
Features Split and Aggregation Network for Camouflaged Object Detection


Abstract
1. Introduction
- We simulate the human observation camouflage scenes to propose a new COD method that includes the spatial detail mining module, the cross-scale feature combination module, and the hierarchical feature aggregation decoder. We rigorously test our model against nineteen others using four public datasets (CAMO [21], CHAMELEON [22], COD10K [1], and NC4K [2]) and evaluate it across seven metrics, where it demonstrates clear advantages.
- To fully mine spatial detail information, we design a spatial detail mining module that interacts with first-level feature information, simulating the human’s cursory examination. To effectively mine information in high-level features, we designed a cross-scale feature combination module to strengthen high-level semantic information by combining features from adjacent scales, simulating humans’ evaluation of features from various angles. Furthermore, we build a hierarchical feature aggregation module to fully integrate multi-level deep features, simulating humans’ aggregation and processing of information.
2. Related Works
2.1. Camouflaged Object Detection (COD)
2.2. Context-Aware Deep Learning
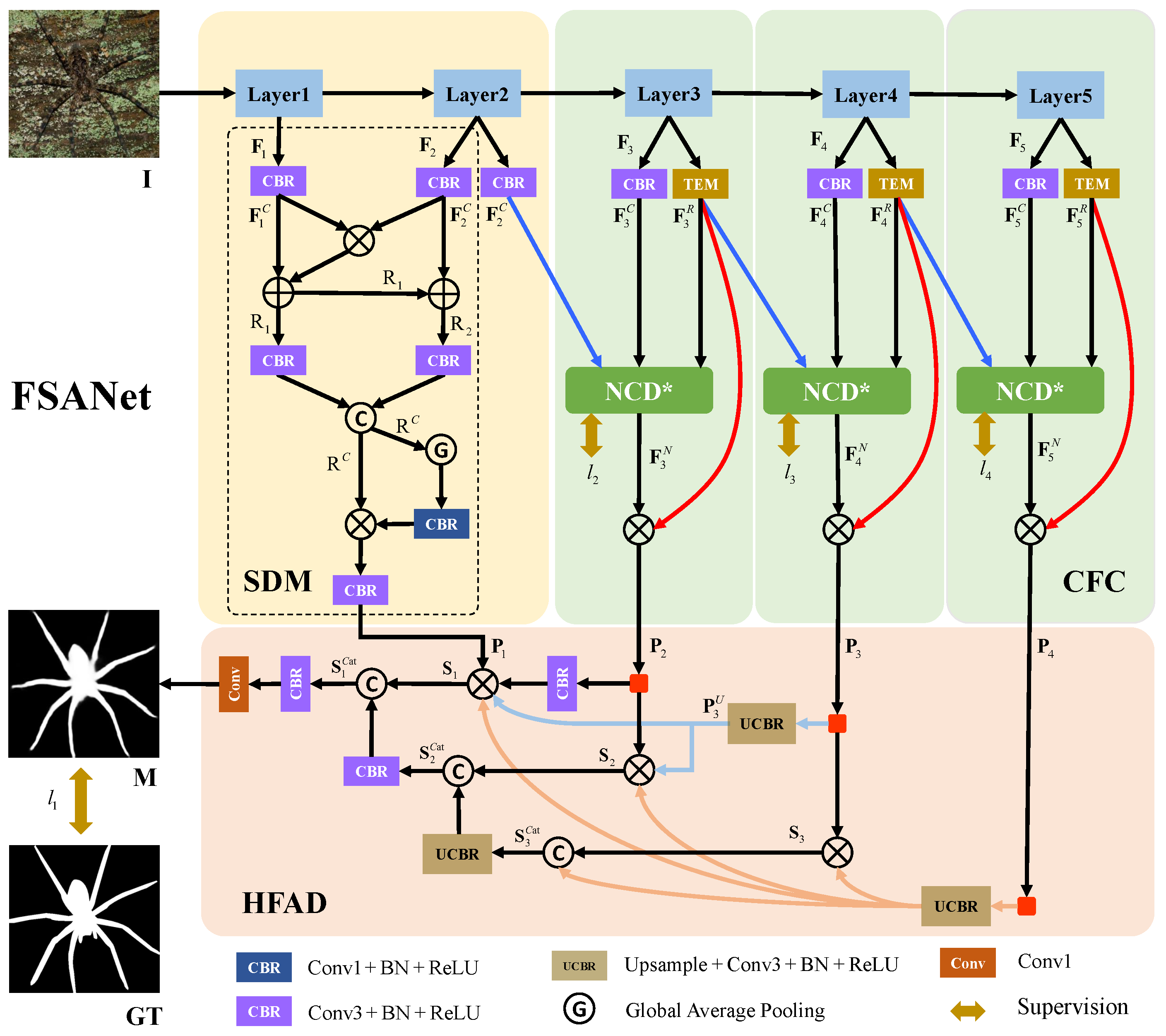
3. The Proposed Method
3.1. Overall Architecture
3.2. Spatial Detail Mining (SDM)
3.3. Cross-Scale Feature Combination (CFC)
3.4. Hierarchical Feature Aggregation Decoder (HFAD)
3.5. Loss Function
4. Experimental Results
4.1. Datasets and Implementation
4.2. Evaluation Metrics
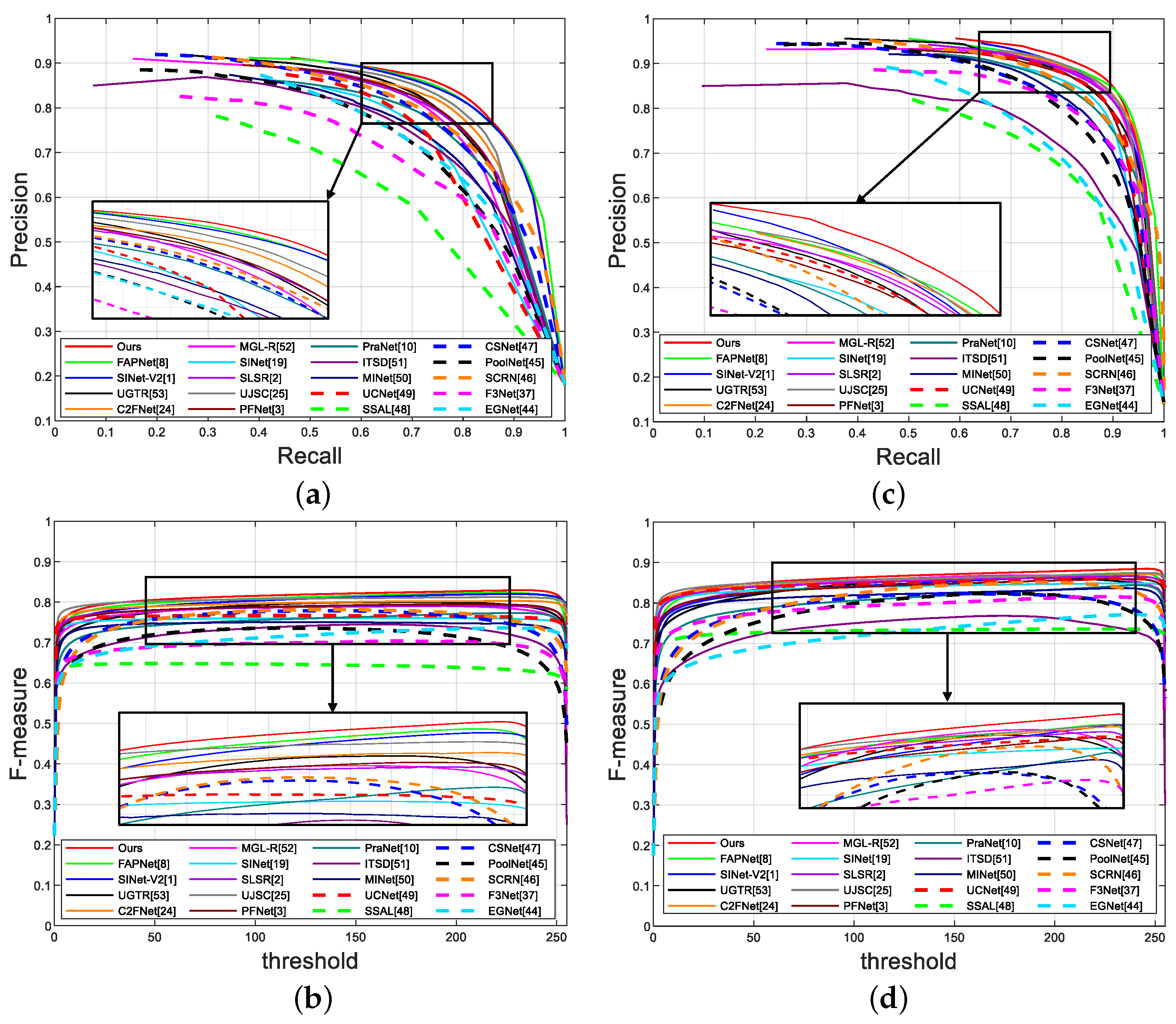
4.3. Comparison with the State-of-the-Art Methods
4.3.1. Quantitative Comparison
4.3.2. Qualitative Comparison
4.4. Ablation Studies
4.5. Failure Cases and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fan, D.P.; Ji, G.P.; Cheng, M.M.; Shao, L. Concealed object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6024–6042. [Google Scholar] [CrossRef]
- Lv, Y.; Zhang, J.; Dai, Y.; Li, A.; Liu, B.; Barnes, N.; Fan, D.P. Simultaneously localize, segment and rank the camouflaged objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11591–11601. [Google Scholar]
- Mei, H.; Ji, G.P.; Wei, Z.; Yang, X.; Wei, X.; Fan, D.P. Camouflaged object segmentation with distraction mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8772–8781. [Google Scholar]
- Ren, J.; Hu, X.; Zhu, L.; Xu, X.; Xu, Y.; Wang, W.; Deng, Z.; Heng, P.A. Deep texture-aware features for camouflaged object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 33, 1157–1167. [Google Scholar] [CrossRef]
- Jiang, X.; Cai, W.; Zhang, Z.; Jiang, B.; Yang, Z.; Wang, X. MAGNet: A camouflaged object detection network simulating the observation effect of a magnifier. Entropy 2022, 24, 1804. [Google Scholar] [CrossRef] [PubMed]
- Zhuge, M.; Fan, D.P.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient object detection via integrity learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3738–3752. [Google Scholar] [CrossRef]
- Merilaita, S.; Scott-Samuel, N.E.; Cuthill, I.C. How camouflage works. Philos. Trans. R. Soc. Biol. Sci. 2017, 372, 20160341. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Zhou, Y.; Gong, C.; Yang, J.; Zhang, Y. Feature Aggregation and Propagation Network for Camouflaged Object Detection. IEEE Trans. Image Process. 2022, 31, 7036–7047. [Google Scholar] [CrossRef] [PubMed]
- Le, X.; Mei, J.; Zhang, H.; Zhou, B.; Xi, J. A learning-based approach for surface defect detection using small image datasets. Neurocomputing 2020, 408, 112–120. [Google Scholar] [CrossRef]
- Fan, D.P.; Ji, G.P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Pranet: Parallel reverse attention network for polyp segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2020; pp. 263–273. [Google Scholar]
- Lidbetter, T. Search and rescue in the face of uncertain threats. Eur. J. Oper. Res. 2020, 285, 1153–1160. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zhang, X.; Lin, W. Lightweight salient object detection in optical remote-sensing images via semantic matching and edge alignment. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, C.; Wang, S.; Liu, Y.; Ye, M. A Bayesian approach to camouflaged moving object detection. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2001–2013. [Google Scholar] [CrossRef]
- Feng, X.; Guoying, C.; Richang, H.; Jing, G. Camouflage texture evaluation using a saliency map. Multimed. Syst. 2015, 21, 169–175. [Google Scholar] [CrossRef]
- Hou, J.Y.Y.H.W.; Li, J. Detection of the mobile object with camouflage color under dynamic background based on optical flow. Procedia Eng. 2011, 15, 2201–2205. [Google Scholar]
- Bi, H.; Zhang, C.; Wang, K.; Tong, J.; Zheng, F. Rethinking camouflaged object detection: Models and datasets. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 5708–5724. [Google Scholar] [CrossRef]
- Tankus, A.; Yeshurun, Y. Detection of regions of interest and camouflage breaking by direct convexity estimation. In Proceedings of the Proceedings 1998 IEEE Workshop on Visual Surveillance, Bombay, India, 2 January 1998; pp. 42–48. [Google Scholar]
- Guo, H.; Dou, Y.; Tian, T.; Zhou, J.; Yu, S. A robust foreground segmentation method by temporal averaging multiple video frames. In Proceedings of the 2008 International Conference on Audio, Language and Image Processing, Shanghai, China, 7–9 July 2008; pp. 878–882. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Sun, G.; Cheng, M.M.; Shen, J.; Shao, L. Camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2777–2787. [Google Scholar]
- Zheng, Y.; Zhang, X.; Wang, F.; Cao, T.; Sun, M.; Wang, X. Detection of people with camouflage pattern via dense deconvolution network. IEEE Signal Process. Lett. 2018, 26, 29–33. [Google Scholar] [CrossRef]
- Le, T.N.; Nguyen, T.V.; Nie, Z.; Tran, M.T.; Sugimoto, A. Anabranch network for camouflaged object segmentation. Comput. Vis. Image Underst. 2019, 184, 45–56. [Google Scholar] [CrossRef]
- Skurowski, P.; Abdulameer, H.; Błaszczyk, J.; Depta, T.; Kornacki, A.; Kozieł, P. Animal camouflage analysis: Chameleon database. Unpubl. Manuscr. 2018, 2, 7. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Sun, Y.; Chen, G.; Zhou, T.; Zhang, Y.; Liu, N. Context-aware cross-level fusion network for camouflaged object detection. arXiv 2021, arXiv:2105.12555. [Google Scholar]
- Li, A.; Zhang, J.; Lv, Y.; Liu, B.; Zhang, T.; Dai, Y. Uncertainty-aware joint salient object and camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10071–10081. [Google Scholar]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-aware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1915–1926. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Tan, J.; Xiong, P.; Lv, Z.; Xiao, K.; He, Y. Local context attention for salient object segmentation. In Proceedings of the Asian Conference on Computer Vision, Seattle, WA, USA, 19 June 2020. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef]
- Wilson, K.D.; Farah, M.J. When does the visual system use viewpoint-invariant representations during recognition? Cogn. Brain Res. 2003, 16, 399–415. [Google Scholar] [CrossRef]
- Burgund, E.D.; Marsolek, C.J. invariant and viewpoint-dependent object recognition in dissociable neural subsystems. Psychon. Bull. Rev. 2000, 7, 480–489. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Li, Y.; Pizlo, Z.; Steinman, R.M. A computational model that recovers the 3D shape of an object from a single 2D retinal representation. Vis. Res. 2009, 49, 979–991. [Google Scholar] [CrossRef]
- Tarr, M.J.; Pinker, S. Mental rotation and orientation-dependence in shape recognition. Cogn. Psychol. 1989, 21, 233–282. [Google Scholar] [CrossRef] [PubMed]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Fan, D.P.; Ji, G.P.; Qin, X.; Cheng, M.M. Cognitive vision inspired object segmentation metric and loss function. Sci. Sin. Informationis 2021, 6, 6. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, feedback and focus for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Seattle, WA, USA, 19 June 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Da, K. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 248–255. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Zhang, D.; Han, J.; Li, C.; Wang, J.; Li, X. Detection of co-salient objects by looking deep and wide. Int. J. Comput. Vis. 2016, 120, 215–232. [Google Scholar] [CrossRef]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Stacked cross refinement network for edge-aware salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7264–7273. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Gao, S.H.; Tan, Y.Q.; Cheng, M.M.; Lu, C.; Chen, Y.; Yan, S. Highly efficient salient object detection with 100 k parameters. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 702–721. [Google Scholar]
- Zhang, J.; Yu, X.; Li, A.; Song, P.; Liu, B.; Dai, Y. Weakly-supervised salient object detection via scribble annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 12546–12555. [Google Scholar]
- Zhang, J.; Fan, D.P.; Dai, Y.; Anwar, S.; Saleh, F.S.; Zhang, T.; Barnes, N. UC-Net: Uncertainty inspired RGB-D saliency detection via conditional variational autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 8582–8591. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 9413–9422. [Google Scholar]
- Zhou, H.; Xie, X.; Lai, J.H.; Chen, Z.; Yang, L. Interactive two-stream decoder for accurate and fast saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 9141–9150. [Google Scholar]
- Zhai, Q.; Li, X.; Yang, F.; Chen, C.; Cheng, H.; Fan, D.P. Mutual graph learning for camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12997–13007. [Google Scholar]
- Yang, F.; Zhai, Q.; Li, X.; Huang, R.; Luo, A.; Cheng, H.; Fan, D.P. Uncertainty-guided transformer reasoning for camouflaged object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4146–4155. [Google Scholar]
- Pei, J.; Cheng, T.; Fan, D.P.; Tang, H.; Chen, C.; Van Gool, L. Osformer: One-stage camouflaged instance segmentation with transformers. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 19–37. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CAMO Dataset | CHAMELEON Dataset | COD10K Dataset | NC4K Dataset | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EGNet [44] | 0.732 | 0.604 | 0.670 | 0.800 | 0.109 | 0.797 | 0.649 | 0.702 | 0.860 | 0.065 | 0.736 | 0.517 | 0.582 | 0.810 | 0.061 | 0.777 | 0.639 | 0.696 | 0.841 | 0.075 |
| PoolNet [46] | 0.730 | 0.575 | 0.643 | 0.747 | 0.105 | 0.845 | 0.691 | 0.749 | 0.864 | 0.054 | 0.740 | 0.506 | 0.576 | 0.777 | 0.056 | 0.785 | 0.635 | 0.699 | 0.814 | 0.073 |
| F3Net [37] | 0.711 | 0.564 | 0.616 | 0.741 | 0.109 | 0.848 | 0.744 | 0.770 | 0.894 | 0.047 | 0.739 | 0.544 | 0.593 | 0.795 | 0.051 | 0.780 | 0.656 | 0.705 | 0.824 | 0.070 |
| SCRN [45] | 0.779 | 0.643 | 0.705 | 0.797 | 0.090 | 0.876 | 0.741 | 0.787 | 0.889 | 0.042 | 0.789 | 0.575 | 0.651 | 0.817 | 0.047 | 0.830 | 0.698 | 0.757 | 0.854 | 0.059 |
| CSNet [47] | 0.771 | 0.642 | 0.705 | 0.795 | 0.092 | 0.856 | 0.718 | 0.766 | 0.869 | 0.047 | 0.778 | 0.569 | 0.635 | 0.810 | 0.047 | 0.750 | 0.603 | 0.655 | 0.773 | 0.088 |
| SSAL [48] | 0.644 | 0.493 | 0.579 | 0.721 | 0.126 | 0.757 | 0.639 | 0.702 | 0.849 | 0.071 | 0.668 | 0.454 | 0.527 | 0.768 | 0.066 | 0.699 | 0.561 | 0.644 | 0.780 | 0.093 |
| UCNet [49] | 0.739 | 0.640 | 0.700 | 0.787 | 0.094 | 0.880 | 0.817 | 0.836 | 0.930 | 0.036 | 0.776 | 0.633 | 0.681 | 0.857 | 0.042 | 0.811 | 0.729 | 0.775 | 0.871 | 0.055 |
| MINet [50] | 0.748 | 0.637 | 0.691 | 0.792 | 0.090 | 0.855 | 0.771 | 0.802 | 0.914 | 0.036 | 0.770 | 0.608 | 0.657 | 0.832 | 0.042 | 0.812 | 0.720 | 0.764 | 0.862 | 0.056 |
| ITSD [51] | 0.750 | 0.610 | 0.663 | 0.780 | 0.102 | 0.814 | 0.662 | 0.705 | 0.844 | 0.057 | 0.767 | 0.557 | 0.615 | 0.808 | 0.051 | 0.811 | 0.680 | 0.729 | 0.845 | 0.064 |
| PraNet [10] | 0.769 | 0.663 | 0.710 | 0.824 | 0.094 | 0.860 | 0.763 | 0.789 | 0.907 | 0.044 | 0.789 | 0.629 | 0.671 | 0.861 | 0.045 | 0.822 | 0.724 | 0.762 | 0.876 | 0.059 |
| SINet [19] | 0.745 | 0.644 | 0.702 | 0.804 | 0.092 | 0.872 | 0.806 | 0.827 | 0.936 | 0.034 | 0.776 | 0.631 | 0.679 | 0.864 | 0.043 | 0.808 | 0.723 | 0.769 | 0.871 | 0.058 |
| PFNet [3] | 0.782 | 0.695 | 0.746 | 0.842 | 0.085 | 0.882 | 0.810 | 0.828 | 0.931 | 0.033 | 0.800 | 0.660 | 0.701 | 0.877 | 0.040 | 0.829 | 0.745 | 0.784 | 0.888 | 0.053 |
| UJSC [25] | 0.800 | 0.728 | 0.772 | 0.859 | 0.073 | 0.891 | 0.833 | 0.847 | 0.945 | 0.030 | 0.809 | 0.684 | 0.721 | 0.884 | 0.035 | 0.842 | 0.771 | 0.806 | 0.898 | 0.047 |
| SLSR [2] | 0.787 | 0.696 | 0.744 | 0.838 | 0.080 | 0.890 | 0.822 | 0.841 | 0.935 | 0.030 | 0.804 | 0.673 | 0.715 | 0.880 | 0.037 | 0.840 | 0.766 | 0.804 | 0.895 | 0.048 |
| MGL-R [52] | 0.775 | 0.673 | 0.726 | 0.812 | 0.088 | 0.893 | 0.813 | 0.834 | 0.918 | 0.030 | 0.814 | 0.666 | 0.711 | 0.852 | 0.035 | 0.833 | 0.740 | 0.782 | 0.867 | 0.052 |
| C2FNet [24] | 0.796 | 0.719 | 0.762 | 0.854 | 0.080 | 0.888 | 0.828 | 0.844 | 0.935 | 0.032 | 0.813 | 0.686 | 0.723 | 0.890 | 0.036 | 0.838 | 0.762 | 0.795 | 0.897 | 0.049 |
| UGTR [53] | 0.784 | 0.684 | 0.736 | 0.822 | 0.086 | 0.887 | 0.794 | 0.820 | 0.910 | 0.031 | 0.817 | 0.666 | 0.711 | 0.853 | 0.036 | 0.839 | 0.747 | 0.787 | 0.875 | 0.052 |
| SINet_V2 [1] | 0.820 | 0.743 | 0.782 | 0.882 | 0.070 | 0.888 | 0.816 | 0.835 | 0.942 | 0.030 | 0.815 | 0.680 | 0.718 | 0.887 | 0.037 | 0.847 | 0.770 | 0.805 | 0.903 | 0.048 |
| FAPNet [8] | 0.815 | 0.734 | 0.776 | 0.865 | 0.076 | 0.893 | 0.825 | 0.842 | 0.940 | 0.028 | 0.822 | 0.694 | 0.731 | 0.888 | 0.036 | 0.851 | 0.775 | 0.810 | 0.899 | 0.047 |
| Ours | 0.821 | 0.752 | 0.792 | 0.883 | 0.068 | 0.897 | 0.841 | 0.856 | 0.952 | 0.026 | 0.822 | 0.699 | 0.734 | 0.890 | 0.034 | 0.846 | 0.773 | 0.808 | 0.899 | 0.047 |
| COD10K-Amphibian | COD10K-Aquatic | COD10K-Flying | COD10K-Terrestrial | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EGNet [44] | 0.776 | 0.588 | 0.650 | 0.843 | 0.056 | 0.712 | 0.515 | 0.584 | 0.784 | 0.091 | 0.769 | 0.558 | 0.621 | 0.838 | 0.046 | 0.713 | 0.467 | 0.531 | 0.794 | 0.056 |
| PoolNet [46] | 0.781 | 0.584 | 0.644 | 0.823 | 0.050 | 0.737 | 0.534 | 0.607 | 0.782 | 0.078 | 0.767 | 0.539 | 0.610 | 0.797 | 0.045 | 0.707 | 0.441 | 0.508 | 0.745 | 0.054 |
| F3Net [37] | 0.808 | 0.657 | 0.700 | 0.846 | 0.039 | 0.728 | 0.554 | 0.611 | 0.788 | 0.076 | 0.760 | 0.571 | 0.618 | 0.818 | 0.040 | 0.712 | 0.490 | 0.538 | 0.770 | 0.048 |
| SCRN [45] | 0.839 | 0.665 | 0.729 | 0.867 | 0.041 | 0.780 | 0.600 | 0.674 | 0.818 | 0.064 | 0.817 | 0.608 | 0.683 | 0.840 | 0.036 | 0.758 | 0.509 | 0.588 | 0.784 | 0.048 |
| CSNet [47] | 0.828 | 0.649 | 0.711 | 0.857 | 0.041 | 0.768 | 0.587 | 0.656 | 0.808 | 0.067 | 0.809 | 0.610 | 0.676 | 0.838 | 0.036 | 0.744 | 0.501 | 0.566 | 0.776 | 0.047 |
| SSAL [48] | 0.729 | 0.560 | 0.637 | 0.817 | 0.057 | 0.632 | 0.428 | 0.509 | 0.737 | 0.101 | 0.702 | 0.504 | 0.576 | 0.795 | 0.050 | 0.647 | 0.405 | 0.471 | 0.756 | 0.060 |
| UCNet [49] | 0.827 | 0.717 | 0.756 | 0.897 | 0.034 | 0.767 | 0.649 | 0.703 | 0.843 | 0.060 | 0.806 | 0.675 | 0.718 | 0.886 | 0.030 | 0.742 | 0.566 | 0.617 | 0.830 | 0.042 |
| MINet [50] | 0.823 | 0.695 | 0.732 | 0.881 | 0.035 | 0.767 | 0.632 | 0.684 | 0.831 | 0.058 | 0.799 | 0.650 | 0.697 | 0.856 | 0.031 | 0.732 | 0.536 | 0.584 | 0.802 | 0.043 |
| ITSD [51] | 0.810 | 0.628 | 0.679 | 0.852 | 0.044 | 0.762 | 0.584 | 0.648 | 0.811 | 0.070 | 0.793 | 0.588 | 0.645 | 0.831 | 0.040 | 0.736 | 0.496 | 0.552 | 0.777 | 0.051 |
| PraNet [10] | 0.842 | 0.717 | 0.750 | 0.905 | 0.035 | 0.781 | 0.643 | 0.692 | 0.848 | 0.065 | 0.819 | 0.669 | 0.707 | 0.888 | 0.033 | 0.756 | 0.565 | 0.607 | 0.835 | 0.046 |
| SINet [19] | 0.820 | 0.714 | 0.756 | 0.891 | 0.034 | 0.766 | 0.643 | 0.698 | 0.854 | 0.063 | 0.803 | 0.663 | 0.707 | 0.887 | 0.031 | 0.749 | 0.577 | 0.625 | 0.845 | 0.042 |
| PFNet [3] | 0.848 | 0.740 | 0.775 | 0.911 | 0.031 | 0.793 | 0.675 | 0.722 | 0.868 | 0.055 | 0.824 | 0.691 | 0.729 | 0.903 | 0.030 | 0.773 | 0.606 | 0.647 | 0.855 | 0.040 |
| UJSC [25] | 0.841 | 0.742 | 0.769 | 0.905 | 0.031 | 0.805 | 0.705 | 0.747 | 0.879 | 0.049 | 0.836 | 0.719 | 0.752 | 0.906 | 0.026 | 0.778 | 0.624 | 0.664 | 0.863 | 0.037 |
| SLSR [2] | 0.845 | 0.751 | 0.783 | 0.906 | 0.030 | 0.803 | 0.694 | 0.740 | 0.875 | 0.052 | 0.830 | 0.707 | 0.745 | 0.906 | 0.026 | 0.772 | 0.611 | 0.655 | 0.855 | 0.038 |
| MGL-R [52] | 0.854 | 0.734 | 0.770 | 0.886 | 0.028 | 0.807 | 0.688 | 0.736 | 0.855 | 0.051 | 0.839 | 0.701 | 0.743 | 0.873 | 0.026 | 0.785 | 0.606 | 0.651 | 0.823 | 0.036 |
| C2FNet [24] | 0.849 | 0.752 | 0.779 | 0.899 | 0.030 | 0.807 | 0.700 | 0.741 | 0.882 | 0.052 | 0.840 | 0.724 | 0.759 | 0.914 | 0.026 | 0.783 | 0.627 | 0.664 | 0.872 | 0.037 |
| UGTR [53] | 0.857 | 0.738 | 0.774 | 0.896 | 0.029 | 0.810 | 0.686 | 0.734 | 0.855 | 0.050 | 0.843 | 0.699 | 0.744 | 0.873 | 0.026 | 0.789 | 0.606 | 0.653 | 0.823 | 0.036 |
| SINet_V2 [1] | 0.858 | 0.756 | 0.788 | 0.916 | 0.030 | 0.811 | 0.696 | 0.738 | 0.883 | 0.051 | 0.839 | 0.713 | 0.749 | 0.908 | 0.027 | 0.787 | 0.623 | 0.662 | 0.866 | 0.039 |
| FAPNet [8] | 0.854 | 0.752 | 0.783 | 0.914 | 0.032 | 0.821 | 0.717 | 0.757 | 0.887 | 0.049 | 0.845 | 0.725 | 0.760 | 0.906 | 0.025 | 0.795 | 0.639 | 0.678 | 0.868 | 0.037 |
| Ours | 0.862 | 0.767 | 0.795 | 0.924 | 0.027 | 0.821 | 0.720 | 0.758 | 0.893 | 0.048 | 0.851 | 0.741 | 0.774 | 0.916 | 0.023 | 0.787 | 0.632 | 0.669 | 0.859 | 0.038 |
| No. | SDM | CFC | Decoder | CAMO Dataset | COD10K Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SDM | TEM | m-m SJM | o-m SJM | PD | HFAD | |||||||||
| #1 | ✔ | ✔ | ✔ | 0.812 | 0.777 | 0.870 | 0.071 | 0.818 | 0.734 | 0.886 | 0.035 | |||
| #2 | ✔ | ✔ | ✔ | 0.812 | 0.783 | 0.870 | 0.072 | 0.819 | 0.732 | 0.889 | 0.034 | |||
| #3 | ✔ | ✔ | ✔ | 0.812 | 0.778 | 0.866 | 0.072 | 0.821 | 0.740 | 0.888 | 0.034 | |||
| #4 | ✔ | ✔ | ✔ | 0.815 | 0.784 | 0.872 | 0.071 | 0.820 | 0.735 | 0.887 | 0.035 | |||
| #5 | ✔ | ✔ | ✔ | ✔ | 0.818 | 0.784 | 0.874 | 0.072 | 0.821 | 0.730 | 0.885 | 0.035 | ||
| Ours | ✔ | ✔ | ✔ | ✔ | 0.821 | 0.792 | 0.883 | 0.068 | 0.822 | 0.734 | 0.890 | 0.034 | ||
| Method | Ours | FAPNet [8] | SINet_V2 [1] | UGTR [53] | C2FNet [24] | MGL-R [52] | SINet [19] | SLSR [2] | UJSC [25] | PFNet [3] |
|---|---|---|---|---|---|---|---|---|---|---|
| Params. | 66.550 M | 29.524 M | 26.976 M | 48.868 M | 28.411 M | 63.595 M | 48.947 M | 50.935 M | 217.982 M | 46.498 M |
| FLOPs | 40.733 G | 59.101 G | 24.481 G | 1.007 T | 26.167 G | 553.939 G | 38.757 G | 66.625 G | 112.341 G | 53.222 G |
| FPS | 29.417 | 28.476 | 38.948 | 15.446 | 36.941 | 12.793 | 34.083 | 32.547 | 18.246 | 29.175 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Wang, T.; Wang, J.; Sun, Y. Features Split and Aggregation Network for Camouflaged Object Detection. J. Imaging 2024, 10, 24. https://doi.org/10.3390/jimaging10010024
Zhang Z, Wang T, Wang J, Sun Y. Features Split and Aggregation Network for Camouflaged Object Detection. Journal of Imaging. 2024; 10(1):24. https://doi.org/10.3390/jimaging10010024
Chicago/Turabian StyleZhang, Zejin, Tao Wang, Jian Wang, and Yao Sun. 2024. "Features Split and Aggregation Network for Camouflaged Object Detection" Journal of Imaging 10, no. 1: 24. https://doi.org/10.3390/jimaging10010024
APA StyleZhang, Z., Wang, T., Wang, J., & Sun, Y. (2024). Features Split and Aggregation Network for Camouflaged Object Detection. Journal of Imaging, 10(1), 24. https://doi.org/10.3390/jimaging10010024