1. Introduction
The World Health Organisation (2002) found that about one in ten couples worldwide experience difficulties conceiving. Today, assisted reproduction techniques account for over 1% of the infants born in developed countries [
1].
The chances of successful conception significantly dependent on sperm morphology, both in natural fertilisation [
2] as well as the various forms of assisted reproduction ([
3,
4,
5]). Hence, it is beneficial to come up with sorting procedures which improve the proportion of such sperm in a sample. While desirable sperm cells can be manually selected for use in in-vitro fertilisation (IVF) or intracytoplasmic sperm injection (ICSI) [
6], this is not feasible for intrauterine insemination (IUI) given the large number of sperm required. Therefore, the procedure should ideally be passive.
There are a variety of methods [
7] to sort human sperm cells by their motility or morphology, as well as a multitude of microfluidic techniques yet to be used on sperm cells [
8,
9,
10]. Dielectrophoresis [
11] has been applied to separate mature spermatozoa from non-mature spermatogenic cells [
12]. A separate group of researchers performed magnetic-activated cell sorting to obtain viable and morphologically normal spermatozoa that enjoy higher cryosurvival rates [
13,
14]. A magnetic particle in diamagnetic medium experiences a magnetic force towards the region of higher magnetic field density, while the opposite is true for a diamagnetic particle in paramagnetic medium [
15]. Therefore, the sperm cells may be doped with paramagnetic nanoparticles [
16] or sorted in their natural form via diamagnetophoresis [
17]. Despite evidence that sperm cells subjected to a magnetic field remain viable with the potential for fertilisation [
16,
18], there is more to be studied before such sorted spermatozoa may be used to increase the success rates of assisted reproduction for the public.
Due to ethical concerns involved in carrying out experiments with human sperm, it is beneficial for researchers to first carry out theoretical studies to assess the feasibility of sorting using the various techniques under different experimental set-ups. Mathematical models of increasing complexity and accuracy have been developed to understand the kinematics of micro-swimmers such as sperm cells [
19,
20]. These theoretical computations are often taken from the deterministic approach. However, as sperm cells differ in their morphology, more insights can be gained by studying their behavior from a statistical approach.
In spite of technological advances, precise theoretical models are still computationally expensive, and running numerical simulations for a large number of samples to obtain statistically reliable results may be time-consuming. Moreover, in the process of testing for convergence, the scale of simulations that are carried out will exceed that which is required for statistical analysis. Notably, the use of machine learning [
21] has been proven to provide accurate predictions and is gaining popularity, but its use in engineering research is still not widespread despite great potential. Common models include k-nearest neighbor regression [
22], ridge regression [
23], random forest regression [
24], and artificial neural networks [
25]. In k-nearest neighbor regression, the predictor and target variables of all known samples are stored. For all new data to be predicted, only the k samples having the least ‘distance’ will be considered, with the simple or weighted-average value taken. Ridge regression is linear regression with L2 regularization, where a penalty term is added to the sum of square errors to be minimized, thus avoiding overly-large coefficients in the linear model. In random forest regression, a large number of decision trees is built, each using a subset of predictor variables so as to avoid overfitting. For each decision tree, the population is split based on one variable at a time, where the chosen variable as well as threshold determining the split minimizes the sum of square errors (in the case of regression). In artificial neural networks, the first layer or nodes receives input from the predictor variables, adds a bias to the weighted sum and passes it through a non-linear function, and feeds the output to the subsequent layer of nodes. This continues until an output is obtained from the final single node after the hidden layer. The weights and bias are ‘learnt’ by minimizing the cost function via optimization. Each model has its own hyperparameters to be tuned, and there are also other well-established supervised learning algorithms, but the four mentioned above will suffice for the scope of this paper. There is no single best learning algorithm [
26], and therefore ensembles often out-perform [
27] their individual components. In this paper, we will apply supervised learning using an ensemble of the aforementioned algorithms.
Slender body theory (SBT) will be used to to compute the kinematic behavior of spermatozoa, with two goals in mind. Statistical analysis will be carried out with varying amounts of data, to find out the quantity of data which is sufficient without being excessive. This will be explored by studying the sorting of spermatozoa via magnetophoresis to enhance the proportion of morphologically normal cells. Secondly, we explore the feasibility of using machine learning on a smaller dataset to predict the results, so as to save computational or laboratory costs. Our findings can be generalised to other theoretical simulations utilising a different model to compute the hydrodynamics of some organism, as well as to experimenters obtaining actual data.
2. Model
A human sperm has a head of length
lh = 4.81 ± 0.43 µm and width
wh = 3.32 ± 0.38 µm [
28], with a typical thickness
gh of 1.1 µm [
29]. Attached to the head is a flagellum of arc length Λ = 42 ± 4 µm [
30] with a radius of 0.25 µm [
31]. The flagellar beat frequency
f and amplitude
b also vary [
32] according to the sperm head morphology. The swimming speed of a human sperm ranges from 36 to 51 µm s
−1 [
32]. Under such small length and velocity scales, the hydrodynamics of human sperms are governed by the Stokes equation. Therefore, we adopt the SBT to solve the velocity of the sperm subjected to an external magnetic field. The use of SBT significantly reduces the computational cost as compared to other numerical methods [
33], at the same time providing accurate computation results which have been experimentally verified [
34,
35].
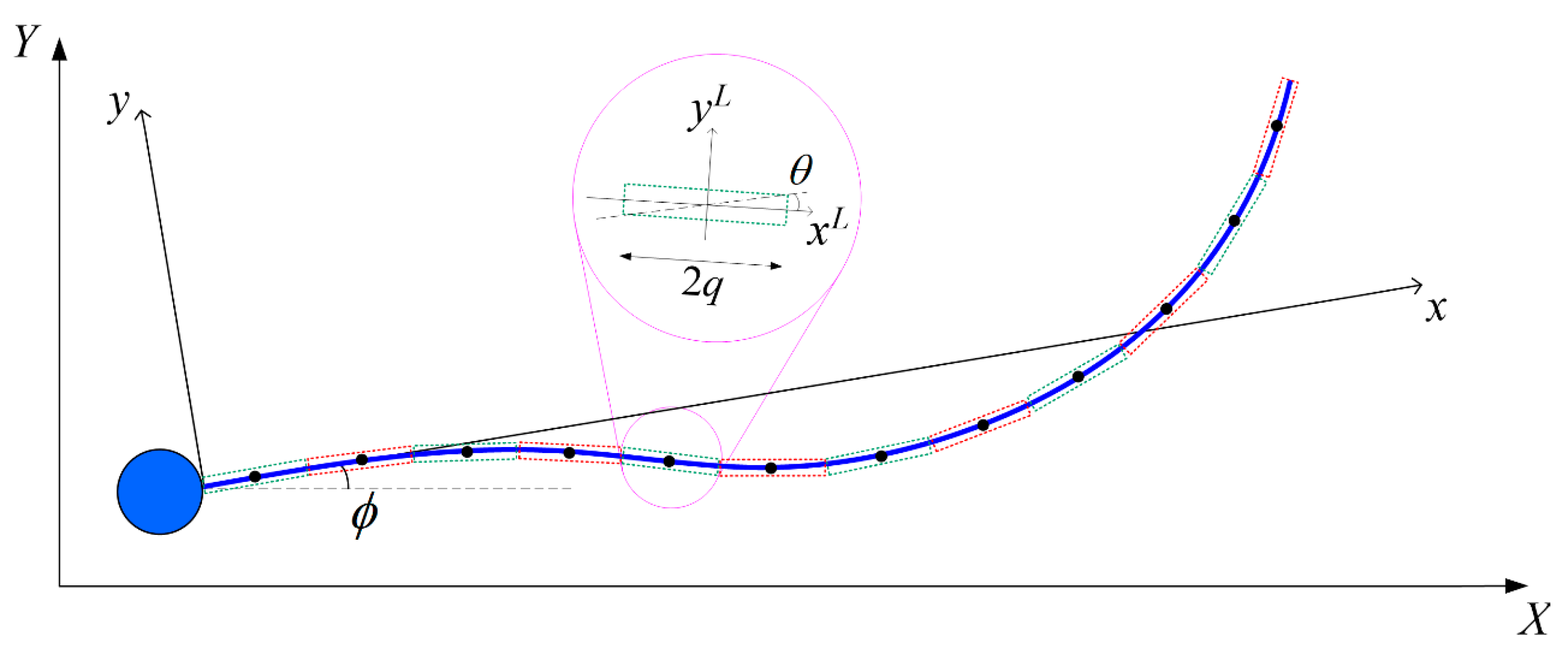
The sperm head is modelled as a sphere of radius
with a volume equivalent to the ellipsoid. The origin of the body-fixed frame is located at the point where the flagellum is attached to the sperm head (
Figure 1). Given that the motion of a human sperm is highly directional [
36], we prescribe the flagellum beating pattern to be a modified sinusoidal waveform [
37]. The centerline of the flagellum in the body-fixed frame
xc = [
x(
t),
y(
x,
t),
z(
x,
t)]
T has a spatial and time dependence of
where
t is the time and
x is the axial coordinate. The exponential term in Equation (1) ensures that the prescribed flagellum is attached to the sperm head with no deflection at the fixed end.
kE controls the tapering [
38] of the flagellum and is chosen to be 1/4 which gives a fair depiction of the actual sperm beating pattern [
39]. At each time frame, the axial length
xf(
t) ends at a different value to satisfy the constraint
.
SBT approximates the hydrodynamic force acting on the flagellum of arc length
and radius
p as that due to a series of Stokeslets and potential dipoles along its centreline [
40,
41]. The flagellum is discretized into
N cylindrical segments, each of length 2
q where
p <<
q << Λ, with a constant force per unit length
f exerted by each element on the fluid [
42]. Following the conventions in
Appendix A, we express the velocity at the centre of the
α-th segment in the body-fixed frame
uα due to the hydrodynamic force per unit length
fβ exerted by the
β-th segment (
α,
β = 1, 2, …,
N) as:
The flagellum segment velocity
uα can also be expressed in terms of the linear and rotational velocities,
uh and
ωh, of the head centre in the body-fixed frame together with the beating of the flagellum,
where
εijk is the permutation symbol,
rα is the displacement vector from the head centre to the centre of the
α-th segment in the body-fixed frame, and
vα = ∂
xc/∂
t is evaluated at the centre of the
α-th segment. The driving force of the flagellum is provided by the relative fluid velocity it experiences due to its beating, according to the kinematics prescribed in Equation (1). This is related to the time-rate of change of the flagellum waveform, ∂
y(
x,
t)/∂
t, which is incorporated in Equation (3) under
. Combining Equations (2) and (3) provides a relation between the sperm velocity and the hydrodynamic force.
We further neglect the interaction between the flagellum and head as this interaction is found to be insignificant [
35,
43], and hence the hydrodynamic force and moment exerted by the fluid on the head centre in the body-fixed frame are
and
, respectively, where
μ is the fluid viscosity. To transform the force and moment from the body-fixed frame to the inertia frame, we adopt a transformation matrix
H which depends on the relative orientation of the two frames. Therefore, the total hydrodynamic force and moment on the sperm in the inertia frame, based on the action and reaction, can be represented as,
We then consider the effect of an external magnetic field to be applied for sperm sorting. A particle of volume
Vp in a magnetic field
B experiences the magnetic force in the inertia frame [
15]:
where
and
are the particle and medium magnetic susceptibility, respectively, and
is the magnetic permeability in vacuum. Building upon a previous work [
44], we adopt the same general framework in which the magnetic field exerted on the sperm in the inertia frame satisfies the first order approximation
due to the small dimension of the sperm, where
C1 and
C2 are constants. When
O(
C2X) ≪
O(
C1), the magnetic force on the sperm head centre and
β-th segment of the flagellum can further be simplified to
and
respectively, where
. The total force acting on the sperm, and the total moment about the centre of the sperm head, due to the external fields can thus be represented as:
As sperm sorting is performed in the low Reynolds number regime, the total force and moment arising from the hydrodynamic propulsion and external field over the entire sperm are zero. Consider the Navier–Stokes equation
in non-dimensionalised form, where Re is the Reynolds number, St the Strouhal number,
p the pressure,
fb the body force and the superscript tilde denotes the non-dimensionalised variable. The right side of the equation represents total force exerted on the control volume. As the Reynolds number of a swimming sperm is many orders of magnitude smaller than unity, the total force can be approximated as 0 [
45], i.e.,
Fhydro +
Fext =
0 and
Mhydro +
Mext =
0. Solving these equations, the instantaneous velocities of the sperm in the body-fixed frame,
uh and
ωh, can be obtained.
Simulations have been run on a multi-core Windows® 64bit PC (CPU E5–1650 v4, 64Gb RAM) installed with MATLAB® R2016b. An average time of 3.0 s is taken to prescribe the flagellum shape at each time frame, calculate the kernel , then to solve the instantaneous and subsequently time-averaged velocity of the sperm. This adds up to over 30 days on a single computer for every one million samples computed.
3. Results and Discussion
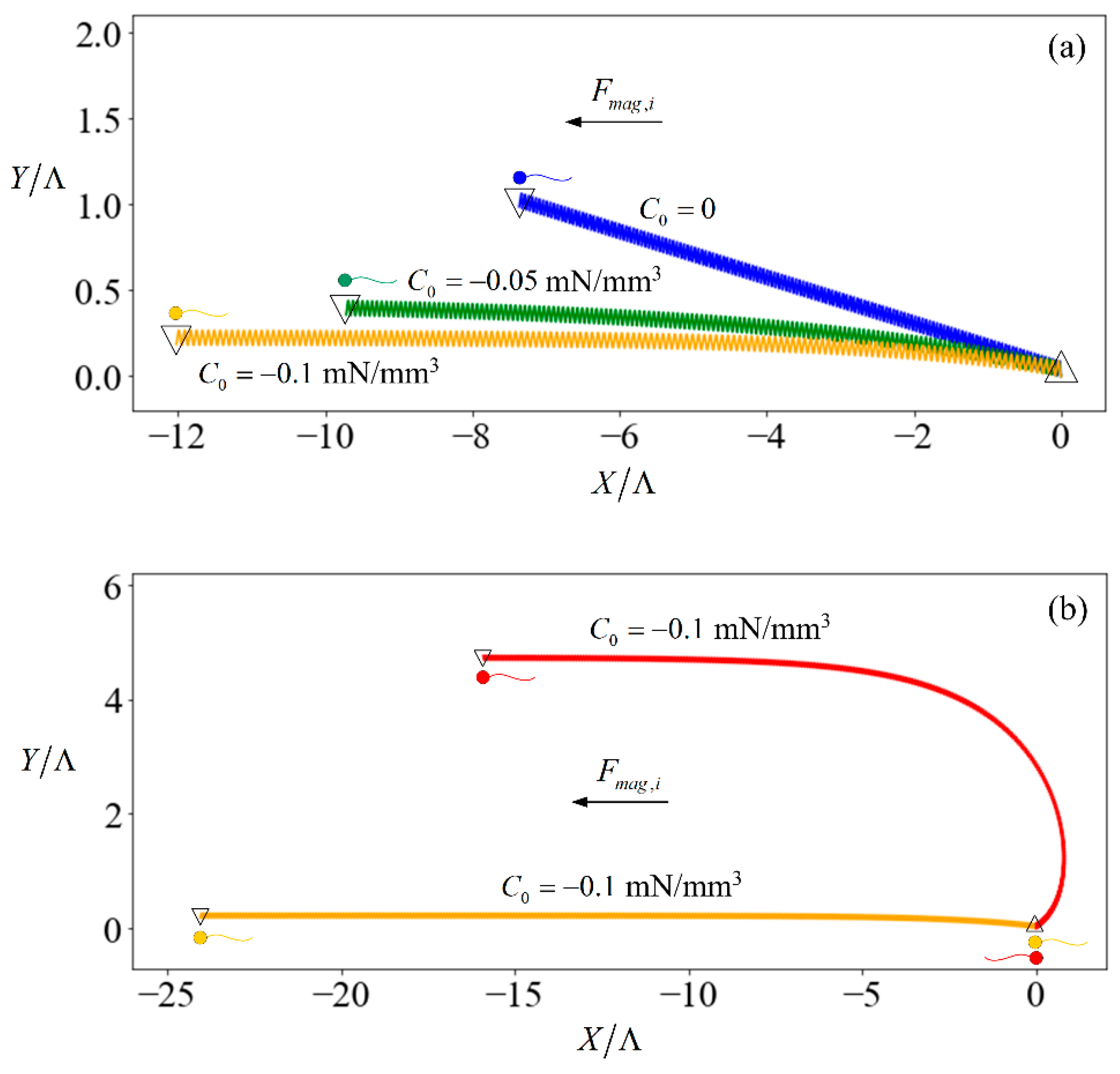
The introduction of an external force results in a stabilising effect.
Figure 2a shows the trajectories of three identical sperms when subjected to no external field (trajectory denoted by blue line) versus relatively weak fields in which the induced force has the same direction as the initial heading of the sperm (trajectory denoted by yellow and green lines) for 20 s. The sperm starts off oriented along the
X-axis of the inertial frame. However, the trajectory is not aligned to the
X-axis due to the finite length of the flagellum. If the swimmer had been an infinite sheet [
46], its motion would remain in the direction of its initial heading. The sperm flagellum motion is symmetrical over a beating cycle with respect to the
x-axis in its body-frame, but asymmetrical with respect to the
X-axis in the inertial frame. The instantaneous rotation of the sperm causes its orientation
to change at each time instance, such that each unit of
and
leads to varying displacement along the
X- or
Y-axis of the inertial frame. The result is a net displacement in the
Y-direction. A greater magnitude of
C0 tends to align the sperm more strongly towards the direction where the external force is applied. This is because the larger magnetic force on the head leads to a higher time-averaged swimming velocity of the head which creates a larger hydrodynamic force to balance with the magnetic force. This difference in velocity between the head and flagellum causes the sperm to align with the external magnetic force. Therefore, our focus in the following discussion is the time-averaged velocity component of the sperm in the
X-direction of the inertia frame:
For other cases that magnetic force is not in the same direction as the initial heading of the sperm; the difference in velocity between the head and flagellum tilts the sperm until it aligns with the magnetic force. To show this, we consider a scenario that the magnetic force and sperm heading are in the opposite direction (red line in
Figure 2b). The magnetic force (with
C0 = 0.1 mN/mm
3) pulls the sperm head to the negative-
X direction at a larger speed as compared to the flagellum. Consequently, the sperm aligns with the direction of the magnetic force in 20 s and continues swimming in that direction thereafter. As such, we only consider the case that the magnetic force is in the same direction as the initial heading of the sperm in the rest of the paper.
Assessment of sperm which satisfies the strict (Tygerberg) condition gives a good indication of the expected fertilisation rates [
47]. Quantitatively, the sperm should have a head length of 3 to 5 µm and width of 2 to 3 µm, as well as a head width to length ratio of between three-fifths and two-thirds, with a tail measuring about 45 µm in length [
48]. Without going into the biological aspects of individual sperm, a cell which fulfils these physical dimensions will be deemed conditionally satisfactory, while a cell which fails at least one condition will be considered abnormal.
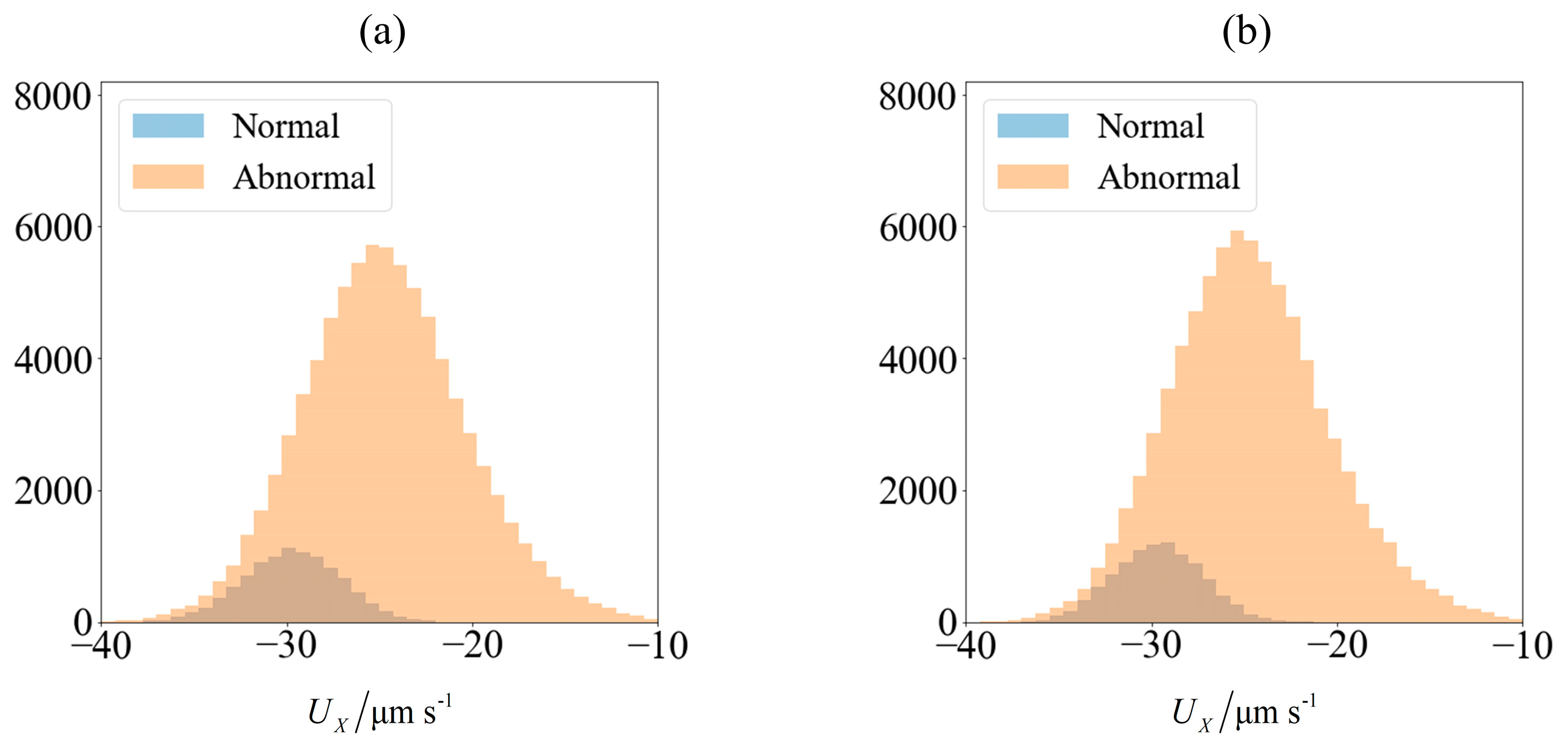
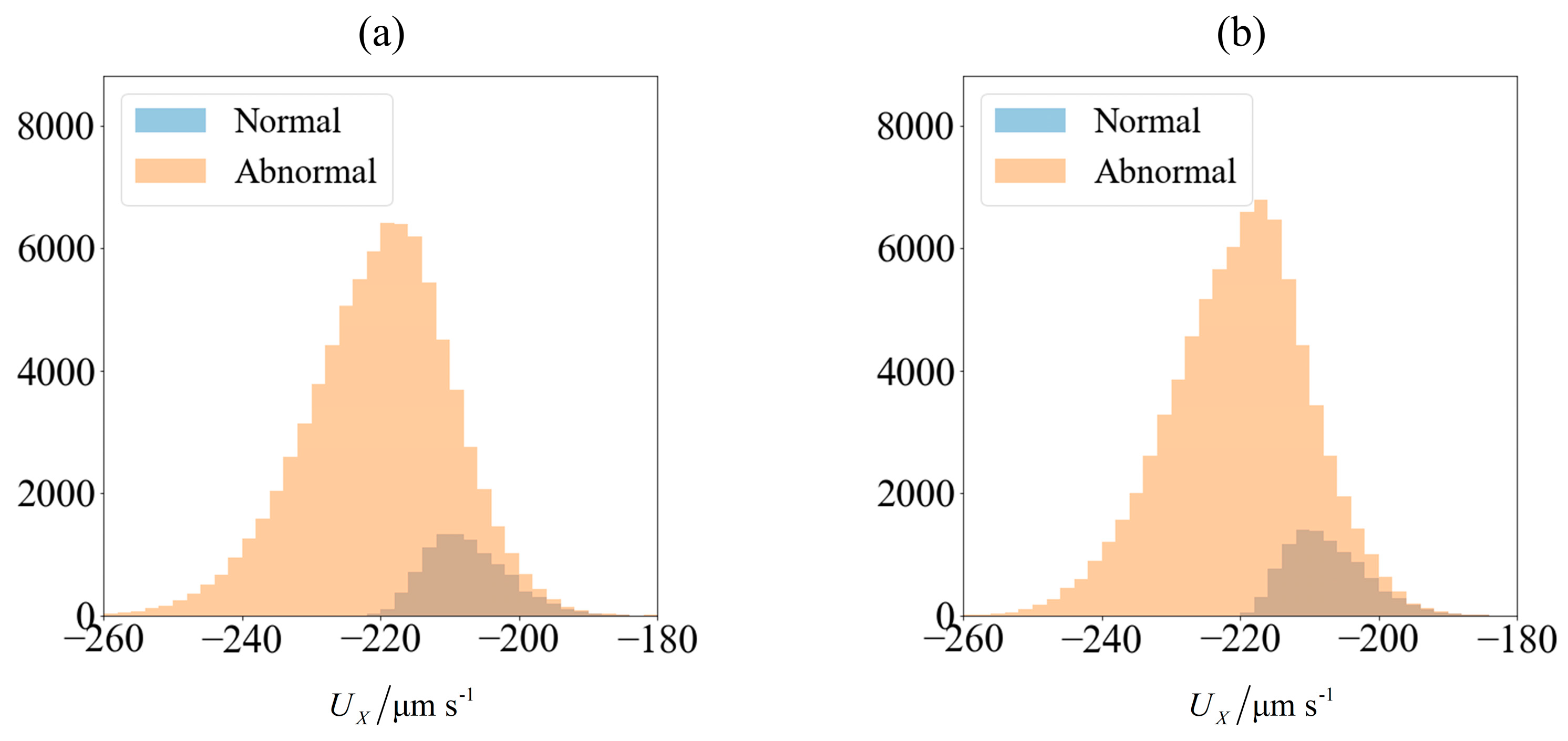
As an illustration of how the application of an external field enables sorting, we consider the velocity distribution of 100,000 sperm cells subjected to no external field (
Figure 3a) and
C0 = −1 mN/mm
3 (
Figure 4a). Using MATLAB
® 2016b and setting the seed number as
i for the
ith sperm, a pseudo-random value is generated from Λ = 42 ± 4 μm,
lh = 4.81 ± 0.43 μm and
wh = 3.32 ± 0.38 μm. Each sperm is categorized based on their head morphology according to
Table 1, and their flagellum beating frequency
f and amplitude
b are generated using the relevant mean and standard deviation. The distribution of computed velocity is presented as a histogram of normal cells super-imposed over the histogram of abnormal cells. The machine learning model is trained using 10,000 of those samples, and based on the parameters of the remaining 90,000 cells, their overall velocity distribution is predicted as shown in
Figure 3b and
Figure 4b. The choice of a sample size of 100,000 will be justified subsequently, as it is necessary to first introduce new parameters that will be involved in this decision.
Due to differences in the morphology as well as wriggling amplitude and frequency, the velocity distribution differs between normal and abnormal sperm. This is consistent with our previous work using resistive force theory [
44]. The proportion of normal cells, as represented by the blue bars, is around 11%. This is reasonable, given that this value is reported to be 6.5 ± 3.9% [
49]. One possibility of sorting cells is to introduce an opposing flow equal in magnitude to the chosen cut-off velocity. In low shear rates where the non-dimensionalised shear
is in the order of
, the effect of shear has insignificant influence on the flagellum waveform or sperm velocity [
50]. Considering the channel width to be over an order of magnitude greater than the sperm characteristic length, the flow far from the walls acts as a bulk advection and boundary effects are negligible [
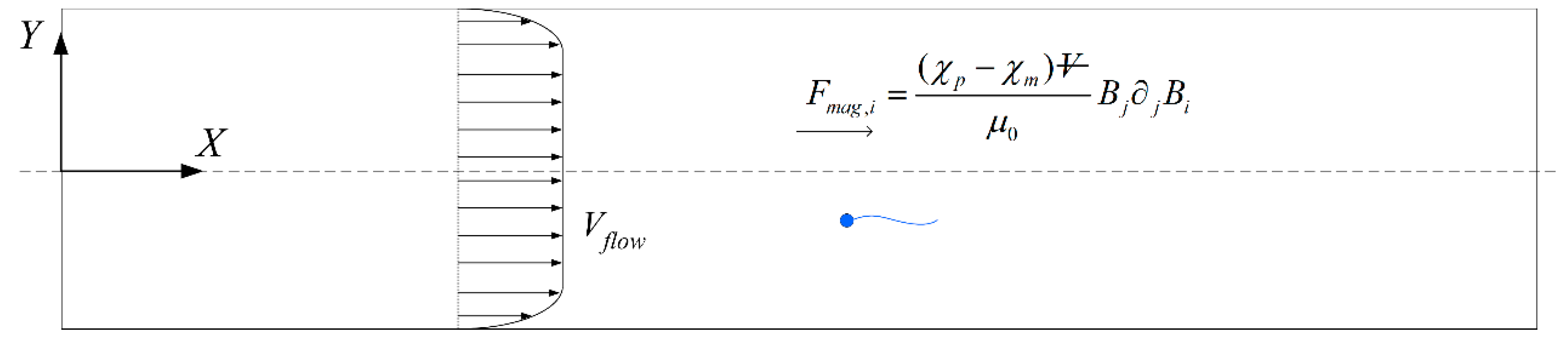
44]. Cells with velocities less negative than the cut-off will acquire a net positive velocity due to advection in the positive
x-direction and be eventually flushed out of the right end of the channel (
Figure 5). Meanwhile, those which overcome the advection will have a net negative velocity and head towards the left end of the channel. The proportion of normal cells can be increased by modifying the cut-off velocity, but will have to come at the expense of discarding some normal cells as well. The effectiveness of sorting will be accessed according to the purity
and yield
as defined here:
The predicted velocities have a lower variance and tend to be distributed closer to the mean velocity, with outliers having less extreme values than what is computed (
Figure 5). This is not surprising, due to the nature of the k-nearest neighbor regressor which averages out the prediction with other less extreme neighbors as well as the nature of regression trees in the random forest. Since the normal and abnormal cells are predicted to have velocities that are more tightly clustered about their respective mean values, the distinction between these two categories of sperm become magnified, leading to an optimistic estimate of the purity that can be achieved by sorting. This effect is more pronounced when a small training set is used to train the learning model, but prevails even when a large amount of data is used. Nonetheless, the qualitative conclusions from both the computed and predicted velocity distributions remain the same, that the normal sperm cells can be segregated. The extent of quantitative in the results will be explored in the following section.
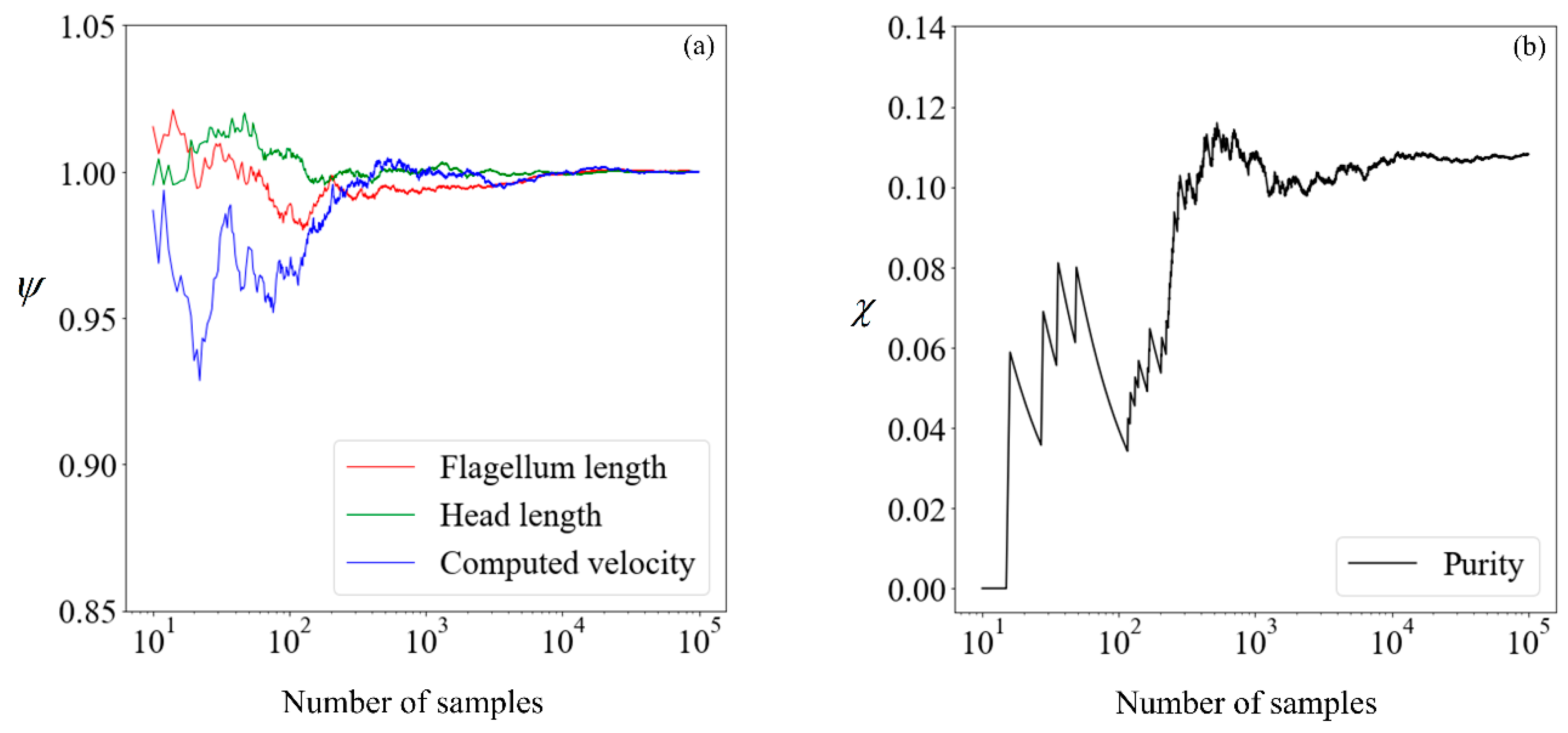
Before proceeding, it is necessary to determine the quantity of data required to obtain convergence in the results, so that a benchmark is available for subsequent comparisons. The cumulative mean flagellum length, head length, and computed velocity are presented in
Figure 6, normalized with their respective mean values obtained from 100,000 samples. For the avoidance of doubt, we chose this number
a posteriori, initially beginning with a small number and making increments until convergence is obtained. This normalized value
is:
where
n is the sample size considered,
nfinal is 10
5, and
is the sperm parameter of interest. The proportion of morphologically normal cells, which by our definition is the purity without sorting, is presented in its absolute percentage points as a function of the sample size.
Given that there are little fluctuations in all parameters when the sample size is increased from 104 to 105, we shall use the results computed using 100,000 samples as our benchmark. Moving forward, we explore the feasibility of running the simulation on a smaller number of samples and making use of supervised learning to predict the expected purity.
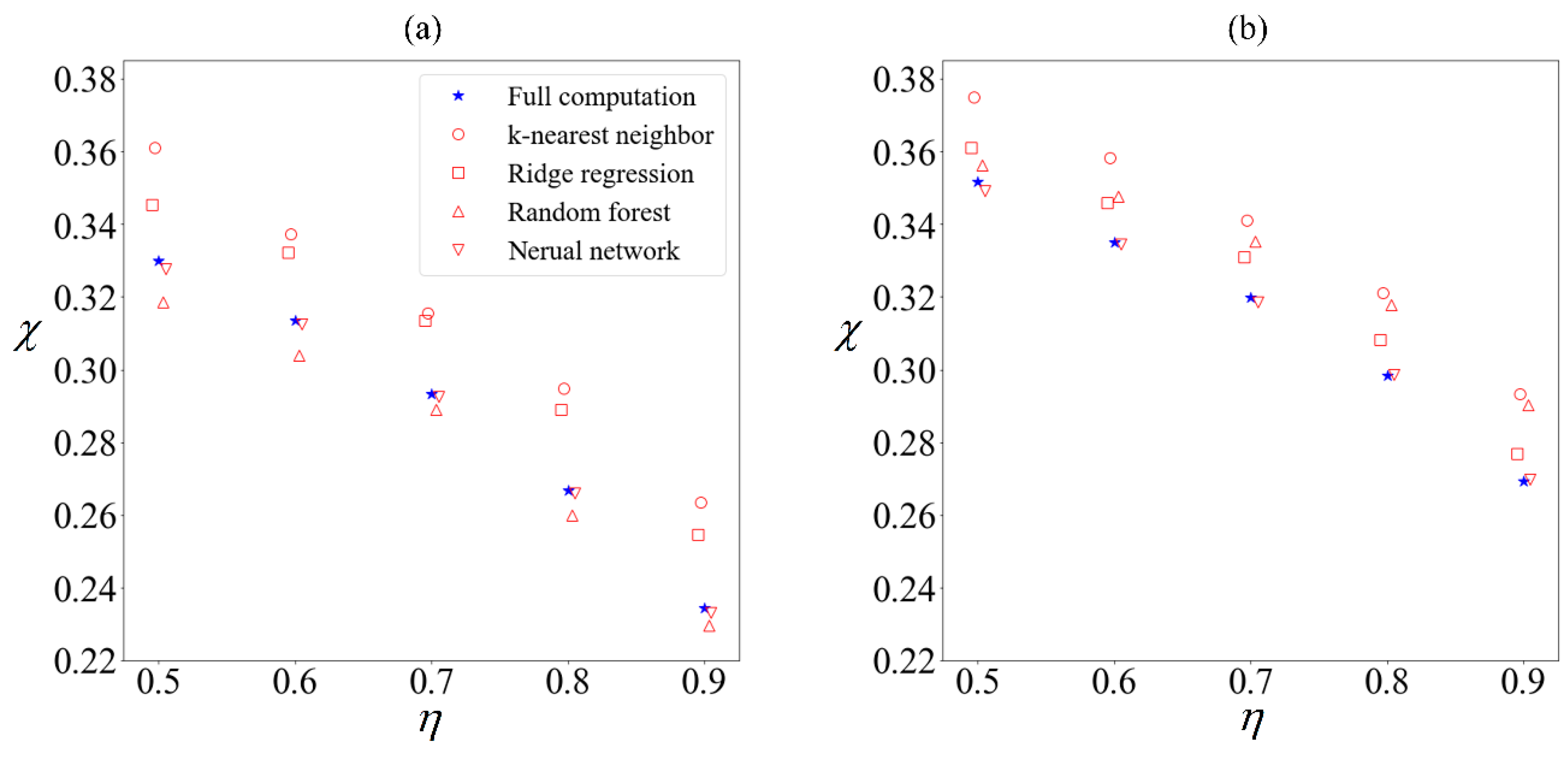
Using supervised learning algorithms from Python’s sklearn package [
51], we build a supervised-learning ensemble comprising k-nearest neighbor, ridge regression, random forest regression, and artificial neural network with two hidden layers. The sperm velocity is predicted using only the following six variables as inputs; the flagellum length, the head length and width, the beating frequency and amplitude, and the applied field strength. Each cell will be classified as collected or excluded depending on its velocity distribution. The purity predicted by each algorithm trained on a tenth of the total samples is compared (
Figure 7) with the purity obtained by computing the velocities of all 100,000 samples.
There are minor variations in the predictions of each algorithm, regardless of whether an external field was applied, but we have chosen not to exclude any of them from the ensemble given that none of them are outliers. Without the benefit of hindsight, it will not be known which algorithm gives a closer prediction to the ‘true’ result. Given that ensembles often out-perform [
27] their individual components, we will use the mean of the predicted results henceforth.
A dataset comprising 2,100,000 rows will be obtained, where each row contains information about the sperm dimensions as well as the computed velocity under 21 different
C0 values ranging from 0 to −1 mN/mm
3 in intervals of 0.05 mN/mm
3. This dataset will be split into training and test sets of different sizes. The test set is unused in the training process, so as to give a fair validation of the model and prevent overfitting [
52].
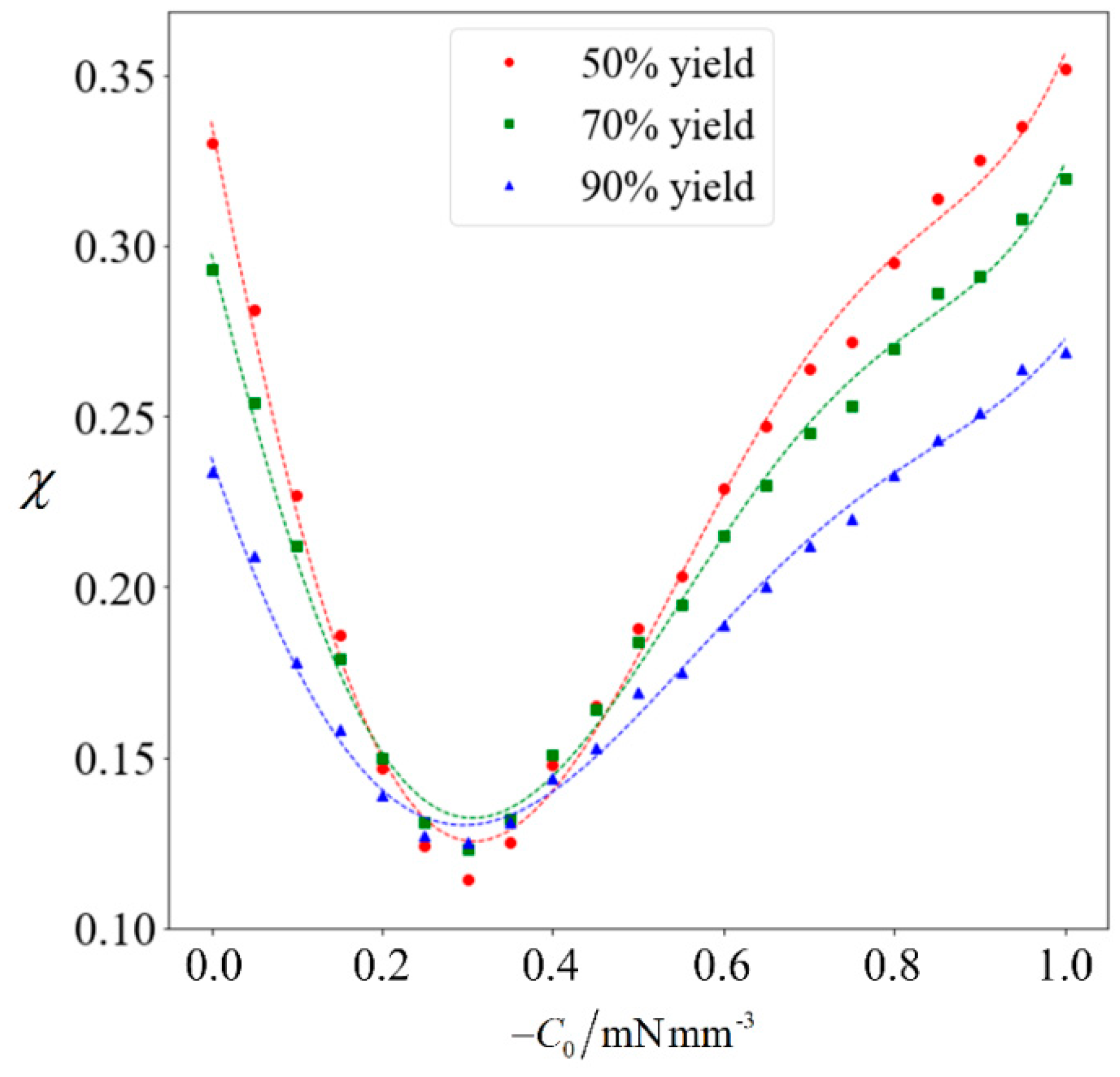
The achievable purity corresponding to a target yield of 50% to 90% will be computed for varying magnitudes of
C0. Each data point in
Figure 8 is obtained by running the full computation on 10
5 samples, and a best-fit polynomial is added for the respective target yield. It can be observed that when the magnitude of
C0 increases, the achievable purity initially decreases. This is because the normal cells generally have a higher speed than abnormal ones. Given that the abnormal sperm are generally larger than the normal ones, they are more strongly influenced when subjected to the external force. Since
C0 is in the swimming direction of the sperm cells, it increases the speed of the abnormal cells to a greater extent than their normal counterparts, thereby causing the abnormal cells to catch-up. Under weak magnetophoresis, the relative shift in velocity distribution causes the two categories to become less distinct, because the abnormal sperm will be moving among the normal ones. However, increasing the strength of magnetophoresis further will increase the extent of the relative shift and eventually amplify the differences. When the magnitude of
C0 increases beyond 0.9 mN/mm
3, sorting can further improve the proportion of normal cells.
To assess the feasibility of sorting sperm with a magnetic force in the order of 1 mN/mm
3, we consider the
as described in the paragraph comprising Equation (6). Given that the magnetic susceptibility of sperm cells is similar to that of water [
53],
is in the order of 10
−1 for sperm in non-magnetic medium, for which a very large magnetic field gradient is required to achieve
mN/mm
3. Hence, it may be more appropriate to dope the sperm with paramagnetic particles or use a magnetic fluid medium. For small values of
and
where demagnetization effects [
54] can be neglected, the doping has to be limited such that
has to be of order 10
−1 or smaller. For
mN/mm
3, the minimum value of
has to be 10, which can be attained using
BX = 5 + 2
X so that O(
C2X) ≪ O(
C1) in the scale of a microchannel. This corresponds to a magnetic field of 5 T, which is technically achievable [
55] but its effects on the viability of sperm cells has not been reported to the best of the authors’ knowledge and remains to be verified in future experiments. To use a weaker magnetic field with a ceiling of 1.5 T [
14], in which human sperm cells have been reported to remain viable in, the value of
has to be of order unity. In this case, demagnetization effects will have to be considered and accounted for, and Equation (6) alone is insufficient. Here, we would like to focus on the analysis procedure using a simple model, where the objective is to introduce the framework of utilising supervised learning in microfluidic sorting. The use of magnetism for biological applications is an exciting field which warrants follow-up experimental work as well as detailed theoretical analysis, and we hope our work can provide insights and serve as a framework for future studies.
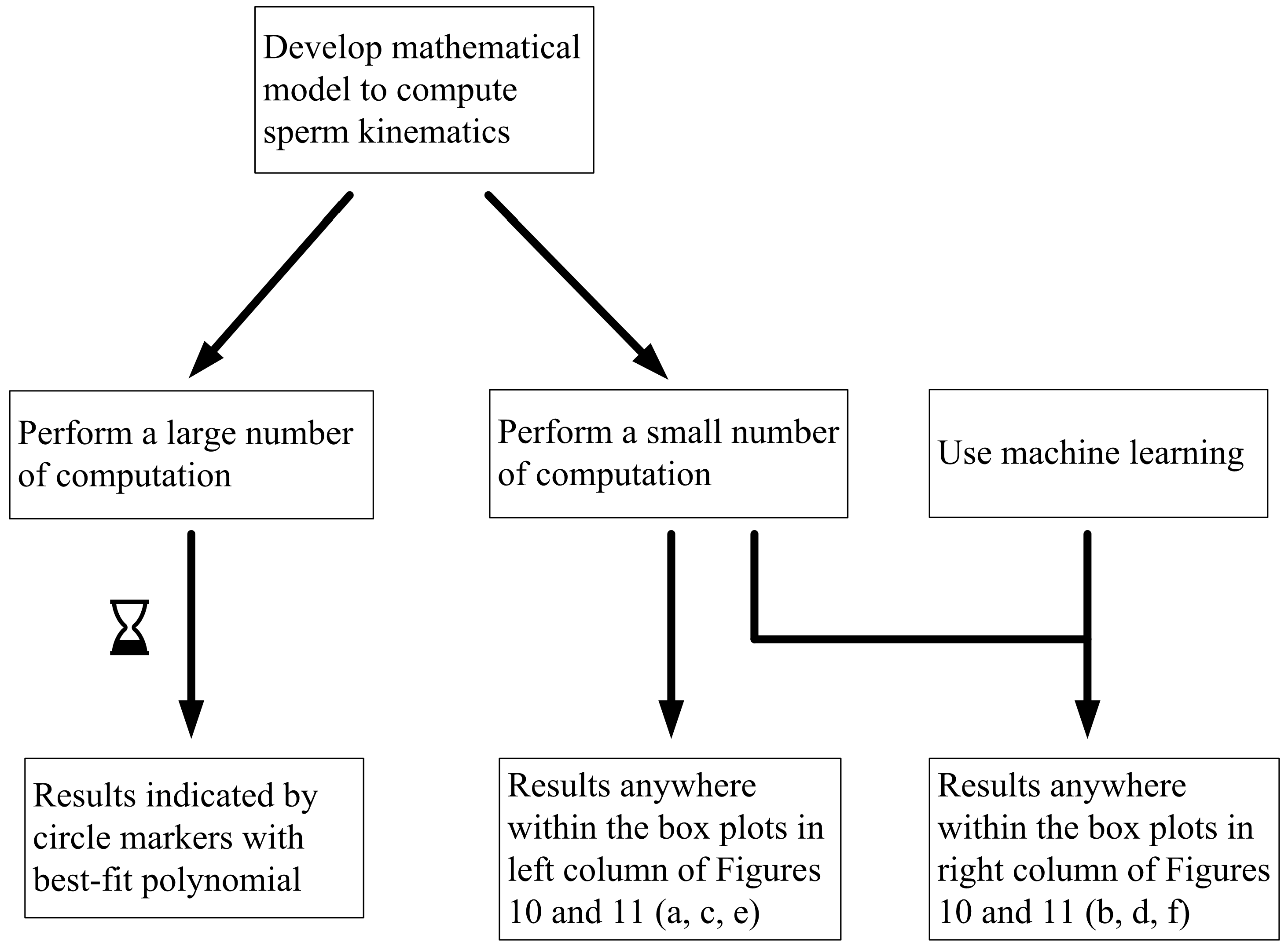
In studying non-deterministic processes such as sperm sorting, there are different approaches which may be taken (
Figure 9). In this paper, we compare the results obtained by these approaches.
Figure 9 compares the computed and predicted purity for a target yield of 50%, presented in box-plots, super-imposed over the best-fit polynomial for results computed using 10
5 samples when
C0 = −1 mN/mm
3. As a sample size of 10
5 has shown convergence, the results, as indicated by the circle markers, will be used as a benchmark. Subsets of size 100, 1000 and 10,000 are considered, by resampling with replacement [
56] from the population of 100,000. Given that the variance of the results is inversely proportional to the sample size, we set the number of repetitions to be 10
5 divided by the size of each training set.
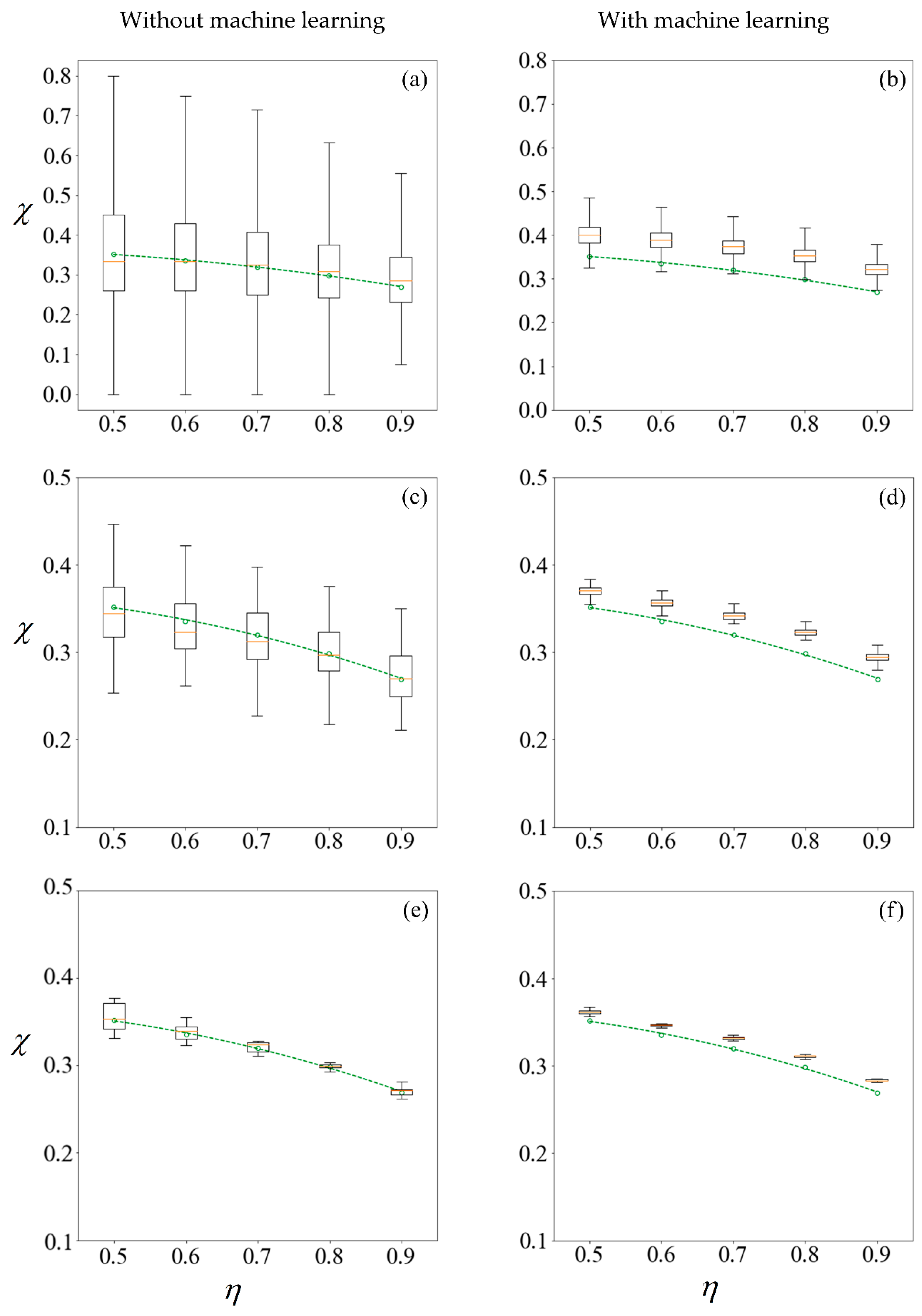
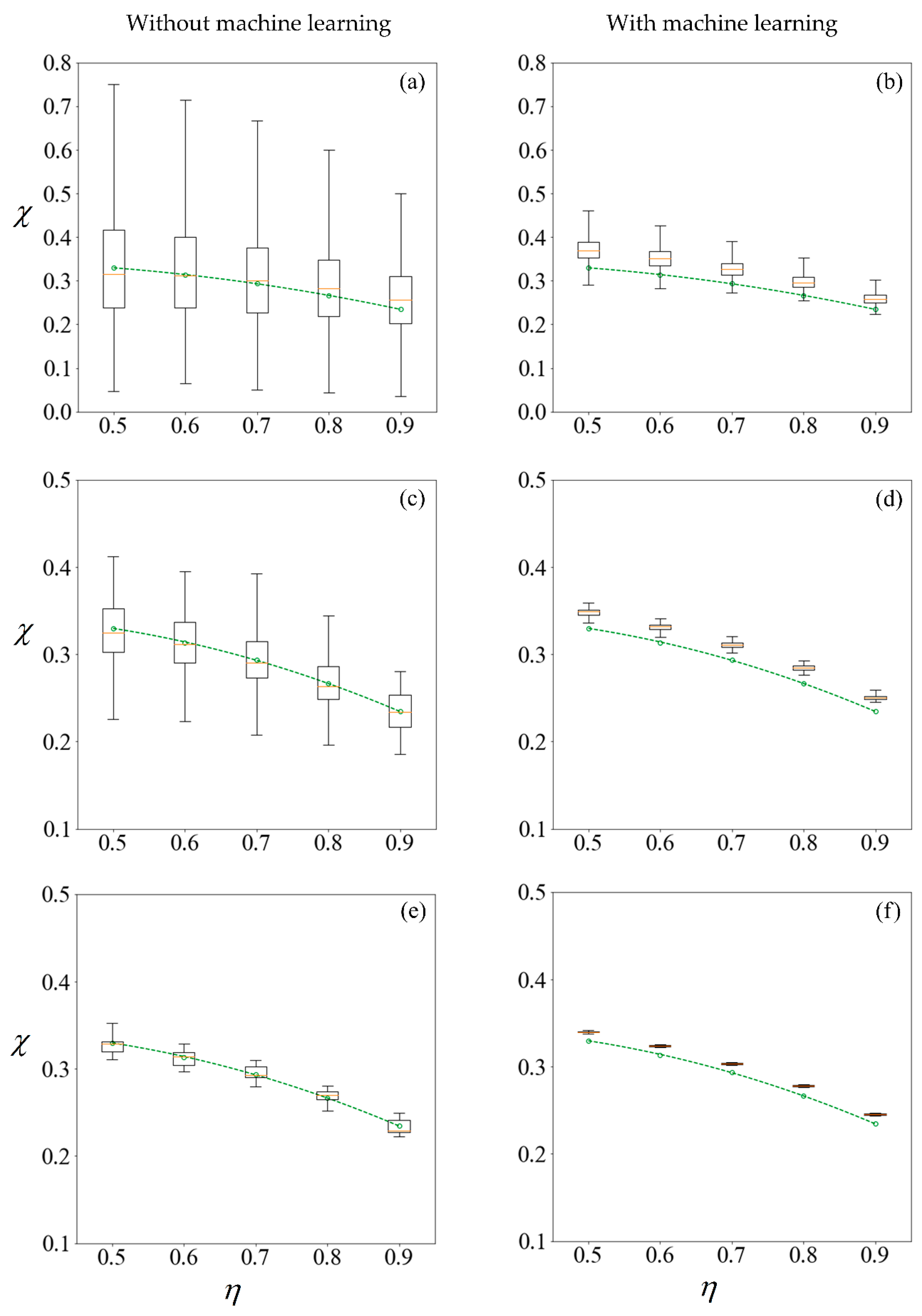
Figure 11 shows the results under no applied field, in the same manner as described. Using the first row of
Figure 10 as an illustration, a set of 100 samples is drawn to train the machine learning models. The purity using these training data are computed using the SBT model. This process is repeated 1000 times to obtain the boxplots in
Figure 10a. Predictions are then made on the remaining 99,900 unseen samples, with a new machine learning model retrained for each repetition, and the results are presented in
Figure 10b.
The left column of
Figure 10 and
Figure 11 reveals that the mean purity computed from the training data of as little as 100 samples is very close to best-fit polynomial obtained from the full computation of 10
5 samples. However, this is obtained from the mean of 1000 repetitions, and the large variance indicates that any individual result obtained from small sample sizes might come with a substantial error. The variance in computed purity from the training set is reduced significantly when a sample size of 10,000 is used.
In the right-hand column of
Figure 10 and
Figure 11, supervised learning is applied to predict the purity of all 10
5 samples for each
C0, less those used for training, using only the six predictor variables for each sperm. Apart from the substantial reduction in variance as the number of samples in the training set increases, the error in the mean predicted purity also diminishes when the training size is increased from 100 to 10,000. Despite the consistent predictions when a training size of 10,000 is used, the mean predictions are larger for all cases considered. This is due to the phenomena where the predicted velocity distributions for each category of sperm tend to be more centered to their mean, as discussed earlier. However, there are significant savings in computational costs. After computing 10,000 samples, the time taken to train the machine learning ensemble and make predictions on the remaining 90,000 is in the order of minutes. If the velocity of those 90,000 sperm were to be computed using SBT, it would require over three days on a Windows
® 64bit PC (CPU E5–1650 v4, 64Gb RAM).
Instead of running the full computation for 10
5 samples, one can draw the same conclusion on how sorting purity depends on yield as well as
C0 by using the results predicted from one-tenth of the sample and using machine learning to make predictions on the rest. This is more reliable than solely making a conclusion from the purity of those one-tenth samples without machine learning, as evident from the shorter whiskers of each plot in the right-hand column of
Figure 10 and
Figure 11 as compared to their counterparts on the left. However, the improved precision obtained by machine learning comes at a cost of some reduction in accuracy, as the purity are consistently over-predicted.
We also consider the use of machine learning in investigating the sorting of sperm by dielectrophoresis, where the force is modelled as
[
57,
58] and where
is the shape factor [
59] rather than volume. The conclusions drawn are similar to those above—consistent predictions with little variance are obtained when a training size of 10,000 is used—but the results are always a couple of percentage points higher than results obtained from the full computation for 10
5 samples.
Depending on the objectives of their study, researchers can substantially reduce computational costs by using an ensemble of a supervised machine learning model trained on a subset of the data. In cases where quantitative accuracy is important but it is not feasible to carry out experiments or the full computation on a larger scale, a number of actions may be taken. Apart from amending the predictor variables or increasing the sample size, a refined hyperparameter tuning can improve the machine learning performance, provided the training set is satisfactory. Other algorithms may also be included in the ensemble, with the weights from each constituent optimized to suit the problem at hand.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}