
Exploration of Interpretability Techniques for Deep COVID-19 Classification Using Chest X-ray Images
 ,
,  , , , and
, , , and 
Abstract
1. Introduction
Related Works
2. Materials and Methods
2.1. Network Models
- ResNet:
- InceptionNet:
- InceptionResNetV2:
- DenseNet:
2.2. Interpretability Techniques
- Occlusion:
- Saliency:
- Input X Gradient:
- Guided Backpropagation:
- Integrated Gradients:
- DeepLIFT:
- Neuron Activation Profiles:
2.3. Implementation
2.4. Data
2.4.1. Data Collection
2.4.2. Dataset Preparation
2.4.3. Pre-Processing
2.4.4. Classification Setup
2.5. Evaluation Metrics
3. Results
3.1. Model Outcome
3.1.1. Overall Comparisons of the Classifiers
3.1.2. Comparisons of the Classifiers for Different Pathologies
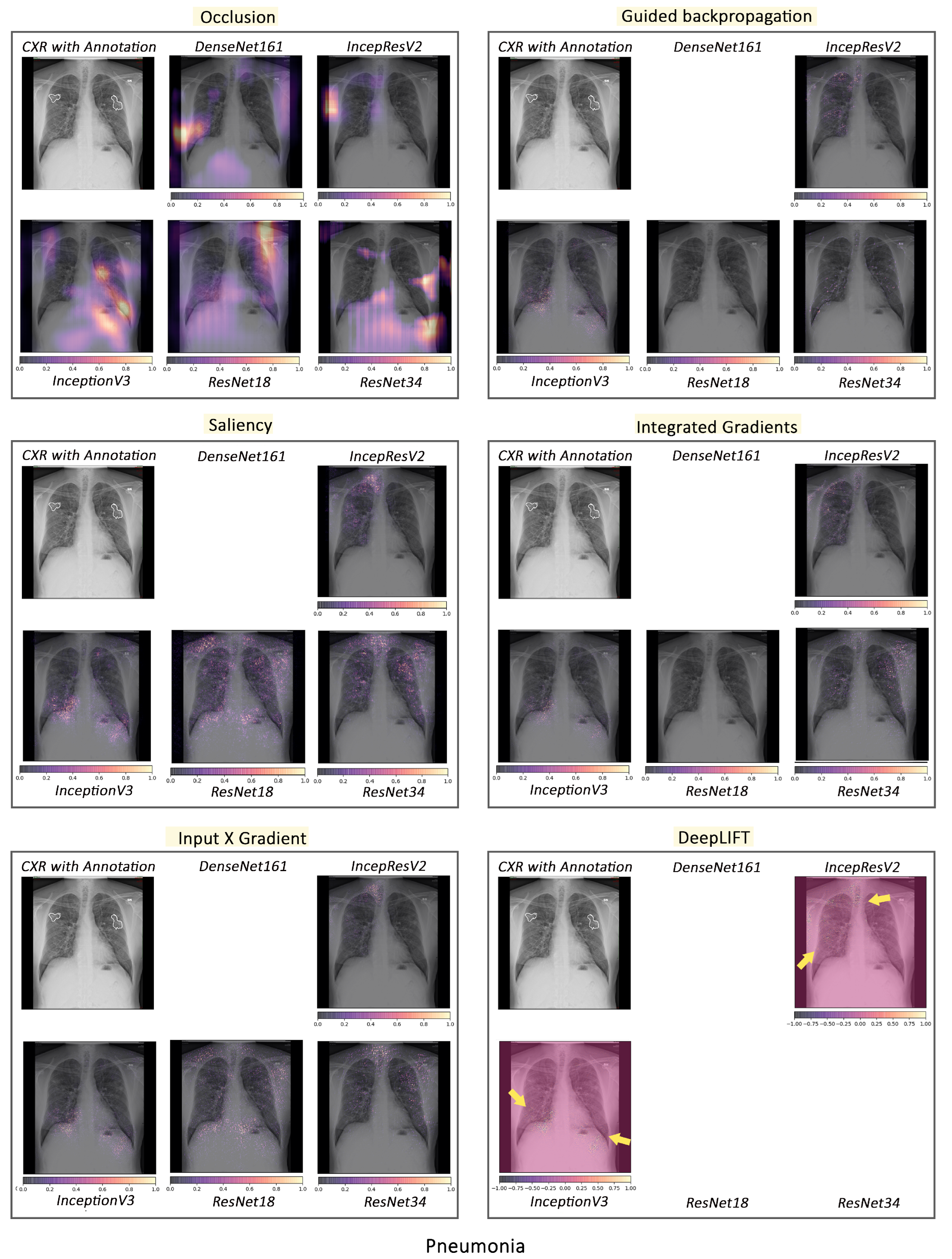
3.2. Interpretability of Models
3.2.1. Pathology-Based Comparisons of Local Interpretability Techniques for Models
3.2.2. Intense Interpretability
- The failure case of the best performing model for COVID-19 classification:
- Representations in DenseNet161 and ResNet18:
- COVID-19, pneumonia and viral pneumonia:
4. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, N.; Zhang, D.; Wang, W.; Li, X.; Yang, B.; Song, J.; Zhao, X.; Huang, B.; Shi, W.; Lu, R.; et al. A novel coronavirus from patients with pneumonia in China, 2019. N. Engl. J. Med. 2020, 382, 727–733. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Guan, X.; Wu, P.; Wang, X.; Zhou, L.; Tong, Y.; Ren, R.; Leung, K.S.; Lau, E.H.; Wong, J.Y.; et al. Early transmission dynamics in Wuhan, China, of novel coronavirus–infected pneumonia. N. Engl. J. Med. 2020, 382, 1199–1207. [Google Scholar] [CrossRef]
- Radiopaedia: COVID-19. Available online: https://radiopaedia.org/articles/covid-19-3 (accessed on 24 January 2024).
- Ai, T.; Yang, Z.; Hou, H.; Zhan, C.; Chen, C.; Lv, W.; Tao, Q.; Sun, Z.; Xia, L. Correlation of chest CT and RT-PCR testing in coronavirus disease 2019 (COVID-19) in China: A report of 1014 cases. Radiology 2020, 296, E32–E40. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Zhang, H.; Xie, J.; Lin, M.; Ying, L.; Pang, P.; Ji, W. Sensitivity of chest CT for COVID-19: Comparison to RT-PCR. Radiology 2020, 296, E115–E117. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xie, Y.; Li, Y.; Shen, C.; Xia, Y. Covid-19 screening on chest x-ray images using deep learning based anomaly detection. arXiv 2020, arXiv:2003.12338. [Google Scholar]
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic detection of coronavirus disease (COVID-19) using x-ray images and deep convolutional neural networks. arXiv 2020, arXiv:2003.10849. [Google Scholar] [CrossRef]
- Apostolopoulos, I.D.; Mpesiana, T.A. COVID-19: Automatic detection from x-ray images utilizing transfer learning with convolutional neural networks. Phys. Eng. Sci. Med. 2020, 43, 635–640. [Google Scholar] [CrossRef]
- Kanne, J.P. Chest CT findings in 2019 novel coronavirus (2019-nCoV) infections from Wuhan, China: Key points for the radiologist. Radiology 2020, 295, 16–17. [Google Scholar] [CrossRef]
- Bernheim, A.; Mei, X.; Huang, M.; Yang, Y.; Fayad, Z.A.; Zhang, N.; Diao, K.; Lin, B.; Zhu, X.; Li, K.; et al. Chest CT findings in coronavirus disease-19 (COVID-19): Relationship to duration of infection. Radiology 2020, 295, 685–691. [Google Scholar] [CrossRef]
- Xie, X.; Zhong, Z.; Zhao, W.; Zheng, C.; Wang, F.; Liu, J. Chest CT for typical 2019-nCoV pneumonia: Relationship to negative RT-PCR testing. Radiology 2020, 296, E41–E45. [Google Scholar] [CrossRef]
- Huang, P.; Liu, T.; Huang, L.; Liu, H.; Lei, M.; Xu, W.; Hu, X.; Chen, J.; Liu, B. Use of chest CT in combination with negative RT-PCR assay for the 2019 novel coronavirus but high clinical suspicion. Radiology 2020, 295, 22–23. [Google Scholar] [CrossRef]
- Omer, S.B.; Malani, P.; Del Rio, C. The COVID-19 pandemic in the US: A clinical update. JAMA 2020, 323, 1767–1768. [Google Scholar] [CrossRef]
- Rubin, G.D.; Ryerson, C.J.; Haramati, L.B.; Sverzellati, N.; Kanne, J.P.; Raoof, S.; Schluger, N.W.; Volpi, A.; Yim, J.J.; Martin, I.B.; et al. The role of chest imaging in patient management during the COVID-19 pandemic: A multinational consensus statement from the Fleischner Society. Radiology 2020, 296, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Harahwa, T.A.; Yau, T.H.L.; Lim-Cooke, M.S.; Al-Haddi, S.; Zeinah, M.; Harky, A. The optimal diagnostic methods for COVID-19. Diagnosis 2020, 7, 349–356. [Google Scholar] [CrossRef] [PubMed]
- Jacobi, A.; Chung, M.; Bernheim, A.; Eber, C. Portable chest X-ray in coronavirus disease-19 (COVID-19): A pictorial review. Clin. Imaging 2020, 64, 35–42. [Google Scholar] [CrossRef] [PubMed]
- Guan, W.J.; Ni, Z.Y.; Hu, Y.; Liang, W.H.; Ou, C.Q.; He, J.X.; Liu, L.; Shan, H.; Lei, C.L.; Hui, D.S.; et al. Clinical characteristics of coronavirus disease 2019 in China. N. Engl. J. Med. 2020, 382, 1708–1720. [Google Scholar] [CrossRef] [PubMed]
- Durrani, M.; Inam ul Haq, U.K.; Yousaf, A. Chest X-rays findings in COVID 19 patients at a University Teaching Hospital—A descriptive study. Pak. J. Med. Sci. 2020, 36, S22. [Google Scholar] [CrossRef] [PubMed]
- Wong, H.Y.F.; Lam, H.Y.S.; Fong, A.H.T.; Leung, S.T.; Chin, T.W.Y.; Lo, C.S.Y.; Lui, M.M.S.; Lee, J.C.Y.; Chiu, K.W.H.; Chung, T.; et al. Frequency and distribution of chest radiographic findings in COVID-19 positive patients. Radiology 2020, 296, E72–E78. [Google Scholar] [CrossRef] [PubMed]
- Ng, M.Y.; Lee, E.Y.; Yang, J.; Yang, F.; Li, X.; Wang, H.; Lui, M.M.s.; Lo, C.S.Y.; Leung, B.; Khong, P.L.; et al. Imaging profile of the COVID-19 infection: Radiologic findings and literature review. Radiol. Cardiothorac. Imaging 2020, 2, e200034. [Google Scholar] [CrossRef]
- Cohen, J.P.; Morrison, P.; Dao, L. COVID-19 image data collection. arXiv 2020, arXiv:2003.11597. [Google Scholar]
- Ozturk, T.; Talo, M.; Yildirim, E.A.; Baloglu, U.B.; Yildirim, O.; Acharya, U.R. Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput. Biol. Med. 2020, 121, 103792. [Google Scholar] [CrossRef]
- Liu, J.; Cao, L.; Akin, O.; Tian, Y. Accurate and Robust Pulmonary Nodule Detection by 3D Feature Pyramid Network with Self-Supervised Feature Learning. arXiv 2019, arXiv:1907.11704. [Google Scholar]
- Yoo, S.; Gujrathi, I.; Haider, M.A.; Khalvati, F. Prostate cancer Detection using Deep convolutional neural networks. Sci. Rep. 2019, 9, 19518. [Google Scholar] [CrossRef] [PubMed]
- Tô, T.D.; Lan, D.T.; Nguyen, T.T.H.; Nguyen, T.T.N.; Nguyen, H.P.; Phuong, L.; Nguyen, T.Z. Ensembled Skin Cancer Classification. ISIC 2019 Challenge Submission, 2019. Available online: https://hal.science/hal-02335240v1/file/Combined_approach_to_skin_cancer_classification.pdf (accessed on 24 January 2024).
- Vial, A.; Stirling, D.; Field, M.; Ros, M.; Ritz, C.; Carolan, M.; Holloway, L.; Miller, A.A. The role of deep learning and radiomic feature extraction in cancer-specific predictive modelling: A review. Transl. Cancer Res. 2018, 7, 803–816. [Google Scholar] [CrossRef]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 2019, 6, 94. [Google Scholar] [CrossRef] [PubMed]
- Sloane, E.B.; Silva, R.J. Artificial intelligence in medical devices and clinical decision support systems. In Clinical Engineering Handbook; Elsevier: Amsterdam, The Netherlands, 2020; pp. 556–568. [Google Scholar]
- Mahadevaiah, G.; Rv, P.; Bermejo, I.; Jaffray, D.; Dekker, A.; Wee, L. Artificial intelligence-based clinical decision support in modern medical physics: Selection, acceptance, commissioning, and quality assurance. Med. Phys. 2020, 47, e228–e235. [Google Scholar] [CrossRef] [PubMed]
- Agrebi, S.; Larbi, A. Use of artificial intelligence in infectious diseases. In Artificial Intelligence in Precision Health; Elsevier: Amsterdam, The Netherlands, 2020; pp. 415–438. [Google Scholar]
- Sweetlin, J.D.; Nehemiah, H.K.; Kannan, A. Computer aided diagnosis of drug sensitive pulmonary tuberculosis with cavities, consolidations and nodular manifestations on lung CT images. Int. J. Bio Inspired Comput. 2019, 13, 71–85. [Google Scholar] [CrossRef]
- Yao, J.; Dwyer, A.; Summers, R.M.; Mollura, D.J. Computer-aided diagnosis of pulmonary infections using texture analysis and support vector machine classification. Acad. Radiol. 2011, 18, 306–314. [Google Scholar] [CrossRef]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Using artificial intelligence to detect COVID-19 and community-acquired pneumonia based on pulmonary CT: Evaluation of the diagnostic accuracy. Radiology 2020, 296, E65–E71. [Google Scholar] [CrossRef]
- Chen, J.; Wu, L.; Zhang, J.; Zhang, L.; Gong, D.; Zhao, Y.; Chen, Q.; Huang, S.; Yang, M.; Yang, X.; et al. Deep learning-based model for detecting 2019 novel coronavirus pneumonia on high-resolution computed tomography. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef]
- Wang, L.; Wong, A.; Qui Lin, Z. COVID-Net: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest X-ray Images. arXiv 2020, arXiv:2003.09871. [Google Scholar] [CrossRef]
- Ghoshal, B.; Tucker, A. Estimating uncertainty and interpretability in deep learning for coronavirus (COVID-19) detection. arXiv 2020, arXiv:2003.10769. [Google Scholar]
- Singh, G.; Yow, K.C. An interpretable deep learning model for COVID-19 detection with chest X-ray images. IEEE Access 2021, 9, 85198–85208. [Google Scholar] [CrossRef] [PubMed]
- Singh, G.; Yow, K.C. Object or background: An interpretable deep learning model for COVID-19 detection from CT-scan images. Diagnostics 2021, 11, 1732. [Google Scholar] [CrossRef] [PubMed]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Deep Learning applications for COVID-19. J. Big Data 2021, 8, 1–54. [Google Scholar] [CrossRef] [PubMed]
- De Falco, I.; De Pietro, G.; Sannino, G. Classification of Covid-19 chest X-ray images by means of an interpretable evolutionary rule-based approach. Neural Comput. Appl. 2023, 35, 16061–16071. [Google Scholar] [CrossRef] [PubMed]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Salient deconvolutional networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 120–135. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 3319–3328. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Interpretable Machine Learning: A Guide for Making Black-Box Models Explainable. 2022. Available online: https://christophm.github.io/interpretable-ml-book (accessed on 24 January 2024).
- Kopitar, L.; Cilar, L.; Kocbek, P.; Stiglic, G. Local vs. global interpretability of machine learning models in type 2 diabetes mellitus screening. In Artificial Intelligence in Medicine: Knowledge Representation and Transparent and Explainable Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 108–119. [Google Scholar]
- Kindermans, P.J.; Schütt, K.; Müller, K.R.; Dähne, S. Investigating the influence of noise and distractors on the interpretation of neural networks. arXiv 2016, arXiv:1611.07270. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 3145–3153. [Google Scholar]
- Krug, A.; Knaebel, R.; Stober, S. Neuron Activation Profiles for Interpreting Convolutional Speech Recognition Models. In Proceedings of the NeurIPS Workshop IRASL: Interpretability and Robustness for Audio, Speech and Language, Montreal, QC, Canada, 8 December 2018. [Google Scholar]
- Krug, A.; Ebrahimzadeh, M.; Alemann, J.; Johannsmeier, J.; Stober, S. Analyzing and visualizing deep neural networks for speech recognition with saliency-adjusted neuron activation profiles. Electronics 2021, 10, 1350. [Google Scholar] [CrossRef]
- Krug, A.; Ratul, R.K.; Stober, S. Visualizing Deep Neural Networks with Topographic Activation Maps. arXiv 2022, arXiv:2204.03528. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Kokhlikyan, N.; Miglani, V.; Martin, M.; Wang, E.; Alsallakh, B.; Reynolds, J.; Melnikov, A.; Kliushkina, N.; Araya, C.; Yan, S.; et al. Captum: A unified and generic model interpretability library for PyTorch. arXiv 2020, arXiv:2009.07896. [Google Scholar]
- Chatterjee, S.; Das, A.; Mandal, C.; Mukhopadhyay, B.; Vipinraj, M.; Shukla, A.; Nagaraja Rao, R.; Sarasaen, C.; Speck, O.; Nürnberger, A. TorchEsegeta: Framework for Interpretability and Explainability of Image-based Deep Learning Models. Appl. Sci. 2022, 12, 1834. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- PyTorch Reproducibility. Available online: https://pytorch.org/docs/stable/notes/randomness.html (accessed on 24 January 2024).
- Nvidia Apex. Available online: https://github.com/NVIDIA/apex (accessed on 24 January 2024).
- COVID-19 Image Data Collection. Available online: https://github.com/ieee8023/covid-chestxray-dataset (accessed on 24 January 2024).
- Kermany, D.; Zhang, K.; Goldbaum, M. Labeled optical coherence tomography (oct) and chest X-ray images for classification. Mendeley Data 2018, 2, 651. [Google Scholar]
- Chest X-ray Images (Pneumonia). Available online: https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia (accessed on 24 January 2024).
- Radiopaedia: Chest Radiograph. Available online: https://radiopaedia.org/articles/chest-radiograph?lang=us (accessed on 24 January 2024).
- Diamond, M.; Peniston, H.L.; Sanghavi, D.; Mahapatra, S.; Doerr, C. Acute Respiratory Distress Syndrome (Nursing); StatPearls Publishing: Treasure Island, FL, USA, 2021. [Google Scholar]
- Matthay, M.A.; Zemans, R.L.; Zimmerman, G.A.; Arabi, Y.M.; Beitler, J.R.; Mercat, A.; Herridge, M.; Randolph, A.G.; Calfee, C.S. Acute respiratory distress syndrome. Nat. Rev. Dis. Prim. 2019, 5, 1–22. [Google Scholar] [CrossRef]
- Fan, E.; Beitler, J.R.; Brochard, L.; Calfee, C.S.; Ferguson, N.D.; Slutsky, A.S.; Brodie, D. COVID-19-associated acute respiratory distress syndrome: Is a different approach to management warranted? Lancet Respir. Med. 2020, 8, 816–821. [Google Scholar] [CrossRef]
- Gattinoni, L.; Chiumello, D.; Rossi, S. COVID-19 pneumonia: ARDS or not? Crit. Care 2020, 24, 154. [Google Scholar] [CrossRef] [PubMed]
- Bain, W.; Yang, H.; Shah, F.A.; Suber, T.; Drohan, C.; Al-Yousif, N.; DeSensi, R.S.; Bensen, N.; Schaefer, C.; Rosborough, B.R.; et al. COVID-19 versus non–COVID-19 acute respiratory distress syndrome: Comparison of demographics, physiologic parameters, inflammatory biomarkers, and clinical outcomes. Ann. Am. Thorac. Soc. 2021, 18, 1202–1210. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I. Multi-label classification: An overview. Int. J. Data Warehous. Min. IJDWM 2007, 3, 1–13. [Google Scholar] [CrossRef]
- Charte, F.; Rivera, A.J.; del Jesus, M.J.; Herrera, F. Addressing imbalance in multilabel classification: Measures and random resampling algorithms. Neurocomputing 2015, 163, 3–16. [Google Scholar] [CrossRef]
- Denise, E.; Morris, D.W.C.; Clarke, S.C. Secondary Bacterial Infections Associated with Influenza Pandemics. Front. Microbiol. 2017, 8, 1041. [Google Scholar]
- Hanada, S.; Pirzadeh, M.; Carver, K.Y.; Deng, J.C. Respiratory Viral Infection-Induced Microbiome Alterations and Secondary Bacterial Pneumonia. Front. Immunol. 2018, 9, 2640. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 4765–4774. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | No of Parameters | GFLOPs | MACs ( ) | GPU Memory (Forward + Backward) in GB |
|---|---|---|---|---|
| ResNet18 | 11,183,694 | 18.95 | 9.53 | 0.15 |
| ResNet34 | 21,291,854 | 38.28 | 19.22 | 0.22 |
| InceptionV3 | 24,382,716 | 35.04 | 17.63 | 0.44 |
| DenseNet161 | 26,502,926 | 80.73 | 40.98 | 1.31 |
| InceptionResNetV2 | 54,327,982 | 81.07 | 40.70 | 0.72 |
| Model | Precision | Recall | F1 |
|---|---|---|---|
| DenseNet161 | 0.864 ± 0.012 | 0.845 ± 0.015 | 0.854 ± 0.008 |
| InceptionResNetV2 | 0.844 ± 0.023 | 0.787 ± 0.063 | 0.814 ± 0.042 |
| InceptionV3 | 0.802 ± 0.065 | 0.792 ± 0.044 | 0.796 ± 0.053 |
| ResNet18 | 0.824 ± 0.014 | 0.824 ± 0.008 | 0.824 ± 0.007 |
| ResNet34 | 0.815 ± 0.022 | 0.800 ± 0.025 | 0.807 ± 0.018 |
| Ensemble | 0.889 ± 0.010 | 0.851 ± 0.005 | 0.869 ± 0.007 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatterjee, S.; Saad, F.; Sarasaen, C.; Ghosh, S.; Krug, V.; Khatun, R.; Mishra, R.; Desai, N.; Radeva, P.; Rose, G.; et al. Exploration of Interpretability Techniques for Deep COVID-19 Classification Using Chest X-ray Images. J. Imaging 2024, 10, 45. https://doi.org/10.3390/jimaging10020045
Chatterjee S, Saad F, Sarasaen C, Ghosh S, Krug V, Khatun R, Mishra R, Desai N, Radeva P, Rose G, et al. Exploration of Interpretability Techniques for Deep COVID-19 Classification Using Chest X-ray Images. Journal of Imaging. 2024; 10(2):45. https://doi.org/10.3390/jimaging10020045
Chicago/Turabian StyleChatterjee, Soumick, Fatima Saad, Chompunuch Sarasaen, Suhita Ghosh, Valerie Krug, Rupali Khatun, Rahul Mishra, Nirja Desai, Petia Radeva, Georg Rose, and et al. 2024. "Exploration of Interpretability Techniques for Deep COVID-19 Classification Using Chest X-ray Images" Journal of Imaging 10, no. 2: 45. https://doi.org/10.3390/jimaging10020045
APA StyleChatterjee, S., Saad, F., Sarasaen, C., Ghosh, S., Krug, V., Khatun, R., Mishra, R., Desai, N., Radeva, P., Rose, G., Stober, S., Speck, O., & Nürnberger, A. (2024). Exploration of Interpretability Techniques for Deep COVID-19 Classification Using Chest X-ray Images. Journal of Imaging, 10(2), 45. https://doi.org/10.3390/jimaging10020045