
Zero-Shot Sketch-Based Image Retrieval Using StyleGen and Stacked Siamese Neural Networks


Abstract
1. Introduction
- Law enforcement and forensic art [12]: In law enforcement, SBIR can help match sketches of suspects or missing persons with photographic databases.
- E-commerce and online retail [13]: SBIR can be used in online shopping platforms to allow users to sketch an item they wish to purchase. This is particularly useful when shoppers are unsure of the technical name of the item but can draw it.
- Digital art and graphic design [14]: Artists and designers can use SBIR to find reference images based on a rough sketch. This is useful in creative processes where visualizing an idea is easier through drawing than describing it in words.
- Education and research [15]: In educational settings, SBIR can assist students and researchers in finding scientific diagrams or historical images based on hand-drawn sketches. This can be particularly useful in fields like archaeology, history, or biology.
- Medical imaging [11]: SBIR can be used in medical diagnostics by allowing doctors to sketch symptoms or conditions and retrieve similar medical images or case studies. This could be particularly useful in dermatology or radiology.
- Cultural heritage and museums [16]: Museums and cultural institutions can use SBIR to help visitors connect with artworks or artifacts. Visitors could sketch an artifact or art piece they are interested in and receive information about similar items in the museum’s collection.
- Architecture and interior design [17]: Architects and interior designers can use SBIR to find building designs, interior decor ideas, or furniture based on sketches. This can streamline the process of translating conceptual sketches into concrete plans or finding matching furniture and decorations.
- Propose a novel approach for the ZS-SBIR problem through the segregation of domain gap reduction and image-retrieval stages.
- Propose the mathematical formulation of the StyleGen approach, illustrating various loss functions involved in training an effective model for domain gap reduction between sketches and images.
- Presents the neural network architectures for the StyleGen model, which comprises generator and discriminator blocks.
- Provides an adaption of the latest SSiNN [26] architecture for image retrieval to maximize the overall system’s retrieval performance.
- Presents the datasets used in the experimental study and the performance metrics used for the evaluation and comparison with the existing approaches.
- Presents a comprehensive presentation of experimental results, illustrating the effectiveness of our approach in ZS-SBIR scenarios.
2. Related Work
2.1. Sketch-Based Image Retrieval
2.2. Zero-Shot Learning
2.3. Zero-Shot Sketch-Based Image Retrieval
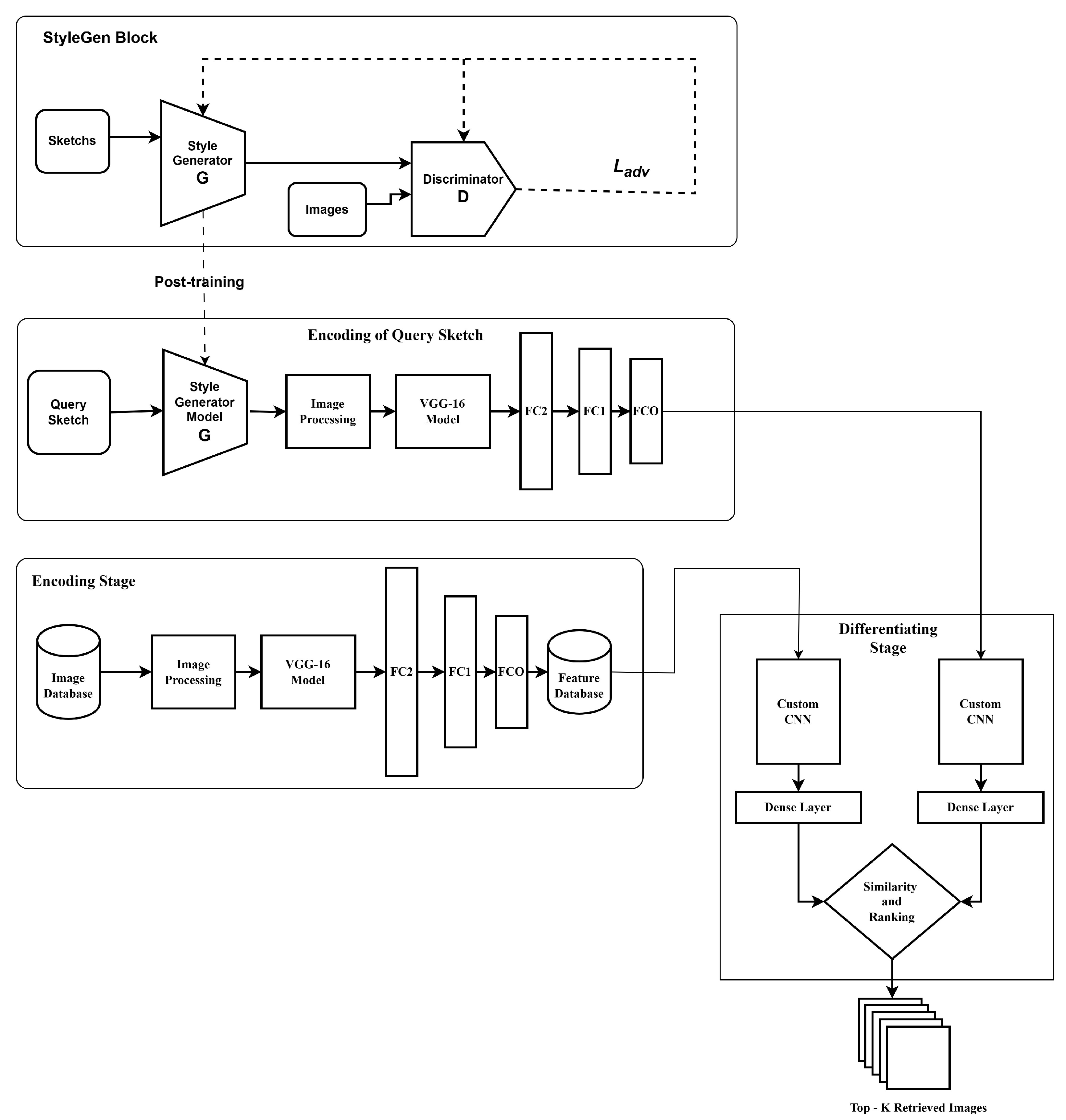
3. Proposed StyleGen for ZS-SBIR
3.1. Problem Formulation
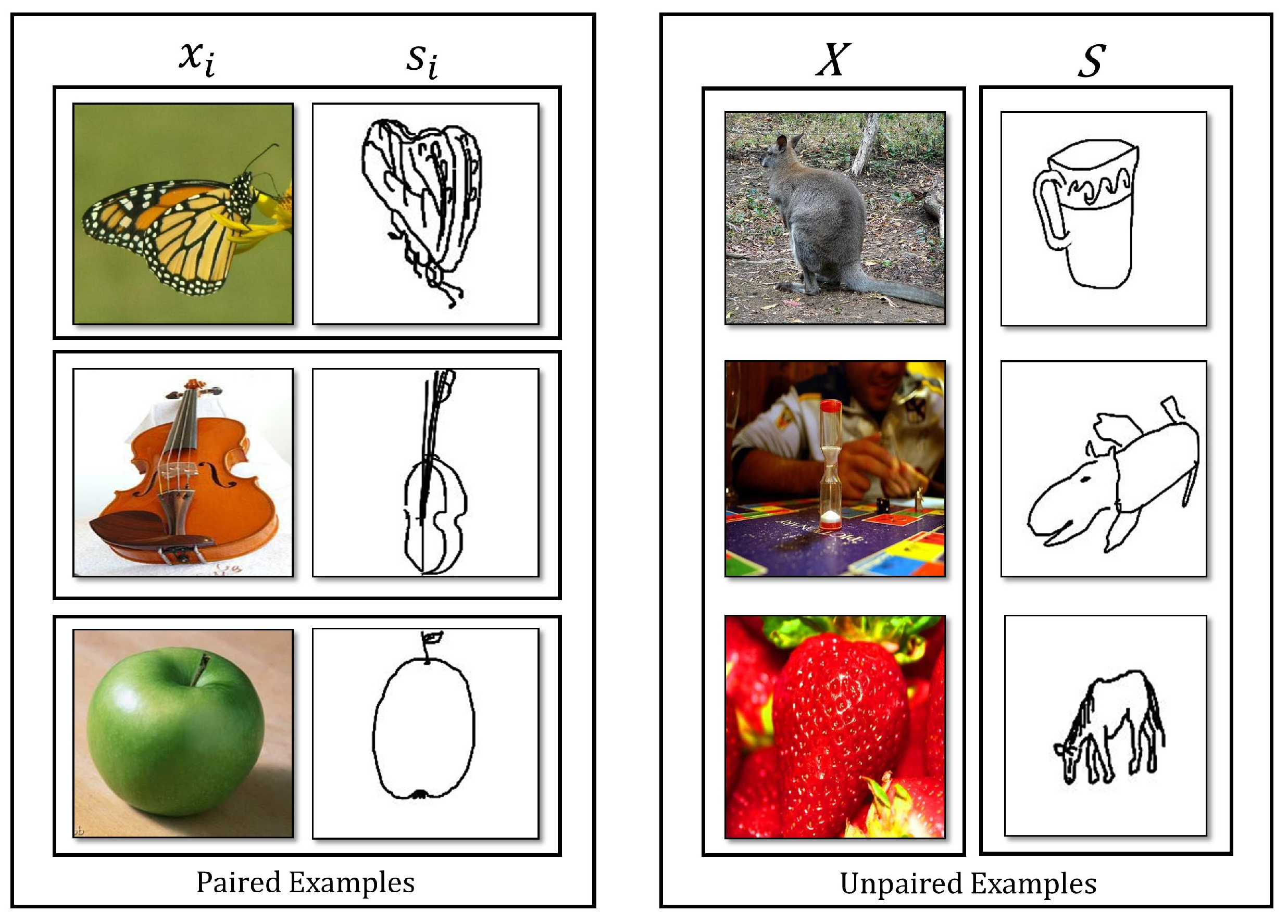
3.2. No Pair Assumption
3.3. Neural StyleGen for Domain Gap Reduction
3.4. StyleGen Approach
3.5. Adversarial Loss
3.6. Cycle Consistency Loss
3.7. Identity Loss
- denotes the sketch-to-image generator function.
- x indicates an image sample from the image dataset.
- denotes the expected value, evaluated over image data distribution.
- denotes the image-to-sketch generator function.
- s indicates a sketch sample from the sketch dataset.
- denotes the expected value, evaluated over sketch data distribution.
3.8. Overall Objective Function
3.9. Network Architecture of Generator
3.10. Network Architecture of Discriminator Neural Network
3.11. Training the Networks of StyleGen Phase
3.12. Stacked Siamese Neural Network for Image Retrieval
- Input the StyleGen model with the query sketch to obtain the image domain equivalent representation.
- To extract the latent space representations of the database Images, run them through the first stage of the SSiNN.
- Run the StyleGen output from step 1 through the first stage of the SSiNN to acquire the sketch’s latent space representation.
- Now, pass the sketch representation through one input of the Siamese neural network and the latent space representations from the database through the other input of the Siamese neural network.
- Rank the outputs and provide the top-K images corresponding to the representations as the SBIR system’s output.
Simplified Decision-Making Process
- The SSiNN model, employed for the retrieval operation, is a two-input model. Henceforth, this model shall be designated as the retrieval model.
- The first input channel of the retrieval model is ingested with images from the database, from which relevant images are to be extracted.
- The second input channel of the retrieval model is allocated for processing the image representation derived from the sketch-based query.
- The transformation of the sketch into its image representation is facilitated by the StyleGen model.
- Subsequently, the retrieval model computes similarity metrics across the dataset images, ranking them based on these scores. Images attaining the highest similarity metrics are identified as the most relevant matches to the input sketch query.
4. Experimental Results
4.1. Datasets
4.2. Evaluation Metric
- Average Precision (AP): The average precision for a query is the mean of the precision scores obtained for each relevant item in the retrieved list, indicating the precision of the system at the rank of that item.
- signifies precision at rank k.
- N is the cardinality of the retrieved list.
- mAP@all (Mean average precision at all ranks): This metric computes the mean of the average precision (AP) scores across all queries, with each AP score calculated using the entire ranked list of retrieved items. Its formula is given by the following:
- is the cardinality of the query list.
- is the average precision for the qth query calculated over the entire retrieved list.
- Average Precision at K (AP@K): This is the precision calculated at the rank in the retrieved list, specifically considering only the top-K items. It is a useful measure in scenarios where the focus is on the relevance of the top part of the ranked list. The formula is as follows:
- K is the predefined number of top items to consider in the list.
- represents the precision at rank k.
- mAP@K (Mean average precision at top-K ranks): This metric calculates the mean of the AP@K scores across all queries, providing a single measure that summarizes the effectiveness of a retrieval system at ranking relevant items within the top-K positions of the ranked list. It is defined as follows:
- is the cardinality of the query list.
- denotes the average precision at K for the query.
4.3. Performance Comparison
- Robustness of the approach: The datasets employed contain images and sketches that are notably diverse within each category. This diversity encompasses a wide range of drawing styles, levels of detail, and artistic interpretations, providing a robust foundation for evaluating the effectiveness of our method across varied real-world scenarios.
- Handling of zero-shot learning: Based on the experimental findings, it is evident that our method outperforms current techniques in terms of performance. This enhanced performance can be attributed to two primary factors. Firstly, the implementation of the no-pair assumption within the StyleGen component significantly contributes to the model’s ability to generalize effectively, enabling the accurate generation of StyleGen images from previously unseen sketches. Secondly, the application of the stacked Siamese neural network (SSiNN) has been finely tuned to excel with zero-shot samples, further bolstering our method’s efficacy.
- Estimation of computation time: The proposed methodology is implemented using the PyTorch framework [47] on a Windows PC with Intel Core I7 and Nvidia Geforce RTX. The models are built and optimized for 10 epochs, with Adam as the optimizer and a learning rate of for the generator and for the discriminator. The number of parameters in the generator network is 32,451, and that of the discriminator is 44,537. The time taken for running one epoch is an average of 8 h. So, the time taken for the one overall training cycle with 10 epochs is 80 h. In model training, it is often necessary to run through all training epochs multiple times to achieve optimal performance and robustness. This repetitive process allows the model to continually refine its parameters, learn from the dataset’s variability, and explore different solutions, improving generalization and stability. Considering this, the time taken for the overall model building will be in multiples of 80 h. Our approach to addressing the zero-shot sketch-based image retrieval (ZS-SBIR) problem by dividing it into two distinct stages—each focusing on a specific aspect of the challenge—is a strategic method that contributes to its superior performance. The following is a deeper analysis of why this method outperforms others, along with its limitations and potential areas for improvement:
- Strengths and reasons for superior performance: Targeted problem-solving approach—in this approach, the ZS-SBIR problem is divided into two stages, with each focusing on a specific challenge—domain gap and knowledge gap. This allows for specialized strategies tailored to each aspect, potentially leading to more effective solutions.
- Stage 1—Domain gap solution with StyleGen framework: The first stage employs the StyleGen framework to specifically address the domain gap problem. By transforming sketches into a style more akin to the target images, we enhance feature compatibility, improving retrieval accuracy.
- Stage 2—Knowledge-gap solution with SSiNN: In the second stage, we utilize the stacked Siamese neural network (SSiNN) to tackle the knowledge gap problem.
- Separate optimization: By separately optimizing each stage, our approach achieves a higher degree of fine-tuning for each specific challenge, contributing to overall superior performance.
- Limitations and Areas for Improvement:
- Complexity and resource intensity: The proposed two-stage process, while effective, is complex and resource-intensive compared to single-stage methods, which could be a limitation in terms of computational efficiency and practicality.
- Integration and cohesion between stages: Ensuring seamless integration and effective cohesion between the two stages is crucial. Any misalignment could potentially reduce the overall effectiveness.
- Cross-dataset generalization: Testing and refining our method on a broader range of datasets is a key focus, aiming to improve its generalizability and applicability to different real-world scenarios.
- Interpretability: While the approach demonstrates impressive performance in matching sketches to images, understanding the decision-making process of these models remains a challenge. This lack of transparency can be problematic, especially in applications where understanding the reasoning behind each match is crucial.
4.4. Ablation Studies
4.4.1. Hyperparameter Selection
4.4.2. Effectiveness of Identity Loss Function
4.4.3. Retrieval Block Selection
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Eitz, M.; Hildebrand, K.; Boubekeur, T.; Alexa, M. Sketch-Based Image Retrieval: Benchmark and Bag-of-Features Descriptors. IEEE Trans. Vis. Comput. Graph. 2010, 17, 1624–1636. [Google Scholar] [CrossRef] [PubMed]
- Hu, R.; Collomosse, J. A Performance Evaluation of Gradient Field HOG Descriptor for Sketch Based Image Retrieval. Comput. Vis. Image Underst. 2013, 117, 790–806. [Google Scholar] [CrossRef]
- Liu, L.; Shen, F.; Shen, Y.; Liu, X.; Shao, L. Deep Sketch Hashing: Fast Free-Hand Sketch-Based Image Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2862–2871. [Google Scholar]
- Song, J.; Yu, Q.; Song, Y.-Z.; Xiang, T.; Hospedales, T.M. Deep Spatial-Semantic Attention for Fine-Grained Sketch-Based Image Retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5551–5560. [Google Scholar]
- Nyemeesha, V.; Ismail, B.M. Implementation of Noise and Hair Removals from Dermoscopy Images Using Hybrid Gaussian Filter. Network Model. Anal. Health Inform. Bioinform. 2021, 10, 1–10. [Google Scholar]
- Ismail, B.M.; Reddy, T.B.; Reddy, B.E. Spiral Architecture Based Hybrid Fractal Image Compression. In Proceedings of the 2016 International Conference on Electrical, Electronics, Communication, Computer and Optimization Techniques (ICEECCOT), Mysuru, India, 9–10 December 2016; pp. 21–26. [Google Scholar]
- Belongie, S.; Malik, J.; Puzicha, J. Shape Matching and Object Recognition Using Shape Contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef]
- Zhu, W.; Peng, B. Manifold-Based Aggregation Clustering for Unsupervised Vehicle Re-identification. Knowl.-Based Syst. 2022, 235, 107624. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep Learning for Person Re-identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Sain, A.; Bhunia, A.K.; Chowdhury, P.N.; Koley, S.; Xiang, T.; Song, Y.-Z. CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2765–2775. [Google Scholar]
- Kobayashi, K.; Gu, L.; Hataya, R.; Mizuno, T.; Miyake, M.; Watanabe, H.; Takahashi, M.; Takamizawa, Y.; Yoshida, Y.; Nakamura, S.; et al. Sketch-Based Semantic Retrieval of Medical Images. Med. Image Anal. 2024, 92, 103060. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.K.; Klare, B.; Park, U. Face Matching and Retrieval in Forensics Applications. IEEE Multimed. 2012, 19, 20. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, C.; Zhang, L.; Zhang, L. Edgel Index for Large-Scale Sketch-Based Image Search. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 761–768. [Google Scholar] [CrossRef]
- Sangkloy, P.; Burnell, N.; Ham, C.; Hays, J. The Sketchy Database: Learning to Retrieve Badly Drawn Bunnies. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Hu, R.; Barnard, M.; Collomosse, J. Gradient Field Descriptor for Sketch Based Retrieval and Localization. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 1025–1028. [Google Scholar]
- Collomosse, J.; Bui, T.; Wilber, M.J.; Fang, C.; Jin, H. Sketching with Style: Visual Search with Sketches and Aesthetic Context. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2660–2668. [Google Scholar]
- Li, B.; Yuan, J.; Ye, Y.; Lu, Y.; Zhang, C.; Tian, Q. 3D Sketching for 3D Object Retrieval. Multimed. Tools Appl. 2021, 80, 9569–9595. [Google Scholar] [CrossRef]
- Madhavi, D.; Mohammed, K.M.C.; Jyothi, N.; Patnaik, M.R. A Hybrid Content Based Image Retrieval System Using Log-Gabor Filter Banks. Int. J. Electr. Comput. Eng. (IJECE) 2019, 9, 237–244. [Google Scholar] [CrossRef]
- Madhavi, D.; Patnaik, M.R. Genetic Algorithm-Based Optimized Gabor Filters for Content-Based Image Retrieval. In Intelligent Communication, Control and Devices: Proceedings of ICICCD 2017; Springer: Singapore, 2018; pp. 157–164. [Google Scholar]
- Bhunia, A.K.; Yang, Y.; Hospedales, T.M.; Xiang, T.; Song, Y.-Z. Sketch Less for More: On-the-Fly Fine-Grained Sketch-Based Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9779–9788. [Google Scholar]
- Bhunia, A.K.; Koley, S.; Khilji, A.F.U.R.; Sain, A.; Chowdhury, P.N.; Xiang, T.; Song, Y.-Z. Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 999–1008. [Google Scholar]
- Yelamarthi, S.K.; Reddy, S.K.; Mishra, A.; Mittal, A. A Zero-Shot Framework for Sketch Based Image Retrieval. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 300–317. [Google Scholar]
- Ren, H.; Zheng, Z.; Wu, Y.; Lu, H.; Yang, Y.; Shan, Y.; Yeung, S.-K. ACNet: Approaching-and-Centralizing Network for Zero-Shot Sketch-Based Image Retrieval. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5022–5035. [Google Scholar] [CrossRef]
- Dutta, T.; Singh, A.; Biswas, S. StyleGuide: Zero-Shot Sketch-Based Image Retrieval Using Style-Guided Image Generation. IEEE Trans. Multimed. 2020, 23, 2833–2842. [Google Scholar] [CrossRef]
- Zhang, L.; Xiang, T.; Gong, S. Learning a Deep Embedding Model for Zero-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2021–2030. [Google Scholar]
- Kumar, G.V.R.M.; Madhavi, D. Stacked Siamese Neural Network (SSiNN) on Neural Codes for Content-based Image Retrieval. IEEE Access 2023, 11, 77452–77463. [Google Scholar] [CrossRef]
- Zhu, M.; Chen, C.; Wang, N.; Tang, J.; Bao, W. Gradually Focused Fine-Grained Sketch-Based Image Retrieval. PLoS ONE 2019, 14, e0217168. [Google Scholar] [CrossRef] [PubMed]
- Bui, T.; Ribeiro, L.; Ponti, M.; Collomosse, J. Sketching Out the Details: Sketch-Based Image Retrieval Using Convolutional Neural Networks with Multi-Stage Regression. Comput. Graph. 2018, 71, 77–87. [Google Scholar] [CrossRef]
- Zhou, W.; Jia, J.; Jiang, W.; Huang, C. Sketch Augmentation-Driven Shape Retrieval Learning Framework Based on Convolutional Neural Networks. IEEE Trans. Vis. Comput. Graph. 2020, 27, 3558–3570. [Google Scholar] [CrossRef] [PubMed]
- Kumar, N.; Ahmed, R.; Honnakasturi, V.B.; Kamath, S.S.; Mayya, V. Sketch-Based Image Retrieval Using Convolutional Neural Networks Based on Feature Adaptation and Relevance Feedback. In Proceedings of the International Conference on Emerging Applications of Information Technology, Online, 13–14 November 2021; pp. 103–113. [Google Scholar]
- Xian, Y.; Schiele, B.; Akata, Z. Zero-Shot Learning-The Good, the Bad and the Ugly. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4582–4591. [Google Scholar]
- Li, X.; Fang, M.; Li, H.; Wu, J. Zero Shot Learning Based on Class Visual Prototypes and Semantic Consistency. Pattern Recognit. Lett. 2020, 135, 368–374. [Google Scholar] [CrossRef]
- Gupta, S.; Chaudhuri, U.; Banerjee, B.; Kumar, S. Zero-Shot Sketch Based Image Retrieval Using Graph Transformer. In Proceedings of the 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1685–1691. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Eitz, M.; Hays, J.; Alexa, M. How Do Humans Sketch Objects? ACM Trans. Graph. 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Shen, Y.; Liu, L.; Shen, F.; Shao, L. Zero-Shot Sketch-Image Hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3598–3607. [Google Scholar]
- Dutta, T.; Biswas, S. Style-Guided Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the 30th British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019; Volume 2. [Google Scholar]
- Dutta, A.; Akata, Z. Semantically Tied Paired Cycle Consistency for Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5089–5098. [Google Scholar]
- Zhu, J.; Xu, X.; Shen, F.; Lee, R.K.W.; Wang, Z.; Shen, H.T. Ocean: A Dual Learning Approach for Generalized Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Wang, Z.; Wang, H.; Yan, J.; Wu, A.; Deng, C. Domain-Smoothing Network for Zero-Shot Sketch-Based Image Retrieval. arXiv 2021, arXiv:2106.11841. [Google Scholar]
- Xu, X.; Yang, M.; Yang, Y.; Wang, H. Progressive Domain-Independent Feature Decomposition Network for Zero-Shot Sketch-Based Image Retrieval. arXiv 2020, arXiv:2003.09869. [Google Scholar]
- Wang, W.; Shi, Y.; Chen, S.; Peng, Q.; Zheng, F.; You, X. Norm-Guided Adaptive Visual Embedding for Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Montreal, QC, Canada, 19–27 August 2021; pp. 1106–1112. [Google Scholar]
- Tian, J.; Xu, X.; Wang, Z.; Shen, F.; Liu, X. Relationship-Preserving Knowledge Distillation for Zero-Shot Sketch Based Image Retrieval. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 5473–5481. [Google Scholar]
- Dey, S.; Riba, P.; Dutta, A.; Llados, J.; Song, Y.-Z. Doodle to Search: Practical Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–19 June 2019; pp. 2179–2188. [Google Scholar]
- Liu, Q.; Xie, L.; Wang, H.; Yuille, A.L. Semantic-Aware Knowledge Preservation for Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3662–3671. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver BC Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Öztürk, Ş. Stacked Auto-Encoder Based Tagging with Deep Features for Content-Based Medical Image Retrieval. Expert Syst. Appl. 2020, 161, 113693. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Block | Configuration | Channels | Output Shape | Parameters |
|---|---|---|---|---|---|
| Convolution2D | Input Block | Filters: 64 Kernel Size: Padding: (3,3), Reflect Stride: 1 | In: 3 Out: 8 | 1184 | |
| InstanceNorm ReLU Activation | Input Block | none | In: 8 Out: 8 | 0 | |
| Convolution2D | Down Sampling Block 1 | Filters: 128 Padding: (1,1) Kernel Size: Stride: 2 | In: 8 Out: 16 | 1168 | |
| InstanceNorm ReLU | Down Sampling Block 1 | none | In: 16 Out: 16 | 0 | |
| Convolution2D | Down Sampling Block 2 | Filters: 256 Kernel Size: Padding: (1,1) Stride: 2 | In: 16 Out: 32 | 4640 | |
| InstanceNorm ReLU | Down Sampling Block 2 | none | In: 32 Out: 32 | 0 | |
| Convolution2D | Residual Block 1 | Filters: 256 Kernel Size: Padding: (1,1) Stride: 1 | In: 32 Out: 32 | 9248 | |
| InstanceNorm ReLU | Residual Block 1 | none | In: 32 Out: 32 | 0 | |
| Convolution2D | Residual Block 1 | Filters: 256 Kernel Size: Padding: (1,1), Reflect Stride: 1 | In: 32 Out: 32 | 9248 | |
| InstanceNorm | Residual Block 1 | none | In: 32 Out: 32 | 0 | |
| ⋮ | Residual Blocks 2 - 8 | ⋮ | ⋮ | ⋮ | ⋮ |
| ConvTranspose 2D | Upsampling Block 1 | Filters: 128 Kernel Size: Padding: (1,1) Stride: 2 | In: 32 Out: 16 | 4624 | |
| ConvTranspose 2D | Upsampling Block 2 | Filters: 64 Kernel Size: Padding: (1,1) Stride: 2 | In: 16 Out: 8 | 1160 | |
| InstanceNorm ReLU | Upsampling Block 2 | none | In: 8 Out: 8 | 0 | |
| Convolution 2D | Output Block | Filters: 3 Kernel Size: Padding: (3,3), Reflect Stride: 1 | In: 8 Out: 3 | 1179 | |
| Tanh | Output Block | none | In: 3 Out: 3 | 0 |
| Layer | Kernel Size | Stride | Channels | Output Shape | Activation | Parameters |
|---|---|---|---|---|---|---|
| InstanceNorm ReLU | Upsampling Block 1 | none | In: 16 Out: 16 | 0 | ||
| Conv 2D | 2 | In: 3 & Out: 64 | LeakyReLU | 392 | ||
| Conv 2D | 2 | In: 64 & Out: 128 | LeakyReLU | 2064 | ||
| Conv 2D | 2 | In: 128 & Out: 256 | LeakyReLU | 8224 | ||
| Conv 2D | 1 | In: 256 & Out: 512 | LeakyReLU | 32,832 | ||
| Conv 2D | 1 | In: 512 & Out: 1 | LeakyReLU | 1025 |
| Approach | mAP@all | AP@100 |
|---|---|---|
| Zero-shot sketch image hashing [37] | 22.0 | 29.1 |
| Content style decomposition [38] | 25.4 | 35.5 |
| Semantically tied paired cycle consistency [39] | 29.3 | 39.2 |
| OCEAN [40] | 33.3 | 46.7 |
| Domain smoothing network [41] | 48.1 | 58.6 |
| Progressive domain-independent feature decomposition network [42] | 48.3 | 60.0 |
| Norm-guided adaptive visual embedding [43] | 49.3 | 60.7 |
| Relationship-preserving knowledge distillation [44] | 48.6 | 61.2 |
| ACNet [23] | 57.5 | 65.8 |
| Proposed approach | 59.4 | 66.3 |
| Approach | mAP@200 |
|---|---|
| Conditional variational autoencoder [22] | 22.5 |
| Content style decomposition [38] | 35.8 |
| Doodle [45] | 47.0 |
| Semantic-aware knowledge preservation [46] | 49.7 |
| Relationship-preserving knowledge distillation [44] | 50.2 |
| ACNet [23] | 51.7 |
| Proposed approach | 52.8 |
| Sketchy Extended mAP@200 | TU-Berlin Extended mAP@all | ||
|---|---|---|---|
| 10.0 | 10.0 | 47.7 | 55.6 |
| 10.0 | 5.0 | 49.5 | 59.1 |
| 10.0 | 0.5 | 52.8 | 59.4 |
| Dataset | Metric | Without | With |
|---|---|---|---|
| TU-Berlin Extended | mAP@all | 58.8 | 59.4 |
| Sketchy Extended | mAP@200 | 52.3 | 52.8 |
| Dataset | Metric | Autoencoder | SSiNN |
|---|---|---|---|
| TU-Berlin Extended | mAP@all | 46.1 | 59.4 |
| Sketchy Extended | mAP@200 | 39.9 | 52.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gopu, V.R.M.K.; Dunna, M. Zero-Shot Sketch-Based Image Retrieval Using StyleGen and Stacked Siamese Neural Networks. J. Imaging 2024, 10, 79. https://doi.org/10.3390/jimaging10040079
Gopu VRMK, Dunna M. Zero-Shot Sketch-Based Image Retrieval Using StyleGen and Stacked Siamese Neural Networks. Journal of Imaging. 2024; 10(4):79. https://doi.org/10.3390/jimaging10040079
Chicago/Turabian StyleGopu, Venkata Rama Muni Kumar, and Madhavi Dunna. 2024. "Zero-Shot Sketch-Based Image Retrieval Using StyleGen and Stacked Siamese Neural Networks" Journal of Imaging 10, no. 4: 79. https://doi.org/10.3390/jimaging10040079
APA StyleGopu, V. R. M. K., & Dunna, M. (2024). Zero-Shot Sketch-Based Image Retrieval Using StyleGen and Stacked Siamese Neural Networks. Journal of Imaging, 10(4), 79. https://doi.org/10.3390/jimaging10040079