1. Background and Summary
While the issue of demeaning and defaming individuals through Internet-based communication has persisted since the inception of online communication, it was especially the emergence of novel handheld mobile devices, such as smartphones and tablet computers, that further accentuated this problem. These devices facilitate Internet access not only within the confines of homes, workplaces, or educational institutions but also during commutes, thereby exacerbating the challenge. Particularly noteworthy is the past decade, marked by the rapid proliferation of social networking services (SNS) such as Facebook and Twitter, which has brought into focus the prevalence of unethical conduct within online environments. This conduct notably impairs the mental well-being of adults and, more significantly, younger users and children. Central to this discourse is the phenomenon of cyberbullying (CB), characterized by the exploitation of open digital communication channels, including Internet forums and SNS, to disseminate harmful and distressing content about specific individuals, often targeting minors and students [
1] (see also section “Cyberbullying—a working definition” for further explanation of the problem of cyberbullying).
In response to this challenge, researchers worldwide have initiated an in-depth exploration of this issue, aiming to achieve an automated identification of such harmful online content. Such identified instances, when detected, need to be reported to SNS providers for in-depth analysis and subsequent removal. Accumulating knowledge spanning more than a decade [
2,
3,
4,
5], researchers have assembled a comprehensive foundation of understanding concerning this matter, predominantly pertaining to languages prevalent in highly developed nations, such as the United States and Japan. Regrettably, the same level of advancement remains notably lacking for less-resourced languages such as the Polish language. Through the dissemination of the dataset introduced herein and the preliminary formulation of classification models derived from said dataset, our objective resides in addressing and bridging this existing research gap.
The growing tendencies of polarization and radicalization in Poland, which started around 2015 [
6] and have proliferated on the Polish Internet [
7,
8,
9], necessitated the need for more active studies on the language of polarization among Polish researchers. This resulted in a number of datasets and shared tasks being proposed. The first attempt to study cyberbullying and hate speech in the Polish language with the use of data science, artificial intelligence, and natural language processing techniques was presented by Troszyński et al. in 2017 [
10], with their dataset being released for a wider public in 2021
1. The first open shared task focused on studying cyberbullying and hate-speech in a more open-science-based approach was the PolEval 2019 shared task on automatic cyberbullying detection in Polish Twitter [
11,
12]. The data collected for that task also became the basis for the improved dataset presented in this data descriptor. The early version of that dataset is also available on the HuggingFace datasets webpage
2. Some data in the Polish language
3 was also included in the compilation of non-English hate-speech datasets compiled by Röttger et al. [
13]. A more recent attempt was presented by Okulska et al. [
14] in their BAN-PL dataset of banned harmful and offensive content collected from the Wykop.pl web service.
The dataset presented in this data descriptor, coupled with the included classification tools, furnishes an avenue for researchers and practitioners operating in the domain of AI to assess the efficacy of their proprietary classification techniques in determining the categorization of Internet entries within the realm of cyberbullying discourse. The dataset encompasses tweets sourced from openly accessible Twitter discussions. Given that a substantial portion of the challenge pertaining to automated cyberbullying detection often hinges upon the meticulous selection and crafting of features [
4,
5], the tweets are provided in their raw form with minimal preprocessing. Any preprocessing implemented is predominantly reserved for instances where the exposure of personal details about a private person could be revealed to the public.
The primary objective of employing the dataset centers on the classification of tweets, distinguishing them into two categories: cyberbullying/harmful and non-cyberbullying/ non-harmful, with the utmost emphasis on achieving optimal precision, recall, F-score, and accuracy. An ancillary sub-task involves the differentiation between distinct forms of detrimental content, specifically cyberbullying (CB) and hate speech (HS), in addition to other forms of non-harmful material.
The remainder of this data descriptor is structured as follows. To begin, we expound upon the procedure by which the dataset was acquired. Subsequently, we explain the process of annotation, encompassing our operational definition of cyberbullying and the guidelines for annotation that underpinned the training of the annotators. Third, we conduct an exhaustive analysis of the generated dataset. This examination encompasses both comprehensive statistical analysis and more intricate instance-specific analysis. Following this, we detail the inaugural task in which the dataset was employed. Specifically, we delineate two classification tasks: (1) the overarching categorization of harmful content and (2) the differentiation between two distinct forms of harmful as well as non-harmful content. Moreover, we put forth the default evaluation metrics and introduce exemplary AI models that were developed employing the dataset. Additionally, we present the dataset’s original iteration alongside the refined annotations contributed by expert annotators. Concluding, we summarize this data descriptor and outline imminent plans and trajectories for advancing the dataset in the immediate future.
2. Methods
2.1. Data Collection
To collect the data, we applied the capabilities of the standard Twitter application programming interface (API)
4. This API presented several inherent constraints, necessitating strategic workarounds. For instance, the API enforces limitations on the volume of requests permissible within a 15-minute interval, as well as the number of tweets accessible per individual request. Our data download procedure conscientiously respected the limitations. When the request limit was exhausted, the download script adeptly awaited the commencement of another download window.
Employing the python-twitter library
5 facilitated seamless interaction with the Twitter API. However, a distinct challenge emerged in the form of temporal constraints governing tweet searches. Within the confines of the standard Twitter API, users are allowed to retrieve tweets spanning the past 7 days only. Consequently, our efforts to compile responses to tweets emanating from our initial anchor accounts were impeded by this temporal restriction.
To archive and manage the data harvested from Twitter, we employed the pymongo library
6 to integrate it into MongoDB. Twitter provides tweet data in JavaScript object notation (JSON) format. This choice expedited the subsequent data handling processes with enhanced convenience.
The Python script was employed to retrieve tweets from nineteen designated official Polish Twitter accounts. These accounts were selected based on their prominence as the foremost Polish Twitter accounts during the year 2017
7. The criteria for prominence encompass accounts with the largest followership, those exhibiting rapid follower growth, those accumulating substantial user engagement, those frequently mentioned in interactions, and those demonstrating prolific tweeting activities. Specifically, our initial focus was directed towards the subsequent set of accounts: @tvn24,
@MTVPolska,
@lewy_official,
@sikorskiradek,
@Pontifex_pl,
@donaldtusk,
@BoniekZibi,
@NewsweekPolska,
@AndrzejDuda,
@lis_tomasz,
@tvp_info,
@pisorgpl,
@K_Stanowski,
@R_A_Ziemkiewicz,
@Platforma_org,
@RyszardPetru,
@RadioMaryja,
@rzeczpospolita,
@PR24_pl.
Additionally, we gathered responses to tweets originating from the accounts referenced earlier (spanning the preceding 7 days). Our cumulative collection encompassed more than 101 thousand tweets procured from 22,687 individual accounts, as denoted by the screen_name attribute within the Twitter API. To initialize subsequent investigations, we adopted a selection process utilizing bash random functions, resulting in the random designation of ten accounts as the initial focal points.
Subsequently, adhering to the same methodology as previously outlined, we proceeded to acquire tweets from these ten designated accounts. Additionally, we procured all responses to their respective tweets, utilizing the Twitter search application programming interface (API), subject to a temporal constraint of the past 7 days. Through this iterative approach, we successfully amassed a corpus of 23,223 tweets originating from Polish accounts, earmarked for subsequent detailed analysis. The data procurement process culminated on the 20 November 2018. This collection of 23,223 tweets forms the foundational dataset that serves as the basis of the presentation within this paper.
2.2. Data Preprocessing and Filtering
Given that the original conversation threads were not traceable in our initial dataset, as the official API did not furnish such contextual information, we treated each tweet as an individual entity.
Initially, we employed a randomization procedure to alter the tweet sequence in the dataset. This was aimed to mitigate the potential anchoring bias [
15] during annotations. The intent was to curtail the likelihood of human annotators assigning identical scores to multiple messages when encountering consecutive tweets from the same account.
Subsequently, tweets containing URLs were systematically excluded from the dataset. This was prompted by the recognition that URLs often occupy valuable character space within tweets, thereby constricting their textual content. In practice, this frequently resulted in tweets being truncated midway through sentences or featuring an abundance of ad hoc abbreviations. Next, tweets sharing identical content were systematically removed, a process that effectively eradicated a substantial portion of duplicates. Tweets solely comprising at-marks (@) or hashtags (#) were also removed. These elements, while serving as integral components of social media communication, lack inherent linguistic value as complete entities and instead function as detached keywords. To further refine the dataset, tweets containing less than five words were eliminated, as were those composed in languages other than Polish. These measures resulted in a remaining corpus of 11,041 tweets. From this collection, a subset of 1000 tweets was randomly extracted for utilization as a test dataset, while the remaining 10,041 tweets constituted the training dataset. This larger subset was earmarked for subsequent application in AI predictive models devised for the purpose of detecting cyberbullying. A comprehensive, step-by-step account of the preprocessing procedure and a thorough analysis outlining the attrition of tweets at each stage are presented below.
Removed tweets containing URLs, retaining solely the tweet text without any accompanying meta-data or timestamps. This resulted in a retention of 15,357 out of 23,223 tweets, representing 66.13% of the total.
Removed exact duplicates, leading to the retention of 15,255 tweets; 102 tweets were eliminated, constituting 0.44% of the entire dataset.
Removed tweets comprising solely @atmarks and #hashtags. Consequently, 15,223 tweets were retained, with 32 tweets, or 0.14% of the total, being removed.
Removed tweets that, apart from @atmarks or #hashtags, consisted solely of a single word, a few words, or emojis:
- (a)
Removed tweets consisting of just one word, resulting in the retention of 14,492 tweets. A total of 731 tweets, corresponding to 3.1% of the dataset, were removed this way.
- (b)
Removed tweets containing only two words, leading to the preservation of 13,238 tweets. The removal of 1254 tweets constituted 5.4% of the total.
- (c)
Removed tweets comprising solely three words, yielding the retention of 12,226 tweets, and 1012 tweets, constituting 4.4% of the dataset, were deleted.
- (d)
Removed tweets with only four words, resulting in 11,135 tweets being retained, and 1091 tweets, representing 4.7% of the total, were removed.
Following the aforementioned operations, our dataset comprised 11,135 tweets, characterized by a word count of five or more, with exclusions made for @atmarks or #hashtags.
The rationale underlying the exclusion of brief tweets was as follows.
A tweet of insufficient length poses a challenge for human annotators, as the limited contextual information hinders comprehensive assessment, thereby leading to a proliferation of ambiguous annotations.
Moreover, from the perspective of machine learning (ML) models, a broader spectrum of content (features) contributes to enhanced training. This, in turn, suggests that lengthier sentences offer a conducive environment for training more precise ML models. While it is plausible to conceive of brevity encompassing instances of aggression, we assume that a system trained on more extensive data will inherently encompass the shorter tweet instances as well.
Within the remaining subset of 11,135 tweets, a discernible fraction was composed in a language distinct from Polish, predominantly in English. To address this particular issue, we harnessed the Text::Guess::Language Perl module
8, renowned for its capability to ascertain the language of a sentence by referencing the top 1000 words of that given language. The preliminary manual scrutiny of a limited tweet sample unveiled that the module occasionally yielded erroneous assessments, categorizing Polish tweets as Slovak or Hungarian. This was attributed to the atypical phrasings of account names and hashtags periodically incorporated in the tweets. However, its performance remained accurate in detecting English-authored tweets without misjudgment. Consequently, as a pragmatic approach, we opted to exclude all English-authored tweets, thereby preserving only the corpus of Polish-authored tweets. Following this ultimate preprocessing step, our dataset was distilled to encompass 11,041 tweets. From this refined collection, 10,041 tweets were selected for training purposes, while the remaining 1000 tweets were used for testing.
In tandem with the dataset release, we are unveiling the Perl scripts that facilitated the removal of English-written tweets from the Polish dataset (onlypolish.pl), alongside scripts for the curation of tweets solely comprising @atmarks or #hashtags (extractnohashatmarks.pl).
4. Technical Validation
4.1. Description of Tasks
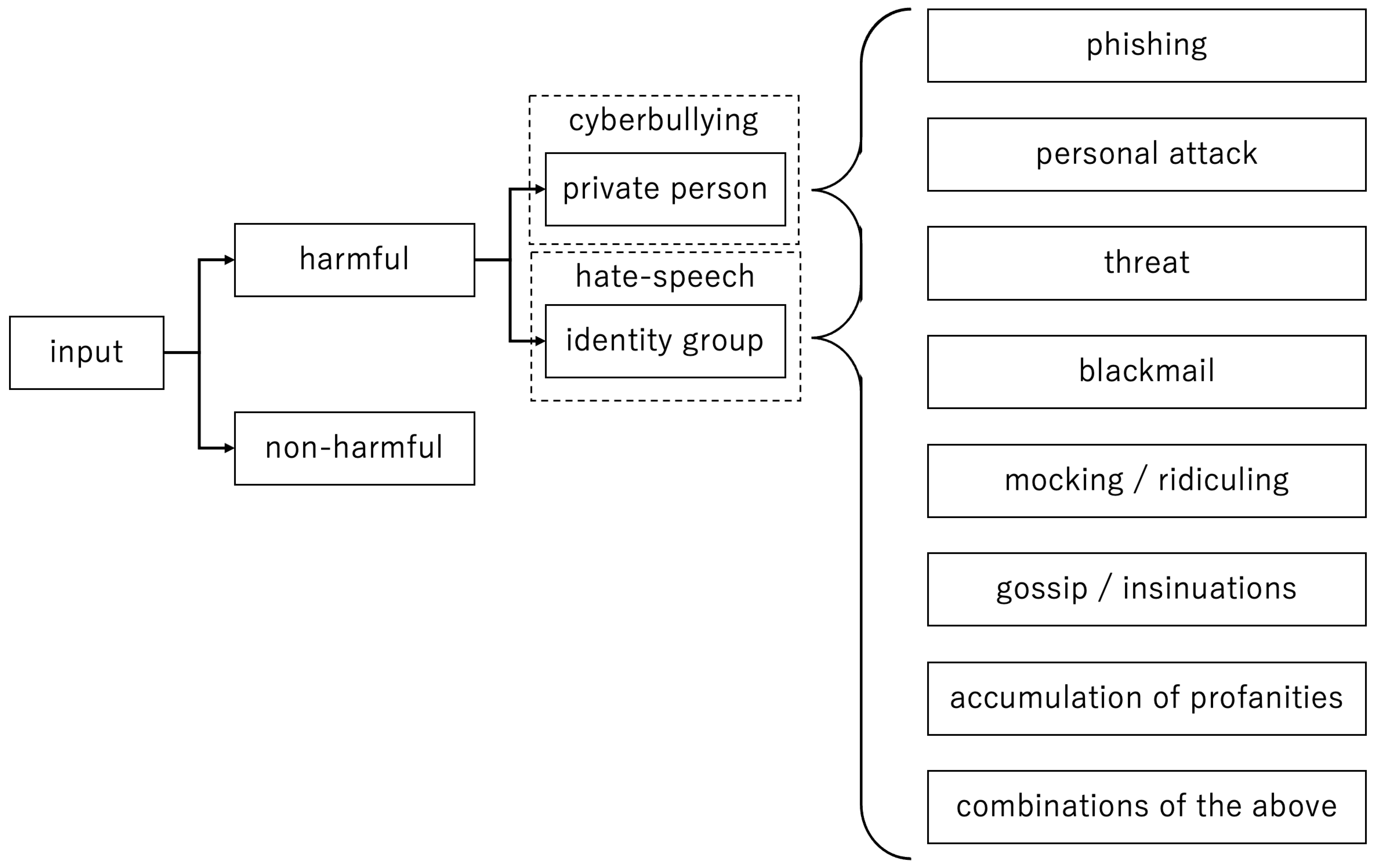
The goal of the preliminary task designed for the dataset is to classify if an online entry should be considered harmful (cyberbullying, hate-speech) or non-harmful. The specific objective revolves around categorizing the supplied tweets into the domains of cyberbullying/harmful and non-cyberbullying/non-harmful, aiming to attain optimal precision, recall, balanced F-score, and accuracy metrics. This task was further divided into two distinct sub-tasks.
4.1.1. Task 1—Harmful vs. Non-Harmful
Within this task, the goal is to classify tweets of a normal/non-harmful nature (class: 0) and tweets containing various forms of harmful content (class: 1), which encompasses cyberbullying, hate speech, and other interconnected phenomena.
4.1.2. Task 2—Type of Harmfulness
In this task, the goal is to classify three tweet categories, denoted as follows: 0 (non-harmful), 1 (cyberbullying), and 2 (hate-speech). Notably, a range of definitions existed for both cyberbullying and hate-speech, with some even classifying these phenomena under a common category. The precise criteria employed for annotating instances of cyberbullying and hate-speech have been meticulously developed over the course of a decade’s worth of research (see [
1]). However, the primary and definitive criterion for differentiation hinges on whether the harmful message is directed at a private individual or individuals (cyberbullying) or towards a public individual, entity, or larger group (hate-speech). The supplementary distinct definitions and guidelines implemented in the creation of the dataset are explained in preceding sections.
4.2. Evaluation Measures
The scoring criteria for the first task were based on standard Precision (P), Recall (R), balanced F-score (F
1), and Accuracy (A), calculated according to the following Equations (
1)–(
4), respectively, with the conditions of being the highest in terms of true positives (TP), true negatives (TN), and the lowest in terms of false positivse (FP) and false negatives (FN) being considered the winner. If the F-scores were equal for more than two compared models, the one with higher accuracy would be declared better. Furthermore, the results closest to the break-even point of precision and recall are given priority.
The evaluation of the second task’s performance was grounded in two metrics: the micro-average F-score (microF) and the macro-average F-score (macroF). The calculation of the micro-average F-score aligns with the conventional F-score equation, yet is based on micro-averaged precision and recall, calculated according to the Equations (
5) and (
6), respectively. In a parallel manner, the macro-average F-score is computed, leaning on the macro-averaged precision and recall, calculated according to Equations (
7) and (
8), respectively. The criterion for a win is primarily obtaining the highest microF. This metric ensures equitability by treating all instances uniformly, where the number of samples across classes could differ. In situations where a model yields identical microF outcomes, precedence is awarded to the model showcasing superior macroF values. The supplementary macroF, while not uniformly treating instances, proffers deeper insights by considering the equality of all classes.
Macro F-score and Micro F-score were not calculated in a standard way. Typically, Macro F-score is calculated based only on all the F-scores, while Micro F-score is calculated only on the basis of the sums of all samples. This way there is only insight into P and R for each class (macroF) or overall (microF), and the scores are grouped as F-scores. This hinders the more general insight into the relations between P and R. Thus, instead, we used the proposed method of calculation specifically to provide insight into how close each score was to the break-even point in case of similar F-scores and accuracies. However, despite the difference in the calculation, the overall tendency in the final macroF and microF remains the same as for the standard way of calculation of those scores, thus assuring fairness in evaluation.
4.3. Initial Task Participants
A total of fourteen submissions were received for the initial installation of the challenge. All the participating groups endeavored to address the initial task, characterized as computationally less challenging and involving the binary classification of tweets into harmful and non-harmful categories. In contrast, the subsequent task, entailing a three-class classification problem, garnered a more limited engagement with only eight endeavors. Herein, we provide a concise overview of the methodologies introduced by each participating team.
4.4. Results
4.4.1. Baselines
The dataset exhibited an imbalance in class distribution, resulting in varying proportions for each class (refer to
Table 4). To ensure an objective assessment of the task participants’ model performance in classification, we initially established a series of baselines.
The initial set of baselines encompassed basic classifiers that generated scores not based on any data-specific insights.
- A.
Classifier only assigning a score of 0.
- B.
Classifier only assigning a score of 1.
- C.
Classifier only assigning a score of 2 (restricted to Task 2).
- D.
Classifier only random scores: 0 or 1 (for Task 1).
- E.
Classifier only random scores: 0, 1, or 2 (for Task 2).
Consequently, the performance of all baseline classifiers exhibited low performance. Concerning Task 1, baseline A (constant value of 0) yielded an F1 score of 0, a foreseeable outcome, confirming that it is not possible to consider the problem as too simple. Baseline D (random prediction) similarly obtained an F1 score of 0, additionally confirming that it is not possible to solve the task of cyberbullying detection by depending on mere chance. Baseline B (constant value of 1), by its inherent nature, effectively captured the entirety of harmful instances, manifesting a recall of 100%, albeit at the cost of an exceedingly low precision (13.4%), consequently yielding a considerably diminished F-score (23.63%). The outcomes for the simple baselines for Task 1 are reported in
Table 8.
Concerning the second task, analogously to task 1, baselines B (constant 1), C (constant 2), and E (random) attained notably low performance scores. Baseline A (constant 0) achieved a substantial microF score (86.6%), primarily due to its automatic success in non-harmful instances, which constituted the dataset’s majority. However, macroF, serving as a more comprehensive evaluation metric, demonstrated a considerably diminished value (30.94%). The outcomes pertaining to the elementary baselines for Task 2 are documented in
Table 9.
4.4.2. Results for Task Participants
Task 1
In Task 1, among fourteen initial submissions, a total of nine distinct teams emerged: n-waves, Plex, Inc., Warsaw University of Technology, Sigmoidal, CVTimeline, AGH and UJ, IPI PAN, UWr, and an independent entity. Certain teams opted for multiple system proposals, notably Sigmoidal (3 submissions) and the independent entity (3), alongside CVTimeline (2). The participants harnessed an array of techniques, frequently drawing upon readily available OpenSource solutions that were then adapted and trained to align with the Polish language and the provided dataset. The various approaches included established methodologies such as fast.ai/ULMFiT (
http://nlp.fast.ai/, accessed on 7 December 2023), SentencePiece (
https://github.com/google/sentencepiece, accessed on 7 December 2023), BERT (
https://github.com/google-research/bert, accessed on 7 December 2023), tpot (
https://github.com/EpistasisLab/tpot, accessed on 7 December 2023), spaCy (
https://spacy.io/api/textcategorizer, accessed on 7 December 2023), fasttext (
https://fasttext.cc/, accessed on 7 December 2023), Flair (
https://github.com/zalandoresearch/flair, accessed on 7 December 2023), neural networks (especially involving a gated recurrent unit (GRU)), or conventional ML models such as support vector machines (SVM). Moreover, there were instances of innovative methods, such as Przetak (
https://github.com/mciura/przetak, accessed on 7 December 2023). Evidently, the most successful strategy stemmed from the recent ULMFiT/fast.ai paradigm, adeptly applied by the n-waves team. Following closely was the initially proposed Przetak method by Plex, Inc., securing the second position, while the third spot was obtained by a fusion of ULMFiT/fast.ai, SentencePiece and the BranchingAttention model. The summary of the results of all participating teams in Task 1 are reported in
Table 10.
Task 2
In the second task, among a total of eight submissions, there emerged five distinct entries. Among the teams that submitted multiple proposals, the independent group presented three and Sigmoidal presented two. The strategies that demonstrated notable effectiveness in the second task encompassed: SVM—proposed by the independent researcher Maciej Biesek, a combination of an ensemble of classifiers from spaCy combined with tpot and BERT—devised by the Sigmoidal team, and the utilization of fasttext—as employed by the AGH and UJ team. A comprehensive presentation of the results attained by all participating teams in Task 2 is reported in
Table 11. Interestingly, although the participants frequently introduced novel methodologies, the majority of these methodologies predominantly hinged on lexical information encapsulated by terms (words, tokens, word embeddings, etc.). Interestingly, the incorporation of more advanced feature engineering, involving elements such as parts-of-speech, named entities, or semantic features, remained unexplored by all participants.
5. Dataset Re-Annotation with Cyberbullying Experts
As the original agreements of annotations were not satisfyingly high, suggesting possible mistakes, especially misses in annotations, we additionally performed a re-annotation of the whole dataset with the help of expert annotators experienced in annotating cyberbullying and other online harm-related data.
5.1. Details concerning the Annotation Team
There were ten annotators (nine female and one male) and three supervisors (female) who worked on the data. The annotators were from 21 to 29 years of age. The annotators had background in linguistics and/or psychology. All of them had experience in working with annotation of harmful content; however, their experience varied. The most experienced person worked as a professional annotator of cyberbullying data for 2 years, while the least experienced one worked for 2 months. On average, annotators had the experience of approximately 10–12 months. The workload was also varied. Two people worked only on 1500 examples, while the highest number of examples per person was 8937.
5.2. Inter-Annotator Agreement among Experts
Inter-annotator agreements for expert annotators with confusion matrices required for reproducibility are represented in
Table 12. The general agreements among experts were much higher than for laypeople (see previous sections) and reached 0.451 for standard Kappa, 0.517 for weighted Kappa, and 0.495 for the proposed Kappa with modified quadratic weights, all of which suggest
moderate agreement. The results for the proposed Kappa also show how the measure corrects the overoptimistic assumption suggested by the traditional weighted Kappa.
5.3. General Overview of Re-Annotated Dataset
The overall number of tweets the final re-annotated dataset contained was 11,038 (three tweets were rejected from the original dataset due to near identical similarity), with 10,038 included in the training set and 1000 in the test set. The overview of the re-annotated dataset is represented in
Table 13.
Similarly to the layperson annotations, in general, it can be said that expert annotators were able to specify with high confidence that a tweet is not harmful (even if it contained some vulgar words). However, differently from layperson annotators, experts were more consistent with both general tags (harmful/non-harmful) and specific tags (cyberbullying vs hate speech). This confirms, as mentioned in previous sections, that for tasks such as cyberbullying, expert annotation is required.
As for specific findings, for over eighty percent of the cases, all three annotators agreed, while there was no case where all three annotators disagreed. Interestingly, annotation lead by all experts resulted in assigning twice as many harmful labels than in annotation performed by trained laypeople. This confirms previous findings that experts are more sensitive in annotation [
23]. It also suggests that when the annotation is entrusted to laypeople, half of the cyberbullying cases will be lost due to annotator mistakes or insufficient training.
5.4. Automatic Classification of Re-Annotated Dataset
For the experiments with the re-annotated dataset, we used both classic machine learning (ML) models and novel neural network-based models.
For the experiments with the re-annotated dataset using classic ML algorithms, we followed Eronen et al.’s [
24] procedure and compared a number of classifiers with various preprocessing methods. In particular, we compared the classifiers including: multinomial naïve Bayes, Bernoulli-based naïve Bayes, linear SVM, SVM with stochastic gradient descent (SGD) optimization, logistic regression, logistic regression with conjugate gradient descent (CGD) optimization, random forest, AdaBoost, and XGBoost. From the various preprocessing and feature extraction methods, we applied only the ones for which Eronen et al.’s [
24] extensive comparison concluded that they usually reached the highest scores. Specifically, we used a selected combinations of features containing tokens (TOK), lemmas (LEM), parts of speech (POS), and named entities (NER), as such features have been previously applied in cyberbullying and hate-speech detection [
24,
25], additionally supported by deleting stop words (stop) or characters other than alphanumerics (alpha). The list of all applied classifiers and all applied feature sets with their representative results for the re-annotated dataset in macro F-score is represented in
Table 14. We also used the same baselines as for the previous version of the dataset.
For the experiments with neural networks, we specifically focused on transformer-based [
26] models for the Polish language available on HuggingFace
10. In particular, we compared the following models:
5.5. Results
5.5.1. Baselines
The results for the baselines on the re-annotated dataset for Task 1 are represented in
Table 15. As the dataset was not balanced, it can be seen that a model that assigns 0 and 1 values randomly, as well as a model that assumes all instances are non-harmful, would still obtain approximately a 44% performance. The results of the baselines are comparable to their respective results from before re-annotation; yet, due to a larger number of harmful samples this time, the results for baseline B (always 1) are slightly higher (a 23% to 32% increase).
5.5.2. Classic ML Models
The initial results for all applied classifiers and all applied feature sets with their representative results for the re-annotated dataset in macro F-score is represented in
Table 14. From the above, we analyzed the classifiers that achieved first five best results in more detail. These are summarized in
Table 16. The first five best scores were achieved all by the support vector machine classifier with linear function. This confirms a strong performance for SVMs in NLP-related tasks. Unfortunately, all those models struggled with the classification of class 1 (harmful), while all had no problems with classifying class 0 (non-harmful). This result might come from the fact that the dataset was imbalanced, with the harmful class accounting only for approximately 15% of the dataset. A general positive conclusion is that re-annotation caused a general increase in the results. This could come from both gain in the quality of the dataset annotation and doubling in the number of samples (from approximately 8% to 15%). Together with the dataset, we are also releasing preprocessing scripts for the two kinds of preprocessing that obtained the highest scores when trained on linear SVM, namely, tokens combined with parts of speech (TOKPOS) and lemmas with added named entities (LEMSNERS).
5.5.3. Transformer-Based Models
As for the applied deep learning (DL) models, specifically Transformer-based models, or bidirectional encoder representations from transformers (BERT) models, all models except one were better than all the classic ML models. The best model, Polbert, achieved a 0.794 macro average F1 score, which is a strong baseline for future attempts. Interestingly, TrelBERT, which was additionally trained on millions of tweets and achieved high scores on the Polish KLEJ benchmark, although still scoring very high, did not achieve the highest scores here. It is difficult to estimate the reason for the lower score, since models pretrained on Twitter have been shown to work better on datasets based on Twitter [
27]; however, a number of unpublished internal evaluations suggest that since Tweets are usually short and contain simplistic language due to the character limitations [
28], even after the extension of character limitation from 140 to 280 introduced in 2017 by Twitter due to users “cramming” too many abbreviations and slang into tweets
11, the knowledge embedded in Twitter-based models is usually more shallow and limited, which could influence the performance for tasks requiring more context-based knowledge and the ability to process a wider/deeper context and implicit language, such as the task of automatic cyberbullying detection.
Unfortunately, all transformer-based models showed a similar bias for the more numerous class (non-harmful) and achieved over 90% for the F1 score for that class. This again supports the need to collect more balanced datasets in the future. Thus, in reality, the results for specifically detecting cyberbullying (class 1) were unsatisfying, reaching barely above 50% precision for the best performing model. This leaves sufficient space for improvement in the future.
The results for all tested transformer-based models are represented in
Table 17.
6. Usage Notes
To contribute to solving the recently growing problem of cyberbullying and hate speech appearing on the Internet, we presented the first dataset to study cyberbullying in the Polish language for the development of automatic cyberbullying detection methods.
The dataset allows the users to try their classification methods to determine whether an Internet entry (e.g., a tweet) is classifiable as harmful (cyberbullying/hate-speech) or non-harmful. The entries contain tweets collected from openly available Twitter discussions and were provided as such, with minimal preprocessing.
The dataset can be used in several ways. First, it can be used as a linguistic resource to qualitatively study how cyberbullying and related phenomena are expressed online in the Polish language, similarly to what we have demonstrated in the above sections. Second, it can be used to create new cyberbullying detection tools for the Polish language. The first attempts are described in the above sections. Third, the best-performing model for automatic cyberbullying detection in the Polish language, released together with the dataset, can be freely applied in cyberbullying detection and prevention architectures for social networking services.
The tools required to run the accompanied scripts include the Perl programming language, the
Text::Guess::Language12 Perl package for language detection, and the Python 3.9.7. programming language, as well as the following Python packages:
pandas13,
spaCy14,
NumPy15,
transformers16.
7. Contributions
In recent years, there has been an increase in releases of datasets containing entries annotated for cyberbullying, toxicity, offensiveness, etc., such as the ones listed in the
https://hatespeechdata.com repository (accessed on 13 December 2023). However, most of those datasets are either (1) annotated by laypeople, (2) using non-standardized taxonomies, or (3) are published without proper quality control. In the majority, more than one of those problems, if not all, apply to most of the available datasets. On the contrary, datasets collected and annotated by experts with proper quality control are scarce. Moreover, if they exist, they are available in high-resource languages such as English. The presented dataset was specifically collected and annotated by experts, with proper quality control (thus, two versions of annotations), and is available for a language that is not as popular as English. Therefore, the dataset presents a valuable contribution and can be reused and analyzed both in linguistic research as well as for training ML models. We were further encouraged to publish the dataset by the increasing tendency for inflammatory entries on the Polish Internet. Thus, with this dataset, we wish to provide two specific contributions. First, various researchers will be able to use this expert-annotated dataset to study cyberbullying in the Polish language. Second, with this dataset, we wish to encourage other researchers to publish their datasets in this topic, especially in low-resource and underrepresented languages.


 ,
, 





{kind=link}
{kind=link}
{kind=link}


