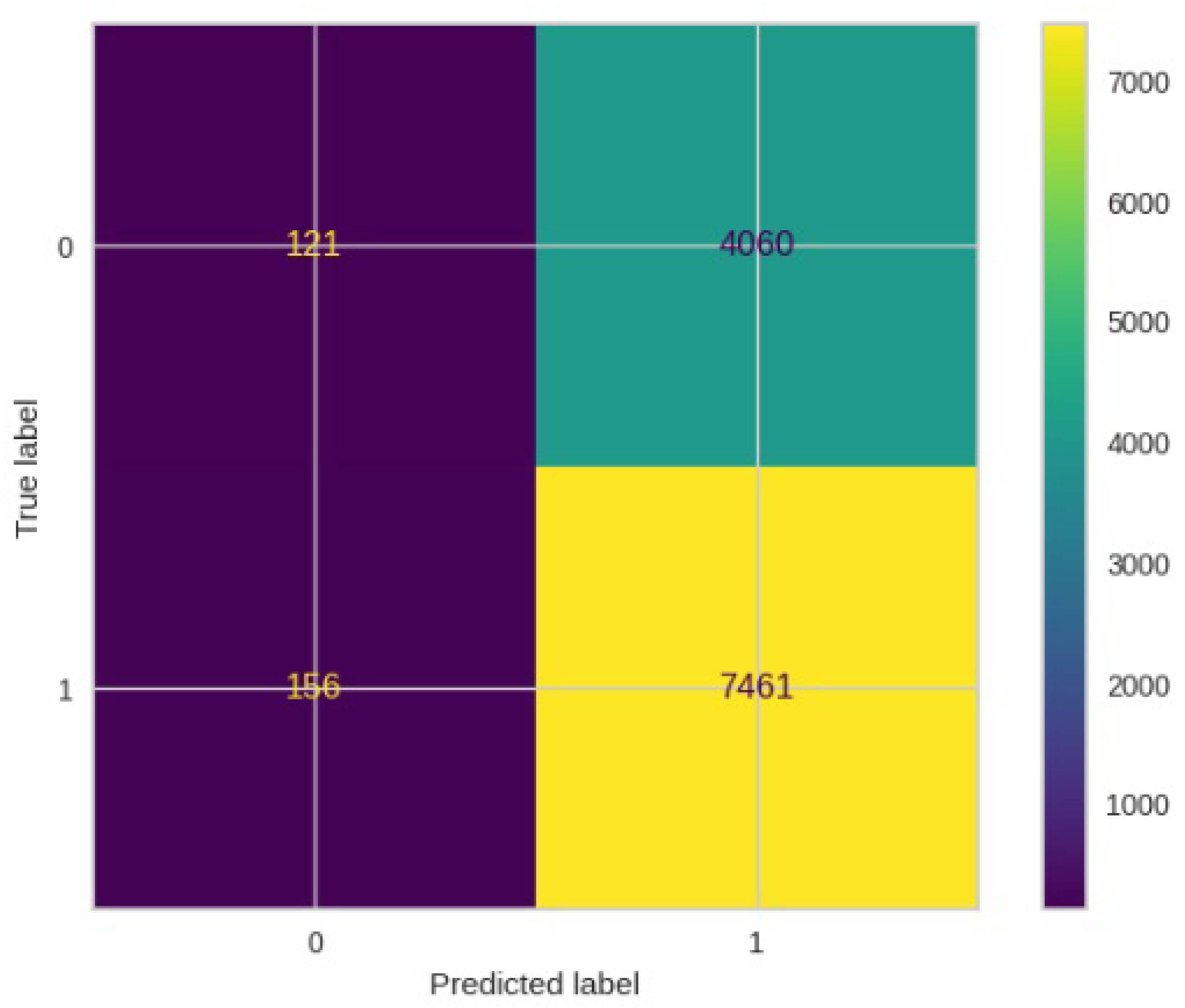
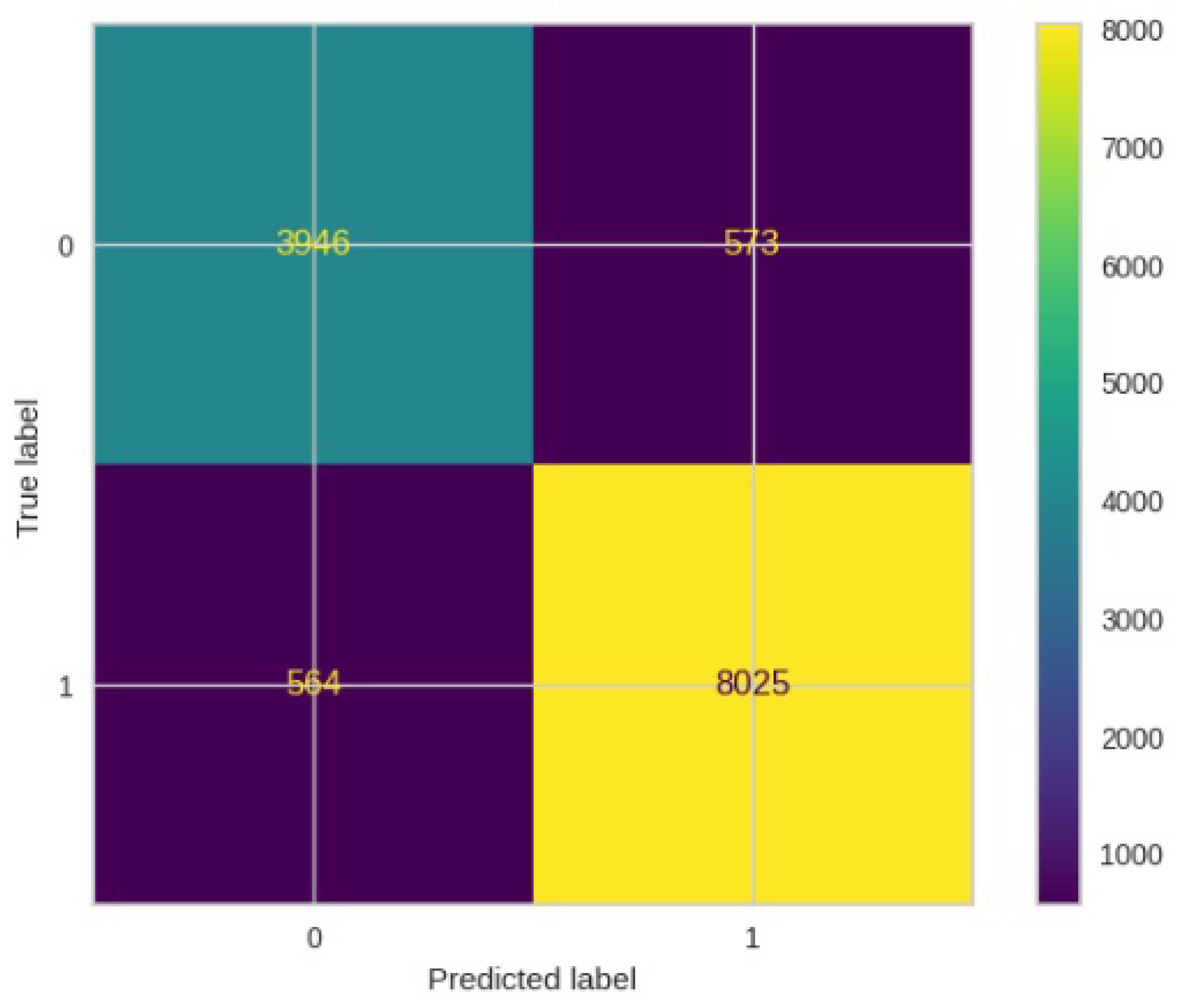
Figure 30.
Confusion matrics for ResNet50.
Figure 30.
Confusion matrics for ResNet50.
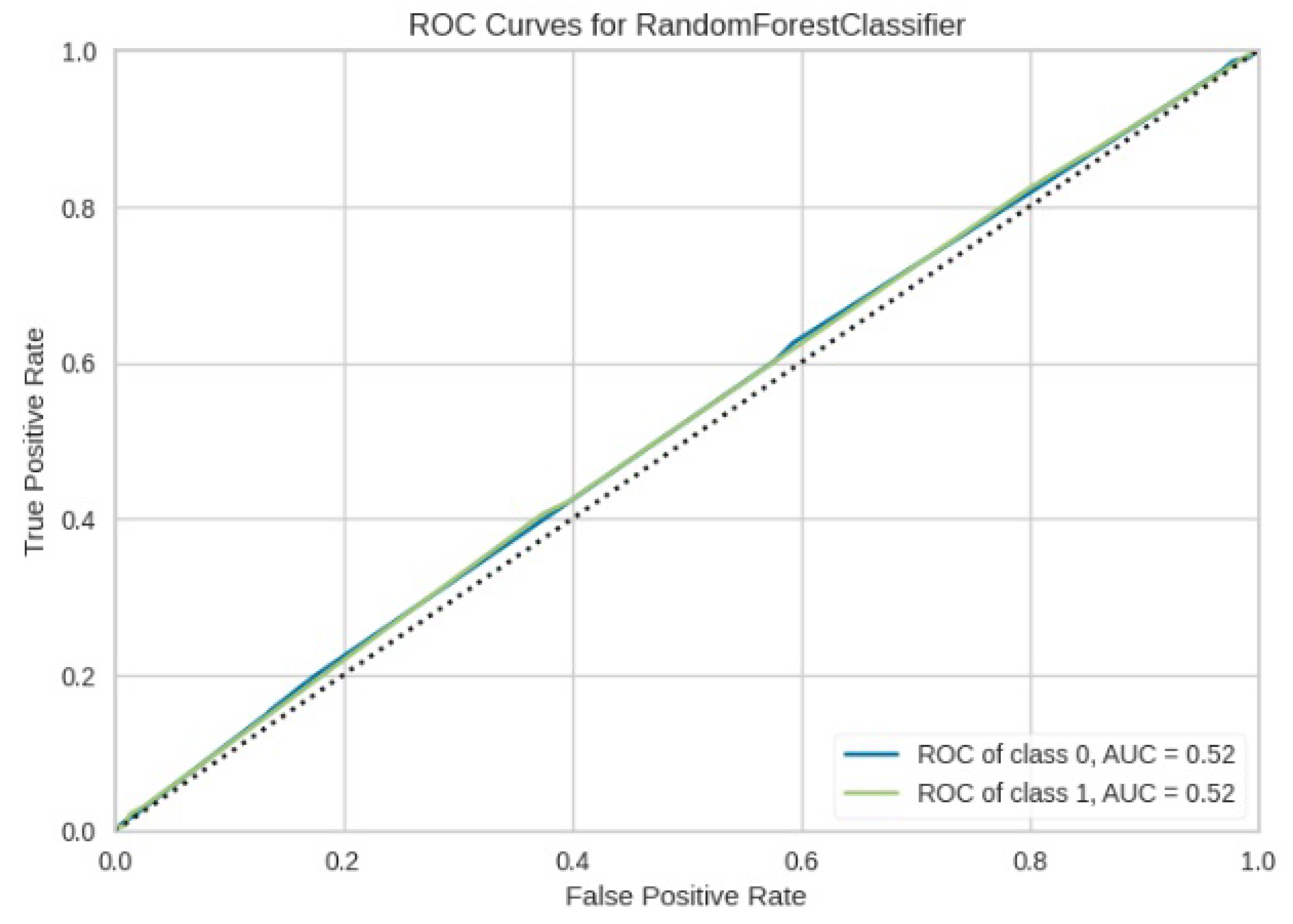
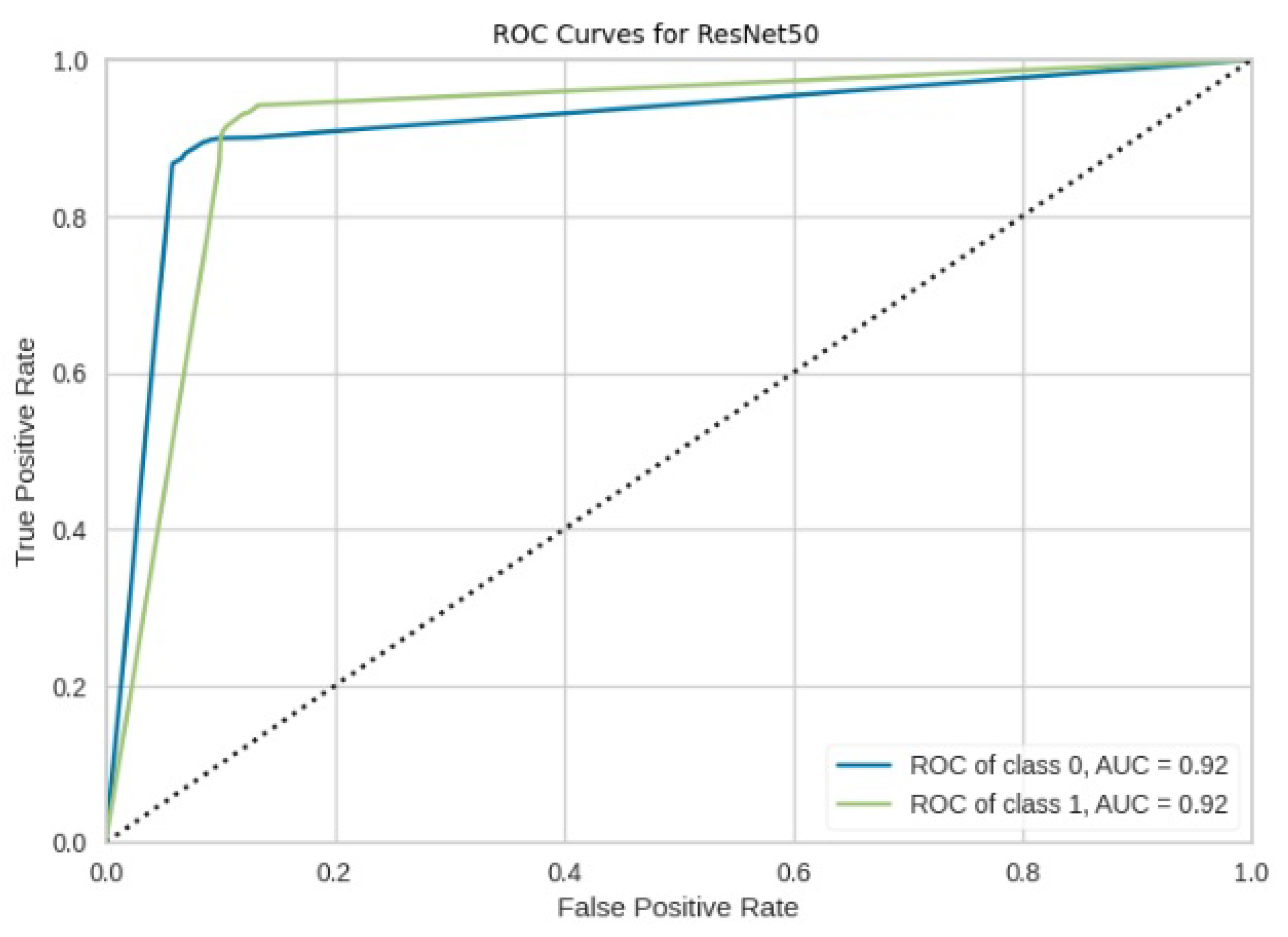
Figure 31.
ROC curves for ResNet50.
Figure 31.
ROC curves for ResNet50.
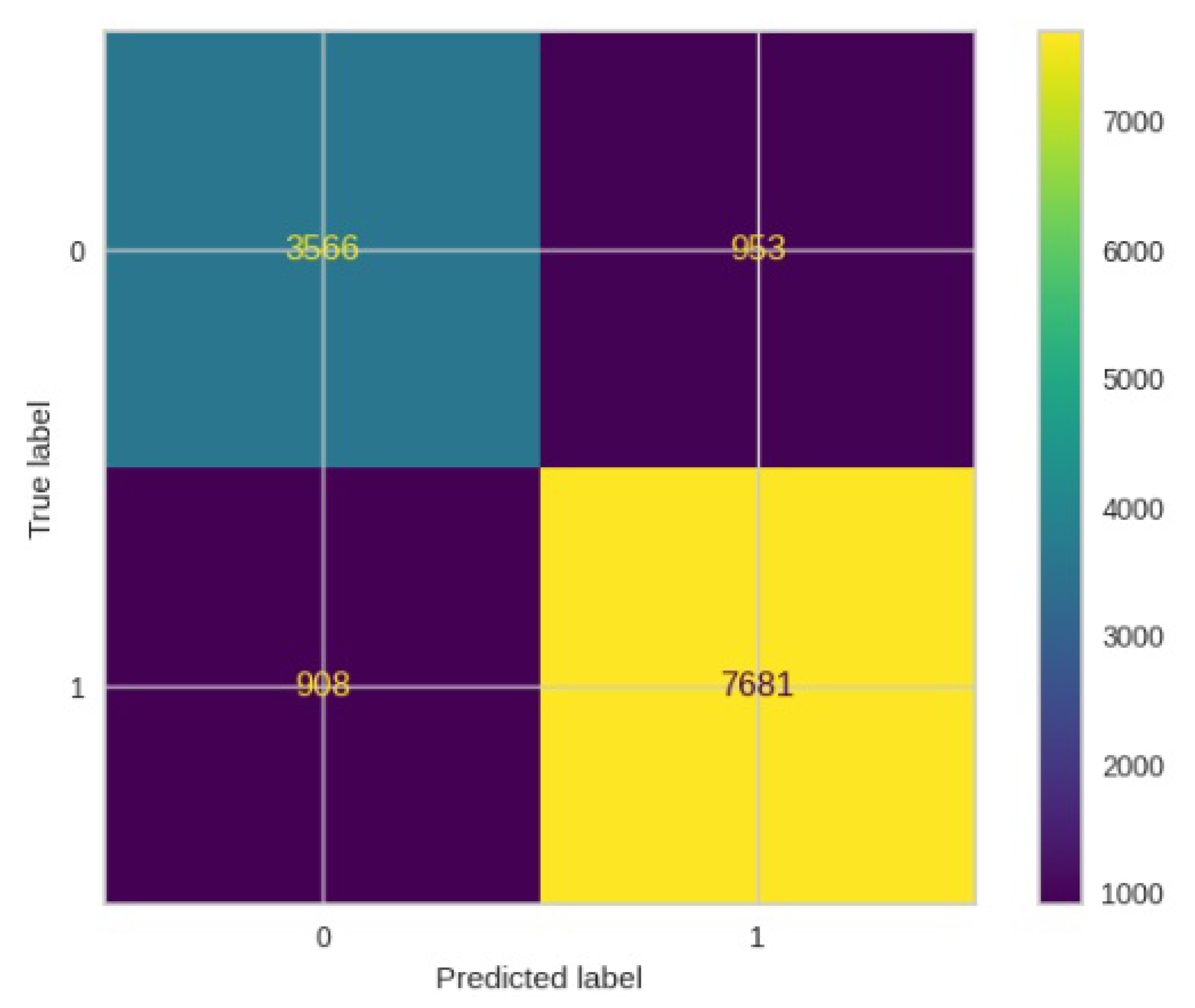
Figure 32.
Confusion matrics for VGG16.
Figure 32.
Confusion matrics for VGG16.
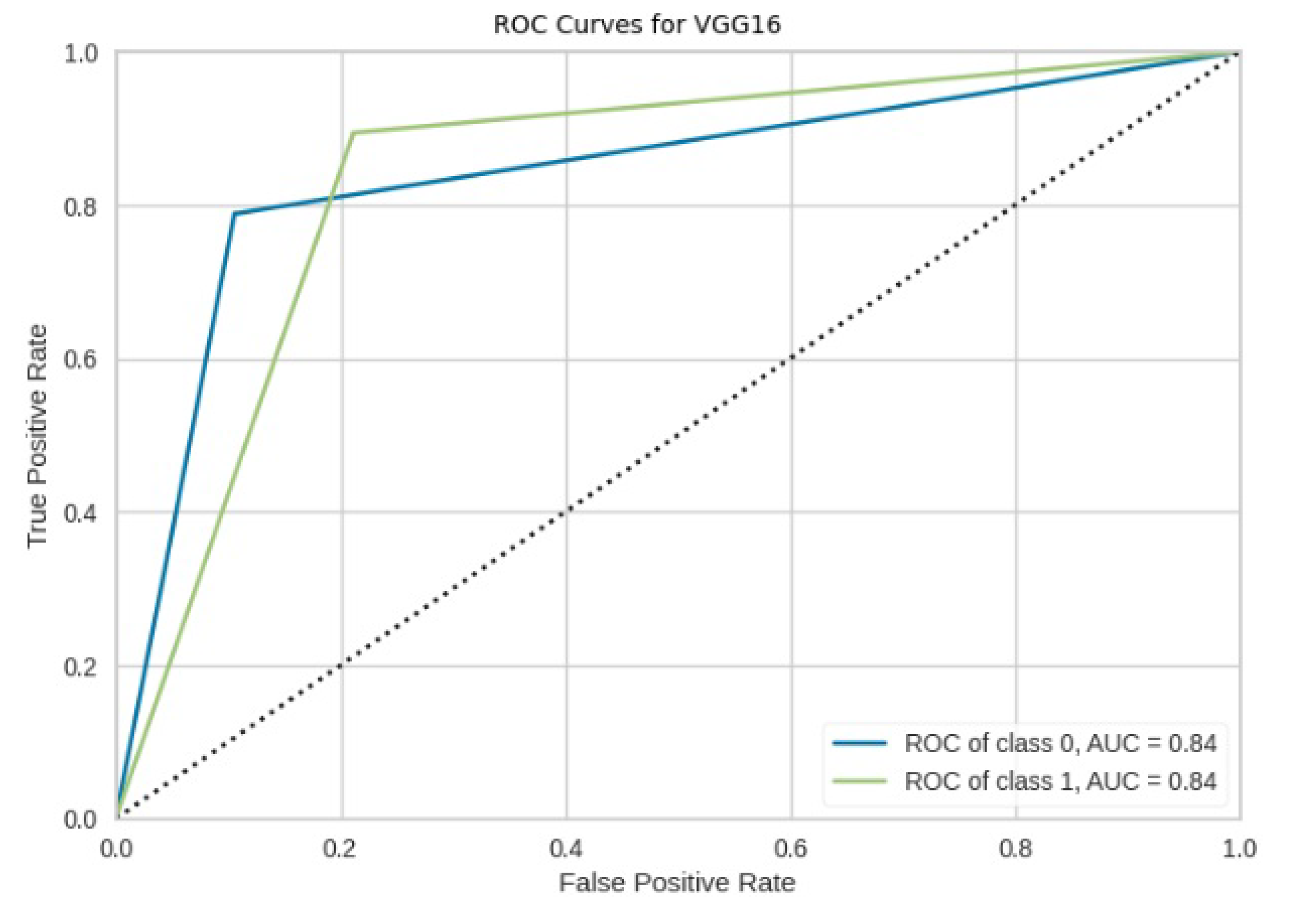
Figure 33.
ROC curves for VGG16.
Figure 33.
ROC curves for VGG16.
Table 1.
Hardware and Software specification for the experiment.
Table 1.
Hardware and Software specification for the experiment.
| Hardware | Software |
|---|
| Processor: core i5 2.2 Gigahertz | Programming language: Python version 3.9 |
| RAM: 32 Gigabytes | Backend: TensorFlow GPU |
| Graphical Processing Unit (GPU) | DeepLearning API: Keras GPU |
| Harddrive: 500 Gigabytes | |
| NVIDIA, 16 Gigabytes RAM | |
Table 2.
Metrics of classifiers in terms of precision, recall, and F1-Score with a hybrid approach of deep learning for detecting forest areas.
Table 2.
Metrics of classifiers in terms of precision, recall, and F1-Score with a hybrid approach of deep learning for detecting forest areas.
| Metric | kNN | RF | LDA | LinearSVM | GNB |
|---|
| Precision | 0.82 | 0.94 | 0.88 | 0.92 | 0.86 |
| Recall | 0.95 | 0.96 | 0.95 | 0.95 | 0.98 |
| F1-Score score | 0.88 | 0.94 | 0.88 | 0.91 | 0.88 |
Table 3.
Metrics of classifiers in terms of precision, recall, and F1-Score with a hybrid approach of deep learning for detecting non-forest areas.
Table 3.
Metrics of classifiers in terms of precision, recall, and F1-Score with a hybrid approach of deep learning for detecting non-forest areas.
| Metric | kNN | RF | LDA | LinearSVM | GNB |
|---|
| Precision | 0.87 | 0.93 | 0.88 | 0.90 | 0.94 |
| Recall | 0.61 | 0.89 | 0.75 | 0.84 | 0.69 |
| F1-Score score | 0.72 | 0.91 | 0.81 | 0.87 | 0.79 |
Table 4.
Metrics of classifiers in terms of accuracy, RMSE, and Jaccard score with a hybrid approach of deep learning in segmenting aerial satellite forest image.
Table 4.
Metrics of classifiers in terms of accuracy, RMSE, and Jaccard score with a hybrid approach of deep learning in segmenting aerial satellite forest image.
| Metric | kNN | RF | LDA | LinearSVM | GNB |
|---|
| RMSE | 0.408 | 0.245 | 0.351 | 0.332 | 0.353 |
| Accuracy | 0.833 | 0.940 | 0.877 | 0.890 | 0.876 |
| Jaccard score | 0.790 | 0.913 | 0.834 | 0.876 | 0.837 |
Table 5.
Metrics of classifiers in terms of precision, recall, and F1-Score without the deep learning hybrid approach in detecting forest areas.
Table 5.
Metrics of classifiers in terms of precision, recall, and F1-Score without the deep learning hybrid approach in detecting forest areas.
| Metric | kNN | RF | LDA | LinearSVM | GNB |
|---|
| Precision | 0.64 | 0.65 | 0.65 | 0.65 | 0.65 |
| Recall | 0.49 | 1.00 | 1.00 | 1.00 | 0.98 |
| F1-Score score | 0.56 | 0.78 | 0.78 | 0.78 | 0.78 |
Table 6.
Metrics of classifiers in terms of precision, recall, and F1-Score without the deep learning hybrid approach in detecting non-forest areas.
Table 6.
Metrics of classifiers in terms of precision, recall, and F1-Score without the deep learning hybrid approach in detecting non-forest areas.
| Metric | kNN | RF | LDA | LinearSVM | GNB |
|---|
| Precision | 0.35 | 0.50 | 0.00 | 0.00 | 0.44 |
| Recall | 0.50 | 0.01 | 0.00 | 0.00 | 0.03 |
| F1-Score score | 0.41 | 0.01 | 0.00 | 0.00 | 0.05 |
Table 7.
Metrics of classifiers in terms of accuracy, RMSE, and Jaccard score without the hybrid approach of deep learning in segmenting aerial satellite forest image.
Table 7.
Metrics of classifiers in terms of accuracy, RMSE, and Jaccard score without the hybrid approach of deep learning in segmenting aerial satellite forest image.
| Metric | kNN | RF | LDA | LinearSVM | GNB |
|---|
| RMSE | 0.711 | 0.595 | 0.595 | 0.595 | 0.598 |
| Accuracy | 0.495 | 0.646 | 0.646 | 0.645 | 0.643 |
| Jaccard score | 0.386 | 0.645 | 0.646 | 0.646 | 0.639 |
Table 8.
Evaluating Deep learning models in terms of precision, recall, and F1-Score in detecting non-forest areas.
Table 8.
Evaluating Deep learning models in terms of precision, recall, and F1-Score in detecting non-forest areas.
| Metric | ResNet50 | VGG16 |
|---|
| Precision | 0.88 | 0.80 |
| Recall | 0.88 | 0.79 |
| F1-Score score | 0.88 | 0.79 |
Table 9.
Evaluating Deep learning models in terms of precision, recall, and F1-Score in detecting forest areas.
Table 9.
Evaluating Deep learning models in terms of precision, recall, and F1-Score in detecting forest areas.
| Metric | ResNet50 | VGG16 |
|---|
| Precision | 0.94 | 0.89 |
| Recall | 0.93 | 0.89 |
| F1-Score score | 0.93 | 0.89 |
Table 10.
Evaluating deep learning models in terms of accuracy, RMSE, and Jaccard score in segmenting aerial satellite forest image.
Table 10.
Evaluating deep learning models in terms of accuracy, RMSE, and Jaccard score in segmenting aerial satellite forest image.
| Metric | ResNET50 | VGG16 |
|---|
| RMSE | 0.29 | 0.38 |
| Accuracy | 0.91 | 0.85 |
| Jaccard score | 0.88 | 0.80 |
Table 11.
Performance comparison of classifiers with hybrid deep learning approach, classifiers alone, and deep learning models in terms of RMSE, Accuracy, and Jaccard score index.
Table 11.
Performance comparison of classifiers with hybrid deep learning approach, classifiers alone, and deep learning models in terms of RMSE, Accuracy, and Jaccard score index.
| Classifiers with Hybrid Deep Learning Approach | Classifiers Alone | Deep Learning Models |
|---|
| Metric | RF | LinearSVM | LDA | GNB | kNN | RF | LinearSVM | LDA | GNB | kNN | ResNet50 | VGG16 |
| Accuracy | 0.940 | 0.890 | 0.877 | 0.876 | 0.833 | 0.646 | 0.646 | 0.646 | 0.643 | 0.49 | 0.913 | 0.852 |
| Jaccard Score | 0.913 | 0.876 | 0.834 | 0.837 | 0.790 | 0.645 | 0.646 | 0.646 | 0.639 | 0.386 | 0.876 | 0.804 |
| RMSE | 0.245 | 0.332 | 0.351 | 0.535 | 0.408 | 0.595 | 0.594 | 0.595 | 0.600 | 0.711 | 0.295 | 0.377 |
Table 12.
Accuracy and IOU obtained from other studies.
Table 12.
Accuracy and IOU obtained from other studies.
| Method | Accuracy | IOU |
|---|
| Unet with spatial pyramid spooling [42] | 86.71 | 75.59 |
| Hnet with Inception as backbone [43] | 68 | 83 |
| Deep Convolutional Neural Networks (DCNN) [48] | 91 | - |
| Unet for forest segmentation [10] | 91 | - |
| SENet and MobileNet embedded in DeepLabV3+ (SMED) [44] | 82.95 | 60 |
| improved tuna swarm optimization (ITSO) [46] | - | 59 |
| Unet semantic segmentation [47] | 95 | - |
| Random Forest | 94 | 91 |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}