

A Preliminary Investigation of a Single Shock Impact on Italian Mortality Rates Using STMF Data: A Case Study of COVID-19


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Demographic Data
- They only cover a subset (38 out of the 48) of countries included in the HMD; moreover, the length of the country-specific data series varies: the longest time series (Finland) starts in 1990, the shorter ones (Chile, Greece, and Germany) in 2016. Most of the country series (23 out of the 38) begin in 2000. The series are neither smoothed nor adjusted for data quality problems such as death undercounts. Deaths are generally collected by date of occurrence, apart from UK data (England, Scotland, Wales, Northern Ireland), which are collected by date of registration;
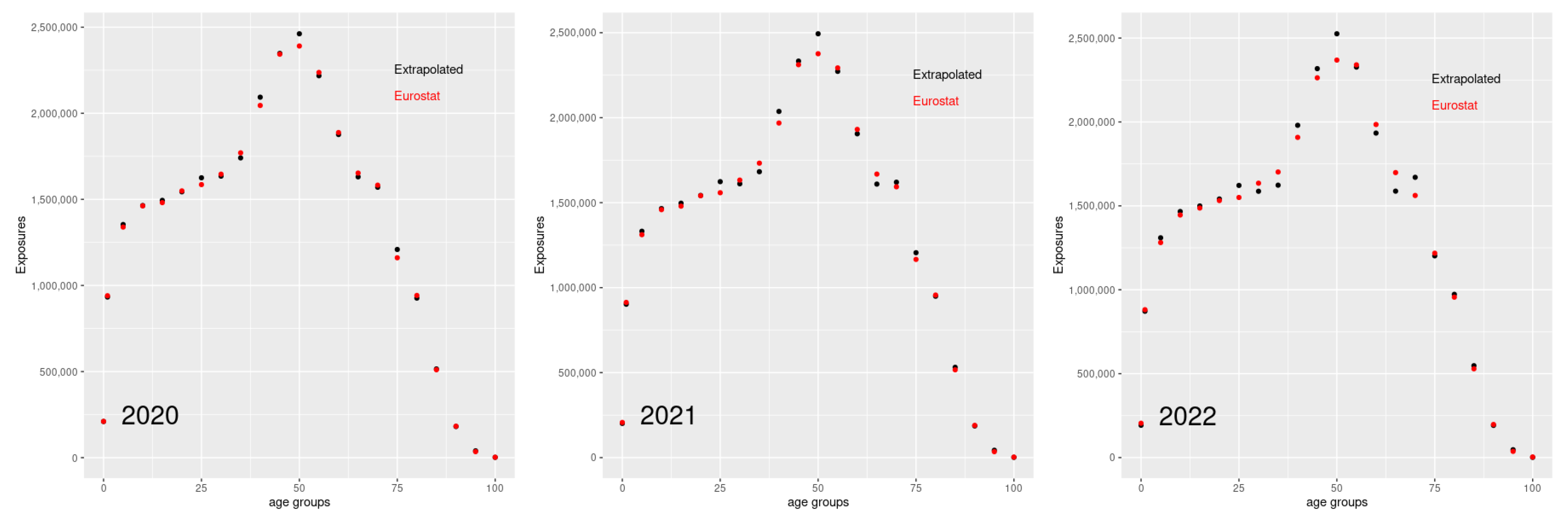
- Weekly death rates are obtained from collected weekly death counts (generally registered by sex and age) and estimated annual population exposures; For the more recent years, when annual data are not yet available, the exposures are estimated after extrapolating annual death rates by fitting a Lee–Carter model to the HMD data; in this case, a relatively short reference period is chosen to appreciate the most recent changes in mortality;
- The original data for each country are split or grouped in standard age groups in order to be consistent across countries; however, raw data at country level with finer age grouping (5 years) are often available; for example, as reported below, Italian raw data contain death counts for all-cause mortality cross-classified by week, year, sex, 5-years age interval.
2.2. Data Processing
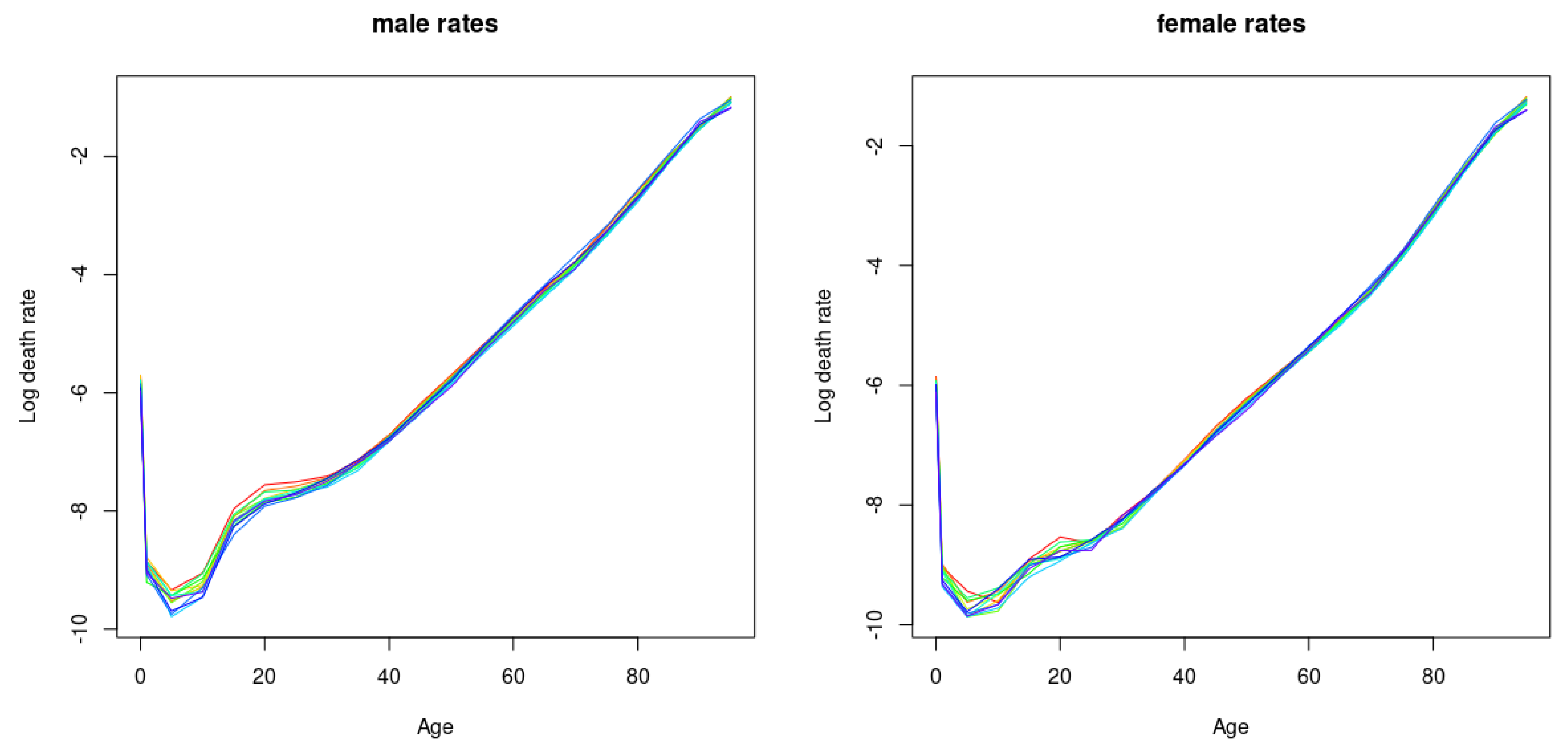
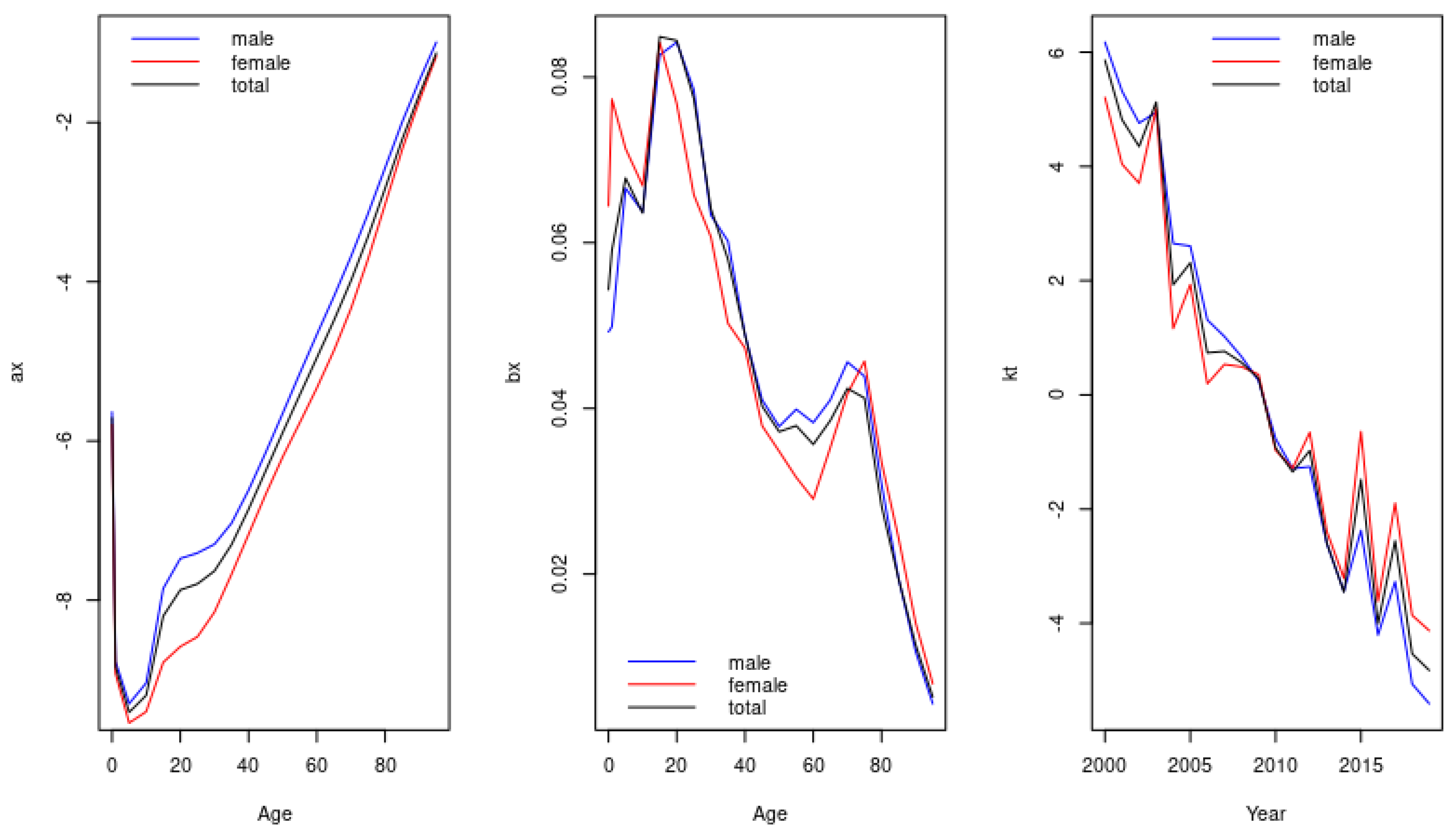
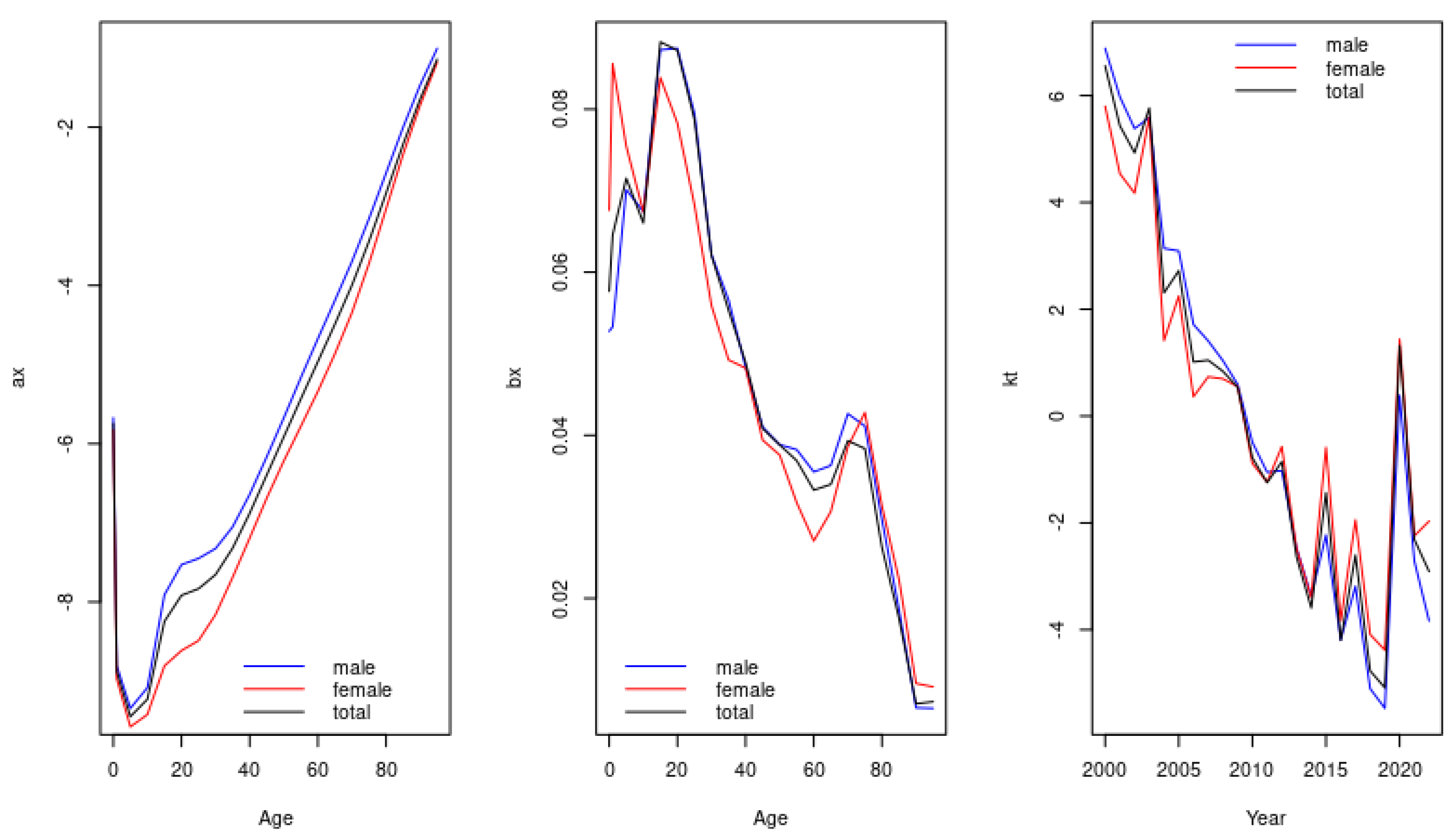
2.3. Basic Mortality Model
2.4. Models including Mortality Jumps
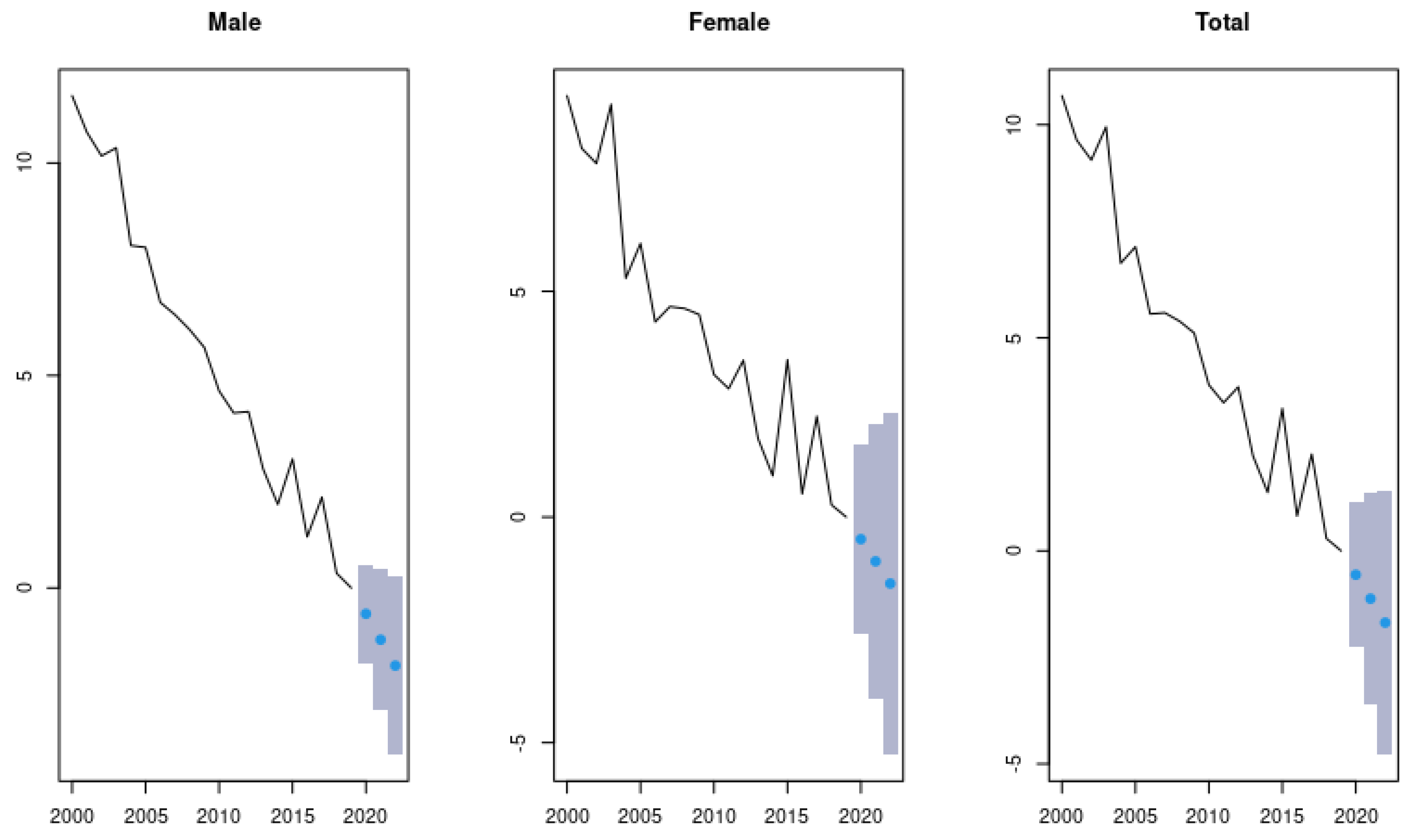
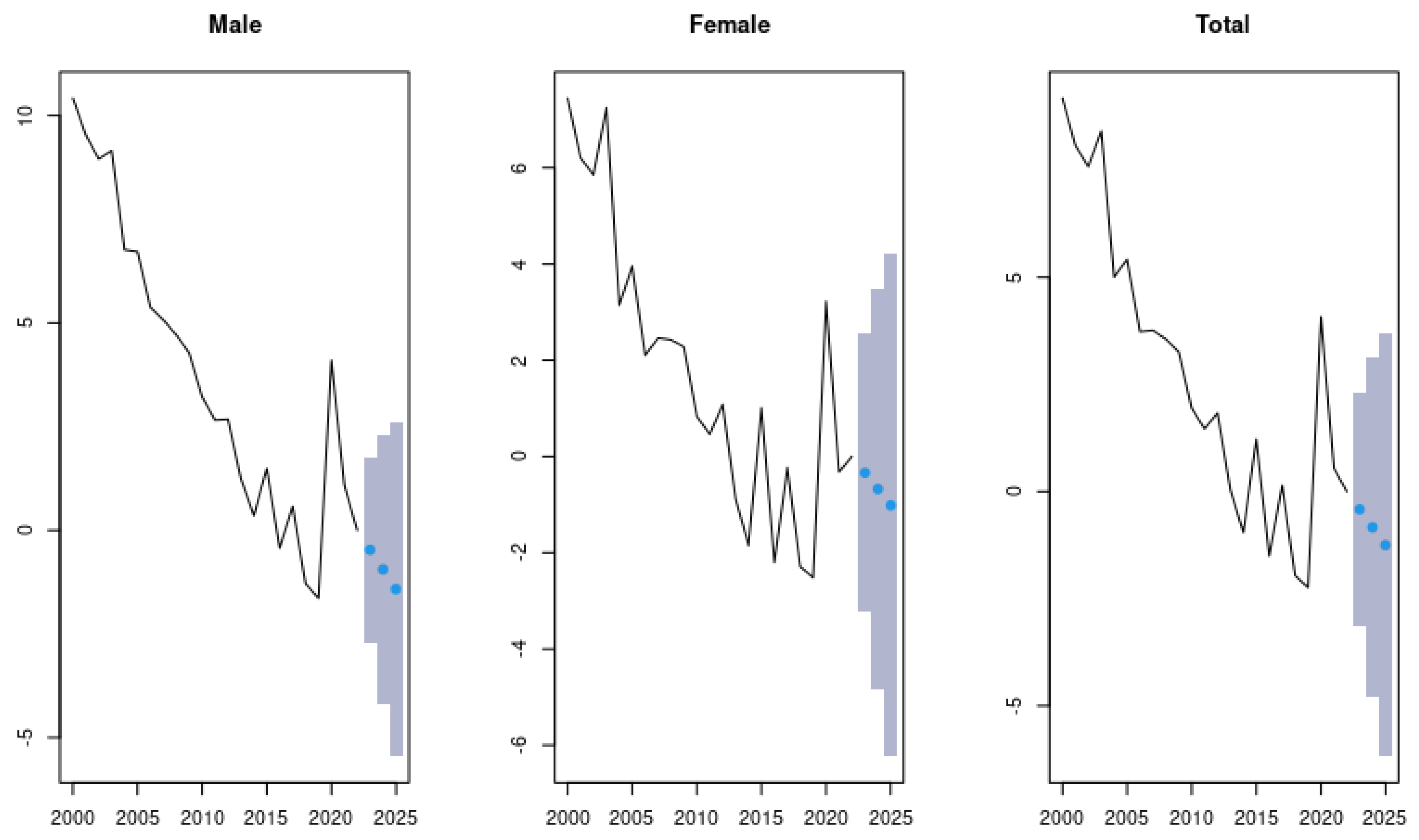
3. Results
4. Conclusions
5. Perspectives for Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Broekhoven, H.; Alm, E.; Tuominen, T.; Hellman, A.; Dziworski, W. Actuarial Reflections on Pandemic Risk and Its Consequences. 2006. Available online: https://actuary.eu/documents/pandemics_web.pdf (accessed on 9 June 2023).
- World Health Organization. 14.9 Million Excess Deaths Associated with the COVID-19 Pandemic in 2020 and 2021. 2022. Available online: who.int/news/item/05-05-2022-14.9-million-excess-deaths-were-associated-with-the-covid-19-pandemic-in-2020-and-2021 (accessed on 9 June 2023).
- Italian Insurance in 2020–2021. Annual Report of the Italian National Association of Insurance Companies. 2021. Available online: https://www.ania.it/pubblicazioni/-/categories/53731 (accessed on 9 June 2023).
- Carannante, M.; D’Amato, V.; Haberman, S. COVID-19 accelerated mortality shocks and the impact on life insurance: The Italian situation. Ann. Actuar. Sci. 2022, 16, 478–497. [Google Scholar] [CrossRef]
- Harryz, T.F.; Yelowitz, A.; Courtemanche, C. Did COVID-19 change life insurance offerings? J. Risk Insur. 2021, 88, 831–861. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Liao, P.; Chen, X. The negative impact of COVID-19 on life insurers. Front. Public Health Health Econ. Sect. 2021, 9, 756977. [Google Scholar] [CrossRef] [PubMed]
- Cairns, A.J.G.; Blake, D.P.; Kessler, A.; Kessler, M. The Impact of COVID-19 on Future Higher-Age Mortality; Technical Report; Pensions Institute: London, UK, 2020. [Google Scholar] [CrossRef]
- Robben, J.; Antonio, K.; Devriendt, S. Assessing the Impact of the COVID-19 Shock on a Stochastic Multi-Population Mortality Model. Risks 2022, 10, 26. [Google Scholar] [CrossRef]
- Schnürch, S.; Kleinow, T.; Korn, R.; Wagner, A. The impact of mortality shocks on modelling and insurance valuation as exemplified by COVID-19. Ann. Actuar. Sci. 2022, 16, 498–526. [Google Scholar] [CrossRef]
- Islam, N.; Jdanov, D.; Shkolnikov, V.; Khunti, K.; Kawachi, I.; White, M.; Lewington, S.; Lacey, B. Effects of COVID-19 pandemic on life expectancy and premature mortality in 2020: Time series analysis in 37 countries. Br. Med. J. 2021, 375, e066768. [Google Scholar] [CrossRef] [PubMed]
- Aburto, J.M.; Schöley, J.; Kashnitsky, I.; Zhang, L.; Rahal, C.; Missov, T.I.; Mills, M.C.; Dowd, J.B.; Kashyap, R. Quantifying impacts of the COVID-19 pandemic through life-expectancy losses: A population-level study of 29 countries. Int. J. Epidemiol. 2021, 51, 63–74. [Google Scholar] [CrossRef] [PubMed]
- Schöley, J.; Aburto, J.M.; Kashnitsky, I.; Kniffka, M.S.; Zhang, L.; Jaadla, H.; Dowd, J.B.; Kashyap, R. Life expectancy changes since COVID-19. Nat. Hum. Behav. 2022, 6, 1649–1659. [Google Scholar] [CrossRef] [PubMed]
- Human Mortality Database. Max Planck Institute for Demographic Research (Germany), University of California, Berkeley (USA), and French Institute for Demographic Studies (France). 2023. Available online: www.mortality.org (accessed on 22 March 2023).
- Carfora, M.; Cutillo, L.; Orlando, A. A quantitative comparison of stochastic mortality models on Italian population data. Comput. Stat. Data Anal. 2017, 112, 198–214. [Google Scholar] [CrossRef]
- Liu, Y.; Li, J.S.H. The age pattern of transitory mortality jumps and its impact on the pricing of catastrophic mortality bonds. Insur. Math. Econ. 2015, 64, 135–150. [Google Scholar] [CrossRef]
- Jdanov, D.; Galarza, A.; Shkolnikov, V.; Jasilionis, D.; Németh, L.; Leon, D.; Boe, C.; Barbieri, M. The short-term mortality fluctuation data series, monitoring mortality shocks across time and space. Sci. Data 2021, 8, 235. [Google Scholar] [CrossRef] [PubMed]
- Németh, L.; Jdanov, D.; Shkolnikov, V. An open-sourced, web-based application to analyze weekly excess mortality based on the Short-term Mortality Fluctuations data series. PLoS ONE 2021, 16, e0246663. [Google Scholar] [CrossRef] [PubMed]
- Nepomuceno, M.R.; Klimkin, I.; Jdanov, D.A.; Alustiza-Galarza, A.; Shkolnikov, V.M. Sensitivity Analysis of Excess Mortality due to the COVID-19 Pandemic. Popul. Dev. Rev. 2022, 48, 279–302. [Google Scholar] [CrossRef] [PubMed]
- Eurostat Database. 2023. Available online: https://ec.europa.eu/eurostat/web/main/data (accessed on 13 April 2023).
- Lee, R.D.; Carter, L.R. Modeling and Forecasting U. S. Mortality. J. Am. Stat. Assoc. 1992, 87, 659–671. [Google Scholar] [CrossRef]
- Chen, H.; Cox, S.H. Modeling Mortality with Jumps: Applications to Mortality Securitization. J. Risk Insur. 2009, 76, 727–751. [Google Scholar] [CrossRef]
- Zhou, R.; Li, J.S.H. A multi-parameter-level model for simulating future mortality scenarios with COVID-alike effects. Ann. Actuar. Sci. 2022, 16, 453–477. [Google Scholar] [CrossRef]
- Hyndman, R.J. Demography: Forecasting Mortality, Fertility, Migration and Population Data, v1.22. 2019. Available online: http://cran.r-project.org/package=demography (accessed on 9 June 2023).






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carfora, M.F.; Orlando, A. A Preliminary Investigation of a Single Shock Impact on Italian Mortality Rates Using STMF Data: A Case Study of COVID-19. Data 2023, 8, 107. https://doi.org/10.3390/data8060107
Carfora MF, Orlando A. A Preliminary Investigation of a Single Shock Impact on Italian Mortality Rates Using STMF Data: A Case Study of COVID-19. Data. 2023; 8(6):107. https://doi.org/10.3390/data8060107
Chicago/Turabian StyleCarfora, Maria Francesca, and Albina Orlando. 2023. "A Preliminary Investigation of a Single Shock Impact on Italian Mortality Rates Using STMF Data: A Case Study of COVID-19" Data 8, no. 6: 107. https://doi.org/10.3390/data8060107
APA StyleCarfora, M. F., & Orlando, A. (2023). A Preliminary Investigation of a Single Shock Impact on Italian Mortality Rates Using STMF Data: A Case Study of COVID-19. Data, 8(6), 107. https://doi.org/10.3390/data8060107