
Characterization and Evolutionary Analyses Reveal Differential Selection Pressures on PGIc and PGIp During Domestication in Castor Bean



Abstract
:1. Introduction
2. Materials and Methods
2.1. Identification of the PGI-Containing Proteins in the Castor Bean Genome
2.2. Phylogenetic Analysis of PGI Proteins
2.3. Gene Expression Analysis
2.4. Genetic Diversity and Evolutionary Selection Analysis
2.5. Measurements of Seed Oil Content, Weight, and Plant Height
2.6. Association Analysis of Agronomic Traits with Amino Acid Variants
3. Results
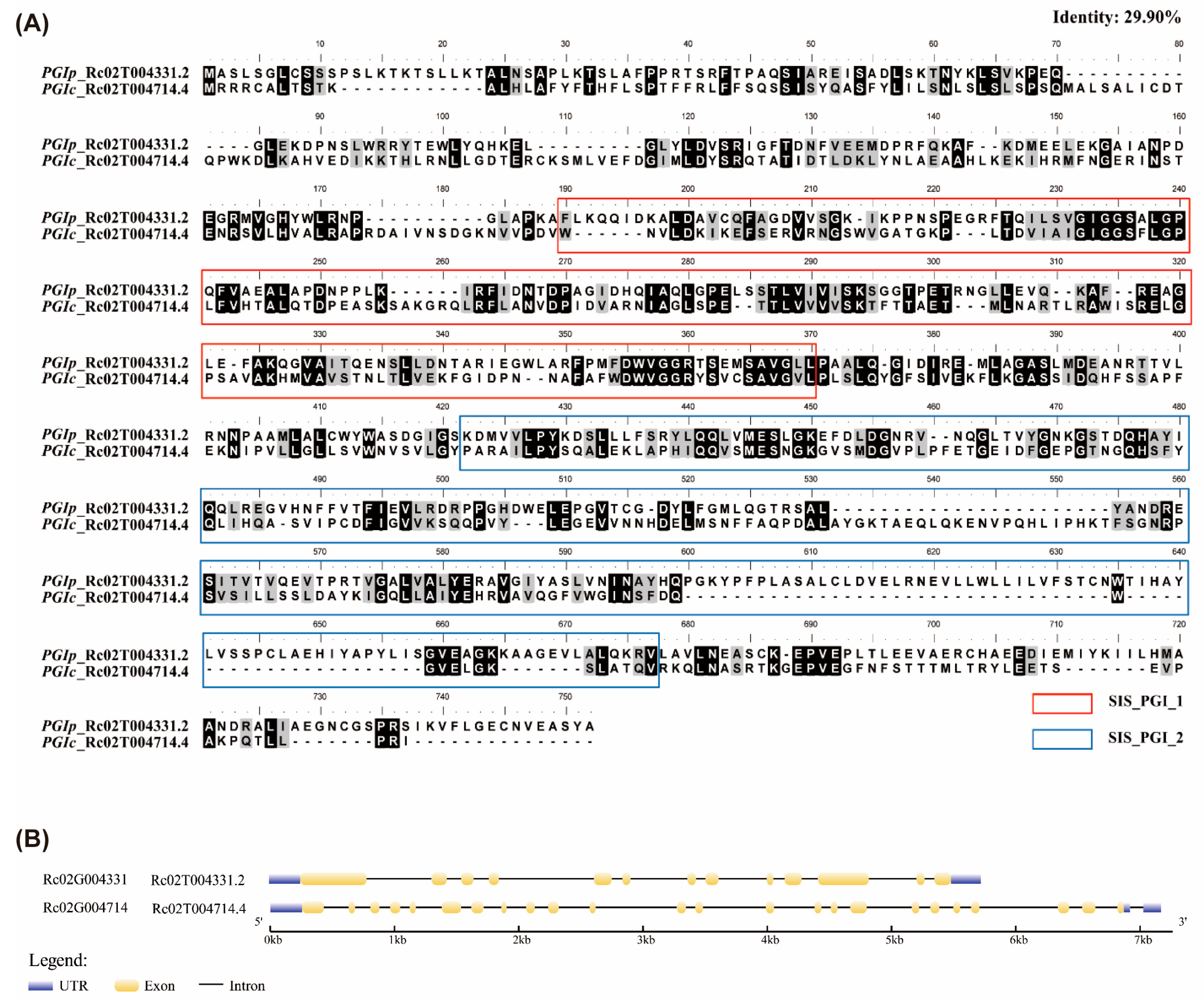
3.1. Identification of RcPGI Proteins
3.2. Different Expression Profiles of RcPGIc and RcPGIp Across Different Tissues
3.3. Variations in Genetic Diversity During Population Differentiation
3.4. Evolutionary Analysis Revealed Different Selection Pressures on RcPGIc and RcPGIp During Population Differentiation
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kunz, H.-H.; Häusler, R.E.; Fettke, J.; Herbst, K.; Niewiadomski, P.; Gierth, M.; Bell, K.; Steup, M.; Flügge, U.I.; Schneider, A. The role of plastidial glucose-6-phosphate/phosphate translocators in vegetative tissues of Arabidopsis thaliana mutants impaired in starch biosynthesis. Plant Biol. 2010, 12, 115–128. [Google Scholar] [CrossRef] [PubMed]
- Santelia, D.; Zeeman, S.C. Progress in Arabidopsis starch research and potential biotechnological applications. Curr. Opin. Biotechnol. 2011, 22, 271–280. [Google Scholar] [CrossRef] [PubMed]
- Schleucher, J.; Vanderveer, P.; Markley, J.L.; Sharkey, T.D. Intramolecular deuterium distributions reveal disequilibrium of chloroplast phosphoglucose isomerase. Plant Cell Environ. 1999, 22, 525–533. [Google Scholar] [CrossRef]
- Vanderwall, M.; Gendron, J.M. HEXOKINASE1 and glucose-6-phosphate fuel plant growth and development. Development 2023, 150, dev202346. [Google Scholar] [CrossRef]
- Kunz, B.A.; Ayre, B.G.; Downes, A.M.; Kohalmi, S.E.; McMaster, C.R.; Peters, M.G. Base-pair substitutions alter the site-specific mutagenicity of UV and MNNG in the SUP4-o gene of yeast. Mutat. Res. Lett. 1989, 226, 273–278. [Google Scholar] [CrossRef]
- Weise, S.E.; Liu, T.; Childs, K.L.; Preiser, A.L.; Katulski, H.M.; Perrin-Porzondek, C.; Sharkey, T.D. Transcriptional Regulation of the Glucose-6-Phosphate/Phosphate Translocator 2 Is Related to Carbon Exchange Across the Chloroplast Envelope. Front. Plant Sci. 2019, 10, 827. [Google Scholar] [CrossRef]
- Yu, T.-S.; Lue, W.-L.; Wang, S.-M.; Chen, J. Mutation of Arabidopsis Plastid Phosphoglucose Isomerase Affects Leaf Starch Synthesis and Floral Initiation. Plant Physiol. 2000, 123, 319–326. [Google Scholar] [CrossRef]
- Bahaji, A.; Almagro, G.; Ezquer, I.; Gámez-Arcas, S.; Sánchez-López, Á.M.; Muñoz, F.J.; Barrio, R.J.; Sampedro, M.C.; Diego, N.D.; Spíchal, L.; et al. Plastidial Phosphoglucose Isomerase is an Important Determinant of Seed Yield through its Involvement in Gibberellin-mediated Reproductive Development and Storage Reserve Biosynthesis in Arabidopsis. Plant Cell 2018, 30, 2082–2098. [Google Scholar] [CrossRef]
- Kunz, H.-H.; Zamani-Nour, S.; Häusler, R.E.; Ludewig, K.; Schroeder, J.I.; Malinova, I.; Fettke, J.; Flügge, U.-I.; Gierth, M. Loss of cytosolic phosphoglucose isomerase affects carbohydrate metabolism in leaves and is essential for fertility of Arabidopsis. Plant Physiol. 2014, 166, 753–765. [Google Scholar] [CrossRef]
- Gao, F.; Zhang, H.; Zhang, W.; Wang, N.; Zhang, S.; Chu, C.; Liu, C. Engineering of the cytosolic form of phosphoglucose isomerase into chloroplasts improves plant photosynthesis and biomass. New Phytol. 2021, 231, 315–325. [Google Scholar] [CrossRef]
- Jiao, J.; Gao, F.; Liu, J.; Lv, Z.; Liu, C. A structural basis for the functional differences between the cytosolic and plastid phosphoglucose isomerase isozymes. PLoS ONE 2022, 17, e0272647. [Google Scholar] [CrossRef] [PubMed]
- Kawabe, A.; Yamane, K.; Miyashita, N.T. DNA polymorphism at the cytosolic phosphoglucose isomerase (PgiC) locus of the wild plant Arabidopsis thaliana. Genetics 2000, 156, 1339–1347. [Google Scholar] [CrossRef] [PubMed]
- Liu, A.; Burke, J.M. Patterns of Nucleotide Diversity in Wild and Cultivated Sunflower. Genetics 2006, 173, 321–330. [Google Scholar] [CrossRef]
- Kawabe, A.; Miyashita, N.T. DNA Polymorphism in Active Gene and Pseudogene of the Cytosolic Phosphoglucose Isomerase (PgiC) Loci in Arabidopsis halleri ssp. gemmifera. Mol. Biol. Evol. 2003, 20, 1043–1050. [Google Scholar] [CrossRef]
- Li, Y.; Hansson, B.; Ghatnekar, L.; Prentice, H.C. Contrasting patterns of nucleotide polymorphism suggest different selective regimes within different parts of the PgiC1 gene in Festuca ovina L. Hereditas 2017, 154, 11. [Google Scholar] [CrossRef]
- Lima Da Silva, N.; Maciel, M.R.W.; Batistella, C.B.; Filho, R.M. Optimization of biodiesel production from castor oil. Appl. Biochem. Biotechnol. 2006, 130, 405–414. [Google Scholar] [CrossRef]
- Ogunniyi, D.S. Castor oil: A vital industrial raw material. Bioresour. Technol. 2006, 97, 1086–1091. [Google Scholar] [CrossRef]
- Patel, V.R.; Dumancas, G.G.; Viswanath, L.C.K.; Maples, R.; Subong, B.J.J. Castor Oil: Properties, Uses, and Optimization of Processing Parameters in Commercial Production. Lipid Insights 2016, 9, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Singh, R.; Geetanjali. Phytochemical and Pharmacological Investigations of Ricinus communis Linn. Alger. J. Nat. Prod. 2015, 3, 120–129. [Google Scholar]
- Rao, M.S.; Rao, C.R.; Srinivas, K.; Pratibha, G.; Sekhar, S.V.; Vani, G.S.; Venkateswarlu, B. Intercropping for Management of Insect Pests of Castor, Ricinus communis, in the Semi-Arid Tropics of India. J. Insect Sci. 2012, 12, 14. [Google Scholar]
- Xu, W.; Wu, D.; Yang, T.; Sun, C.; Wang, Z.; Han, B.; Wu, S.; Yu, A.; Chapman, M.A.; Muraguri, S.; et al. Genomic insights into the origin, domestication and genetic basis of agronomic traits of castor bean. Genome Biol. 2021, 22, 113. [Google Scholar] [CrossRef] [PubMed]
- Katoh, K.; Standley, D.M. MAFFT multiple sequence alignment software version 7: Improvements in performance and usability. Mol. Biol. Evol. 2013, 30, 772–780. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, L.-T.; Schmidt, H.A.; von Haeseler, A.; Minh, B.Q. IQ-TREE: A Fast and Effective Stochastic Algorithm for Estimating Maximum-Likelihood Phylogenies. Mol. Biol. Evol. 2014, 32, 268–274. [Google Scholar] [CrossRef] [PubMed]
- Minh, B.Q.; Nguyen, M.A.T.; von Haeseler, A. Ultrafast Approximation for Phylogenetic Bootstrap. Mol. Biol. Evol. 2013, 30, 1188–1195. [Google Scholar] [CrossRef]
- Han, B.; Wu, D.; Zhang, Y.; Li, D.Z.; Xu, W.; Liu, A. Epigenetic regulation of seed-specific gene expression by DNA methylation valleys in castor bean. BMC Biol. 2022, 20, 57. [Google Scholar] [CrossRef]
- Han, B.; Li, Y.; Wu, D.; Li, D.-Z.; Liu, A.; Xu, W. Dynamics of imprinted genes and their epigenetic mechanisms in castor bean seed with persistent endosperm. New Phytol. 2023, 240, 1868–1882. [Google Scholar] [CrossRef]
- Livak, K.J.; Schmittgen, T.D. Analysis of Relative Gene Expression Data Using Real-Time Quantitative PCR and the 2−ΔΔCT Method. Methods 2001, 25, 402–408. [Google Scholar] [CrossRef]
- Danecek, P.; Bonfield, J.K.; Liddle, J.; Marshall, J.; Ohan, V.; Pollard, M.O.; Whitwham, A.; Keane, T.; McCarthy, S.A.; Davies, R.M.; et al. Twelve years of SAMtools and BCFtools. GigaScience 2021, 10, giab008. [Google Scholar] [CrossRef]
- Rozas, J.; Ferrer-Mata, A.; Sánchez-DelBarrio, J.C.; Guirao-Rico, S.; Librado, P.; Ramos-Onsins, S.; Sánchez-Gracia, A. DnaSP 6: DNA Sequence Polymorphism Analysis of Large Data Sets. Mol. Biol. Evol. 2017, 34, 3299–3302. [Google Scholar] [CrossRef]
- Wright, S.I.; Charlesworth, B. The HKA Test Revisited: A Maximum-Likelihood-Ratio Test of the Standard Neutral Model. Genetics 2004, 168, 1071–1076. [Google Scholar] [CrossRef]
- Xu, W.; Yang, T.; Qiu, L.; Chapman, M.A.; Li, D.Z.; Liu, A. Genomic analysis reveals rich genetic variation and potential targets of selection during domestication of castor bean from perennial woody tree to annual semi-woody crop. Plant Direct 2019, 3, e00173. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; Chen, C.; Arab, D.; Du, Z.; He, Y.; Ho, S.Y.W. EasyCodeML: A visual tool for analysis of selection using CodeML. Ecol. Evol. 2019, 9, 3891–3898. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z. Complexity of the Simplest Phylogenetic Estimation. Proc. Biol. Sci. 2000, 267, 109–116. [Google Scholar] [CrossRef] [PubMed]
- Wong, W.S.W.; Yang, Z.; Nick Goldman, R.N. Accuracy and power of statistical methods for detecting adaptive evolution in protein coding sequences and for identifying positively selected sites. Genetics 2004, 168, 1041–1051. [Google Scholar] [CrossRef] [PubMed]
- Álvarez-Carretero, S.; Kapli, P.; Yang, Z. Beginner’s Guide on the Use of PAML to Detect Positive Selection. Mol. Biol. Evol. 2023, 40, msad041. [Google Scholar] [CrossRef]
- Yang, Z.; Wong, W.S.W.; Nielsen, R. Bayes empirical bayes inference of amino acid sites under positive selection. Mol. Biol. Evol. 2005, 22, 1107–1118. [Google Scholar] [CrossRef]
- Tan, Q.; Han, B.; Haque, M.E.; Li, Y.-L.; Wang, Y.; Wu, D.; Wu, S.-B.; Liu, A.-Z. The molecular mechanism of WRINKLED1 transcription factor regulating oil accumulation in developing seeds of castor bean. Plant Divers. 2023, 45, 469–478. [Google Scholar] [CrossRef]
- Yang, Z. PAML: A program package for phylogenetic analysis by maximum likelihood. Comput. Appl. Biosci. Cabios 1997, 13, 555–556. [Google Scholar] [CrossRef]
- Chen, L.; Kuai, P.; Lu, J.; Li, L.; Lou, Y. A Cytosolic Phosphoglucose Isomerase, OsPGI1c, Enhances Plant Growth and Herbivore Resistance in Rice. Int. J. Mol. Sci. 2025, 26, 169. [Google Scholar] [CrossRef]
- Bahaji, A.; Sánchez-López, Á.M.; Diego, N.D.; Muñoz, F.J.; Baroja-Fernández, E.; Li, J.; Ricarte-Bermejo, A.; Baslam, M.; Aranjuelo, I.; Almagro, G.; et al. Plastidic Phosphoglucose Isomerase Is an Important Determinant of Starch Accumulation in Mesophyll Cells, Growth, Photosynthetic Capacity, and Biosynthesis of Plastidic Cytokinins in Arabidopsis. PLoS ONE 2015, 10, e0119641. [Google Scholar] [CrossRef]
- Preiser, A.L.; Banerjee, A.; Weise, S.E.; Renna, L.; Brandizzi, F.; Sharkey, T.D. Phosphoglucoisomerase Is an Important Regulatory Enzyme in Partitioning Carbon out of the Calvin-Benson Cycle. Front. Plant Sci. 2020, 11, 580726. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.-C.; Chen, H.-C.; Huang, T.-H.; Lue, W.-L.; Chen, J.; Suen, D.-F. Cytosolic phosphoglucose isomerase is essential for microsporogenesis and embryogenesis in Arabidopsis. Plant Physiol. 2023, 191, 177–198. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
| Protein ID | Gene ID | Protein Length (aa) | Gene Length (bp) | Exon No. | Intron No. |
|---|---|---|---|---|---|
| Rc02T004331.2 (RcPGIp) | Rc02G004331 | 676 | 5729 | 13 | 12 |
| Rc02T004714.4 (RcPGIc) | Rc02G004714 | 626 | 7261 | 24 | 23 |
| Gene_ID | Population | θw | π | πsil | πsyn | πnonsyn | πnonsyn/πsyn | Tajima’s D | p-Value in the ML-HKA Test |
|---|---|---|---|---|---|---|---|---|---|
| Rc02G004331 | Total | 0.00104 | 0.00117 | 0.00145 | 0.00097 | 0.00042 | 0.43299 | 0.36572 | - |
| (RcPGIp) | LC | 0.00049 | 0.00048 | 0.0006 | 0 | 0.00016 | - | −0.0409 | 0.1386 |
| Wild | 0.00086 | 0.00144 | 0.00176 | 0.00162 | 0.00056 | 0.34568 | 2.1135 * | 0.0210 * | |
| Rc02G004714 | Total | 0.00103 | 0.00092 | 0.00091 | 0.00093 | 0.001 | 1.07527 | −0.30889 | - |
| (RcPGIc) | LC | 0.00089 | 0.0005 | 0.00047 | 0.00051 | 0.00062 | 1.21569 | 1.41291 | 0.0074 ** |
| Wild | 0.00106 | 0.00127 | 0.00128 | 0.0013 | 0.00119 | 0.91538 | 0.61903 | 0.1738 |
| Protein Name | Model | Ln L | Estimates of Parameters | Model Compared | LRT p-Value | Positive Sites |
|---|---|---|---|---|---|---|
| RcPGIp | M3 (discrete) | −2786.800012 | p0 = 0.98946, p1 = 0.00002, p2 = 0.01053; ω0 = 0.00000, ω1 = 0.00000, ω2 = 76.79742 | M0 vs. M3 | 0.076124393 | Not Allowed |
| M0 (one-ratio) | −2791.029762 | ω0 = 0.56896 | ||||
| M2a (Selection) | −2786.801929 | p0 = 0.98947, p1 = 0.00000, p2 = 0.01053; ω2 = 76.81691 (ω0 = 0.00000, ω1 = 1.00000) | M1a vs. M2a | 0.033215455 | Not Allowed | |
| M1a (Neutral) | −2790.206669 | p0 = 0.65994, p1 = 0.34006; ω0 = 0.00000, ω1 = 1.00000 | ||||
| M8 (beta and ω) | −2786.799758 | p0 = 0.98947, p1 = 0.01053; p = 0.00500, q = 1.64348; ω1= 76.78703 | M7 vs. M8 | 0.033118077 | 9 S Pr = 0.575, 107 N Pr = 0.870, 292 D Pr = 0.569, 537 C Pr = 0.567 | |
| M7 (beta) | −2790.207434 | p = 0.03048, q = 0.06257 | ||||
| RcPGIc | M3 (discrete) | −2625.365411 | p0 = 0.98663, p1 = 0.00549, p2 = 0.00789; ω0 = 0.00000, ω1 = 0.00000, ω2 = 77.09957 | M0 vs. M3 | 0.000000121 | Not Allowed |
| M0 (one-ratio) | −2644.286875 | ω0 = 0.42373 | ||||
| M2a (Selection) | −2625.365469 | p0 = 0.99211, p1 = 0.00000, p2 = 0.00789; ω2 = 77.07921 (ω0 = 0.00000, ω1 = 1.00000) | M1a vs. M2a | 0.000002433 | Not Allowed | |
| M1a (Neutral) | −2638.291883 | p0 = 0.88274, p1 = 0.11726; ω0 = 0.00000, ω1 = 1.00000 | ||||
| M8 (beta and ω) | −2625.365392 | p0 = 0.99211, p1= 0.00789; p = 0.00500, q = 1.48765; ω1= 77.10353 | M7 vs. M8 | 0.000000462 | 114 T Pr = 0.977 *, 310 T Pr = 0.978 *, 338 A Pr = 0.976 *, 613 S Pr = 0.979 * | |
| M7 (beta) | −2639.953038 | p = 0.00526, q = 0.01852 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Jiang, L.; Yu, A.; Han, B.; Liu, A. Characterization and Evolutionary Analyses Reveal Differential Selection Pressures on PGIc and PGIp During Domestication in Castor Bean. Horticulturae 2025, 11, 569. https://doi.org/10.3390/horticulturae11060569
Guo J, Jiang L, Yu A, Han B, Liu A. Characterization and Evolutionary Analyses Reveal Differential Selection Pressures on PGIc and PGIp During Domestication in Castor Bean. Horticulturae. 2025; 11(6):569. https://doi.org/10.3390/horticulturae11060569
Chicago/Turabian StyleGuo, Jiayu, Lanxin Jiang, Anmin Yu, Bing Han, and Aizhong Liu. 2025. "Characterization and Evolutionary Analyses Reveal Differential Selection Pressures on PGIc and PGIp During Domestication in Castor Bean" Horticulturae 11, no. 6: 569. https://doi.org/10.3390/horticulturae11060569
APA StyleGuo, J., Jiang, L., Yu, A., Han, B., & Liu, A. (2025). Characterization and Evolutionary Analyses Reveal Differential Selection Pressures on PGIc and PGIp During Domestication in Castor Bean. Horticulturae, 11(6), 569. https://doi.org/10.3390/horticulturae11060569