Historical Text Line Segmentation Using Deep Learning Algorithms: Mask-RCNN against U-Net Networks

 , , ,
, , ,
Abstract
1. Introduction
2. Related Work
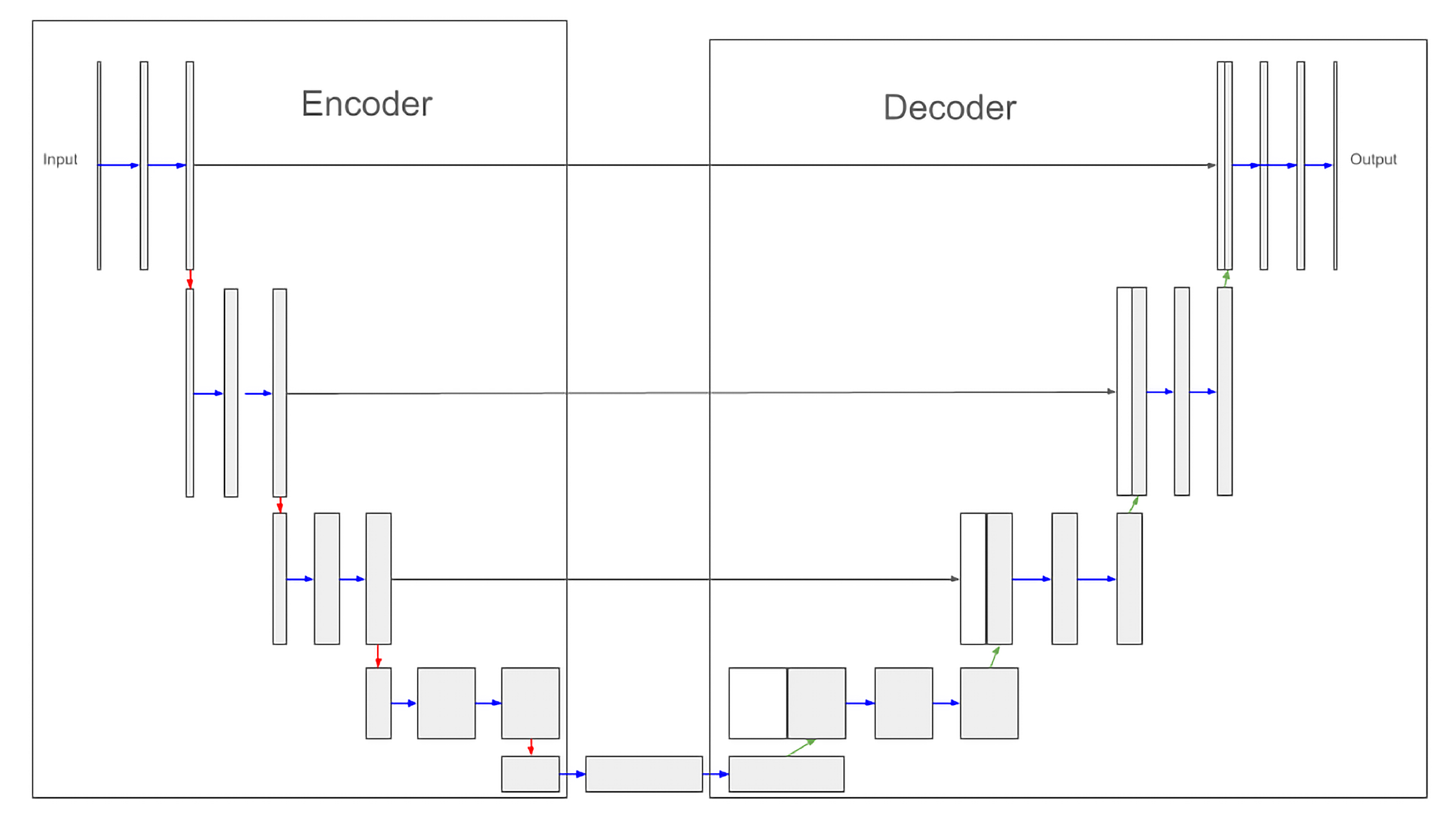
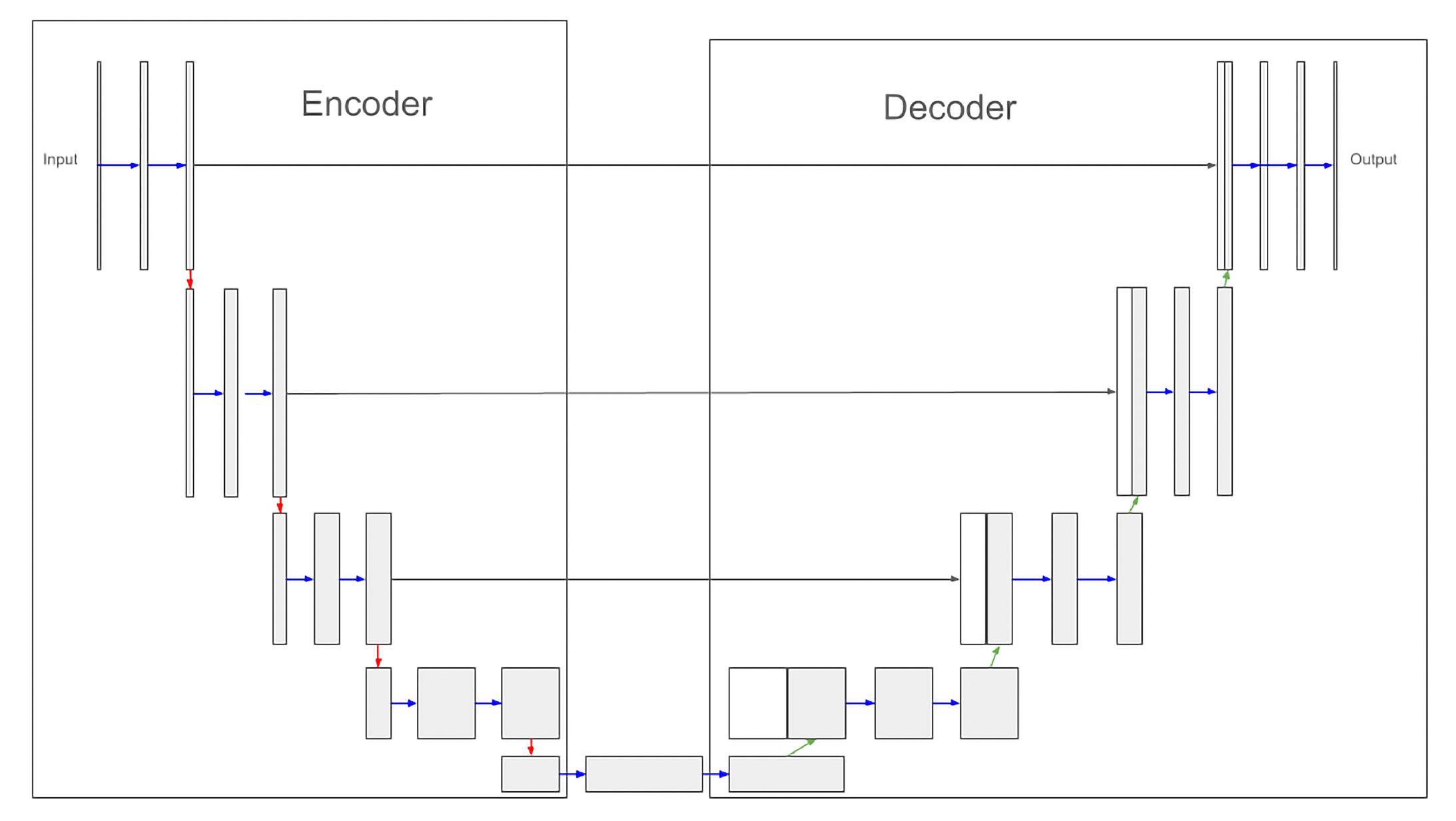
2.1. U-Net
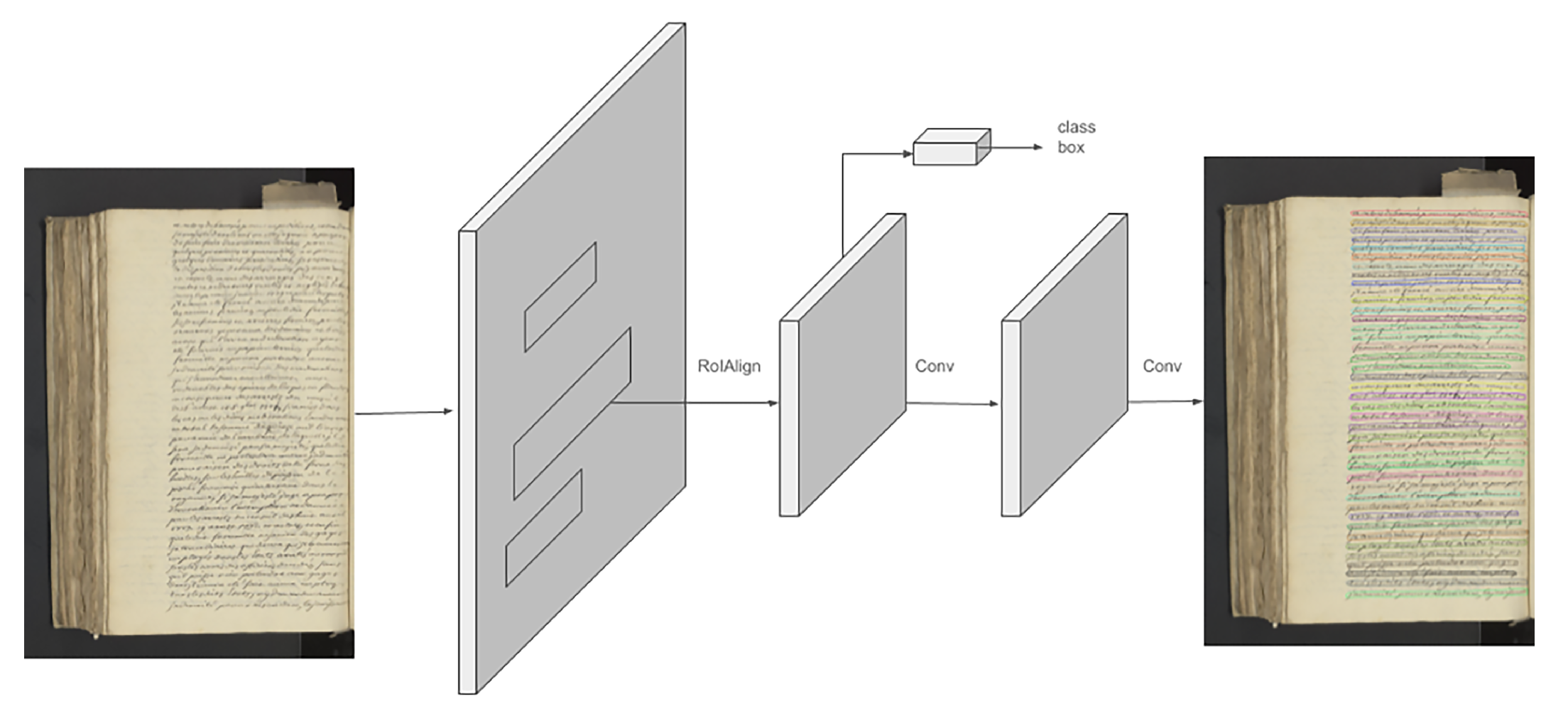
2.2. Mask-RCNN
2.3. Conceptual Comparison between U-Net and Mask-RCNN
2.4. Mask-RCNN and Text Line Extraction in Historical Documents
3. Materials and Methods
3.1. Data Preparation for the Ground Truth of the Deliberation Registers of the States of Burgundy
3.1.1. Creation of Segmentation Masks
3.1.2. Image Format for Training and Inference
3.2. Choice of Public Databases and U-Net Networks
3.3. Evaluation of Segmentation Performance of the Tested Networks
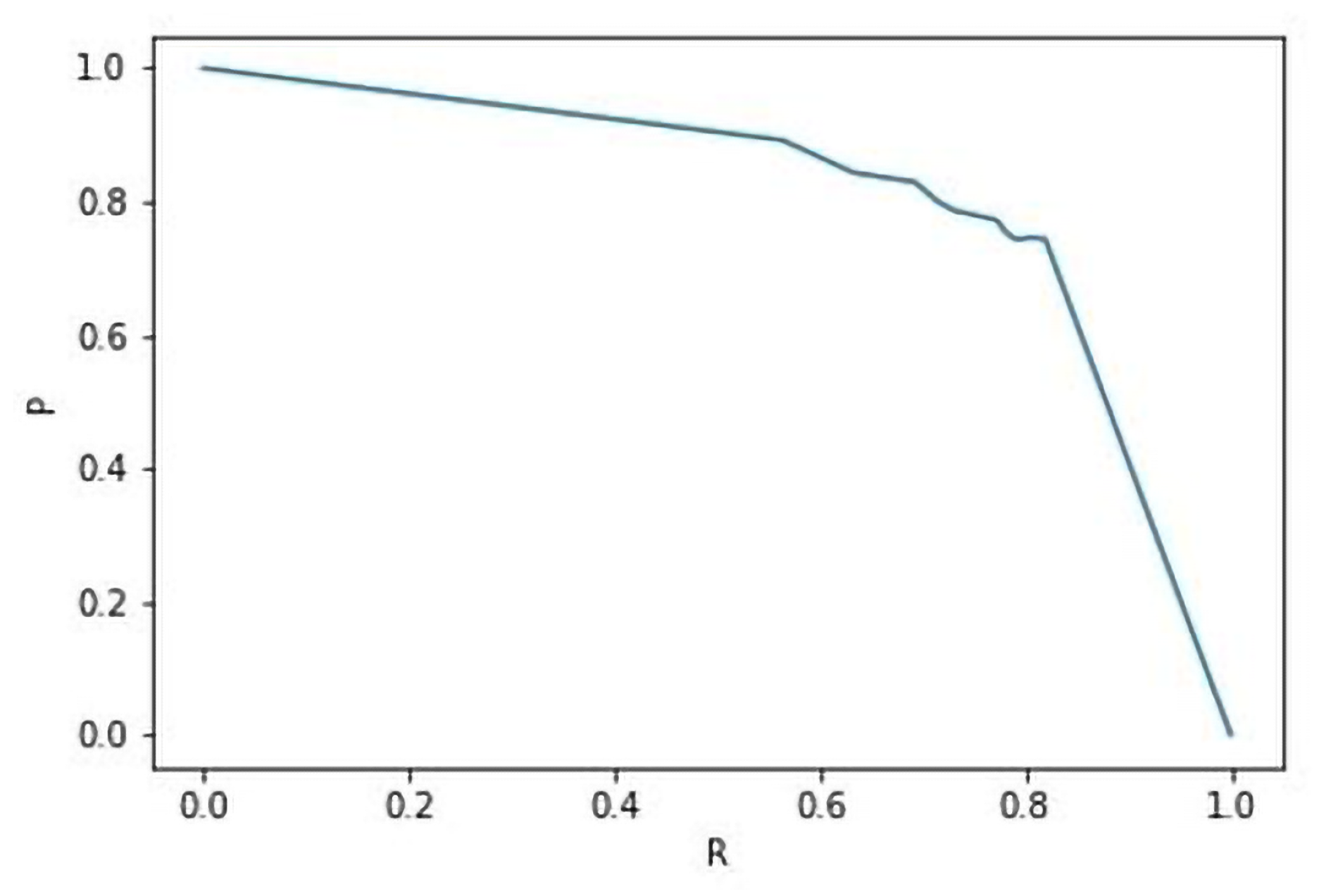
3.3.1. Pixel-Level Metrics
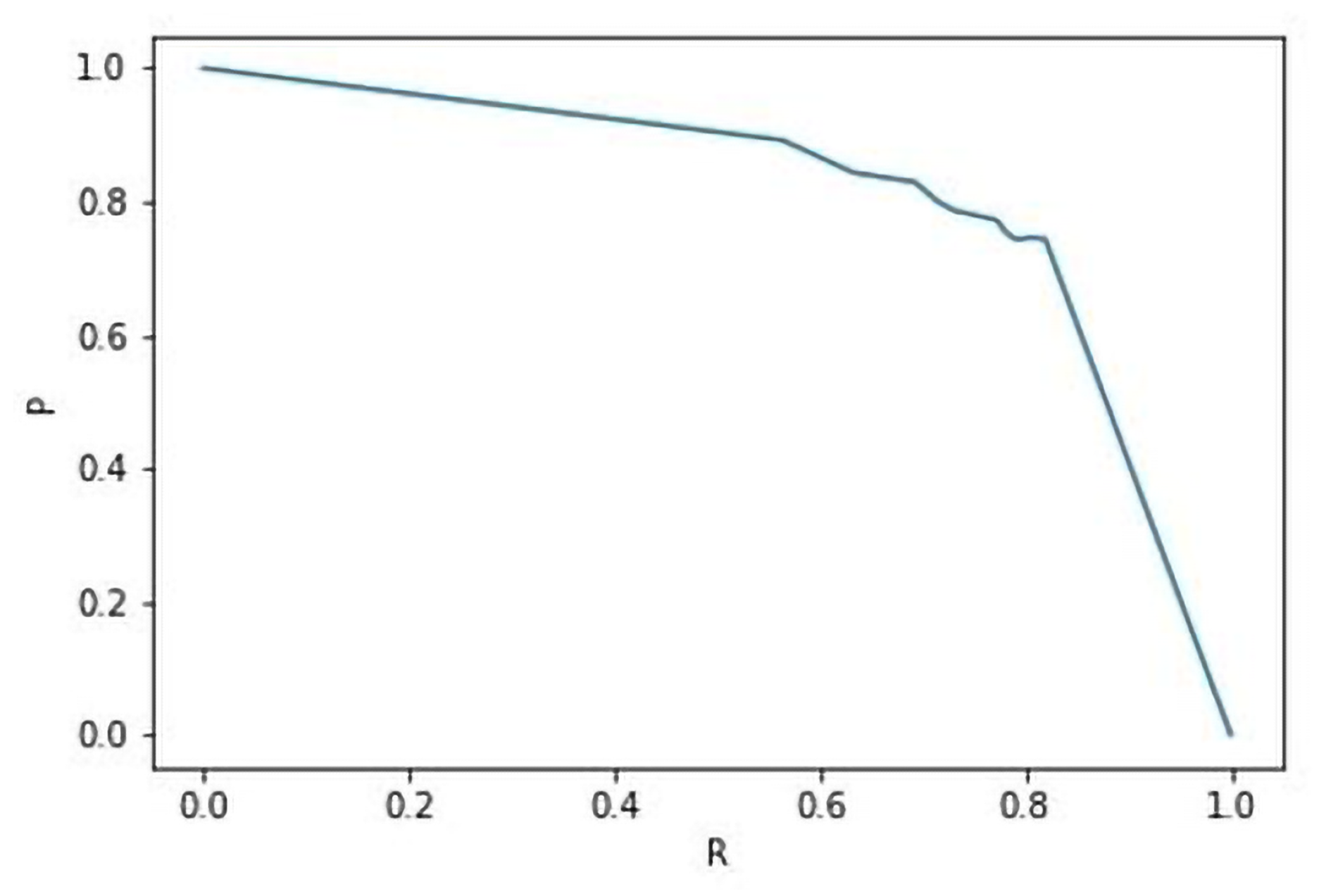
3.3.2. Object-Level Metrics
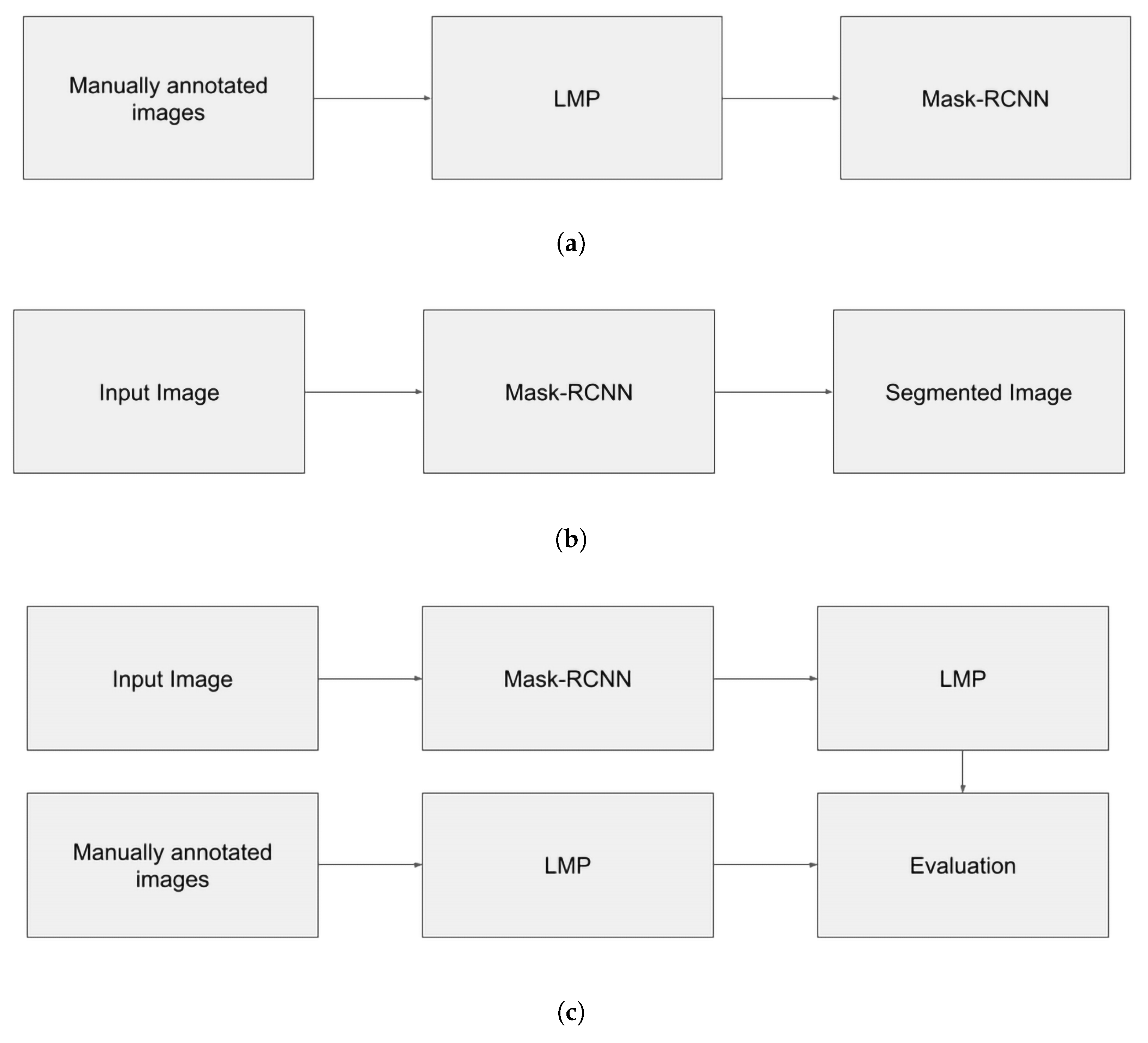
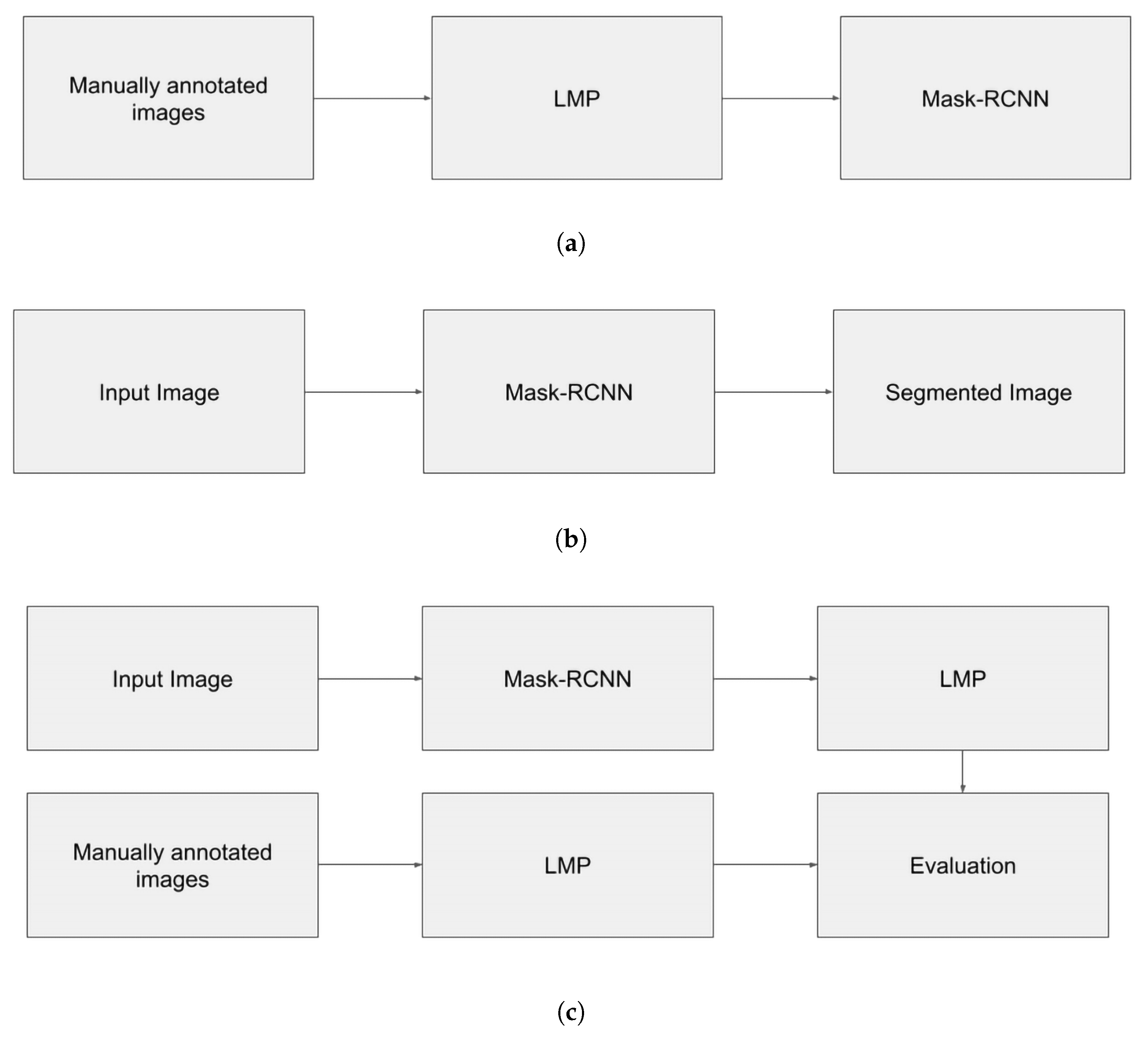
3.3.3. Light Mask Processing for Evaluation When Using the DRoSB Database
3.4. Implementation of Networks
3.5. Computational Requirements
4. Results
4.1. Study 1: Mask-RCNN against U-Net Networks on cBaD 2017 READ-Complex, DIVA-HisDB and HOME-Alcar
4.2. Study 2: Mask-RCNN against Doc-UFCN on the DRoSB Dataset
4.3. Study 3: Mask-RCNN Segmentation against Doc-UFCN Segmentation on Transcription Performance
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Archives, F.N. Gallica; The BnF Digital Library: Paris, France, 1997. [Google Scholar]
- Paillard, J. Nouveaux objectifs pour l’étude de la performance motrice intégrée: Les niveaux de contrôle. In Psychology of Motor Behavior and Sport; Nadeau, C., Haliwell, W., Roberts, K., Roberts, G., Eds.; Human Kinetic Publisher: Champaign, IL, USA, 1980. [Google Scholar]
- Likforman-Sulem, L.; Zahour, A.; Taconet, B. Text line segmentation of historical documents: A survey. Int. J. Doc. Anal. Recognit. (IJDAR) 2007, 9, 123–138. [Google Scholar] [CrossRef]
- Diem, M.; Kleber, F.; Fiel, S.; Gruning, T.; Gatos, B. cBAD: ICDAR2017 Competition on Baseline Detection. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; p. 1360. [Google Scholar] [CrossRef]
- Kurar Barakat, B.; Cohen, R.; Droby, A.; Rabaev, I.; El-Sana, J. Learning-Free Text Line Segmentation for Historical Handwritten Documents. Appl. Sci. 2020, 10, 8276. [Google Scholar] [CrossRef]
- Nguyen, T.N.; Burie, J.C.; Le, T.L.; Schweyer, A.V. An effective method for text line segmentation in historical document images. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1593–1599. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Clérice, T. You Actually Look Twice At it (YALTAi): Using an object detection approach instead of region segmentation within the Kraken engine. arXiv 2022, arXiv:2207.11230. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Sharma, R.; Saqib, M.; Lin, C.T.; Blumenstein, M. A Survey on Object Instance Segmentation. SN Comput. Sci. 2022, 3, 499. [Google Scholar] [CrossRef]
- Droby, A.; Kurar Barakat, B.; Alaasam, R.; Madi, B.; Rabaev, I.; El-Sana, J. Text Line Extraction in Historical Documents Using Mask R-CNN. Signals 2022, 3, 535–549. [Google Scholar] [CrossRef]
- Boillet, M.; Kermorvant, C.; Paquet, T. Robust text line detection in historical documents: Learning and evaluation methods. Int. J. Doc. Anal. Recognit. (IJDAR) 2022, 25, 95–114. [Google Scholar] [CrossRef]
- Simistira, F.; Seuret, M.; Eichenberger, N.; Garz, A.; Liwicki, M.; Ingold, R. DIVA-HisDB: A Precisely Annotated Large Dataset of Challenging Medieval Manuscripts. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 471–476. [Google Scholar] [CrossRef]
- Stutzmann, D.; Torres Aguilar, S.; Chaffenet, P. HOME-Alcar: Aligned and Annotated Cartularies. 2021. Available online: https://doi.org/10.5281/zenodo.5600884 (accessed on 26 February 2024).
- Oliveira, S.A.; Seguin, B.; Kaplan, F. dhSegment: A generic deep-learning approach for document segmentation. In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 7–12. [Google Scholar] [CrossRef]
- Grüning, T.; Leifert, G.; Strauß, T.; Michael, J.; Labahn, R. A Two-Stage Method for Text Line Detection in Historical Documents. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 285–302. [Google Scholar] [CrossRef]
- Boillet, M.; Maarand, M.; Paquet, T.; Kermorvant, C. Including Keyword Position in Image-based Models for Act Segmentation of Historical Registers. In Proceedings of the 6th International Workshop on Historical Document Imaging and Processing, New York, NY, USA, 13–18 September 2021; HIP ’21. pp. 31–36. [Google Scholar] [CrossRef]
- Renton, G.; Chatelain, C.; Adam, S.; Kermorvant, C.; Paquet, T. Handwritten Text Line Segmentation Using Fully Convolutional Network. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 5–9. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Vuola, A.O.; Akram, S.U.; Kannala, J. Mask-RCNN and U-net Ensembled for Nuclei Segmentation. arXiv 2019, arXiv:1901.10170. [Google Scholar]
- Marechal, E.; Jaugey, A.; Tarris, G.; Martin, L.; Paindavoine, M.; Rebibou, J.; Mathieu, L. FC046: Automated Mest-C Classification in IGA Nephropathy using Deep-Learning based Segmentation. Nephrol. Dial. Transplant. 2022, 37, gfac105-002. [Google Scholar] [CrossRef]
- Van Wymelbeke-Delannoy, V.; Juhel, C.; Bole, H.; Sow, A.K.; Guyot, C.; Belbaghdadi, F.; Brousse, O.; Paindavoine, M. A Cross-Sectional Reproducibility Study of a Standard Camera Sensor Using Artificial Intelligence to Assess Food Items: The FoodIntech Project. Nutrients 2022, 14, 221. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, W.; Cai, Z.; Zhang, G.; Lu, Y. Accurate Fine-grained Layout Analysis for the Historical Tibetan Document Based on the Instance Segmentation. IEEE Access 2021, 9, 154435–154447. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. SOLOv2: Dynamic and Fast Instance Segmentation. arXiv 2020, arXiv:2003.10152. [Google Scholar] [CrossRef]
- Fizaine, F.C.; Robin, C.; Paindavoine, M. Transcription Automatique de textes du XVIIIe siècle à l’aide de l’intelligence artificielle. In Proceedings of the Conference of AI4LAM Les Futurs Fantastiques, Paris, France, 8–10 December 2021; Available online: https://www.bnf.fr/fr/les-futurs-fantastiques (accessed on 26 February 2024).
- Fizaine, F.C.; Bouyé, E. Lettres en Lumières. In Proceedings of the Conference of CremmaLab Documents Anciens et Reconnaissance Automatique des éCritures Manuscrites, Paris, France, 23–24 June 2022. [Google Scholar]
- Ostu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man, Cybern. 1979, 9, 62–66. [Google Scholar]
- Mechi, O.; Mehri, M.; Ingold, R.; Essoukri Ben Amara, N. Text Line Segmentation in Historical Document Images Using an Adaptive U-Net Architecture. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; p. 374. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Wick, C.; Puppe, F. Fully Convolutional Neural Networks for Page Segmentation of Historical Document Images. In Proceedings of the 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 287–292. [Google Scholar] [CrossRef]
- Li, M.; Lv, T.; Cui, L.; Lu, Y.; Florencio, D.; Zhang, C.; Li, Z.; Wei, F. TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models. arXiv 2021, arXiv:2109.10282. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255, ISSN 1063-6919. [Google Scholar] [CrossRef]
- Marti, U.V.; Bunke, H. The IAM-database: An English sentence database for offline handwriting recognition. Int. J. Doc. Anal. Recognit. 2002, 5, 39–46. [Google Scholar] [CrossRef]
- Sánchez, J.A.; Romero, V.; Toselli, A.H.; Vidal, E. Bozen Dataset. 2016. Available online: https://doi.org/10.5281/zenodo.218236 (accessed on 26 February 2024).
- Boillet, M.; Bonhomme, M.L.; Stutzmann, D.; Kermorvant, C. HORAE: An annotated dataset of books of hours. In Proceedings of the 5th International Workshop on Historical Document Imaging and Processing, Sydney, NSW, Australia, 20–21 September 2019; pp. 7–12. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IoU | F1-Score | |||||
|---|---|---|---|---|---|---|
| Network | cBaD | DIVA | HOME | cBaD | DIVA | HOME |
| ARU-Net 1 | 0.73 | 0.60 | 0.67 | 0.81 | 0.96 | 0.94 |
| dhSegment 1 | 0.58 | 0.46 | 0.55 | 0.73 | 0.60 | 0.73 |
| Doc-UFCN 1 | 0.49 | 0.67 | 0.60 | 0.70 | 0.80 | 0.77 |
| Dilated-FCN 2 | - | - | - | 0.75 | 0.92 | - |
| Mask-RCNN | 0.64 | 0.55 | 0.85 | 0.76 | 0.70 | 0.91 |
| AP@0.5 | AP@0.75 | AP@[0.5,0.95] | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Network | cBaD | DIVA | HOME | cBaD | DIVA | HOME | cBaD | DIVA | HOME |
| ARU-Net 1 | 0.22 | 0.10 | 0.19 | 0.08 | 0.03 | 0.00 | 0.08 | 0.04 | 0.04 |
| dhSegment 1 | 0.62 | 0.39 | 0.78 | 0.15 | 0.11 | 0.12 | 0.24 | 0.17 | 0.28 |
| Doc-UFCN 1 | 0.61 | 0.77 | 0.85 | 0.16 | 0.33 | 0.49 | 0.24 | 0.36 | 0.46 |
| Mask-RCNN | 0.87 | 0.96 | 0.98 | 0.34 | 0.60 | 0.86 | 0.42 | 0.55 | 0.65 |
| Network | LMP | R | P | IoU | F1-Score |
|---|---|---|---|---|---|
| Doc-UFCN | No | 0.73 (0.04) | 0.88 (0.06) | 0.65 (0.03) | 0.78 (0.03) |
| Mask-RCNN | No | 0.83 (0.08) | 0.85 (0.07) | 0.71 (0.05) | 0.82 (0.03) |
| Doc-UFCN | Yes | 0.92 (0.04) | 0.60 (0.06) | 0.55 (0.06) | 0.70 (0.05) |
| Mask-RCNN | Yes | 0.89 (0.04) | 0.94 (0.02) | 0.84 (0.04) | 0.91 (0.02) |
| Network | LMP | AP@0.5 | AP@0.75 | AP@[0.5,0.95] |
|---|---|---|---|---|
| Doc-UFCN | No | 0.61 (0.06) | 0.18 (0.08) | 0.26 (0.04) |
| Mask-RCNN | No | 0.90 (0.13) | 0.46 (0.21) | 0.48 (0.10) |
| Doc-UFCN | Yes | 0.62 (0.08) | 0.52 (0.08) | 0.50 (0.08) |
| Mask-RCNN | Yes | 0.96 (0.02) | 0.85 (0.06) | 0.78 (0.06) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fizaine, F.C.; Bard, P.; Paindavoine, M.; Robin, C.; Bouyé, E.; Lefèvre, R.; Vinter, A. Historical Text Line Segmentation Using Deep Learning Algorithms: Mask-RCNN against U-Net Networks. J. Imaging 2024, 10, 65. https://doi.org/10.3390/jimaging10030065
Fizaine FC, Bard P, Paindavoine M, Robin C, Bouyé E, Lefèvre R, Vinter A. Historical Text Line Segmentation Using Deep Learning Algorithms: Mask-RCNN against U-Net Networks. Journal of Imaging. 2024; 10(3):65. https://doi.org/10.3390/jimaging10030065
Chicago/Turabian StyleFizaine, Florian Côme, Patrick Bard, Michel Paindavoine, Cécile Robin, Edouard Bouyé, Raphaël Lefèvre, and Annie Vinter. 2024. "Historical Text Line Segmentation Using Deep Learning Algorithms: Mask-RCNN against U-Net Networks" Journal of Imaging 10, no. 3: 65. https://doi.org/10.3390/jimaging10030065
APA StyleFizaine, F. C., Bard, P., Paindavoine, M., Robin, C., Bouyé, E., Lefèvre, R., & Vinter, A. (2024). Historical Text Line Segmentation Using Deep Learning Algorithms: Mask-RCNN against U-Net Networks. Journal of Imaging, 10(3), 65. https://doi.org/10.3390/jimaging10030065