An Efficient Deep Learning for Thai Sentiment Analysis


Abstract
1. Introduction
- We collected data and constructed a Thai sentiment corpus in the hotel domain;
- We focused on and applied deep learning models to discover a suitable architecture for Thai hotel sentiment classification;
- We applied the Word2Vec model with the CBOW and skip-gram techniques to build a word embedding model with different vector dimensions, highlighting their effect on the accuracy of sentiment classification in the Thai language. We then compared the Word2Vec, FastText, and BERT pre-trained models;
- We also evaluated the classification accuracy of deep learning models using Word2Vec and term frequency-inverse document frequency (TF-IDF) models, comparing their performance with various traditional machine learning models.
2. Related Works
3. Background
3.1. Word2Vec
3.2. FastText Pre-Training Model
3.3. BERT Pre-Training Model
3.4. Deep Learning
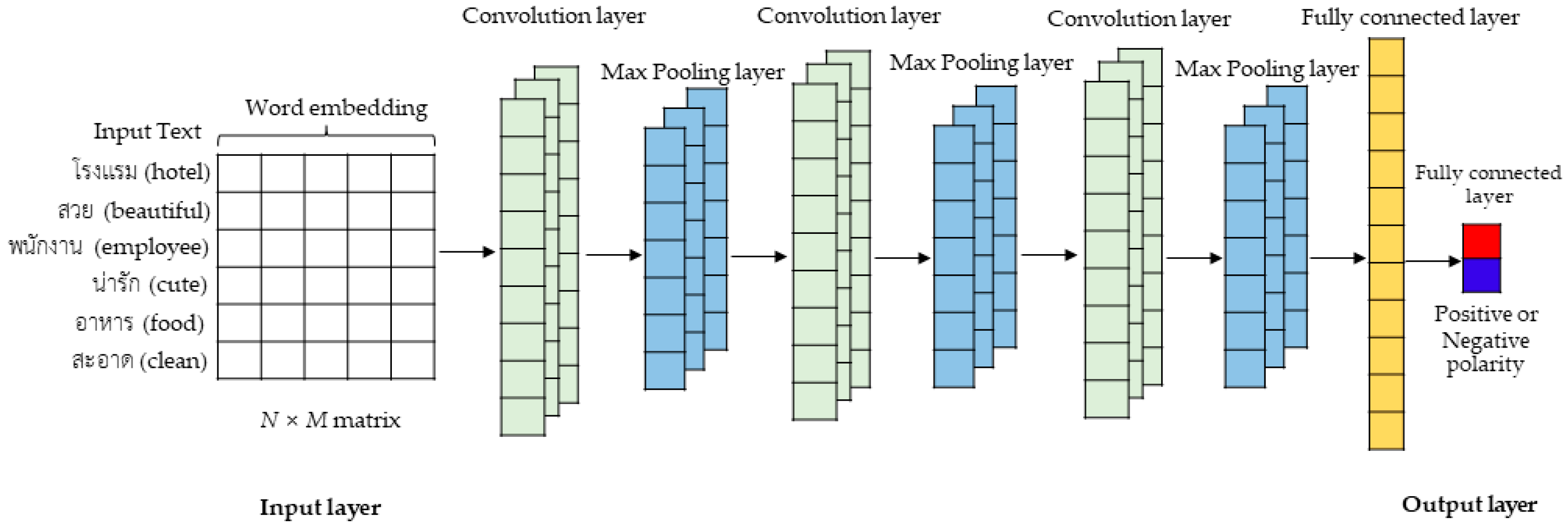
3.4.1. Convolutional Neural Network (CNN)
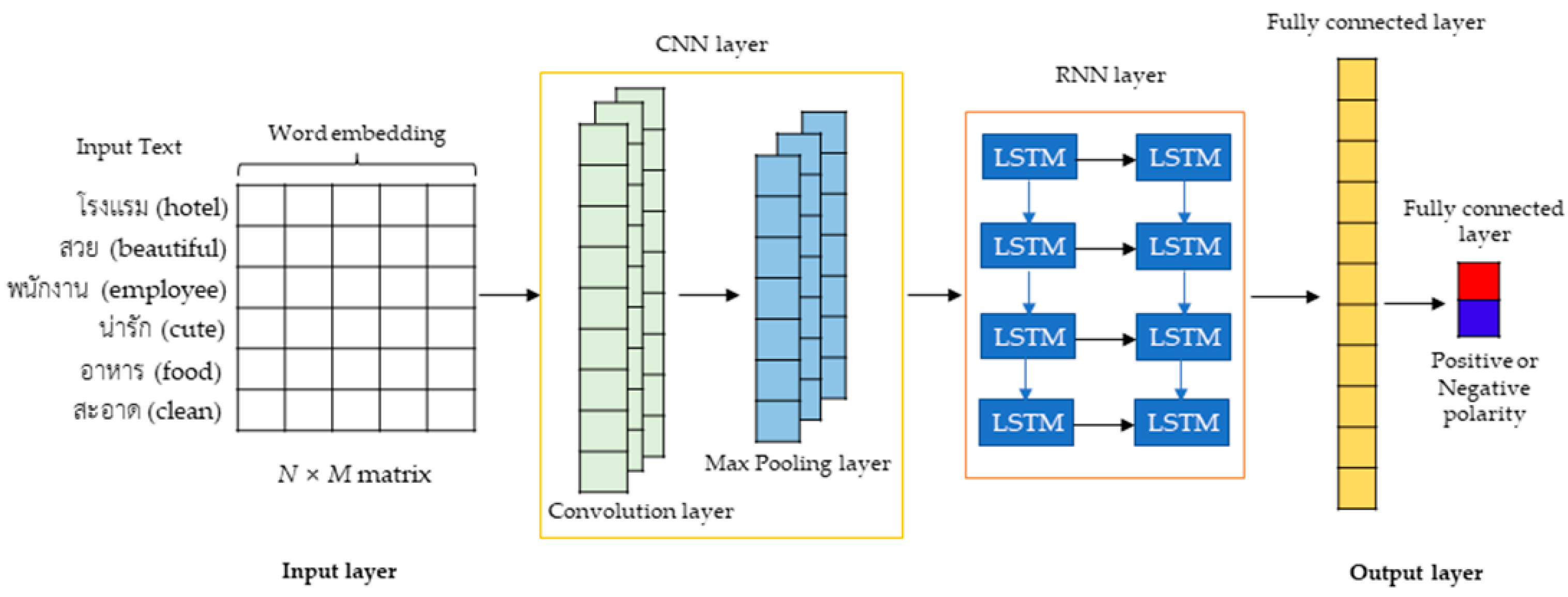
3.4.2. Recurrent Neural Network (RNN)
- Long short-term memory (LSTM) and bi-directional long short-term memory (Bi-LSTM).
- Gated recurrent unit (GRU) and bi-directional gated recurrent unit (Bi-GRU).
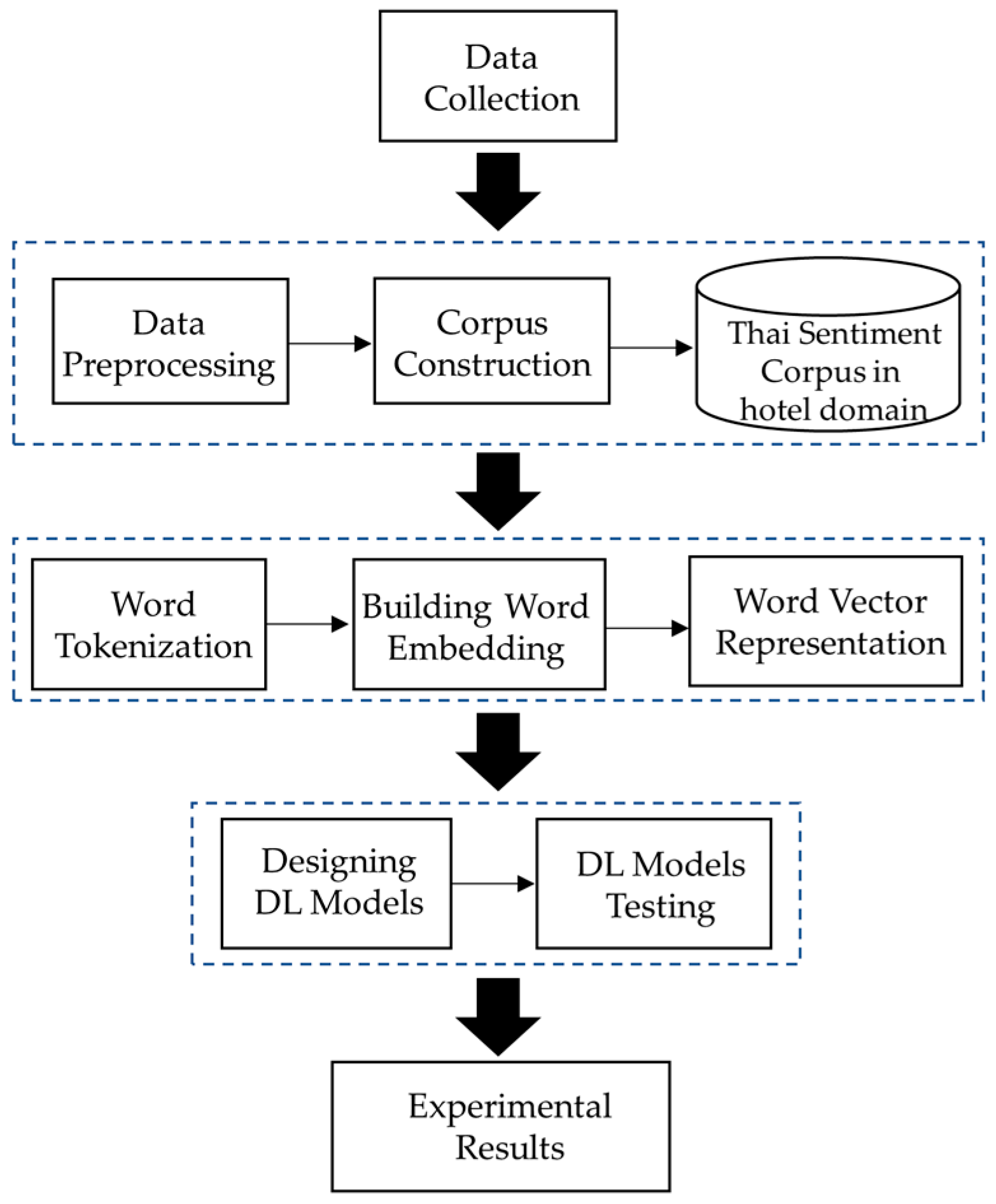
4. Methodology
4.1. Data Collection
4.2. Thai Sentiment Corpus Construction in the Hotel Domain
4.2.1. Data Pre-Processing
- Symbol removal: the regular expression is applied to remove a symbol, such as “<, >, () {}, = , +, @”, and punctuation is also removed, such as “:, ;, ?, !, -, .”;
- Number removal: Numbers do not convey the writer’s feelings and they are useless for sentiment analysis. Thus, all numbers are removed from the text review;
- English word removal: English words are not considered in the text pre-processing, and they also affect the word tokenization step;
- Emoji and emoticon removal: Emojis and emoticons are a short form to convey the writer’s feelings using keyboard characters. However, there are many emojis and emoticons that do not give information about the feeling of the writer, such as 🦇 (Bat), 🐼 (Bear), 🍻 (Cheer), \o/ (Cheer), @}; (Rose), > < > (Fish);
- Text normalization: This process aims to improve the quality of the input text. This step transforms the mistyped word into a correct form. For example, the sentence “ห้องเก่า บิรการแย่ พนกังานไม่สุภาพ” will be normalized as “ห้องเก่า บริการแย่ พนักงานไม่สุภาพ” (old room, poor service, impolite staff), which is the correct form of the Thai text. We can see that the word “บิรการ” and “พนกังาน” have been transformed into the “บริการ” (service) and “พนักงาน” (employee). However, the text normalization step cannot transform the word into a complex misspelled word (i.e., ”บริ้การแย่ม๊าก”, “ไม๊สุภาพม๊าก”);
- Word tokenization: The Thai writing system has no spaces between words. Instead, a space is utilized to identify the end of a sentence. In Thai text reviews, the expression of feelings is written in free form and contains many sentences. This makes the process difficult if the sentence contains complex words and misspellings. Thus, word tokenization is a crucial part of Thai sentiment analysis. For example, a sentence “ห้องเก่า บริ้การแย่ม๊าก พนักงานไม่สุภาพ” will be tokenized into an individual word as {“ห้อง“, “เก่า“, “ “, “บริ้“, “การ“, “แย่“, “ม๊าก“, “ “, “พนักงาน“, “ไม่“, “สุภาพ“}. We can see that the words “บริ้“, “การ“, “แย่“,“ม๊าก“, “ไม่“, and “สุภาพ“ were tokenized incorrectly. Hence, the database was created to store custom words (i.e., the words “บริ้การ”,“แย่ม๊าก”, and “ไม่สุภาพ”) and to refine words in the sentences for word tokenization. Thus, the output of word tokenization is split into individual words, such as {“ห้อง“, “เก่า“, “ “, “บริ้การ“, “แย่ม๊าก“, “ “, “พนักงาน“, “ไม่สุภาพ“}. However, the words “บริ้การ“ and “แย่ม๊าก“ are misspelled mistakes in the Thai text. They are converted into the correct form in the checking spelling errors step.
- Whitespace and tap removal: After the sentences are tokenized into individual words, there are whitespaces, blanks, and taps that are not useful for text analysis. These are removed, and the output, such as {“ห้อง“, “เก่า“, “บริ้การ“, “แย่ม๊าก“, “พนักงาน“, “ไม่สุภาพ“}, is produced;
- Single character removal: Single characters often appear after the word tokenization step. They have no meaning in the review;
- Converting abbreviations: “กม.“ and “จว.“ are examples of abbreviations. They are converted into “กิโลเมตร“ (kilometer) and “จังหวัด“ (province);
- Checking spelling errors: The text reviews contain misspelled words. These lead to incorrect tokenization. For example, the words “บริ้การ“ (service) and “แย่ม๊าก“ (very bad) are spelled incorrectly. They are converted into “บริการ” and “แย่มาก“;
- Stop-word removal: Stop-words are commonly used words in the Thai language, and they are useless for sentiment analysis. Examples of stop-words are “คือ” (is), “หรือ” (or), “มัน” (it), “ฉัน” (I), and “อื่นๆ” (other). These stop-words must be removed from reviews.
4.2.2. Cosine Similarity
4.3. Building Word Embedding
4.4. DL Model Design for Evaluation
5. Experimental Results
5.1. Experimental Setup
5.2. Evaluation Metrics
5.3. Results Comparison and Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Orden-Mejía, M.; Carvache-Franco, M.; Huertas, A.; Carvache-Franco, W.; Landeta-Bejarano, N.; Carvache-Franco, O. Post-COVID-19 Tourists’ Preferences, Attitudes and Travel Expectations: A Study in Guayaquil, Ecuador. Int. J. Environ. Res. Public Health 2022, 19, 4822. [Google Scholar] [CrossRef]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment Analysis of Comment Texts Based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Ombabi, A.H.; Ouarda, W.; Alimi, A.M. Deep learning CNN–LSTM framework for Arabic sentiment analysis using textual information shared in social networks. Soc. Netw. Anal. Min. 2020, 10, 53. [Google Scholar] [CrossRef]
- Razali, N.A.M.; Malizan, N.A.; Hasbullah, N.A.; Wook, M.; Zainuddin, N.M.; Ishak, K.K.; Ramli, S.; Sukardi, S. Opinion mining for national security: Techniques, domain applications, challenges and research opportunities. J. Big Data 2021, 8, 150. [Google Scholar] [CrossRef] [PubMed]
- Manalu, B.U.; Tulus; Efendi, S. Deep Learning Performance in Sentiment Analysis. In Proceedings of the 4rd International Conference on Electrical, Telecommunication and Computer Engineering (ELTICOM), Medan, Indonesia, 3–4 September 2020; pp. 97–102. [Google Scholar]
- Yue, W.; Li, L. Sentiment Analysis using Word2vec-CNN-BiLSTM Classification. In Proceedings of the Seventh International Conference on Social Networks Analysis, Management and Security (SNAMS), Paris, France, 14–16 December 2020; pp. 1–5. [Google Scholar]
- Zhou, Y. A Review of Text Classification Based on Deep Learning. In Proceedings of the 3rd International Conference on Geoinformatics and Data Analysis, Marseille, France, 15–17 April 2020; ACM: Marseille, France, 2020; pp. 132–136. [Google Scholar]
- Regina, I.A.; Sengottuvelan, P. Analysis of Sentiments in Movie Reviews using Supervised Machine Learning Technique. In Proceedings of the 4th International Conference on Computing and Communications Technologies (ICCCT), Chennai, India, 16–17 December 2021; pp. 242–246. [Google Scholar]
- Tusar, T.H.K.; Islam, T. A Comparative Study of Sentiment Analysis Using NLP and Different Machine Learning Techniques on US Airline Twitter Data. arXiv 2021, arXiv:2110.00859. [Google Scholar]
- Mandloi, L.; Patel, R. Twitter Sentiments Analysis Using Machine Learninig Methods. In Proceedings of the International Conference for Emerging Technology (INCET), Belgaum, India, 26–28 May 2020; pp. 1–5. [Google Scholar]
- Kusrini; Mashuri, M. Sentiment Analysis in Twitter Using Lexicon Based and Polarity Multiplication. In Proceedings of the International Conference of Artificial Intelligence and Information Technology (ICAIIT), Yogyakarta, Indonesia, 13–15 March 2019; pp. 365–368. [Google Scholar]
- Alshammari, N.F.; AlMansour, A.A. State-of-the-art review on Twitter Sentiment Analysis. In Proceedings of the 2nd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 1–3 May 2019; pp. 1–8. [Google Scholar]
- Pandya, V.; Somthankar, A.; Shrivastava, S.S.; Patil, M. Twitter Sentiment Analysis using Machine Learning and Deep Learning Techniques. In Proceedings of the 2nd International Conference on Communication, Computing and Industry 4.0 (C2I4), Bangalore, India, 16–17 December 2021; pp. 1–5. [Google Scholar]
- Zhou, J.; Lu, Y.; Dai, H.-N.; Wang, H.; Xiao, H. Sentiment Analysis of Chinese Microblog Based on Stacked Bidirectional LSTM. IEEE Access 2019, 7, 38856–38866. [Google Scholar] [CrossRef]
- Mohbey, K.K. Sentiment analysis for product rating using a deep learning approach. In Proceedings of the International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 121–126. [Google Scholar]
- Demirci, G.M.; Keskin, S.R.; Dogan, G. Sentiment Analysis in Turkish with Deep Learning. In Proceedings of the IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2215–2221. [Google Scholar]
- Xiang, S. Deep Learning Framework Study for Twitter Sentiment Analysis. In Proceedings of the 2nd International Conference on Information Science and Education (ICISE-IE), Chongqing, China, 26–28 November 2021; pp. 517–520. [Google Scholar]
- Kim, H.; Jeong, Y.-S. Sentiment Classification Using Convolutional Neural Networks. Appl. Sci. 2019, 9, 2347. [Google Scholar] [CrossRef]
- Poncelas, A.; Pidchamook, W.; Liu, C.-H.; Hadley, J.; Way, A. Multiple Segmentations of Thai Sentences for Neural Machine Translation. arXiv 2020, arXiv:2004.11472. [Google Scholar]
- Piyaphakdeesakun, C.; Facundes, N.; Polvichai, J. Thai Comments Sentiment Analysis on Social Networks with Deep Learning Approach. In Proceedings of the International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Jeju Island, Republic of Korea, 23–26 June 2019; pp. 1–4. [Google Scholar]
- Ayutthaya, T.S.N.; Pasupa, K. Thai Sentiment Analysis via Bidirectional LSTM-CNN Model with Embedding Vectors and Sentic Features. In Proceedings of the International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Pattaya, Thailand, 15–17 November 2018; pp. 1–6. [Google Scholar]
- Pasupa, K.; Seneewong Na Ayutthaya, T. Thai sentiment analysis with deep learning techniques: A comparative study based on word embedding, POS-tag, and sentic features. Sustain. Cities Soc. 2019, 50, 101615. [Google Scholar] [CrossRef]
- Pasupa, K.; Seneewong Na Ayutthaya, T. Hybrid Deep Learning Models for Thai Sentiment Analysis. Cogn Comput. 2022, 14, 167–193. [Google Scholar] [CrossRef]
- Leelawat, N.; Jariyapongpaiboon, S.; Promjun, A.; Boonyarak, S.; Saengtabtim, K.; Laosunthara, A.; Yudha, A.K.; Tang, J. Twitter Data Sentiment Analysis of Tourism in Thailand during the COVID-19 Pandemic Using Machine Learning. Heliyon 2022, 8, e10894. [Google Scholar] [CrossRef]
- Bowornlertsutee, P.; Paireekreng, W. The Model of Sentiment Analysis for Classifying the Online Shopping Reviews. J. Eng. Digit. Technol. 2022, 10, 71–79. [Google Scholar]
- Pugsee, P.; Ongsirimongkol, N. A Classification Model for Thai Statement Sentiments by Deep Learning Techniques. In Proceedings of the 2nd International Conference on Computational Intelligence and Intelligent Systems, Bangkok Thailand, 23–25 November 2019; ACM: New York, NY, USA, 2019; pp. 22–27. [Google Scholar]
- Vateekul, P.; Koomsubha, T. A study of sentiment analysis using deep learning techniques on Thai Twitter data. In Proceedings of the 13th International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016; pp. 1–6. [Google Scholar]
- Thiengburanathum, P.; Charoenkwan, P. A Performance Comparison of Supervised Classifiers and Deep-learning Approaches for Predicting Toxicity in Thai Tweets. In Proceedings of the Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunication Engineering, Cha-am, Thailand, 3–6 March 2021; pp. 238–242. [Google Scholar]
- Khamphakdee, N.; Seresangtakul, P. Sentiment Analysis for Thai Language in Hotel Domain Using Machine Learning Algorithms. Acta Inform. Pragensia 2021, 10, 155–171. [Google Scholar] [CrossRef]
- Li, L.; Yang, L.; Zeng, Y. Improving Sentiment Classification of Restaurant Reviews with Attention-Based Bi-GRU Neural Network. Symmetry 2021, 13, 1517. [Google Scholar] [CrossRef]
- Lai, C.-M.; Chen, M.-H.; Kristiani, E.; Verma, V.K.; Yang, C.-T. Fake News Classification Based on Content Level Features. Appl. Sci. 2022, 12, 1116. [Google Scholar] [CrossRef]
- Muhammad, P.F.; Kusumaningrum, R.; Wibowo, A. Sentiment Analysis Using Word2vec And Long Short-Term Memory (LSTM) For Indonesian Hotel Reviews. Procedia Comput. Sci. 2021, 179, 728–735. [Google Scholar] [CrossRef]
- Naqvi, U.; Majid, A.; Abbas, S.A. UTSA: Urdu Text Sentiment Analysis Using Deep Learning Methods. IEEE Access 2021, 9, 114085–114094. [Google Scholar] [CrossRef]
- Fayyoumi, E.; Idwan, S. Semantic Partitioning and Machine Learning in Sentiment Analysis. Data 2021, 6, 67. [Google Scholar] [CrossRef]
- Ay Karakuş, B.; Talo, M.; Hallaç, İ.R.; Aydin, G. Evaluating deep learning models for sentiment classification. Concurr. Comput. Pr. Exper. 2018, 30, e4783. [Google Scholar] [CrossRef]
- Rehman, A.U.; Malik, A.K.; Raza, B.; Ali, W. A Hybrid CNN-LSTM Model for Improving Accuracy of Movie Reviews Sentiment Analysis. Multimed. Tools Appl. 2019, 78, 26597–26613. [Google Scholar] [CrossRef]
- Feizollah, A.; Ainin, S.; Anuar, N.B.; Abdullah, N.A.B.; Hazim, M. Halal Products on Twitter: Data Extraction and Sentiment Analysis Using Stack of Deep Learning Algorithms. IEEE Access 2019, 7, 83354–83362. [Google Scholar] [CrossRef]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Tashtoush, Y.; Alrababash, B.; Darwish, O.; Maabreh, M.; Alsaedi, N. A Deep Learning Framework for Detection of COVID-19 Fake News on Social Media Platforms. Data 2022, 7, 65. [Google Scholar] [CrossRef]
- Mishra, R.K.; Urolagin, S.; Jothi, J.A.A. A Sentiment analysis-based hotel recommendation using TF-IDF Approach. In Proceedings of the International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 11–12 December 2019; pp. 811–815. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Sohrabi, M.K.; Hemmatian, F. An efficient preprocessing method for supervised sentiment analysis by converting sentences to numerical vectors: A twitter case study. Multimed. Tools Appl. 2019, 78, 24863–24882. [Google Scholar] [CrossRef]
- Onishi, T.; Shiina, H. Distributed Representation Computation Using CBOW Model and Skip–gram Model. In Proceedings of the 9th International Congress on Advanced Applied Informatics (IIAI-AAI), Kitakyushu, Japan, 1–15 September 2020; pp. 845–846. [Google Scholar]
- Styawati, S.; Nurkholis, A.; Aldino, A.A.; Samsugi, S.; Suryati, E.; Cahyono, R.P. Sentiment Analysis on Online Transportation Reviews Using Word2Vec Text Embedding Model Feature Extraction and Support Vector Machine (SVM) Algorithm. In Proceedings of the International Seminar on Machine Learning, Optimization, and Data Science (ISMODE), Jakarta, Indonesia, 29–30 January 2022; pp. 163–167. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguistics 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How Multilingual Is Multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 4996–5001. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-Lingual Representation Learning at Scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Lowphansirikul, L.; Polpanumas, C.; Jantrakulchai, N.; Nutanong, S. WangchanBERTa: Pretraining Transformer-Based Thai Language Models. arXiv 2021, arXiv:2101.09635. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing. arXiv 2018, arXiv:1708.02709. [Google Scholar]
- Tam, S.; Said, R.B.; Tanriover, O.O. A ConvBiLSTM Deep Learning Model-Based Approach for Twitter Sentiment Classification. IEEE Access 2021, 9, 41283–41293. [Google Scholar] [CrossRef]
- Nosratabadi, S.; Mosavi, A.; Duan, P.; Ghamisi, P.; Filip, F.; Band, S.; Reuter, U.; Gama, J.; Gandomi, A. Data Science in Economics: Comprehensive Review of Advanced Machine Learning and Deep Learning Methods. Mathematics 2020, 8, 1799. [Google Scholar] [CrossRef]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Seo, S.; Kim, C.; Kim, H.; Mo, K.; Kang, P. Comparative study of Deep Learning-based Setiment classification. IEEE Access 2020, 8, 6861–6875. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Raza, M.R.; Hussain, W.; Merigo, J.M. Cloud Sentiment Accuracy Comparison using RNN, LSTM and GRU. In Proceedings of the Innovations in Intelligent Systems and Applications Conference (ASYU), Elazig, Turkey, 6–8 October 2021; pp. 1–5. [Google Scholar]
- Santur, Y. Sentiment Analysis Based on Gated Recurrent Unit. In Proceedings of the International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; pp. 1–5. [Google Scholar]
- Dehkordi, P.E.; Asadpour, M.; Razavi, S.N. Sentiment Classification of reviews with RNNMS and GRU Architecture Approach Based on online customers rating. In Proceedings of the 28th Iranian Conference on Electrical Engineering (ICEE), Tabriz, Iran, 4–6 August 2020; pp. 1–7. [Google Scholar]
- Shrestha, N.; Nasoz, F. Deep Learning Sentiment Analysis of Amazon.Com Reviews and Ratings. Int. J. Soft Comput. Artif. Intell. Appl. 2019, 8, 1–15. [Google Scholar] [CrossRef]
- Gao, Z.; Li, Z.; Luo, J.; Li, X. Short Text Aspect-Based Sentiment Analysis Based on CNN + BiGRU. Appl. Sci. 2022, 12, 2707. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, Y.; Wang, Y.; Cui, Y.; Zhang, Z. Mixed Word Representation and Minimal Bi-GRU Model for Sentiment Analysis. In Proceedings of the Twelfth International Conference on Ubi-Media Computing (Ubi-Media), Bali, Indonesia, 5–8 August 2019; pp. 30–35. [Google Scholar]
- Saeed, H.H.; Shahzad, K.; Kamiran, F. Overlapping Toxic Sentiment Classification Using Deep Neural Architectures. In Proceedings of the IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 1361–1366. [Google Scholar]
- Pan, Y.; Liang, M. Chinese Text Sentiment Analysis Based on BI-GRU and Self-attention. In Proceedings of the IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 1983–1988. [Google Scholar]
- Khamphakdee, N.; Seresangtakul, P. A Framework for Constructing Thai Sentiment Corpus using the Cosine Similarity Technique. In Proceedings of the 13th International Conference on Knowledge and Smart Technology (KST-2021), Chonburi, Thailand, 21–24 January 2021. [Google Scholar]
- Step 5: Tune Hyperparameters|Text Classification Guide|Google Developers. Available online: https://developers.google.com/machine-learning/guides/text-classification/step-5 (accessed on 23 November 2021).
- Keras Layers API. Available online: https://keras.io/api/layers/ (accessed on 17 November 2021).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 17 November 2021).
- Pandas—Python Data Analysis Library. Available online: https://pandas.pydata.org/ (accessed on 17 November 2021).
- Scikit-Learn: Machine Learning in Python—Scikit-Learn 1.0.2 Documentation. Available online: https://scikit-learn.org/stable/ (accessed on 17 November 2021).
- Matplotlib—Visualization with Python. Available online: https://matplotlib.org/ (accessed on 17 November 2021).
- Salur, M.U.; Aydin, I. A Novel Hybrid Deep Learning Model for Sentiment Classification. IEEE Access 2020, 8, 58080–58093. [Google Scholar] [CrossRef]
- Isaac, E.R. Test of Hypothesis-Concise Formula Summary; Anna University: Tamil Nadu, India, 2015; pp. 1–5. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Reviews |
|---|---|
| 1 | ห้องน่ารัก สะอาด ไม่ใหญ่มาก เดินทางไปไหนสะดวก … พนักงานผู้ชายไม่น่ารักค่ะ ตอนเช็คอินไม่สวัสดี ไม่อธิบายอะไรเลย… แต่ตอนเช็คเอาส์พนักงานผู้หญิงน่ารักดีค่ะ Lovely room, clean, not very big, easy to travel anywhere … Male employees are not cute. Check-in is not good. Doesn’t explain anything… But when checking out, the female staff are nice. |
| 2 | อุปกร์เครื่องใช้ภายในชำรุดเช่่น ที่ทำน้ำอุ่นไม่ทำงาน/สายชำระไม่มี/ผ้าม่านขาดสกปรก/ของใช้เก่ามากผ้าเช็ดตัวและชุดเครื่องนอนเก่าดำไม่สมราคา Internal equipment is damaged, such as the water heater does not work/there is no payment line/the curtains are dirty/the items are very old, the towels and bedding are old, black, not worth the price. |
| 3 | โรงแรมเก่า ผ้าปูที่นอนยับ เก้าอี้ในห้องเบาะขาดและจะหักแล้ว ถ้าพักแบบไม่คิดอะไรก็ได้นะ Old hotel, wrinkled sheets, the chair in the cushion room is torn and will be broken. If you can rest without thinking about anything. |
| 4 | ขนาดห้องก็ก้วางมีกาแฟและที่ต้มนำ้ส่วนห้องอาบน้ำนั้นนำ้ไม่อุ่นพอดีไปช่วงอากาศเย็นและเวลาอาบน้ำระบายน้ำไม่ค่อยได้ดีเท่าที่ควร The size of the room is large, there is coffee and a water boiler, and the shower room is not warm enough in the cold weather and the water drainage is not as good as it should be. |
| No | Reviews | Class |
|---|---|---|
| 1 | ห้องไม่สะอาด ห้องน้ำสกปรก ผนังขึ้นรา ควรปรับปรุงนะคับ The room is not clean, the bathroom is dirty, the walls are moldy, should be improved. | 0 (negative) |
| 2 | สภาพห้องเป็นห้องเก่าๆ ห้องน้ำเหม็นมาก ไม่มีแชมพู ไม่มีตู้เย็น พนักงานบริการไม่ดี The room is old. The bathroom is very smelly, no shampoo, no refrigerator, bad service from staff. | 0 (negative) |
| 3 | บริการด้วยรอยยิ้ม อยู่ใจกลางเมือง ด้สนหลังมีผับ ใกลๆก็มีร้านขายของกินเพียบเลย Service with a smile, located in the center of the city. There is a pub in the back. There are many food shops nearby. | 1 (positive) |
| 4 | ชอบมาก เตียงใหญ่นุ่ม สะอาด สบาย น้ำก็แรง เครื่องทำน้ำอุ่นก็ดีมาก อาบสบายสุดๆ ชอบค่ะ I like it very much; the bed is soft, clean, and comfortable; the water pressure is strong; the water heater is very good; the bath is very comfortable; I like it. | 1 (positive) |
| Embedding Hyperparameters | Values |
|---|---|
| Dimensions | 50, 100, 150, 200, 250, 300 |
| Architectures | CBOW, skip-gram |
| Window size | 2 |
| Min_count | 1 |
| Workers | 2 |
| Sample | 1 × 103 |
| Embedding Hyperparameters | Values |
|---|---|
| Number of convolution layers | 3, 4, 5 |
| Number of units | 8, 16, 32, 64, 128 |
| Batch size | 128 |
| Learning rate | 0.0001 |
| Dropout rate | 0.2 |
| Kernel size | 2 |
| Epochs | 30 |
| Embedding Hyperparameters | Values |
|---|---|
| Number of layers | 3, 4, 5 |
| Number of units | 8, 16, 32, 64, 128 |
| Batch size | 128 |
| Learning rate | 0.0001 |
| Dropout | 0.2 |
| Epochs | 30 |
| Embedding Hyperparameters | Values |
|---|---|
| Number of convolution layers | 3, 4, 5 |
| RNN layer | LSTM, BiLSTM, GRU, BiGRU |
| Number of units | 8, 16, 32, 64, 128 |
| Batch size | 128 |
| Learning rate | 0.0001 |
| Dropout | 0.2 |
| Epochs | 30 |
| Vector Dimensions | DL Models | Layers | Units | Matrix | |||
|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||||
| 50 | CNN-LSTM | 3 | 64 | 0.9098 | 0.9204 | 0.8995 | 0.9099 |
| CNN-BiLSTM | 4 | 64 | 0.9119 | 0.9127 | 0.9133 | 0.9130 | |
| LSTM | 5 | 16 | 0.9107 | 0.9185 | 0.9037 | 0.9111 | |
| 100 | CNN-LSTM | 3 | 32 | 0.9077 | 0.8855 | 0.9390 | 0.9115 |
| CNN | 4 | 64 | 0.9146 | 0.9167 | 0.9145 | 0.9156 | |
| LSTM | 5 | 16 | 0.9128 | 0.9134 | 0.9134 | 0.9134 | |
| 150 | GRU | 3 | 16 | 0.9107 | 0.9232 | 0.8983 | 0.9106 |
| GRU | 4 | 16 | 0.9098 | 0.9124 | 0.9091 | 0.9107 | |
| CNN-BiGRU | 5 | 64 | 0.9095 | 0.9214 | 0.8977 | 0.9094 | |
| 200 | CNN-GRU | 3 | 32 | 0.9137 | 0.9170 | 0.9121 | 0.9145 |
| GRU | 4 | 16 | 0.9119 | 0.9127 | 0.9133 | 0.9130 | |
| CNN-BiLSTM | 5 | 32 | 0.9122 | 0.9032 | 0.9258 | 0.9144 | |
| 250 | CNN-LSTM | 3 | 64 | 0.9104 | 0.8954 | 0.9318 | 0.9132 |
| GRU | 4 | 8 | 0.9113 | 0.9171 | 0.9067 | 0.9119 | |
| BiGRU | 5 | 8 | 0.9101 | 0.9273 | 0.8933 | 0.9095 | |
| 300 | CNN-BiLSTM | 3 | 32 | 0.9113 | 0.9212 | 0.9019 | 0.9115 |
| CNN-GRU | 4 | 32 | 0.9095 | 0.9163 | 0.9037 | 0.9100 | |
| GRU | 5 | 16 | 0.9122 | 0.9098 | 0.9175 | 0.9136 | |
| Vector Dimensions | DL Models | Layers | Units | Matrix | |||
|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||||
| 50 | CNN-BiGRU | 3 | 64 | 0.9116 | 0.9088 | 0.9175 | 0.9131 |
| CNN-LSTM | 4 | 128 | 0.9143 | 0.9136 | 0.9175 | 0.9155 | |
| CNN-BiGRU | 5 | 128 | 0.9113 | 0.9102 | 0.9151 | 0.9126 | |
| 100 | CNN-LSTM | 3 | 128 | 0.9140 | 0.9201 | 0.9091 | 0.9146 |
| CNN | 4 | 64 | 0.9170 | 0.9294 | 0.9094 | 0.9170 | |
| CNN | 5 | 64 | 0.9113 | 0.8924 | 0.9378 | 0.9146 | |
| 150 | CNN-BiGRU | 3 | 32 | 0.9143 | 0.9088 | 0.9234 | 0.9160 |
| CNN-BiLSTM | 4 | 64 | 0.9149 | 0.9243 | 0.9061 | 0.9151 | |
| CNN | 5 | 32 | 0.9137 | 0.9160 | 0.9133 | 0.9146 | |
| 200 | CNN | 3 | 32 | 0.9146 | 0.9117 | 0.9205 | 0.9161 |
| CNN-GRU | 4 | 64 | 0.9119 | 0.9177 | 0.9073 | 0.9125 | |
| CNN-GRU | 5 | 64 | 0.9146 | 0.9098 | 0.9228 | 0.9163 | |
| 250 | CNN-BiGRU | 3 | 64 | 0.9128 | 0.9134 | 0.9145 | 0.9139 |
| CNN | 4 | 32 | 0.9125 | 0.9046 | 0.9246 | 0.9145 | |
| CNN | 5 | 64 | 0.9128 | 0.9042 | 0.9258 | 0.9149 | |
| 300 | CNN-BiLSTM | 3 | 32 | 0.9101 | 0.9104 | 0.9121 | 0.9113 |
| CNN | 4 | 32 | 0.9116 | 0.9197 | 0.9043 | 0.9119 | |
| CNN | 5 | 32 | 0.9128 | 0.9184 | 0.9085 | 0.9134 | |
| DL Models | Layers | Units | Matrix | |||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |||
| CNN | 3 | 16 | 0.8871 | 0.8648 | 0.9077 | 0.8857 |
| 4 | 32 | 0.8883 | 0.8815 | 0.8960 | 0.8887 | |
| 5 | 128 | 0.8880 | 0.8923 | 0.8870 | 0.8896 | |
| LSTM | 3 | 32 | 0.8886 | 0.8839 | 0.8946 | 0.8892 |
| 4 | 64 | 0.8831 | 0.9126 | 0.8640 | 0.8877 | |
| 5 | 128 | 0.9091 | 0.8983 | 0.9254 | 0.9116 | |
| Bi-LSTM | 3 | 16 | 0.8874 | 0.9019 | 0.8787 | 0.8901 |
| 4 | 64 | 0.8804 | 0.8839 | 0.8802 | 0.8821 | |
| 5 | 16 | 0.8843 | 0.8977 | 0.8767 | 0.8870 | |
| GRU | 3 | 8 | 0.8856 | 0.8857 | 0.8878 | 0.8868 |
| 4 | 8 | 0.8816 | 0.9001 | 0.8704 | 0.8850 | |
| 5 | 16 | 0.8868 | 0.8869 | 0.8890 | 0.8880 | |
| Bi-GRU | 3 | 16 | 0.8847 | 0.8983 | 0.8768 | 0.8874 |
| 4 | 32 | 0.8780 | 0.8863 | 0.8743 | 0.8802 | |
| 5 | 8 | 0.8880 | 0.8659 | 0.9083 | 0.8866 | |
| CNN-LSTM | 3 | 16 | 0.7172 | 0.8013 | 0.6899 | 0.7414 |
| 4 | 128 | 0.7374 | 0.7971 | 0.7141 | 0.7533 | |
| 5 | 128 | 0.7581 | 0.8306 | 0.7290 | 0.7765 | |
| CNN-BiLSTM | 3 | 64 | 0.7299 | 0.8019 | 0.7049 | 0.7503 |
| 4 | 16 | 0.8485 | 0.7606 | 0.6961 | 0.7269 | |
| 5 | 32 | 0.7944 | 0.8612 | 0.7630 | 0.8091 | |
| CNN-GRU | 3 | 64 | 0.6897 | 0.7606 | 0.6704 | 0.7126 |
| 4 | 64 | 0.7992 | 0.9081 | 0.7230 | 0.8050 | |
| 5 | 128 | 0.7520 | 0.7923 | 0.7372 | 0.7638 | |
| CNN-BiGRU | 3 | 8 | 0.7060 | 0.7151 | 0.7071 | 0.7111 |
| 4 | 128 | 0.7605 | 0.8013 | 0.7447 | 0.7720 | |
| 5 | 64 | 0.7793 | 0.8671 | 0.7408 | 0.7990 | |
| ML Models | Matrix | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |
| CNN + FastText | 0.9028 | 0.9132 | 0.8954 | 0.9042 |
| LSTM + FastText | 0.8925 | 0.8631 | 0.9391 | 0.8995 |
| CNN-LSTM + FastText | 0.9037 | 0.9013 | 0.9119 | 0.9066 |
| CNN + Word2Vec (skip-gram) | 0.9170 | 0.9294 | 0.9094 | 0.9170 |
| CNN + Word2Vec (CBOW) | 0.9146 | 0.9167 | 0.9145 | 0.9156 |
| WangchanBERTa | 0.9225 | 0.9204 | 0.9291 | 0.9247 |
| XML-RoBERTa | 0.9195 | 0.9201 | 0.9195 | 0.9194 |
| M-BERT | 0.7545 | 0.6914 | 0.6914 | 0.7969 |
| ML Models | Matrix | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |
| SGD | 0.8962 | 0.8951 | 0.8983 | 0.8967 |
| LR | 0.8965 | 0.8900 | 0.9030 | 0.8964 |
| BNB | 0.8789 | 0.8704 | 0.8869 | 0.8786 |
| SVM | 0.8966 | 0.8921 | 0.9015 | 0.8968 |
| RR | 0.8924 | 0.8821 | 0.9019 | 0.8919 |
| Models | Z-Test | |||
|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | |
| CNN + FastText–WangchanBERTa | −2.836 | −1.059 | −4.843 | −2.979 |
| LSTM + FastText–WangchanBERTa | −4.208 | −7.495 | 1.639 | −3.616 |
| CNN-LSTM + FastText–WangchanBERTa | −2.712 | −2.724 | −2.584 | −2.645 |
| CNN + Word2Vec (skip-gram)–WangchanBERTa | −0.823 | 1.388 | −2.940 | −1.159 |
| CNN + Word2Vec (CBOW)–WangchanBERTa | −1.174 | −0.550 | −2.211 | −1.364 |
| XML-RoBERTa–WangchanBERTa | −0.452 | −0.045 | −1.475 | −0.803 |
| M-BERT–WangchanBERTa | −18.552 | −23.532 | −24.640 | −15.001 |
| SVM–WangchanBERTa | −4.001 | −4.593 | −3.347 | −3.976 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khamphakdee, N.; Seresangtakul, P. An Efficient Deep Learning for Thai Sentiment Analysis. Data 2023, 8, 90. https://doi.org/10.3390/data8050090
Khamphakdee N, Seresangtakul P. An Efficient Deep Learning for Thai Sentiment Analysis. Data. 2023; 8(5):90. https://doi.org/10.3390/data8050090
Chicago/Turabian StyleKhamphakdee, Nattawat, and Pusadee Seresangtakul. 2023. "An Efficient Deep Learning for Thai Sentiment Analysis" Data 8, no. 5: 90. https://doi.org/10.3390/data8050090
APA StyleKhamphakdee, N., & Seresangtakul, P. (2023). An Efficient Deep Learning for Thai Sentiment Analysis. Data, 8(5), 90. https://doi.org/10.3390/data8050090