1. Introduction
Computer vision using artificial intelligence is being integrated into many industrial processes to improve their performance by supervising the processes, collecting information for defect reduction [
1,
2], object localization [
3], and obtaining more knowledge about the process. With better access to depth data and its addition to pre-installed computer vision systems, the range of applications of computer vision within quality insurance and decision-making has increased. In applications such as bridge inspection [
1], railway quality insurance [
2], agriculture [
3,
4], and robotics [
5], RGB-D data are being utilized. By adding RGB data to depth data, the collection of shape-based information in addition to texture- and color-based information RGB-D data is generated. These data can ensure a deeper understanding of industrial processes and their defect sources. Therefore, applications such as approximate weight determination, defect size determination, defect localization, and additional support in decision-making can benefit from RGB-D data.
In order to create RGB-D data from a multi-view system, a data fusion algorithm is necessary to combine RGB and depth data. By fusing data, information from different sources are combined into one data object. However, a combination of these data can be challenging since different information sources can have different attributes. Data fusion can be beneficial not only in terms of additional information but also for an improvement in data quality, as shown, for example, by Okafor et al. [
6] and Nemati et al. [
7]. Given the capabilities of different systems, a smart combination of these systems can result in the compensation of the disadvantages of each system respectively. In order to process images with different resolutions and boundaries, more complex methods are needed. Boström et al. [
8] collected multiple definitions of information fusion. The goals of information fusion are defined as “the provision of a better understanding of a given scene” and to “obtain information of greater quality”, among others. That is why RGB-D data have such vast potential when implemented in industrial processes for quality insurance.
Setting up a high-resolution sensor system for RGB-D data imaging can be expensive since at least two cameras are necessary, with one of them imaging the depth data while the other images RGB data, depending on the imaging techniques, and costs can become high. In order to obtain the precise RGB-D data from an analyzed sample, the sensor systems have to be either spatially adjusted, e.g., inclined under a certain angle towards each other to capture the same section of the sample at the same time, or temporally adjusted, e.g., not capturing the same sample section and adjusting the time shift due to different spatial acquisition positions via object tracking. The adjustment of the sensor systems is carried out via a co-ordinate system transformation of one type of data into the co-ordinate system of another system. Regarding sensor systems, there are many different setups for color- and shape-based imaging. Siepmann et al. [
9] used a setup that utilized pattern projection. Another method with which to obtain RGB-D images is the combination of known depth imaging systems, such as the time of flight (ToF) [
10,
11,
12,
13], confocal microscopy [
14], light detection and ranging (LIDAR) [
15], or laser scanning [
16,
17,
18] in combination with an RGB camera system.
Hach et al. [
19] present an RGB-D camera containing a combination of a ToF sensor and an RGB camera. Both systems are combined in the system without inclination to each other. A typical system used in the literature [
20,
21,
22] for a combination of a ToF sensor and an RGB camera is the Microsoft Kinect system. Another possibility for generating multimodal data is the combination of thermal data acquired by thermal infrared (TIR) cameras and depth imaging systems [
16,
17,
23,
24,
25]. Regarding the adjustment of the sensor systems, different acquisition structures can be differentiated. These structures are either stationary, e.g., fixing the different imaging systems onto a stationary structure [
12,
13,
15,
16,
17], or dynamic structures, e.g., a terrestrial scanner moving in the ambient air [
15,
18,
20,
23,
26]. In order to summarize the state-of-the-art multimodal imaging for obtaining depth and color information, different depth-imaging systems are viable depending on the specific application.
Setting up an RGB-D imaging system can also become quite complex [
27,
28]. The more the camera parameters are the same, such as resolution, the easier it is to implement the data fusion algorithm. However, high-resolution depth cameras are more expensive than RGB cameras of the same resolution. Adjusting both cameras is also a challenging but necessary task. By calibrating both systems, the imaged regions are able to overlap and, thus, enable more precise data fusion. Therefore, a lot of thought needs to be put into setting up a viable imaging system for fused RGB-D data before data processing.
This work will analyze the required samples with a laboratory setup based on optical sorting processes [
29,
30]. Industrial processes based on optical sorting using a conveyor belt need to analyze a high quantity of samples in a short period of time. Therefore, only two depth acquisition methods, ToF and laser triangulation, respectively, should be considered for laser scanning in more detail. Other methods, such as interferometry, confocal microscopy, pattern projection, or photogrammetry, have a higher resolution than ToF or laser scanning methods but require more measuring time and come with greater costs. Due to the higher spatial resolution of a non-time-based measurement compared to ToF, this work uses a triangulation-based laser line scanning system as an effective depth imaging system. After setting up the imaging system, a fitting algorithm was needed for data fusion. In the past, a wide range of such data fusion methods have been proposed. Eichhardt et al. [
11] give an overview of data fusion methods. A brief overview of different data fusion classifications, techniques, and architectures is given by Castanedo [
31] and Elmenreich [
32].
The fitting algorithm, also called data fusion, consists of data acquisition and preprocessing in case of different camera resolutions, as well as up or downsampling and the co-ordinate system transformation of one data type into the co-ordinate system of the reference system [
33]. Usually, the system with the higher resolution is the preferred reference system; however, due to hardware limitations, this is not always viable. When transforming one image into the co-ordinate system of the reference system, false values can occur. These are pixel values that are seen by one system but not the other. The way these false values are dealt with is managed by the upsampling algorithm used to adjust the image resolution before transforming the co-ordinate system [
34]. Therefore, this paper focuses on the variation of upsampling algorithms.
In the following sections, first, the data and imaging setup used in this work are introduced, and some background on data preprocessing is given; then, different upsampling methods, such as joint bilateral upsampling (JBU) [
35,
36] and Markov random fields (MRFs) [
37,
38], and different interpolation algorithms [
39,
40] are briefly described. For further reading on the matter of data fusion, Junger et al. [
41] also compare multiple data fusion methods. In
Section 4, the complete process of data acquisition, preprocessing, and data fusion, including post-processing, is described in detail. Afterward, a closer look at the evaluation process and its parameters is given. Finally, the results of each data fusion method applied to the same raw images are shown and evaluated based on the root mean square error (RSME), correlation (CORR), signal-to-noise ratio (SNR), universal quality index (UQI), and contour offset (
).
2. Data Fusion Process
Data fusion is the process of combining data from different sources [
42]. By doing so, one can gain deeper knowledge and access combined information. The resolution, offset, and regions of interest (ROI) of the images must be adjusted by the data fusion algorithm so that each pixel of the RGB image gets a corresponding depth value in addition to the color values. This progress is difficult due to an offset in images both in the translational and rotational direction caused by different resolutions, non-commensurability, and missing or inconsistent data, as described by Illmann et al. [
43] and Lahat et al. [
44].
The main steps of data fusion are the following [
33]:
The ROI is defined by a cropping algorithm that crops the objects and works as a segmentation algorithm. In order to adjust the resolution of the data, the up- or downsampling and the combination of both must be realized. For this process, a reference image must be established before the resolution of the other image is adjusted. In this paper, the RGB image was chosen as the reference image for the fused RGB-D image. In addition to the higher resolution, it contains fewer defects and contains sharper imaged edges. The offset can be dealt with by translating the depth image based on information from an object registration algorithm. In order to accomplish this, the image-based data must be transformed into the same co-ordinate system to represent correlating areas. For this data registration, extracting the corresponding features in each image is necessary. Illmann et al. [
43] provide further details and strategies for merging data. Feature extraction and data registration also deal with the time delay between both imaging systems. Therefore, both offset and time delay are solved.
This paper compares three simple interpolation methods with more complex methods, such as MRF and JBU, to achieve RGB-D-fused data. In the following, each upsampling method is presented in more detail.
2.1. Interpolation Methods
The classic interpolation methods used in this paper are given by Dianyuan [
39] and Nischwitz et al. [
40]. These methods were used as direct fusion methods to obtain corresponding depth pixel values for each respective RGB pixel. First, nearest-neighbor interpolation is chosen, where the unknown value of a pixel is calculated based on the interpolation of the pixel closest to the new pixel position. The second interpolation method used is a bi-linear interpolation, where four weight pixels are used for value calculation. The third and last interpolation method uses a cubic interpolation. Here, the unknown pixel is calculated using 16 surrounding pixels. Moreover, the interpolation methods are basic methods in image processing and are used in MRF and JBU as well.
2.2. Joint Bi-lateral Upsampling
Joint bi-lateral upsampling [
35] is a guided depth upsampling method that uses bi-lateral filters to calculate a high-resolution depth map,
. It is considered a local depth upsampling method [
11] because the weight for the convolution is calculated based on the local pixel position. JBU uses the weighted convolution of a high-resolution RGB image,
, with a lower-resolution depth map,
. The weight can be calculated with a range filter,
r, which is a Gaussian kernel with
, and the intensity differences of the high-resolution image,
, and the low-resolution image,
, at their pixel positions. The high-resolution depth map can be obtained with the simplified Equation (
1) [
45]:
where
S is the neighborhood of the pixel,
p is the pixel position of the high-resolution data, and
q is the pixel position of the low-resolution data. Since JBU is a guided upsampling method, to apply this method, the resolution of both data needs to be an integer multiple of each other. In order to apply JBU, the resolution difference between
and
needs to be an integer multiple of two. Moreover, Riemens et al. [
45] proposed a multistep upsampling method to smoothen the edges. The multistep upsampling approach utilizes a cascade of
upsampling factors to reach factors of
or
.
2.3. Markov Random Fields
Depth upsampling by Markov random fields (MRFs) [
37,
38] is a guided, global method [
11] because it is used as an optimization method to find the global optimum. It utilizes a Markov network to calculate the pixel values of the upsampled depth map based on weighted high-resolution image data and estimated upsampled depth data. With an iterative process, the current calculated depth map can be optimized by considering the high-resolution image data. Liu et al. [
46] proposed a model that considers a data term and a smoothing term to calculate the high-resolution depth map. The data term calculates the quadratic differences between the real and estimated data, and the smoothing term calculates the given potential with a weight that depends on the given image data. Equation (
2) [
46] shows the proposed model:
where
is an empirical factor,
i and
j are indices, and
is the initial cubic interpolated high-resolution depth map of the low-resolution depth map. The weight is given in Equation (
3) [
46]:
where
C represents the three RGB values,
k is an index, and
is an empirical factor. Deriving Equation (
2) [
46] and setting it equal to zero leads to Equation (
4) [
46]:
where
n corresponds to the current iteration.
3. Hardware and Data Preprocessing
Industrial processes are usually stationary systems; therefore, the lab setup used for this work is also a stationary system. Since the integration of an imaging system into an industrial process can be expensive and complex, a conveyor belt system was chosen. These systems are widely utilized in industry and provide simpler setup options compared to free-falling objects. However, one should note that when imaging the depth information of free-falling objects, the complete object can be imaged when using conveyor belts, but the bottom of the object cannot be imaged due to the top-down view of the system [
47]. Therefore, only a 2.5-dimensional image can be generated.
In order to image objects in the same scene in an industrial environment, a setup consisting of a feeding system and an imaging system was built. In the feeding system, two conveyor belts are moved at different speeds, and five plates are arranged horizontally along the second belt to separate the incoming objects. The imaging system is positioned along the second belt. This system consists of an RGB line camera and a 3D laser line scanner. As described in
Section 1, for depth imaging, a 3D laser line scanner was chosen since, when compared to systems such as the time of flight system of Microsoft Kinect, it obtains a better overall resolution (see Refs. [
48,
49]). The 3D laser line scanner images a 3D point cloud. However, JBU, MRFs, and interpolation upsampling were proposed for the depth map data. Therefore, the imaged point cloud was transferred into a depth map.
Both cameras were chosen based on each other’s parameters to ease the data fusion process later on. Although imaging objects placed on a conveyor belt results in a shadow below the object due to illumination, this is a cheaper alternative. The shadow below the object does not exist with planar objects and is not relevant for the detection of defects on the surface of the object. The important attributes of each camera are shown in
Table 1 [
49,
50]. The number of active pixels for the laser line scanner was reduced by binning due to the necessary speed of the converter belt to ensure the proper separation of the objects. Using the full scanner would have resulted in missing pixels in the depth image.
Since the cameras optical axes are horizontally shifted, the number of pixels covering the ROI (the conveyor belt) is not the same as the number of active pixels. According to the definition of ROI, both sensor systems lose some pixels at the edges. Therefore, the ratio between the used pixels of both systems is no longer exactly two; it is a decimal number. This is important for the use of JBU and will be explained in
Section 2.2.
The laboratory setup by Anding et al. [
29,
30] is shown in
Figure 1. The feeding system with object separation can be seen on the right, and the imaging area is next to the separation plates. Both cameras are positioned above the illumination system and imaging area. The separation of objects is implemented by the combination of two conveyor belts moving at different speeds and the array of separation plates, which are arranged orthogonal to the movement direction of the second conveyor belt. In order to accomplish homogeneous illumination for the reduction of object shadows, the objects were illuminated using two angled light sources from above and one light source below the conveyor belt. For depth data acquisition, no additional illumination was needed.
This study features natural objects such as stones from quarries. These complex objects were chosen to show the limits of the presented data fusion approach. Since they don’t have a planar surface, the missing depth data below the objects need to be considered. A coin was used as a simple known round object for the validation of each individual process. In order to avoid losing pixels while imaging, the line frequency is calculated automatically. In this way, the speed of the conveyor belt in the imaging path and the line frequency of both cameras can be adjusted. An incorrect line frequency results in compressed or stretched images. A round normal object and Equation (
5) were used to find the correct line frequency, since the round normal object is imaged as an ellipse at incorrect line frequencies:
With
a and
b describing both ellipsoid axles. These parameters are calculated using elliptical Hough transformation.
Figure 2 shows examples of the objects of the featured dataset and the coin used for validation.
By using a 3D laser line scanner, the depth images are subjected to artifacts called depth shadows (along the edges), as seen in
Figure 3. These artifacts are an inaccuracy, as can be seen from the depth value reading zero in the image, causing a bigger offset between the RGB image and depth data. Removing these artifacts is necessary to fuse the images accurately. With the help of interpolation and averaging over neighboring pixels, in addition to a threshold-based edge detection algorithm, the removal of the artifacts was achieved. Using this algorithm, the edges of the depth shadow were removed, and, therefore, the edges of the depth data were improved, resulting in sharper edges closer to the real edges of the imaged object.
4. Data Acquisition and Processing
In order to understand the complete process, different levels of processing needed to be considered. First, one needs to understand what happens in data acquisition. This process is shown in
Figure 4. In order to take a closer look at the data fusion process in the grey area in
Figure 4, the flowchart in
Figure 5 is shown.
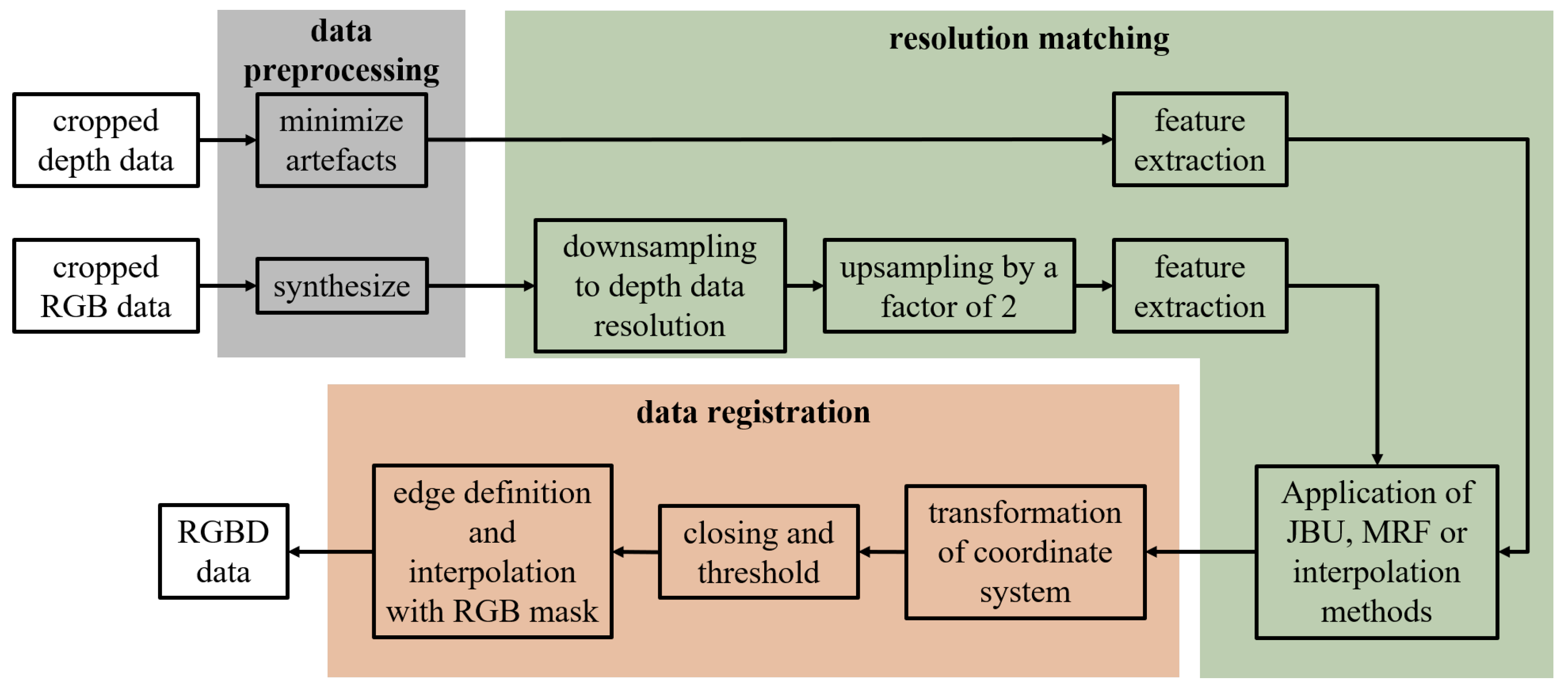
Since the camera systems are positioned along the conveyor belt behind each other, there is a temporal difference, , in acquisition. Since both data need to be present to combine them, the processing of both data needs to be delayed until both data are acquired. For segmentation, a cropping algorithm is used. This, however, can be carried out right after acquisition.
An overview of the data fusion process is shown in
Figure 5. Before the preprocessing algorithm is used, the incoming samples of the conveyor belt are cropped to remove the background. Afterward, the preprocessing algorithm is used on the acquired samples. On the one hand, the RGB data need to be synthesized to create an image of the full object without the RGB artifacts caused by the conveyor belt. Meanwhile, the depth shadows mentioned in
Figure 3 are removed from the 3D data.
Next, resolution matching is implemented. This step uses different up- and downsampling steps to increase the resolution of the depth data and fit the RGB data accordingly. First, a combination of down- and upsampling methods based on classical interpolation methods is applied to the RGB data to create a resolution difference between RGB and depth data of a factor of 2 × 2.
The downsampling is necessary due to the ROI issue, as described in
Section 3. The resolution of both data is not exactly an integer multiple of each other. The RGB data were chosen as reference data due to their higher source resolution. So, the RGB data were first downsampled to the resolution of the depth data. In the second step, they are upsampled by a factor of two to meet the requirement for guided upsampling methods such as JBU and MRF.
Next, the depth data need to be assigned to their corresponding RGB data. This is carried out by feature extraction and feature matching. Features such as area, convexity, etc., are extracted from the data and assigned over difference tolerances. The features used are the following:
After the assignment, the JBU, MRFs, and classical interpolation methods are finally applied, respectively, to match the RGB data resolution and the depth data resolution. Since the RGB data resolution was set to double the depth data resolution in the previous steps, the depth data were upsampled by a factor of 2 × 2. For classical interpolation methods, the RGB data are not used. However, since JBU and MRFs are guided upsampling methods, RGB data with double the resolution are necessary (see
Section 2.2 and
Section 2.3).
As a last step, data registration is carried out. First, the co-ordinate system of the RGB data and the 3D data must be transformed into the same co-ordinate system to ensure an offset-free fusion process. With the transformation of the co-ordinate system, the fusion itself can be carried out. After fusion, a morphological operation, more precisely, closing, and a threshold to minimize the created noise are executed. In order to obtain a fully overlapping fusion of depth data and RGB data, points outside of the matching edges have to be eliminated by applying an RGB contour mask. Pixels inside the edges have to be interpolated to extend to the boundaries.
5. Evaluation Process
In order to be able to compare the different methods used for upsampling in terms of their performance for data fusion, different evaluation methods were used. For evaluation, the RMSE, CORR, SNR, and UQI based on the work of Jagalingam et al. [
51] and Naidu et al. [
52] are used. In addition to these assessment parameters, an offset between the depth data and RGB data was used.
N and
L are the number of pixels in each spatial dimension, and
I corresponds to the intensity of the pixels at positions
i and
j of the depth data or RGB data, respectively.
RMSE measures the quadratic error between the source images, the RGB and upsampled depth data, and the fused RGB-D image, with zero being the best possible score. Equation (
6) [
51,
52] can be used to calculate the RMSE:
where
represents the intensity of the image acquired by the RGB line camera, and
is the intensity calculated using the acquired depth data and the respective upsampling method. In order to measure the information similarities between the source images and the fused image SNR, which can be seen in Equation (
7) [
51,
52], this equation can be used. The higher the score, the better the method has performed:
CORR is the correlation coefficient given in Equations (
10) and (
11) [
51,
52]. It is used as an evaluation method to measure the similarity of an RGB or depth image and an RGB-D image, with 1 being a perfect score:
UQI is the universal quality index given in Equation (
12) [
51,
52]. It is used to describe the information brought into the fused image, with 1 being the best possible score.
being the mathematical expected value, respectively;
being the standard deviation, respectively.
The offset,
, is measured to evaluate the overlap of the object maps between the source and fused images. Equation (
13) gives the if statement to calculate the offset:
These assessment parameters are used to compare and evaluate the upsampling methods presented in
Section 6.
6. Results
In total, more than 225 data fusion experiments using 11 different objects (10 stones and the validation coin) and upsampling parameters were conducted.
Table 2,
Table 3 and
Table 4 show the mean of the evaluation parameters for each of the upsampling methods presented in
Section 2. Based on the results,
Table 5 shows a comparison using the best-performing parameters. The mean was calculated considering all analyzed objects. Due to computational costs, the upsampling of the factors to 2 × 2 the resolution of the RGB data was analyzed.
For MRFs, 30 different parameter scenarios were conducted to find the best parameters.
Table 2 shows the mean evaluation results of Markov random field upsampling using a cubic interpolation algorithm [
46] since the performance of the MRFs using nearest neighbor and bi-linear interpolation did not perform as well.
or
were varied while the other parameters were fixed. The variation in the parameters was chosen arbitrarily. A total of 60 iterations were carried out; for the majority of the dataset, this quantity of iterations was sufficient, and the performance was saturated. When comparing the negative and positive values of
, equal results were achieved. However, varying the sign of
does show an effect. Based on this, the best parameters were chosen for upsampling using MRFs. In the first step of the experiments,
was set while
was varied, with
achieving the best performance. For
,
was varied in the second step of experiments. With this arrangement,
performs the best. A third iteration of experiments was conducted to find the best fitting
value for
. While
and
performed best,
and
also performed well. Since these parameters are recommended by [
46], choosing these parameters ensures comparability with other publications.
Table 3 displays the evaluation results for different up- and downsampling scenarios for each interpolation method. Direct downsampling and upsampling were achieved in one process without any intermediate sampling stages, whereas in other scenarios, the resolution was adjusted in multiple cascading processes. In each scenario, nearest neighbor and bi-linear interpolation outperform cubic interpolation. Moreover, the best result was achieved by iterating the downsampling process by a factor of 2 × 2 with nearest neighbor interpolation.
Table 4 gives an overview of the JBU performance for different upsampling scenarios. All evaluation parameters are the means and standard deviations of multiple objects. Overall, one can see JBU performs best with a nearest neighbor interpolation. Moreover, downsampling the RGB data by a factor of 4 × 4 and later upsampling the data to the depth data resolution results in the best performance in terms of the assessment parameters chosen in this work.
Based on two example objects, all the evaluation values are given in
Table 5. For each upsampling method, the best-performing parameter setup is shown. For Markov random fields,
iterations were used.
is used in addition to RSME, CORR, and UQI to show the overlap of the RGB image and the depth map in the fused RGB-D image. Due to the cheap computational costs, JBU and interpolation fusion have an advantage over MRFs because of the iterations MRFs have to undergo in order to optimize the results. JBU clearly outperforms MRFs and interpolation in this work. Due to the guided fusion over a convolutional weight, JBU shows good performance in the fusion process. Nearest neighbor outperformes the bi-linear and cubic interpolation and is, therefore, more benefitial for preprocessing.
Naidu et al. [
52] also achieved
. Moreover, the authors of [
53] report correlation coefficients between 0.95 and 0.99 for various data fusion methods. Zhang [
54] achieved a maximum of
by modifying a multispectral image; however, other methods presented by [
54] perfrom worse, with correlation coefficients between
and
. When comparing the evaluation metrics RMSE, UQI, SNR, and CORR of JBU with Zhu et al. [
53], Naidu et al. [
52], and Zhang [
54], we can see that JBU performance is similar and comparable. However, one must note that Zhu et al. [
53] and Zheng [
54] fused the spectral images, e.g., panchromatic, RGB, or multispectral images, whereas, in our work, the spatial and spectral data in the form of RGB and depth data were fused.
7. Conclusions
This publication compares different upsampling methods for their use in data fusion based on complex objects. Three different processes—classical interpolation methods, MRFs, and JBU—are compared. First, the best parameter for each method was determined before they were compared. By applying JBU, downsampling the RGB data by a factor of 4 × 4, and later upsampling the data to the depth data resolution, as well as using nearest neighbor interpolation, the other methods were outperformed.
Figure 6 shows the RGB-D point cloud of the validation coin. One can see the texture on the coin combined with the height profile, with a total diameter of 23
; the height resolution matches the texture resolution provided by the RGB image.
Figure 7 shows the resulting RGB-D point cloud for the two example stones, which were retrieved using the described JBU setup. By using a 3D laser line scanner and an RGB line camera, high-resolution RGB-D images were created. This enables volume approximation and the detailed location of textual and form-based features. However, there are also flaws seen in
Figure 7b.
Figure 7b shows noisy depth points due to the rough or reflective topography of the analyzed object, which leads to measurement errors in the depth measurement due to the scattering of the laser beam. Smoothing over this region via the neighborhood would lead to fewer deviations.
Figure 8 shows the results of the different steps of data processing, for example, stone number one.
Figure 8a shows the depth map of the cropped depth data, whereas
Figure 8b shows the edge correlation between the RGB image and the depth map. After minimizing the artifacts of the depth shadow, a blurry edge at the bottom of
Figure 8a can be seen. This noisy region is due to the depth shadows.
Figure 8c shows the results of the synthesized depth map of
Figure 8a. The synthesizing step uses a threshold defined by the histogram of the depth map in order to minimize these blurry edges.
Figure 8d shows an improvement in correlation due to the exclusion of depth shadows.
Figure 8e,f depict the result of the JBU data fusion process. Using JBU increases the correlation between the depth data and RGB data but leads to the synthesized RGB image having a few noise residuals, which are visible in the blurry bottom left part of
Figure 8e. Feature extraction of the RGB image is used in order to create an edge mask to cut out these blurry residuals and overlap both images. With this step, the correlation of the edges increases even further, as depicted in
Figure 8g,h. For the final interpolation of the missing depth map edges with the neighborhood of the missing data, the edge matching of the RGB data and depth data can be achieved.
To conclude this work, data fusion was used for image enhancement by removing artifacts and improving the depth map edge quality by removing the depth shadow and matching the edges of the RGB data and depth data. Moreover, different interpolation methods for RGB data and depth map fusion are compared for multiple assessment parameters. The parameters of each interpolation method were varied to find the best-performing settings. The results show JBU outperforming MRFs and the direct interpolation methods. This work shows the capabilities of RGB-D imaging with temporarily separated imaging systems. The setup-based time delay between both imaging systems was solved using feature extraction and data registration. By imaging RGB data and depth data separately along a conveyor belt system and fusing additional information, the quality of the imaged data was improved.
In future works, other data fusion methods will be compared, including the novel polygon-based approach of triangle-mesh-rasterization projection (TMRP) [
41]. Moreover, the spectral dimension in this work is confined to RGB, and this will be expanded by using multispectral and hyperspectral imaging systems in addition to the RGB camera system.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}