
MN-DS: A Multilabeled News Dataset for News Articles Hierarchical Classification



Abstract
:1. Background and Summary
- Predicting future events based on past news articles.
- Understanding the news cycle.
- Determining the sentiment of news articles.
- Extracting information from news articles (e.g., named entities, location, dates).
- Classifying news articles into predefined categories.
2. Methods
- Obtain a random article from the NELA dataset;
- Classify it for the second-level category of the NewsCodes Media Topic taxonomy by checking the keywords and thorough reading of the article; the news article is assigned to exactly one category;
- If there are already 100 articles in that category discard it, otherwise assign a second-level category to the article;
- Return to step 1 and repeat until each second-level category has 100 articles assigned.
3. Data Records
Description of Columns in the Data Table
- id: Unique identifier of the article.
- date: Date of the article release.
- source: Publisher information of the article.
- title: Title of the news article.
- content: Text of the news article.
- author: Author of the news article.
- url: Link to the original article.
- published: Date of article publication in local time.
- published_utc: Date of article publication in utc time.
- collection_utc: Date of article scraping in utc time.
- category_level_1: First level category of Media Topic NewsCodes’s taxonomy.
- category_level_2: Second level category of Media Topic NewsCodes’s taxonomy.
4. Usage Example
- Tf-idf embedding, where Tf-idf stands for term frequency-inverse document frequency [15]. Tf-idf transforms text into a numerical representation called a tf-idf matrix. The term frequency is the number of times a word appears in a document. The inverse document frequency measures how common a word is across all documents. Tf-idf is used to weigh words so that important words are given more weight. The dataset’s news texts and categories were combined and vectorized with TfidfVectorizer [16].
- GloVe (Global Vectors for Word Representation) embeddings with an algorithm based on a co-occurrence matrix, which counts how often words appear together in a text corpus. The resulting vectors are then transformed into a lower-dimensional space using singular value decomposition [17].
- DistilBertTokenizer [18], which is a distilled version of BERT, a popular pre-trained model for natural language processing. DistilBERT is smaller and faster than BERT, making it more suitable for fast training with limited resources. The trade-off is that DistilBERT’s performance is 3% lower than BERT’s. DistilBERT embeddings are trained on the same data as BERT, so they are equally good at capturing the meaning of words in context.
- The multinomial NB is a text classification algorithm that uses Bayesian inference to classify text. It is a simple and effective technique that can be used for various tasks, such as spam filtering and document classification. The algorithm is based on the assumption that the features in a document are independent of each other, which allows it to make predictions about the category of a document based on its individual features.
- The logistic regression classifier works by using a sigmoid function to map data points from an input space to an output space, where the categories are assigned based on a linear combination of the features. The weights of the features are learned through training, and the predictions are made by taking the dot product of the feature vector and the weight vector.
- The SVC classifier is a powerful machine learning model based on the support vector machines algorithm. The model is based on finding the optimal decision boundary between categories to maximize the margin of separation between them. The SVC model can be used for linear and non-linear classification tasks and is particularly well-suited for problems with high dimensional data. The classifier is also robust to overfitting and can generalize well to new data.
- DistilBERTModel, a light version of the BERT classifier [18], developed and open-sourced by the team at Hugging Face. DistilBERTModel can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of NLP tasks with minimal training data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Paullada, A.; Raji, I.D.; Bender, E.M.; Denton, E.; Hanna, A. Data and its (dis)contents: A survey of dataset development and use in machine learning research. Patterns 2021, 2, 100336. [Google Scholar] [CrossRef] [PubMed]
- Jayakody, N.; Mohammad, A.; Halgamuge, M. Fake News Detection using a Decentralized Deep Learning Model and Federated Learning. In Proceedings of the IECON 2022—48th Annual Conference of the IEEE Industrial Electronics Society, Brussels, Belgium, 17–20 October 2022. [Google Scholar]
- Stefansson, J.K. Quantitative Measure of Evaluative Labeling in News Reports: Psychology of Communication Bias Studied by Content Analysis and Semantic Differential. Master’s Thesis, UiT, Norway’s Arctic University, Tromsø, Norway, 2014. [Google Scholar]
- Gezici, G. Quantifying Political Bias in News Articles. arXiv 2022, arXiv:2210.03404. [Google Scholar]
- Mitchell, T. 20 Newsgroups Data Set. 1999. Available online: http://qwone.com/~jason/20Newsgroups/ (accessed on 10 April 2023).
- AG’s Corpus of News Articles. 2005. Available online: http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html (accessed on 10 April 2023).
- Soni, A.; Mehdad, Y. RIPML: A Restricted Isometry Property-Based Approach to Multilabel Learning. In Proceedings of the Thirtieth International Florida Artificial Intelligence Research Society Conference, FLAIRS 2017, Marco Island, FL, USA, 22–24 May 2017; Rus, V., Markov, Z., Eds.; AAAI Press: Palo Alto, CA, USA, 2017; pp. 532–537. [Google Scholar]
- Chen, S.; Soni, A.; Pappu, A.; Mehdad, Y. DocTag2Vec: An Embedding Based Multi-label Learning Approach for Document Tagging. In Proceedings of the Rep4NLP@ACL, Vancouver, BC, Canada, 3 August 2017. [Google Scholar]
- Misra, R. News Category Dataset. arXiv 2022, arXiv:2209.11429. [Google Scholar]
- Roberts, H.; Bhargava, R.; Valiukas, L.; Jen, D.; Malik, M.; Bishop, C.; Ndulue, E.; Dave, A.; Clark, J.; Etling, B.; et al. Media Cloud: Massive Open Source Collection of Global News on the Open Web. arXiv 2021, arXiv:v15i1.18127. [Google Scholar]
- Gruppi, M.; Horne, B.D.; Adalı, S. NELA-GT-2019: A Large Multi-Labelled News Dataset for The Study of Misinformation in News Articles. arXiv 2020, arXiv:2003.08444. [Google Scholar]
- IPTC NewsCodes Scheme (Controlled Vocabulary). 2010. Available online: https://cv.iptc.org/newscodes/mediatopic/ (accessed on 10 April 2023).
- IPTC Media Topics—Vocabulary Published on 25 February 2020. 2020. Available online: https://www.iptc.org/std/NewsCodes/previous-versions/IPTC-MediaTopic-NewsCodes_2020-02-25.xlsx (accessed on 10 April 2023).
- NewsCodes—Controlled Vocabularies for the Media. Available online: https://iptc.org/standards/newscodes/#:~:text=Who%20uses%20IPTC%20NewsCodes%3F,becoming%20more%20and%20more%20popular (accessed on 21 November 2022).
- Sammut, C.; Webb, G.I. (Eds.) TF–IDF. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; pp. 986–987. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, MA, USA, 2008; pp. 234–265. [Google Scholar]
- Cox, D.R. The regression analysis of binary sequences. J. R. Stat. Soc. Ser. B (Methodol.) 1958, 20, 215–242. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Silla, C.; Freitas, A. A survey of hierarchical classification across different application domains. Data Min. Knowl. Discov. 2011, 22, 31–72. [Google Scholar] [CrossRef]
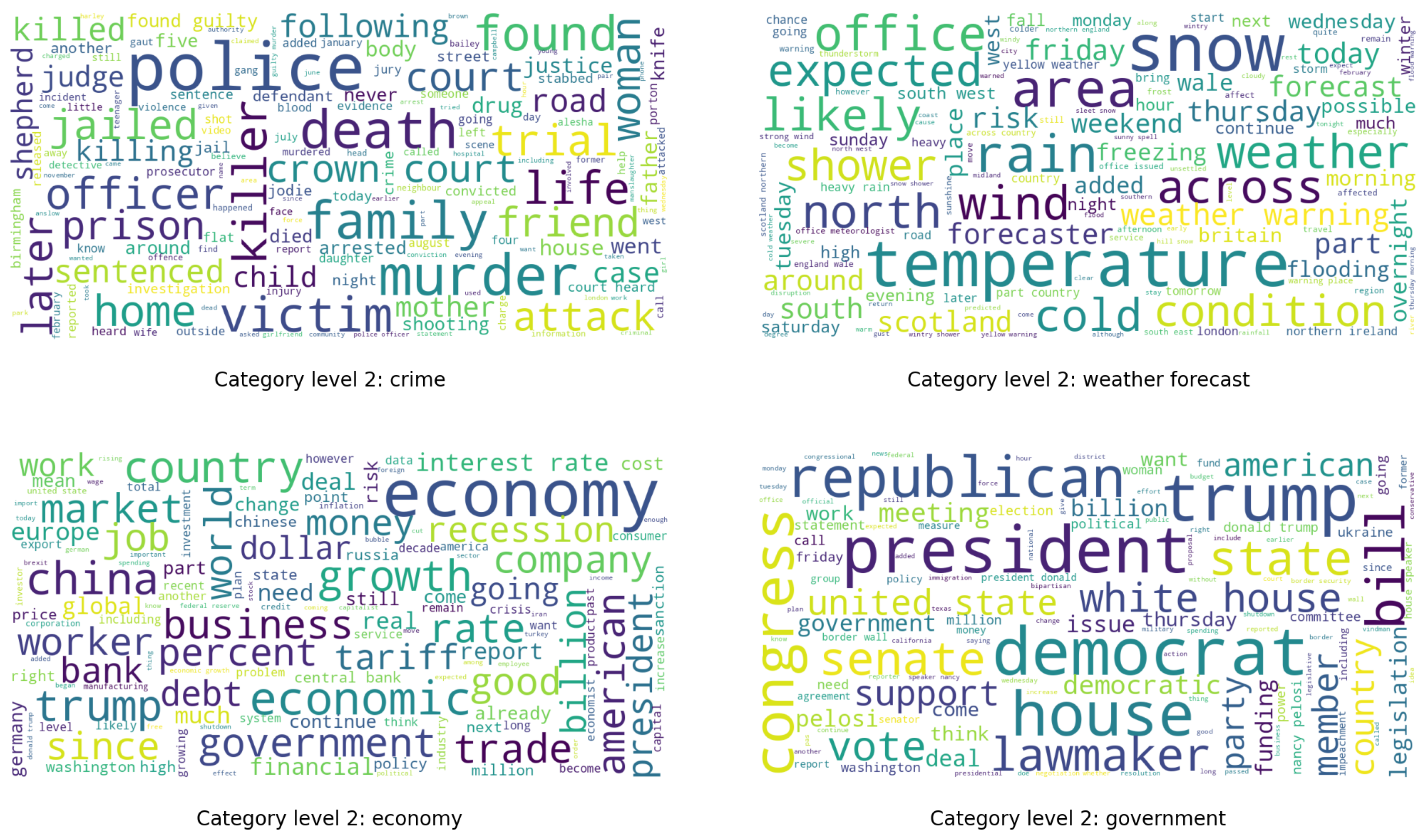

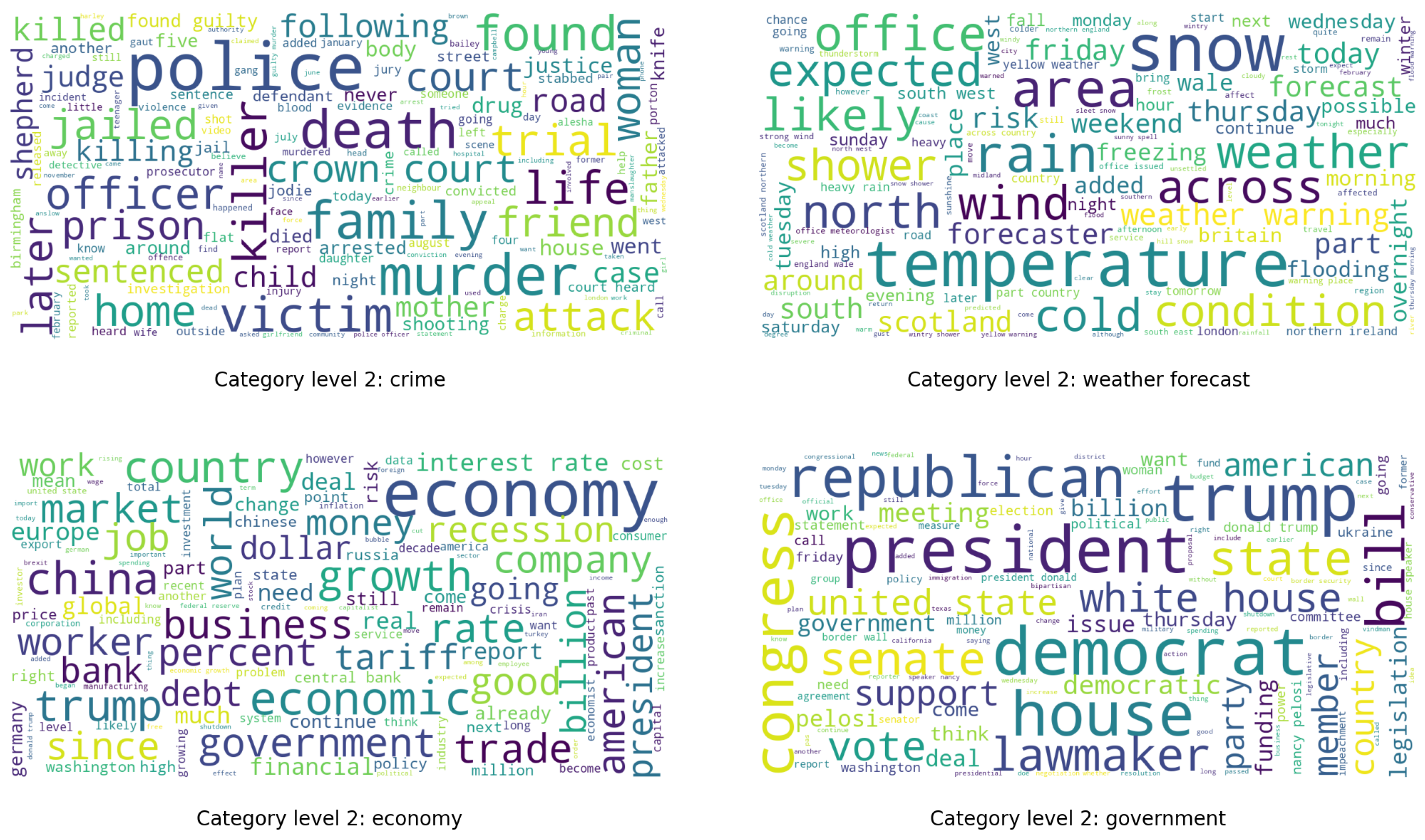{kind=link}
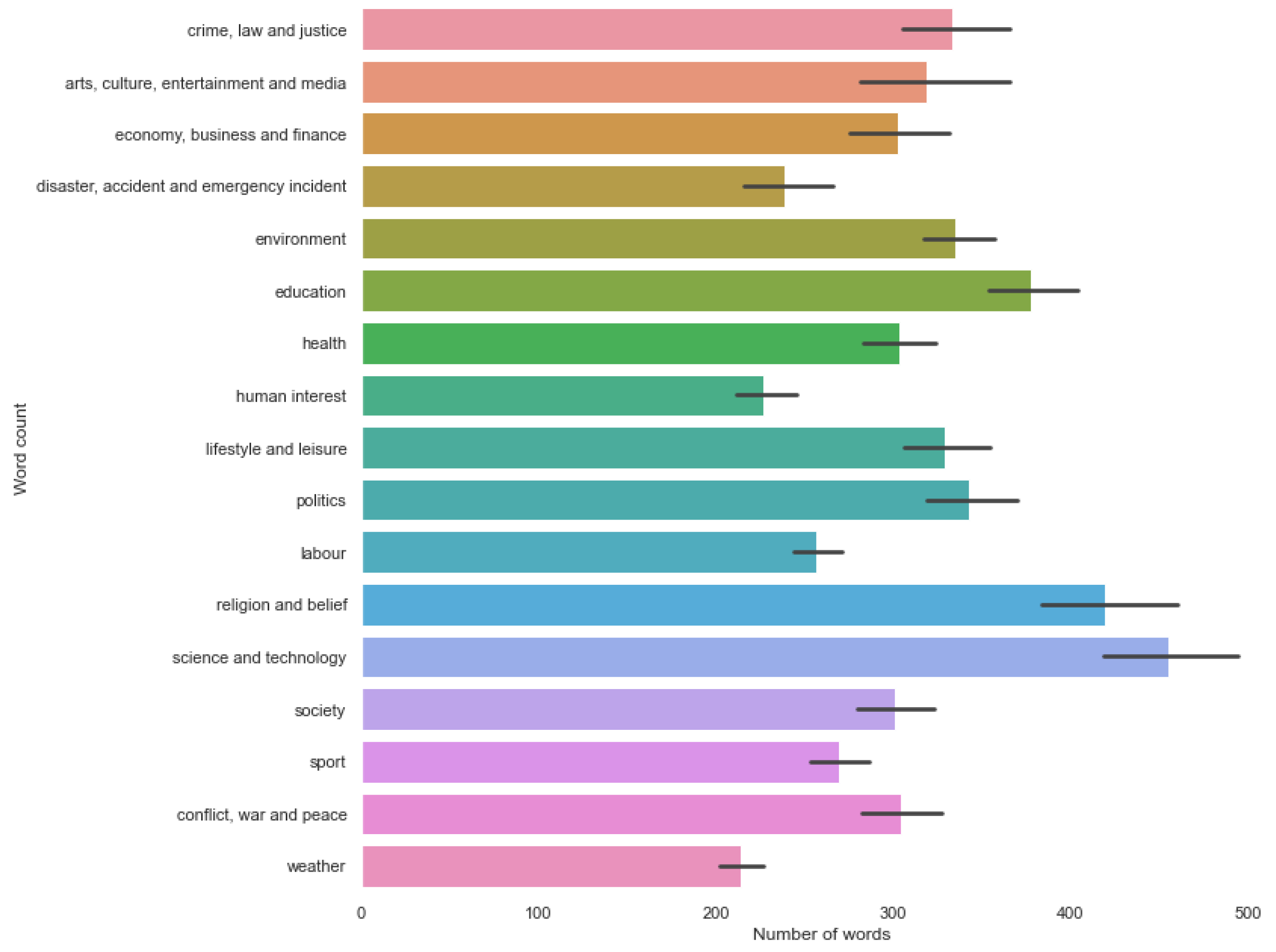
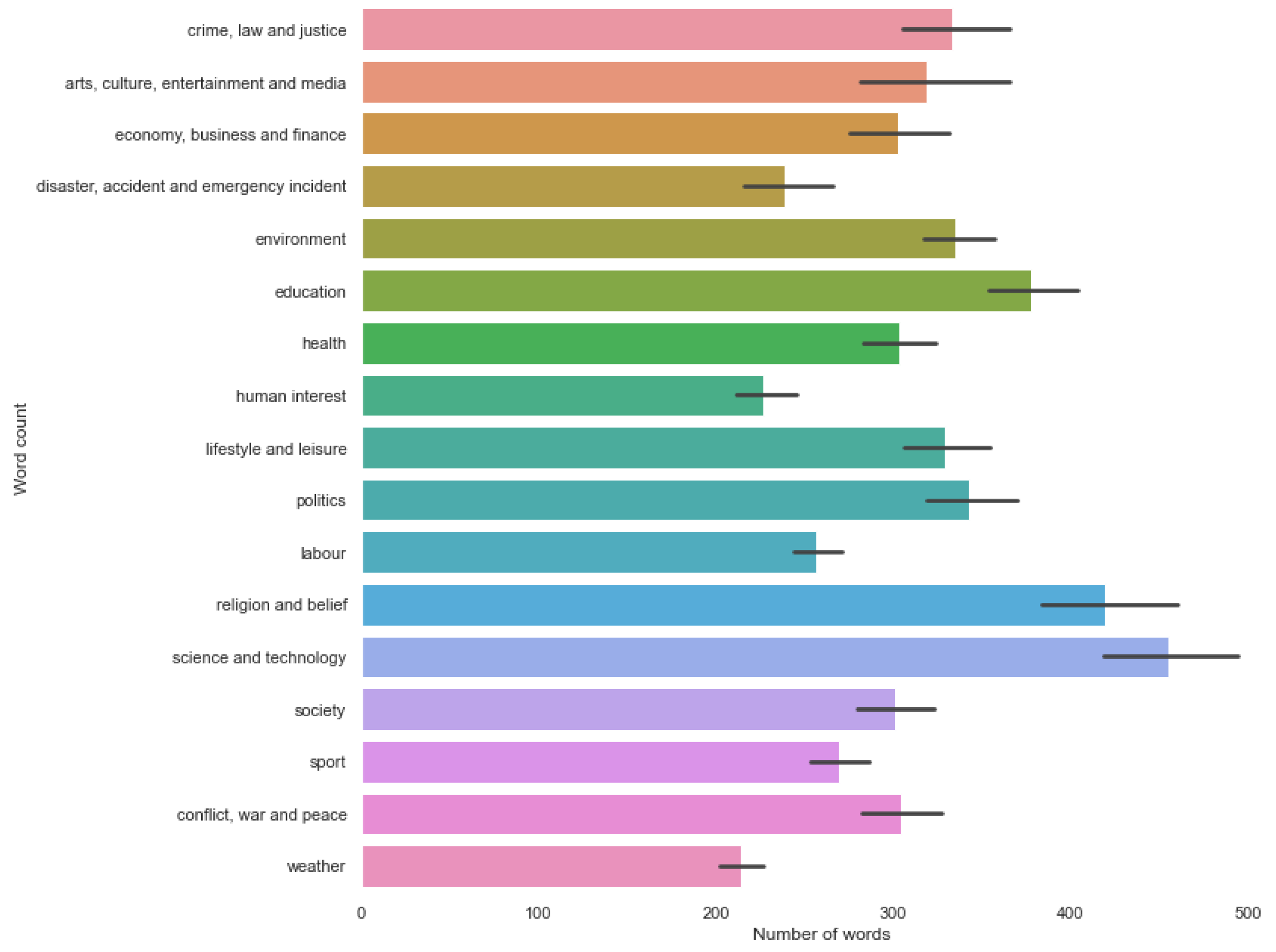{kind=link}
| Categories | Count |
|---|---|
| Arts, culture, entertainment, and media | 300 |
| Conflict, war, and peace | 800 |
| Crime, law, and justice | 500 |
| Disaster, accidents, and emergency incidents | 500 |
| Economy, business and finance | 400 |
| Education | 607 |
| Environment | 600 |
| Health | 700 |
| Human interest | 600 |
| Labor | 703 |
| Lifestyle and leisure | 300 |
| Politics | 900 |
| Religion and belief | 800 |
| Science and technology | 800 |
| Society | 1100 |
| Sport | 907 |
| Weather | 400 |
| Embeddings | TFIDF | Glove | DistilBertTokenizer | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Precision | Recall | f1 Score | Precision | Recall | f1 Score | Precision | Recall | f1 Score |
| Multinomial NB | 0.802 | 0.631 | 0.649 | 0.629 | 0.499 | 0.529 | n/a | n/a | n/a |
| Logistic Regression | 0.800 | 0.763 | 0.774 | 0.747 | 0.739 | 0.739 | n/a | n/a | n/a |
| SVC Classifier | 0.808 | 0.796 | 0.799 | 0.768 | 0.762 | 0.760 | n/a | n/a | n/a |
| DistilBERTModel | n/a | n/a | n/a | n/a | n/a | n/a | 0.849 | 0.842 | 0.844 |
| Embeddings | TFIDF | Glove | DistilBertTokenizer | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Precision | Recall | f1 Score | Precision | Recall | f1 Score | Precision | Recall | f1 Score |
| Multinomial NB | 0.628 | 0.602 | 0.583 | 0.496 | 0.484 | 0.469 | n/a | n/a | n/a |
| Logistic Regression | 0.646 | 0.649 | 0.635 | 0.589 | 0.589 | 0.577 | n/a | n/a | n/a |
| SVC Classifier | 0.645 | 0.646 | 0.628 | 0.581 | 0.595 | 0.571 | n/a | n/a | n/a |
| DistilBERTModel | n/a | n/a | n/a | n/a | n/a | n/a | 0.735 | 0.715 | 0.715 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petukhova, A.; Fachada, N. MN-DS: A Multilabeled News Dataset for News Articles Hierarchical Classification. Data 2023, 8, 74. https://doi.org/10.3390/data8050074
Petukhova A, Fachada N. MN-DS: A Multilabeled News Dataset for News Articles Hierarchical Classification. Data. 2023; 8(5):74. https://doi.org/10.3390/data8050074
Chicago/Turabian StylePetukhova, Alina, and Nuno Fachada. 2023. "MN-DS: A Multilabeled News Dataset for News Articles Hierarchical Classification" Data 8, no. 5: 74. https://doi.org/10.3390/data8050074
APA StylePetukhova, A., & Fachada, N. (2023). MN-DS: A Multilabeled News Dataset for News Articles Hierarchical Classification. Data, 8(5), 74. https://doi.org/10.3390/data8050074