1. Introduction
Tomato (
Solanum lycopersicum) is an important global crop and ranked first in the world’s vegetable production with 189 million metric tons and a gross production value of approximately USD 100 billion according to the latest statistics of the United Nations Food and Agriculture Organization (FAO) [
1]. Climate change affects extreme weather events’ intensity, frequency, and spatio-temporal extent [
2]. There is a severe concern for food security and economic losses due to extreme weather events [
3]. The increasing global average temperature not only affects plant growth patterns but also reduces surface runoff and water availability [
4,
5]. Boyer [
6] compiled the main environmental factors limiting agricultural production in the U.S., finding that 25.3% of the U.S. land surface had low water availability. In addition, drought accounts for 40.8% of the total indemnification of crop losses for U.S. farmers. Moreover, the FAO pointed out that less than 60% of irrigation water is used by crops. Therefore, the efficiency of agricultural water use needs to be improved due to the increase in global water demand and the decline in available water resources [
7].
Increasingly, more crops are cultivated in greenhouses to resist extreme weather events. Greenhouse cultivation can not only reduce the limitations of the natural environment but also provide more suitable growth conditions. For example, when tomato cultivation in Mexico was converted from open field to greenhouse, the yield increased from about 40 to 250–300 t/ha [
8], showing the benefits of greenhouse cultivation. The tomato crop has a large canopy and transpiration area with relatively low root and stem hydraulic conductivity, and therefore it is prone to drought stress [
9,
10]. If tomatoes suffer from water shortage during the flowering, fruit development, and ripening stages, this can seriously affect the fruit quality and yield [
11]. Although water shortage damages crops in most cases, a moderate reduction in irrigation at the right time can benefit tomato production. Nangare et al. [
12] reported that deficit irrigation during the vegetative stage could enhance tomato root growth, which may stimulate water and nutrient transport. Moderately reducing the irrigation volume not only achieves efficient water use but also increases the Brix and vitamin C content. More importantly, this treatment reduces the proportion of poor-quality fruits without jeopardizing the tomato yield [
13,
14,
15]. However, if deficit irrigation is to be adopted, appropriate water shortage detection methods are needed to avoid adverse effects on tomatoes.
Although irrigation refers to the atmospheric or soil conditions that improve plant growth and increase crop yield [
16], conducting irrigation based on the plant response is sometimes more appropriate and accurate [
17,
18,
19]. Initially, the plants respond to stress by reducing one or several physiological functions, and most plants activate their stress-coping mechanisms in this phase. Additionally, when the stressors are removed before senescence becomes dominant, the plants can quickly recover from stress status [
20]. Therefore, early detection of plant stress is critical to minimize both acute and chronic loss of productivity [
21]. Theoretically, early drought is defined as the period before any apparent changes in morphology related to the drought stress (except for physiological responses that are invisible to the naked eye) can be detected [
22,
23]. Relative water content, sap flow, water potential, and hydraulic conductivity can serve as indicators of plant water status, but measuring these indicators usually needs destructive methods. Therefore, nondestructive and rapid drought detection technology using spectroscopy is gradually emerging [
24]. The spectrum is divided into three ranges: visible (400–700 nm), near-infrared (700–1100 nm), and shortwave infrared (1100–2500 nm), with visible and near-infrared spectroscopy widely used to monitor plant physiological responses. For example, the reflectance of the visible wavebands increases when the leaf pigment decreases, and the reflectance of the near-infrared wavebands increases when the leaf structure changes [
22]. In the early stage of plant water shortage, the reflectance of 400–1300 nm varies due to the slight change in the inner structure of the leaf [
25]. The most sensitive wavebands for tomato drought stress are 451–554 nm, 660–770 nm, and 835–941 nm [
26,
27]; thus, spectroscopy may be an effective tool for detecting drought stress in tomato.
Although spectroscopy has many advantages, the raw spectral data are not suitable for classifying crop water status. This is because spectral data consist of many wavebands with high dimensionality. Furthermore, spectral reflectance is easily affected by measurement conditions such as light intensity and the angle of the sun [
22], which means that the conditions for measuring the spectrum are limited and the data need to be further corrected. The spectral reflectance index (SRI) can be used to reduce environmental interference and the dimensionality of spectral data. The SRI is composed of two or more wavebands and can link spectral data with plant physiological indicators [
28,
29]. For example, water index (WI) and normalized difference vegetation index (NDVI) are well-known SRIs related to crop water status [
21]. Additionally, an SRI is not easily affected by changes in measurement conditions [
26]. Rosa et al. [
30] identified several SRIs for detecting drought stress responses before the signs of plant damage were visible. In applications, multiple SRIs can be used simultaneously to monitor physiological status to effectively manage crop growth in the greenhouse [
21,
26]. However, when data consisting of multiple SRIs are used to classify crop physiological status, the information is often limited by the fact that the values of SRIs are correlated with each other, which is called collinearity in statistics. In the presence of collinearity, spectral data analysis is prone to noise [
31]. Therefore, it is necessary to employ appropriate statistical methods to solve the problems of collinearity in spectral data [
32]. There is also a phenomenon present in most datasets that the instances of one class outnumber the instances of other classes, the so-called class imbalance [
33,
34,
35]. The class imbalance often occurs due to the nature of the data or the cost of data collection. In professional terminology, the class with more data is the majority class, while the class with less data is the minority class [
35,
36,
37]. When training a model using class-imbalanced data, the classification ability of the model tends to decline and involves a large bias, so the classification ability of the model for the minority classes can be poor [
33,
34,
35]. In addition, several classes often share a common region in the data space, which is called class overlap [
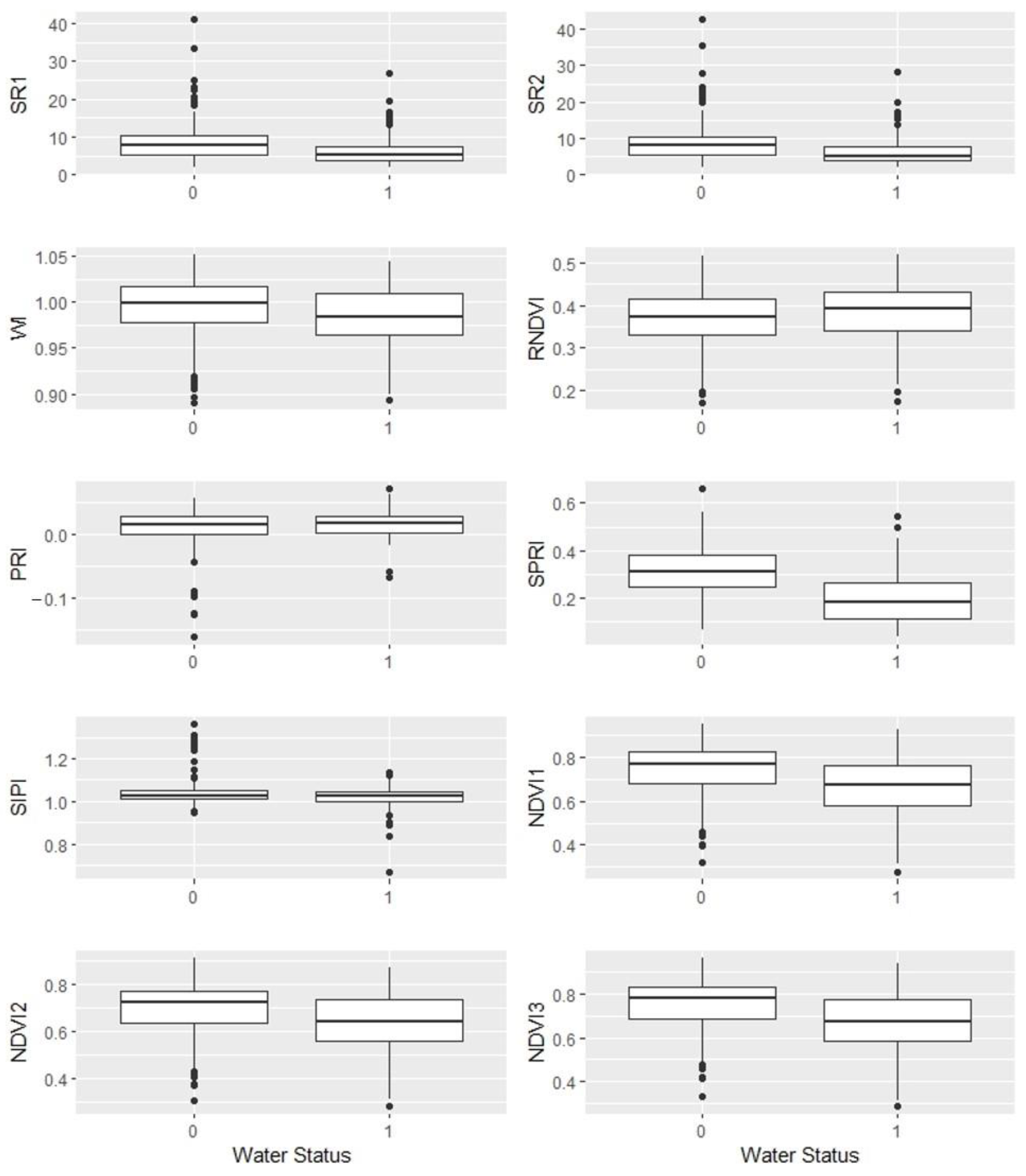
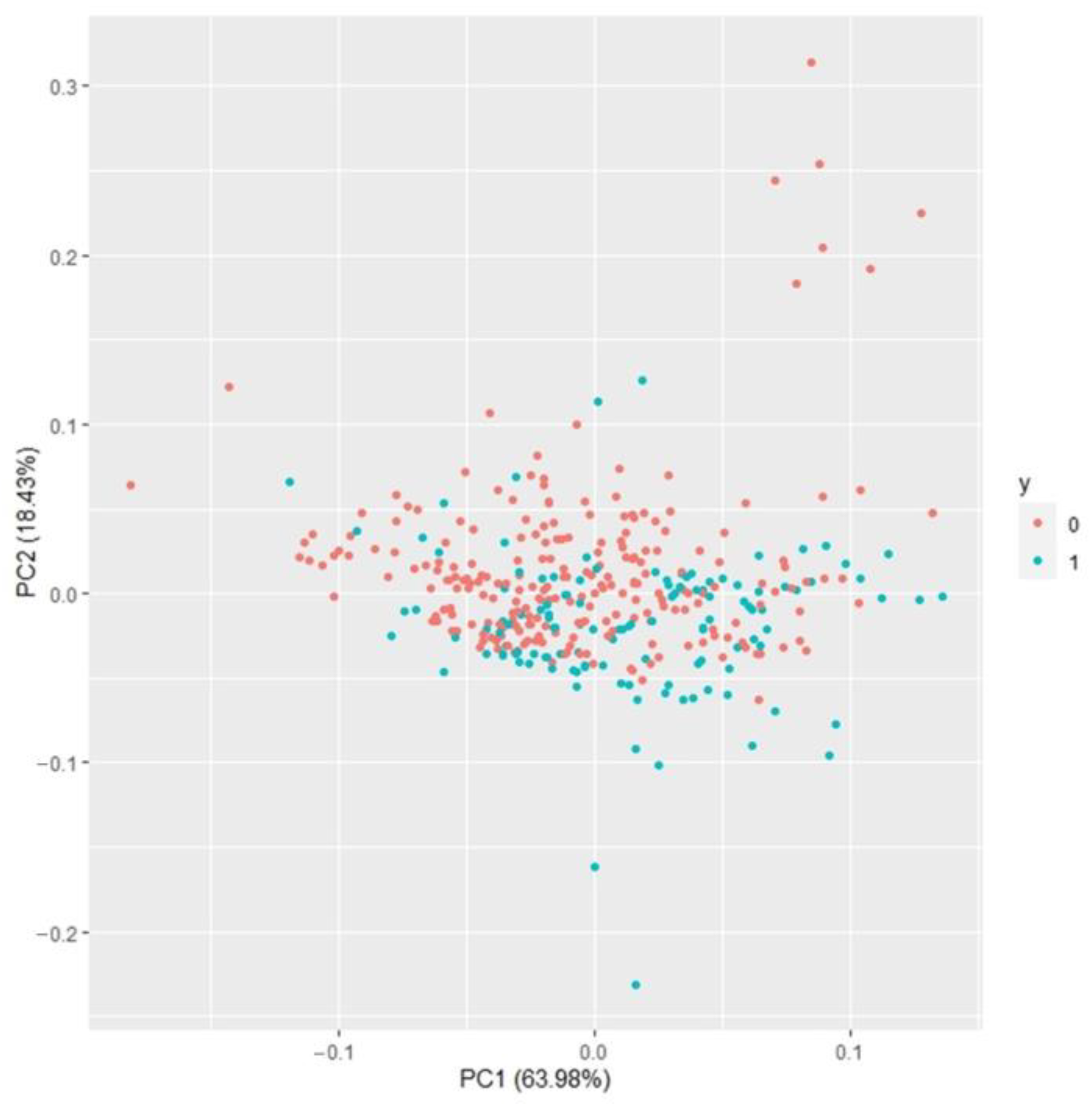
38], so they have similar feature values even though they belong to different classes, and this is a substantial obstacle in classification tasks. Consequently, the problems of collinearity, class imbalance, and class overlap must be considered when utilizing multiple SRI data to classify crop water status.
The difficulty of training models on collinear data can be overcome using machine learning, especially nonparametric methods [
39]. Among the many nonparametric machine learning methods, random forest (RF) has a light computational burden [
40] and can achieve excellent performance when the number of samples is small [
41]. In addition, RF is robust when extreme values or noise exist, and it is not prone to overfitting [
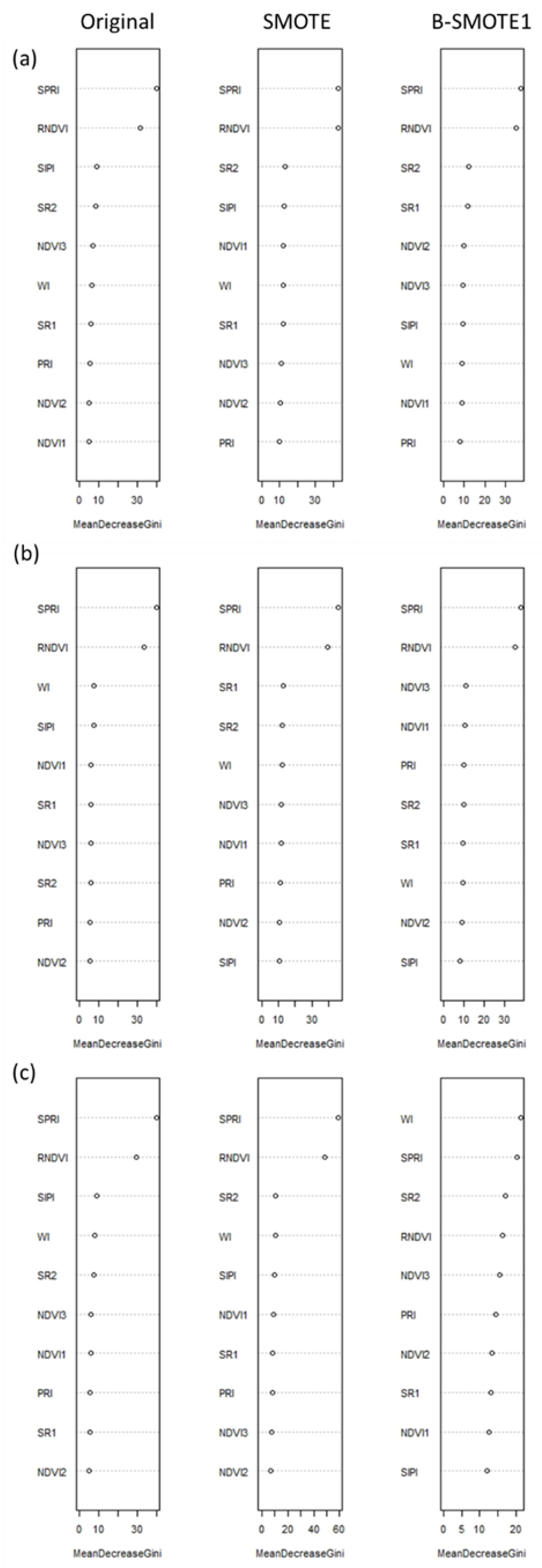
40]. It can also assess the importance of each predictor, allowing researchers to further select important predictors to simplify the model [
42]. There are two types of methods widely used to solve class imbalance and class overlap, namely, data-level and algorithm-level methods. The data-level methods are based on resampling the training dataset before the model training stage. The imbalanced data distribution can be adjusted or the boundaries strengthened between classes by oversampling the minority classes [
35,
38]. The algorithm-level methods involve proposing novel algorithms or modifying existing algorithms to directly handle datasets with class imbalance and overlap. However, algorithm-level methods require many technical thresholds in mathematics, statistics, and information engineering, so most studies focus on data-level methods that are simpler to implement [
35].
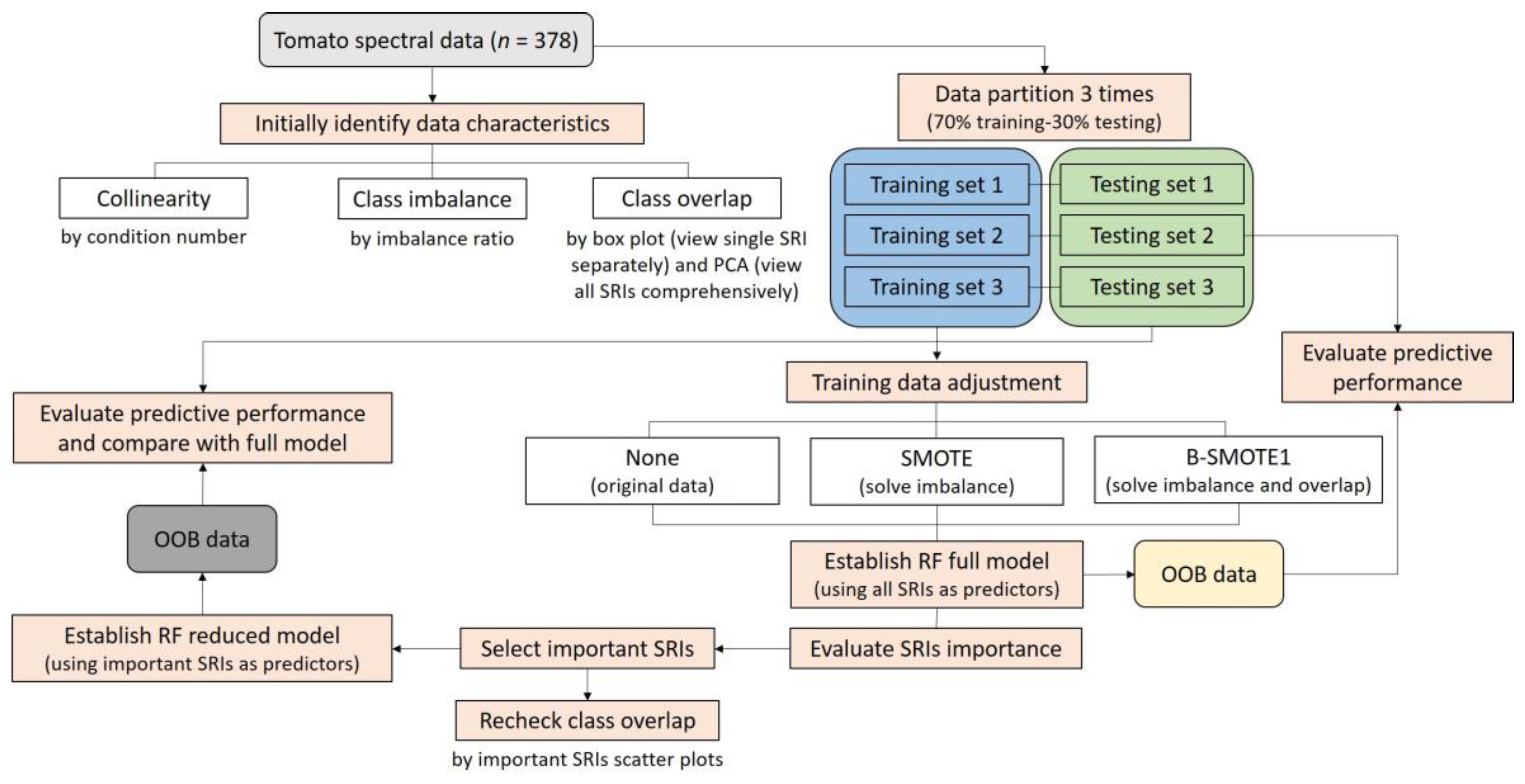
Available water resources are becoming more precious due to climate change and global warming. Agriculture, as an industry with a huge demand for water resources, must use water more precisely, reducing the amount of irrigation water without seriously negatively affecting the crop. This requires effective methods for detecting drought stress; therefore, this study combined SRIs, resampling techniques, and the RF algorithm to detect early drought stress in the vegetative stage of tomato. The study results are useful for the precise irrigation of greenhouse tomatoes and provide suggestions for spectral data analysis in detecting early drought stress.
4. Conclusions
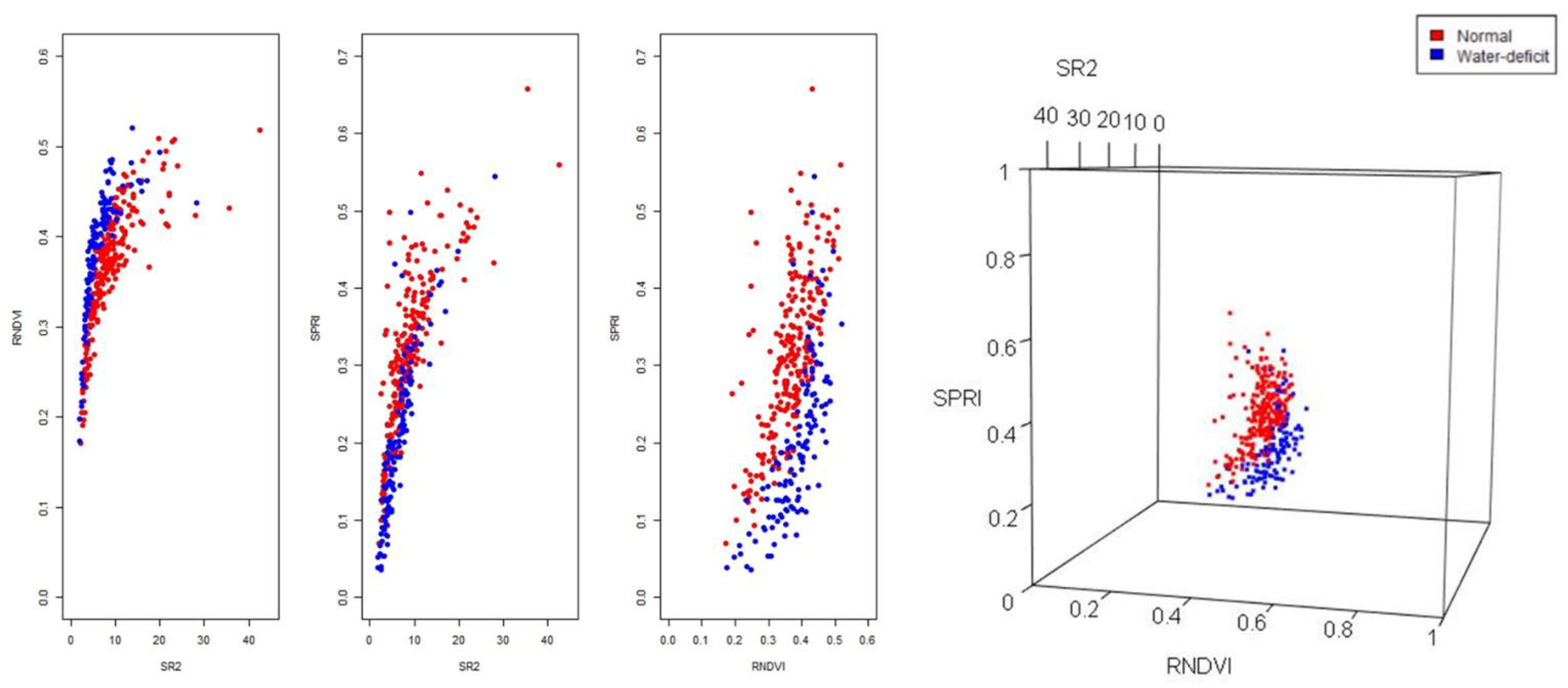
Real-time detection of plant drought stress through noncontact and nondestructive sensors to meet the water needs of greenhouse crop production is one of the directions of precision irrigation. Many SRIs have been proposed to establish the prediction model, but the spectral data often suffer from problems of collinearity, class imbalance, and class overlap, which require some effective strategies to overcome. This study developed an early drought detection model for the vegetative stage of greenhouse tomatoes and explored the strategies for analyzing multiple SRI data. It was found that using RF to build the model can overcome collinearity well. For class imbalance, SMOTE can be used to adjust the training data distribution to improve the model’s ability to identify minority classes. For the class overlap in high-dimensional data, we suggest that researchers can first screen out two to three important predictors and then use scatter plots to detect the class overlap. When there is indeed class overlap in the data, resampling techniques developed to address class overlap (e.g., B-SMOTE1) can be used to process the training data. Finally, the proposed RF model for detecting early drought stress based on three SRIs, namely, SPRI, RNDVI, and SR2, which only require six spectral wavebands, i.e., 510, 560, 680, 705, 750, and 900 nm, achieved more than 85% accuracy. We concluded that this reduced model can serve as a useful and cost-effective tool for precise irrigation in greenhouse tomato production. A sensor prototype can be developed and tested in different situations to make it more comprehensive and reliable.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}