



An Efficient Detection of the Pitaya Growth Status Based on the YOLOv8n-CBN Model

 ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Construction of Data Sets
2.2. Methods
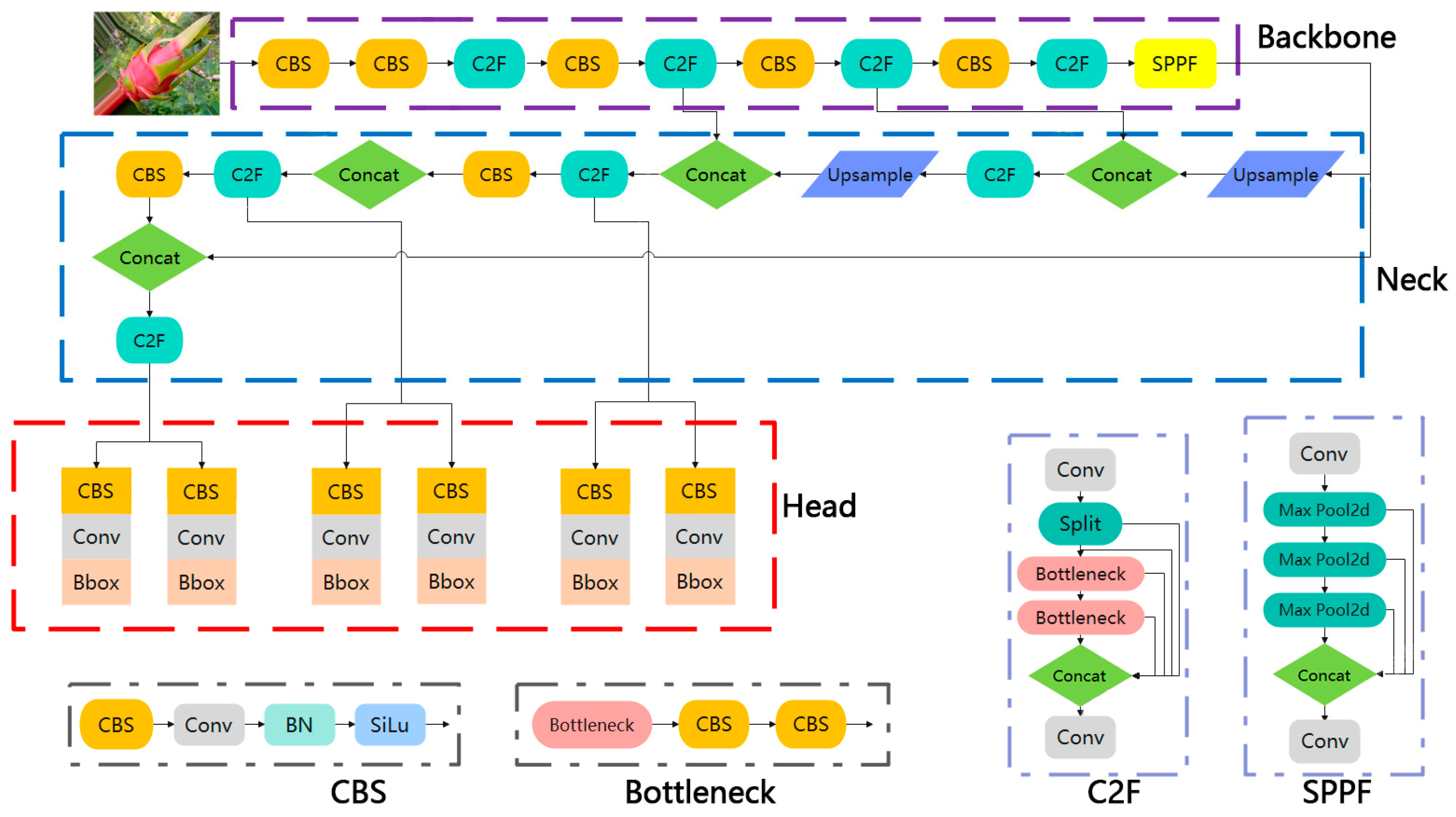
2.2.1. YOLOv8n Network Structure
2.2.2. CBAM Attentional Mechanisms
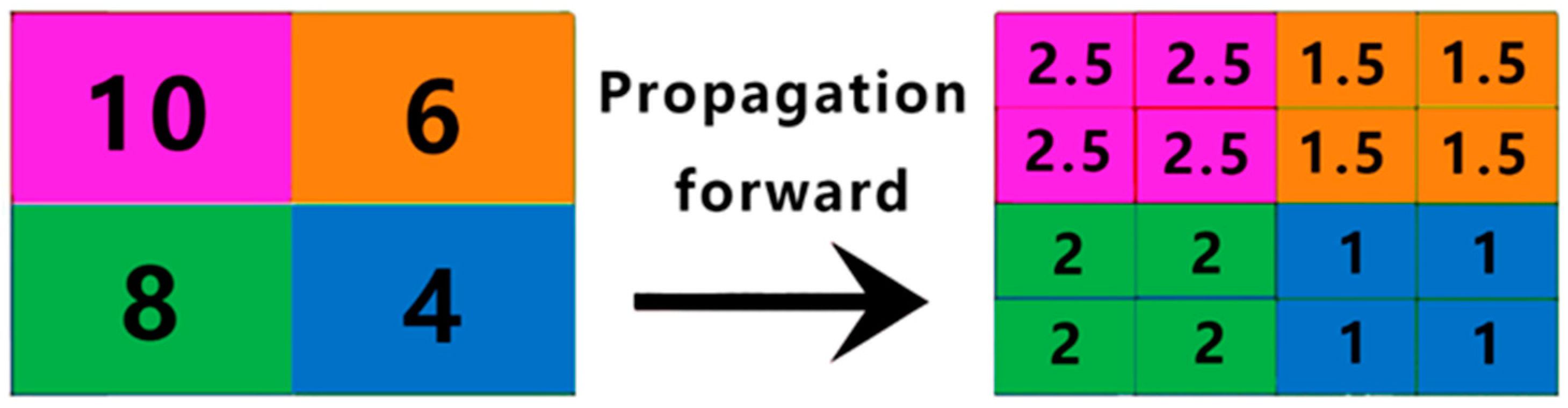
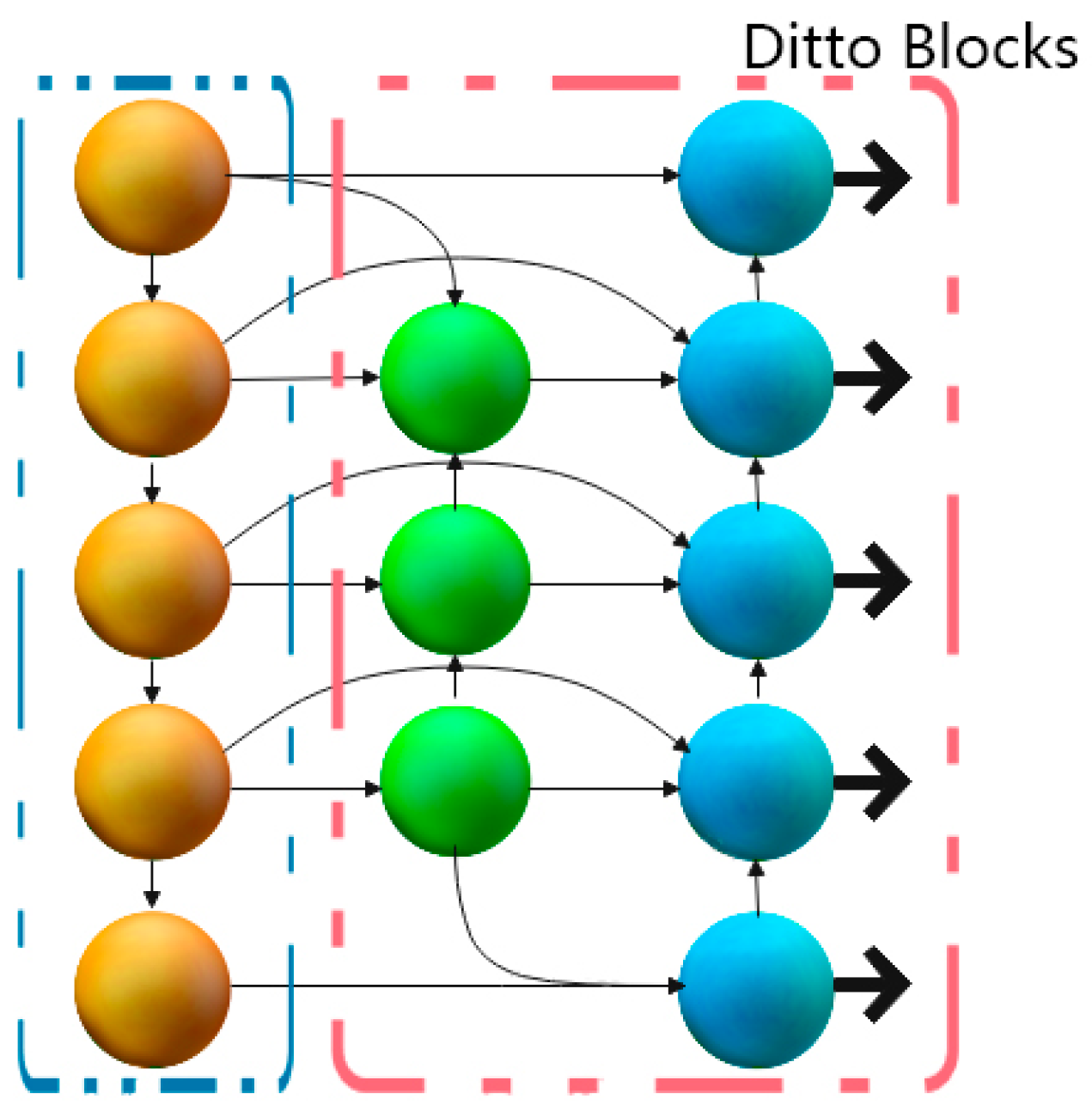
2.2.3. The BiFPN Network
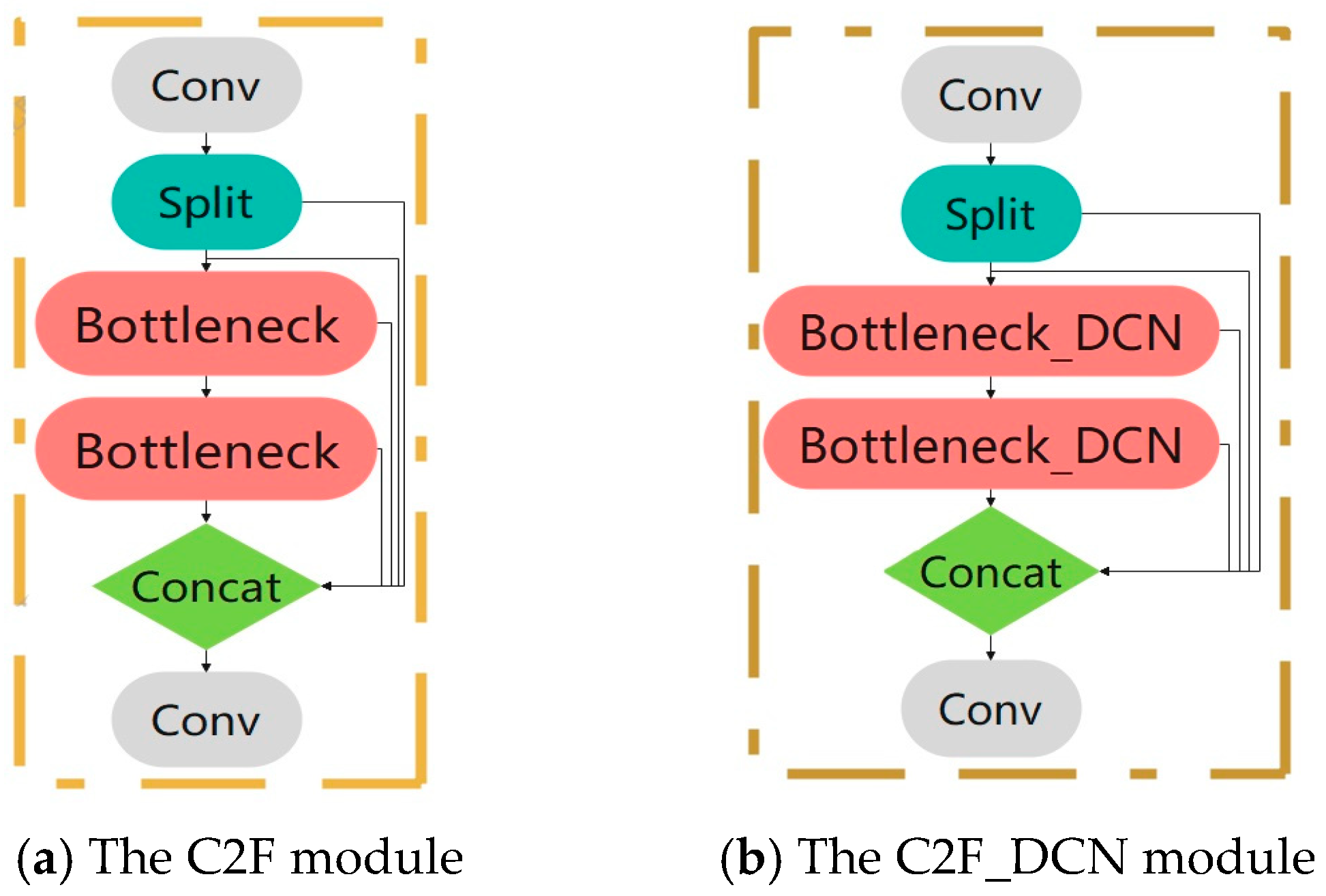
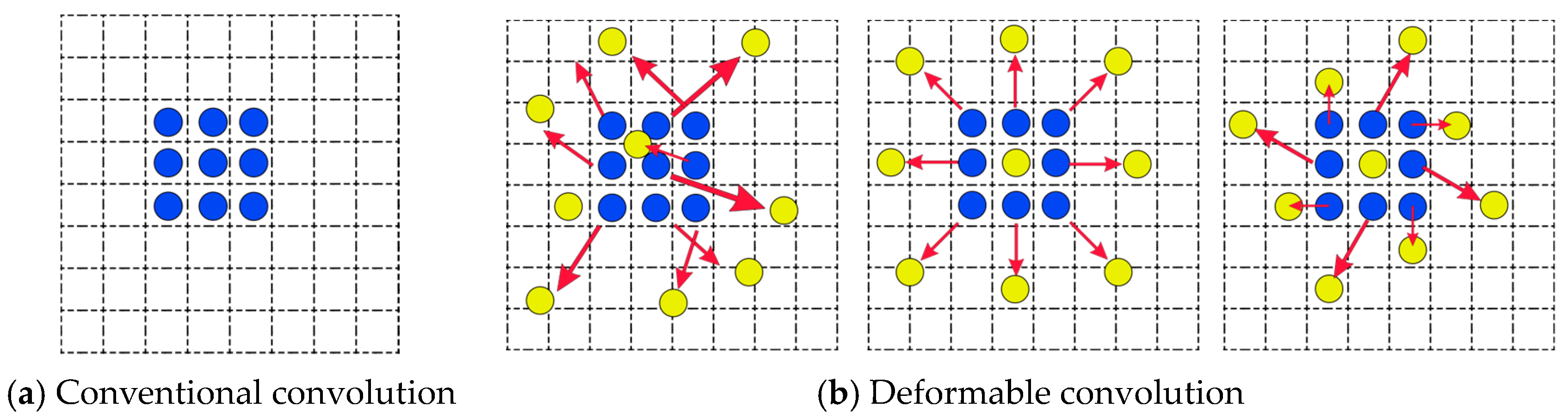
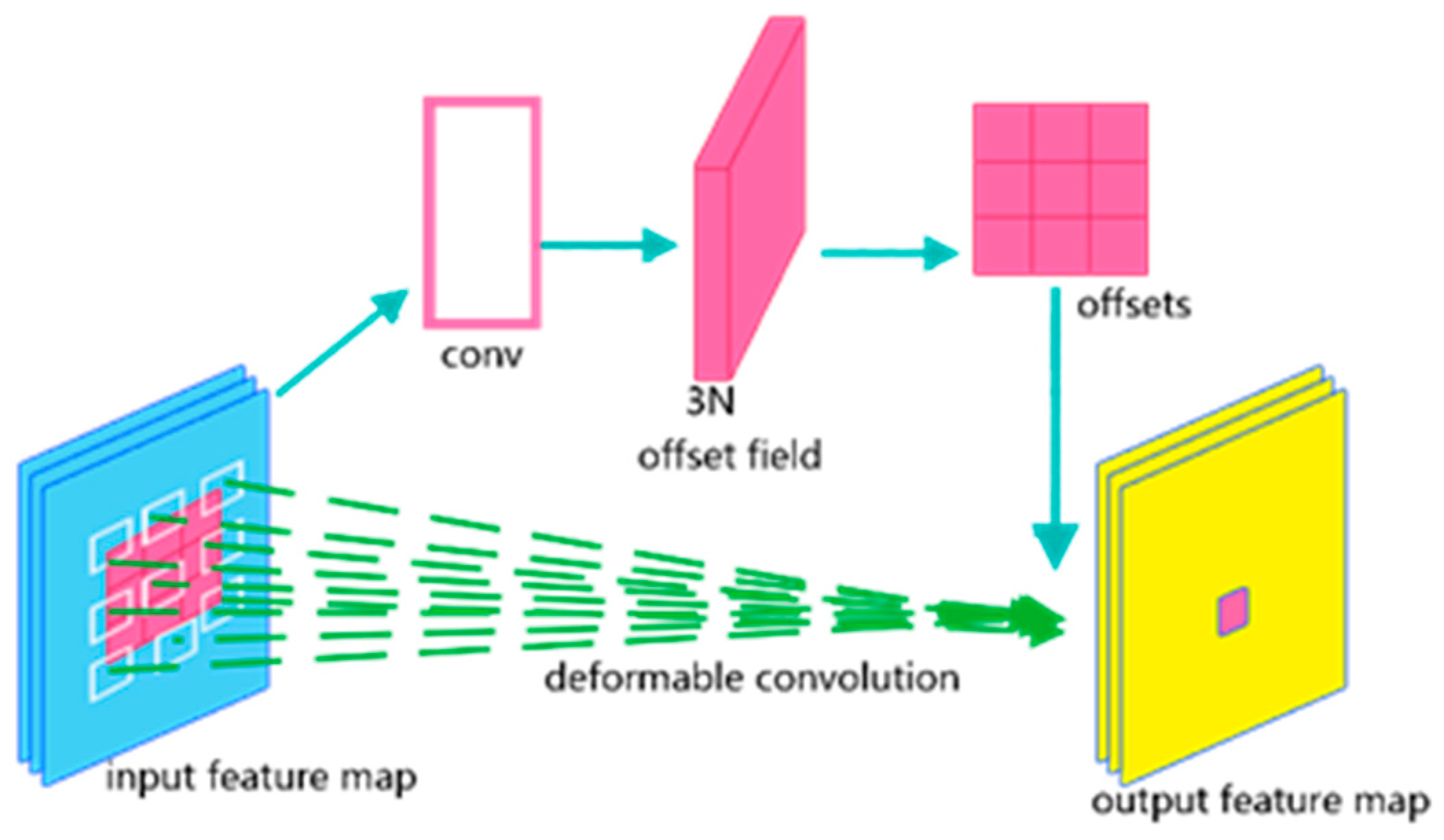
2.2.4. The C2F_DCN Module
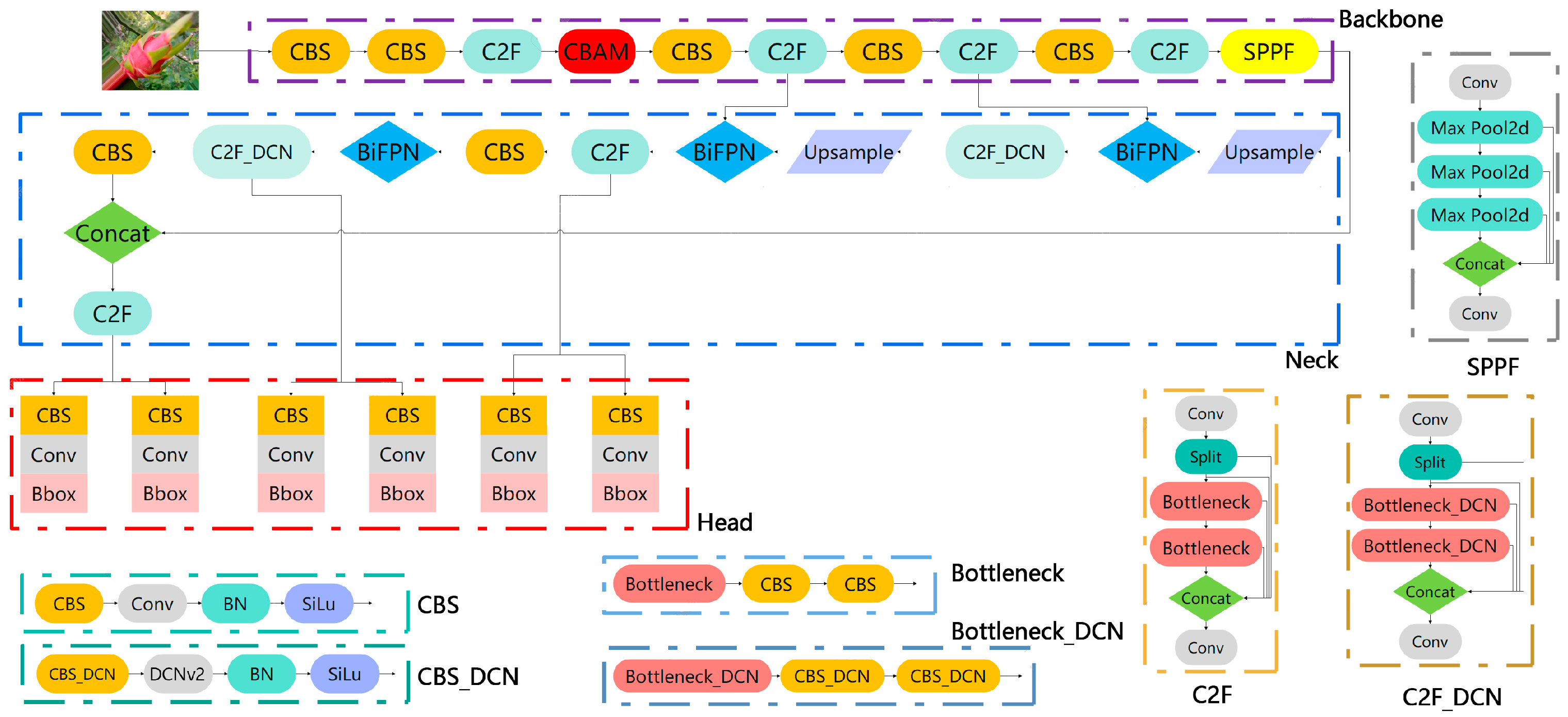
2.2.5. YOLOv8n-CBN Network Architecture
3. Results and Discussion
3.1. Experimental Environment
3.2. Ablation Experiment
3.3. Performance Comparison of Different Models
3.4. A Comparative Analysis of the Loss Function Prior to and following Improvement
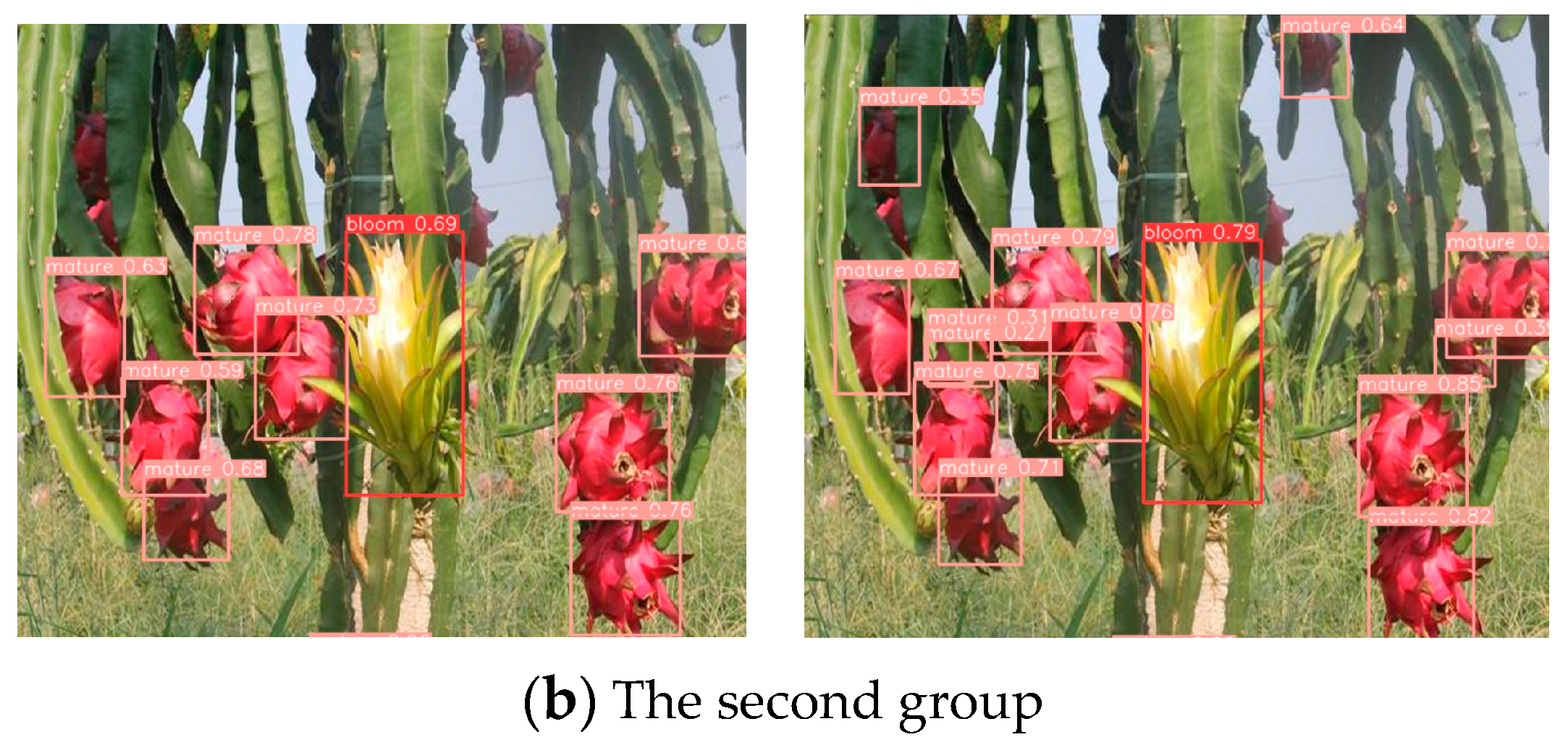
3.5. Comparison of the Growth State of Pitaya Fruit Results before and after the Improved Model
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Khatun, T.; Nirob, M.A.S.; Bishshash, P.; Akter, M.; Uddin, M.S. A comprehensive dragon fruit image dataset for detecting the maturity and quality grading of dragon fruit. Data Brief 2023, 52, 109936. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Gu, Z.; He, D.; Wang, X.; Huang, J.; Mo, Y.; Li, P.; Huang, Z.; Wu, F. A lightweight improved YOLOv5s model and its deployment for detecting pitaya fruits in daytime and nighttime light-supplement environments. Comput. Electron. Agric. 2024, 220, 108914. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, Y.; Wang, A.J. A Dragon Fruit Picking Detection Method Based on YOLOv7 and PSP-Ellipse. Sensors 2023, 23, 3803. [Google Scholar] [CrossRef]
- Kenta, O.; Hiroki, Y. Comparison of the Noise Robustness of FVC Retrieval Algorithms Based on Linear Mixture Models. Remote Sens. 2011, 3, 1344–1364. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H. Automatic Detection of Transformer Components in Inspection Images Based on Improved Faster R-CNN. Energies 2018, 11, 3496. [Google Scholar] [CrossRef]
- Wang, X.; Hua, X.; Xiao, F.; Li, Y.; Hu, X.; Sun, P. Multi-Object Detection in Traffic Scenes Based on Improved SSD. Electronics 2018, 7, 302. [Google Scholar] [CrossRef]
- Ma, H.; Liu, Y.; Ren, Y.; Yu, J. Detection of Collapsed Buildings in Post-Earthquake Remote Sensing Images Based on the Improved YOLOv3. Remote Sens. 2019, 12, 44. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.; Sun, W.; Wu, H.; Zhao, C.; Teng, G.; Yang, Y.; Du, P. A Low-Altitude Remote Sensing Inspection Method on Rural Living Environments Based on a Modified YOLOv5s-ViT. Remote Sens. 2022, 14, 4784. [Google Scholar] [CrossRef]
- Su, X.; Zhang, J.; Ma, Z.; Dong, Y.; Zi, J.; Xu, N.; Zhang, H.; Xu, F.; Chen, F. Identification of Rare Wildlife in the Field Environment Based on the Improved YOLOv5 Model. Remote Sens. 2024, 16, 1535. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, Y.; Wang, J. RDE-YOLOv7: An Improved Model Based on YOLOv7 for Better Performance in Detecting Dragon Fruits. Agronomy 2023, 13, 1042. [Google Scholar] [CrossRef]
- Yang, S.; Wang, W.; Gao, S.; Deng, Z. Strawberry ripeness detection based on YOLOv8 algorithm fused with LW-Swin Transformer. Comput. Electron. Agric. 2023, 215, 108360. [Google Scholar] [CrossRef]
- Qi, J.; Liu, X.; Liu, K.; Xu, F.; Guo, H.; Tian, X.; Li, M.; Bao, Z.; Li, Y. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Lan, K.; Jiang, X.; Ding, X.; Lin, H.; Chan, S. High-Efficiency and High-Precision Ship Detection Algorithm Based on Improved YOLOv8n. Mathematics 2024, 12, 1072. [Google Scholar] [CrossRef]
- Jing, J.; Li, S.; Qiao, C.; Li, K.; Zhu, X.; Zhang, L. A tomato disease identification method based on leaf image automatic labeling algorithm and improved YOLOv5 model. J. Sci. Food Agric. 2023, 103, 7070–7082. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhu, W.; He, Y.; Li, Y. YOLOv8-based Spatial Target Part Recognition. In Proceedings of the 2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 26–28 May 2023; Volume 3, pp. 1684–1687. [Google Scholar]
- Ayaz, I.; Kutlu, F.; Cömert, Z. DeepMaizeNet: A novel hybrid approach based on CBAM for implementing the doubled haploid technique. Agron. J. 2023, 116, 861–870. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Touko Mbouembe, P.L.; Liu, G.; Park, S.; Kim, J.H. Accurate and fast detection of tomatoes based on improved YOLOv5s in natural environments. Front. Plant Sci. 2024, 14, 1292766. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, B.; Li, Y.; Li, R.; Jia, Q.; Yu, X.; Sun, J.; Hu, S.; Gao, J. Concurrent Improvement in Maize Grain Yield and Nitrogen Use Efficiency by Enhancing Inherent Soil Productivity. Front. Plant Sci. 2022, 13, 790188. [Google Scholar]
- Zhu, R.; Wang, X.; Yan, Z.; Qiao, Y.; Tian, H.; Hu, Z.; Zhang, Z.; Li, Y.; Zhao, H.; Xin, D.; et al. Exploring Soybean Flower and Pod Variation Patterns During Reproductive Period Based on Fusion Deep Learning. Front. Plant Sci. 2022, 13, 922030. [Google Scholar] [CrossRef]
- Wang, Q.; Zheng, W.; Wu, F.; Xu, A.; Zhu, H.; Liu, Z. A New GNSS-R Altimetry Algorithm Based on Machine Learning Fusion Model and Feature Optimization to Improve the Precision of Sea Surface Height Retrieval. Front. Earth Sci. 2021, 9, 730565. [Google Scholar] [CrossRef]
- Pan, P.; Shao, M.; He, P.; Hu, L.; Zhao, S.; Huang, L.; Zhou, G.; Zhang, J. Lightweight cotton diseases real-time detection model for resource-constrained devices in natural environments. Front. Plant Sci. 2024, 15, 1383863. [Google Scholar] [CrossRef]
- Mbouembe, P.L.T.; Liu, G.; Sikati, J.; Kim, S.C.; Kim, J.H. An efficient tomato-detection method based on improved YOLOv4-tiny model in complex environment. Front. Plant Sci. 2023, 14, 1150958. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Cao, Y.; Wu, S.; Yang, C. Real-time detection of deep-sea hydrothermal plume based on machine vision and deep learning. Front. Mar. Sci. 2023, 10, 1124185. [Google Scholar] [CrossRef]
- Liu, M.; Li, R.; Hou, M.; Zhang, C.; Hu, J.; Wu, Y. SD-YOLOv8: An Accurate Seriola dumerili Detection Model Based on Improved YOLOv8. Sensors 2024, 24, 3647. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Jiang, J.; Chen, Y.; Sun, Z.; Tang, Y.; Lai, Q.; Zhu, H. Rapid detection of Yunnan Xiaomila based on lightweight YOLOv7 algorithm. Front. Plant Sci. 2023, 14, 1200144. [Google Scholar] [CrossRef] [PubMed]
- He, C.; Wan, F.; Ma, G.; Mou, X.; Zhang, K.; Wu, X.; Huang, X. Analysis of the Impact of Different Improvement Methods Based on YOLOV8 for Weed Detection. Agriculture 2024, 14, 674. [Google Scholar] [CrossRef]
- Ping, X.; Yao, B.; Niu, K.; Yuan, M. A Machine Learning Framework with an Intelligent Algorithm for Predicting the Isentropic Efficiency of a Hydraulic Diaphragm Metering Pump in the Organic Rankine Cycle System. Front. Energy Res. 2022, 10, 851513. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| None | CBAM | BiFPN | C2F-DCN | P | R | F1 | mAP @0.5 | mAP @0.50–0.95 | Inference Time | Weight |
|---|---|---|---|---|---|---|---|---|---|---|
| ✓ | 0.880 | 0.805 | 0.842 | 0.890 | 0.470 | 5.6 ms | 6.2 MB | |||
| ✓ | 0.895 | 0.853 | 0.873 | 0.905 | 0.477 | 5.6 ms | 6.2 MB | |||
| ✓ | ✓ | 0.881 | 0.854 | 0.867 | 0.911 | 0.476 | 5.8 ms | 6.2 MB | ||
| ✓ | ✓ | 0.893 | 0.835 | 0.863 | 0.902 | 0.478 | 6.3 ms | 6.4 MB | ||
| ✓ | ✓ | ✓ | 0.911 | 0.843 | 0.876 | 0.911 | 0.482 | 6.4 ms | 6.4 MB |
| YOLOv3-Tiny | YOLOv5s | YOLOv5m | YOLOv8n | YOLOv8n-CBN | |
|---|---|---|---|---|---|
| P | 0.823 | 0.859 | 0.872 | 0.880 | 0.911 |
| R | 0.780 | 0.884 | 0.872 | 0.805 | 0.843 |
| F1 | 0.801 | 0.871 | 0.872 | 0.842 | 0.876 |
| mAP@0.50 | 0.844 | 0.904 | 0.906 | 0.890 | 0.911 |
| mAP@0.50–0.95 | 0.381 | 0.432 | 0.466 | 0.470 | 0.482 |
| inference time | 3.9 ms | 5.7 ms | 11.6 ms | 5.6 ms | 6.4 ms |
| weight | 16.9 MB | 14.1 MB | 40.8 MB | 6.2 MB | 6.4 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Zhuo, S.; Li, M.; Huang, F.; Mo, D.; Tian, X.; Tian, X. An Efficient Detection of the Pitaya Growth Status Based on the YOLOv8n-CBN Model. Horticulturae 2024, 10, 899. https://doi.org/10.3390/horticulturae10090899
Qiu Z, Zhuo S, Li M, Huang F, Mo D, Tian X, Tian X. An Efficient Detection of the Pitaya Growth Status Based on the YOLOv8n-CBN Model. Horticulturae. 2024; 10(9):899. https://doi.org/10.3390/horticulturae10090899
Chicago/Turabian StyleQiu, Zhi, Shiyue Zhuo, Mingyan Li, Fei Huang, Deyun Mo, Xuejun Tian, and Xinyuan Tian. 2024. "An Efficient Detection of the Pitaya Growth Status Based on the YOLOv8n-CBN Model" Horticulturae 10, no. 9: 899. https://doi.org/10.3390/horticulturae10090899
APA StyleQiu, Z., Zhuo, S., Li, M., Huang, F., Mo, D., Tian, X., & Tian, X. (2024). An Efficient Detection of the Pitaya Growth Status Based on the YOLOv8n-CBN Model. Horticulturae, 10(9), 899. https://doi.org/10.3390/horticulturae10090899