
The Role of Human Knowledge in Explainable AI



Abstract
:1. Introduction
2. Explainability and Explainable AI
2.1. Definitions
“Given an audience, an explainable Artificial Intelligence is one that produces details or reasons to make its functioning clear or easy to understand.”
2.2. An Overview of the State of the Art
3. Research Methodology
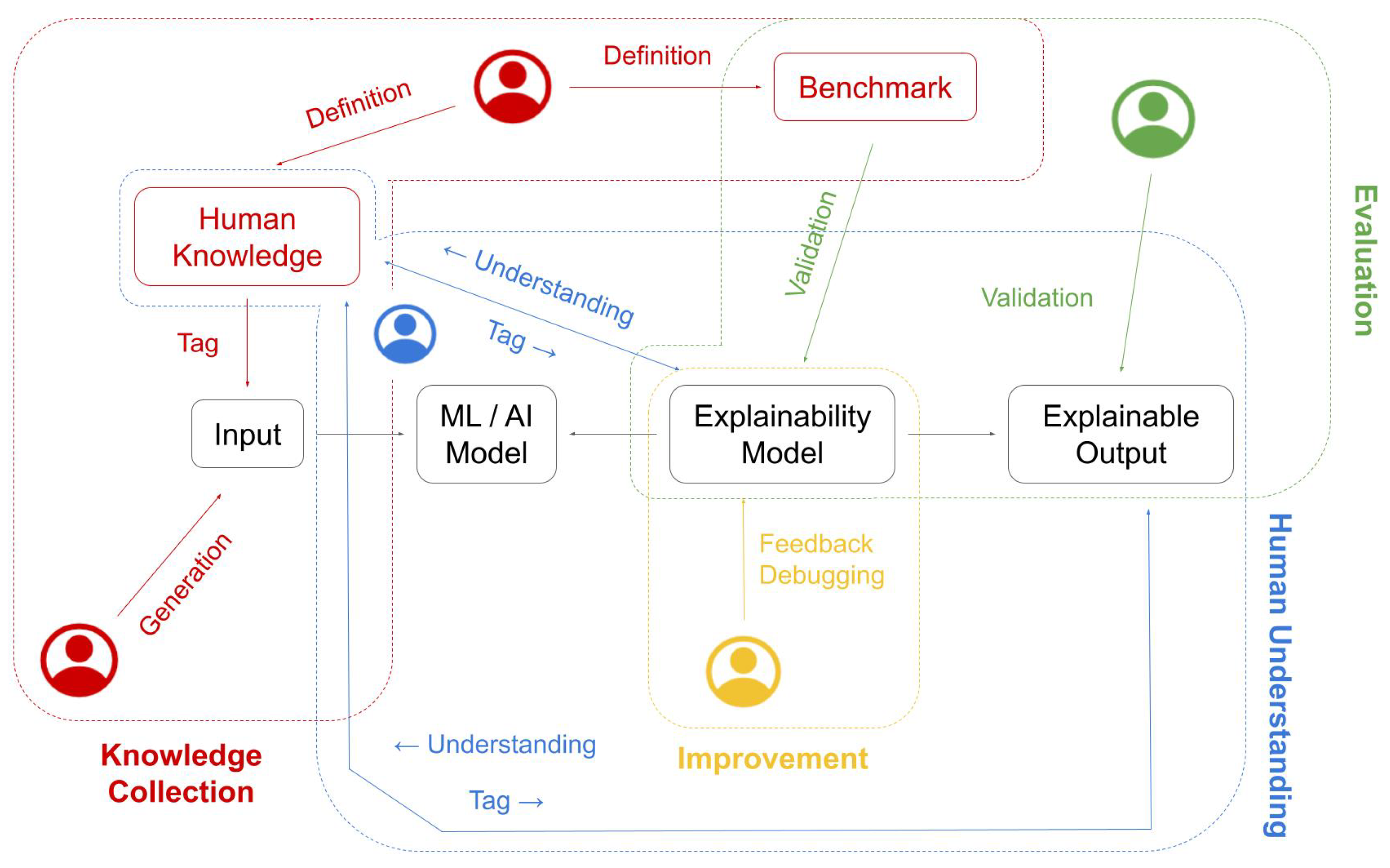
4. Human Knowledge and Explainability
4.1. Explainability and Human Knowledge Collection
4.2. Evaluation of Explainability Methods by Means of Human Knowledge
4.3. Understanding the Human’s Perspective in Explainable AI
4.4. Human Knowledge as a Mean to Improve Explanations
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- Years: 2017–2022;
- Title words: NOT Survey NOT Review NOT Systematic;
- Keywords: “Explainability-related Keyword”, “Knowledge-related Keyword”.
References
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Explainable Artificial Intelligence: A Systematic Review. arXiv 2020, arXiv:2006.00093. [Google Scholar]
- Chou, Y.; Moreira, C.; Bruza, P.; Ouyang, C.; Jorge, J.A. Counterfactuals and Causability in Explainable Artificial Intelligence: Theory, Algorithms, and Applications. Inf. Fusion 2022, 81, 59–83. [Google Scholar] [CrossRef]
- Holm, E.A. In defense of the black box. Science 2019, 364, 26–27. [Google Scholar] [CrossRef]
- Poursabzi-Sangdeh, F.; Goldstein, D.G.; Hofman, J.M.; Vaughan, J.W.; Wallach, H.M. Manipulating and Measuring Model Interpretability. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar]
- Feng, S.; Boyd-Graber, J.L. What can AI do for me: Evaluating Machine Learning Interpretations in Cooperative Play. In Proceedings of the 24th International Conference on Intelligent User Interfaces, Marina del Ray, CA, USA, 17–20 March 2019. [Google Scholar]
- Hahn, T.; Ebner-Priemer, U.; Meyer-Lindenberg, A. Transparent Artificial Intelligence—A Conceptual Framework for Evaluating AI-based Clinical Decision Support Systems. OSF Preprints 2019. [Google Scholar] [CrossRef]
- O’Neil, C. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy; Crown Publishing Group: New York, NY, USA, 2016. [Google Scholar]
- Guidotti, R.; Monreale, A.; Turini, F.; Pedreschi, D.; Giannotti, F. A Survey Of Methods For Explaining Black Box Models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Narang, S.; Raffel, C.; Lee, K.; Roberts, A.; Fiedel, N.; Malkan, K. WT5?! Training Text-to-Text Models to Explain their Predictions. arXiv 2020, arXiv:2004.14546. [Google Scholar]
- Narayanan, M.; Chen, E.; He, J.; Kim, B.; Gershman, S.; Doshi-Velez, F. How do Humans Understand Explanations from Machine Learning Systems? An Evaluation of the Human-Interpretability of Explanation. arXiv 2018, arXiv:1802.00682. [Google Scholar]
- Xu, F.; Li, J.J.; Choi, E. How Do We Answer Complex Questions: Discourse Structure of Long-form Answers. arXiv 2022, arXiv:2203.11048. [Google Scholar] [CrossRef]
- Schuff, H.; Yang, H.; Adel, H.; Vu, N.T. Does External Knowledge Help Explainable Natural Language Inference? Automatic Evaluation vs. Human Ratings. arXiv 2021, arXiv:2109.07833. [Google Scholar]
- Jeyakumar, J.V.; Noor, J.; Cheng, Y.H.; Garcia, L.; Srivastava, M. How Can I Explain This to You? An Empirical Study of Deep Neural Network Explanation Methods. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 4211–4222. [Google Scholar]
- Sokol, K.; Flach, P.A. Explainability Is in the Mind of the Beholder: Establishing the Foundations of Explainable Artificial Intelligence. arXiv 2021, arXiv:2112.14466. [Google Scholar]
- Danilevsky, M.; Qian, K.; Aharonov, R.; Katsis, Y.; Kawas, B.; Sen, P. A Survey of the State of Explainable AI for Natural Language Processing. arXiv 2020, arXiv:2010.00711. [Google Scholar]
- Carvalho, D.; Pereira, E.; Cardoso, J. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar]
- Lundberg, S.M.; Lee, S. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. arXiv 2016, arXiv:1611.07450. [Google Scholar]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.B.; Wattenberg, M. SmoothGrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar]
- Omeiza, D.; Speakman, S.; Cintas, C.; Weldemariam, K. Smooth Grad-CAM++: An Enhanced Inference Level Visualization Technique for Deep Convolutional Neural Network Models. arXiv 2019, arXiv:1908.01224. [Google Scholar]
- Ghaeini, R.; Fern, X.; Tadepalli, P. Interpreting Recurrent and Attention-Based Neural Models: A Case Study on Natural Language Inference. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4952–4957. [Google Scholar] [CrossRef]
- Dunn, A.; Inkpen, D.; Andonie, R. Context-Sensitive Visualization of Deep Learning Natural Language Processing Models. In Proceedings of the 2021 25th International Conference Information Visualisation (IV), Sydney, Australia, 5–9 July 2021. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). arXiv 2017, arXiv:1711.11279. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Syst. Rev. 2021, 10, 89. [Google Scholar] [CrossRef] [PubMed]
- Abhigna, B.S.; Soni, N.; Dixit, S. Crowdsourcing—A Step Towards Advanced Machine Learning. Procedia Comput. Sci. 2018, 132, 632–642. [Google Scholar] [CrossRef]
- Steging, C.; Renooij, S.; Verheij, B. Discovering the Rationale of Decisions: Experiments on Aligning Learning and Reasoning. arXiv 2021, arXiv:2105.06758. [Google Scholar]
- Strout, J.; Zhang, Y.; Mooney, R.J. Do Human Rationales Improve Machine Explanations? arXiv 2019, arXiv:1905.13714. [Google Scholar]
- Gomez, O.; Holter, S.; Yuan, J.; Bertini, E. ViCE: Visual Counterfactual Explanations for Machine Learning Models. In Proceedings of the 25th International Conference on Intelligent User Interfaces, Cagliari, Italy, 17–20 March 2020. [Google Scholar]
- Magister, L.C.; Kazhdan, D.; Singh, V.; Liò, P. GCExplainer: Human-in-the-Loop Concept-based Explanations for Graph Neural Networks. arXiv 2021, arXiv:2107.11889. [Google Scholar]
- Wang, J.; Zhao, C.; Xiang, J.; Uchino, K. Interactive Topic Model with Enhanced Interpretability. In Proceedings of the IUI Workshops, Los Angeles, CA, USA, 20 March 2019. [Google Scholar]
- Lage, I.; Ross, A.S.; Kim, B.; Gershman, S.J.; Doshi-Velez, F. Human-in-the-Loop Interpretability Prior. arXiv 2018, arXiv:1805.11571. [Google Scholar] [CrossRef]
- Celino, I. Who is this explanation for? Human intelligence and knowledge graphs for eXplainable AI. In Knowledge Graphs for eXplainable Artificial Intelligence: Foundations, Applications and Challenges; IOS Press: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Estivill-Castro, V.; Gilmore, E.; Hexel, R. Human-In-The-Loop Construction of Decision Tree Classifiers with Parallel Coordinates. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 3852–3859. [Google Scholar] [CrossRef]
- Estellés-Arolas, E.; de Guevara, F.G.L. Towards an integrated crowdsourcing definition. J. Inf. Sci. 2012, 38, 189–200. [Google Scholar] [CrossRef] [Green Version]
- Gadiraju, U.; Yang, J. What Can Crowd Computing Do for the Next Generation of AI Systems? In Proceedings of the CSW@NeurIPS, Online, 11 December 2020.
- Lage, I.; Chen, E.; He, J.; Narayanan, M.; Kim, B.; Gershman, S.J.; Doshi-Velez, F. Human Evaluation of Models Built for Interpretability. Proc. AAAI Conf. Hum. Comput. Crowdsourcing 2019, 7, 59–67. [Google Scholar]
- Lampathaki, F.; Agostinho, C.; Glikman, Y.; Sesana, M. Moving from ‘black box’ to ‘glass box’ Artificial Intelligence in Manufacturing with XMANAI. In Proceedings of the 2021 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Cardiff, UK, 21–23 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Hudec, M.; Mináriková, E.; Mesiar, R.; Saranti, A.; Holzinger, A. Classification by ordinal sums of conjunctive and disjunctive functions for explainable AI and interpretable machine learning solutions. Knowl.-Based Syst. 2021, 220, 106916. [Google Scholar] [CrossRef]
- Sharifi Noorian, S.; Qiu, S.; Gadiraju, U.; Yang, J.; Bozzon, A. What Should You Know? A Human-In-the-Loop Approach to Unknown Unknowns Characterization in Image Recognition. In Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 882–892. [Google Scholar] [CrossRef]
- Balayn, A.; Soilis, P.; Lofi, C.; Yang, J.; Bozzon, A. What Do You Mean? Interpreting Image Classification with Crowdsourced Concept Extraction and Analysis. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1937–1948. [Google Scholar] [CrossRef]
- Mishra, S.; Rzeszotarski, J.M. Crowdsourcing and Evaluating Concept-Driven Explanations of Machine Learning Models. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–26. [Google Scholar] [CrossRef]
- Mitsuhara, M.; Fukui, H.; Sakashita, Y.; Ogata, T.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Embedding Human Knowledge in Deep Neural Network via Attention Map. arXiv 2019, arXiv:1905.03540. [Google Scholar]
- Li, Z.; Sharma, P.; Lu, X.H.; Cheung, J.C.K.; Reddy, S. Using Interactive Feedback to Improve the Accuracy and Explainability of Question Answering Systems Post-Deployment. arXiv 2022, arXiv:2204.03025. [Google Scholar] [CrossRef]
- Uchida, H.; Matsubara, M.; Wakabayashi, K.; Morishima, A. Human-in-the-loop Approach towards Dual Process AI Decisions. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 3096–3098. [Google Scholar] [CrossRef]
- Balayn, A.; He, G.; Hu, A.; Yang, J.; Gadiraju, U. FindItOut: A Multiplayer GWAP for Collecting Plural Knowledge. In Proceedings of the Ninth AAAI Conference on Human Computation and Crowdsourcing, Online, 14–18 November 2021; p. 190. [Google Scholar]
- Balayn, A.; He, G.; Hu, A.; Yang, J.; Gadiraju, U. Ready Player One! Eliciting Diverse Knowledge Using A Configurable Game. In Proceedings of the ACM Web Conference Virtual Event, Lyon France, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1709–1719. [Google Scholar] [CrossRef]
- Tocchetti, A.; Corti, L.; Brambilla, M.; Celino, I. EXP-Crowd: A Gamified Crowdsourcing Framework for Explainability. Front. Artif. Intell. 2022, 5, 826499. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Xu, P.; Scheidegger, C.; Ren, L. Human-in-the-loop Extraction of Interpretable Concepts in Deep Learning Models. IEEE Trans. Vis. Comput. Graph. 2022, 28, 780–790. [Google Scholar] [CrossRef]
- Lage, I.; Doshi-Velez, F. Learning Interpretable Concept-Based Models with Human Feedback. arXiv 2020, arXiv:2012.02898. [Google Scholar]
- Zhang, Z.; Rudra, K.; Anand, A. FaxPlainAC: A Fact-Checking Tool Based on EXPLAINable Models with HumAn Correction in the Loop. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, Queensland, Australia, 1–5 November 2021. [Google Scholar]
- Sevastjanova, R.; Jentner, W.; Sperrle, F.; Kehlbeck, R.; Bernard, J.; El-assady, M. QuestionComb: A Gamification Approach for the Visual Explanation of Linguistic Phenomena through Interactive Labeling. ACM Trans. Interact. Intell. Syst. 2021, 11, 1–38. [Google Scholar] [CrossRef]
- Mohseni, S.; Block, J.E.; Ragan, E. Quantitative Evaluation of Machine Learning Explanations: A Human-Grounded Benchmark. In Proceedings of the 26th International Conference on Intelligent User Interfaces, College Station, TX, USA, 14–17 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 22–31. [Google Scholar] [CrossRef]
- DeYoung, J.; Jain, S.; Rajani, N.; Lehman, E.; Xiong, C.; Socher, R.; Wallace, B. ERASER: A Benchmark to Evaluate Rationalized NLP Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4443–4458. [Google Scholar] [CrossRef]
- Schuessler, M.; Weiß, P.; Sixt, L. Two4Two: Evaluating Interpretable Machine Learning—A Synthetic Dataset For Controlled Experiments. arXiv 2021, arXiv:2105.02825. [Google Scholar]
- Hase, P.; Bansal, M. Evaluating Explainable AI: Which Algorithmic Explanations Help Users Predict Model Behavior? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5540–5552. [Google Scholar] [CrossRef]
- Nguyen, D. Comparing Automatic and Human Evaluation of Local Explanations for Text Classification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 1069–1078. [Google Scholar] [CrossRef]
- Nauta, M.; Trienes, J.; Pathak, S.; Nguyen, E.; Peters, M.; Schmitt, Y.; Schlötterer, J.; van Keulen, M.; Seifert, C. From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI. arXiv 2022, arXiv:2201.08164. [Google Scholar]
- Lu, X.; Tolmachev, A.; Yamamoto, T.; Takeuchi, K.; Okajima, S.; Takebayashi, T.; Maruhashi, K.; Kashima, H. Crowdsourcing Evaluation of Saliency-based XAI Methods. In Proceedings of the ECML PKDD: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 13–17 September 2021. [Google Scholar]
- Fel, T.; Colin, J.; Cadène, R.; Serre, T. What I Cannot Predict, I Do Not Understand: A Human-Centered Evaluation Framework for Explainability Methods. arXiv 2021, arXiv:2112.04417. [Google Scholar]
- Schuff, H.; Adel, H.; Vu, N.T. F1 is Not Enough! Models and Evaluation Towards User-Centered Explainable Question Answering. arXiv 2020, arXiv:2010.06283. [Google Scholar]
- Friedler, S.A.; Roy, C.D.; Scheidegger, C.; Slack, D. Assessing the Local Interpretability of Machine Learning Models. arXiv 2019, arXiv:1902.03501. [Google Scholar]
- Yu, H.; Taube, H.; Evans, J.A.; Varshney, L.R. Human Evaluation of Interpretability: The Case of AI-Generated Music Knowledge. arXiv 2020, arXiv:2004.06894. [Google Scholar]
- Heimerl, A.; Weitz, K.; Baur, T.; Andre, E. Unraveling ML Models of Emotion with NOVA: Multi-Level Explainable AI for Non-Experts. IEEE Trans. Affect. Comput. 2020. early access. [Google Scholar] [CrossRef]
- Wang, Y.; Venkatesh, P.; Lim, B.Y. Interpretable Directed Diversity: Leveraging Model Explanations for Iterative Crowd Ideation. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022. [Google Scholar]
- Soltani, S.; Kaufman, R.; Pazzani, M. User-Centric Enhancements to Explainable AI Algorithms for Image Classification. In Proceedings of the Annual Meeting of the Cognitive Science Society, Toronto, ON, Canada, 27–30 July 2022; p. 44. [Google Scholar]
- Rebanal, J.C.; Tang, Y.; Combitsis, J.; Chang, K.; Chen, X.A. XAlgo: Explaining the Internal States of Algorithms via Question Answering. arXiv 2020, arXiv:2007.07407. [Google Scholar]
- Zhao, W.; Oyama, S.; Kurihara, M. Generating Natural Counterfactual Visual Explanations. In Proceedings of the IJCAI’20: Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Ray, A.; Burachas, G.; Yao, Y.; Divakaran, A. Lucid Explanations Help: Using a Human-AI Image-Guessing Game to Evaluate Machine Explanation Helpfulness. arXiv 2019, arXiv:1904.03285. [Google Scholar]
- Alvarez-Melis, D.; Kaur, H.; III, H.D.; Wallach, H.M.; Vaughan, J.W. A Human-Centered Interpretability Framework Based on Weight of Evidence. arXiv 2021, arXiv:2104.13299v2. [Google Scholar]
- Zeng, X.; Song, F.; Li, Z.; Chusap, K.; Liu, C. Human-in-the-Loop Model Explanation via Verbatim Boundary Identification in Generated Neighborhoods. In Proceedings of the Machine Learning and Knowledge Extraction, Virtual Event, 17–20 August 2021; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 309–327. [Google Scholar]
- Baur, T.; Heimerl, A.; Lingenfelser, F.; Wagner, J.; Valstar, M.; Schuller, B.; Andre, E. eXplainable Cooperative Machine Learning with NOVA. KI Künstliche Intell. 2020, 34, 143–164. [Google Scholar] [CrossRef] [Green Version]
- Zöller, M.A.; Titov, W.; Schlegel, T.; Huber, M.F. XAutoML: A Visual Analytics Tool for Establishing Trust in Automated Machine Learning. arXiv 2022, arXiv:2202.11954. [Google Scholar] [CrossRef]
- de Bie, K.; Lucic, A.; Haned, H. To Trust or Not to Trust a Regressor: Estimating and Explaining Trustworthiness of Regression Predictions. arXiv 2021, arXiv:2104.06982. [Google Scholar]
- Nourani, M.; Roy, C.; Rahman, T.; Ragan, E.D.; Ruozzi, N.; Gogate, V. Don’t Explain without Verifying Veracity: An Evaluation of Explainable AI with Video Activity Recognition. arXiv 2020, arXiv:2005.02335. [Google Scholar]
- Schmidt, P.; Biessmann, F. Calibrating Human-AI Collaboration: Impact of Risk, Ambiguity and Transparency on Algorithmic Bias. In Proceedings of the Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 431–449. [Google Scholar]
- Bauer, K.; von Zahn, M.; Hinz, O. Expl(Ai)Ned: The Impact of Explainable Artificial Intelligence on Cognitive Processes; Working Paper Series; Leibniz Institute for Financial Research SAFE: Frankfurt, Germany, 2021. [Google Scholar]
- Jin, W.; Fan, J.; Gromala, D.; Pasquier, P.; Hamarneh, G. EUCA: A Practical Prototyping Framework towards End-User-Centered Explainable Artificial Intelligence. arXiv 2021, arXiv:2102.02437. [Google Scholar]
- Chen, C.; Feng, S.; Sharma, A.; Tan, C. Machine Explanations and Human Understanding. arXiv 2022, arXiv:2202.04092. [Google Scholar] [CrossRef]
- Zhang, Z.; Singh, J.; Gadiraju, U.; Anand, A. Dissonance Between Human and Machine Understanding. Proc. ACM Hum.-Comput. Interact. 2019, 3, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Anand, A.; Bizer, K.; Erlei, A.; Gadiraju, U.; Heinze, C.; Meub, L.; Nejdl, W.; Steinroetter, B. Effects of Algorithmic Decision-Making and Interpretability on Human Behavior: Experiments using Crowdsourcing. In Proceedings of the 6th AAAI Conference on Human Computation and Crowdsourcing (HCOMP 2018), Zurich, Switzerland, 5–8 July 2018. [Google Scholar]
- Smith, A.; Nolan, J. The Problem of Explanations without User Feedback. CEUR Workshop Proc. 2018, 2068, 1–3. [Google Scholar]
- Fulton, L.B.; Lee, J.Y.; Wang, Q.; Yuan, Z.; Hammer, J.; Perer, A. Getting Playful with Explainable AI: Games with a Purpose to Improve Human Understanding of AI. In Proceedings of the CHI ’20: CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Ghai, B.; Liao, Q.V.; Zhang, Y.; Bellamy, R.K.E.; Mueller, K. Explainable Active Learning (XAL): An Empirical Study of How Local Explanations Impact Annotator Experience. arXiv 2020, arXiv:2001.09219. [Google Scholar]
- Linder, R.; Mohseni, S.; Yang, F.; Pentyala, S.K.; Ragan, E.D.; Hu, X.B. How level of explanation detail affects human performance in interpretable intelligent systems: A study on explainable fact checking. Appl. AI Lett. 2021, 2, e49. [Google Scholar] [CrossRef]
- Ehsan, U.; Riedl, M.O. Human-centered Explainable AI: Towards a Reflective Sociotechnical Approach. In Proceedings of the International Conference on Human-Computer Interaction, Copenhagen, Denmark, 19–24 July 2020. [Google Scholar]
- Kumar, A.; Vasileiou, S.L.; Bancilhon, M.; Ottley, A.; Yeoh, W. VizXP: A Visualization Framework for Conveying Explanations to Users in Model Reconciliation Problems. Proc. Int. Conf. Autom. Plan. Sched. 2022, 32, 701–709. [Google Scholar]
- Ribera Turró, M.; Lapedriza, A. Can we do better explanations? A proposal of User-Centered Explainable AI. In Proceedings of the ACM IUI 2019 Workshops, Los Angeles, CA, USA, 20 March 2019. [Google Scholar]
- Cabour, G.; Morales, A.; Ledoux, E.; Bassetto, S. Towards an Explanation Space to Align Humans and Explainable-AI Teamwork. arXiv 2021, arXiv:2106.01503. [Google Scholar] [CrossRef]
- Hohman, F.; Head, A.; Caruana, R.; DeLine, R.; Drucker, S.M. Gamut: A Design Probe to Understand How Data Scientists Understand Machine Learning Models. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–13. [Google Scholar] [CrossRef]
- Nourani, M.; King, J.T.; Ragan, E.D. The Role of Domain Expertise in User Trust and the Impact of First Impressions with Intelligent Systems. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Online, 26–28 October 2020. [Google Scholar]
- Chu, E.; Roy, D.; Andreas, J. Are Visual Explanations Useful? A Case Study in Model-in-the-Loop Prediction. arXiv 2020, arXiv:2007.12248. [Google Scholar]
- Wang, D.; Zhang, W.; Lim, B.Y. Show or Suppress? Managing Input Uncertainty in Machine Learning Model Explanations. arXiv 2021, arXiv:2101.09498. [Google Scholar] [CrossRef]
- Shen, H.; Huang, T.H. How Useful Are the Machine-Generated Interpretations to General Users? A Human Evaluation on Guessing the Incorrectly Predicted Labels. Proc. AAAI Conf. Hum. Comput. Crowdsourcing 2020, 8, 168–172. [Google Scholar]
- Dinu, J.; Bigham, J.P.; Kolter, J.Z. Challenging common interpretability assumptions in feature attribution explanations. arXiv 2020, arXiv:2005.02748. [Google Scholar]
- Yang, F.; Huang, Z.; Scholtz, J.; Arendt, D.L. How Do Visual Explanations Foster End Users’ Appropriate Trust in Machine Learning? In Proceedings of the 25th International Conference on Intelligent User Interfaces, Cagliari, Italy, 17–20 March 2020. [CrossRef] [Green Version]
- Ferguson, W.; Batra, D.; Mooney, R.; Parikh, D.; Torralba, A.; Bau, D.; Diller, D.; Fasching, J.; Fiotto-Kaufman, J.; Goyal, Y.; et al. Reframing explanation as an interactive medium: The EQUAS (Explainable QUestion Answering System) project. Appl. AI Lett. 2021, 2, e60. [Google Scholar] [CrossRef]
- Coma-Puig, B.; Carmona, J. An Iterative Approach based on Explainability to Improve the Learning of Fraud Detection Models. CoRR 2020, abs/2009.13437. Available online: https://scholar.google.com.sg/scholar?hl=en&as_sdt=0%2C5&q=An+Iterative+Approach+based+on+Explainability+to+Improve+the+Learning+++of+Fraud+Detection+Models&btnG= (accessed on 20 May 2022).
- Kouvela, M.; Dimitriadis, I.; Vakali, A. Bot-Detective: An Explainable Twitter Bot Detection Service with Crowdsourcing Functionalities. In Proceedings of the 12th International Conference on Management of Digital EcoSystems, Online, 2–4 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 55–63. [Google Scholar] [CrossRef]
- Collaris, D.; van Wijk, J. ExplainExplore: Visual Exploration of Machine Learning Explanations. In Proceedings of the 2020 IEEE Pacific Visualization Symposium (PacificVis), Tianjin, China, 3–5 June 2020; pp. 26–35. [Google Scholar] [CrossRef]
- Yang, Y.; Kandogan, E.; Li, Y.; Sen, P.; Lasecki, W.S. A Study on Interaction in Human-in-the-Loop Machine Learning for Text Analytics. In Proceedings of the IUI Workshops, Los Angeles, CA, USA, 20 March 2019. [Google Scholar]
- Arous, I.; Dolamic, L.; Yang, J.; Bhardwaj, A.; Cuccu, G.; Cudré-Mauroux, P. MARTA: Leveraging Human Rationales for Explainable Text Classification. Proc. AAAI Conf. Artif. Intell. 2021, 35, 5868–5876. [Google Scholar]
- Confalonieri, R.; Weyde, T.; Besold, T.R.; Moscoso del Prado Martín, F. Using ontologies to enhance human understandability of global post-hoc explanations of black-box models. Artif. Intell. 2021, 296, 103471. [Google Scholar] [CrossRef]
- El-Assady, M.; Sperrle, F.; Deussen, O.; Keim, D.; Collins, C. Visual Analytics for Topic Model Optimization based on User-Steerable Speculative Execution. IEEE Trans. Vis. Comput. Graph. 2019, 25, 374–384. [Google Scholar] [CrossRef] [Green Version]
- Correia, A.H.C.; Lecue, F. Human-in-the-Loop Feature Selection. Proc. AAAI Conf. Artif. Intell. 2019, 33, 2438–2445. [Google Scholar] [CrossRef]
- Spinner, T.; Schlegel, U.; Schäfer, H.; El-Assady, M. explAIner: A Visual Analytics Framework for Interactive and Explainable Machine Learning. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1064–1074. [Google Scholar] [CrossRef] [Green Version]
- Hadash, S.; Willemsen, M.; Snijders, C.; IJsselsteijn, W. Improving understandability of feature contributions in model-agnostic explainable AI tools. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022. [Google Scholar] [CrossRef]
- Lertvittayakumjorn, P.; Specia, L.; Toni, F. FIND: Human-in-the-Loop Debugging Deep Text Classifiers. arXiv 2020, arXiv:2010.04987. [Google Scholar]
- Hohman, F.; Srinivasan, A.; Drucker, S.M. TeleGam: Combining Visualization and Verbalization for Interpretable Machine Learning. In Proceedings of the IEEE Visualization Conference (VIS), Vancouver, BC, Canada, 20–25 October 2019. [Google Scholar]
- Guo, L.; Daly, E.M.; Alkan, O.; Mattetti, M.; Cornec, O.; Knijnenburg, B. Building Trust in Interactive Machine Learning via User Contributed Interpretable Rules. In Proceedings of the 27th International Conference on Intelligent User Interfaces, Helsinki, Finland, 22–25 March 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 537–548. [Google Scholar] [CrossRef]
- Nushi, B.; Kamar, E.; Horvitz, E. Towards Accountable AI: Hybrid Human-Machine Analyses for Characterizing System Failure. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Zurich, Switzerland, 5–8 July 2018. [Google Scholar]
- Liu, Z.; Guo, Y.; Mahmud, J. When and Why does a Model Fail? A Human-in-the-loop Error Detection Framework for Sentiment Analysis. arXiv 2021, arXiv:2106.00954. [Google Scholar]
- Balayn, A.; Rikalo, N.; Lofi, C.; Yang, J.; Bozzon, A. How Can Explainability Methods Be Used to Support Bug Identification in Computer Vision Models? In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; Association for Computing Machinery: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Afzal, S.; Chaudhary, A.; Gupta, N.; Patel, H.; Spina, C.; Wang, D. Data-Debugging Through Interactive Visual Explanations. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Delhi, India, 11 May 2021; pp. 133–142. [Google Scholar] [CrossRef]

{kind=link}
| Explainability-Related Keywords | Knowledge-Related Keywords |
|---|---|
| Interpretable Machine Learning | Knowledge Extraction |
| Explainable Machine Learning | Knowledge Elicitation |
| Explainable Artificial Intelligence | Crowdsourcing |
| Explainable AI | Human-in-the-Loop |
| Explainability | Human-centred Computing |
| Interpretability | Human-centred Computing |
| Human Computation | |
| Concept Extraction |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tocchetti, A.; Brambilla, M. The Role of Human Knowledge in Explainable AI. Data 2022, 7, 93. https://doi.org/10.3390/data7070093
Tocchetti A, Brambilla M. The Role of Human Knowledge in Explainable AI. Data. 2022; 7(7):93. https://doi.org/10.3390/data7070093
Chicago/Turabian StyleTocchetti, Andrea, and Marco Brambilla. 2022. "The Role of Human Knowledge in Explainable AI" Data 7, no. 7: 93. https://doi.org/10.3390/data7070093
APA StyleTocchetti, A., & Brambilla, M. (2022). The Role of Human Knowledge in Explainable AI. Data, 7(7), 93. https://doi.org/10.3390/data7070093