1. Introduction
In recent years, the world has faced persistent extreme weather events, leading to significant economic losses and serious impacts on human safety. In 2015, a 7.8 magnitude earthquake in Nepal resulted in 449 deaths and widespread devastation, with nearly 90% of buildings in the worst-hit districts damaged. The economic impact amounted to losses equivalent to Nepal’s annual GDP, necessitating at least USD 5 billion for reconstruction [
1]. In 2013, in Colorado, USA, a tragedy occurred when massive boulders, some exceeding 100 tons and similar in size to cars, unexpectedly tumbled from a cliff at an elevation of 4267 m on Princeton Mountain, causing casualties [
2]. On 31 August 2013, heavy rainfall led to a rockfall disaster in Badouzih, Keelung [
3]. The impact of rockfall on the retaining structures of a mountain road in Taiwan was assessed in a case study, revealing significant damage to the retaining structures of a mountain road (Miao 62 Line) in Miaoli County, Taiwan [
4]. These incidents underscore the necessity for effective management and prevention strategies for rockfall. Further exploration on these topics can be found in studies from
Geoenvironmental Disasters and
Social Sciences [
5,
6], with innovative approaches to rockfall monitoring and early warning systems detailed in a
Scientific Reports article [
7,
8,
9] and strategies for mitigation, especially in Colorado’s mountainous terrain, provided by the Colorado Geological Survey [
10,
11].
Given that mountainous slopes constitute a significant portion, approximately three-quarters, of Taiwan’s land area [
12,
13,
14], Taiwan faces a high occurrence rate of rockfall disasters. This has resulted in numerous casualties and an increase in national compensation cases. Moreover, rockfall disasters significantly impact transportation safety, with approximately one-third of travel time disruption in Taiwan’s eastern region being attributed to rockfall incidents. For instance, in Taroko National Park, the estimated annual loss in tourism revenue amounts to around TWD 20 billion due to frequent rockfall incidents, leading to temporary closures or visitors refraining from visiting due to safety concerns. These circumstances highlight the urgency of enhancing rockfall prevention, detection, and warning capabilities. The occurrence of these events underscores the threats posed by climate change globally and emphasizes the importance of prevention and mitigation measures against extreme weather events [
1,
5]. To minimize the impacts of disasters on society and the economy, governments and relevant organizations worldwide need to strengthen disaster risk management, promote climate change adaptation measures, and enhance public awareness and response capabilities. These efforts will help reduce the irreversible consequences of future disasters. Therefore, this paper proposes a rockfall hazard identification system. The system is expected to be deployed on roadside cameras. Images from cameras along roads prone to disasters will be fed into a computing system for real-time monitoring. When a disaster occurs, the system can quickly issue alerts by sending notifications through LINE messenger and email, along with photographs from the current monitoring footage to facilitate subsequent assessment. One-dimensional sensing data such as tilt and vibration will be presented on the Grafana information platform. If a suspected rockfall impact on protection nets is detected, a trigger value will be activated, prompting a red alert to notify monitoring personnel. The system could enhance rockfall disaster prevention, detection, and warning capabilities.
This rockfall hazard identification system contributes to multiple United Nations Sustainable Development Goals (SDGs). By quickly identifying and providing early warning for rockfall disasters, it helps improve the disaster resilience of road and transportation infrastructure (SDG 9), reduce risks of disruptions, and enhance overall infrastructure resilience. Rockfall disasters pose threats to the safety of urban populations and transportation systems. The application of this system can mitigate such risks, facilitating the creation of inclusive, safe, resilient, and sustainable cities and communities (SDG 11). Moreover, extreme weather conditions exacerbated by climate change often trigger rockfall and other disasters. This system enhances capabilities to respond to climate-related disasters, strengthening disaster prevention and management related to climate change impacts. This advancement positively contributes to taking urgent action to combat climate change in line with SDG 13. Therefore, this rockfall monitoring system supports the realization of key sustainable development targets centered on resilient infrastructure, sustainable cities and communities, and climate action.
In the past, due to hardware limitations, complex deep learning algorithms such as neural networks were not widely supported for object detection and tracking, leading to a reliance on traditional image processing techniques. It is important to note that rock texture patterns present similar challenges for image recognition across different environments. The intricate and irregular surface features of rocks, along with varying lighting conditions and backgrounds, make it challenging to accurately detect and identify rock formations from visual data. This complexity is consistent across various settings, highlighting the universal difficulty in processing and analyzing rock textures and forms through visual data. Methods based on polygonal Haar-like features were employed [
15]. For rock detection, a Random Forest (RF) model using Support Vector Machine (SVM) and Histogram of Oriented Gradients (HOG) features was utilized [
16]. Kalman filtering was applied for expanded space Multi-Criteria Evaluation (MCE) aggregation in slope sliding monitoring [
17], while a combination of photogrammetry and optical flow was used for rockfall slope monitoring [
18].
These techniques required manual feature design and were sensitive to factors such as lighting and background, resulting in subpar detection and tracking performance. In the past, object detection and tracking heavily relied on these traditional image processing techniques. However, with advancements in hardware and technology, modern approaches increasingly incorporate complex deep learning algorithms to achieve more accurate and efficient object detection and tracking. With the continuous advancement of hardware devices and artificial intelligence technology, we no longer rely solely on computers and central processing units (CPUs) for complex computing tasks. Specifically, Nvidia’s Cuda [
19] has opened up a new era by enabling computations on graphics processing units (GPUs), further driving the development of computer vision, machine learning, and deep learning. These significant advancements have not only propelled research progress in various fields but have also laid a solid foundation for the study of rockfall recognition systems. As for specific application examples, machine learning and deep learning models have been widely applied in various domains. In a research study related to machine learning, researchers employed classification and regression methods for rockfall prediction tasks [
20]. The study develops a warning system integrating various sensors with a logistic regression model to predict rockfall occurrences along a mountainous road. It classifies hazard levels into low, medium, and high based on rockfall occurrence probabilities, aiming to enhance traffic safety by providing dynamic alerts. In another research report, researchers utilized the XGBoost [
21] algorithm from gradient boosting methods, specifically designed for rock classification tasks. In the field of object detection, despite the successes achieved by deep learning models such as Faster-RCNN [
22], SSD [
23], and RetinaNet [
24], directly applying these models to tracking tasks may not always yield satisfactory results. Especially in complex and dynamic backgrounds, such as branches, leaves, and everyday structures, they can generate significant amounts of noise, posing significant challenges for object tracking and recognition tasks.
To address these issues, we have made a series of improvements and optimizations to the existing algorithms. Firstly, we combined the popular image detection model MobileNet with SSD [
25]. This combination not only enables the effective tracking and detection of targets but also exhibits highly efficient characteristics. Secondly, we integrated Faster-RCNN with OpenCV’s CSRT [
26] for improved tracking results. Lastly, we enhanced RetinaNet by optimizing the feature extraction layer and adjusting the size and quantity of detection boxes, further enhancing the model’s detection performance. By implementing these strategies and techniques, we can effectively improve the tracking and detection performance of the models in the presence of complex and dynamic backgrounds. This has significant academic and practical value for our research work. These studies not only demonstrate the power of these advanced computational methods but also reveal their wide applicability across various domains, including research and applications in rockfall recognition systems.
This study focuses on enhancing rockfall detection by optimizing existing algorithms and integrating deep learning models for superior tracking, along with adjustments for improved detection in complex scenes. Key objectives include surpassing target frame rates for real-time recognition, increasing accuracy in tracking the trajectories of falling objects, and pioneering the use of RGB images for rockfall recognition. These efforts contribute significantly to both academic research and practical disaster prevention applications.
2. Methods
In our study, we developed an innovative object tracking technique that integrates deep learning with motion analysis and data association methods. Initially, we use the Motion History Image (MHI) [
27] algorithm to capture motion trajectories of objects in videos. Next, we apply YOLO, a deep learning-based object detection system, to identify targets and evaluate their confidence levels. Our model, trained on the COCO dataset and further refined with our unique dataset of falling rocks, undergoes 300 training cycles, optimizing for minimum loss. Utilizing the Nvidia 4090 GPU, we enhance the processing speed for image analysis, overlaying the results with MHI for accurate detection. Target positions in successive frames are estimated using the Kalman filter and the Hungarian algorithm, with the Euclidean distance aiding in ID assignment [
28]. Finally, the Perceptual Hash Algorithm and template matching techniques are employed to boost tracking and detection reliability.
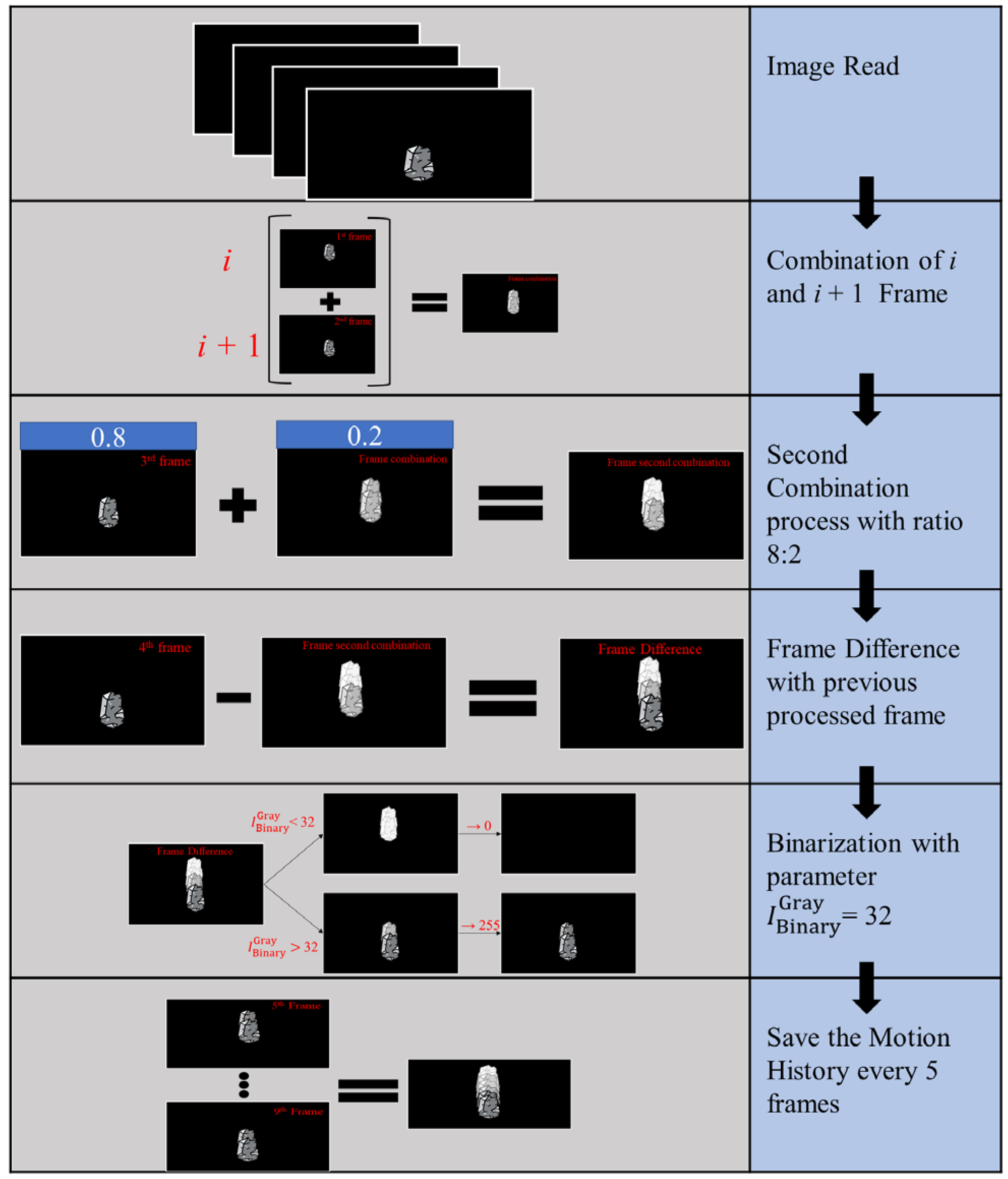
2.1. Optimization of Motion History: Enhancing Image Change Effectiveness through Internal Parameter Optimization
In the process of image analysis, we first convert the images to grayscale, which effectively reduces computational complexity and accelerates subsequent processing. When analyzing motion history trajectories, we select four frames as a processing unit and perform image differencing analysis. Specifically, we add the first
F1st and second frames
F2nd to obtain preliminary image changes
. Then, we overlay the third frame
F3rd with the previous two frames in an 8:2 ratio to obtain
. Subsequently, we perform differencing between this overlaid image
and the fourth frame
F4th to obtain further image changes.
α,
β,
γ, and
ω represent the i. The equation is as follows:
The next step involves the binarization of the images, which helps us to differentiate and label the regions of interest more clearly. In grayscale images, 0 represents full black, while 255 represents full white. We choose a threshold of 32 for binarization, meaning that we label regions with grayscale values greater than 32 as 255 (full white) and regions with grayscale values less than or equal to 32 as 0 (full black). The threshold value of 32 is experimentally determined and effectively distinguishes motion trajectories from the background.
is the initial gray image and
is the image after the binary preprocess. The equation is as follows:
After obtaining the binarized image, to better observe and analyze the motion trajectories, we choose to retain the history of the previous five frames. This step helps us to better understand the motion patterns and regularities of moving objects. Overall, this grayscale-based method effectively reduces computational complexity and accurately extracts the desired motion trajectory information, enabling the effective identification and tracking of moving objects. The entire processing workflow is illustrated in
Figure 1.
2.2. YOLO
YOLOv5 is an advanced deep learning model for object detection and recognition. It introduces improvements such as the Focus module and CSP structures to enhance detection accuracy and efficiency. It leverages FPN and PAN for feature fusion, improving the model’s ability to handle objects of different sizes and proportions. Additionally, it employs data augmentation techniques to increase the diversity and variability of the training data, improving the model’s generalization and robustness. YOLOv5 is widely used in various applications and domains.
2.3. Kalman Filter
Kalman filtering is a dynamic model for systems, such as the physical laws of motion, that estimates the system’s change based on known sequential measurements. It is a common sensor and data fusion algorithm. In this study, Kalman filtering is used to predict the coordinates of falling rocks in the image. There are two main methods in the Kalman filtering process: Predict and Correct. Below are the formulas and explanations for each parameter in each method:
- (1)
Prediction Step (Predict):
In this stage, we first update the predicted value
u using the state transition matrix
F. This update process can be achieved by multiplying the state transition matrix
F with the current predicted value
u, as shown in Formula (5). Next, we need to update the predicted error covariance matrix
P. The calculation involves multiplying the state transition matrix
F with the current predicted error covariance matrix
P and adding the model noise covariance matrix
Q, as shown in Formula (6).
- (2)
Correction Step (Correct):
In this stage, we first compute the relevant values for the observation noise covariance matrix
R and the observation matrix
A, as shown in Formula (7). Then, we calculate the Kalman gain
K and use it to correct the predicted value
u. This correction process is based on the error between the observed value b and the predicted value, as shown in Formulas (8) and (9). Finally, we update the predicted error covariance matrix
P based on the Kalman gain
K and other relevant values, as shown in Formula (10).
2.4. Hungarian Algorithm
We utilize the Hungarian algorithm to calculate the Euclidean distance between trajectories and detections. The Hungarian algorithm is a method for solving the assignment problem optimally. In our research, it is employed to assign the trajectories of falling rocks to the detected targets, determining which detections correspond to which tracking targets. The calculation process involves three steps as follows:
- (1)
Compute the cost matrix:
Given
N trajectories and
M detections, we first compute a cost matrix
C of size
N ×
M. Each element
represents the Euclidean distance between the predicted position of trajectory
i and detection
j, as shown in Formula (11).
- (2)
Assign trajectories and detections using the Hungarian algorithm:
We create a matrix
X of size
N ×
M. When trajectory
i is assigned to detection
j,
X[
i,
j] is set to 1; otherwise,
X[
i,
j] is set to 0. The objective function is formulated as shown in Formula (12). Each trajectory can only be assigned to one detection, and each detection can only be assigned to one trajectory. The constraint is represented by Formula (13).
- (3)
Update the trajectory states:
For each trajectory assigned to a detection, we update its state using the Kalman filter. If a trajectory is not assigned to any detection, its state prediction remains unchanged.
2.5. Normalized Cross-Correlation
In the process of normalized cross-correlation [
29] matching, we compare the similarity between a template image (template) and a region of the target detection image of the same size. By calculating the correlation between the template and the image region, we can identify the region that best matches the template. The calculation process is shown in Formulas (14) to (18):
- (1)
Compute the pixel intensity difference between the template T and the image region I:
- (2)
Compute the product of the differences:
- (3)
Sum all the products:
- (4)
Calculate the product of the standard deviation of the template T and the image region I:
- (5)
Combine the sum of the products with the product of standard deviation and multiply by a constant:
2.6. Difference Hash Table
Differential hashing [
30] is a method for computing image hash values that enables the fast comparison of the similarity between two images. It compresses the images to a specific aspect ratio, such as a 9 × 8 pixels matrix, calculates the grayscale intensity value for each pixel, converts it to binary, and then computes the binary difference between adjacent elements. Finally, it concatenates all the binary values to obtain the image hash. The process can be summarized in three steps as follows:
- (1)
Resize image and convert to grayscale:
The image is resized to a specific size, such as 9 × 8, and then converted to grayscale intensity values ranging from 0 to 255.
- (2)
Compute differences:
Calculate the grayscale intensity difference between adjacent pixels. If the intensity of the first pixel is greater than the second pixel, it is assigned a value of 1; otherwise, it is assigned a value of 0. This is represented by Formula (19).
- (3)
Compute the hash value:
First, convert the binary differences to decimal values to obtain the decimal hash value
for each row. Then, concatenate all the row hash values to generate the differential hash value Dhash, as shown in Formula (20).
2.7. Overview the System
Before starting the analysis, some basic processing and calibration are applied to the collected images. The input resolution of the images is 1920 × 1080, with a frame rate of 30 FPS, and they are captured in RGB color mode. The images are obtained from two lenses with different focal lengths (26 mm and 52 mm), each with a resolution of 12 million pixels. The process can be divided into two parts. Firstly, the image input undergoes image differencing and motion history trajectory calculation, and the result is output as the red channel. The foreground is considered as moving objects, while the background is considered as non-moving objects. The trajectory of the target is marked with a blue rectangular box, as shown in
Figure 2. For the size of rockfalls that cause serious damage, we define 80 × 160 as big rockfall and 40 × 40 as small rockfall, shown in
Figure 3. Secondly, YOLO is used for image prediction, and the predicted ROI objects are extracted and output as the green channel along with their confidence scores. These confidence scores are saved in the image information.
Next, the red channel of the MHI and the green channel of YOLO are overlaid to create the overlaid image. In this overlaid image, the yellow area represents the overlap between the two channels, and we can process this yellow overlap region. Then, we obtain the coordinates of the yellow area and use the Kalman filter to predict their next position. Then, we assign an ID to each target using the Hungarian algorithm. This approach allows us to effectively detect multiple targets even when they appear simultaneously, and the results are saved in the image information.
Finally, a decision strategy is applied to interpret the image information. When the predicted confidence score is greater than 0.9, the target is considered as a foreground falling object. When the predicted confidence score is lower than 0.6, the target is considered as background. When the predicted confidence score is between 0.6 and 0.9, two algorithms are used: normalized correlation matching and the difference hash table. The difference hash table is compressed into a 9 × 8 matrix. If the normalized correlation matching value is greater than 0.85 and the hash value of the difference hash table is greater than 35, we update our template and output the coordinates of the target and the current time, generating a warning in the terminal about the possibility of falling rocks. This process demonstrates our image processing and analysis methods, utilizing mathematics and computer vision techniques for tasks such as image calibration, target detection, trajectory prediction, and target identification, and integrating the results into a single workflow, as shown in
Figure 4.
3. Datasets
In our research, we conducted a simulated experiment in a small-scale field to simulate the occurrence of falling rocks in real-life situations. By conducting such a localized and on-site simulated experiment, we can gain a deeper understanding of real-world falling rock scenarios and optimize our system to better adapt to these situations. Such on-site experiments provide a practical and intuitive evaluation criterion to help assess and improve our methods and techniques.
The optical measurement device is the iPhone 13 Pro, which has an aperture of f/2.8, and we used two different focal lengths, 26 mm and 52 mm. To ensure the accuracy of the test results, we maintained a distance of 2 m between the camera and the target object, as shown in
Figure 5 and
Figure 6.
In our research, we conducted shooting and testing from various angles and backgrounds, including scenarios where both people and rocks coexist. These shooting and testing results were organized into a dataset that we used for pre-training YOLO to obtain training weights for rock detection. To improve the accuracy of the training results, we employed a data augmentation strategy.
Our training set consists of self-captured and self-annotated 1920 × 1080 RGB images. The annotation principle we followed was to outline the edges of the target objects with bounding boxes. To ensure our model can respond appropriately to various scenarios, our dataset covers different situations such as single and multiple targets and moving and stationary rocks. In the end, our dataset consisted of 2298 training images and 192 validation images. We applied nine different image augmentation techniques, and the details of these techniques are as follows: (1) Flip: Ho Flip: Horizontal; (2) 90° Rotate: Clockwise, Counter-Clockwise; (3) Rotate: Between −15°and +15°; (4) Shear: ±15° Horizontal and ±15° Vertical; (5) Saturation: Between −25% and +25%; (6) Brightness: Between −25% and +25%; (7) Exposure: Between −25% and +25%; (8) Blur: Up to 10px; and (9) Noise: Up to 5% of pixels. The choice of parameters and settings, particularly in data augmentation, is driven by the need to enhance the model’s generalization ability by exposing it to a wide variety of data scenarios.
5. Discussion
Existing solutions are based on sensors deployed on rockfall protection nets, and data analysis is performed on these sensors. However, these approaches are geared towards analyzing data from rockfall disasters that have already occurred. Our solution focuses on real-time detection in specific road sections.
In our experiment, considering the scenario of the roadside camera, we adopted a single lens for shooting. Therefore, we did not perform conversions for image and distance, relying solely on pixels.
However, among all the rockfall detection systems, it is rare to use image recognition and tracking for identifying and tracing falling rocks. Comparing our system with others is challenging. And it is also rare to capture birds and falling rocks in the wilderness; we conducted experiments using manually labeled bird species and rocks in a small experimental field with complex backgrounds. The experiments indicated that we can accurately distinguish between two common objects in the mountains, falling rocks and birds, as shown in
Figure 12. In the scenario of rock falling, our system will calculate information locally in real-time. The local system is expected to be installed on-site and transmit short messages via wireless networks to notify nearby pedestrians. The combination of short text messages and real-time calculations enables the system to achieve the real-time notification of falling rocks for pedestrians.
In our dataset testing, we discovered that the detection of small rockfall targets was not ideal. Although we chose not to apply blurring filters to the images in order to maintain their authenticity, we found that preprocessing with bilateral filtering to remove noise can significantly improve image recognition accuracy and reduce noise during YOLO detection. Compared to the Distributed Acoustic Sensing (DAS) approach [
8], which utilizes fiber-optic technology for detailed analysis and monitoring, our proposed system provides a forward-looking solution for real-time detection and disaster prevention. It offers additional advantages, such as the capability to monitor actual rockfall locations and assess the volume of rockfall spaces.
6. Conclusions
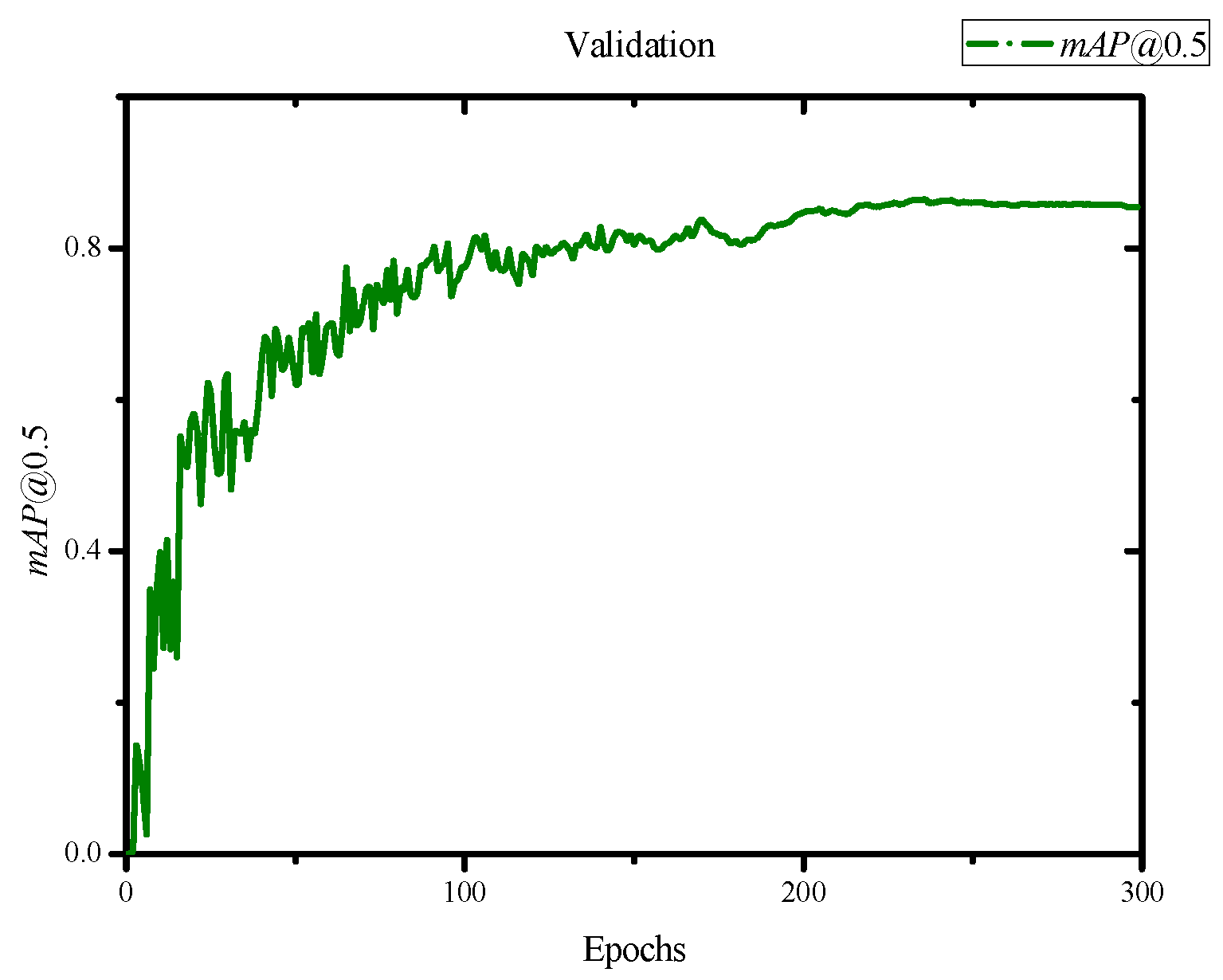
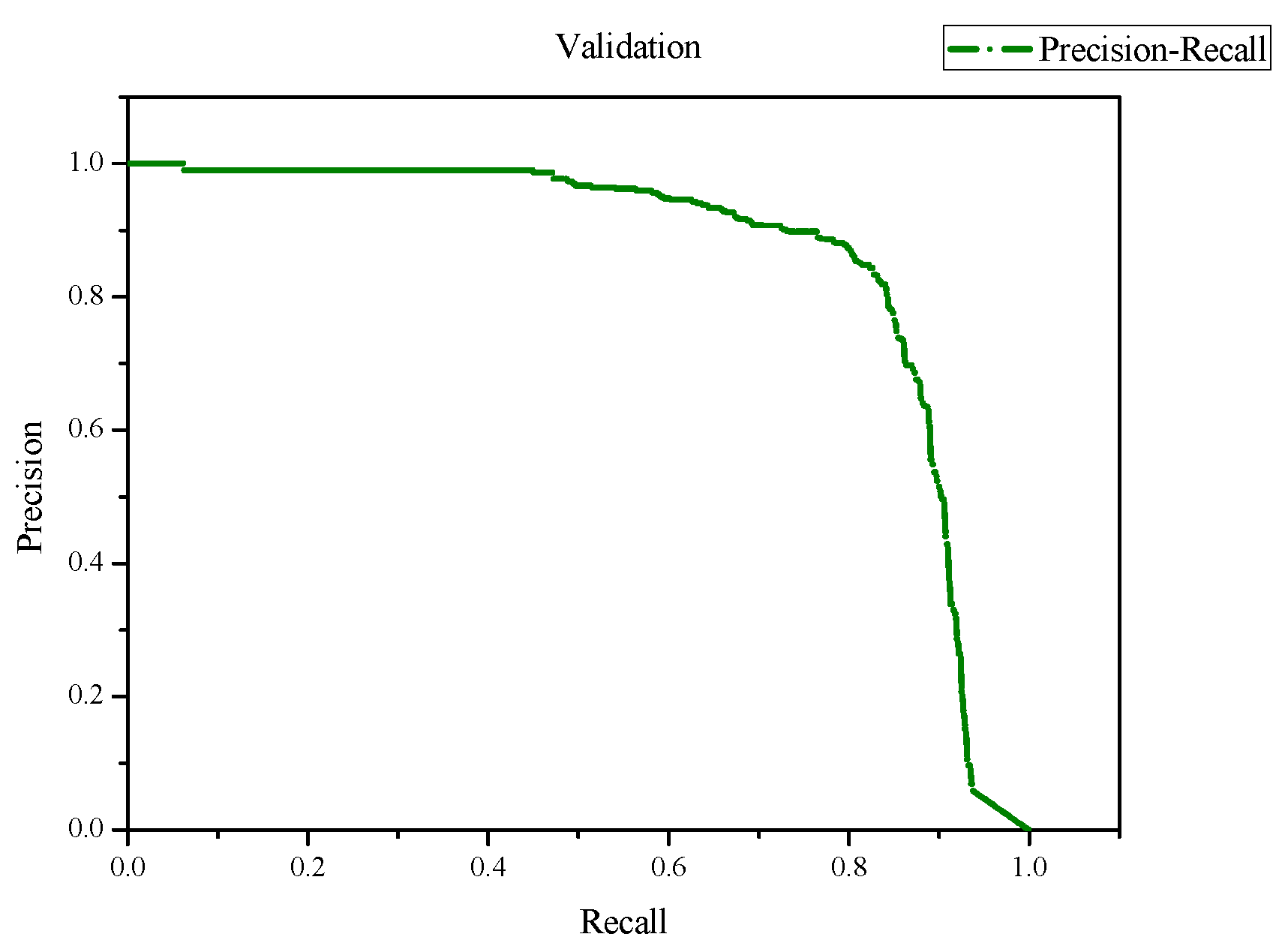
In this study, we have designed and implemented a rockfall detection and tracking system tailored for cliffs. The system adeptly navigates the detection challenges posed by complex backgrounds. Through the analysis and processing of a dataset comprising 2490 RGB rockfall images and 30 high-definition (1920 × 1080 resolution) rockfall test videos, our algorithm exhibits strong performance in detecting large-sized rockfalls. Despite not testing different zoom levels in the training dataset, our system showcases remarkable generalization capabilities. Moreover, with an execution time of 12.9 FPS on a GPU, our rockfall recognition system achieves rapid and efficient detection, given adequate data support. However, in tests focusing on smaller targets, we identified limitations due to the narrow scope of the annotated dataset and the suboptimal image acquisition speed, leading to potential deformations and transparency issues in the images. To mitigate these issues, we plan to broaden the dataset and enhance the image acquisition speed, aiming to improve detection performance. Additionally, we aim to relocate our experimental setup to real-world sites, like the Nine Turns Trail in Taiwan, to further refine and validate our system. For implementation, a robust computing server, wireless transmission towers, and cameras are necessary. This infrastructure ensures timely alerts for pedestrians and safety personnel, facilitating emergency road closures during rockfall incidents. In the case of an accident, instant visual data provision and streamlined post-disaster repairs are enabled by the recorded image data.
Moving forward, we intend to utilize tools like Blender to simulate real-world scenes in a virtual environment, thereby expanding our dataset with these simulations. We will assess the discrepancies between Blender-generated images and actual photos, striving to transpose the characteristics learned from real images to the Blender-generated ones using diffusion models, thus enhancing the training dataset’s quality and diversity. The Stable Diffusion Model will be employed to sketch a black mask along the predicted rockfall trajectory and generate rockfall images. However, to address the temporal sequence challenges in the rockfall trajectory, we will integrate an attention model to bolster the connections between sequential falling rockfall images, facilitating dataset generation. Moreover, we plan to manually establish a small experimental field for collecting diverse scale rockfall image data. Our research, merging image recognition and deep learning, addresses rockfall disasters with significant implications for future innovations in this domain, applicable across intelligent disaster prevention and traffic safety. Our real-time image recognition and detection system marks a leap towards identifying dynamic objects in scenarios such as debris flows and avalanches, contributing to the evolution of intelligent transportation and vehicle safety systems.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}