A Deep Learning Framework for Detection of COVID-19 Fake News on Social Media Platforms




Abstract
:1. Introduction
2. Related Works
2.1. Related Fake News Detection Methods
2.2. Related Fake News Detection Datasets
3. Experimental Dataset
3.1. Dataset Collection Stage
3.2. Dataset Filtering Stage
- Remove Duplicate Data: we verified the collected dataset and removed the redundant news data. We used “drop_duplicates()” method in the panda python library to find and remove duplicate data instances.
- Dataset Standardization: because we collected our dataset from different sources, this stage was performed to standardize our dataset by making the data fit into a standard structure containing the following fields:
- •
- ID: each news instance is given a unique id.
- •
- Text (content): news content for COVID-19 and its vaccines.
- •
- Publisher: WHO, ICRC, UNICEF, UN, PolitiFact, Snopes, Factcheck, etc.
- •
- Label: Real or Fake.
- •
- Language In this paper, we used the English language only.
3.3. Dataset Preprocessing Stage
- Dataset Cleaning: each dataset instance is tokenized and then applied with regular expressions to remove all punctuation, links, hashtags, symbols, repeating text, and non-English alphabets.
- Stop Words Removal: removing stop words, which are functional words that do not have any necessary information when analyzing the text, including propositions, pronouns, and conjunctions.
- Word Lemmatization: removing the suffix or prefix from words to avoid redundant patterns. WordNet Lemmatizer was used to perform the Word Lemmatization process.
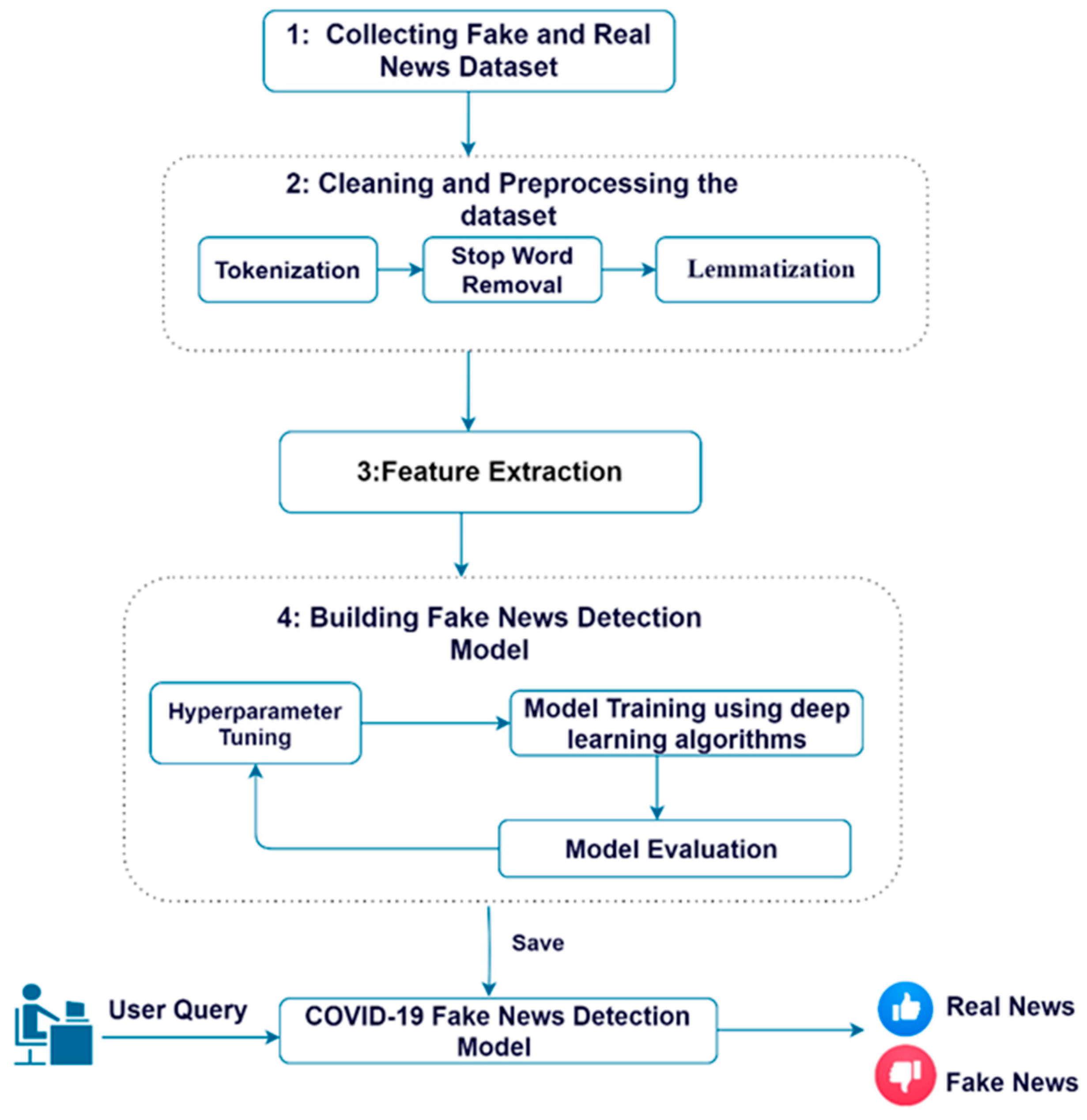
4. Methodology
4.1. Dataset Preparation and Integration
4.2. Converting Text to Vectors Using Pre-Trained Embeddings
4.3. Deep Neural Networks for Fake News Detection
4.3.1. Long Short-Term Memory Networks (LSTM)
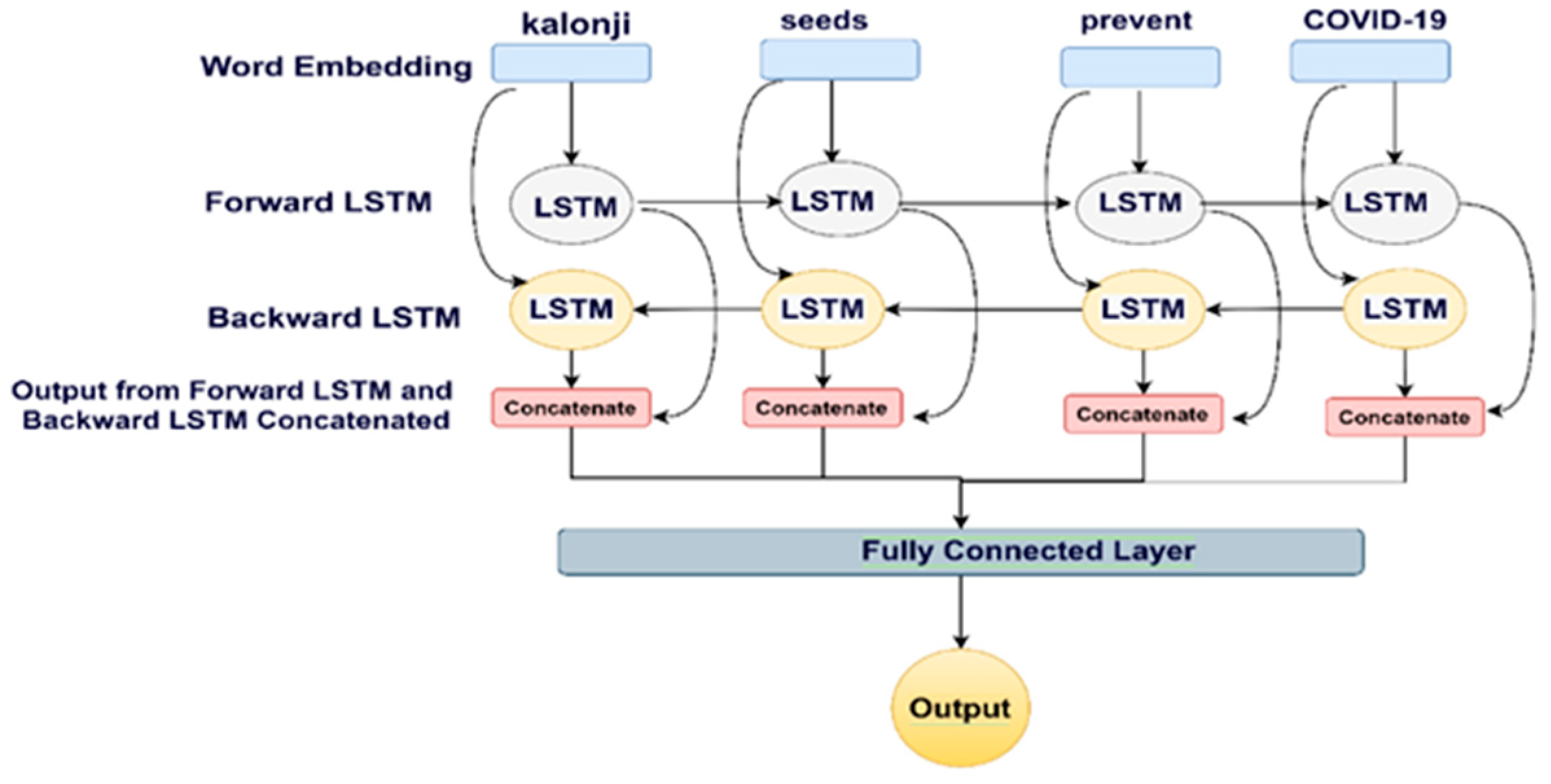
4.3.2. Bi-Directional Long Short-Term Memory Networks (Bi-LSTM)
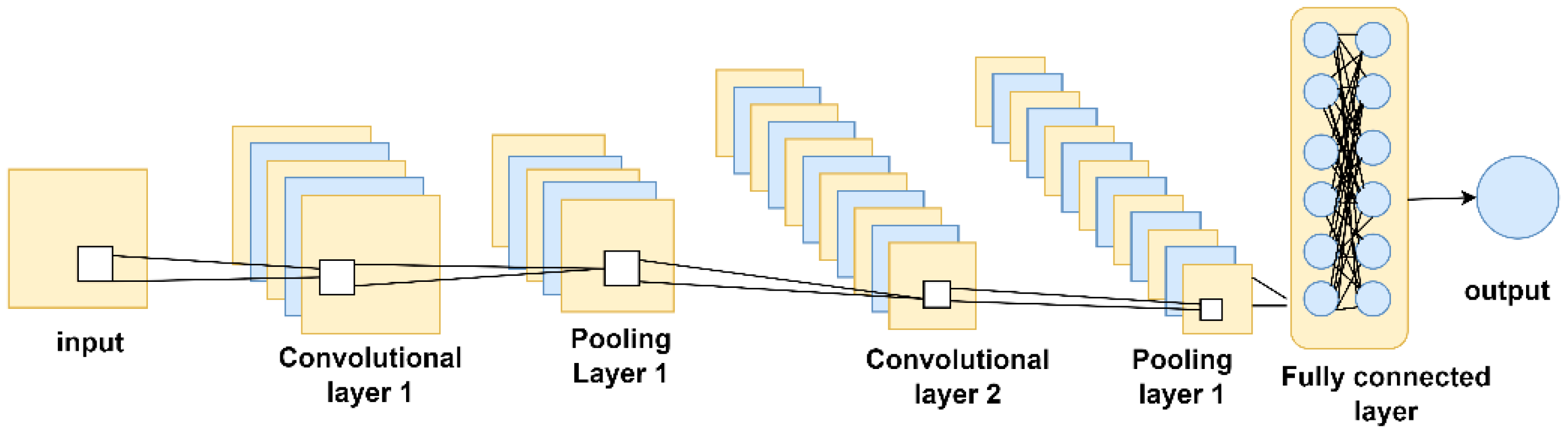
4.3.3. Convolutional Neural Networks (CNN)
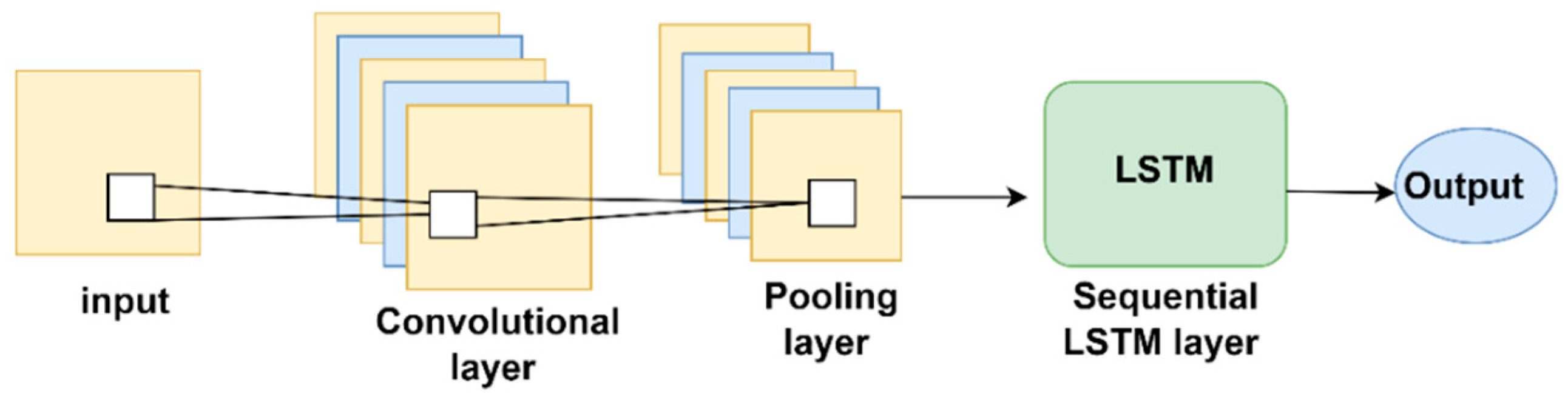
4.3.4. Hybrid Model (CNN and LSTM)
4.4. Hyperparameter Tuning
5. Evaluation and Result Analysis
5.1. Evaluation Metrics
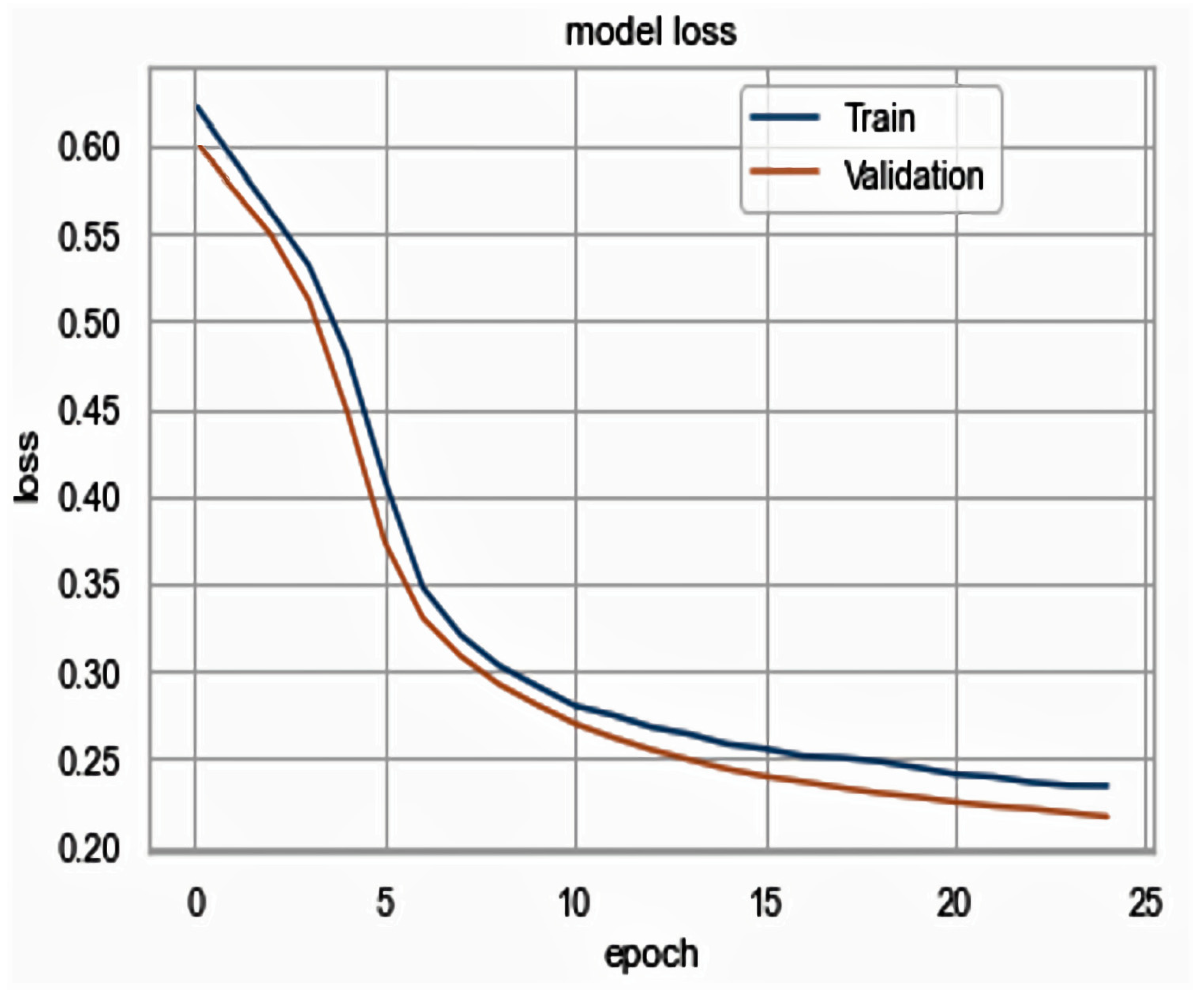
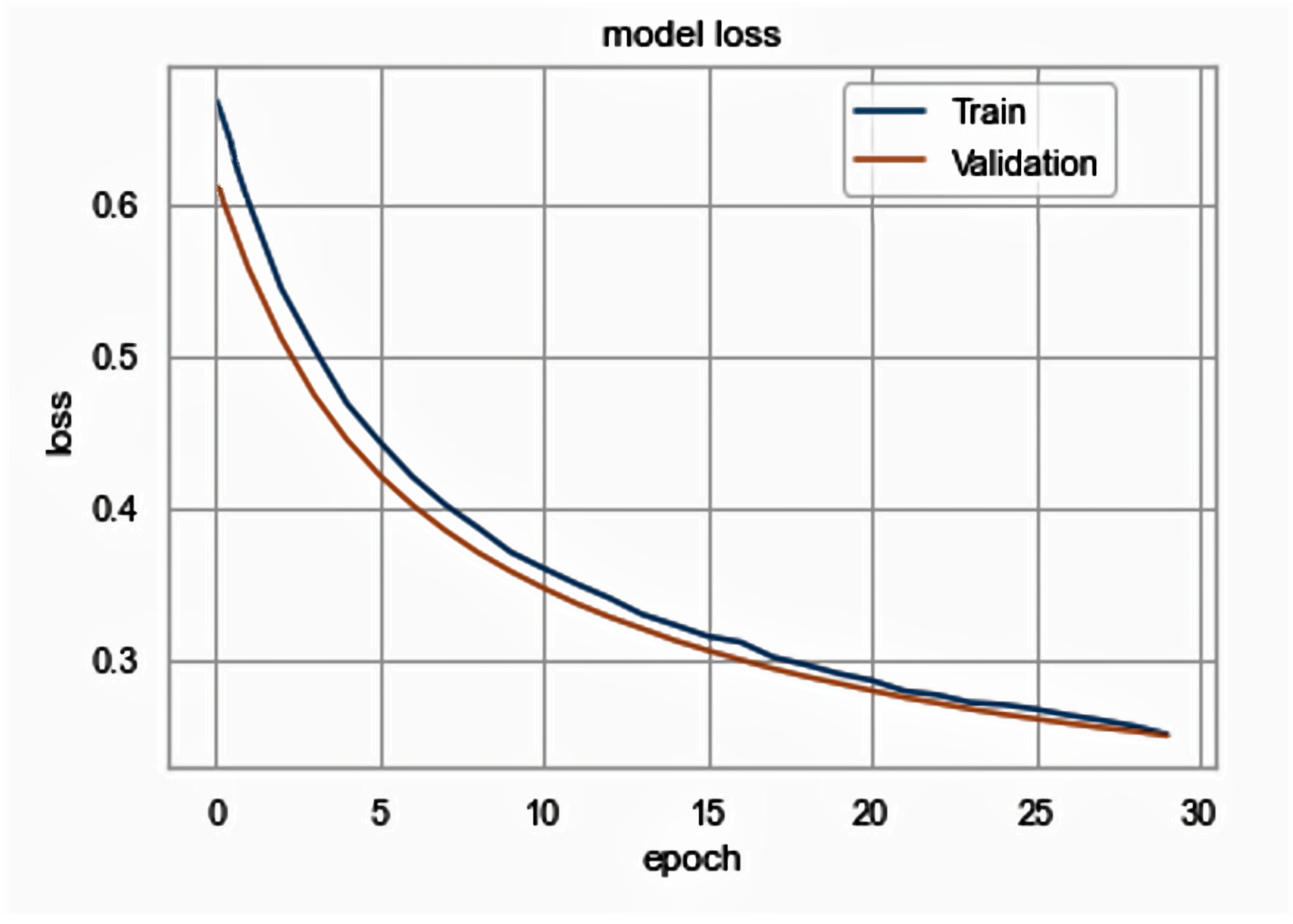
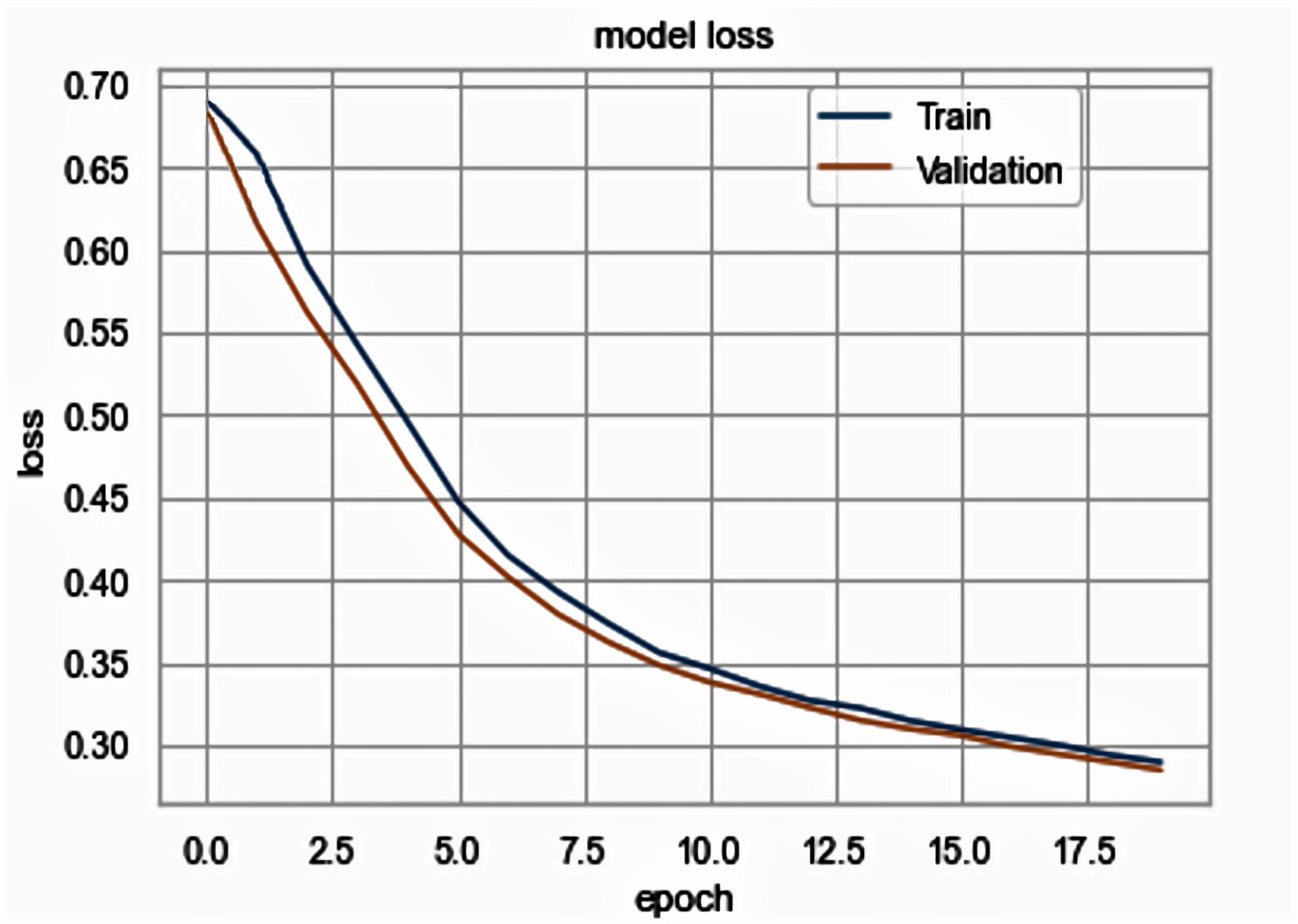
5.2. Results Analysis
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Ahmad, B.; Al-Zoubi, A.M.; Abu Khurma, R.; Aljarah, I. An Evolutionary Fake News Detection Method for COVID-19 Pandemic Information. Symmetry 2021, 13, 1091. [Google Scholar] [CrossRef]
- COVID-19 Pandemic—Wikipedia. Available online: https://en.wikipedia.org/wiki/COVID-19_pandemic (accessed on 20 December 2021).
- Coronavirus: Hundreds Dead in Iran from Drinking Methanol Amid Fake Reports It Cures Disease. Available online: https://www.independent.co.uk/news/world/middle-east/iran-coronavirus-methanol-drink-cure-deaths-fake-a9429956.html (accessed on 15 April 2022).
- Arizona Man Dies after Attempting to Take Trump Coronavirus ‘cure’. Available online: https://www.theguardian.com/world/2020/mar/24/coronavirus-cure-kills-man-after-trump-touts-chloroquine-phosphate (accessed on 15 April 2022).
- Kaliyar, R.K. Fake news detection using a deep neural network. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018; pp. 1–7. [Google Scholar]
- Gupta, A.; Sukumaran, R.; John, K.; Teki, S. Hostility detection and COVID-19 fake news detection in social media. arXiv 2021, arXiv:2101.05953. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef] [PubMed]
- Elhadad, M.K.; Li, K.F.; Gebali, F. Detecting misleading information on COVID-19. IEEE Access 2020, 8, 165201–165215. [Google Scholar] [CrossRef]
- Raza, S. Automatic Fake News Detection in Political Platforms-A Transformer-based Approach. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-Political Events from Text (CASE 2021), Online, 5–6 August 2021; pp. 68–78. [Google Scholar]
- Zhang, X.; Ghorbani, A.A. An overview of online fake news: Characterization, detection, and discussion. Inf. Process. Manag. 2020, 57, 102025. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Yazıcı, A.; Keser, S.B.; Günal, S.; Yayan, U. A Multi-Criteria Decision Strategy to Select a Machine Learning Method for Indoor Positioning System. Int. J. Artif. Intell. Tools 2018, 27, 1850018. [Google Scholar] [CrossRef]
- Ali, R.; Lee, S.; Chung, T.C. Accurate multi-criteria decision making methodology for recommending machine learning algorithm. Expert Syst. Appl. 2017, 71, 257–278. [Google Scholar] [CrossRef]
- Chowdhury, N.K.; Kabir, M.A.; Rahman, M. An Ensemble-based Multi-Criteria Decision Making Method for COVID-19 Cough Classification. arXiv 2021, arXiv:2110.00508. [Google Scholar]
- Pirouz, B.; Ferrante, A.P.; Pirouz, B.; Piro, P. Machine Learning and Geo-Based Multi-Criteria Decision Support Systems in Analysis of Complex Problems. ISPRS Int. J. Geo-Inf. 2021, 10, 424. [Google Scholar] [CrossRef]
- Kumar, S.; Asthana, R.; Upadhyay, S.; Upreti, N.; Akbar, M. Fake news detection using deep learning models: A novel approach. Trans. Emerg. Telecommun. Technol. 2020, 31, e3767. [Google Scholar] [CrossRef]
- Rodríguez, Á.I.; Iglesias, L.L. Fake news detection using Deep Learning. arXiv 2019, arXiv:1910.03496. [Google Scholar]
- Jiang, T.; Li, J.P.; Haq, A.U.; Saboor, A. Fake News Detection using Deep Recurrent Neural Networks. In Proceedings of the 2020 17th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 18–20 December 2020; pp. 205–208. [Google Scholar]
- Umer, M.; Imtiaz, Z.; Ullah, S.; Mehmood, A.; Choi, G.S.; On, B.W. Fake news stance detection using deep learning architecture (CNN-LSTM). IEEE Access 2020, 8, 156695–156706. [Google Scholar] [CrossRef]
- Zhi, X.; Xue, L.; Zhi, W.; Li, Z.; Zhao, B.; Wang, Y.; Shen, Z. Financial Fake News Detection with Multi fact CNN-LSTM Model. In Proceedings of the 2021 IEEE 4th International Conference on Electronics Technology (ICET), Chengdu, China, 7–10 May 2021; pp. 1338–1341. [Google Scholar]
- Wani, A.; Joshi, I.; Khandve, S.; Wagh, V.; Joshi, R. Evaluating deep learning approaches for COVID-19 fake news detection. In International Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situation; Springer: Cham, Switzerland, 2021; pp. 153–163. [Google Scholar]
- Abdelminaam, D.S.; Ismail, F.H.; Taha, M.; Taha, A.; Houssein, E.H.; Nabil, A. Coaiddeep: An optimized intelligent framework for automated detecting COVID-19 misleading information on twitter. IEEE Access 2021, 9, 27840–27867. [Google Scholar] [CrossRef] [PubMed]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake news identification on twitter with hybrid cnn and rnn models. In Proceedings of the 9th International Conference on Social Media and Society, Copenhagen, Denmark, 18–20 July 2018; pp. 226–230. [Google Scholar]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Pathwar, P.; Gill, S. Tackling COVID-19 infodemic using deep learning. In Lecture Notes on Data Engineering and Communications Technologies; Springer: Singapore, 2022; Volume 99, pp. 319–335. [Google Scholar]
- Wang, W.Y. “liar, liar pants on fire”: A new benchmark dataset for fake news detection. arXiv 2017, arXiv:1705.00648. [Google Scholar]
- Shu, K.; Mahudeswaran, D.; Wang, S.; Lee, D.; Liu, H. Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media. Big Data 2020, 8, 171–188. [Google Scholar] [CrossRef]
- Horne, B.; Adali, S. This just in: Fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11. [Google Scholar]
- Riedel, B.; Augenstein, I.; Spithourakis, G.P.; Riedel, S. A simple but tough-to-beat baseline for the Fake News Challenge stance detection task. arXiv 2017, arXiv:1707.03264. [Google Scholar]
- Barbado, R.; Araque, O.; Iglesias, C.A. A framework for fake review detection in online consumer electronics retailers. Inf. Process. Manag. 2019, 56, 1234–1244. [Google Scholar] [CrossRef] [Green Version]
- Anoop, K.; Gangan, M.P.; Deepak, P.; Lajish, V.L. Leveraging heterogeneous data for fake news detection. In Linking and Mining Heterogeneous and Multi-View Data; Springer: Cham, Switzerland, 2019; pp. 229–264. [Google Scholar]
- Papadopoulou, O.; Zampoglou, M.; Papadopoulos, S.; Kompatsiaris, I. A corpus of debunked and verified user-generated videos. Online Inf. Rev. 2019, 43, 72–88. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, H.; Traore, I.; Saad, S. Detecting opinion spams and fake news using text classification. Secur. Priv. 2018, 1, e9. [Google Scholar] [CrossRef] [Green Version]
- Posadas-Durán, J.P.; Gómez-Adorno, H.; Sidorov, G.; Escobar, J.J.M. Detection of fake news in a new corpus for the Spanish language. J. Intell. Fuzzy Syst. 2019, 36, 4869–4876. [Google Scholar] [CrossRef]
- Banik, S. COVID Fake News Dataset. Zenodo. 2021. Available online: https://zenodo.org/record/4282522#.YcEjUWhBzIV (accessed on 21 December 2021).
- Who.int. Coronavirus Disease (COVID-19)—World Health Organization. 2021. Available online: https://www.who.int/ (accessed on 21 December 2021).
- Nations, U.N. Coronavirus | United Nations. 2021. Available online: https://www.un.org (accessed on 21 December 2021).
- Unicef.org. Coronavirus Disease (COVID-19) Information Centre. 2021. Available online: https://www.unicef.org (accessed on 21 December 2021).
- International Committee of the Red Cross. Coronavirus: COVID-19 Pandemic. 2021. Available online: https://www.icrc.org (accessed on 21 December 2021).
- Makice, K. Twitter API: Up and Running: Learn How to Build Applications with the Twitter API; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2009. [Google Scholar]
- Nakov, P.; Da San Martino, G.; Elsayed, T.; Barrón-Cedeño, A.; Míguez, R.; Shaar, S.; Alam, F.; Haouari, F.; Hasanain, M.; Mansour, W.; et al. Overview of the CLEF–2021 CheckThat! Lab on Detecting Check-Worthy Claims, Previously Fact-Checked Claims, and Fake News. In International Conference of the Cross-Language Evaluation Forum for European Languages; Springer: Cham, Switzerland, 2021; pp. 264–291. [Google Scholar]
- Alasadi, S.A.; Bhaya, W.S. Review of data preprocessing techniques in data mining. J. Eng. Appl. Sci. 2017, 12, 4102–4107. [Google Scholar]
- Hardeniya, N.; Perkins, J.; Chopra, D.; Joshi, N.; Mathur, I. Natural Language Processing: Python and NLTK; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Nandanwar, A.K.; Choudhary, J. Semantic Features with Contextual Knowledge-Based Web Page Categorization Using the GloVe Model and Stacked BiLSTM. Symmetry 2021, 13, 1772. [Google Scholar] [CrossRef]
- Nisha, S.S.; Meeral, M.N. Applications of deep learning in biomedical engineering. In Handbook of Deep Learning in Biomedical Engineering; Academic Press: Cambridge, MA, USA, 2021; pp. 245–270. [Google Scholar]
- Rani, S.; Bashir, A.K.; Alhudhaif, A.; Koundal, D.; Gündüz, E.S. An efficient CNN-LSTM model for sentiment detection in# BlackLivesMatter. Expert Syst. Appl. 2022, 193, 116256. [Google Scholar]
- Srivastava, S.; Raj, R.; Saumya, S. COVID-19 Fake News Identification Using Multi-layer Convolutional Neural Network. In Advanced Computational Paradigms and Hybrid Intelligent Computing; Springer: Singapore, 2022; pp. 149–157. [Google Scholar]
- Shaaban, M.A.; Hassan, Y.F.; Guirguis, S.K. Deep convolutional forest: A dynamic deep ensemble approach for spam detection in text. Complex Intell. Syst. 2022. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F. A C-LSTM neural network for text classification. arXiv 2015, arXiv:1511.08630. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Dataset | Content | Domain | Size | Source | Classes |
|---|---|---|---|---|---|---|
| Wang [26] | Liar | Text | Politics | 12,836 short statements | PolitiFact (Fact-Checking website) | Mostly true, True, Barely True, Half True, False, Pants Fire |
| Shu et al. [27] | FakeNewsNet | Text, images | Politics, Society | 422 news | PolitiFact and GossipCop (Fact-Checking website) | True, Fake |
| Adali [28] | BuzzFeed News dataset | Text | Politics | 2283 news samples | Mostly true, Mixed True, False, Mixed False | |
| Riedel et al. [29] | Fake News Challenges (FNC-1 dataset) | Text | Politics, Society, Technology | 75,385 articles | - | Agree, Disagree, Discuss, Unrelated |
| Barbado et al. [30] | Yelp dataset | Text | Technology | 18,912 reviews | - | Trust, Fake |
| Anoop et al. [31] | Getting Real about Fake News | Text | Politics, Arts, Entertainment | 12,999 posts | 244 different websites | Fake, Real |
| Papadopoulou et al. [32] | FVC-2018 | Videos, Text | Society | 380 videos and 77,258 tweets | YouTube, Facebook, Twitter | Fake, Real |
| Ahmad et al. [33] | Fake and real news dataset | Text | Society | 25,200 news article | News website and Kaggle | Fake, Truthful |
| Duran et al. [34] | Spanish fake news corpus | Text | Politics, Health, Education, Economy, Science, Security, Sport, Entertainment, Society. | 971 news | Different news websites | Fake, Real |
| Sources | COVID-19 Pandemic and Vaccine Keywords | Data Collection Method |
|---|---|---|
| WHO website UNICEF website UN website ICRC website WHO on twitter UNICEF on twitter UN on Twitter ICRC on Twitter | COVID-19, Coronavirus, Novel Coronavirus, 2019-nCoV, nCoV, SARS-CoV-2, Pfizer, Sinopharm, AstraZeneca, Moderna, Covaxin, Janssen, CoronaVac, ZyCoV-D, Convidecia, ZF2001, Sputnik V, Sputnik Light, Abdala, ZF2001, EpiVacCorona, Medigen, Soberana 02 | (1) We developed our text extraction program, and (2) Twitter API [40]. |
| Sources | COVID-19 Pandemic and Vaccine Keywords | Data Collection Method |
|---|---|---|
| Fact-Checking website, Zenodo dataset | COVID-19, Coronavirus, Novel Coronavirus, 2019-nCoV, nCoV, SARS-CoV-2, Pfizer, Sinopharm, AstraZeneca, Moderna, Covaxin, Janssen, CoronaVac, ZyCoV-D, Convidecia, ZF2001, Sputnik V, Sputnik Light, Abdala, ZF2001, EpiVacCorona, Medigen, Soberana 02 | Google Fact-Check tool API |
| Dataset | Real | Fake | Total |
|---|---|---|---|
| Training dataset | 9179 | 7924 | 17,103 |
| Testing dataset | 2186 | 2090 | 4276 |
| Total | 11,365 | 10,014 | 21,379 |
| Hyperparameter | Value (LSTM) | Value (Bidirectional LSTM) | Values Examined by Grid Search |
|---|---|---|---|
| Learning rate | 0.00001 | 0.00001 | 0.01, 0.001, 0.0001, 0.00001 |
| Batch size | 64 | 64 | 32, 64, 128 |
| Loss function | Binary cross-entropy | Binary cross-entropy | - |
| Activation function | Sigmoid | Sigmoid | - |
| Optimizer | Adam | Adam | - |
| Number of epochs | 25 | 25 | 10, 15, 20, 25, 30, 35, 40, 45, 50 |
| Dropout rates | 0.2 | 0.1 | 0.1, 0.2, 0.3, 0.4, 0.5 |
| Hyperparameter | Value (CNN) | Value (Hybrid CNN and LSTM) | Values Examined by Grid Search |
|---|---|---|---|
| Number of filters | 64, 128 | 32 | 32, 64, 128 |
| Kernel size | 2 | 2 | - |
| Batch size | 32 | 64 | 32, 64, 128 |
| Loss function | Binary cross-entropy | Binary cross-entropy | - |
| Learning rate | 0.00001 | 0.00001 | 0.01, 0.001, 0.0001, 0.00001 |
| Activation Function | Sigmoid, Relu | Sigmoid, Relu | - |
| Optimizer | Adam | Adam | - |
| Number of epochs | 30 | 20 | 10, 15, 20, 25, 30, 35, 40, 45, 50 |
| Dropout rate | 0.3 | 0.4 | 0.1, 0.2, 0.3, 0.4 |
| Predicted Real News | Predicted Fake News | |
|---|---|---|
| Actual Real News | 2069 | 198 |
| Actual Fake News | 194 | 1815 |
| Predicted Real News | Predicted Fake News | |
|---|---|---|
| Actual Real News | 2129 | 182 |
| Actual Fake News | 197 | 1768 |
| Predicted Real News | Predicted Fake News | |
|---|---|---|
| Actual Real News | 2168 | 127 |
| Actual Fake News | 121 | 1860 |
| Predicted Real News | Predicted Fake News | |
|---|---|---|
| Actual Real News | 2121 | 197 |
| Actual Fake News | 136 | 1822 |
| Deep Learning Model | Evaluation Metrics (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Specificity | Error Rate | Miss Rate | FPR | |
| LSTM | 90.8 | 90.2 | 90.3 | 90.3 | 90.3 | 9.2 | 8.7 | 9.7 |
| Bidirectional LSTM | 91.1 | 90.7 | 90.0 | 90.3 | 90.0 | 8.9 | 7.9 | 10.0 |
| CNN and LSTM (Hybrid) | 92.2 | 90.2 | 93.1 | 91.6 | 93.1 | 7.8 | 8.5 | 6.9 |
| CNN | 94.2 | 93.6 | 93.9 | 93.7 | 93.9 | 5.8 | 5.5 | 6.1 |
| CNN and LSTM (Hybrid) without preprocessing steps | 85.0 | 82.8 | 85.3 | 84.0 | 84.2 | 15.0 | 14.5 | 14.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tashtoush, Y.; Alrababah, B.; Darwish, O.; Maabreh, M.; Alsaedi, N. A Deep Learning Framework for Detection of COVID-19 Fake News on Social Media Platforms. Data 2022, 7, 65. https://doi.org/10.3390/data7050065
Tashtoush Y, Alrababah B, Darwish O, Maabreh M, Alsaedi N. A Deep Learning Framework for Detection of COVID-19 Fake News on Social Media Platforms. Data. 2022; 7(5):65. https://doi.org/10.3390/data7050065
Chicago/Turabian StyleTashtoush, Yahya, Balqis Alrababah, Omar Darwish, Majdi Maabreh, and Nasser Alsaedi. 2022. "A Deep Learning Framework for Detection of COVID-19 Fake News on Social Media Platforms" Data 7, no. 5: 65. https://doi.org/10.3390/data7050065
APA StyleTashtoush, Y., Alrababah, B., Darwish, O., Maabreh, M., & Alsaedi, N. (2022). A Deep Learning Framework for Detection of COVID-19 Fake News on Social Media Platforms. Data, 7(5), 65. https://doi.org/10.3390/data7050065